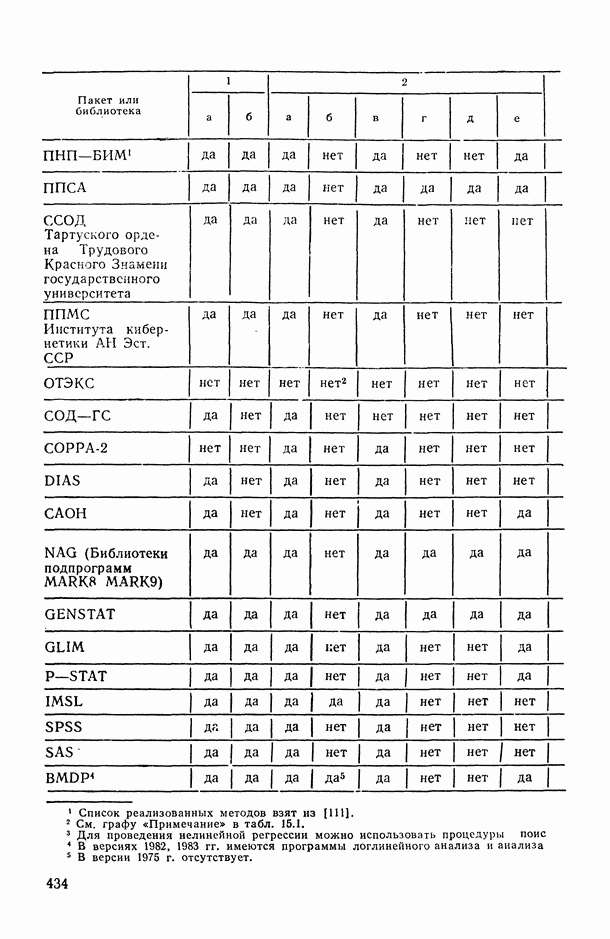
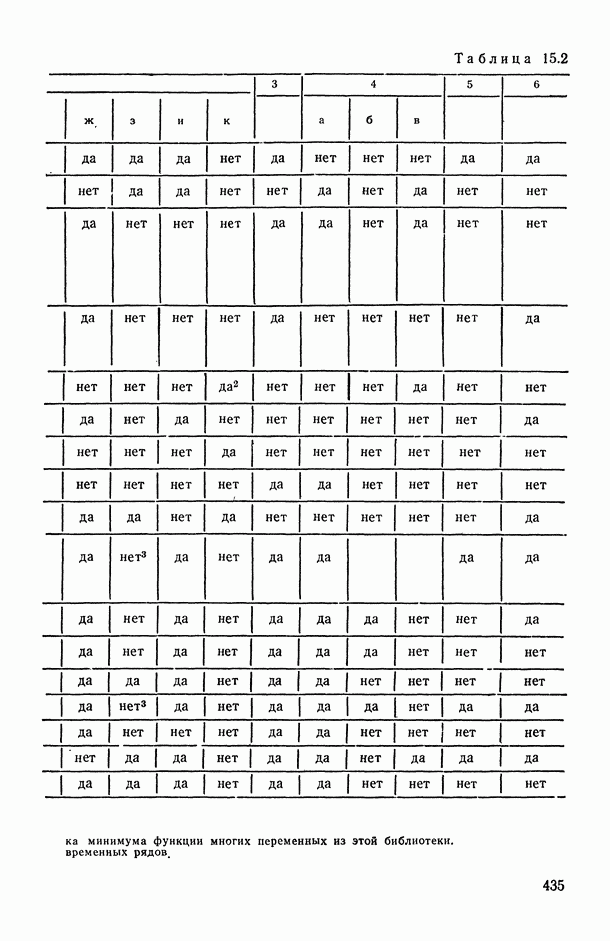
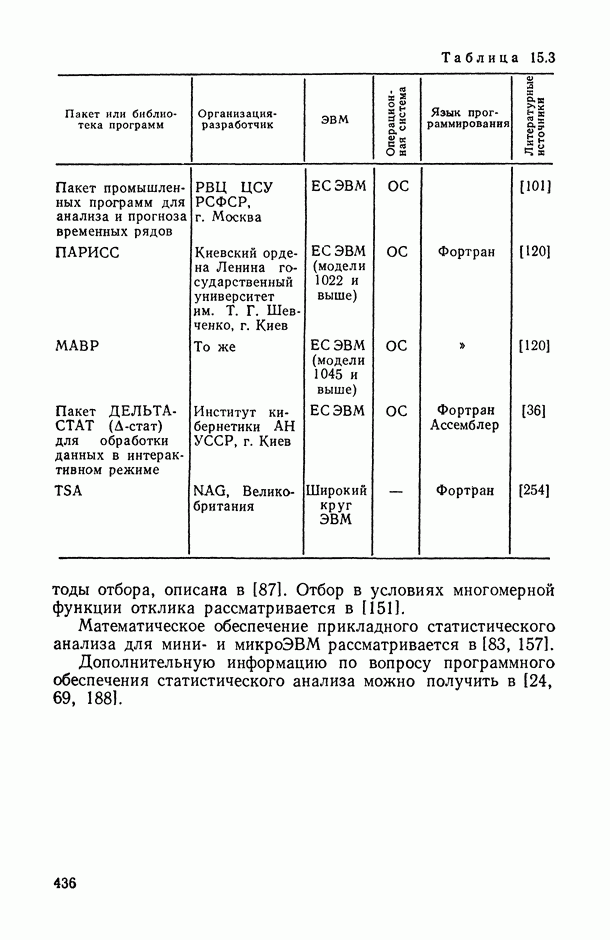
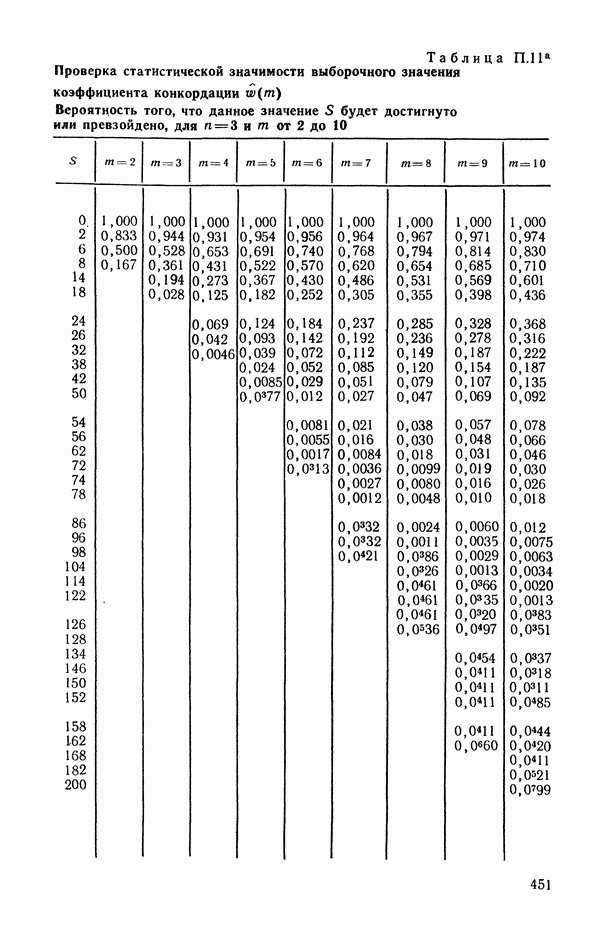
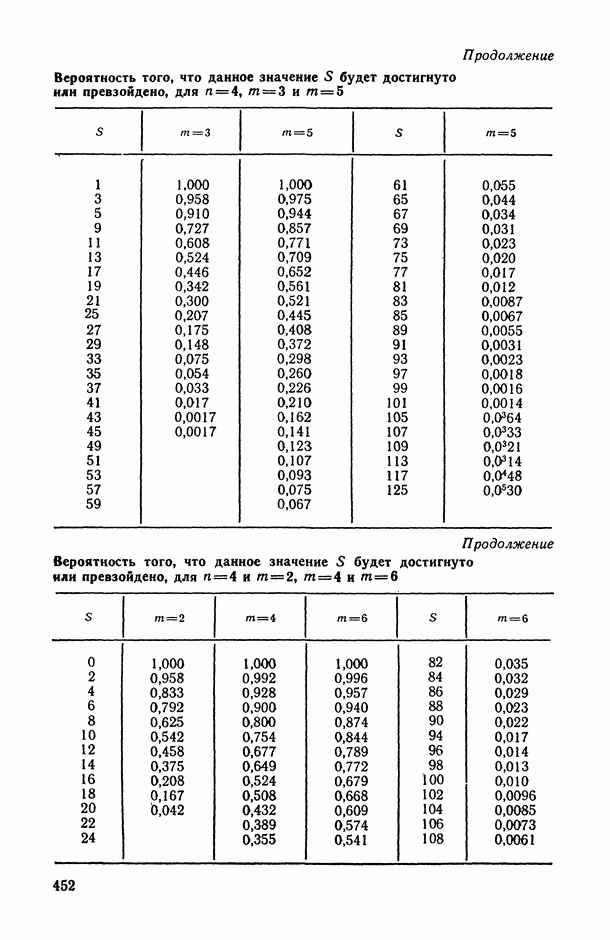
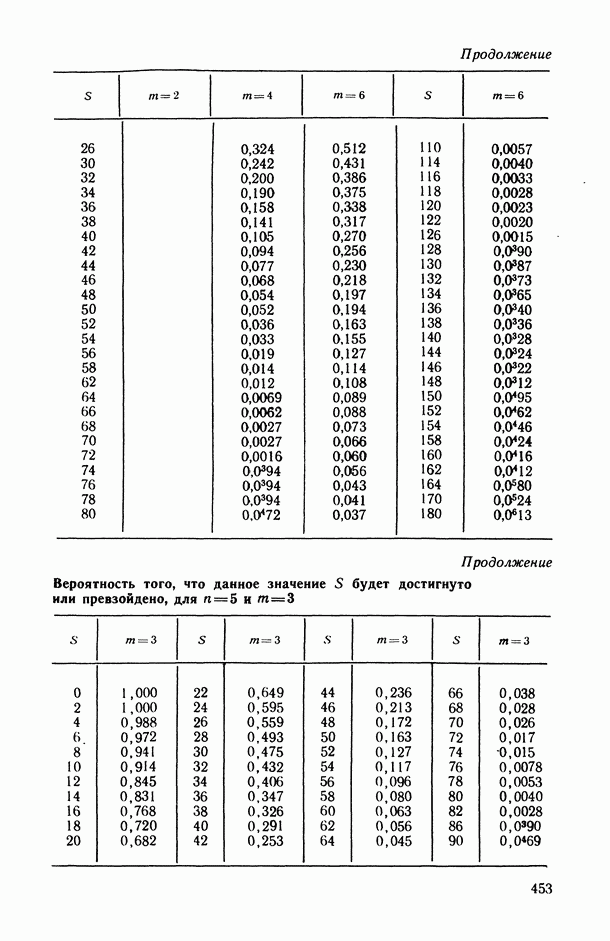
Пред.
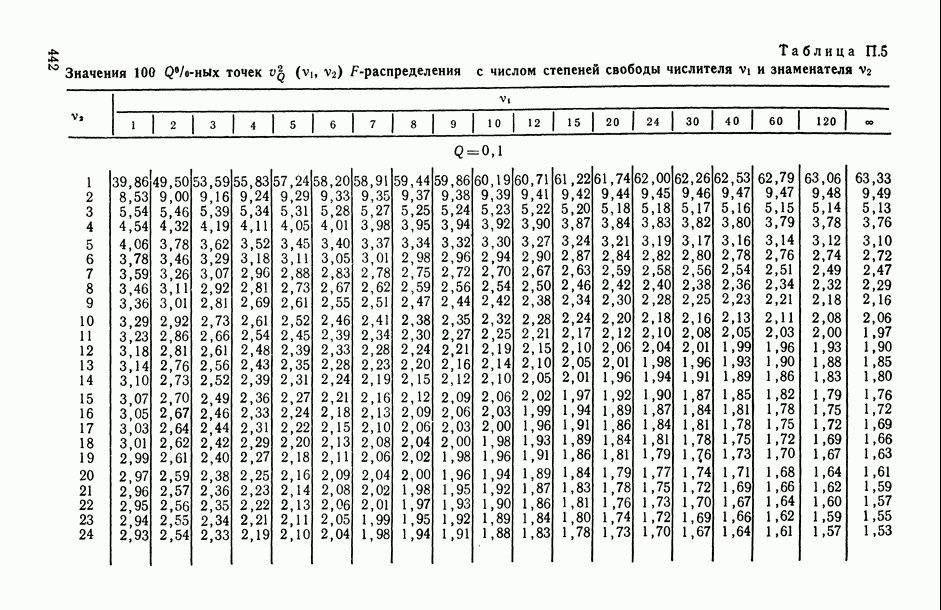
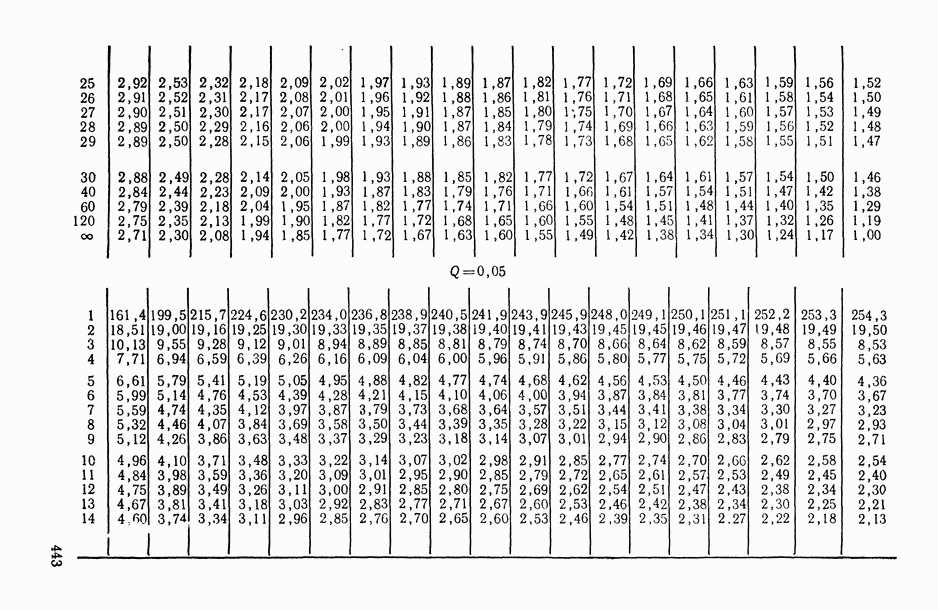
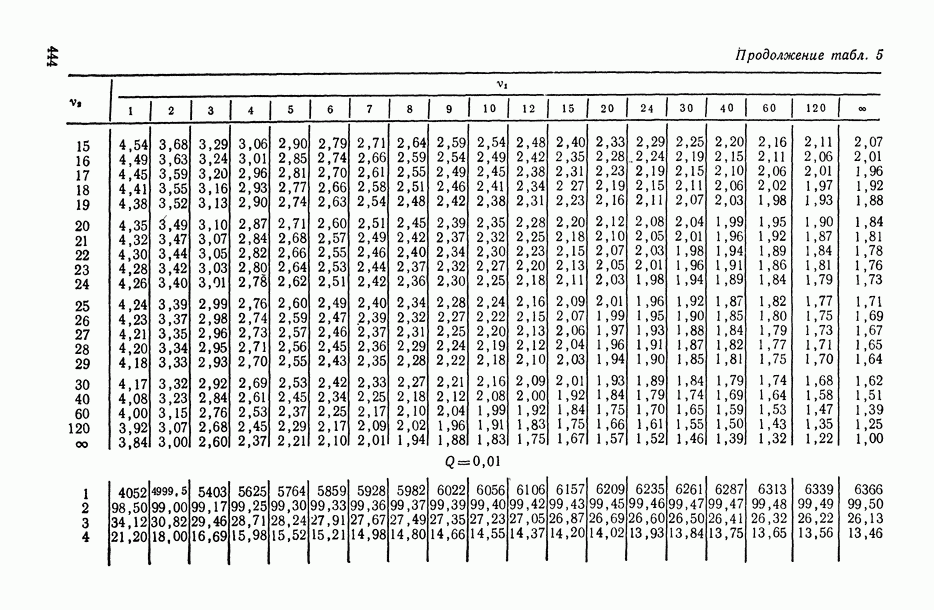
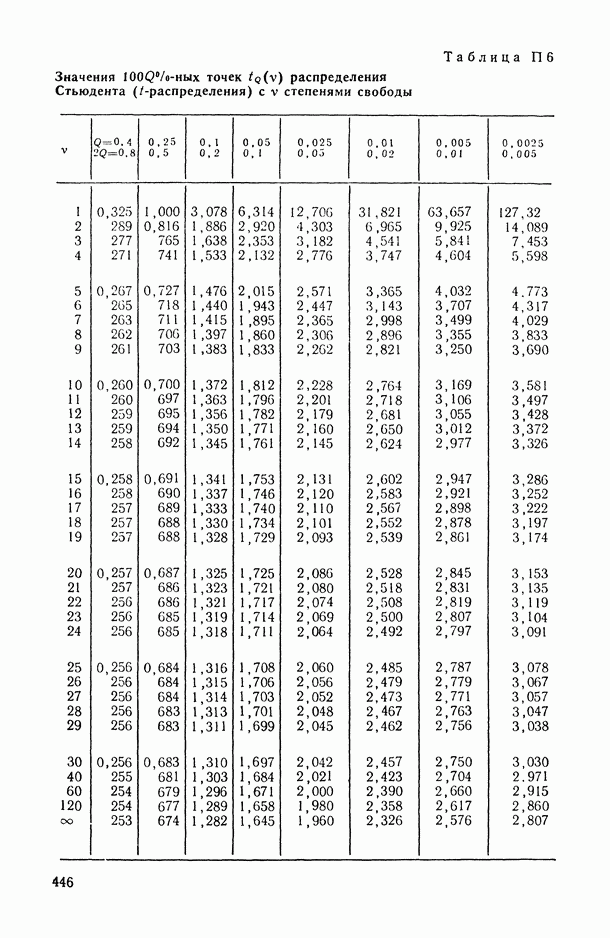
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
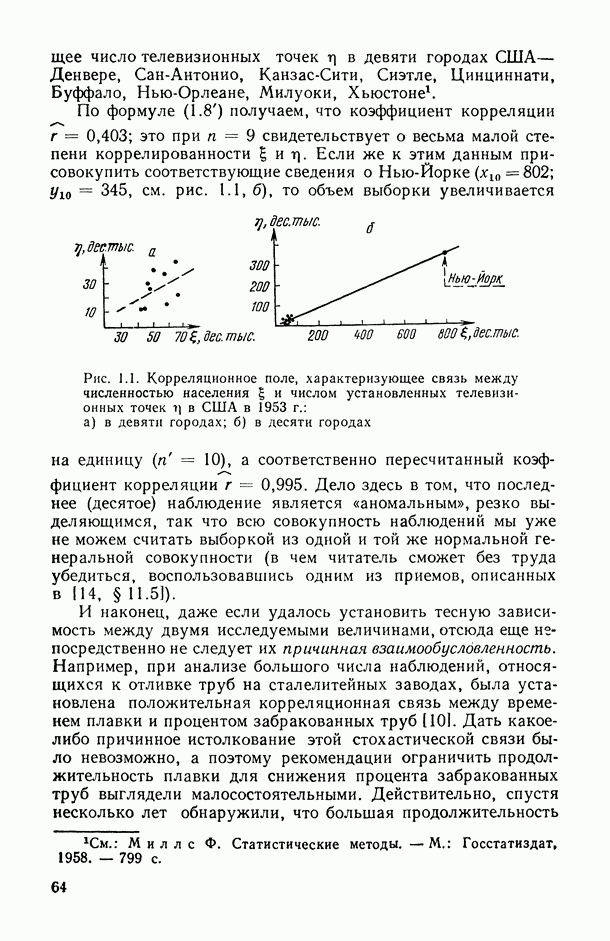
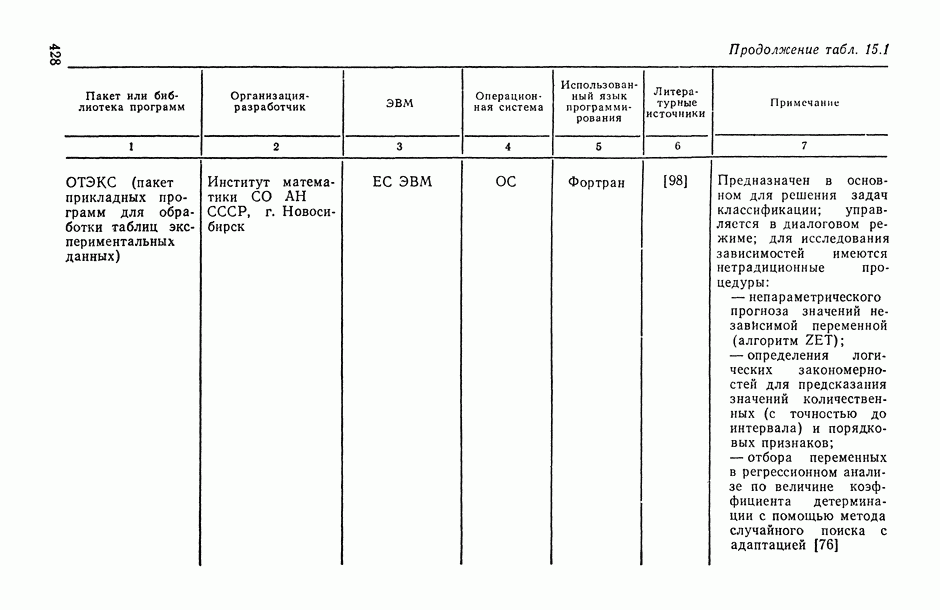
6.3. Математико-статистические методы в задаче параметризации модели регрессии6.3.1. Компромисс между сложностью регрессионной модели и точностью ее оценивания.Из общих результатов математической статистики, относящихся к анализу точности оценивания исследуемой модели при ограниченных объемах выборки, следует, что с увеличением сложности модели (например, размерности неизвестного векторного параметра 0, участвующего в ее уравнении) точность оценивания падает. Мы с этим уже сталкивались, например, при анализе точности оценивания частных и