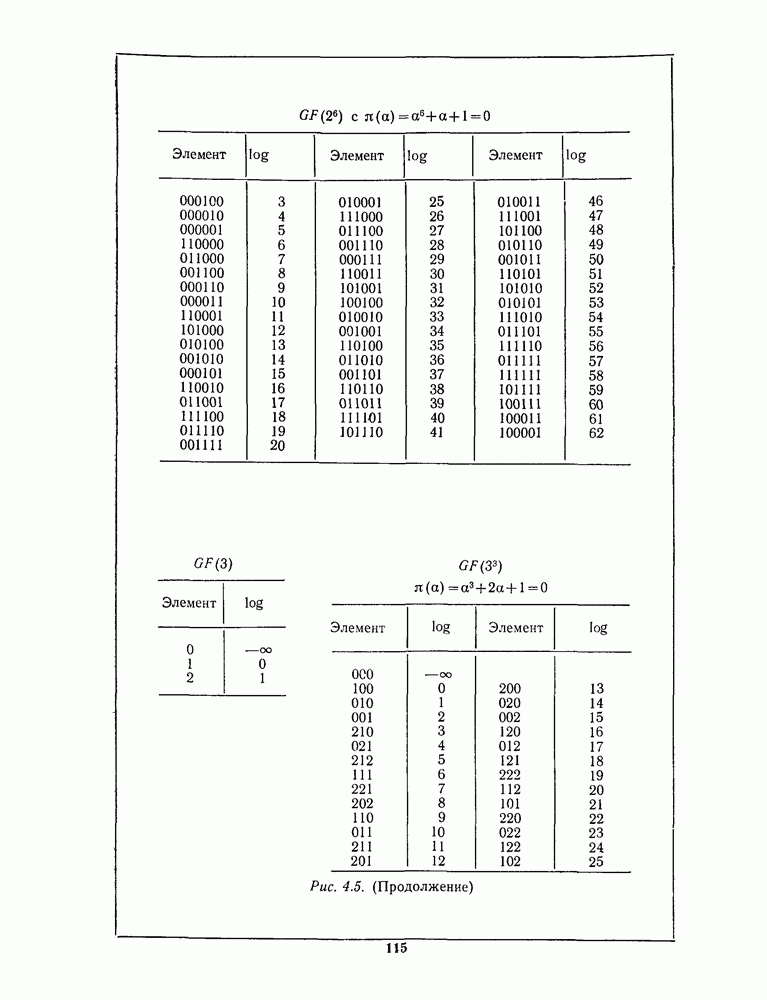
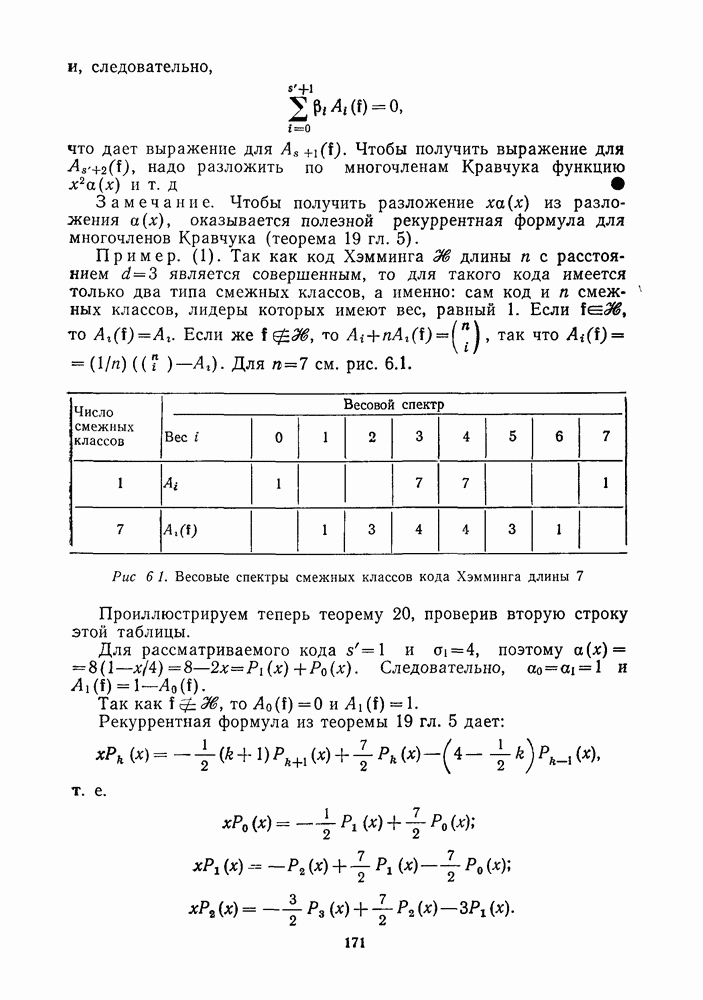
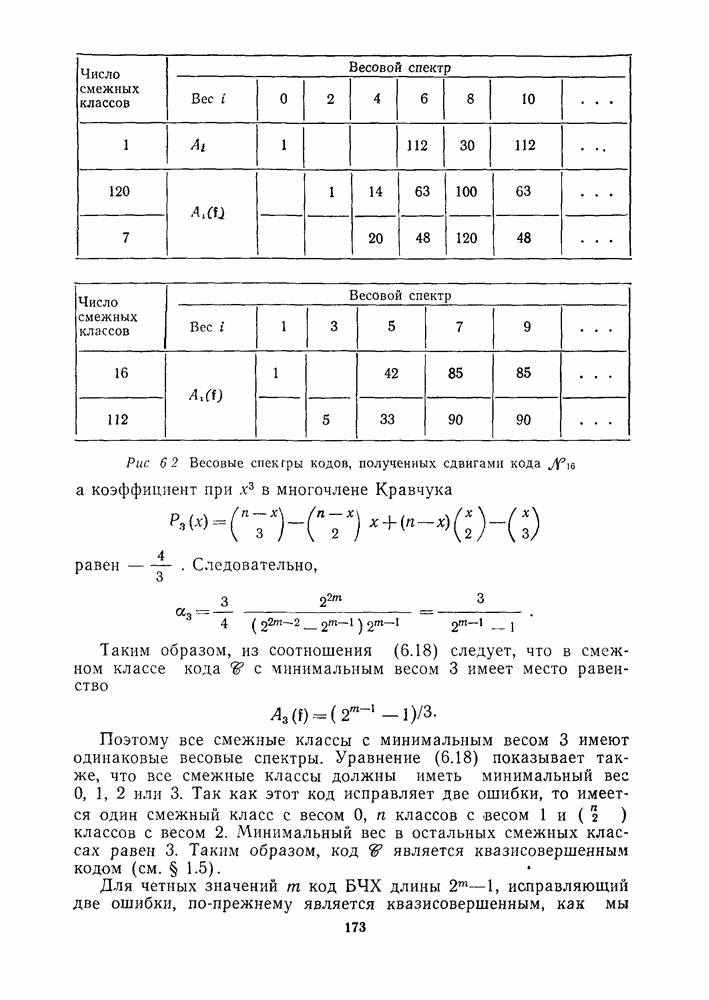
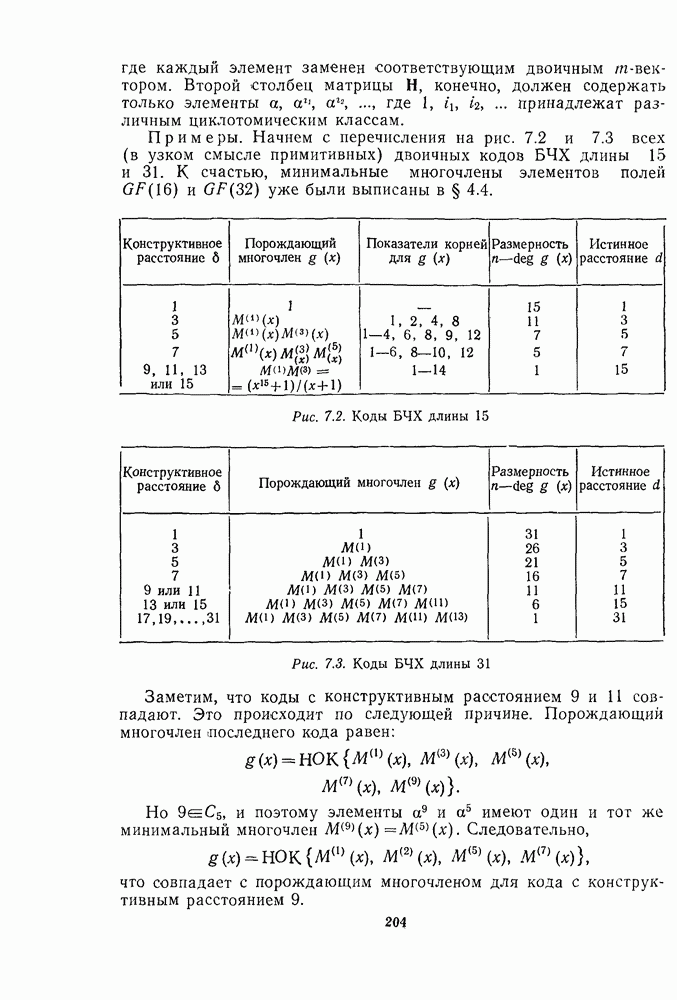
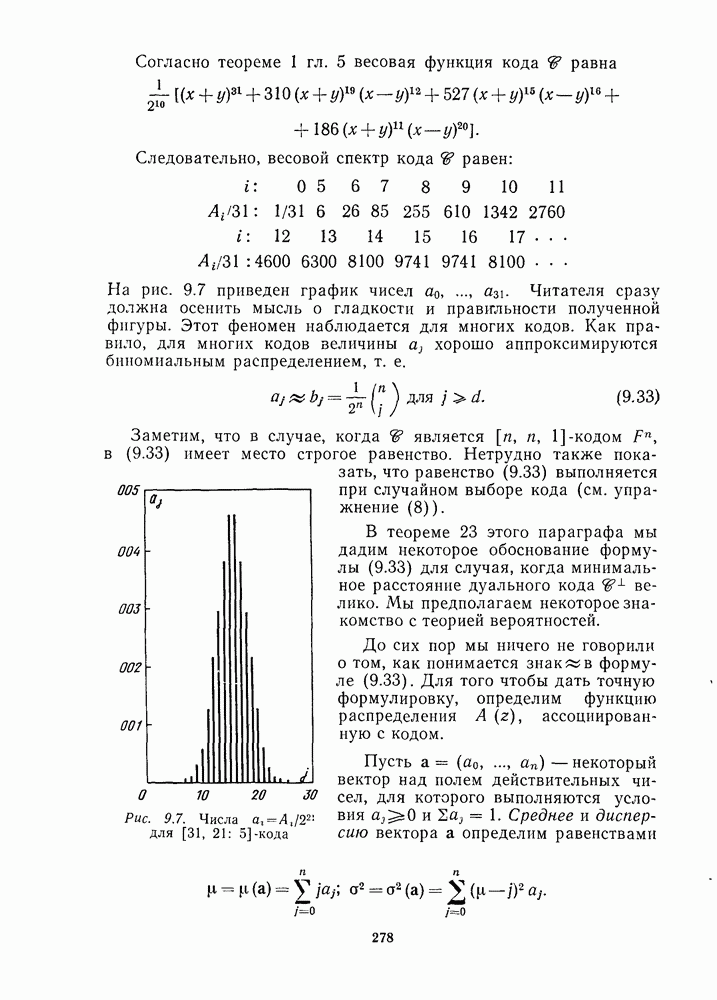
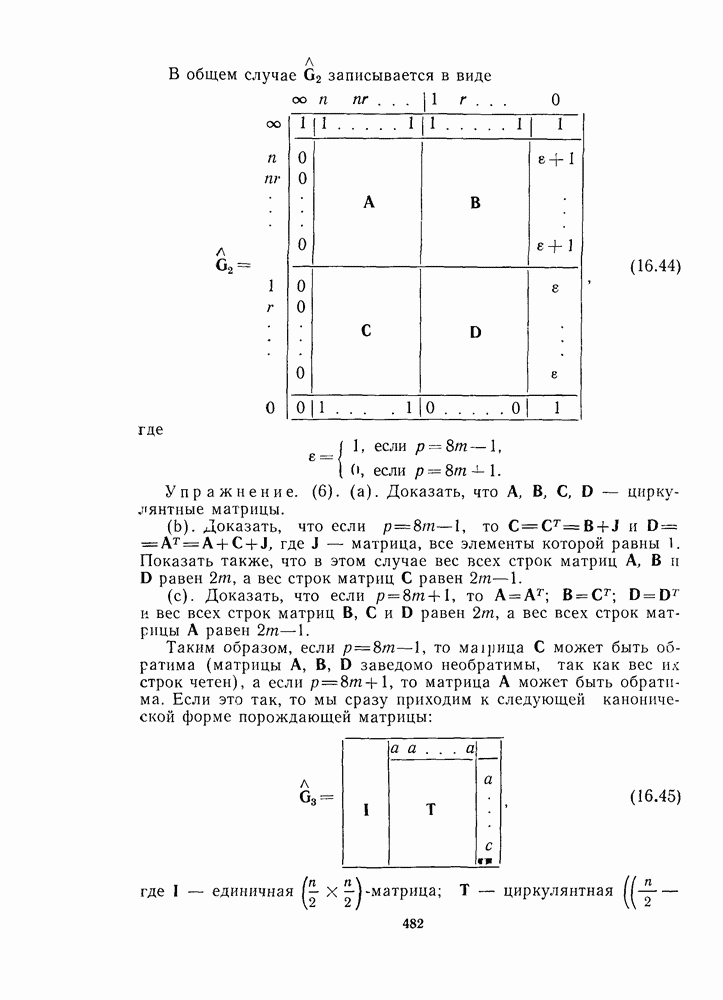
