Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
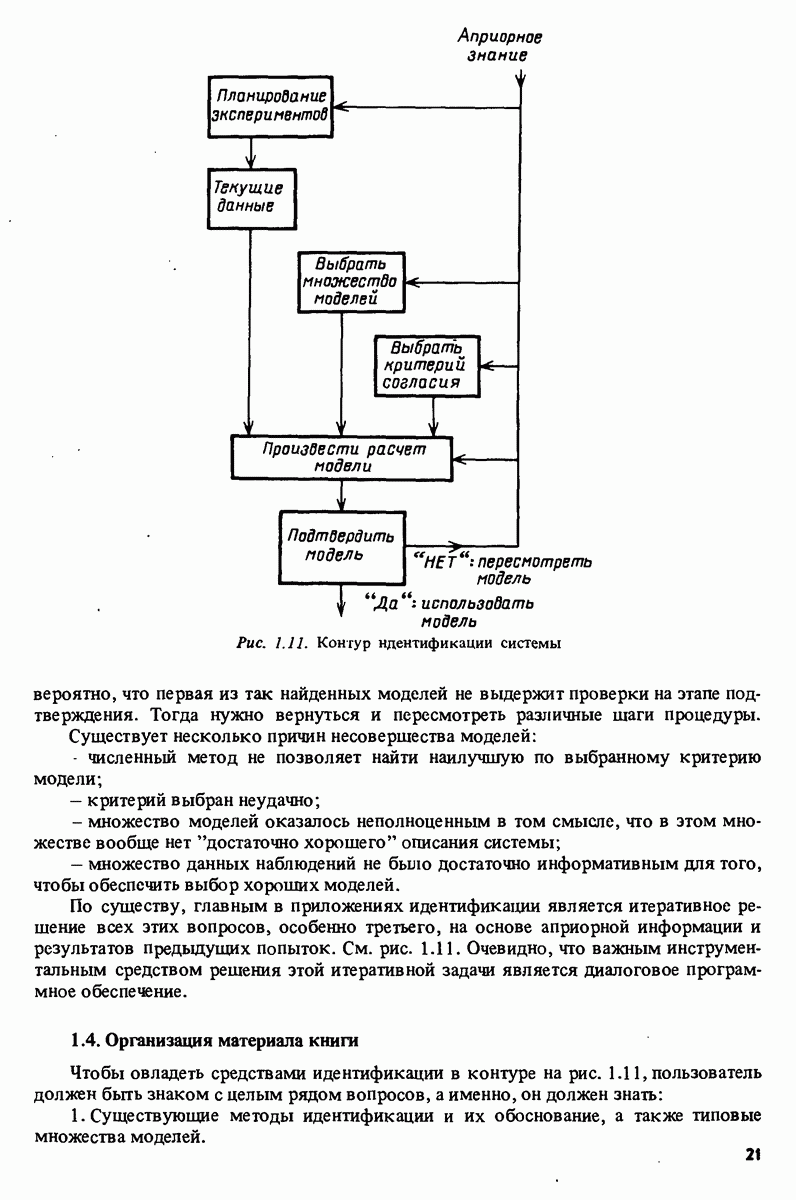
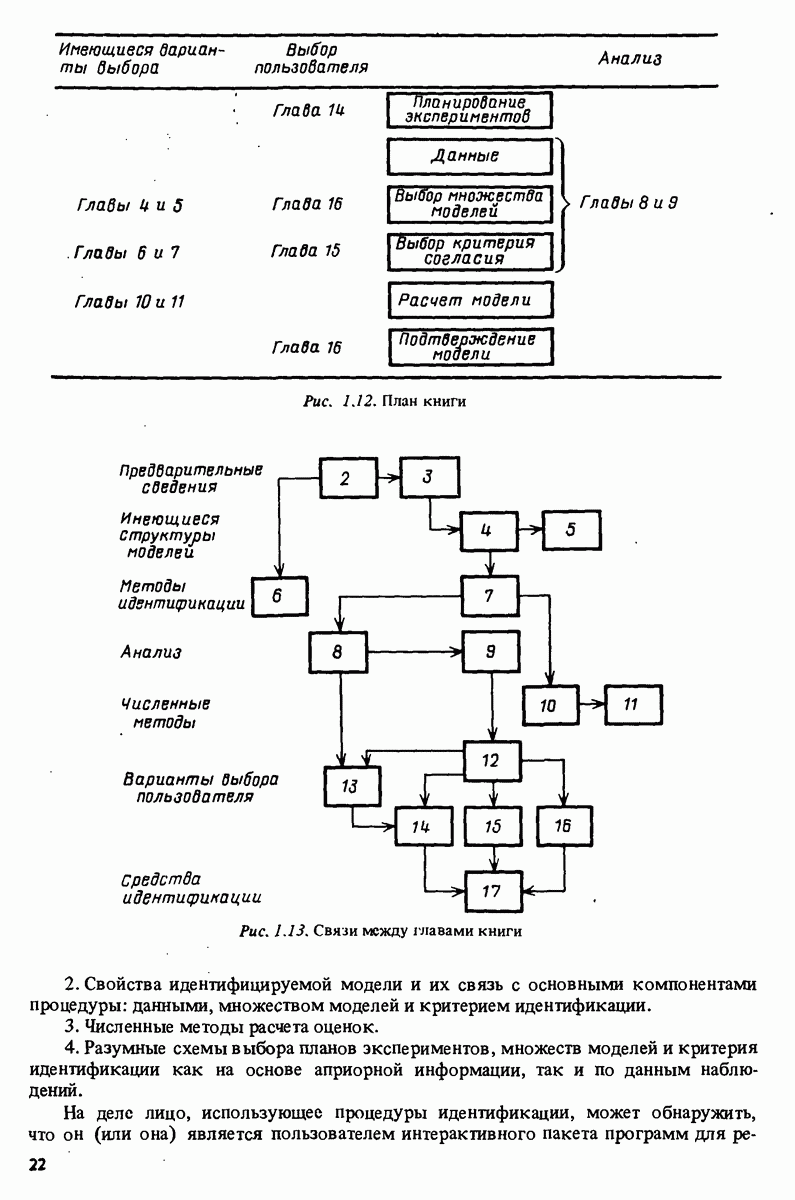
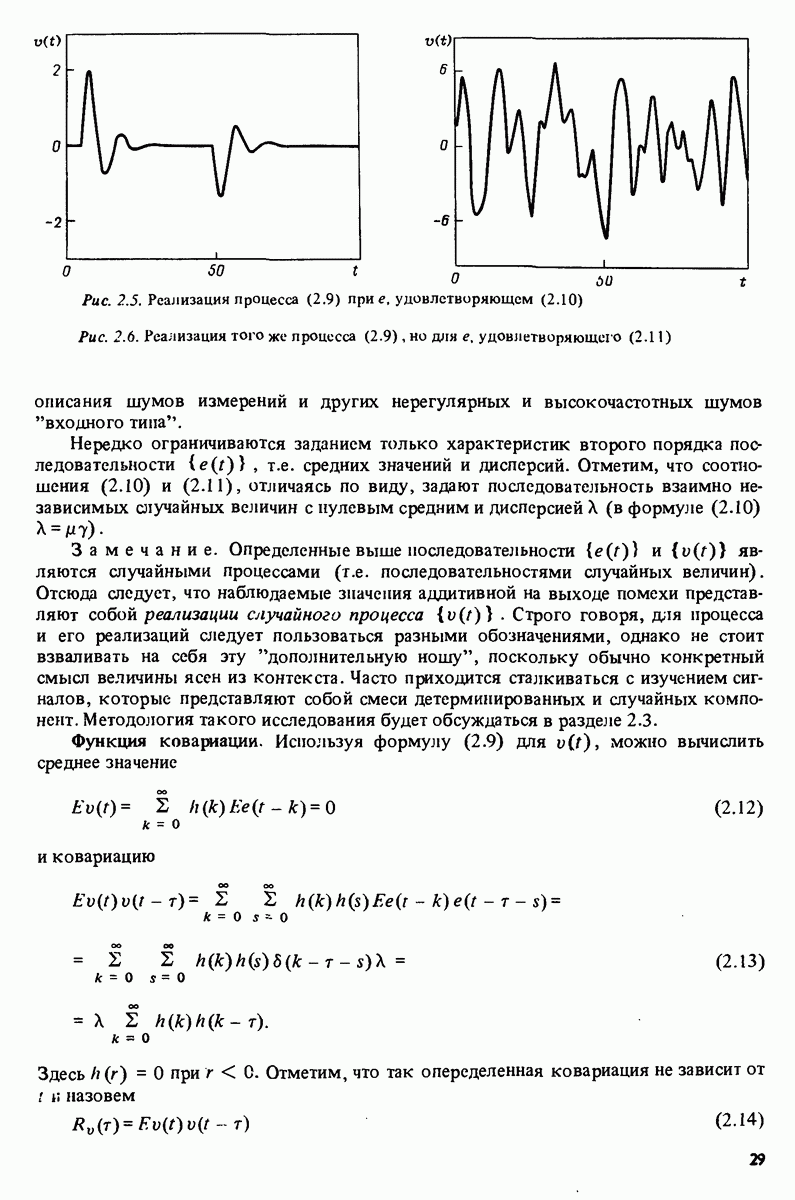
Глава 10. МЕТОДЫ ВЫЧИСЛЕНИЯ ОЦЕНОКВ гл. 7 были представлены две основные процедуры параметрического оценивания: 1. Подход, основанный на ошибке предсказания, когда некоторая функция 2. Корреляционный подход, в котором ищется решение некоторого уравнения В данной главе будут обсуждаться вопросы наилучшего численного решения этих задач. В момент времени действительного вектора параметров 10.1. Линейные регрессии и наименьшие квадратыНормальные уравнения. Для линейных регрессий предсказание задается в виде
Применение к
где
Вектор в можно также рассматривать как решение системы уравнений
Эти уравнения известны как нормальные уравнения. Заметим, что основное уравнение (7.104) метода инструментальных переменных совершенно аналогично (10.5), и большая часть того, что говорится в данном разделе о методе наименьших квадратов, применимо также и к методу инструментальных переменных с очевидными изменениями. Матрица коэффициентов
Поэтому в инженерной литературе этот класс методов обычно называют алгоритмами квадратного корня. Термин не совсем подходящий, поскольку никакие квадратные корни не берутся. Возможно, при решении (10.5) более подходящим был бы термин квадратичные методы. Нахождение оценки наименьших квадратов посредством ортогональных преобразований. Известно несколько различных подходов к построению В общем многомерном случае (4.53) и (4.54) положим