множественных коэффициентов корреляции (см. п. 1.2.3, 1.3.3, а также формулы (1.34), (1.34)). Об этом же свидетельствуют и результаты, приведенные в гл. 11. Это означает, в частности, что в ситуациях, когда исследователь располагает лишь ограниченной исходной выборочной информацией, он вынужден искать компромисс между степенью общности привлекаемого класса допустимых решений F и точностью оценивания, которой возможно при этом добиться. Перед тем как изложить общую схему, в рамках которой можно математически ставить и решать задачу достижения такого компромисса (метод структурной минимизации критерия адекватности Определение оптимального числа предикторов в модели линейной множественной регрессии. Пусть мы строим линейную множественную регрессию результирующего показателя
причем величины С одной стороны, мы уже знаем (см. (1.30)), что присоединение каждой новой предсказывающей переменной может только увеличить величину множественного коэффициента корреляции R между результирующим показателем Поэтому естественно было бы добиваться максимизации не
Опираясь на (6.8), можно предложить следующую процедуру определения оптимального состава и числа предикторов модели множественной линейной регрессии. Последовательно для каждого
а затем по формуле (6.8) — величина
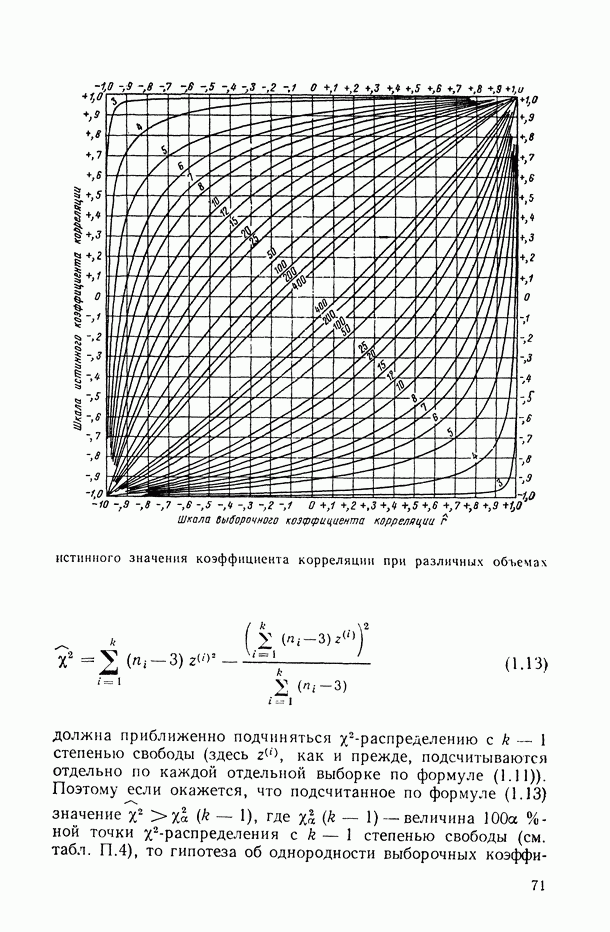
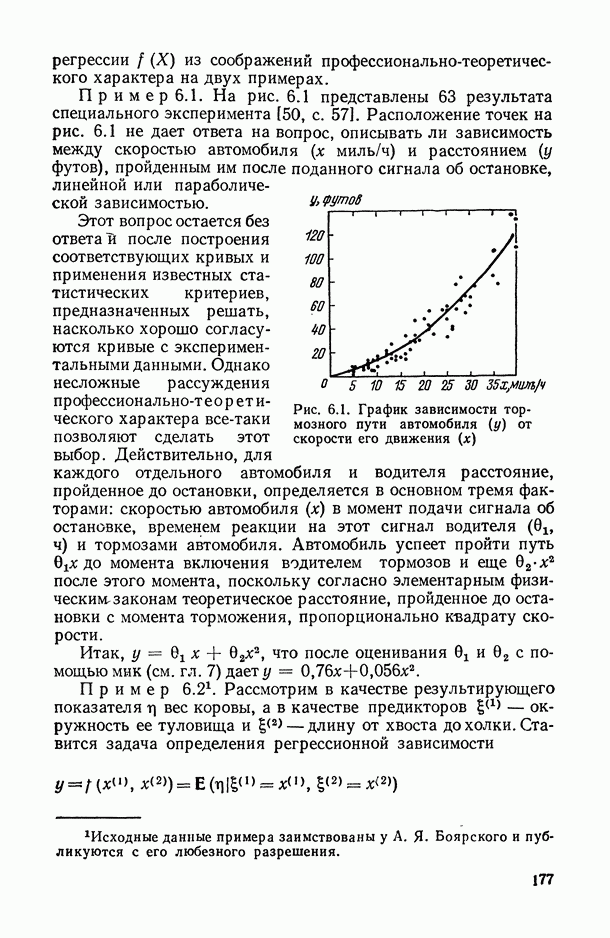
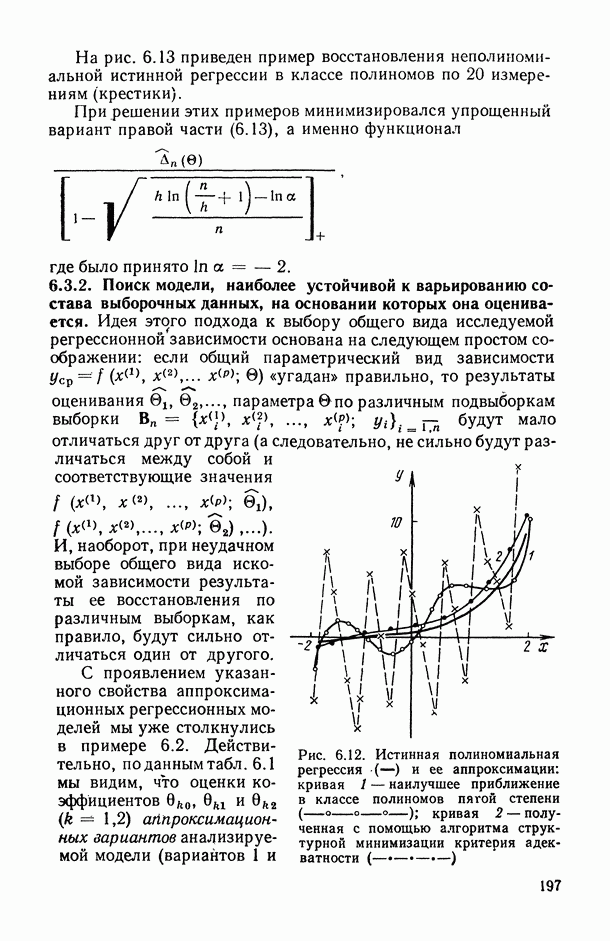
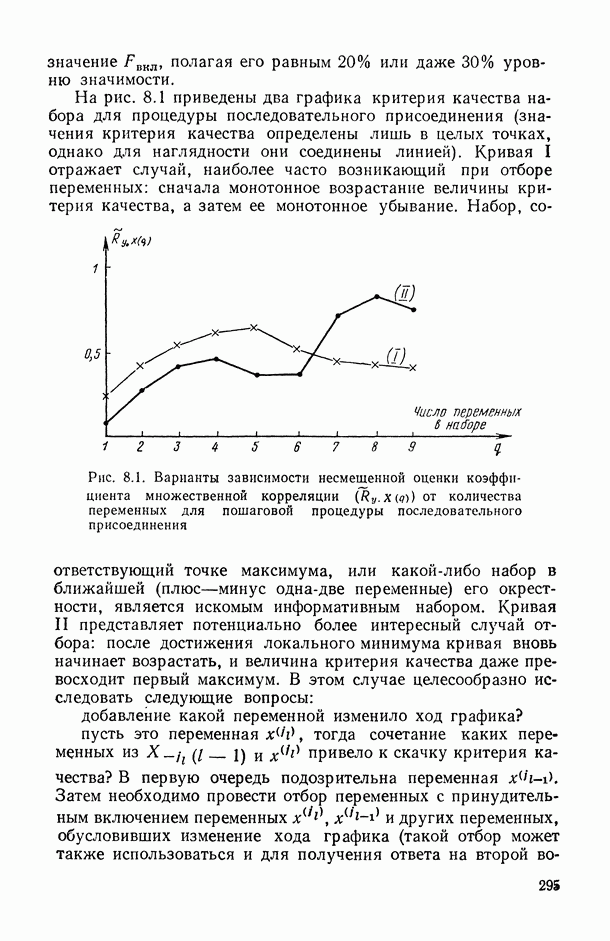
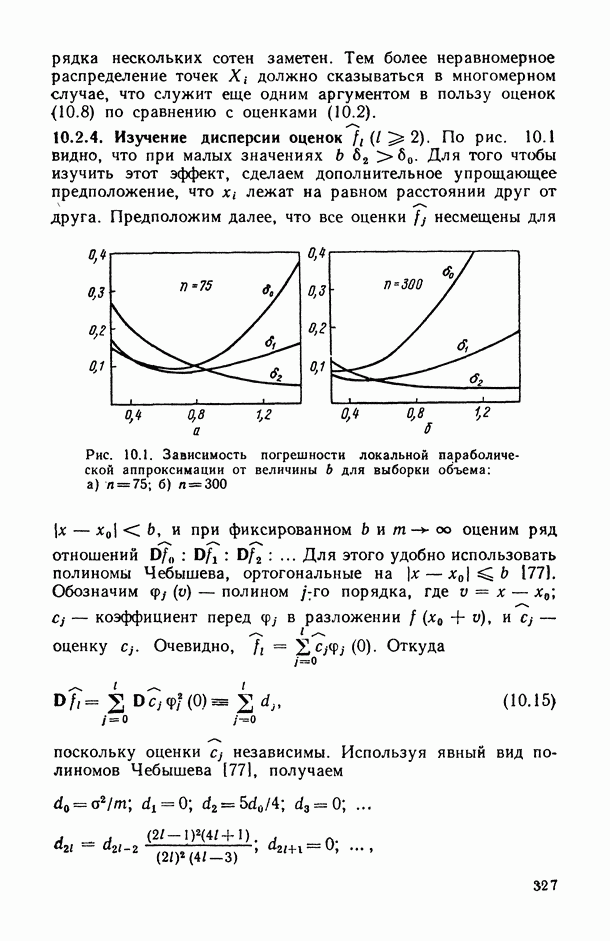
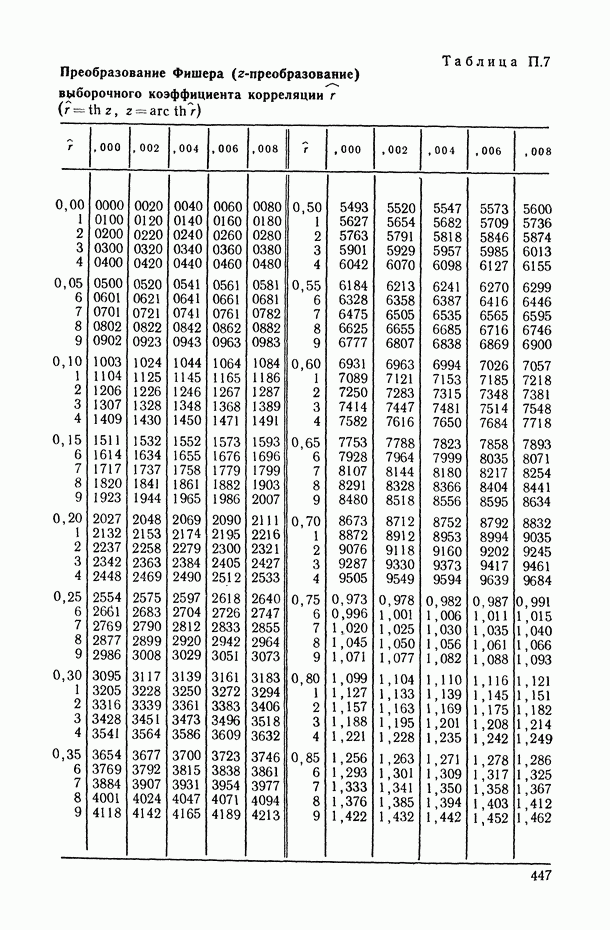
Рис. 6.11. Зависимость нижней доверительной границы коэффициента детерминации от числа предикторов (пунктирная кривая) На рис. 6.11 представлены схематические графики величин В качестве оптимального числа предикторов, включаемых в модель, естественно взять то значение Метод структурной минимизации критерия адекватности. Опишем теперь, следуя [34], общую схему, в рамках которой решается задача выбора оптимальной сложности параметрического семейства Однако в условиях полного отсутствия какой бы то ни было априорной информации о характере совместного распределения
Ниже в целях упрощения формулировок будем требовать выполнения неравенства для случая