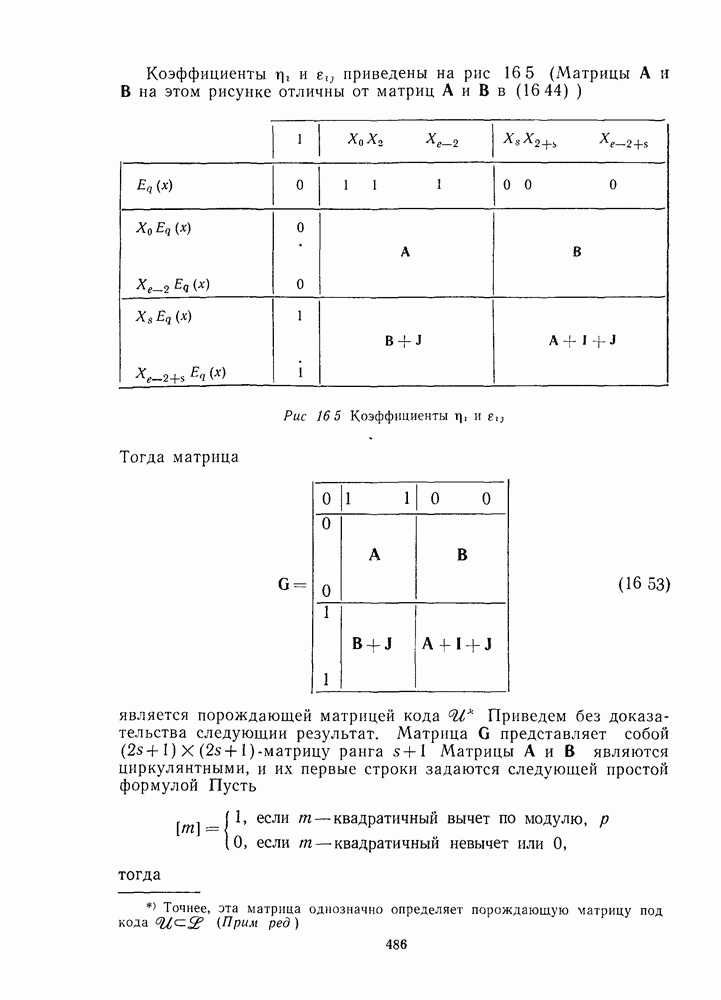
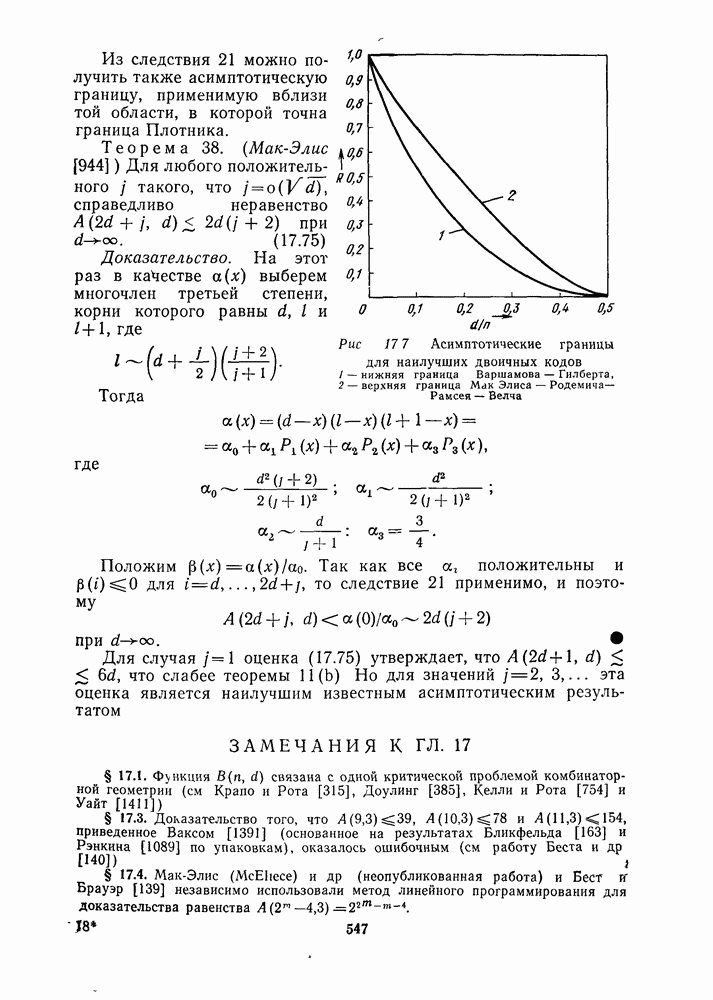
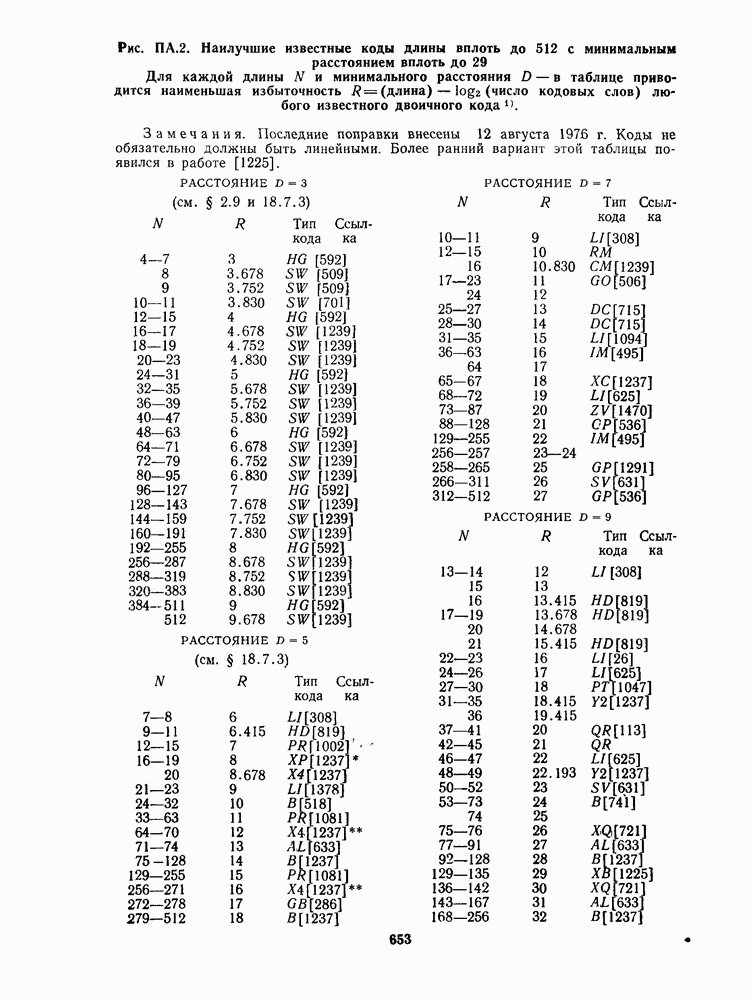
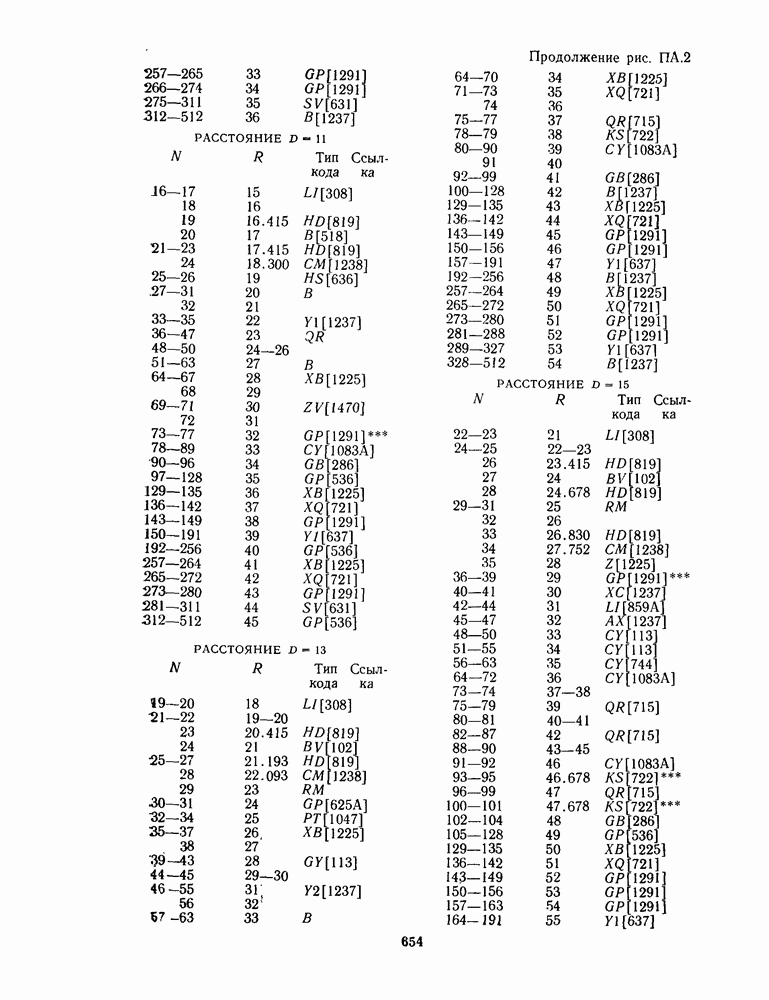
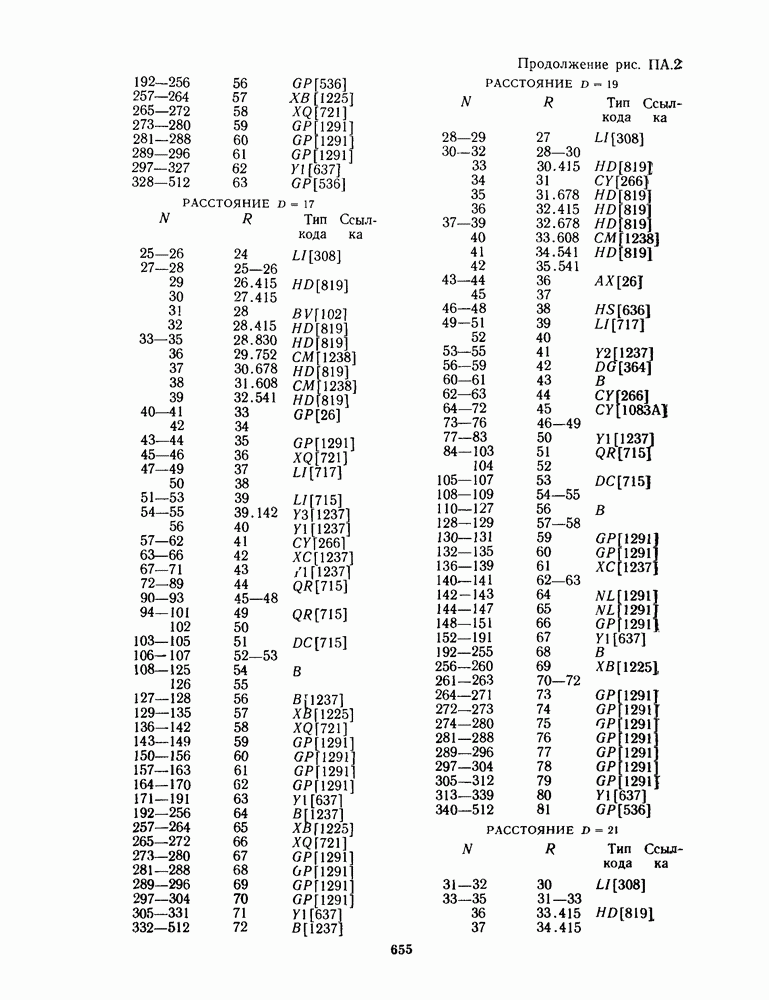
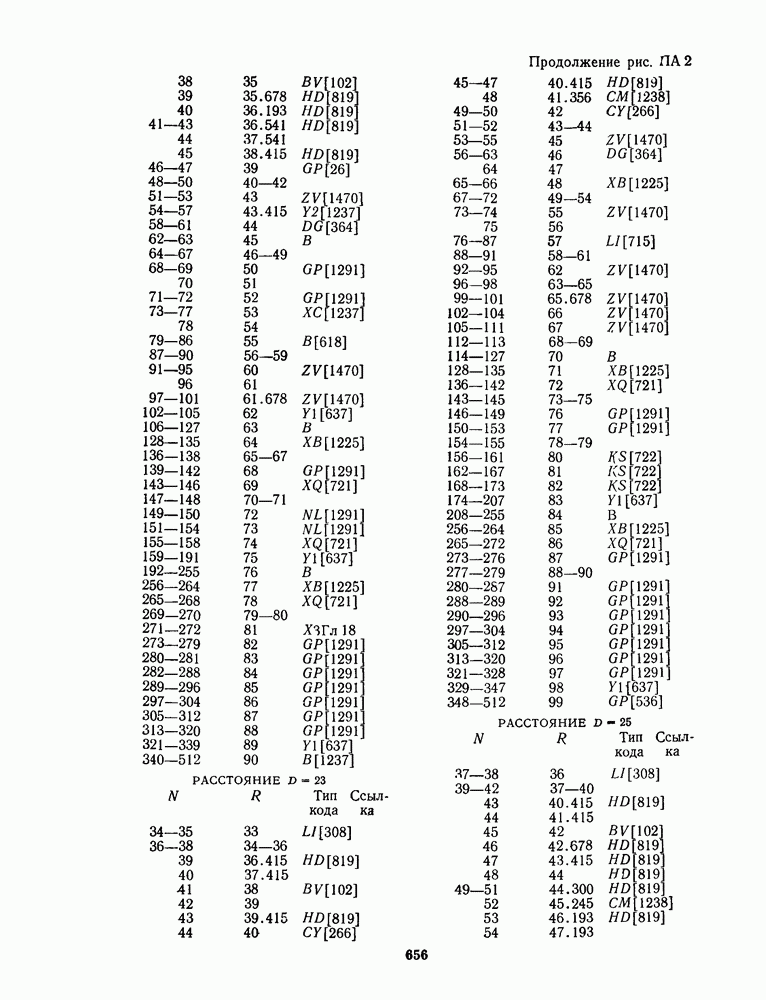
