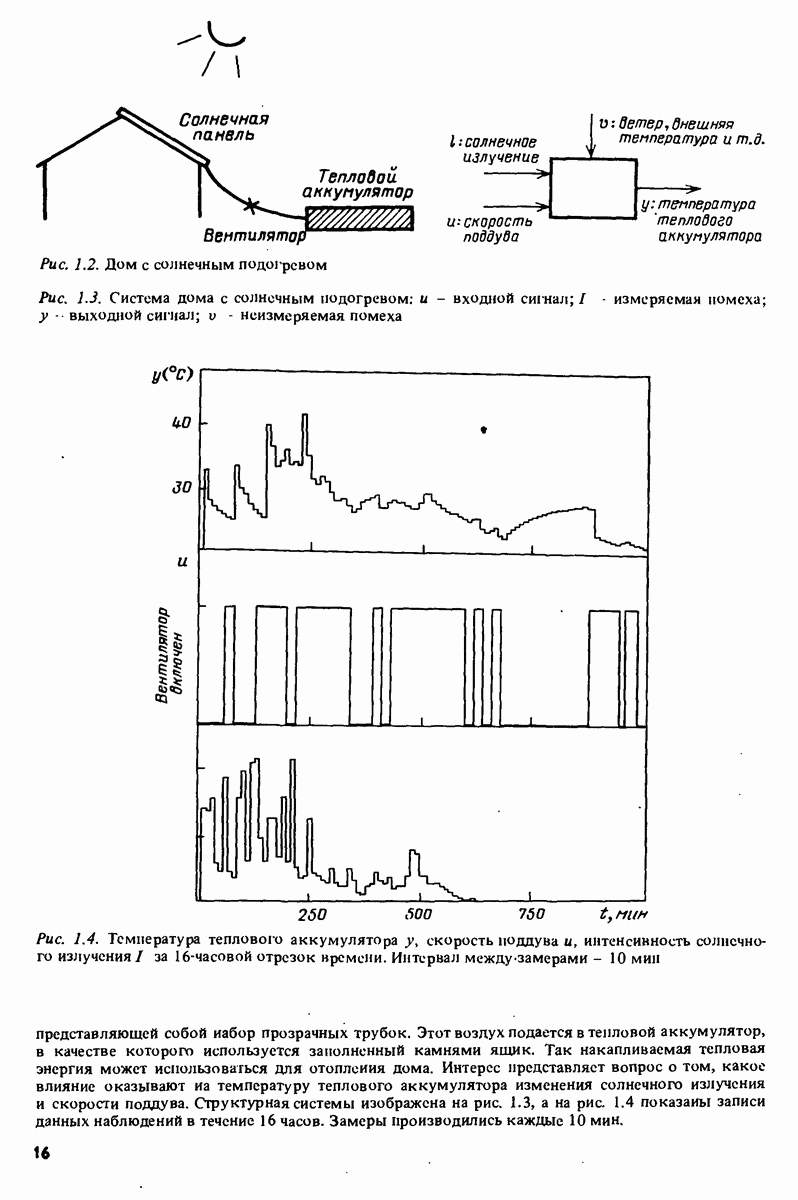
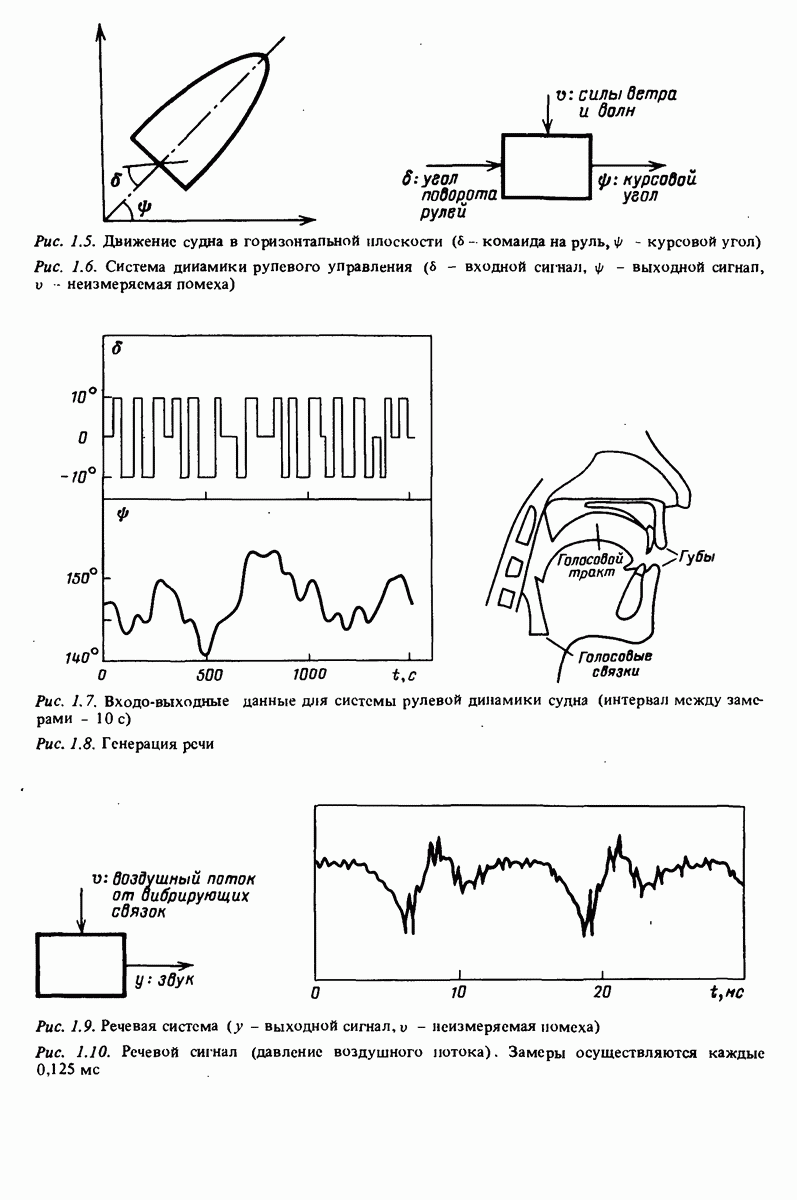
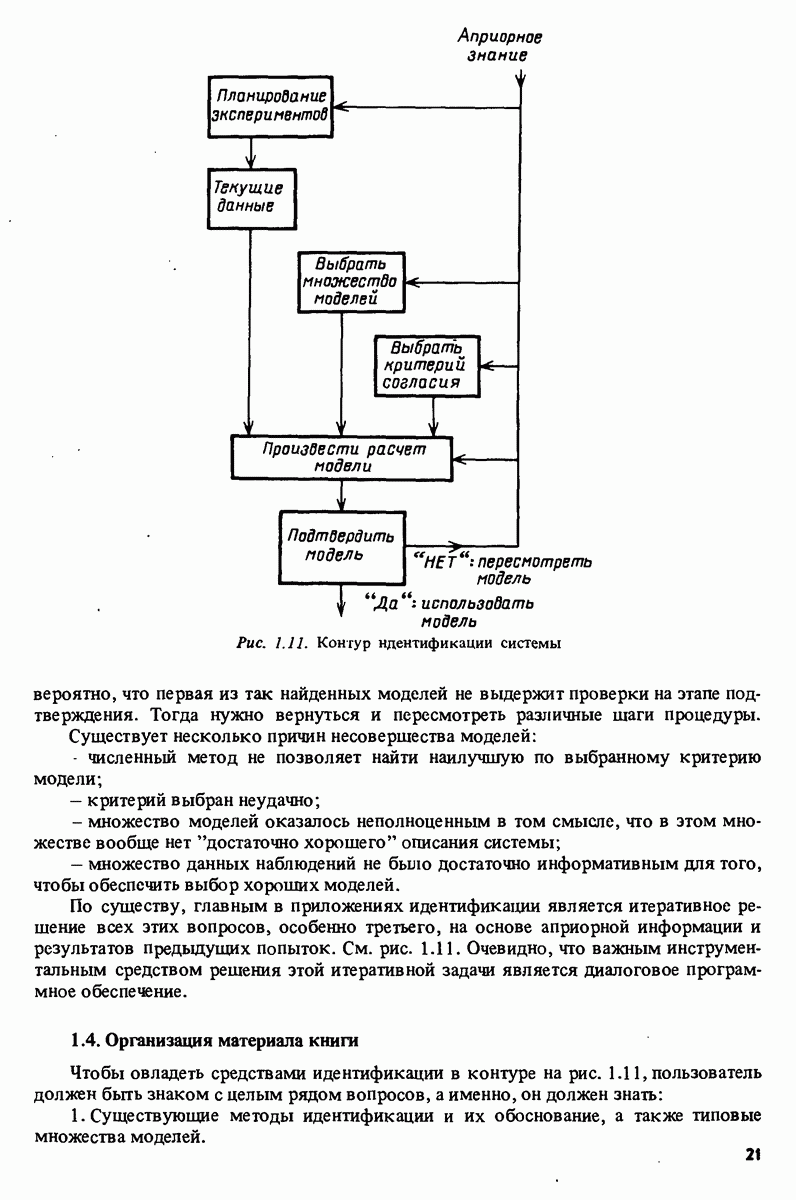
