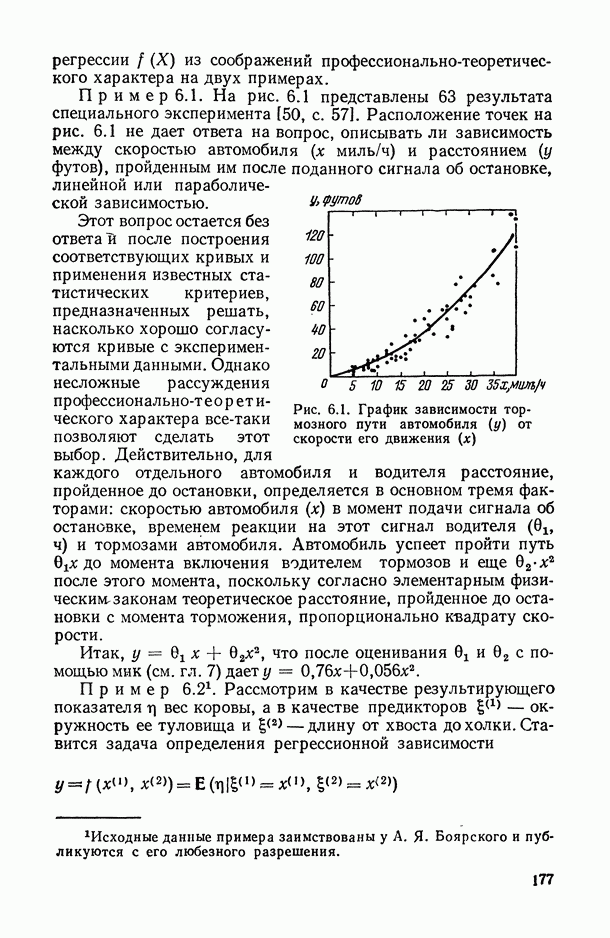
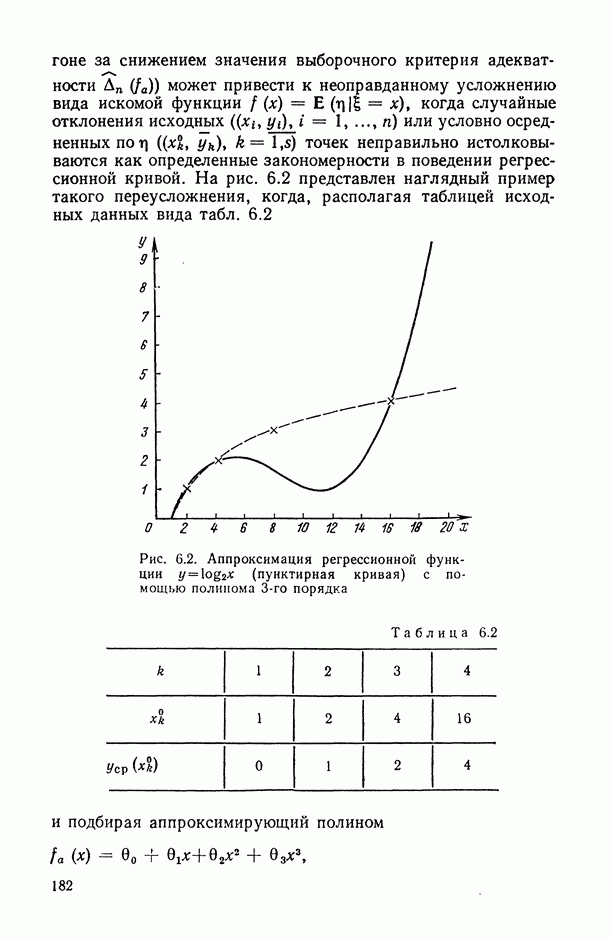
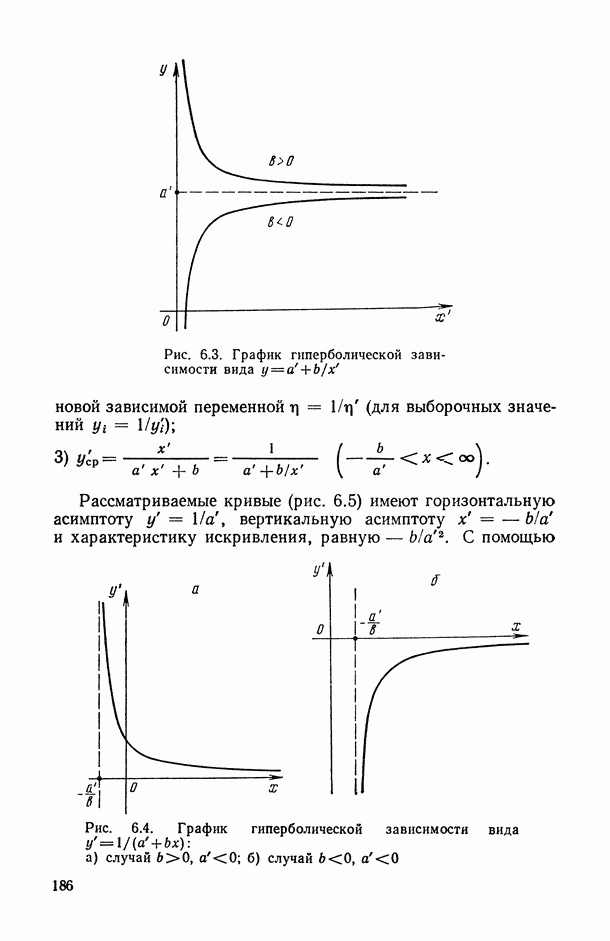
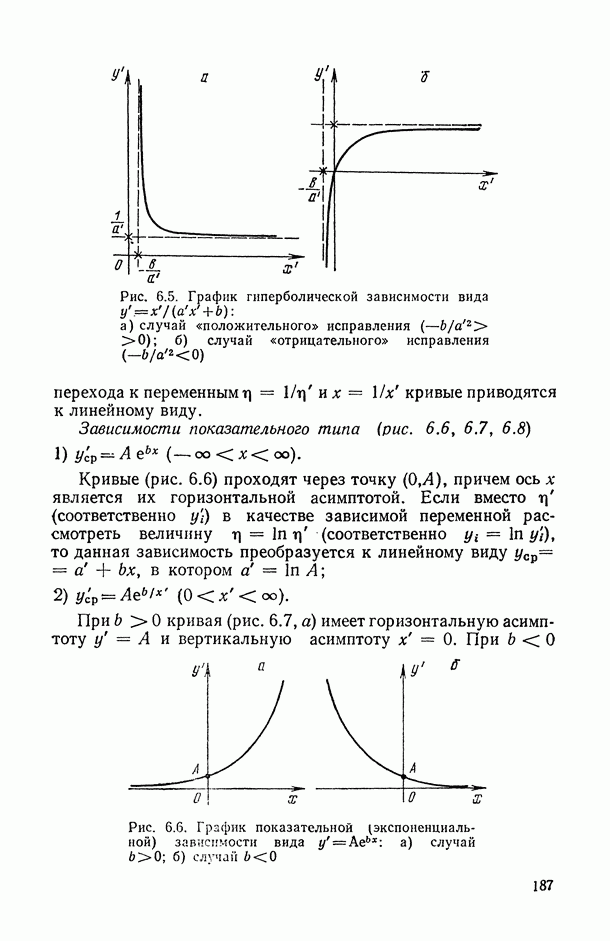
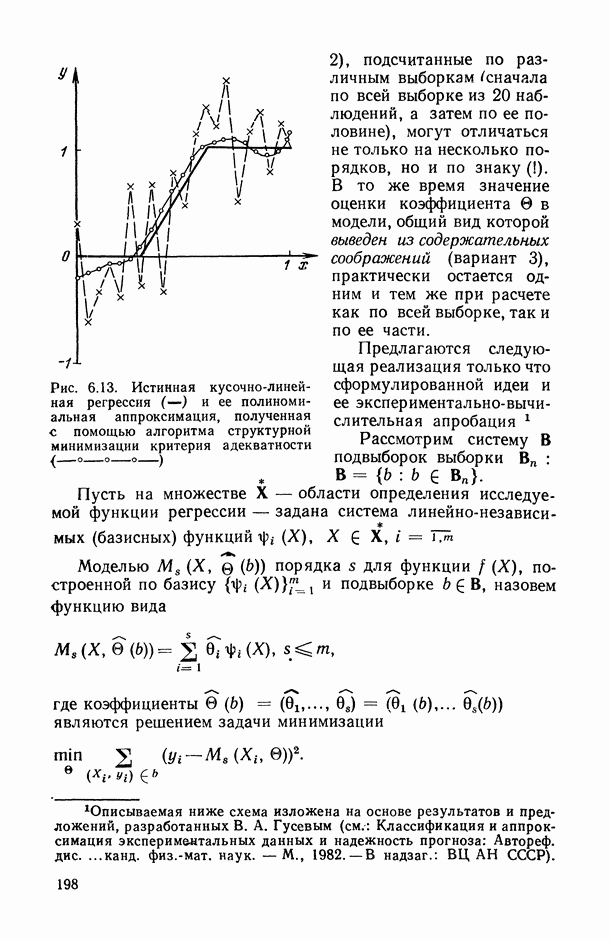
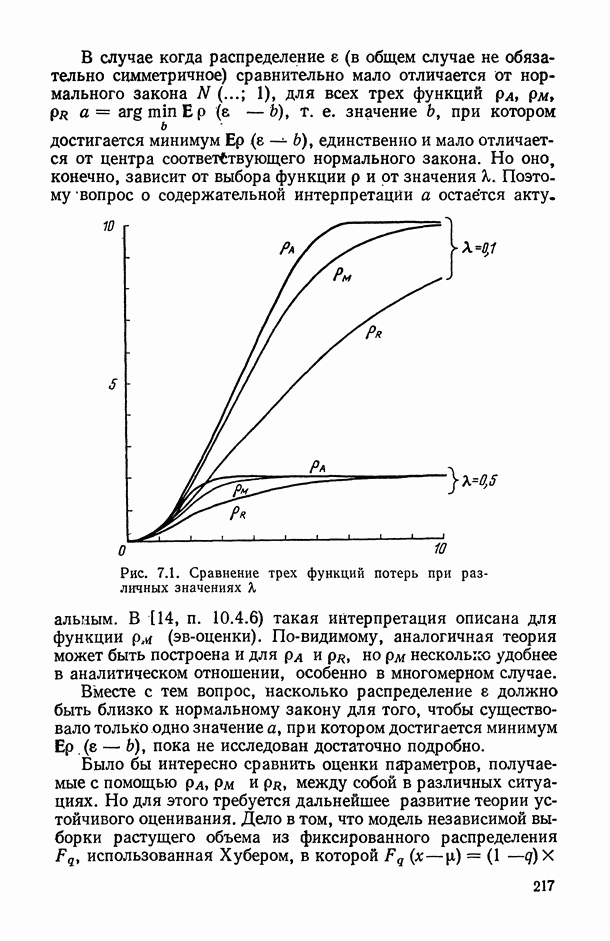
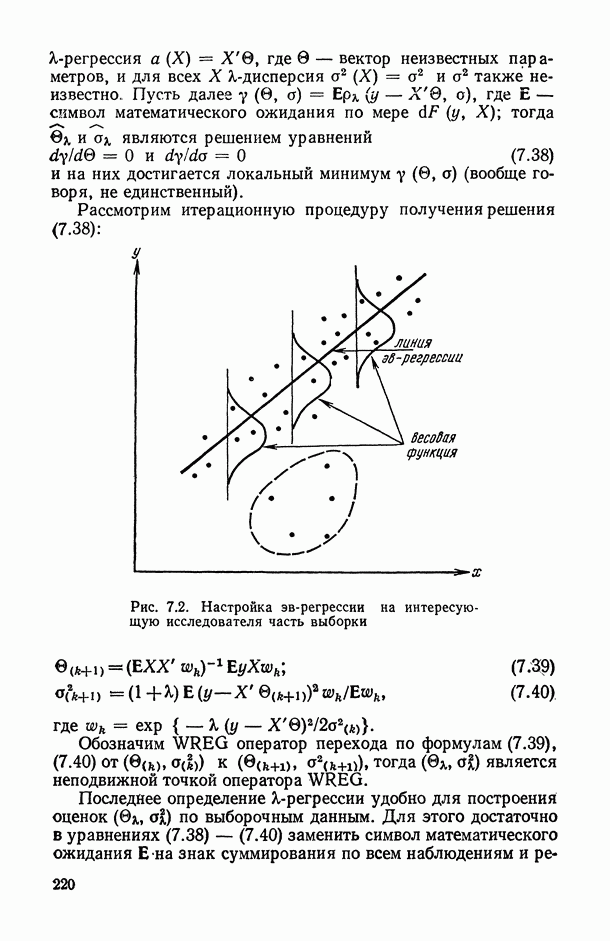
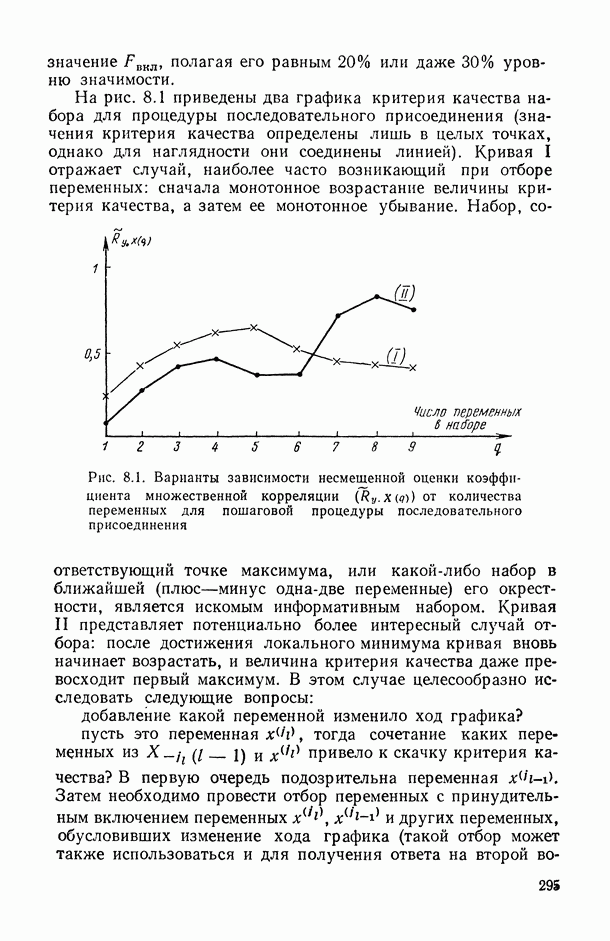
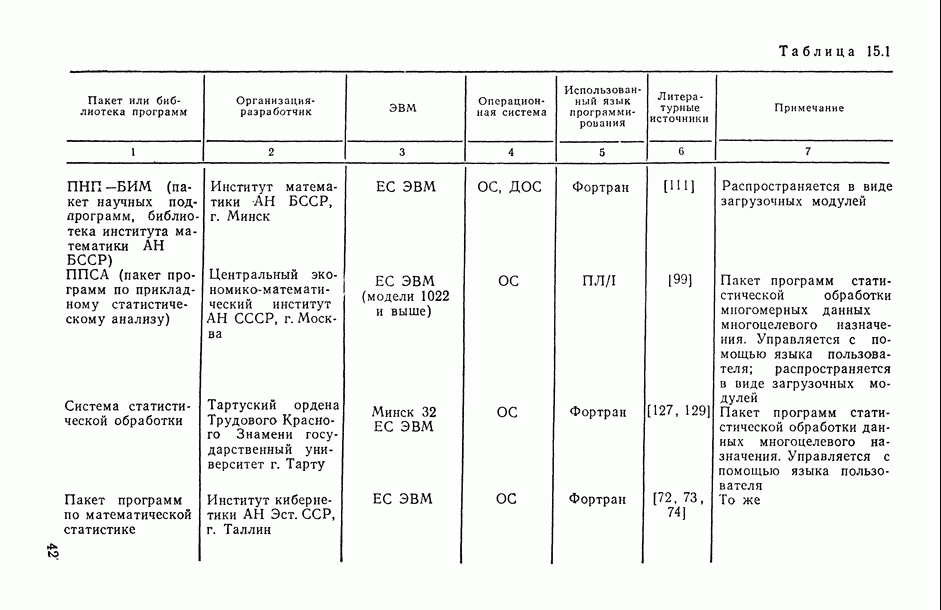
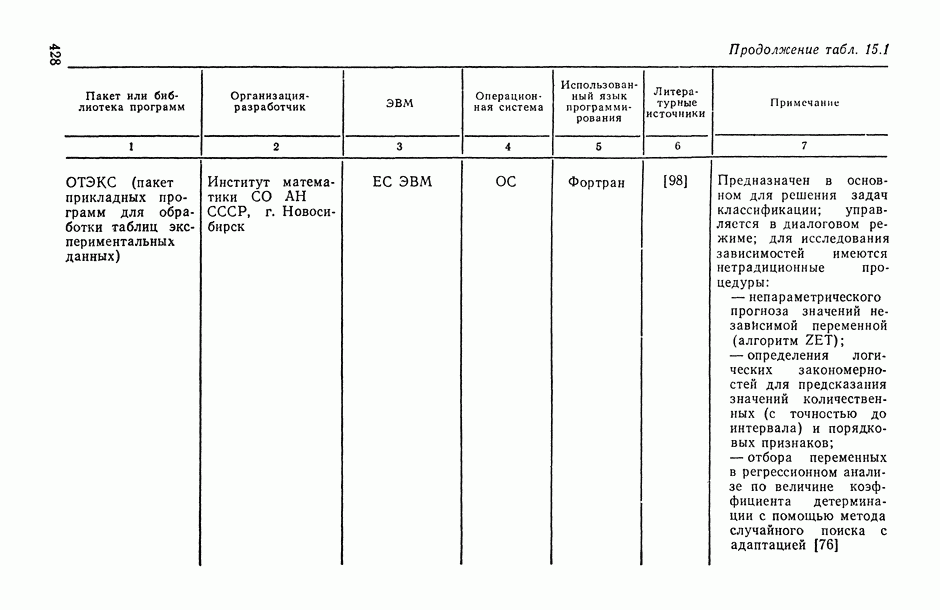
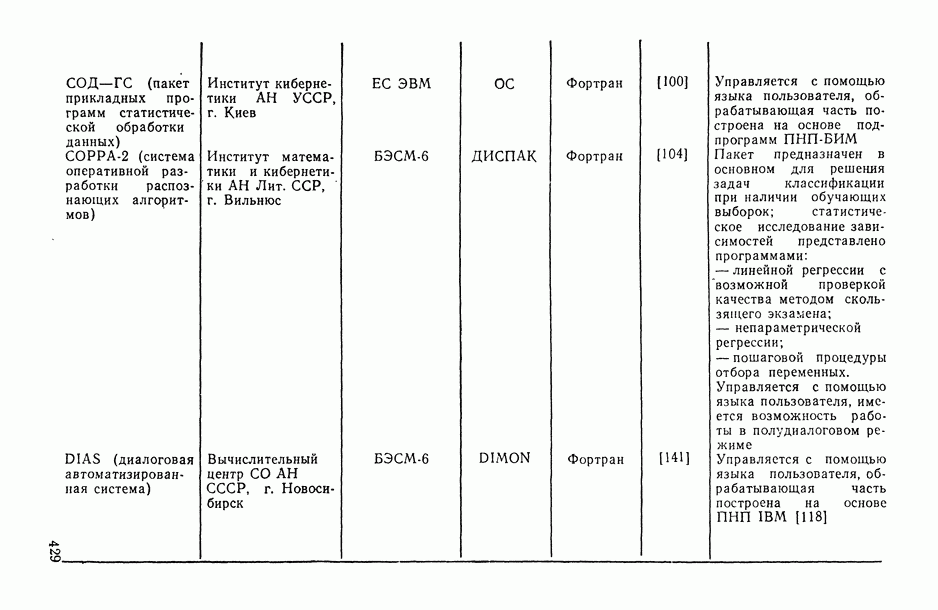
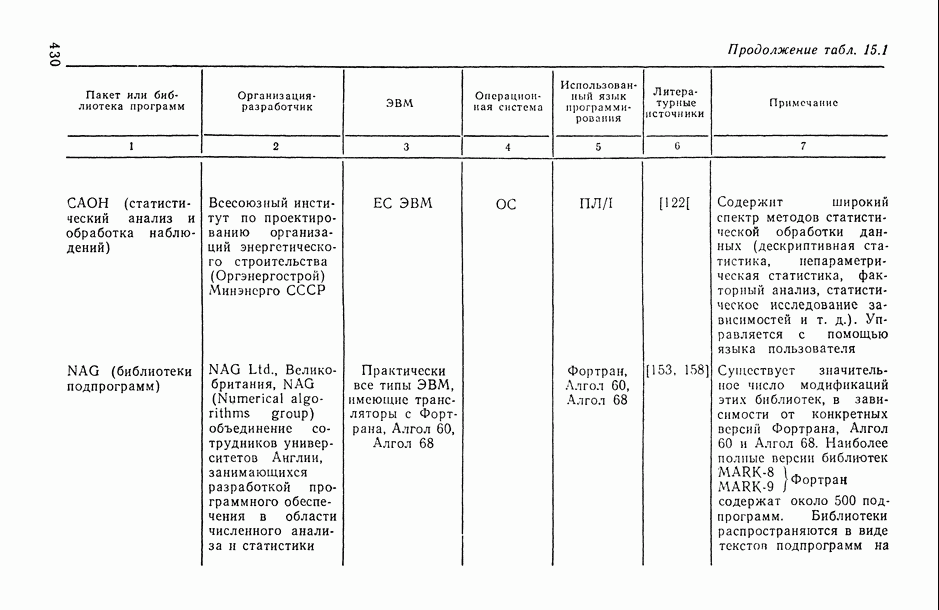
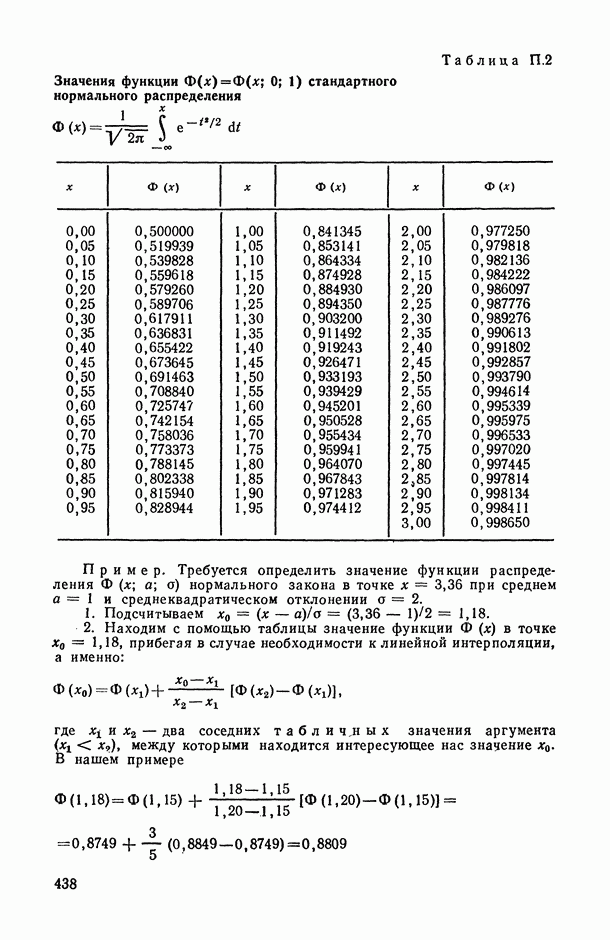
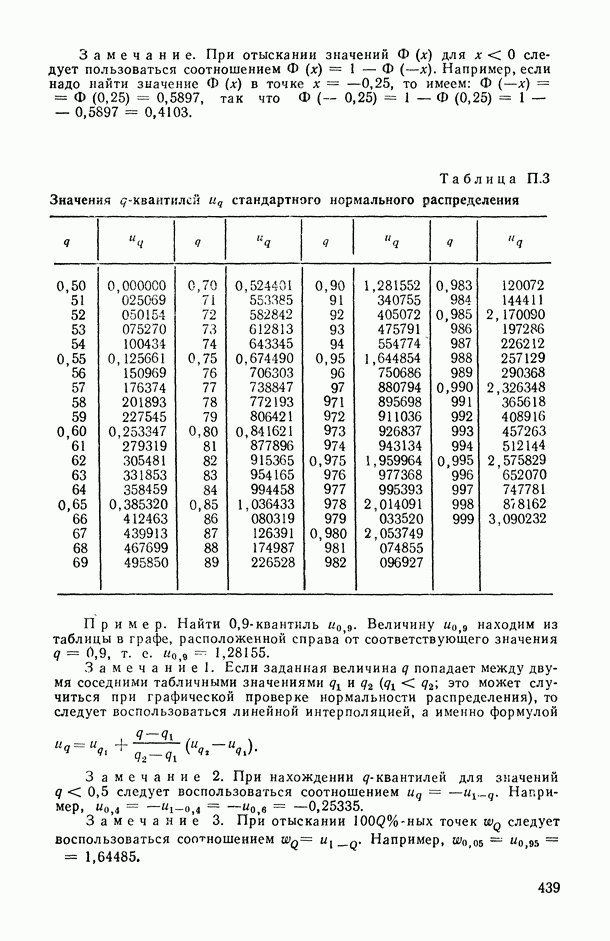
