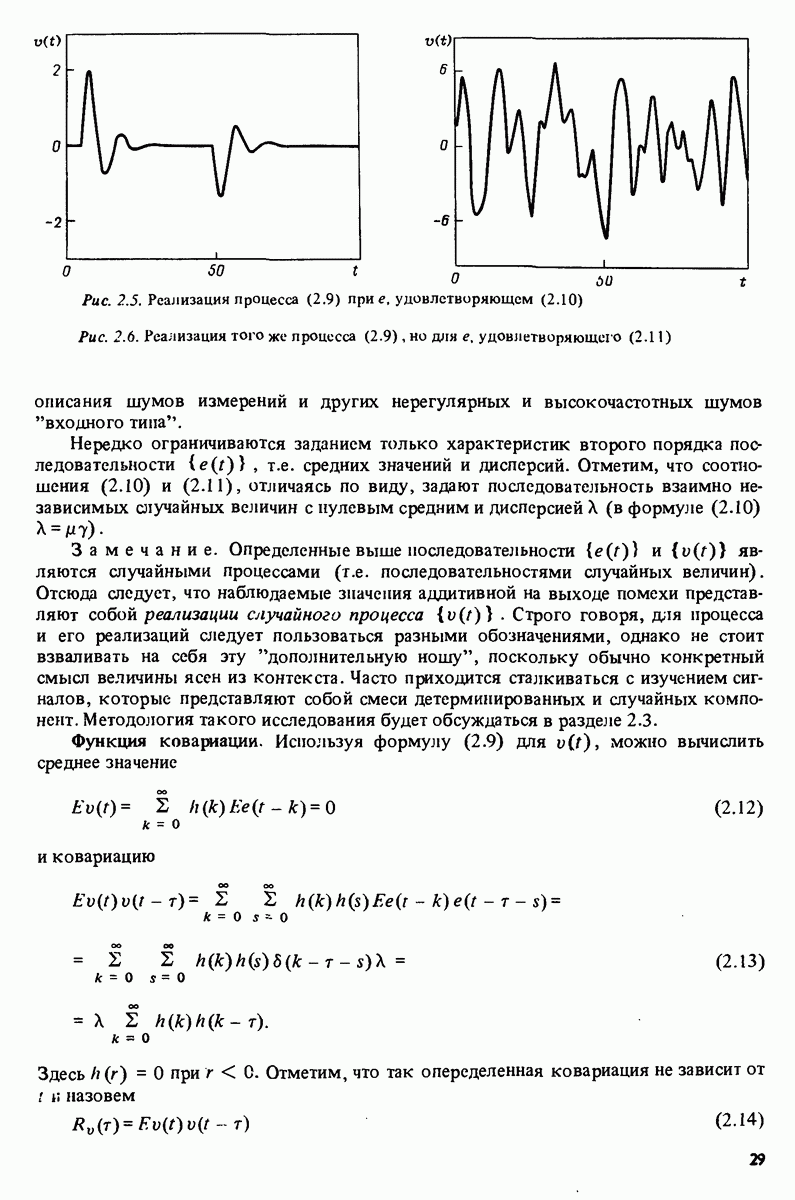
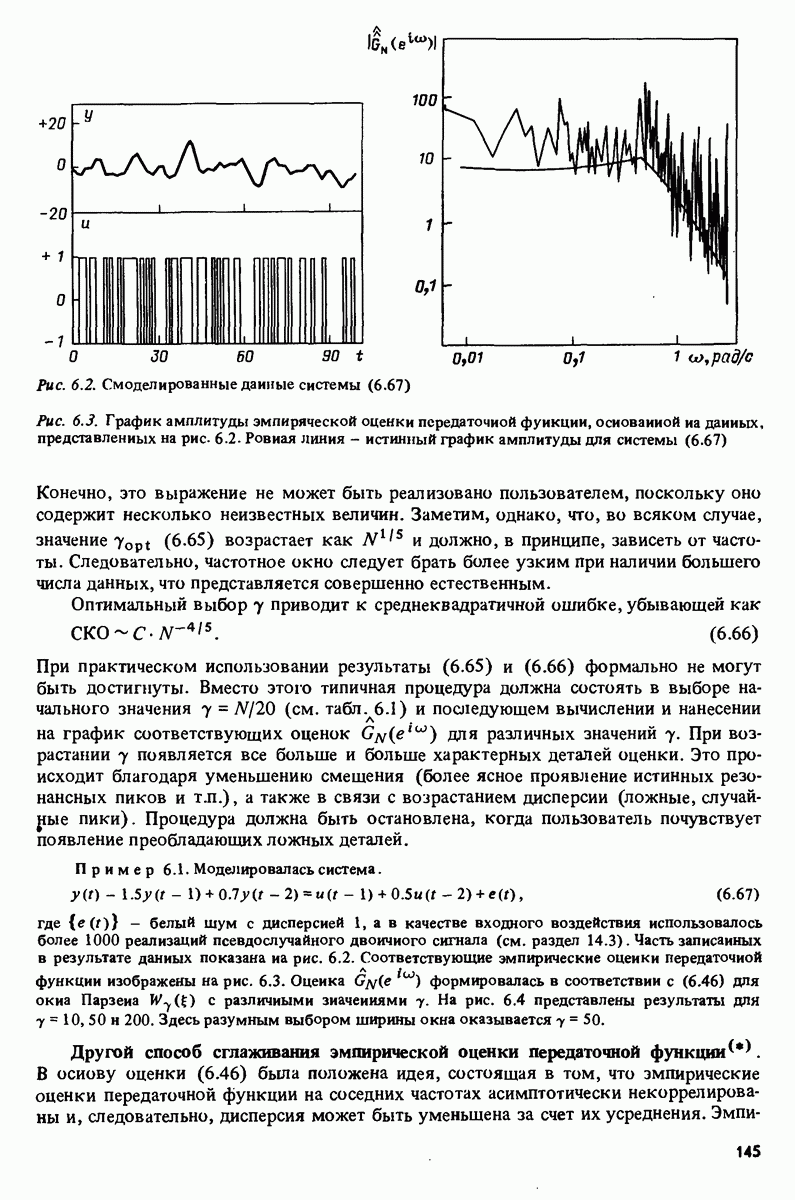
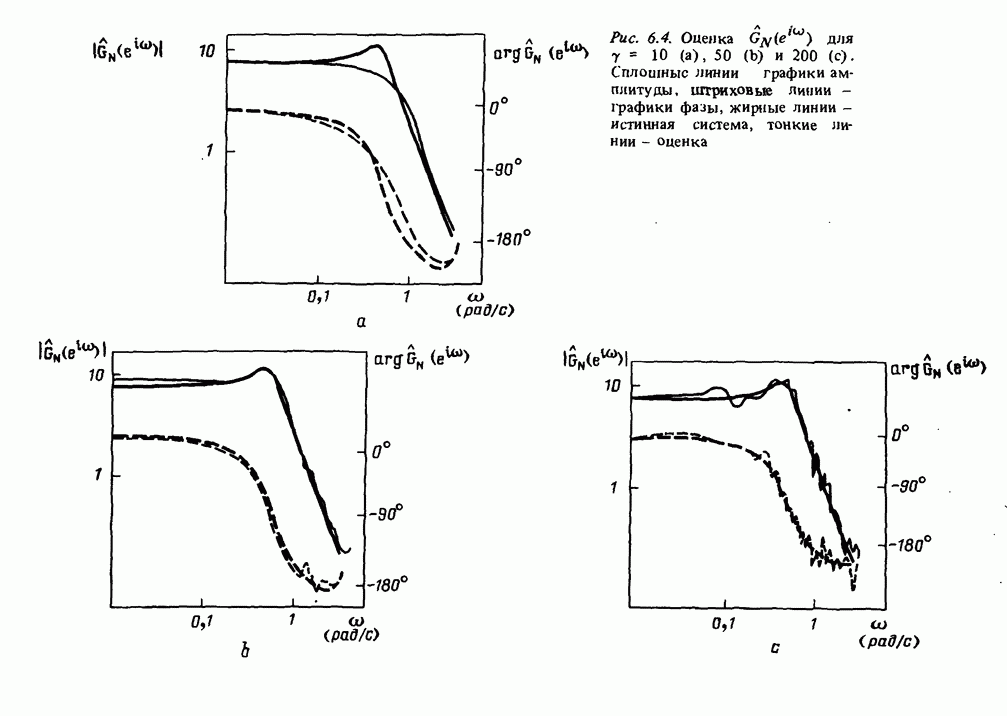
II.2. Статистические свойства оценки наименьших квадратов
Вероятностная структура. Чтобы получить дальнейшие результаты относительно свойств оценки наименьших квадратов, введем несколько более специфичные предположения о генерации наблюдений у. Обычно это следующие предположения:
- последовательность регрессоров  является детерминированной; (11.45)
является детерминированной; (11.45)
-  , где
, где  последовательность независимых случайных величин с нулевыми средними значениями и дисперсией
последовательность независимых случайных величин с нулевыми средними значениями и дисперсией 
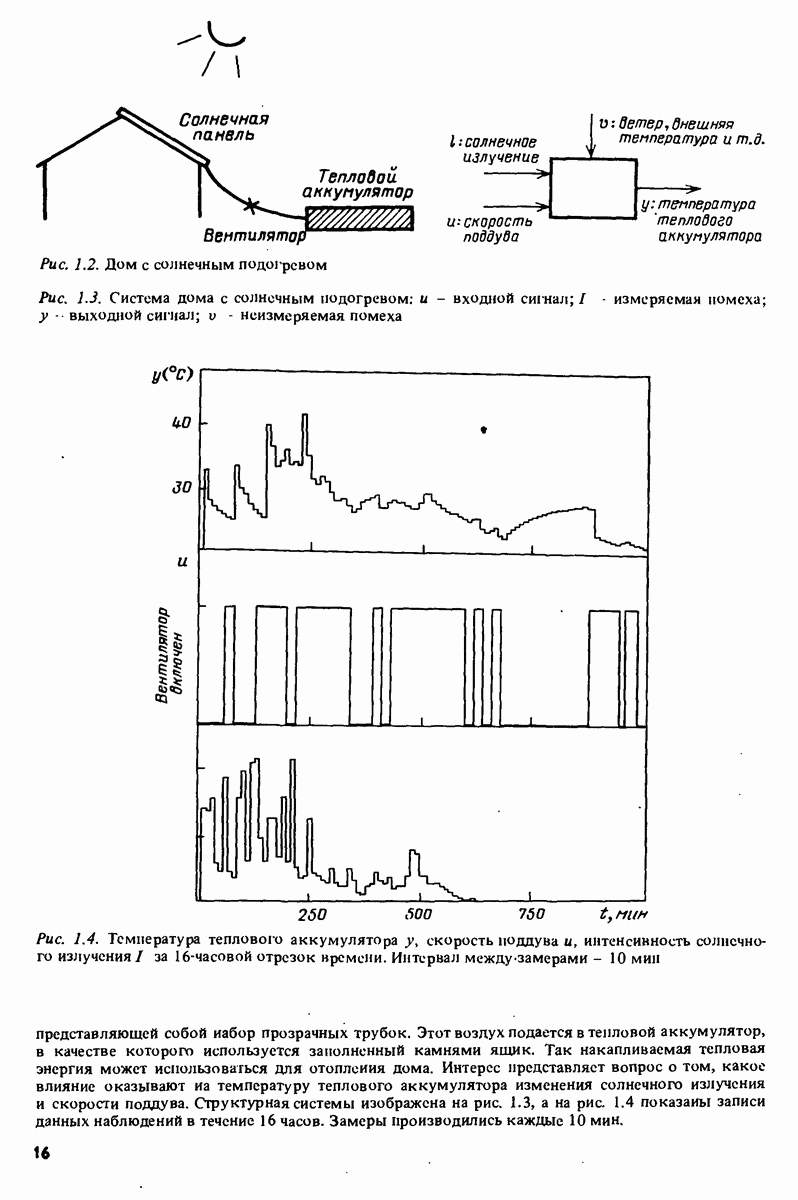
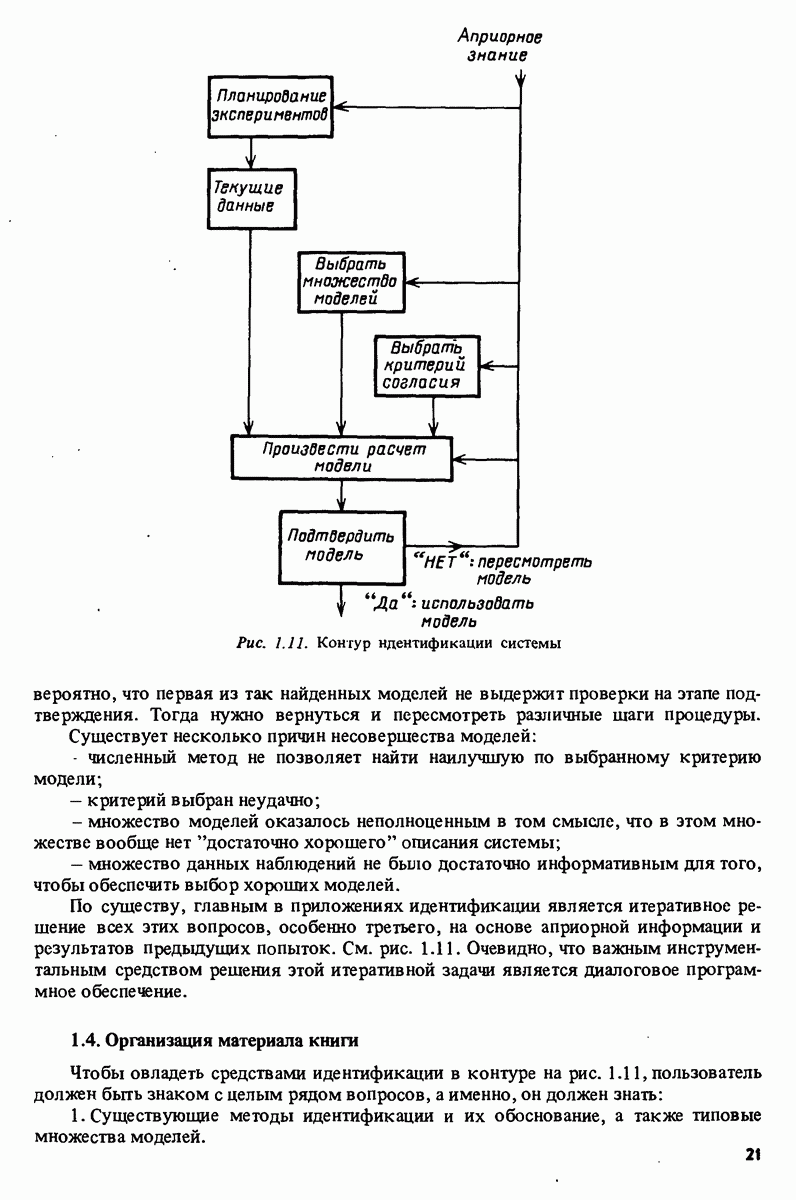
