Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
7.4. Статистическая трактовка параметрического оценивания и метод максимального правдоподобияДо сих пор мы не использовали какую-либо статистическую аргументацию для оценивания. Действительно, принцип подгонки моделей к данным имеет смысл безотносительно к статистической трактовке данных. Однако полезно и поучительно в данном случае кратко описать основные аспекты статистического параметрического оценивания и соотнести их с вышеизложенным. Оценивание и принцип максимального правдоподобия. Область теории статистических выводов также, как идентификация систем и параметрическое оценивание, представляет собой проблему извлечения информации из наблюдений, которые сами могут быть не достоверными. При этом наблюдения рассматриваются как реализации случайных величин. Допустим, что наблюдения представляют собой случайный вектор
т. е.
В (7.55)
которая является функцией, отображающей Можно использовать много таких функций оценивания. Оценка, максимизирующая вероятность наблюдаемого события, была введена Фишером в [117] и получила название оценки максимального правдоподобия. Она может быть определена следующим образом. Функция плотности совместного распределения вероятностей наблюдаемого случайного вектора задается (7.55). Таким образом, вероятность того, что реализация
Это детерминированная функция
где максимизация производится при фиксированном у. Эта функция известна как оценка максимального правдоподобия (оценка ММП). Пример. Пусть
Обычной оценкой
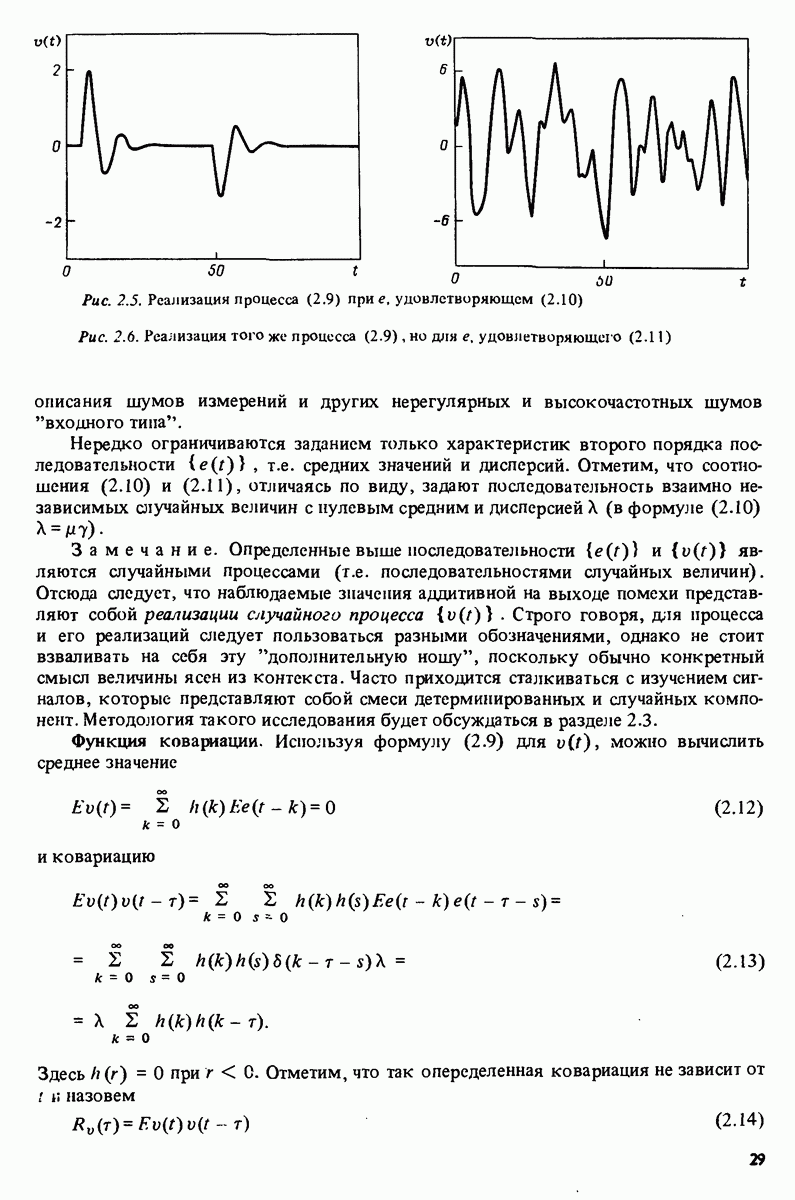
Чтобы вычислить оценку ММП определим сначала функцию плотности совместного распределения (7.55) для наблюдений. Поскольку для
а
Таким образом, функция правдоподобия равна
откуда находим
Связь с оценкой максимума апостериорной вероятности. Байесовский подход дает близкую, но концептуально отличную трактовку задачи параметрического оценивания. В байесовском подходе сам параметр рассматривается как случайная величина. Основываясь на наблюдении других случайных величин, коррелирующих с параметром, можно извлечь информацию о его значении. Допустим, свойства наблюдений могут быть описаны в терминах вектора параметров в. С позиций байесовского подхода вектор в рассматривается, таким образом, как случайный вектор с некоторым априорным распределением (априорный означает заданный до наблюдений). Очевидно, наблюдения Предположим, что условная плотность распределения вероятностей для
а априорная плотность распределения для в имеет вид
(Здесь Р(АВ) - условная вероятность события А при заданном В. Мы допускаем несколько нестандартное обозначение.) Используя правило Байеса (1.10), при некоторой неточности обозначений находим, таким образом, апостериорную плотность распределения для 0, т. е. условную плотность распределения вероятностей для в при заданных наблюдениях:
Таким образом, апостериорная плотность распределения вероятностей как функция в пропорциональна функции правдоподобия, умноженной на априорную плотность распределения. Часто влияние априорной плотности распределения незначительно. Тогда оценка максимума апостериорной вероятности
близка к оценке ММП (7.58). Неравенство Крамера-Рао. Качество оценки можно определить ее матрицей среднеквадратичной ошибки:
Здесь Представляет интерес выбор такой оценки, для которой Пусть в
где
Поскольку в является Доказательство неравенства Крамера-Рао приводится в Приложении 7А. Асимптотические свойства оценки максимального правдоподобия. Обычно установить свойства оценки, например вычислить (7.66), трудно. Поэтому определяют асимптотические свойства, когда размер выборки (в рассматриваемом случае число Предположим, что случайные величины
