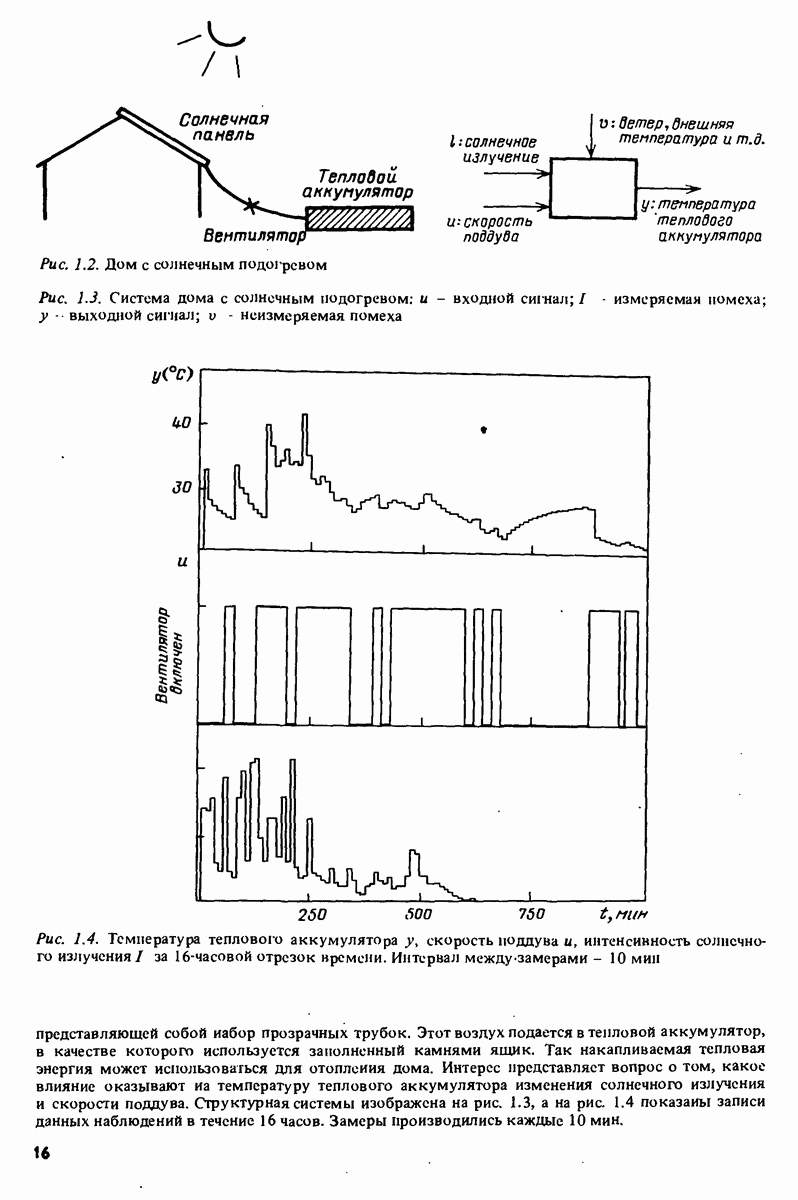
Пред.
След.
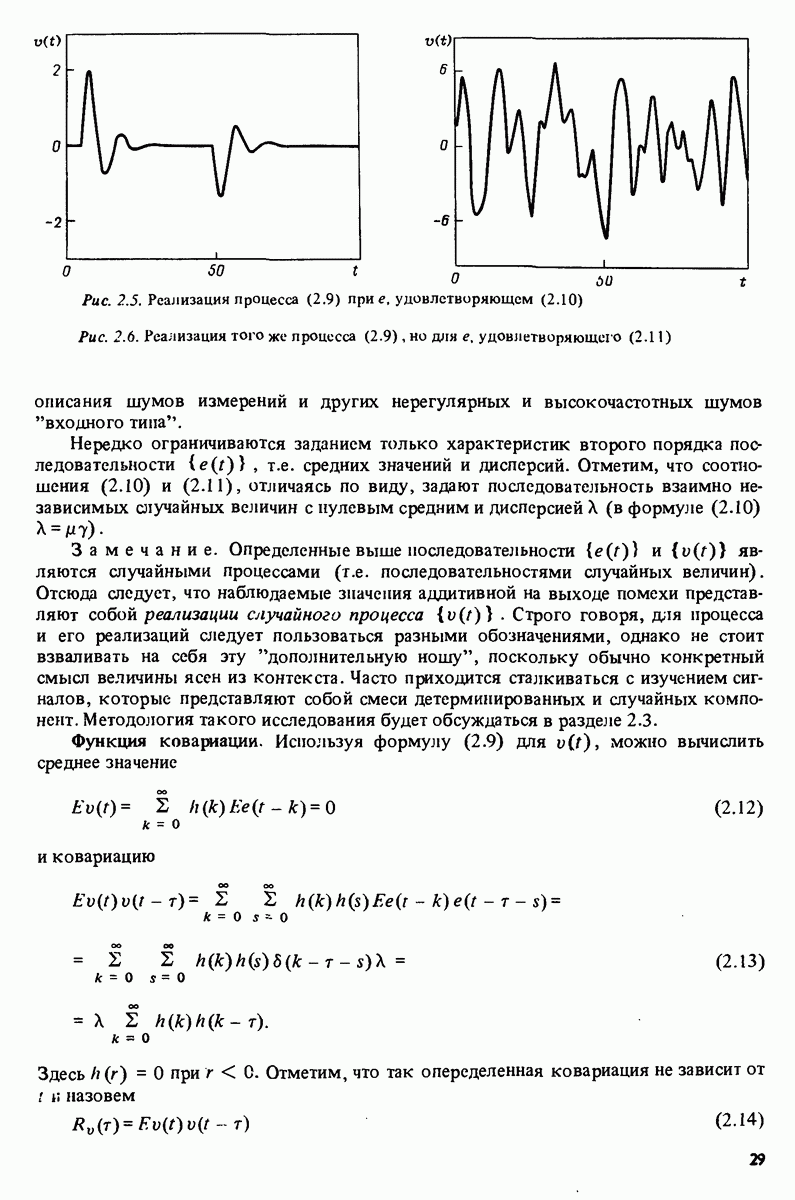
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
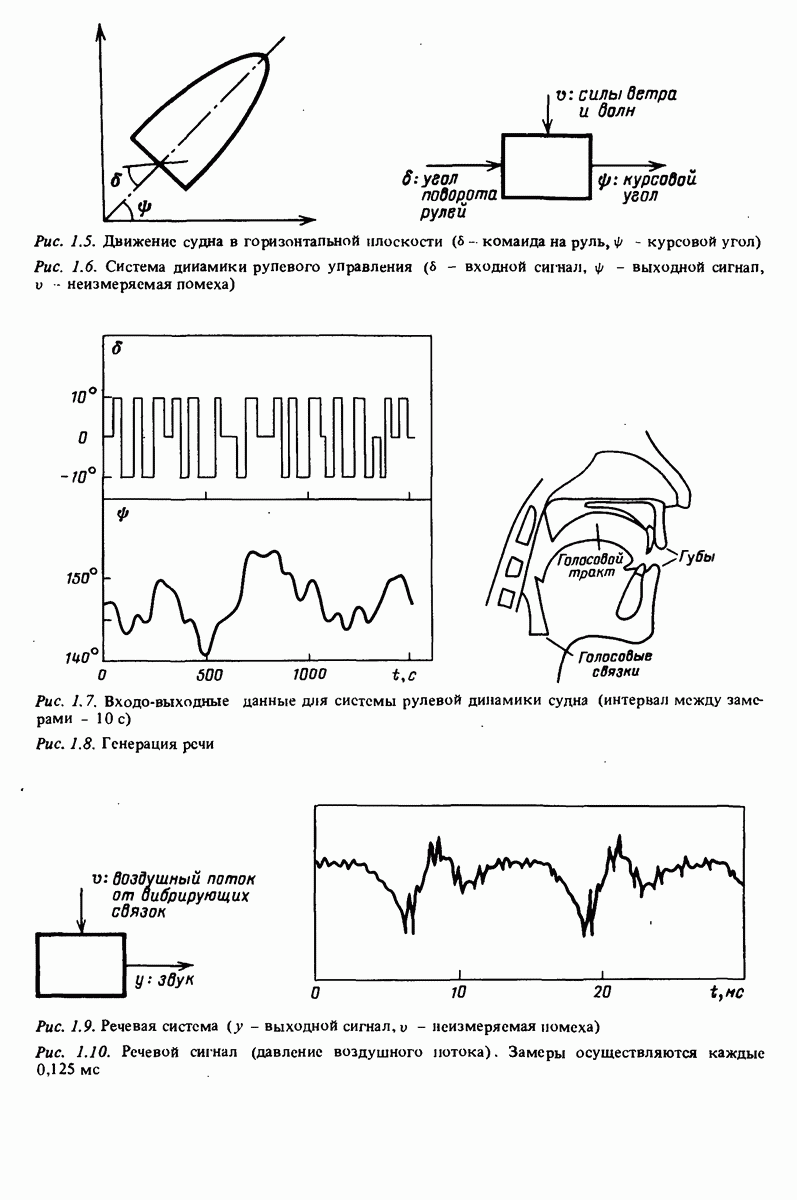
ZADANIA.TO
16.4. Сравнение модельных структурНаиболее естественно при поиске подходящей структуры модели перебрать несколько вариантов и сравнить полученные результаты. В этом разделе мы обсудим, как осуществляется сравнение при разной степени формализации. Большое значение при просмотре разных моделей имеют также методы подтверждения моделей из раздела 16.5. Сравнение моделей на новых данных: взаимное подтверждение. Нет ничего удивительного в том, что модель будет хорошо работать на том множестве данных, которое использовалось для ее настройки. Настоящая проверка состоит в том, чтобы убедиться в возможности применения модели взаимного подтверждения, они известны в нескольких вариантах. См., наиример, работы Стоуна [403] и Сни [363]. Критерием при сравнении могла бы быть, например, сумма квадратов ошибок предсказания или рассогласования между фактическими выходными сигналами и смоделированными Ум Сравнение моделей на уже использованных множествах данных: предварительная оценка с позиций практики. Если возможность сохранить часть информационного материала нетронутой в целях взаимного подтверждения отсутствует, то для сравнения двух моделей приходится вновь воспользоваться теми же множествами данных, на которых осуществлялась настройка моделей. Последнее существенно усложняет процесс сравнения. Модель, которая строилась в рамках более широкой структуры, будет автоматически придавать меньшее значение критерию согласия, поскольку соответствующее значение получено как минимальное при минимизации на множестве большего размера. Поэтому по мере расширения модельной структуры (как в
Рис. 16.1. Минимальное значение функции потерь как функции размера модельных структур Начнем с того, что чем больше особенностей, присущих данным, учитывается в модели, тем меньше становится значение Предложено несколько формализованных процедур, которые используются для формальной регистрации коленоподобных фрагментов. Мы в данном разделе эти процедуры опишем, но сначала прокомментируем их содержательный смысл. Имеется две основные идеи. Первая состоит в том, чтобы проимитировать идею метода взаимного подтверждения, т. е. использовать величину Критерий подтверждения модели. Рассмотрим скалярную меру подтверждения
где
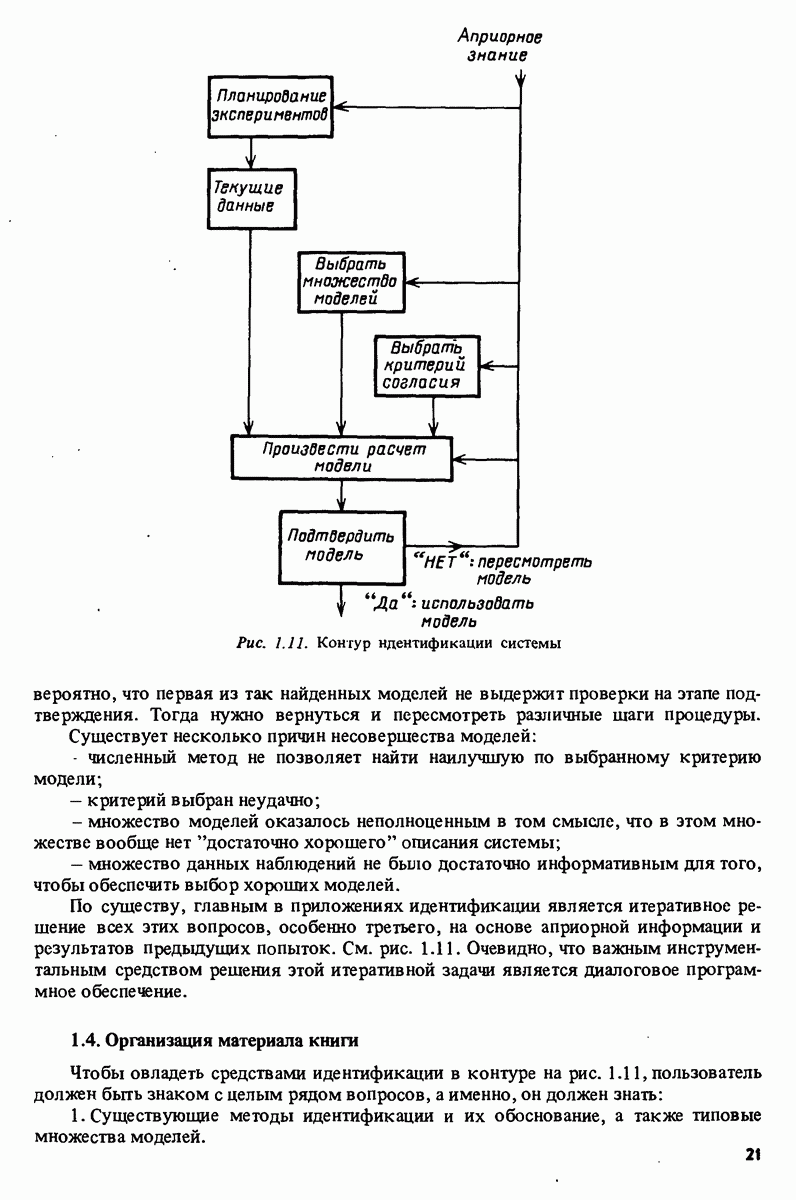
На этом этапе функция Пусть
Аналогично в силу того, что
Чтобы определить математические ожидания от этих двух выражений, используются следующие асимптотические формулы:
где Кроме того,
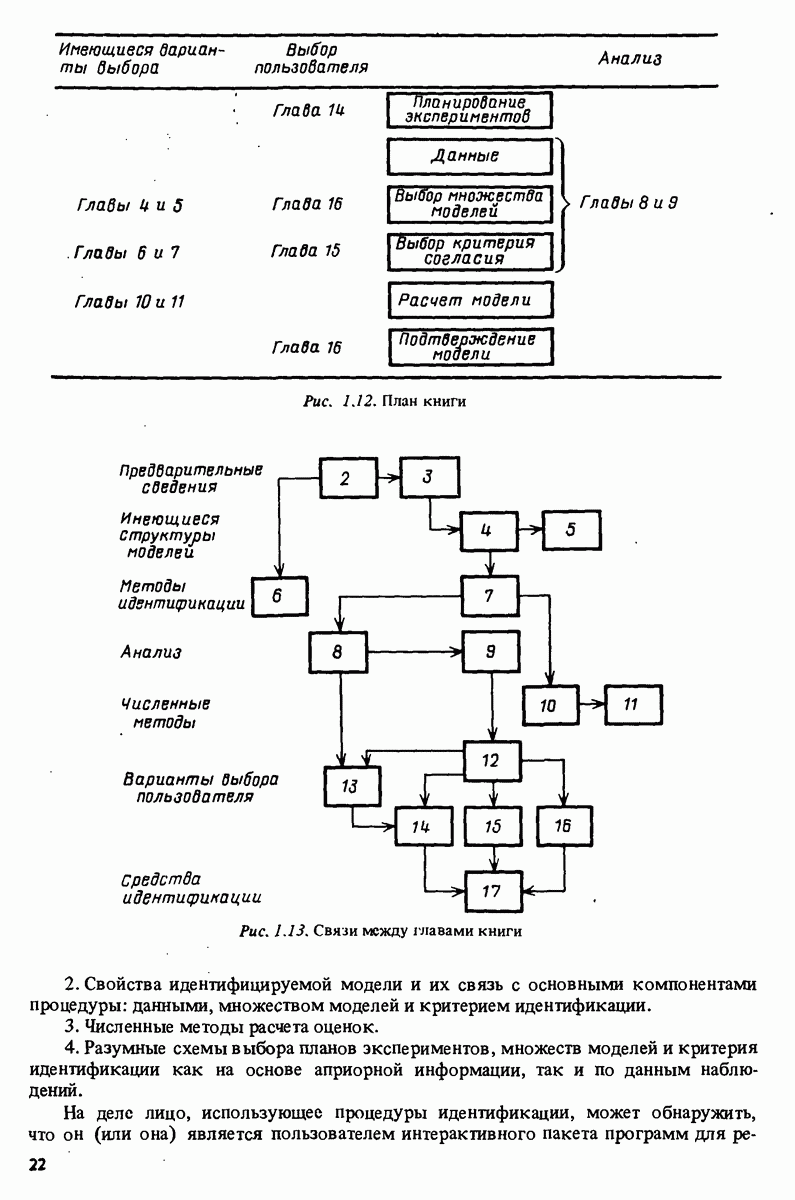
и
Это при усреднении формул (16.19) и (16.20) соответственно дает
Отсюда находим, что
где последнее приближение состояло в том, что среднее значение Используя это общее выражение, мы можем рассмотреть несколько частных вариантов Информационный критерий Акаике (ИКА). Пусть критерий ошибки предсказания выбран в виде нормированной логарифмированной функции правдоподобия (см. (3.72) ):
Для случая, когда: — истинная система описывается вектором - параметры идентифицируемы так, что матрица из асимптотического результата раздела 9.3 известно, что
(см. (7.68), (7.77) и (9.29)). Подстановка (16.27) в (16.24) позволяет записать критерий в виде
поскольку
Это выражение совпадает с ИКА (7.94). Таким образом, можно сформулировать совместную задачу определения структуры модели и оценивания параметров как
где Пример 16.1. ИКА для гауссовых обновлений. Предположим, что обновления процесса гауссовы с неизвестной дисперсией
где
а внешняя минимизация
Существенный в процессе минимизации член имеет вид
где последнее приближение получено из того, что Критерий финальной ошибки предсказания Акаике (ФОП). Вернемся к формуле (16.24) и допустим, что
В предположениях (16.26) из формулы (9.17) известно, что
где
Это дает в (16.24)
В силу формул (16.23)
