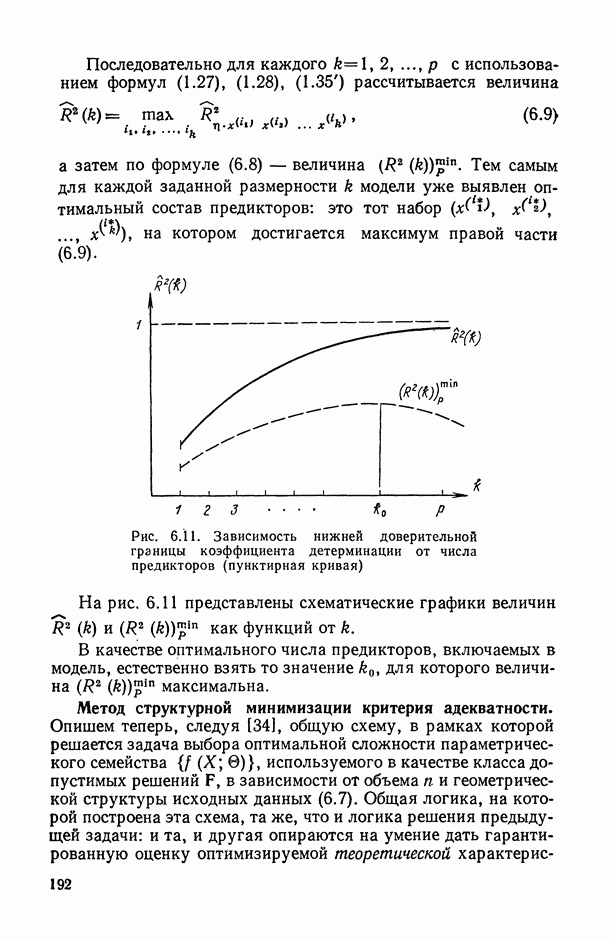
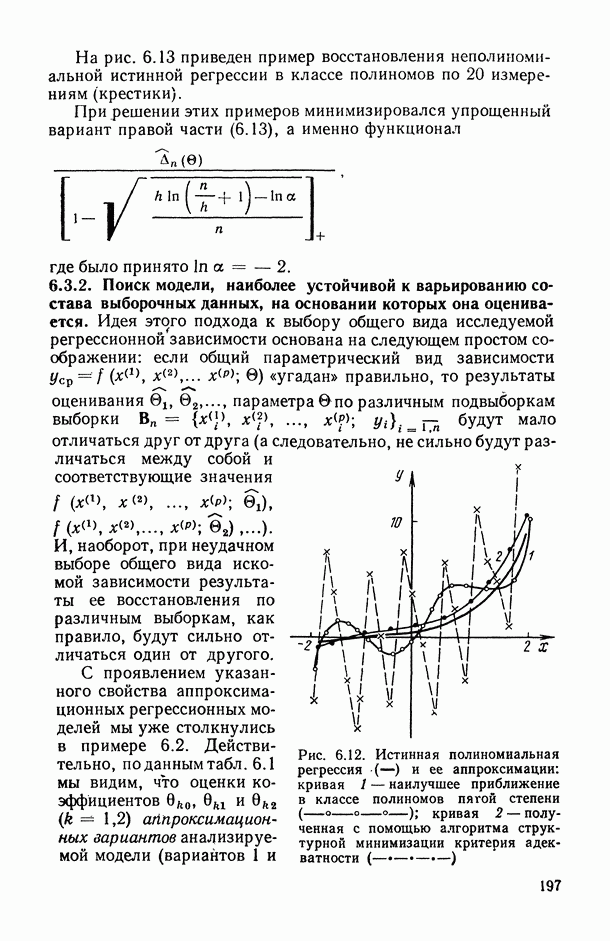
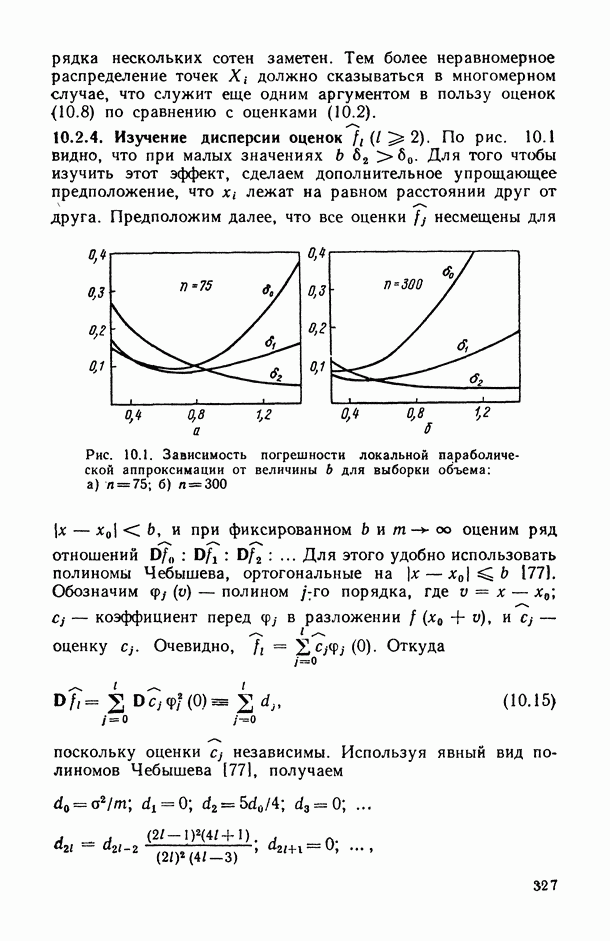
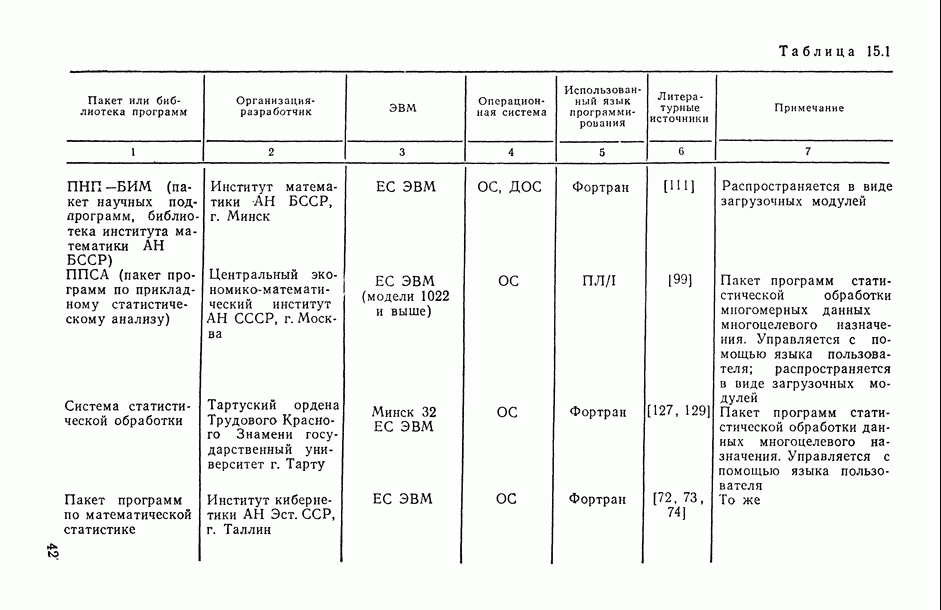
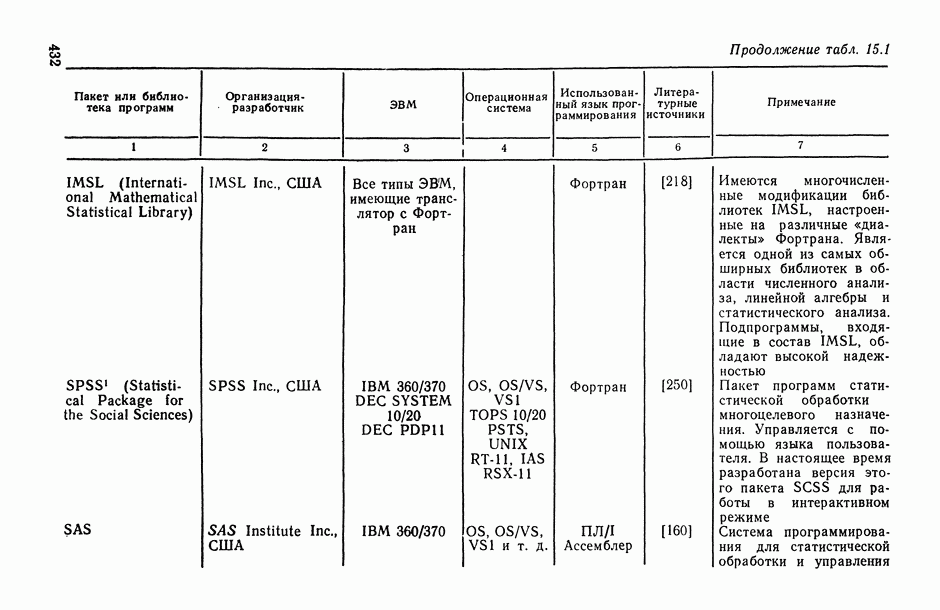
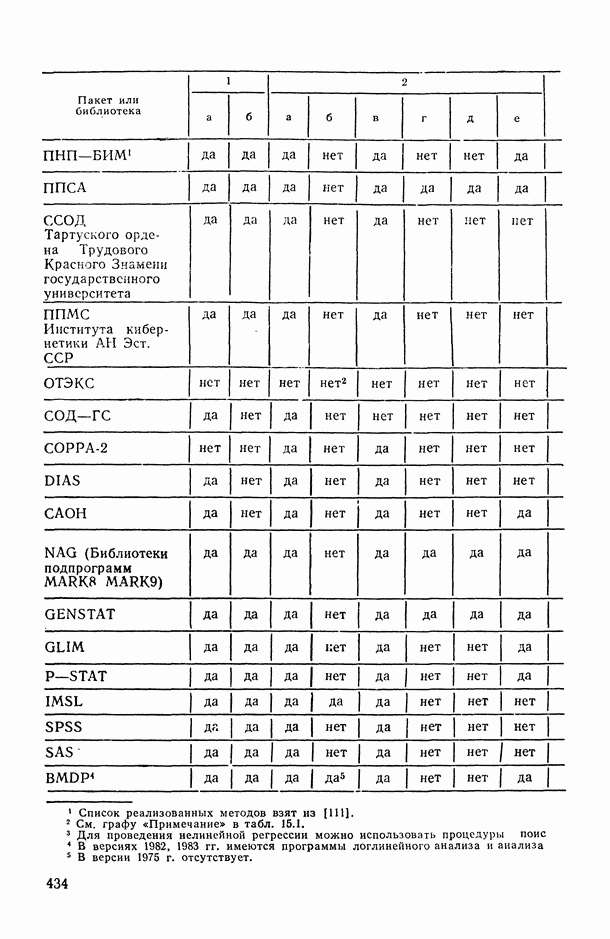
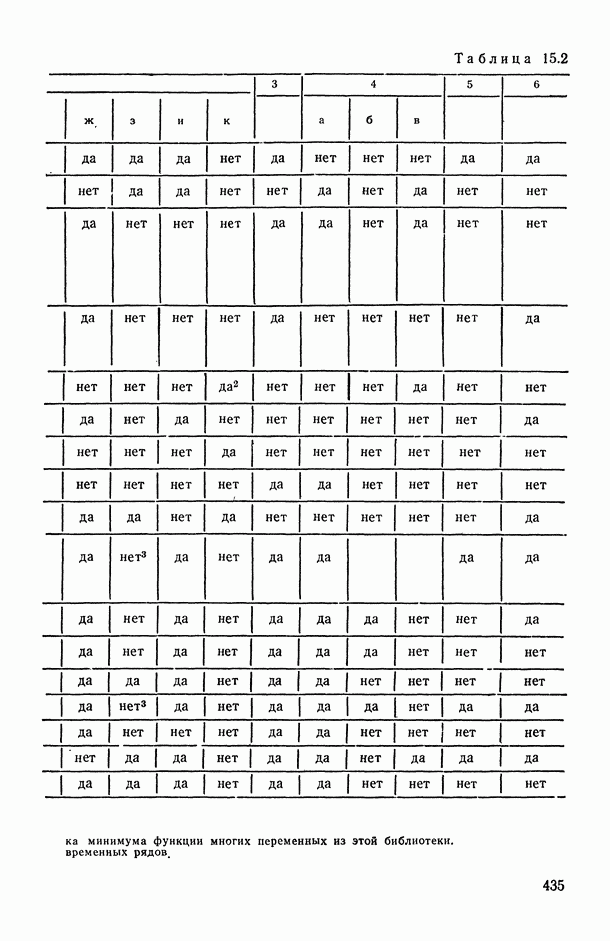
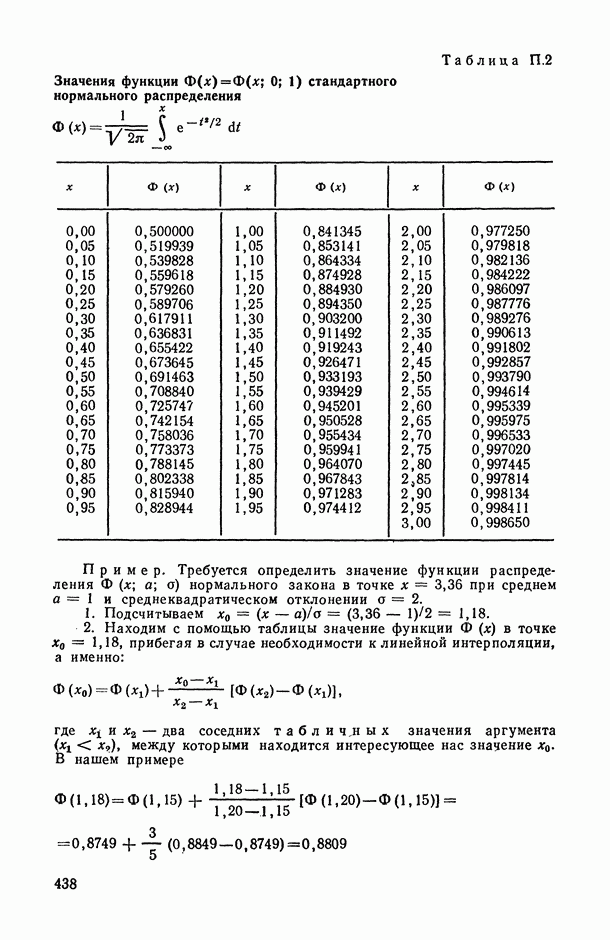
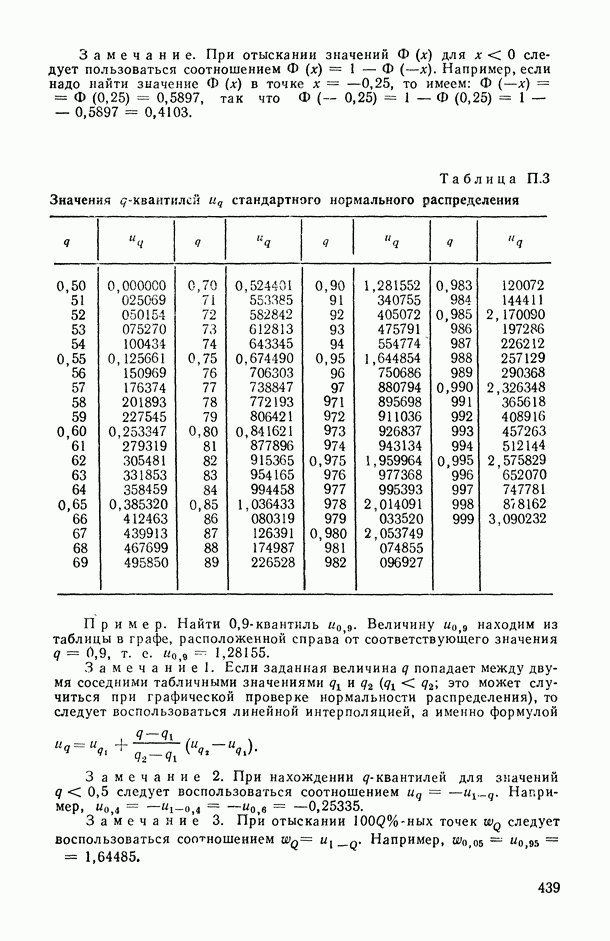
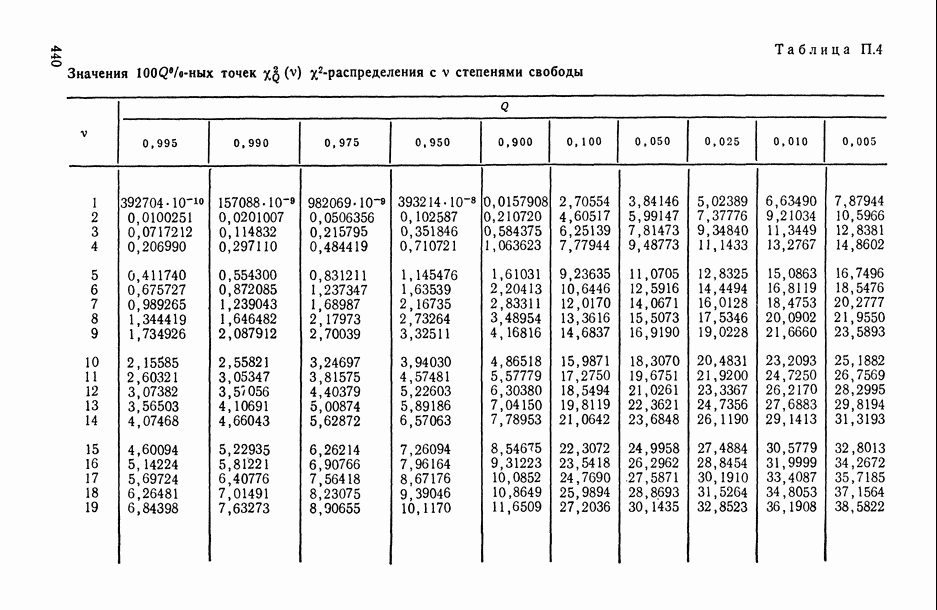
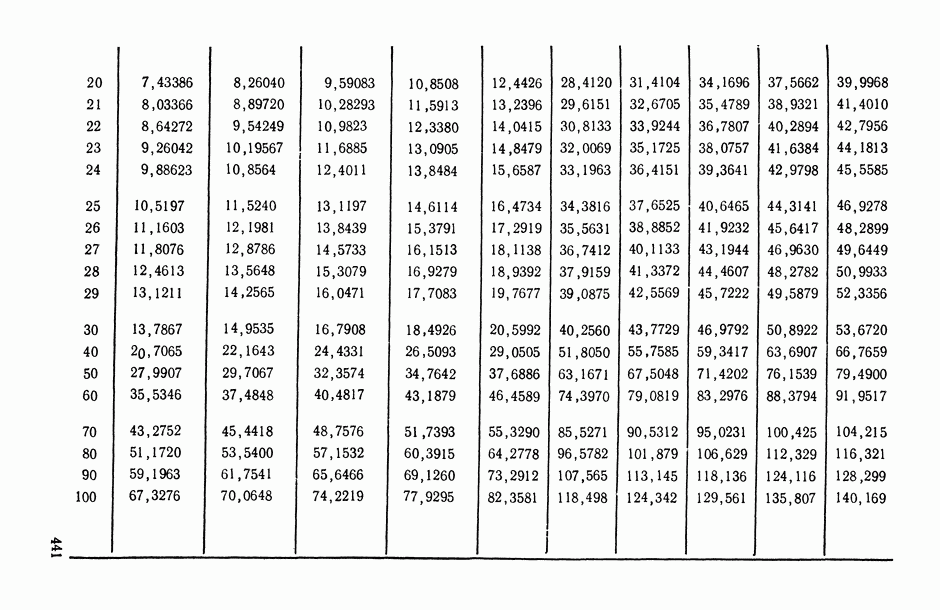
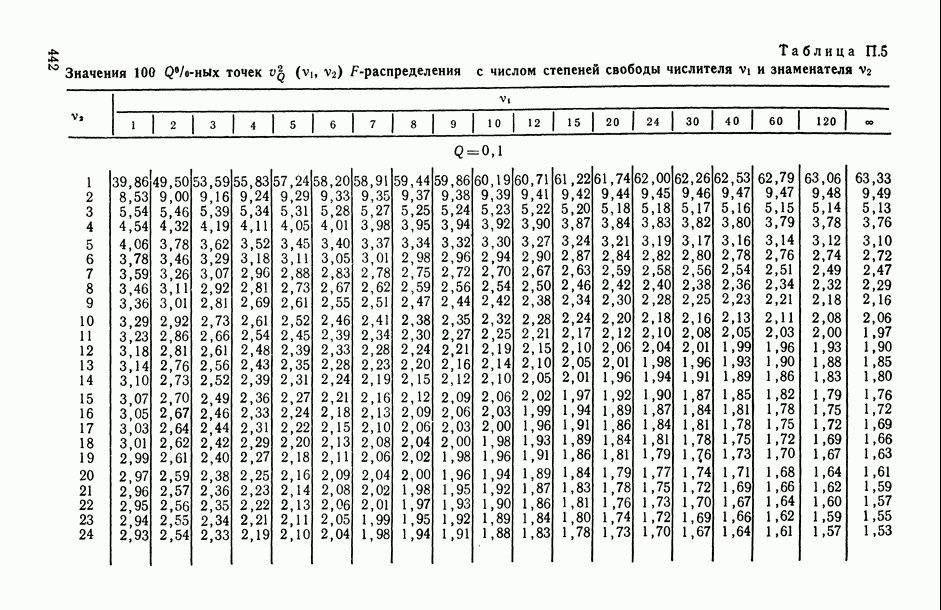
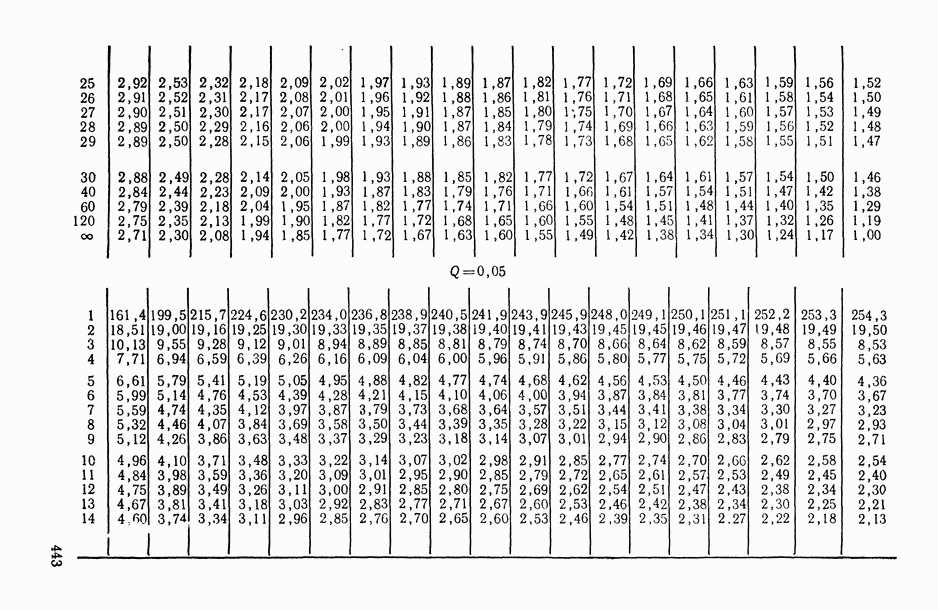
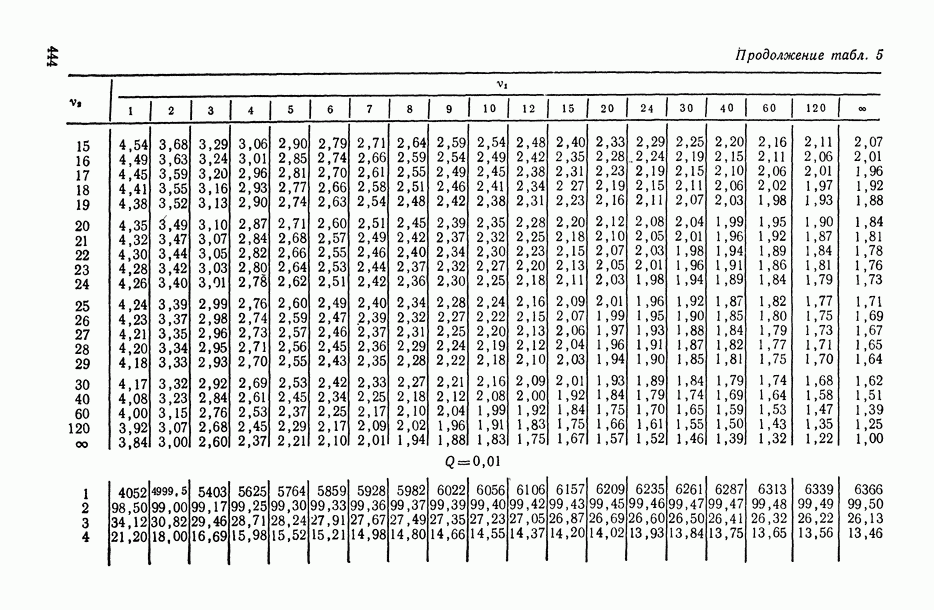
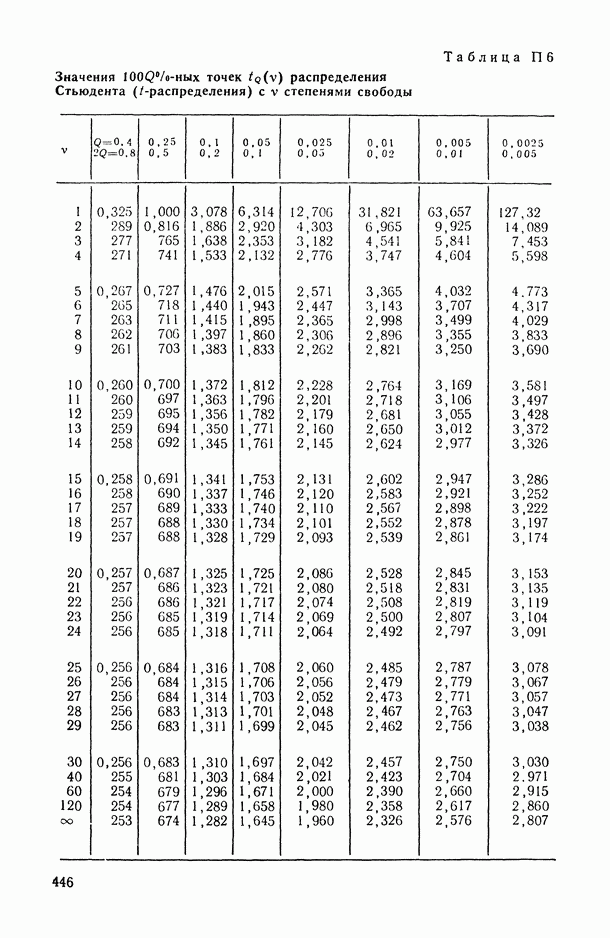
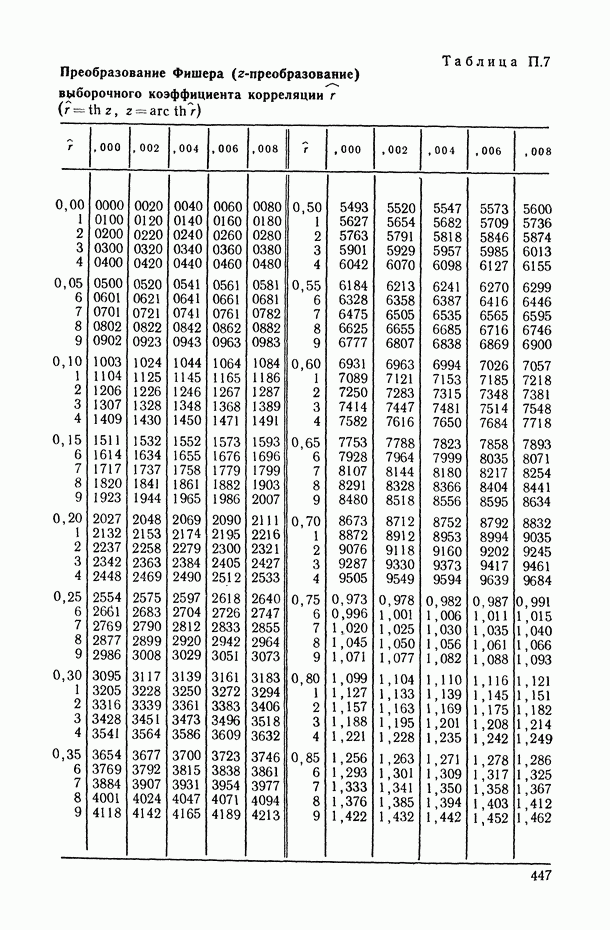
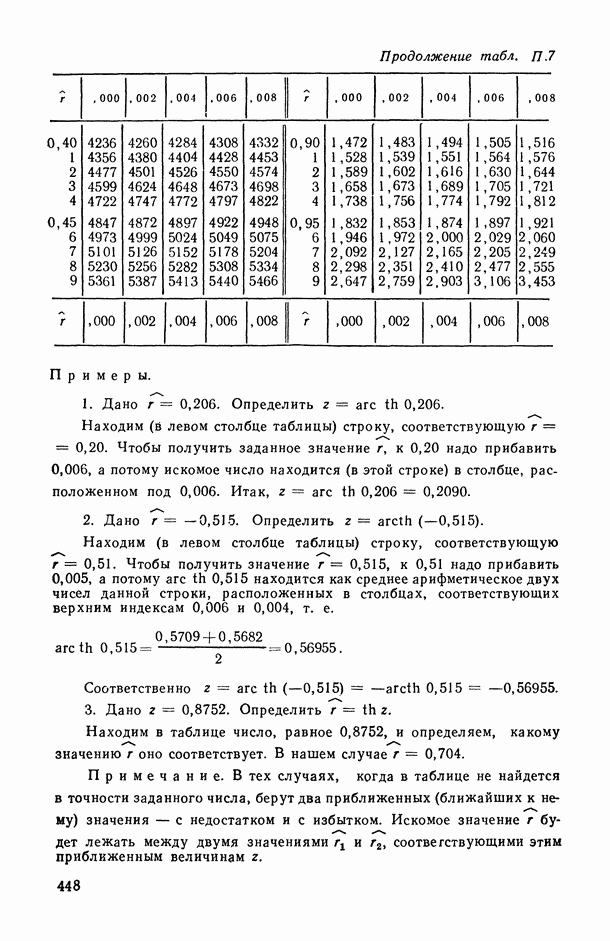
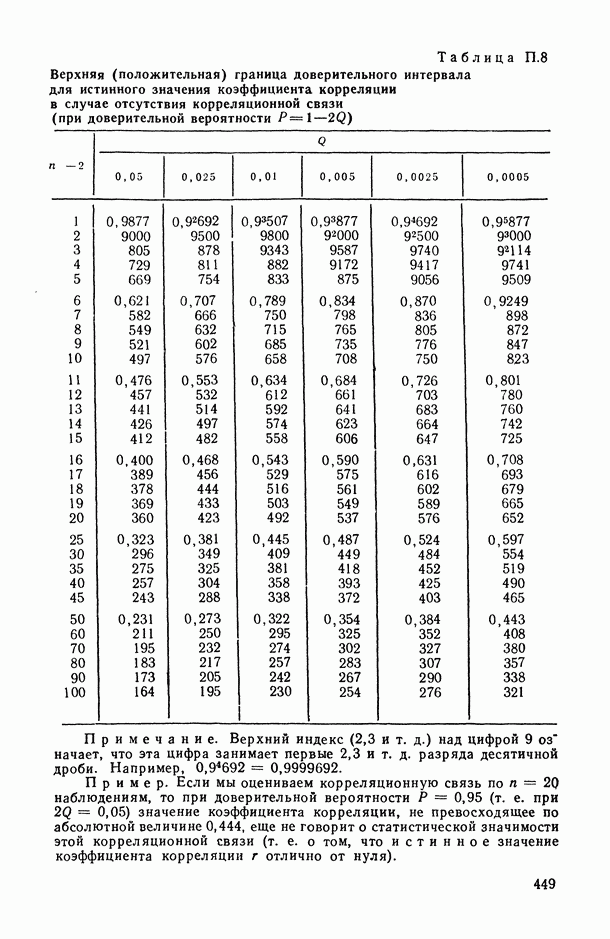
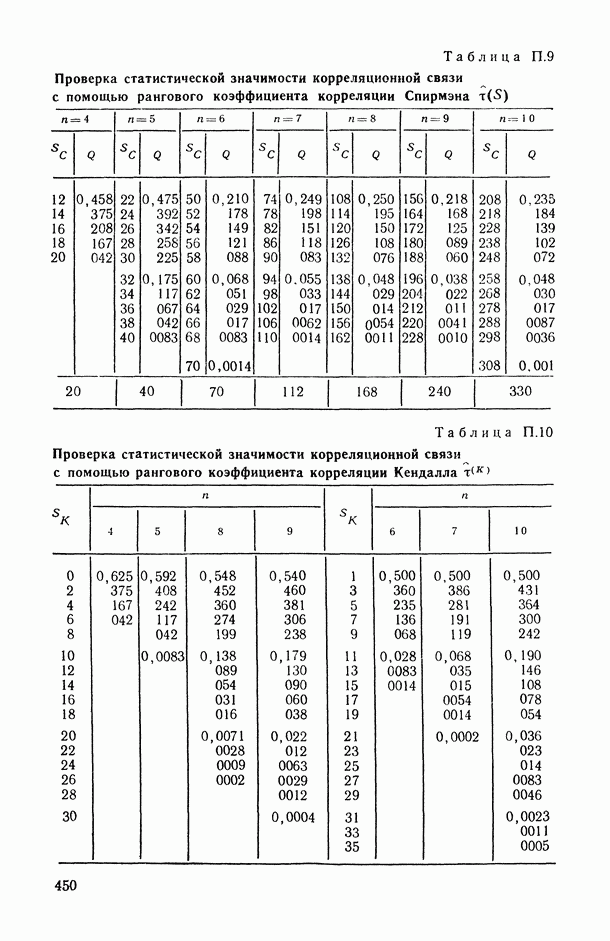
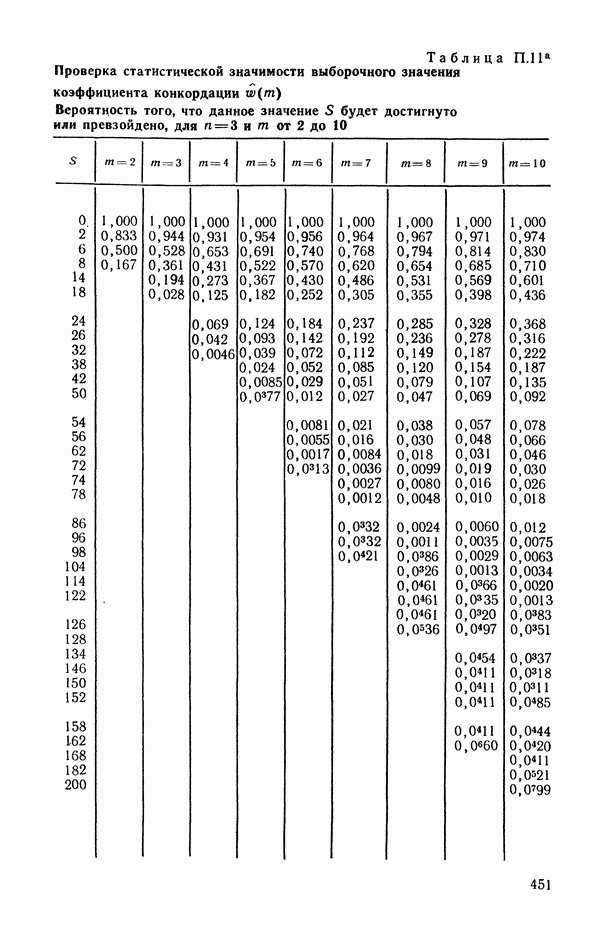
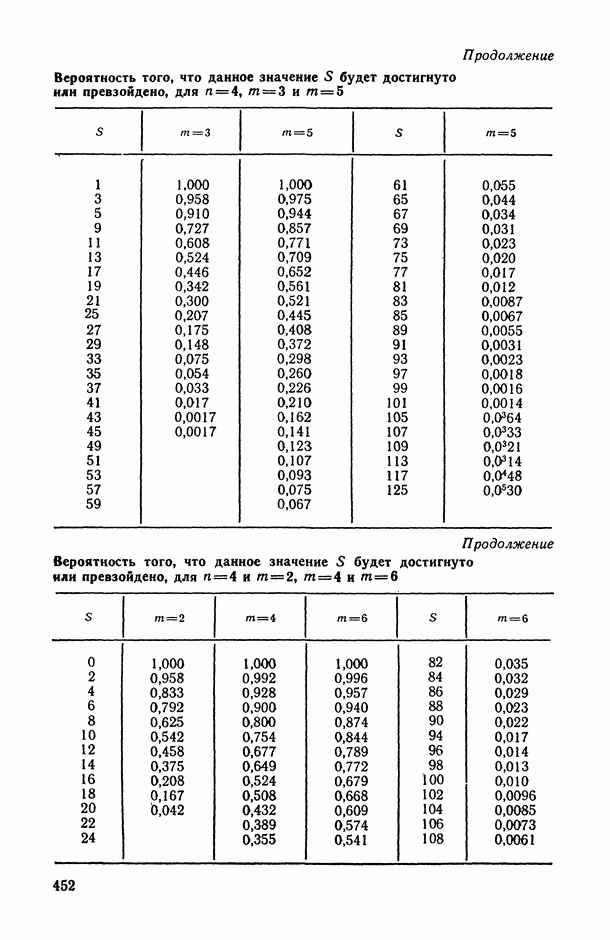
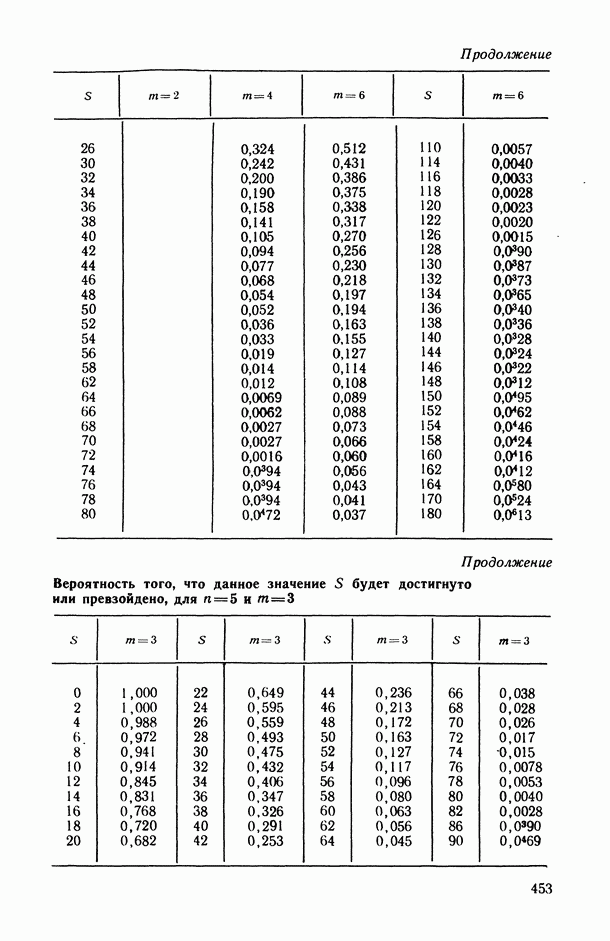
В.5. Основные типы зависимостей между количественными переменными
При изучении взаимосвязей между анализируемыми количественными показателями следует установить, к какому именно типу зависимостей относится исследуемая схема. Под типом зависимости мы подразумеваем в данном случае не аналитический вид функции  в моделях вида (В.11) (о выборе общего аналитического вида функции
в моделях вида (В.11) (о выборе общего аналитического вида функции  см. гл. 6), а природу анализируемых переменных (X, у) и соответственно интерпретацию функции
см. гл. 6), а природу анализируемых переменных (X, у) и соответственно интерпретацию функции  в каждом конкретном случае.
в каждом конкретном случае.
Зависимость между неслучайными переменными (схема А).
В этом случае результирующий показатель у детерминированно (т. е. вполне определенно, однозначно) восстанавливается по значениям неслучайных объясняющих переменных  т. е. значения у зависят только от соответствующих значений X и полностью ими определяются. Это — обычная схема чисто функциональной зависимости между неслучайными переменными, когда у является некоторой функцией от
т. е. значения у зависят только от соответствующих значений X и полностью ими определяются. Это — обычная схема чисто функциональной зависимости между неслучайными переменными, когда у является некоторой функцией от  переменных X (т. е.
переменных X (т. е.  ), что является вырожденным случаем зависимостей вида (В. 11), когда остаточная случайная компонента
), что является вырожденным случаем зависимостей вида (В. 11), когда остаточная случайная компонента  равна нулю (с вероятностью единица).
равна нулю (с вероятностью единица).
Известно, например, что возраст дерева у (в годах) можно однозначно восстановить по числу колец х на срезе его ствола, а именно у = х. Примеры адекватного описания реальных зависимостей с помощью чисто функциональных (нестохастических) связей, к сожалению, крайне редки в практике исследований. Кроме того, при проведении их анализа нет необходимости использовать методы вероятностно-статистической теории. Поэтому в дальнейшем изложении мы не будем больше возвращаться к этому типу зависимостей.
Регрессионная зависимость случайного результирующего показателя  от неслучайных предсказывающих переменных X (схема В). Природа такой связи может носить двойственный характер: а) регистрация результирующего показателя
от неслучайных предсказывающих переменных X (схема В). Природа такой связи может носить двойственный характер: а) регистрация результирующего показателя  неизбежно связана с некоторыми случайными ошибками измерения
неизбежно связана с некоторыми случайными ошибками измерения  , в то время как предикторные (объясняющие) переменные
, в то время как предикторные (объясняющие) переменные  измеряются без ошибок (или величины этих ошибок пренебрежимо малы по сравнению с соответствующими ошибками измерения результирующего показателя); б) значения результирующего показателя
измеряются без ошибок (или величины этих ошибок пренебрежимо малы по сравнению с соответствующими ошибками измерения результирующего показателя); б) значения результирующего показателя  зависят не только от соответствующих значений X, но и еще от
зависят не только от соответствующих значений X, но и еще от
В этом случае предикторные переменные X играют роль неслучайного (векторного при  параметра, от которого зависит закон распределения вероятностей (в частности, среднее значение и дисперсия) исследуемого результирующего показателя
параметра, от которого зависит закон распределения вероятностей (в частности, среднее значение и дисперсия) исследуемого результирующего показателя  Удобной математической моделью такого рода зависимостей является разложение вида
Удобной математической моделью такого рода зависимостей является разложение вида