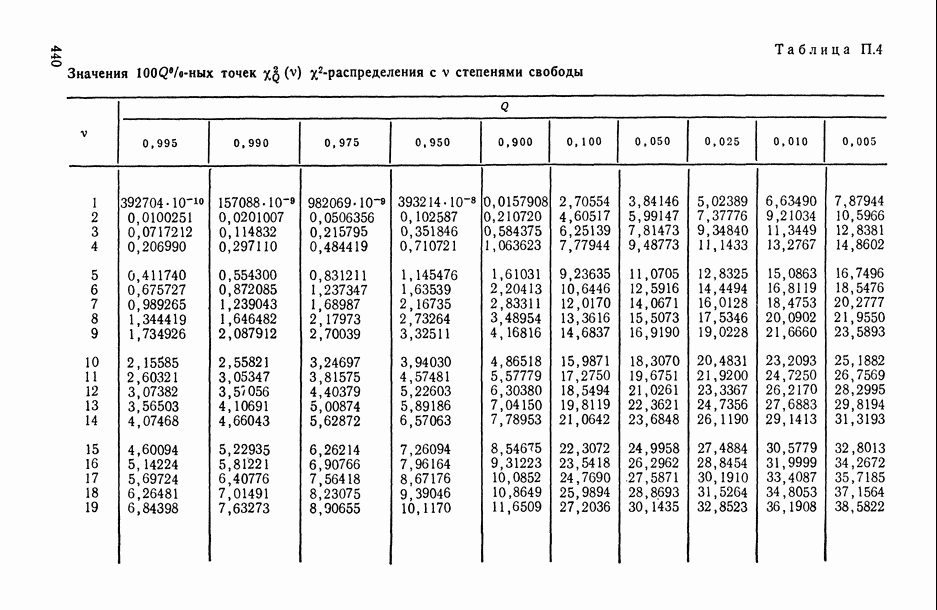
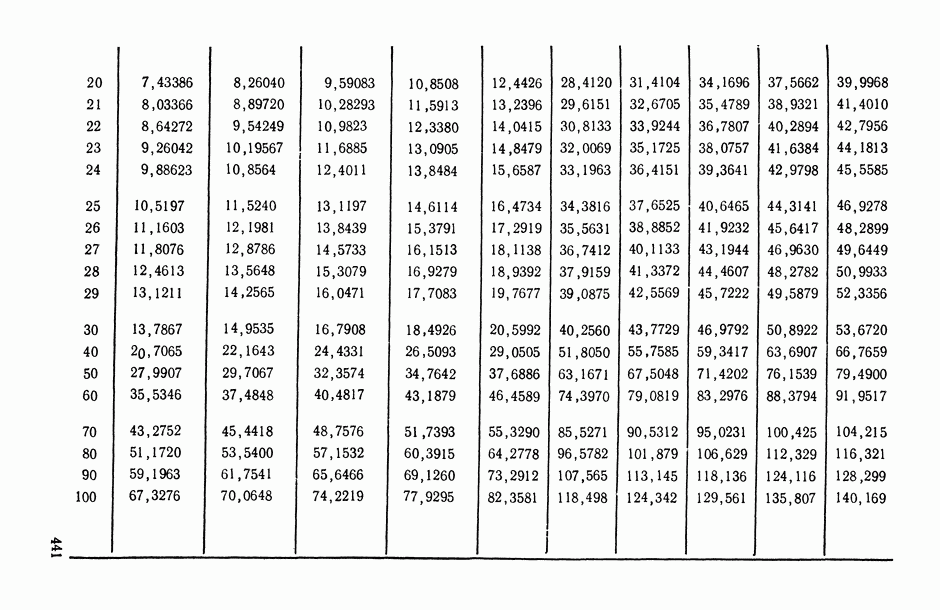
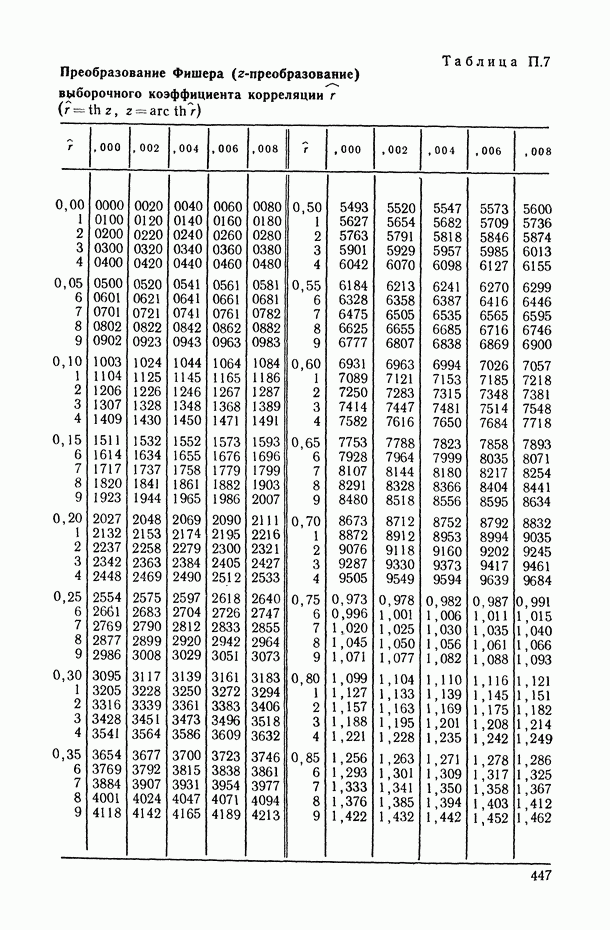
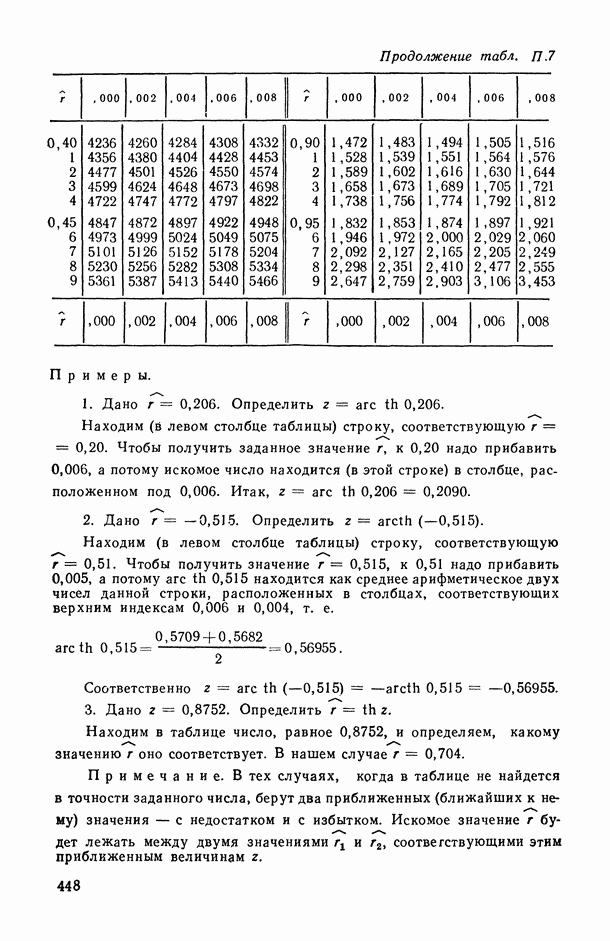
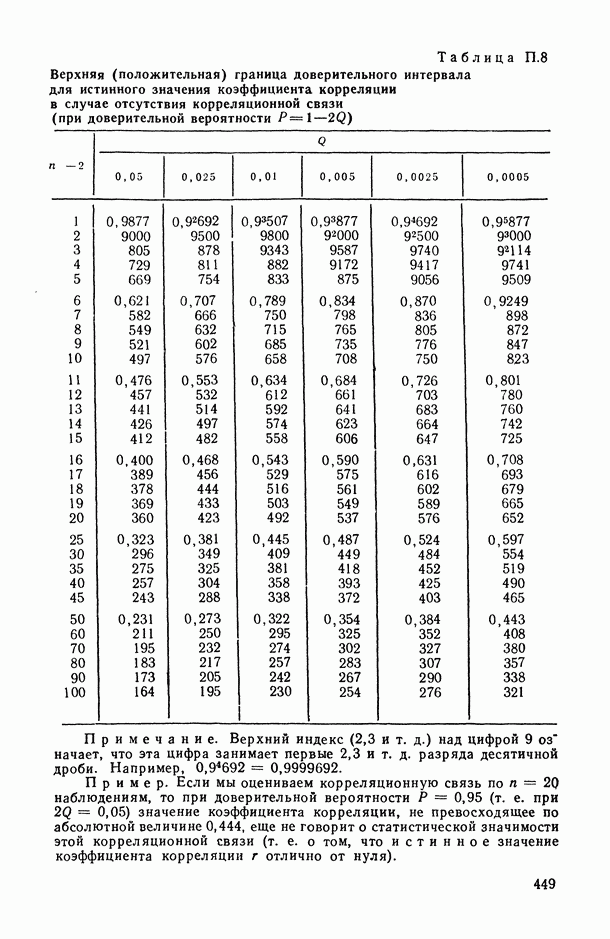
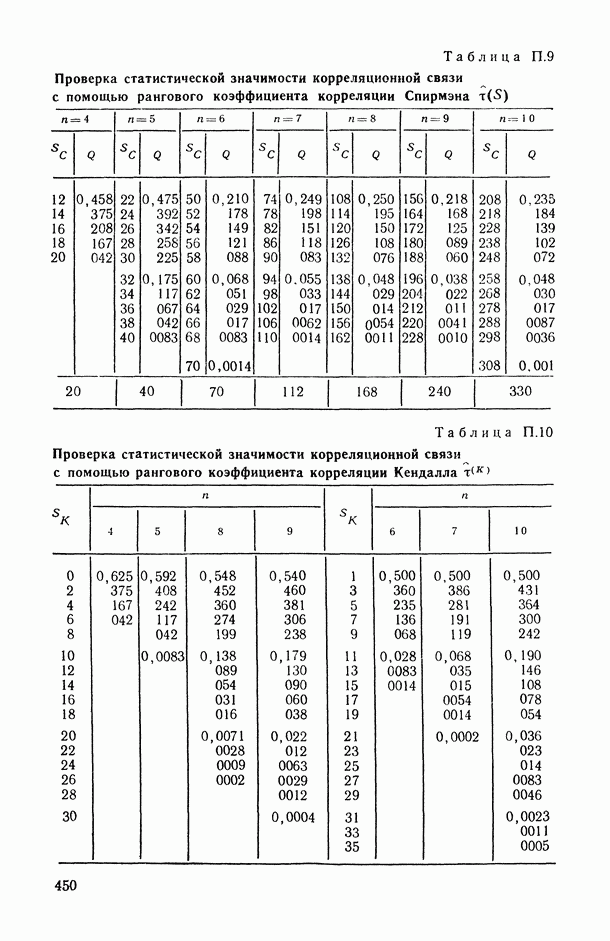
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
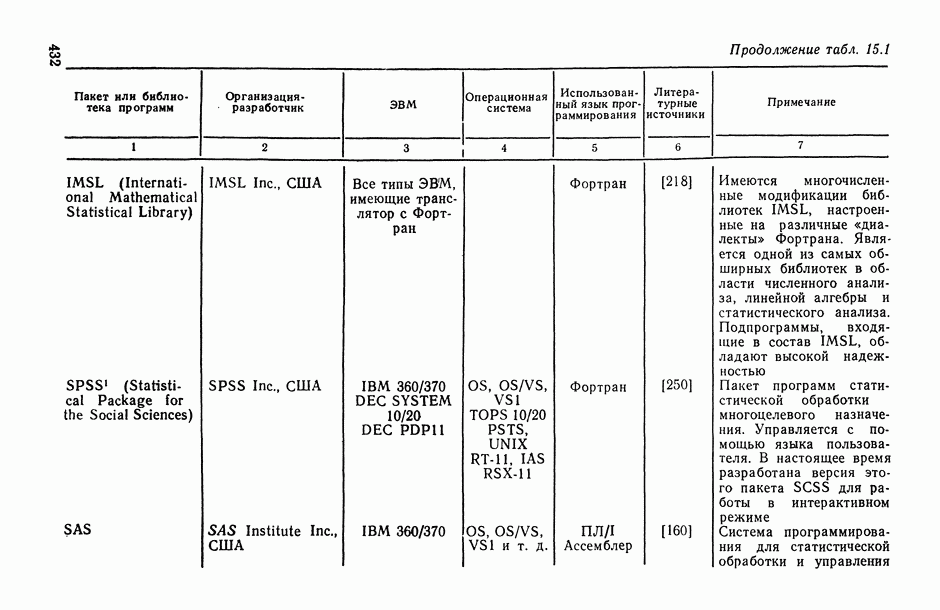
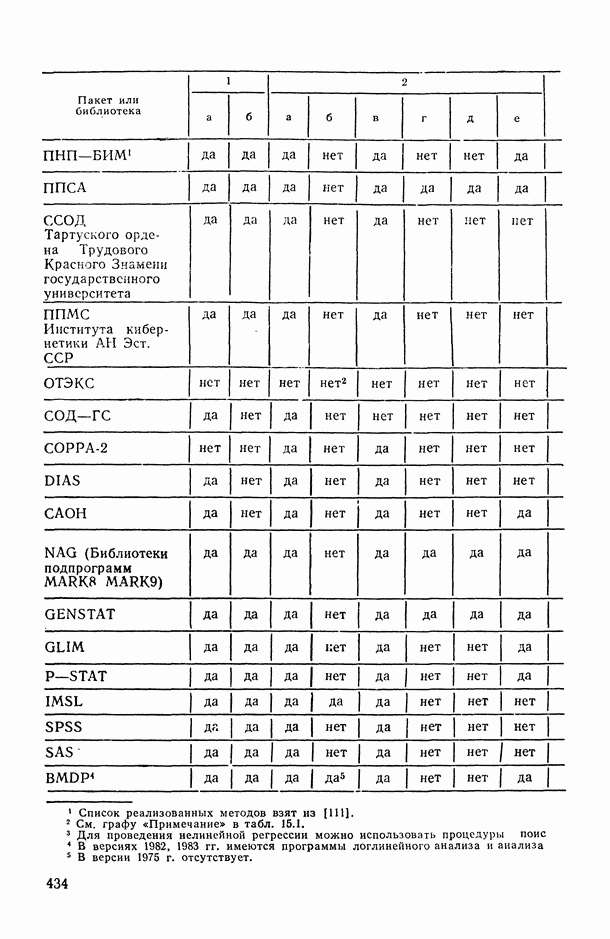
13.4. Модели дисперсионного анализа со случайными факторами
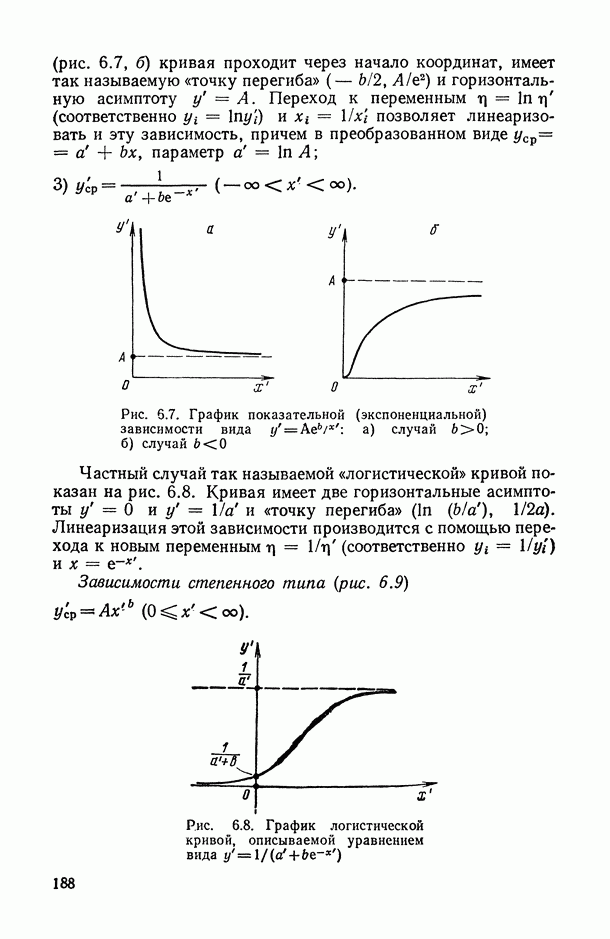
13.4.1. Место моделей со случайными факторами.