(Здесь
Очевидно, норма не изменится при ортогональном преобразовании вектора
Выберем теперь ортогональную матрицу
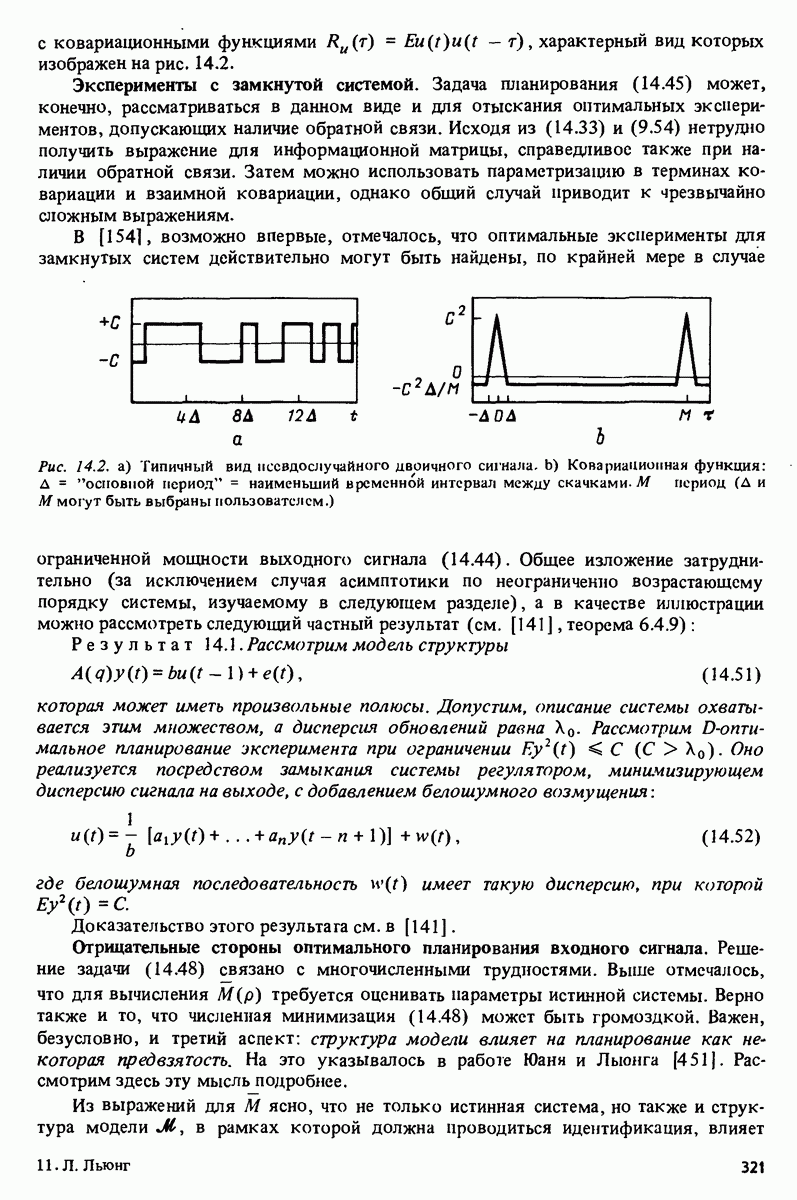
где
что представляет собой
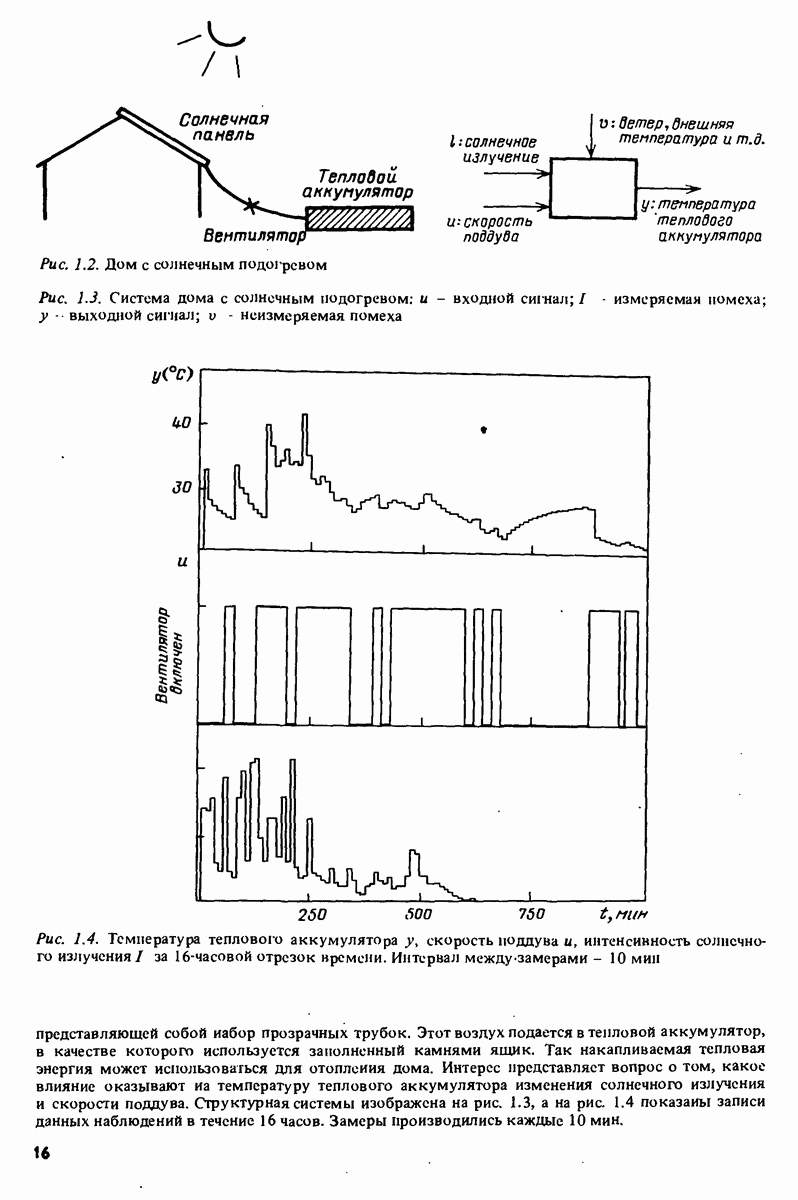
Тогда
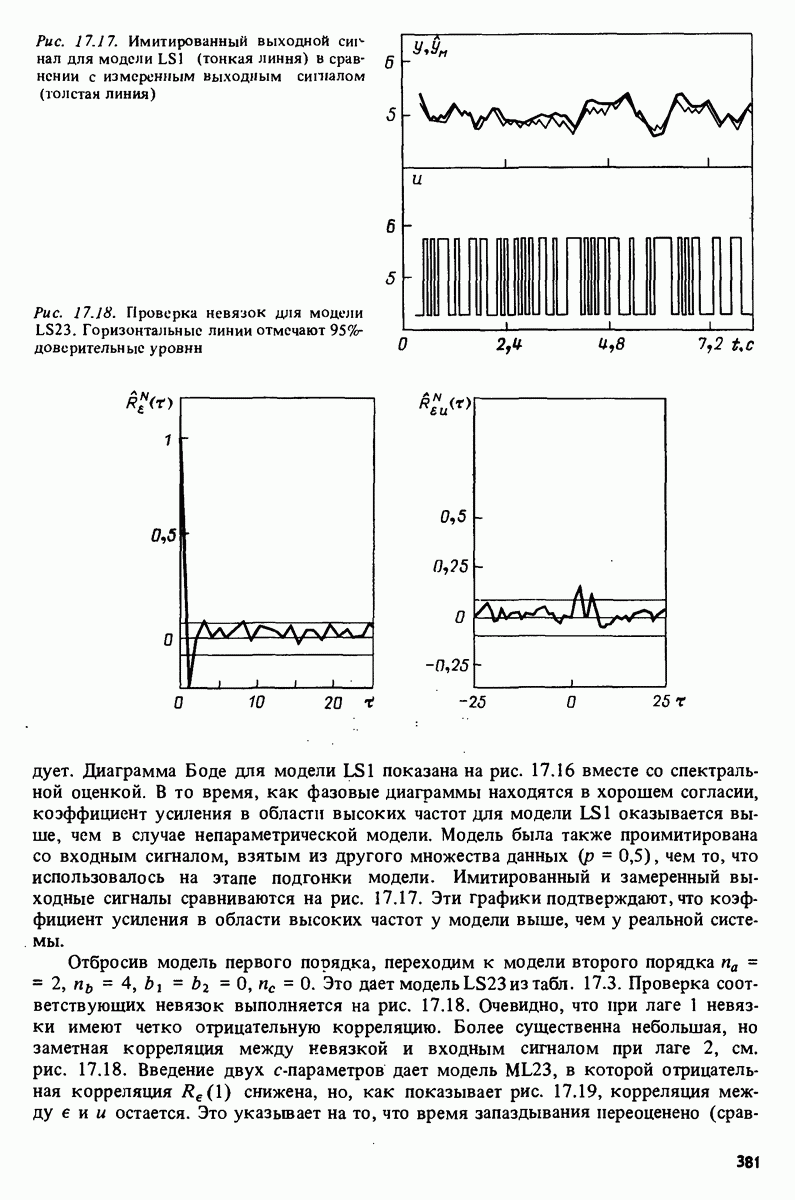
и при
достигает минимума
Заметим, что из (10.8) следует, что
Показатель обусловленности (отношение наибольшего собственного значения к наименьшему) матрицы непосредственное решение (10.2) или (10.5) дает вполне удовлетворительную точность, если размерность вектора в не слишком велика. Нахождение в одним из описанных методов требует выполнения количества арифметических операций, пропорционального Начальные условия: вырезанные данные. Типичная структура вектора регрессии
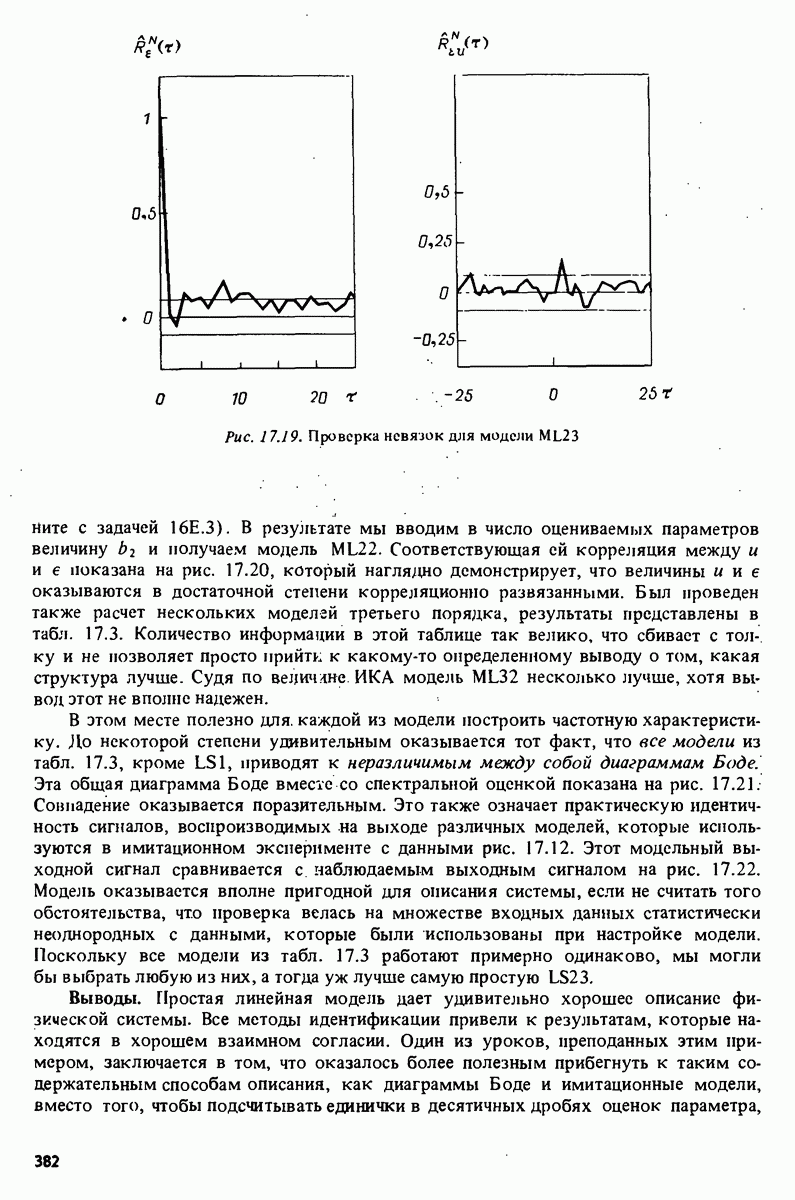
Здесь
в то время как AR-модель для Для структуры (10.13) матрица
Если имеются сведения относительно 1. Начинать суммирование в (10.3) и (10.4) в момент 2. Заменить неизвестные начальные условия нулями (предварительное вырезание) . Для симметрии опытные данные В работах по обработке речевой информации эти подходы известны как ковариационный и автокорреляционный методы соответственно [273]. Нет сомнения, с логической точки зрения подход 1 выглядит более естественным. Подход 2, однако, имеет особенность, состоящую в том, что блоки (10.14) зависят только от разности между индексами:
Это делает Очевидно, при Алгоритм Левинсона Сдвиговая структура (10.13) придает специфическую структуру матрице Рассмотрим случай AR-модели сигнала
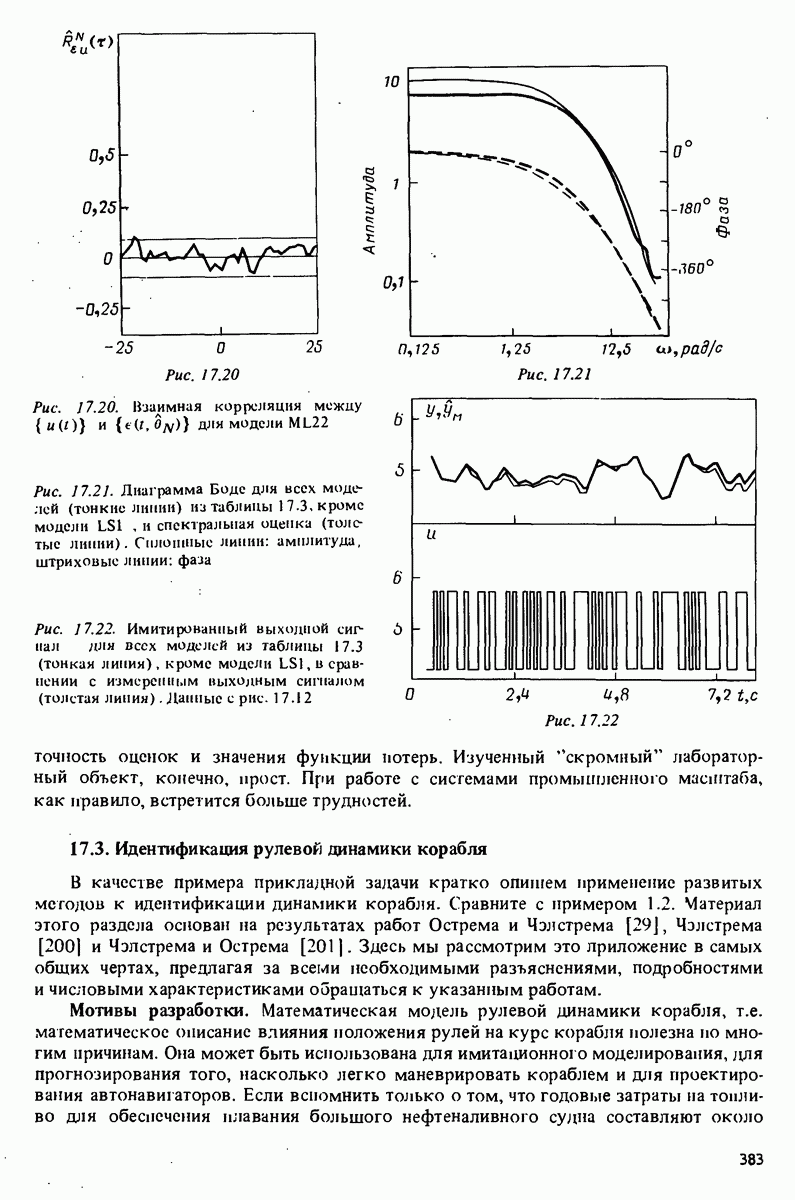
(верхний индекс показывает, что производится подгонка модели
для
а аргумент
Здесь Допустим, что найдено решение (10.19) относительно
Здесь первые образом, попробуем убрать
поскольку матрица коэффициентов представляет собой матрицу Теилица. Можно, кроме того, рассматривать последние
Она представляет собой модель сигнала Умножим теперь (10.21) на
Это определяющее соотношение для а
(Здесь шляпка обозначает действительную оценку, основанную на
имеем схему для вычисления оценок произвольного порядка. Заметим, что переход от а к деление. Вычисление Алгоритм Левинсона (10.24) широко применялся и был распространен на случай векторной величины z, а также на случай ковариационного метода. См., например, работы Уиттла Замечание. Наиболее важное изменение при работе с векторной величиной z состоит в том, что соответствующая модель в обратном времени (10.20)
порождает оценки параметров
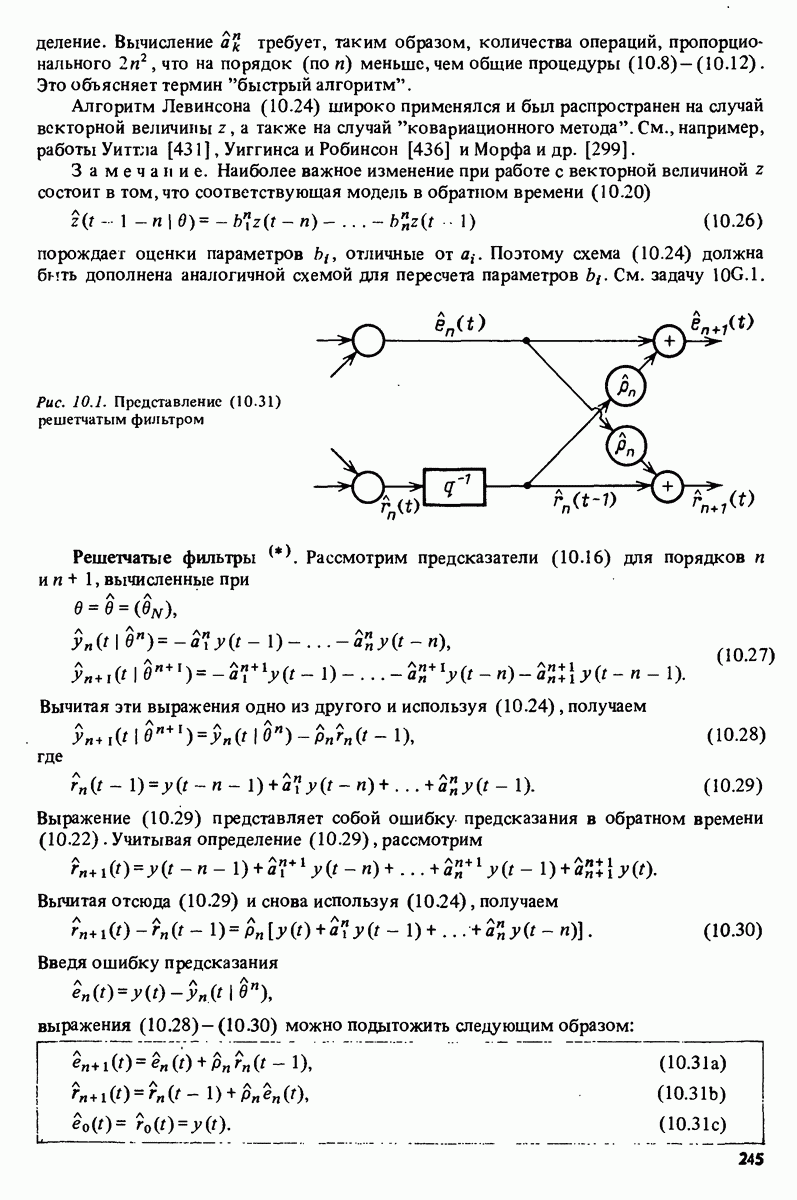
Рис. 10.1. Представление (10.31) решетчатым фильтром Решетчатые фильтры Рассмотрим предсказатели (10.16) для порядков
Вычитая эти выражения одно из другого и используя (10.24), получаем
где
Выражение (10.29) представляет собой ошибку предсказания в обратном времени (10.22). Учитывая определение (10.29), рассмотрим
Вычитая отсюда (10.29) и снова используя (10.24), получаем
Введя ошибку предсказания
выражения (10.28)-(10.30) можно подытожить следующим образом:
Это простое представление ошибок предсказания (и предсказаний Характерной чертой представления (10.31) является то, что величины
(см. задачу 10D.1). Следовательно, коэффициенты отражения
Схема (10.31) вместе с (10.33) образует эффективный способ оценивания коэффициентов отражения а также предсказаний как альтернативу алгоритму Левинсона. Важный аспект состоит в том, что схема порождает предсказания всех более низких порядков как промежуточный результат. Решетчатые фильтры широко применялись в приложениях по обработке сигналов. См., например, работы Макхоула [272], Гриффитса [148] и Ли, Морфа и Фридландера [229]. По поводу рекуррентной версии см. также раздел 11.7.
|
 |
Оглавление
|













































































































































































































































































































































































































