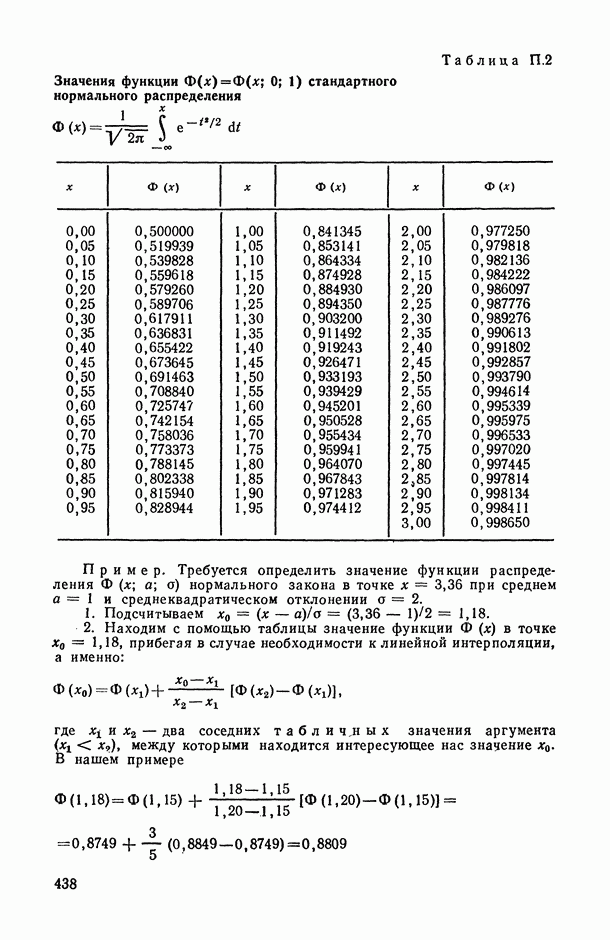
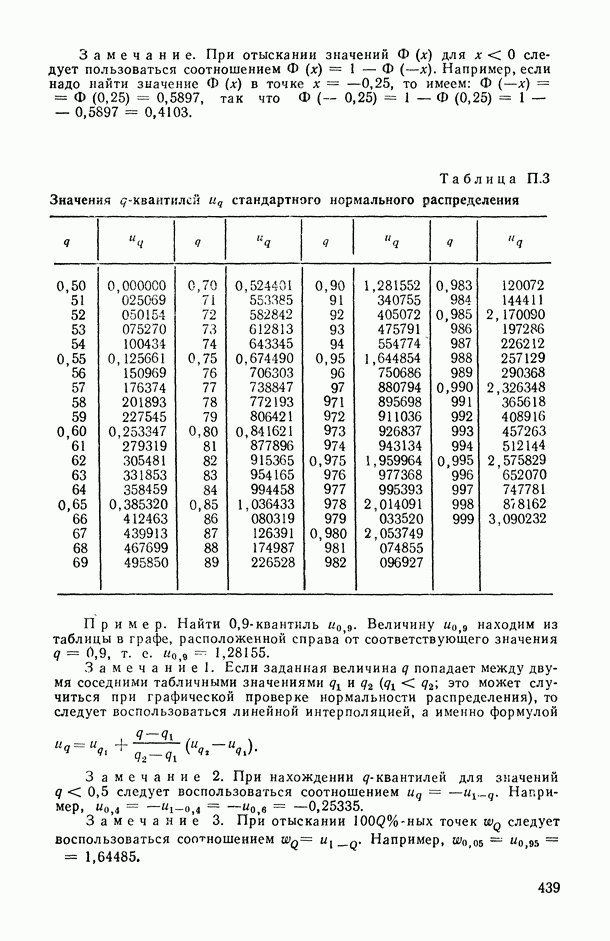
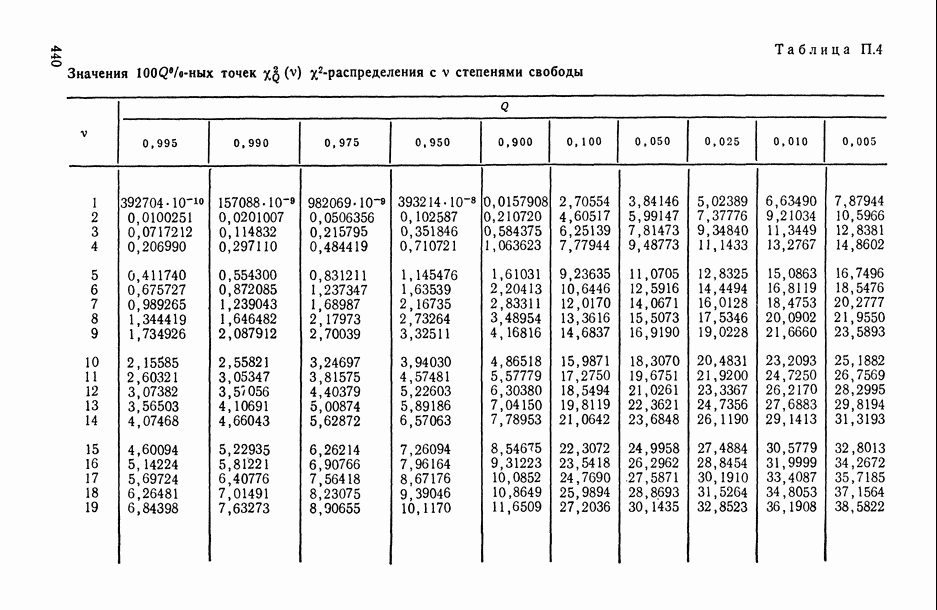
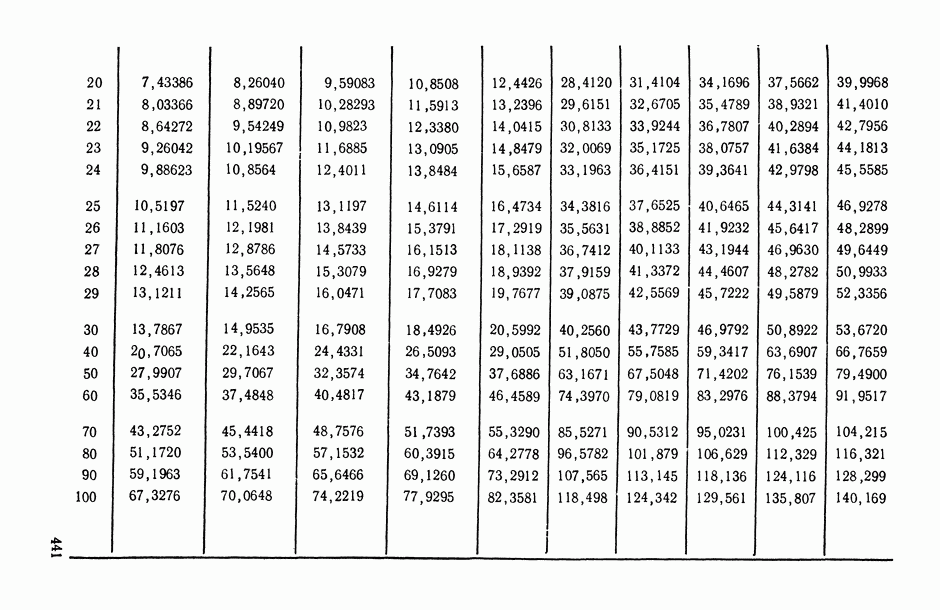
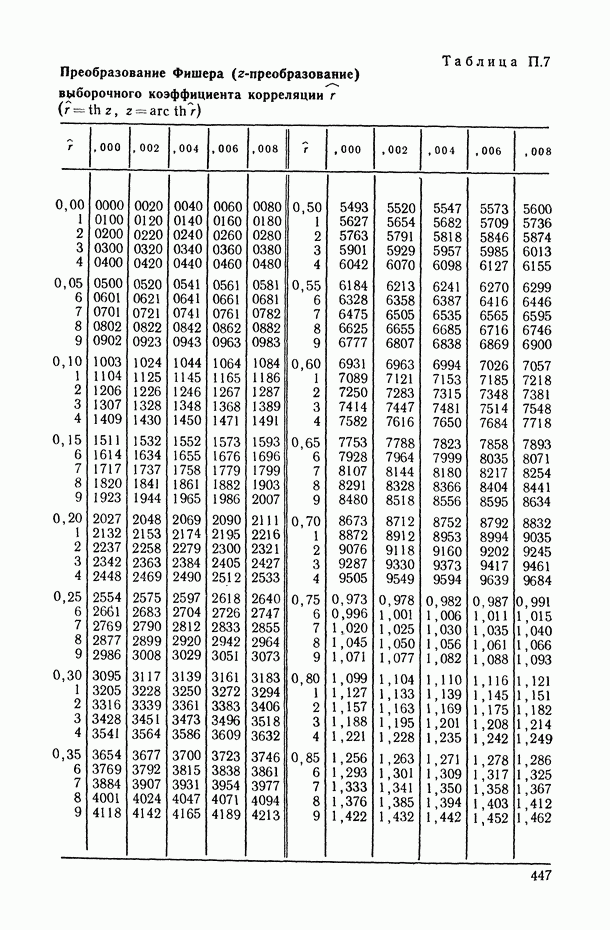
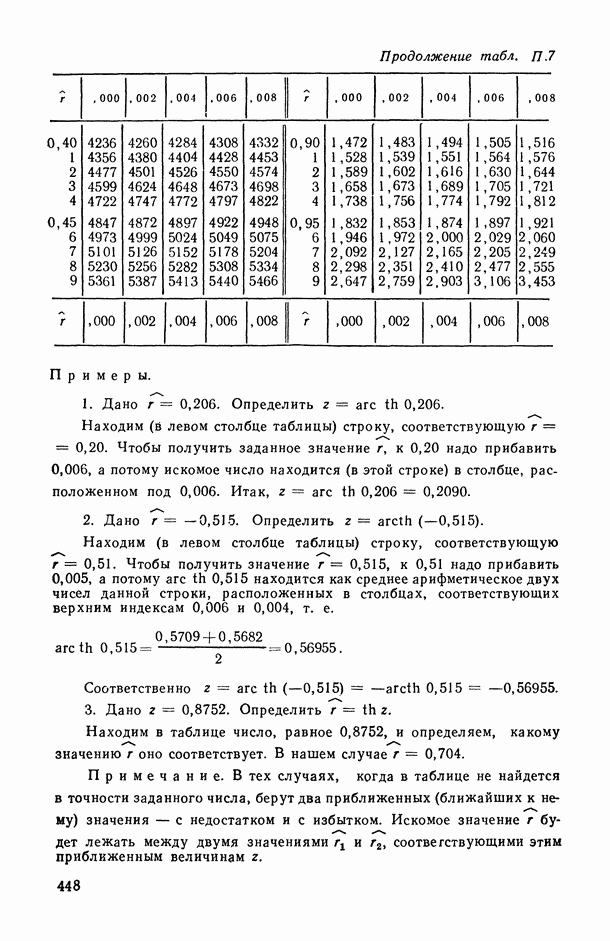
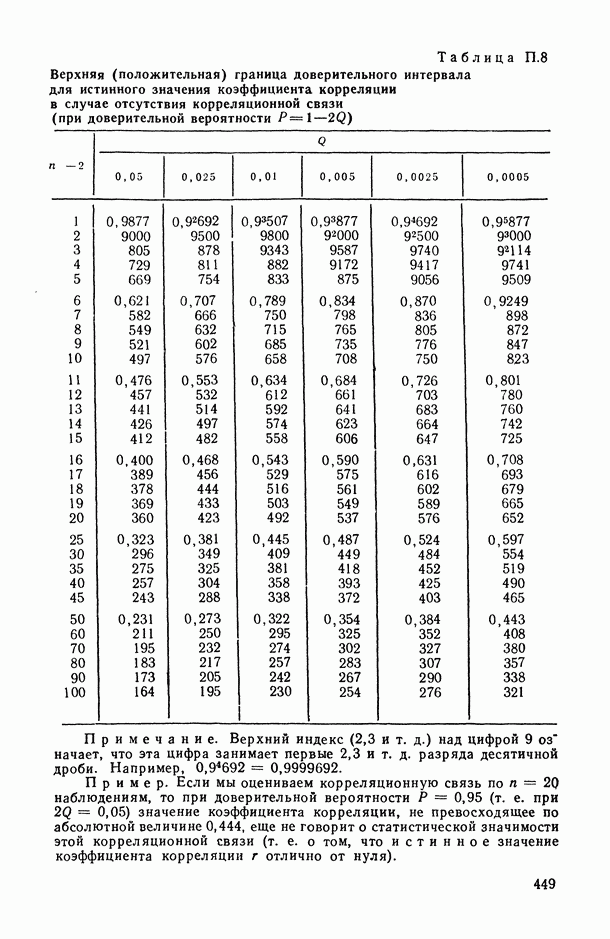
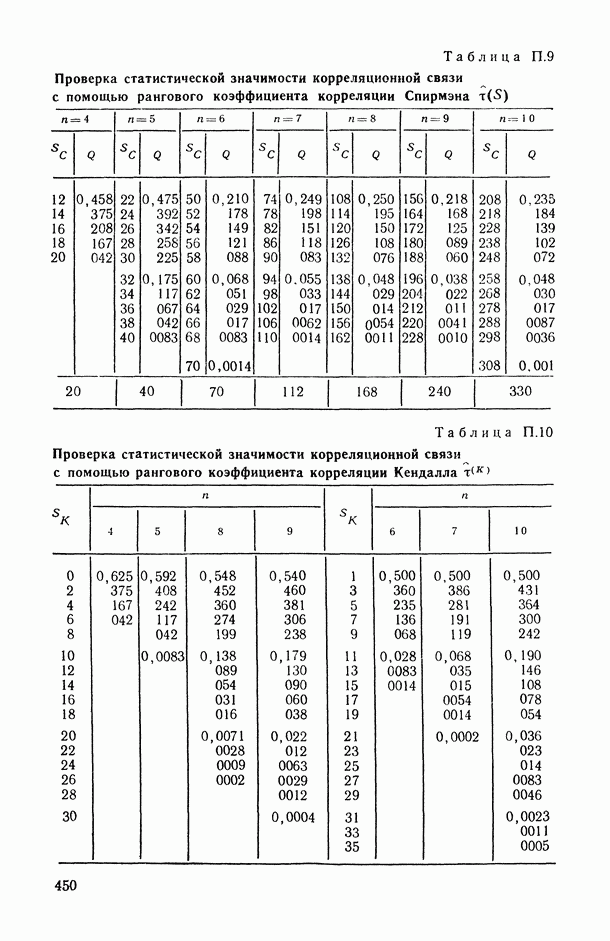
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
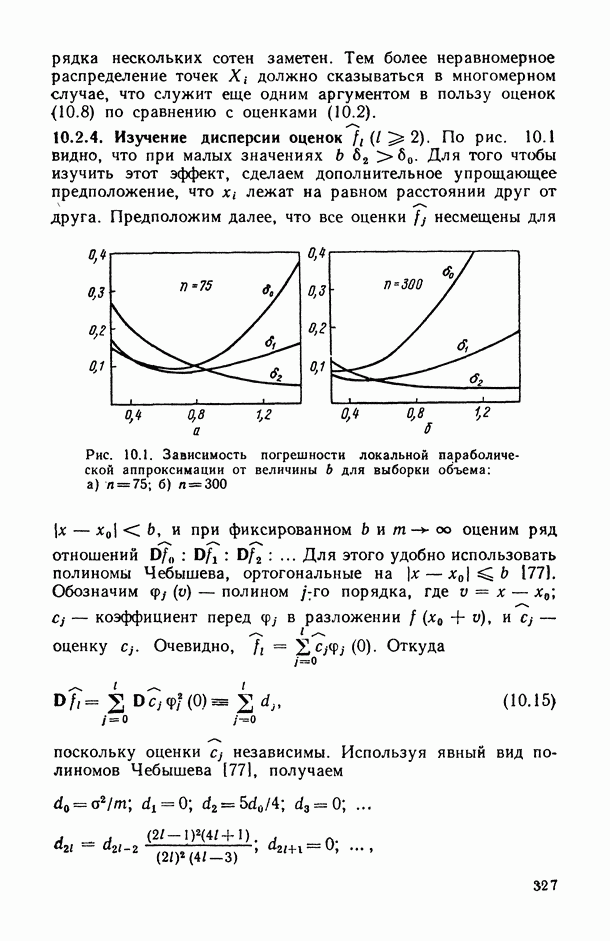
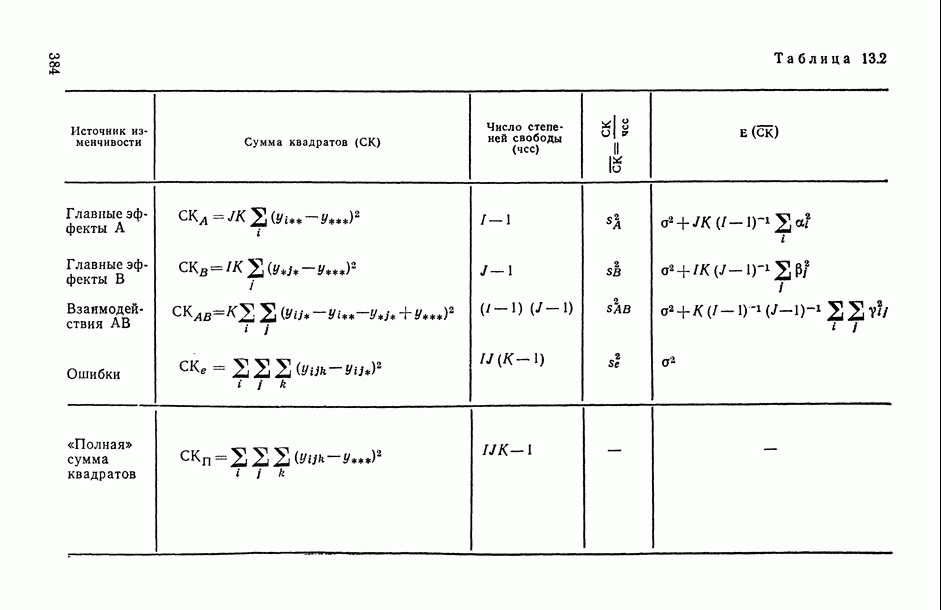
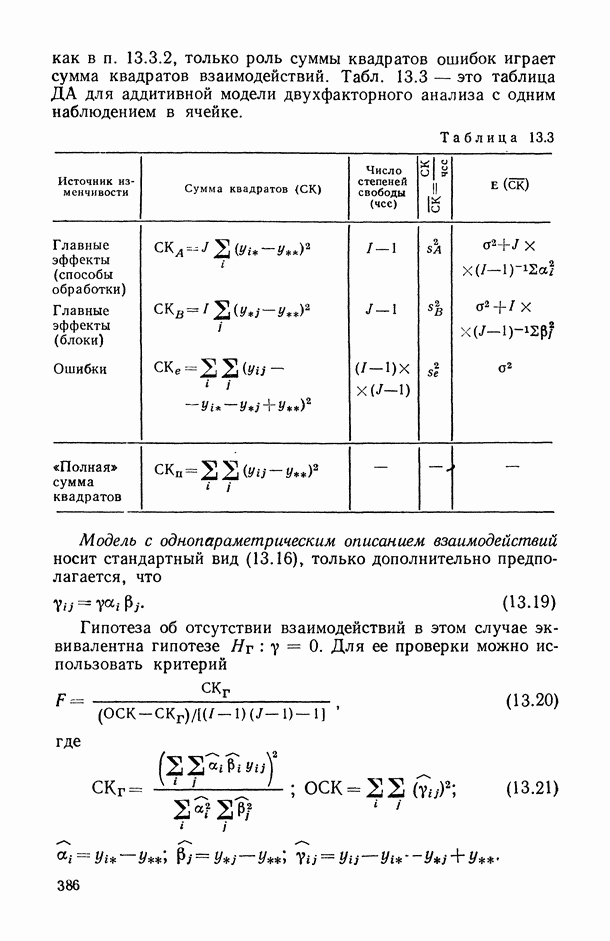