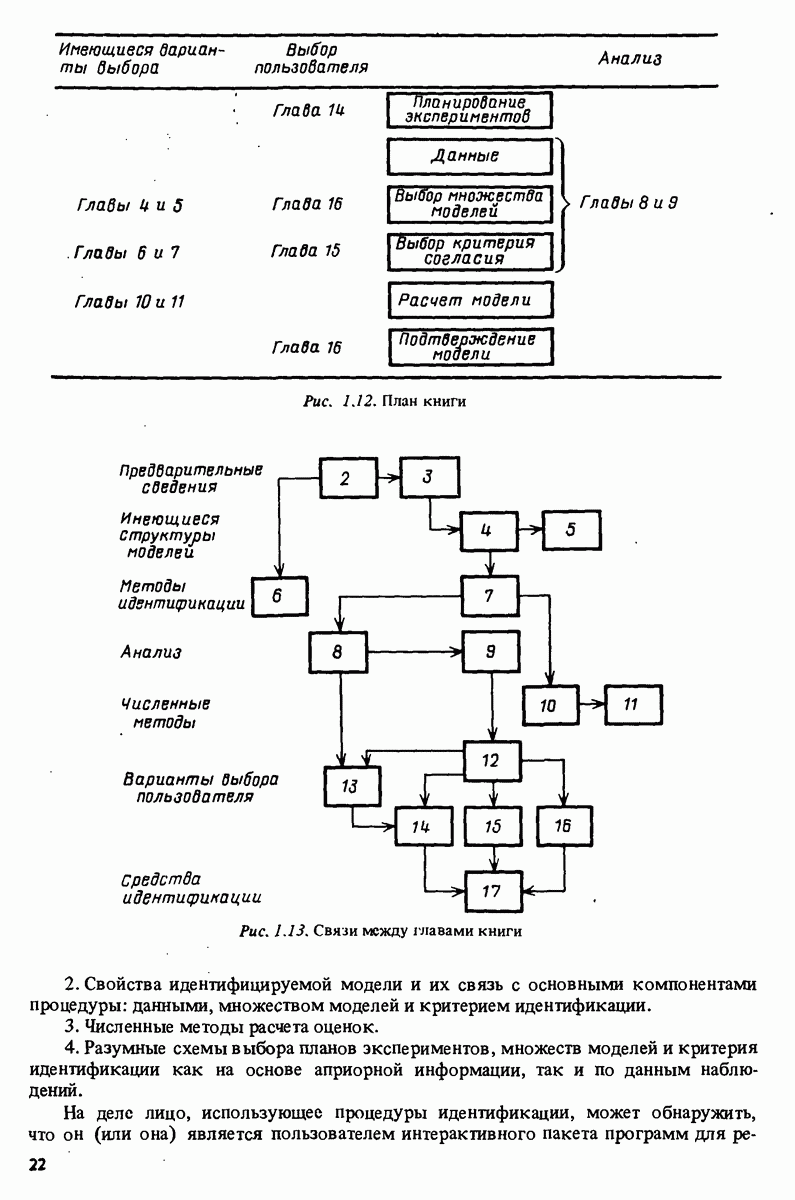
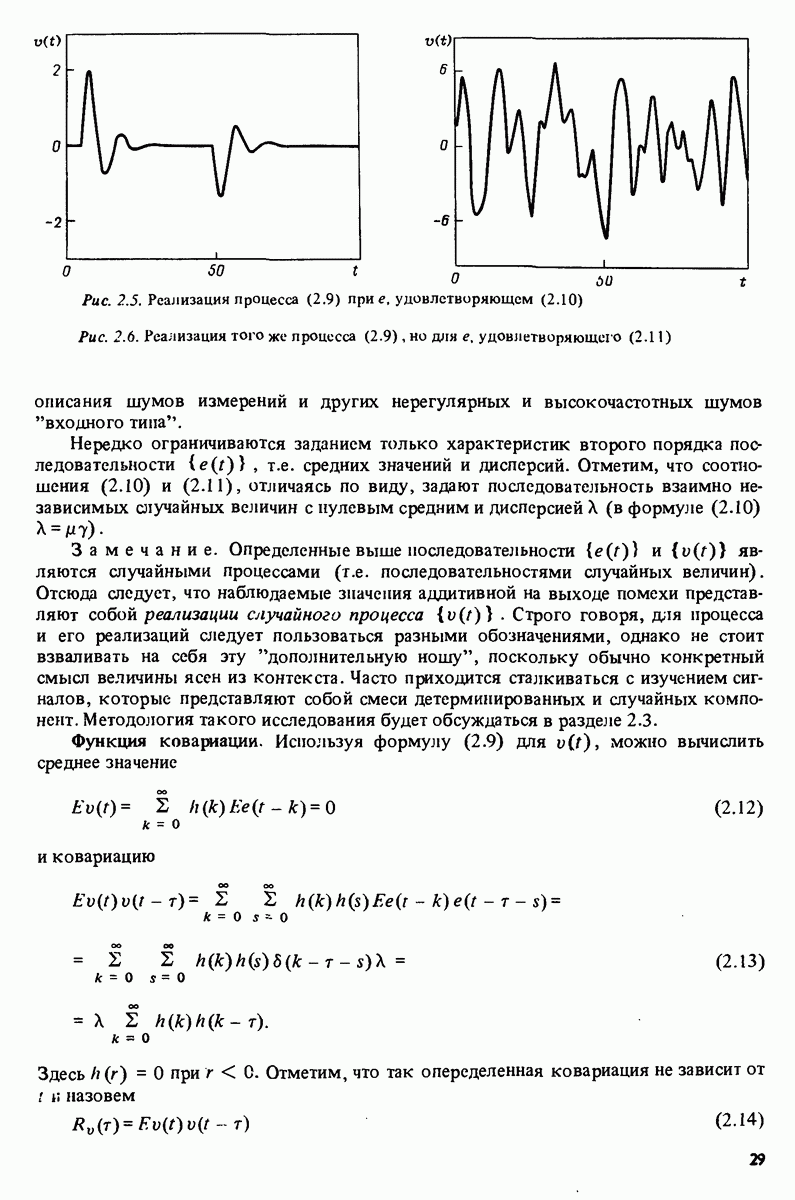
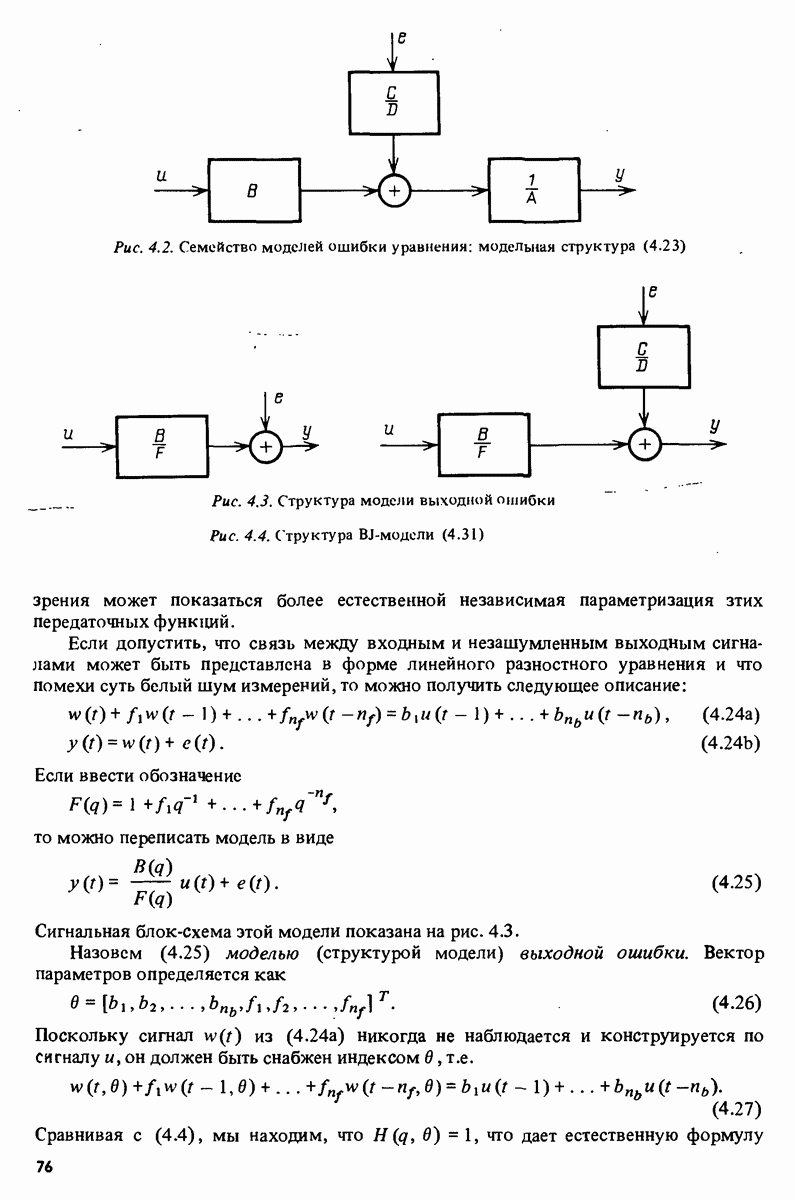
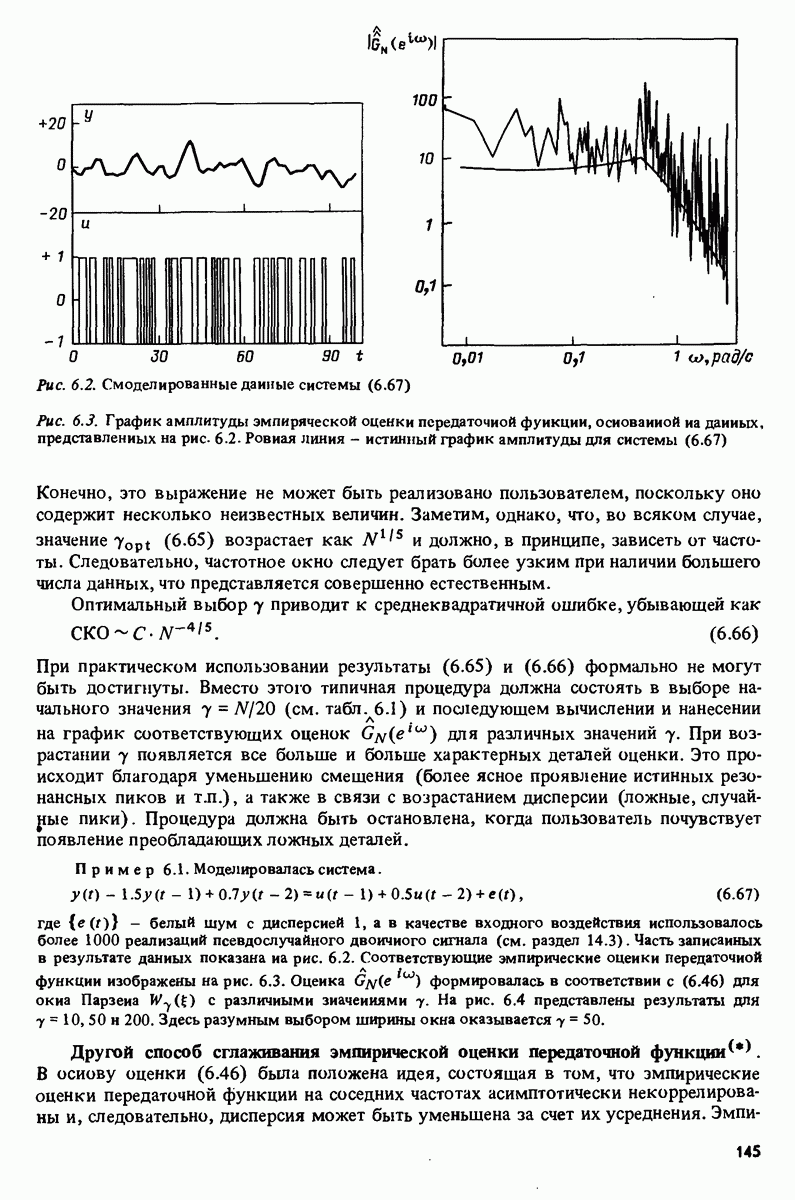
