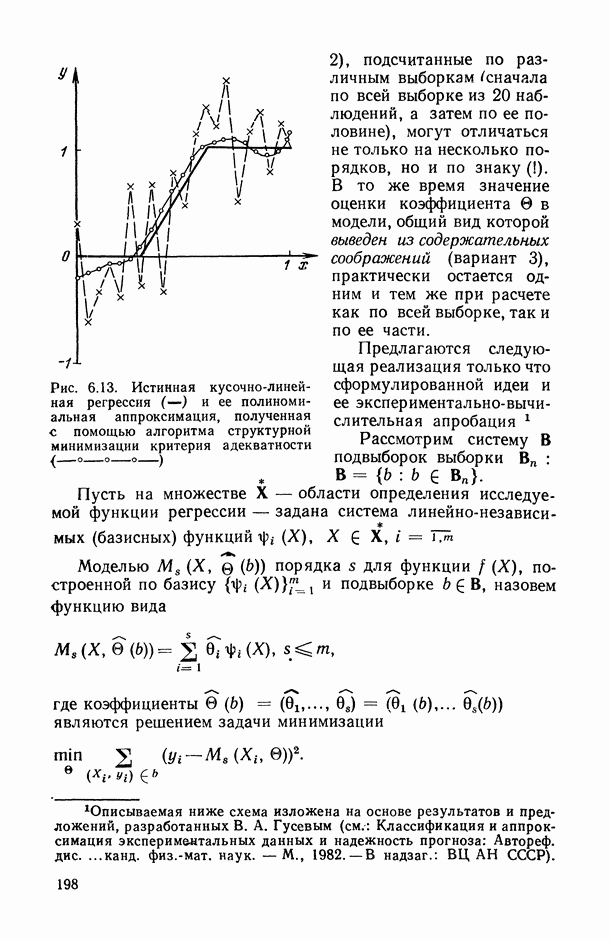
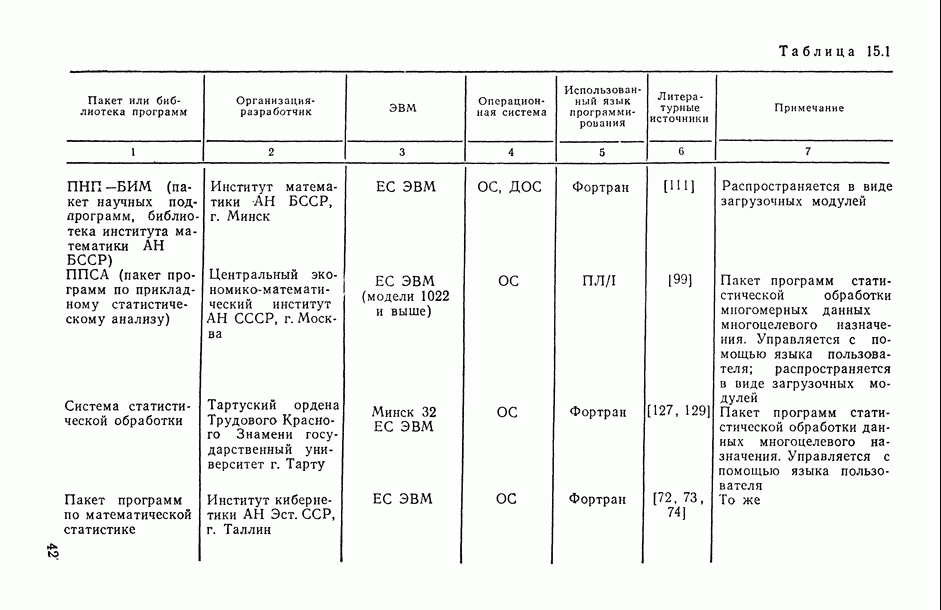
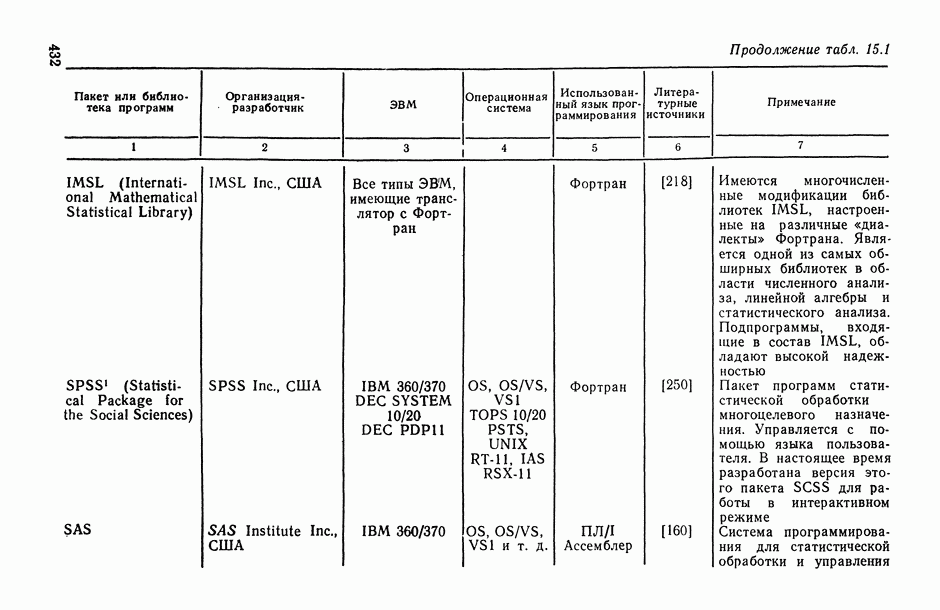
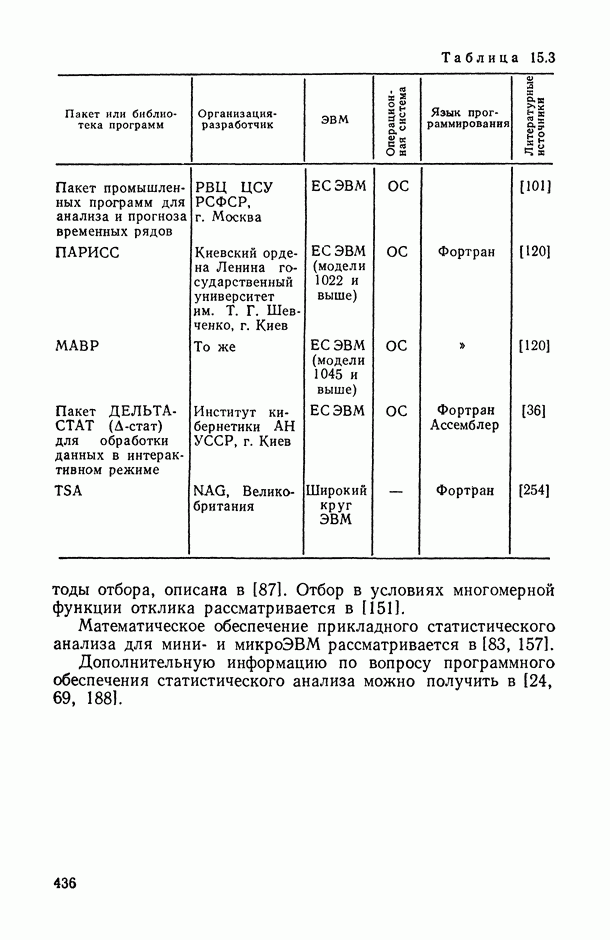
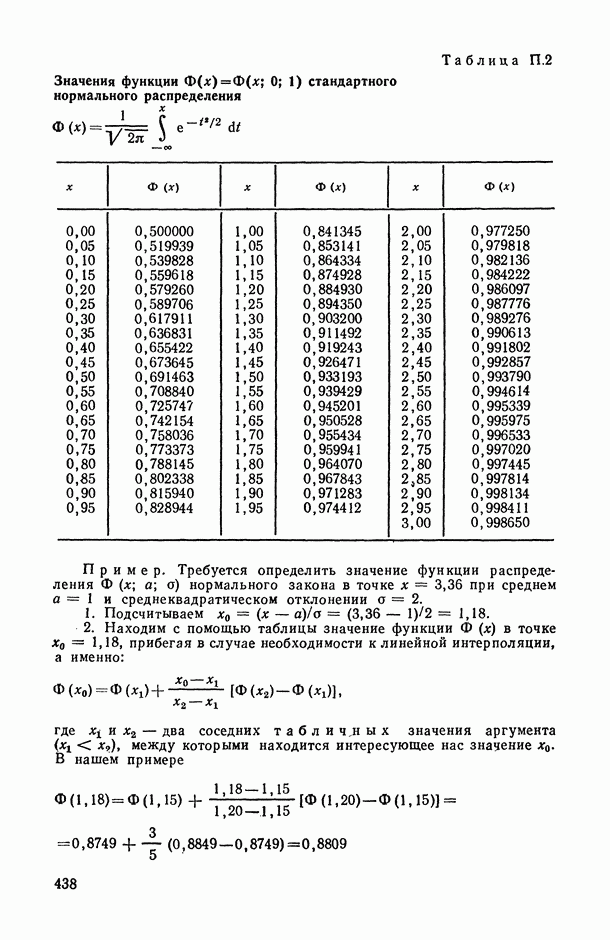
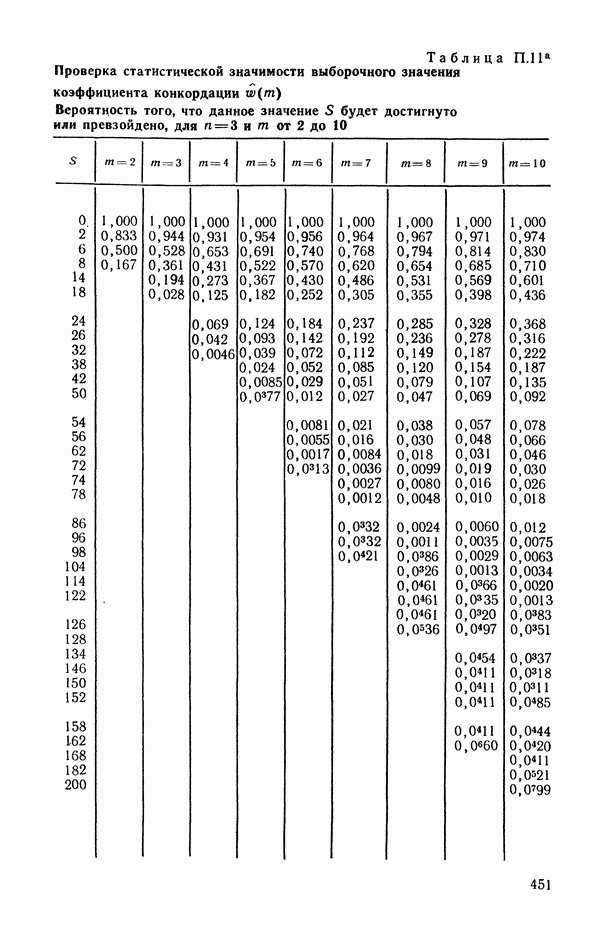
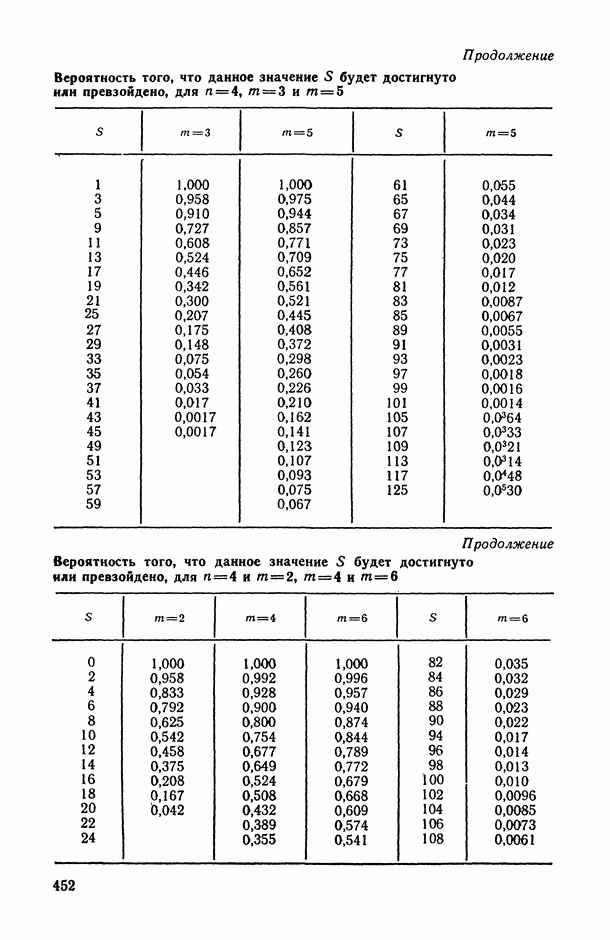
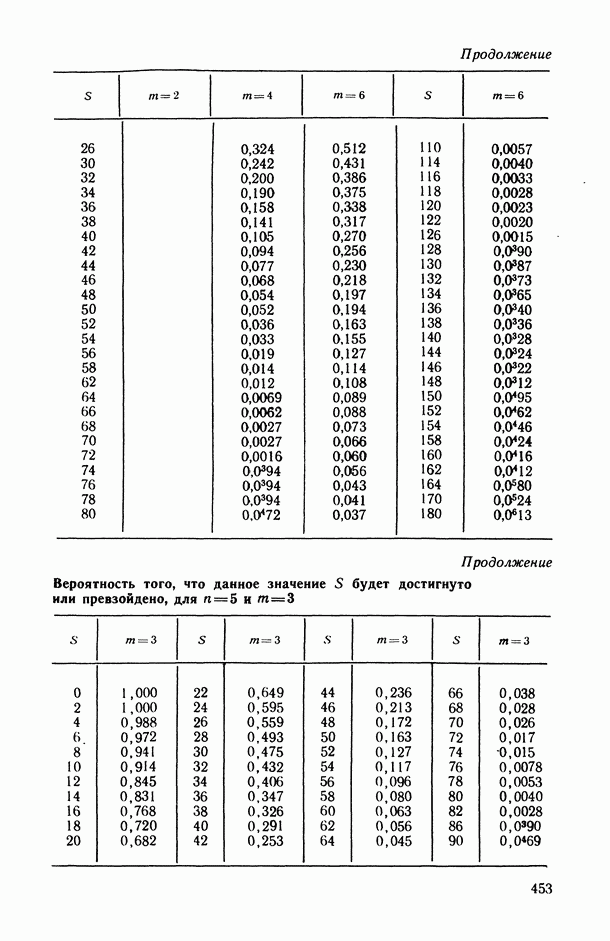
Задача В. В приложениях, особенно при статистическом анализе совокупности экспертных мнений (представленных в виде ранжировок), существенным оказывается вопрос упорядочения самих переменных (интерпретируемых, например, в качестве экспертов) по степени их коррелированности со всеми остальными переменными или с какой-то их частью (представляющей, например, основное ядро высококоррелированных переменных). Для решения этой задачи может быть предложена следующая процедура.