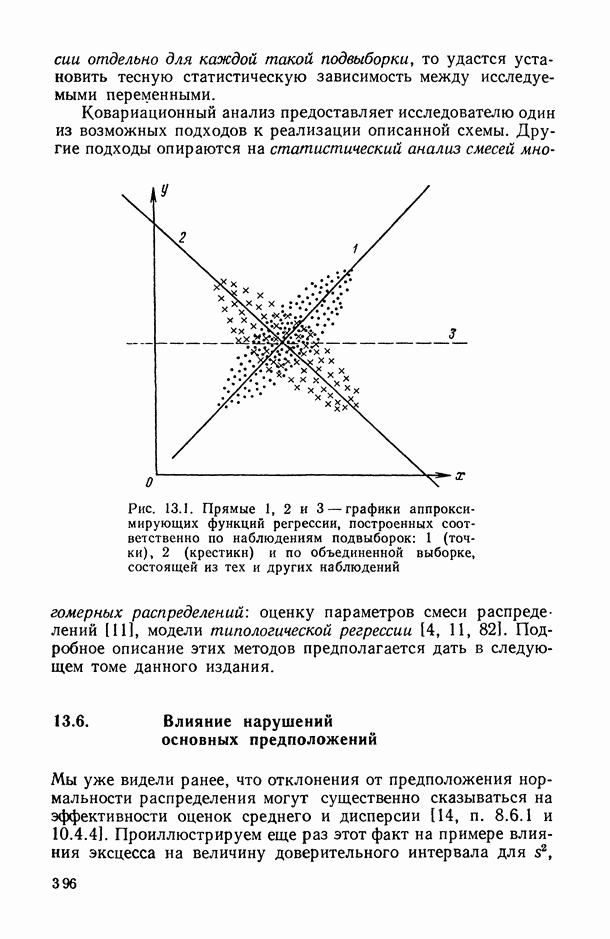
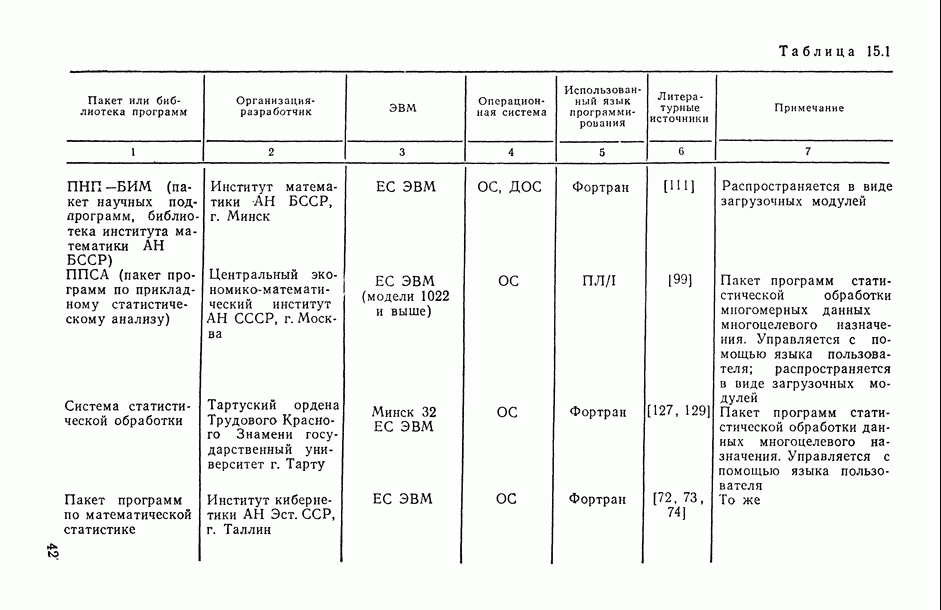
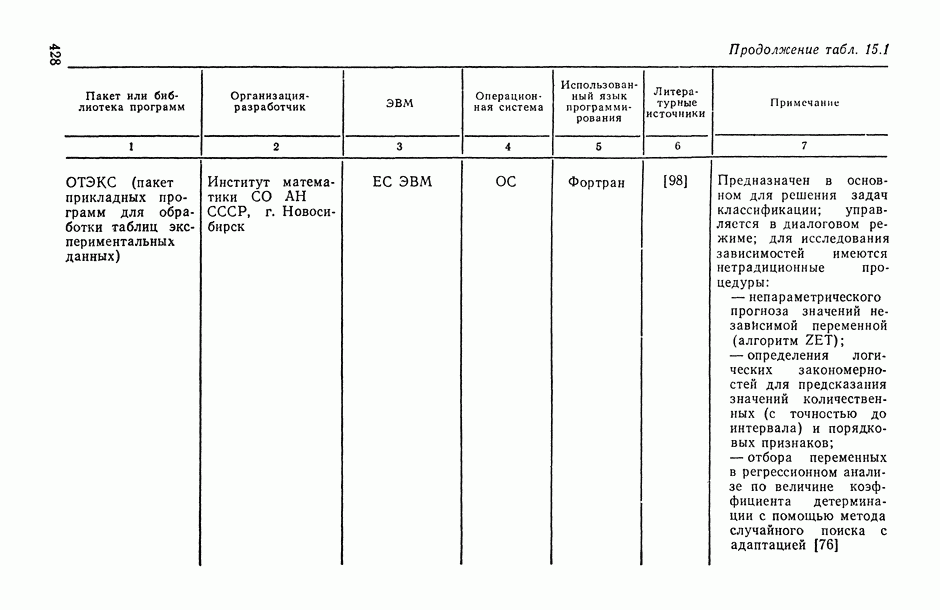
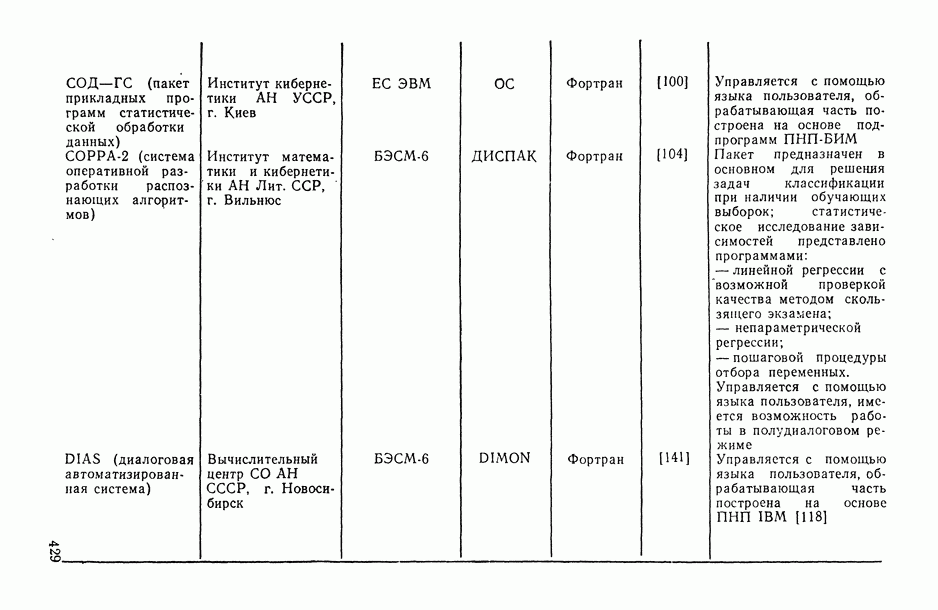
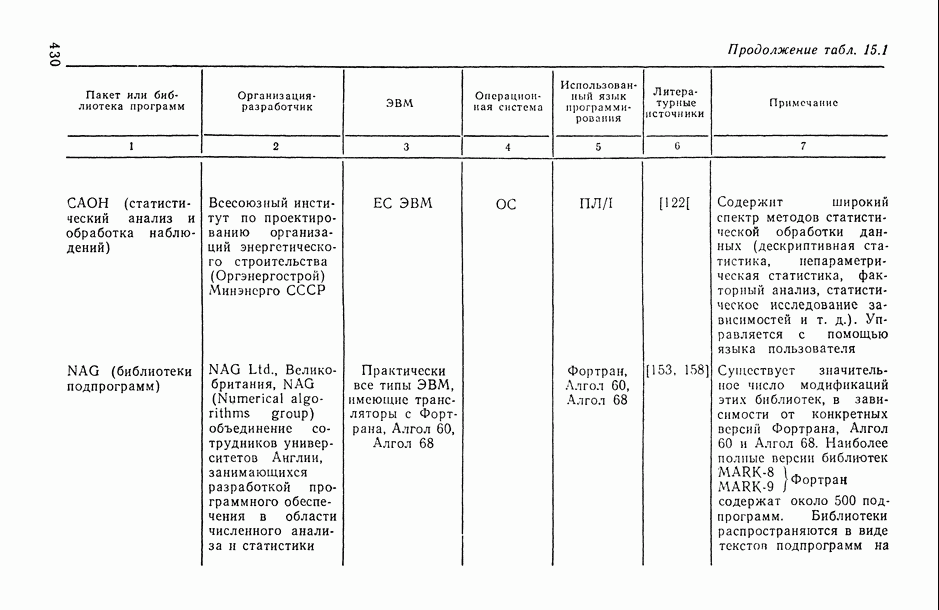
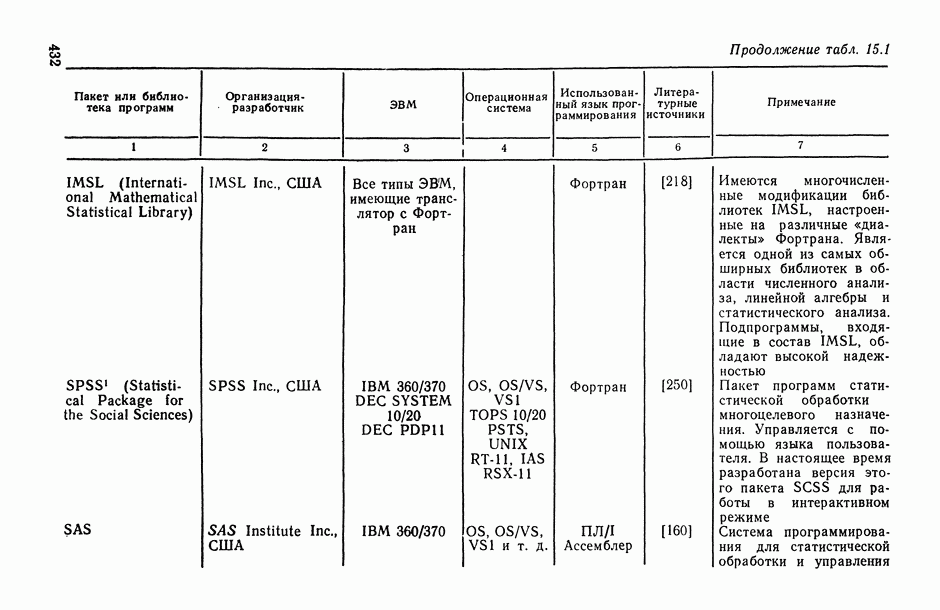
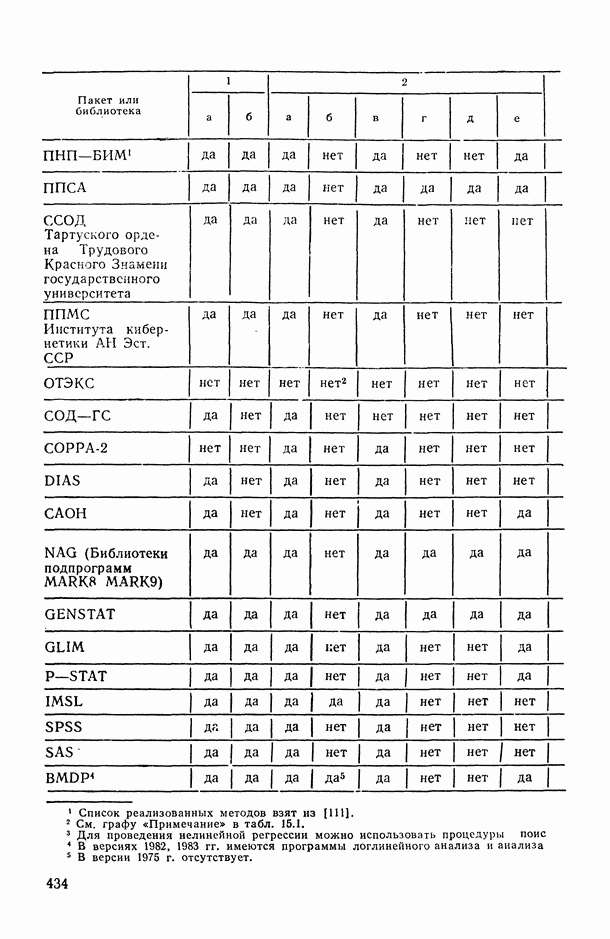
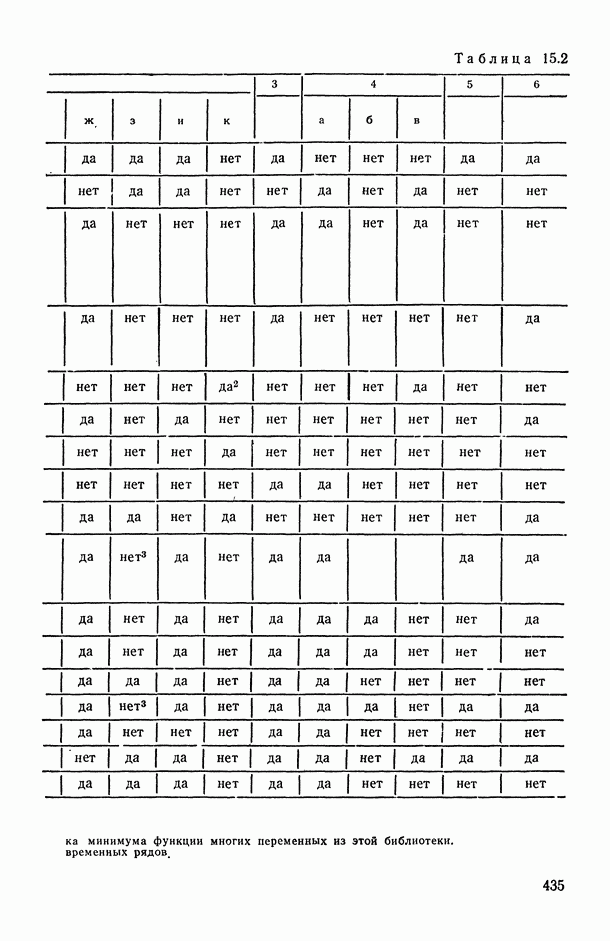
7.2.5. Минимизация систематической ошибки.
Практическое использование излагаемых выше предложений по повышению устойчивости оценок коэффициентов регрессии наталкивается на следующие неопределенности. Какую минимизируемую функцию риска выбрать? Все предлагаемые оценки содержат параметры: v — в п. 7.2.1, k — в п. 7.2.2 и  — в п. 7.2.3 и 7.2.4. Какими брать значения этих параметров? Если полезно уменьшать веса больших отклонений прогнозируемой переменной, то, может быть, полезно взвешивать и предикторные переменные?
— в п. 7.2.3 и 7.2.4. Какими брать значения этих параметров? Если полезно уменьшать веса больших отклонений прогнозируемой переменной, то, может быть, полезно взвешивать и предикторные переменные?
В общем случае ответов на эти вопросы пока нет. Однако ориентиром может стать изучение модельных ситуаций. В частности, воспользуемся моделью засорения Шурыгина [14, п. 6.1.11].
От способов оценивания коэффициентов регрессии зависит лишь третье слагаемое, которое, варьируя эти способы, можно минимизировать. Обозначив  момент стандартной нормальной величины через
момент стандартной нормальной величины через

