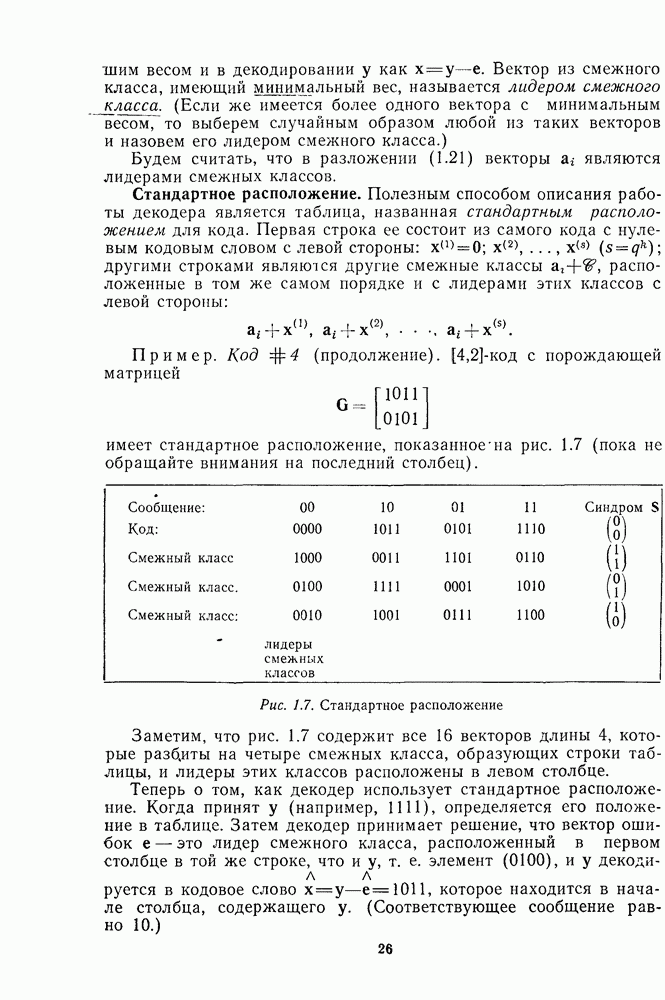
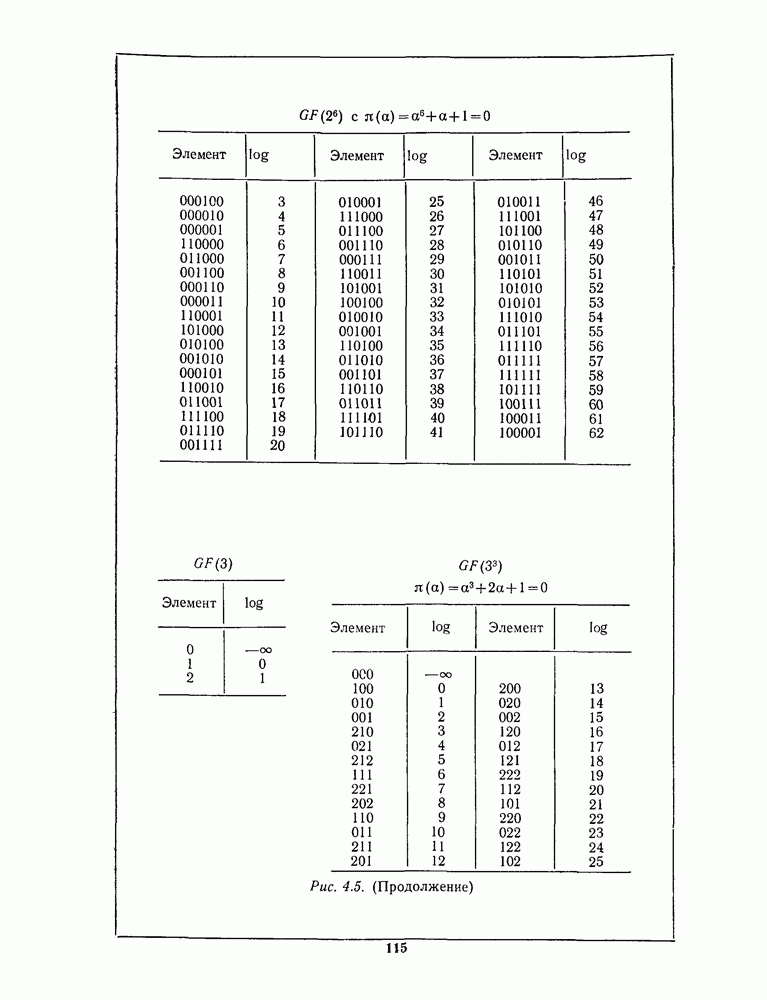
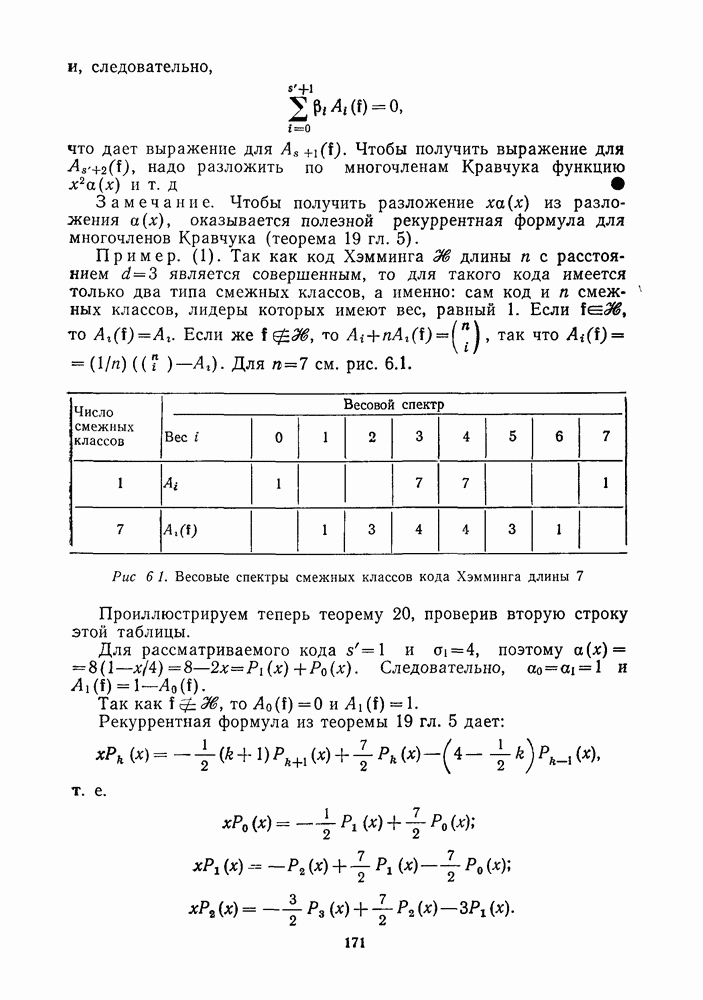
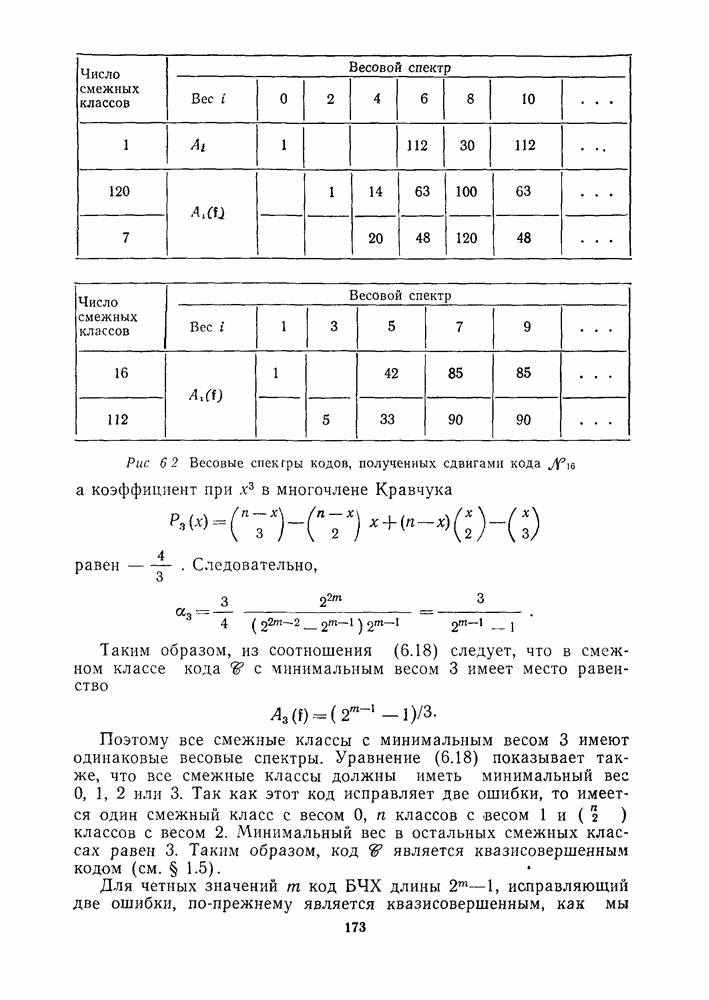
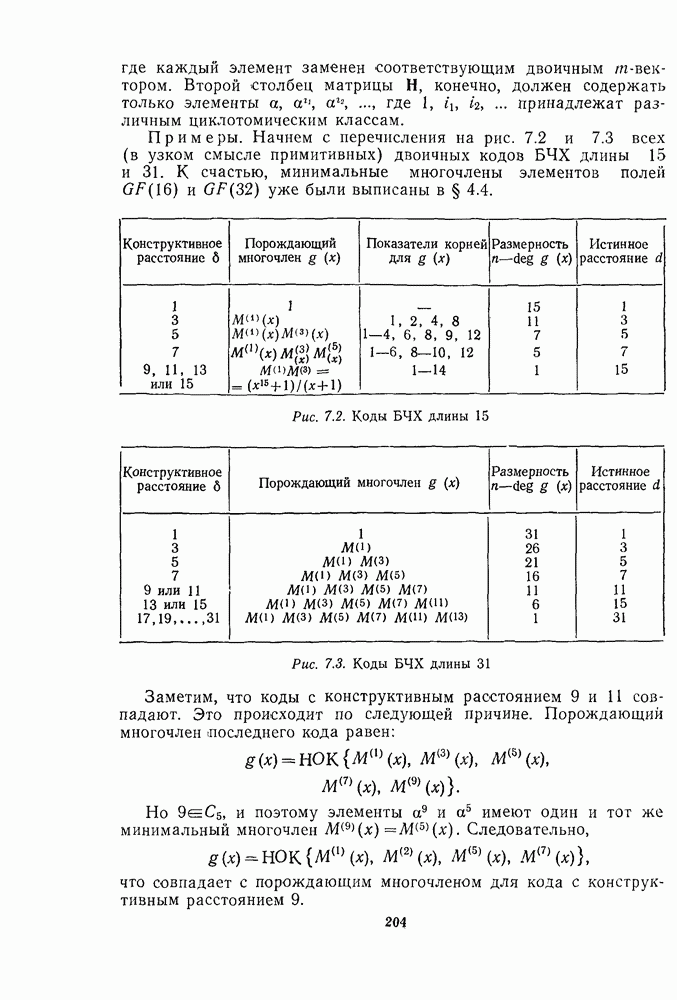
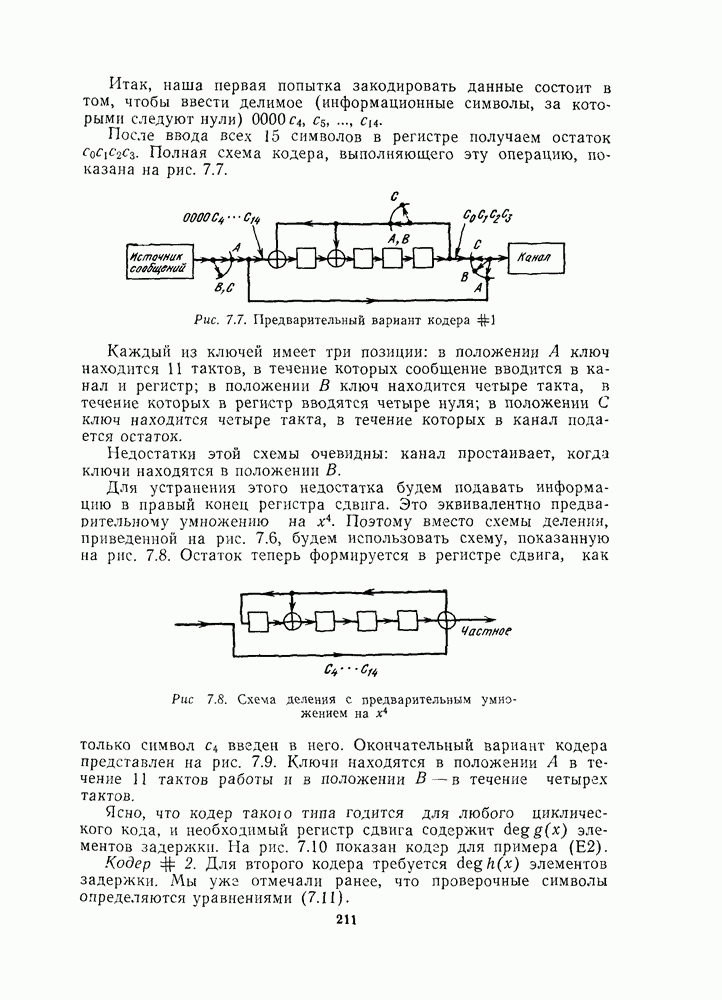