Сразу укажем на существенную ограничительность предположения (11.45) для большинства приложений к идентификации систем, поскольку в этом случае регрессоры обычно содержат прошлые значения выходной величины. Это означает, что анализ не будет применим к методам идентификации систем. Однако (11.45) сильно облегчает анализ, в то же время результаты являются прототипом тех, которые имеют место в общем случае. Содержание данного раздела может, следовательно, рассматриваться как упрощенное предварительное изложение материала гл. 8 и 9.
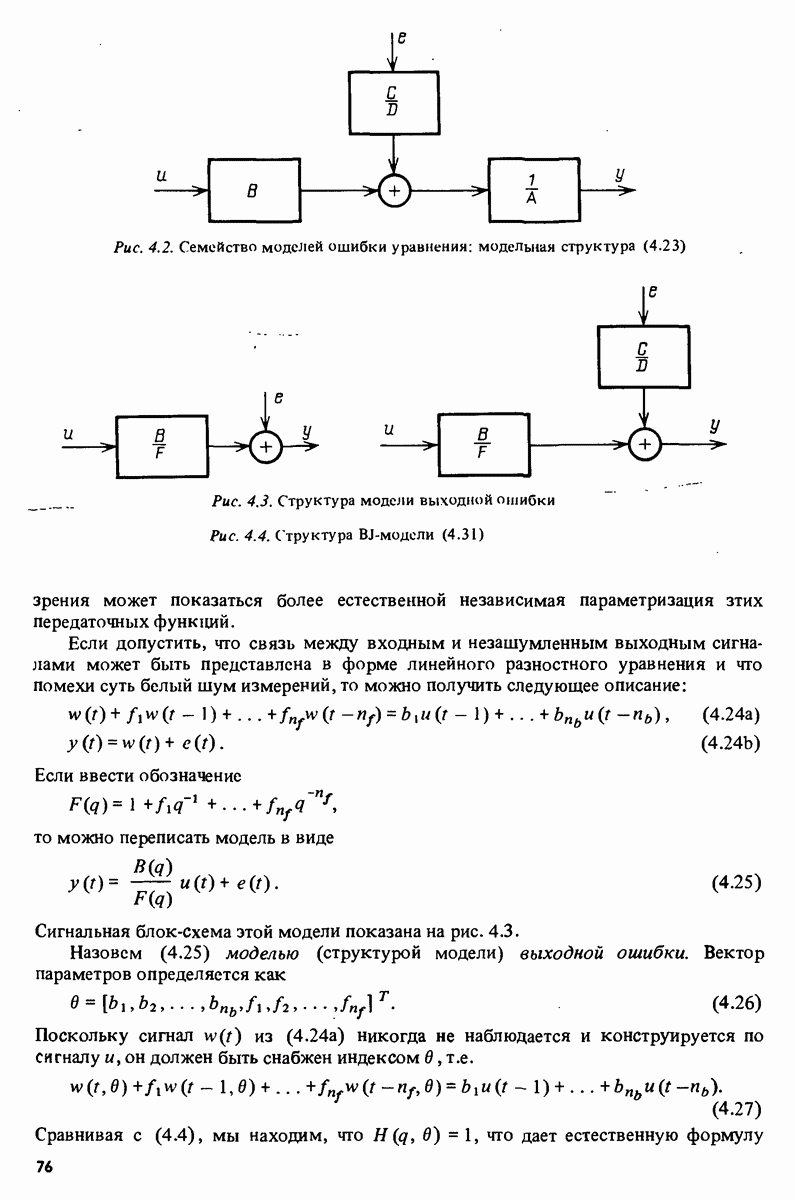
В этом разделе предположение (11.46) будет несколько ослаблено. Будут допускаться более общие возмущения  также иногда будет предполагаться, что истинная функция регрессии не соответствует данной линейной модели. Таким образом, будем рассматривать описание
также иногда будет предполагаться, что истинная функция регрессии не соответствует данной линейной модели. Таким образом, будем рассматривать описание

