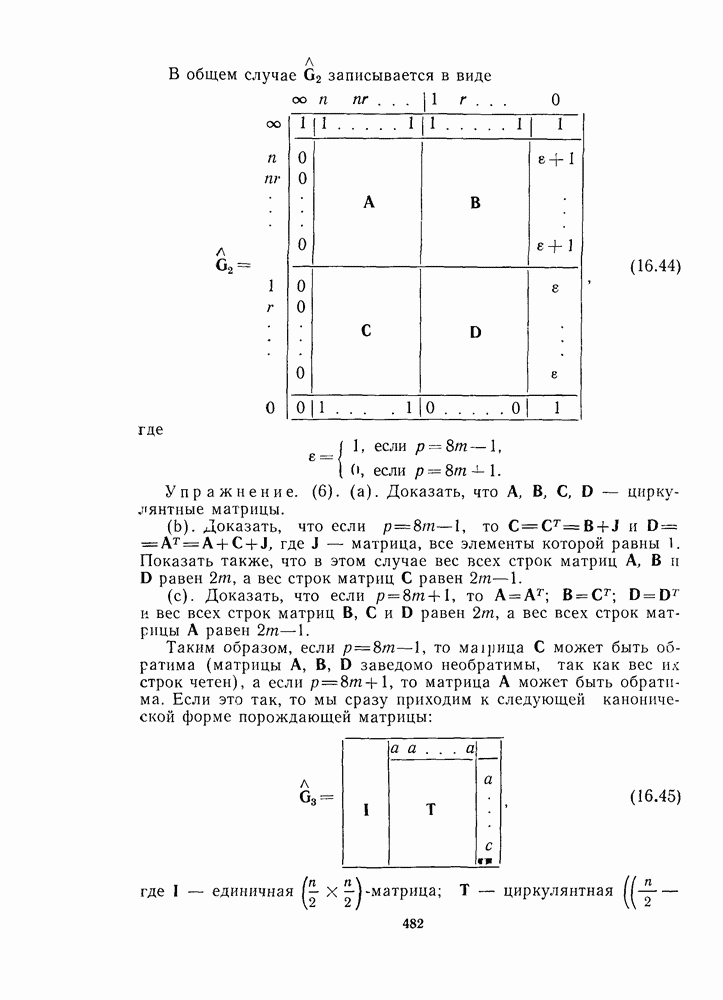
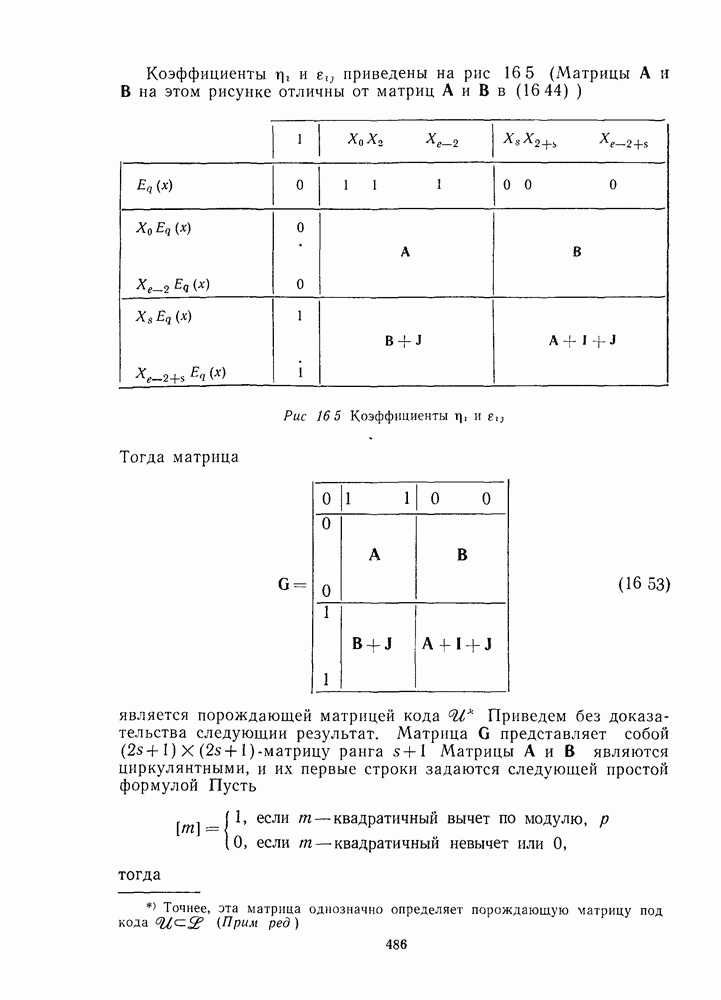
Пред.
След.
Макеты страниц
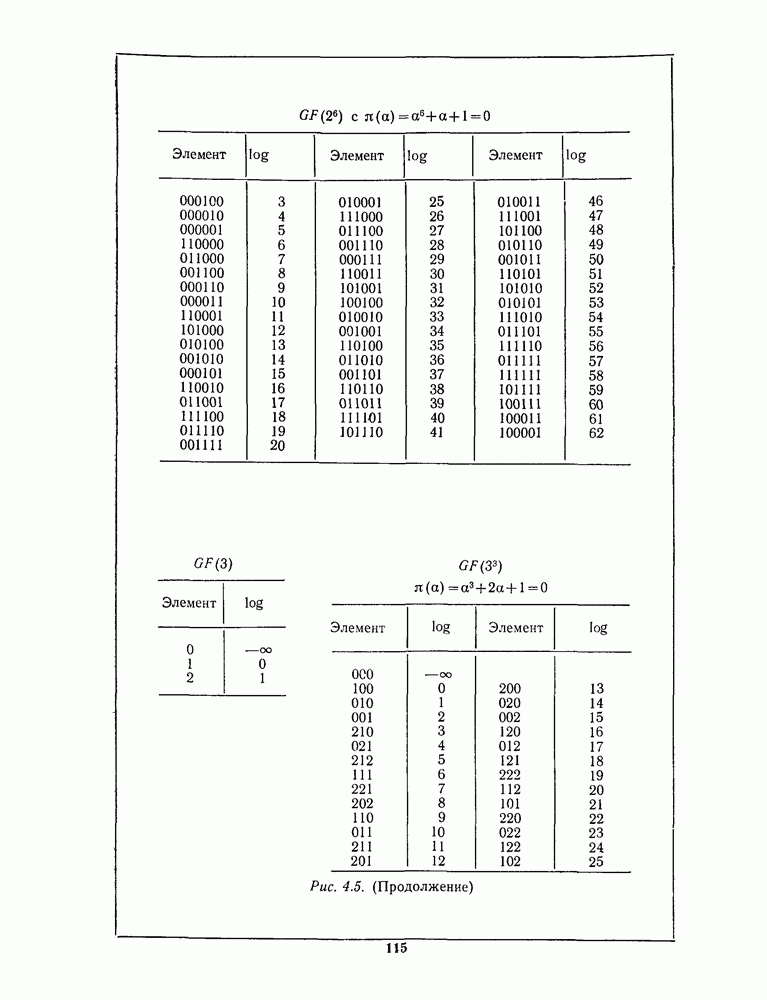
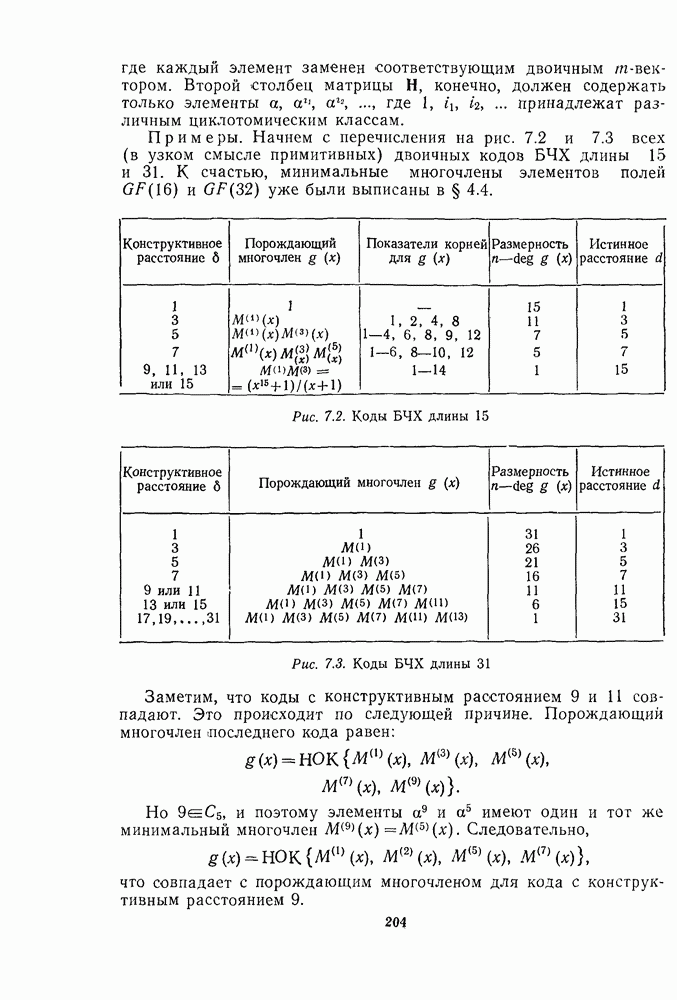
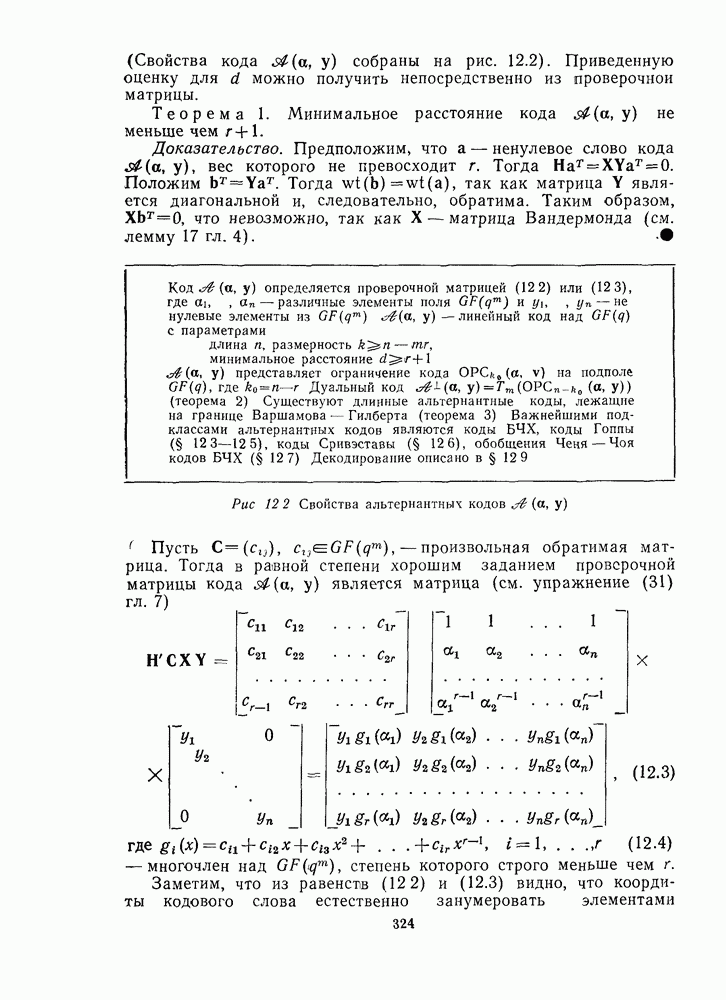
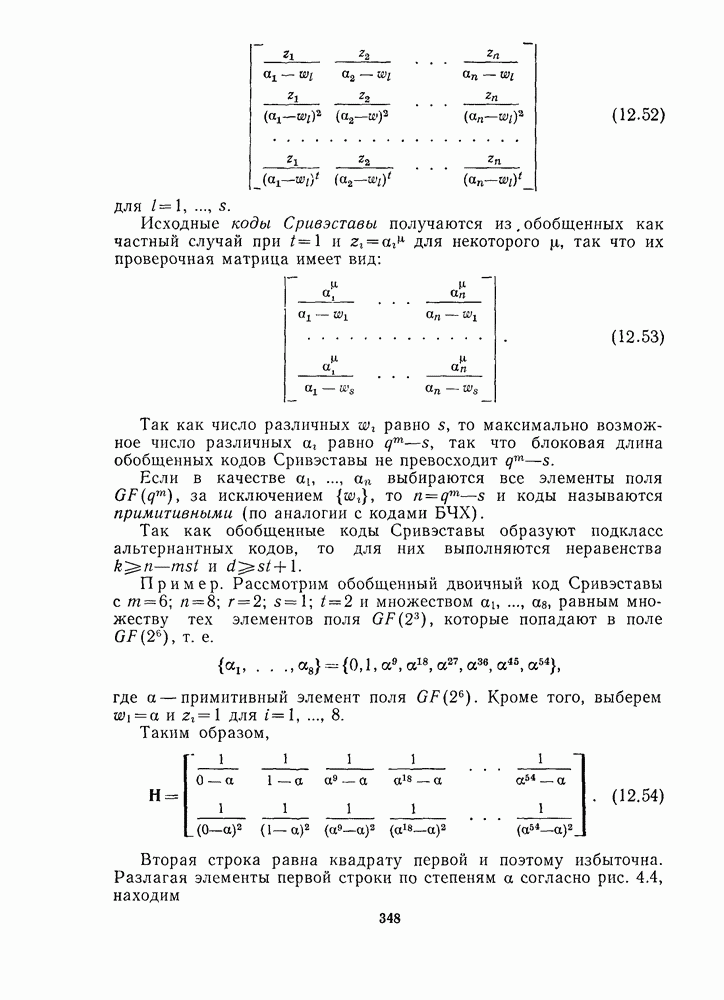
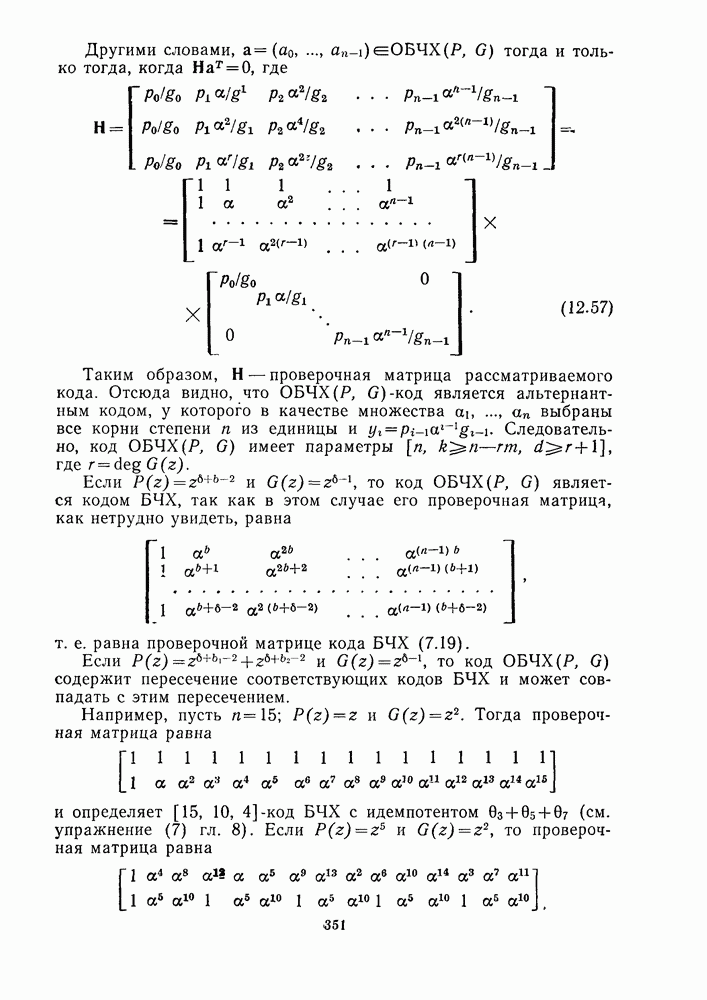
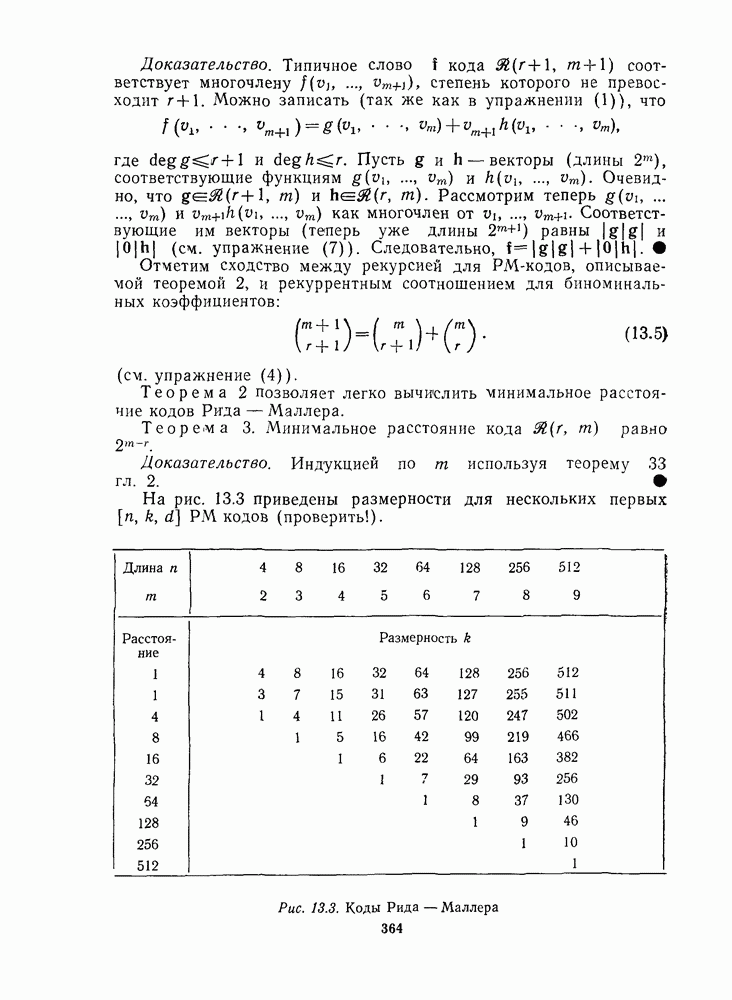
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.5. ВЕРОЯТНОСТЬ ОШИБКИКогда декодирование использует стандартное расположение, выбранный декодером вектор ошибок всегда представляет собой один из лидеров смежных классов. Декодирование является правильным, если и только если истинный вектор ошибок в действительности является лидером смежного класса. Если это не так, то декодер совершает ошибку и выдает неправильное кодовое слово. (Хотя при этом некоторые из информационных символов могут быть правильными.) Определение. Вероятностью ошибки, или вероятностью ошибки на слово, Если имеется
Если мы декодируем, пользуясь стандартным расположением, то ошибка декодирования происходит тогда и только тогда, когда вектор ошибок
Предположим, что имеется
(Так как стандартное расположение обеспечивает декодирование по максимуму правдоподобия, то любая другая схема декодирования будет иметь вероятность ошибки Примеры. Для кода
Для кода
Если код имеет минимальное расстояние вектор ошибок веса не более
Но для значений Если вероятность ошибки в канале
или
являются полезными аппроксимациями. В любом случае правые части формул (1 26) или (1.27) являются верхними границами для Совершенные коды. Конечно, если Таким образом, совершенный код, исправляющий Квазисовершенные коды. Если же теперь Таким образом, квазисовершенный код, исправляющий Граница сферической упаковки, или граница Хэмминга. Предположим, что Теорема 6. (Граница сферической упаковки, или граница Хэмминга). Если существует двоичный код длины исправляющий
Аналогично для кода над полем из
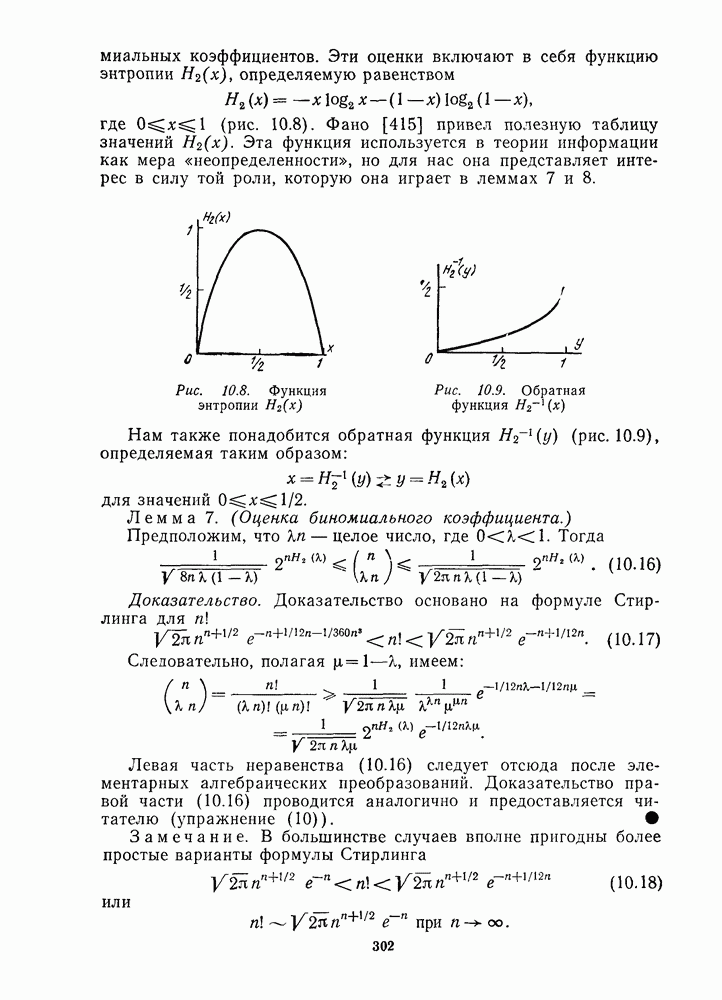