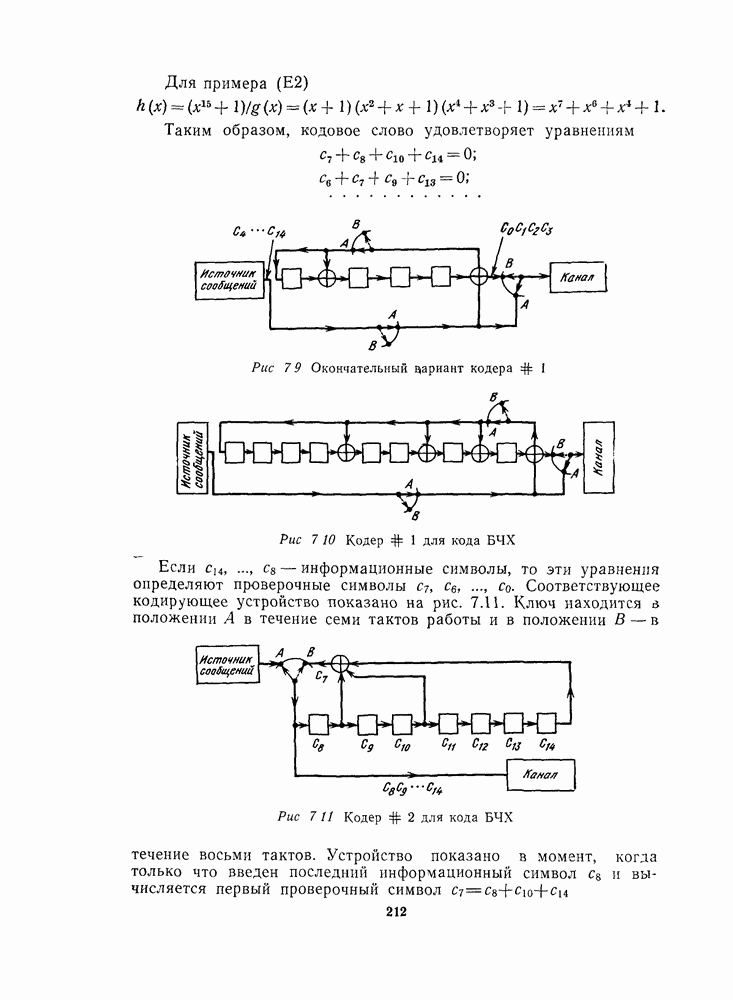
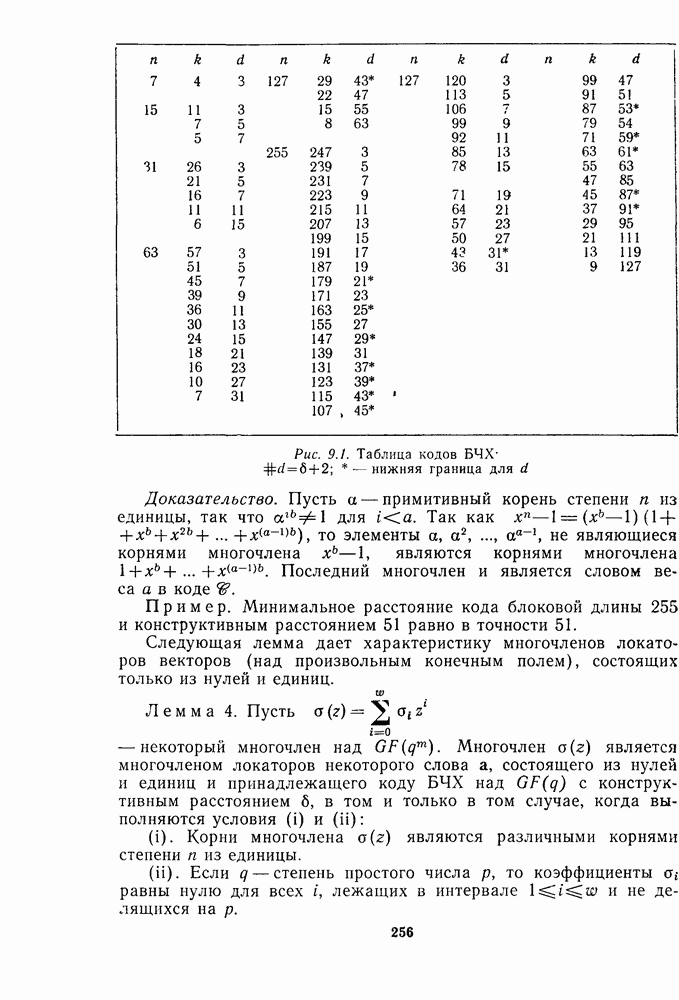
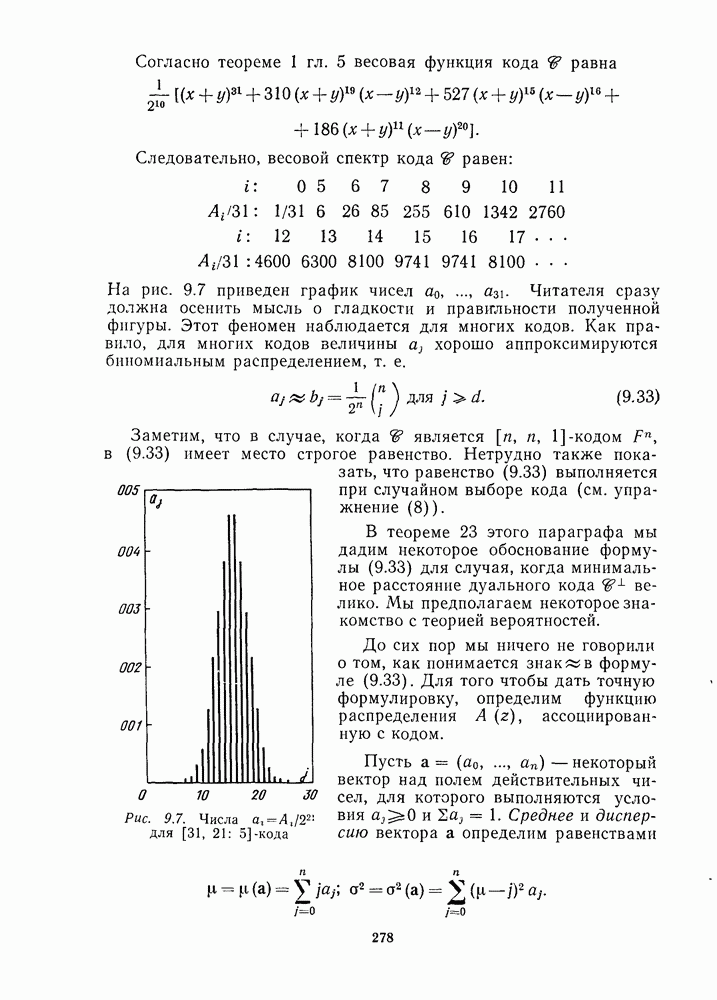
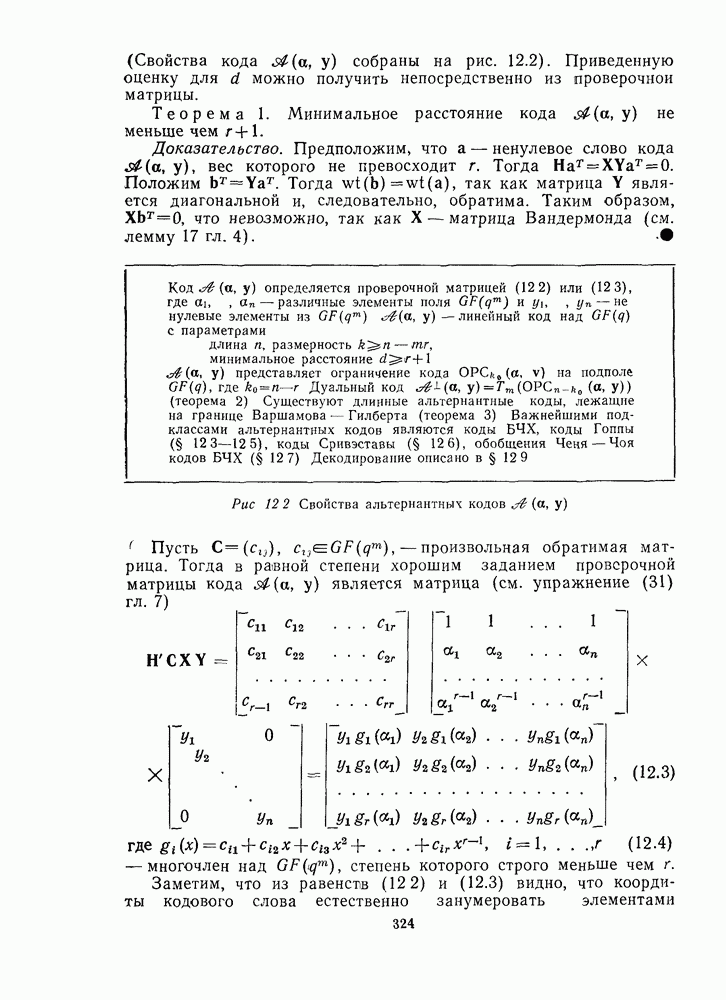
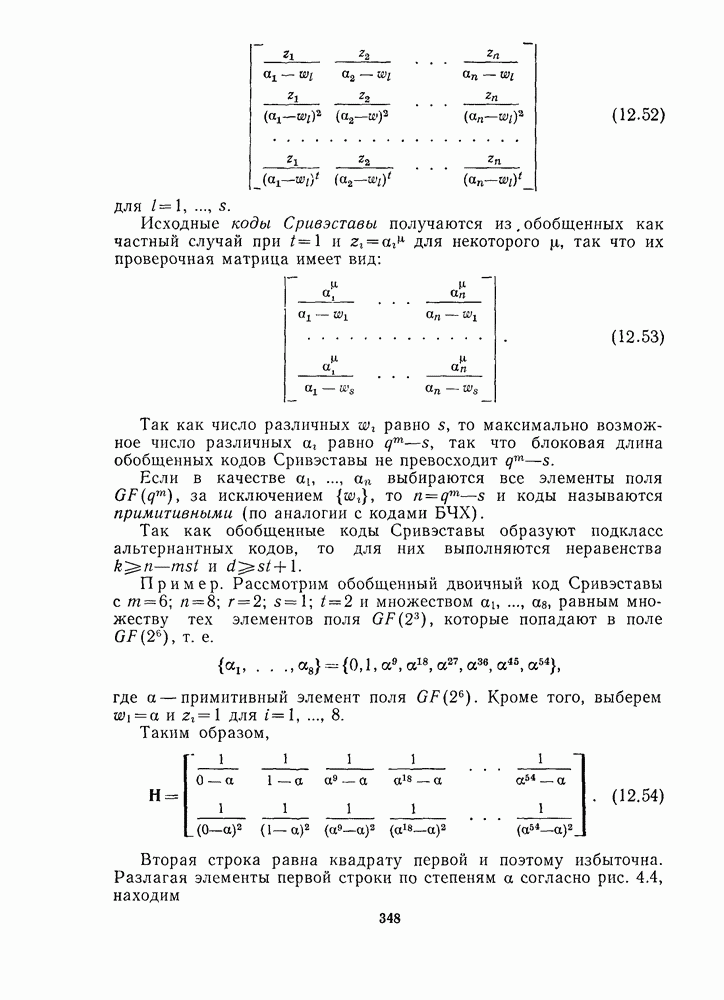
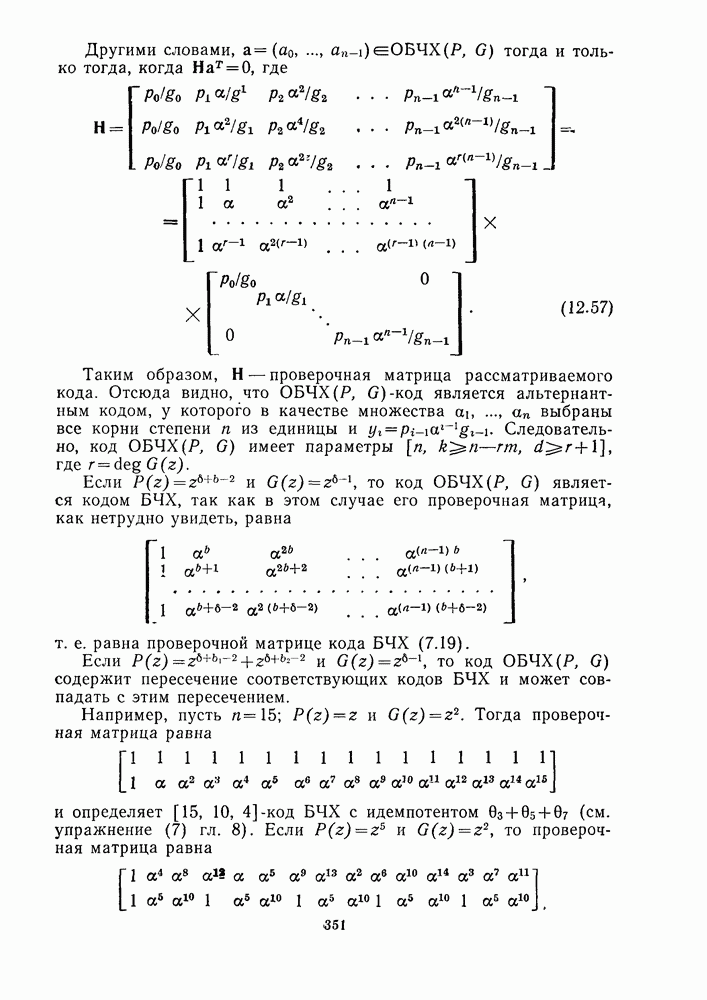