Априорная информация, заданная в терминах неравенства (6.10), является более практически доступной, чем обычно используемая связанная с типом распределения регрессионных остатков. Так, если параметрическое семейство случайных величин
таково, что каждая случайная величина В ситуации, когда соблюдается условие (6.10), метод структурной минимизации критерия адекватности может быть построен на основе емкостных характеристик класса функций Для определения понятия «емкость класса
на элементах Индикаторные функции определяются параметрами
Определение. Назовем функцию
функцией роста класса Утверждение. Определенная соотношением (6.12) функция роста либо тождественно равна
Это утверждение позволяет оценивать функцию роста любого класса В частности, для функций
где
Итак, функция роста
Определение. Будем говорить, что класс функций Справедливо утверждение: с вероятностью
где
Так как неравенство (6.13) с вероятностью Таким образом, в условиях Теперь на основе полученной оценки (6.13) сконструируем метод структурной минимизации критерия адекватности. Пусть на исходном классе
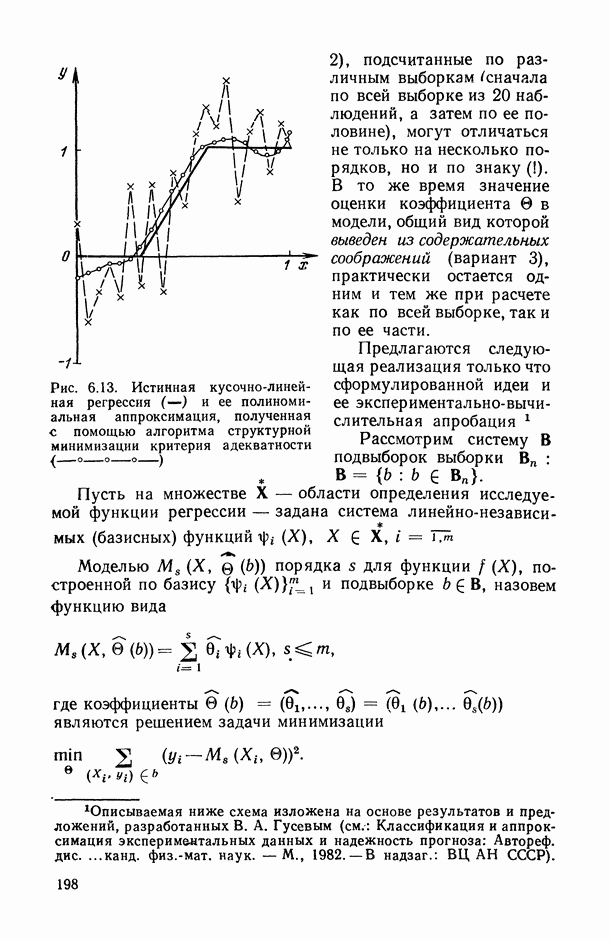
