Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Приложение II. Некоторые статистические методы линейной регрессииЦель этого приложения двоякая: первая — напомнить о статистических методах как о теоретическом фундаменте части II этой книги, вторая - рассмотрение методов, алгоритмов, теоретического анализа и статистических свойств оценок линейной регрессии как прототипов более сложных структур, обсуждаемых в части II. Это приложение можно рассматривать, таким образом, как предварительное ознакомление с идеями и анализом, максимально свободными от технических деталей. Приложение составлено так, что его можно читать независимо от остальной части книги (и наоборот). 11.1. Линейные регрессии и оценка МНКЛинейные регрессии относятся к наиболее часто употребляемым в статистике, а метод наименьших квадратов уходит корнями в классическую работу Гаусса 1809 года [128]. Эти методы изложены во многих учебниках, из которых упомянем книги Рао [335, гл. 4], Дрейпера и Смита [101] и Дениела и Вуда [90]. Понятие регрессии. Статистическая теория регрессии связана с задачей предсказания величины у на основе информации, полученной при измерении других величин системы (в данное время)
Задача состоит в нахождении функции регрессоров
была мала (т.е. чтобы
Хорошо известно, что функция
Эта функция известна также как функция регрессии или регрессия у на Другой подход состоит в поиске функции Линейные регрессии. Если свойства величину и неизвестны, определить функцию регрессии
Обозначая вектор
(11.3) можно переписать в виде
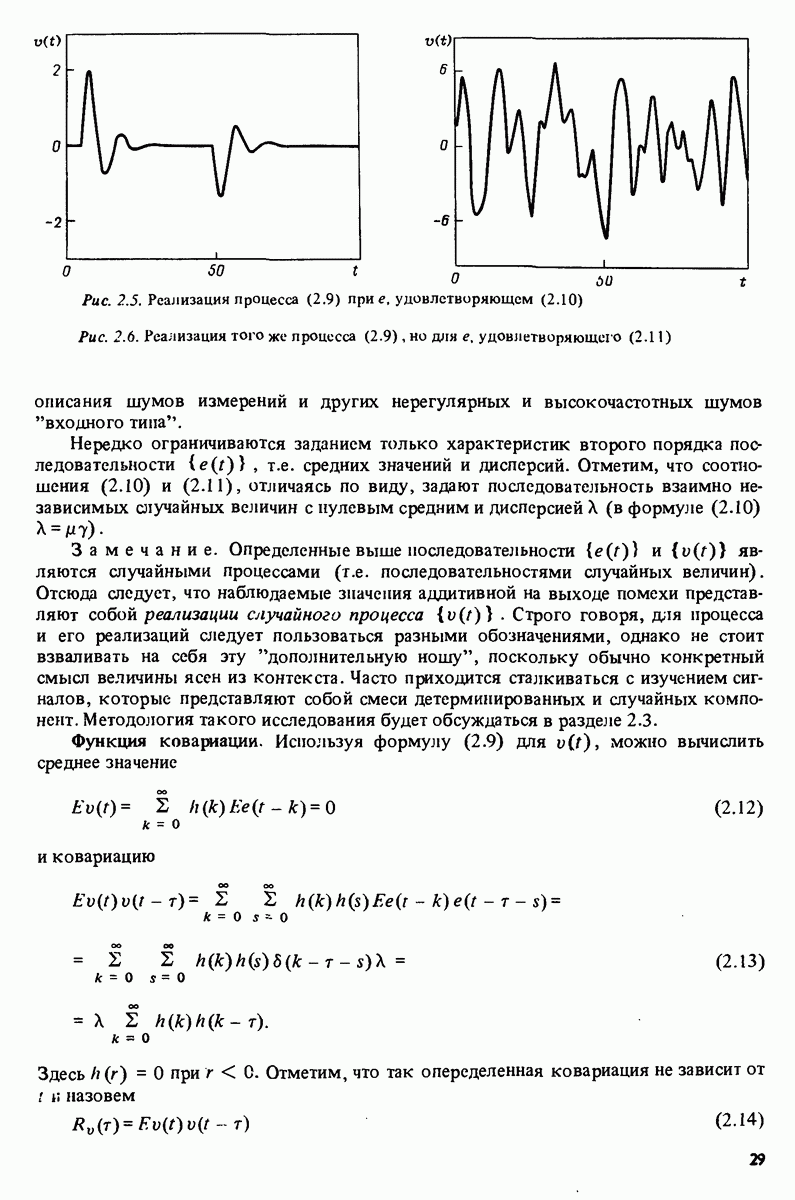
Замечание. Конечно, можно также рассмотреть близкую функцию
