Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.5. Необходимые статистические предпосылкиНабор измерений называется выборкой. Слово «выборка» часто применяется как для отдельного измерения, так и для набора измерений, даже если это повторные измерения одного и того же объекта. Этот термин появился потому, что статистики считают основой множество или ансамбль возможных измерений, а вы получаете один возможный набор результатов (одну реализацию), который связан с вероятностью получения отдельно наблюдаемого результата и с эффектами повторений эксперимента. Измерения в выборке могут быть взяты все в одной точке. Например, выборка может представлять собой ряд измерений длины определенного провода. Кроме того, измерения могут быть рассеяны по различным местам в диапазоне изменения функции, например, скорость судна в различное время дня. Часто бывает необходимо найти модель для распределения отсчетов, т. е. необходимо представить себе ансамбль, из которого извлечена отдельная выборка. Для иллюстрации предположим, что
где
В таком случае Часто встречающаяся плотность, которая имеет место в таких случаях как при измерении длины куска провода, представляет гауссово (или нормальное) распределение
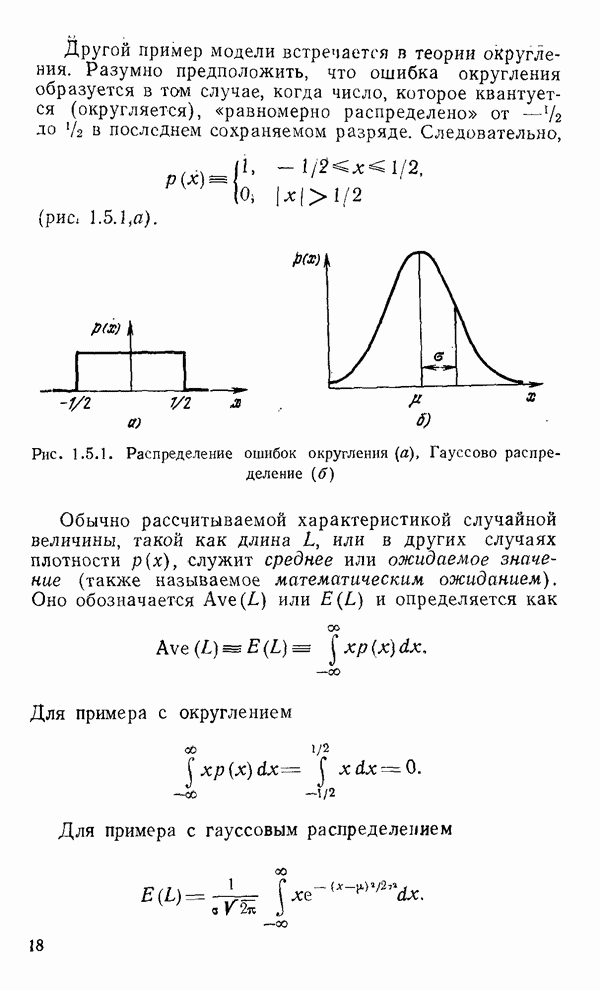
где Другой пример модели встречается в теории округления. Разумно предположить, что ошибка округления образуется в том случае, когда число, которое квантуется (округляется), «равномерно распределено» от