В результате пригодную оценку
что при подстановке в (16.32) даст
Критерий (16.33) впервые был описан Акаике [3] и назван им критерием финальной ошибки предсказания (ФОП). Он отражает величину дисперсии ошибки предсказания, которая получается в усредненном варианте использования модели Штраф за сложность модели. С более практической точки зрения рассмотренные нами сейчас критерии могут интерпретироваться как совместные критерии для определения структуры модели и значений параметров в пределах фиксированной структуры. В принципе эти критерии можно было бы записать в виде
где
Эти критерии нанравлены на отыскание таких описаний систем, которые дают наименьшую среднеквадратическую ошибку. Та модель, которая определит лучшее согласие по заметно меньшей среднеквадратической ошибке (предсказания), может быть выбрана, даже если она будет достаточно сложной. На практике может возникнуть желание ввести в функционал (16.35) добавок, штрафующий за увеличение сложности и отражающий представления субъекта о плате за сложность: ”Я собираюсь взять более сложную модель (по моей собственной мере сложности), она должна оказаться существенно лучше!”. Что же такое сложная модель и какой штраф связывать с этой сложностью? Такие вопросы обычно решаются субъективно. Интересный подход предложен Риссаненом [338]. Он утверждает, что главная цель идентификации состоит в формировании максимально короткого описания. Это ведет к критерию типа (16.34), в котором
Критерии проверки статистических гипотез Выбор между двумя модельными структурами
Эта гипотеза проверяется на фоне альтернативной гипотезы
Если теперь Теперь нам хотелось бы принять решение о выборе между гипотезами Пусть обозначает предельную оценку в рамках модельной структуры Если эта величина определяет правильное описание системы
При пулевой гипотезе (16.37) из (16.39) следует, что
Таким образом, с помощью этого выражения нулевая гипотеза может быть проверена на любом желательном доверительном уровне а. Если Использование (16.40) сводится к решению отвергнуть
где
Это соотношение в зависимости от значения разности Для малых
(сравните с леммой 11.4). Опираясь на это асимптотическое Сравнение линейных регрессий. Использование критерия (16.33) или критериев проверки гипотез (16.40) требует проведения расчетов модели для каждой из проверяемых структур. Это может оказаться трудоемкой работой. При этом важно, что применительно к модельным структурам типа линейной регрессии эта процедура существенно упрощается. Пусть самая большая модельная структура, которая будет рассматриваться в семействе
Пусть в этой структуре минимальное значение функции потерь равно
Построим ортонормальную матрицу
Тогда из
Предположим теперь, что в формуле (16.44) удаляется последний регрессор
т. е. оно возросло на Лемма 16.1. Рассмотрим линейную регрессию (16.44). Пусть
Наибольшие вычислительные трудности связаны с расчетом значений обсуждавшихся в этом разделе критериев может быть выполнена на высоком уровне эффективности. Характерным примером применения подобных методов к системной идентификации является решение задачи оценивания порядков модели и временных запаздываний. Соответствующее упорядочение регрессоров очевидно. Для общих задач регрессии с упорядочением ясности меньше. Подробное обсуждение этих вопросов можно найти в книгах Дрейпера и Смита [101] и Дэниела и Вуда [90]. В 1968 году Ивахненко [188] предложил особый способ перебора на множестве возможных модельных структур (типа линейной регрессии), который ведется только на основе экспериментальных данных - это метод группового учета аргументов (МГУА). Этот метод, который вызвал интерес, может быть представлен как процедура поиска на дереве всевозможных комбинаций регрессоров вида
где
|
 |
Оглавление
|





























































































































































































