В. Линейное прогнозирование речи.
Для усовершенствования формантного анализа и синтеза речи отдельные системы второго порядка форматной модели объединяют в общую линейную систему порядка  равного удвоенному числу указанных систем второго порядка, или большему. Одновременно задаются передаточная функция голосового тракта, форма возбуждающих импульсов и характеристики звуков, получаемые при использовании в качестве входных сигналов последовательности входных
равного удвоенному числу указанных систем второго порядка, или большему. Одновременно задаются передаточная функция голосового тракта, форма возбуждающих импульсов и характеристики звуков, получаемые при использовании в качестве входных сигналов последовательности входных
отсчетов или шума  При линейном прогнозировании речи в такой системе по Представленной на рис. 5.2,д схеме передаточной функцией прогнозирующего фильтра является
При линейном прогнозировании речи в такой системе по Представленной на рис. 5.2,д схеме передаточной функцией прогнозирующего фильтра является

Коэффициенты  определяются методом наименьших квадратов. При этом исходят из следующего. Отсчеты речи приближенно описываются разностным уравнением
определяются методом наименьших квадратов. При этом исходят из следующего. Отсчеты речи приближенно описываются разностным уравнением

где  предсказываемое значение отсчета
предсказываемое значение отсчета 
Для того чтобы при показанной на рис. 5.2, д схеме включения блока прогнозирования 5 ошибка предсказания  была возможно малой, коэффициенты
была возможно малой, коэффициенты  которые вводятся в прогнозирующий фильтр по. каналу 6, определяются следующим образом. Они находятся из условия сведения к минимуму усредненной по всем
которые вводятся в прогнозирующий фильтр по. каналу 6, определяются следующим образом. Они находятся из условия сведения к минимуму усредненной по всем  величины
величины

Для определения указанных коэффициентов дифференцируется правая часть уравнения (5.4) по а,- при  приравниваются нулю производные и решается получаемая для
приравниваются нулю производные и решается получаемая для  система уравнений
система уравнений

Решение этой системы уравнений сводится к относительно несложным операциям определения зависимости между соответствующими автокорреляционной матрицей и вектором автокорреляции [100].
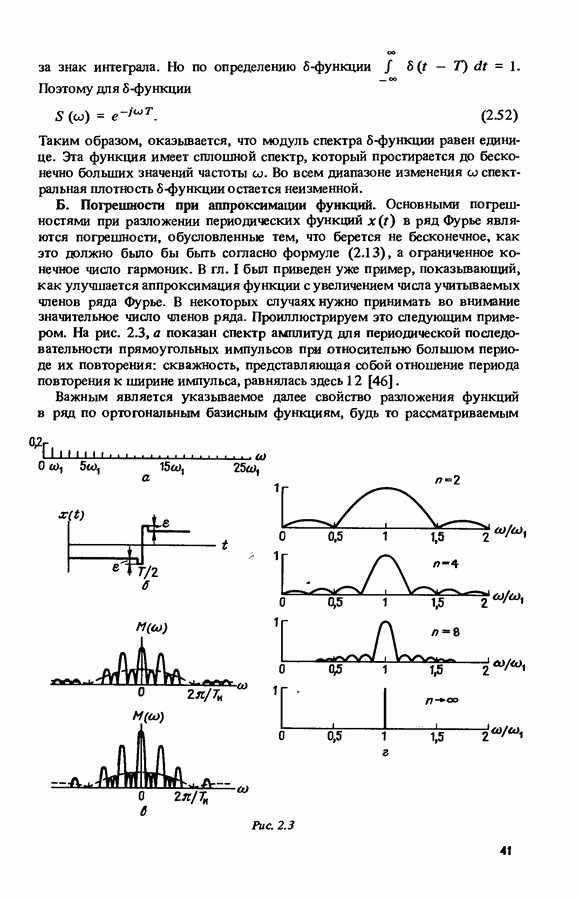
Для пояснения принципов обработки речевых сигналов нами были рассмотрены относительно несложные схемы выполнения анализа и синтеза. С развитием микроэлектронной вычислительной техники появляется возможность выполнения этих функций усовершенствованными методами с использованием большего количества цифровых фильтров. В качестве примера укажем использование для быстрого выполнения спектрального анализа речи банка фильтров [180]. С применением этой методики обработки речевых сигналов она осуществляется в реальном масштабе времени с помощью программы, построенной так, что она эквивалентна 128 параллельно включенным цифровым фильтрам. На выходе спектрального анализатора получается последовательность из  -разрядных слов, каждое из которых дает значение логарифма средней мощности входного сигнала в соответствующем диапазоне частот. Количество параллельных каналов цифровой обработки речевого сигнала временно ограничено здесь 128 каналами и согласно [180] должно быть увеличено еще больше при выполнении схемы обработки на СБИС.
-разрядных слов, каждое из которых дает значение логарифма средней мощности входного сигнала в соответствующем диапазоне частот. Количество параллельных каналов цифровой обработки речевого сигнала временно ограничено здесь 128 каналами и согласно [180] должно быть увеличено еще больше при выполнении схемы обработки на СБИС.
К числу вновь примененных методов прогнозирования речи относится метод стохастического моделирования, принятый фирмой IBM для речевых систем с большим словарем, известный как метод скрытых марковских моделей. Здесь информация, получаемая из акустических и лингвистических источников, связывается воедино, анализируются полученные таким образом данные и производится сравнение их с ранее поступившими. При упоминании в работе [103] об этом методе он характеризуется так: "Марковская цепь представляет собой математическую модель, поведение которой в некоторый момент времени зависит от ее состояния в конечном числе прошедших временных интервалов. Применительно к речи такая модель позволяет абстрагировать поведение системы, представляя ее в виде модели с конечным числом состояний, где каждое текущее состояние зависит от прежних состояний. Поскольку речевые сигналы чрезвычайно изменчивы, их состояния можно определять приближенно. Они остаются скрытыми от разработчиков — отсюда и произошел термин "скрытая марковская цепь". При анализе речи эта модель помогает выделять и классифицировать спектральную и лингвистическую информацию".
Получают также применение линейные предикативные синтезаторы речи, при работе которых предсказания производятся на основе анализа энергетических максимумов и частоты основного тона. Такие синтезаторы речи согласно [103] "содержат набор фильтров, которые предсказывают моменты малых изменений между соседними речевыми сегментами, устраняя таким образом спектральную избыточность. В фильтрах прямого линейного предикативного кодирования речь синтезируется путем предсказания коэффициентов фильтра. Этот алгоритм основан на использовании взвешенной суммы прошлых выборок и важнейших параметрах исходного сигнала, например периодичности. Фильтр линейного предикативного кодирования с решетчатой структурой менее критичен к неточности применяемых коэффициентов, что повышает надежность его работы и приближает синтезированную речь к естественной".