Однако, расширяя регрессоры константой Оценки наименьших квадратов. Обычно мы не располагаем точной априорной информацией относительно соотношения между
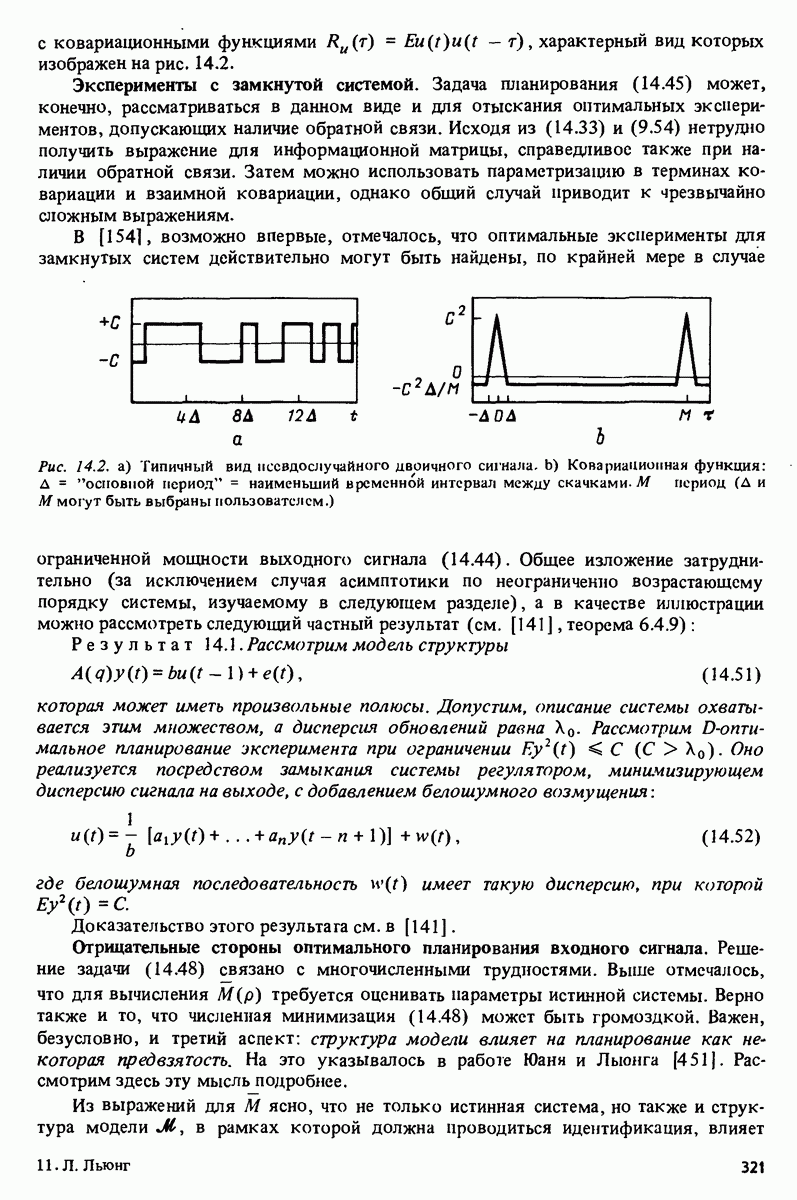
Используя эти данные, можно заменить дисперсию
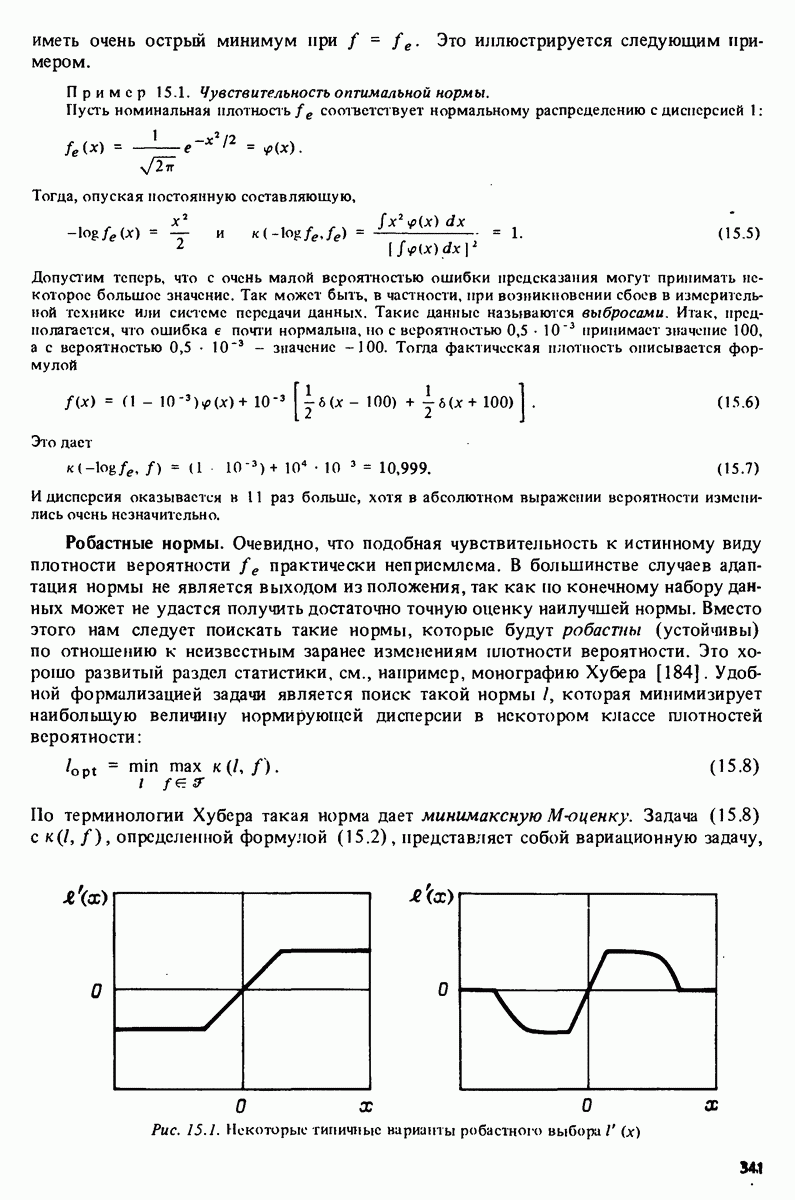
В линейном случае
и теперь в удобно выбирать как аргумент, минимизирующий
Это - оценка наименьших квадратов. В качестве функции предсказания, основанного на предыдущих наблюдениях, можно, таким образом, использовать
Отметим, что этот метод выбора в имеет смысл независимо от того, рассматриваем ли мы задачу в рамках стохастического подхода. Параметр в является величиной, дающей наилучшее предсказание по полученным данным. Эту прагматическую интериретацию оценки наименьших квадратов дал еще ее автор К.