где

В матричной форме, используя 

имеем

Часто будет рассматриваться

и

Сходимость и состоятельность. Рассмотрим случай (11.10) (т.е.  Тогда, если имеет место (11.50), то можно аналогично (11.43) записать
Тогда, если имеет место (11.50), то можно аналогично (11.43) записать

Первая сумма состоит из детерминированных величин. Допустим, что она сходится к обратимой матрице 

Вторая сумма состоит из случайных величин с нулевыми средними значениями, причем выполняются предположения  Различные варианты усиленного закона больших чисел описывают условия, при которых такие суммы сходятся к нулю с вероятностью 1. Это будет зависеть от свойств
Различные варианты усиленного закона больших чисел описывают условия, при которых такие суммы сходятся к нулю с вероятностью 1. Это будет зависеть от свойств  Подробное изложение таких результатов см., например, в [78] и [160]. Теорема 2.3 показывает, что
Подробное изложение таких результатов см., например, в [78] и [160]. Теорема 2.3 показывает, что

если последовательность  может быть описана как профильтрованный белый шум аналогично (2.86) и
может быть описана как профильтрованный белый шум аналогично (2.86) и  ограниченная последовательность. При выполнении (11.53) и (11.54) имеем
ограниченная последовательность. При выполнении (11.53) и (11.54) имеем

Это означает, что  сильно состоятельная оценка
сильно состоятельная оценка 
Смещение и дисперсия. Рассмотрим общую оценку взвешенных наименьших квадратов

Так как  и
и  детерминированные, легко вычислить математическое ожидание (11.56):
детерминированные, легко вычислить математическое ожидание (11.56):

При выполнении (11.50) имеем

Это равенство означает, что оценки  являются несмещенными при истинном описании (11.50).
являются несмещенными при истинном описании (11.50).
Для отклонения оценки параметра от среднего получаем из (11.56), (11.57) и 

откуда получаем матрицу ковариаций 

Отметим, что это выполняется, независимо от формы 
Для оценки невзвешенных наименьших квадратов  и независимых возмущений, случай
и независимых возмущений, случай  находим, что
находим, что

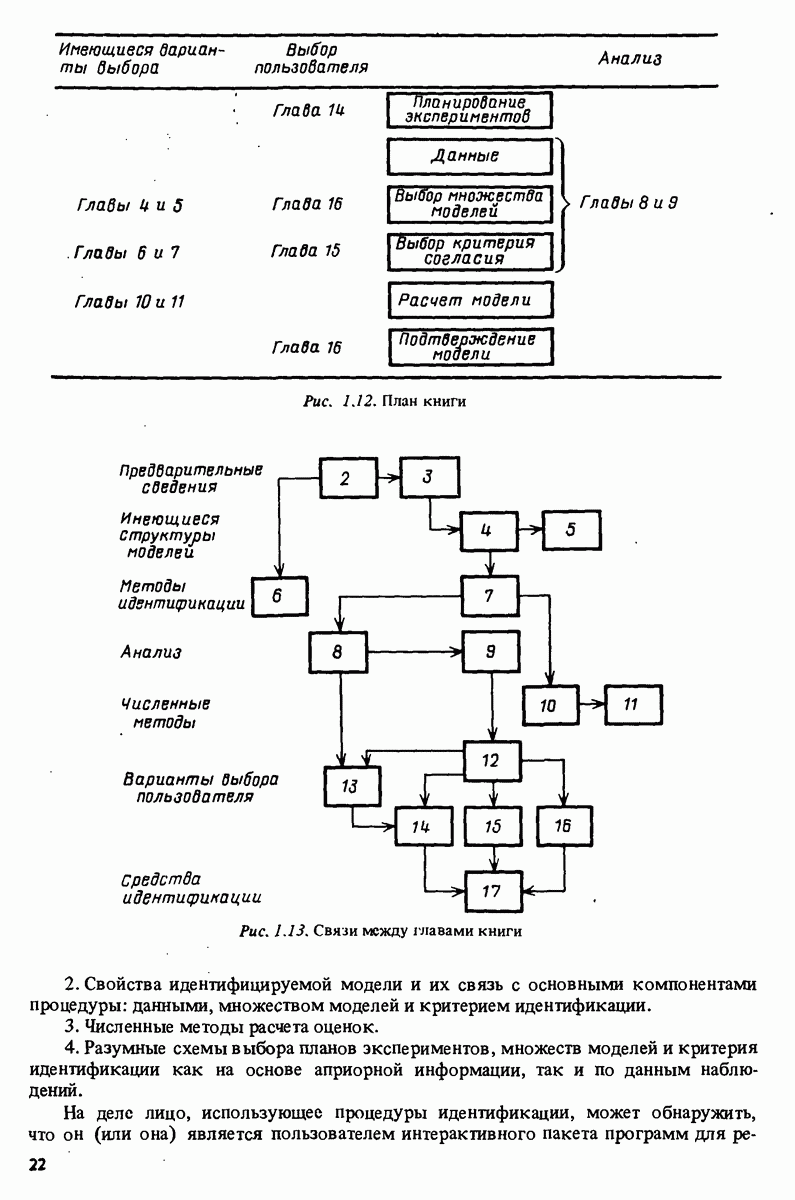
Матрица ковариации оценки  определяется, таким образом, дисперсией невязок и свойствами регрессоров. Если можно менять в процессе сбора данных, появляется важная возможность планирования эксперимента с целью уменьшения обратной матрицы в (11.61) с учетом имеющихся ограничений.
определяется, таким образом, дисперсией невязок и свойствами регрессоров. Если можно менять в процессе сбора данных, появляется важная возможность планирования эксперимента с целью уменьшения обратной матрицы в (11.61) с учетом имеющихся ограничений.
Отметим, что дня вычисления  требуется знать
требуется знать  Поскольку эта величина может быть не известна пользователю, важно оценивать ее по данным.
Поскольку эта величина может быть не известна пользователю, важно оценивать ее по данным.
Оценивание дисперсии шума. Имеем следующий результат:
Лемма 11.1. Пусть задан критерий  и допустим, что выполняются соотношения
и допустим, что выполняются соотношения 

