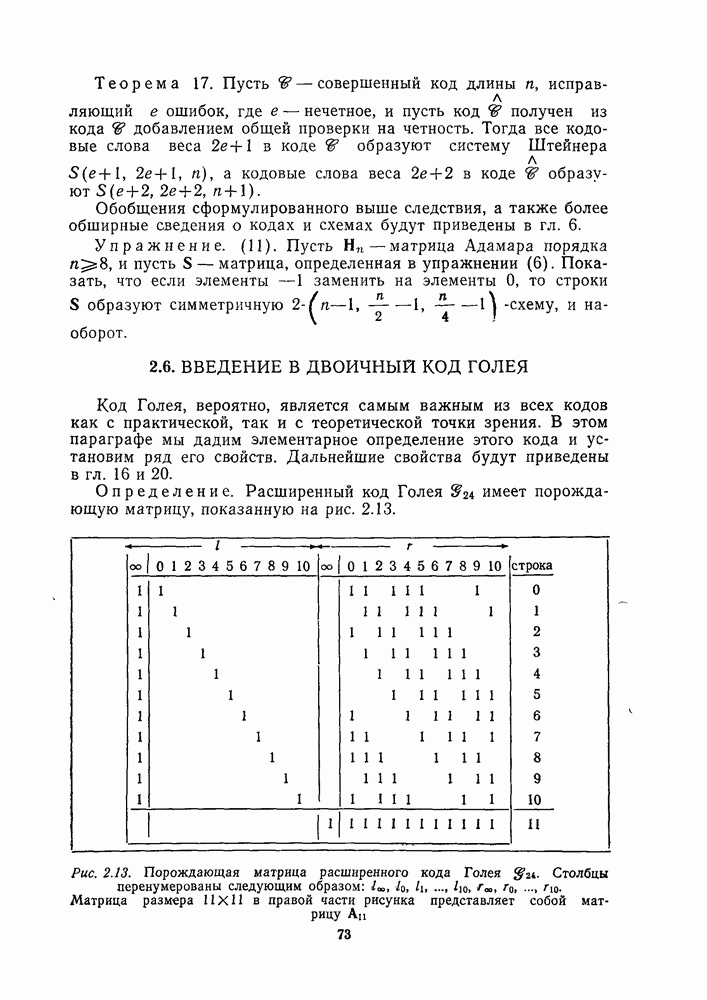
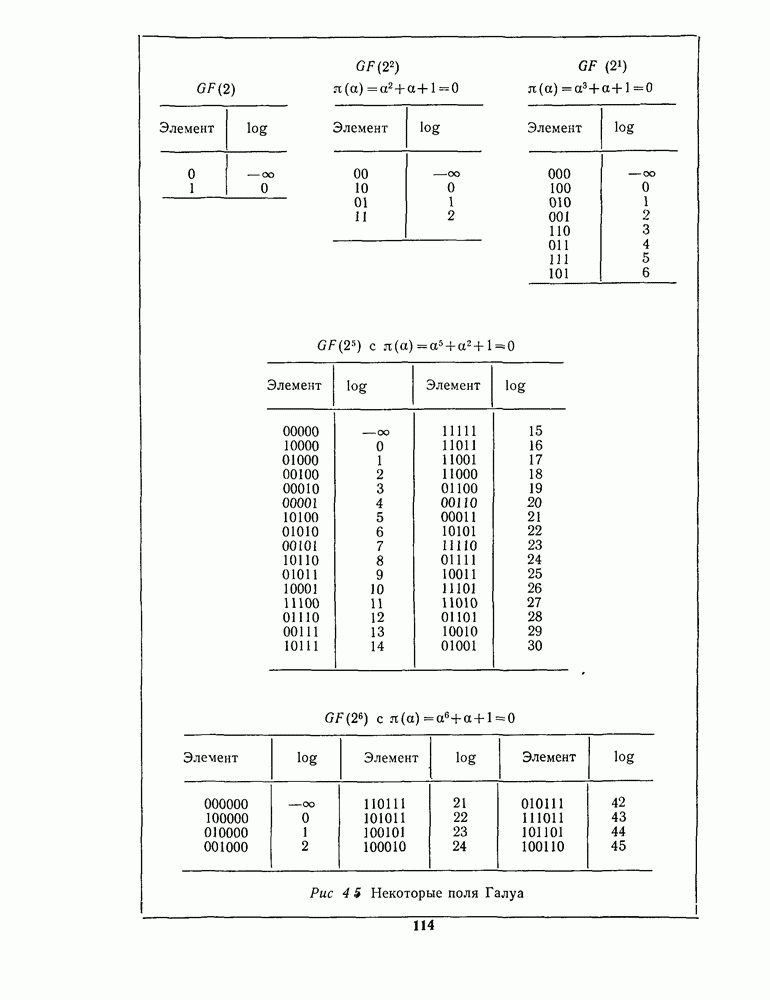
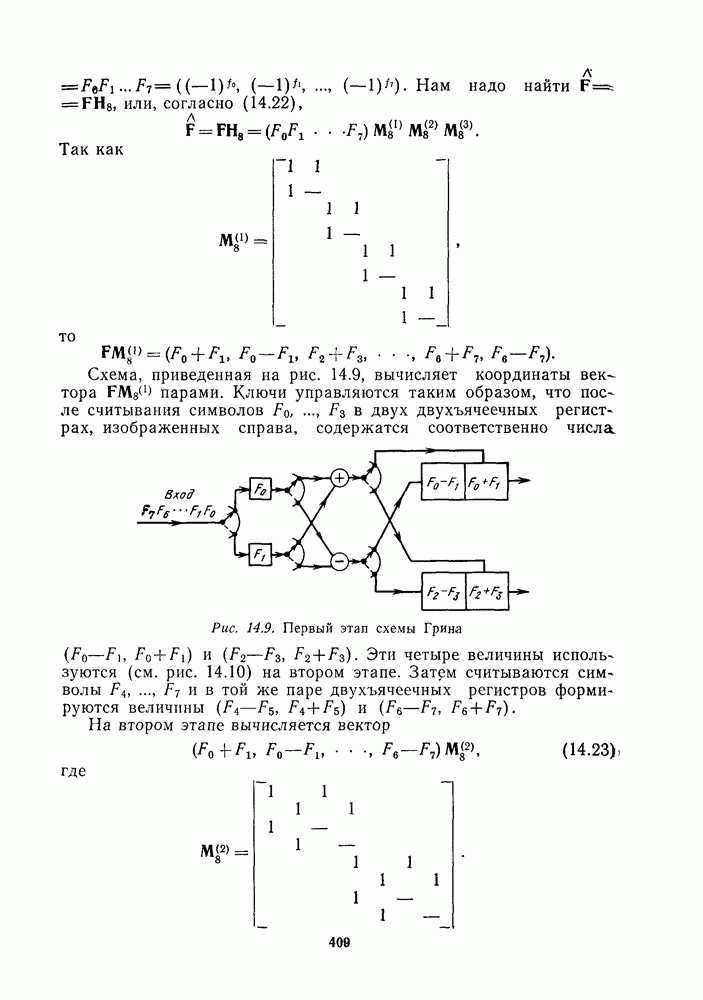
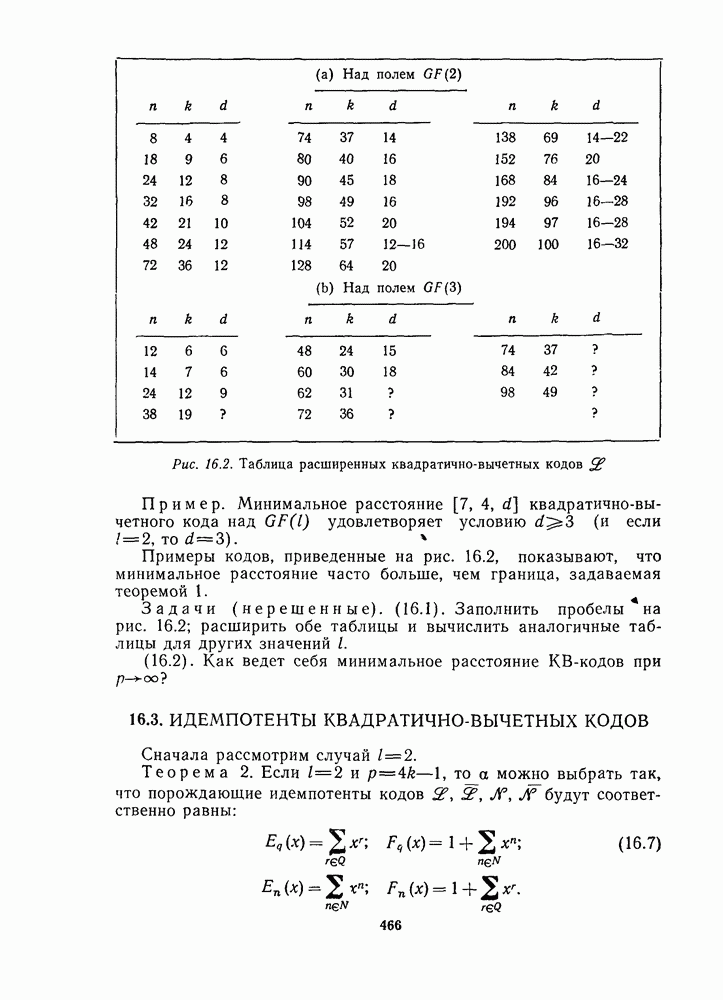
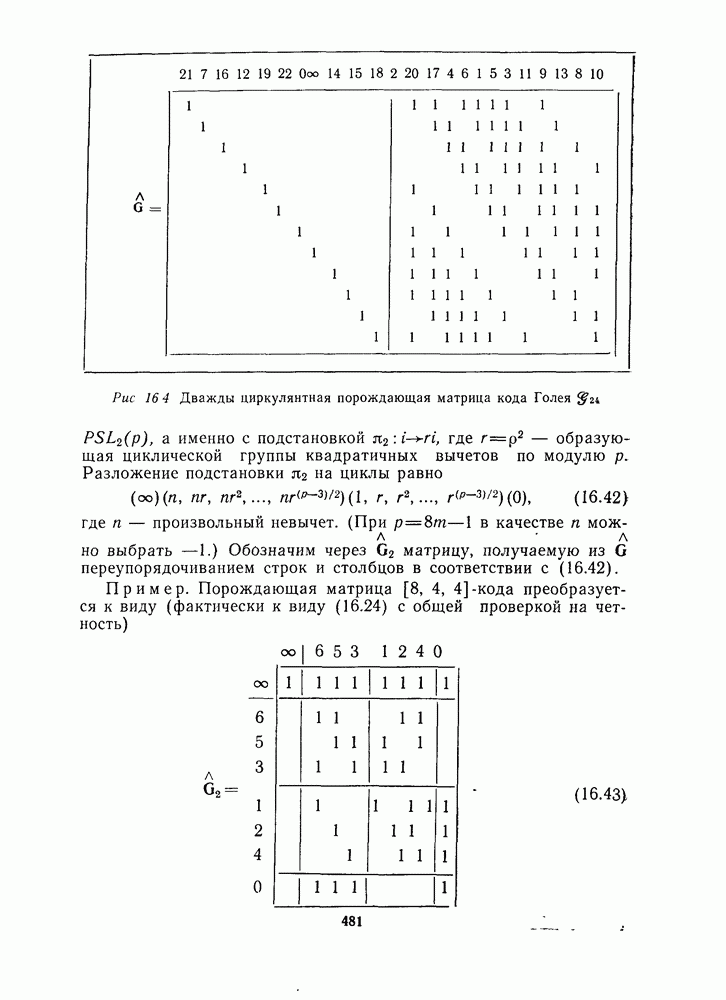
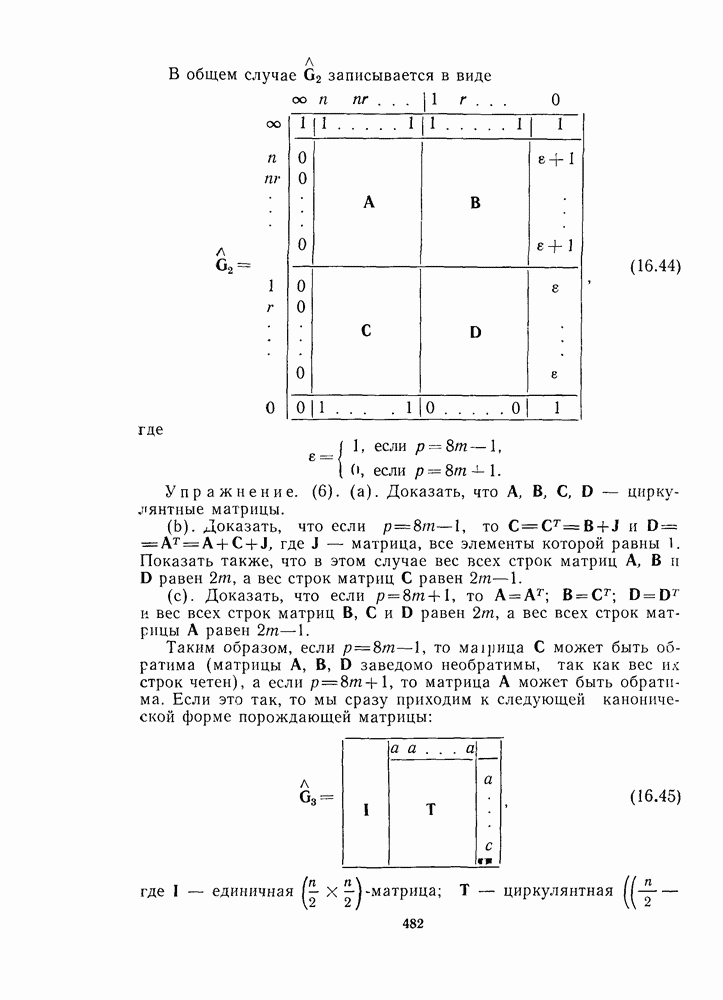
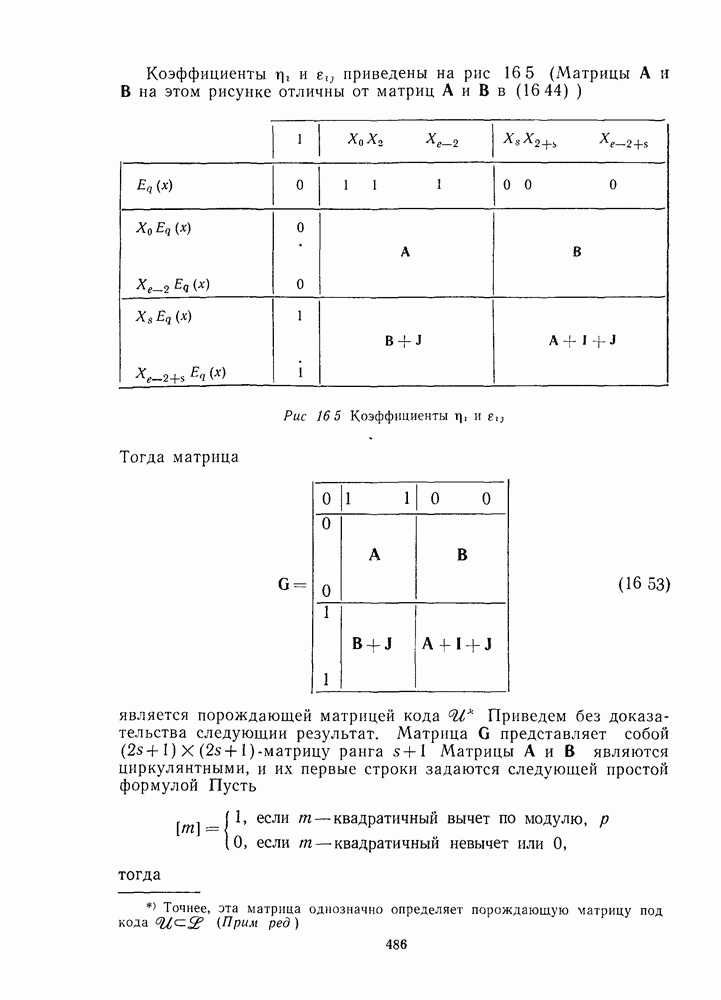
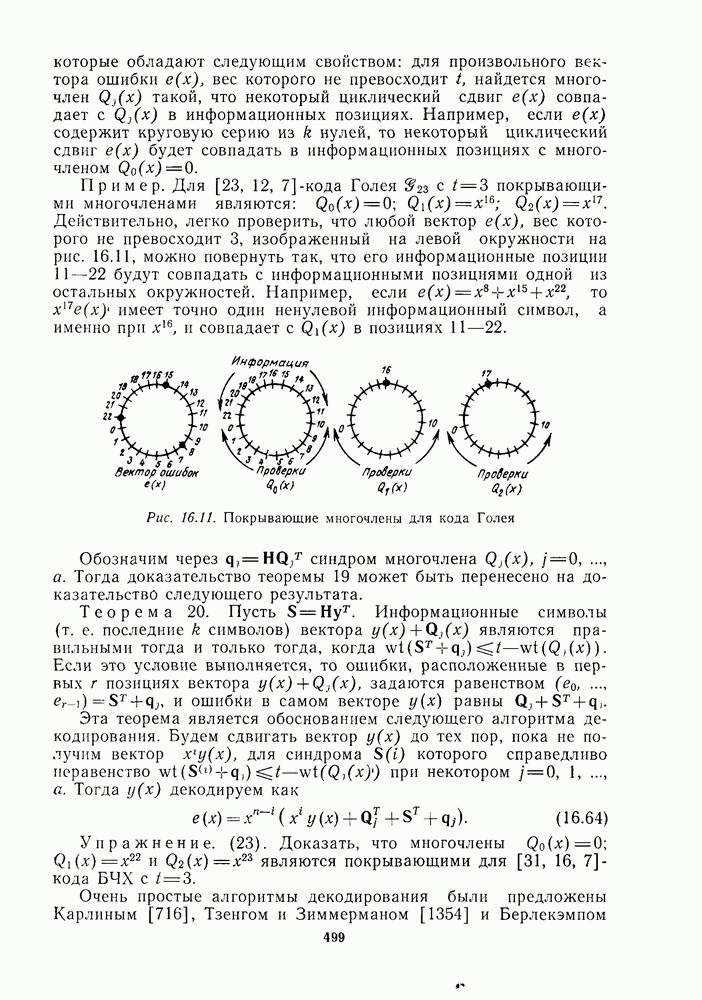