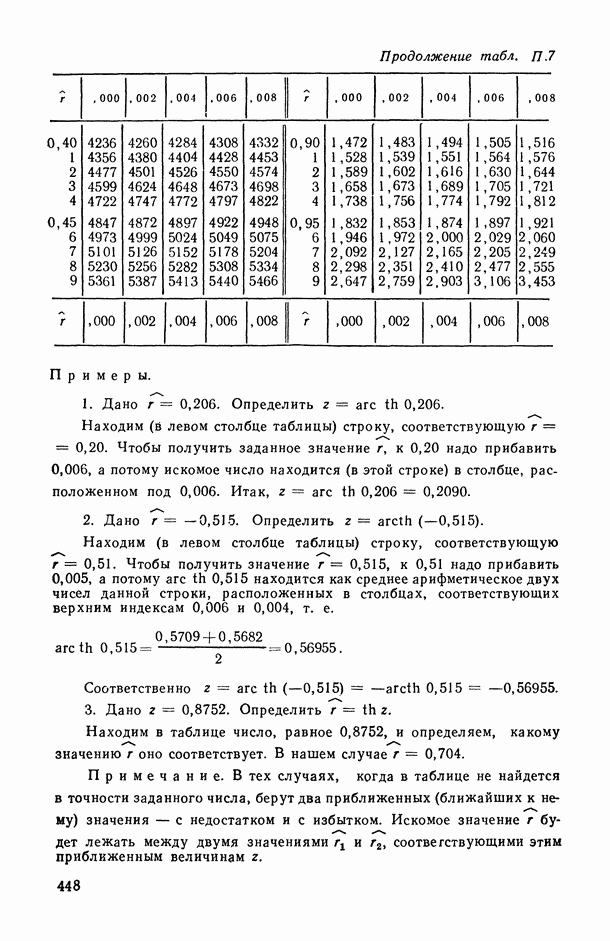
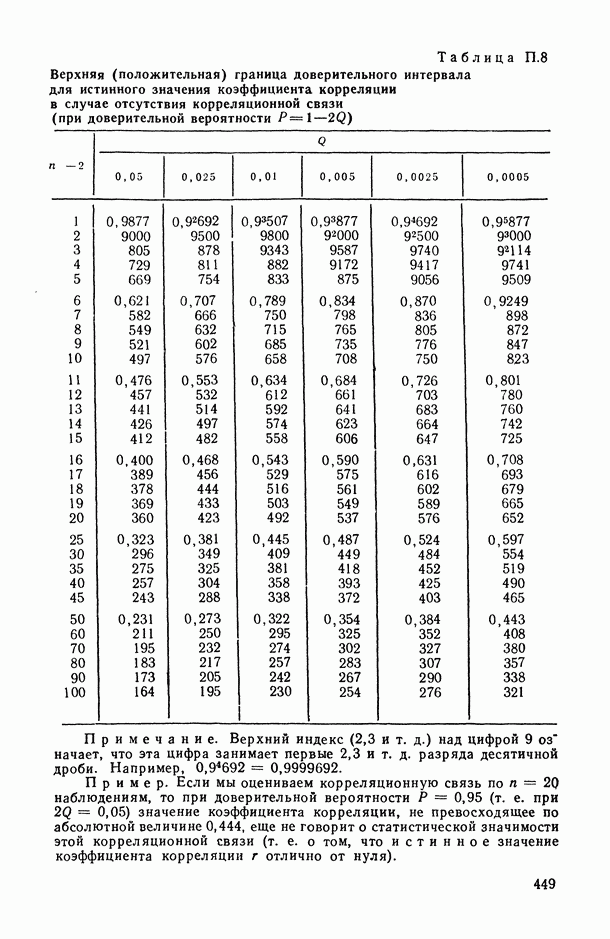
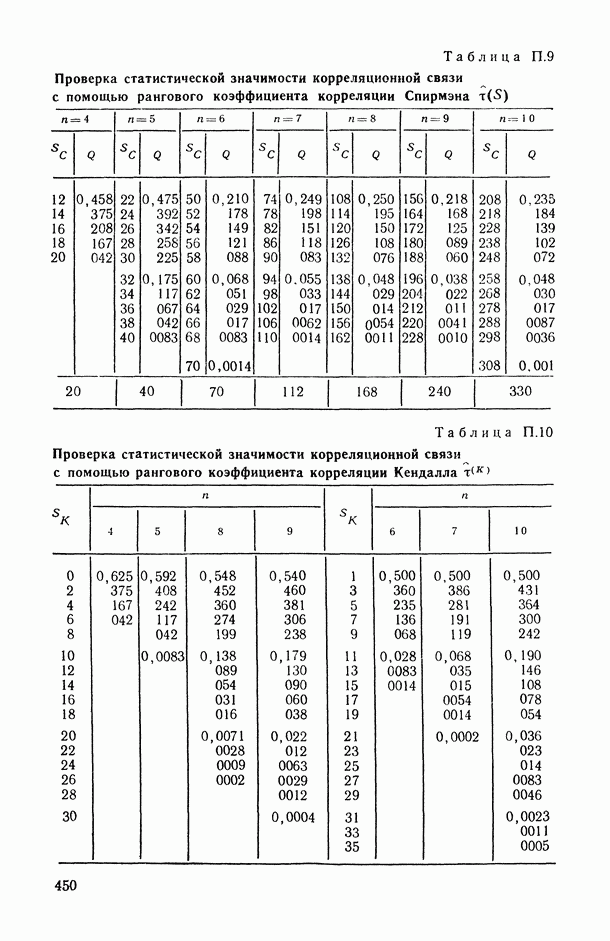
т. е. задано минимальное подмножество Итак, подмножества На каждом из подмножеств Но при фиксированных Метод структурной минимизации риска может быть использован для восстановления регрессии в различных классах функций. Применим его для построения полиномиальной регрессии. Пусть структура На рис. 6.12 показан пример восстановления полинома пятой степени на отрезке [-2,2]. Восстановление проводилось по измерениям функции в 20 случайно взятых точках (крестики). Видно, что кривая 2 лучше приближает истинную регрессию, чем кривая На рис. 6.13 приведен пример восстановления неполиномиальной истинной регрессии в классе полиномов по 20 измерениям (крестики). При решении этих примеров минимизировался упрощенный вариант правой части (6.13), а именно функционал
где было принято
|
 |
Оглавление
|








































































































































