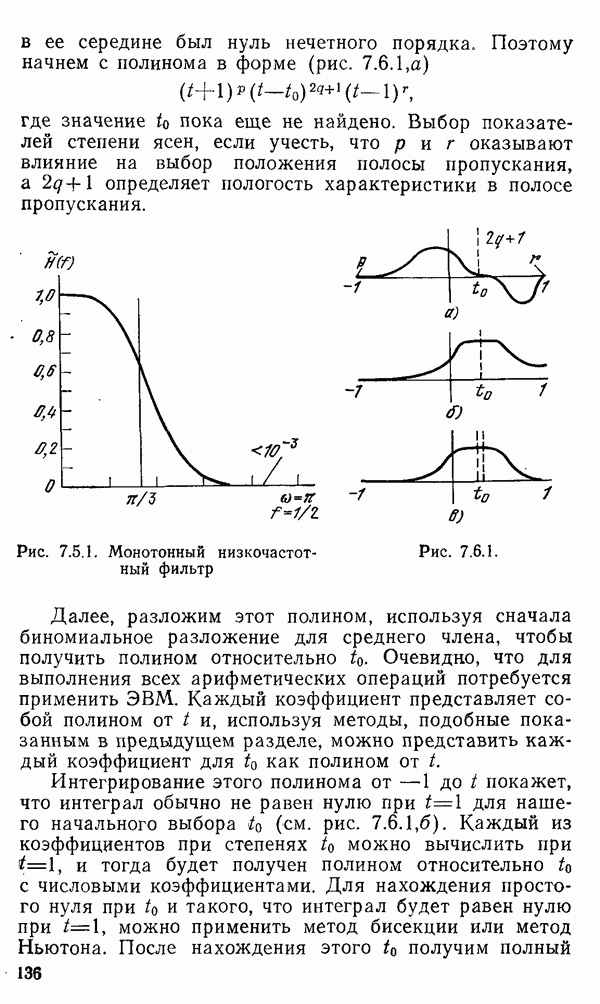
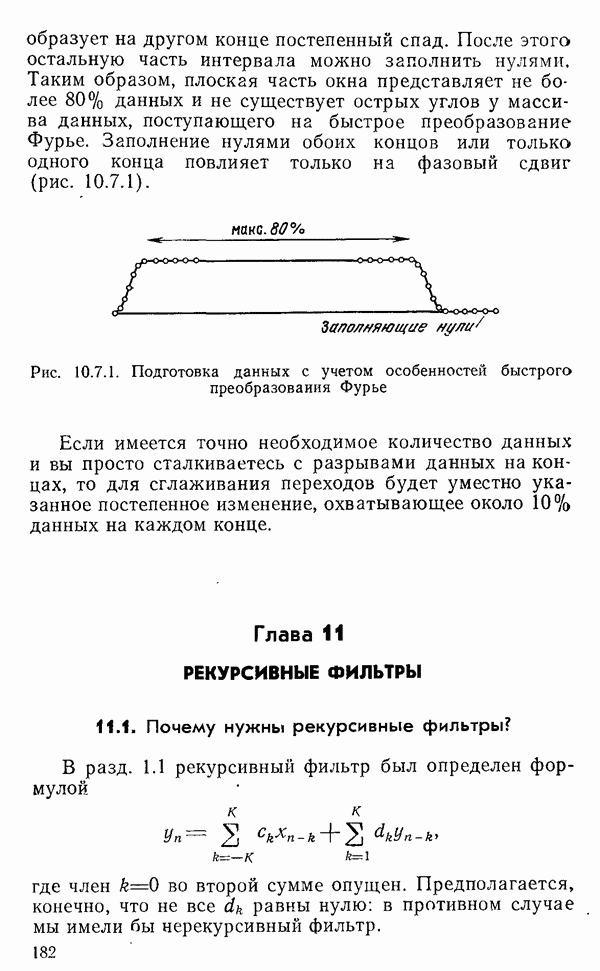
(рис. 1.5.1, а).
Рис. 1.5.1. Распределение ошибок округления (а), Гауссово распределение (б) Обычно рассчитываемой характеристикой случайной величины, такой как длина
Для примера с округлением
Для примера с гауссовым распределением
Заменяя
Этот результат следует из того, что первое подынтегральное выражение нечетное, а второй интеграл дает
Можно рассматривать вычисление математического ожидания как воздействие оператора Помимо среднего значения, широко используются и другие «типовые» величины. Одной из них является мода — наиболее частое значение или значение с максимальной плотностью. Другой — медиана — значение, соответствующее половине распределения. Но в этой книге мы не будем пользоваться какой-либо из этих величин. Еще одной, обычно вычисляемой, характеристикой случайной величины или в других случаях ее распределения служит дисперсия. Она обозначается
где В случае округления имеем
а для гауссового распределения
Если положить
то получим
Интегрирование по частям при обозначениях
дает
Этот результат поясняет, почему мы выбрали специфическую форму записи гауссового распределения:
Ясно, что дисперсия, которая есть сумма квадратов отклонений распределения от его среднего значения [взвешенная вероятностью текущего значения Упражнения(см. скан)
|
 |
Оглавление
|






