В ряде экспериментов, проводимых по схеме дисперсионного анализа, значения, которые принимает некоторый фактор, нельзя охарактеризовать ничем, кроме того, что они «наудачу» извлечены из некоторой генеральной совокупности. В этом случае вряд ли целесообразно связывать с индивидуальными значениями фактора числовые характеристики их вклада в общий итог  , а лучше оценить вклад фактора в целом в общую изменчивость у. В этом случае, как указано в § 13.1, и возникают модели со случайными факторами. При этом, если окажется, что вклад фактора в общую изменчивость достаточно велик, то целесообразно из профессиональных содержательных соображений найти характеристики значений фактора, предположительно связанные с у, и изучить с помощью традиционного анализа их влияние на итог. Так, если нас интересует влияние личности рабочего на его производительность труда, то здесь целесообразна случайная выборка среди всех рабочих, заня
, а лучше оценить вклад фактора в целом в общую изменчивость у. В этом случае, как указано в § 13.1, и возникают модели со случайными факторами. При этом, если окажется, что вклад фактора в общую изменчивость достаточно велик, то целесообразно из профессиональных содержательных соображений найти характеристики значений фактора, предположительно связанные с у, и изучить с помощью традиционного анализа их влияние на итог. Так, если нас интересует влияние личности рабочего на его производительность труда, то здесь целесообразна случайная выборка среди всех рабочих, заня  однотипным трудом, и использование модели со случайным фактором — влиянием личности рабочего.
однотипным трудом, и использование модели со случайным фактором — влиянием личности рабочего.