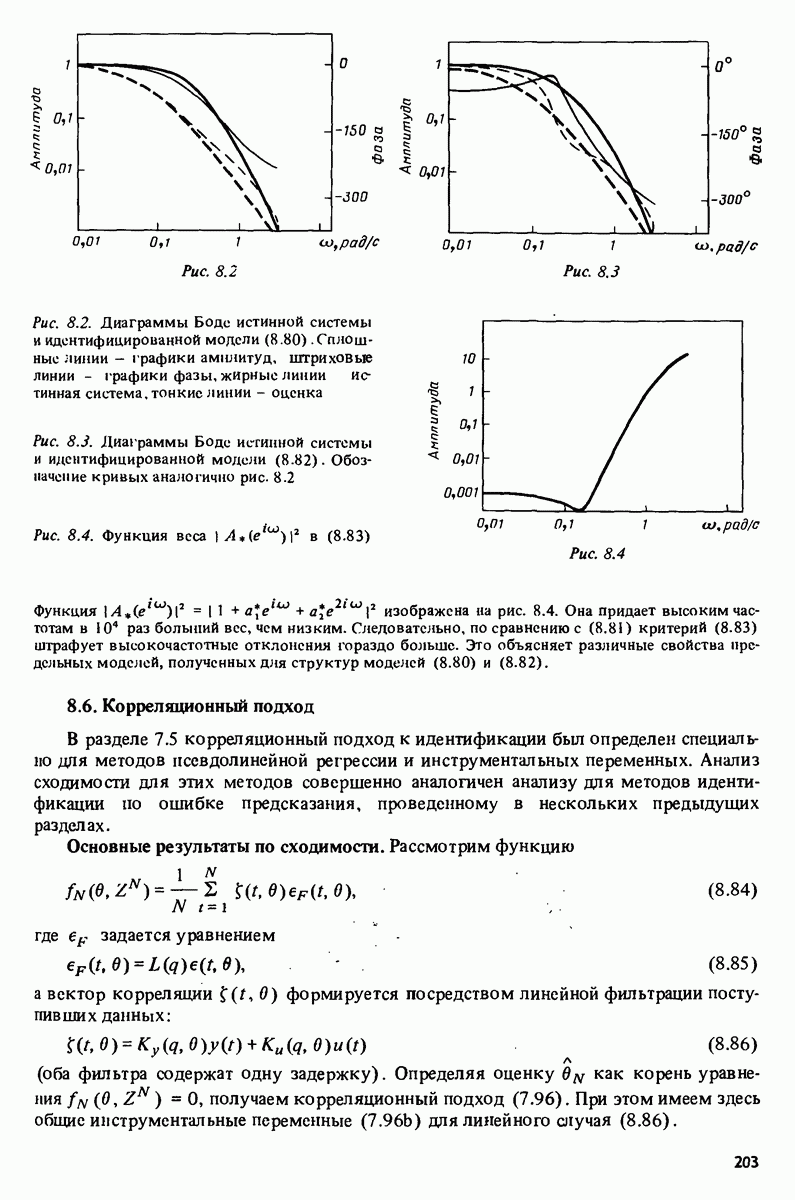


















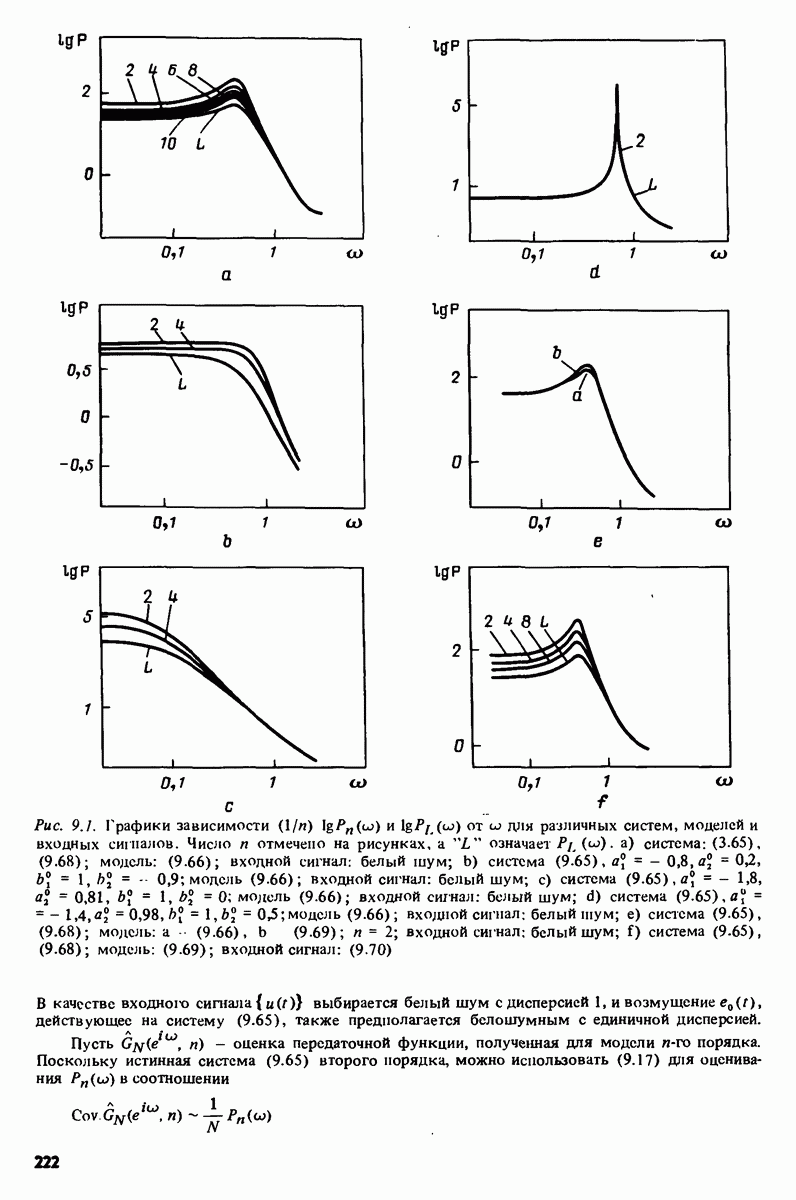






















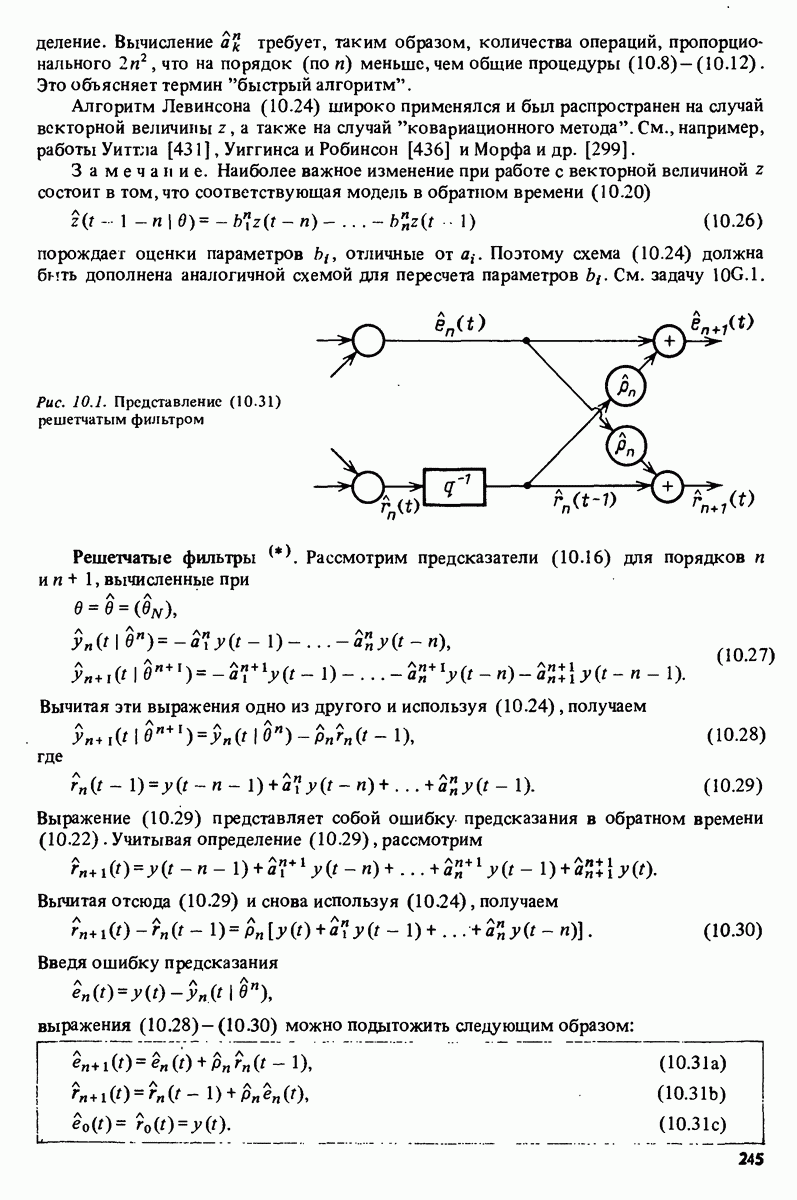










































