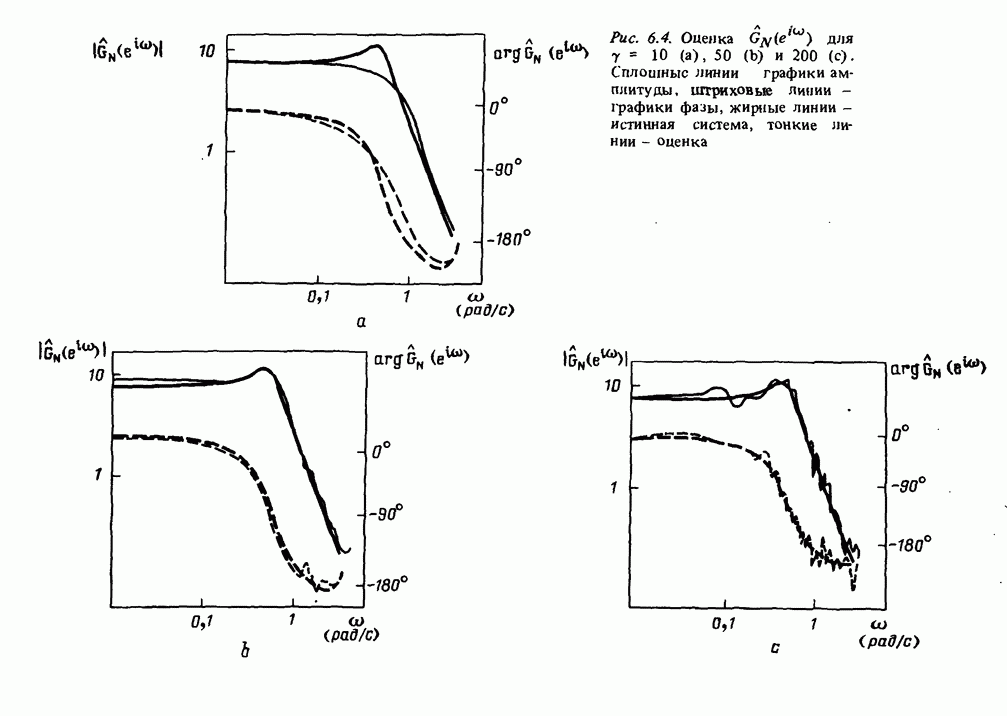
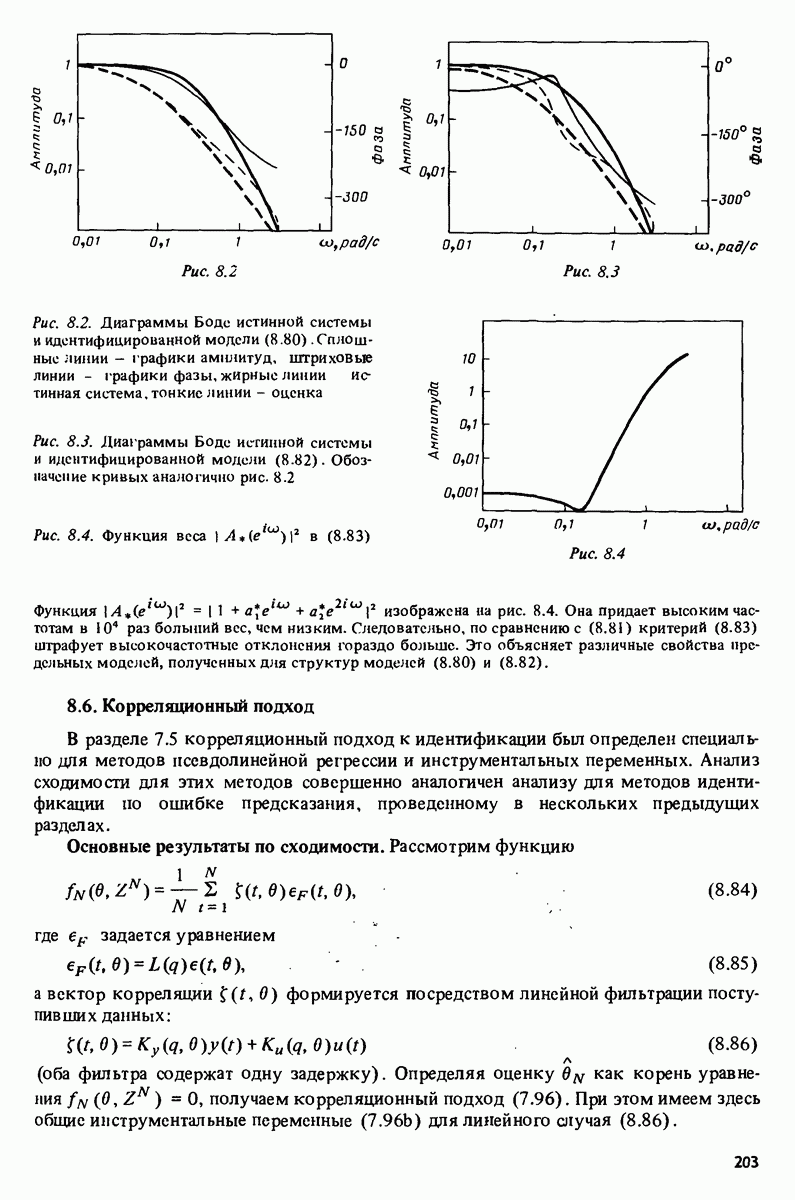
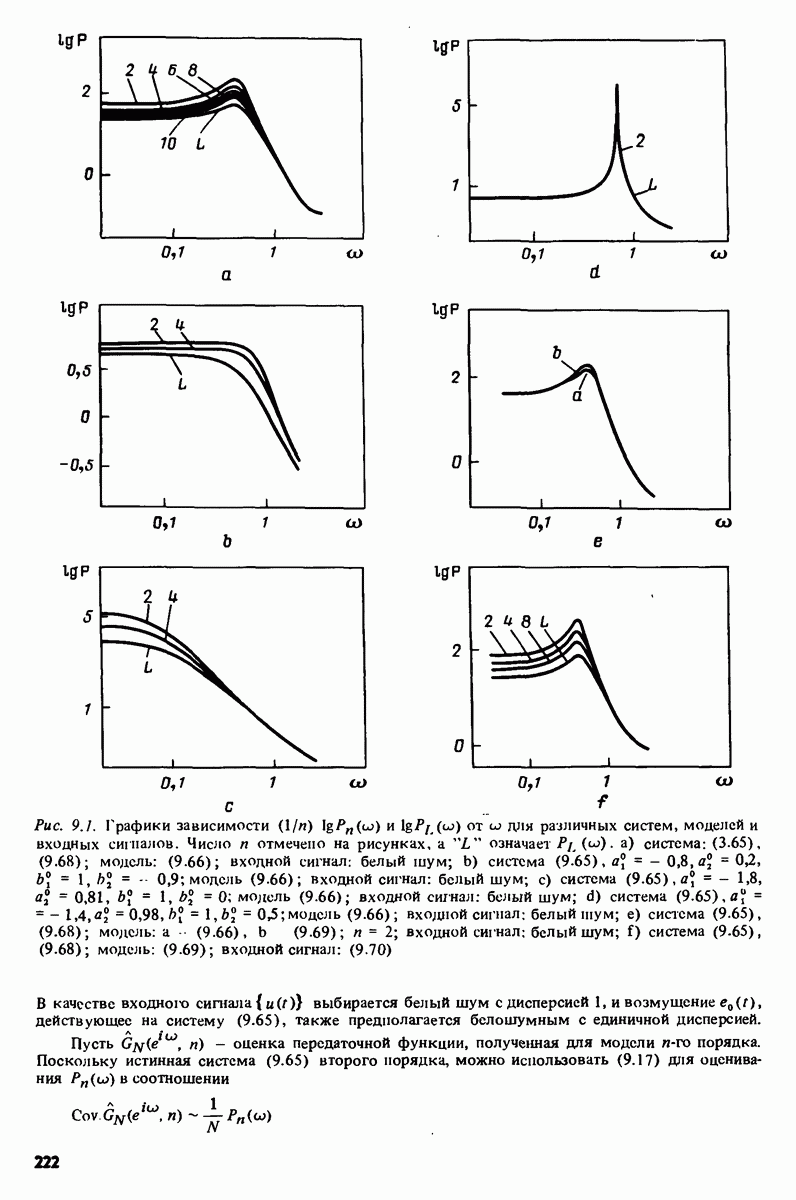