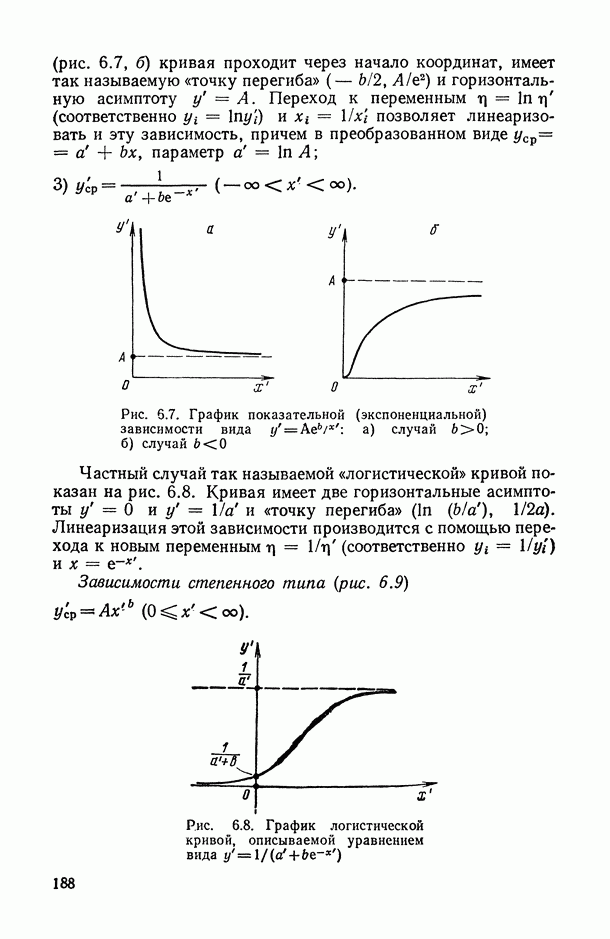
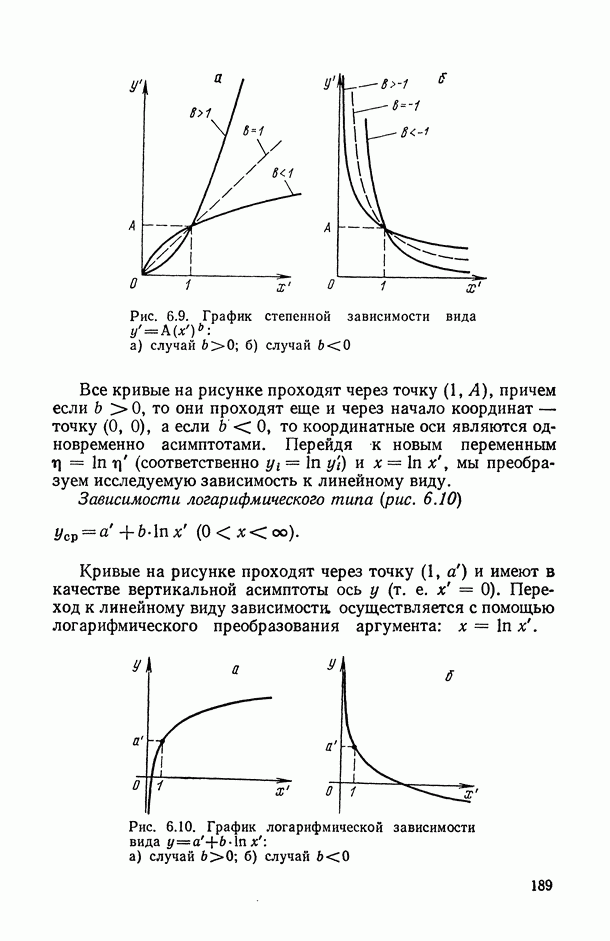