в котором неслучайная составляющая правой части (функция  ) описывает поведение условного среднего
) описывает поведение условного среднего  в зависимости от X, а остаточная случайная компонента в (X) отражает случайную природу
в зависимости от X, а остаточная случайная компонента в (X) отражает случайную природу  . В широком классе исследуемых схем модель (В.14) строится таким образом, что математическое ожидание случайного остатка
. В широком классе исследуемых схем модель (В.14) строится таким образом, что математическое ожидание случайного остатка  равно нулю
равно нулю  тождественно по X; предполагается обычно, что при всех X существует конечная дисперсия
тождественно по X; предполагается обычно, что при всех X существует конечная дисперсия  (т. е.
(т. е.  причем величина этой дисперсии, вообще говоря, может зависеть от X (т. е.
причем величина этой дисперсии, вообще говоря, может зависеть от X (т. е.  Подчеркнем то обстоятельство, что в описанной модели (В. 14) ни природа случайной компоненты
Подчеркнем то обстоятельство, что в описанной модели (В. 14) ни природа случайной компоненты  , ни соответственно характеристики ее вероятностного распределения никак не связаны со структурой функции
, ни соответственно характеристики ее вероятностного распределения никак не связаны со структурой функции  и, в частности, не зависят от значений ее параметра 0 в параметрической записи модели (т. е. когда вместо всех возможных функций
и, в частности, не зависят от значений ее параметра 0 в параметрической записи модели (т. е. когда вместо всех возможных функций  рассматривают какое-либо параметрическое семейство
рассматривают какое-либо параметрическое семейство  , см., например, (В.12), (В.13)).
, см., например, (В.12), (В.13)).
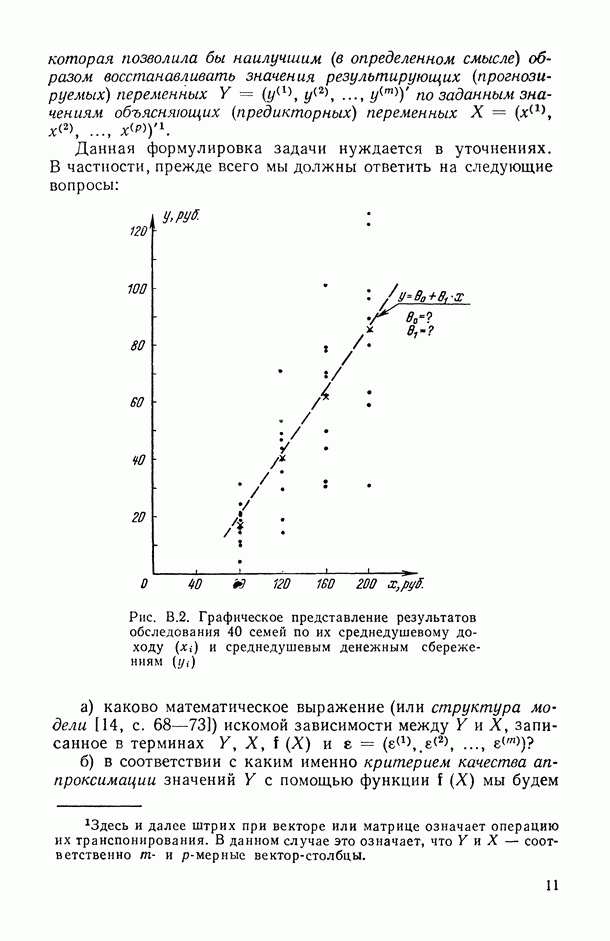
Если вернуться к примеру В.1, то можно убедиться, что он хорошо укладывается в рамки модели (В. 14). Для этого следует  ишь заметить, что имевшаяся в этом примере возможность контролировать значения предикторной переменной по существу, переводит эту переменную из категории случайных величин в категорию неслучайных (контролируемых) параметров модели. Дальнейший анализ примера В.1 (см. табл. В.1, формулу (В.5) и рис. В.2) подсказал нам следующую конкретизацию допущений о природе составных частей модели (В. 14):
ишь заметить, что имевшаяся в этом примере возможность контролировать значения предикторной переменной по существу, переводит эту переменную из категории случайных величин в категорию неслучайных (контролируемых) параметров модели. Дальнейший анализ примера В.1 (см. табл. В.1, формулу (В.5) и рис. В.2) подсказал нам следующую конкретизацию допущений о природе составных частей модели (В. 14):