Ф. Гаусс: В заключение принцип, по которому сумма квадратов разностей между наблюдаемыми и вычисляемыми величинами должна быть минимальна, может рассматриваться следующим образом независимо от исчисления вероятностей [128]. Важной чертой
доставляет глобальный минимум функции
Формирование матрицы. Иногда выражения
и
Тогда критерий
Нормальные уравнения принимают вид
а оценка
В (11.15) можно выделить псевдообратную к
Таким образом, уравнение
Геометрическая интерпретация. Решению наименьших квадратов можно дать геометрическую интерпретацию, которая полезна для определения некоторых свойств. Положим
и рассмотрим
Рис. II.]. Оптимальное среднеквадратическос решение как ортогональная проекция Пусть Обозначим эту проекцию
Это значит, что
и, поскольку
Отсюда
что в матричной форме имеет вид Взвешенные наименьшие квадраты. В критерии
Это может иметь две причины. 1. Наблюдения у могут быть различной надежности. Некоторые наблюдения могут, например, содержать большие возмущения и, следовательно, должны иметь меньшие веса. (11.20) 2. Наблюдения могут быть изменяющейся информативности. Возможно, нет уверенности, что линейная модель имеет место во всей области изменения Наблюдение, относящееся к такой подозрительной области, даже если оно точное, должно, следовательно, иметь меньший вес. (11.21) Обозначив диагональную матрицу
критерий (11.19) можно переписать в виде
Нетрудно проверить, что минимум достигается при значении аргумента
По некоторым причинам можно также использовать критерий (11.23) для произвольной симметрической, положительно определенной матрицы
где
Элементы этих матриц равны
Таким образом, имеем