 минимизируется по
минимизируется по 
 в.
в.
 когда известен набор данных
когда известен набор данных  обе рассмотренные выше функции являются обыкновенными функциями конечномерного
обе рассмотренные выше функции являются обыкновенными функциями конечномерного
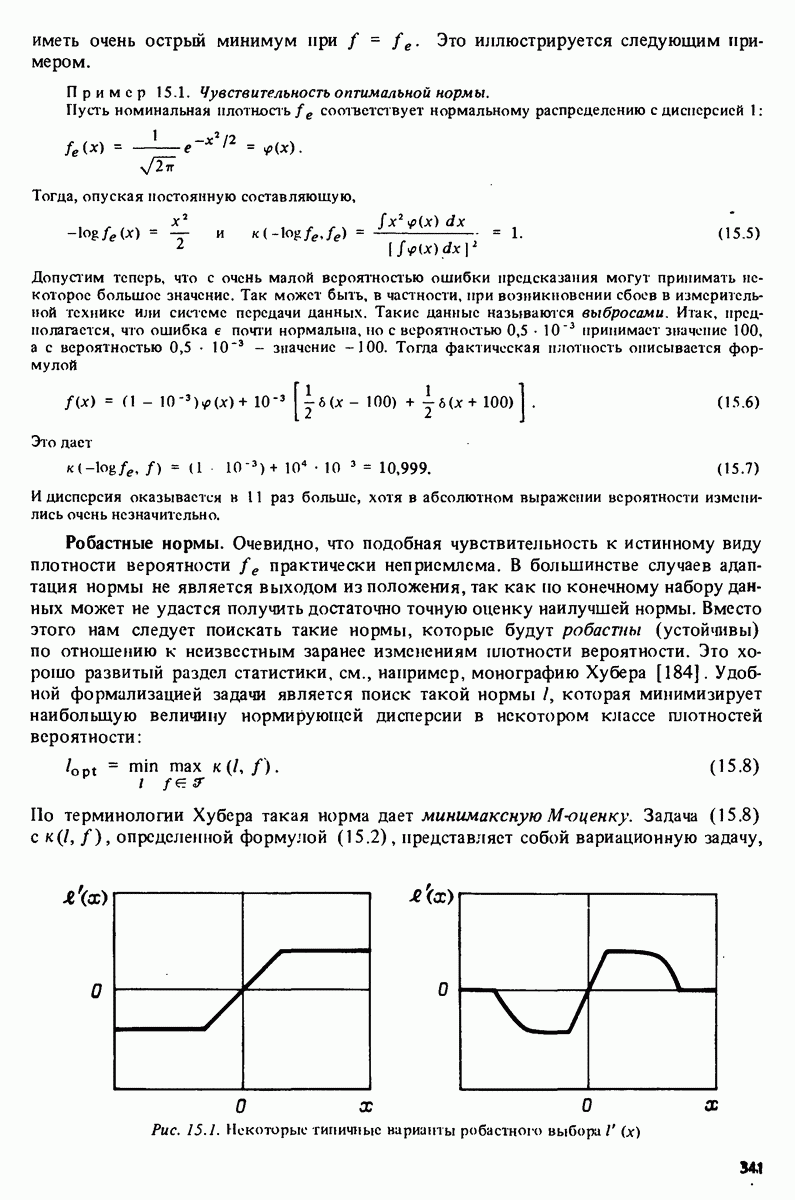
 Следовательно, решение задач сводится к стандартным вопросам нелинейного программирования и численного анализа. Тем не менее, заслуживает внимания рассмотрение этих вопросов для задач параметрического оценивания, учитывающее специфику в структуре введенных выше функций.
Следовательно, решение задач сводится к стандартным вопросам нелинейного программирования и численного анализа. Тем не менее, заслуживает внимания рассмотрение этих вопросов для задач параметрического оценивания, учитывающее специфику в структуре введенных выше функций.