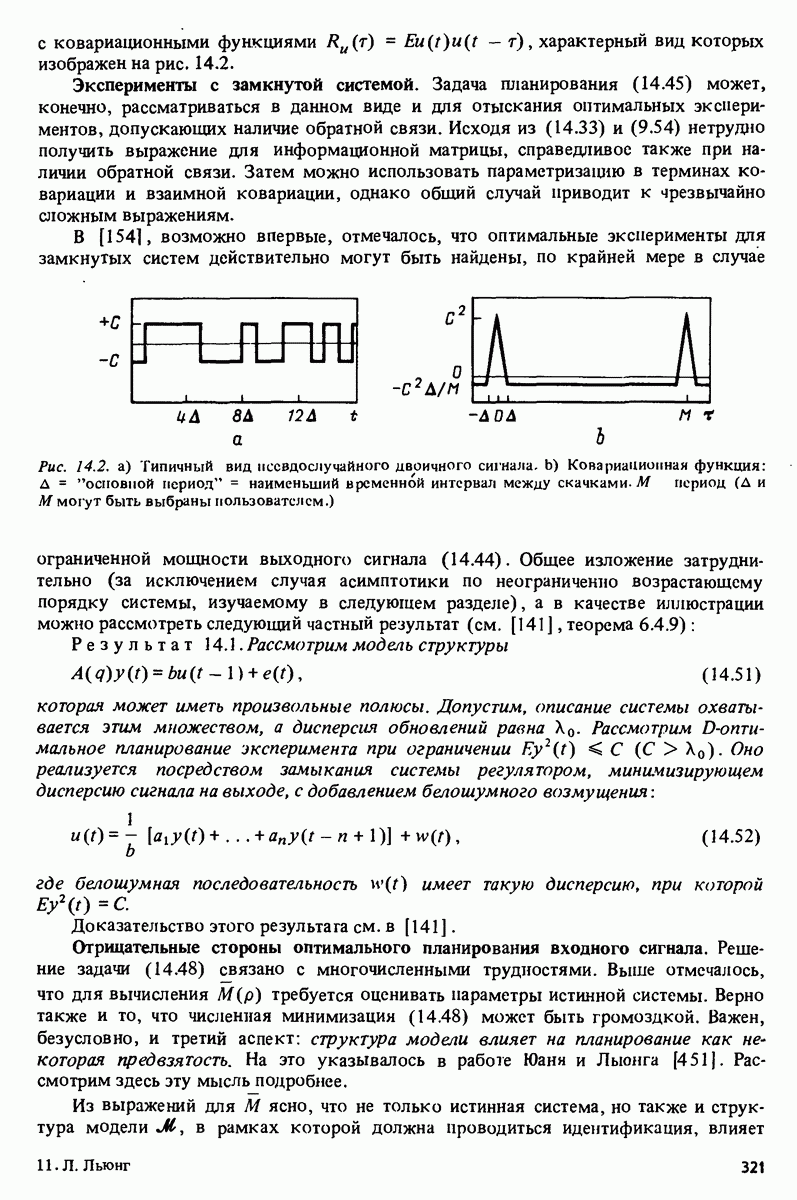








































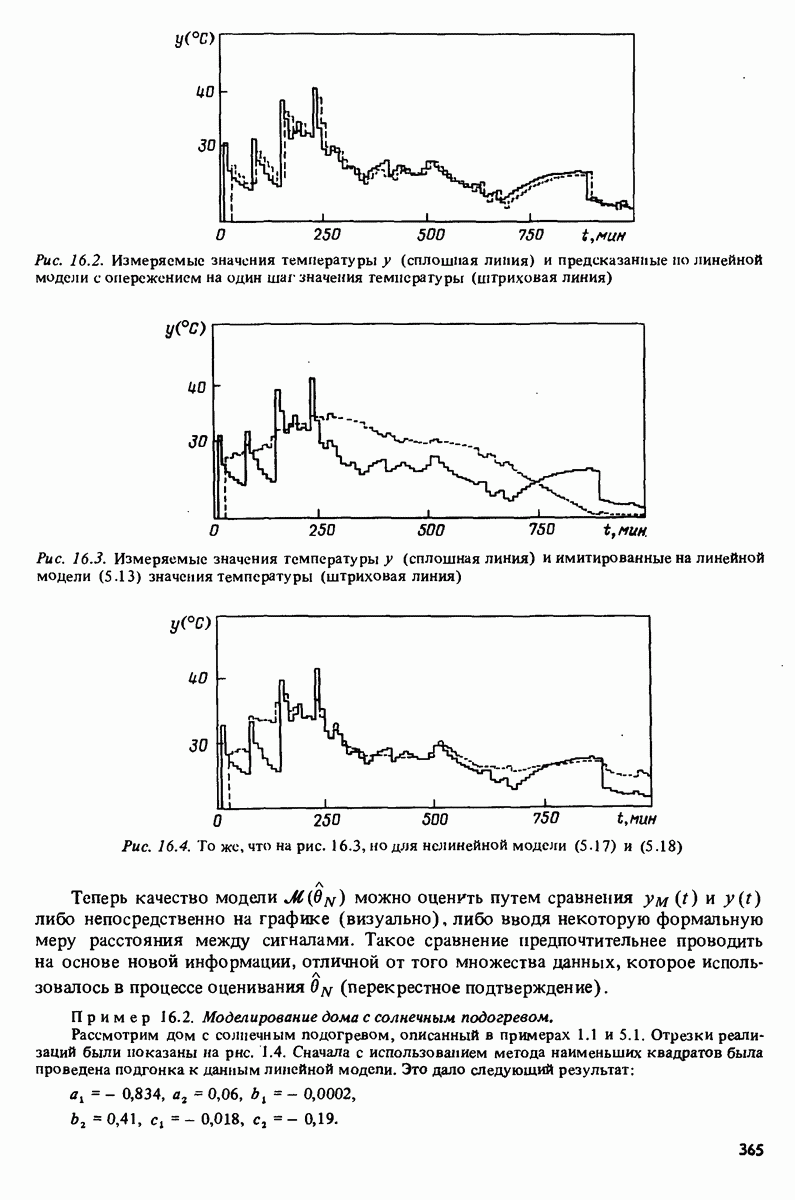






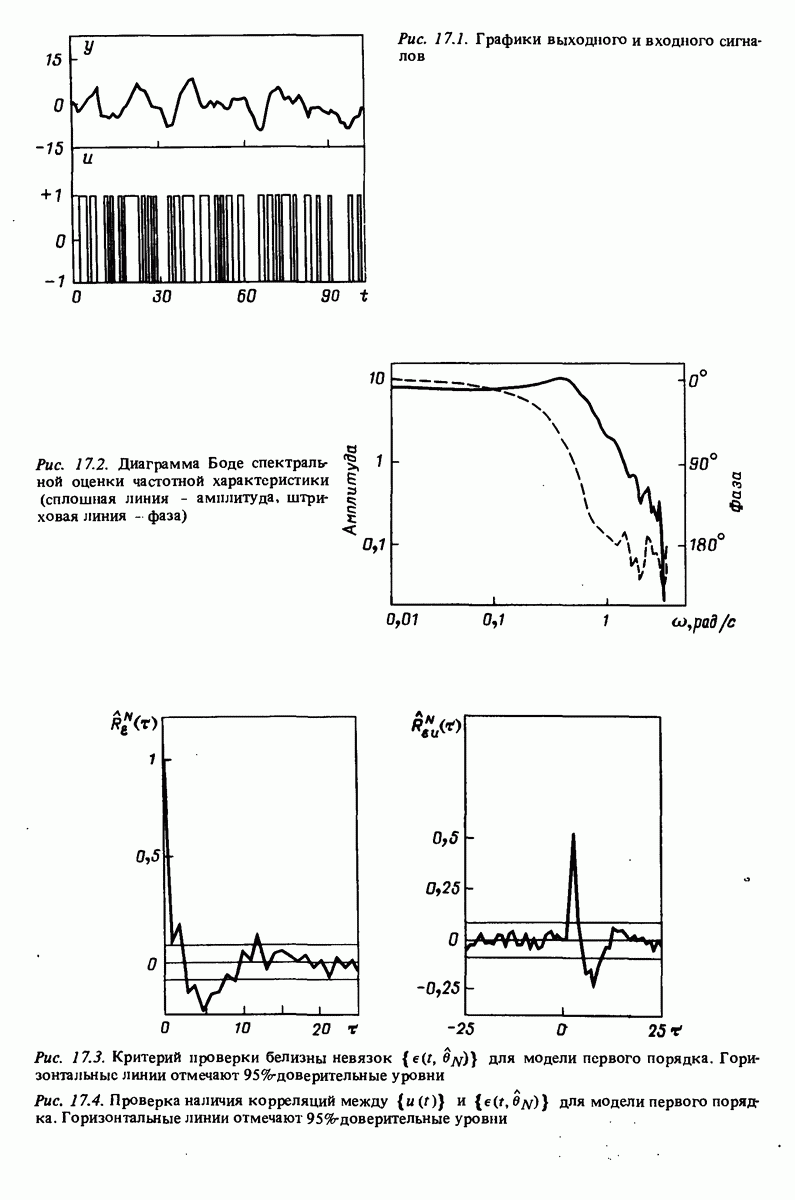
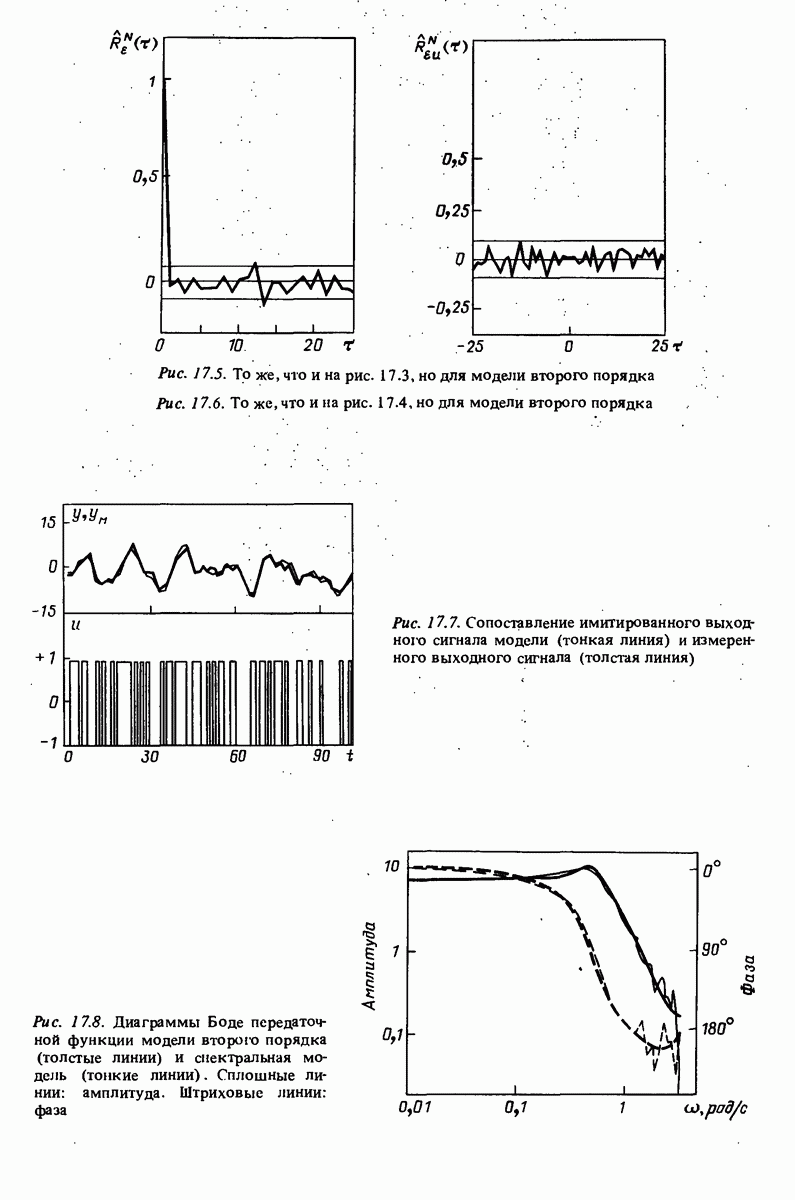