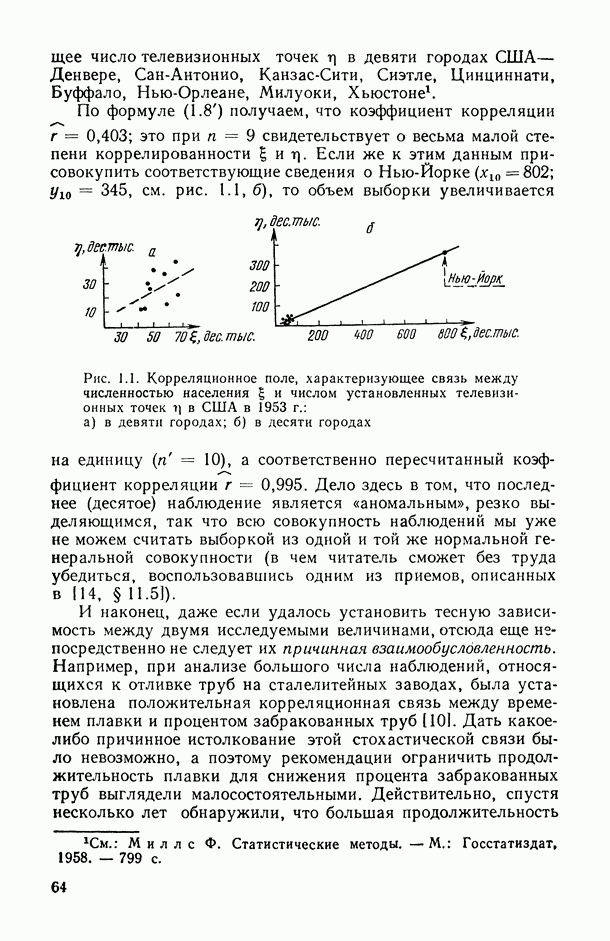
Пусть  — коэффициент конкордации, подсчитанный по всем рассматриваемым переменным
— коэффициент конкордации, подсчитанный по всем рассматриваемым переменным  за исключением переменных Варьируя состав группы исключенных переменных, мы получим
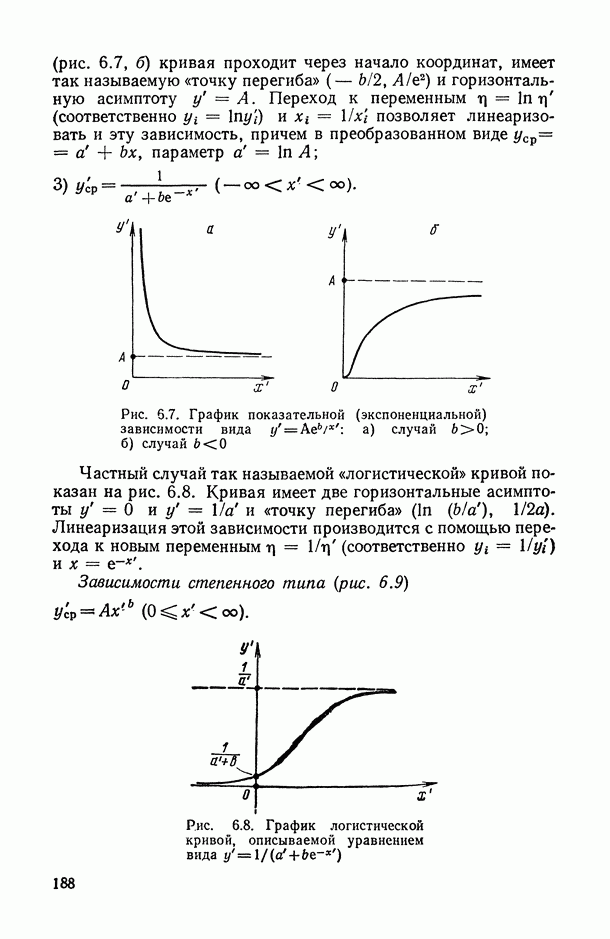
за исключением переменных Варьируя состав группы исключенных переменных, мы получим  различных значений
различных значений  . Последовательно вычислим значения всех этих коэффициентов для
. Последовательно вычислим значения всех этих коэффициентов для  и упорядочим их (при каждом фиксированном k) в соответствии с убыванием их значений. Получим:
и упорядочим их (при каждом фиксированном k) в соответствии с убыванием их значений. Получим:

Эти упорядочения (на каждом «этаже») и дают нам одновременно ранжировки самих переменных (по одной, но паре, по тройке и т. д.) по степени их согласованности с остальными переменными: очевидно, ту переменную (или ту пару, тройку и т. д. переменных), выбрасывание которой приводит к максимальному значению меры согласованности по остальным переменным, естественно объявить наименее связанной (согласующейся) с остальными переменными. Это правило, в частности, было с успехом использовано при обработке экспертных мнений в работе, описанной в [11, § 5.1].
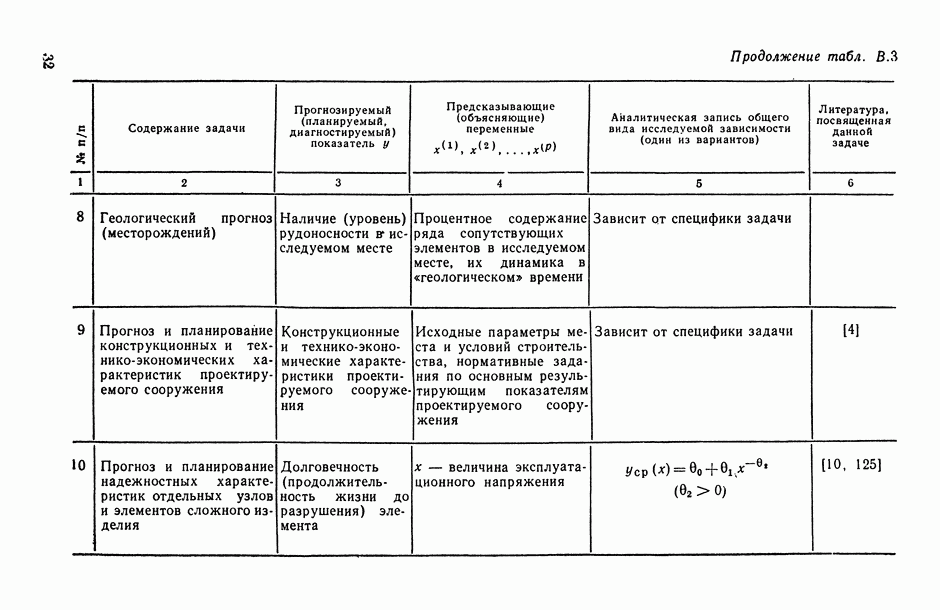
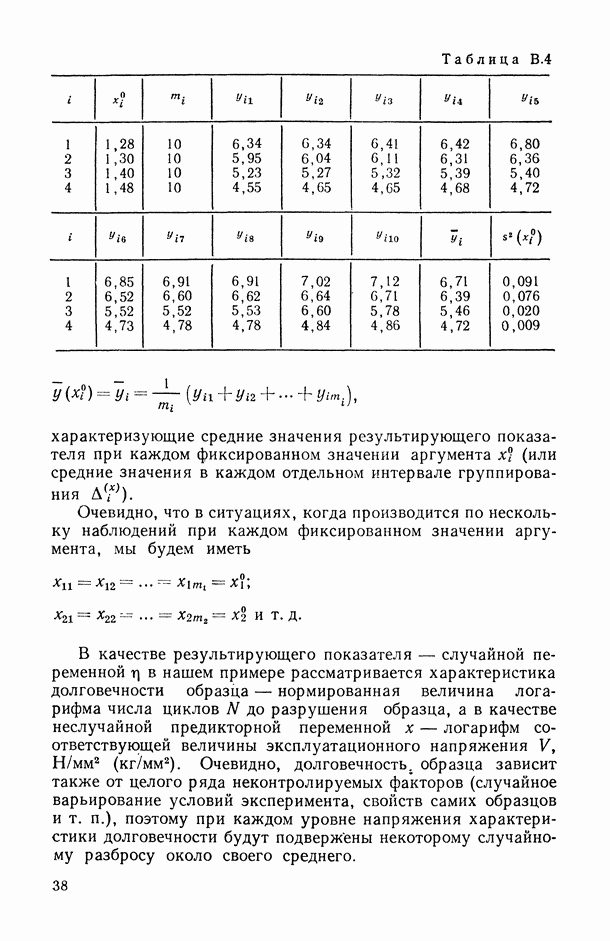
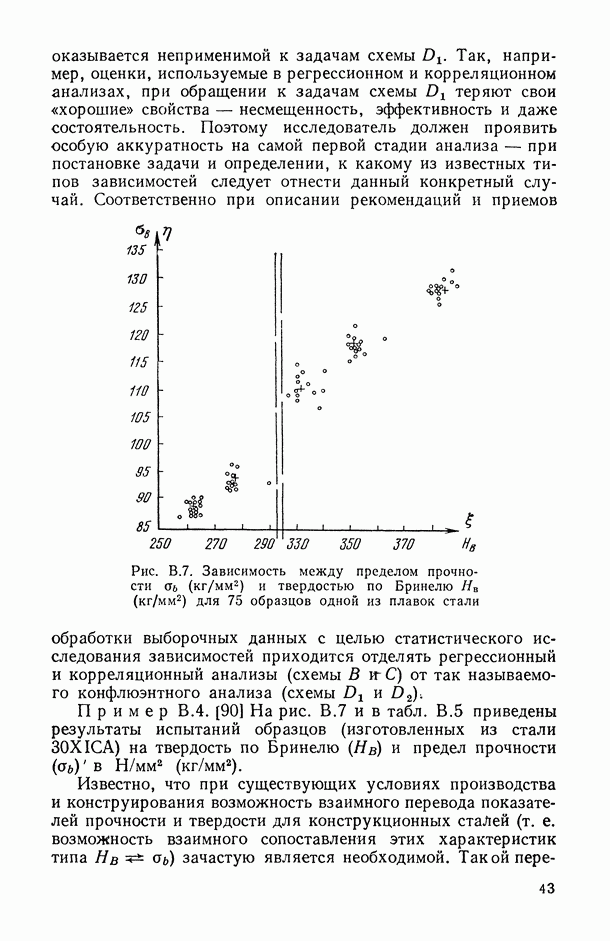
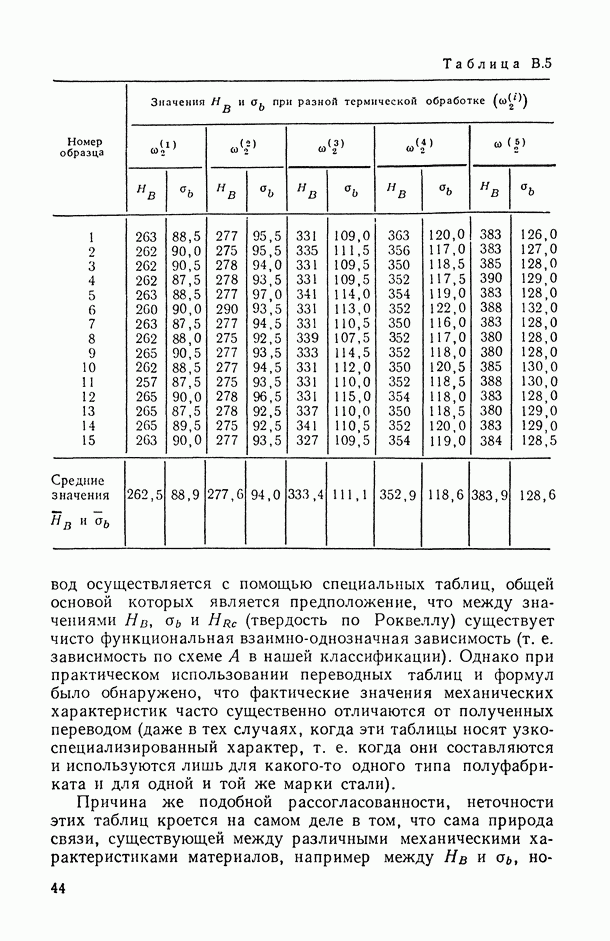
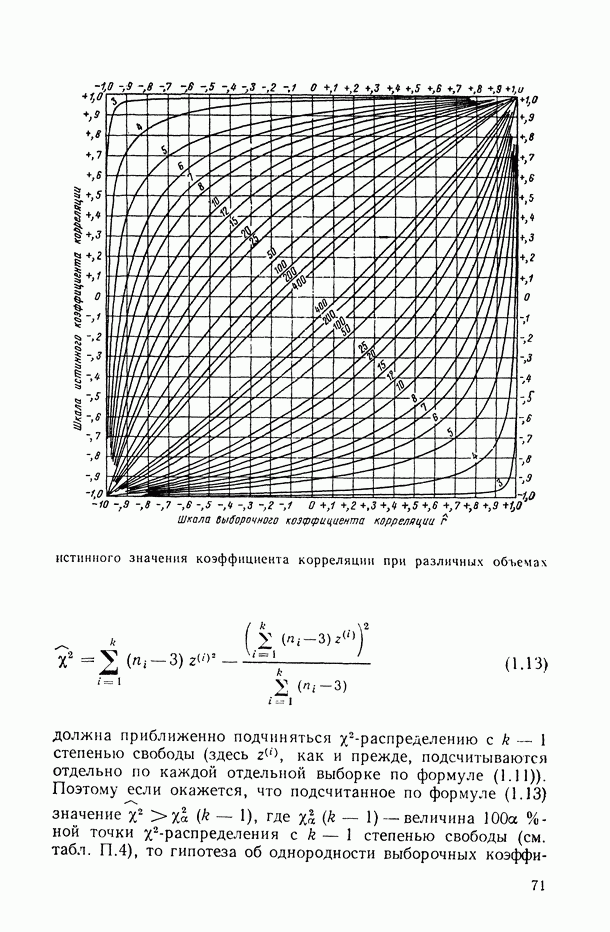
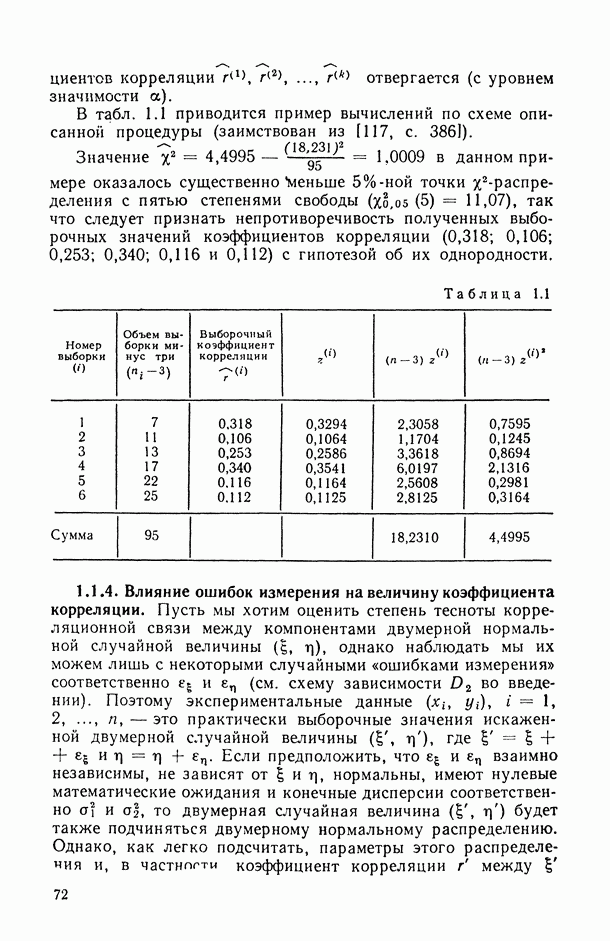
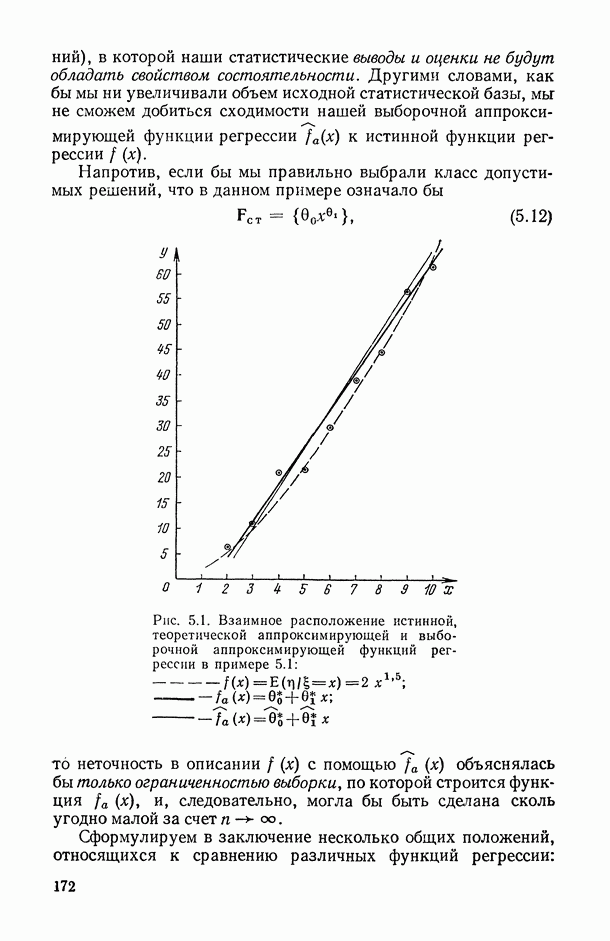
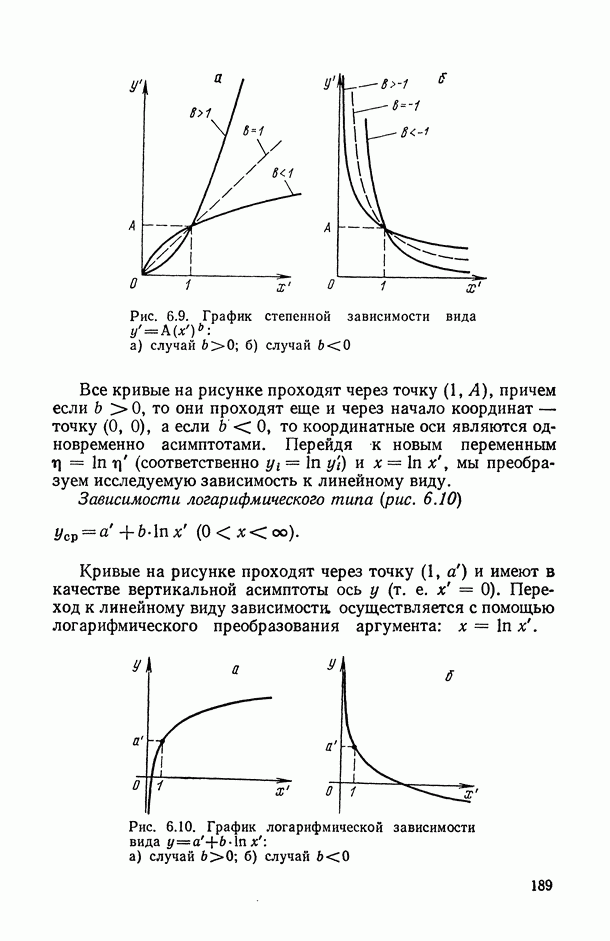