является несмещенной оценкой  (Напомним, что
(Напомним, что  Доказательство. Имеем
Доказательство. Имеем

Заметим, что  Значит,
Значит,

Далее

Напомним, что  -матрица, а
-матрица, а  -матрица. Здесь использовано равенство
-матрица. Здесь использовано равенство 
Таким образом,

и лемма доказана.
Отметим важность обоих предположений (11.50) и (11.51) для справедливости этого результата. Оценить всю матрицу ковариаций  по данным не представляется возможным. Аналогично, если истинное описание имеет общую форму
по данным не представляется возможным. Аналогично, если истинное описание имеет общую форму  оценка
оценка  будет содержать член
будет содержать член

который не будет стремиться к нулю. Это приводит к систематическому завышению оценкой Лдгвеличины  и в результате уровень шума переоценивается. Такая ситуация свидетельствует о наличии типичной дилеммы во многих приложениях: отличать шумовые эффекты от эффектов смещения.
и в результате уровень шума переоценивается. Такая ситуация свидетельствует о наличии типичной дилеммы во многих приложениях: отличать шумовые эффекты от эффектов смещения. 
Минимизация дисперсии. Из (11.60) видно, что дисперсия  зависит от выбора нормы
зависит от выбора нормы  Возникает вопрос о наилучшем выборе
Возникает вопрос о наилучшем выборе  в смысле малости матрицы ковариации. На него отвечает следующая лемма:
в смысле малости матрицы ковариации. На него отвечает следующая лемма:
Лемма 11.2. Пусть  положительно определенная матрица. Определим
положительно определенная матрица. Определим

Тогда для любой симметрической, положительно полуопределенной матрицы 

Доказательство. Матрица

положительно гюлуопредслена но построению. Значит, в соответствии с задачей 

Обращение обеих частей этого неравенства доказьюает лемму.
Оценка (11.24), получающаяся при  известна также как оценка Маркова или наилучшая линейная несмещенная оценка. Заметим, что для ее реализации требуется знать матрицу
известна также как оценка Маркова или наилучшая линейная несмещенная оценка. Заметим, что для ее реализации требуется знать матрицу  что, как правило, не реально.
что, как правило, не реально.
В случае независимых шумов в  с различными дисперсиями,
с различными дисперсиями,

лемма утверждает, что дисперсия оценки минимизируется, если критерий (11.19) используется с

Другими словами, наблюдения должны быть взвешены обратно пропорционально их дисперсиям. Такой выбор весов является, следовательно, оптимальным в смысле  Заметим, однако, что если
Заметим, однако, что если  не выполняется, веса
не выполняется, веса  также будут влиять на смещение оценки
также будут влиять на смещение оценки  а это может привести к противоречию с (11.65).
а это может привести к противоречию с (11.65).
Распределение оценок. Оценки  параметров
параметров  соответственно являются случайными величинами, поскольку они формируются по случайным величинам
соответственно являются случайными величинами, поскольку они формируются по случайным величинам  Таким образом, интересно определить их распределение. Дня того чтобы это сделать, введем следующее дополнительное предположение:
Таким образом, интересно определить их распределение. Дня того чтобы это сделать, введем следующее дополнительное предположение:
вектор возмущений  имеет гауссово распределение.
имеет гауссово распределение.
Это предположение приводит к гауссовости распределения  со средним значением
со средним значением  и дисперсией
и дисперсией 

Так как  в (11.56) является линейной комбинацией величин
в (11.56) является линейной комбинацией величин  оценка
оценка  также будет гауссовой:
также будет гауссовой:

где  задаются соотношениями (11.57) и
задаются соотношениями (11.57) и  соответственно. Это отвечает на вопрос о распределении
соответственно. Это отвечает на вопрос о распределении  при условии
при условии 
Даже если наблюдения не являются нормально распределенными, часто случается, что распределение оценки  приближается к нормальному распределению при
приближается к нормальному распределению при  стремящемся к бесконечности. Это следует из центральной предельной теоремы при ее применении к сумме случайных величин, формирующих оценку. См. задачу 11.3.
стремящемся к бесконечности. Это следует из центральной предельной теоремы при ее применении к сумме случайных величин, формирующих оценку. См. задачу 11.3.
Определить распределение  в
в  несколько сложнее. Рассмотрим опять частный случай
несколько сложнее. Рассмотрим опять частный случай  и (11.51), и пусть
и (11.51), и пусть  определяется соотношением
определяется соотношением  Тогда
Тогда

Теперь из (11.51) и (11.66) следует,  является последовательностью независимых гауссовских величин с дисперсией
является последовательностью независимых гауссовских величин с дисперсией  Следовательно,
Следовательно,

Другими словами, левая часть этого соотношения имеет  -распределение с N степенями свободы, чтол непосредственно следует из определения
-распределение с N степенями свободы, чтол непосредственно следует из определения  спределения. Если
спределения. Если  заменить на
заменить на  получим соответствующий результат:
получим соответствующий результат:
Лемма 11.3. Предположим, что выполняются соотношения (11-49) —  и
и  Тогда
Тогда

Доказательство. Сравните с доказательством леммы 11.1. Положим

что представляет собой симметрическую  -матрицу. Тогда, как и в (11.63),
-матрицу. Тогда, как и в (11.63),  откуда следует, что все собственные значения
откуда следует, что все собственные значения  равны либо 0, либо 1. Поскольку
равны либо 0, либо 1. Поскольку  в силу (11.64), находим, что существует
в силу (11.64), находим, что существует  собственных значений, равных
собственных значений, равных  равных 0. Так как
равных 0. Так как  является симметрической, ее можно диагонализовать посредством ортогональной матрицы
является симметрической, ее можно диагонализовать посредством ортогональной матрицы 

где  состоит из
состоит из  единиц и
единиц и  пулей по диагонали. Как и при доказательстве леммы 11.1,
пулей по диагонали. Как и при доказательстве леммы 11.1,

где  компоненты вектора
компоненты вектора  Но так как компоненты
Но так как компоненты  являются независимыми и нормальными, с дисперсией
являются независимыми и нормальными, с дисперсией  это же справедливо и в отношении
это же справедливо и в отношении  в силу ортогональности матрицы
в силу ортогональности матрицы  Это доказывает лемму.
Это доказывает лемму.
Из леммы следует, что оценка  дисперсии
дисперсии  подчиняется соотношению
подчиняется соотношению

что обеспечивает равенство

Доверительные интервалы. В случае  когда истинный параметр
когда истинный параметр  существует, результат
существует, результат  по распределению оценки показывает, как распределено отклонение оценки
по распределению оценки показывает, как распределено отклонение оценки  от 60:
от 60:

 компоненты имеем, таким образом,
компоненты имеем, таким образом,

или

Здесь означает  диагональный элемент
диагональный элемент  Следовательно, вероятность того, что
Следовательно, вероятность того, что  отююняется от 0 более, чем на
отююняется от 0 более, чем на  представляет собой
представляет собой  -уровень нормального распределения, которое присутствует во всех стандартных таблицах по статистике.
-уровень нормального распределения, которое присутствует во всех стандартных таблицах по статистике.
Соотношение (11.68) фактически дает больше, чем распределение вероятностей каждой компоненты  .
.