Допустим также, что распределение
сходится по распределению к нормальной с нулевым средним и матрицей ковариации, равной нижней границе неравенства Крамера-Рао ((7.67) и (7.68)). В гл. 8 и 9 эти результаты будут установлены для оценок ММП, используемых при идентификации динамических систем. В этом смысле оценка ММП является наилучшей возможной оценкой. Однако следует сказать, что оценка ММП иногда подвергается критике за недостаточно хорошие свойства при малых выборках, и что существуют, кроме (7.66), другие способы задания критерия качества оценки. Вероятностные модели динамических систем. Предположим, что рассмотренные в разделе 7.1 модели содержат как функцию предсказания, так и предполагаемую функцию плотности распределения вероятностей для соответствующих ошибок предсказания, как описано в разделе 5.4:
Напомним, что модель типа (7.69), содержащая плотность распределения для Функция правдоподобия для вероятностных моделей динамических систем. Заметим, что в соответствии с моделью (7.69) выходная величина равна
где
Максимизация этой функции эквивалентна максимизации (7-71)
Если определить
то можно записать
Таким образом, метод максимального правдоподобия может рассматриваться как частный случай критерия ошибки предсказания (7.12). Следует подчеркнуть, что (7.33) и (7.74) реализуют точный метод максимального правдоподобия для сформулированной задачи. Иногда отмечают чрезвычайную сложность функции правдоподобия в задачах анализа временных рядов, из-за чего часто приходится прибегать к ее аппроксимации (см., например, [5,108,210]). В определенных случаях это так. Причина состоит в трудности представления, скажем, ARMA-модели в форме предсказателя (7.69) (обычно это требует использования нестационарных калмановских предсказателей). Проблема, таким образом, относится не к самому ММП как таковому, а к нахождению точного предсказателя. Если используются стационарные предсказатели, то предполагают известными все предыдущие наблюдения (см. Гауссовский случай. В случае, когда ошибки предсказания предполагаются гауссовскими с нулевыми средними значениями и (не зависящими от дисперсиями X, имеем
Если X известна, то функция (7.75) эквивалентна квадратичному критерию (7.15). При неизвестной дисперсии X (7.75) представляет собой пример критерия параметризованной нормы (7.16). В зависимости от положенной в основу структуры модели, X может быть или не быть параметризована независимо от параметров предсказателя. Для иллюстрации этого см. задачу Информационная матрица Фишера и граница Крамера — Рао для динамических систем. Зная выражение логарифма функции правдоподобия (7.72) для рассматриваемой структуры модели, можно вычислить информационную матрицу (7.68), Для простоты далее предполагаем, что плотность распределения
где, как и
при
поскольку
Если
Неравенство Крамера - Рао утверждает, что для любой несмещенной оценки
параметра в (т.е. такой оценки, что значении
Заметим, что эта граница, применима при любом
Многомерный гауссовский случай В случае, когда ошибки предсказания являются р-мерными векторами и имеют гауссовское совместное распределение с нулевым средним и матрицей ковариаций А, подучаем из выражения для многомерного гауссовского распределения
Тогда логарифм правдоподобия, взятый с минусом, принимает вид
Если матрица ковариаций А полностью неизвестна и не зависит от параметра
Тогда
(см. задачу 7D.3), где