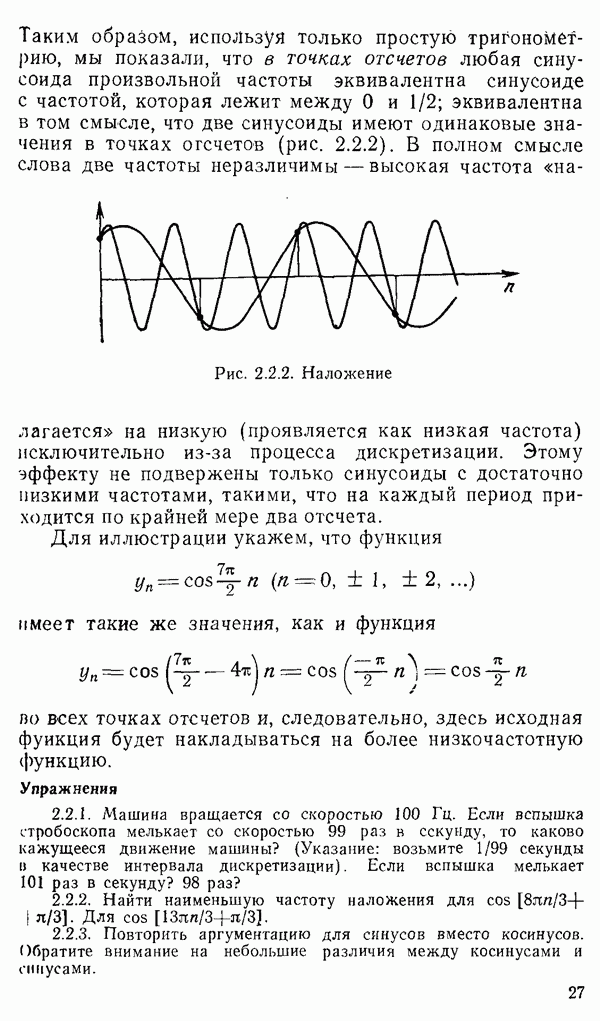











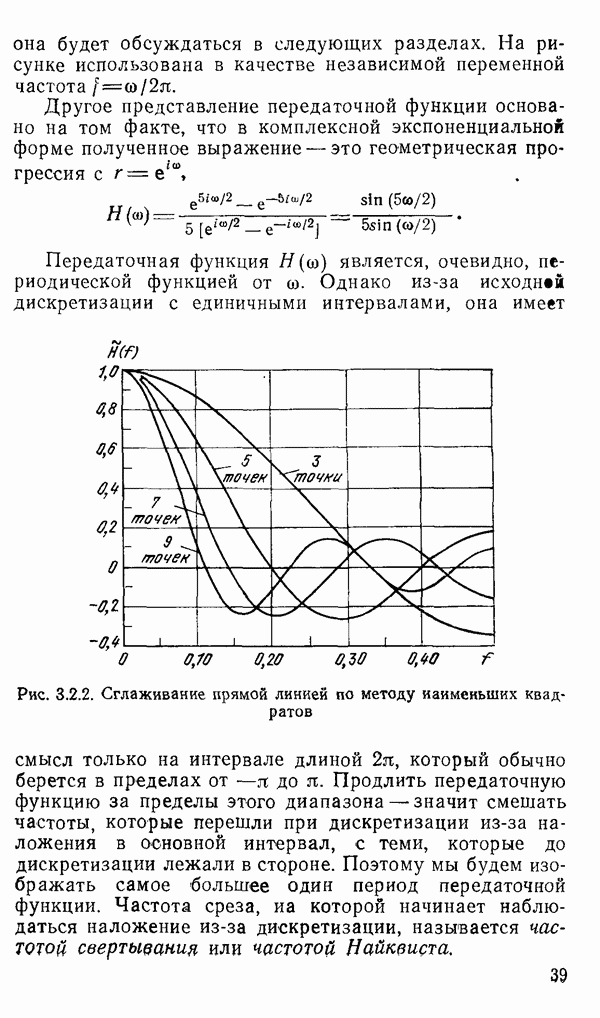



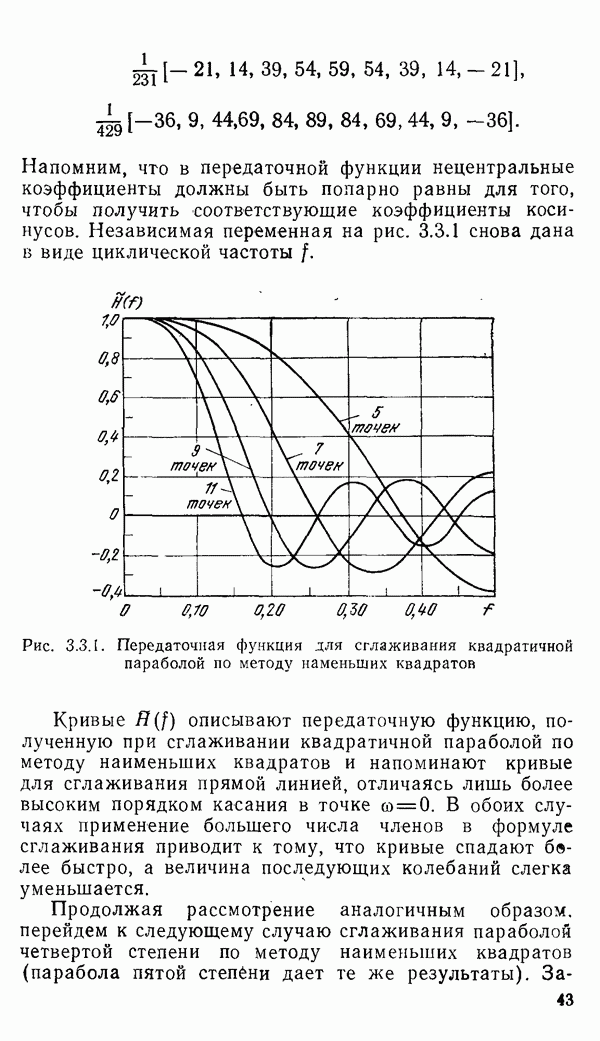














































