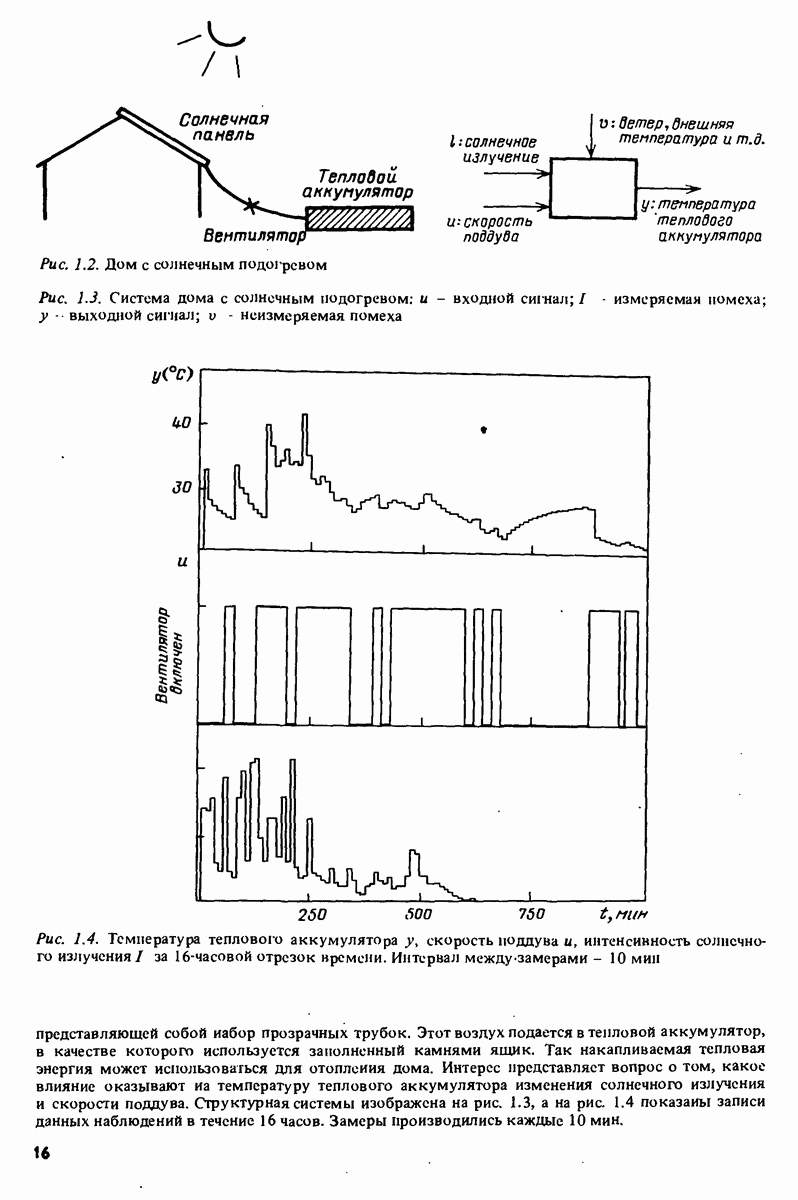
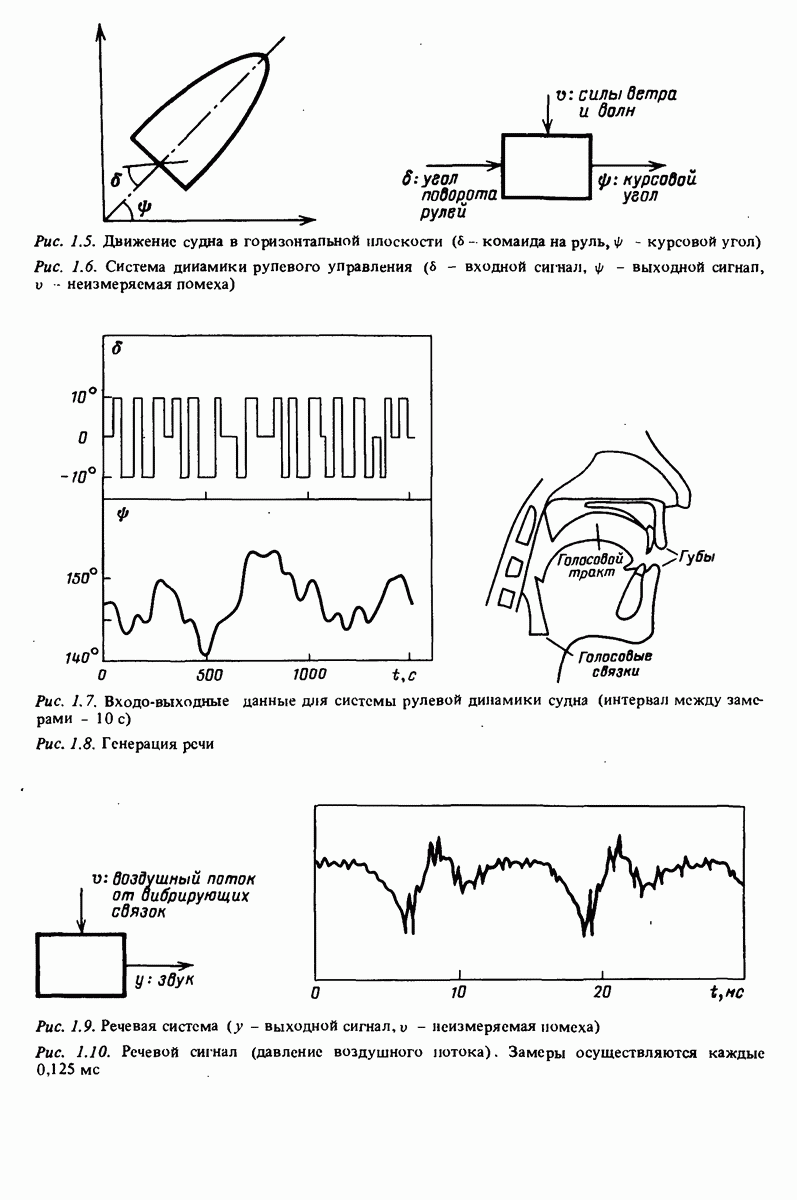
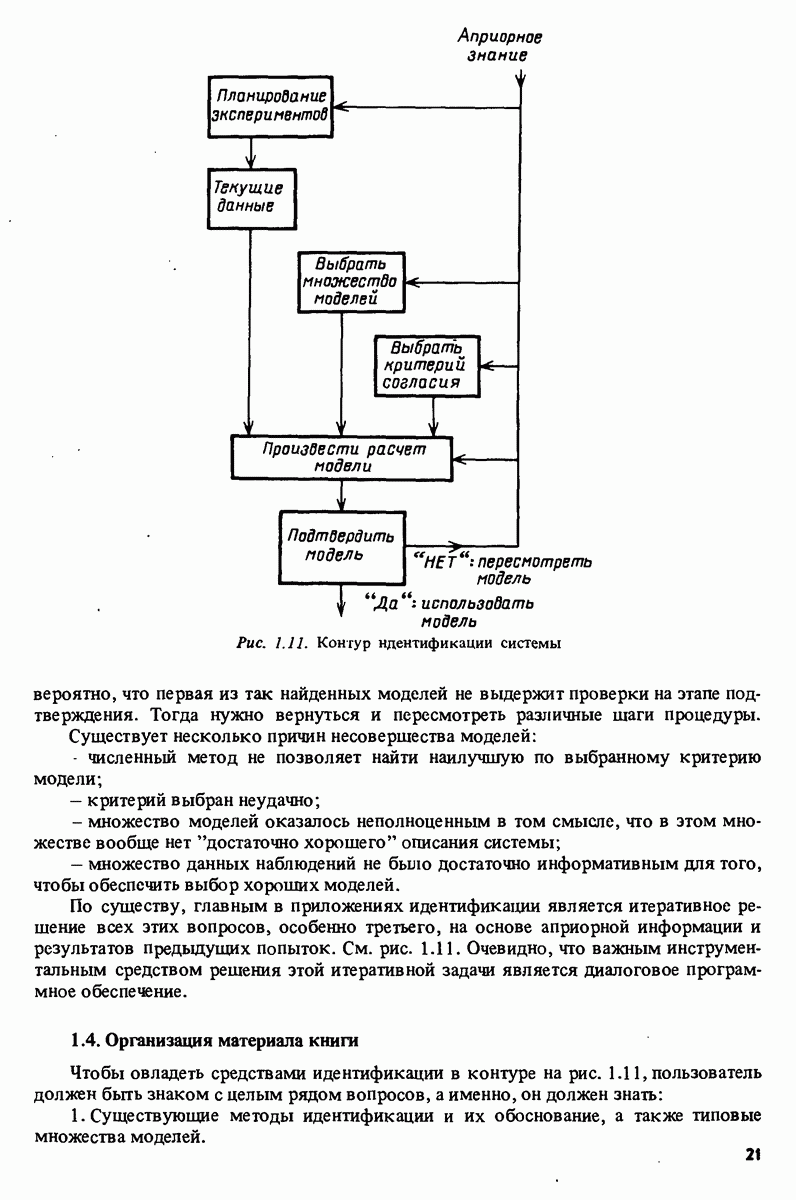
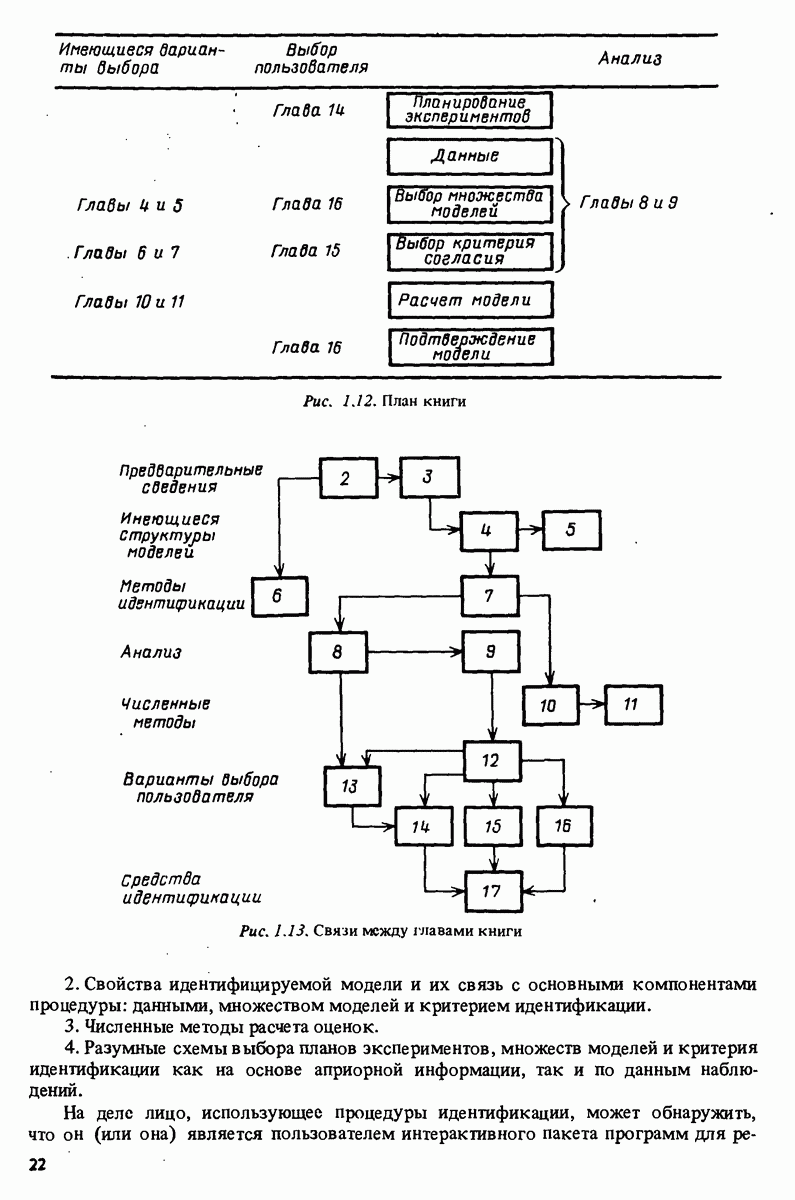
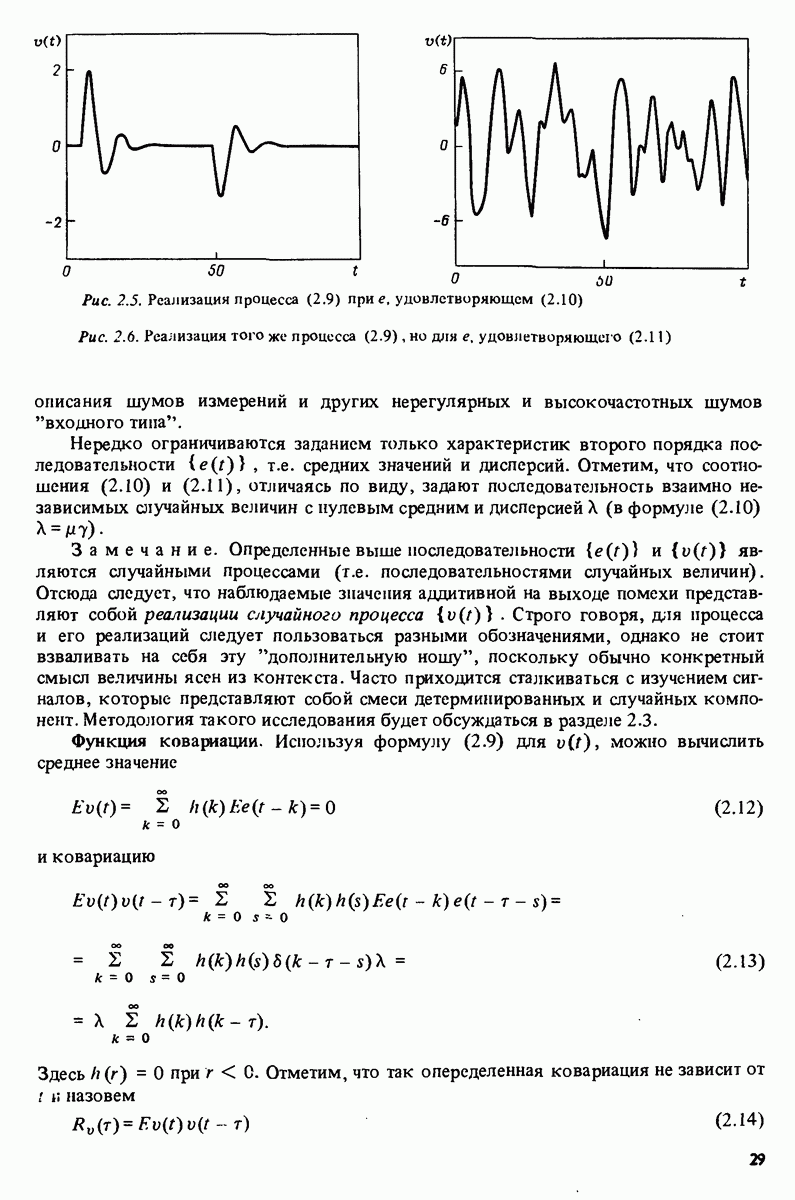
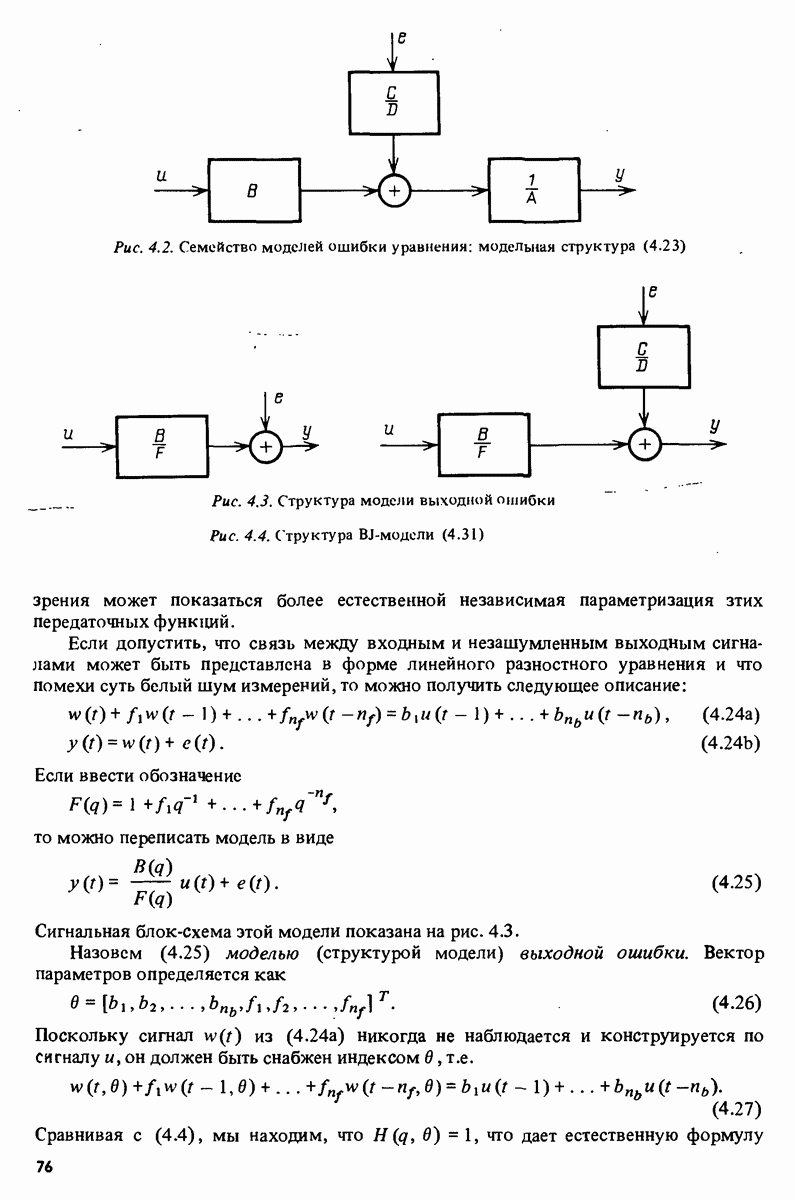
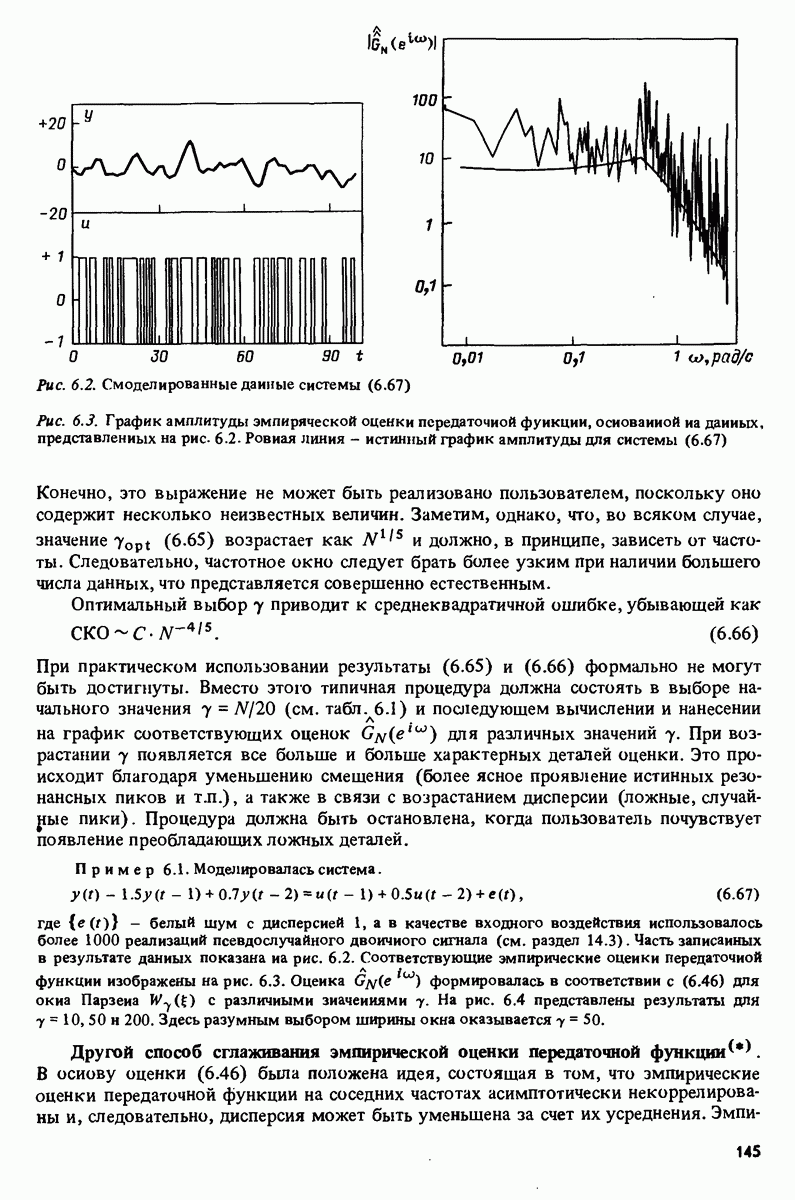