Действительно, к этому выражению приводит критерий типа (7.29), (7.30) с Меры информации и энтропии. В (5.36) и (5.37) была дана общая формулировка модели как предполагаемой функции плотности распределения вероятностей для наблюдений
Пусть
Здесь
или негэнтропии. Естественной формулировкой задачи идентификации является отыскание модели, максимизирующей энтропию по отношению к истинной системе или, иначе, минимизирующей информационное расстояние до истинной системы. Этой формулировкой в различных интересных ее комбинациях занимался Акаике [4], [6], [8]. Таким образом, при параметризованном множестве моделей
Мера информации может быть переписана в виде
где Задача (7.88) эквивалентна, следовательно, задаче
Конечно же, проблема здесь состоит в том, что математическое ожидание невозможно вычислить, поскольку истинная плотность распределения неизвестна. Наиболее простая оценка математического ожидания состоит в замене его наблюдением
Это приводит к логарифмической функции правдоподобия, и тогда (7.89) совпадает с оценкой ММП. Следовательно, подход к идентификации, основанный на максимизации функции правдоподобия, может также интерпретироваться как стратегия максимизации энтропии или метод минимизации информационного расстояния. Расстояние между получаемой в результате моделью и истинной системой равно, таким образом,
Это — случайная величина, поскольку в зависит
Этот критерий должен быть минимизирован как но множеству моделей, так и по
Вычисления, приводящие к этой оценке, будут даны в разделе 16.4. Выражение (7.93), используемое в (7.89) с учетом (7.72) и (7.73), приводит к оценке
Это - теоретический информационный критерий Акаике. Если он используется для фиксированной структуры модели, получаемая оценка совпадает с оценкой ММП той же структуры. Однако преимущество (7.94) состоит в том, что минимизация может быть проведена по отношению к различным структурам модели, учитывая, таким образом, общую теорию идентификации. Дальнейшее обсуждение этого аспекта см. в разделе 16.4. Подход, развитый Риссаненом и названный принципом описания минимальной длины, концептуально связан с информационными мерами. В соответствии с этим подходом следует искать такую модель, которая допускает наиболее короткий код или описание наблюдаемых данных; см. [338] и [341]. При заданной структуре модели результат вновь совпадает с оценкой ММП. См. также раздел 16.4. Прагматическая точка зрения. Безусловно, хорошо известно, что общие и основные принципы, такие как максимизация правдоподобия, максимизация энтропии и минимизация информационного расстояния, приводят к критериям типа (7.11). Однако в конечном счете мы располагаем последовательностью чисел, которую следует сравнить с отгадками модели. Кроме того, всегда существует вопрос, применимы ли вероятностный подход и абстрактные принципы, поскольку мы наблюдаем только конкретную последовательность данных, а подход основан на предположении, что эксперимент, порождающий этот набор данных, может быть повторен бесконечно много раз при одинаковых условиях. Важно, таким образом, что минимизация (7.11) имеет смысл даже безотносительно к вероятностному подходу и без алиби, обеспечиваемым абстрактными принципами.
|
 |
Оглавление
|































































































































































































































































































































