третье слагаемое можно записать в виде

Предположим для простоты, что величины  известны (устойчивые способы их оценки излагаются в [14, п. 10.4.4-10.4.6). Пусть оценки коэффициентов регрессии
известны (устойчивые способы их оценки излагаются в [14, п. 10.4.4-10.4.6). Пусть оценки коэффициентов регрессии  находятся из системы уравнений
находятся из системы уравнений

во всех выборках серии (7.44). Обозначим через  оператор математического ожидания, вычисляемого в соответствии с распределением
оператор математического ожидания, вычисляемого в соответствии с распределением  из (7.44). Мы можем искать минимум
из (7.44). Мы можем искать минимум  по способам оценивания коэффициентов регрессии.
по способам оценивания коэффициентов регрессии.
Асимптотическое (при  ) поведение величины
) поведение величины  в любой из выборок (7.44) слагается из двух компонент: из дисперсии в модели (7.43) («случайная ошибка») и квадрата смещения за счет засорения («систематическая ошибка»). При росте
в любой из выборок (7.44) слагается из двух компонент: из дисперсии в модели (7.43) («случайная ошибка») и квадрата смещения за счет засорения («систематическая ошибка»). При росте  первая уменьшается как
первая уменьшается как  вторая — как
вторая — как  Между этими величинами возможны следующие соотношения:
Между этими величинами возможны следующие соотношения:
а) величина  уменьшается быстрее, чем
уменьшается быстрее, чем  . Тогда «систематическая ошибка» оказывается асимптотически пренебрежимой по сравнению со «случайной», имеющей порядок
. Тогда «систематическая ошибка» оказывается асимптотически пренебрежимой по сравнению со «случайной», имеющей порядок  классические оценки максимума правдоподобия оказываются асимптотически наилучшими, и приведенные выше рассуждения окажутся ненужными;
классические оценки максимума правдоподобия оказываются асимптотически наилучшими, и приведенные выше рассуждения окажутся ненужными;
б) величина  уменьшается медленнее, чем
уменьшается медленнее, чем  например как
например как  , где
, где  . Тогда дисперсия пренебрежимо мала по сравнению с квадратом смещения, и классические оценки не оптимальны, оптимальными будут оценки, минимизирующие «систематическую ошибку»; квадратическая погрешность оценки уменьшается не как
. Тогда дисперсия пренебрежимо мала по сравнению с квадратом смещения, и классические оценки не оптимальны, оптимальными будут оценки, минимизирующие «систематическую ошибку»; квадратическая погрешность оценки уменьшается не как  а медленнее, как
а медленнее, как  ;
;
в) величины  имеют одинаковый порядок малости.
имеют одинаковый порядок малости.
Этот вариант сводится к б) при рассмотрении иерархии серий [149].
Главный член асимптотического разложения  в асимптотике б) определяется «систематической ошибкой» из-за засорения выборки и в среднем по серии (7.44), которое будем обозначать через
в асимптотике б) определяется «систематической ошибкой» из-за засорения выборки и в среднем по серии (7.44), которое будем обозначать через  , зависит от плотности
, зависит от плотности  у, так что существует
у, так что существует

Используя известные методы минимаксной оптимизации, мы можем найти наилучшие оценки для наихудшей  , т. е. найти
, т. е. найти

Результат зависит от множества  , среди которого отыскивается наихудшая
, среди которого отыскивается наихудшая  . Наиболее просто предположить, что h отличается от
. Наиболее просто предположить, что h отличается от  лишь значениями параметров:
лишь значениями параметров:  . В этом случае решение минимаксной задачи (7.45) приводит к следующей системе уравнений:
. В этом случае решение минимаксной задачи (7.45) приводит к следующей системе уравнений:

где весовые функции

являются экспонентами. Коэффициенты  растут при росте р, оставаясь меньше единицы:
растут при росте р, оставаясь меньше единицы:  . Учитывая некоторую условность рассматриваемой модели, можно использовать аппроксимацию
. Учитывая некоторую условность рассматриваемой модели, можно использовать аппроксимацию  . Система (7.46) решается итерациями.
. Система (7.46) решается итерациями.
Рассмотрим теперь задачу нормальной многомерной линейной регрессии, когдар предикторных переменных, образующих
Вектор  , используются для предсказания скалярной величины
, используются для предсказания скалярной величины  так что плотность совместного распределения
так что плотность совместного распределения  имеет вид
имеет вид

Рассмотрение аналогичной (7.44) схемы  -загрязненных выборок
-загрязненных выборок

и вполне аналогичная оптимизация погрешности предсказания  с помощью регрессии у по X при известных
с помощью регрессии у по X при известных  приводят к следующей системе уравнений для оценки коэффициентов регрессии:
приводят к следующей системе уравнений для оценки коэффициентов регрессии:

где весовая функция также экспоненциальна:

но величины  убывают с ростом
убывают с ростом  :
:

Сравним полученные оценки коэффициентов регрессии с излагавшимися в предыдущих разделах. Если весовые функции  положить равными единице, то системы (7.46) и (7.50) дадут оценки максимального правдоподобия соответственно для плотностей (7.43) и (7.48). Каждая из весовых функций (7.47) и (7.51) распадается на два экспоненциальных множителя, первая экспонента одинакова у обеих функций. Если вторые экспоненты заменить единицами, то решения совпадут с изложенной в предыдущем пункте эв-регрессией при
положить равными единице, то системы (7.46) и (7.50) дадут оценки максимального правдоподобия соответственно для плотностей (7.43) и (7.48). Каждая из весовых функций (7.47) и (7.51) распадается на два экспоненциальных множителя, первая экспонента одинакова у обеих функций. Если вторые экспоненты заменить единицами, то решения совпадут с изложенной в предыдущем пункте эв-регрессией при  . Вторые экспоненты определяют взвешивание по предикторным переменным.
. Вторые экспоненты определяют взвешивание по предикторным переменным.