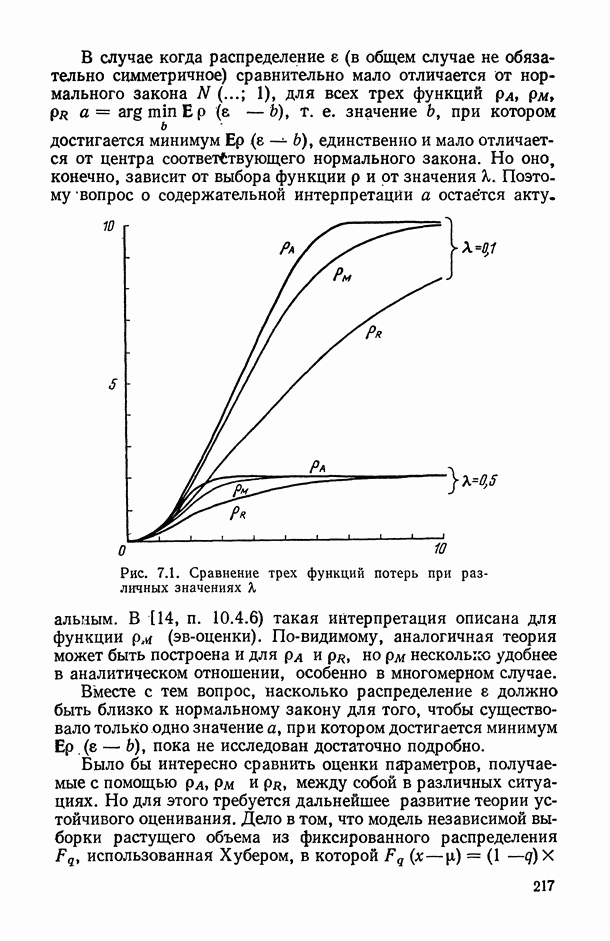
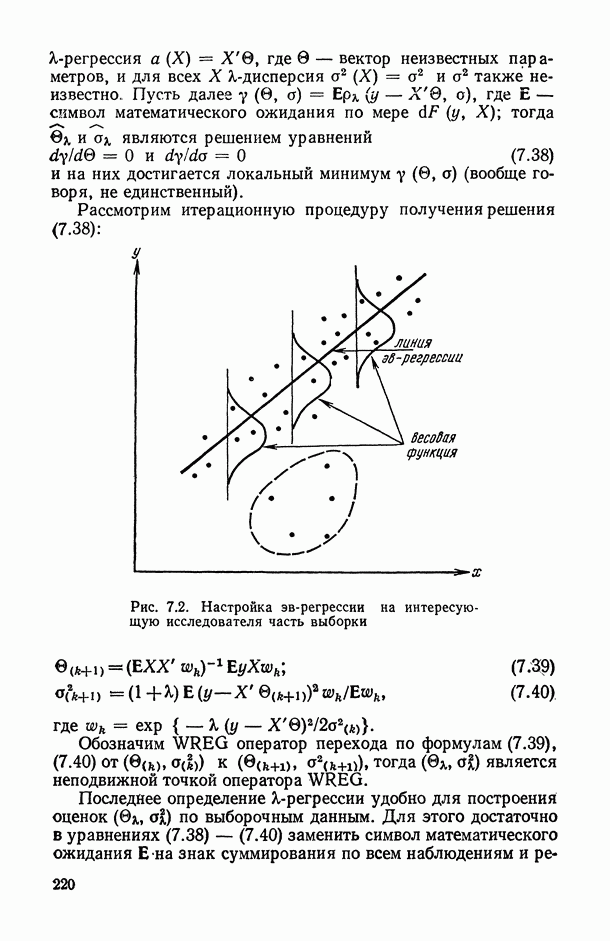
Задача С. Если коэффициент  свидетельствует о наличии статистически значимой связи между анализируемыми показателями
свидетельствует о наличии статистически значимой связи между анализируемыми показателями  то представляет интерес задача построения оценки неизвестной «истинной» упорядоченности Хисг рассматриваемых объектов. Эта оценка должна быть, по-видимому, результатом некоторого агрегирования имеющихся ранжировок
то представляет интерес задача построения оценки неизвестной «истинной» упорядоченности Хисг рассматриваемых объектов. Эта оценка должна быть, по-видимому, результатом некоторого агрегирования имеющихся ранжировок 







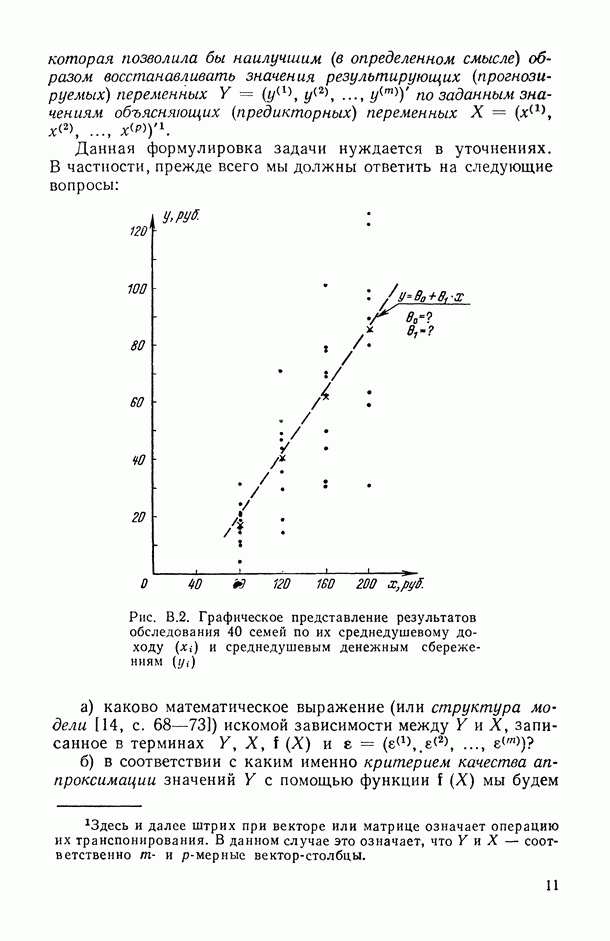












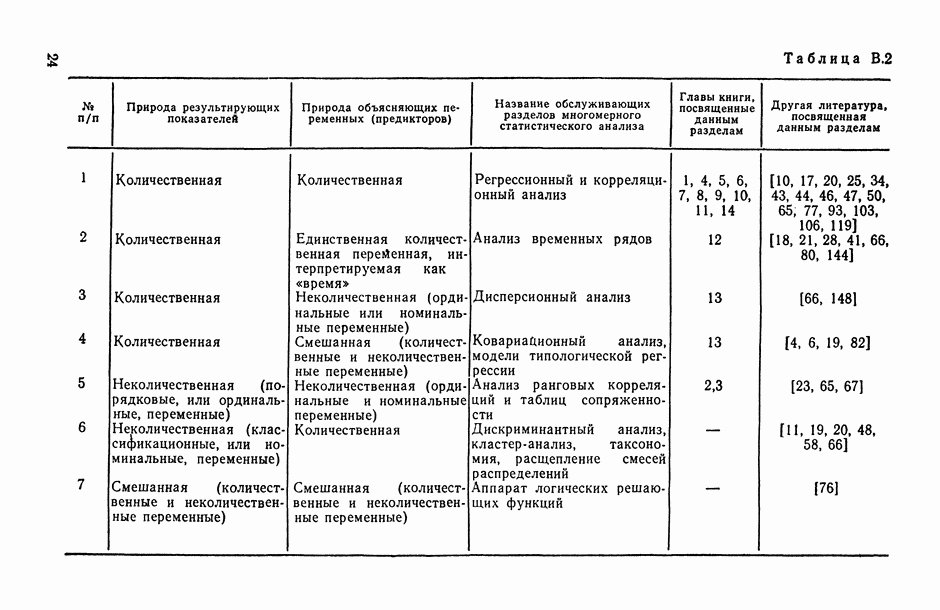