Для больших По определению код совершенен тогда и только тогда, когда в (1.28) или (1.29) выполняется равенство. Вероятность ошибки на символ. Так как некоторые из информационных символов могут быть правильными, даже если декодер выдает неправильное кодовое слово, то более полезной мерой качества декодирования является вероятность ошибки на символ, определяемая следующим образом. Определение. Предположим, что код содержит
Упражнение. (23). Показать, что если при декодировании используется стандартное расположение и все сообщения равновероятны, то
где
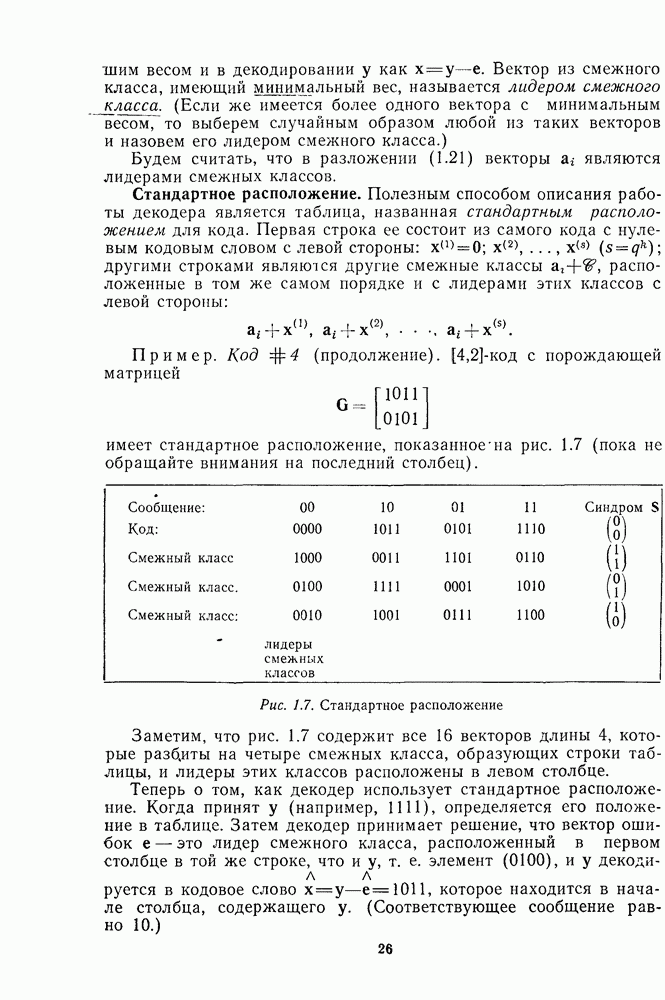
где Пример. Вернемся к стандартному расположению на рис. 1.7. Здесь
Использование этого очень простого кода понизило среднюю вероятность ошибки на символ от 0,01 до 0,0053. Упражнения. (24). Показать, что при декодировании кода
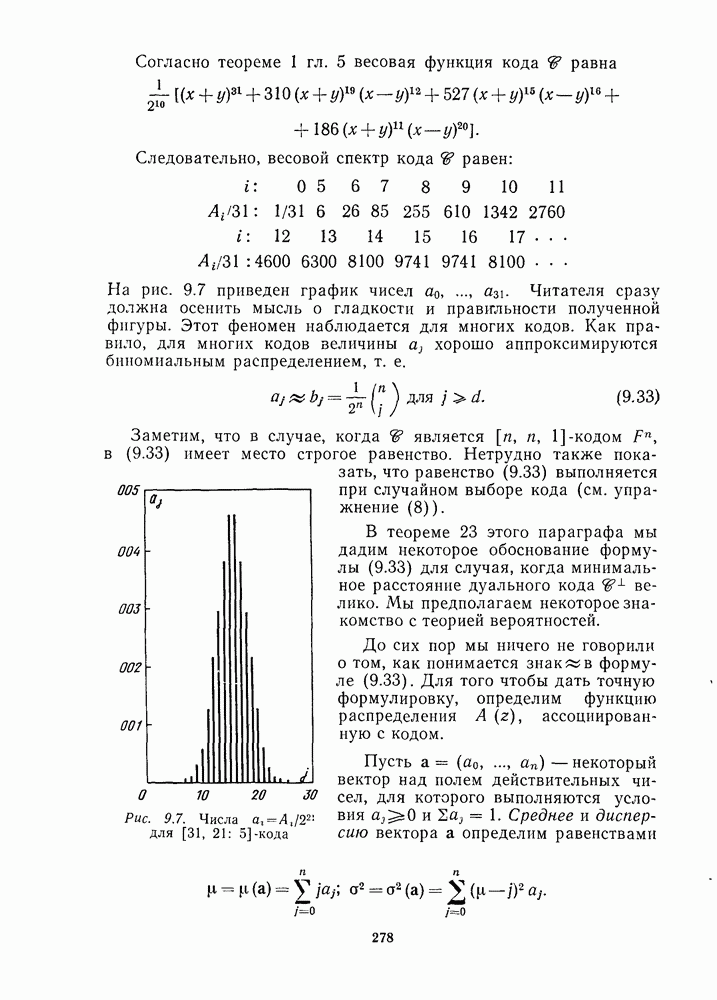
Как видно из этих примеров, значение
Неполное декодирование. Схему неполного декодирования, которая исправляет ошибки кратности не более чем
Рис. 1.8 Неполное декодирование, использующее стандартное расположение Если принятый вектор у лежит в верхней части таблицы, то, как и прежде, у декодируется в кодовое слово, являющееся самым верхним в столбце, содержащим у. Если же у лежит в нижней половине, то декодер просто обнаруживает, что произошло больше чем Обнаружение ошибок. При обнаружении ошибок декодер ошибется и допустит кодовое слово, отличное от переданного, тогда и только тогда, когда вектор ошибок является ненулевым кодовым словом. Если код содержит
Вероятность же того, что ошибка будет обнаружена и сообщение будет передано еще раз, равна
Пример. Для кода Это значение намного меньше, чем вероятность ошибки 0,00136, полученная при декодировании этого кода с помощью стандартного расположения. Вероятность повторной передачи равна переспроса Задача (нерешенная). (1.1). Найти распределение
|
 |
Оглавление
|







































































































































































