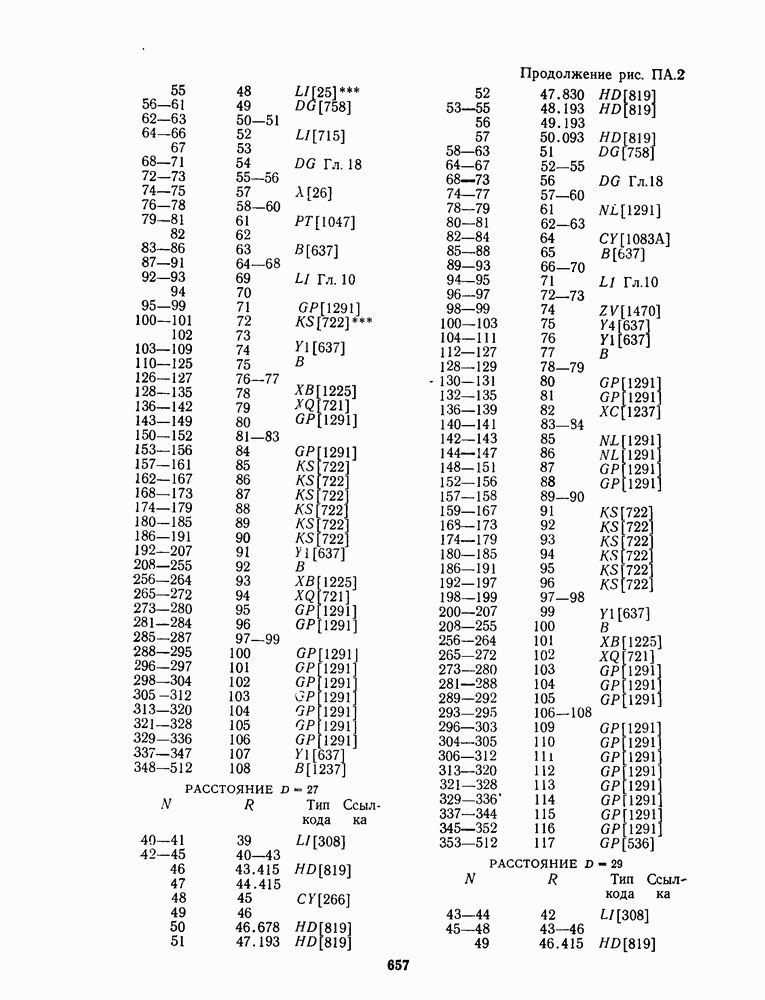
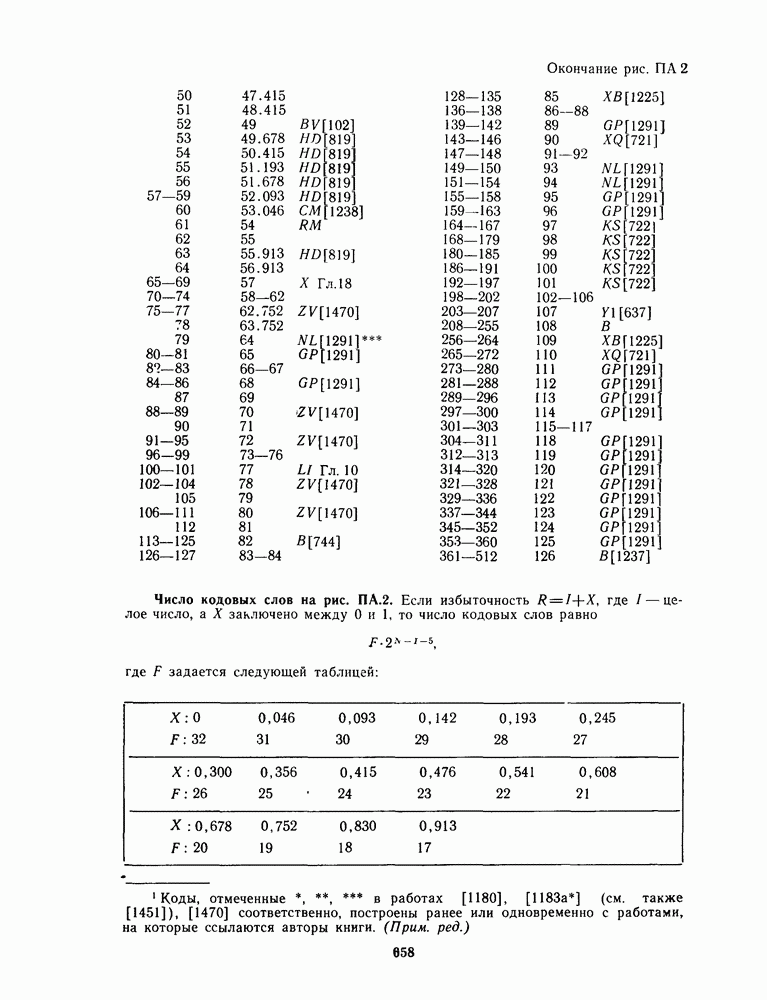
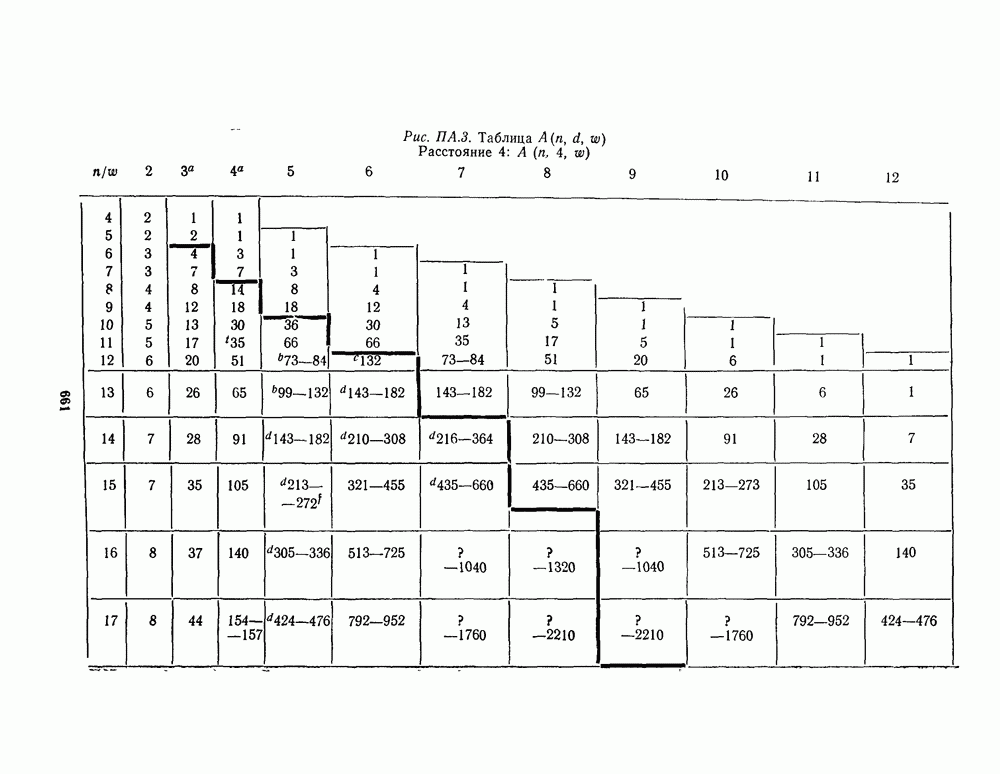
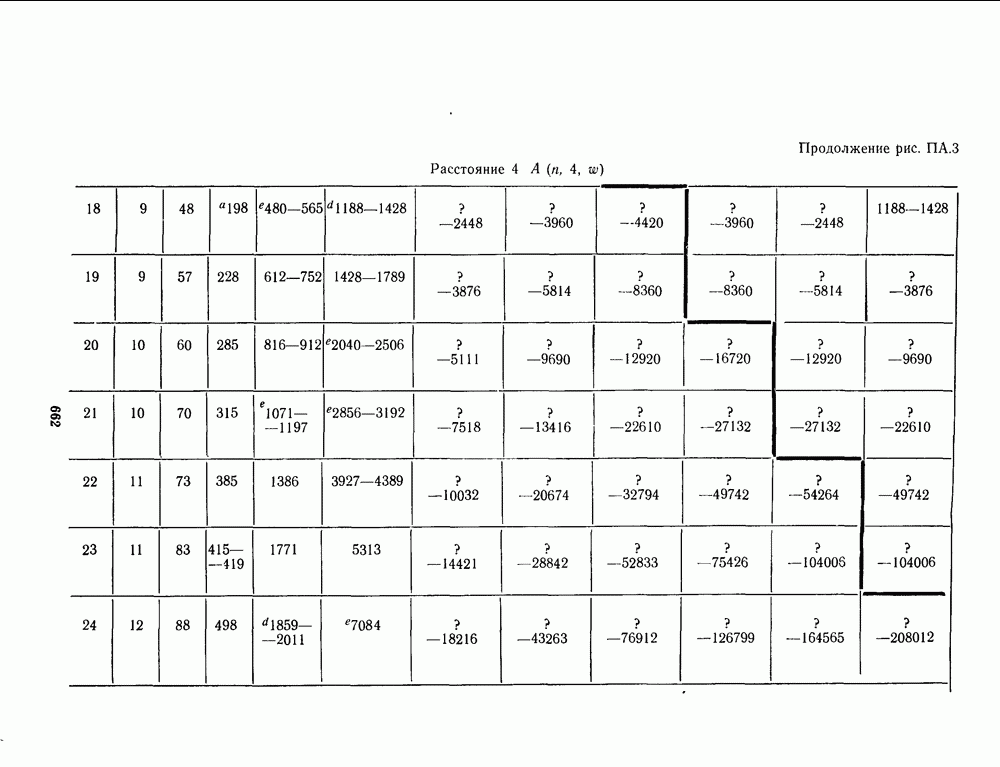
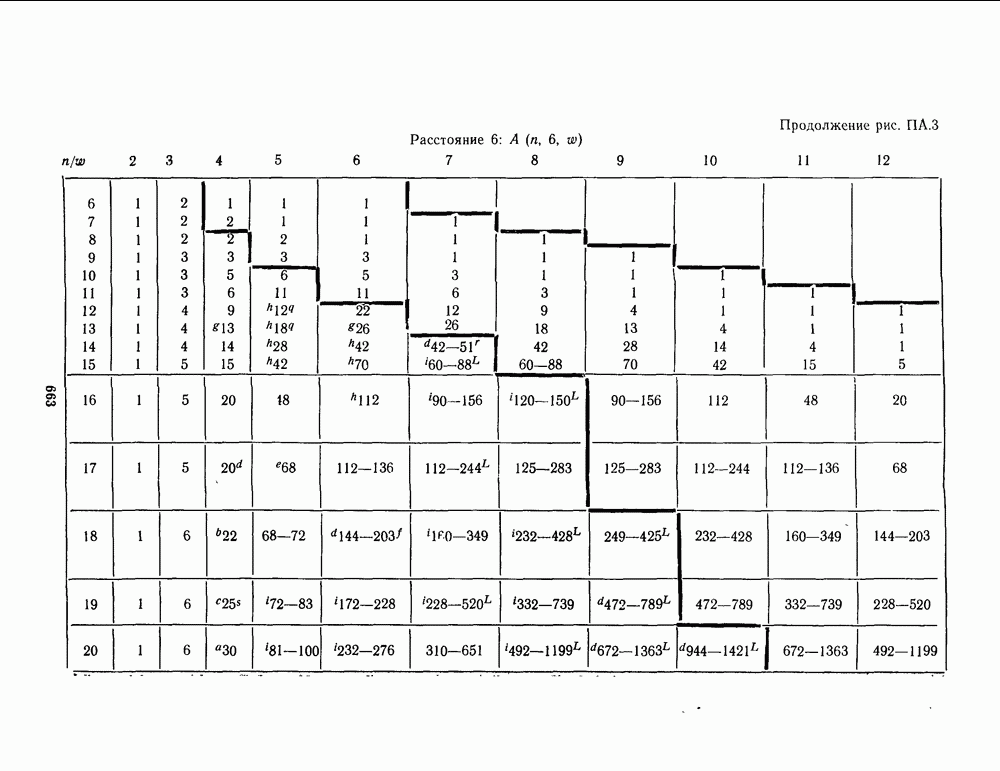
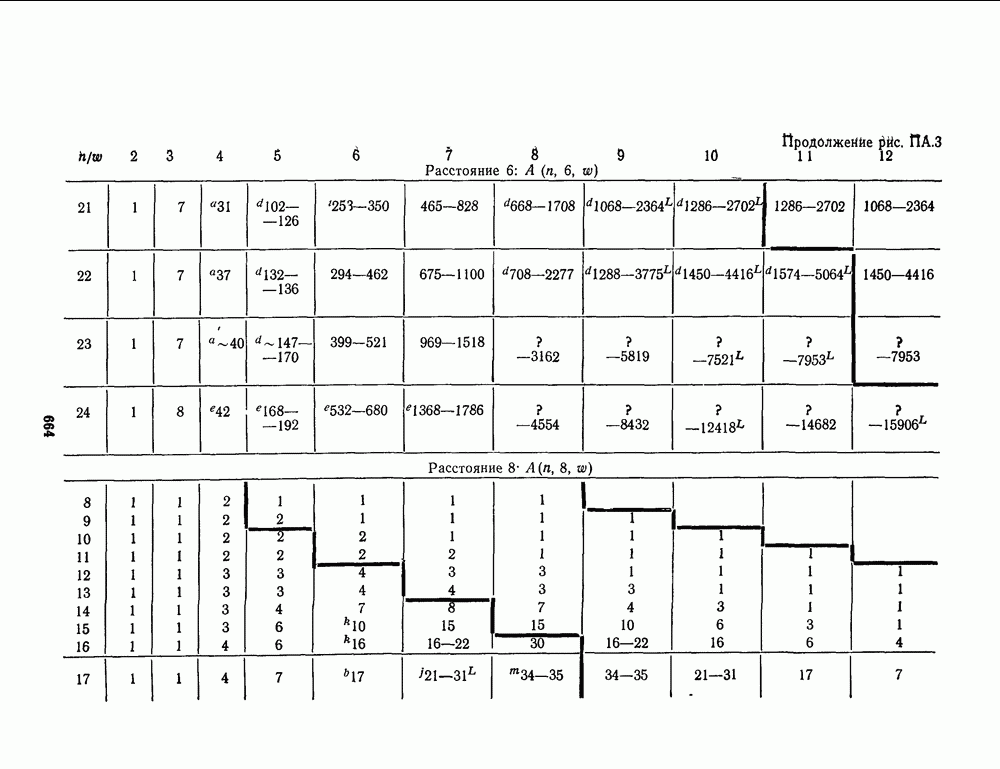