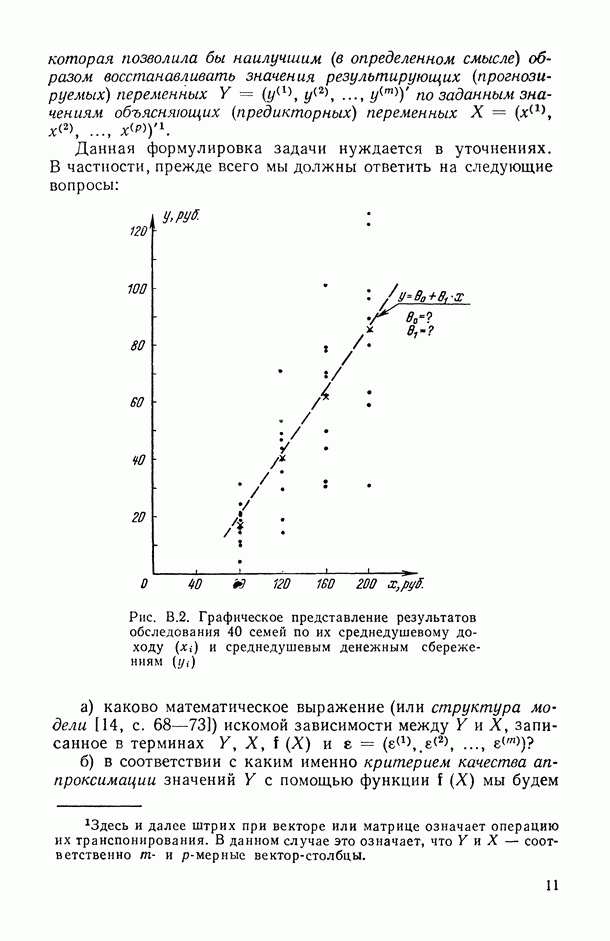












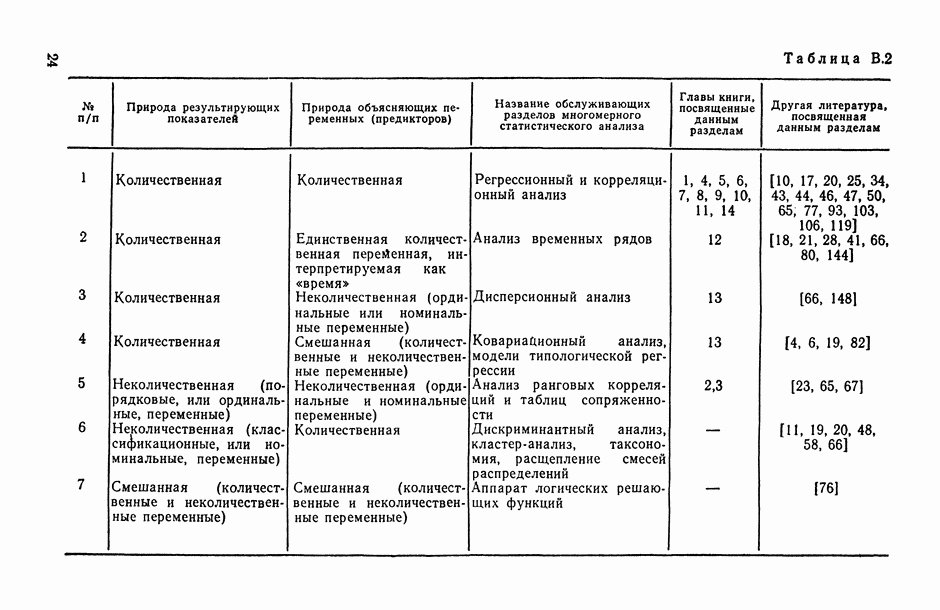
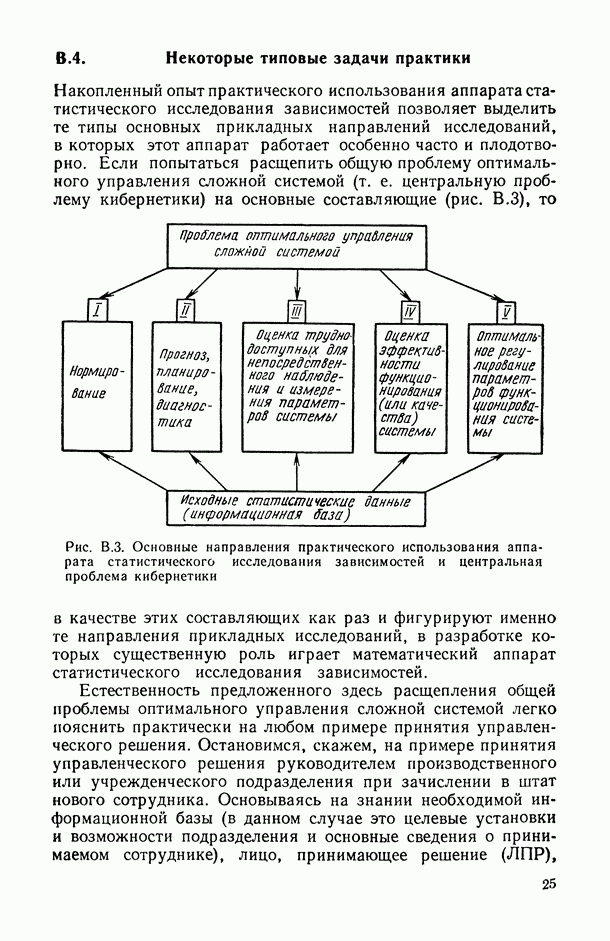





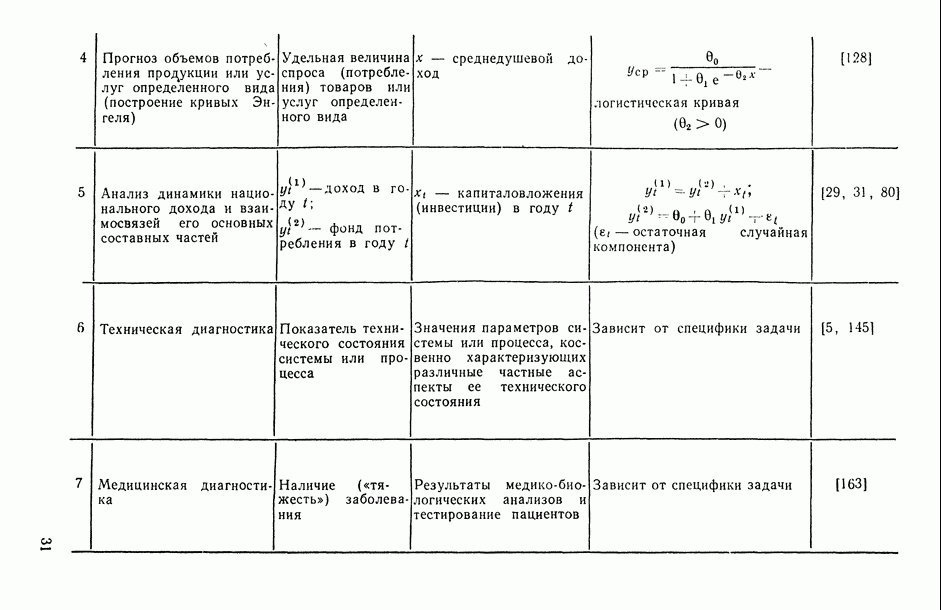




























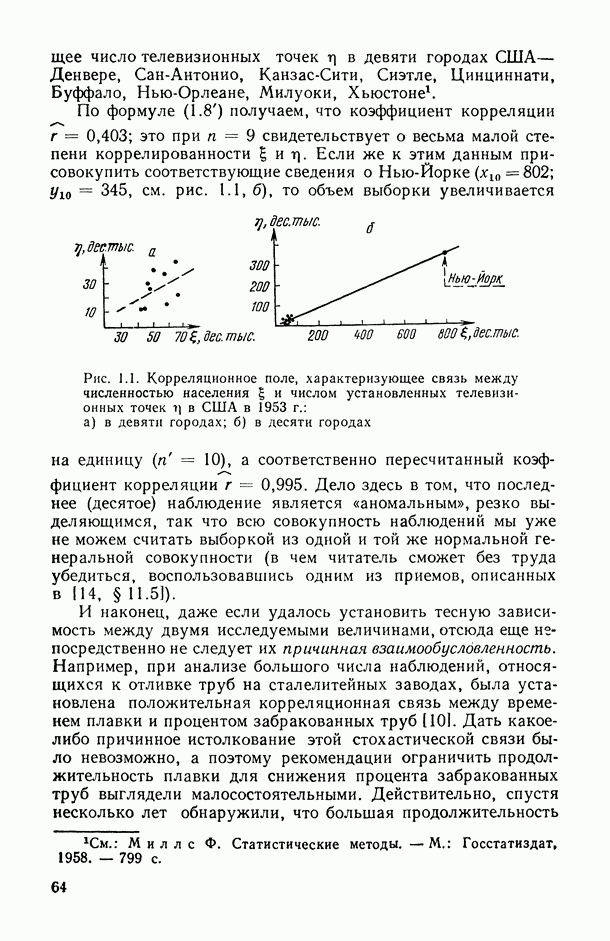






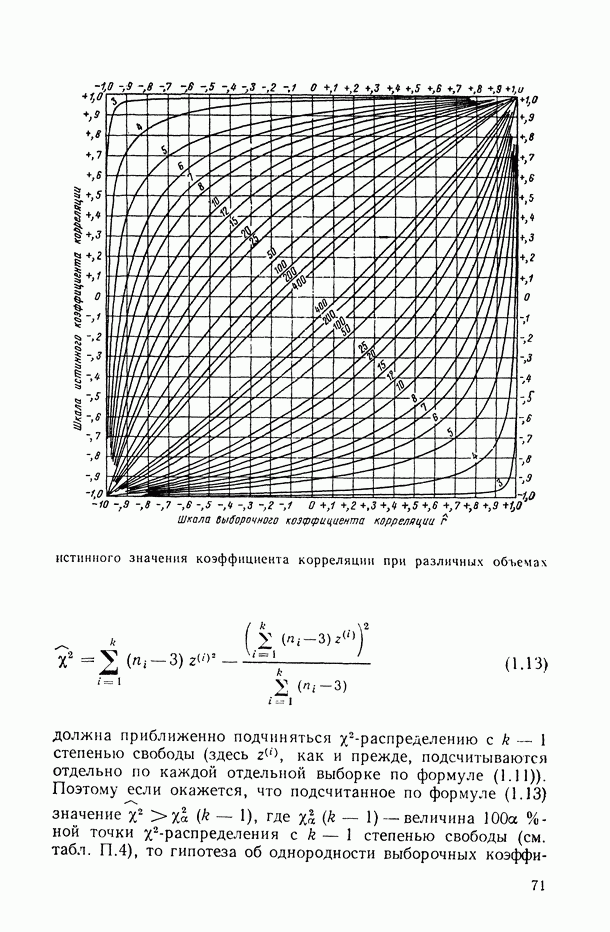
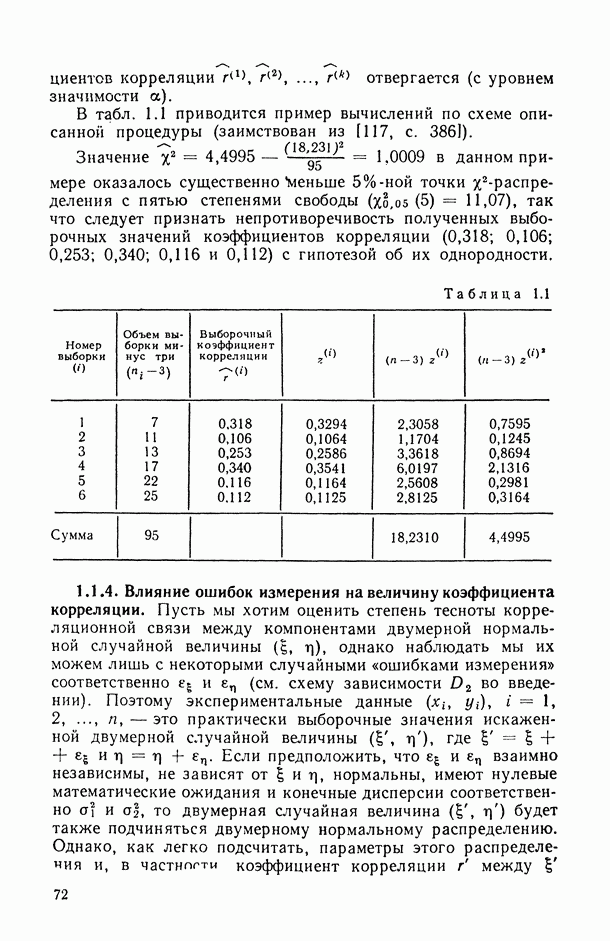



































































