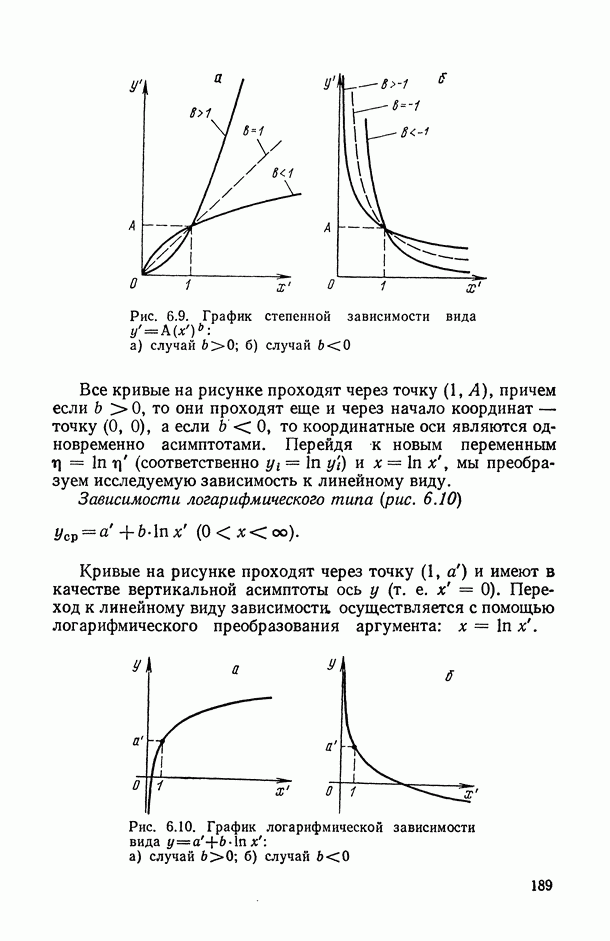
Если же нас интересует различие в производительности труда рабочих с различным уровнем образования, то целесообразно разбить рабочих на группы по уровню образования и взять для сравнения по нескольку человек из каждой группы. Здесь больше подходит смешанная модель вида
 (13.22)
(13.22)
где  — производительность в
— производительность в  день
день  рабочего с
рабочего с  уровнем образования;
уровнем образования;  — среднее значение производительности труда;
— среднее значение производительности труда;  — постоянная, отражающая влияние
— постоянная, отражающая влияние  уровня образования
уровня образования  — случайный фактор, характеризующий отклонение от общего среднего производительности труда
— случайный фактор, характеризующий отклонение от общего среднего производительности труда  рабочего из группы с уровнем образования
рабочего из группы с уровнем образования  — случайное колебание в производительности труда в
— случайное колебание в производительности труда в  день эксперимента этого рабочего.
день эксперимента этого рабочего.
Другой пример. При изучении воспроизводимости химических анализов часто говорят о средней межлабораторной ошибке [95]. В этом термине различные лаборатории рассматриваются как случайные, наудачу выбранные из совокупности лабораторий какой-либо отрасли. Для оценки этой ошибки подходит модель со случайным фактором — названием лаборатории. Если же лаборатории можно классифицировать по какому-нибудь доступному и существенному для точности анализов признаку, например по уровню оснащения современным оборудованием, то межлабораторную ошибку целесообразно определять отдельно внутри однородных по этому признаку классов. В частности, можно использовать модель вида (13.22), в которой первый фактор  соответствует уровню оснащения лаборатории современным оборудованием, а второй фактор
соответствует уровню оснащения лаборатории современным оборудованием, а второй фактор  отражает условный номер лаборатории среди однотипных по оборудованию лабораторий.
отражает условный номер лаборатории среди однотипных по оборудованию лабораторий.
В модели (13.22) мы встретились с так называемым иерархическим или группированным, или, как еще говорят, гнездовым планом, в котором каждому уровню первого фактора  соответствует свое подмножество значений второго фактора
соответствует свое подмножество значений второго фактора 
13.4.2. Однофакторный анализ.
Простейшая математическая модель имеет вид
 (13.23)
(13.23)
где  — постоянная; — случайная составляющая, отражающая влияние
— постоянная; — случайная составляющая, отражающая влияние  выборочного значения фактора
выборочного значения фактора  ;
;  — случайная ошибка;
— случайная ошибка;  случайные величины
случайные величины  независимы в совокупности и
независимы в совокупности и 
3) провести с наблюдениями  обычный дисперсионный анализ по описанным выше формулам.
обычный дисперсионный анализ по описанным выше формулам.
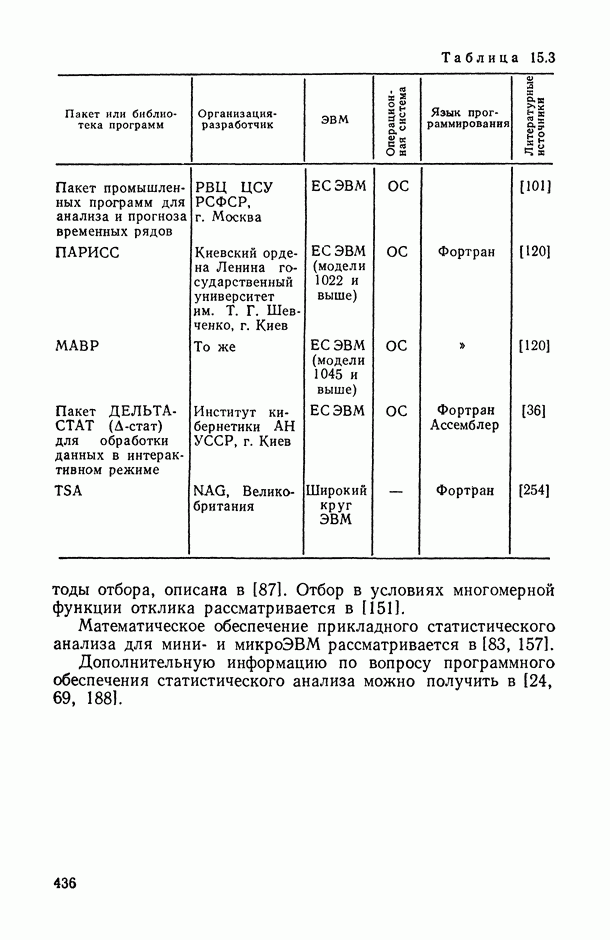
13.4.3. Иерархический план на двух уровнях.
В качестве примера рассмотрим сначала описанную, в п. 13.4.1 задачу по определению точности проведения химического анализа в лабораториях какой-либо отрасли промышленности. Предположим, что все лаборатории отрасли могут быть разбиты на группы, примыкающие к городам, в которых есть метрологические центры по данному виду анализа. Эксперимент состоит в том, что сначала наудачу выбирается несколько метрологических центров (городов), а затем для каждого из выбранных центров также наудачу отбирается несколько из примыкающих к нему лабораторий, и в каждой из лабораторий проводится несколько повторных определений одного и того же образца. Простейшая математическая модель для рассматриваемого иерархического плана с двумя случайными факторами имеет вид
 (13.27)
(13.27)
где  — результат
— результат  анализа в
анализа в  лаборатории, примыкающей к
лаборатории, примыкающей к  городу;
городу;  — истинная (обычно неизвестная) определяемая концентрация;
— истинная (обычно неизвестная) определяемая концентрация;  — эффект
— эффект  метрологического центра;
метрологического центра;  — эффект
— эффект  лаборатории
лаборатории  центра и
центра и  — случайная ошибка
— случайная ошибка  повторения анализа в
повторения анализа в  лаборатории
лаборатории  центра; величины
центра; величины  взаимно независимы и нормально распределены с нулевыми средними и дисперсиями
взаимно независимы и нормально распределены с нулевыми средними и дисперсиями  соответственно.
соответственно.