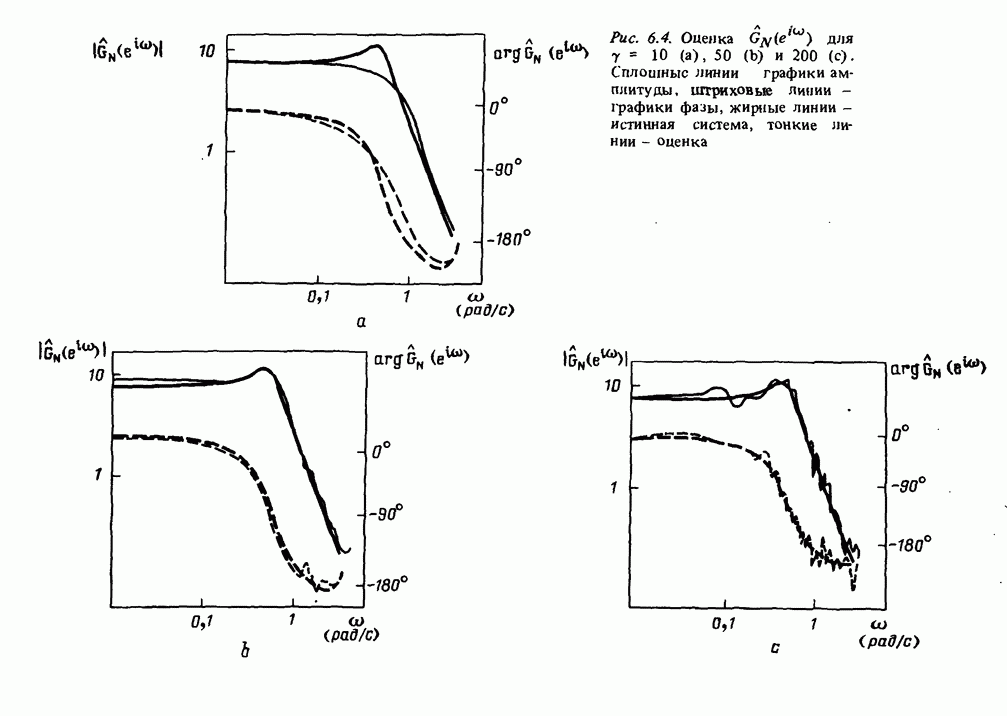
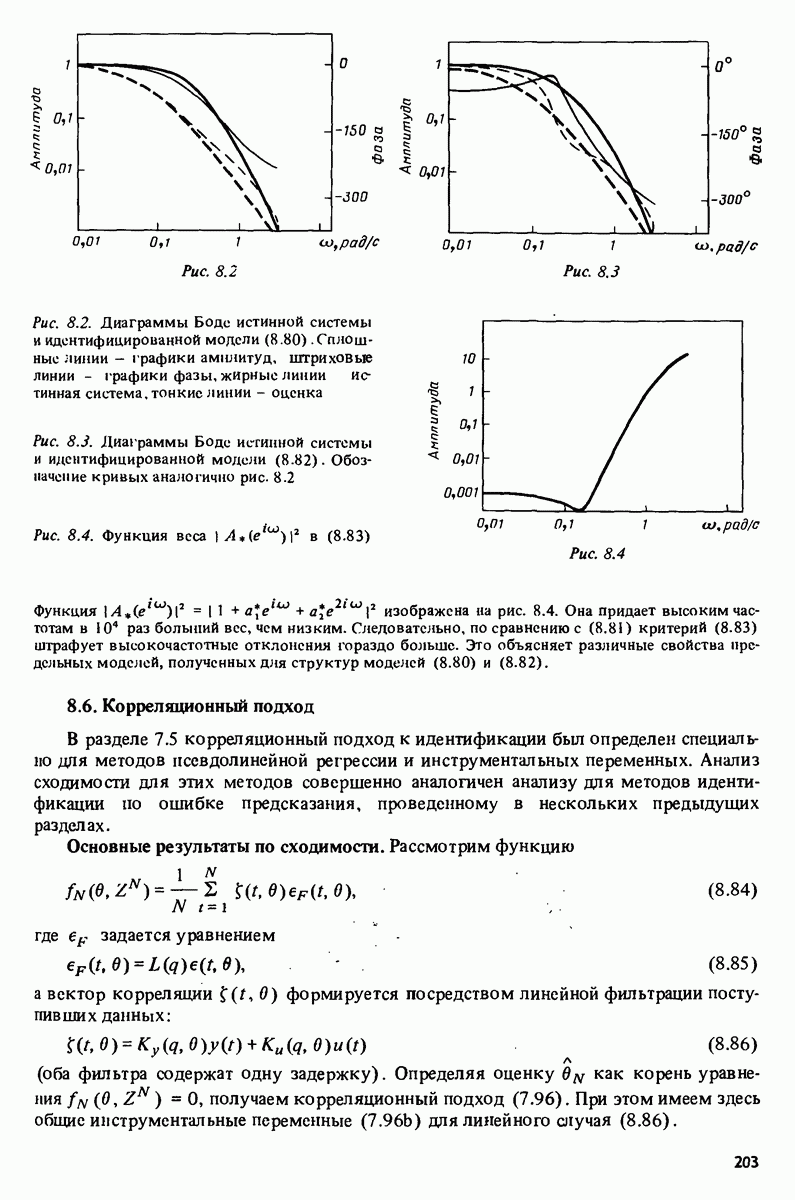
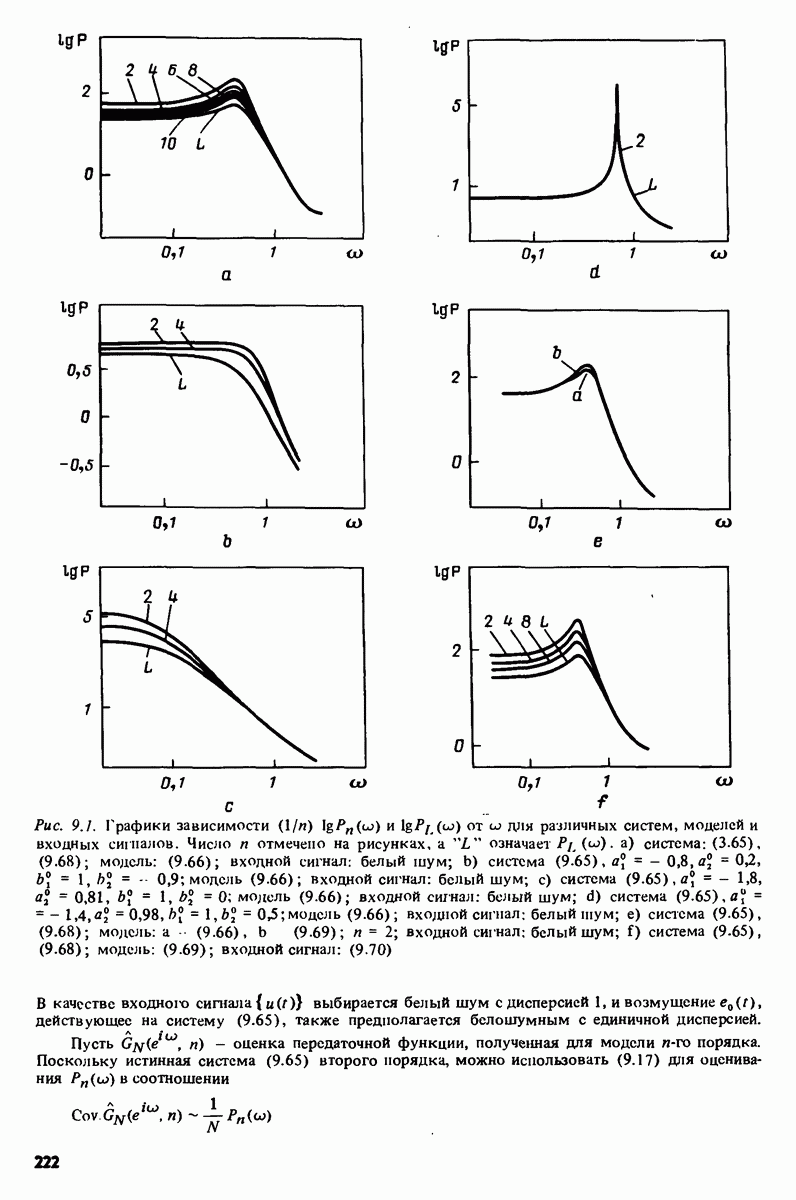
7.5. Корреляция ошибок предсказания с прошлыми данными
В идеале ошибка предсказания  для хорошей модели не должна зависеть от прошлых данных. Прежде всего это условие является неотъемлемой частью вероятностной модели типа (7.69). Другой, более прагматический способ понять это условие состоит в том, что если
для хорошей модели не должна зависеть от прошлых данных. Прежде всего это условие является неотъемлемой частью вероятностной модели типа (7.69). Другой, более прагматический способ понять это условие состоит в том, что если  коррелирует с
коррелирует с  то в
то в  содержится больше доступной информации о
содержится больше доступной информации о  чем представлено величиной
чем представлено величиной  Предсказатель, таким образом, не является идеальным. Это приводит к определению хорошей модели, которая порождает ошибки предсказания, не зависящие от прошлых наблюдений.
Предсказатель, таким образом, не является идеальным. Это приводит к определению хорошей модели, которая порождает ошибки предсказания, не зависящие от прошлых наблюдений.
Проверка, является ли  независимой от всего (причем возрастающего) набора данных
независимой от всего (причем возрастающего) набора данных  равносильна проверке того, является ли произвольное нелинейное преобразование ошибки
равносильна проверке того, является ли произвольное нелинейное преобразование ошибки  некоррслирующей с любой возможной функцией от
некоррслирующей с любой возможной функцией от  Конечно же, практически это не осуществимо.