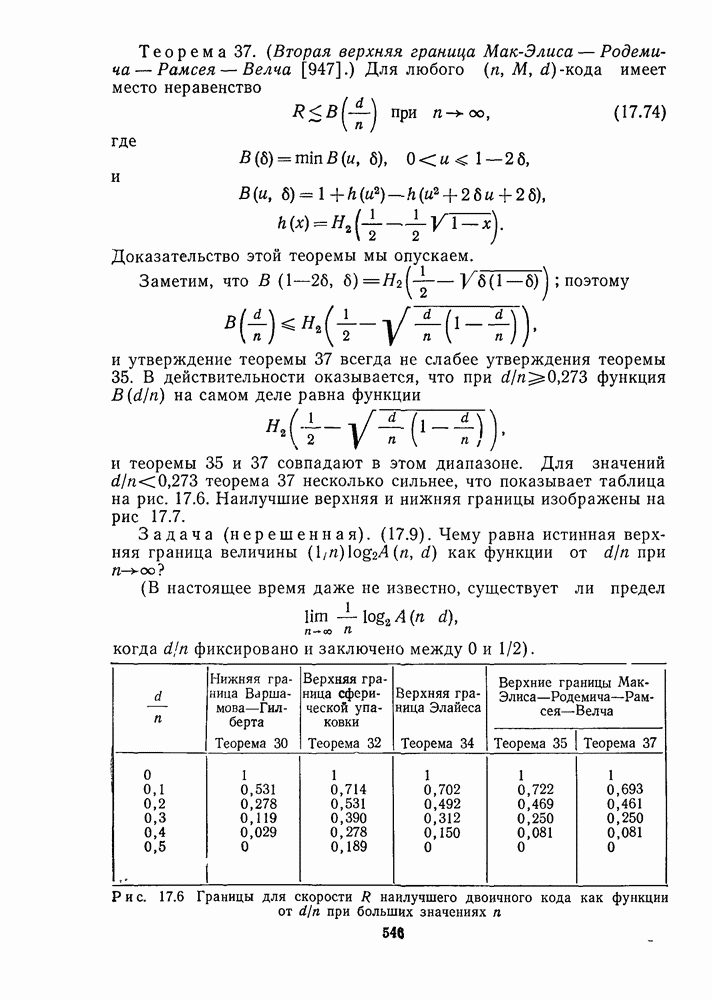
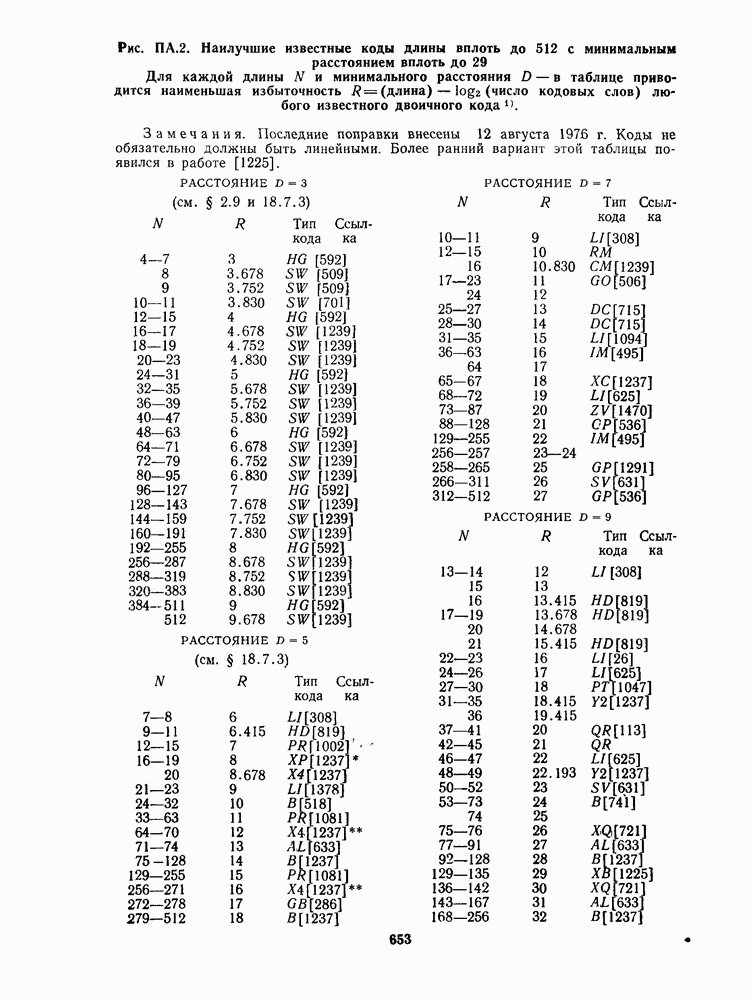
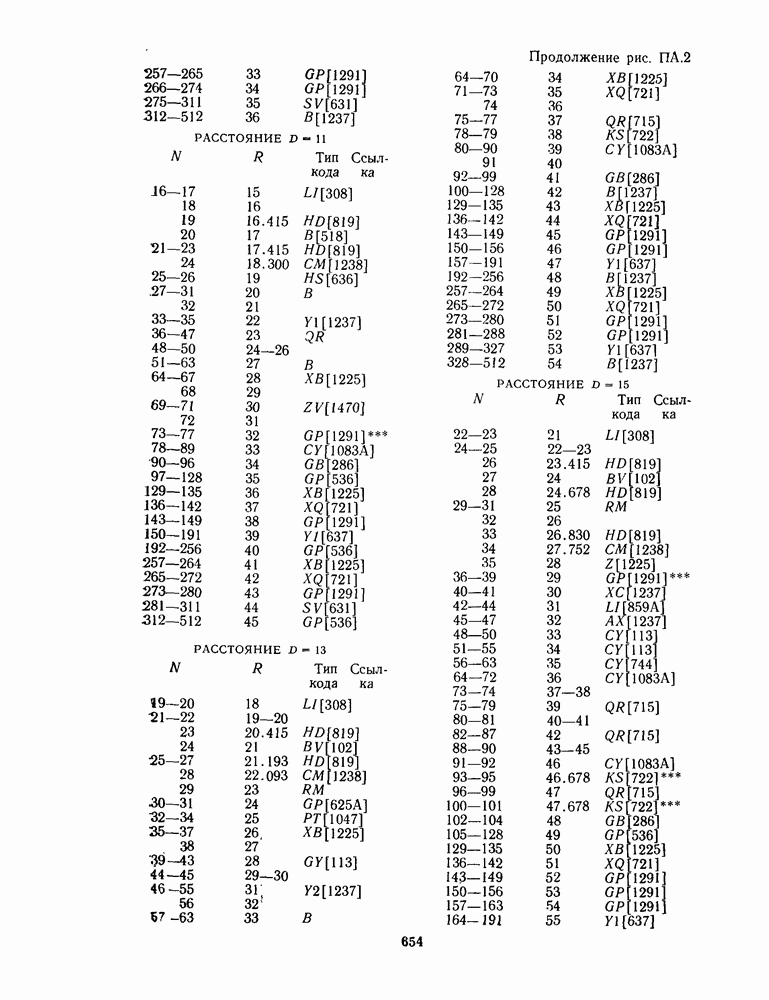
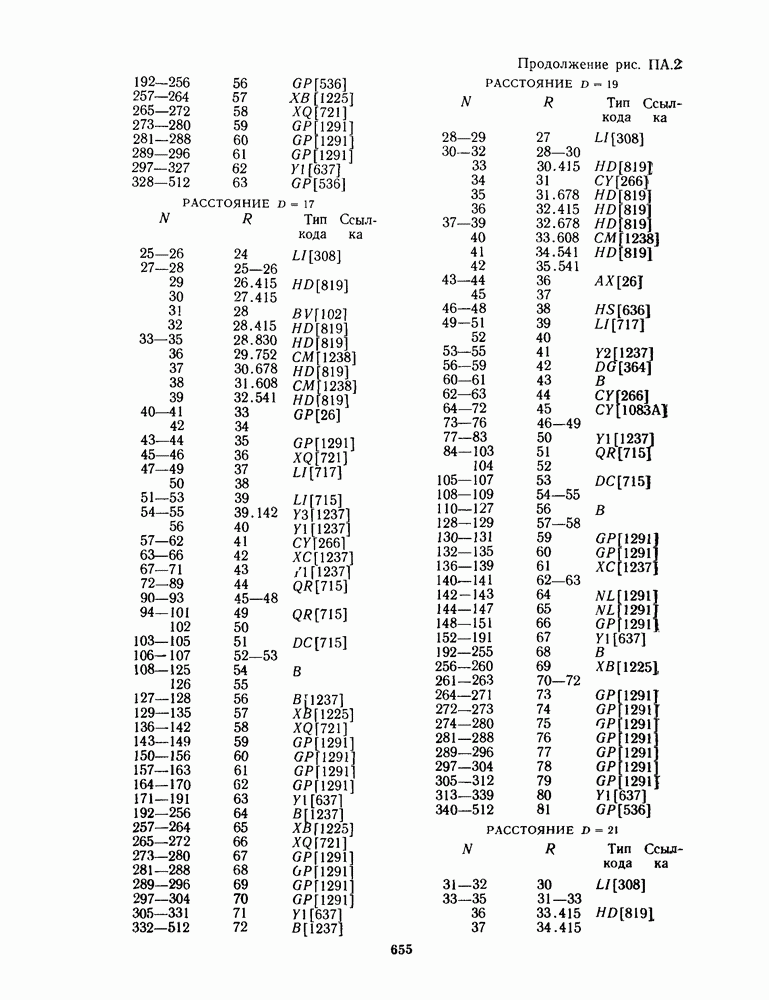
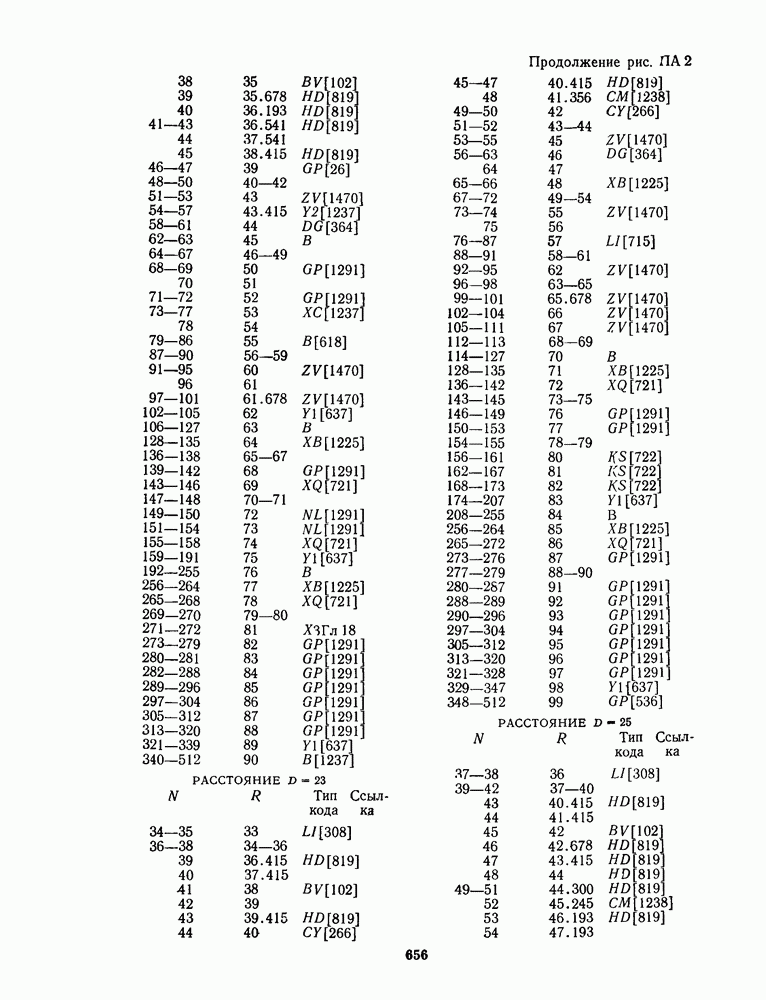
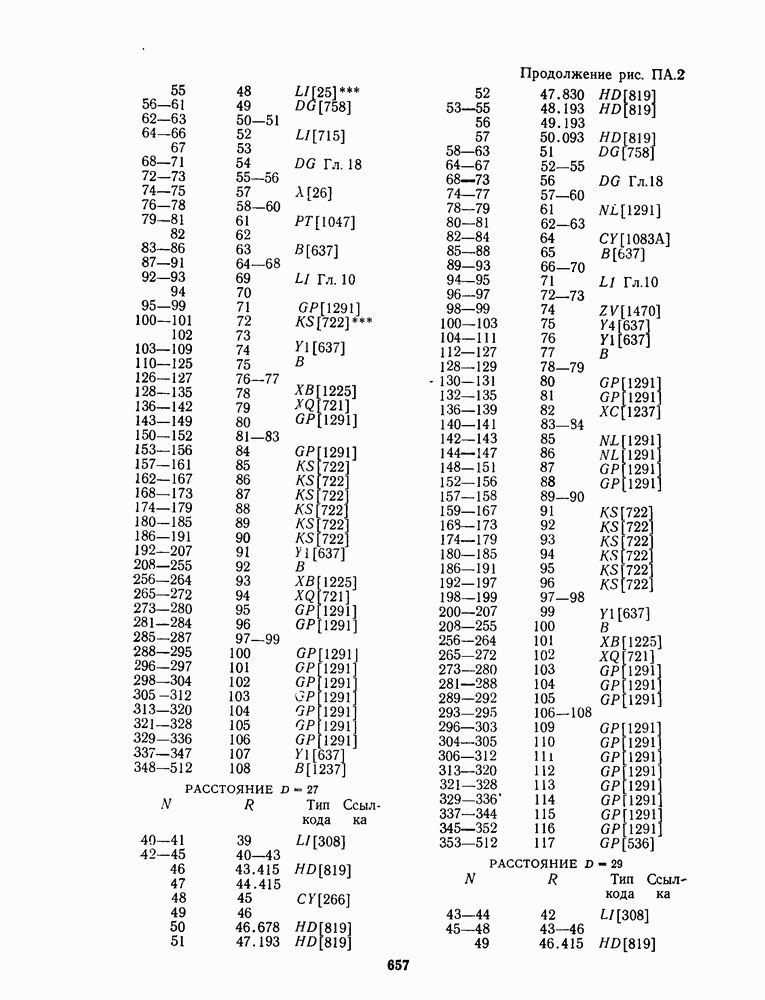
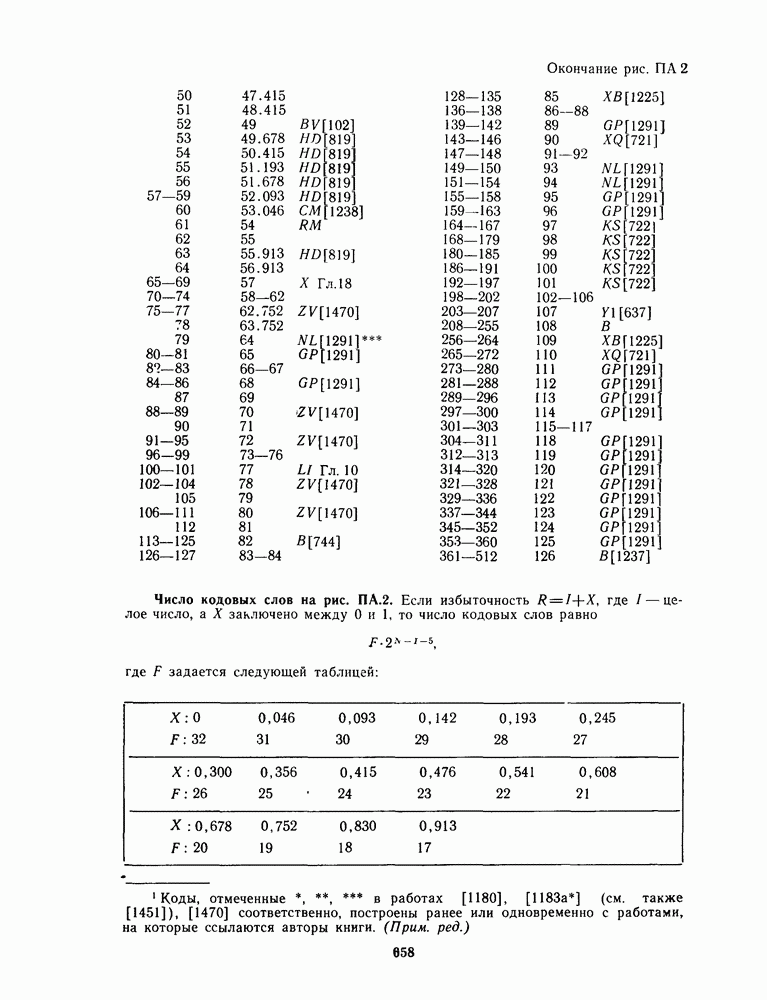