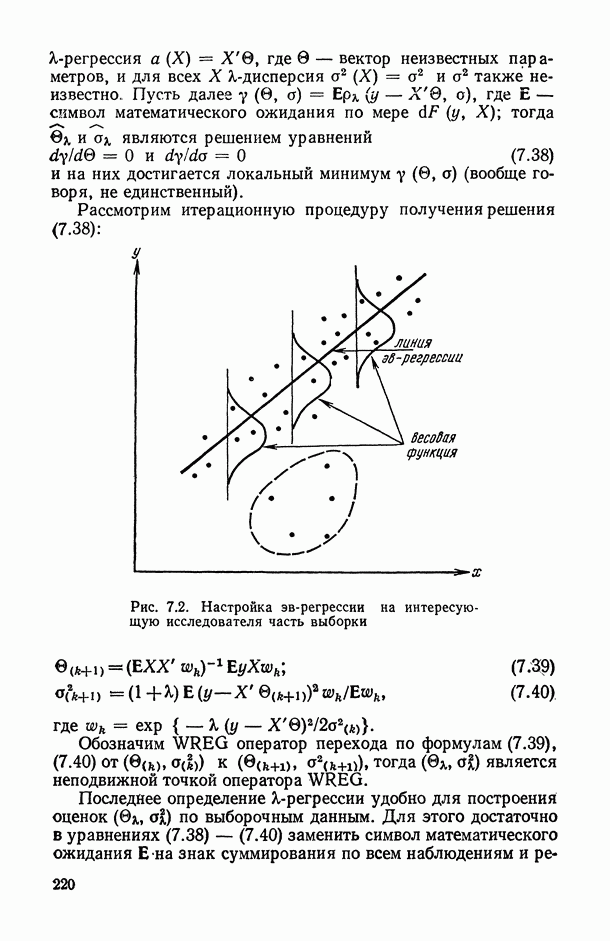
где  — константа, не зависящая от х.
— константа, не зависящая от х.
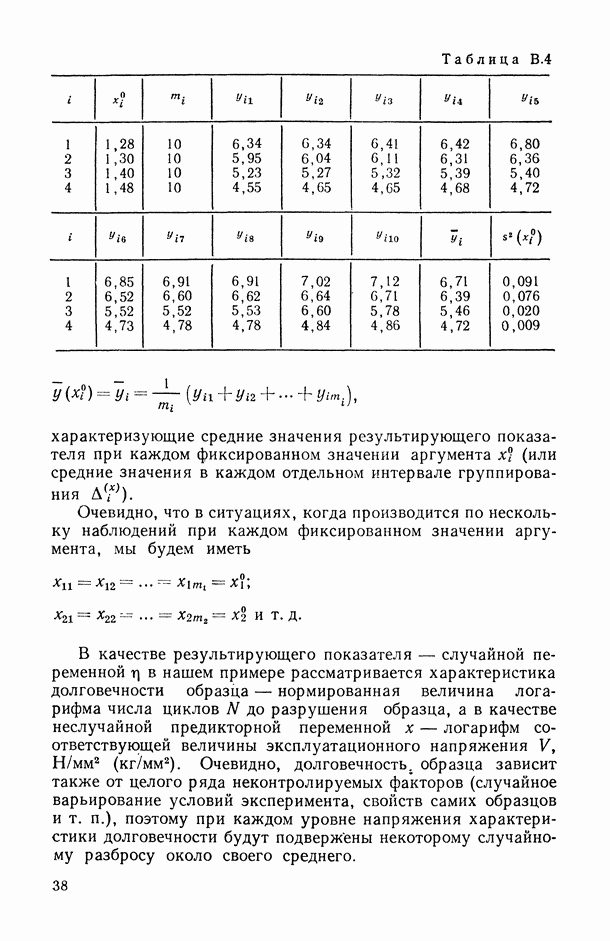
Пример В.2. В табл. В.4 и на рис. В.5 представлены результаты усталостных испытаний алюминиевых сплавов 1125], т. е. набор сорока пар  экспериментальных значений величин
экспериментальных значений величин  соответственно.
соответственно.
Если при сборе выборочных данных, составляющих двумерную систему наблюдений, производится по нескольку наблюдений при каждом фиксированном значении аргумента, а также в случае разбиения диапазона переменной — аргумента на интервалы группирования  в общую схему обозначений двумерной системы наблюдений (В.1) целесообразно внести некоторые изменения.
в общую схему обозначений двумерной системы наблюдений (В.1) целесообразно внести некоторые изменения.