 подхода, основанного на ошибке предсказания и использующего квадратичную норму, приводит к методу наименьших квадратов, описанному в разделе 7.3. При этом параметр
подхода, основанного на ошибке предсказания и использующего квадратичную норму, приводит к методу наименьших квадратов, описанному в разделе 7.3. При этом параметр  при котором достигается минимум, может быть записан в виде (7.34):
при котором достигается минимум, может быть записан в виде (7.34):



 в (10.5) может быть плохо облусловленной, в частности, если ее размерность велика. Существуют методы нахождения вы с более хорошим численным поведением, причем они не основываются на нормальных уравнениях. Это интенсивно обсуждалось в литературе по численному исследованию решения линейных задач методом наименьших квадратов. В качестве основной ссылки по рассматриваемой проблеме можно упомянуть книгу Лоусона и Хансона [228]. Основополагающая идея этих методов состоит в том, что не следует формировать матрицу
в (10.5) может быть плохо облусловленной, в частности, если ее размерность велика. Существуют методы нахождения вы с более хорошим численным поведением, причем они не основываются на нормальных уравнениях. Это интенсивно обсуждалось в литературе по численному исследованию решения линейных задач методом наименьших квадратов. В качестве основной ссылки по рассматриваемой проблеме можно упомянуть книгу Лоусона и Хансона [228]. Основополагающая идея этих методов состоит в том, что не следует формировать матрицу  поскольку она содержит произведения исходных данных. Вместо нее строится матрица
поскольку она содержит произведения исходных данных. Вместо нее строится матрица  обладающая свойством
обладающая свойством