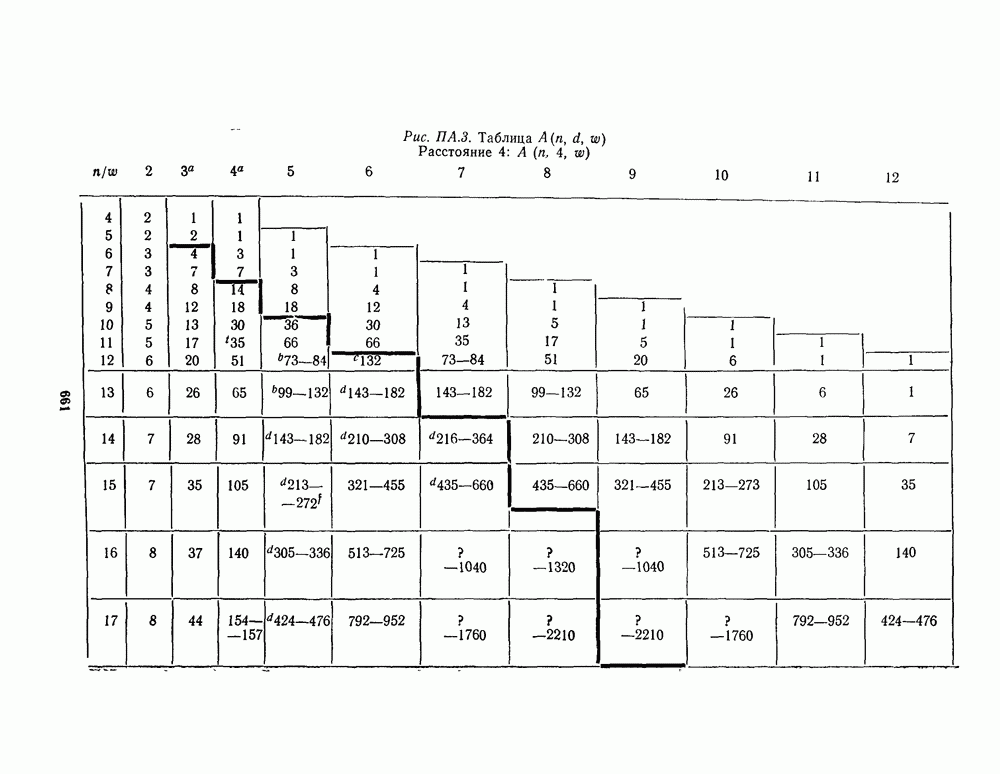
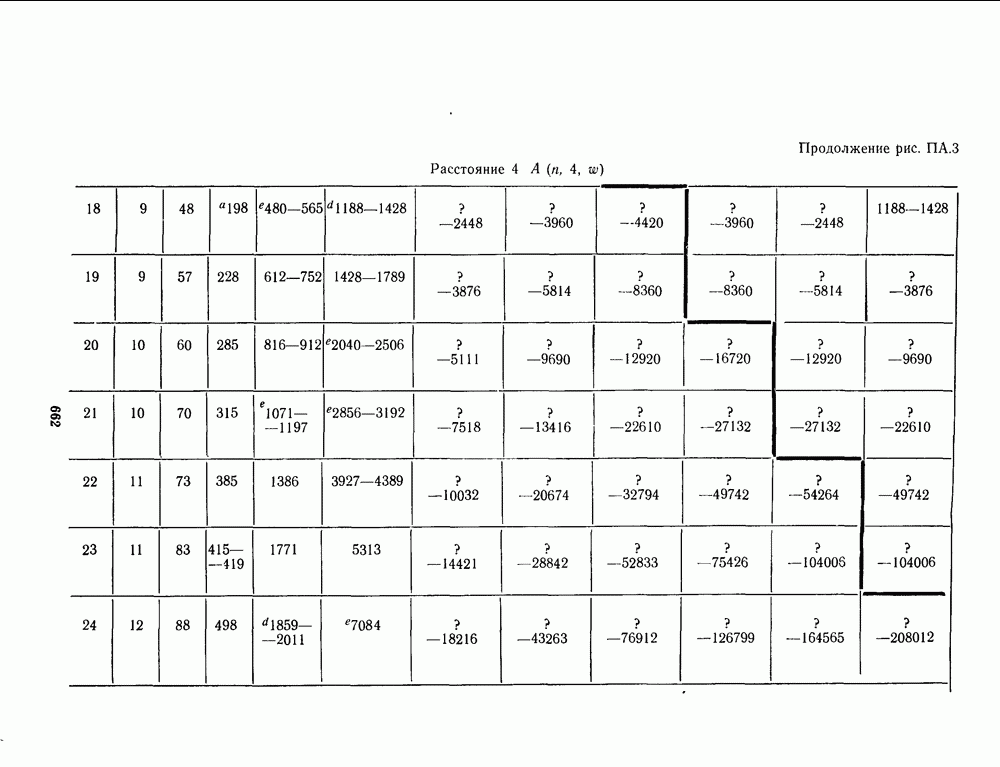
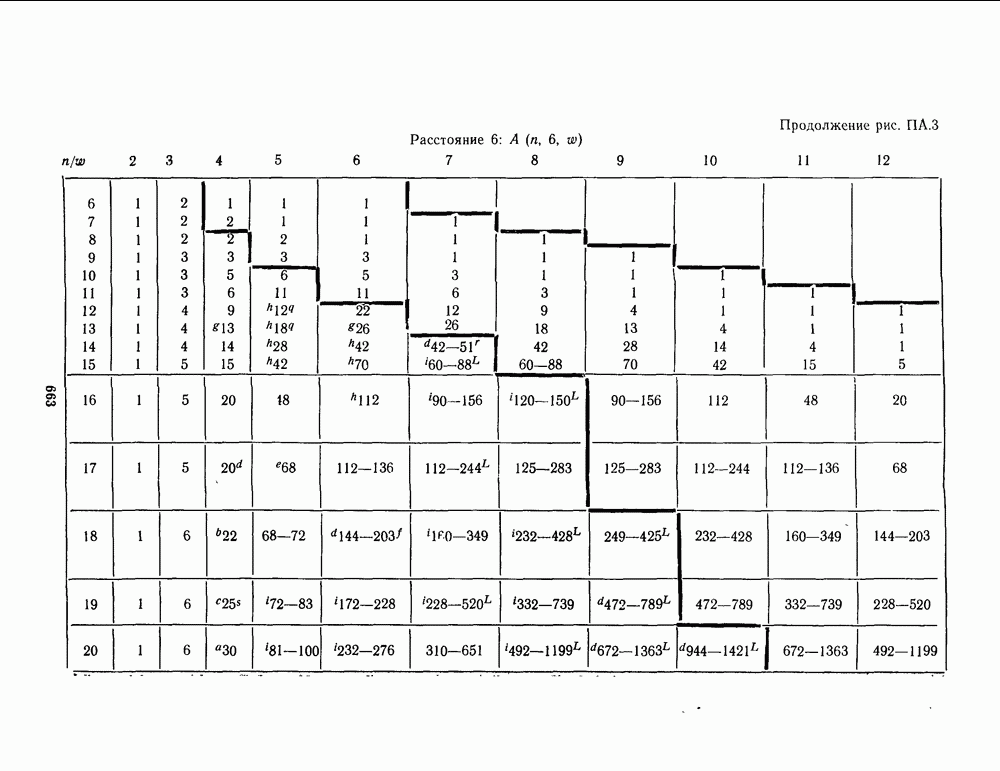
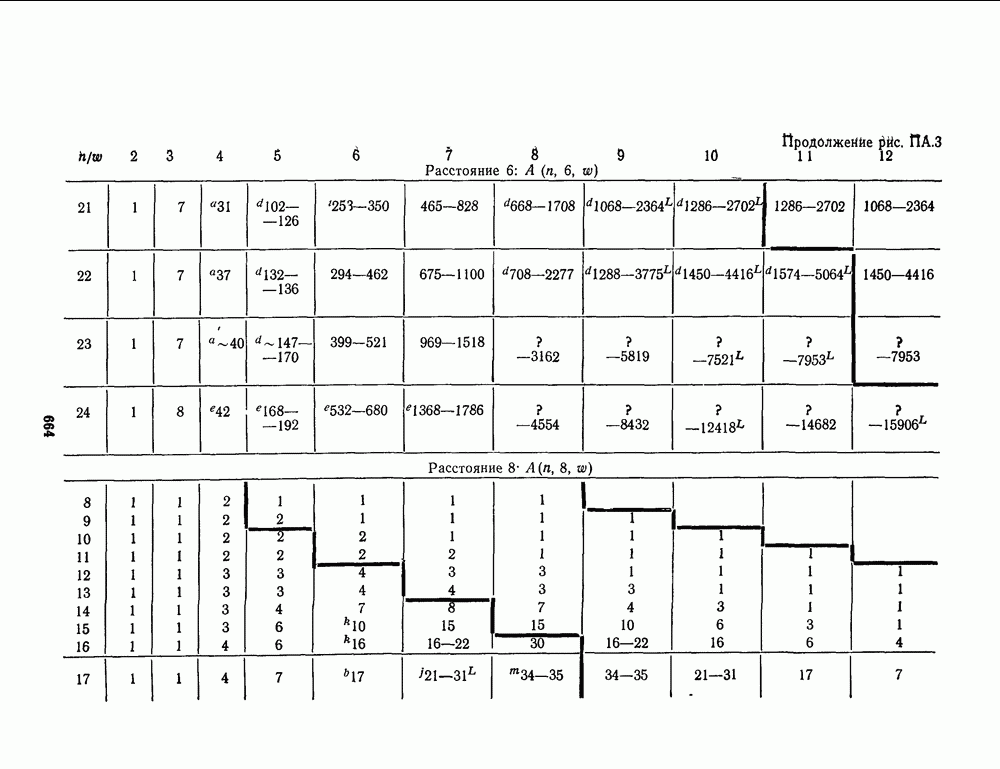
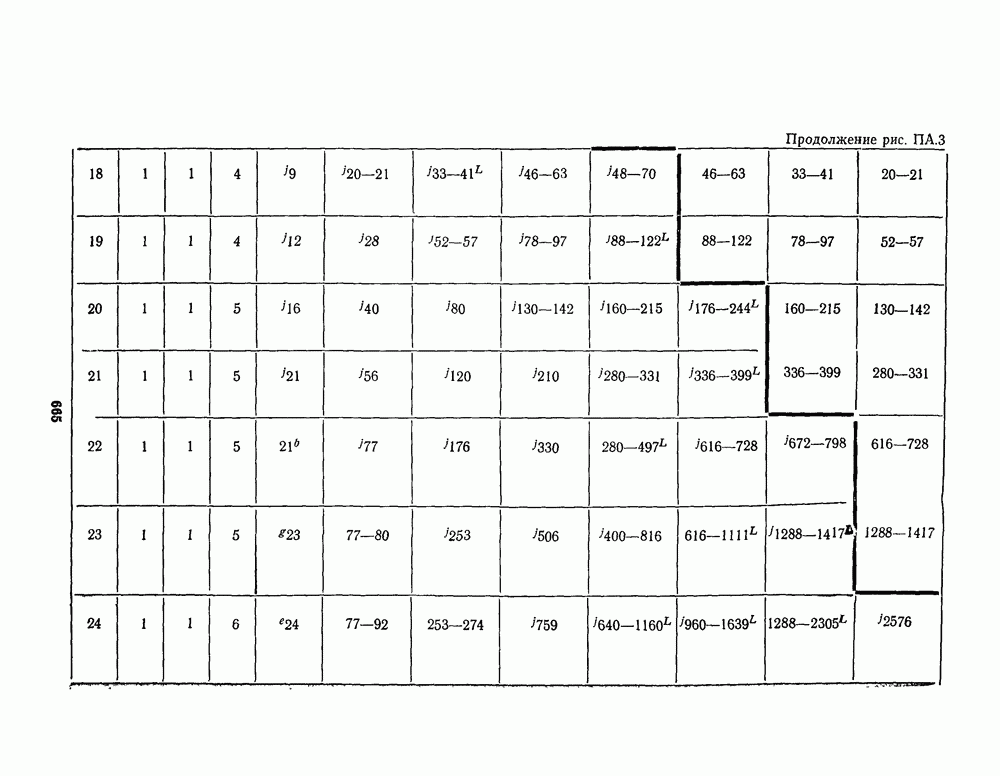
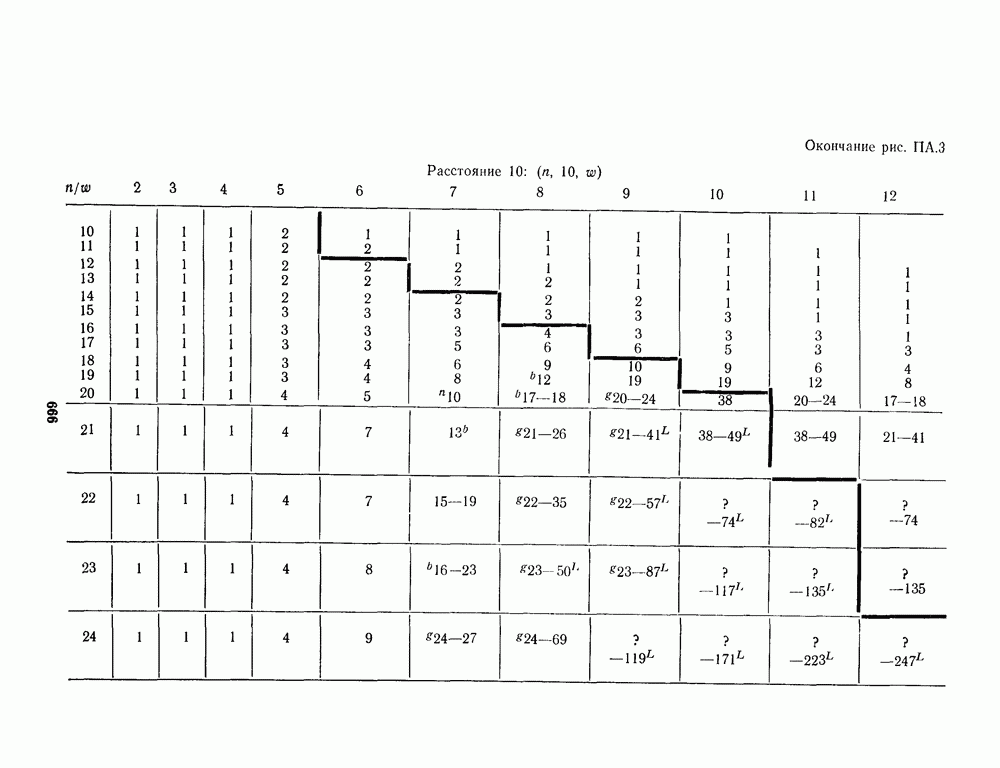
1.4. НЕМНОГО ПОДРОБНЕЕ О ДЕКОДИРОВАНИИ ЛИНЕЙНОГО КОДА
Определение смежного класса. Пусть  является