Рис. В.5. Графическое представление результатов усталостных испытаний алюминиевых сплавов
Так, если  — число различных фиксированных значений предикторной переменной (или количество интервалов группирования
— число различных фиксированных значений предикторной переменной (или количество интервалов группирования  на которые разбит весь обследованный диапазон этой переменной),
на которые разбит весь обследованный диапазон этой переменной),  .
.
— количество наблюдений, произведенных при  фиксированном значении аргумента (или количество наблюдений, попавших в
фиксированном значении аргумента (или количество наблюдений, попавших в  интервал разбиения
интервал разбиения  ), то результаты наблюдений удобнее снабдить двумя индексами, т. е. записать в виде (
), то результаты наблюдений удобнее снабдить двумя индексами, т. е. записать в виде ( ), где
), где  . Здесь первый индекс
. Здесь первый индекс  обозначает порядковый номер фиксированного значения независимой переменной (или порядковый номер интервала группирования), а второй индекс
обозначает порядковый номер фиксированного значения независимой переменной (или порядковый номер интервала группирования), а второй индекс  порядковый номер наблюдения, произведенного приданном
порядковый номер наблюдения, произведенного приданном  фиксированном значении аргумента (или порядковый номер наблюдения, попадающего в
фиксированном значении аргумента (или порядковый номер наблюдения, попадающего в  интервал группирования). Так, например, под
интервал группирования). Так, например, под  понимается результат пятого по порядку наблюдения, произведенного при третьем фиксированном значении аргумента (или попадающего в третий интервал группирования
понимается результат пятого по порядку наблюдения, произведенного при третьем фиксированном значении аргумента (или попадающего в третий интервал группирования  ). В наших рассмотрениях будут фигурировать также величины
). В наших рассмотрениях будут фигурировать также величины  представляющие собой последовательность различных фиксированных значений аргумента, при которых производились наблюдения (или средние точки интервалов группирования
представляющие собой последовательность различных фиксированных значений аргумента, при которых производились наблюдения (или средние точки интервалов группирования  ), а также условные средние зависимой переменной
), а также условные средние зависимой переменной
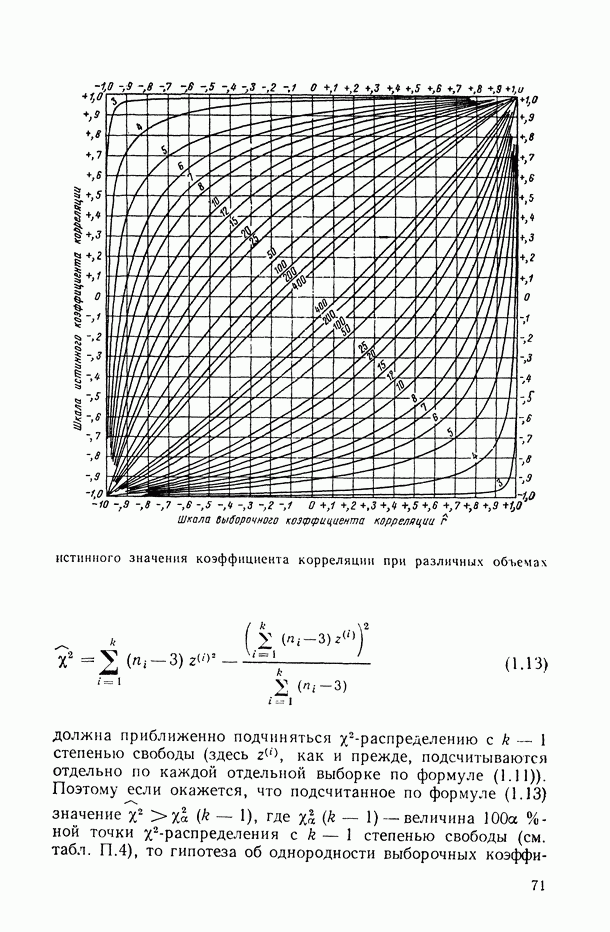
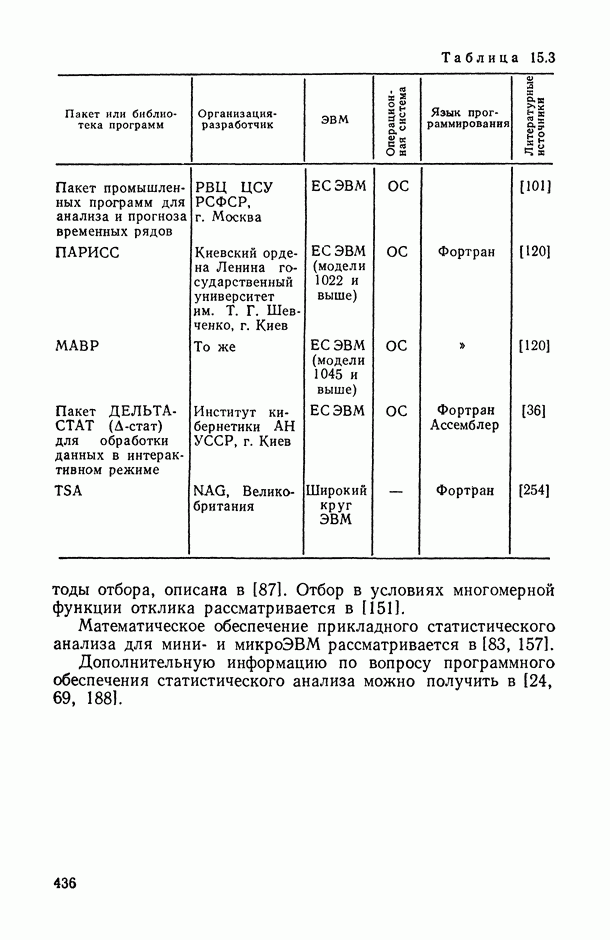
Таблица В.4