Следовательно, влияние общей нормы Невязки и ошибки предсказания. Разность
представляет собой ошибку, соответствующую значению в. Будем называть эту ошибку ошибкой предсказания, соответствующей параметру в. Вектор ошибок предсказания равен
а критерии (11.7) и (11.23) являются квадратичными нормами этого вектора. Нормы; Будем называть
невязками (остатками), связанными с моделью Рассмотрим теперь дня простоты случай
а предсказание выходной величины
Из геометрической интерпретации известно, что Ем и
что также можно записать в виде
показывающем, каким образом сумма квадратов наблюдений расщепляется на суммы квадратов предсказаний
и невязок
Идеальной представляется ситуация, когда по предсказанным значениям выходной величины ум можно описать и изменение большей части действительных выходных величин. Отношение
является мерой доли общего изменения у, описываемого регрессией. Оно известно как множественный коэффициент корреляции (квадратичный) и часто выражается в процентах. Иногда прежде, чем вычислять Качество оценки параметров. Чтобы исследовать свойства оценки
где
можно записать (11.39) как
Подставляя это выражение в
где
что в случае
Это выражение для ошибки по параметру имеет чисто алгебраическую природу и справедливо для произвольных последовательностей
где использовано обозначение (2.62). Если матрица (0) обратима (это соответствует предположению, что последовательность регрессорами и возмущением), то Для того чтобы можно было сказать большее относительно свойств
|
 |
Оглавление
|










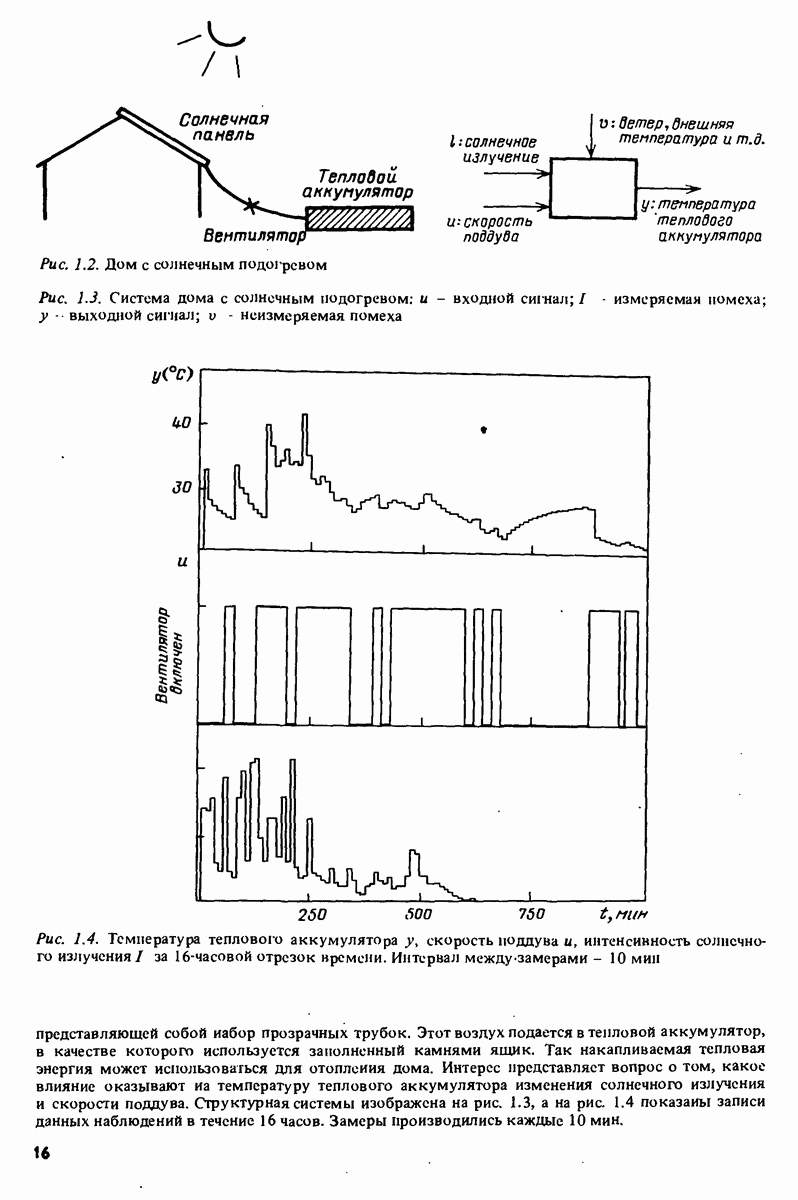
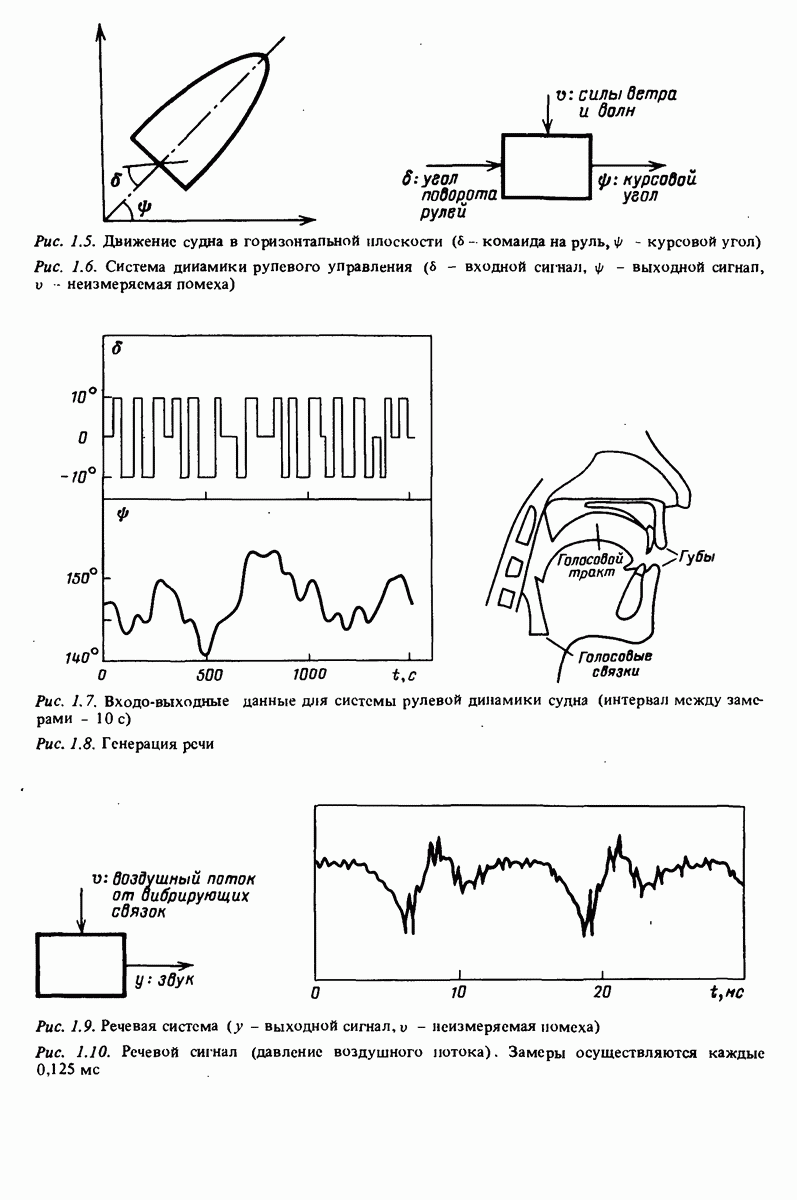