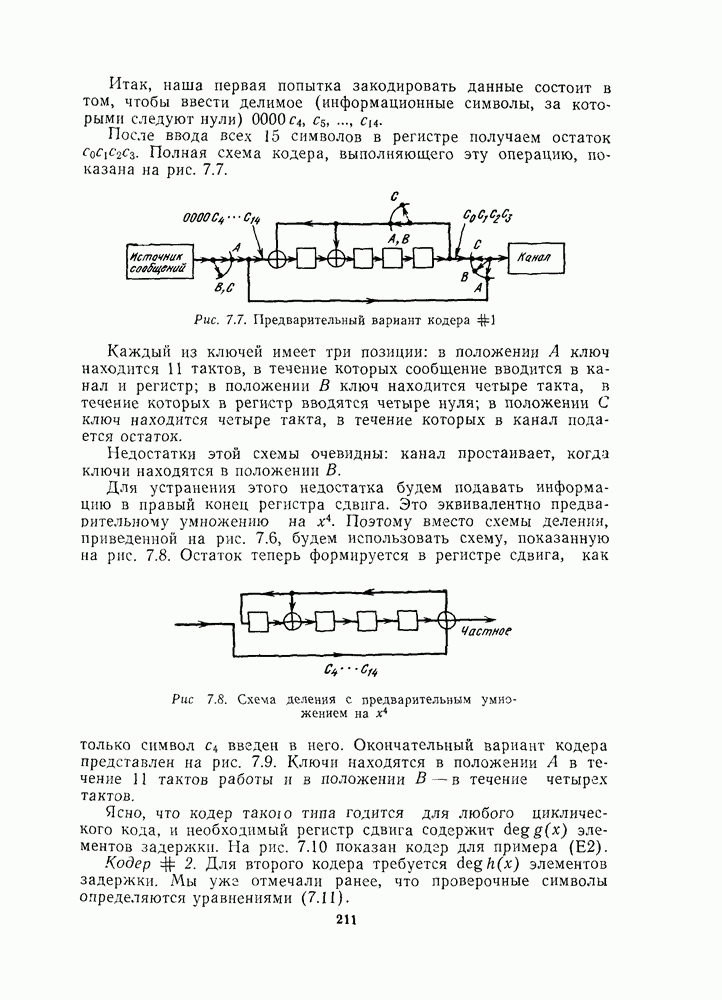
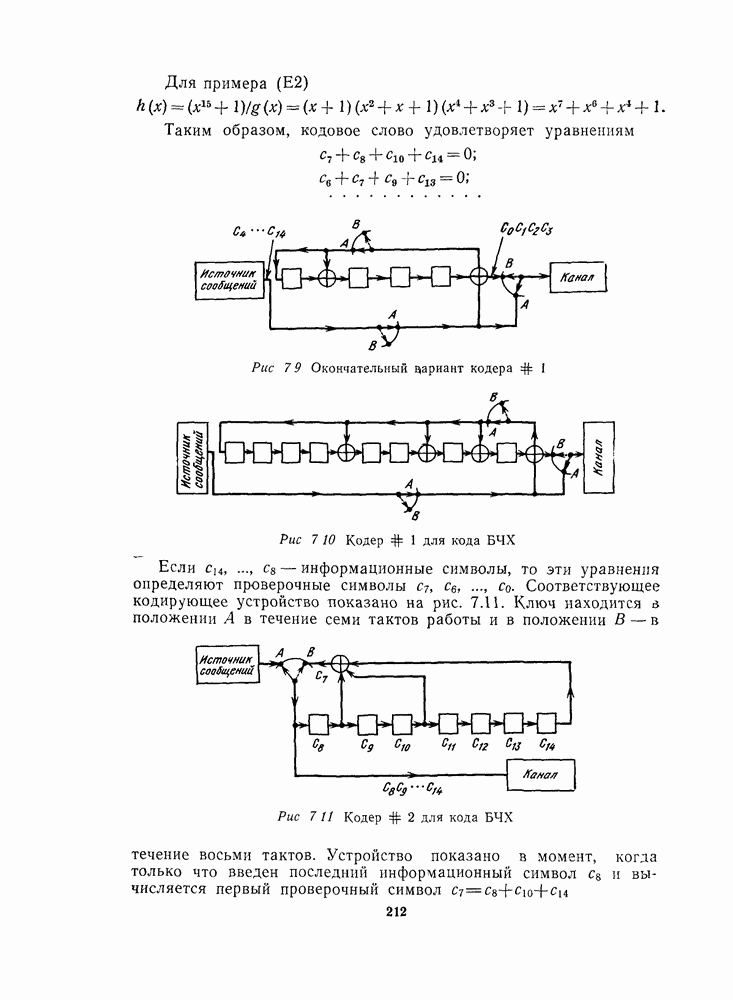











