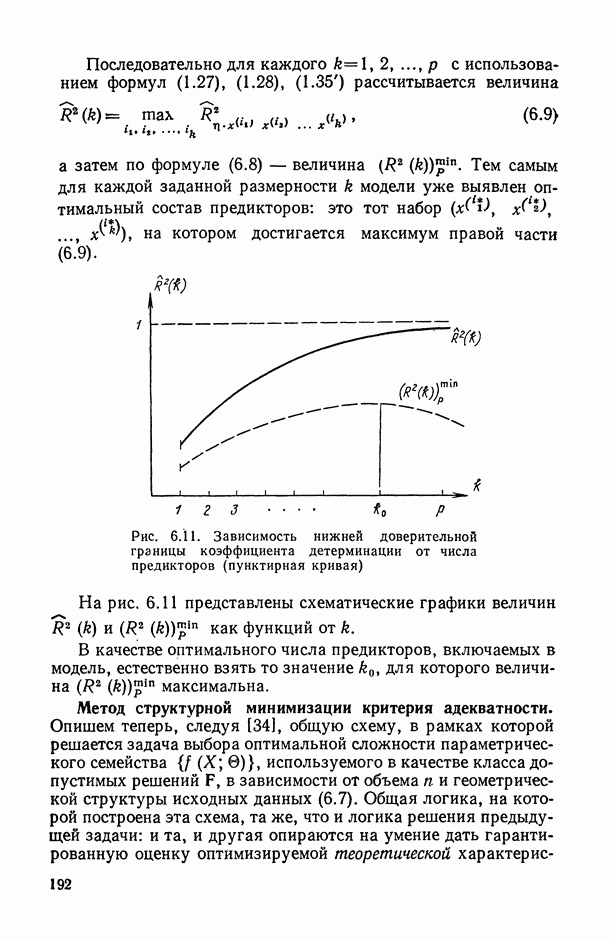




































































































































































































































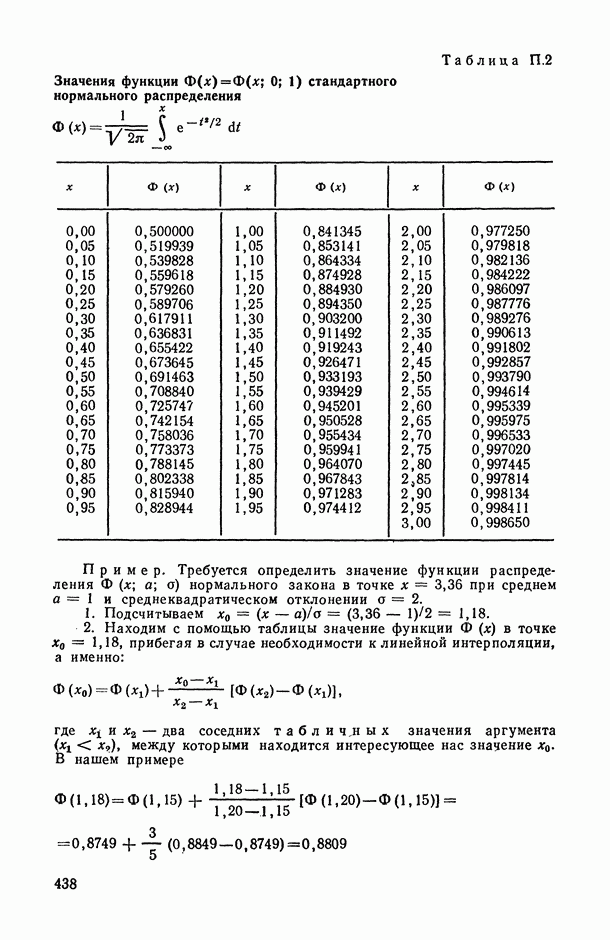
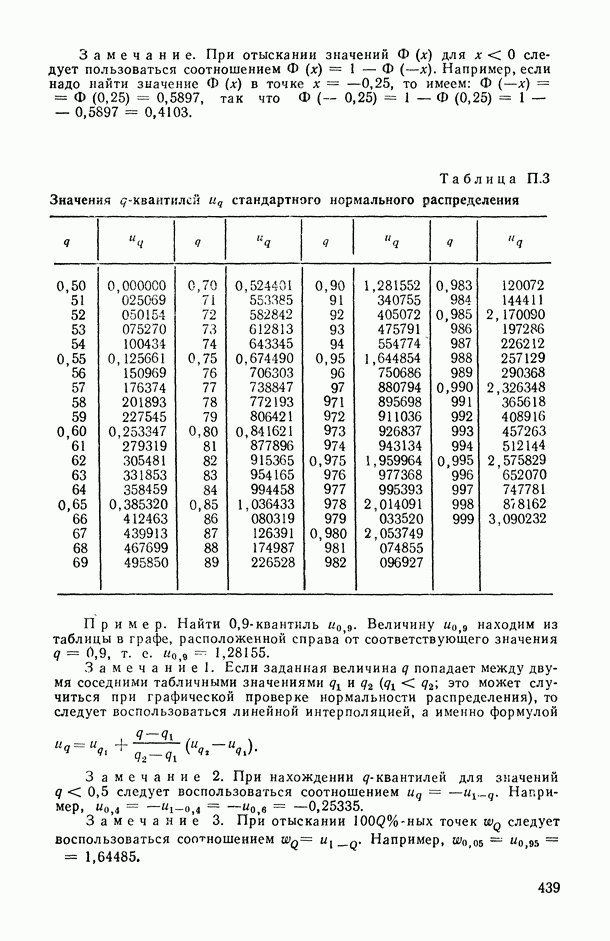
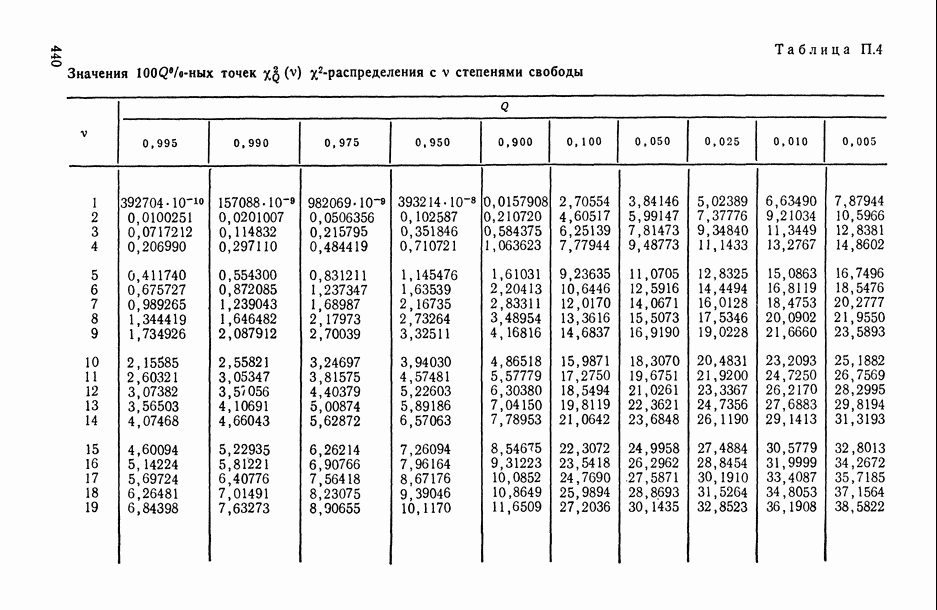
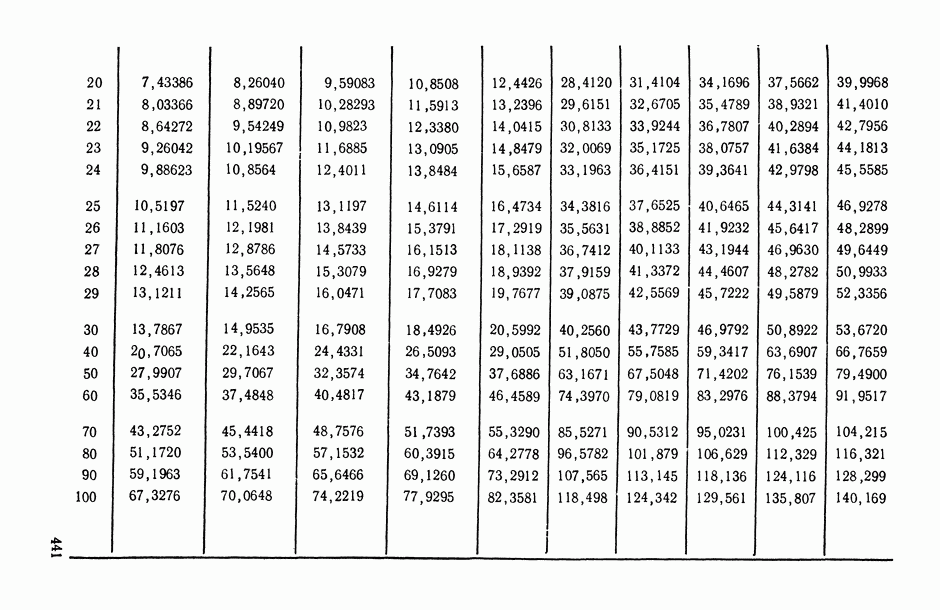



















 ), поясним эту идею на следующем полуэвристическом приеме решения одной частной задачи.
), поясним эту идею на следующем полуэвристическом приеме решения одной частной задачи.
 по предикторам
по предикторам  , используя для этого выборку ограниченного объема
, используя для этого выборку ограниченного объема

 — одного порядка (но
— одного порядка (но  ) Очевидно, в данном случае сложность модели будет определяться числом включенных в нее предикторов. Нужно ли для достижения максимальной точности в задаче восстановления неизвестных значений результирующего показателя
) Очевидно, в данном случае сложность модели будет определяться числом включенных в нее предикторов. Нужно ли для достижения максимальной точности в задаче восстановления неизвестных значений результирующего показателя  по значениям предикторов включать в модель все предикторные переменные, а если не все, то сколько и какие именно?
по значениям предикторов включать в модель все предикторные переменные, а если не все, то сколько и какие именно?
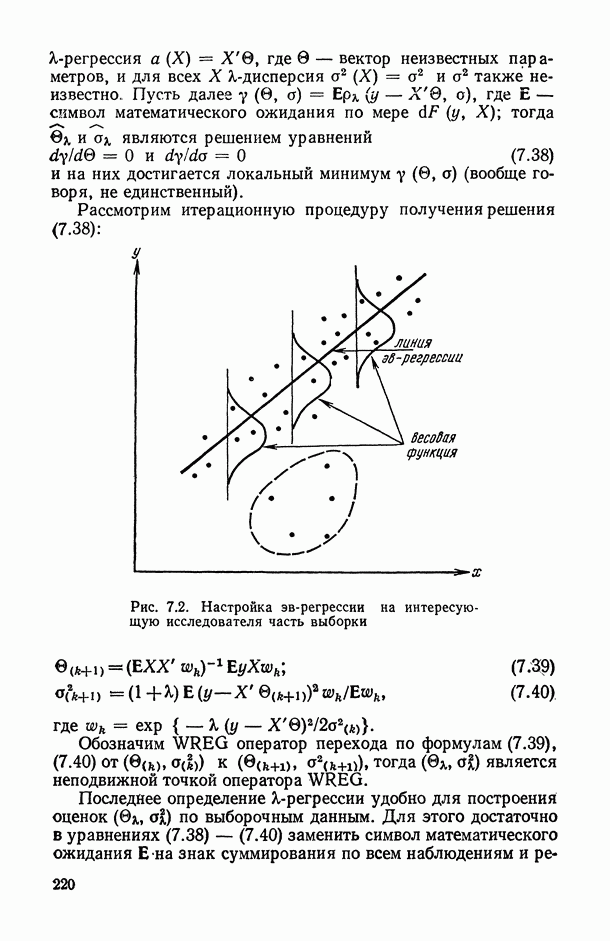
 и предикторами и, следовательно, уменьшить ошибку в предсказании
и предикторами и, следовательно, уменьшить ошибку в предсказании  (см. (1.26)). С другой стороны, нам известны не точные значения теоретических характеристик R, участвующих в (1.26) — (1.30), а лишь их выборочные аналоги —
(см. (1.26)). С другой стороны, нам известны не точные значения теоретических характеристик R, участвующих в (1.26) — (1.30), а лишь их выборочные аналоги —  а нижней доверительной границы
а нижней доверительной границы  для истинного значения коэффициента детерминации
для истинного значения коэффициента детерминации  (при заданной
(при заданной  меньше точечной оценки
меньше точечной оценки  на величину, пропорциональную среднеквадратической ошибке
на величину, пропорциональную среднеквадратической ошибке  (множитель пропорциональности
(множитель пропорциональности  , конечно, зависит от заданной величины доверительной вероятности Р), и воспользоваться приближенной формулой (1.34), то получаем следующую формулу для определения
, конечно, зависит от заданной величины доверительной вероятности Р), и воспользоваться приближенной формулой (1.34), то получаем следующую формулу для определения 

 с использованием формул (1.27), (1.28), (1.35) рассчитывается величина
с использованием формул (1.27), (1.28), (1.35) рассчитывается величина

 . Тем самым для каждой заданной размерности k модели уже выявлен оптимальный состав предикторов: это тот набор
. Тем самым для каждой заданной размерности k модели уже выявлен оптимальный состав предикторов: это тот набор  на котором достигается максимум правой части (6.9).
на котором достигается максимум правой части (6.9).