 например, преобразования Хаусхолдера [182], процедура Грамма — Шмидта [52] и декомпозиция Холецкого.
например, преобразования Хаусхолдера [182], процедура Грамма — Шмидта [52] и декомпозиция Холецкого.


 Тогда критерий наименьших квадратов можно записать (ср. с
Тогда критерий наименьших квадратов можно записать (ср. с  )
)

 Следовательно, если
Следовательно, если  ортогональная
ортогональная  -матрица, т. е.
-матрица, т. е.  то
то

 так, чтобы
так, чтобы

 верхняя треугольная
верхняя треугольная  -матрица. Так как Тортогональна, можно записать
-матрица. Так как Тортогональна, можно записать

 -факторизацию
-факторизацию  Существуют различные хорошие в численном отношении методы
Существуют различные хорошие в численном отношении методы  -факторизации, имеющиеся в большинстве программных пакетов по матричному исчислению. Один способ построения
-факторизации, имеющиеся в большинстве программных пакетов по матричному исчислению. Один способ построения  состоит в использовании произведения преобразований Хаусхолдера (см. задачу
состоит в использовании произведения преобразований Хаусхолдера (см. задачу  Положим
Положим





 равен, таким образом, квадратному корню из показателя обусловленности
равен, таким образом, квадратному корню из показателя обусловленности  Следовательно, система линейных уравнений (10.12а) обусловлена значительно лучше, чем (10.5). Описанная процедура нахождения
Следовательно, система линейных уравнений (10.12а) обусловлена значительно лучше, чем (10.5). Описанная процедура нахождения  является, таким образом, более предпочтительной благодаря своим лучшим численным свойствам. Однако следует также сказать, что во многих случаях
является, таким образом, более предпочтительной благодаря своим лучшим численным свойствам. Однако следует также сказать, что во многих случаях
 При этом не принимается во внимание возможная специфика внутренней структуры матрицы
При этом не принимается во внимание возможная специфика внутренней структуры матрицы 
 представляет собой структуру сдвинутых данных (возможно, после тривиального переупорядочения):
представляет собой структуру сдвинутых данных (возможно, после тривиального переупорядочения):

 -мерный вектор. Например, ARX-модель (4.11) с
-мерный вектор. Например, ARX-модель (4.11) с  дает
дает

 -мерного процесса
-мерного процесса  (ср. с (4.54),
(ср. с (4.54),  приводит к
приводит к 
 в (10.3) будет представлять собой блочную матрицу,
в (10.3) будет представлять собой блочную матрицу,  -блоком которой является
-блоком которой является  -матрица
-матрица

 только для
только для  возникает вопрос, как быть с неизвестными начальными условиями для
возникает вопрос, как быть с неизвестными начальными условиями для  в (10.14). Возможны два подхода:
в (10.14). Возможны два подхода:
 а не при
а не при  Тогда все суммы в (10.14) будут содержать только известные данные. (После соответствующего переопределения величины
Тогда все суммы в (10.14) будут содержать только известные данные. (После соответствующего переопределения величины  и начала отсчета времени, можно, конечно, сохранить обычные выражения, предполагая
и начала отсчета времени, можно, конечно, сохранить обычные выражения, предполагая  известными для
известными для 
 могут также быть заменены нулями (последующее вырезание), а суммирование в (10.3) распространено до
могут также быть заменены нулями (последующее вырезание), а суммирование в (10.3) распространено до  . В этом случае (10.5) известно также как уравнения Юла-Уокера. Чао то применяют другие способы модификации (повторение; ср. с задачей
. В этом случае (10.5) известно также как уравнения Юла-Уокера. Чао то применяют другие способы модификации (повторение; ср. с задачей  на обоих концах записи данных с целью смягчения эффекта присоединенных нулей.
на обоих концах записи данных с целью смягчения эффекта присоединенных нулей.

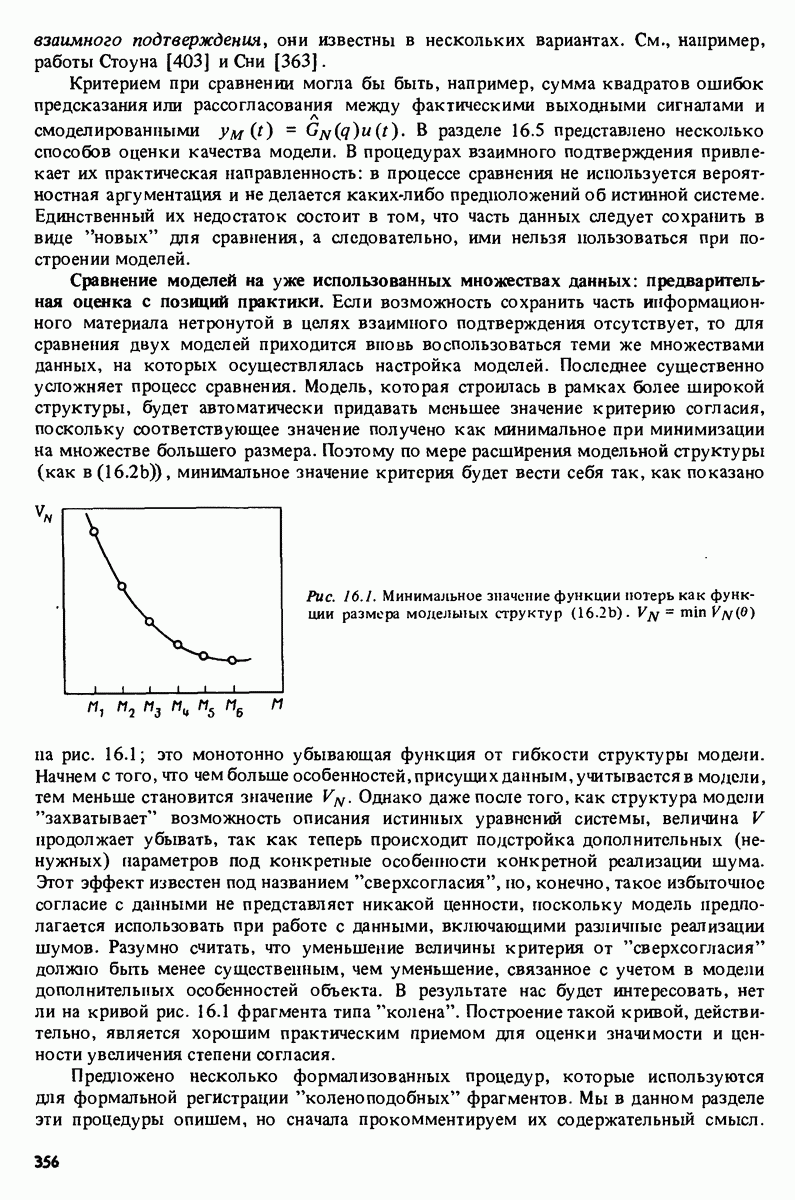
 блочной матрицей Теплица, что обеспечивает, как будет кратко показано, различные преимущества при решении (10.5).
блочной матрицей Теплица, что обеспечивает, как будет кратко показано, различные преимущества при решении (10.5).
 различие между двумя подходами становится незначительным.
различие между двумя подходами становится незначительным.
 Существует обширная литература по быстрым алгоритмам, которые используют такую структуру. Наиболее простым, но общим примером этих алгоритмов является алгоритм Левинсона [235], описание которого приводится ниже.
Существует обширная литература по быстрым алгоритмам, которые используют такую структуру. Наиболее простым, но общим примером этих алгоритмов является алгоритм Левинсона [235], описание которого приводится ниже.

 порядка). Это соответствует линейной регрессии с
порядка). Это соответствует линейной регрессии с  при
при  Если применить автокорреляционный метод, приходится решать (10.5), т.е.
Если применить автокорреляционный метод, приходится решать (10.5), т.е.