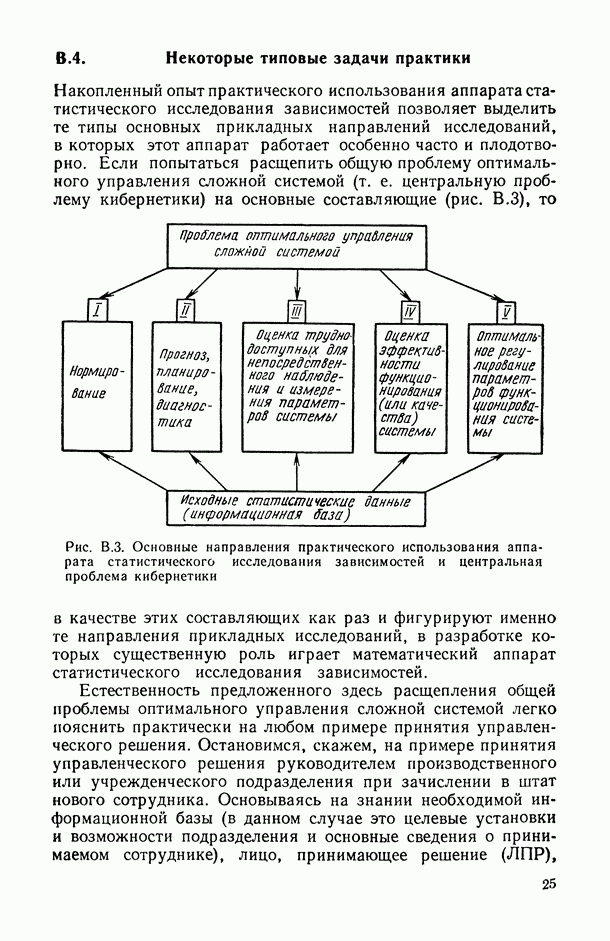





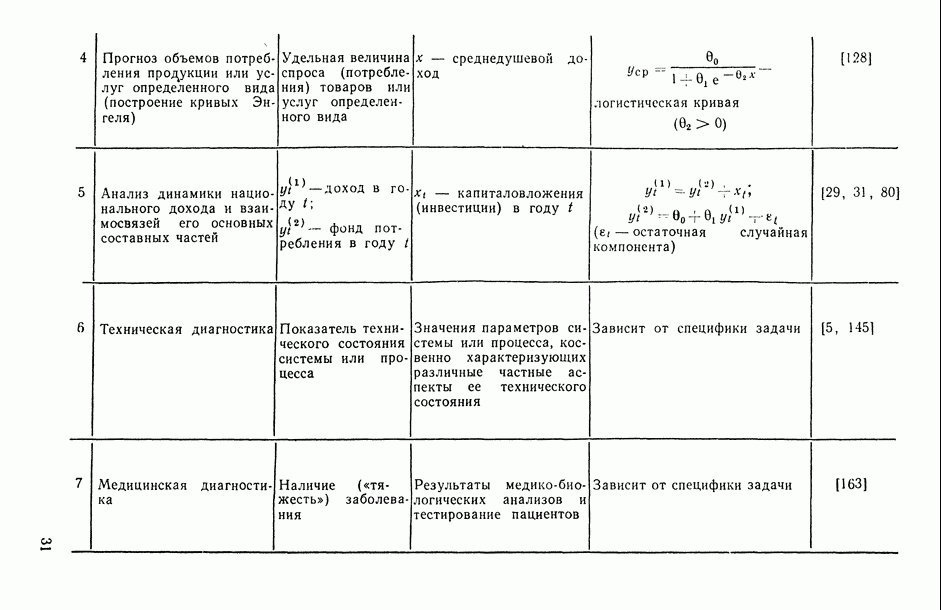


















































































































































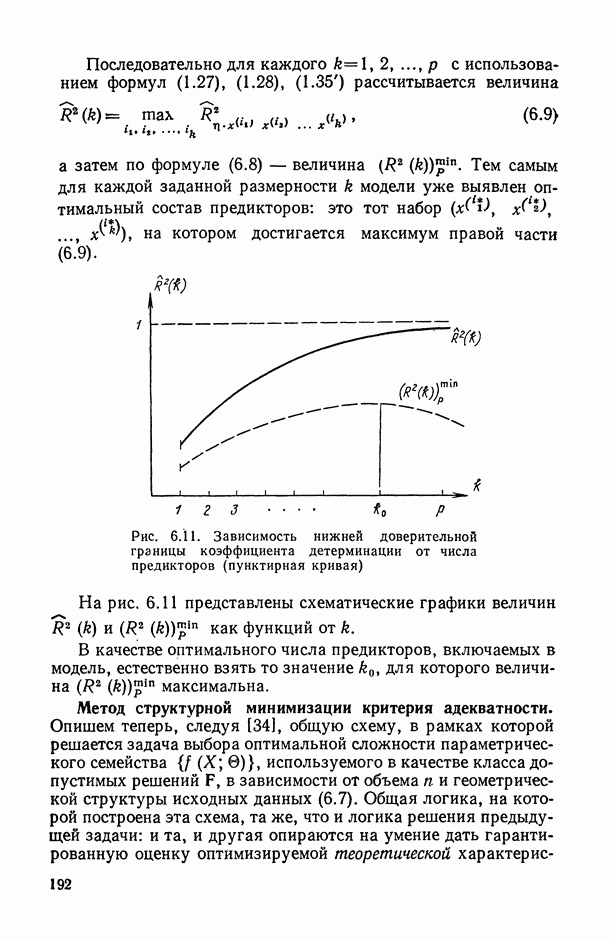


































































































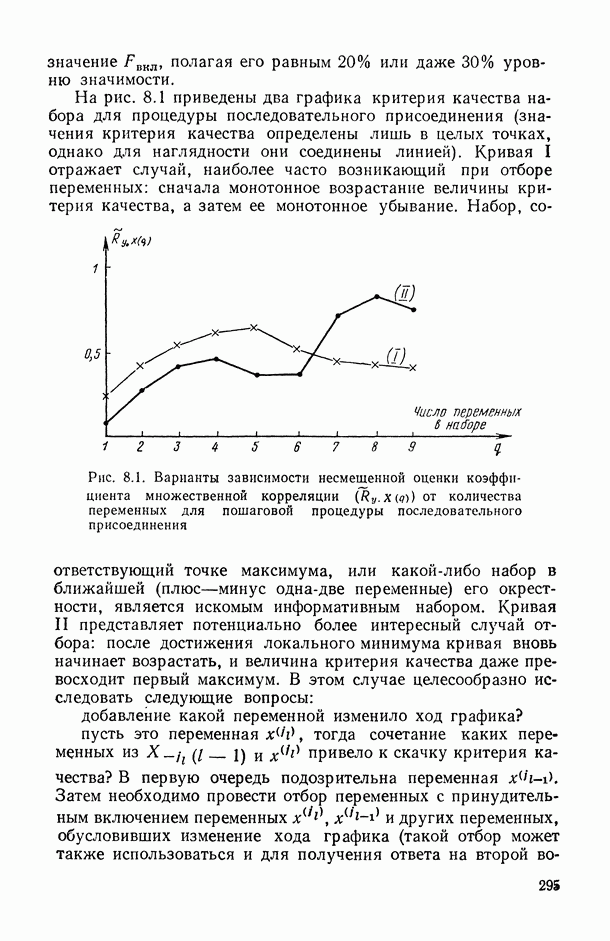































































































































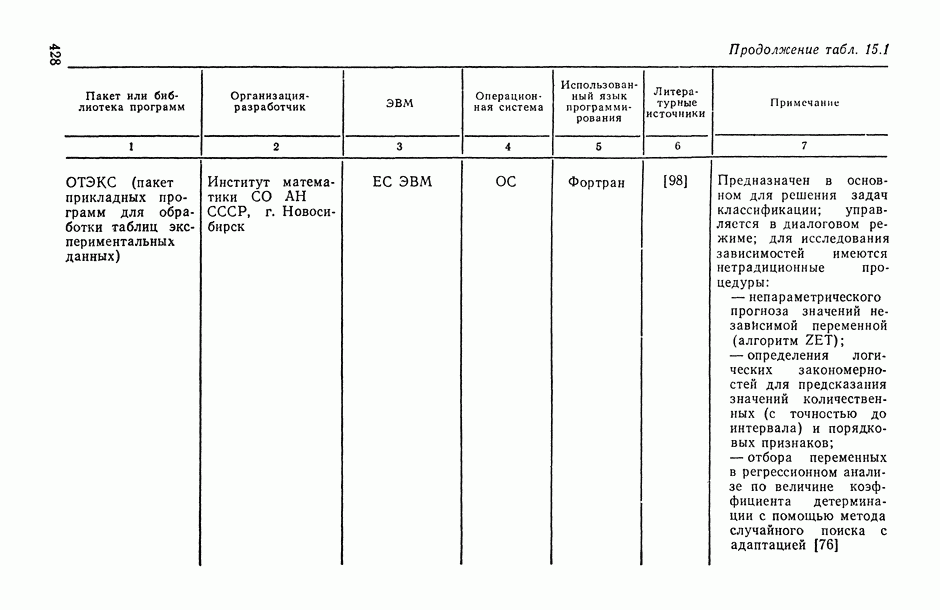


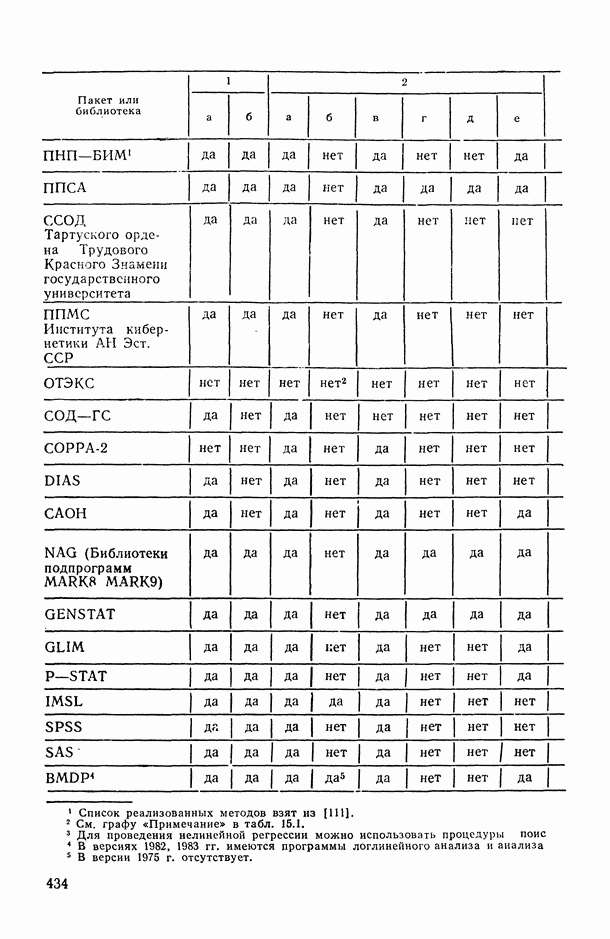
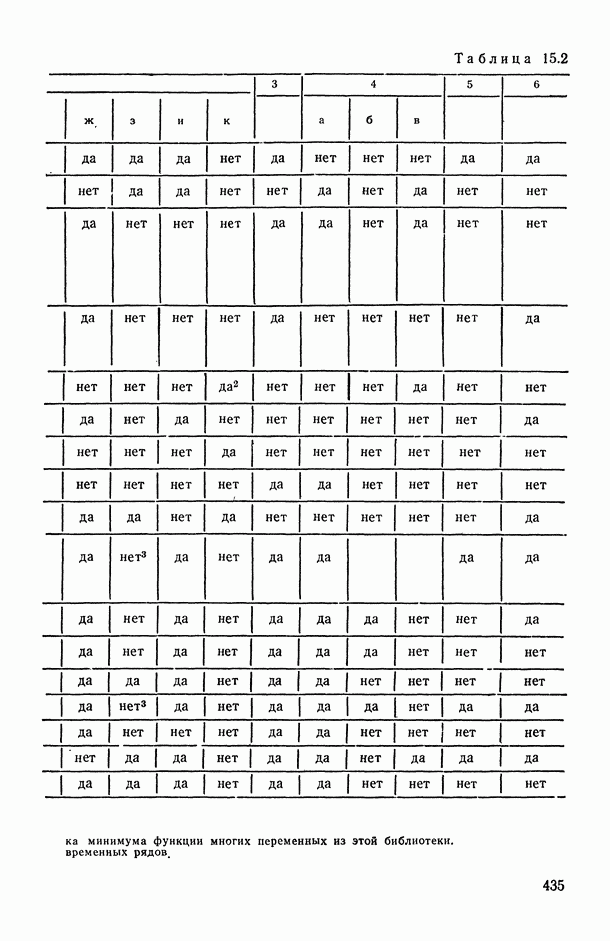

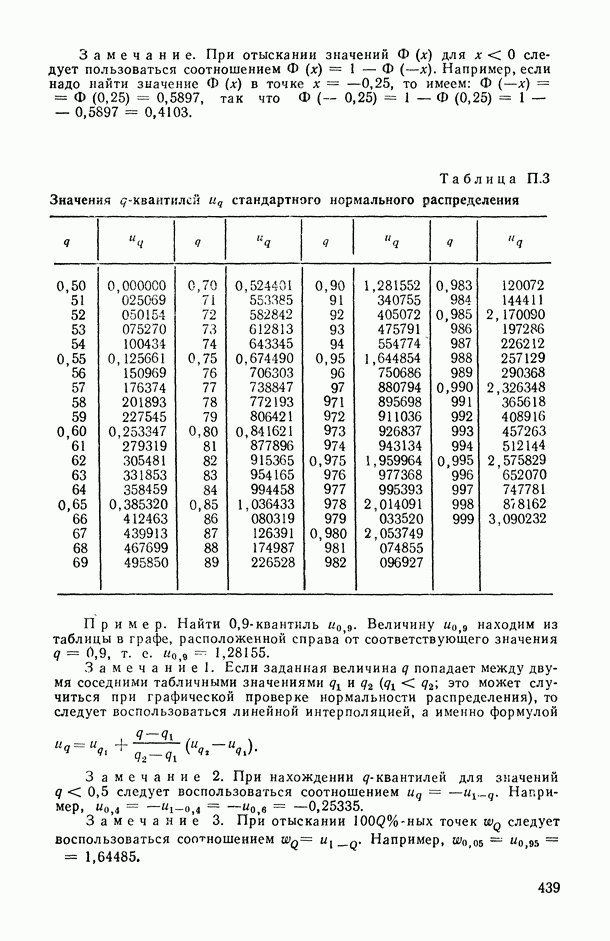
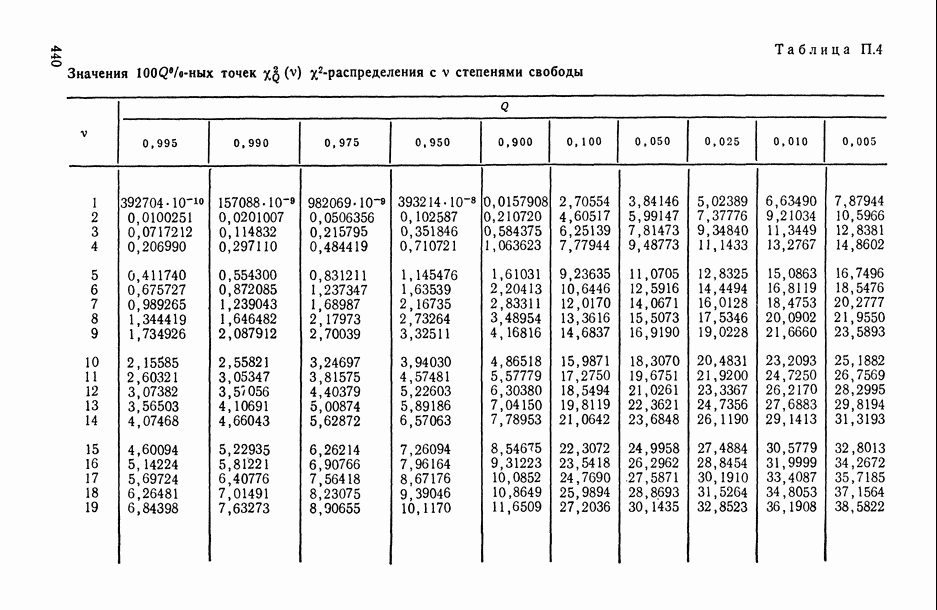



















 на заданное число t непересекающихся групп, оптимаьное в смысле максимизации критерия