 как функций от k.
как функций от k.
 для которого величина
для которого величина  максимальна.
максимальна.
 используемого в качестве класса допустимых решений F, в зависимости от объема
используемого в качестве класса допустимых решений F, в зависимости от объема  и геометрической структуры исходных данных (6.7). Общая логика, на которой построена эта схема, та же, что и логика решения предыдущей задачи: и та, и другая опираются на умение дать гарантированную оценку оптимизируемой теоретической характеристики (в общей схеме — оценку сверху для теоретического критерия адекватности
и геометрической структуры исходных данных (6.7). Общая логика, на которой построена эта схема, та же, что и логика решения предыдущей задачи: и та, и другая опираются на умение дать гарантированную оценку оптимизируемой теоретической характеристики (в общей схеме — оценку сверху для теоретического критерия адекватности  по значению соответствующей выборочной характеристики (в общей схеме — по
по значению соответствующей выборочной характеристики (в общей схеме — по 
 исследуемых переменных
исследуемых переменных  никаких надежных заключений о величине
никаких надежных заключений о величине  по значению
по значению  сделать нельзя. Минимальная информация такого рода, используемая в описываемом методе, состоит в том, чтобы для некоторого
сделать нельзя. Минимальная информация такого рода, используемая в описываемом методе, состоит в том, чтобы для некоторого  знать величину определяющую
знать величину определяющую 



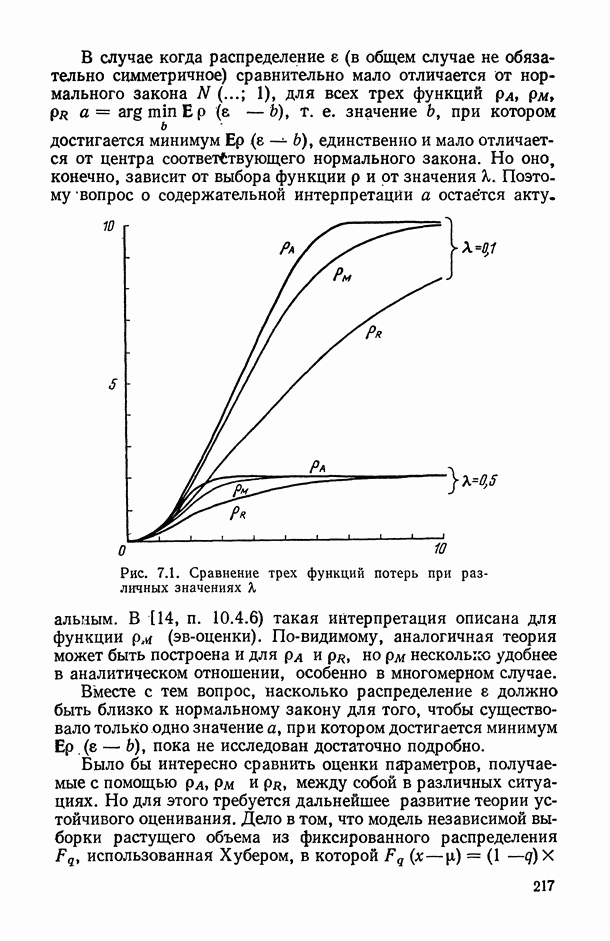
 распределена по нормальному закону (со своими параметрами, зависящими от
распределена по нормальному закону (со своими параметрами, зависящими от  ), то
), то  если семейство (6.11) подчинено закону Лапласа [14, п. 6.1.8], то
если семейство (6.11) подчинено закону Лапласа [14, п. 6.1.8], то  если же
если же  подчинено равномерному закону распределения, то
подчинено равномерному закону распределения, то 
 в котором ведется восстановление
в котором ведется восстановление 
 внедем множество индикаторных функций
внедем множество индикаторных функций

 выборки (6.7).
выборки (6.7).
 , где
, где  — параметры, определяющие
— параметры, определяющие  , и
, и  — некоторое число из интервала
— некоторое число из интервала  . Каждая индикаторная функция
. Каждая индикаторная функция  делит выборку (6.7) на две подвыборки:
делит выборку (6.7) на две подвыборки:  количество различных разделений множества (6.7) на два подмножества с помощью индикаторных функций из класса
количество различных разделений множества (6.7) на два подмножества с помощью индикаторных функций из класса  . Очевидно, что
. Очевидно, что


 на выборках вида (6.7). Для функции роста справедливо следующее утверждение.
на выборках вида (6.7). Для функции роста справедливо следующее утверждение.
 либо, если для некоторого
либо, если для некоторого  это не так, т. е.
это не так, т. е.  то для
то для  справедлива оценка
справедлива оценка

 функций. Для получения соответствующей оценки достаточно указать такие
функций. Для получения соответствующей оценки достаточно указать такие  пар, которые не могут быть разеделены всеми
пар, которые не могут быть разеделены всеми  способами с помощью индикаторных функций
способами с помощью индикаторных функций  .
.
 линейных по параметрам 0, т. е.
линейных по параметрам 0, т. е.

 — некоторая заданная система известных функций, имеет место оценка
— некоторая заданная система известных функций, имеет место оценка

 оценивается либо
оценивается либо 

 имеет бесконечную емкость, если соответствующая функция роста тождественно равна
имеет бесконечную емкость, если соответствующая функция роста тождественно равна  и имеет конечную емкость h, если функция роста оценивается сверху величиной
и имеет конечную емкость h, если функция роста оценивается сверху величиной 
 одновременно для всех функций
одновременно для всех функций  имеет место
имеет место 

 выполняется одновременно для всех функций, то оно справедливо и для функции, минимизирующей эмпирический критерий адекватности. Оценка (6.13), по существу, зависит от относительного (по отношению h) объема выборки
выполняется одновременно для всех функций, то оно справедливо и для функции, минимизирующей эмпирический критерий адекватности. Оценка (6.13), по существу, зависит от относительного (по отношению h) объема выборки  .
.
 для класса F функций ограниченной емкости по величине эмпирического критерия адекватности
для класса F функций ограниченной емкости по величине эмпирического критерия адекватности  удается оценить величину теоретического критерия адекватности
удается оценить величину теоретического критерия адекватности  .
.
 задана структура
задана структура

 элементов из F, затем подмножество элементов
элементов из F, затем подмножество элементов  содержащее
содержащее  и т. д. и, наконец, подмножество
и т. д. и, наконец, подмножество  содержащее все элементы класса
содержащее все элементы класса 
 таковы, что с ростом номера
таковы, что с ростом номера  емкость их растет:
емкость их растет: 
 найдем функцию
найдем функцию  минимизирующую выборочный критерий адекватности. Вычислим для функции
минимизирующую выборочный критерий адекватности. Вычислим для функции  величину выборочного критерия адекватности
величину выборочного критерия адекватности  . Очевидно, что с ростом номера
. Очевидно, что с ростом номера  личина
личина  не возрастает.
не возрастает.
 оценка (6.13) величины теоретического критерия адекватности для функции, минимизирующей выборочный критерий адекватности на элементах структуры достигает своего наименьшего значения не обязательно на подмножестве
оценка (6.13) величины теоретического критерия адекватности для функции, минимизирующей выборочный критерий адекватности на элементах структуры достигает своего наименьшего значения не обязательно на подмножестве  Иначе говоря, для фиксированного объема выборки наилучшее приближение к функции
Иначе говоря, для фиксированного объема выборки наилучшее приближение к функции  он позволяет установить компромисс между «сложностью» выбираемой модели регрессии (номером элемента структуры (6.14) — чем больше номер, тем сложнее модель
он позволяет установить компромисс между «сложностью» выбираемой модели регрессии (номером элемента структуры (6.14) — чем больше номер, тем сложнее модель  и качеством приближения к выборочным данным (величиной
и качеством приближения к выборочным данным (величиной  при котором достигается наименьшая гарантированная оценка теоретического критерия адекватйости. Можно сказать, что дальнейшее усложнение модели приводит к приближению к имеющемуся эмпирическому материалу, а не к искомой зависимости.
при котором достигается наименьшая гарантированная оценка теоретического критерия адекватйости. Можно сказать, что дальнейшее усложнение модели приводит к приближению к имеющемуся эмпирическому материалу, а не к искомой зависимости.
 такова, что элемент F, содержит полиномы степени
такова, что элемент F, содержит полиномы степени  . В этом случае емкость класса F; равна
. В этом случае емкость класса F; равна  . И проблема заключается в том, чтобы минимизировать выборочный критерий адекватности в классе полиномов такой степени
. И проблема заключается в том, чтобы минимизировать выборочный критерий адекватности в классе полиномов такой степени  чтобы достичь минимума оценки (6.13).
чтобы достичь минимума оценки (6.13).


