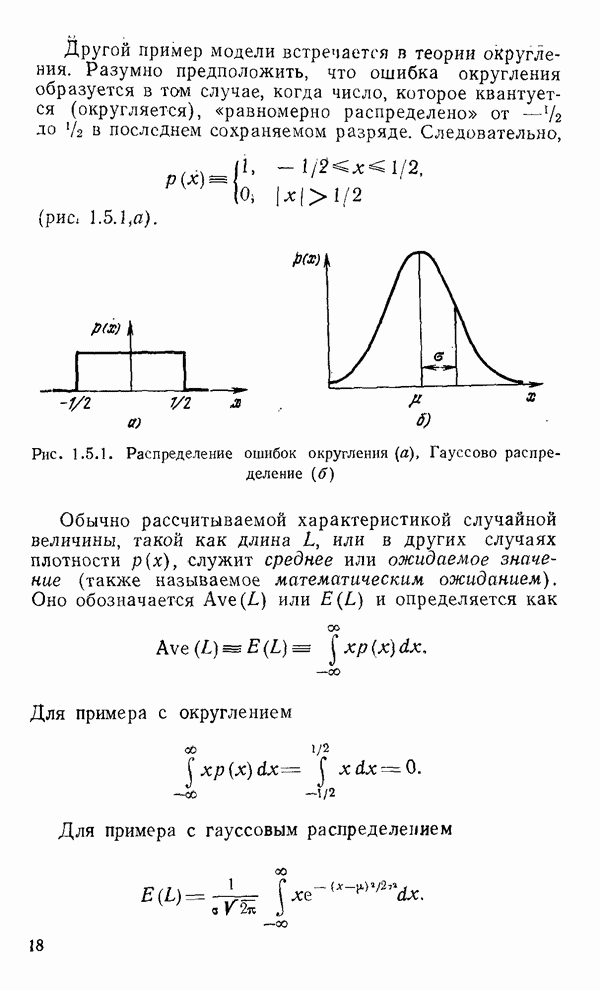
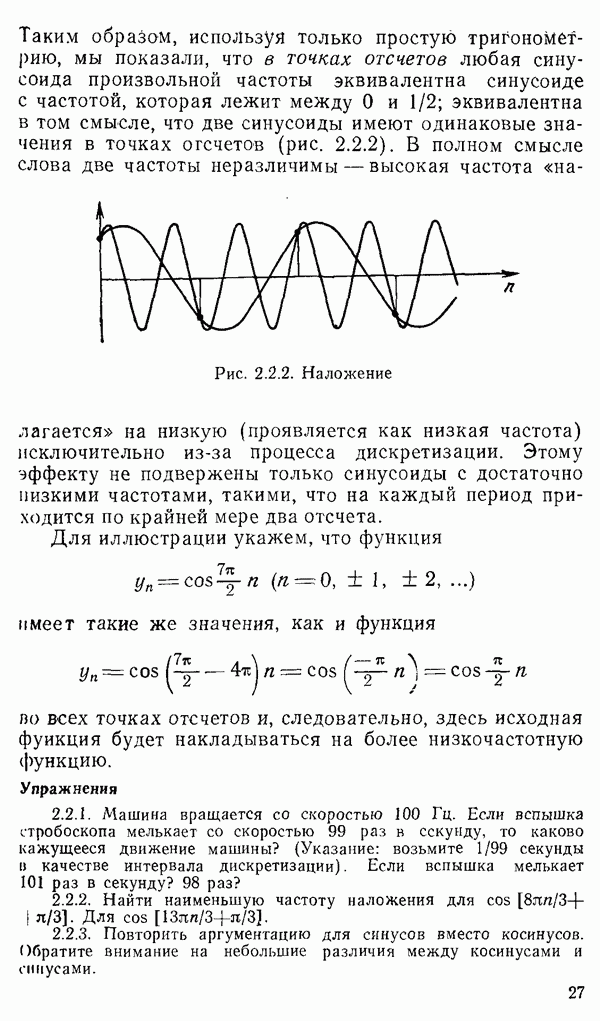
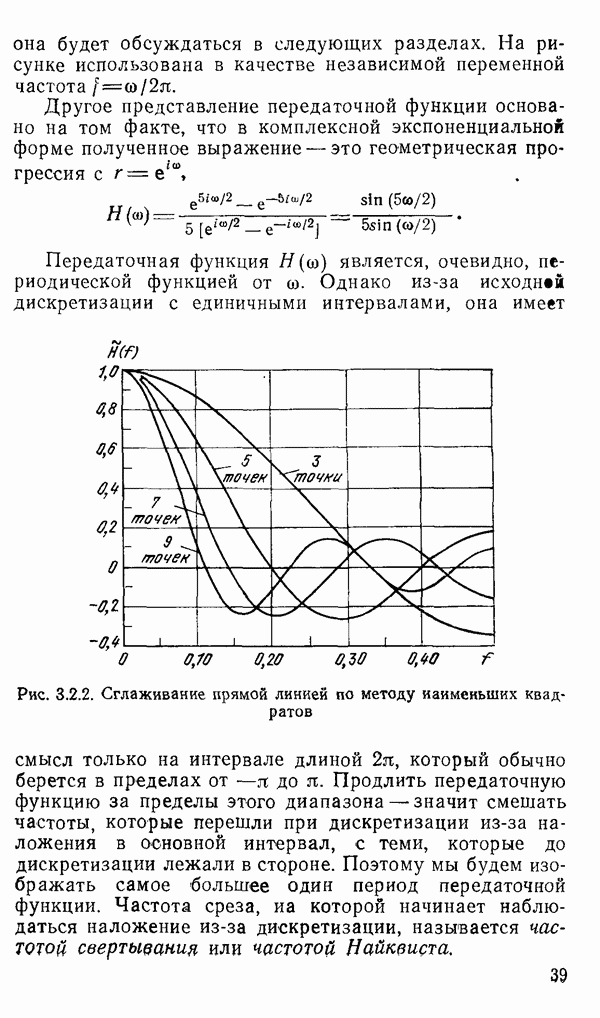
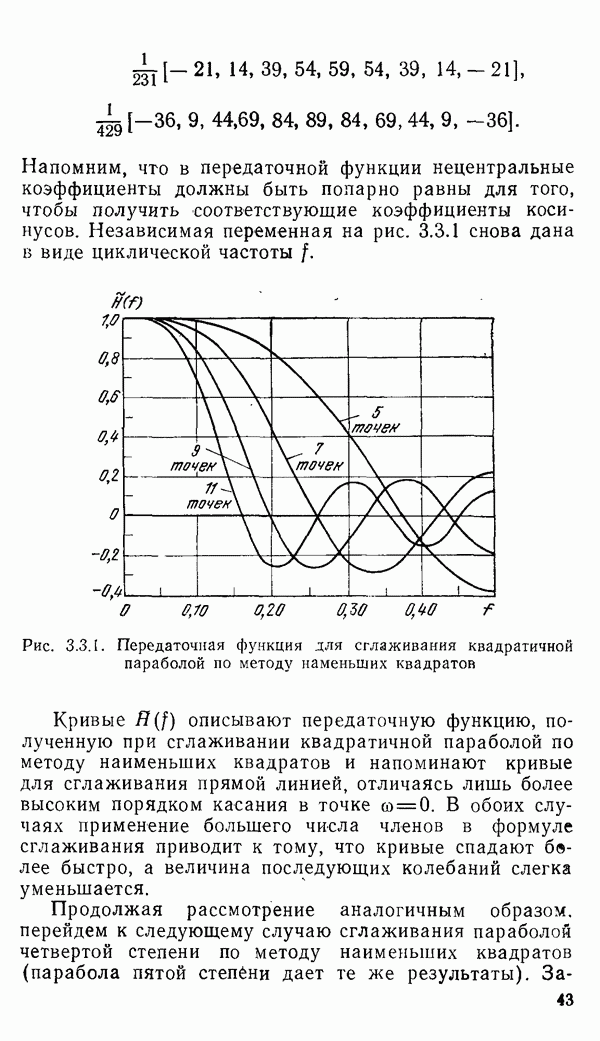
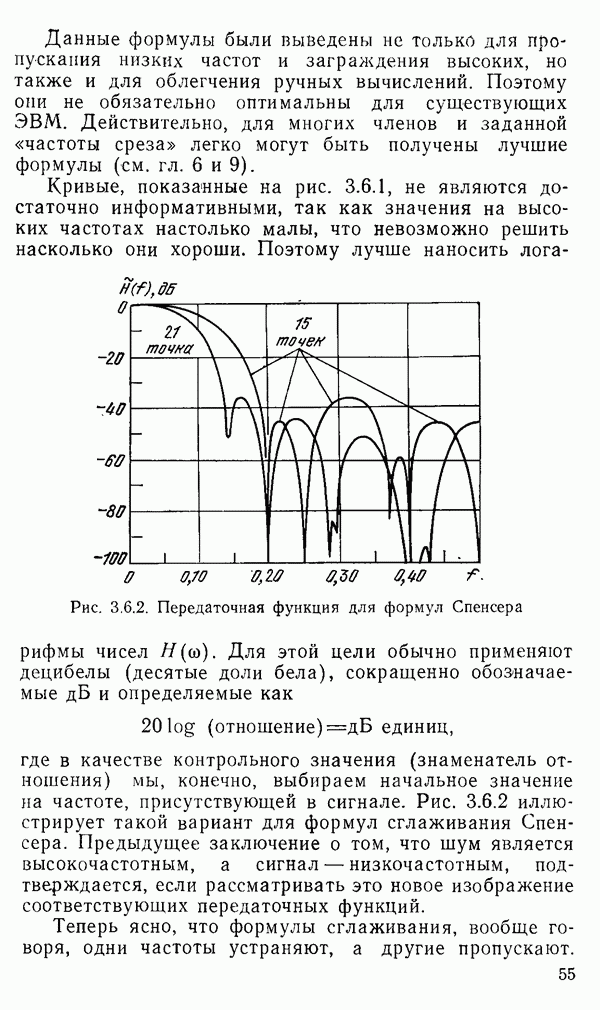
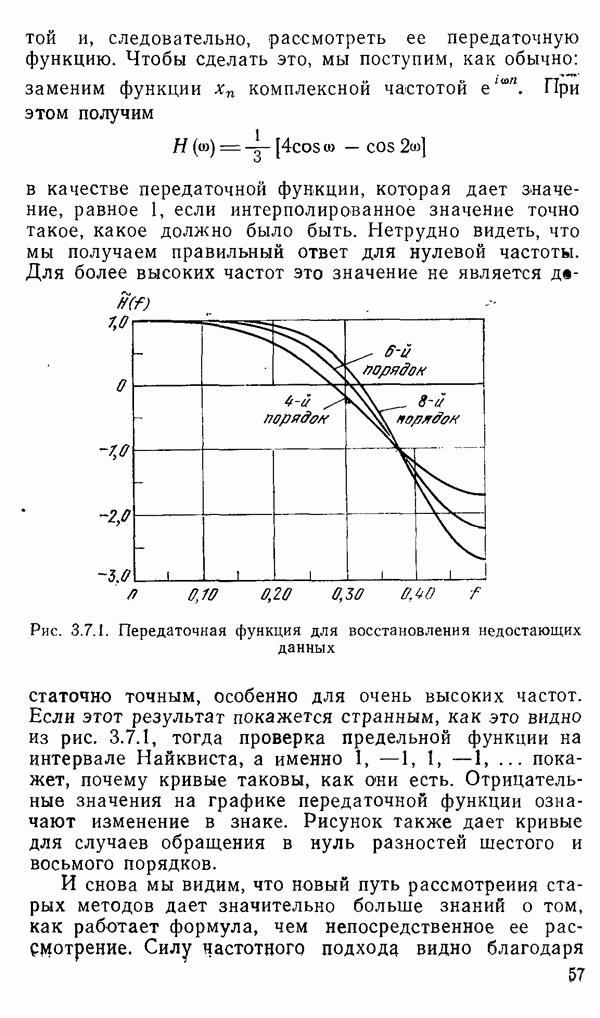
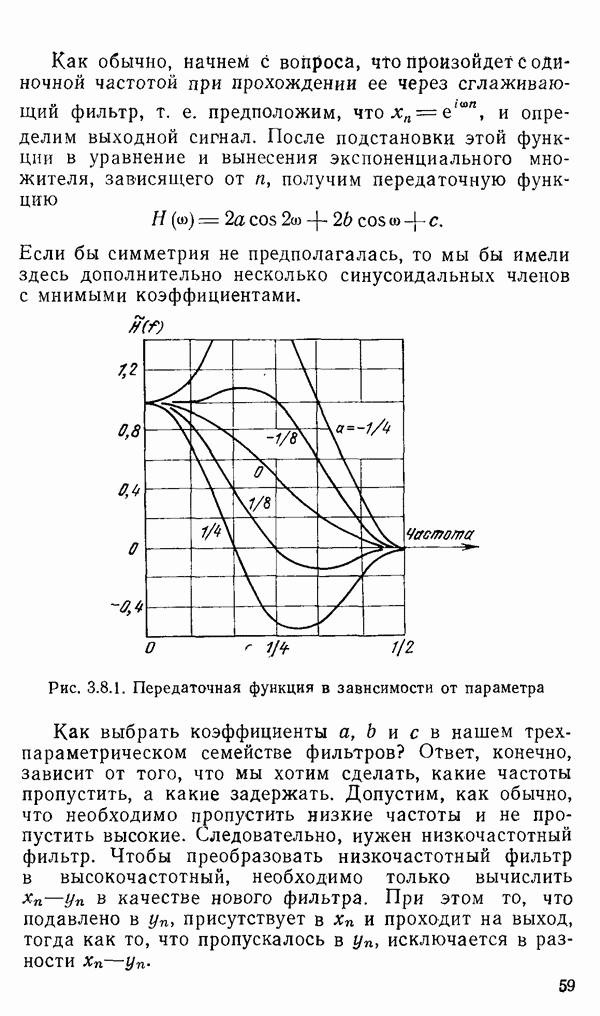
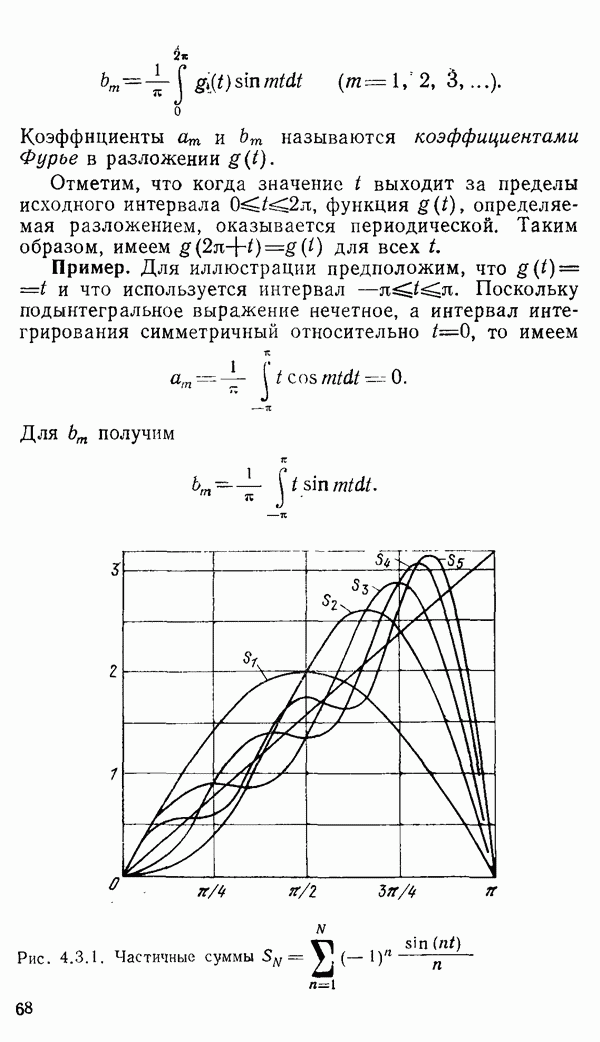
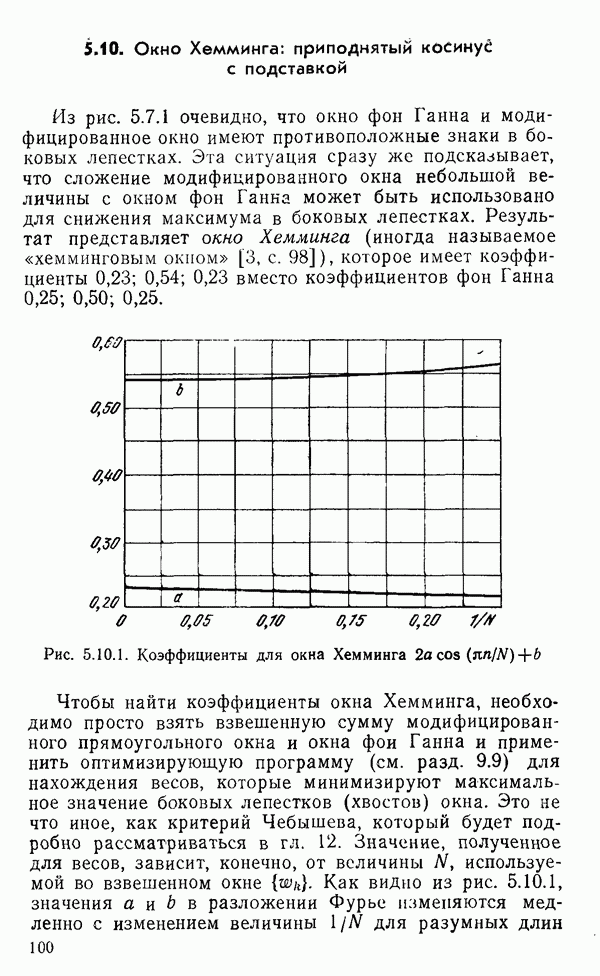
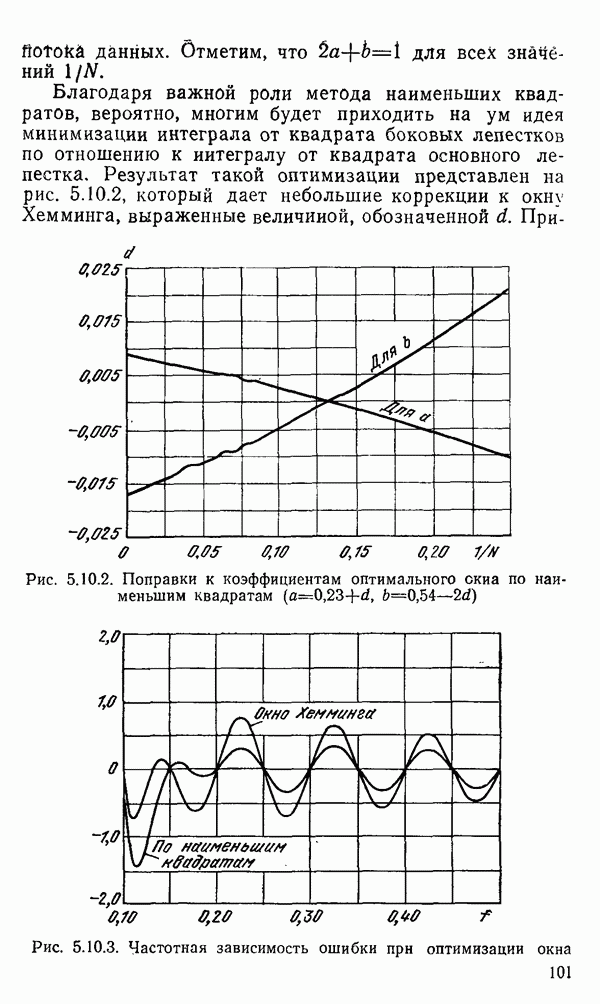
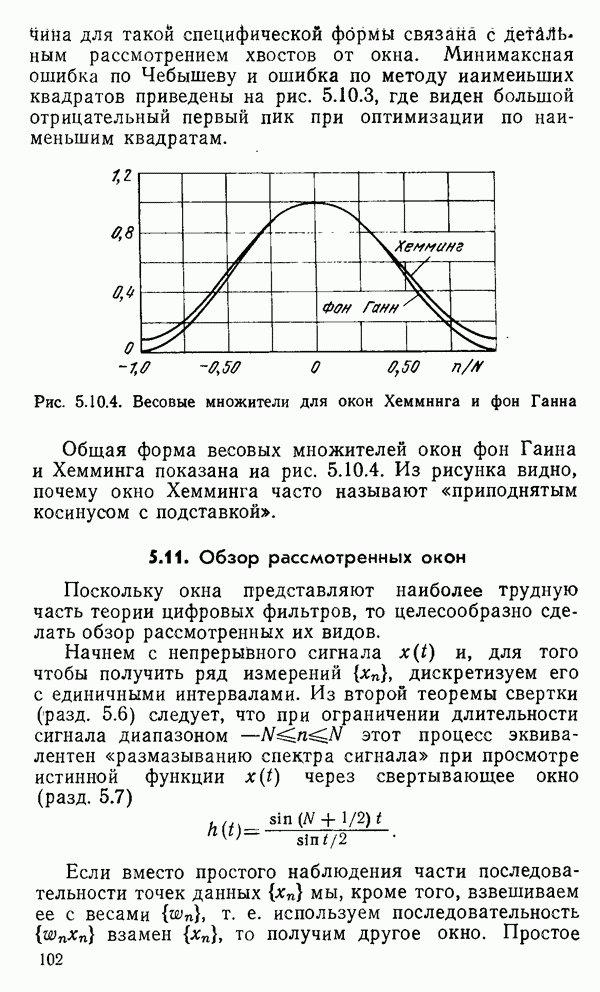
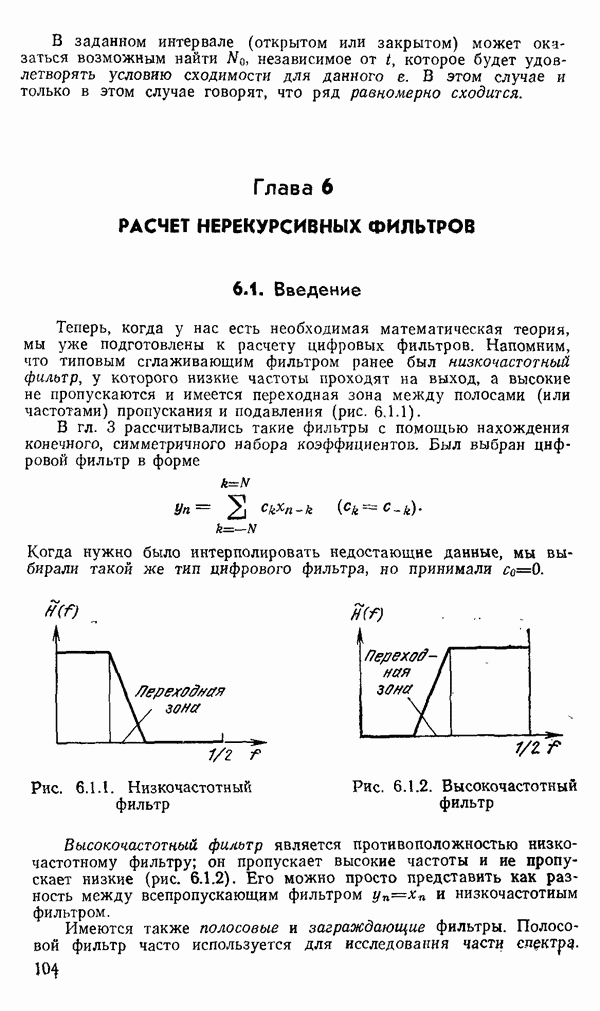
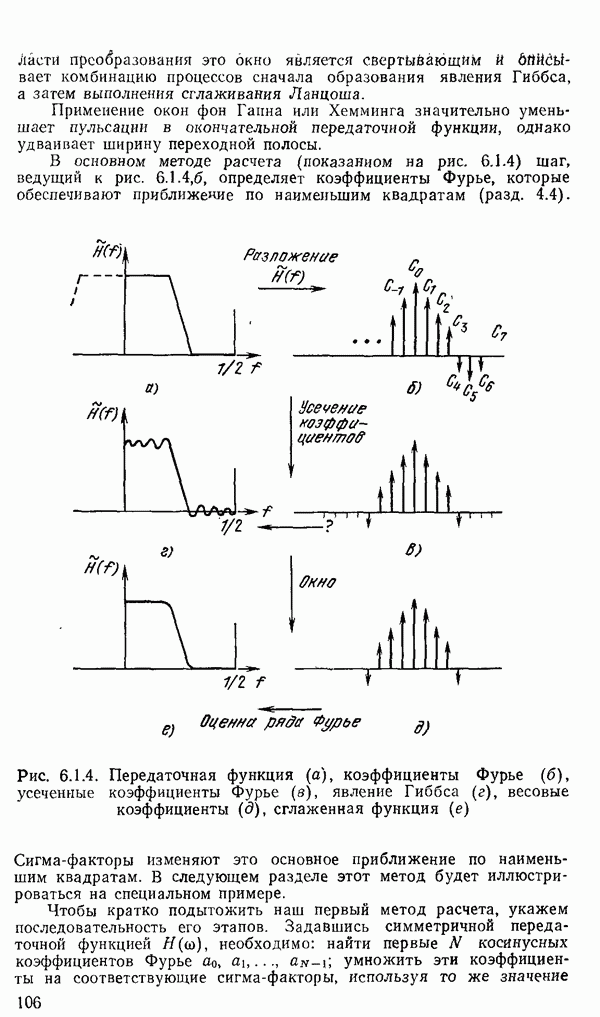