характеризующие средние значения результирующего показателя при каждом фиксированном значении аргумента х? (или средние значения в каждом отдельном интервале группирования
Очевидно, что в ситуациях, когда производится по нескольку наблюдений при каждом фиксированном значении аргумента, мы будем иметь

В качестве результирующего показателя — случайной переменной  в нашем примере рассматривается характеристика долговечности образца — нормированная величина логарифма числа циклов N до разрушения образца, а в качестве неслучайной предикторной переменной х — логарифм соответствующей величины эксплуатационного напряжения
в нашем примере рассматривается характеристика долговечности образца — нормированная величина логарифма числа циклов N до разрушения образца, а в качестве неслучайной предикторной переменной х — логарифм соответствующей величины эксплуатационного напряжения  . Очевидно, долговечность образца зависит также от целого ряда неконтролируемых факторов (случайное варьирование условий эксперимента, свойств самих образцов и т. п.), поэтому при каждом уровне напряжения характеристики долговечности будут подвержены некоторому случайному разбросу около своего среднего.
. Очевидно, долговечность образца зависит также от целого ряда неконтролируемых факторов (случайное варьирование условий эксперимента, свойств самих образцов и т. п.), поэтому при каждом уровне напряжения характеристики долговечности будут подвержены некоторому случайному разбросу около своего среднего.
Первая из них определяется некоторой (векторнозначной) функцией  от объясняющей переменной
от объясняющей переменной  , а вторая отражает остаточные влияния неучтенных случайных факторов на анализируемый результирующий показатель
, а вторая отражает остаточные влияния неучтенных случайных факторов на анализируемый результирующий показатель  Итак
Итак

При этом разложение (В. 16) строится таким образом, чтобы для компонент векторов  и
и  выполнялись соотношения
выполнялись соотношения 
В частном случае единственного результирующего показателя  и линейного вида функции
и линейного вида функции  имеем:
имеем:

Подразумевая, как и прежде, под  условное математическое ожидание результирующего показателя
условное математическое ожидание результирующего показателя  (при условии, что объясняющая переменная
(при условии, что объясняющая переменная  приняла значение, равное X), мы от (В. 17) приходим к линейному уравнению регрессии
приняла значение, равное X), мы от (В. 17) приходим к линейному уравнению регрессии

Возможны случаи, когда вторая (остаточная) компонента в разложении (В. 16) с полной мерой достоверности (т. е. с вероятностью единица) равна нулю. При этом исследуемые случайные величины  оказываются связанными чисто функциональной зависимостью
оказываются связанными чисто функциональной зависимостью  но ее следует отличать от функциональной зависимости неслучайных переменных (см. выше, схема А).
но ее следует отличать от функциональной зависимости неслучайных переменных (см. выше, схема А).
Пример В.3. Рис. В.6 иллюстрирует связь между вакуумом в печи для отжига стекла  и процентом брака
и процентом брака  в стекольном производстве [101.
в стекольном производстве [101.
Случайные изменения свойств сырья, а также ряда неконтролируемых факторов приводят к случайным колебаниям обеих исследуемых переменных. Однако расположение точек на рис. В.6 свидетельствует о том, что эти колебания взаимосвязаны, подчинены вполне определенной закономерности: «облако» рассеяния вытянуто вдоль некоторой прямой, не параллельной ни одной из координатных осей. Все это подтверждает целесообразность разложения случайной величины  по формуле (В. 16) и исследования связи между
по формуле (В. 16) и исследования связи между  и которая в этом случае носит название корреляционной.
и которая в этом случае носит название корреляционной.
К перечисленным вопросам регрессионного анализа (построение конкретного вида зависимости между переменными, различные оценки ее точности) в этом случае присоединяется круг вопросов, связанных с исследованием степени тесноты связи между этими переменными. Совокупность методов, позволяющих решать эти вопросы, принято называть корреляционным анализом (см. гл. 1—3).