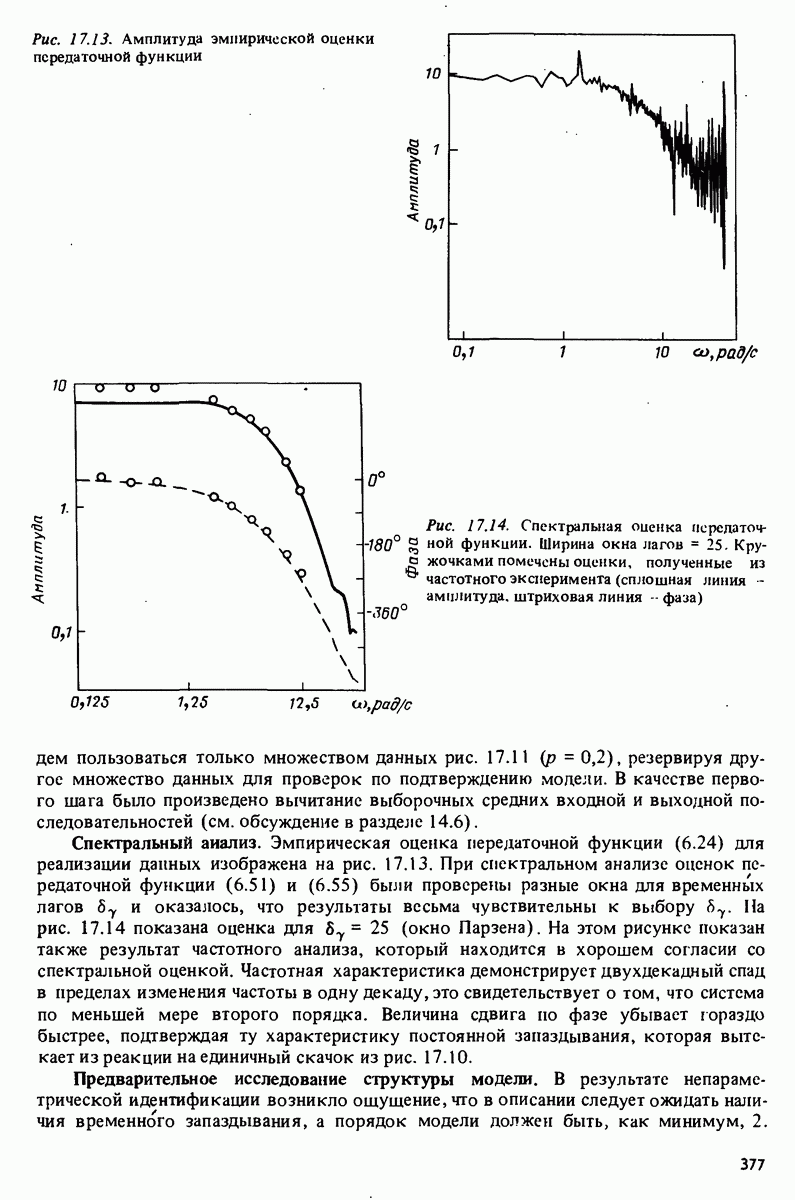
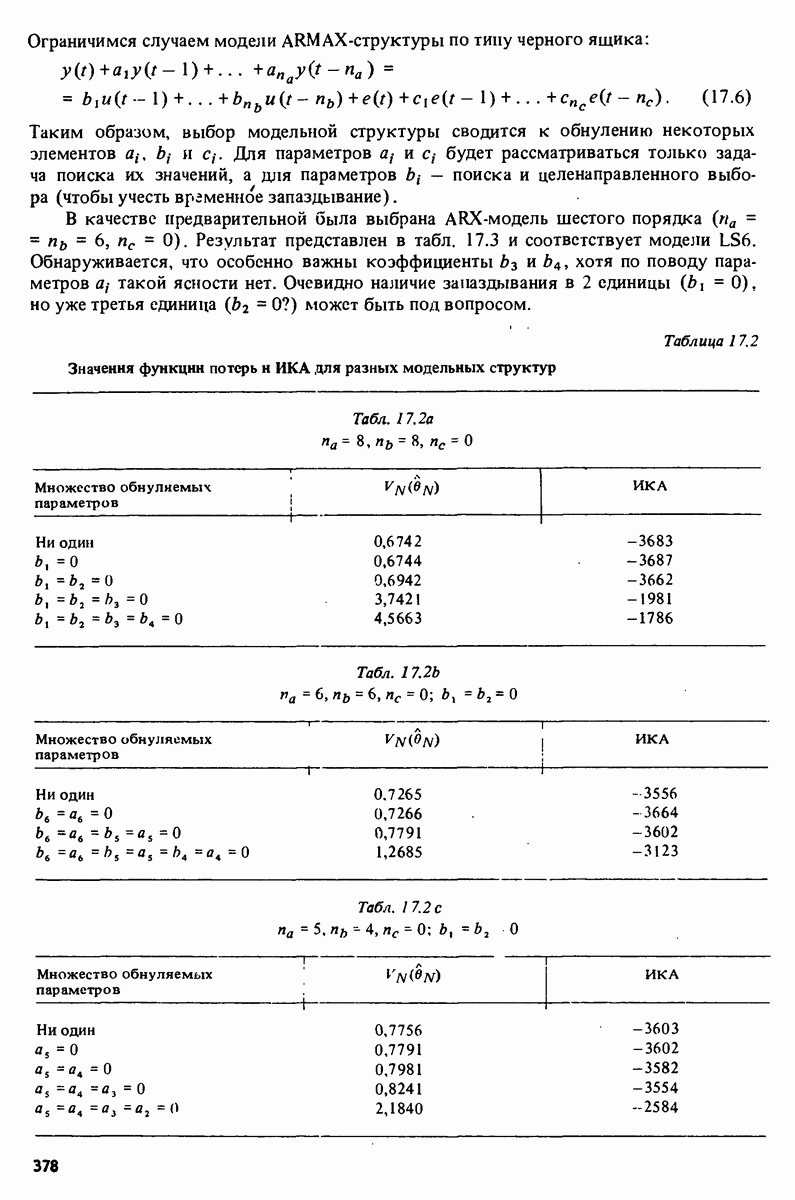
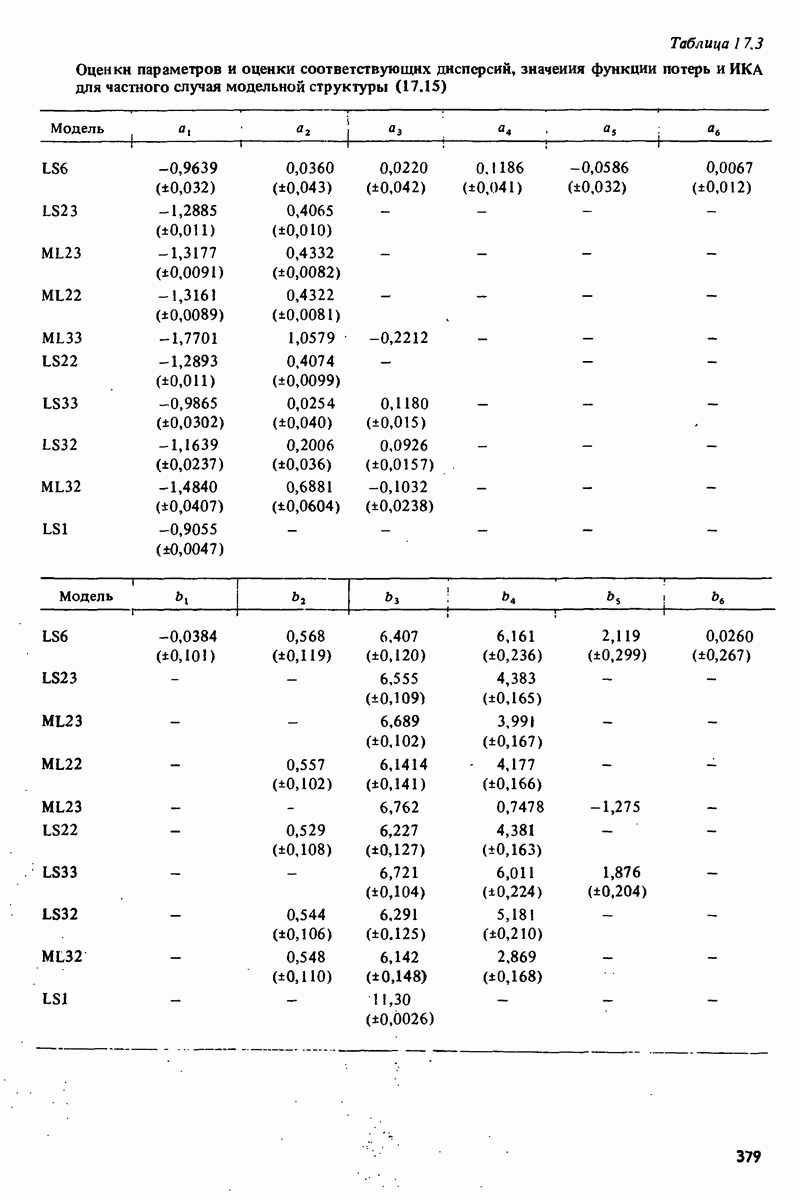
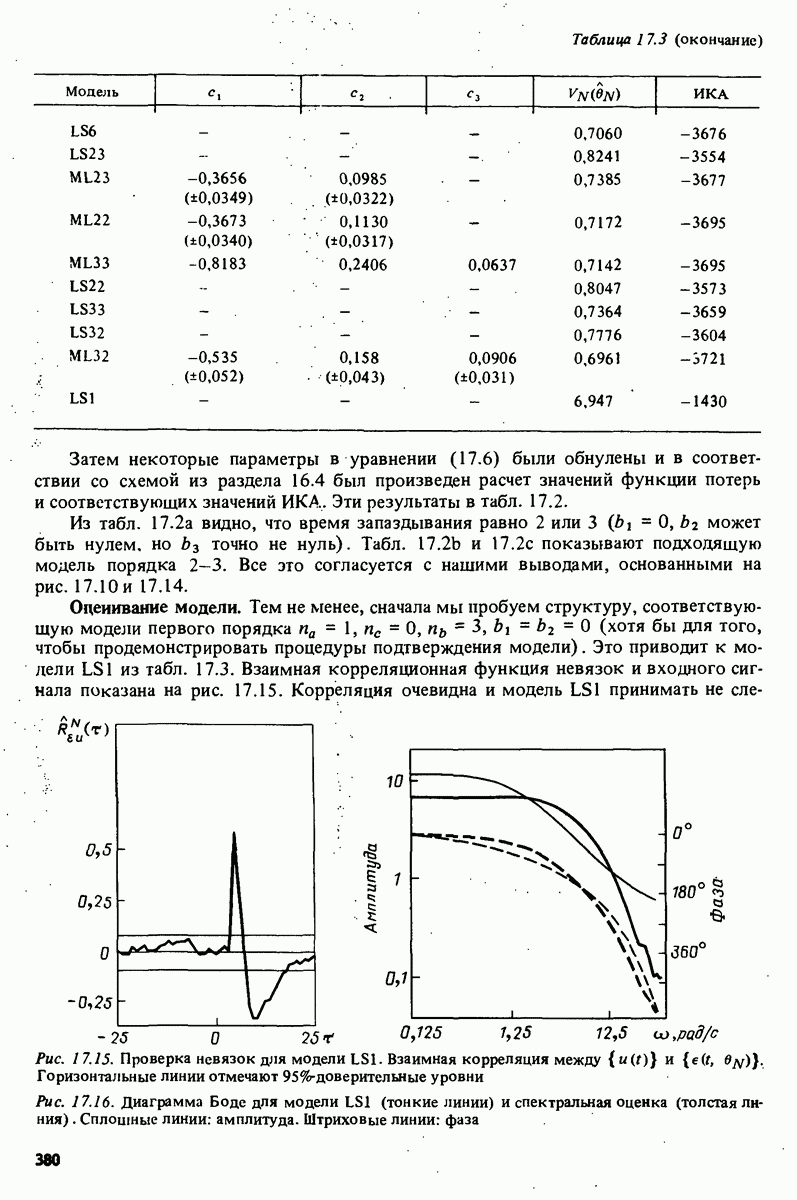
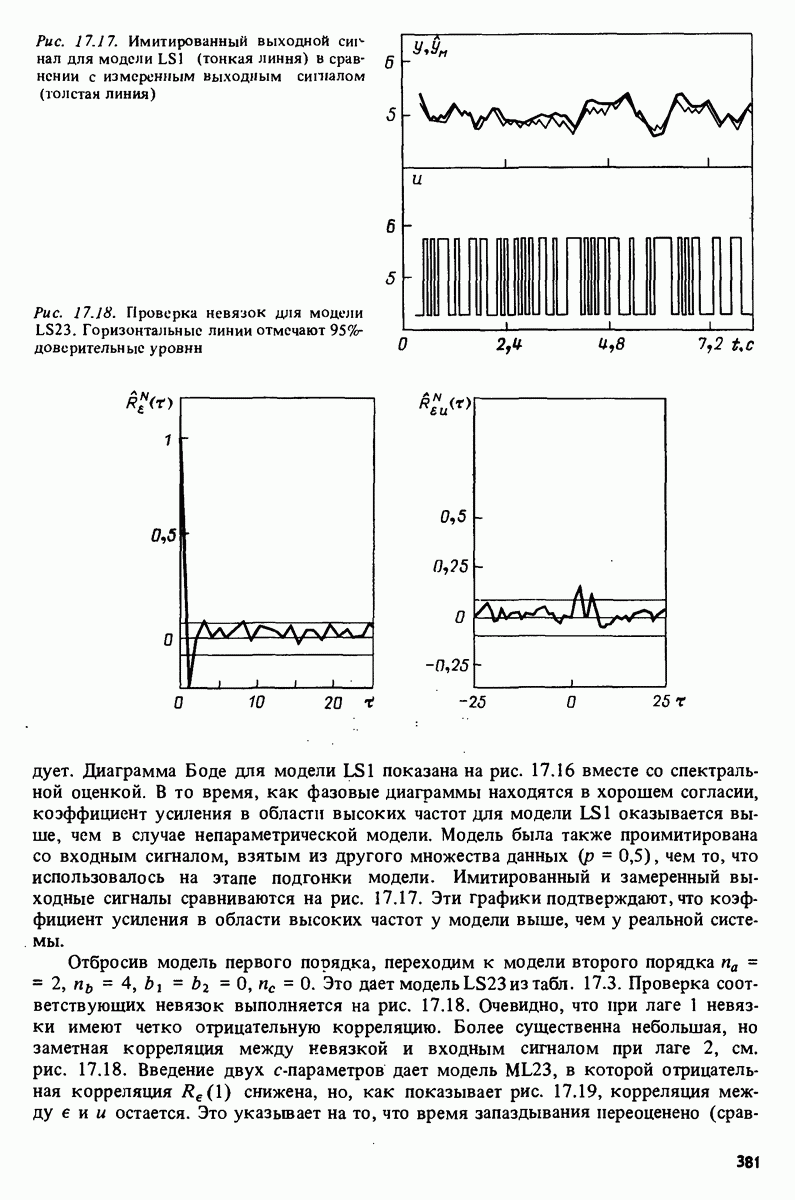
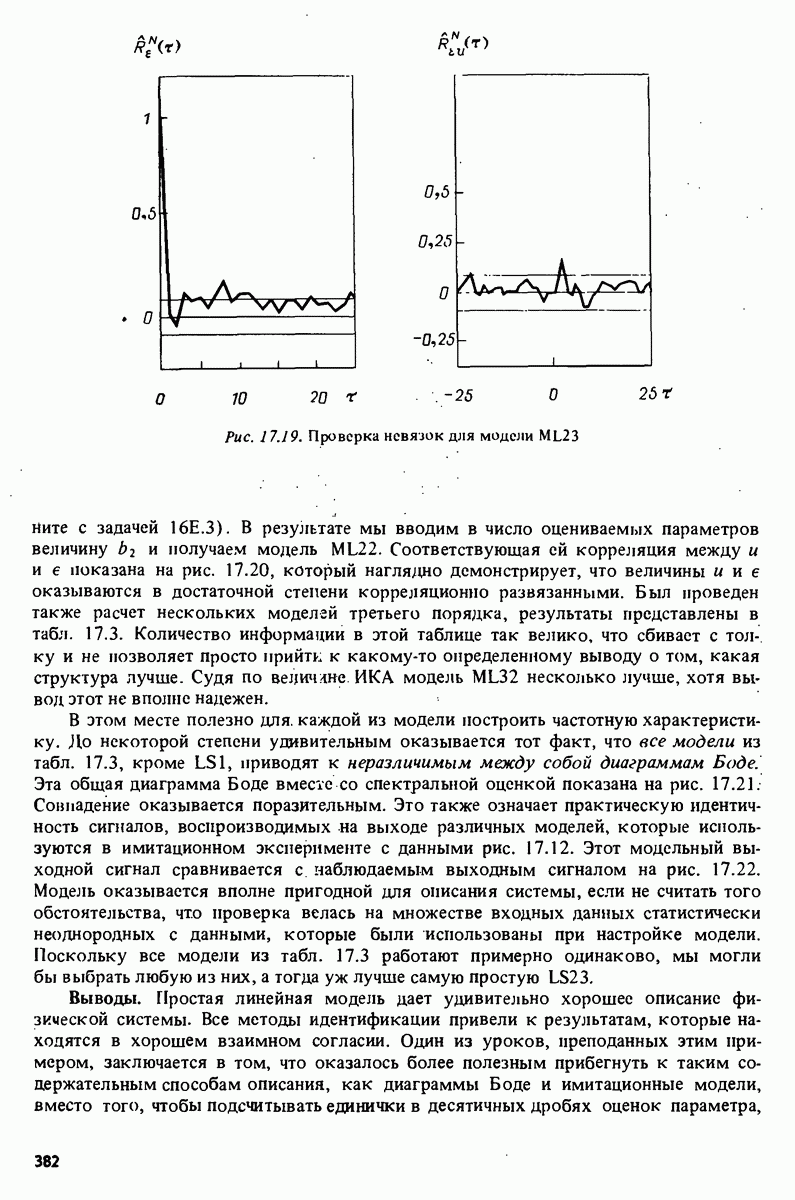
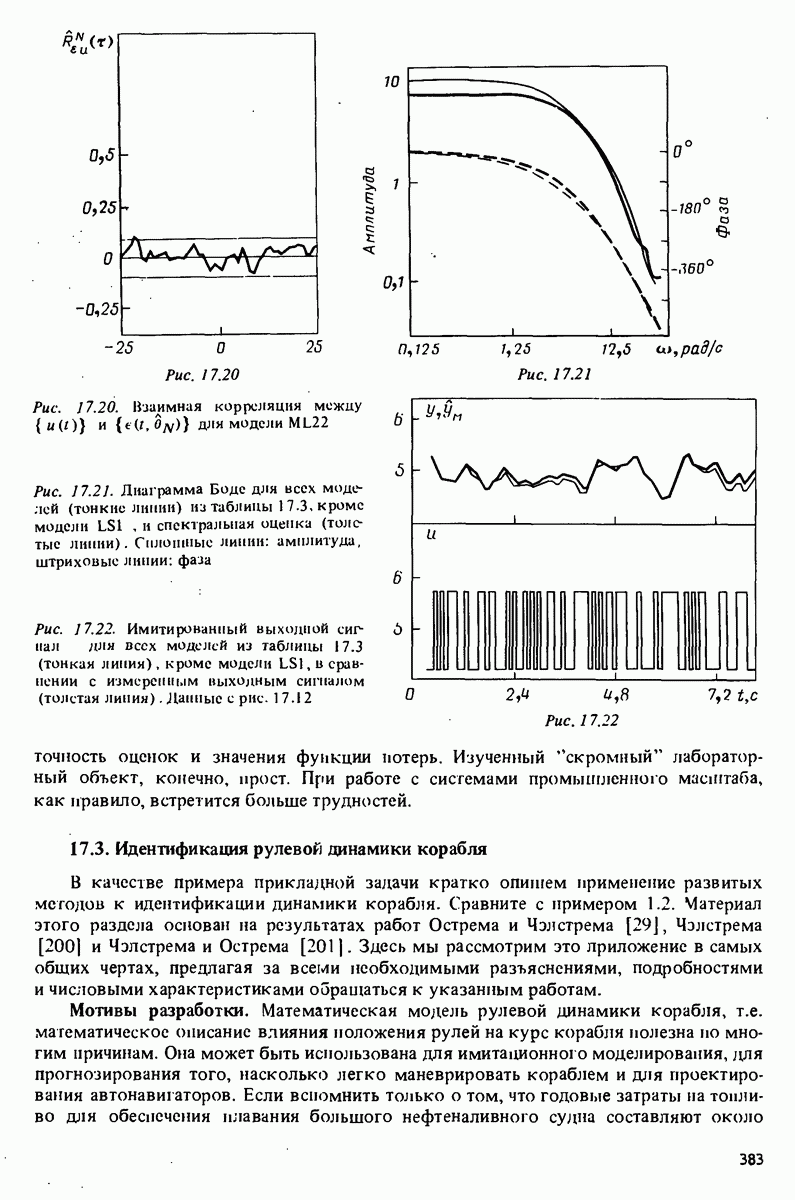














