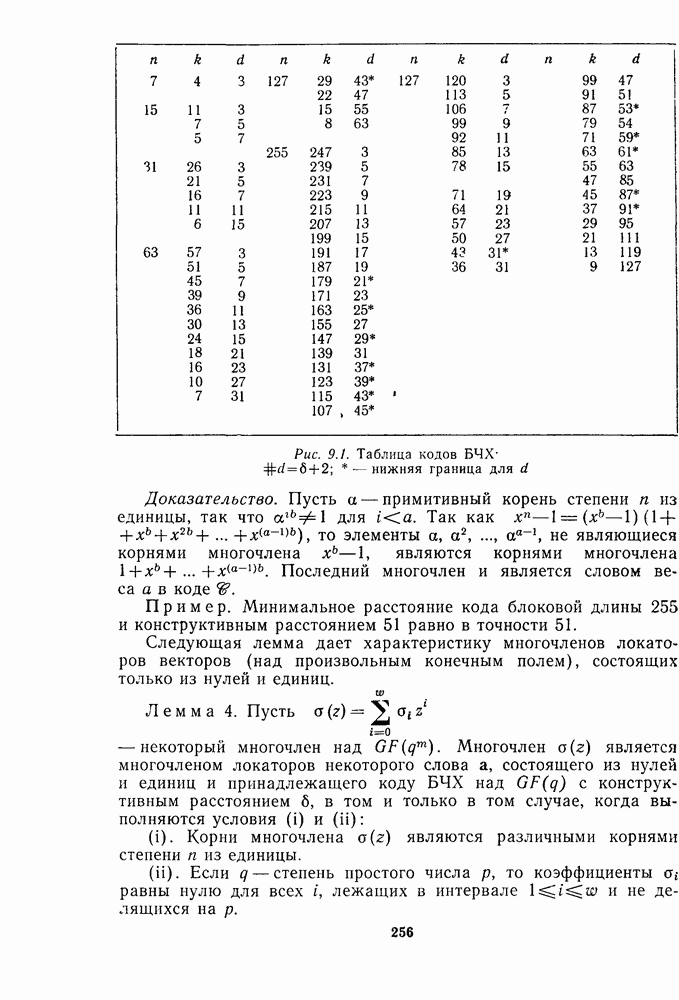














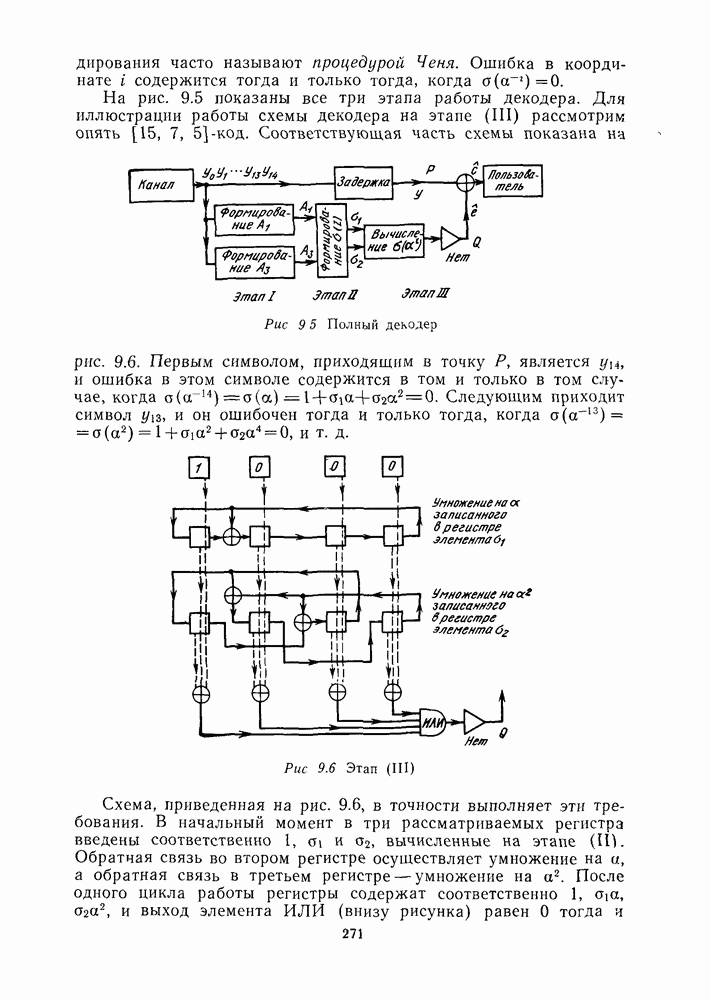




































































































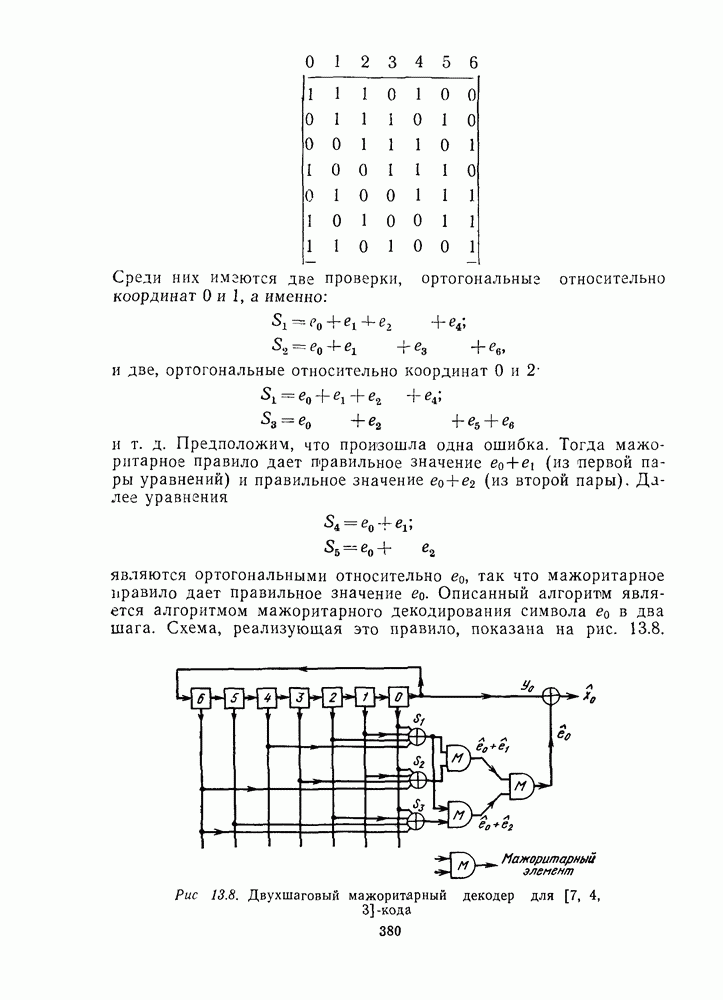




