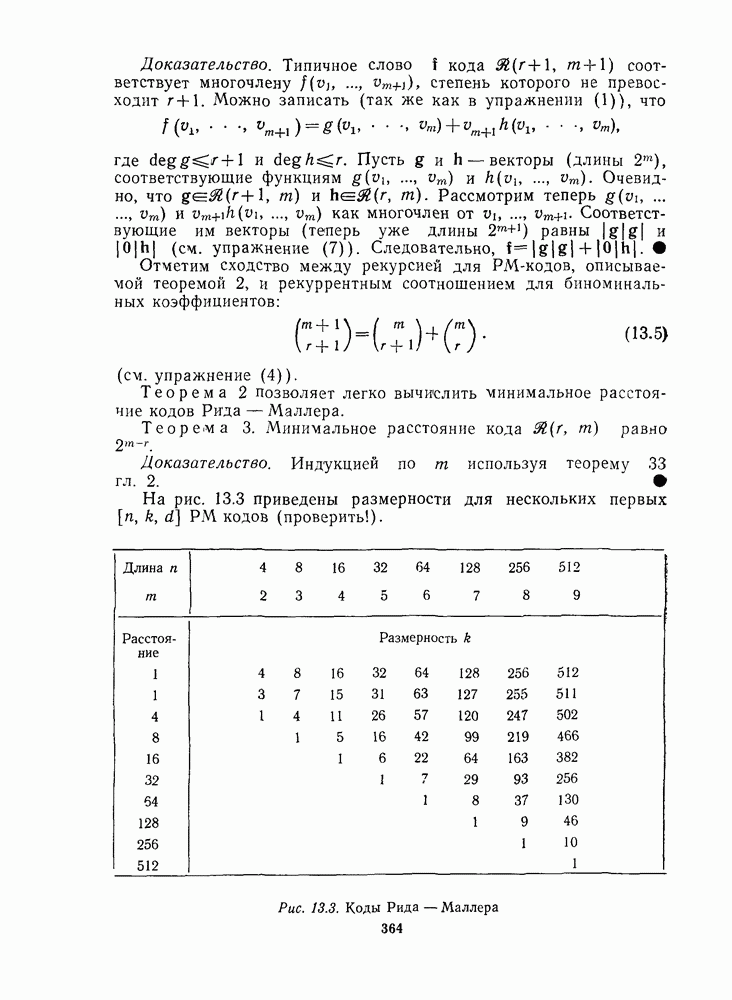
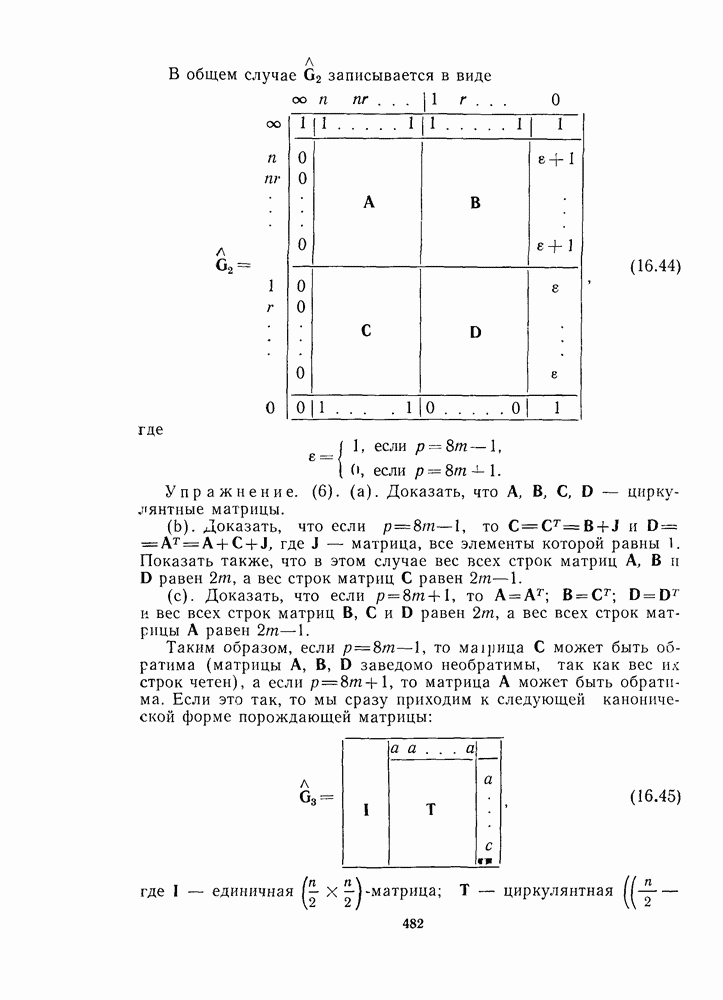
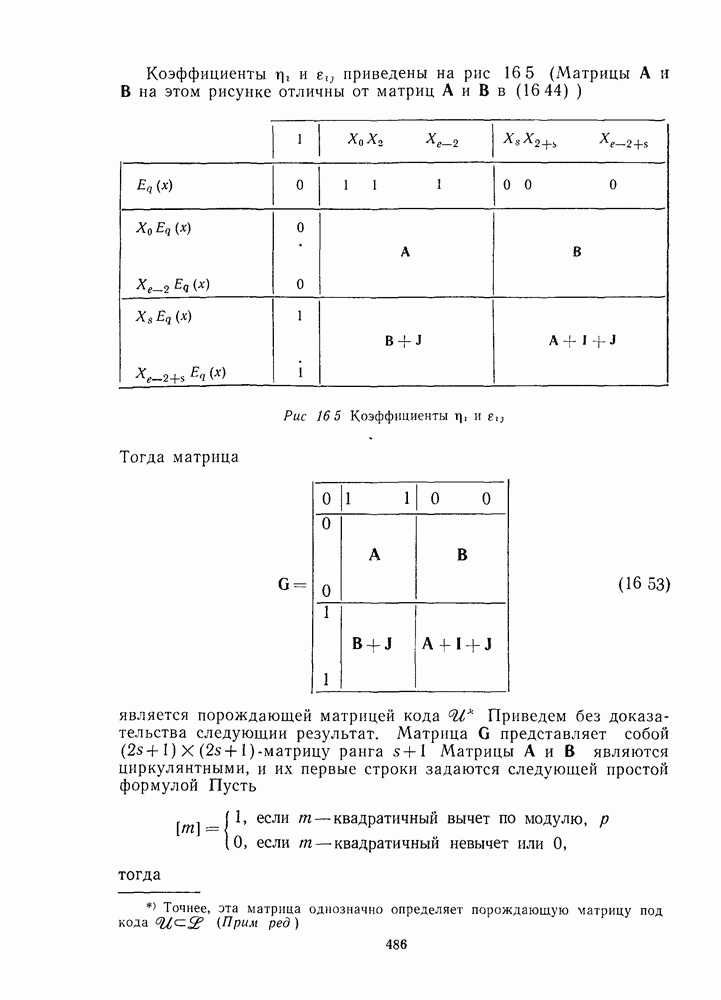
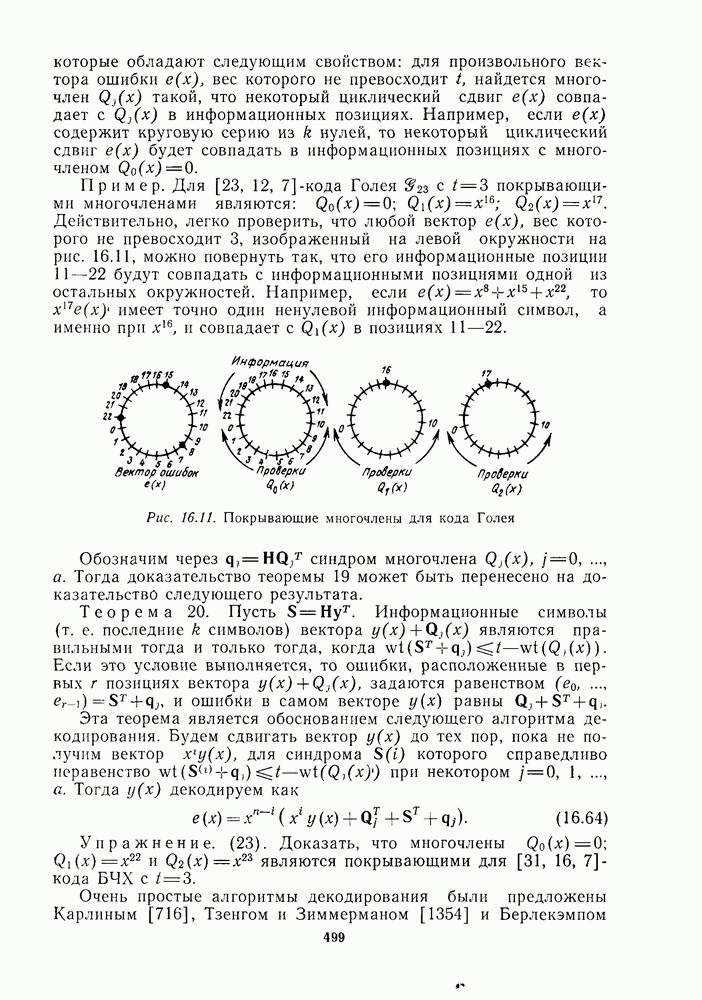
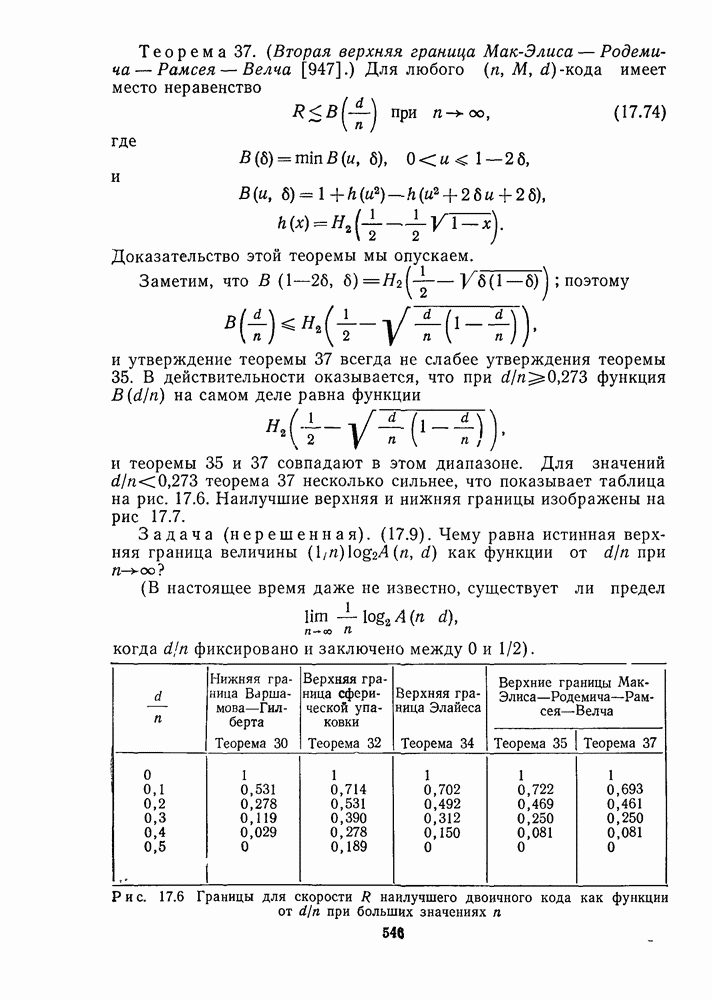
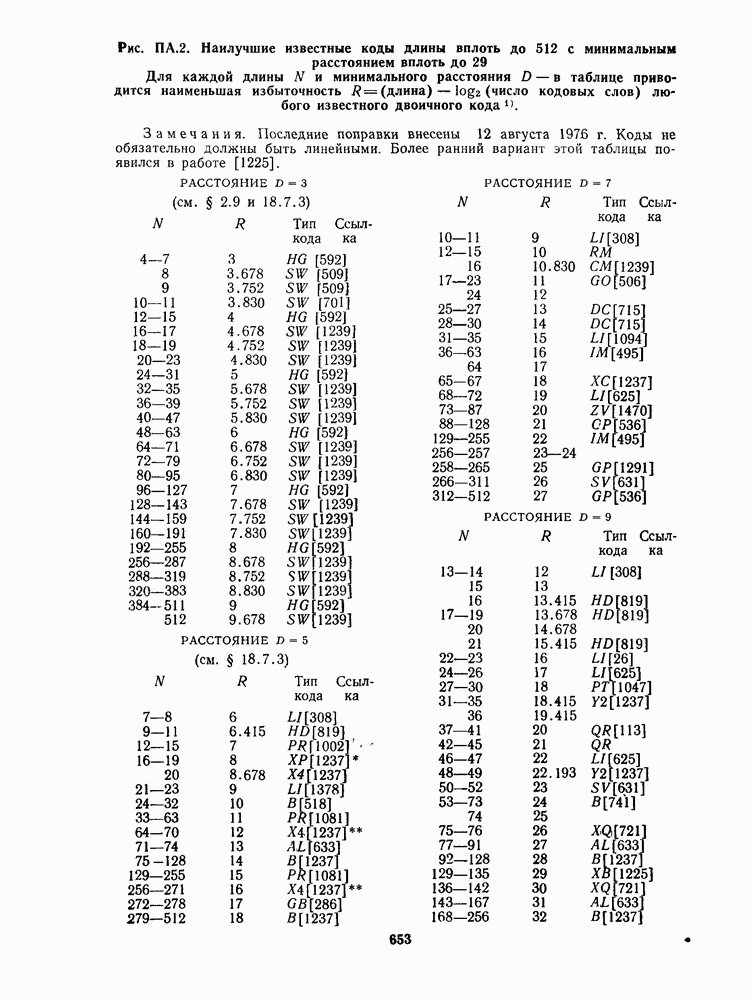