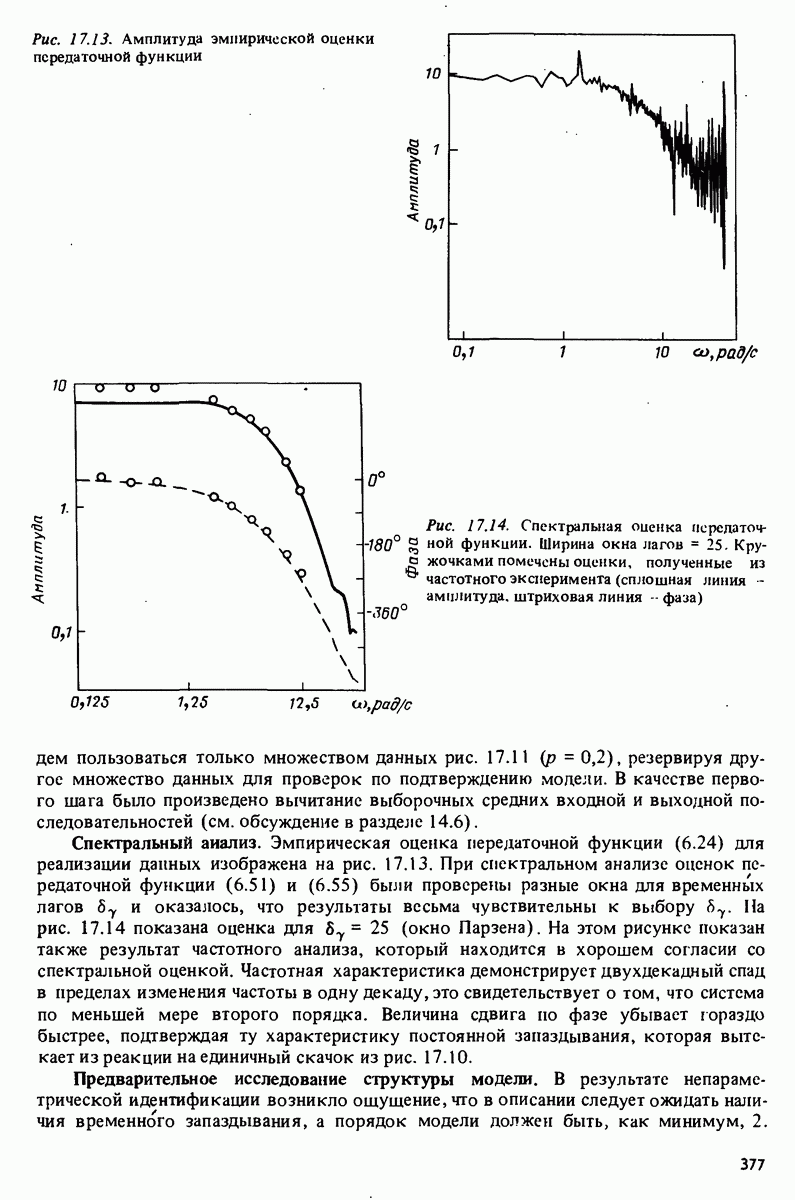
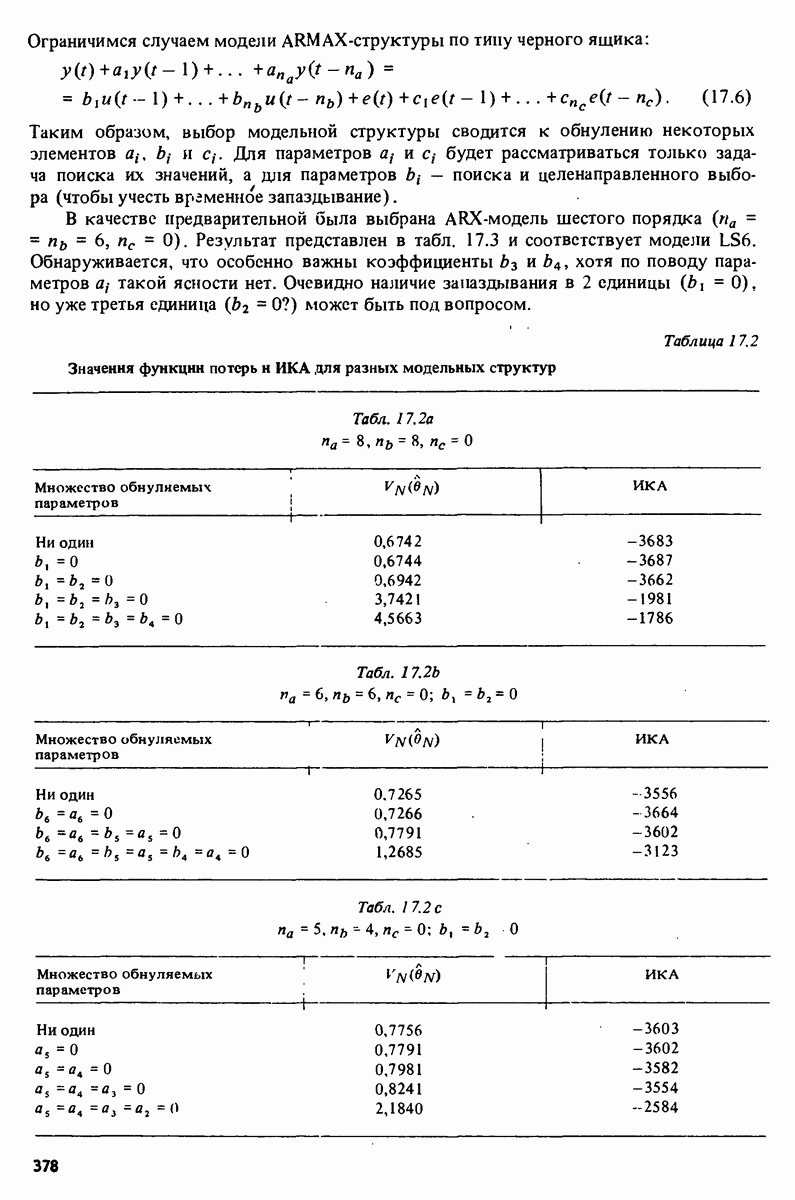














