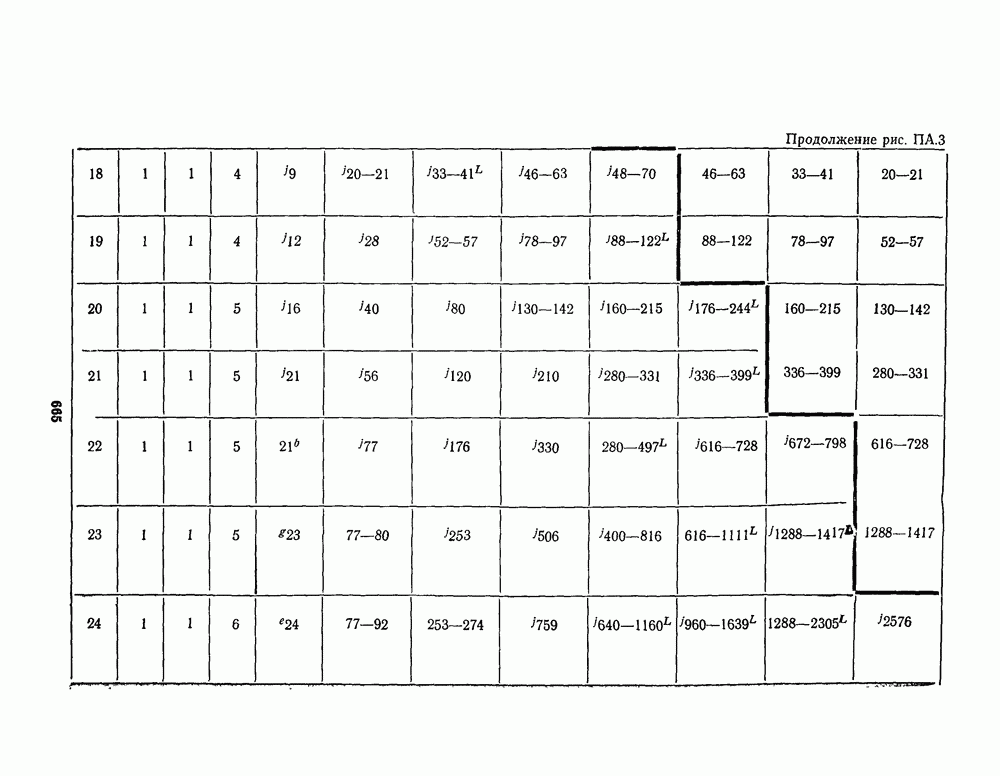
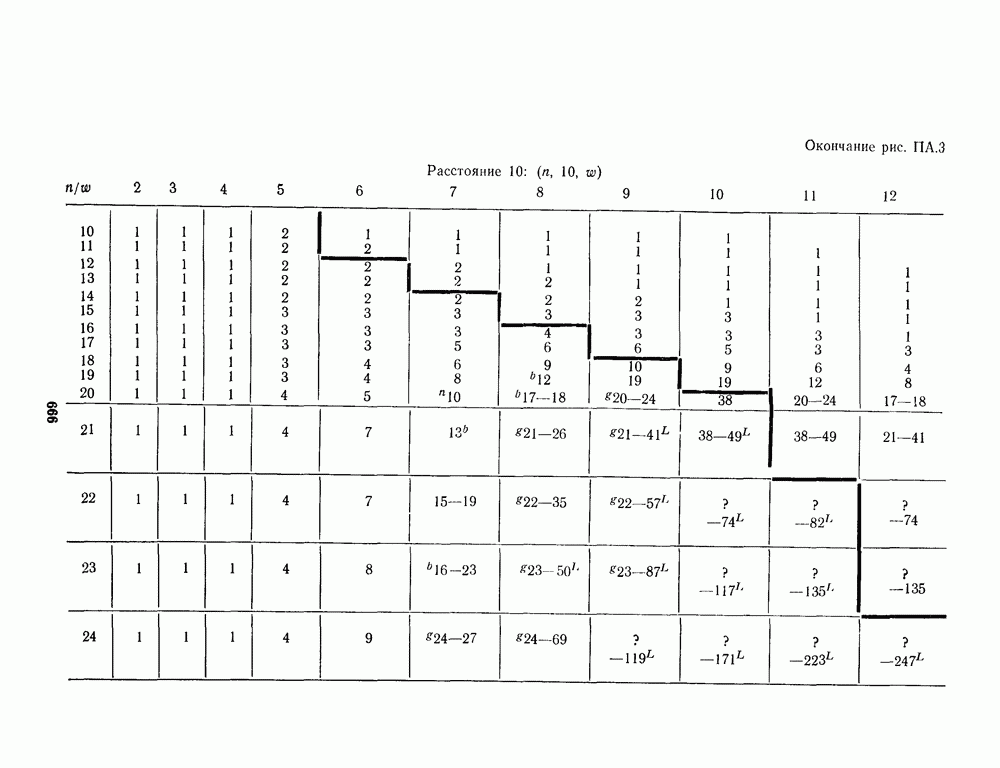
16.9. ДЕКОДИРОВАНИЕ ЦИКЛИЧЕСКИХ И НЕКОТОРЫХ ДРУГИХ КОДОВ
Кодирование циклических кодов было описано в § 7.8; специфические методы декодирования кодов БЧХ были рассмотрены в § 9.6, декодирование альтернантных кодов — в § 12.9, декодирование кодов Рида-Маллера - в § 13.6, 13.7. В данном параграфе описываются некоторые методы декодирования, пригодные для всех циклических и дважды циркулянтных кодов.