 описания полученной на объекте новой информация. Достойным и привлекательным способом сравнения между собой двух разных моделей, полученных в рамках двух разных модельных структур, представляется оценка их функционирования на таком множестве данных, которое не использовалось в настройке ни одной из них. В этом случае мы бы предпочли модель, показавшую лучшие результаты. Такие процедуры известны под названием
описания полученной на объекте новой информация. Достойным и привлекательным способом сравнения между собой двух разных моделей, полученных в рамках двух разных модельных структур, представляется оценка их функционирования на таком множестве данных, которое не использовалось в настройке ни одной из них. В этом случае мы бы предпочли модель, показавшую лучшие результаты. Такие процедуры известны под названием
 . В разделе 16.5 представлено несколько способов оценки качества модели. В процедурах взаимного подтверждения привлекает их практическая направленность: в процессе сравнения не используется вероятностная аргументация и не делается каких-либо предположений об истинной системе. Единственный их недостаток состоит в том, что часть данных следует сохранить в виде новых для сравнения, а следовательно, ими нельзя пользоваться при построении моделей.
. В разделе 16.5 представлено несколько способов оценки качества модели. В процедурах взаимного подтверждения привлекает их практическая направленность: в процессе сравнения не используется вероятностная аргументация и не делается каких-либо предположений об истинной системе. Единственный их недостаток состоит в том, что часть данных следует сохранить в виде новых для сравнения, а следовательно, ими нельзя пользоваться при построении моделей.
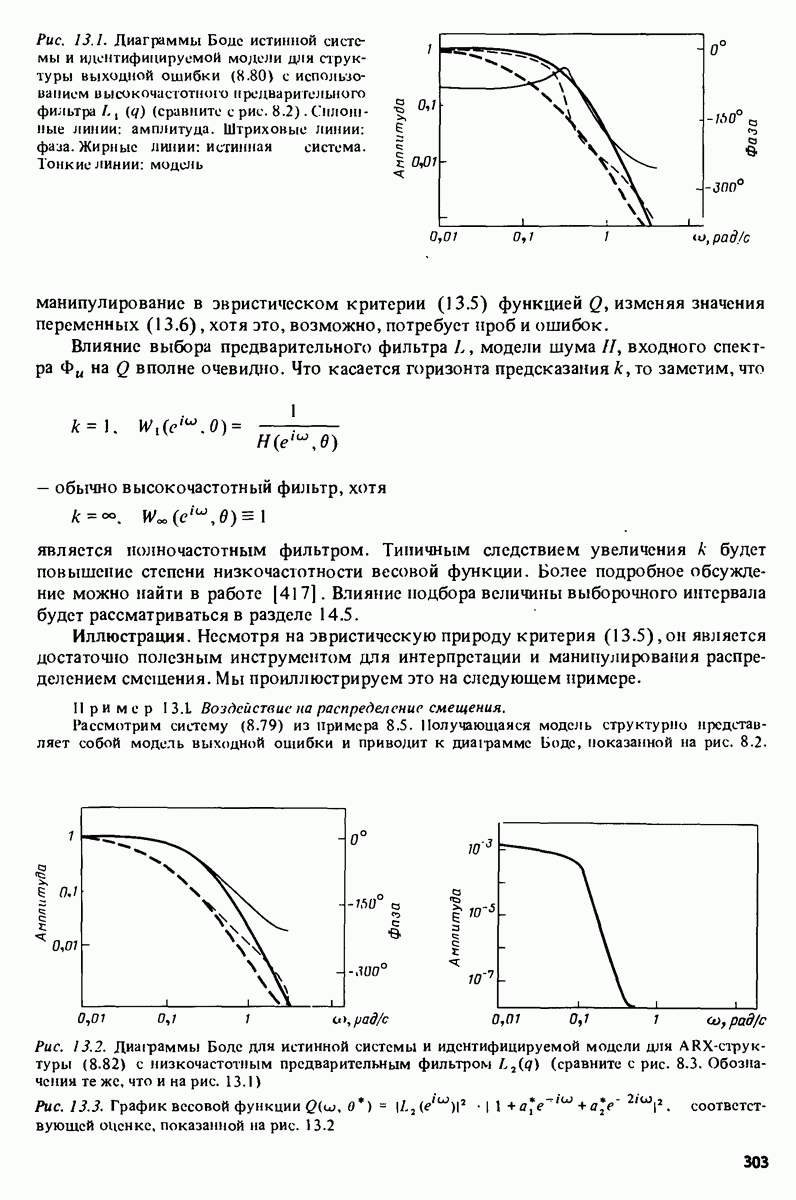
 минимальное значение критерия будет вести себя так, как показано на рис. 16.1; это монотонно убывающая функция от гибкости структуры модели.
минимальное значение критерия будет вести себя так, как показано на рис. 16.1; это монотонно убывающая функция от гибкости структуры модели.