 принимающий значения в
принимающий значения в  . Предполагаем, что существует функция плотности распределения вероятностей, равная
. Предполагаем, что существует функция плотности распределения вероятностей, равная


 — d-мерный вектор параметров, описывающий свойства наблюдаемых величин. Он предполагается неизвестным, а цель наблюдений фактически состоит в оценивании вектора в по
— d-мерный вектор параметров, описывающий свойства наблюдаемых величин. Он предполагается неизвестным, а цель наблюдений фактически состоит в оценивании вектора в по  Эта цель реализуется оценкой
Эта цель реализуется оценкой

 в
в  Если наблюдаемое значение
Если наблюдаемое значение  является вектором
является вектором  то, следовательно, получающаяся оценка равна
то, следовательно, получающаяся оценка равна 
 наблюдение) действительно должна принять значение
наблюдение) действительно должна принять значение  пропорциональна
пропорциональна

 , поскольку вместо
, поскольку вместо  подставлены численные значения у. Она называется функцией правдоподобия и отражает правдоподобие того, что наблюдаемое событие имеет место на самом деле. Разумной оценкой вектора в тогда может быть выбрана такая величина, при которой наблюдаемое событие наиболее правдоподобно. Таким образом, ищем
подставлены численные значения у. Она называется функцией правдоподобия и отражает правдоподобие того, что наблюдаемое событие имеет место на самом деле. Разумной оценкой вектора в тогда может быть выбрана такая величина, при которой наблюдаемое событие наиболее правдоподобно. Таким образом, ищем

 независимые нормально распределенные случайные величины с (неизвестными) средними
независимые нормально распределенные случайные величины с (неизвестными) средними  (не зависящими от
(не зависящими от  и (известными) дисперсиями
и (известными) дисперсиями 

 является текущее среднее
является текущее среднее

 она равна
она равна

 независимы, имеем
независимы, имеем

 Максимизация функции правдоподобия эквивалентна максимизации
Максимизация функции правдоподобия эквивалентна максимизации  логарифма. Таким образом,
логарифма. Таким образом,


 коррелируют с в. После того, как наблюдения получены, можно сформировать апостериорную функцию плотности распределения вероятностей для в. Используя ее, можно определить различные оценки в, например, величину, для которой плотность распределения вероятностей достигает своего максимума (наиболее вероятное значение). Эта оценка известна как оценка максимума апостериорной вероятности.
коррелируют с в. После того, как наблюдения получены, можно сформировать апостериорную функцию плотности распределения вероятностей для в. Используя ее, можно определить различные оценки в, например, величину, для которой плотность распределения вероятностей достигает своего максимума (наиболее вероятное значение). Эта оценка известна как оценка максимума апостериорной вероятности.
 при заданном в имеет вид
при заданном в имеет вид





 обозначает истинное значение
обозначает истинное значение  , а (7.66) вычисляется в предположении, что плотность распределения
, а (7.66) вычисляется в предположении, что плотность распределения  равна
равна 
 мала. Причем интересно, что существует нижний предел значений
мала. Причем интересно, что существует нижний предел значений  для любых несмещенных оценок. Это - так называемое неравенство Крамера-Рао:
для любых несмещенных оценок. Это - так называемое неравенство Крамера-Рао:
 оценка 0, для которой
оценка 0, для которой  где
где  означает среднее, вычисляемое но плотности распределения
означает среднее, вычисляемое но плотности распределения  (равенство должно выполняться для всех значений
(равенство должно выполняться для всех значений  и предположим, что у принимает значения в подмножестве
и предположим, что у принимает значения в подмножестве  граница которого не зависит от
граница которого не зависит от  . Тогда
. Тогда


 -мерным вектором,
-мерным вектором,  -мерный вектор-столбец, а гессиан
-мерный вектор-столбец, а гессиан  -матрица. Матрица
-матрица. Матрица  называется информационной матрицей Фишера. Заметим, что для вычисления матрицы
называется информационной матрицей Фишера. Заметим, что для вычисления матрицы  обычно требуется знать
обычно требуется знать  поэтому точное значение
поэтому точное значение  может быть недоступно пользователю.
может быть недоступно пользователю.
 стремится к бесконечности. Классические результаты подобного рода для оценки максимального правдоподобия в случае независимых наблюдений были получены Вальдом [418] и Крамером [87]:
стремится к бесконечности. Классические результаты подобного рода для оценки максимального правдоподобия в случае независимых наблюдений были получены Вальдом [418] и Крамером [87]:
 независимы и одинаково распределены, так что
независимы и одинаково распределены, так что

 определяется плотностью
определяется плотностью  для некоторого значения
для некоторого значения  Тогда случайная величина
Тогда случайная величина  стремится к
стремится к  с вероятностью 1 при
с вероятностью 1 при  а случайная величина
а случайная величина


 называется (полной) вероятностной моделью.
называется (полной) вероятностной моделью.