Пусть — двоичный  -код. Предположим, что передавалось слово
-код. Предположим, что передавалось слово  что получено слово
что получено слово  причем вес вектора ошибок
причем вес вектора ошибок  равен
равен  где Для простоты предположим, что порождающая и проверочная матрицы кода равны соответственно
где Для простоты предположим, что порождающая и проверочная матрицы кода равны соответственно  Таким образом,
Таким образом,  являются
являются  проверочными символами кодового слова, а
проверочными символами кодового слова, а  информационными символами. Например, мы могли бы использовать кодер
информационными символами. Например, мы могли бы использовать кодер  из § 7.8.
из § 7.8.
Рассматриваемые ниже методы декодирования основываются на следующей теореме.
Теорема 19. Предположим, что вес вектора ошибок  равен
равен  где
где  Пусть
Пусть  синдром принятого вектора у. Если
синдром принятого вектора у. Если  то принятые информационные символы
то принятые информационные символы  правильны и вектор ошибки равен
правильны и вектор ошибки равен  Если
Если  то по крайней мере один из информационных символов —1) неправилен.
то по крайней мере один из информационных символов —1) неправилен.
Доказательство, (i). Предположим, что все информационные символы правильны, т. е.  для всех
для всех  Тогда
Тогда  Пусть
Пусть  и предположим, что
и предположим, что  Рассмотрим кодовое слово
Рассмотрим кодовое слово  Так как
Так как  то, по предположению,
то, по предположению,  Следовательно,
Следовательно,  Далее
Далее

Метод декодирования I: перестановочное декодирование. Этот метод применим к кодам с достаточно большой группой автоморфизмов, например к циклическим кодам или, еще лучше, к квадратично-вычетным кодам.
Предположим, что мы хотим исправлять все векторы ошибок  вес которых не превосходит
вес которых не превосходит  при некотором фиксированном
при некотором фиксированном  Для выполнения декодирования надо найти такое множество подстановок
Для выполнения декодирования надо найти такое множество подстановок  чтобы код был инвариантен относительно этого множества и чтобы для каждого вектора
чтобы код был инвариантен относительно этого множества и чтобы для каждого вектора  вес которого не превосходит
вес которого не превосходит  нашлась бы подстановка
нашлась бы подстановка  передвигающая все ошибки из информационных позиций в проверочные.
передвигающая все ошибки из информационных позиций в проверочные.
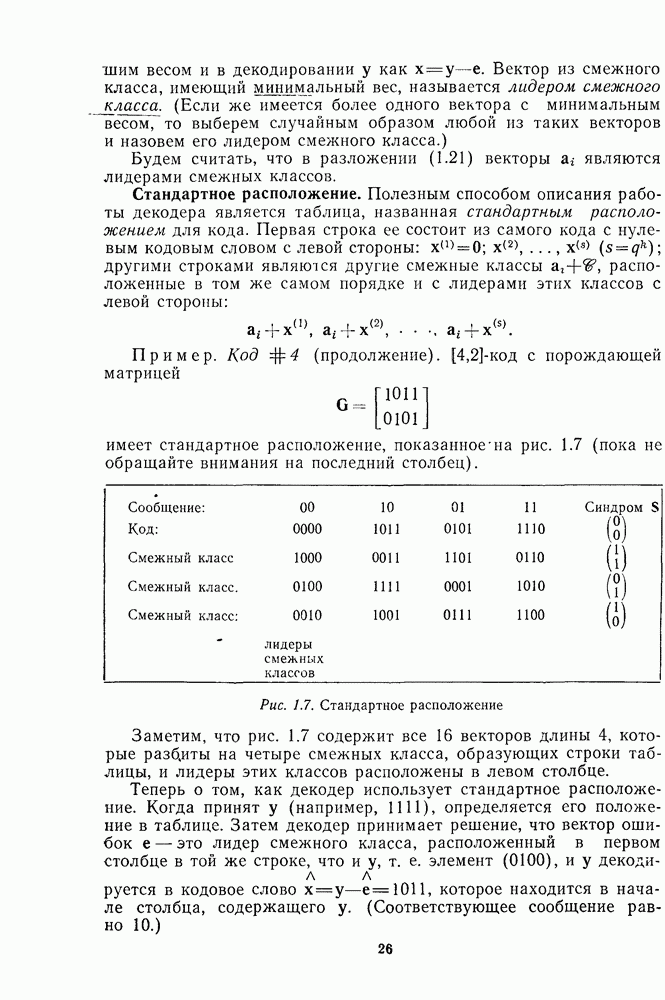
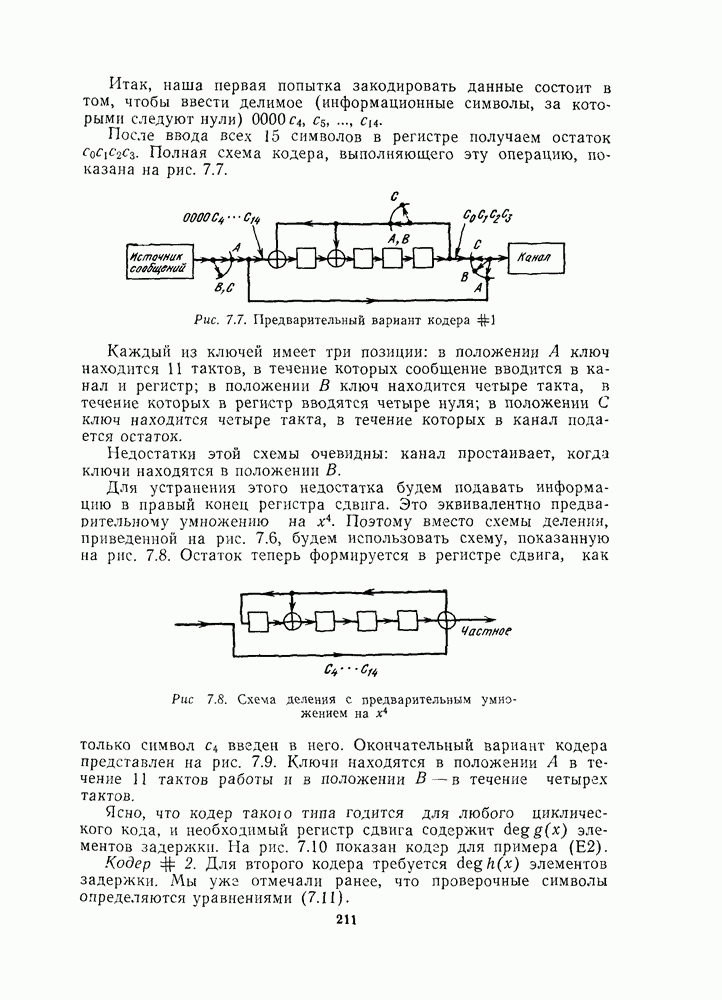
Пример. Пусть  -код Хэмминга и
-код Хэмминга и  Тогда, как показано на рис. 16.10, подходящим множеством подстановок является множество
Тогда, как показано на рис. 16.10, подходящим множеством подстановок является множество  где
где  циклический сдвиг. Например, если
циклический сдвиг. Например, если  то
то  выводит символ 1 из информационных позиций:
выводит символ 1 из информационных позиций: 

Рис. 16.10 Три перестановки для перестановочного декодирования  -кода
-кода
Метод декодирования состоит в следующем. По полученному вектору у вычисляются векторы  и их синдромы
и их синдромы  до тех пор, пока не будет найден индекс
до тех пор, пока не будет найден индекс  для которого
для которого 
При этом согласно теореме 19 все ошибки сосредоточены в первых  позициях вектора
позициях вектора  и задаются равенством
и задаются равенством  Следовательно, полученный вектор декодируется как слово
Следовательно, полученный вектор декодируется как слово

Если  для всех
для всех  то заключаем, что произошло более чем
то заключаем, что произошло более чем  ошибок.