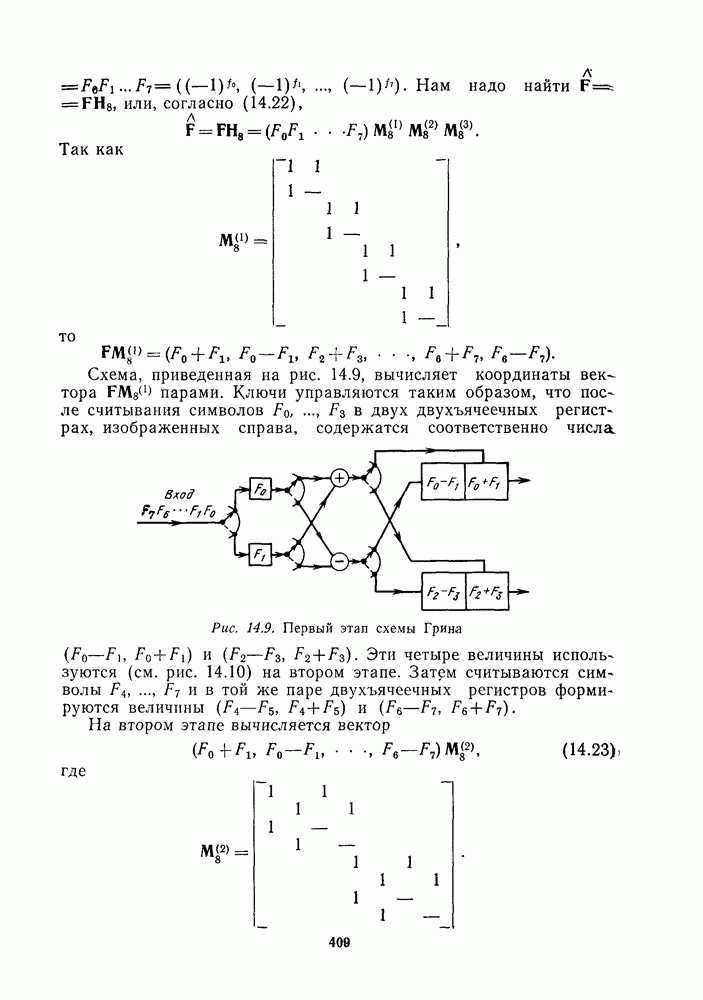
























































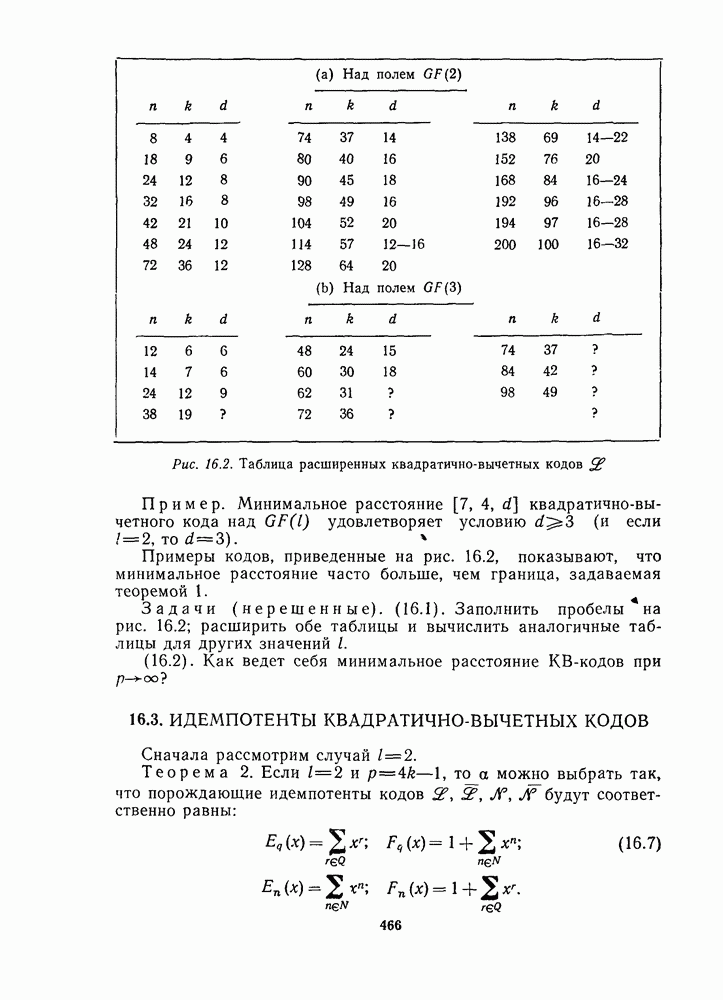














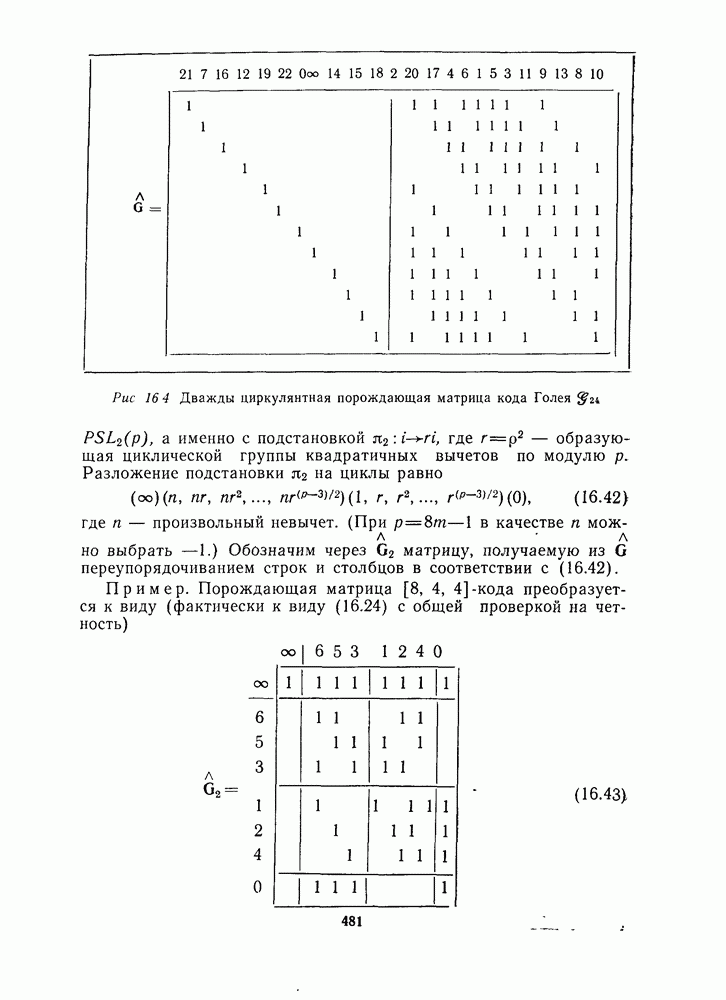



































































































































