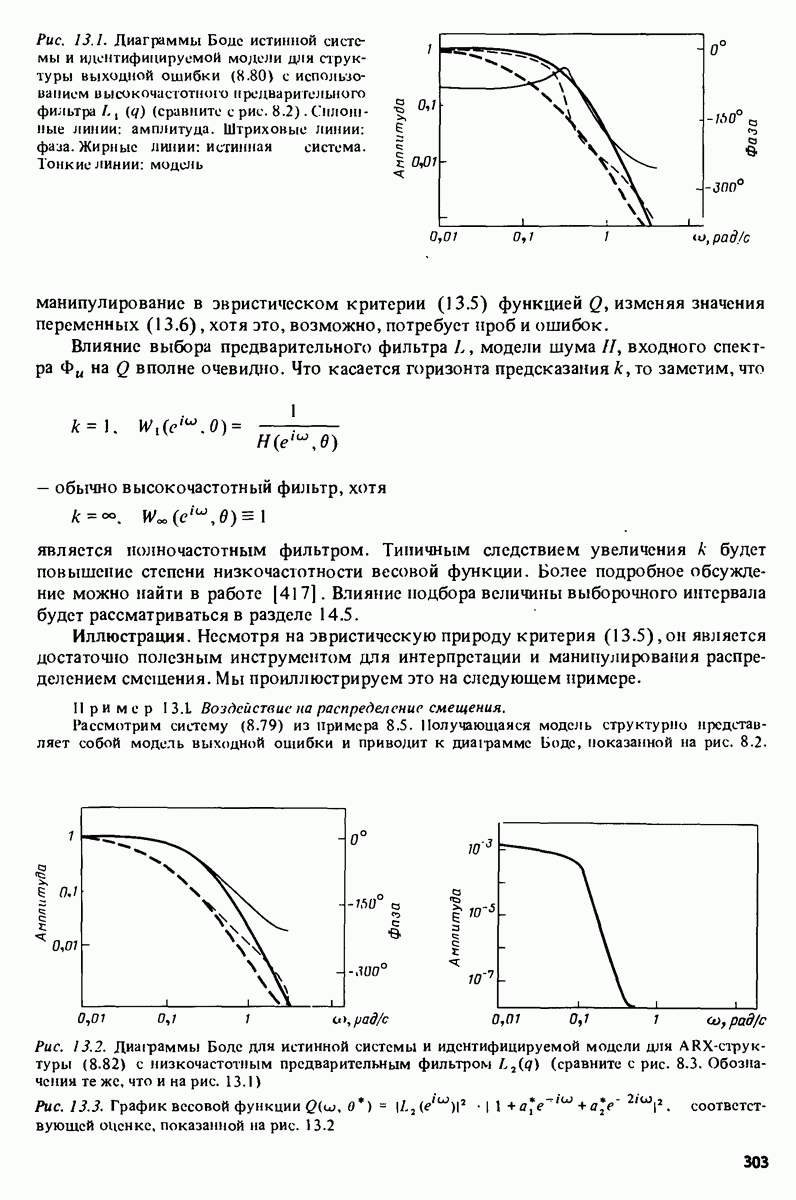
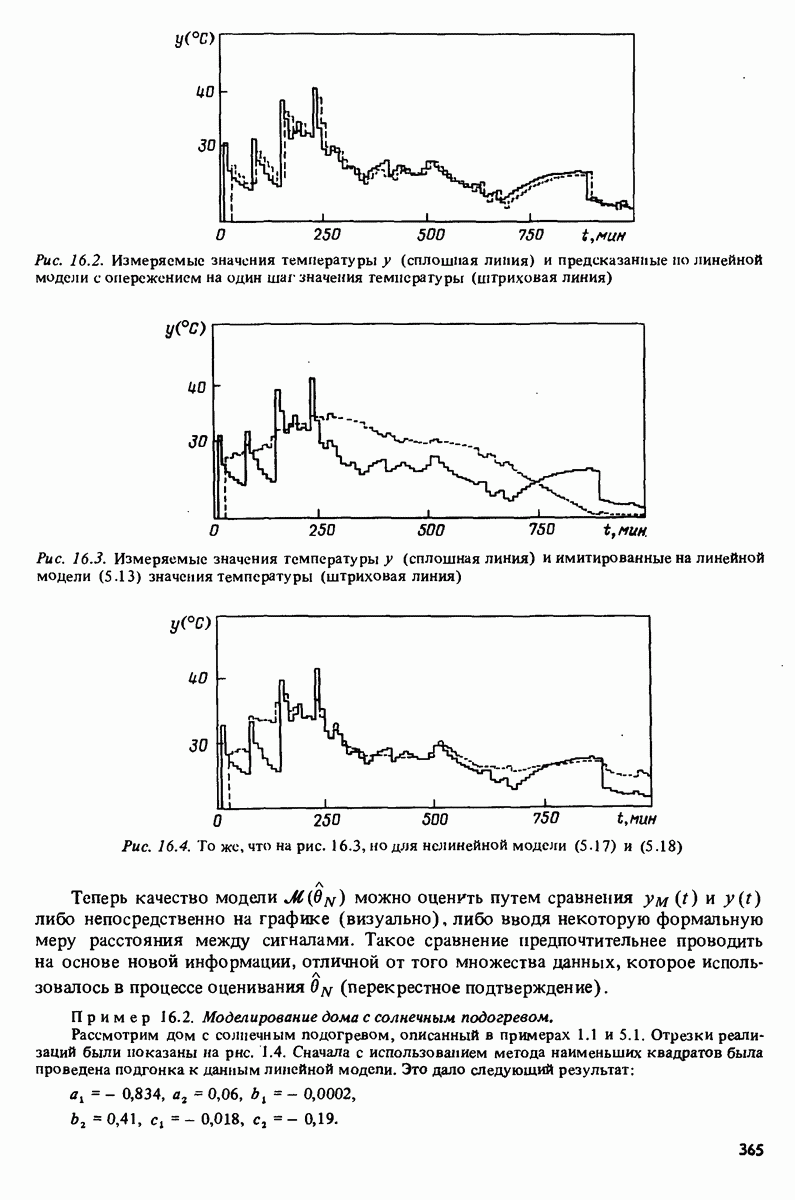
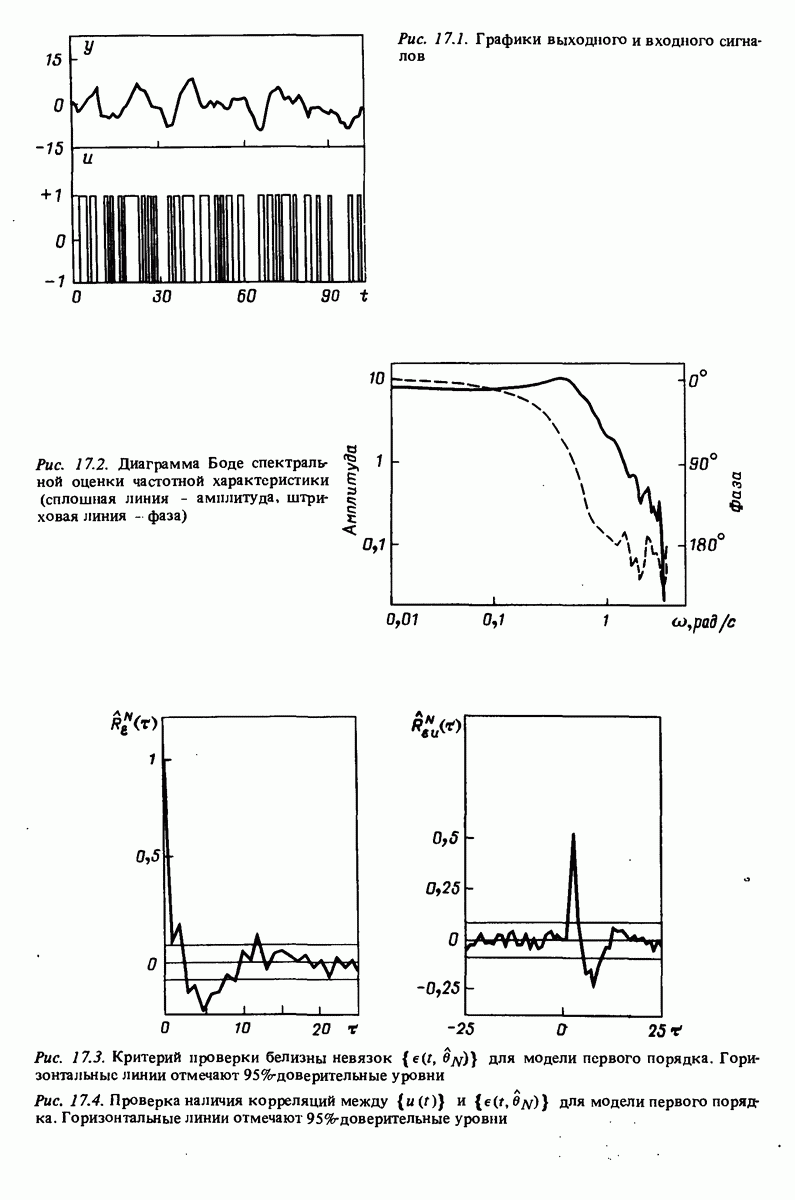