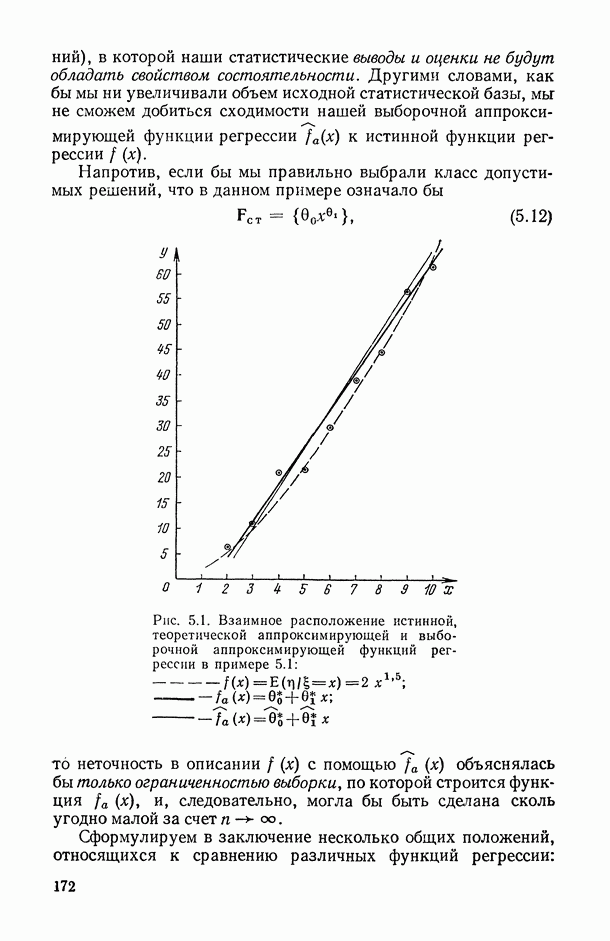




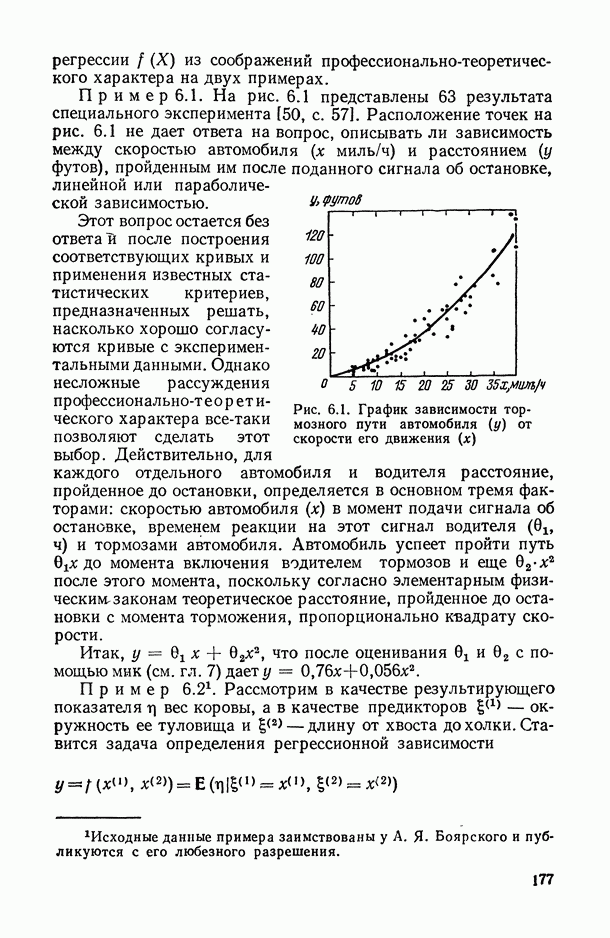




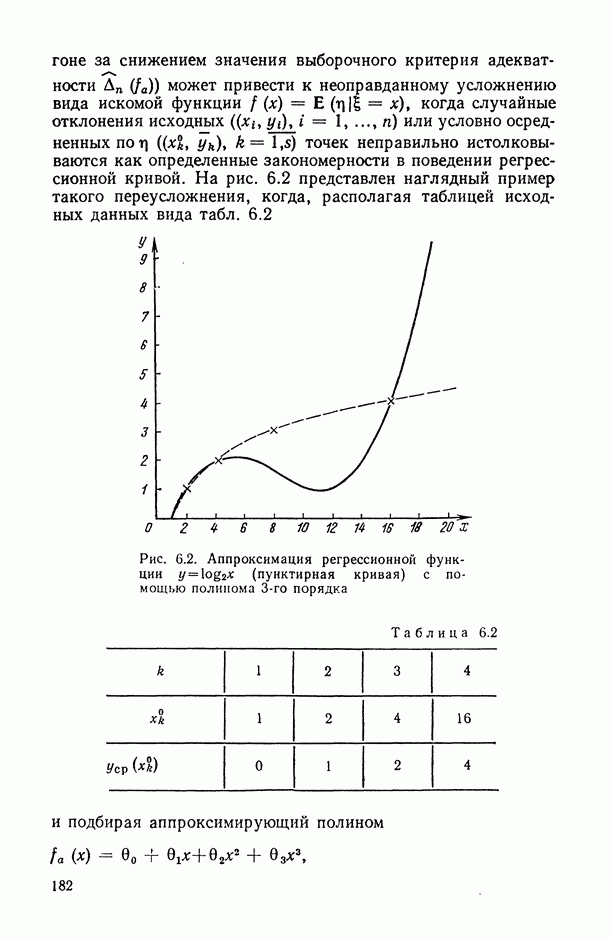



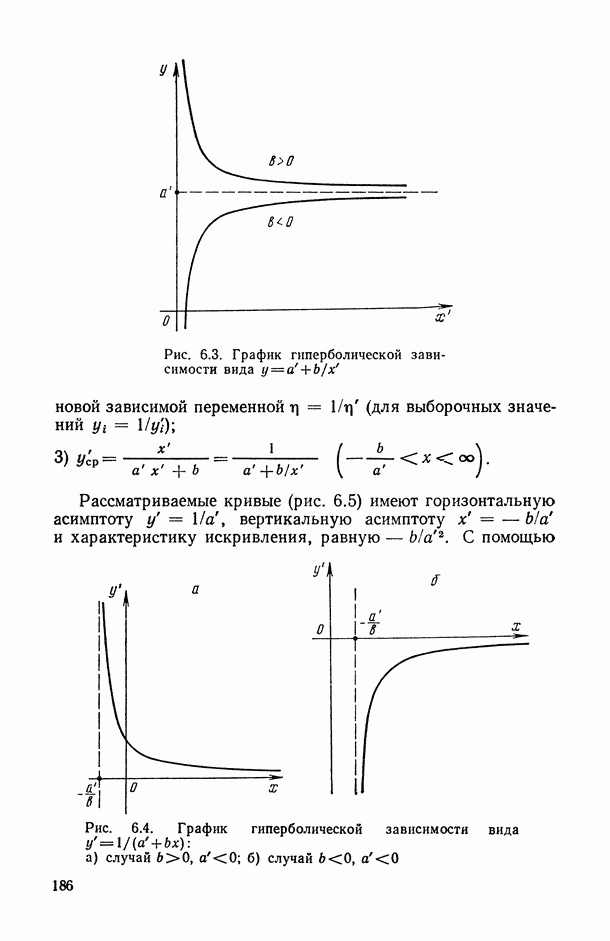
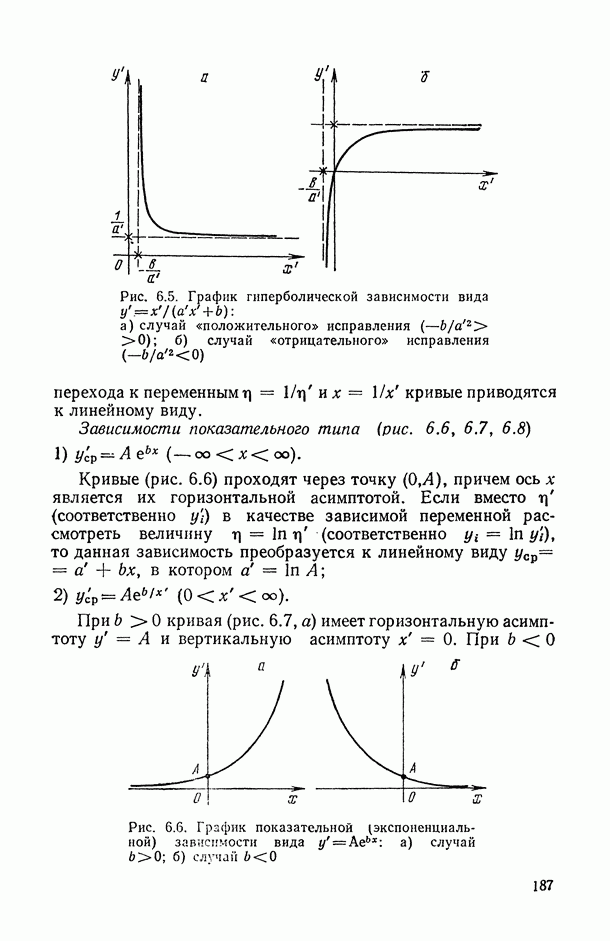
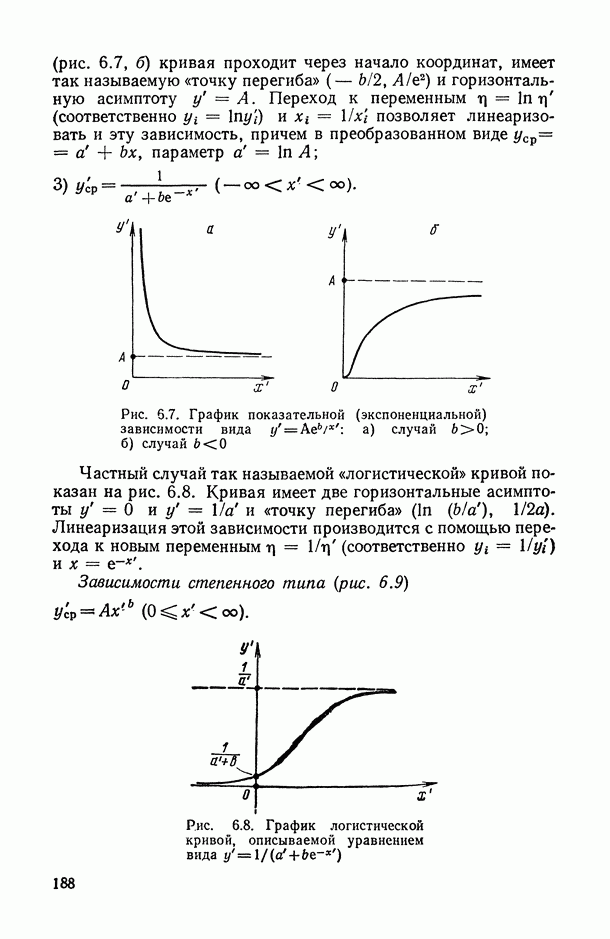
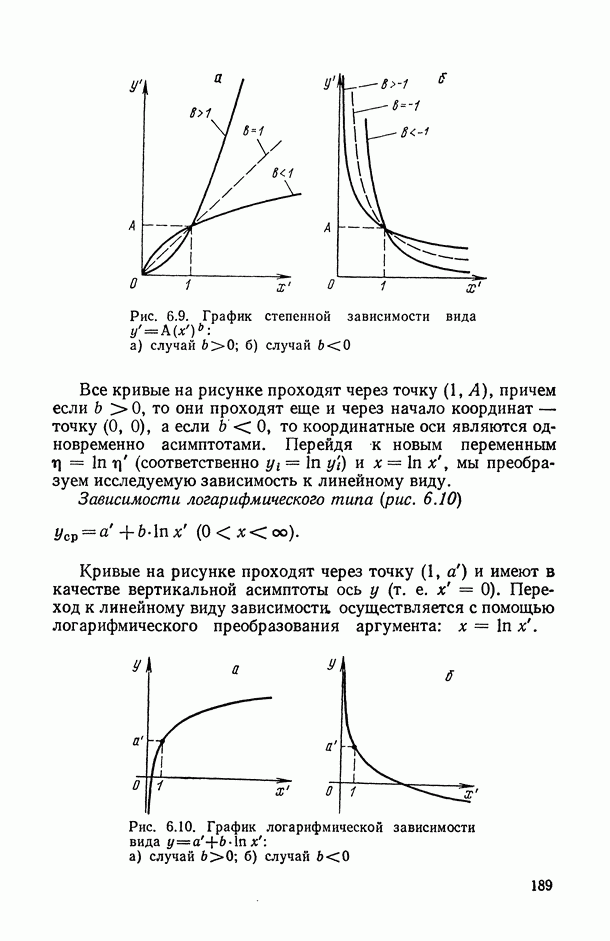


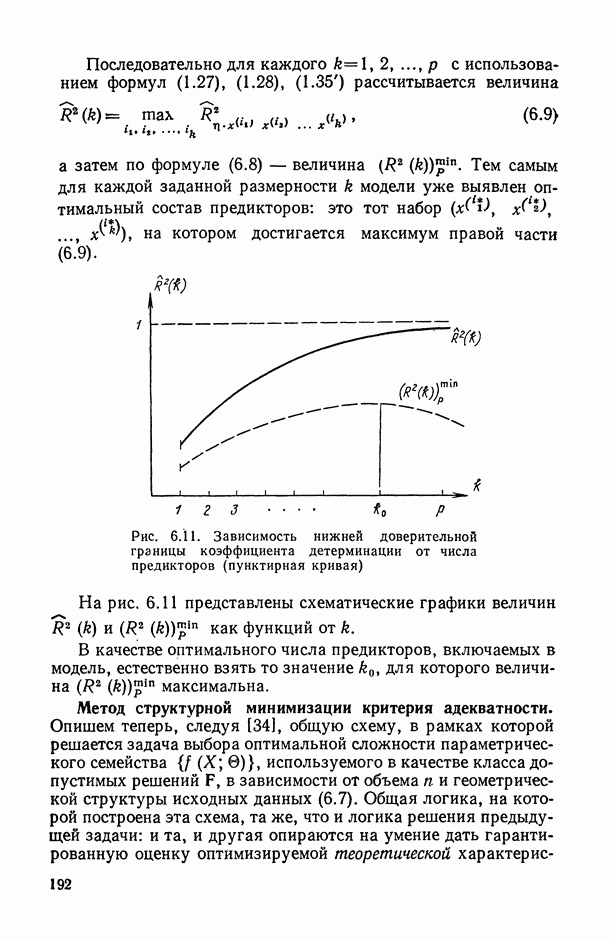




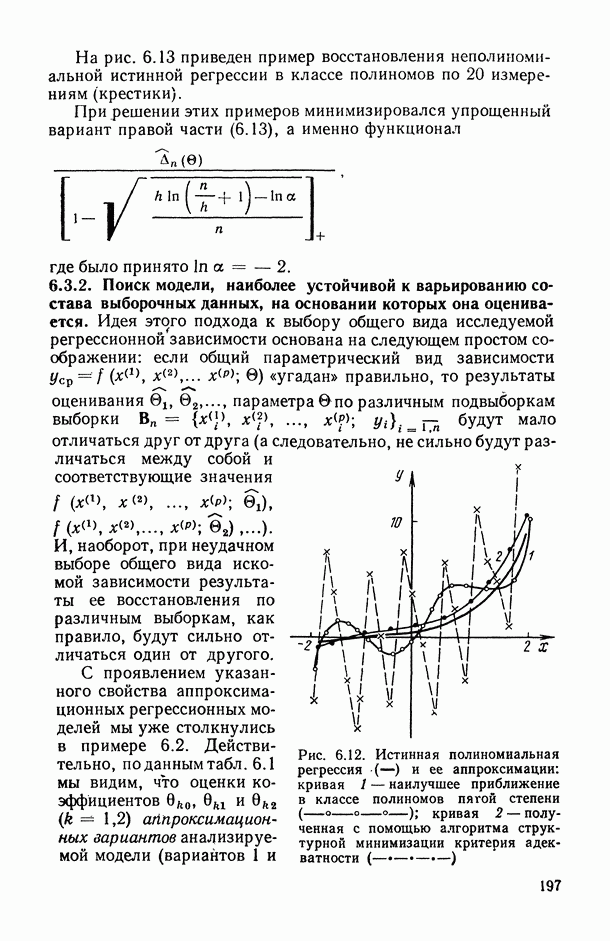



















































































































































































































































 , когда плотность совместного распределения предикторной переменной х и прогнозируемой переменной у имеет вид
, когда плотность совместного распределения предикторной переменной х и прогнозируемой переменной у имеет вид

 -засоренных выборок одинаковой длины
-засоренных выборок одинаковой длины  выборке засорение концентрируется в точке
выборке засорение концентрируется в точке  так что плотности распределения выборок серии имеют вид
так что плотности распределения выборок серии имеют вид

 — дельта-функция Дирака от точки
— дельта-функция Дирака от точки  . Пусть в серии выборок эта точка имеет плотность распределения
. Пусть в серии выборок эта точка имеет плотность распределения  .
.
 для неизвестного значения результирующего показателя
для неизвестного значения результирующего показателя  измеренного при
измеренного при  когда двумерное распределение
когда двумерное распределение  описывается плотностью распределения (7.43), а прогноз
описывается плотностью распределения (7.43), а прогноз  строится по оценкам, основанным на произвольной выборке (7.44):
строится по оценкам, основанным на произвольной выборке (7.44):

 и по
и по  ). Далее
). Далее

 и не может быть минимизировано. Во втором слагаемом сомножители независимы, и математическое ожидание первого из них равно нулю, так что нулю равно все слагаемое.
и не может быть минимизировано. Во втором слагаемом сомножители независимы, и математическое ожидание первого из них равно нулю, так что нулю равно все слагаемое.