Рис. II.2. Заштрихованная область: 
Поскольку  матрица ковариаций совместного распределения вектора
матрица ковариаций совместного распределения вектора  мы также имеем полезную информацию о ковариации и корреляции между различными компонентами
мы также имеем полезную информацию о ковариации и корреляции между различными компонентами  . Наиболее просто использовать это следующим образом. Из (11.74) имеем
. Наиболее просто использовать это следующим образом. Из (11.74) имеем

что непосредственно следует из определения  -распределения. Вероятность того, что
-распределения. Вероятность того, что

равна, таким образом,  «
« -уровню
-уровню  -распределения. Выражения (11.77) задают эллипсоиды в
-распределения. Выражения (11.77) задают эллипсоиды в  поверхности которых определяются матрицей
поверхности которых определяются матрицей  См. рис. 11.2.
См. рис. 11.2.
В случае  выражение для
выражение для  принимает вид (11.61):
принимает вид (11.61):

В то время как матрица известна пользователю,  обычно не известна, что затрудняет использование результатов (11.75) и (11.76). Следует попытаться заменить
обычно не известна, что затрудняет использование результатов (11.75) и (11.76). Следует попытаться заменить  оценкой
оценкой  В соответствии с (11.73) это является хорошей аппроксимацией при больших
В соответствии с (11.73) это является хорошей аппроксимацией при больших  а использование предыдущих доверительных границ представляется разумным. По лемме
а использование предыдущих доверительных границ представляется разумным. По лемме  однако, можно достичь более точного результата. Имеем
однако, можно достичь более точного результата. Имеем