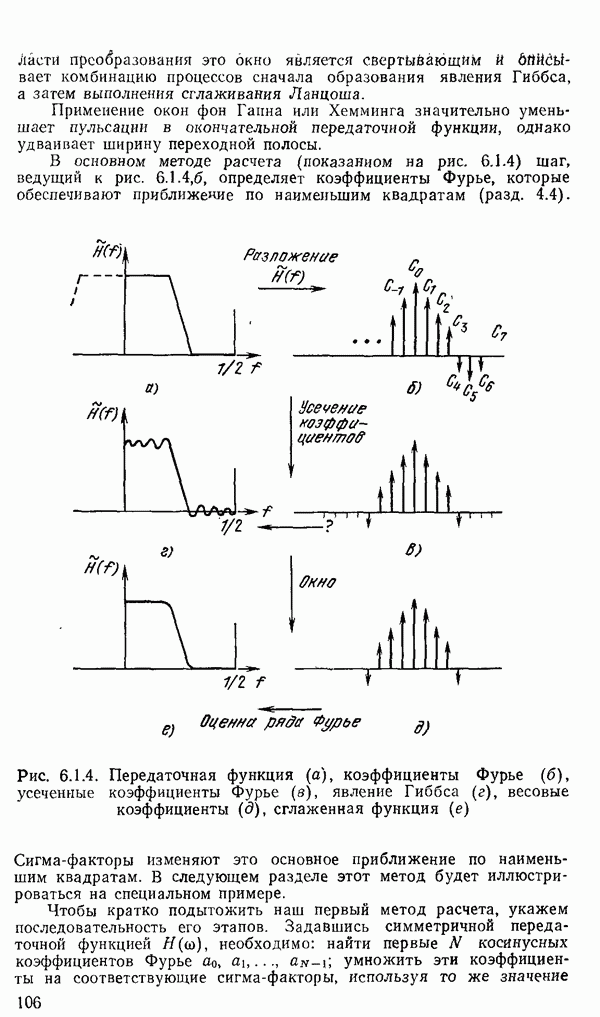
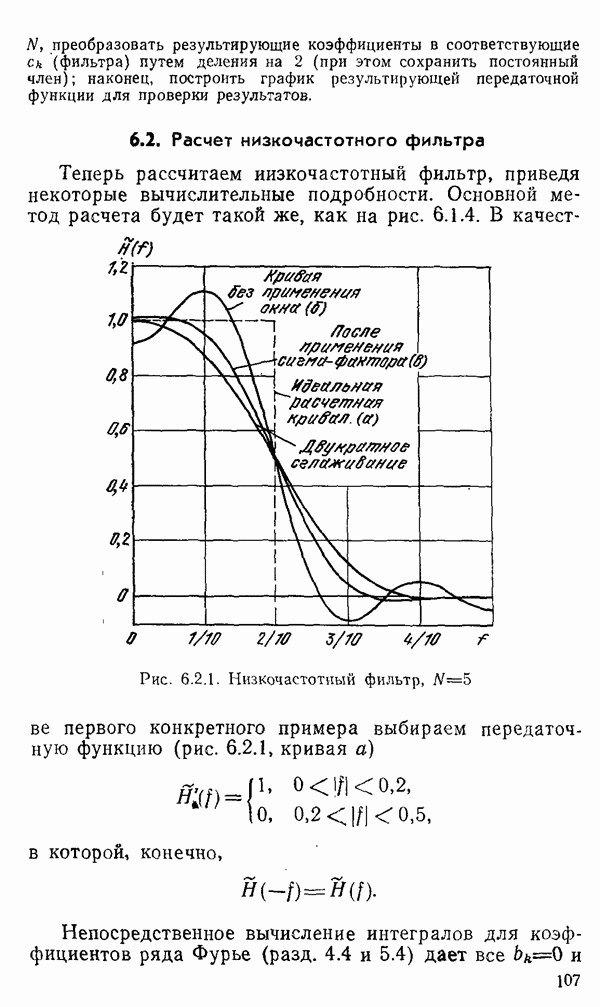