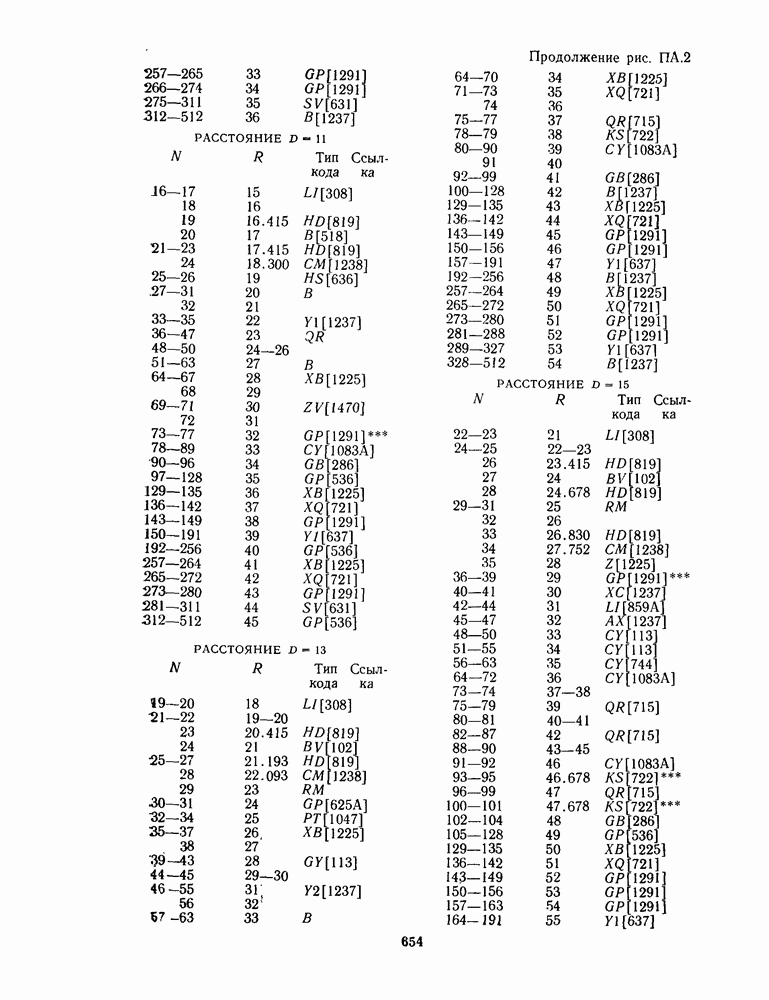
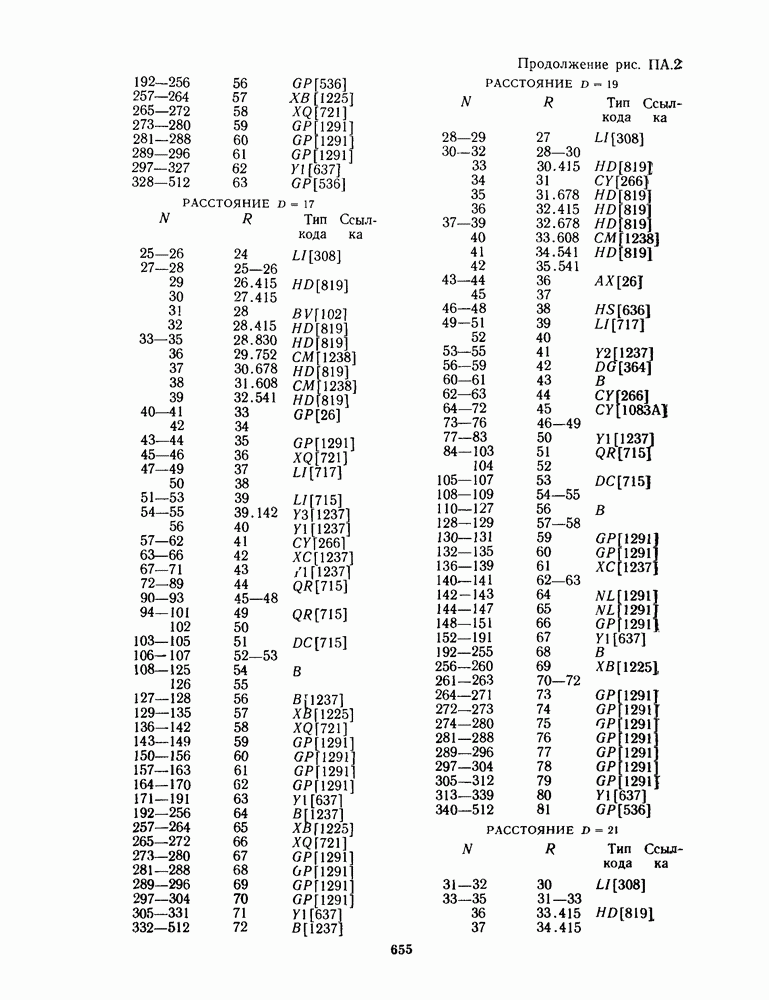
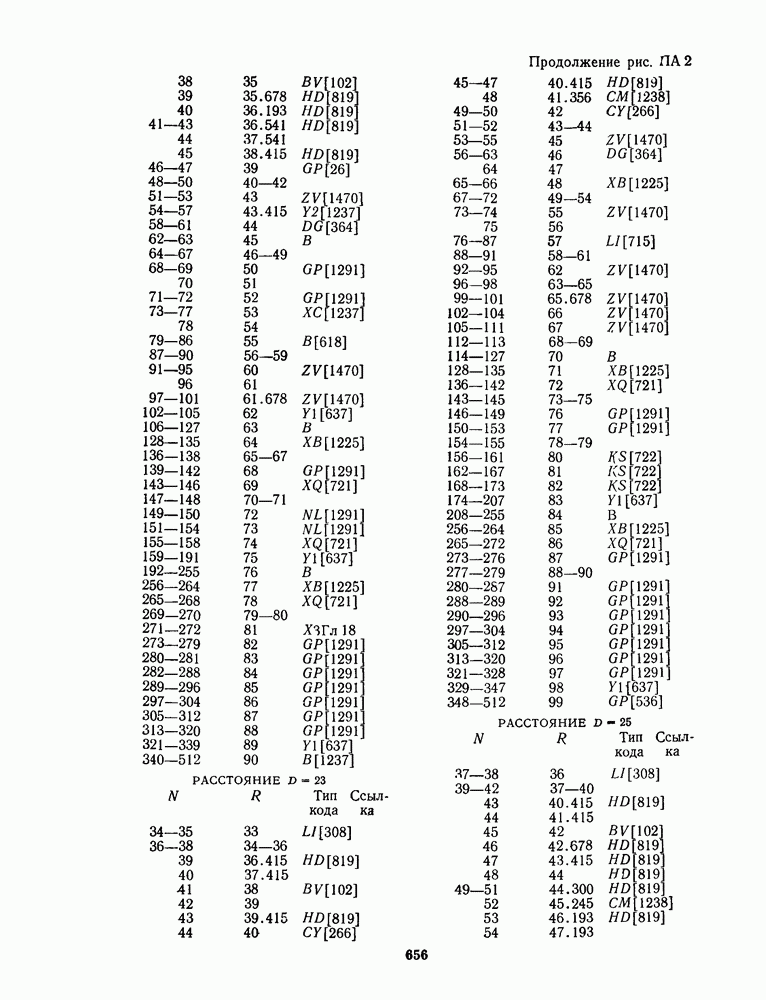
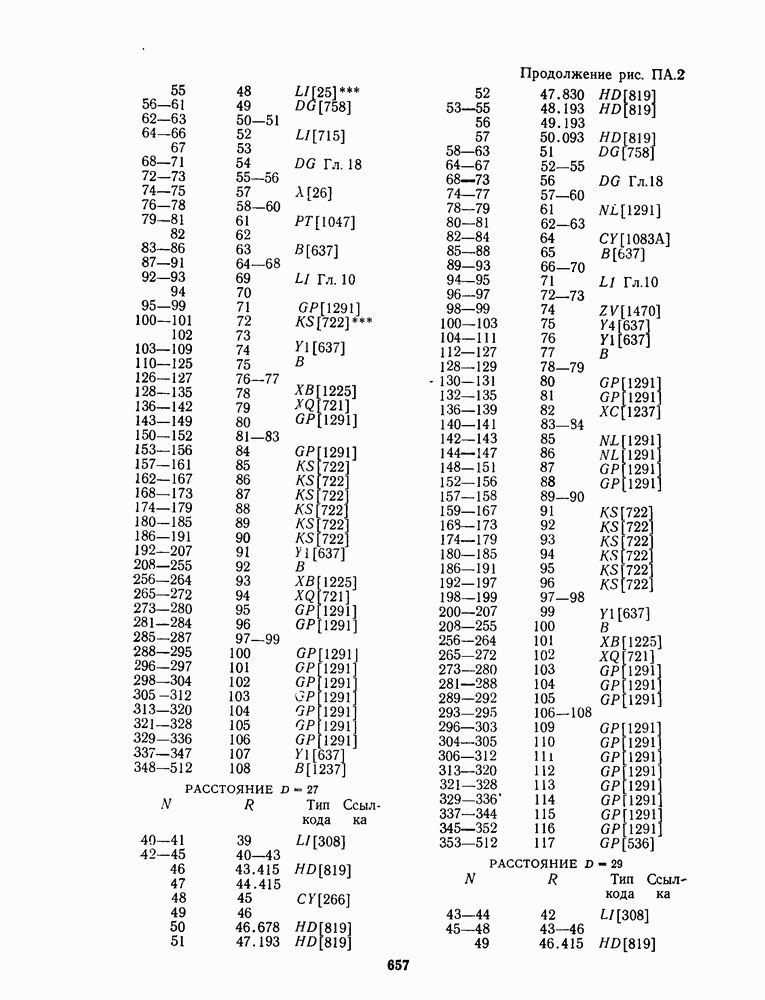
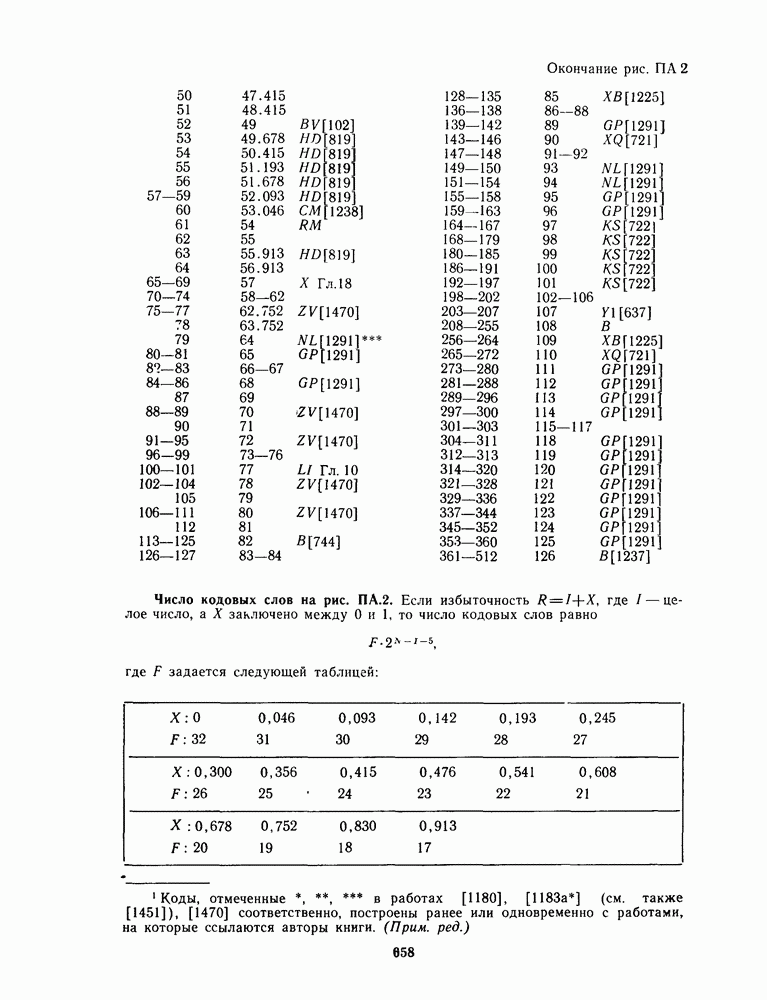
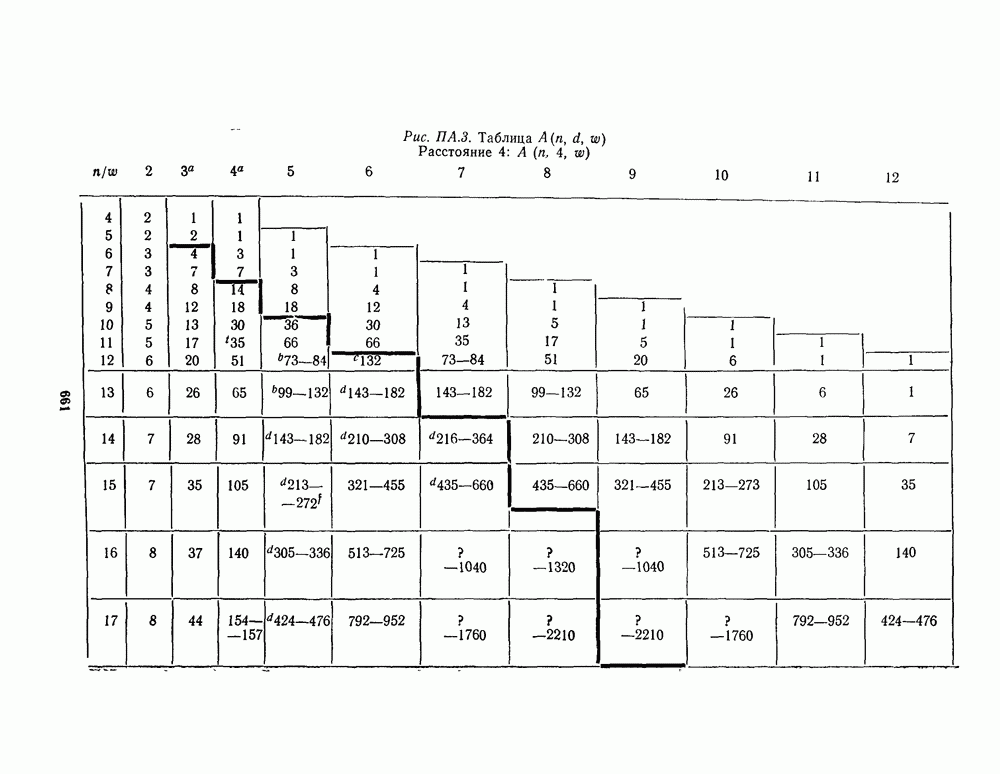