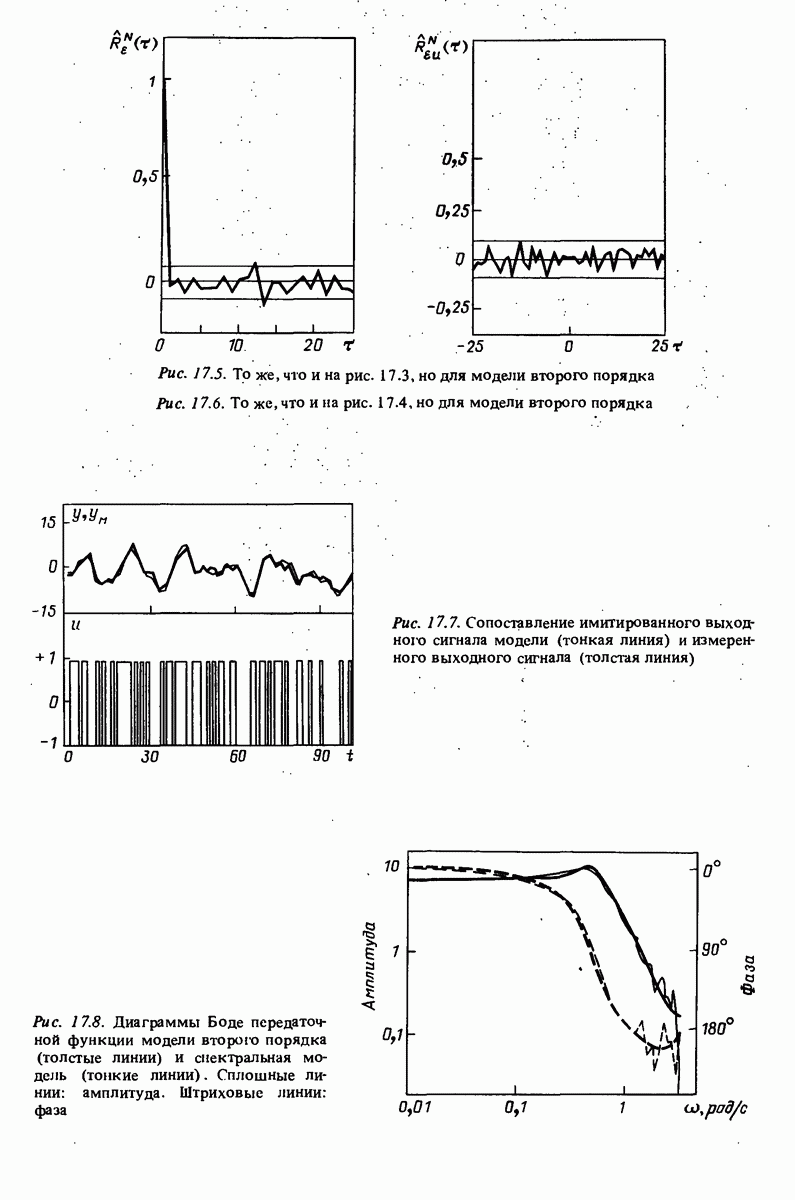
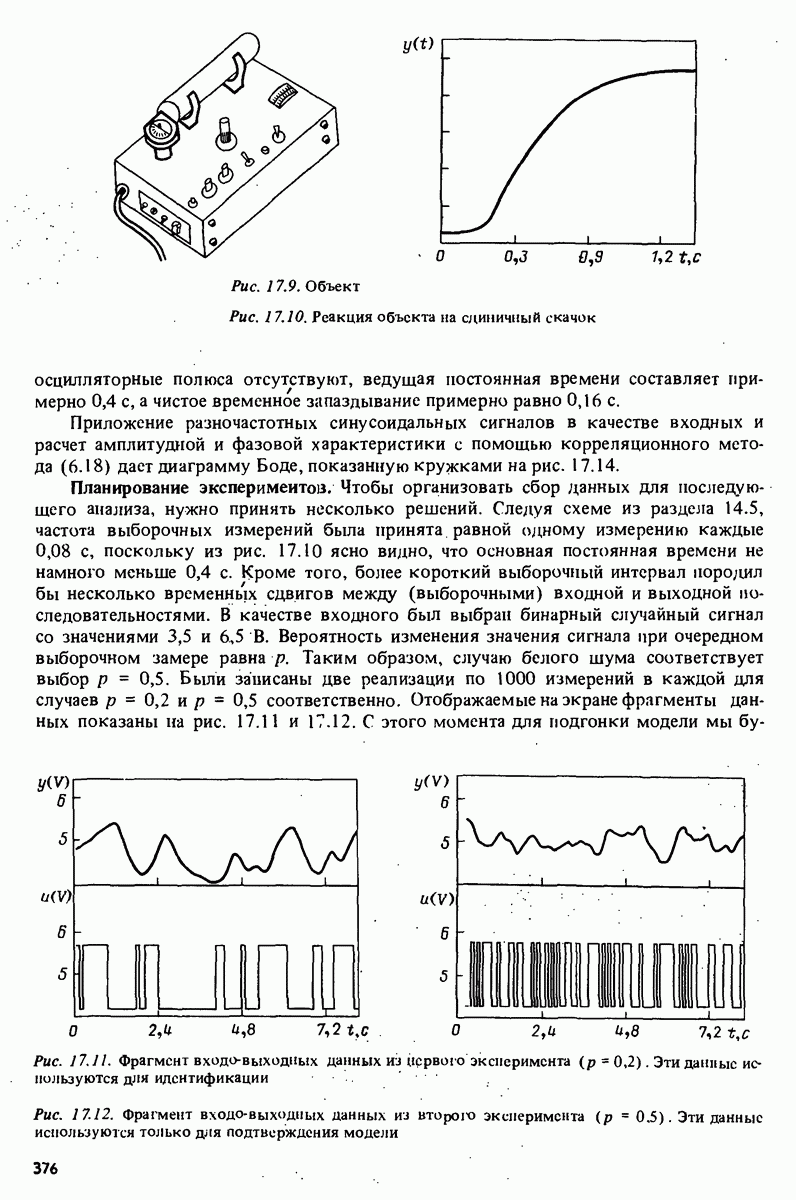
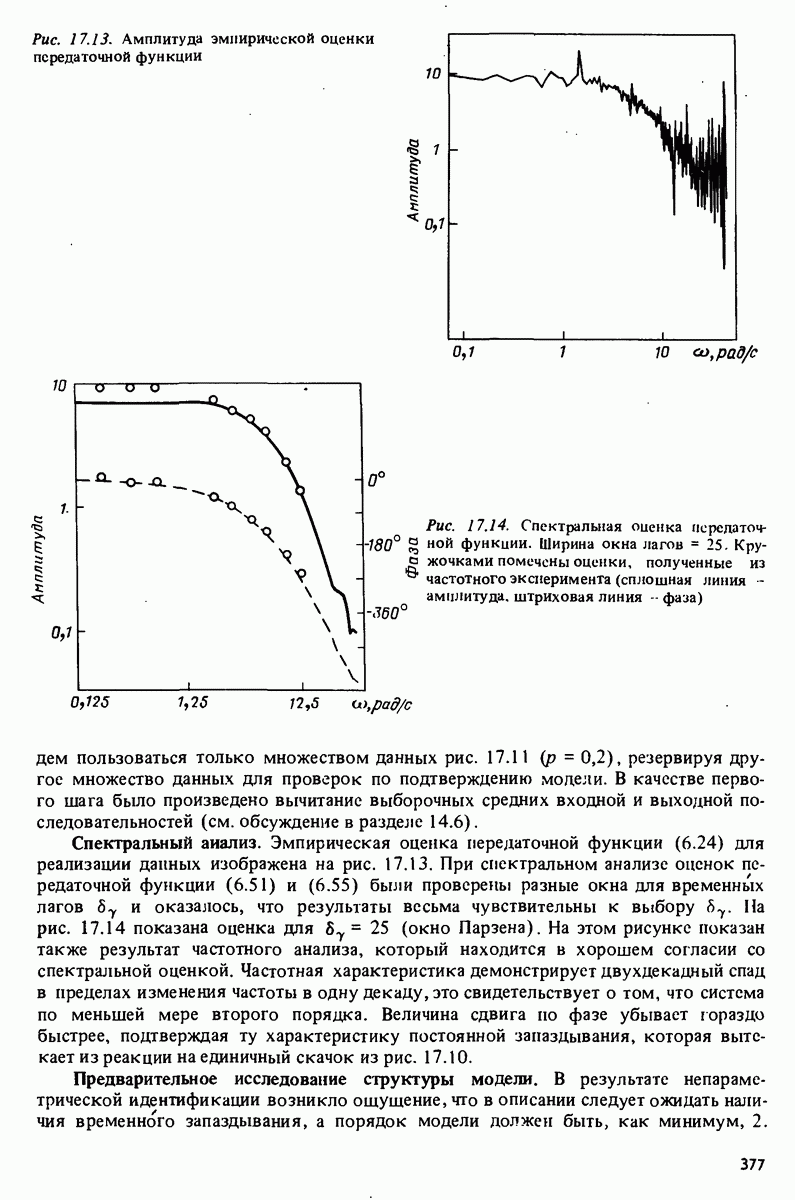