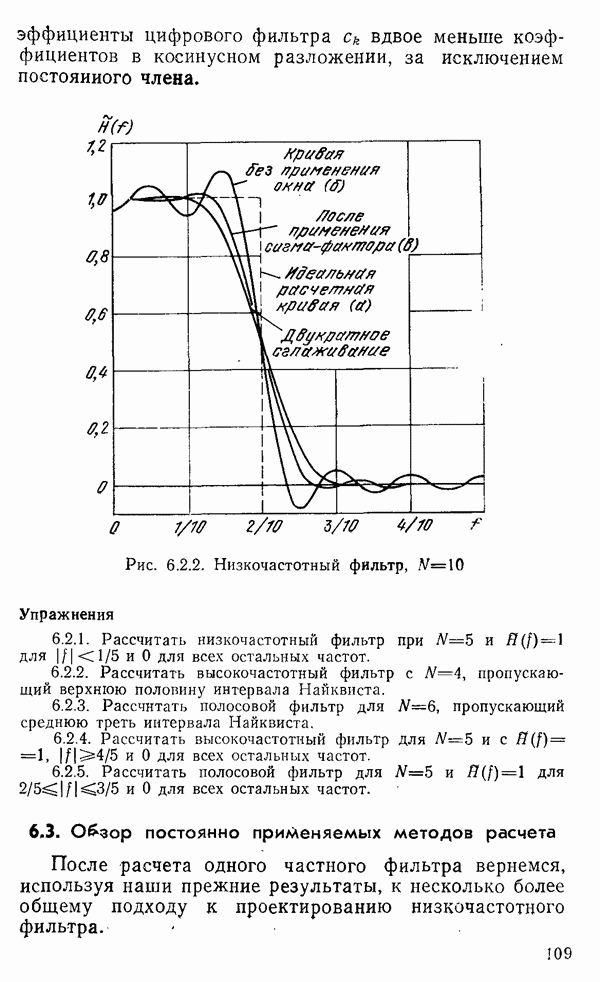




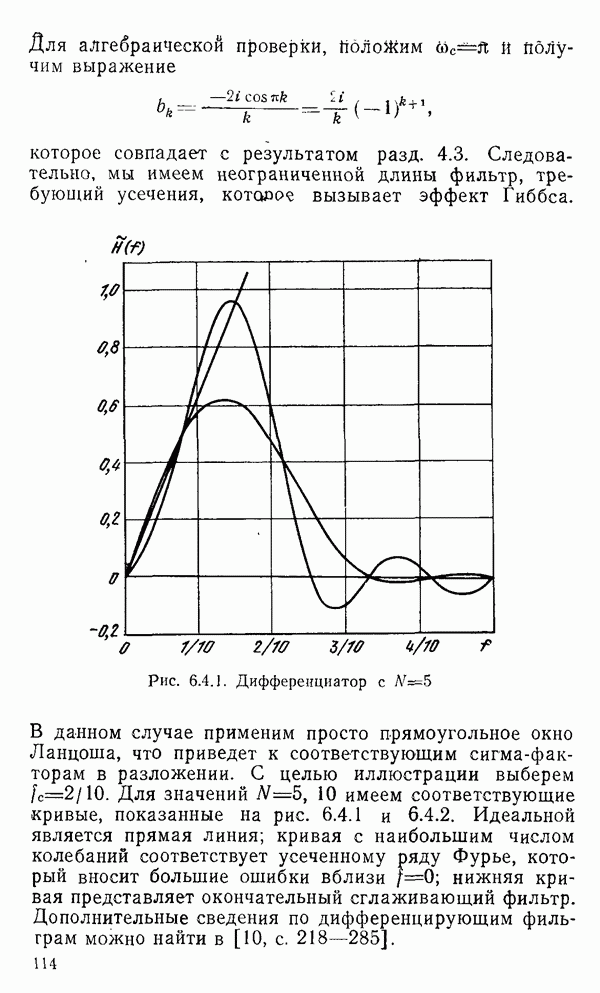