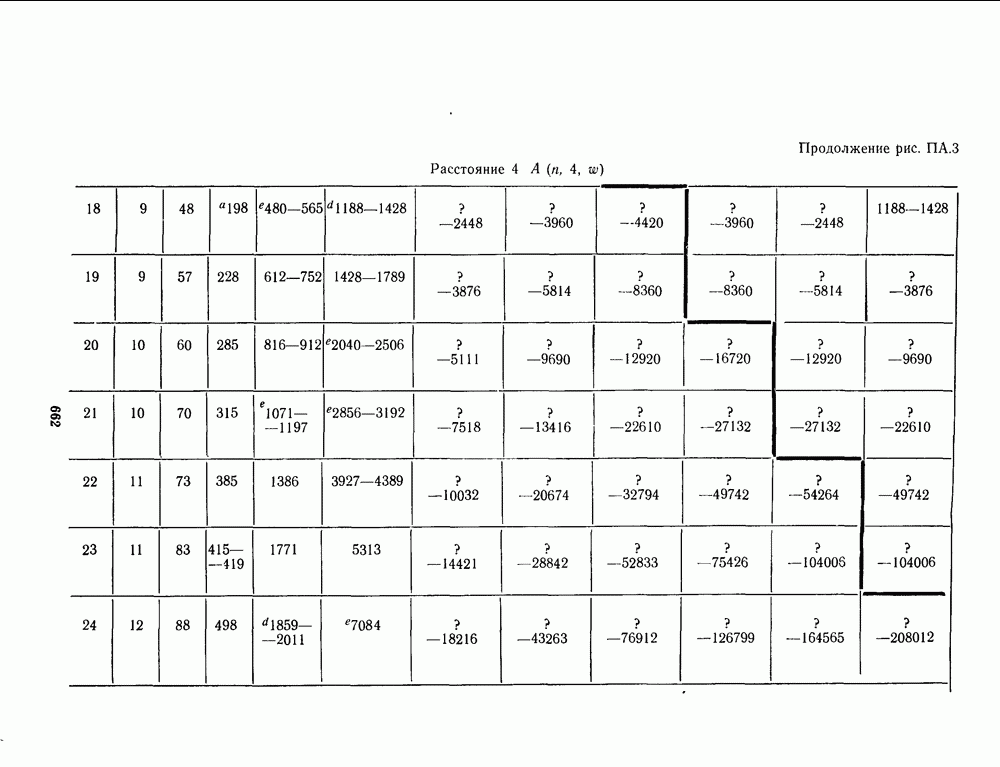
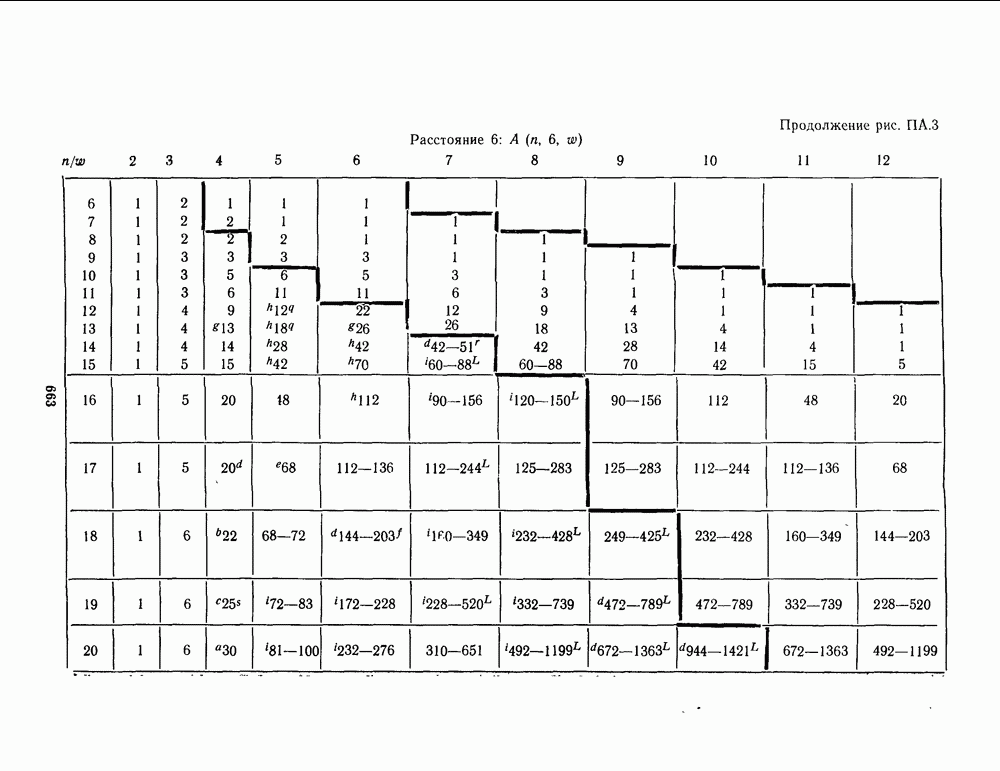
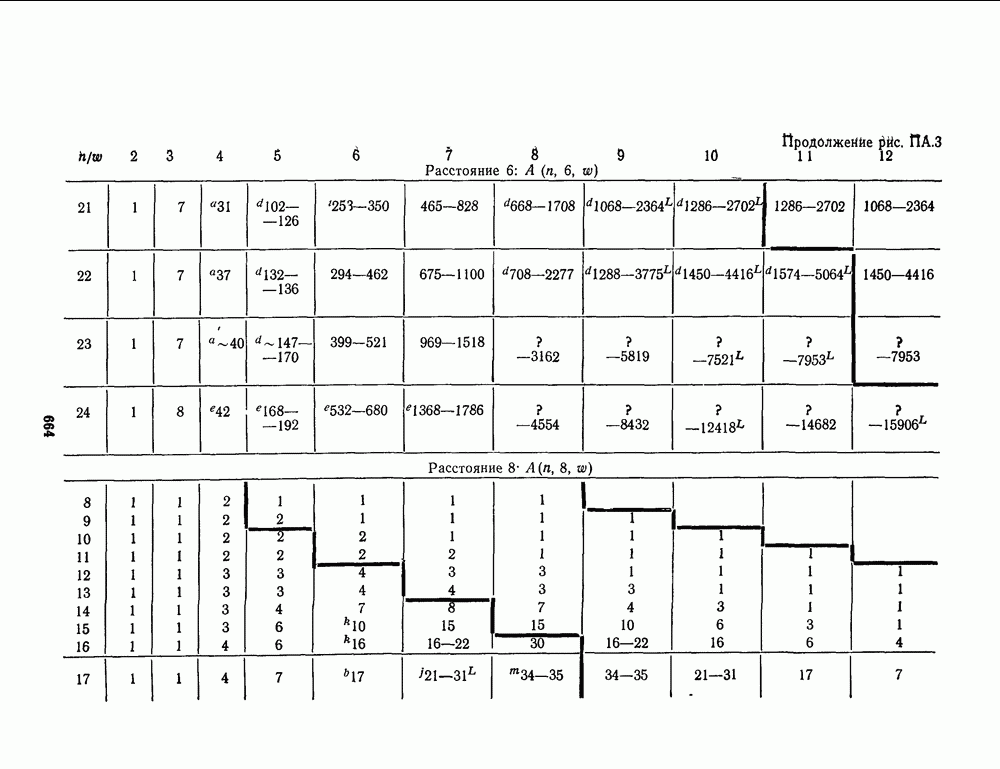
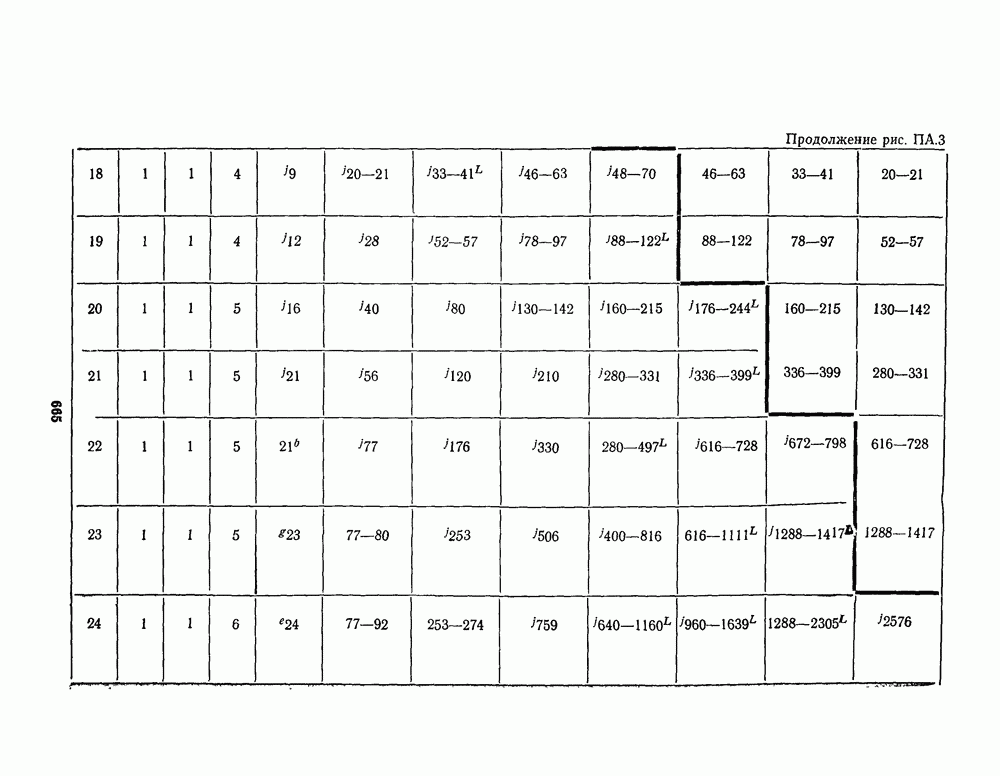
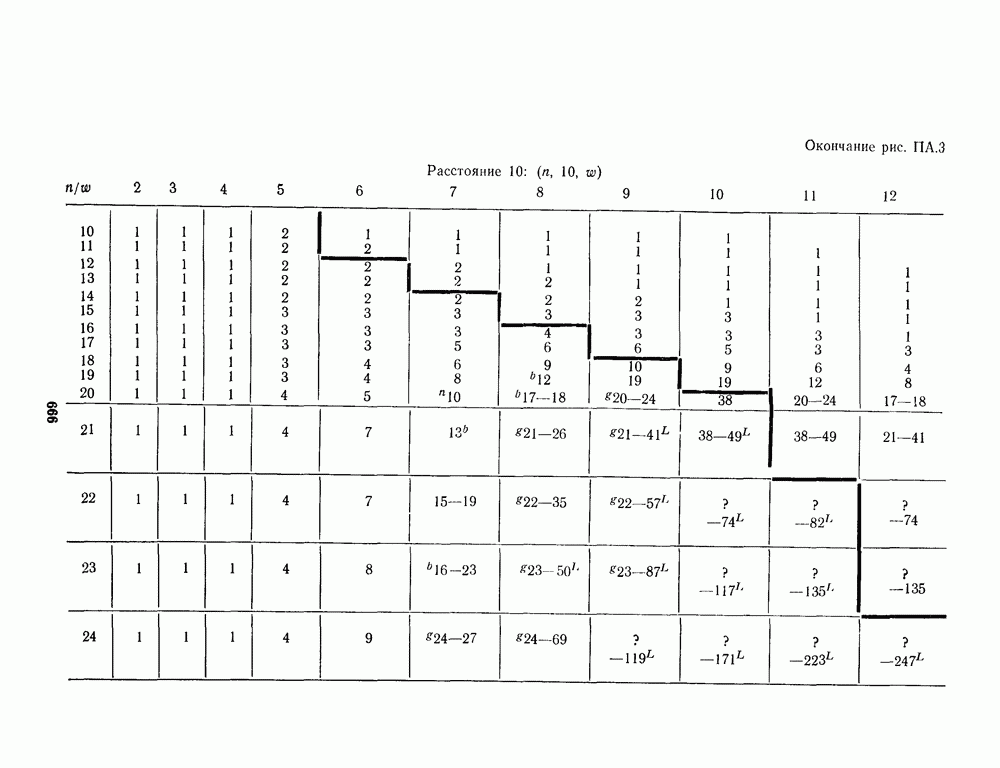
13.6. КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ (I)
Имеются два очевидных способа кодирования РМ кодов. Первый основан на записи порождающей матрицы в форме, показанной на рис. 13.2, что приводит к несистематическому кодеру. Второй, являющийся систематическим, основан на том факте (доказанном в теореме 11), что РМ коды являются расширенными циклическими кодами. В данном параграфе мы приведем алгоритм декодирования, пригодный именно для первого кодера, а затем в § 13.7 опишем более общий алгоритм декодирования, применимый к любому кодеру.