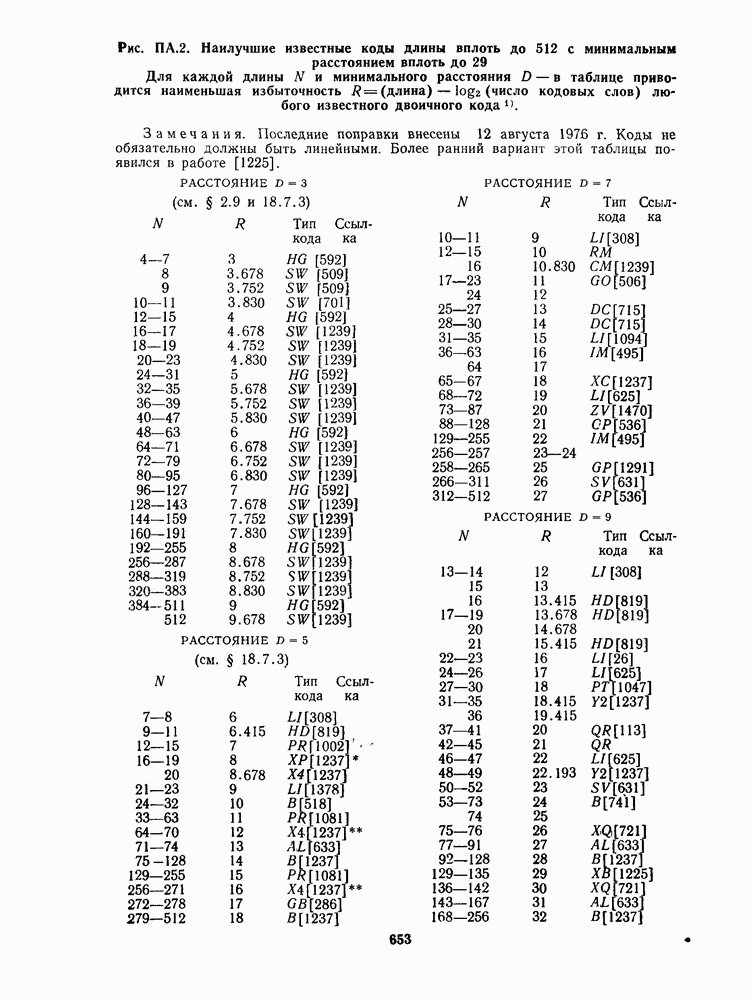
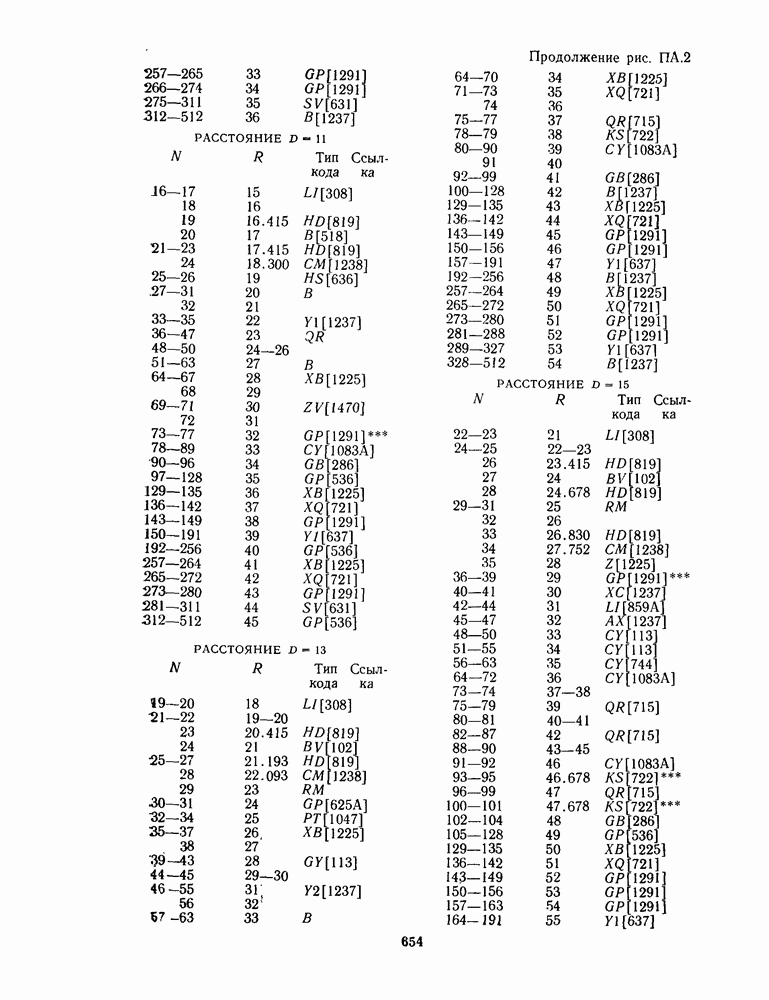
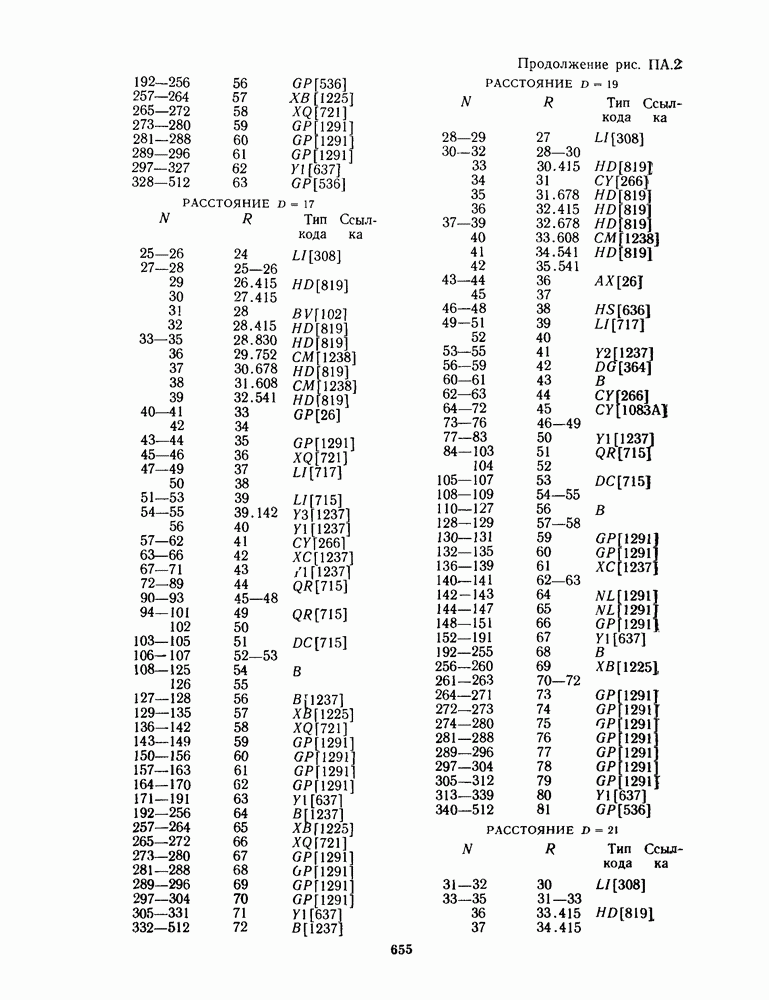
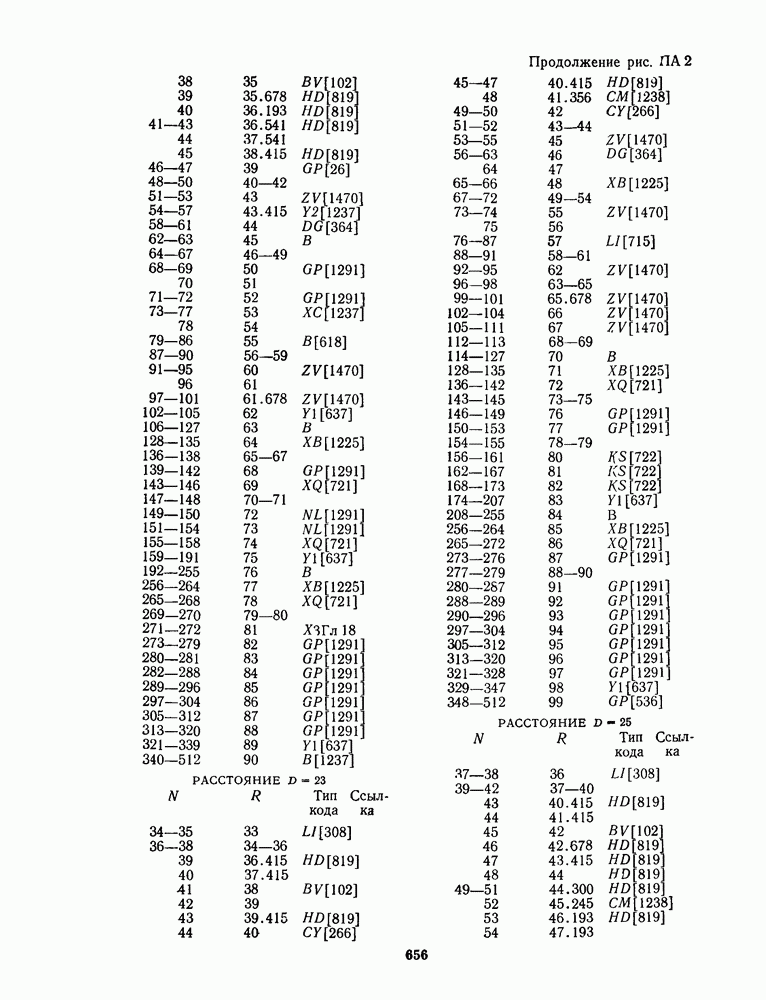
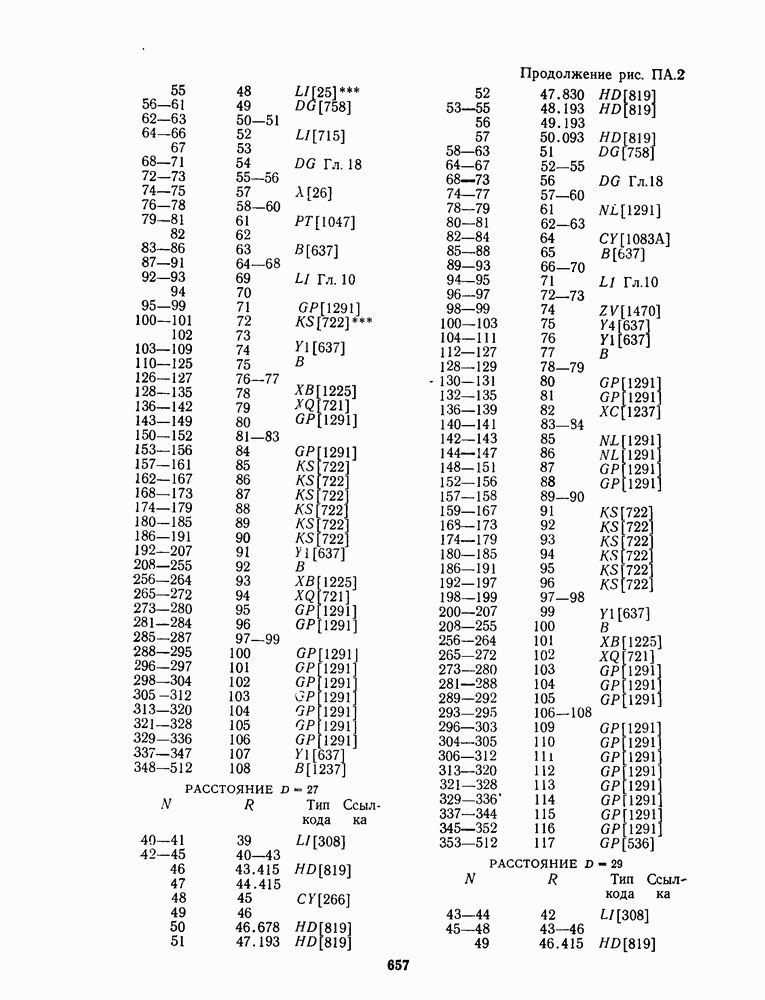
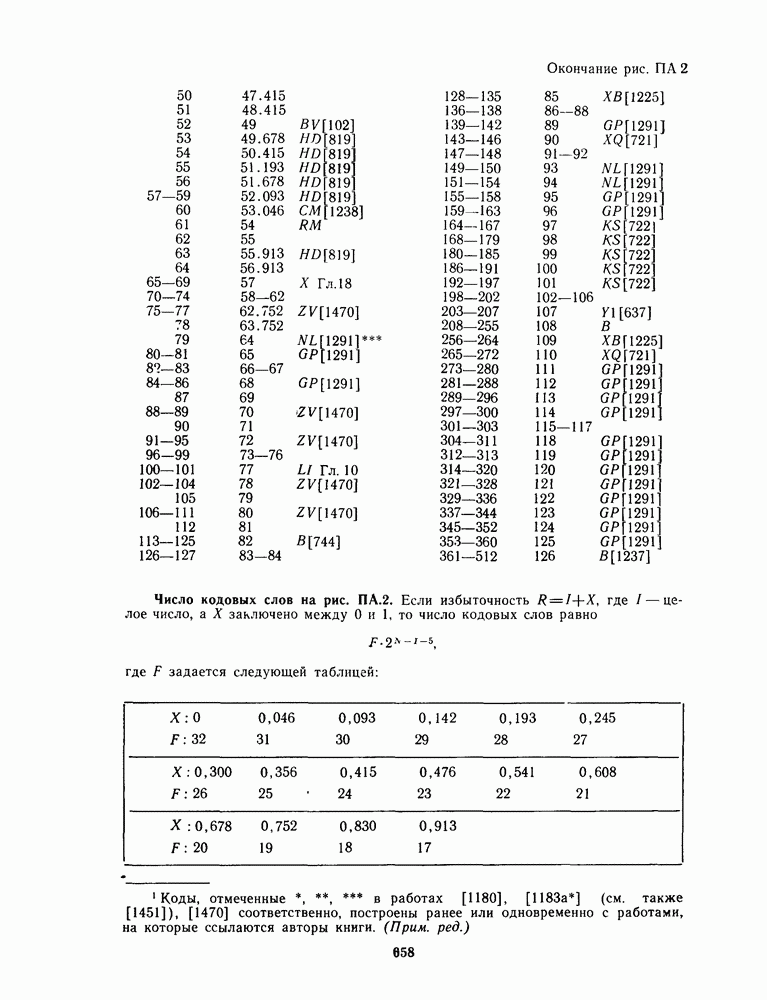