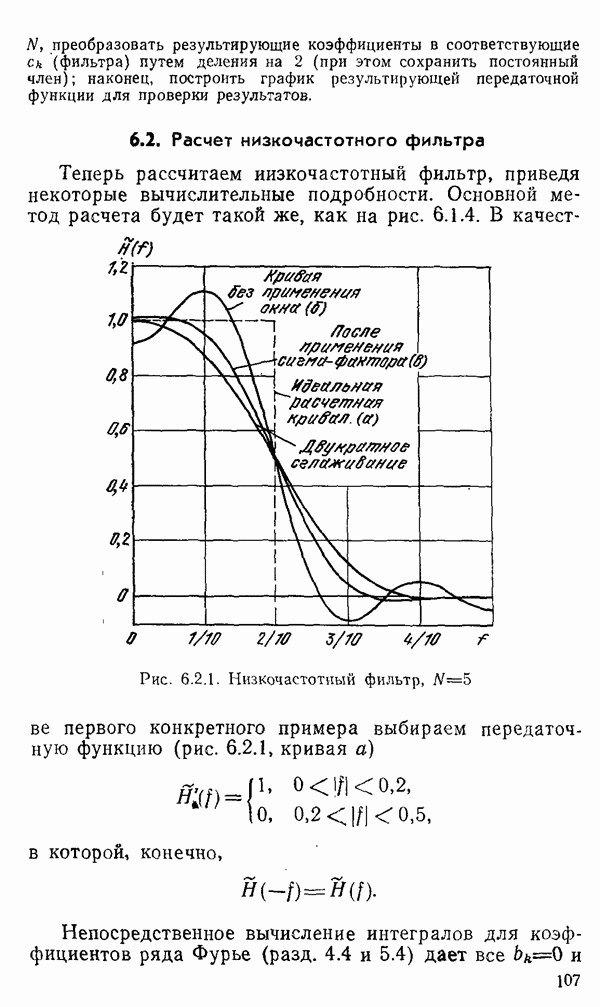
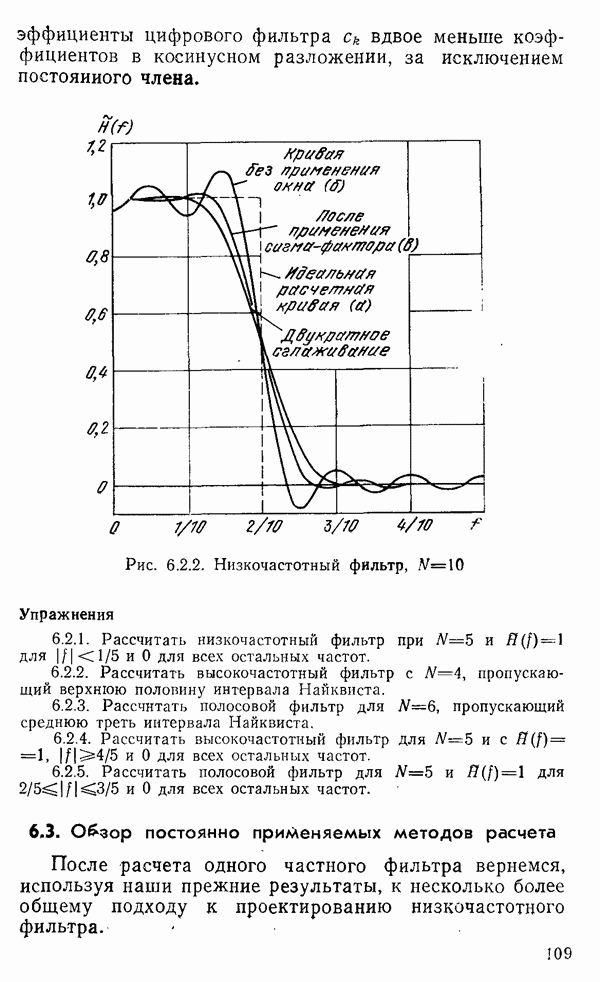
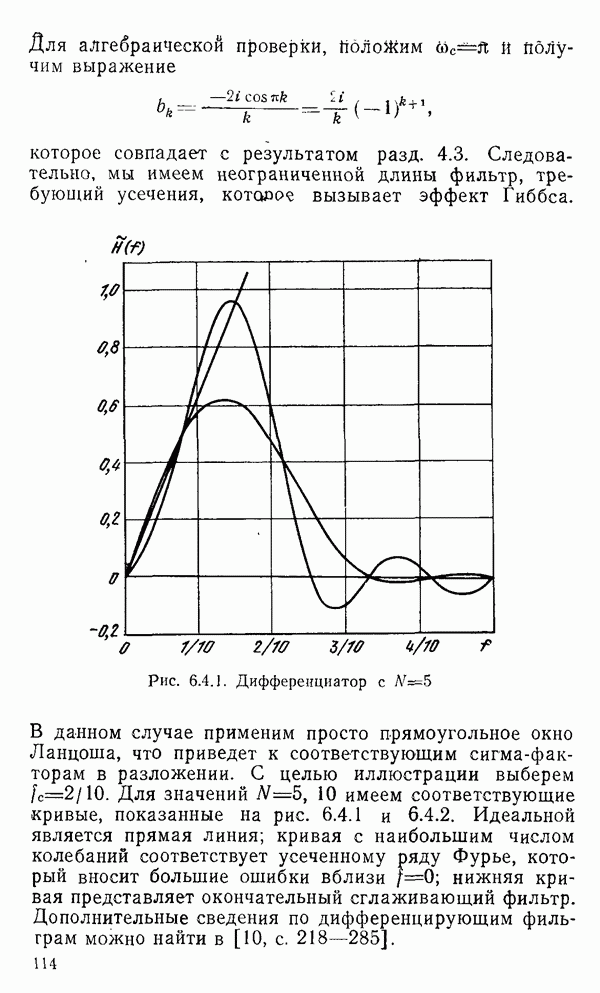
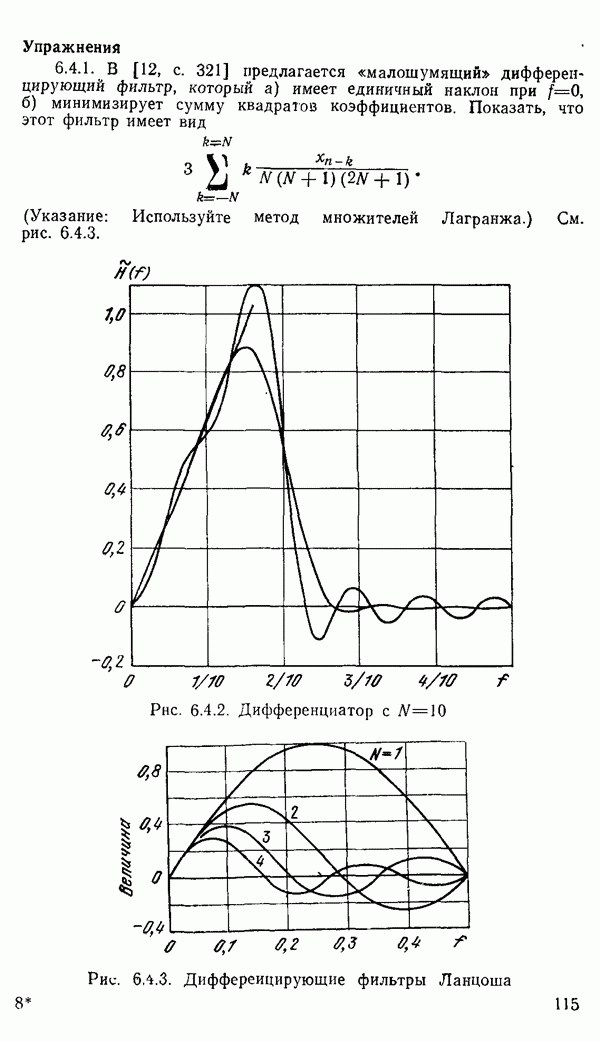
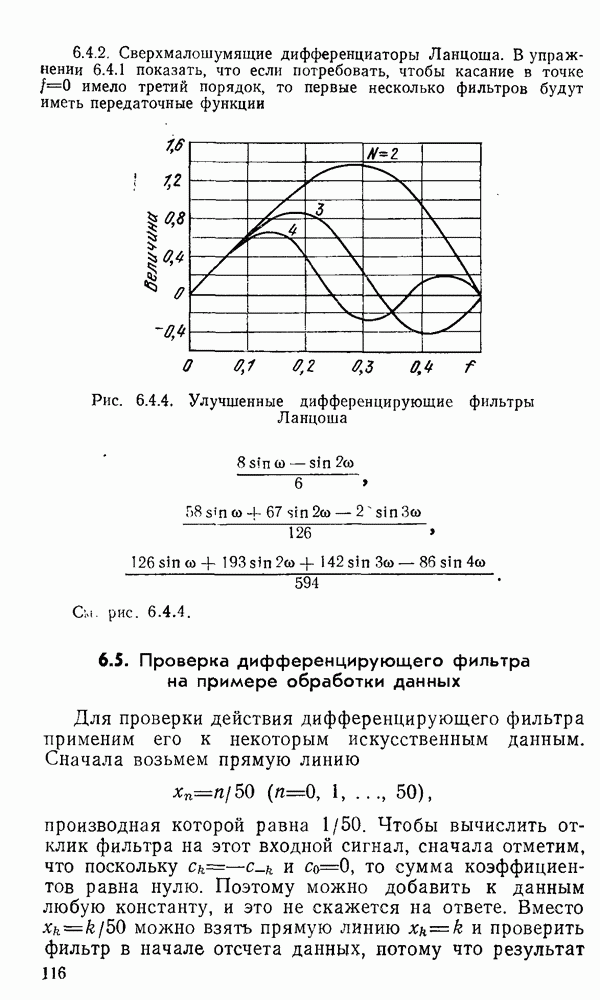
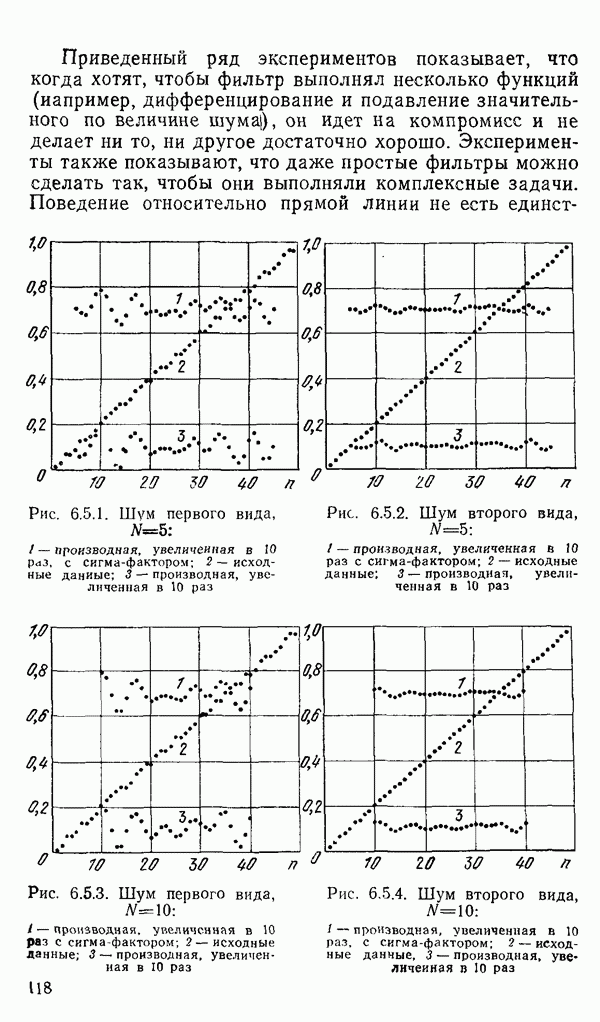
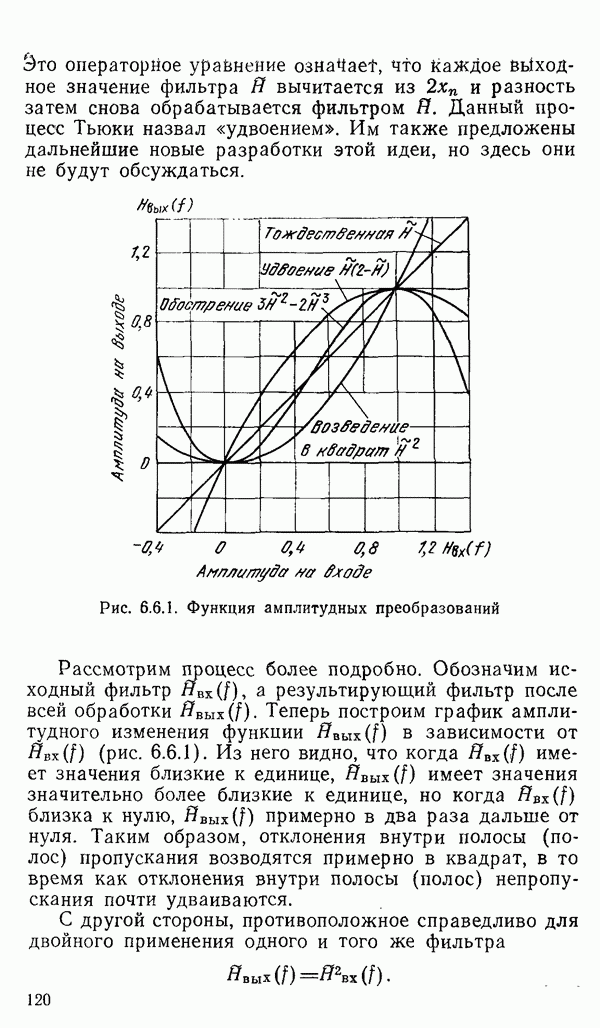
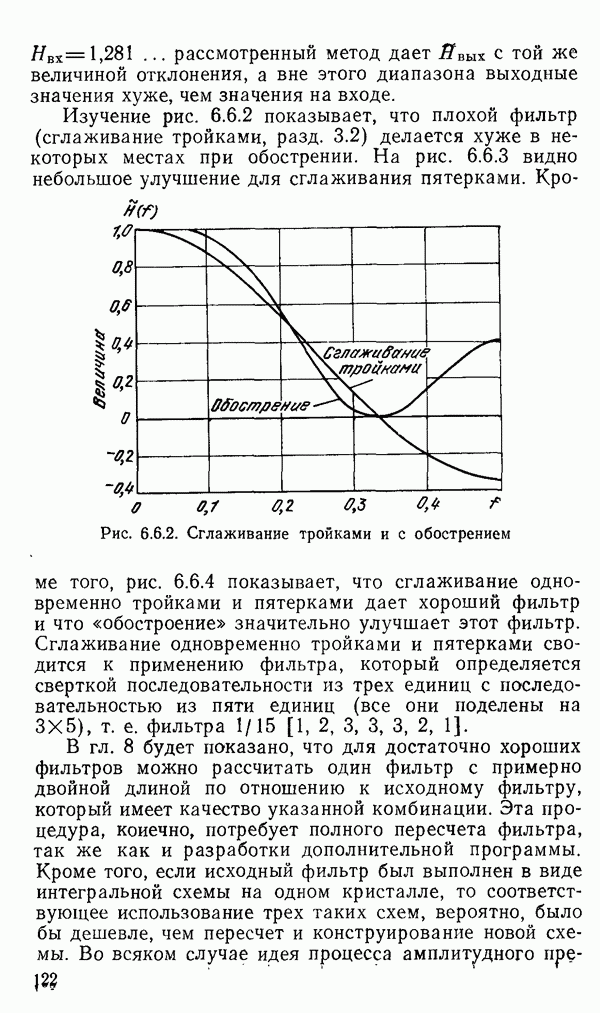
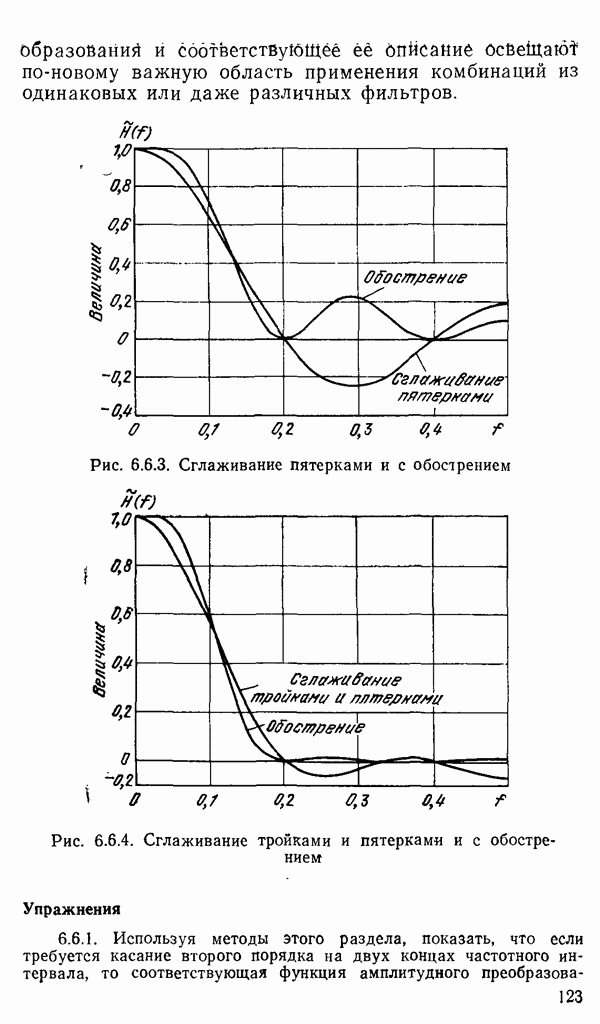
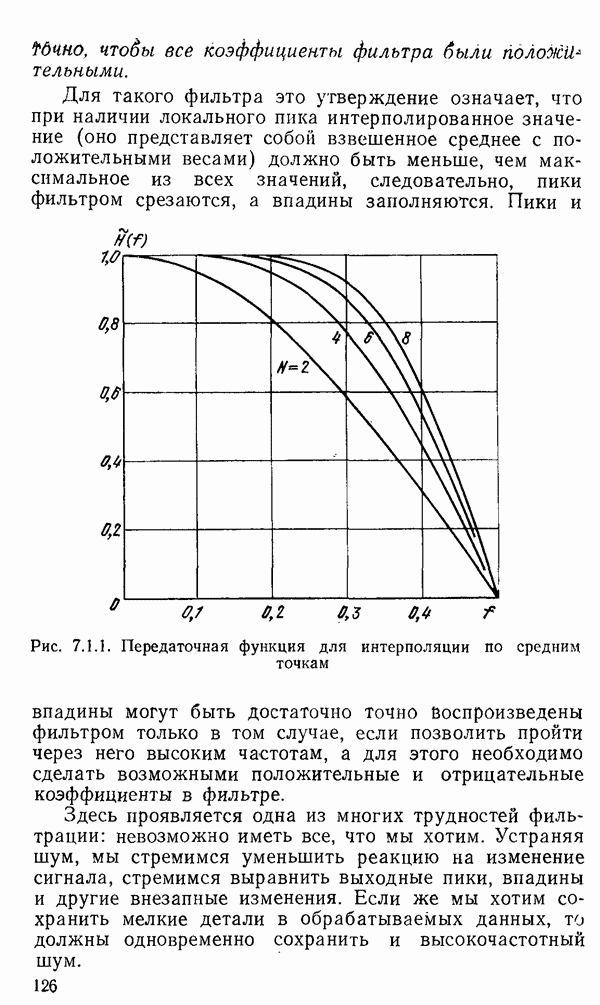
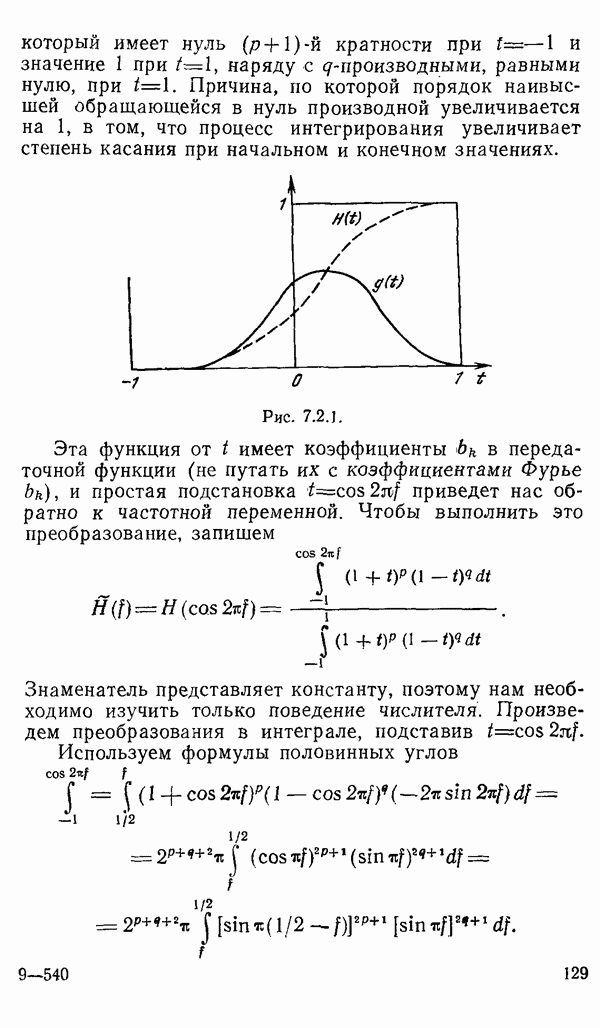
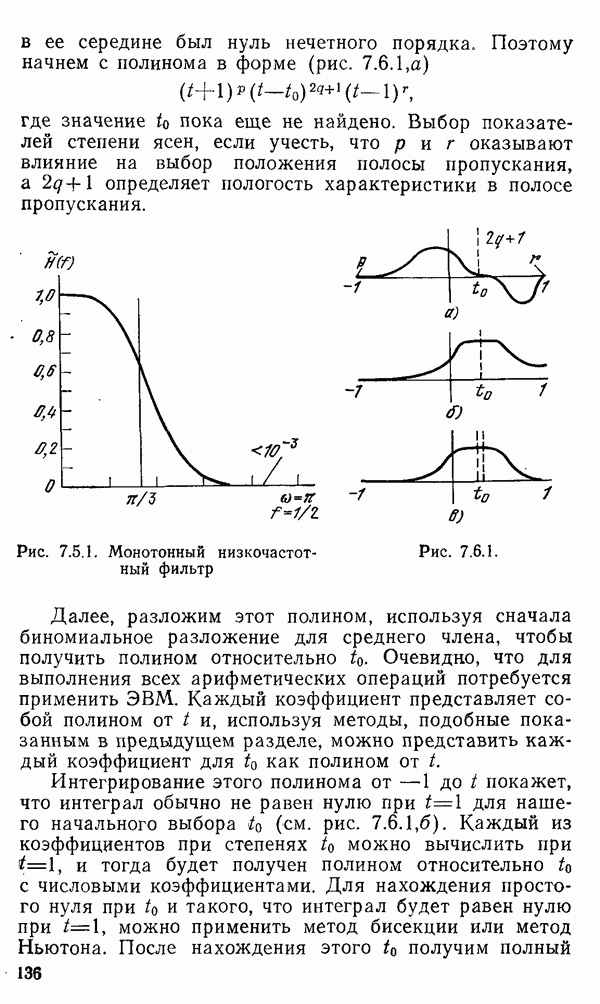
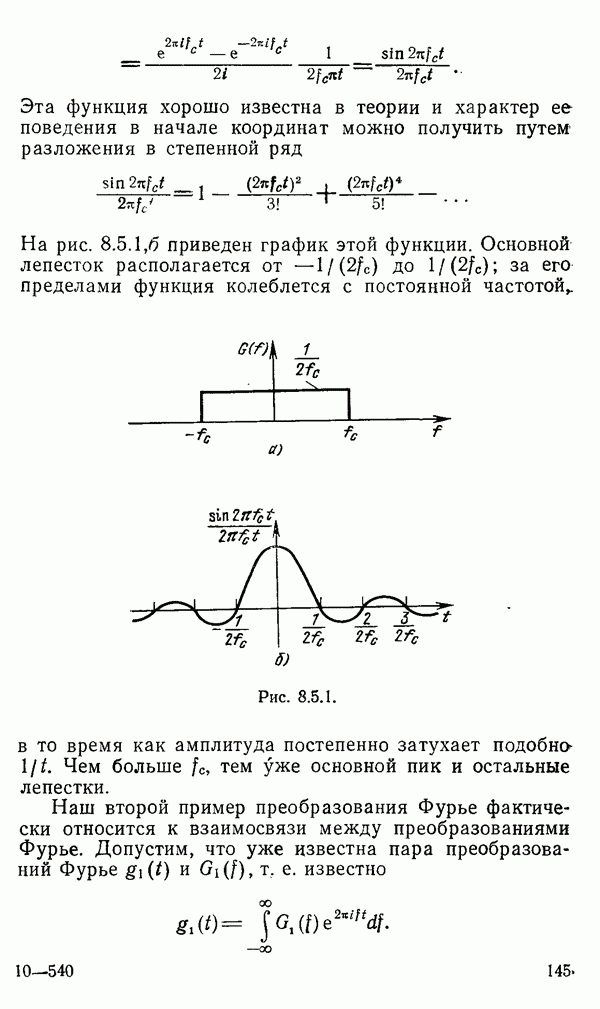