Конечно же, практически это не осуществимо.
Вместо этого можно образовать из  конкретную последовательность конечномерных векторов
конкретную последовательность конечномерных векторов  и потребовать ее некоррелированности с некоторой преобразованной величиной ошибки
и потребовать ее некоррелированности с некоторой преобразованной величиной ошибки  что привело бы к уравнению
что привело бы к уравнению

а удовлетворяющее ему значение 0 могло бы считаться наилучшей оценкой  основанной на имеющихся наблюдениях. Здесь
основанной на имеющихся наблюдениях. Здесь  выбранное преобразование
выбранное преобразование  и обычно берут
и обычно берут 
Эту идею можно было бы в значительной степени обобщить. Во-первых, можно было бы заменить ошибку предсказания преобразованной с помощью линейного фильтра величиной (7.10). Во-вторых, имеется, очевидно, значительная свобода выбора последовательности  Представляется вполне возможным, что наилучший
Представляется вполне возможным, что наилучший
выбор  должен зависеть от свойств системы. В таком случае следует допустить зависимость
должен зависеть от свойств системы. В таком случае следует допустить зависимость  от
от  и мы приходим к следующему методу.
и мы приходим к следующему методу.
Выбираем линейный фильтр  и полагаем
и полагаем

Выбираем последовательность корреляционных векторов

образованных но прошлым данным и, возможно, зависящих от в. Задаемся функцией  Затем вычисляем
Затем вычисляем

Здесь использовано определение  решение (решения) уравнения
решение (решения) уравнения 
Обычно, размерность  следует выбирать так, чтобы был бы
следует выбирать так, чтобы был бы  -мерным вектором (это означает, что
-мерным вектором (это означает, что  -матрица, если выходная величина —
-матрица, если выходная величина —  -мерный вектор). Тогда
-мерный вектор). Тогда  содержит столько же уравнений, сколько и неизвестных, В некоторых случаях полезно рассмотреть расширенную корреляционную последовательность
содержит столько же уравнений, сколько и неизвестных, В некоторых случаях полезно рассмотреть расширенную корреляционную последовательность  большей чем
большей чем  размерности, когда (
размерности, когда ( представляет собой переопределенную систему уравнений, обычно не имеющую решения. Тогда в качестве оценки выбирается значение, минимизирующее некоторую квадратичную норму
представляет собой переопределенную систему уравнений, обычно не имеющую решения. Тогда в качестве оценки выбирается значение, минимизирующее некоторую квадратичную норму 

Эти корреляционные подходы, очевидно, формально связаны с минимизационным подходом раздела 7.2 (см. также задачу 
Процедура (7.96) представляет собой концептуальный метод, принимающий различные формы в зависимости от того, для каких структур моделей он применяется, или от конкретного выбора  . В следующем разделе мы обсудим возможно наилучший известный метод из семейства (7.96) — метод инструментальных переменных. Сначала обсудим псевдолинейные регрессионные модели.
. В следующем разделе мы обсудим возможно наилучший известный метод из семейства (7.96) — метод инструментальных переменных. Сначала обсудим псевдолинейные регрессионные модели.
Псевдолинейные регрессии. В гл. 4 отмечалось, что различные общие модели могут быть записаны в виде

(см. (4.21) и  Если вектор данных
Если вектор данных  не зависит от
не зависит от  , это соотношение представляет собой линейную регрессию. Отсюда происходит название псевдолинейная регрессия для (7.98) [380]. Для модели (7.98) псевдорегрессионный вектор
, это соотношение представляет собой линейную регрессию. Отсюда происходит название псевдолинейная регрессия для (7.98) [380]. Для модели (7.98) псевдорегрессионный вектор  содержит соответствующие прошлые данные, частично перестраиваемые с использованием текущей модели. Таким образом, разумно потребовать от модели, чтобы получающиеся в результате ошибки предсказания не коррелировали с
содержит соответствующие прошлые данные, частично перестраиваемые с использованием текущей модели. Таким образом, разумно потребовать от модели, чтобы получающиеся в результате ошибки предсказания не коррелировали с  Другими словами, выбираем в
Другими словами, выбираем в  и
и  и приходим к оценке
и приходим к оценке

которую называем оценкой псевдолинейной регрессии.
Для моделей, нодчинающихся (7.98), применимы также различные варианты (7.99), соответствующие в основном замене  на векторы, у которых перестраиваемые (зависящие от 0) элементы определяются несколько иначе. См. раздел 10.4.
на векторы, у которых перестраиваемые (зависящие от 0) элементы определяются несколько иначе. См. раздел 10.4.