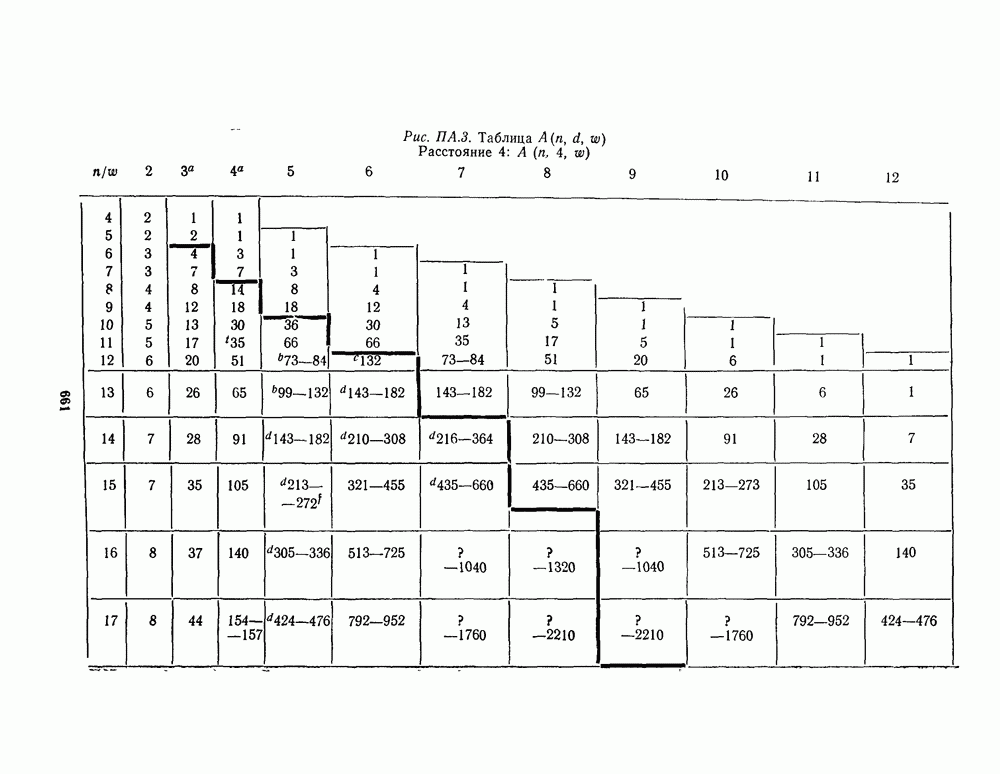
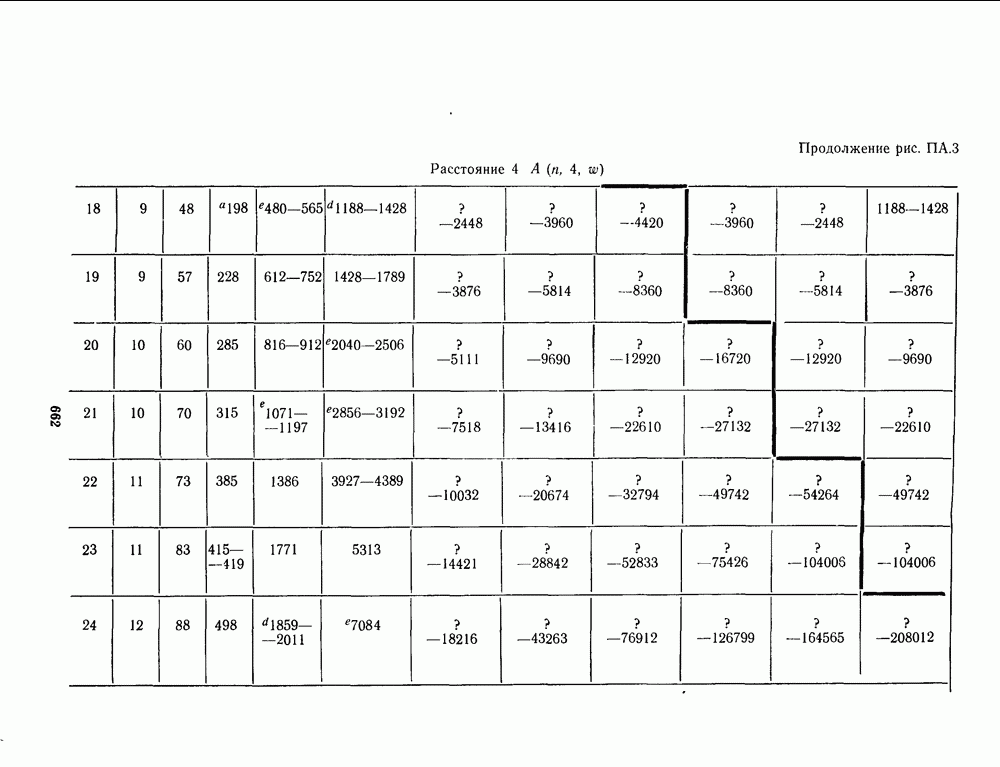
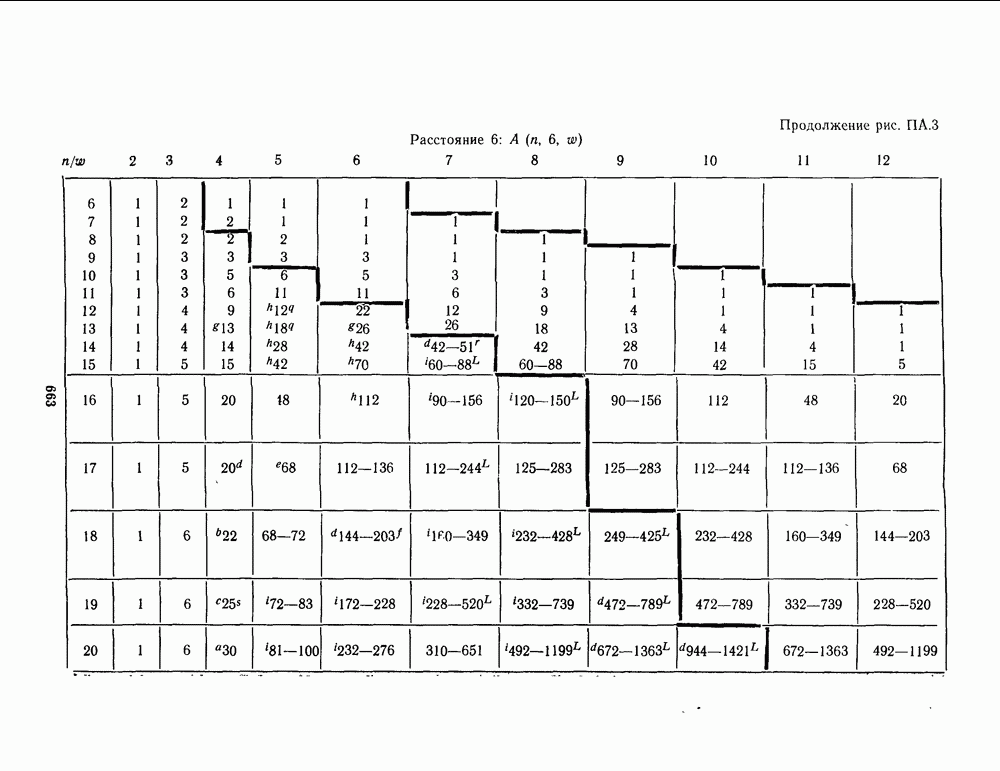
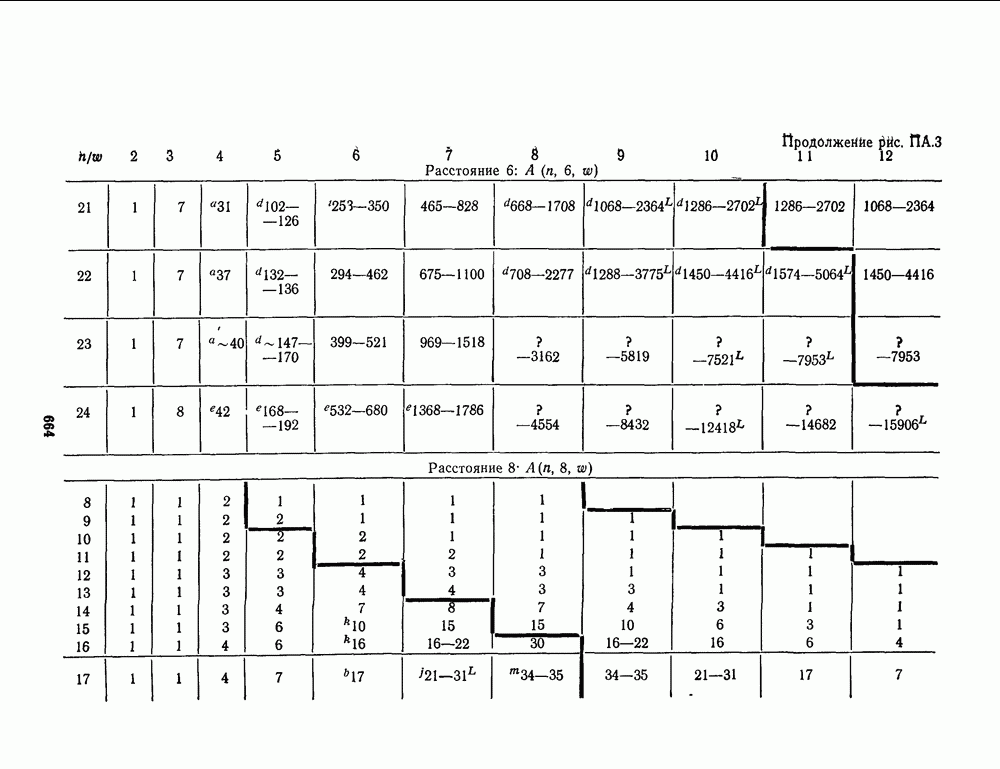
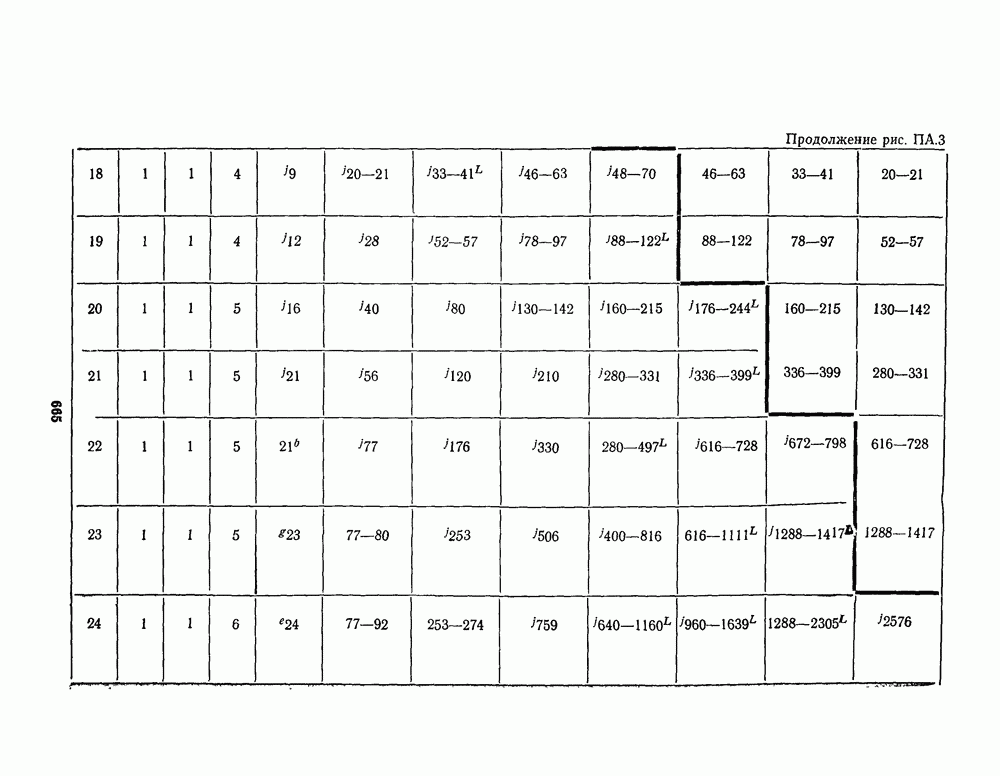
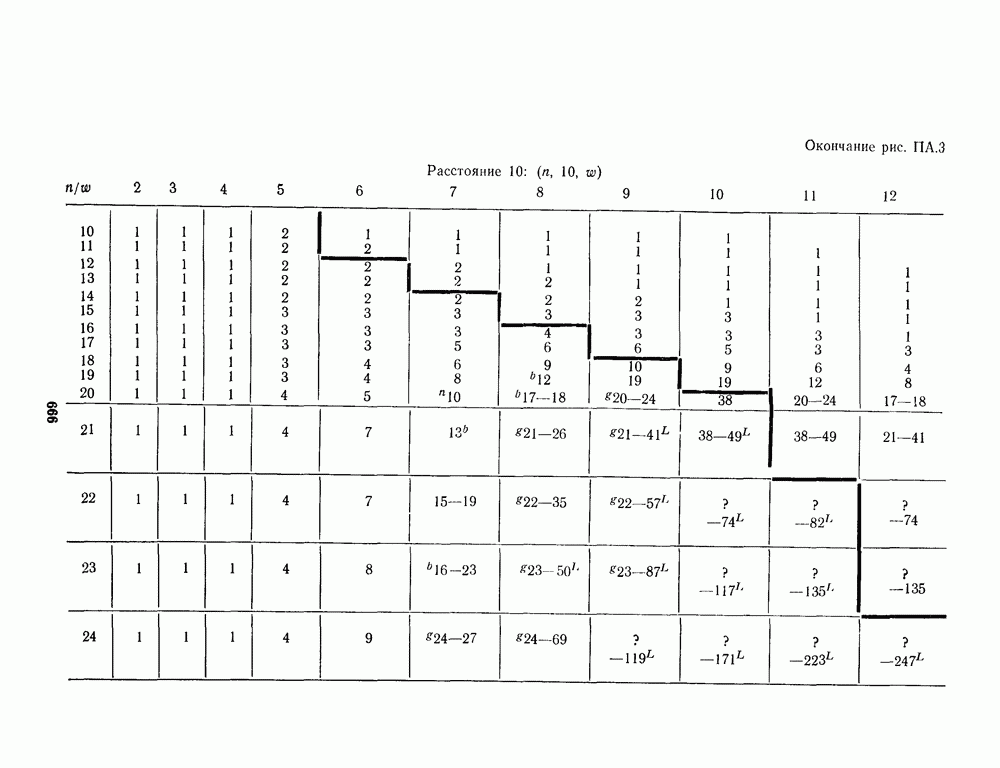




































