Первый алгоритм опишем на конкретном примере [16, 11, 4] РМ-кода второго порядка,  . В качестве порождающей матрицы кода
. В качестве порождающей матрицы кода  выберем первые 11 строк на рис. 13.2. Тогда последовательность информационных символов
выберем первые 11 строк на рис. 13.2. Тогда последовательность информационных символов  кодируется в кодовое слово
кодируется в кодовое слово

Этот код исправляет одну ошибку, и мы покажем, как она может быть исправлена при помощи мажоритарной" логики. (В отличие от приводимого в гл. 10 мажоритарного декодера для кодов РС данный декодер является практически работающей схемой.) Первый шаг декодирования состоит в определении шести символов  Из рис. 13.2 видим, что если ошибок не было, то
Из рис. 13.2 видим, что если ошибок не было, то

Уравнения (13.12) дают четыре независимые проверки для определения символа  Уравнения (13.13) дают четыре независимые проверки для определения символа
Уравнения (13.13) дают четыре независимые проверки для определения символа  Если произошло не более одной ошибки, то голосование по большинству
Если произошло не более одной ошибки, то голосование по большинству
проверок приводит к правильному результату, так что каждое  будет правильно определено.
будет правильно определено.
Для определения символов  вычтем
вычтем  из значения х, и результат обозначим через
из значения х, и результат обозначим через  Из рис. 13.2 опять видно, что
Из рис. 13.2 опять видно, что

Теперь легче: имеется восемь независимых проверочных уравнений для каждого символа  следовательно, если произошла только одна ошибка, то голосование по большинству проверок дает правильное значение
следовательно, если произошла только одна ошибка, то голосование по большинству проверок дает правильное значение  Имеем:
Имеем:

и  равно 0 или 1 в соответствии с числом единиц в векторе
равно 0 или 1 в соответствии с числом единиц в векторе 
Эта схема называется алгоритмом декодирования Рида и, очевидно, пригодна для любого РМ-кода.
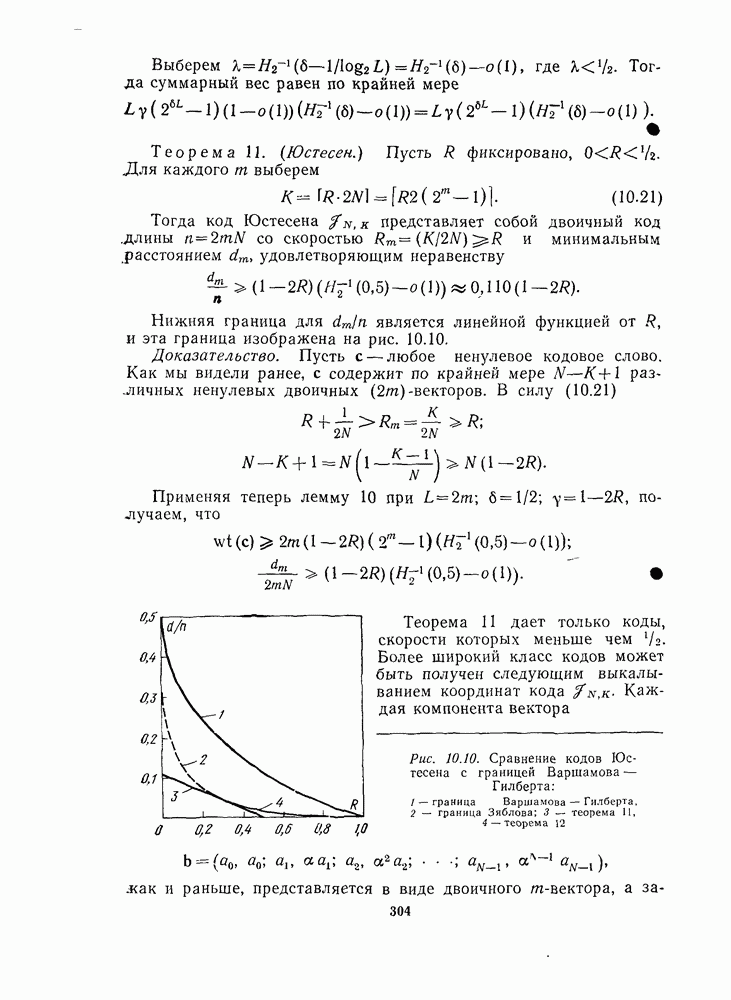
Как были найдены координаты вектора х, включенные в проверки (13.12), (13.13), ...? Чтобы ответить на этот вопрос, дадим геометрическое описание алгоритма Рида для декодирования кода  Прежде всего найдем
Прежде всего найдем  для некоторого
для некоторого  Соответствующая строка порождающей матрицы
Соответствующая строка порождающей матрицы  равна вектору инцидентности некоторого
равна вектору инцидентности некоторого  -мерного подпространства
-мерного подпространства  геометрии
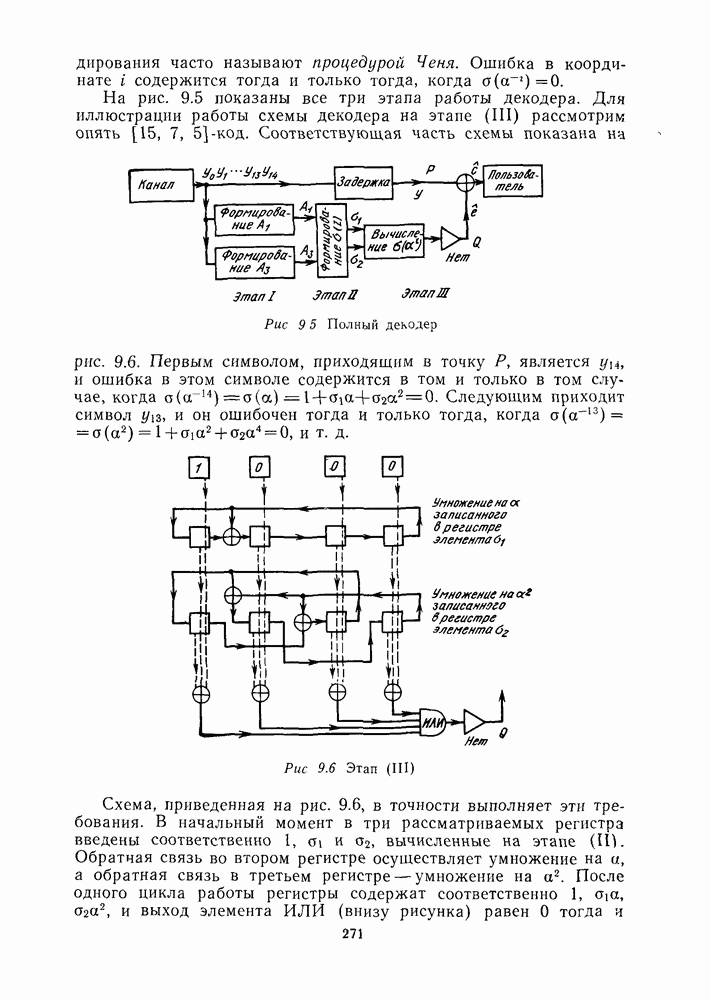
геометрии  Например, на рис. 13.6 двойной линией выделена плоскость
Например, на рис. 13.6 двойной линией выделена плоскость  соответствующая символу
соответствующая символу  Пусть
Пусть  обозначает «дополнительное» к
обозначает «дополнительное» к  подпространство с вектором инцидентности
подпространство с вектором инцидентности  где множество индексов
где множество индексов  является дополнением к множеству
является дополнением к множеству  во всем множестве
во всем множестве  Очевидно, что подпространства
Очевидно, что подпространства  пересекаются в одной точке — в начале координат.
пересекаются в одной точке — в начале координат.
Пусть  все параллельные переносы подпространства
все параллельные переносы подпространства  в
в  включая и само
включая и само  (на рис. 13.6 они заштрихованы). Каждое подмножество
(на рис. 13.6 они заштрихованы). Каждое подмножество  пересекается с 5 точно в одной точке.
пересекается с 5 точно в одной точке.

Рис. 13.6. Геометрия  ; показаны пространство
; показаны пространство  (двойные линии) и
(двойные линии) и  (заштрихованы)
(заштрихованы)
Теорема 14. При условии отсутствия ошибок символ а задается равенствами

Эти уравнения являются обобщениями уравнений (13.12), (13.13) и определяют  проверок для символа
проверок для символа 
Доказательство. В соответствии с видом порождающей матрицы кодовое слово может быть записано в виде

где суммирование ведется по всем подмножествам  множества индексов
множества индексов  объем которых не превосходит
объем которых не превосходит  (Это обобщение равенства
(Это обобщение равенства  Следовательно,
Следовательно,

где  -число точек в пересечении подмножества
-число точек в пересечении подмножества  и подпространства
и подпространства  с вектором инцидентности
с вектором инцидентности 
Воспользуемся тем, что пересечение двух подпространств является подпространством, и тем, что все подпространства (за исключением одноточечных) содержат четное число точек. Подпространства  пересекаются по подпространству
пересекаются по подпространству

Если  то размерность этого подпространства равна по меньшей мере
то размерность этого подпространства равна по меньшей мере  четно. С другой стороны, если
четно. С другой стороны, если  но то одно из
но то одно из  должно равняться одному из
должно равняться одному из  скажем,
скажем,  Тогда
Тогда  пересекаются по подпространству
пересекаются по подпространству

и размерность этого пересечения опять равна по меньшей мере 1, так что  четно. Наконец, если
четно. Наконец, если  то
то  Из этой теоремы следует, что если произошло не более чем —
Из этой теоремы следует, что если произошло не более чем —  ошибок, то мажоритарное декодирование дает правильное значение символа а, где
ошибок, то мажоритарное декодирование дает правильное значение символа а, где  любая цепочка из
любая цепочка из  символов. Остальные символы определяются так же, как и в рассмотренном примере. Таким образом, алгоритм Рида позволяет исправлять
символов. Остальные символы определяются так же, как и в рассмотренном примере. Таким образом, алгоритм Рида позволяет исправлять  ошибок.
ошибок.