Рис. В.6. Графическое представление данных по связи вакуума в печи для обжига стекла  и процента брака в стекольном производстве
и процента брака в стекольном производстве 
Зависимости структурного типа, или зависимости по схеме конфлюэнтного анализа (схемы  ). В обеих описываемых ниже схемах речь идет о восстановлении искомых зависимостей по искаженным наблюдениям анализируемых переменных, причем, в отличие от регрессионной схемы В, искаженными оказываются при наблюдении не только значения результирующего показателя, но и значения объясняющих (предик-торных) переменных
). В обеих описываемых ниже схемах речь идет о восстановлении искомых зависимостей по искаженным наблюдениям анализируемых переменных, причем, в отличие от регрессионной схемы В, искаженными оказываются при наблюдении не только значения результирующего показателя, но и значения объясняющих (предик-торных) переменных  . В зависимости оттого, между какими именно переменными — неслучайными или случайными — исследуются связи, мы будем иметь соответственно тип связи по схеме
. В зависимости оттого, между какими именно переменными — неслучайными или случайными — исследуются связи, мы будем иметь соответственно тип связи по схеме  или
или  . Оба эти типа связей упоминаются в специальной литературе как структурные зависимости [65, с. 500—557] или как зависимости по схеме конфлюэнтного анализа [7, 10]. Таким образом, конфлюэнтный анализ предоставляет исследователю совокупность методов математико-статистической обработки данных, относящихся к анализу априори постулируемых функциональных связей между количественными (случайными или неслучайными) переменными
. Оба эти типа связей упоминаются в специальной литературе как структурные зависимости [65, с. 500—557] или как зависимости по схеме конфлюэнтного анализа [7, 10]. Таким образом, конфлюэнтный анализ предоставляет исследователю совокупность методов математико-статистической обработки данных, относящихся к анализу априори постулируемых функциональных связей между количественными (случайными или неслучайными) переменными  в условиях, когда наблюдаются не сами переменные, а случайные величины
в условиях, когда наблюдаются не сами переменные, а случайные величины

где  — случайные ошибки измерений соответственно переменных
— случайные ошибки измерений соответственно переменных  наблюдении, а
наблюдении, а  — общее число наблюдений. При этом общий вид исследуемых функциональных (структурных)- связей
— общее число наблюдений. При этом общий вид исследуемых функциональных (структурных)- связей

между ненаблюдаемыми, а точнее, наблюдаемыми с ошибками переменными считается заданным (неизвестным является лишь значение векторного параметра  участвующего в уравнениях искомых зависимостей (В.20)).
участвующего в уравнениях искомых зависимостей (В.20)).
Схема  исследуемые переменные
исследуемые переменные  не случайны. Для упрощения обозначений проанализируем зависимости (В.19)-(В.20) в рамках данной схемы лишь для одного результирующего показателя и одной объясняющей переменной (случай
не случайны. Для упрощения обозначений проанализируем зависимости (В.19)-(В.20) в рамках данной схемы лишь для одного результирующего показателя и одной объясняющей переменной (случай  обобщение этого анализа на случай
обобщение этого анализа на случай  не представляет принципиальных трудностей.
не представляет принципиальных трудностей.
Учитывая формулы (В.19) и (В.20) и воспользовавшись формальным разложением функции  в ряд Тейлора около точки
в ряд Тейлора около точки  , получаем соотношение между
, получаем соотношение между  и
и

Здесь под  подразумевается
подразумевается  производная функции
производная функции  по
по  взятая в точке
взятая в точке  . В частности, при линейном виде имеем
. В частности, при линейном виде имеем

Из (В.21) непосредственно следует, что уравнение регрессии  по
по  (т. е. вид зависимости условного математического ожидания
(т. е. вид зависимости условного математического ожидания  )
)  от
от  совпадает со структурным соотношением (В.20). Однако в схеме
совпадает со структурным соотношением (В.20). Однако в схеме  в отличие от схем В и С, остаточная случайная компонента в разложениях (В.21) и (В.22) (т. е. соответственно
в отличие от схем В и С, остаточная случайная компонента в разложениях (В.21) и (В.22) (т. е. соответственно  зависит от неизвестных параметров, участвующих в описании функции
зависит от неизвестных параметров, участвующих в описании функции  и оцениваемых на основании имеющихся у нас выборочных данных.
и оцениваемых на основании имеющихся у нас выборочных данных.
Эта специфичность природы зависимости, присущая схеме  сильно усложняет задачу построения хороших оценок для неизвестных параметров, входящих в соотношение (В.20). Дело в том, что достаточно хорошо разработанная теория построения таких оценок для схем В и С, в частности оценок максимального правдоподобия, оценок наименьших квадратов, оказывается неприменимой к задачам схемы
сильно усложняет задачу построения хороших оценок для неизвестных параметров, входящих в соотношение (В.20). Дело в том, что достаточно хорошо разработанная теория построения таких оценок для схем В и С, в частности оценок максимального правдоподобия, оценок наименьших квадратов, оказывается неприменимой к задачам схемы 
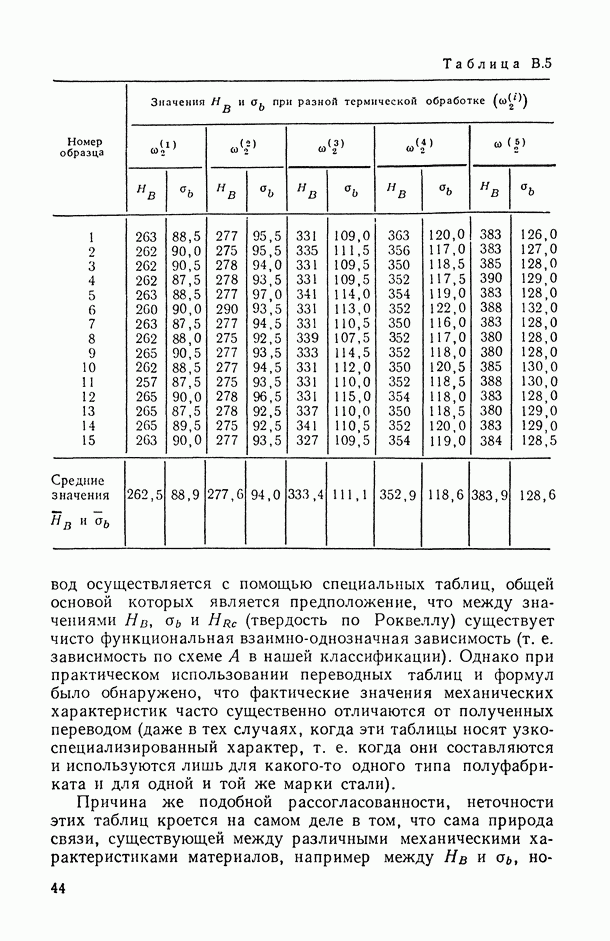
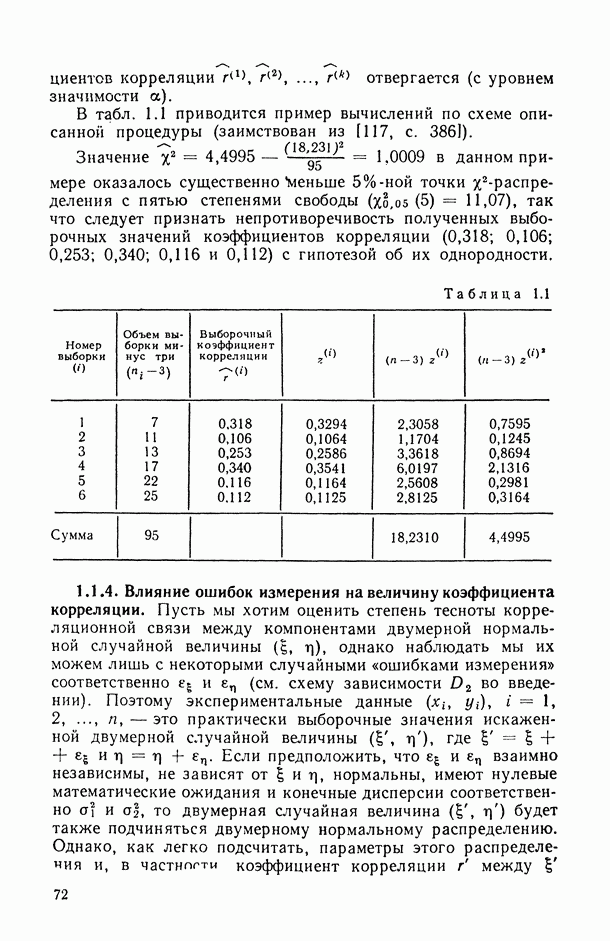
Таблица В.5

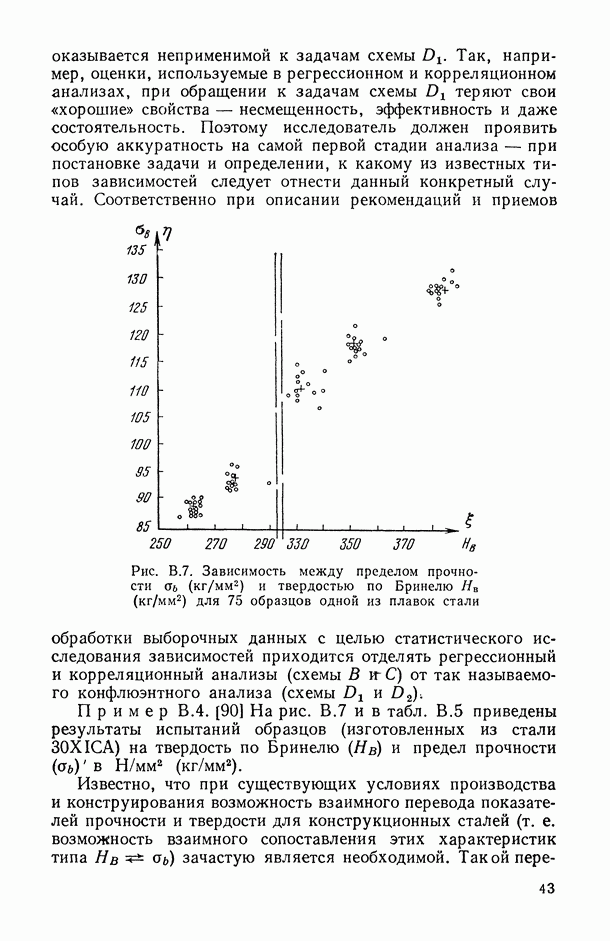
Такой перевод осуществляется с помощью специальных таблиц, общей основой которых является предположение, что между значениями  (твердость по Роквеллу) существует чисто функциональная взаимно-однозначная зависимость (т. е. зависимость по схеме А в нашей классификации). Однако при практическом использовании переводных таблиц и формул было обнаружено, что фактические значения механических характеристик часто существенно отличаются от полученных переводом (даже в тех случаях, когда эти таблицы носят узкоспециализированный характер, т. е. когда они составляются и используются лишь для какого-то одного типа полуфабриката и для одной и той же марки стали).
(твердость по Роквеллу) существует чисто функциональная взаимно-однозначная зависимость (т. е. зависимость по схеме А в нашей классификации). Однако при практическом использовании переводных таблиц и формул было обнаружено, что фактические значения механических характеристик часто существенно отличаются от полученных переводом (даже в тех случаях, когда эти таблицы носят узкоспециализированный характер, т. е. когда они составляются и используются лишь для какого-то одного типа полуфабриката и для одной и той же марки стали).
Причина же подобной рассогласованности, неточности этих таблиц кроется на самом деле в том, что сама природа связи, существующей между различными механическими характеристиками материалов, например между  носит не функциональный (детерминированный), а стохастический характер.
носит не функциональный (детерминированный), а стохастический характер.
Так, например, на рис. В.7 видно, что при каждом фиксированном значении твердости соответствующие значения предела прочности  подвержены некоторому неконтролируемому разбросу.
подвержены некоторому неконтролируемому разбросу.
Более детальный профессионально-статистический анализ [90] приводит нас в данном случае к следующей схеме.
На значения  так же как и на вид связи, существующей между ними, влияют следующие факторы:
так же как и на вид связи, существующей между ними, влияют следующие факторы:
1) химический состав плавки 
2) термическая обработка  ;
;
3) особенности исследуемого образца — локальный химсостав, размеры зерна в зоне отпечатка, локальная термическая обработка и т. п.  ;
;
4) погрешности измерения, связанные с приборами, установкой образца и т. п.  .
.
Если величину твердости по Бринелю  обозначим а соответствующую величину предела прочности
обозначим а соответствующую величину предела прочности  то можно воспользоваться выражением, где роль неслучайных (структурных) компонент
то можно воспользоваться выражением, где роль неслучайных (структурных) компонент  и у играют значения
и у играют значения  и
и  взятые для некоторой фиксированной плавки
взятые для некоторой фиксированной плавки  при некотором фиксированном режиме термической обработки
при некотором фиксированном режиме термической обработки  и усредненные по всевозможным комбинациям факторов
и усредненные по всевозможным комбинациям факторов  (их «наблюденные значения», полученные усреднением по пятнадцати однородным плавкам, изображены на рис. В.7). Что касается остаточных случайных компонент
(их «наблюденные значения», полученные усреднением по пятнадцати однородным плавкам, изображены на рис. В.7). Что касается остаточных случайных компонент  , то наличие каждой из них обусловлено в данном случае различиями в особенностях исследуемых образцов (фактор
, то наличие каждой из них обусловлено в данном случае различиями в особенностях исследуемых образцов (фактор  ). При этом из наших определений следует, что
). При этом из наших определений следует, что  Кроме того, специфика данной конкретной задачи такова, что мы вправе принять в качестве исходных предпосылок для дальнейшего исследования следующие допущения:
Кроме того, специфика данной конкретной задачи такова, что мы вправе принять в качестве исходных предпосылок для дальнейшего исследования следующие допущения:
а) между структурными компонентами у их имеется линейная зависимость вида В. 15, причем коэффициенты  вообще говоря, зависят от химического состава (от фактора
вообще говоря, зависят от химического состава (от фактора  ), т. е. могут меняться при переходе от одной плавки к другой;
), т. е. могут меняться при переходе от одной плавки к другой;
б) пары случайных величин  не зависят друг от друга;
не зависят друг от друга;
в) при любых фиксированных  (т. е. для любой фиксированной плавки и при любом фиксированном режиме ее термической обработки) существуют дисперсии
(т. е. для любой фиксированной плавки и при любом фиксированном режиме ее термической обработки) существуют дисперсии 
г) «общая» остаточная случайная компонента  — подчинена нормальному распределению, параметры которого не зависят от характера термической обработки (т. е. от фактора
— подчинена нормальному распределению, параметры которого не зависят от характера термической обработки (т. е. от фактора  );
);
д) диапазоны изменения структурных компонент х и у во много раз превосходят практические диапазоны остаточных случайных компонент  (см. рис. В.7).
(см. рис. В.7).
Схема  исследуемые переменные
исследуемые переменные  случайны. Этот тип зависимости, нередко встречающийся в практике статистических исследований, является в некотором смысле обобщением схемы
случайны. Этот тип зависимости, нередко встречающийся в практике статистических исследований, является в некотором смысле обобщением схемы 
Итак, под схемой  мы будем понимать такую схему зависимости, в которой исследуемые случайные переменные I и
мы будем понимать такую схему зависимости, в которой исследуемые случайные переменные I и  связаны соотношением (В.20), однако наблюдать мы их можем лишь с некоторыми случайными ошибками — соответственно и Поэтому экспериментальными данными
связаны соотношением (В.20), однако наблюдать мы их можем лишь с некоторыми случайными ошибками — соответственно и Поэтому экспериментальными данными  в действительности представлены выборочные значения случайных величин
в действительности представлены выборочные значения случайных величин  , где
, где