 имеет плотность распределения
имеет плотность распределения  Тогда совместная плотность распределения наблюдений
Тогда совместная плотность распределения наблюдений  (для заданной детерминированной входной последовательности
(для заданной детерминированной входной последовательности  определяется леммой 5.1. Заменяя фиктивные переменные
определяется леммой 5.1. Заменяя фиктивные переменные  соответствующими наблюдениями, получим функцию правдоподобия:
соответствующими наблюдениями, получим функцию правдоподобия:




 и обычно заменяют соответствующие начальные величины нулями. Тогда это соответствует функции правдоподобия как условной по отношению к этим величинам, а метод называют условным ММП (см., например, [210]).
и обычно заменяют соответствующие начальные величины нулями. Тогда это соответствует функции правдоподобия как условной по отношению к этим величинам, а метод называют условным ММП (см., например, [210]).


 Сравните также с задачей
Сравните также с задачей 
 известная (не зависящая от в) и не зависящая от
известная (не зависящая от в) и не зависящая от  функция. Пусть
функция. Пусть  Следовательно,
Следовательно,

 -мерный вектор-столбец,
-мерный вектор-столбец,  производная
производная  по
по  Чтобы найти информационную матрицу Фишера, вычисляем математическое ожидание случайной матрицы
Чтобы найти информационную матрицу Фишера, вычисляем математическое ожидание случайной матрицы

 в предположении, что истинная плотность распределения для
в предположении, что истинная плотность распределения для  на самом деле равна
на самом деле равна  Последнее предположение означает, что
Последнее предположение означает, что  будет рассматриваться как последовательность независимых случайных величин с плотностью распределения
будет рассматриваться как последовательность независимых случайных величин с плотностью распределения  Обозначим это математическое ожидание
Обозначим это математическое ожидание  Таким образом,
Таким образом,

 независимы при
независимы при  Кроме того, имеем
Кроме того, имеем  и
и

 гауссовская величина с дисперсией
гауссовская величина с дисперсией  то, как легко проверить,
то, как легко проверить,  Следовательно,
Следовательно,



 при произвольном истинном
при произвольном истинном
 )
)

 и для всех методов оценивания параметров. Таким образом, имеем
и для всех методов оценивания параметров. Таким образом, имеем



 можно аналитически минимизировать (7.81) по Лиля любого фиксированного 0:
можно аналитически минимизировать (7.81) по Лиля любого фиксированного 0:


 . Следовательно, в этом частном случае можно использовать критерий
. Следовательно, в этом частном случае можно использовать критерий




 обозначает истинную плотность распределения для наблюдений. Соответствие между двумя распределениями может измеряться в терминах информационного расстояния Кульбака-Лейблера [220]:
обозначает истинную плотность распределения для наблюдений. Соответствие между двумя распределениями может измеряться в терминах информационного расстояния Кульбака-Лейблера [220]:

 используется в качестве переменной интегрирования для
используется в качестве переменной интегрирования для  Это расстояние равно также энтропии
Это расстояние равно также энтропии  по отношению к
по отношению к  взятой со знаком минус:
взятой со знаком минус:

 и необходимо определить
и необходимо определить


 означает математическое ожидание но отношению к истинной системе.
означает математическое ожидание но отношению к истинной системе.



 . В качестве основного критерия подгонки Акаике [8] предложил использовать среднее информационное расстояние, или среднюю энтропию
. В качестве основного критерия подгонки Акаике [8] предложил использовать среднее информационное расстояние, или среднюю энтропию

 . Акаике предложил следующую несмещенную оценку величины (7.92):
. Акаике предложил следующую несмещенную оценку величины (7.92):