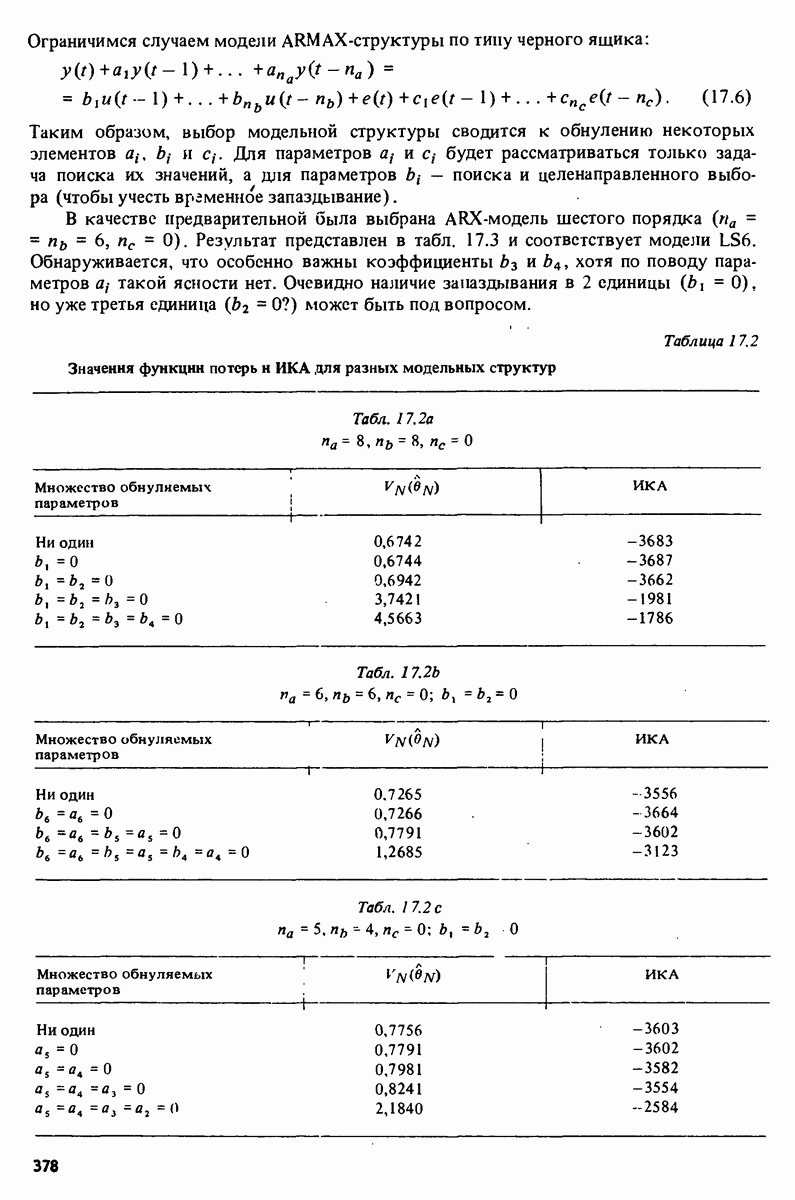
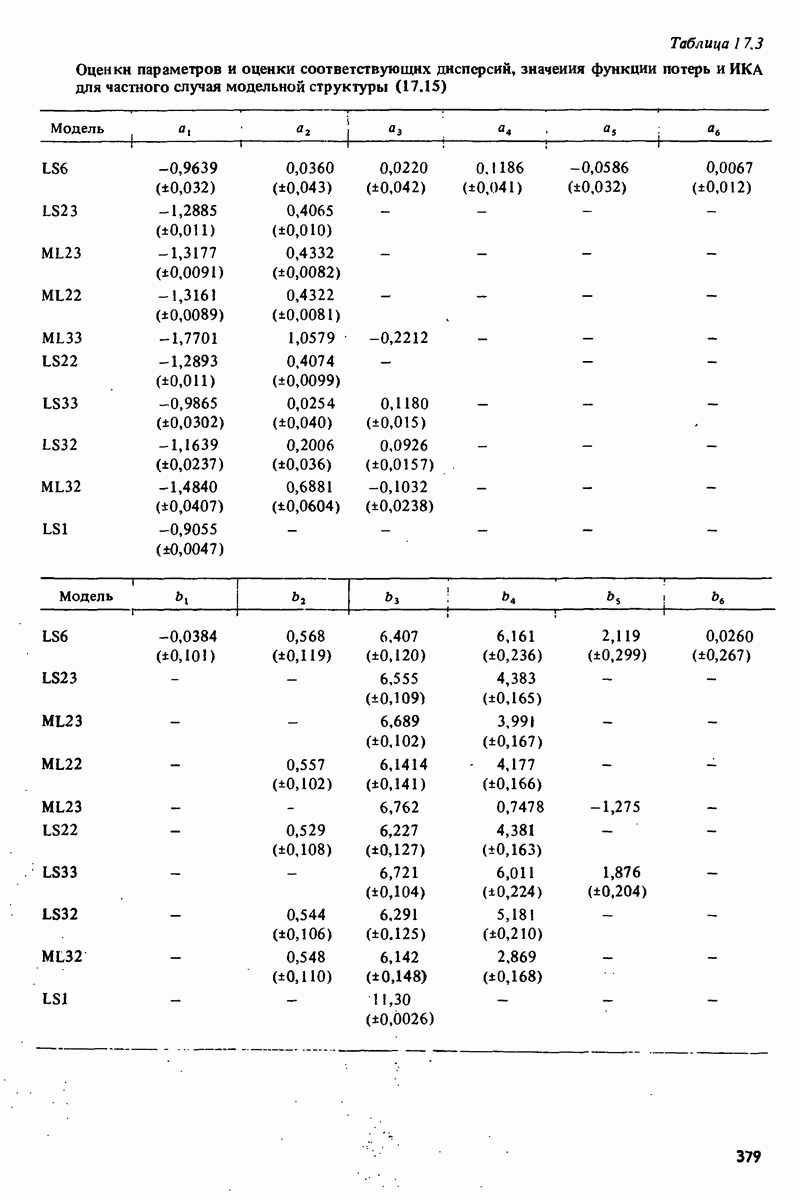
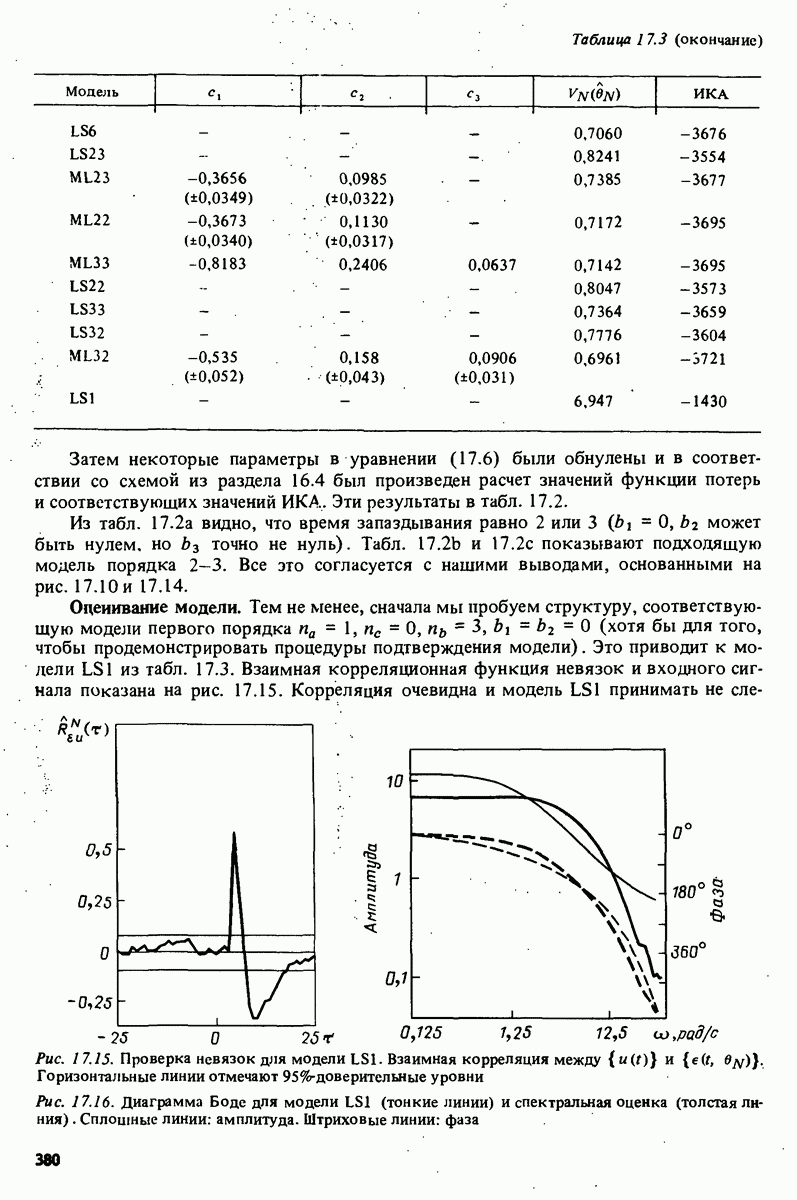
11.4. Рекуррентные методы ошибки предсказания
Аналогично случаю взвешенных наименьших квадратов рассмотрим взвешенный квадратичный критерий ошибки предсказания