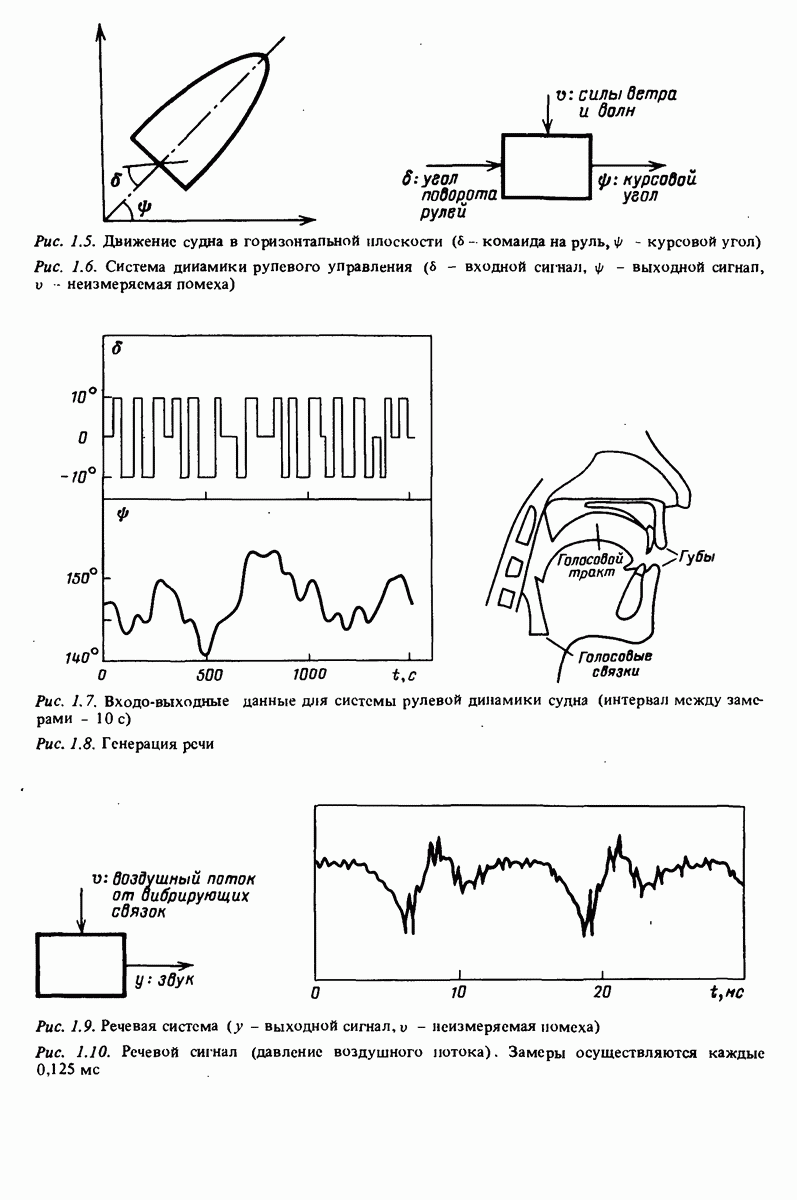



















































































































































































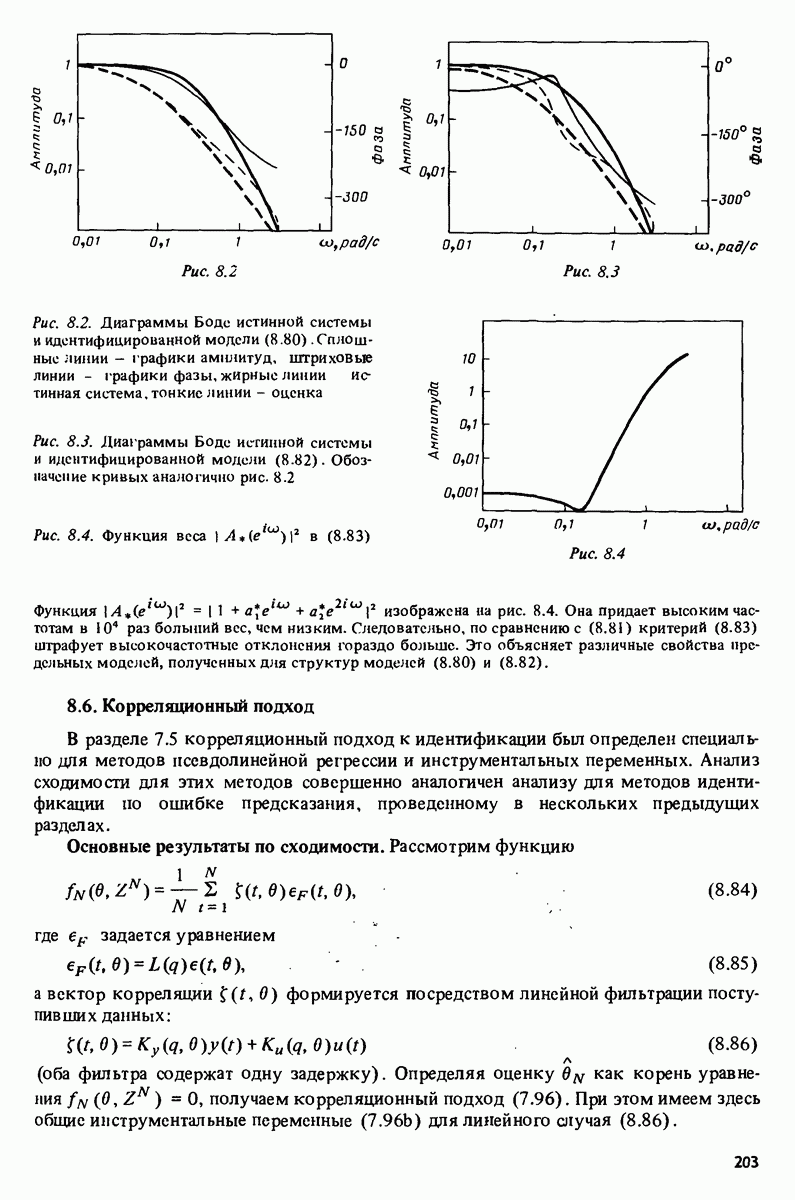


















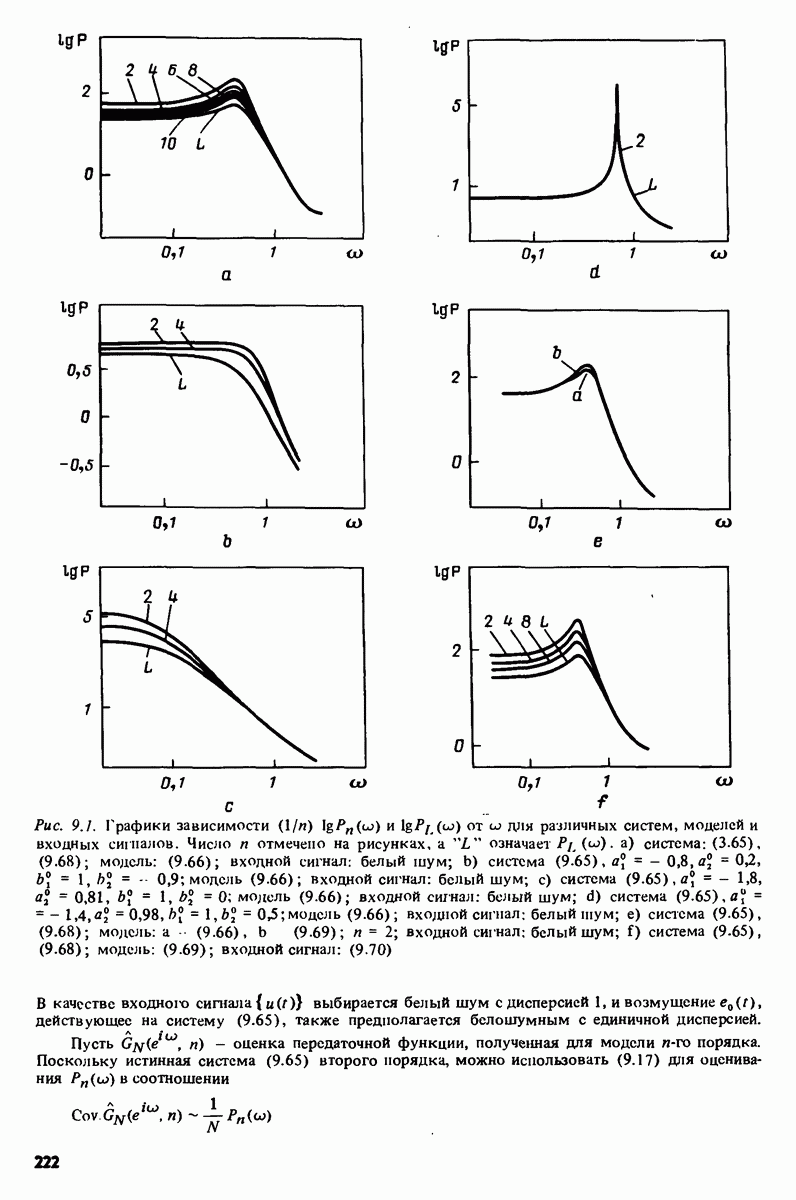






















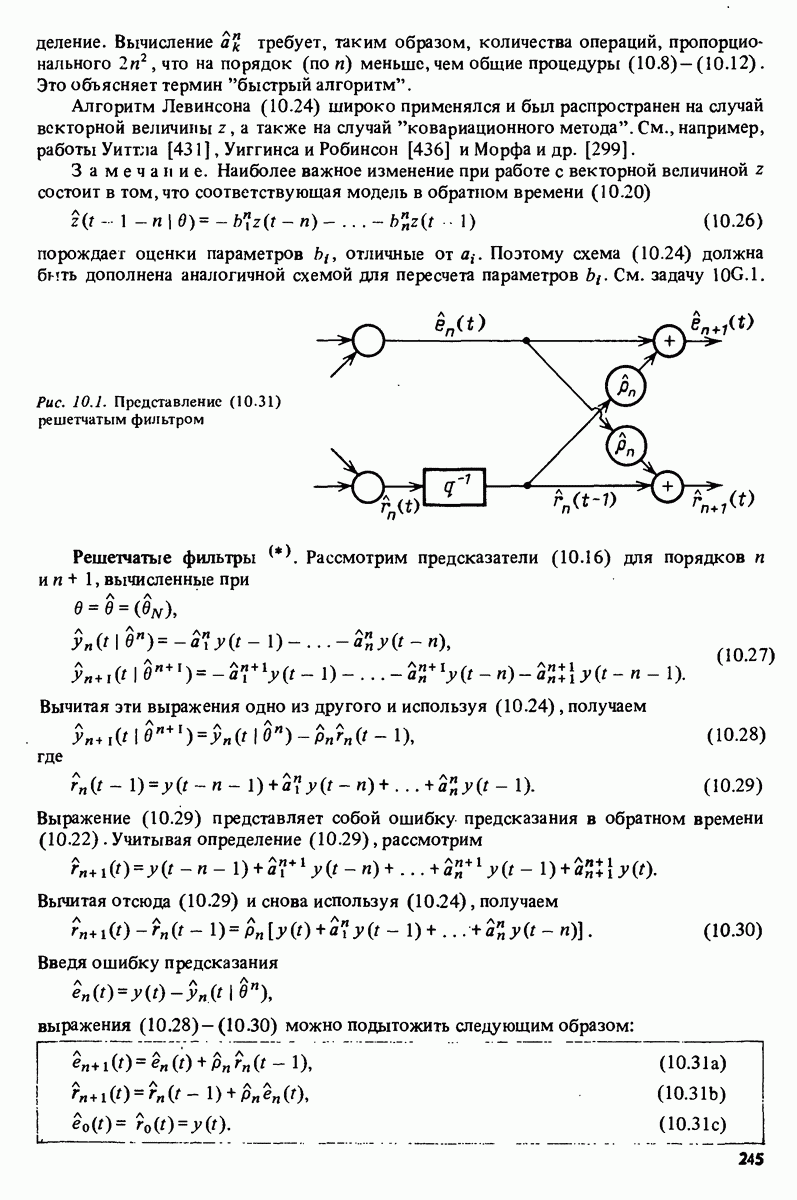

























































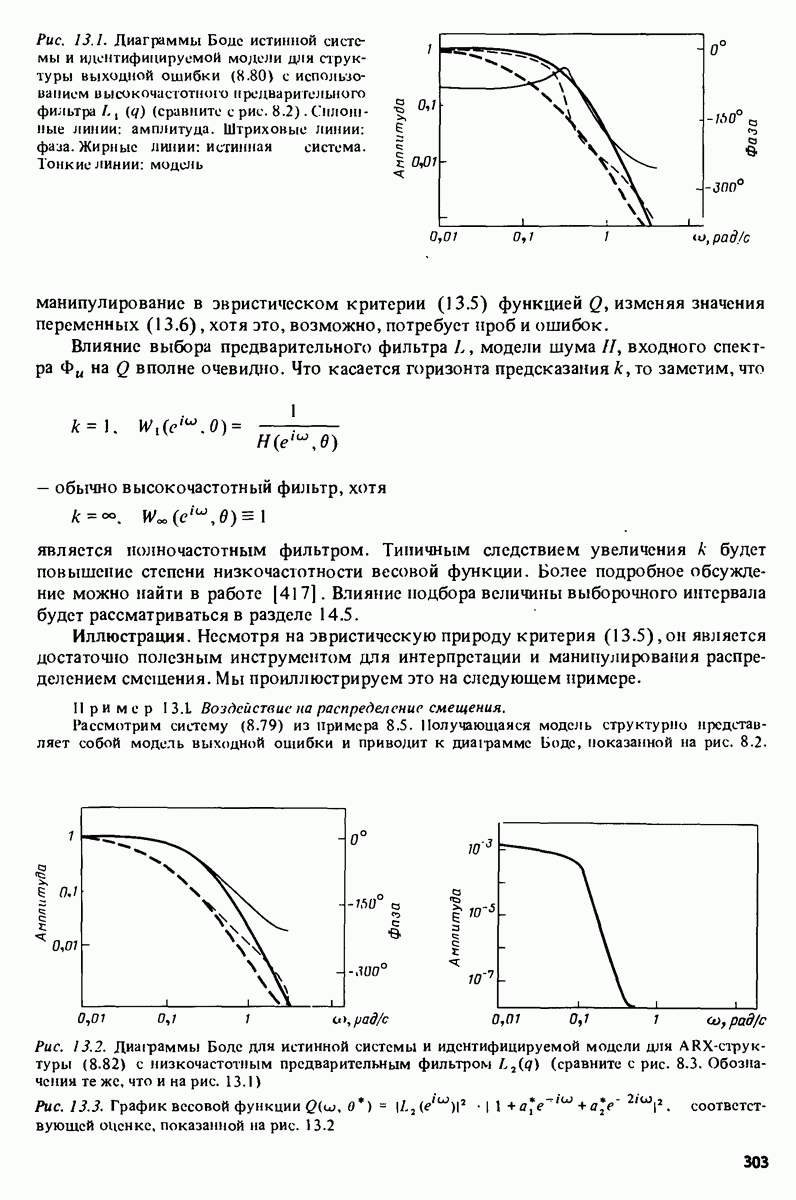

