является  линейным кодом над полем из
линейным кодом над полем из  элементов. Для любого вектора а множество
элементов. Для любого вектора а множество

называется смежным классом (или сдвигом) кода  . Любой вектор
. Любой вектор  находится в некотором смежном классе (например, в
находится в некотором смежном классе (например, в  Два вектора
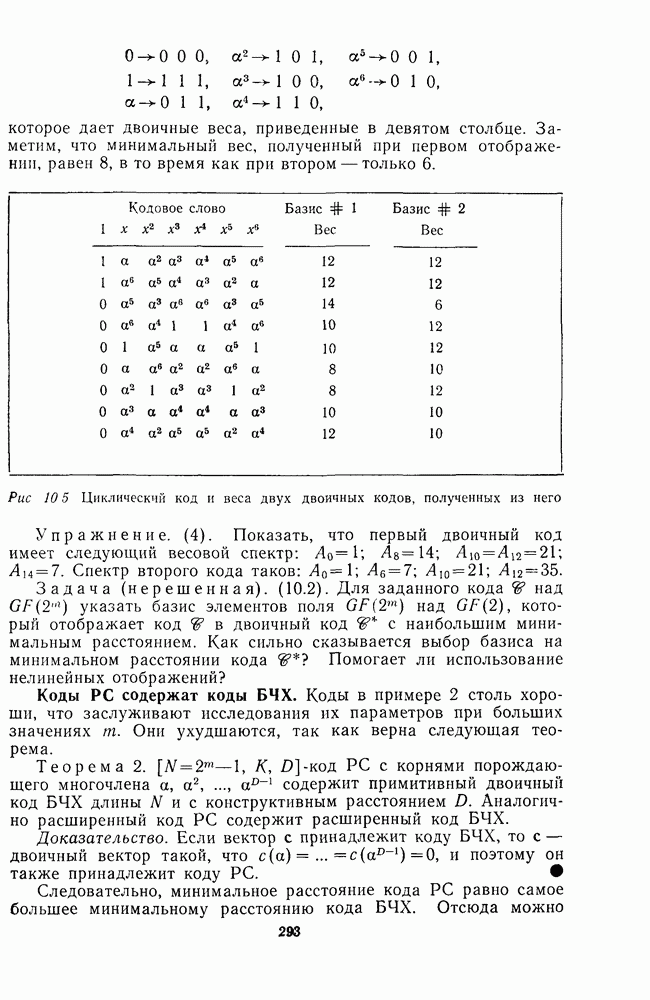
Два вектора  лежат в одном и том же смежном классе, тогда и только тогда, когда
лежат в одном и том же смежном классе, тогда и только тогда, когда  Каждый смежный класс содержит
Каждый смежный класс содержит  векторов.