 Однако даже после того, как структура модели захватывает возможность описания истинных уравнений системы, величина V продолжает убывать, так как теперь происходит подстройка дополнительных (ненужных) параметров под конкретные особенности конкретной реализации шума. Этот эффект известен под названием сверхсогласия, но, конечно, такое избыточное согласие с данными не представляет никакой ценности, поскольку модель предполагается использовать при работе с данными, включающими различные реализации шумов. Разумно считать, что уменьшение величины критерия от сверхсогласия должно быть менее существенным, чем уменьшение, связанное с учетом в модели дополнительных особенностей объекта. В результате нас будет интересовать, нет ли на кривой рис. 16.1 фрагмента типа колена. Построение такой кривой, действительно, является хорошим практическим приемом для оценки значимости и ценности увеличения степени согласия.
Однако даже после того, как структура модели захватывает возможность описания истинных уравнений системы, величина V продолжает убывать, так как теперь происходит подстройка дополнительных (ненужных) параметров под конкретные особенности конкретной реализации шума. Этот эффект известен под названием сверхсогласия, но, конечно, такое избыточное согласие с данными не представляет никакой ценности, поскольку модель предполагается использовать при работе с данными, включающими различные реализации шумов. Разумно считать, что уменьшение величины критерия от сверхсогласия должно быть менее существенным, чем уменьшение, связанное с учетом в модели дополнительных особенностей объекта. В результате нас будет интересовать, нет ли на кривой рис. 16.1 фрагмента типа колена. Построение такой кривой, действительно, является хорошим практическим приемом для оценки значимости и ценности увеличения степени согласия.
 как основу для оценки тех потенциальных возможностей, которые были бы связаны с приложением модели к множеству новых данных. В результате нужно будет устранить и скорректировать эффект сверхсогласия. Этот метод будет рассматриваться в следующих четырех подразделах. Другая процедура опирается на несколько иную философию, когда делается предположение, что на меньшей информационной структуре уже достигнуто правильное описание системы и осуществляется попытка расчета средней величины выигрыша сверхсогласия при переходе к более широкой структуре. После этого проводится проверка того, насколько наблюдаемый выигрыш больше теоретического. Такая идея проверки гипотез будет описана в предпоследнем разделе. Оказывается, однако, что в функциональном отношении эти два подхода являются тесно связанными.
как основу для оценки тех потенциальных возможностей, которые были бы связаны с приложением модели к множеству новых данных. В результате нужно будет устранить и скорректировать эффект сверхсогласия. Этот метод будет рассматриваться в следующих четырех подразделах. Другая процедура опирается на несколько иную философию, когда делается предположение, что на меньшей информационной структуре уже достигнуто правильное описание системы и осуществляется попытка расчета средней величины выигрыша сверхсогласия при переходе к более широкой структуре. После этого проводится проверка того, насколько наблюдаемый выигрыш больше теоретического. Такая идея проверки гипотез будет описана в предпоследнем разделе. Оказывается, однако, что в функциональном отношении эти два подхода являются тесно связанными.