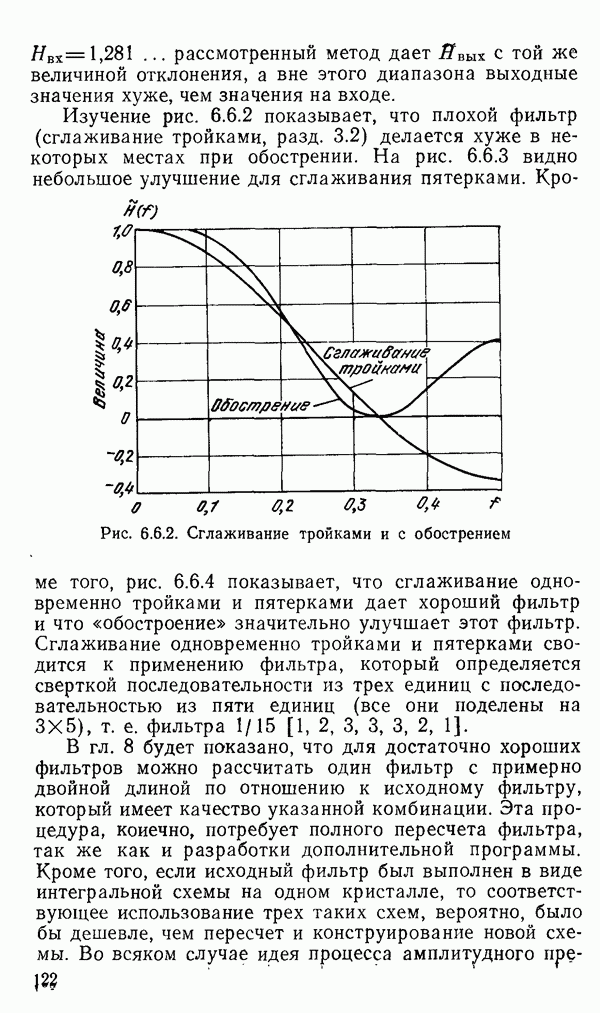
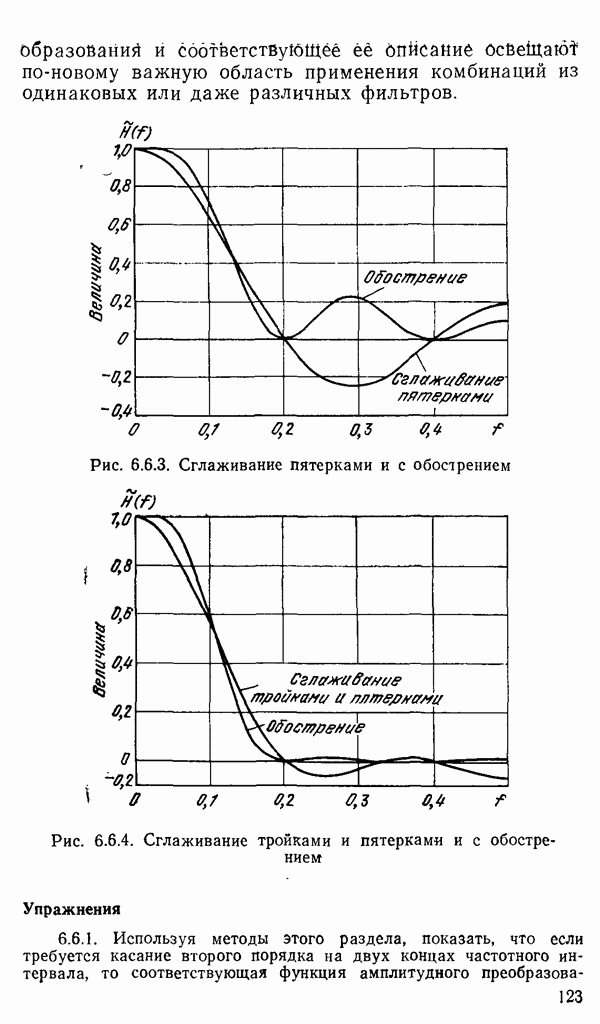