векторов.
Утверждение 3. Два смежных класса либо не пересекаются, либо совпадают (частичное перекрытие невозможно).
Доказательство. Если смежные классы  пересекаются, то возьмем
пересекаются, то возьмем  Тогда
Тогда  где
где  Следовательно,
Следовательно,  и поэтому
и поэтому  Аналогичным образом получается, что
Аналогичным образом получается, что  значит,
значит, 
Следовательно, множество  всех векторов может быть разбито на смежные классы
всех векторов может быть разбито на смежные классы

где 
Предположим теперь, что декодер принимает вектор у. Этот вектор должен принадлежать некоторому смежному классу в разложении (1.21), скажем,  Что собой представляют возможные векторы ошибок
Что собой представляют возможные векторы ошибок  которые могли произойти? Если было передано кодовое слово х, то вектор ошибок — это вектор
которые могли произойти? Если было передано кодовое слово х, то вектор ошибок — это вектор  Отсюда мы заключаем, что возможными векторами ошибок являются в точности все векторы из смежного класса, содержащего у.
Отсюда мы заключаем, что возможными векторами ошибок являются в точности все векторы из смежного класса, содержащего у.
Поэтому при данном у стратегия декодера заключается в выборе из смежного класса, содержащего у, вектора  с
с
наименьшим весом и в декодировании у как  . Вектор из смежного класса, имеющий минимальный вес, называется лидером смежного класса. (Если же имеется более одного вектора с минимальным весом, то выберем случайным образом любой из таких векторов и назовем его лидером смежного класса.)
. Вектор из смежного класса, имеющий минимальный вес, называется лидером смежного класса. (Если же имеется более одного вектора с минимальным весом, то выберем случайным образом любой из таких векторов и назовем его лидером смежного класса.)
Будем считать, что в разложении (1.21) векторы  являются лидерами смежных классов.
являются лидерами смежных классов.
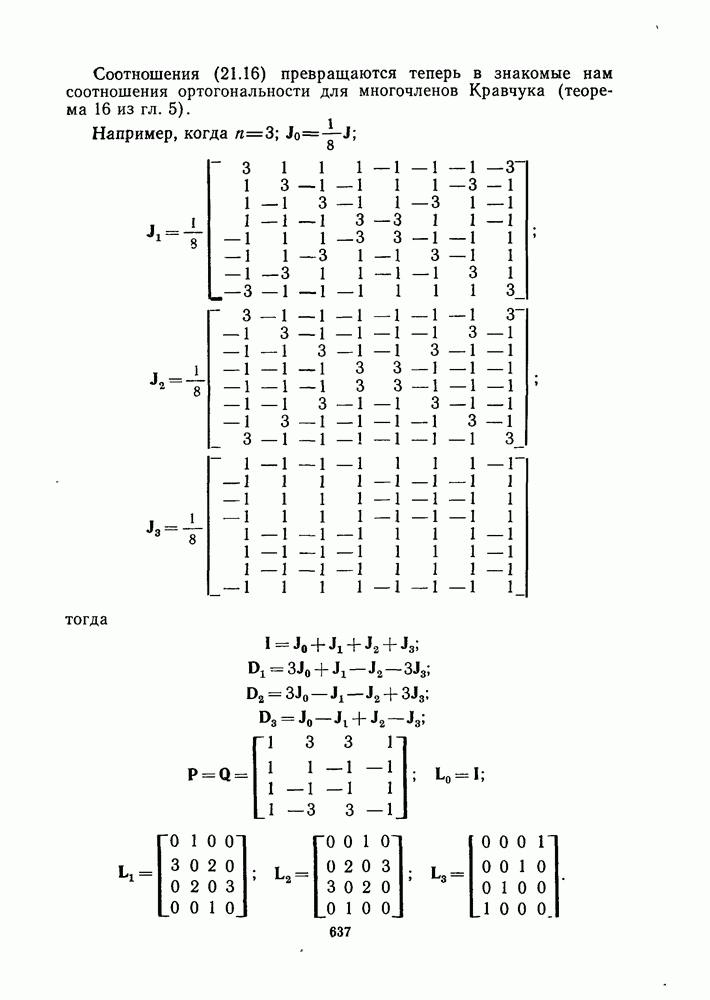
Стандартное расположение. Полезным способом описания работы декодера является таблица, названная стандартным расположением для кода. Первая строка ее состоит из самого кода с нулевым кодовым словом с левой стороны:  другими строками являются другие смежные классы а, расположенные в том же самом порядке и с лидерами этих классов с левой стороны:
другими строками являются другие смежные классы а, расположенные в том же самом порядке и с лидерами этих классов с левой стороны:

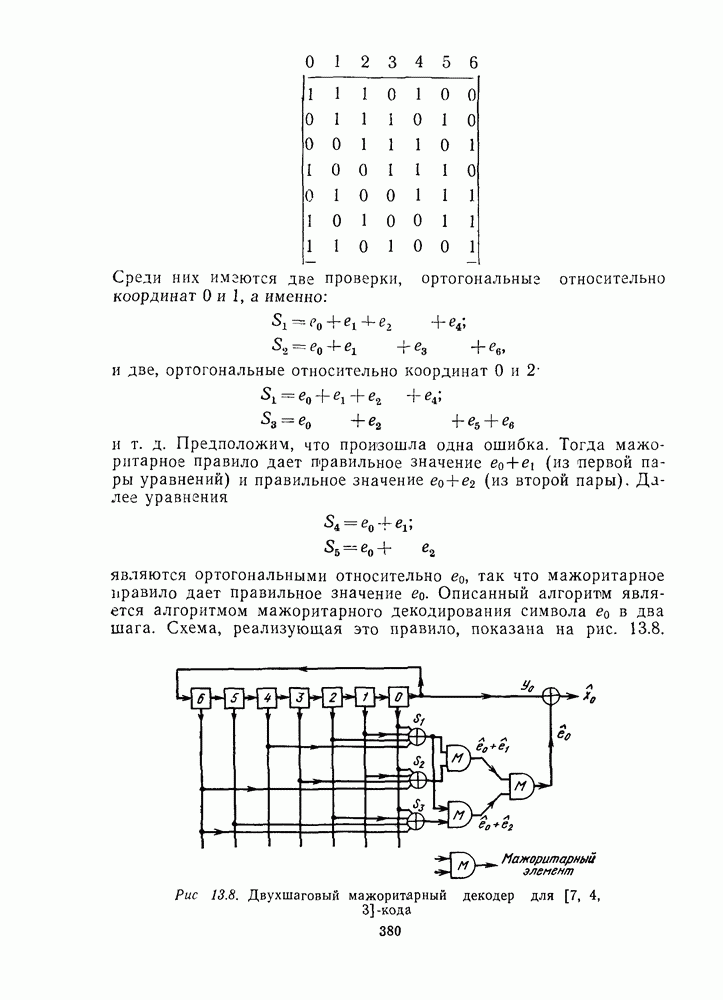
Пример. Код  (продолжение).