 критерии ошибки предсказания, который используется при параметрическом оценивании. Пусть
критерии ошибки предсказания, который используется при параметрическом оценивании. Пусть  оценка, полученная в рамках структуры
оценка, полученная в рамках структуры  Возникает естественная мысль попробовать оценить среднюю эффективность модельной структуры
Возникает естественная мысль попробовать оценить среднюю эффективность модельной структуры  подсчитав
подсчитав

 и критерий
и критерий  не известны пользователю, так как в них входит вычисление математических ожиданий по распределениям фактических данных. Следовательно, нужно заменить
не известны пользователю, так как в них входит вычисление математических ожиданий по распределениям фактических данных. Следовательно, нужно заменить  какой-то аппроксимацией или оценкой.
какой-то аппроксимацией или оценкой.
 - точка минимума функции
- точка минимума функции  разложим эту функцию в ряд в окрестности
разложим эту функцию в ряд в окрестности 




 асимптотическая матрица ковариации оценки
асимптотическая матрица ковариации оценки  как и в формуле (9.15). Заметим, что
как и в формуле (9.15). Заметим, что  убывает как
убывает как 




 заменяется единственным имеющимся наблюдением и берется
заменяется единственным имеющимся наблюдением и берется 


 (т.е. §
(т.е. § 
 является обратимой;
является обратимой;




 функция логарифмического правдоподобия, а верхний индекс
функция логарифмического правдоподобия, а верхний индекс  обозначает связь оценки
обозначает связь оценки  с модельной структурой.
с модельной структурой.
 Тогда
Тогда

 При осуществлении внутренней минимизации (в рамках заданной структуры модели) в (16.29) имеем (см. задачу
При осуществлении внутренней минимизации (в рамках заданной структуры модели) в (16.29) имеем (см. задачу 

 Слсдо вательно,
Слсдо вательно,

 в (16.29) реализуется в следующей записи:
в (16.29) реализуется в следующей записи:



 выбрано в виде
выбрано в виде





 можно получить, если определить
можно получить, если определить


 в качестве предсказателя на множествах данных, не использовавшихся на этапе идентификации. Отметим тесную связь ФОП-критерия с ИКА (16.30) при гауссовых обновлениях и
в качестве предсказателя на множествах данных, не использовавшихся на этапе идентификации. Отметим тесную связь ФОП-критерия с ИКА (16.30) при гауссовых обновлениях и 

 критерий ошибки предсказания (7.120) в рамках некоторых модельных структур
критерий ошибки предсказания (7.120) в рамках некоторых модельных структур  функция, которой измеряется сложность модельной структуры. До сих пор эта мера была связана с размерностью вектора в:
функция, которой измеряется сложность модельной структуры. До сих пор эта мера была связана с размерностью вектора в:


 удовлетворяющими условию
удовлетворяющими условию  можно также осуществить с помощью теории статистических критериев. Идея состоит в выдвижении гипотезы
можно также осуществить с помощью теории статистических критериев. Идея состоит в выдвижении гипотезы


 нам следует придерживаться принципа предвзятости против выбора
нам следует придерживаться принципа предвзятости против выбора  Это означает, что мы будем всегда выбирать
Это означает, что мы будем всегда выбирать  за исключением тех случаев, когда предъявляются неопровержимые улики истинности гипотезы
за исключением тех случаев, когда предъявляются неопровержимые улики истинности гипотезы  . В статистике это выражают тем, что называют
. В статистике это выражают тем, что называют  нулевой гипотезой.
нулевой гипотезой.
 так, чтобы риск (вероятность) отвергнуть гипотезу
так, чтобы риск (вероятность) отвергнуть гипотезу  если она истинна, был меньше некоторого числа
если она истинна, был меньше некоторого числа  (чем меньшее значение а выбрано, тем выше степень настроя против структуры
(чем меньшее значение а выбрано, тем выше степень настроя против структуры  В то же время хотелось бы максимизировать вероятность того, что при истинности гипотезы
В то же время хотелось бы максимизировать вероятность того, что при истинности гипотезы  гипотеза
гипотеза  будет отвергнута. Последняя вероятность известна иод названием мощности статистического критерия.
будет отвергнута. Последняя вероятность известна иод названием мощности статистического критерия.

 то при самых общих условиях можно показать, что
то при самых общих условиях можно показать, что

 есть случайная величина в левой части сходится по распределению к
есть случайная величина в левой части сходится по распределению к  -распределению с
-распределению с  степенями свободы. Для случая линейной регрессии это доказано в лемме 11.4, а для ARMAX-модели - в работе Острема и Бохлина [27]. Отметим, что в случае
степенями свободы. Для случая линейной регрессии это доказано в лемме 11.4, а для ARMAX-модели - в работе Острема и Бохлина [27]. Отметим, что в случае  при подстановке
при подстановке  оценка (16.39) оказывается состоятельной.
оценка (16.39) оказывается состоятельной.

 выбрана в виде функции логарифмического правдоподобия, то этот критерии переходит в критерий отношения правдоподобия (см. Кендалл, Стюарт [212]), который обладает максимальной мощностью. В работе [57] Бохлином построен критерии максимальной мощности, который не требует расчета модели на более широком множестве.
выбрана в виде функции логарифмического правдоподобия, то этот критерии переходит в критерий отношения правдоподобия (см. Кендалл, Стюарт [212]), который обладает максимальной мощностью. В работе [57] Бохлином построен критерии максимальной мощности, который не требует расчета модели на более широком множестве.
 (и, следовательно, выбрать структуру
(и, следовательно, выбрать структуру  если
если

 -квантиль
-квантиль  -распределения с
-распределения с  степенями свободы. Для
степенями свободы. Для  с точки зрения пользователя (16.41) совпадает с
с точки зрения пользователя (16.41) совпадает с  или с ФОП-критерием (16.33), если а выбрать из соотношения
или с ФОП-критерием (16.33), если а выбрать из соотношения

 (в разумном диапазоне) удовлетворяется при выборе а от 7% до 1%. Таким образом, в плане практического использования между ФОП-методом, ИКА и проверкой статистических гипотез имеется ясная связь.
(в разумном диапазоне) удовлетворяется при выборе а от 7% до 1%. Таким образом, в плане практического использования между ФОП-методом, ИКА и проверкой статистических гипотез имеется ясная связь.
 можно привести формулу, более точную чем формула (16.40):
можно привести формулу, более точную чем формула (16.40):

 -распределение, можно применять
-распределение, можно применять  -критерии.
-критерии.
 задается соотношением
задается соотношением

 Посмотрим, насколько увеличится это значение при отбрасывании в формуле (16.44) отдельных параметров
Посмотрим, насколько увеличится это значение при отбрасывании в формуле (16.44) отдельных параметров  и соответствующих им регрессоров
и соответствующих им регрессоров  С помощью (10.6) можно переписать (16.44) в виде
С помощью (10.6) можно переписать (16.44) в виде

 которая приводит матрицу
которая приводит матрицу  к треугольному виду (см. (10.8)), и пусть
к треугольному виду (см. (10.8)), и пусть

 известно, что
известно, что

 и в формулу (16.45) также вносятся соответствующие изменения. Ясно, что
и в формулу (16.45) также вносятся соответствующие изменения. Ясно, что  -матрица
-матрица  будет триангулировать и новую матрицу
будет триангулировать и новую матрицу  (без последнего столбца). Таким образом, (10.11) по-прежнему верно и минимальное значение V на меньшей из структур равно
(без последнего столбца). Таким образом, (10.11) по-прежнему верно и минимальное значение V на меньшей из структур равно

 Очевидно, что такие рассуждения могут быть повторены. Следовательно, имеет место следующий результат.
Очевидно, что такие рассуждения могут быть повторены. Следовательно, имеет место следующий результат.
 и определены, как и выше. Допустим, что под меньшей модельной структурой понимается структура, которая будет получена из (16.44) удалением последних регрессоров
и определены, как и выше. Допустим, что под меньшей модельной структурой понимается структура, которая будет получена из (16.44) удалением последних регрессоров  Тогда минимальное значение функции потерь увеличится на
Тогда минимальное значение функции потерь увеличится на

 в формуле (16.46). Значения этих величин зависят от порядка регрессоров. Поэтому соответствующий порядок необходимо выбрать так, чтобы при устранении регрессоров, начиная с последних, из формулы (16.44) получались интересные подструктуры. После того, как
в формуле (16.46). Значения этих величин зависят от порядка регрессоров. Поэтому соответствующий порядок необходимо выбрать так, чтобы при устранении регрессоров, начиная с последних, из формулы (16.44) получались интересные подструктуры. После того, как  определены, проверка таких подструктур с использованием
определены, проверка таких подструктур с использованием
 пр
пр

 — исходные переменные-регрессоры. Просмотр структур ведется с использованием критерия перекрестного подтверждения (отсюда группы), или ИКА, или ФОП-критерия (16.33). Доскональное исследование МГУА проводится в работе Фэрлоу [113].
— исходные переменные-регрессоры. Просмотр структур ведется с использованием критерия перекрестного подтверждения (отсюда группы), или ИКА, или ФОП-критерия (16.33). Доскональное исследование МГУА проводится в работе Фэрлоу [113].