ошибок.
Задаче нахождения минимальных множеств  посвящено очень мало работ.
посвящено очень мало работ.
Метод вылавливания ошибок. (Рудольф и Митчел [1133].) Этот метод декодирования является частным случаем перестановочного декодирования, при котором используется только циклическая подстановка  так что
так что  Метод позволяет исправлять все векторы ошибок
Метод позволяет исправлять все векторы ошибок  содержащие круговую серию нулей длины не менее
содержащие круговую серию нулей длины не менее  т. е. содержащие цепочку нулей длины по меньшей мере
т. е. содержащие цепочку нулей длины по меньшей мере  при записи координат вектора
при записи координат вектора  по кругу.
по кругу.
Упражнение. (22). Доказать, что при этом могут быть исправлены все ошибки, вес которых не превосходит  где
где 
Таким образом, этот метод декодирования оказывается пригодным только в тех случаях, когда символы 1 в векторе ошибок  разделены большими отрезками нулей; иначе говоря, в случаях малого числа случайных независимых ошибок или в случае пакетов ошибок. Например, применительно к [23, 12, 7]-коду Голея имеем:
разделены большими отрезками нулей; иначе говоря, в случаях малого числа случайных независимых ошибок или в случае пакетов ошибок. Например, применительно к [23, 12, 7]-коду Голея имеем:  так что некоторые ошибки веса 2 и 3 не могут быть исправлены.
так что некоторые ошибки веса 2 и 3 не могут быть исправлены.
Однако этот метод очень легко реализуем. Единственное, что требуется, это сдвигать вектор у до тех пор, пока не получится вектор  вес которого не превосходит
вес которого не превосходит  а затем использовать равенство (16.63). Заметим, что согласно упражнению
а затем использовать равенство (16.63). Заметим, что согласно упражнению  гл. 7 если для вычисления синдрома вектора у использовать схему деления кодера
гл. 7 если для вычисления синдрома вектора у использовать схему деления кодера  то синдромы всех циклических сдвигов вектора у вычисляются очень легко: они просто равны содержимому регистра сдвигов в соответствующие моменты времени.
то синдромы всех циклических сдвигов вектора у вычисляются очень легко: они просто равны содержимому регистра сдвигов в соответствующие моменты времени.
Примеры. (1). Код БЧХ [31, 21, 5] с исправлением двух ошибок. В этом случае [30/21]  так что использование метода вылавливания ошибок не позволит исправить некоторые двойные ошибки. Используем, однако, подстановку
так что использование метода вылавливания ошибок не позволит исправить некоторые двойные ошибки. Используем, однако, подстановку  переводящую вектор
переводящую вектор  в вектор
в вектор  где
где  (индексы вычисляются по модулю 31). Как было показано в § 8.5, код инвариантен относительно
(индексы вычисляются по модулю 31). Как было показано в § 8.5, код инвариантен относительно  Кроме того,
Кроме того,  Легко показать, что множество
Легко показать, что множество  содержащее 155 подстановок, передвигает из информационных позиций любую ошибку веса 2 и, следовательно, пригодно для перестановочного декодирования.
содержащее 155 подстановок, передвигает из информационных позиций любую ошибку веса 2 и, следовательно, пригодно для перестановочного декодирования.
(2). Код Голея [23, 12, 7]. Метод вылавливания ошибок опять позволяет исправлять только одиночные ошибки. Однако множество  содержащее 92 подстановки, позволяет передвинуть за пределы информационных позиций любую ошибку, вес которой не превосходит 3 (см. Мак-Вильямс [873]), и может быть использовало для перестановочного декодирования.
содержащее 92 подстановки, позволяет передвинуть за пределы информационных позиций любую ошибку, вес которой не превосходит 3 (см. Мак-Вильямс [873]), и может быть использовало для перестановочного декодирования.
Ни одно из указанных множеств не является минимальным.
Задача (нерешенная). (16.9). Найти минимальное множество  для перестановочного декодирования
для перестановочного декодирования  кодов Голея
кодов Голея  -кода
-кода  -кода 2 и т. д.
-кода 2 и т. д.
Метод декодирования II: покрывающие многочлены. (Касами  Этот метод представляет собой модификацию метода вылавливания ошибок, позволяющую исправлять большее число ошибок. Мы теперь будем пытаться исправить любую ошибку, вес которой не превосходит
Этот метод представляет собой модификацию метода вылавливания ошибок, позволяющую исправлять большее число ошибок. Мы теперь будем пытаться исправить любую ошибку, вес которой не превосходит  где
где 
С этой целью выберем множество покрывающих многочленов

которые обладают следующим свойством: для произвольного вектора ошибки  вес которого не превосходит
вес которого не превосходит  найдется многочлен
найдется многочлен  такой, что некоторый циклический сдвиг
такой, что некоторый циклический сдвиг  совпадает с
совпадает с  в информационных позициях. Например, если
в информационных позициях. Например, если  содержит круговую серию из
содержит круговую серию из  нулей, то некоторый циклический сдвиг
нулей, то некоторый циклический сдвиг  будет совпадать в информационных позициях с многочленом
будет совпадать в информационных позициях с многочленом  .
.
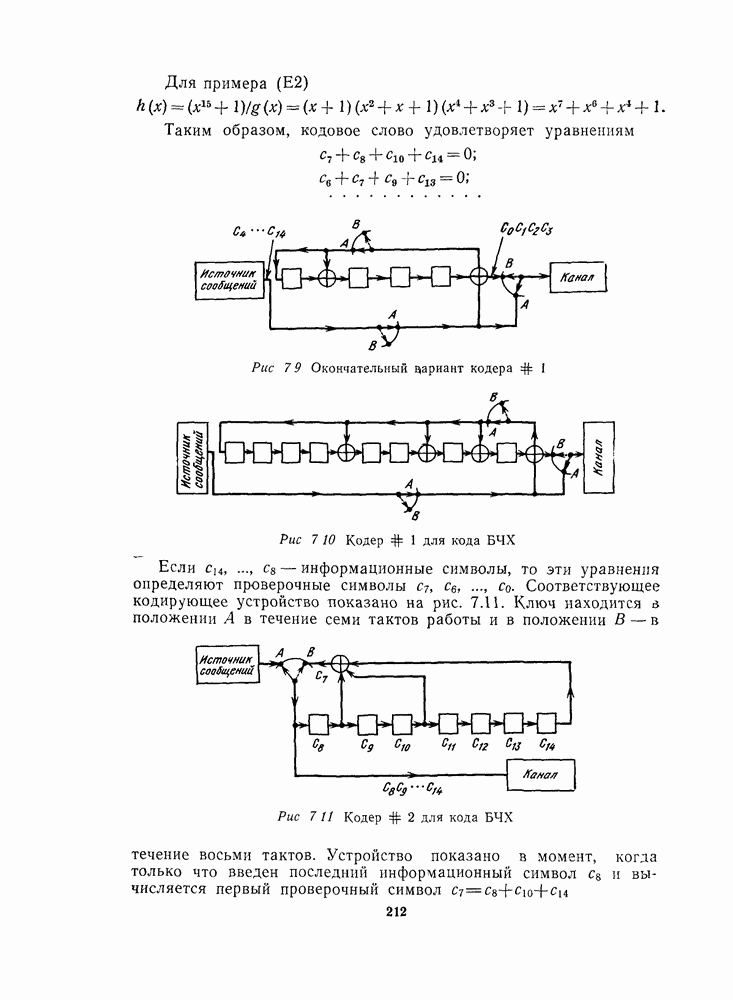
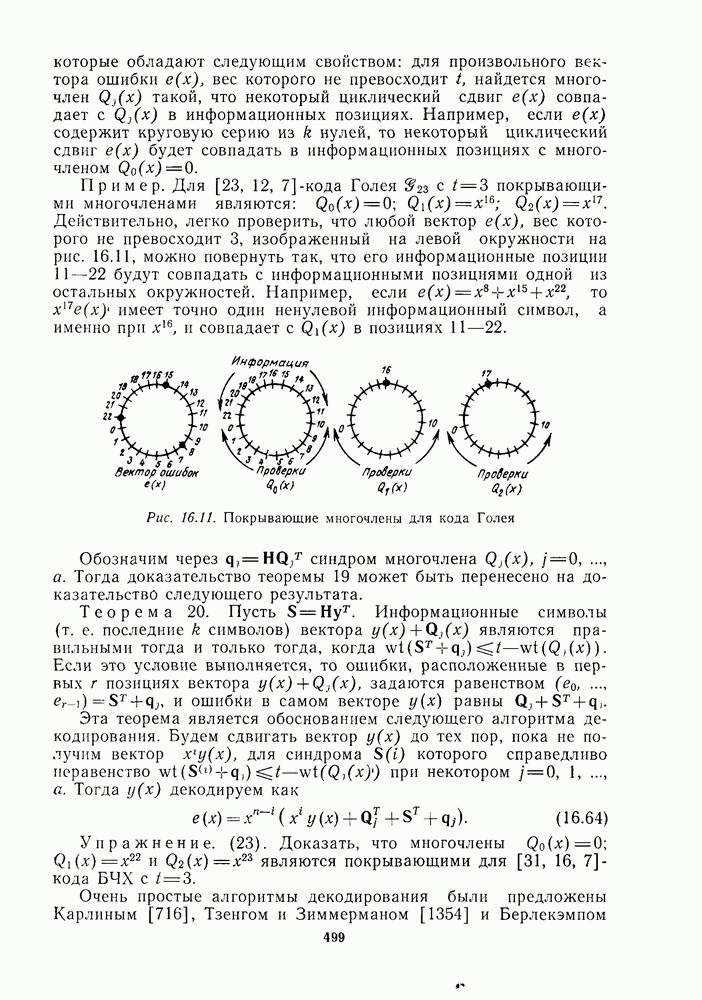
Пример. Для [23, 12, 7]-кода Голея с  покрывающими многочленами являются:
покрывающими многочленами являются:  Действительно, легко проверить, что любой вектор
Действительно, легко проверить, что любой вектор  вес которого не превосходит 3, изображенный на левой окружности на рис. 16.11, можно повернуть так, что его информационные позиции 11—22 будут совпадать с информационными позициями одной из остальных окружностей. Например, если
вес которого не превосходит 3, изображенный на левой окружности на рис. 16.11, можно повернуть так, что его информационные позиции 11—22 будут совпадать с информационными позициями одной из остальных окружностей. Например, если  то
то  имеет точно один ненулевой информационный символ, а именно при
имеет точно один ненулевой информационный символ, а именно при  и совпадает с
и совпадает с  в позициях 11—22.