Обычно предполагают, что ошибки  взаимно независимы, но зависят от
взаимно независимы, но зависят от  и имеют нулевые математические ожидания
и имеют нулевые математические ожидания  и конечные дисперсии
и конечные дисперсии 
При этом оказывается, что корреляционные и регрессионные характеристики схемы  могут существенно отличаться от соответствующих характеристик исходной (неискаженной) схемы
могут существенно отличаться от соответствующих характеристик исходной (неискаженной) схемы  . Так, например, ниже (см. п. 1.1.4) показано, что наложение случайных нормальных ошибок на исходную двумерную нормальную схему
. Так, например, ниже (см. п. 1.1.4) показано, что наложение случайных нормальных ошибок на исходную двумерную нормальную схему  ) всегда уменьшает абсолютную величину коэффициента регрессии
) всегда уменьшает абсолютную величину коэффициента регрессии  в соотношении (В. 15), а также ослабляет степень тесноты связи между
в соотношении (В. 15), а также ослабляет степень тесноты связи между  (т. е. уменьшает абсолютную величину коэффициента корреляции
(т. е. уменьшает абсолютную величину коэффициента корреляции  ).
).
Зависимости по схеме  имеют место, в частности, в задачах исследования хода технологических процессов, когда взаимосвязанные флюктуирующие значения параметров процесса (
имеют место, в частности, в задачах исследования хода технологических процессов, когда взаимосвязанные флюктуирующие значения параметров процесса ( ) могут быть измерены лишь с некоторыми случайными ошибками.
) могут быть измерены лишь с некоторыми случайными ошибками.





















































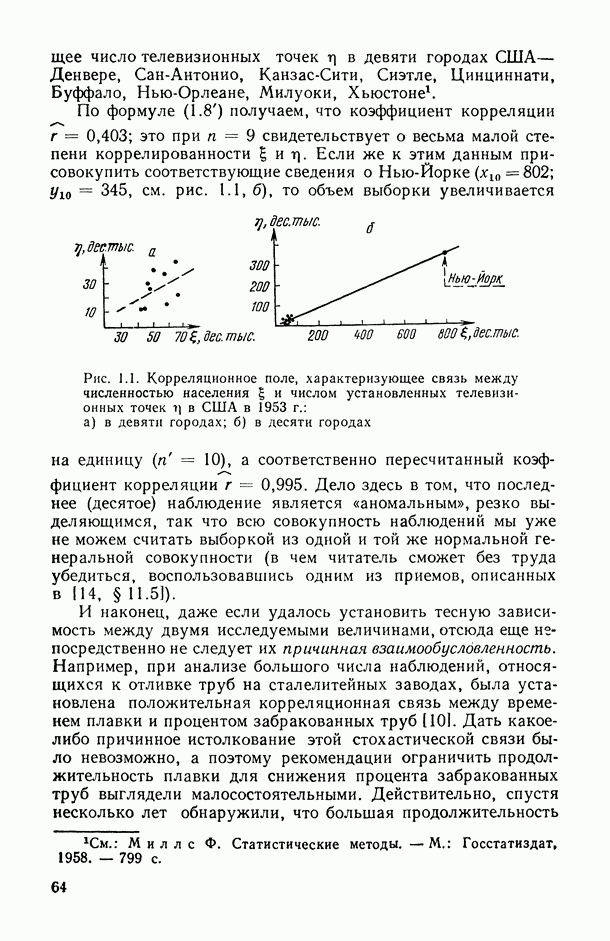













































































































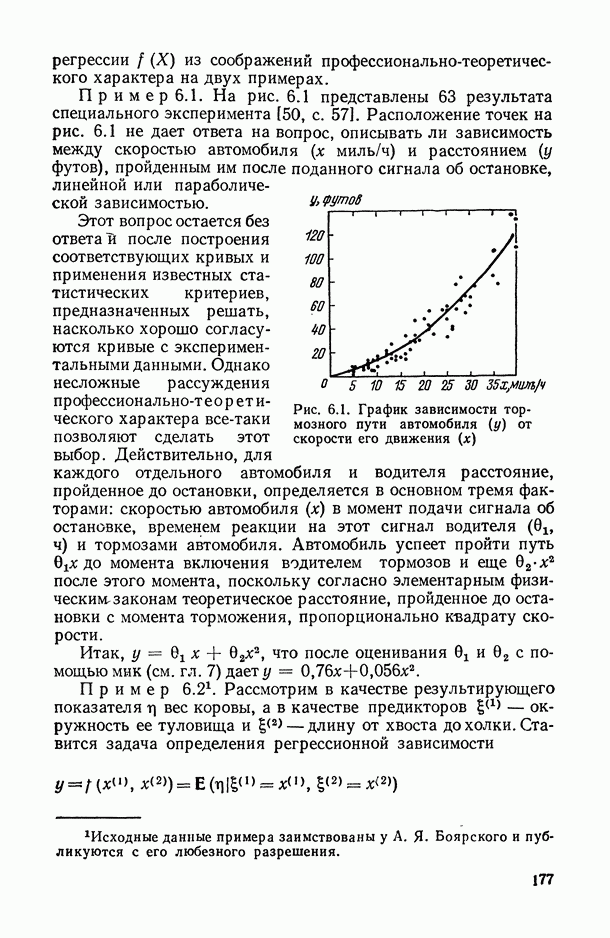







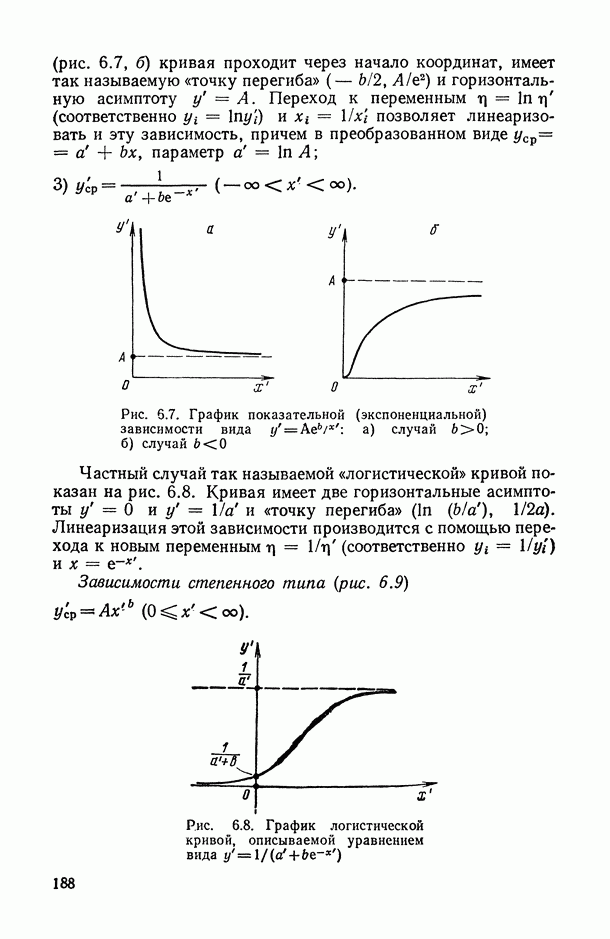
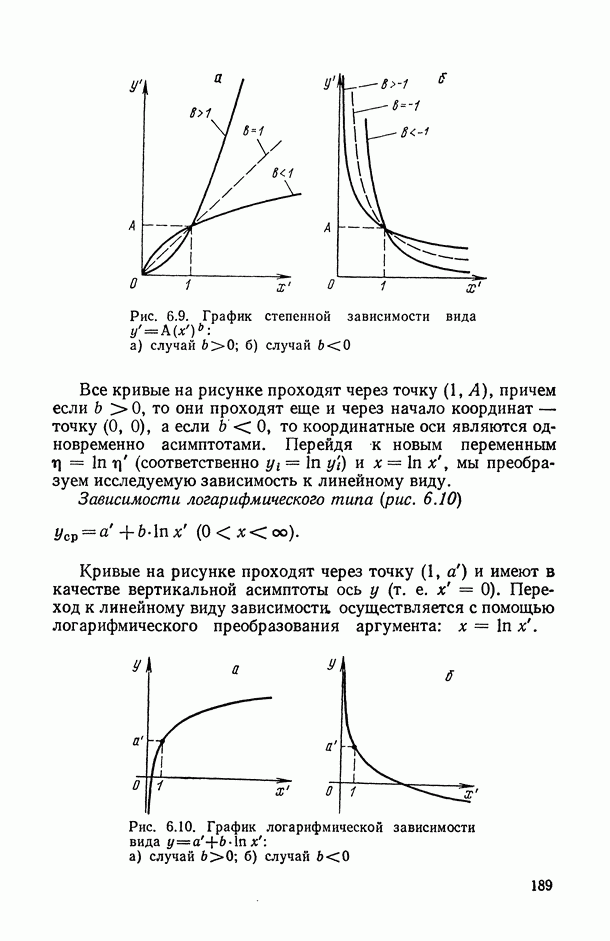