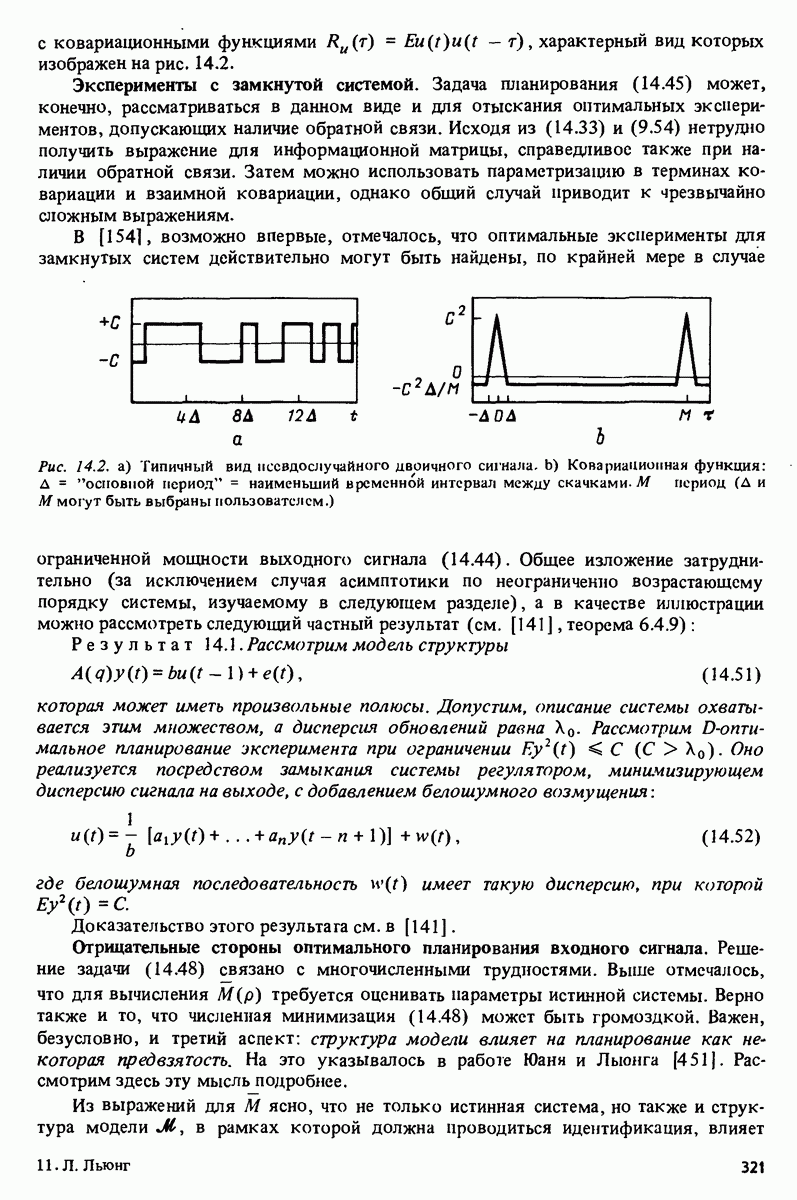









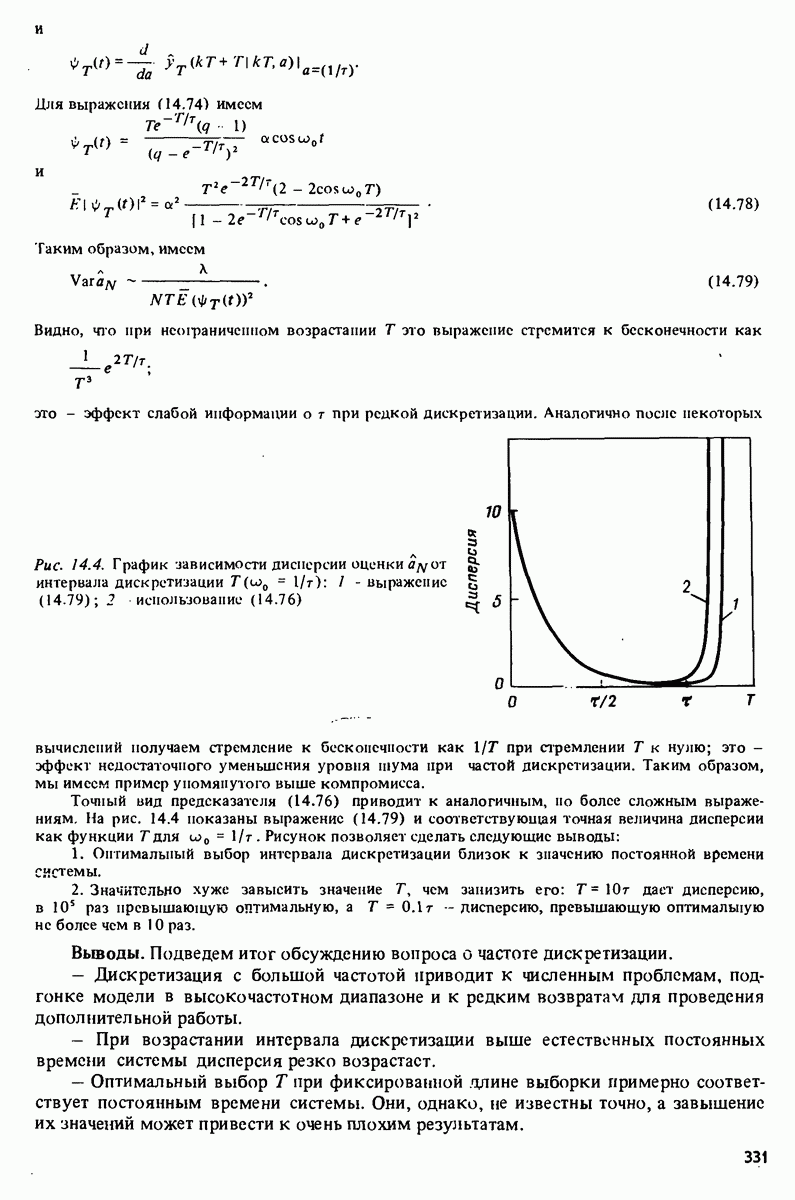









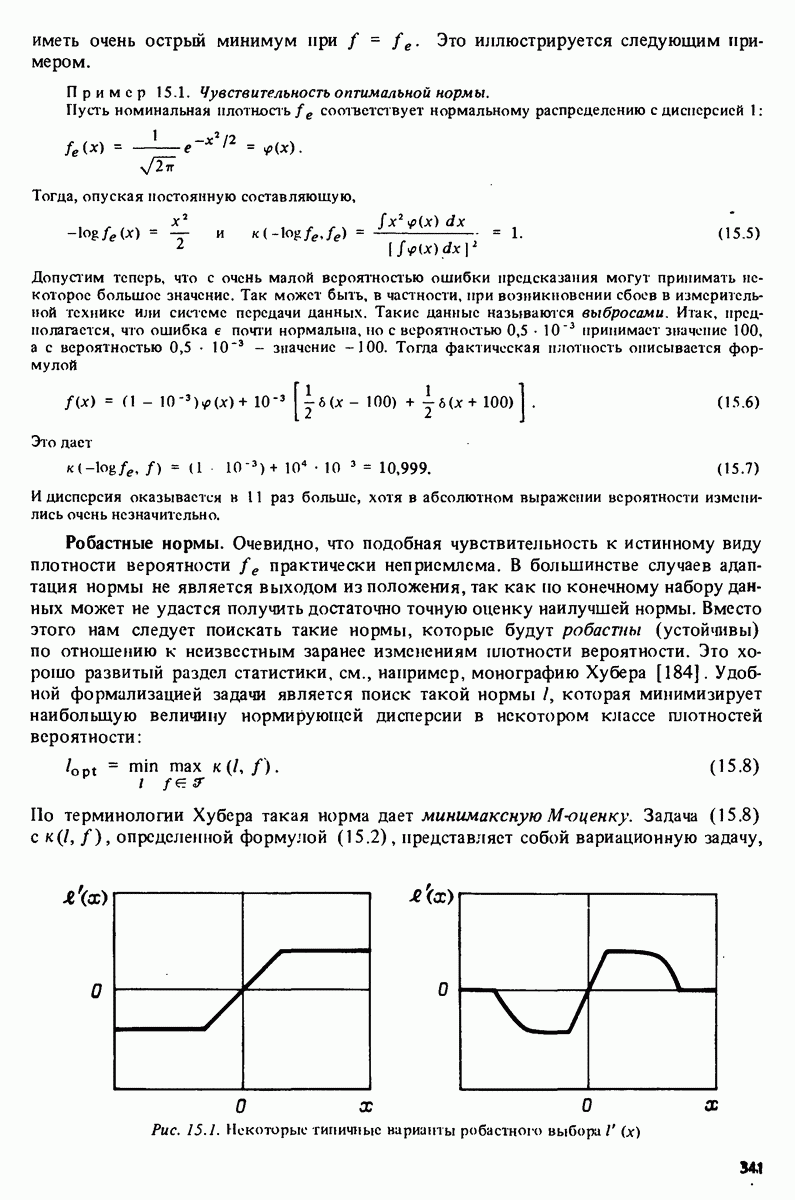














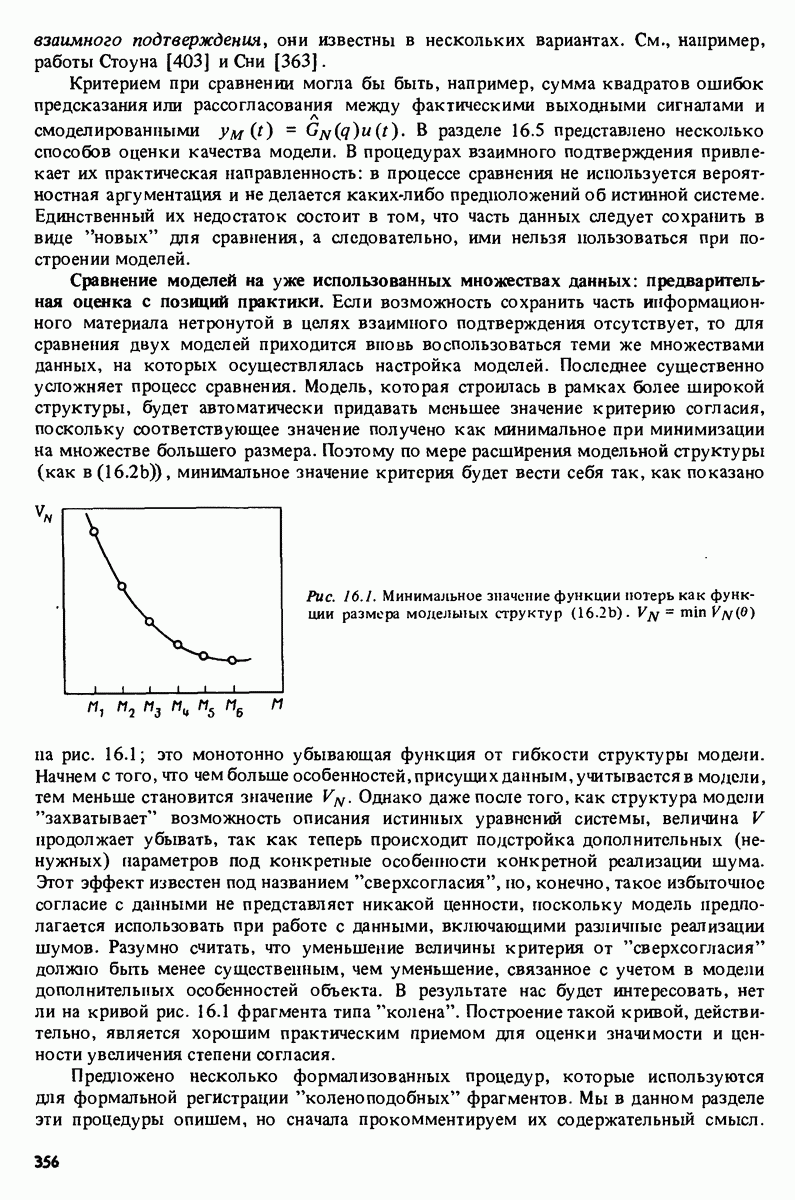






























































 -распределения как распределения отношения двух
-распределения как распределения отношения двух  -распределенных величин. Самое левое выражение доступно пользователю, и, таким образом, вероятность того, что
-распределенных величин. Самое левое выражение доступно пользователю, и, таким образом, вероятность того, что  отклоняется от
отклоняется от  на столько, что
на столько, что

 -уровень
-уровень  -распределения. Заметим, что
-распределения. Заметим, что  стремится к
стремится к  при
при  Следовательно, использование
Следовательно, использование  вместо
вместо  в
в  часто разумно. Аналогично использование
часто разумно. Аналогично использование  вместо
вместо  в (11.75) заменяет нормальное распределение
в (11.75) заменяет нормальное распределение  -распределением Стьюдента.
-распределением Стьюдента.