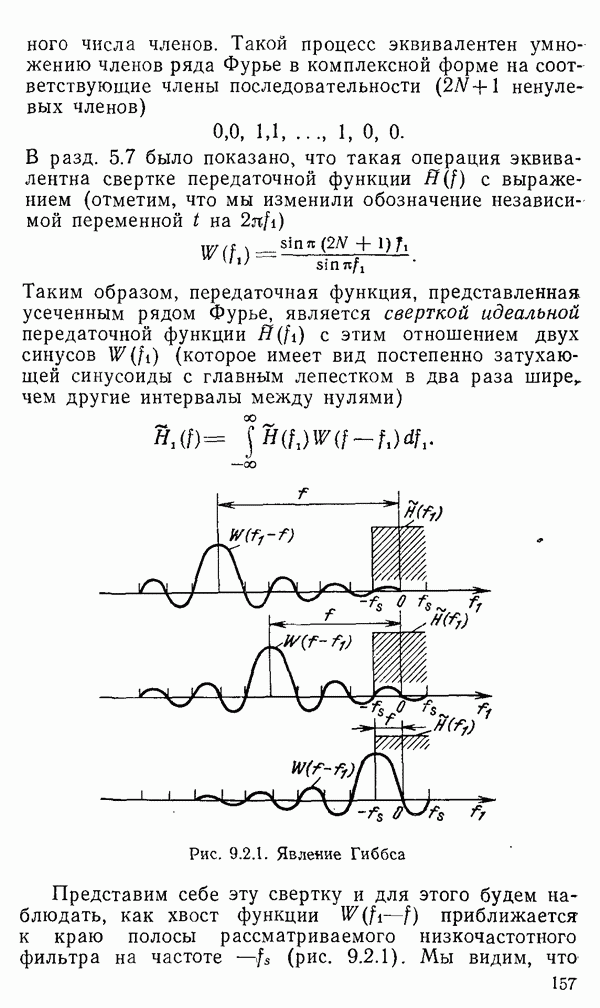
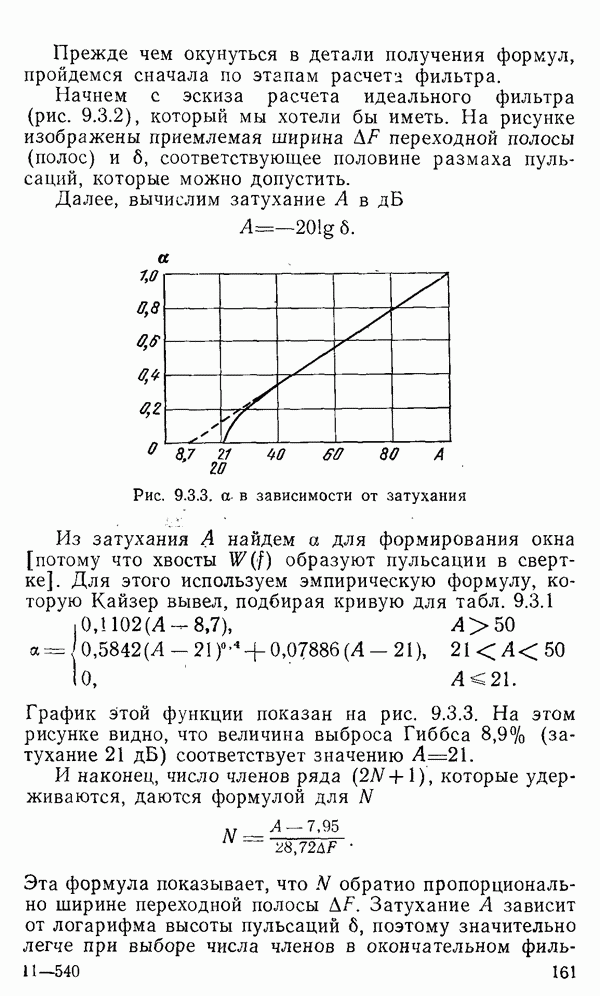
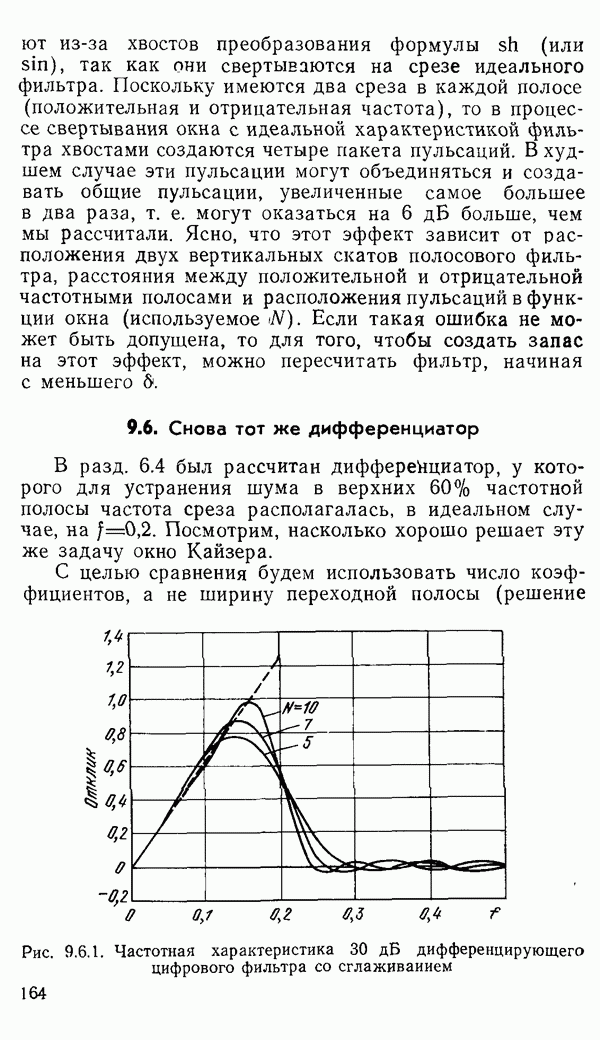
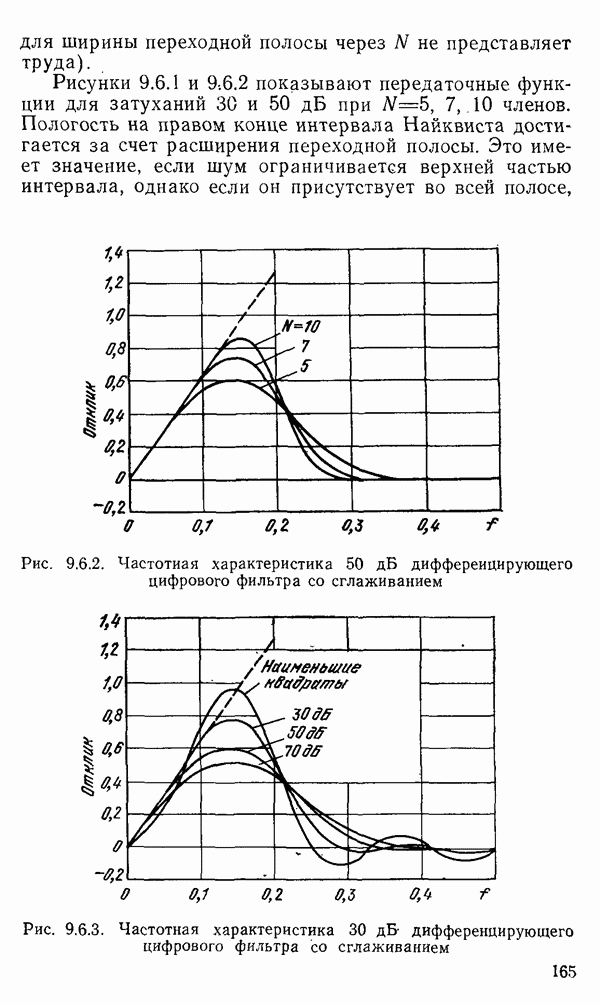
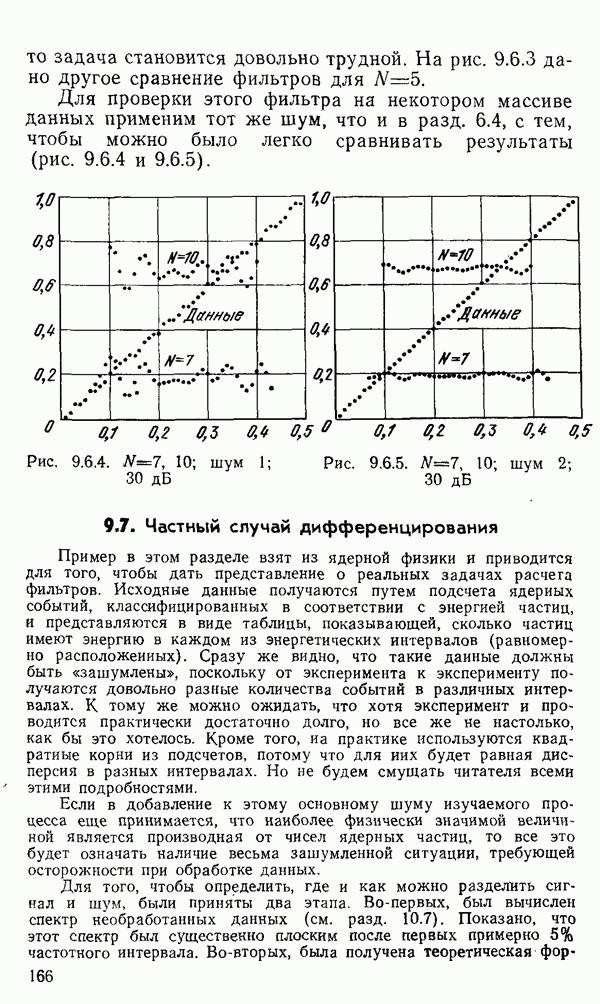
1.6. Распределение статистики
Теперь вернемся к тому, что, вероятно, представляет наиболее трудную проблему для начинающего изучать математическую статистику: к понятию распределения статистики (или статистических параметров, таких как среднее значение или дисперсия выборки).