 для данной схемы декодирования называется вероятность появления неправильного кодового слова на выходе декодера.
для данной схемы декодирования называется вероятность появления неправильного кодового слова на выходе декодера.
 кодовых слов
кодовых слов  которые, как мы предполагаем, используются с равной вероятностью, то
которые, как мы предполагаем, используются с равной вероятностью, то

 не является лидером смежного класса, так что
не является лидером смежного класса, так что

 лидеров смежного класса веса
лидеров смежного класса веса  Тогда, используя (1.13), получаем
Тогда, используя (1.13), получаем

 не меньше чем правая часть
не меньше чем правая часть 
 (см. рис. 1.7) имеем
(см. рис. 1.7) имеем  так что
так что

 имеем
имеем  так что
так что

 или
или  то (по теореме 2) он может исправлять
то (по теореме 2) он может исправлять  ошибок. Поэтому каждый
ошибок. Поэтому каждый
 является лидером смежного класса. Другими словами,
является лидером смежного класса. Другими словами,

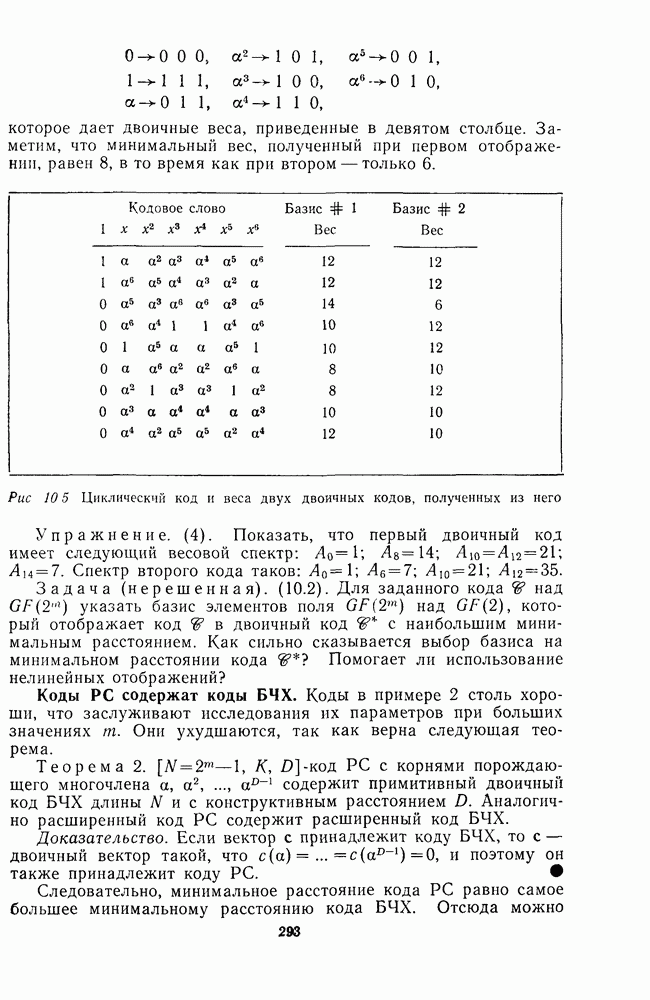
 вычислить а, чрезвычайно трудно, и они известны только для очень немногих кодов.
вычислить а, чрезвычайно трудно, и они известны только для очень немногих кодов.
 очень мала, то
очень мала, то  . В этом случае в (1.24) можно пренебречь членами с большими
. В этом случае в (1.24) можно пренебречь членами с большими  и формулы
и формулы



 то формула (1.26) становится точной. Такой код называется совершенным.
то формула (1.26) становится точной. Такой код называется совершенным.
 ошибок, может исправлять все ошибки веса не более
ошибок, может исправлять все ошибки веса не более  и не может исправлять ни одной ошибки веса больше, чем
и не может исправлять ни одной ошибки веса больше, чем  Это эквивалентно тому, что шары радиуса
Это эквивалентно тому, что шары радиуса  проведенные вокруг всех кодовых слов, не пересекаются и вместе содержат все векторы длины
проведенные вокруг всех кодовых слов, не пересекаются и вместе содержат все векторы длины  . В гл. 6 и 20 мы узнаем гораздо больше о совершенных кодах.
. В гл. 6 и 20 мы узнаем гораздо больше о совершенных кодах.
 при
при  то становится точной формула (1.27). Такой код называется квазисовершенным.
то становится точной формула (1.27). Такой код называется квазисовершенным.
 ошибок, может исправлять все ошибки веса не более
ошибок, может исправлять все ошибки веса не более  некоторые ошибки веса
некоторые ошибки веса  и не может исправлять ни одной ошибки веса больше, чем
и не может исправлять ни одной ошибки веса больше, чем  Шары радиуса
Шары радиуса  проведенные вокруг кодовых слов, могут пересекаться, и вместе они содержат все векторы длины
проведенные вокруг кодовых слов, могут пересекаться, и вместе они содержат все векторы длины  Мы снова встретимся с квазисовершенными кодами в гл. 6, 9 и 15.
Мы снова встретимся с квазисовершенными кодами в гл. 6, 9 и 15.
 двоичный код длины
двоичный код длины  содержащий
содержащий  кодовых слов, который может исправлять
кодовых слов, который может исправлять  ошибок. Шары радиуса
ошибок. Шары радиуса  проведенные вокруг всех кодовых слов, не пересекаются. Каждый из этих
проведенные вокруг всех кодовых слов, не пересекаются. Каждый из этих  шаров содержит
шаров содержит  векторов (см. упражнение 18 (b)). Но число векторов во всем пространстве равно
векторов (см. упражнение 18 (b)). Но число векторов во всем пространстве равно  Поэтому мы получаем следующую теорему.
Поэтому мы получаем следующую теорему.

 ошибок и содержащий
ошибок и содержащий  кодовых слов, то должно выполняться неравенство
кодовых слов, то должно выполняться неравенство

 элементов
элементов

 см. теорему 31 гл. 17. Так как при доказательстве этих двух границ не используется линейность кода, то они также справедливы и для нелинейных кодов (см. гл. 2).
см. теорему 31 гл. 17. Так как при доказательстве этих двух границ не используется линейность кода, то они также справедливы и для нелинейных кодов (см. гл. 2).
 кодовых слов
кодовых слов  и первые
и первые  символов
символов  в каждом кодовом слове являются информационными символами. Пусть
в каждом кодовом слове являются информационными символами. Пусть  символы на выходе декодера. Тогда вероятность ошибки на символ Рсичв определяется как средняя вероятность того, что после декодирования информационный символ является ошибочным:
символы на выходе декодера. Тогда вероятность ошибки на символ Рсичв определяется как средняя вероятность того, что после декодирования информационный символ является ошибочным:

 с и
с и  в не зависит от того, какое кодовое слово было послано. В самом деле, если послано кодовое слово
в не зависит от того, какое кодовое слово было послано. В самом деле, если послано кодовое слово  и оно декодировано как
и оно декодировано как  то
то

 обозначает число неправильных информационных символов после декодирования при условии, что
обозначает число неправильных информационных символов после декодирования при условии, что  вектор ошибок, и поэтому
вектор ошибок, и поэтому

 вес первых
вес первых  позиций кодового слова в начале
позиций кодового слова в начале  столбца стандартного расположения, а
столбца стандартного расположения, а  - суммарная вероятность появления всех двоичных векторов этого столбца.
- суммарная вероятность появления всех двоичных векторов этого столбца.
 если
если  находится в первом столбце таблицы (где расположены лидеры смежных классов),
находится в первом столбце таблицы (где расположены лидеры смежных классов),  если
если  находится во
находится во  или
или  столбцах, и
столбцах, и  если
если  находится в последнем столбце. Тогда из (1.32)
находится в последнем столбце. Тогда из (1.32)

 с помощью стандартного расположения
с помощью стандартного расположения

 трудно вычислять, и оно неизвестно для большинства кодов.
трудно вычислять, и оно неизвестно для большинства кодов.

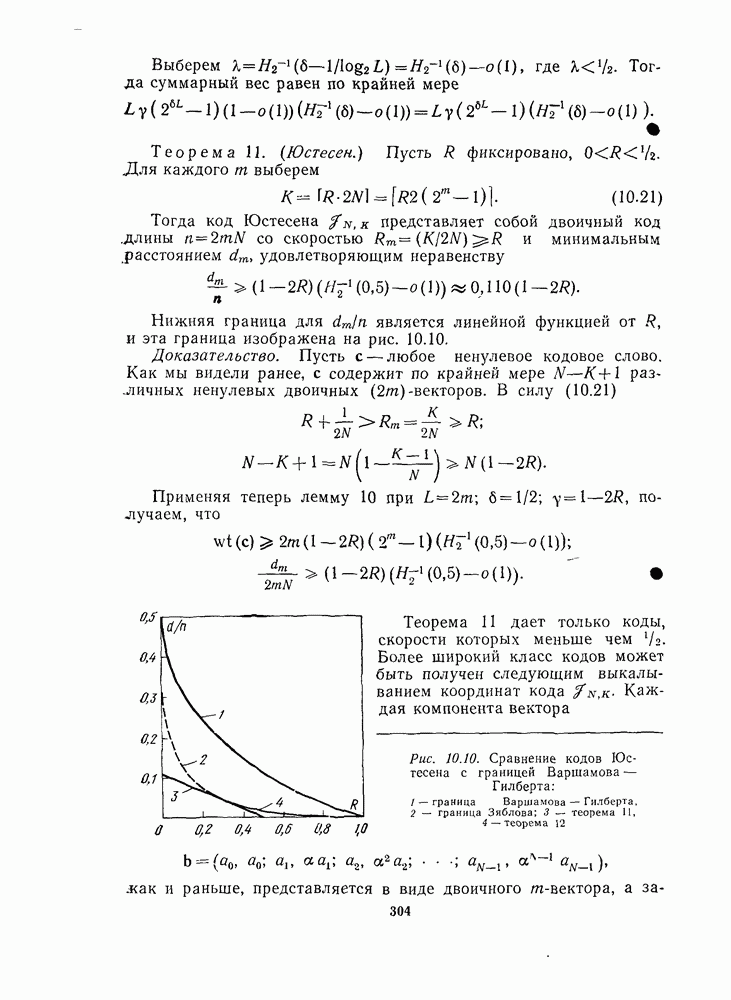
 следующим образом можно описать в терминах стандартного расположения. Расположим смежные классы в порядке увеличения веса (т. е. уменьшения вероятности) их лидеров (рис. 1.8).
следующим образом можно описать в терминах стандартного расположения. Расположим смежные классы в порядке увеличения веса (т. е. уменьшения вероятности) их лидеров (рис. 1.8).

 ошибок.
ошибок.
 кодовых слов веса
кодовых слов веса  то вероятность ошибки равна:
то вероятность ошибки равна:


 если
если 

 лидеров смежных классов для любого из известных семейств кодов. Эта задача все еще не решена даже для кодов Рида — Маллера первого порядка (см. гл. 14, а также работы Берлекэмпа и Велча [133], Лечнера [797—799], Сарвейта [1144] и Слоэна и Дика [1233]).
лидеров смежных классов для любого из известных семейств кодов. Эта задача все еще не решена даже для кодов Рида — Маллера первого порядка (см. гл. 14, а также работы Берлекэмпа и Велча [133], Лечнера [797—799], Сарвейта [1144] и Слоэна и Дика [1233]).