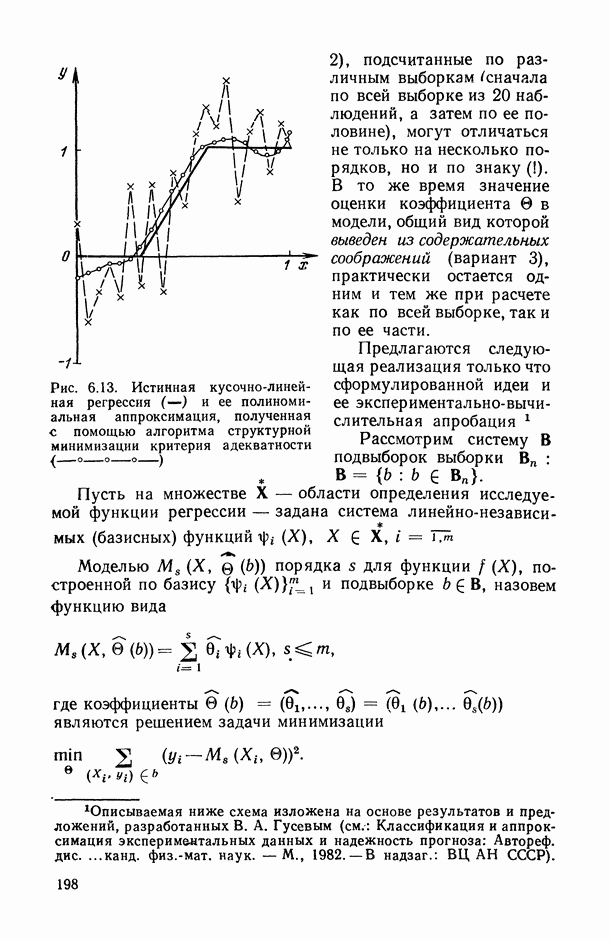



















































































































































































































































 на рис. В.5 указывает на систематическую закономерность в поведении условных средних
на рис. В.5 указывает на систематическую закономерность в поведении условных средних  в зависимости от номера т. е. от величины
в зависимости от номера т. е. от величины  их расположение близко к прямолинейному. Это приводит к гипотезе о целесообразности представления исследуемой случайной величины выражением
их расположение близко к прямолинейному. Это приводит к гипотезе о целесообразности представления исследуемой случайной величины выражением  Первыми шагами исследователя может быть приближенная оценка прямой
Первыми шагами исследователя может быть приближенная оценка прямой  а также меры случайного разброса индивидуальных значений
а также меры случайного разброса индивидуальных значений  вокруг этой прямой, характеризующейся в первом приближении только эмпирическими дисперсиями
вокруг этой прямой, характеризующейся в первом приближении только эмпирическими дисперсиями  . Однако при проведении более точного количественного анализа возникают следующие вопросы: как наиболее точно провести прямую
. Однако при проведении более точного количественного анализа возникают следующие вопросы: как наиболее точно провести прямую  как оценить степень точности построенной зависимости; нельзя ли строить математически обоснованные зоны (так называемые доверительные интервалы и границы) около исследуемой прямой, попадание в которые эмпирических индивидуальных или средних значений
как оценить степень точности построенной зависимости; нельзя ли строить математически обоснованные зоны (так называемые доверительные интервалы и границы) около исследуемой прямой, попадание в которые эмпирических индивидуальных или средних значений  при каждом фиксированном
при каждом фиксированном  гарантировалось бы с заранее заданной вероятностью? Ответы на все эти вопросы и дает регрессионный анализ (см. гл. 5.11).
гарантировалось бы с заранее заданной вероятностью? Ответы на все эти вопросы и дает регрессионный анализ (см. гл. 5.11).
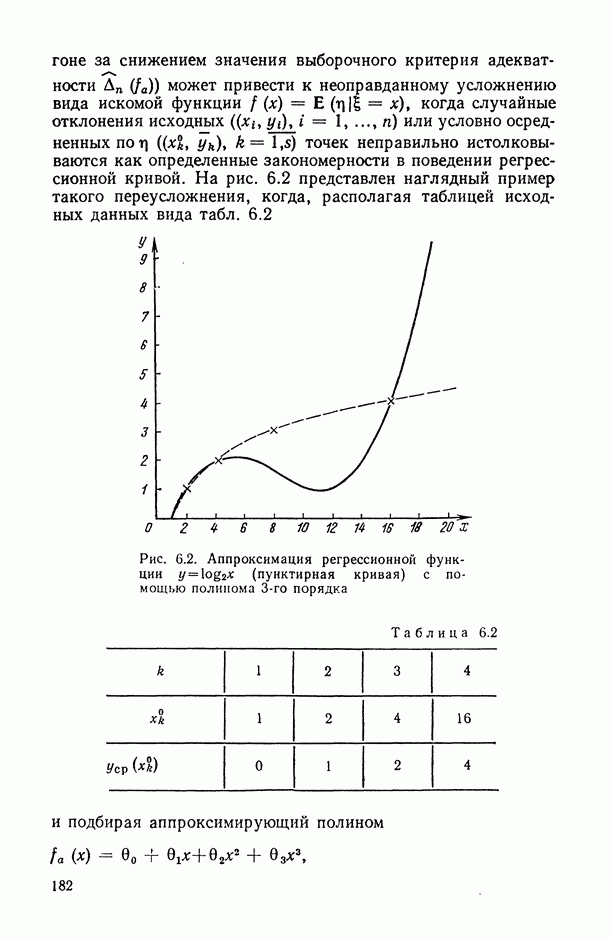
 — результирующим показателем и
— результирующим показателем и  — предикторной переменной (схема С). В данном типе моделей и компоненты вектора результирующего показателя
— предикторной переменной (схема С). В данном типе моделей и компоненты вектора результирующего показателя  и компоненты вектора объясняющих переменных
и компоненты вектора объясняющих переменных  зависят от множества неконтролируемых факторов, так что являются случайными по своей физической сущности. Мы уже сталкивались с такой ситуацией в примере, в котором исследовалась связь между производительностью мартеновских печей и процентным содержанием углерода в металле (см. рис. В.4). Зависимости такого типа вообще характерны для описания хода технологических процессов, реальные значения параметров которых
зависят от множества неконтролируемых факторов, так что являются случайными по своей физической сущности. Мы уже сталкивались с такой ситуацией в примере, в котором исследовалась связь между производительностью мартеновских печей и процентным содержанием углерода в металле (см. рис. В.4). Зависимости такого типа вообще характерны для описания хода технологических процессов, реальные значения параметров которых  равно как и характеризующие их результирующие показатели
равно как и характеризующие их результирующие показатели  как правило, флюктуируют случайным (но взаимосвязанным) образом около установленных номиналов.
как правило, флюктуируют случайным (но взаимосвязанным) образом около установленных номиналов.
 на две случайные составляющие по формуле типа (В.3).
на две случайные составляющие по формуле типа (В.3).
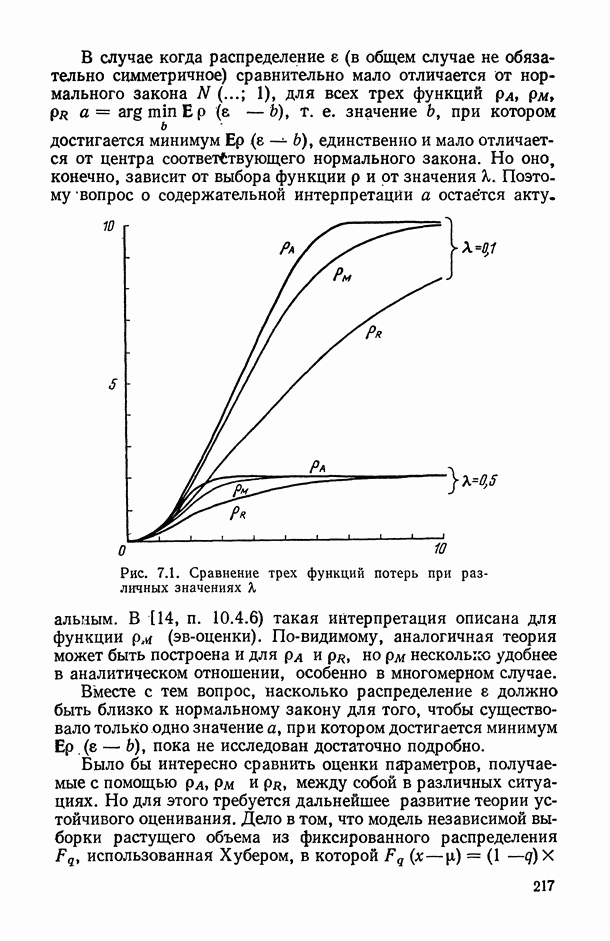
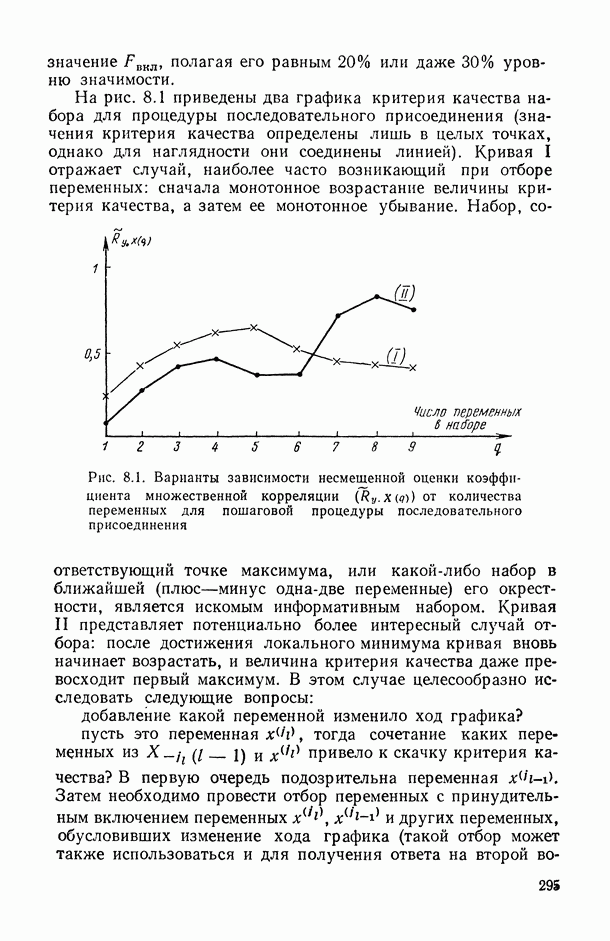
 теряют свои «хорошие» свойства — несмещенность, эффективность и даже состоятельность. Поэтому исследователь должен проявить особую аккуратность на самой первой стадии анализа — при постановке задачи и определении, к какому из известных типов зависимостей следует отнести данный конкретный случай.
теряют свои «хорошие» свойства — несмещенность, эффективность и даже состоятельность. Поэтому исследователь должен проявить особую аккуратность на самой первой стадии анализа — при постановке задачи и определении, к какому из известных типов зависимостей следует отнести данный конкретный случай.

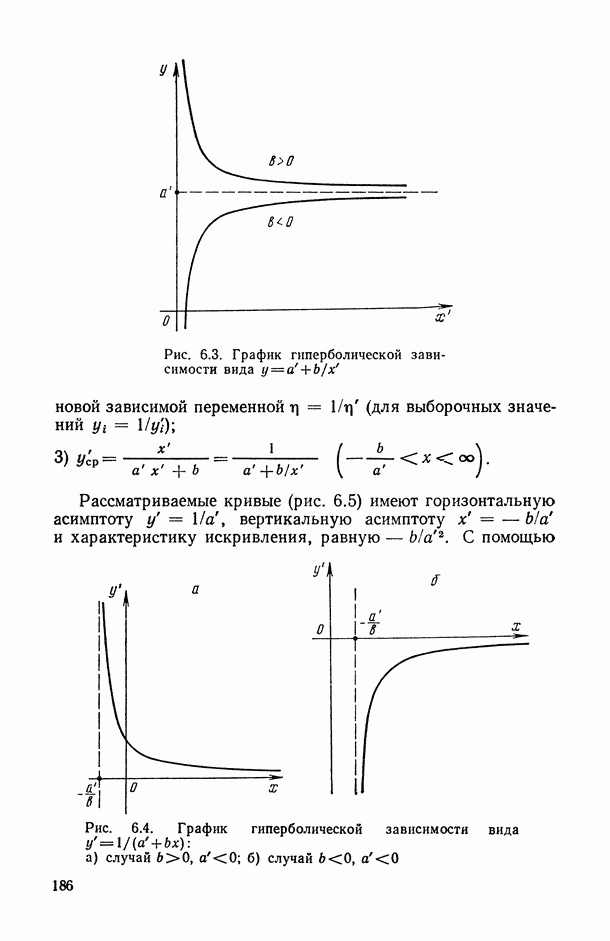
 и твердостью по Бринелю
и твердостью по Бринелю  для 75 образцов одной из плавок стали
для 75 образцов одной из плавок стали
 ).
).
 ) на твердость по Бринелю
) на твердость по Бринелю  и предел прочности
и предел прочности  .
.
 ) зачастую является необходимой.
) зачастую является необходимой.