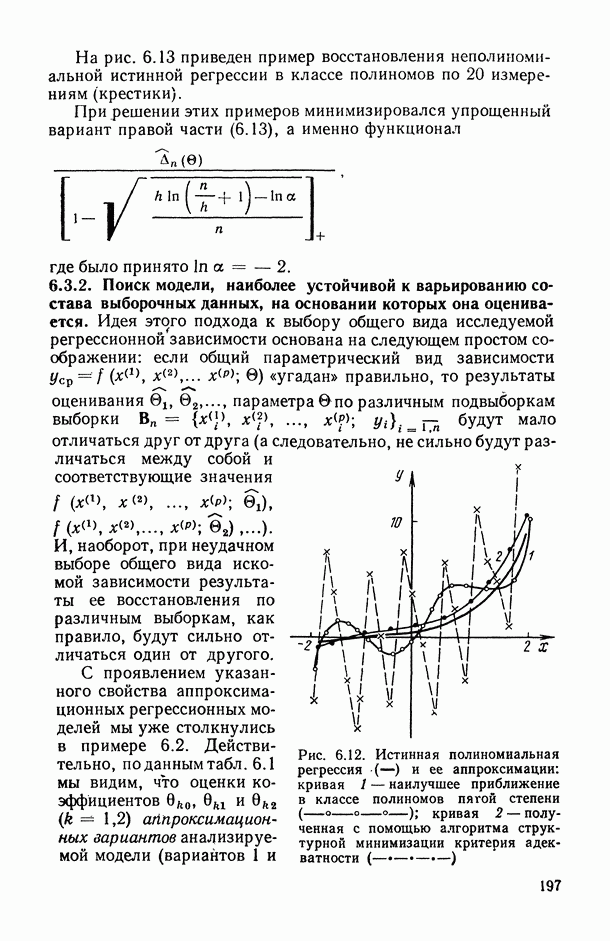
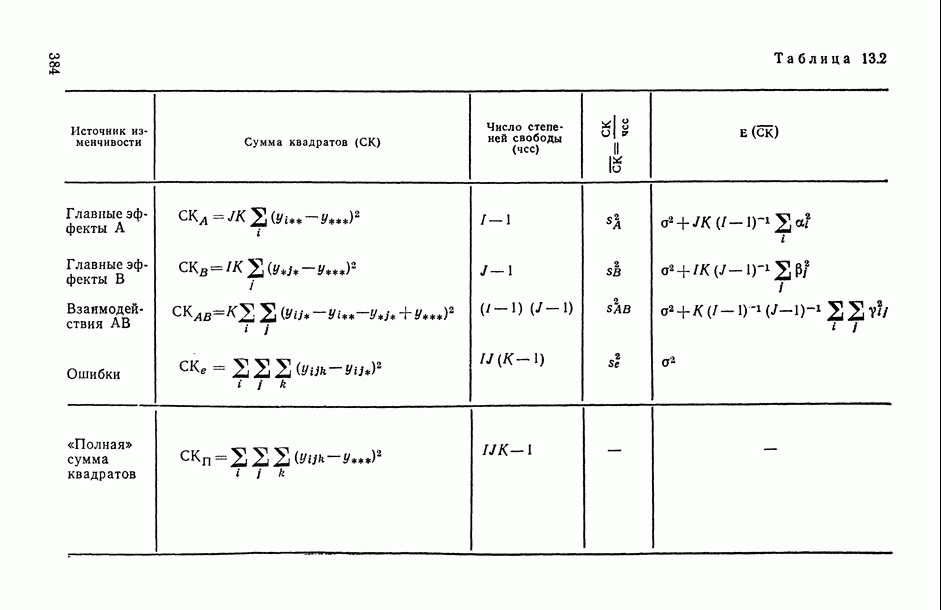
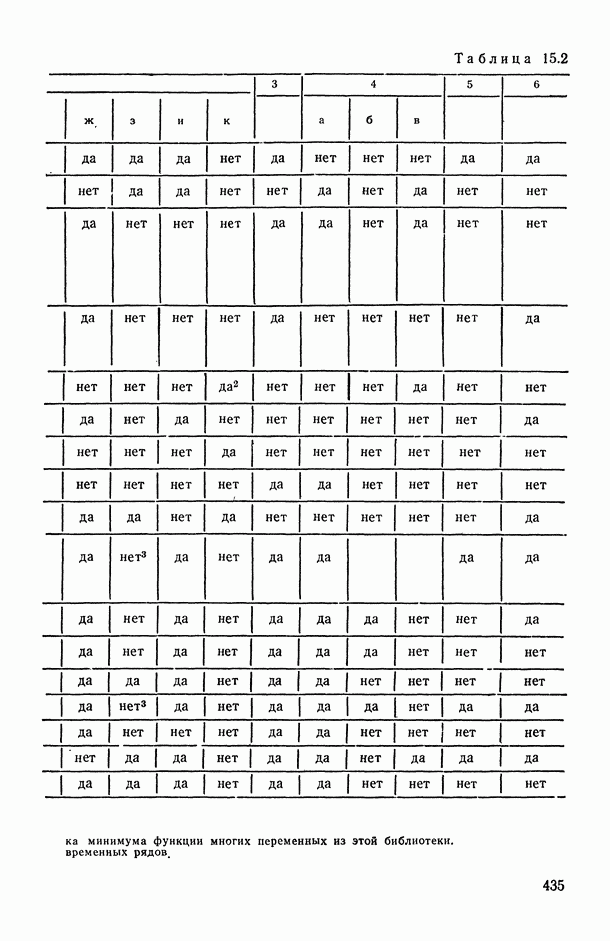
Разложение общей суммы квадратов на части, соответствующие рассматриваемой модели, показано в таблице ДА для иерархического плана с двумя случайными факторами (табл. 13.4).
F-критерии для гипотез  строятся с помощью соответствующих отношений средних квадратов. Например, для проверки
строятся с помощью соответствующих отношений средних квадратов. Например, для проверки  ; используется отношение
; используется отношение  которое в случае, когда гипотеза
которое в случае, когда гипотеза  верна, имеет
верна, имеет  распределение. В рассматриваемом случае имеет смысл и оценка суммы
распределение. В рассматриваемом случае имеет смысл и оценка суммы  которая является характеристикой воспроизводимости анализа в случайно выбранной лаборатории.
которая является характеристикой воспроизводимости анализа в случайно выбранной лаборатории.
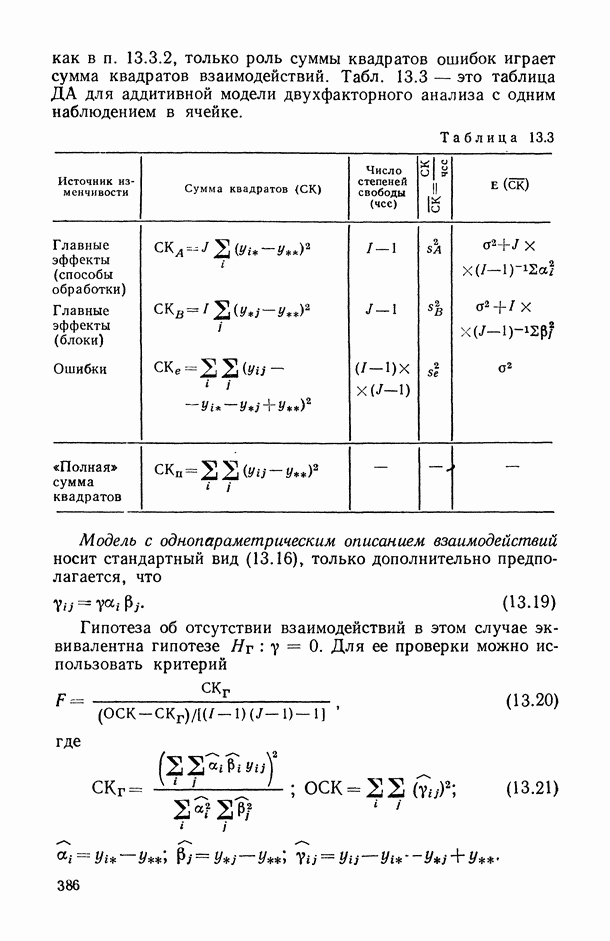
В заключение рассмотрим иерархическую смешанную модель (13.22). В дополнение к сделанным выше (п. 13.4.1) предположениям допустим, что  взаимно независимы,
взаимно независимы, 
Таблица 13.4

В этом случае таблица дисперсионного анализа для модели (13.22) получается из табл. 13.4 путем замены в первой строке  на
на  на
на 




















