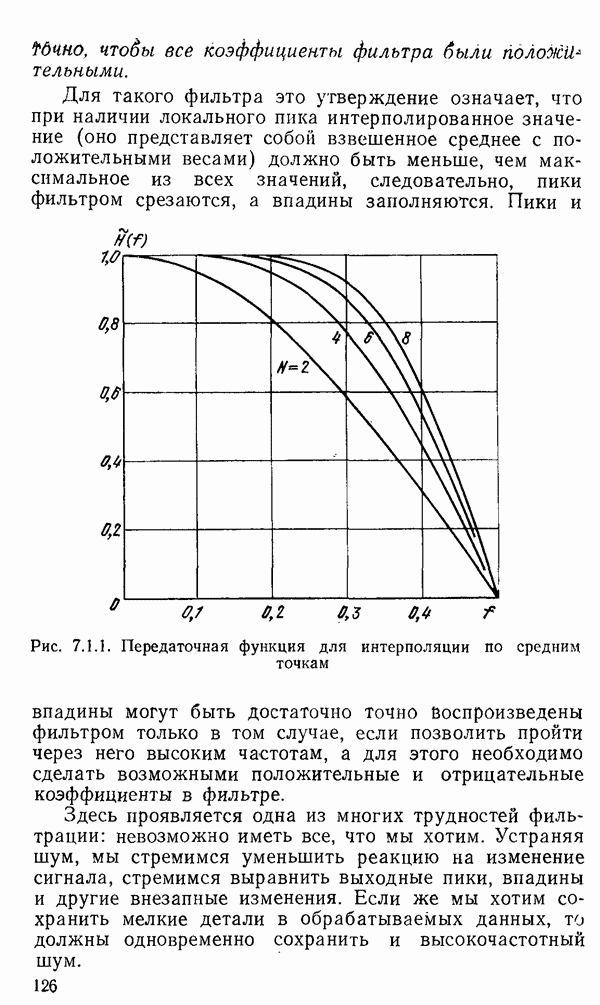


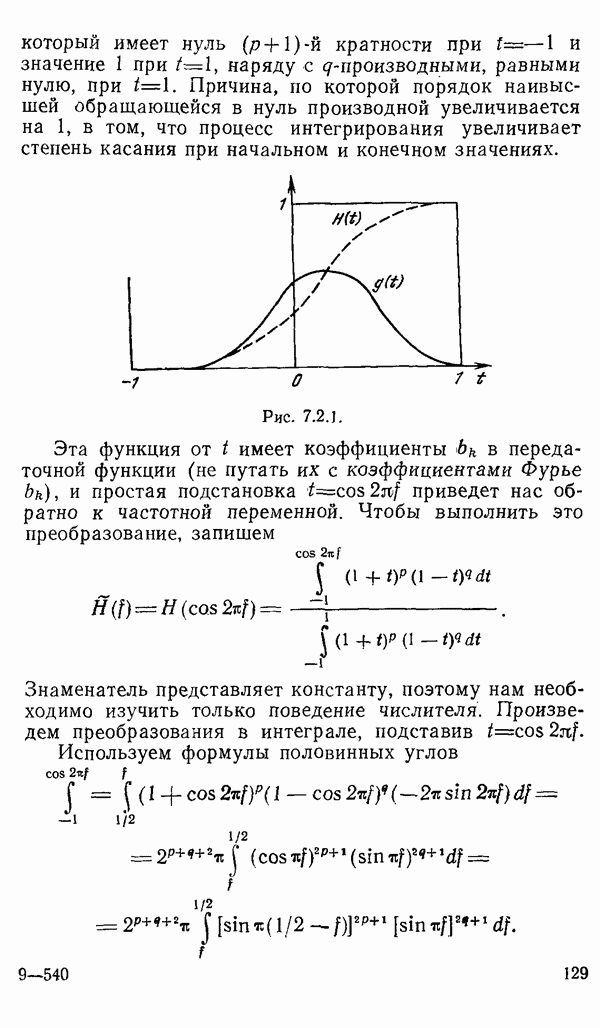














































































 есть длина только что упомянутого провода, тогда модель измерений будет иметь вид
есть длина только что упомянутого провода, тогда модель измерений будет иметь вид

 читается: «вероятность того, что длина
читается: «вероятность того, что длина  меньше или равна х. Таким образом,
меньше или равна х. Таким образом,  есть вероятность того, что измеренная длина
есть вероятность того, что измеренная длина  меньше или равна
меньше или равна  называется интегральной функцией распределения для
называется интегральной функцией распределения для  Во многих случаях
Во многих случаях  имеет производную
имеет производную  т. е.
т. е.

 называется плотностью, либо плотностью вероятности для
называется плотностью, либо плотностью вероятности для 

 — параметры, значения которых зависят от конкретной моделируемой ситуации (рис. 1.5,1, б).
— параметры, значения которых зависят от конкретной моделируемой ситуации (рис. 1.5,1, б).
 до
до  в последнем сохраняемом разряде. Следовательно,
в последнем сохраняемом разряде. Следовательно,


 или в других случаях плотности
или в других случаях плотности  служит среднее или ожидаемое значение (также называемое математическим ожиданием). Оно обозначается
служит среднее или ожидаемое значение (также называемое математическим ожиданием). Оно обозначается  или
или  и определяется как
и определяется как



 на у, получим
на у, получим