 Здесь
Здесь

 опущен. Уравнение (10.17) может быть записано в виде
опущен. Уравнение (10.17) может быть записано в виде 

 последних строк идентичны (19.17), а первая строка представляет собой определение
последних строк идентичны (19.17), а первая строка представляет собой определение 
 и требуется отыскать решение для модели (10.16) более высокого порядка
и требуется отыскать решение для модели (10.16) более высокого порядка  Тогда оценки
Тогда оценки  будут определяться аналогично
будут определяться аналогично  Чтобы найти их, заметим сначала, что
Чтобы найти их, заметим сначала, что

 строк идентичны (10.19), а последняя строка является определением
строк идентичны (10.19), а последняя строка является определением  Определение
Определение  выглядит совершенно так же, как (10.20), с той лишь разницей, что все строки правой части, кроме первой, должны быть нулевыми. Таким
выглядит совершенно так же, как (10.20), с той лишь разницей, что все строки правой части, кроме первой, должны быть нулевыми. Таким
 Легко видеть, что (10.20) можно записать в виде
Легко видеть, что (10.20) можно записать в виде

 строк (10.20) как нормальные уравнения для регрессии
строк (10.20) как нормальные уравнения для регрессии

 в обратном времени. Так как скалярный стационарный сигнал симметричен по отношению к направлению времени, коэффициенты в (10.22) совпадают с коэффициентами в (10.16). Это является теоретической причиной равенства между (10.20) и (10.21). См. также замечание в конце этого подраздела.
в обратном времени. Так как скалярный стационарный сигнал симметричен по отношению к направлению времени, коэффициенты в (10.22) совпадают с коэффициентами в (10.16). Это является теоретической причиной равенства между (10.20) и (10.21). См. также замечание в конце этого подраздела.
 и прибавим к
и прибавим к  Получим
Получим 

 Следовательно,
Следовательно,

 данных, в противоположность параметрам модели
данных, в противоположность параметрам модели  . Это выражение позволяет легко вычислить
. Это выражение позволяет легко вычислить  по
по  При начальных условиях
При начальных условиях

 в (10.24) требует произвести
в (10.24) требует произвести  сложений и умножений и одно
сложений и умножений и одно
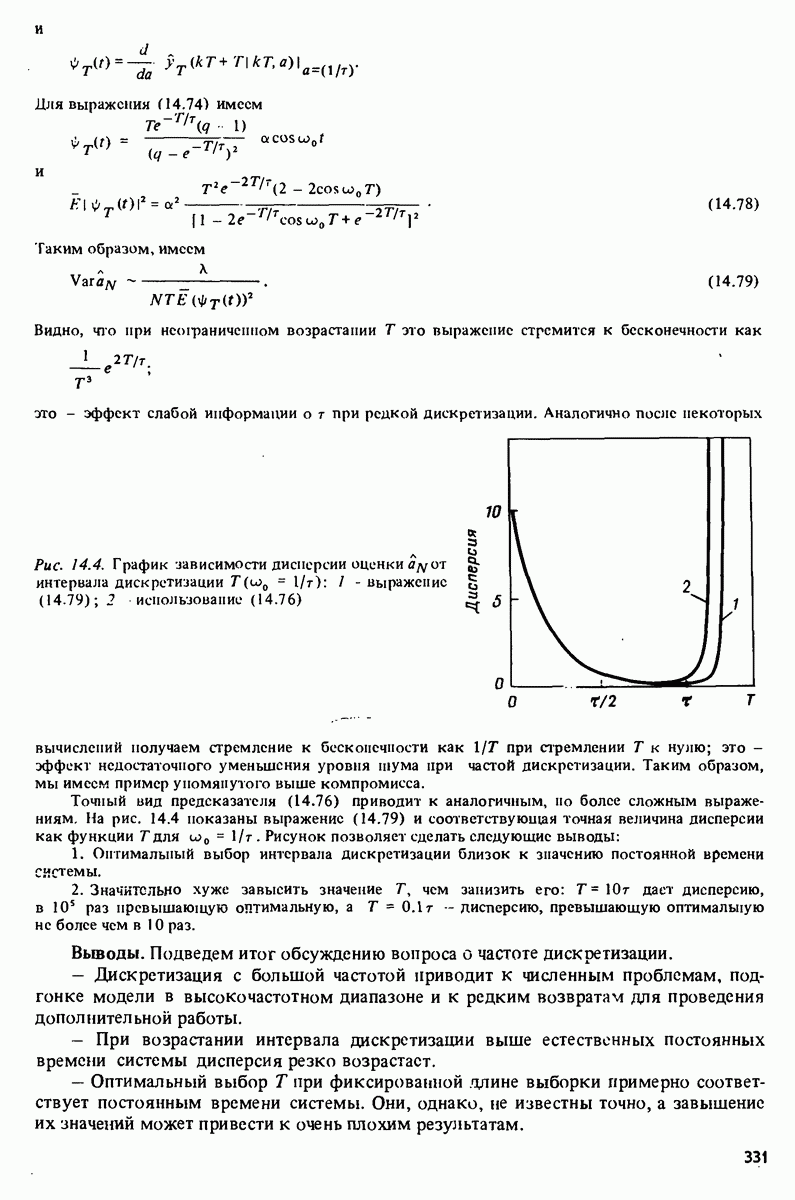
 требует, таким образом, количества операций, пропорционального
требует, таким образом, количества операций, пропорционального  что на порядок
что на порядок  меньше, чем общие процедуры (10.8)- (10.12). Это объясняет термин быстрый алгоритм.
меньше, чем общие процедуры (10.8)- (10.12). Это объясняет термин быстрый алгоритм.
 Уиггинса и Робинсон [436] и Морфа и др. [299].
Уиггинса и Робинсон [436] и Морфа и др. [299].

 отличные от
отличные от  Поэтому схема (10.24) должна бить дополнена аналогичной схемой для пересчета параметров
Поэтому схема (10.24) должна бить дополнена аналогичной схемой для пересчета параметров  См. задачу 10G.1.
См. задачу 10G.1.

 вычисленные при
вычисленные при







 графически изображено на рис. 10.1. В связи со структурей этого представления (10.31) принято называть решетчатым фильтром (иногда лестничным фильтром)
графически изображено на рис. 10.1. В связи со структурей этого представления (10.31) принято называть решетчатым фильтром (иногда лестничным фильтром) 
 удовлетворяют следующим соотношениям ортогональности:
удовлетворяют следующим соотношениям ортогональности:

 можно легко вычислить по формуле
можно легко вычислить по формуле