на заданное число t непересекающихся групп, оптимаьное в смысле максимизации критерия  , где
, где  — коэффициент конкордации, подсчитанный по переменным, входящим в
— коэффициент конкордации, подсчитанный по переменным, входящим в  группу. Задаваясь различными значениями
группу. Задаваясь различными значениями  и прослеживая характер изменения
и прослеживая характер изменения  в зависимости от t, можно добиться успеха в выявлении групп высококоррелированных переменных
в зависимости от t, можно добиться успеха в выявлении групп высококоррелированных переменных
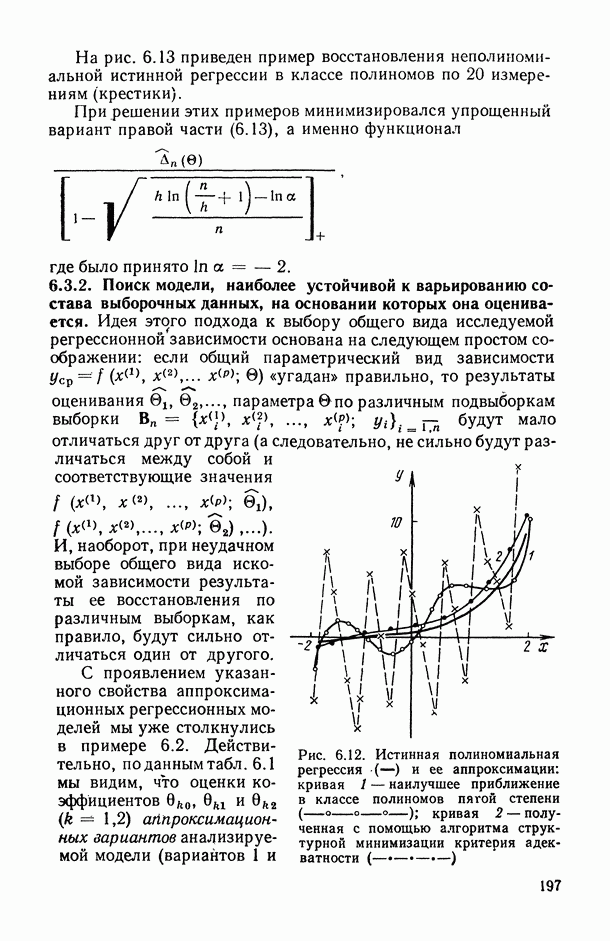
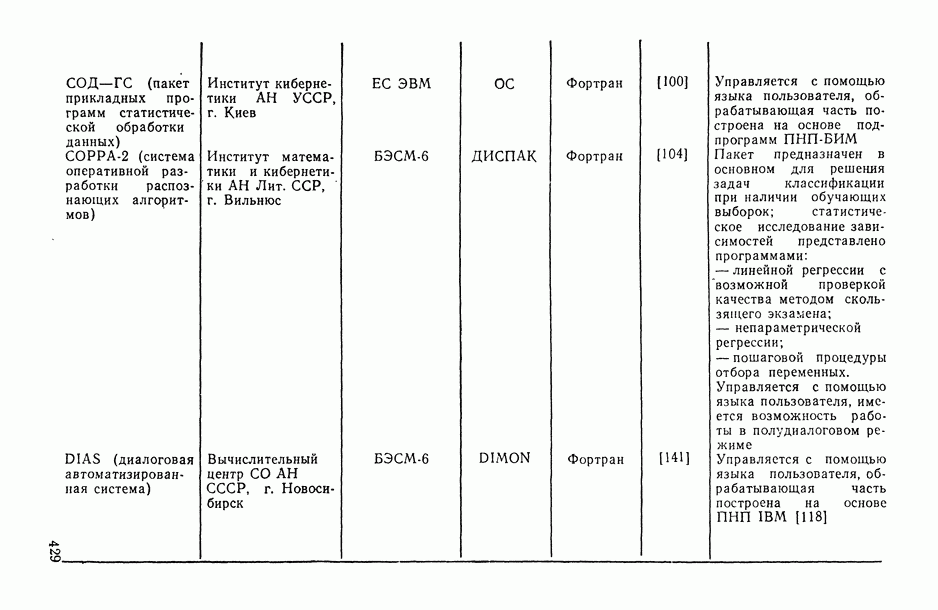
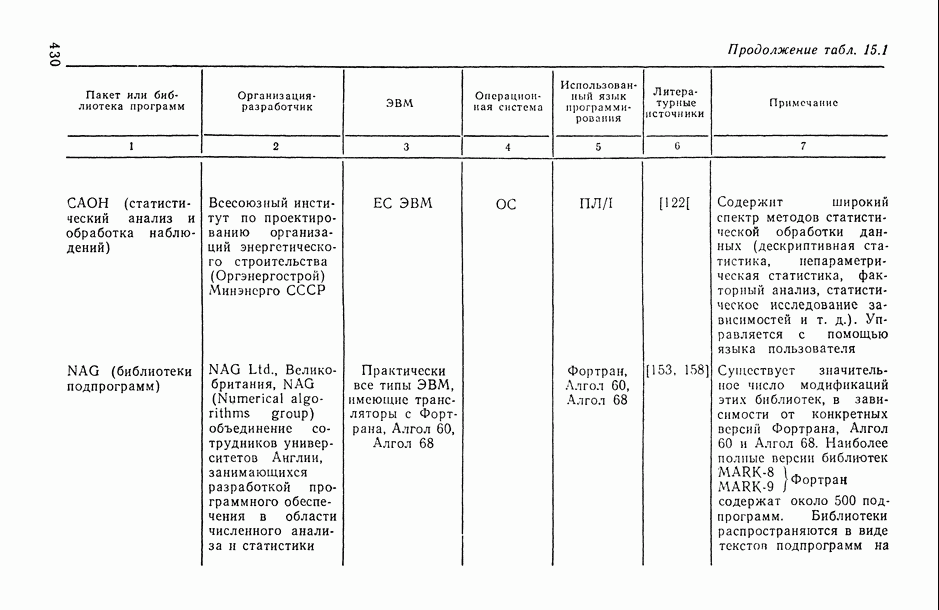
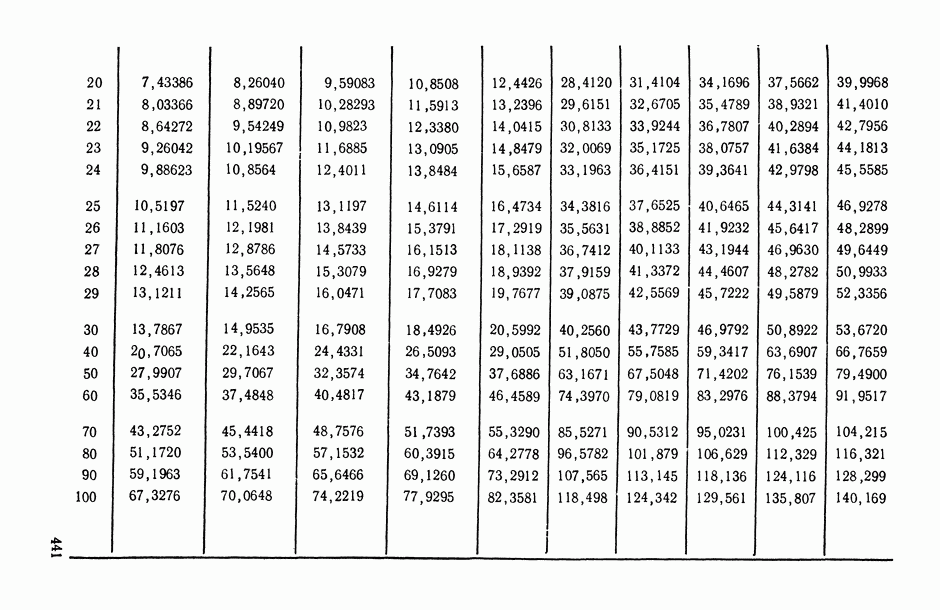
 определяются в результате сравнения сумм рангов, приписываемых каждому объекту упорядочениями
определяются в результате сравнения сумм рангов, приписываемых каждому объекту упорядочениями 
 определяются в результате сравнения выборочных медиан рангов, приписываемых каждому объекту анализируемыми упорядочениями;
определяются в результате сравнения выборочных медиан рангов, приписываемых каждому объекту анализируемыми упорядочениями;
 основано на «большинстве голосов», поданных за данный объект в ранжировках
основано на «большинстве голосов», поданных за данный объект в ранжировках  за то или иное место; например, больше других первых мест в анализируемых ранжировках получил объект
за то или иное место; например, больше других первых мест в анализируемых ранжировках получил объект  , тогда ему и присуждается ранг 1 в ранжировке
, тогда ему и присуждается ранг 1 в ранжировке  и т. д.
и т. д.