в позициях 11—22.

Рис. 16.11. Покрывающие многочлены для кода Голея
Обозначим через  синдром многочлена
синдром многочлена  Тогда доказательство теоремы 19 может быть перенесено на доказательство следующего результата.
Тогда доказательство теоремы 19 может быть перенесено на доказательство следующего результата.
Теорема 20. Пусть  Информационные символы (т. е. последние
Информационные символы (т. е. последние  символов) вектора
символов) вектора  являются правильными тогда и только тогда, когда
являются правильными тогда и только тогда, когда  Если это условие выполняется, то ошибки, расположенные в первых
Если это условие выполняется, то ошибки, расположенные в первых  позициях вектора
позициях вектора  задаются равенством
задаются равенством  и ошибки в самом векторе
и ошибки в самом векторе  равны
равны 
Эта теорема является обоснованием следующего алгоритма декодирования. Будем сдвигать вектор  до тех пор, пока не получим вектор
до тех пор, пока не получим вектор  для синдрома
для синдрома  которого справедливо неравенство
которого справедливо неравенство  при некотором
при некотором  Тогда
Тогда  декодируем как
декодируем как

Упражнение. (23). Доказать, что многочлены  являются покрывающими для [31, 16, 7]-кода БЧХ с
являются покрывающими для [31, 16, 7]-кода БЧХ с  .
.
Очень простые алгоритмы декодирования были предложены Карлиным [716], Тзенгом и Зиммерманом [1354] и Берлекэмпом
[123]. Например, вместо того, чтобы сдвигать принятый вектор и прибавлять синдромы покрывающих многочленов, можно прибавлять все векторы, вес которых не превосходит  к информационным позициям принятого вектора или к проверочным позициям до тех пор, пока не будет найден синдром, вес которого не превосходит
к информационным позициям принятого вектора или к проверочным позициям до тех пор, пока не будет найден синдром, вес которого не превосходит 
В качестве иллюстрации приведем метод Берлекэмпа декодирования [24, 12, 8]-кода Голея  Он использует задание кода порождающей матрицей вида (16.48), которую мы перепишем в виде
Он использует задание кода порождающей матрицей вида (16.48), которую мы перепишем в виде

где буквами обозначены столбцы матрицы  причем
причем  обозначает вектор с 1 в координате
обозначает вектор с 1 в координате  Так как код самодуален, т. е. если
Так как код самодуален, т. е. если  то
то  или
или  Положим также
Положим также

где буквами обозначены строки матрицы В.
Предположим, что передавалось кодовое слово  и что вектор ошибок равен
и что вектор ошибок равен  так что получен вектор
так что получен вектор  Синдром равен
Синдром равен

Кроме того,

Предположим, что  Тогда должно выполняться по меньшей мере одно из следующих условий:
Тогда должно выполняться по меньшей мере одно из следующих условий:
Случай I:  .
.
Случай II: 
Случай III:  так что для некоторого
так что для некоторого  выполняются условия
выполняются условия  и
и

Случай  так что для некоторого
так что для некоторого 
Таким образом, для декодирования надо вычислить веса 26 векторов 
Пример.  так что имеет место случай
так что имеет место случай 
Метод декодирования III: использование t-схем. (Ассмус и др. [33, 42, 43], Геталс  Если дуальный код содержит
Если дуальный код содержит  -схемы, то часто оказывается возможным применение порогового декодирования (см. § 13.6 и 13.7). Идея состоит в следующем. Предположим, что для некоторого
-схемы, то часто оказывается возможным применение порогового декодирования (см. § 13.6 и 13.7). Идея состоит в следующем. Предположим, что для некоторого  слова дуального кода некоторого фиксированного веса
слова дуального кода некоторого фиксированного веса  образуют
образуют  -схему. Пусть
-схему. Пусть  блоки этой схемы
блоки этой схемы  -кодовые слова веса
-кодовые слова веса  в коде
в коде  в первой координате которых стоит символ 1. Сформируем а проверок
в первой координате которых стоит символ 1. Сформируем а проверок  где
где  — полученный вектор, и обозначим через
— полученный вектор, и обозначим через  число случаев, в которых
число случаев, в которых 
Рассматриваемый нами алгоритм состоит в следующем:
(i). Если  то ошибок не произошло.
то ошибок не произошло.
(ii). Если  или если
или если  принадлежит некоторому специальному множеству значений, то первая координата является правильной.
принадлежит некоторому специальному множеству значений, то первая координата является правильной.
(iii). Если  или если
или если  то первая координата ошибочна.
то первая координата ошибочна.
(iv). Для всех остальных значений  принимается решение, что произошла неисправимая ошибка.
принимается решение, что произошла неисправимая ошибка.
Процедуру повторить для всех координат полученного вектора.
Этот метод мы проиллюстрируем описанием порогового декодирования для кода Голея  (см. [493]). Так как
(см. [493]). Так как  самодуален, то любое кодовое слово может быть взято в качестве проверки. Рассмотрим, как происходит декодирование какой-нибудь одной координаты, скажем, первой. Выберем в качестве проверок 253 кодовых слова веса 8, содержащих 1 в первой координате (см. рис. 2.14). Если произошла точно одна ошибка, то число
самодуален, то любое кодовое слово может быть взято в качестве проверки. Рассмотрим, как происходит декодирование какой-нибудь одной координаты, скажем, первой. Выберем в качестве проверок 253 кодовых слова веса 8, содержащих 1 в первой координате (см. рис. 2.14). Если произошла точно одна ошибка, то число  невыполняемых проверок равно либо 253, либо 77 в зависимости от того, ошибочен или нет первый символ. Если произошло две ошибки, то
невыполняемых проверок равно либо 253, либо 77 в зависимости от того, ошибочен или нет первый символ. Если произошло две ошибки, то  равно либо 176, либо
равно либо 176, либо  в зависимости от наличия или отсутствия ошибки в первой позиции. Наконец, если произошло три ошибки, то
в зависимости от наличия или отсутствия ошибки в первой позиции. Наконец, если произошло три ошибки, то  равно либо
равно либо  либо
либо  в зависимости от двух указанных возможностей. Подводя итог, получаем:
в зависимости от двух указанных возможностей. Подводя итог, получаем:

Таким образом, имеется простой пороговый тест если из 253 проверок не выполняется более 133, то координата ошибочна, а если меньше чем 133, то координата правильна Этот тест может быть успешно применен ко всем координатам (на основании транзитивности группы  теорем 9 и 10)
теорем 9 и 10)
В работе [43] описан (более сложный) алгоритм декодирования [48, 24, 12] КВ-кода
Задача построения общего порогового алгоритма декодирования такого типа представляется весьма трудной, не ясен даже вопрос, сколько ошибок можно исправлять таким алгоритмом Рахман и Блейк [1086] дали нижнюю границу для этого числа в терминах параметров  -схемы
-схемы
Задача (нерешенная). (16 10) Сколько ошибок можно исправ лять пороговым декодированием, если слова каждого веса в коде  образуют
образуют  -схему
-схему
Конечно, если разрешается в качестве проверок выбирать слова произвольного веса, то теоретически, как мы знаем из теоремы 21 гл 13, можно для любого кода исправлять  ошибок (мы только не знаем, как надо это делать)
ошибок (мы только не знаем, как надо это делать)
ЗАМЕЧАНИЯ К ГЛ. 16
(см. скан)