с  , задаваемыми выражениями (11.6) и (11.13). Заметим, что
, задаваемыми выражениями (11.6) и (11.13). Заметим, что

и градиент по 0, как в (11.15), имеет вид

При оценивании на основе метода ошибки предсказания поисковый алгоритм имеет общий вид (10.41):

Здесь индекс  означает, что оценка основана на
означает, что оценка основана на  данных (т.е. на
данных (т.е. на  ). Верхний индекс
). Верхний индекс  обозначает
обозначает  итерацию процедуры минимизации.
итерацию процедуры минимизации.
Допустим, что на каждой итерации  производится еще одно измерение данных. Это привело бы к алгоритму
производится еще одно измерение данных. Это привело бы к алгоритму

Для упрощения обозначений введем

Сделаем теперь предположение индукции, что в  действительно минимизирует и
действительно минимизирует и

(безусловно, это будет выполняться приближенно)  Тогда из (11.34) имеем
Тогда из (11.34) имеем

Используя эту аппроксимацию (и выбирая  ), приходим, таким образом, к алгоритму
), приходим, таким образом, к алгоритму

Ниже мы обсудим вкратце выбор  но наш основной интерес связан теперь с переменными
но наш основной интерес связан теперь с переменными  Они выводятся из выражения для предсказания
Они выводятся из выражения для предсказания  . В общем случае, вычисление
. В общем случае, вычисление  для произвольно заданного значения в требует знания всей последовательности данных
для произвольно заданного значения в требует знания всей последовательности данных  Для конечно-мерных линейных моделей это означает, что
Для конечно-мерных линейных моделей это означает, что  образуется на выходе линейного фильтра, коэффициенты которого зависят от 0. Это видно из основополагающих соотношений (10.57) и (10.61). Отсюда следует, что
образуется на выходе линейного фильтра, коэффициенты которого зависят от 0. Это видно из основополагающих соотношений (10.57) и (10.61). Отсюда следует, что  не могут быть вычислены рекуррентно (т.е. при фиксированной длине памяти). Это приводит к необходимости использования некоторой аппроксимации указанных переменных. Естественным представляется следующий подход:
не могут быть вычислены рекуррентно (т.е. при фиксированной длине памяти). Это приводит к необходимости использования некоторой аппроксимации указанных переменных. Естественным представляется следующий подход:
На каждом шаге рекуррентного определения  по
по  для произвольно заданного
для произвольно заданного  заменяем, в момент к, параметр имеющейся текущей оценкой
заменяем, в момент к, параметр имеющейся текущей оценкой  Полученные приближения величин
Полученные приближения величин  обозначаем
обозначаем 
Для конечно-мерной линейной стационарной модели (10.61) аппроксимация (11.41) принимает вид

При выборе  как в методе Гаусса-Ньютона (10.46) и (10.47), из правила (10.41) получаем следующее приближение:
как в методе Гаусса-Ньютона (10.46) и (10.47), из правила (10.41) получаем следующее приближение:

Используя теперь в (11.40) соотношения (11.41) и  приходим к следующей
приходим к следующей
схеме:

Полученная схема (11.44) совместно с (11.42) представляет собой рекуррентный алгоритм Гаусса-Ньютона метода ошибки предсказания.
Семейство рекуррентных методов ошибки предсказания. В зависимости от выбранной структуры модели, а также от выбора  схема
схема  соответствует специальным типам алгоритмов, принадлежащих широкому семейству методов, которые будем называть рекуррентными методами ошибки предсказания. Например, для линейной регрессии
соответствует специальным типам алгоритмов, принадлежащих широкому семейству методов, которые будем называть рекуррентными методами ошибки предсказания. Например, для линейной регрессии

имеем  превращается в рекуррентный метод наименьших квадратов (11.16). Применение градиентного варианта
превращается в рекуррентный метод наименьших квадратов (11.16). Применение градиентного варианта  к той же структуре приводит к алгоритму
к той же структуре приводит к алгоритму

где последовательность коэффициентов  может быть заданной или нормализованной в соответствии с выражением
может быть заданной или нормализованной в соответствии с выражением

Эта схема широко использовалась, в частности, Уидроу и его соавторами для различных задач адаптивной обработки сигналов. (См. книгу Уидроу и Стернса  Для ARMАХ-модели имеем следующий пример.
Для ARMАХ-модели имеем следующий пример.
Пример 11.1. Рекуррентный метод максимального правдоподобия.
Рассмотрим ARMAX-модель (4.15). Введем  как в (4.20). Тогда
как в (4.20). Тогда

(см.  При этом правило (11.41) даст следующие приближения:
При этом правило (11.41) даст следующие приближения:

и алгоритм принимает вид

Эта схема известна как рекуррентный метод максимального правдоподобия и исследовалась Остремом [22] и Седерстремом 1364].
Отметим различие между (ошибкой предсказания)  и (невязкой)
и (невязкой)  . Последняя величина является компонентой вектора
. Последняя величина является компонентой вектора  , и ее значение не требуется при вычислении
, и ее значение не требуется при вычислении  Следовательно, естественно проводить различие между указанными величинами (ср. с [262, раздел 5.11]).
Следовательно, естественно проводить различие между указанными величинами (ср. с [262, раздел 5.11]).
Аналогично применение метода Гаусса-Ньютона ошибки предсказания к ARARX-структуре (4.22) порождает другой рекуррентный метод максимального правдоподобия, полученный Гертлером и Бенешем [131], в то время как этот же
алгоритм с блочно-диагональной структурой матрицы  введенный в [174] принято называть рекуррентным алгоритмом обобщенных наименьших квадратов. См. также табл. 11.1 в разделе 11.5.
введенный в [174] принято называть рекуррентным алгоритмом обобщенных наименьших квадратов. См. также табл. 11.1 в разделе 11.5.
Применение рекуррентного метода ошибки предсказания к моделям в пространстве состояний тесно связано с хорошо известным расширенным фильтром Калмана, как отмечается в [247]. Таким образом, алгоритм  порождает как частные случаи богатый спектр конкретных, имеющих "имя” алгоритмов. Одним из его основных достоинств является также возможность широкого применения. Единственное требование к структуре модели состоит в вычисляемости градиента
порождает как частные случаи богатый спектр конкретных, имеющих "имя” алгоритмов. Одним из его основных достоинств является также возможность широкого применения. Единственное требование к структуре модели состоит в вычисляемости градиента 
Проекция на  Структура модели корректно определена только для
Структура модели корректно определена только для  когда предсказатели устойчивы (т.е. модель соответствует множеству параметров
когда предсказатели устойчивы (т.е. модель соответствует множеству параметров  которых матрица
которых матрица  в (11.42) устойчива). При минимизации критериальной функции в режиме оценивания по накопленным данным это следует учитывать как ограничение. То же самое справедливо и относительно рекуррентной минимизации (11.44). Наиболее простой способ состоит в проектировании оценок на множество
в (11.42) устойчива). При минимизации критериальной функции в режиме оценивания по накопленным данным это следует учитывать как ограничение. То же самое справедливо и относительно рекуррентной минимизации (11.44). Наиболее простой способ состоит в проектировании оценок на множество  например, следующим образом:
например, следующим образом:

Введенные в (11.50) дополнительные вычислительные трудности связаны с проверкой условия устойчивости  Оказывается, что для успешного функционирования (11.44) проверка типа (11.50) необходима. Однако, как показывает опыт, проектирование обычно имеет место только на нескольких начальных шагах. Следовательно, при игнорировании соответствующих данных в (11.50) происходит умеренная потеря информации.
Оказывается, что для успешного функционирования (11.44) проверка типа (11.50) необходима. Однако, как показывает опыт, проектирование обычно имеет место только на нескольких начальных шагах. Следовательно, при игнорировании соответствующих данных в (11.50) происходит умеренная потеря информации.
Асимптотические свойства. Рекуррентный метод ошибки предсказания (11.44) построен таким образом, что пересчет ”в среднем” производится в модифицированном направлении антиградиента функции

т. е.

Поэтому естественно ожидать, что  будет сходиться к локальному минимуму функции
будет сходиться к локальному минимуму функции  Фактически это имеет место при выполнении соответствующих условий регулярности [249]. Более того, для метода Гаусса-Ньютона ошибки предсказания с
Фактически это имеет место при выполнении соответствующих условий регулярности [249]. Более того, для метода Гаусса-Ньютона ошибки предсказания с  можно показать, что
можно показать, что  имеет асимптотически нормальное распределение, совпадающее с асимптотическим распределением оценки по накопленным данным (см.
имеет асимптотически нормальное распределение, совпадающее с асимптотическим распределением оценки по накопленным данным (см.  Таким образом, имеем
Таким образом, имеем 
- Если  и
и  при
при  то с вероятностью
то с вероятностью  сходится к локальному минимуму функции
сходится к локальному минимуму функции  (Меры, обеспечивающие условие
(Меры, обеспечивающие условие  называются регуляризацией и обсуждаются в разделе 11.7.)
называются регуляризацией и обсуждаются в разделе 11.7.)
- Допустим, что  (см.
(см.  и что
и что  сходится к параметру
сходится к параметру  Допустим, что используется метода Гаусса-Ньютона ошибки предсказания
Допустим, что используется метода Гаусса-Ньютона ошибки предсказания
 Тогда
Тогда

По поводу техники доказательства и дальнейших результатов см. Приложение 
Общие нормы, многомерный случай. Введение общего критерия

где  приводит к методу Гаусса-Ньютона ошибки предсказания
приводит к методу Гаусса-Ньютона ошибки предсказания

Здесь  -вектор-столбец,
-вектор-столбец,  -матрица, а
-матрица, а  -матрица. Случай явной зависимости от 0 функции
-матрица. Случай явной зависимости от 0 функции  аналогичен.
аналогичен.