 на функцию. Если вспомнить о моментах (да это и очевидно), получим, что среднее значение постоянной величины есть сама эта величина
на функцию. Если вспомнить о моментах (да это и очевидно), получим, что среднее значение постоянной величины есть сама эта величина  Помимо этого, если в модели
Помимо этого, если в модели  — константа,
— константа,  переменная величина, то
переменная величина, то  а если, кроме того, еще и
а если, кроме того, еще и  — константа, тогда
— константа, тогда 
 если
если  — случайная величина, и определяется как
— случайная величина, и определяется как

 имеет плотность
имеет плотность  Дисперсия
Дисперсия  значается также символом
значается также символом 






 представляет собой дисперсию,
представляет собой дисперсию,  среднее значение гауссового (нормального) распределения
среднее значение гауссового (нормального) распределения

 тесно связана с принципом наименьших квадратов (который устанавливает, что «наилучшее соответствие» имеет место тогда, когда сумма квадратов ошибок минимальна). В обоих случаях это сумма квадратов текущих разностей. При дисперсии имеют дело с отличием от используемого среднего значения, а при приближении по наименьшим квадратам — с отличием данных от используемой аппроксимации.
тесно связана с принципом наименьших квадратов (который устанавливает, что «наилучшее соответствие» имеет место тогда, когда сумма квадратов ошибок минимальна). В обоих случаях это сумма квадратов текущих разностей. При дисперсии имеют дело с отличием от используемого среднего значения, а при приближении по наименьшим квадратам — с отличием данных от используемой аппроксимации.