(продолжение).  -код с порождающей матрицей
-код с порождающей матрицей

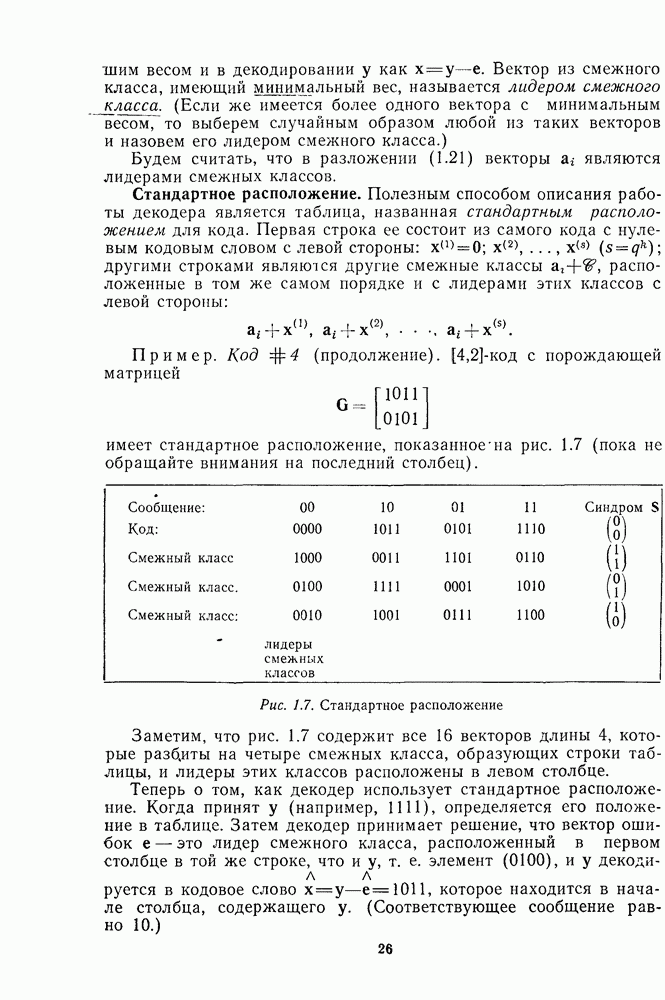
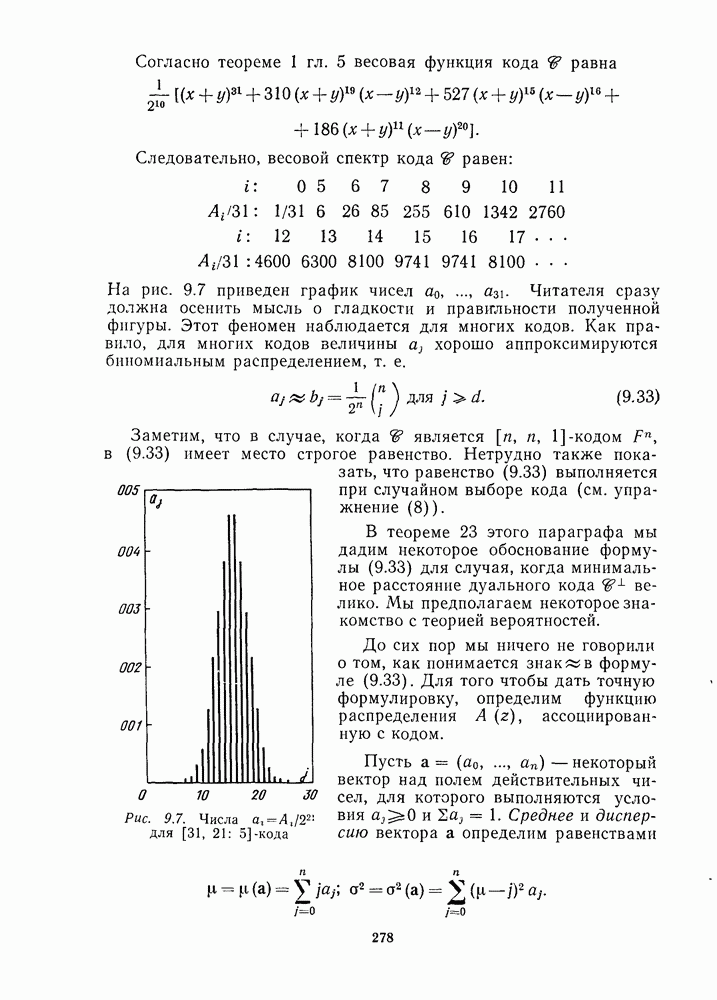
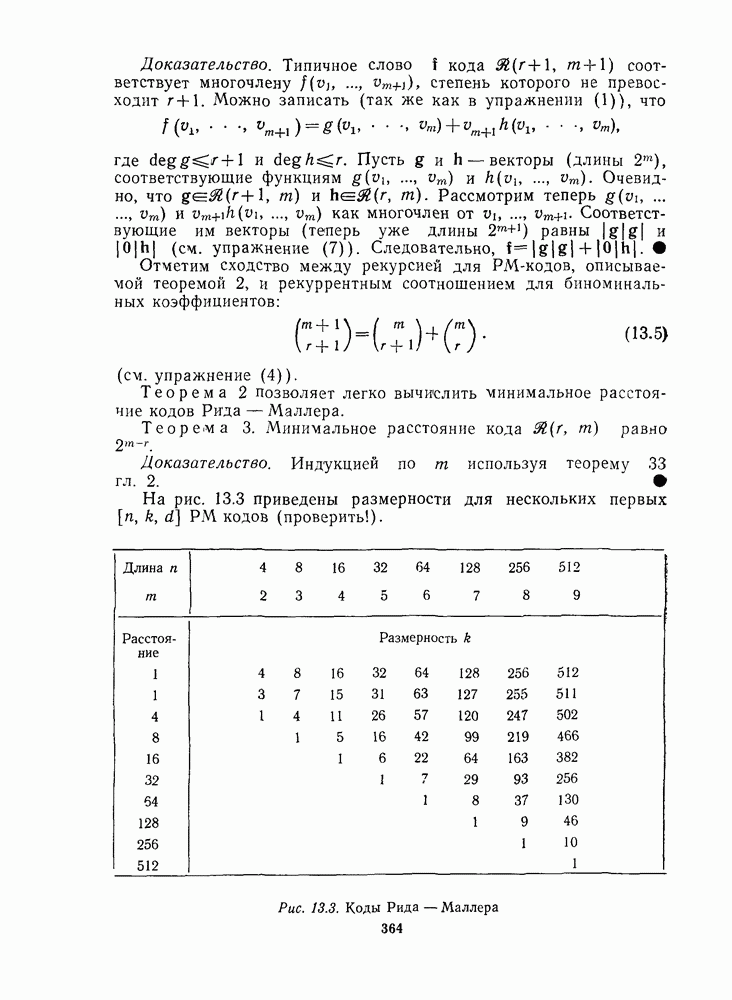
имеет стандартное расположение, показанное на рис. 1.7 (пока не обращайте внимания на последний столбец).

Рис. 1.7. Стандартное расположение
Заметим, что рис. 1.7 содержит все 16 векторов длины 4, которые разбиты на четыре смежных класса, образующих строки таблицы, и лидеры этих классов расположены в левом столбце.
Теперь о том, как декодер использует стандартное расположение. Когда принят у (например, 1111), определяется его положение в таблице. Затем декодер принимает решение, что вектор ошибок  это лидер смежного класса, расположенный в первом столбце в той же строке, что и у, т. е. элемент
это лидер смежного класса, расположенный в первом столбце в той же строке, что и у, т. е. элемент  декодируется в кодовое слово
декодируется в кодовое слово  которое находится в начале столбца, содержащего у. (Соответствующее сообщение равно 10.)
которое находится в начале столбца, содержащего у. (Соответствующее сообщение равно 10.)
Декодирование, использующее стандартное расположение, является декодированием по максимуму правдоподобия.
Синдром. Имеется простой способ, как определить, в каком смежном классе находится у: надо вычислить вектор  который называется синдромом у.
который называется синдромом у.
Свойства синдрома. (1). S представляет собой вектор-столбец, длины 
(2). Синдром вектора  равен нулю, если и только если у — кодовое слово
равен нулю, если и только если у — кодовое слово  определению кода). Поэтому, если никаких ошибок не произошло, синдром вектора у равен нулю (но не обратное). В общем случае, если
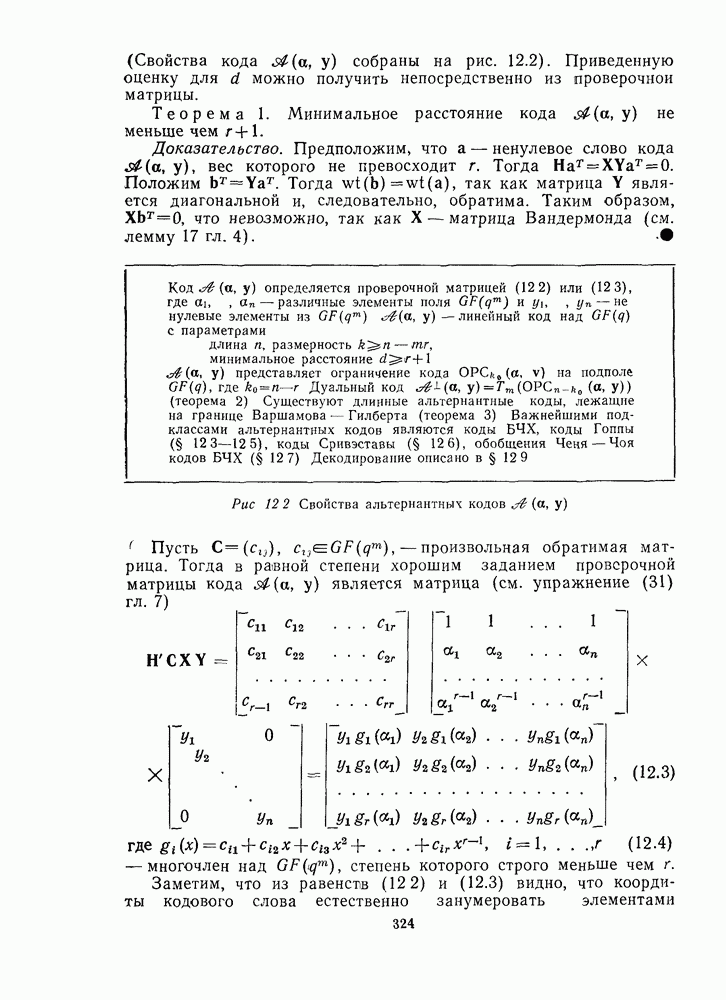
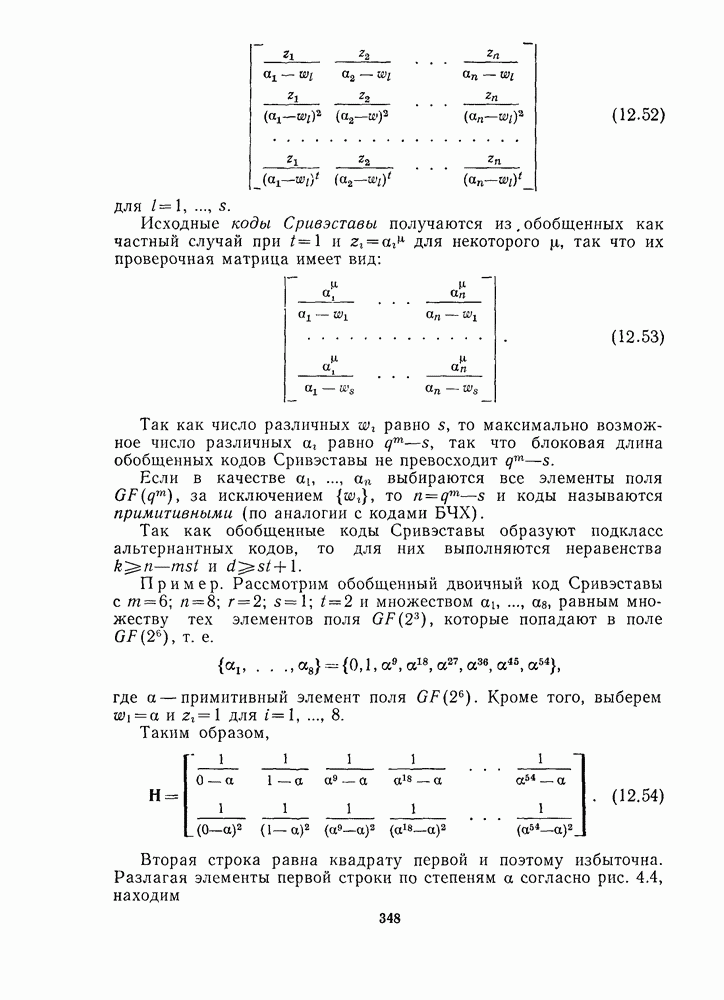
определению кода). Поэтому, если никаких ошибок не произошло, синдром вектора у равен нулю (но не обратное). В общем случае, если  где
где  то
то

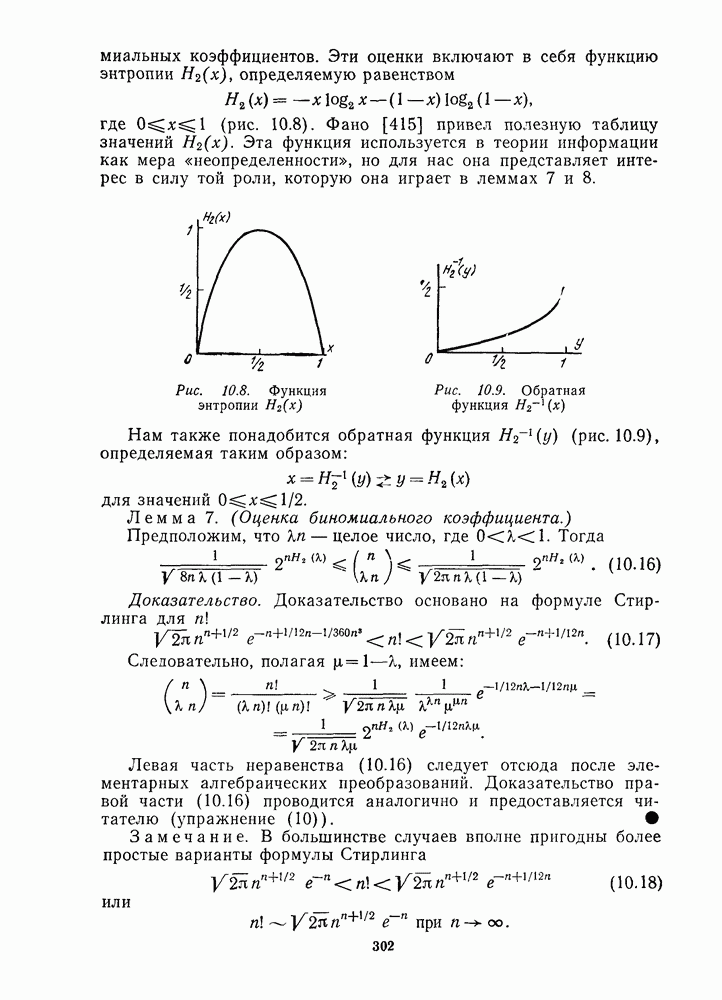