Предположим, что мы сделали ряд измерений и что по этой выборке вычислили одну или несколько статистик. Например, мы можем случайным образом выбрать 1000 американцев из общего населения около 200 миллионов и измерить рост каждого. Исходя из полученных данных, можно вычислить среднее значение выборки х. Дисперсия  выборки определяется следующим образом:
выборки определяется следующим образом:

Для ясности, обычно используют греческие буквы для обозначения статистик модели и латинские буквы для соответствующей статистики выборки.
Хорошо бы знать указанные два числа для выборки, которую мы взяли. Однако, если от этих чиеел ждут большой пользы, то сразу же возникает вопрос: что разумного можно получить для уточнения среднего значения, если весь процесс повторить снова, используя
Таблица 1.6.1. (см. скан)
Связь статистик выборки и множества
разную случайную выборку 1000 американцев? Короче говоря, что такое «среднее» распределения статистики? Очевидно, повторение всего процесса выбора людей, проведение измерений и вычисление среднего даст нам распределение величин среднего значения х (и распределение дисперсии 
В примере с округлением имелась уникальная модель для исходного множества чисел, из которого извлекались округленные значения, а в примере с гауссовым распределением достаточно оценить два неизвестных параметра множества: распределение  по статистикам выборки
по статистикам выборки  Можно поинтересоваться, какая существует связь между этими парами чисел (табл. 1.6.1). В руководствах по статистике доказывается, что для любого распределения среднее выборки есть несмещенная оценка среднего значения исходной совокупности. Аналогично дисперсия выборки
Можно поинтересоваться, какая существует связь между этими парами чисел (табл. 1.6.1). В руководствах по статистике доказывается, что для любого распределения среднее выборки есть несмещенная оценка среднего значения исходной совокупности. Аналогично дисперсия выборки  определяется несмещенной оценкой
определяется несмещенной оценкой  Несмещенная оценка означает, что в среднем оценки не слишком велики и не слишком малы, т. е. среднее значение статистики равно той величине, которая оценивается.
Несмещенная оценка означает, что в среднем оценки не слишком велики и не слишком малы, т. е. среднее значение статистики равно той величине, которая оценивается.
Если выборка достаточно велика  тогда центральная предельная теорема утверждает, что статистика, называемая средним значением, имеет распределение, очень близкое к гауссовому (нормальному) распределению
тогда центральная предельная теорема утверждает, что статистика, называемая средним значением, имеет распределение, очень близкое к гауссовому (нормальному) распределению

с параметрами 
Упражнение
(см. скан)