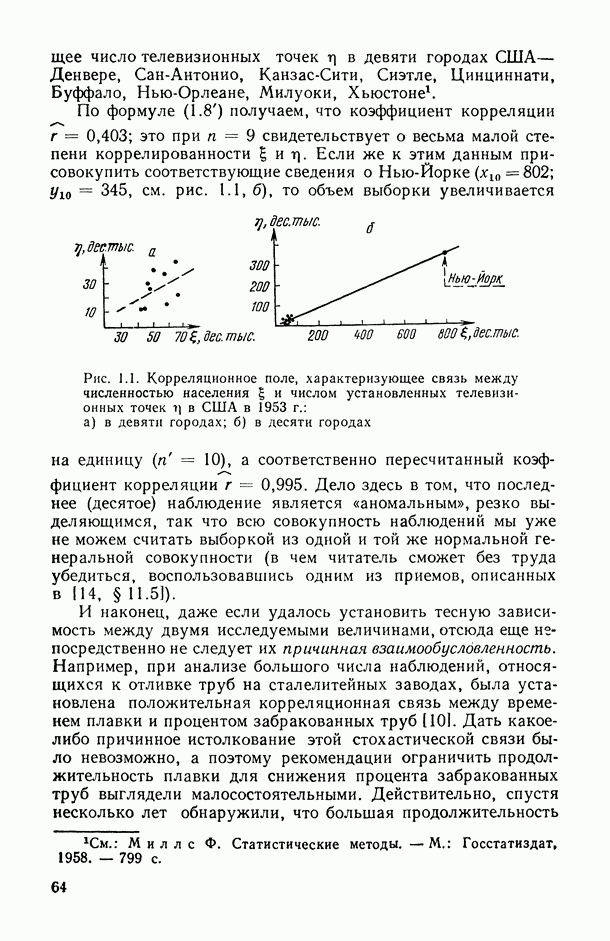


























































































































































































































































































































































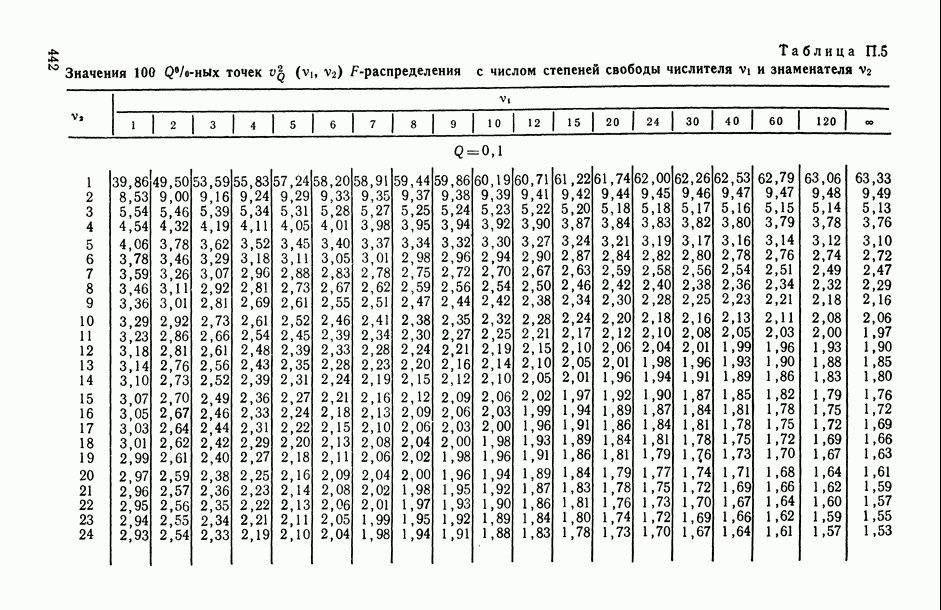
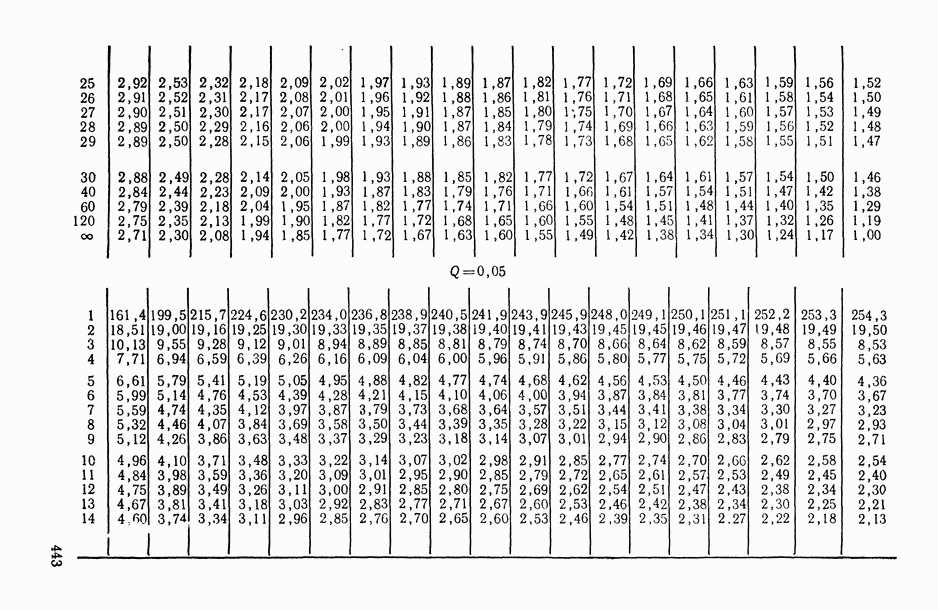
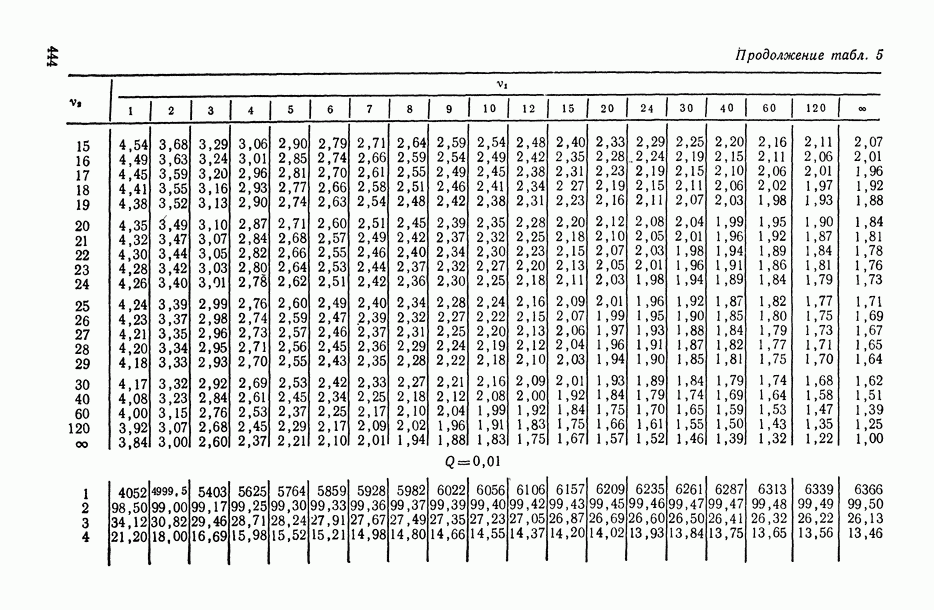

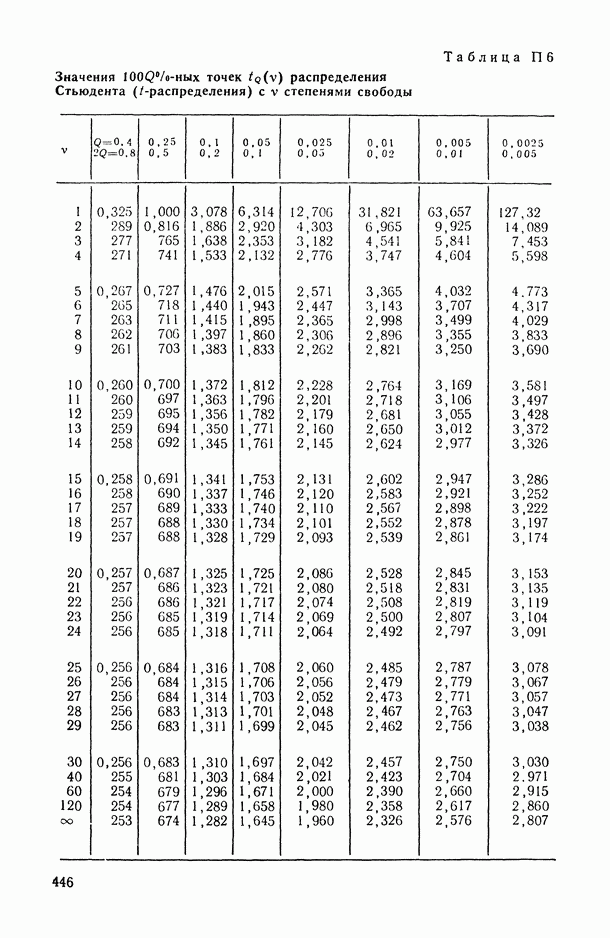


















 величины
величины  называют компонентами дисперсии (наблюдения).
называют компонентами дисперсии (наблюдения).
 соответствующие одному и тому же значению
соответствующие одному и тому же значению  изучаемого фактора. Соответствующий коэффициент корреляции, равный
изучаемого фактора. Соответствующий коэффициент корреляции, равный  называют коэффициентом внутриклассовой корреляции.
называют коэффициентом внутриклассовой корреляции.
 (13.24)
(13.24)
 — заданная константа. Определим
— заданная константа. Определим  так, как указано в табл. 13.1, и построим
так, как указано в табл. 13.1, и построим  -отношение (13.5). Статистический критерий для проверки гипотезы (13.24)
-отношение (13.5). Статистический критерий для проверки гипотезы (13.24)  имеет мощность, выражающуюся только через центральное
имеет мощность, выражающуюся только через центральное  -распределение [148],
-распределение [148],
 (13.25)
(13.25)

 вычислить устойчивые оценки положения и масштаба. Обозначить их у
вычислить устойчивые оценки положения и масштаба. Обозначить их у  и
и
 на
на

 —
—  -квантиль стандартного
-квантиль стандартного  -распределения).
-распределения).