(3). Если для двоичного кода имеются ошибки на позициях с номерами  так что
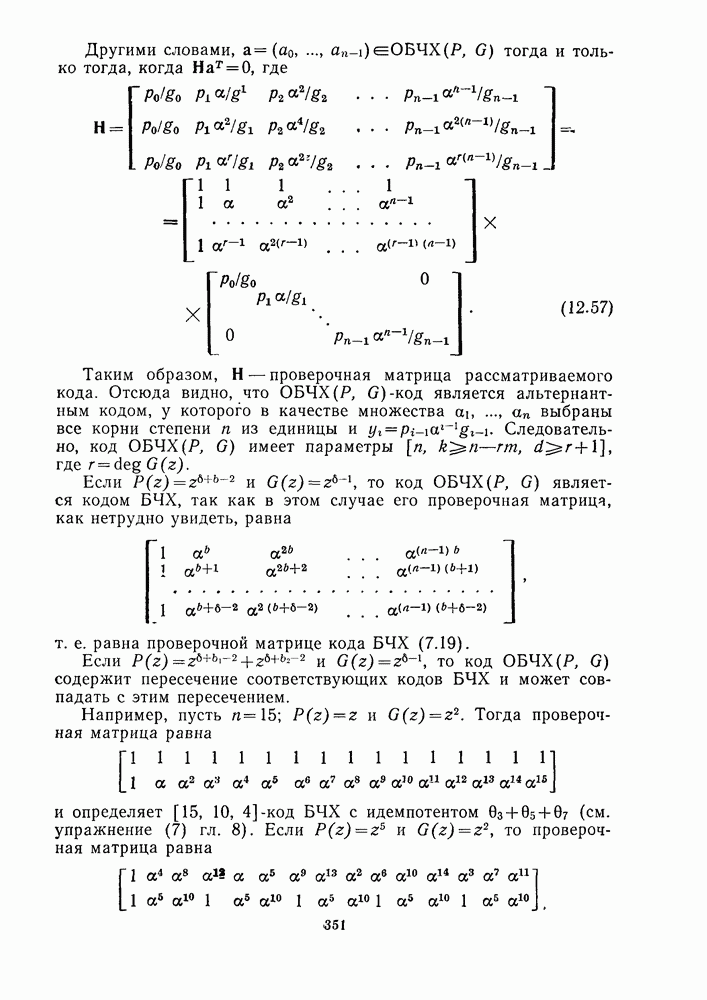
так что  то из (1.22) получаем, что
то из (1.22) получаем, что

где  столбец
столбец 
Словами это можно сказать так:
Теорема 4. Для двоичного кода синдром равен сумме тех столбцов  где произошли ошибки. [Таким образом,
где произошли ошибки. [Таким образом,  называется синдромом, так как он выделяет совокупность ошибок.]
называется синдромом, так как он выделяет совокупность ошибок.]
(4). Два вектора находятся в одном и том же смежном классе кода  если и только если они имеют один и тот же синдром. Действительно,
если и только если они имеют один и тот же синдром. Действительно,  находятся в одном смежном классе, если и только если
находятся в одном смежном классе, если и только если  что эквивалентно
что эквивалентно  или
или  Следовательно, справедливо утверждение, приведенное ниже.
Следовательно, справедливо утверждение, приведенное ниже.
Теорема 5. Имеется взаимно однозначное соответствие между синдромами и смежными классами.
Например, смежные классы на рис. 1.7 занумерованы их синдромами.
Таким образом, синдром содержит всю информацию, которую имеет приемник об ошибках.
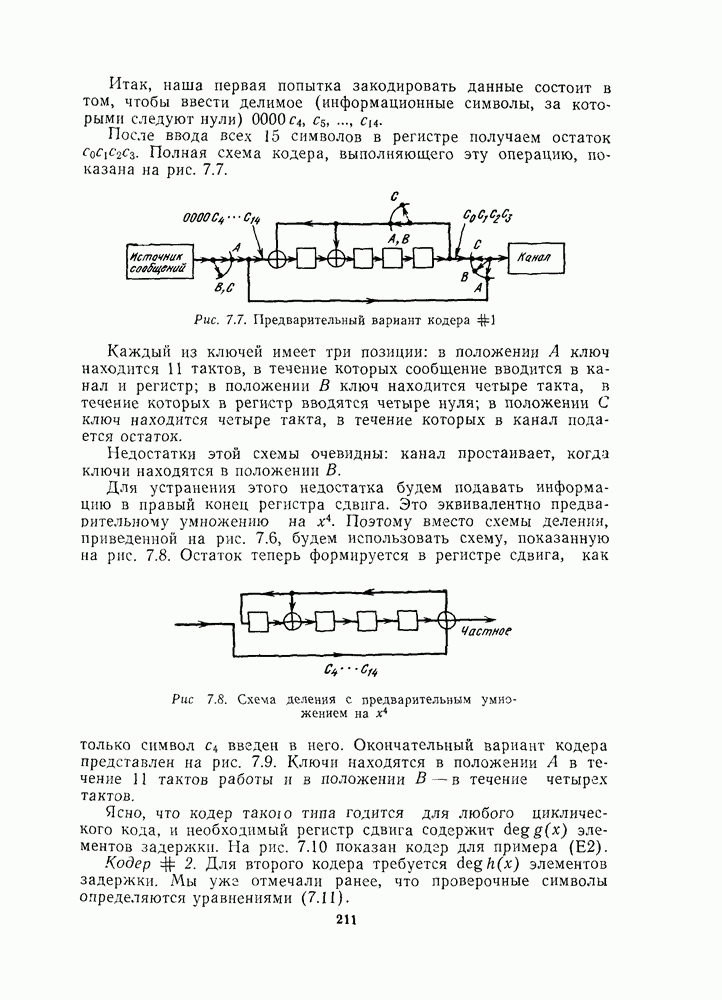
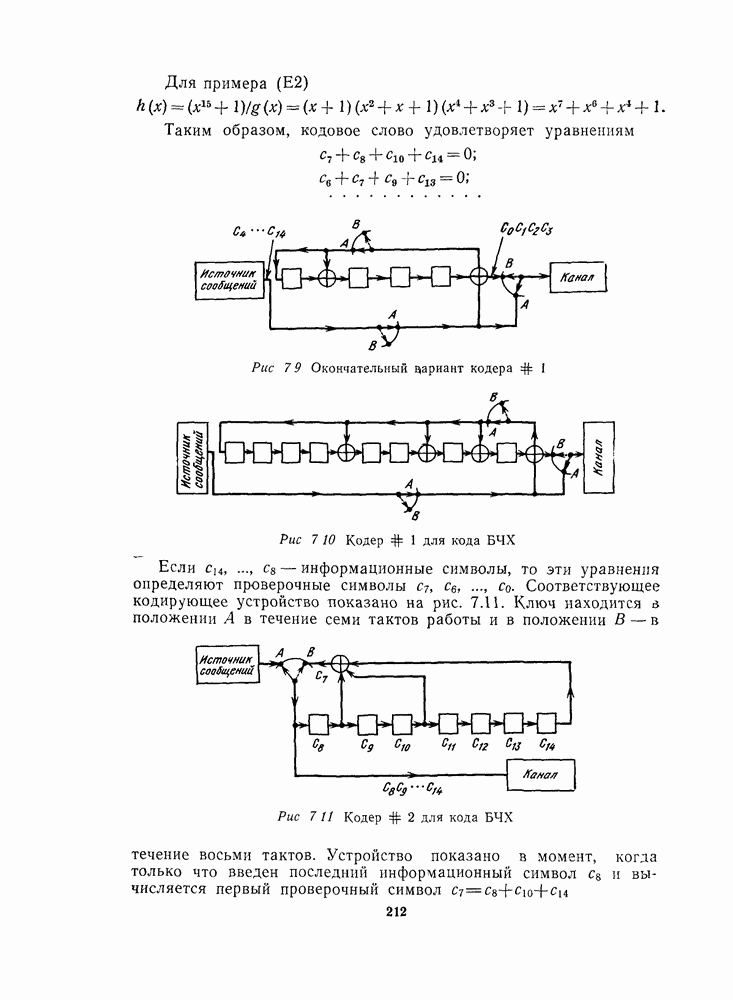
По свойству (2) схема обнаружения ошибок, упомянутая в последнем разделе, как раз состоит в сравнении синдрома с нулем. Для этого мы еще раз вычисляем проверочные символы, используя принятые информационные символы, и смотрим, совпадают ли они с принятыми проверочными символами. Иначе говоря, мы перекодируем принятые информационные символы. Для этого требуется еще одно кодирующее устройство, которое обычно является весьма простым в сравнении с декодером (см. рис. 7.8).
Упражнения (21). Построить стандартное расположение для кода Используя его, декодировать векторы 110100 и 111111.
(22). Показать, что, если — двоичныи линейный код и то  также является линейным кодом.
также является линейным кодом.