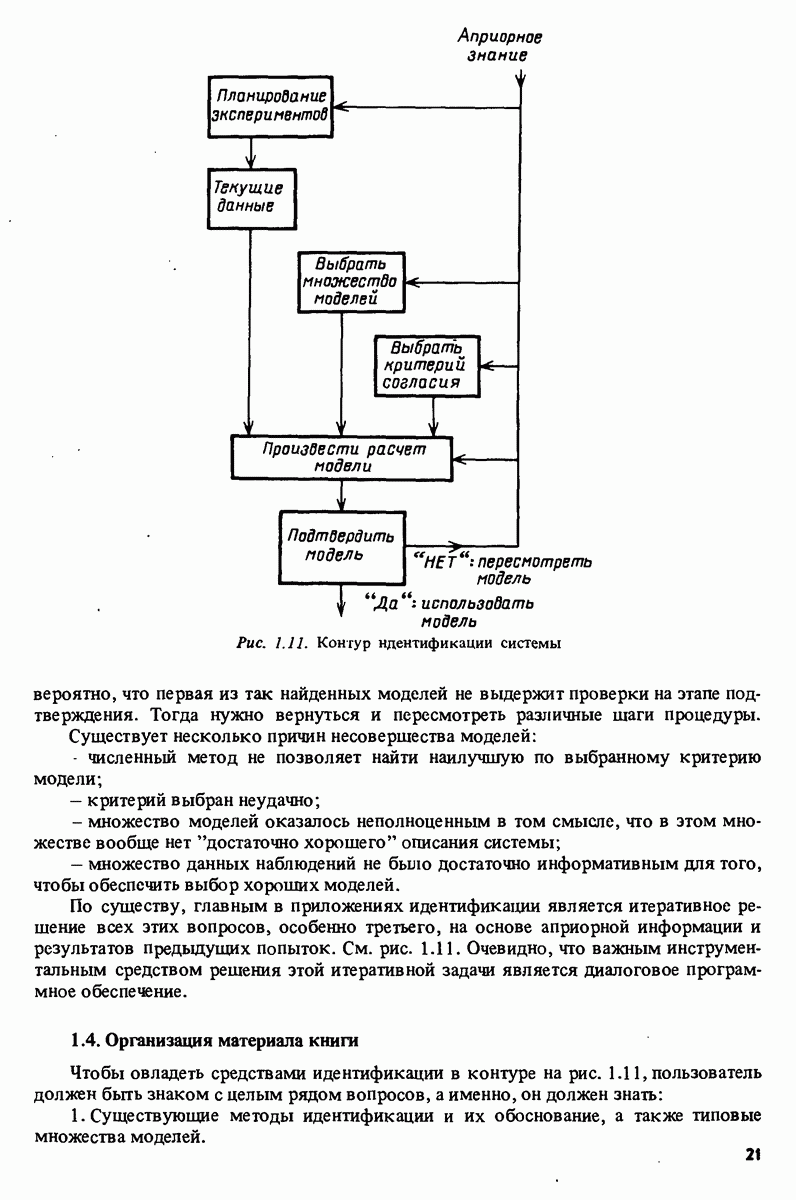
















































































































































































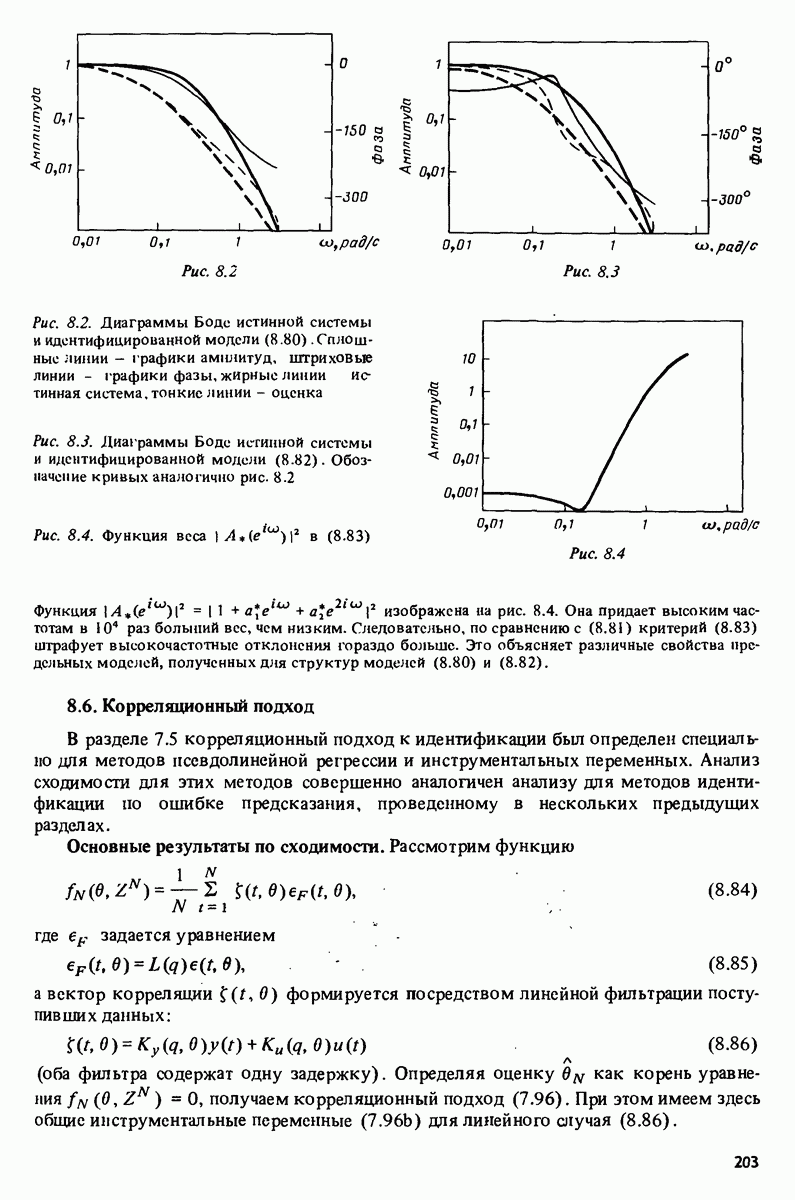


















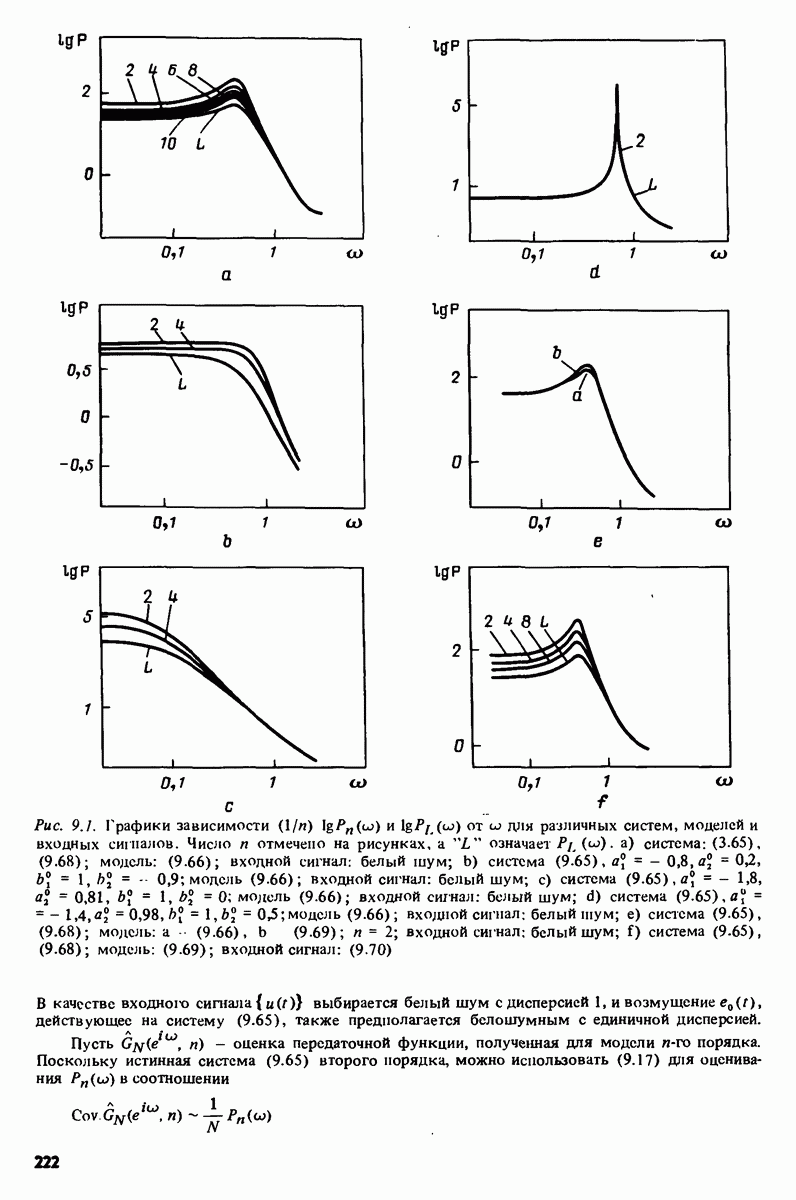






















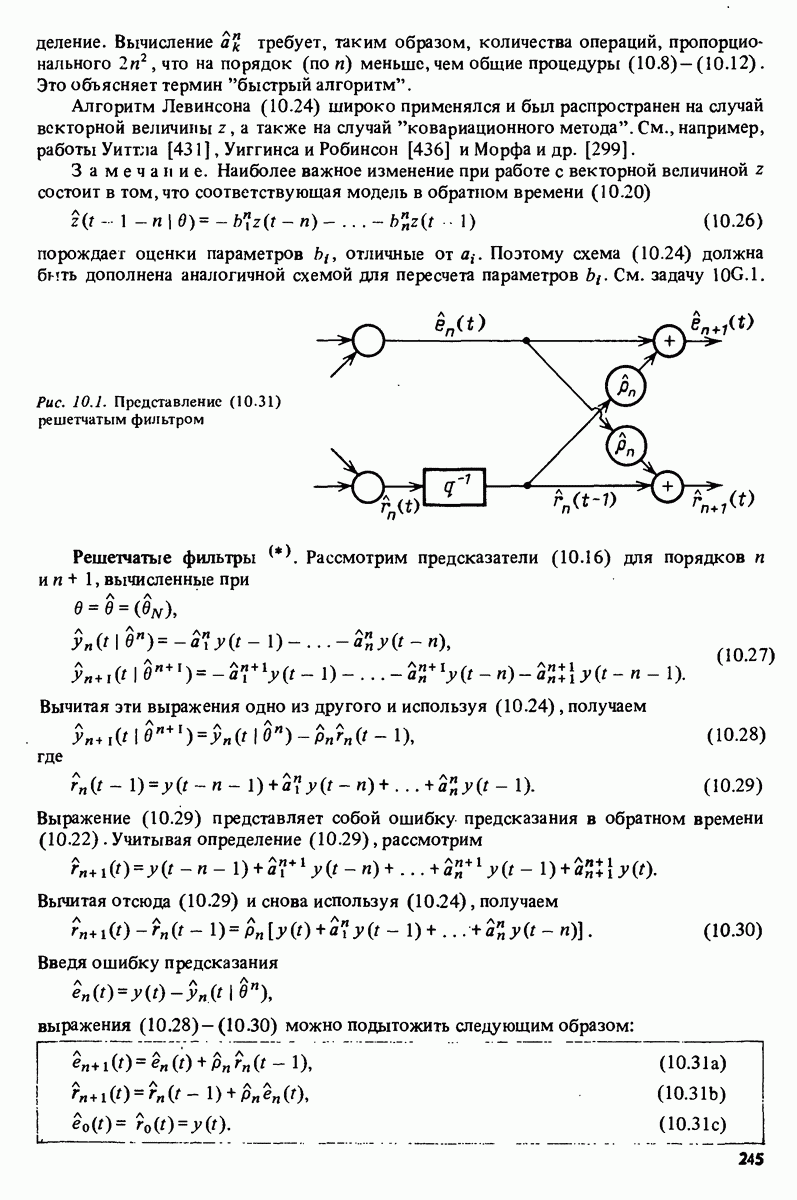

























































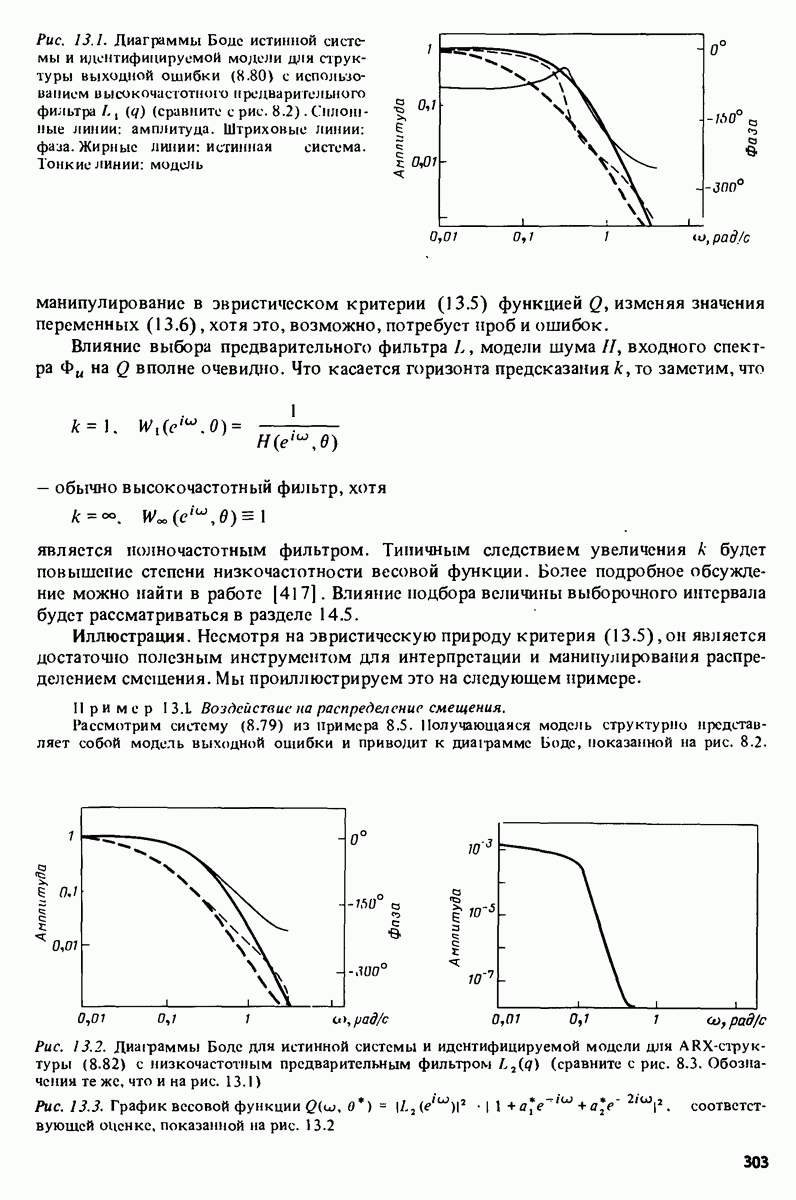


























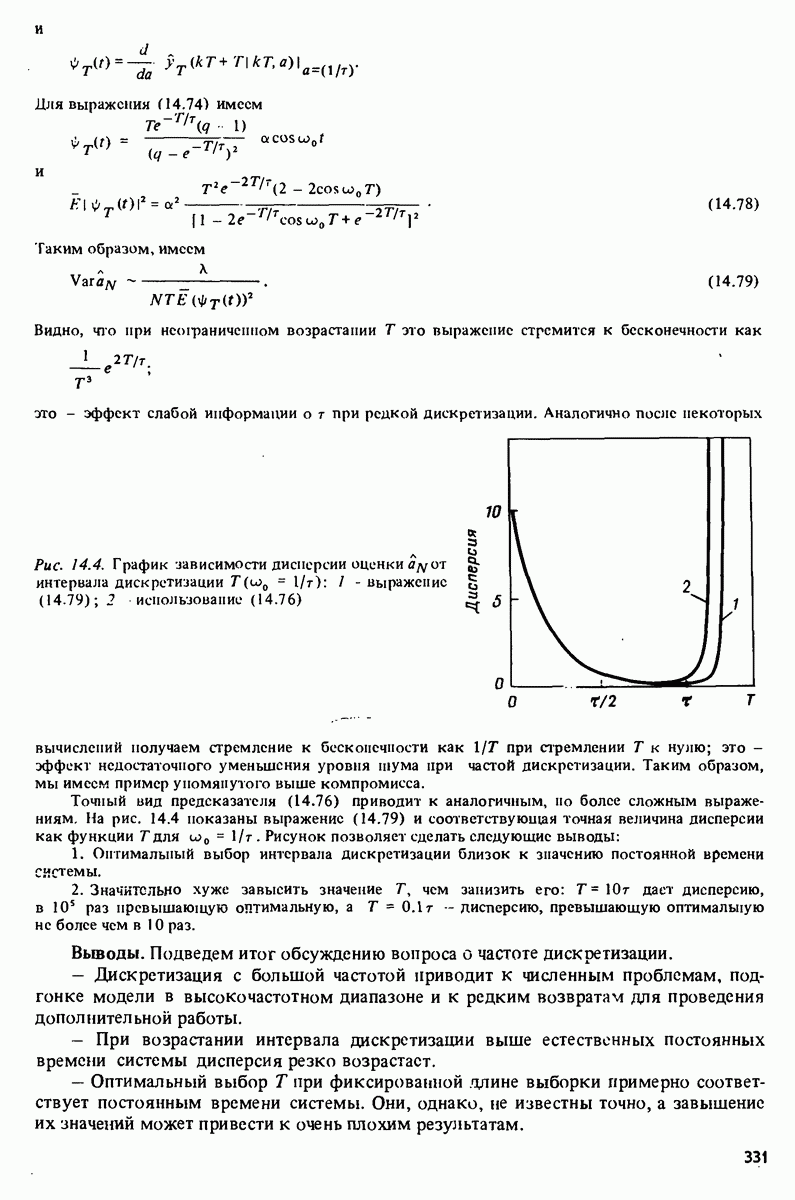























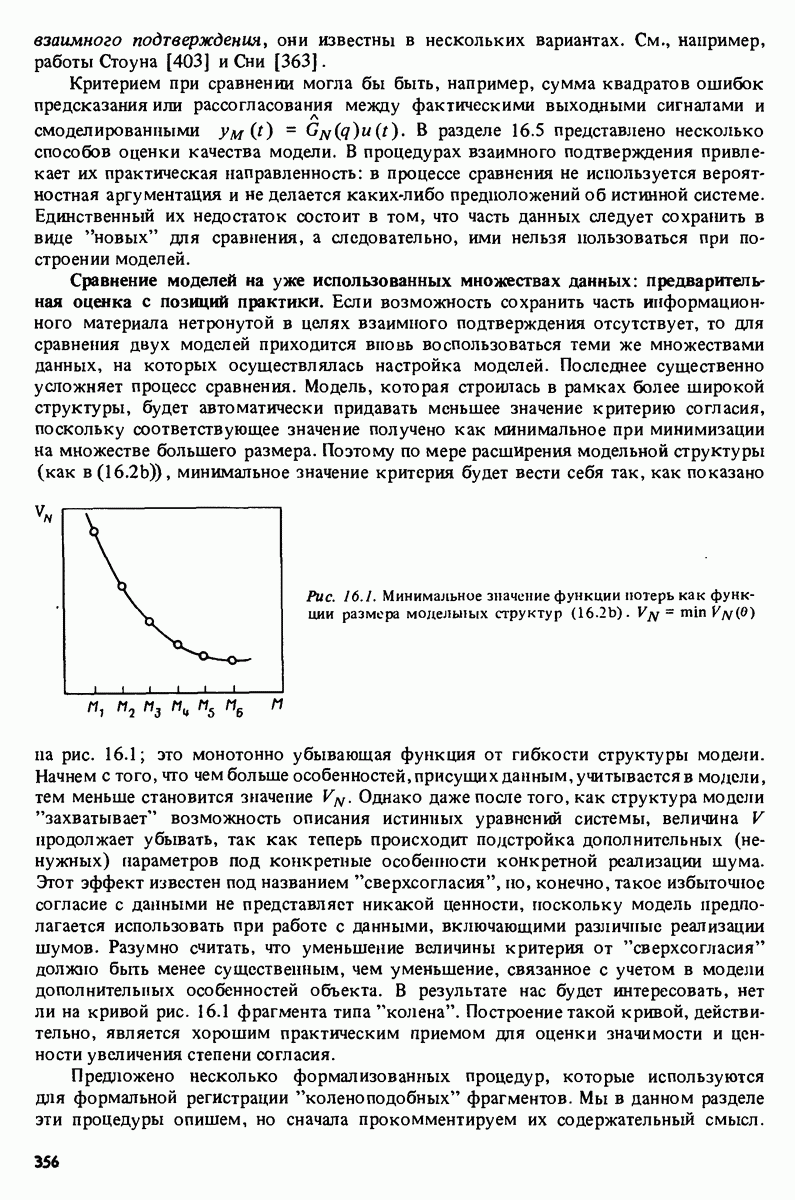








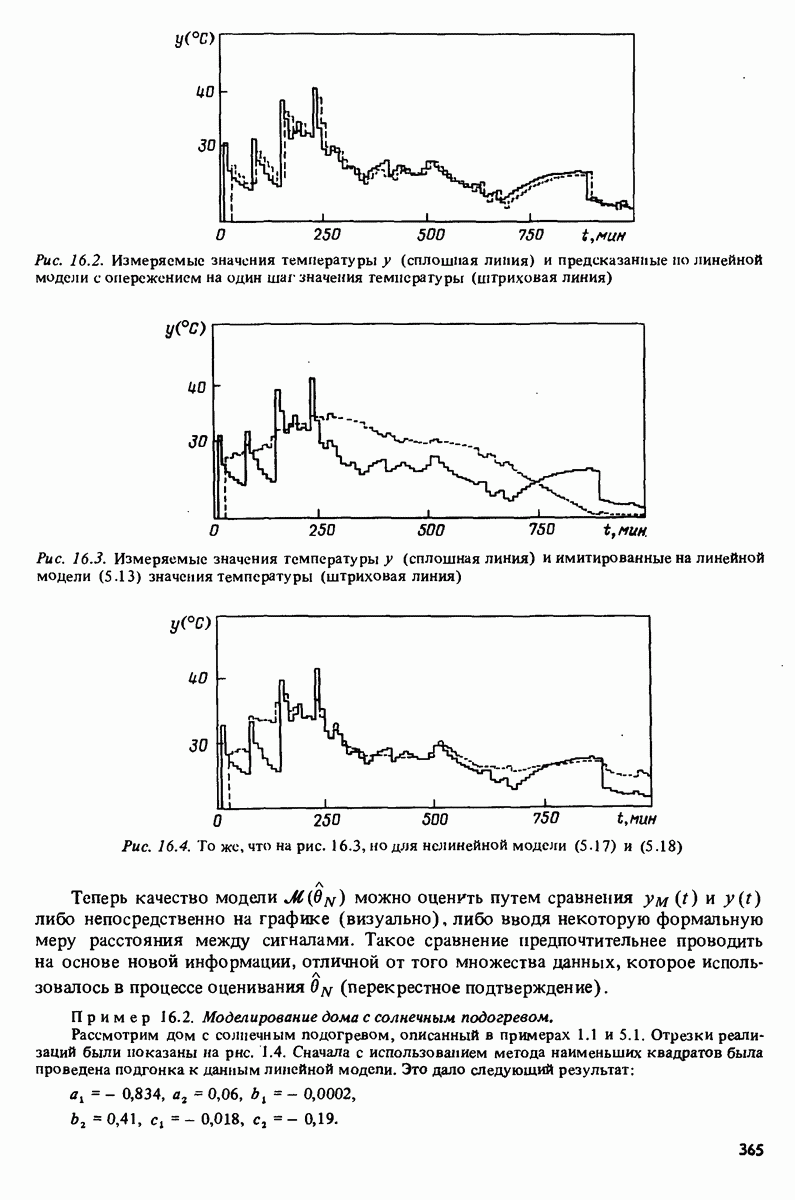






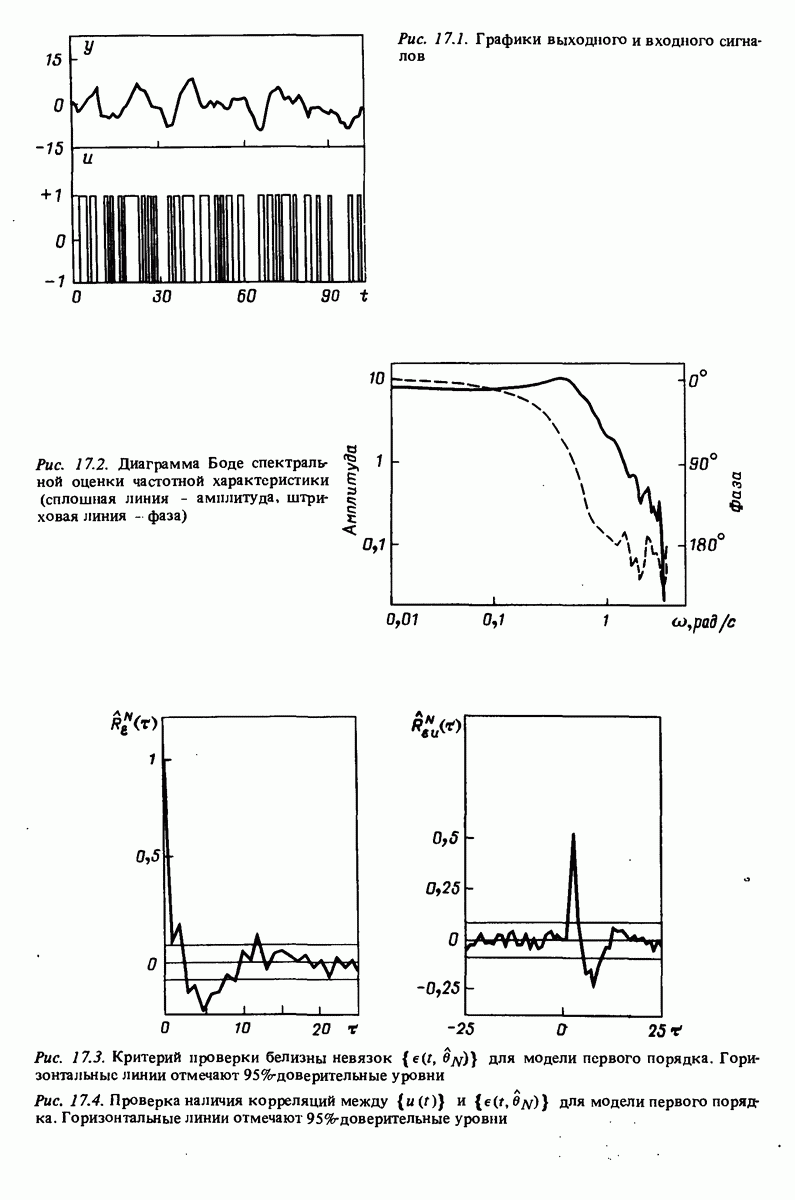
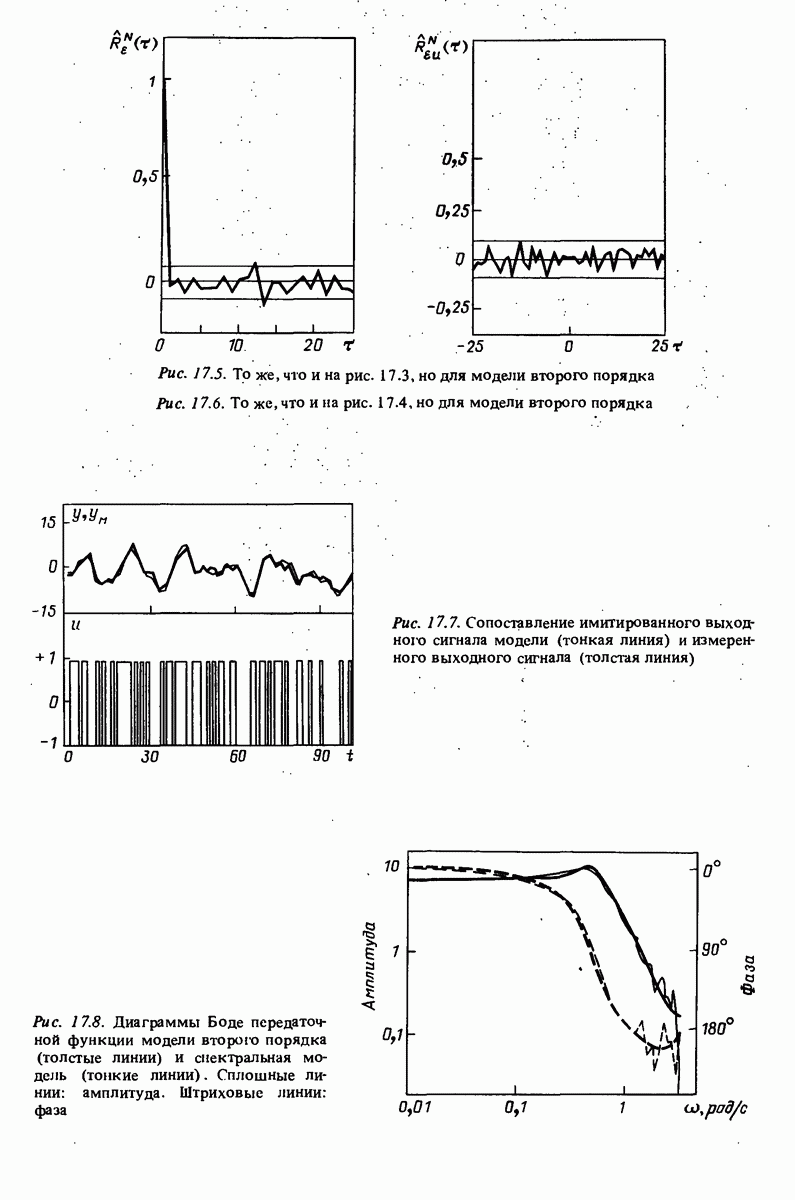


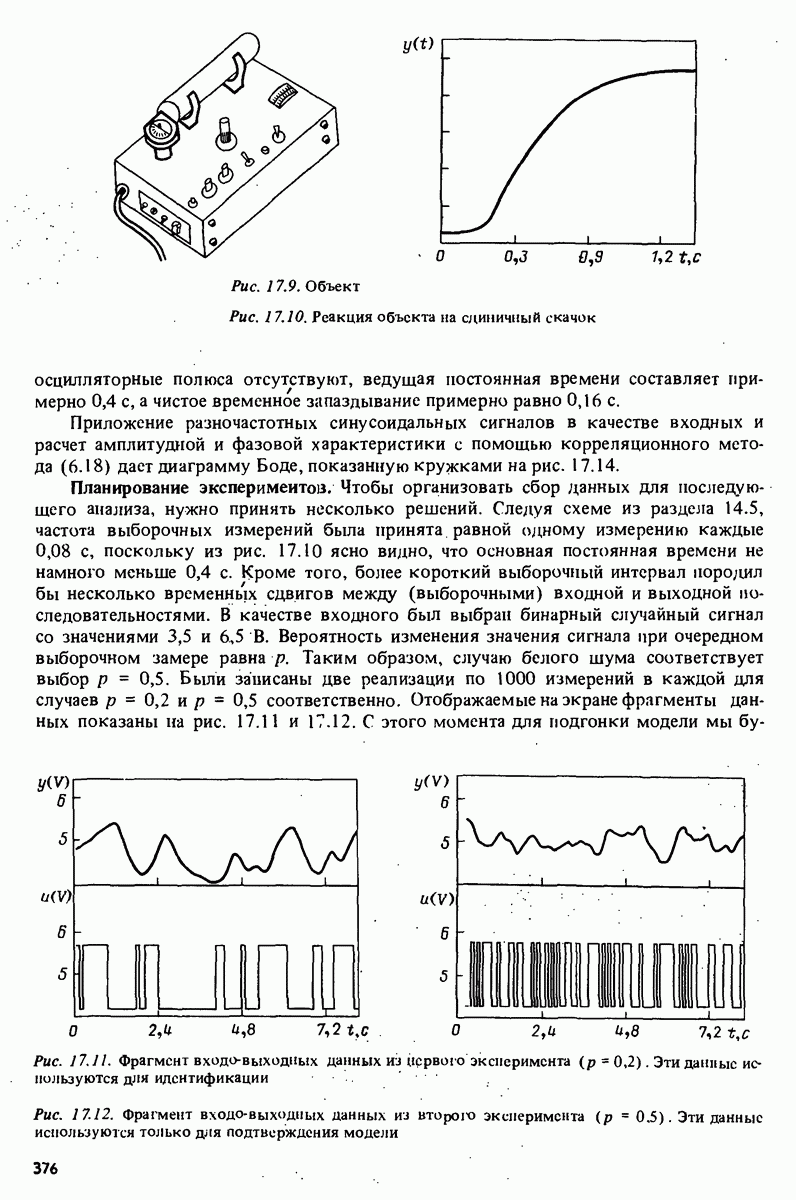
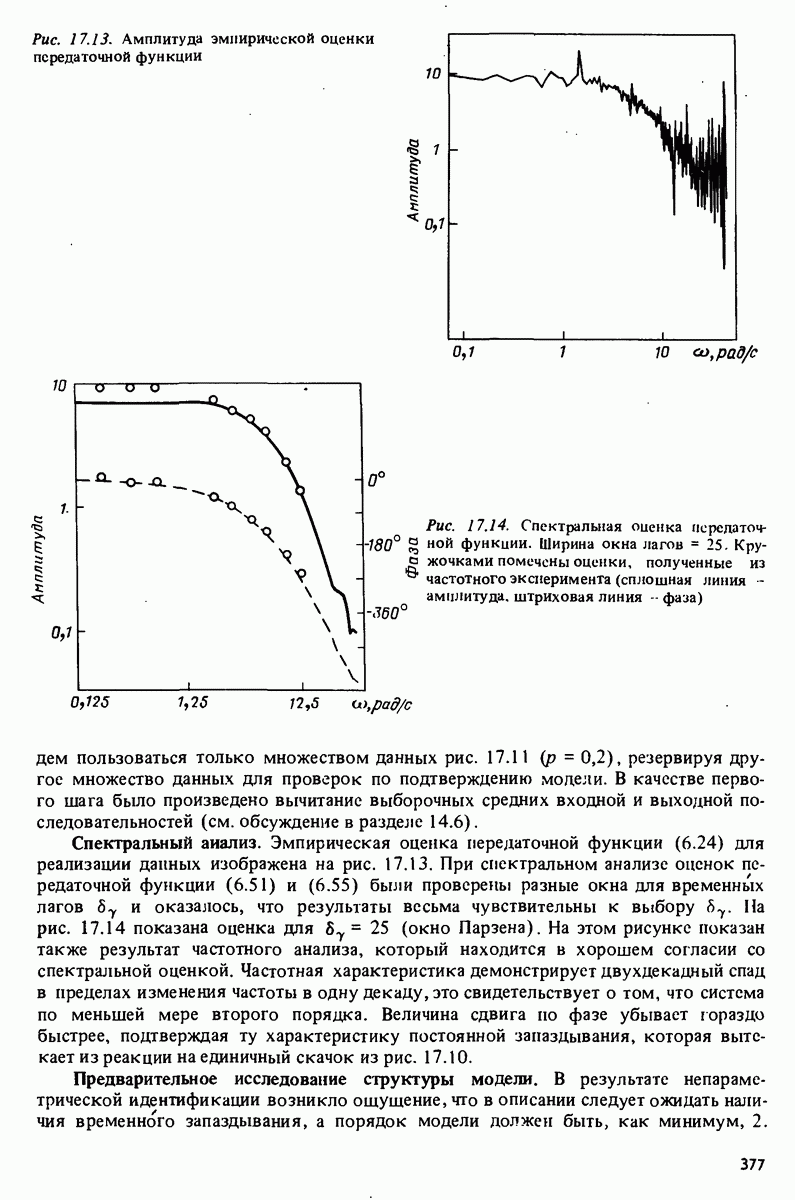
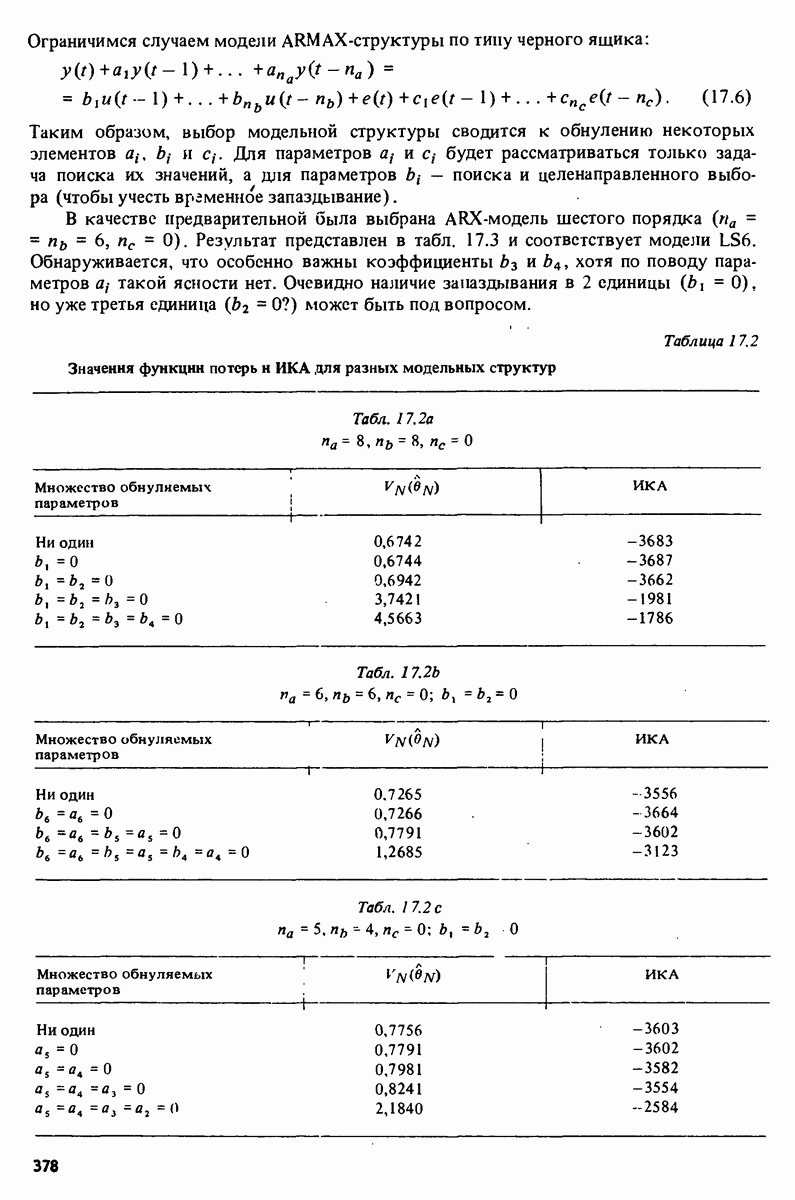
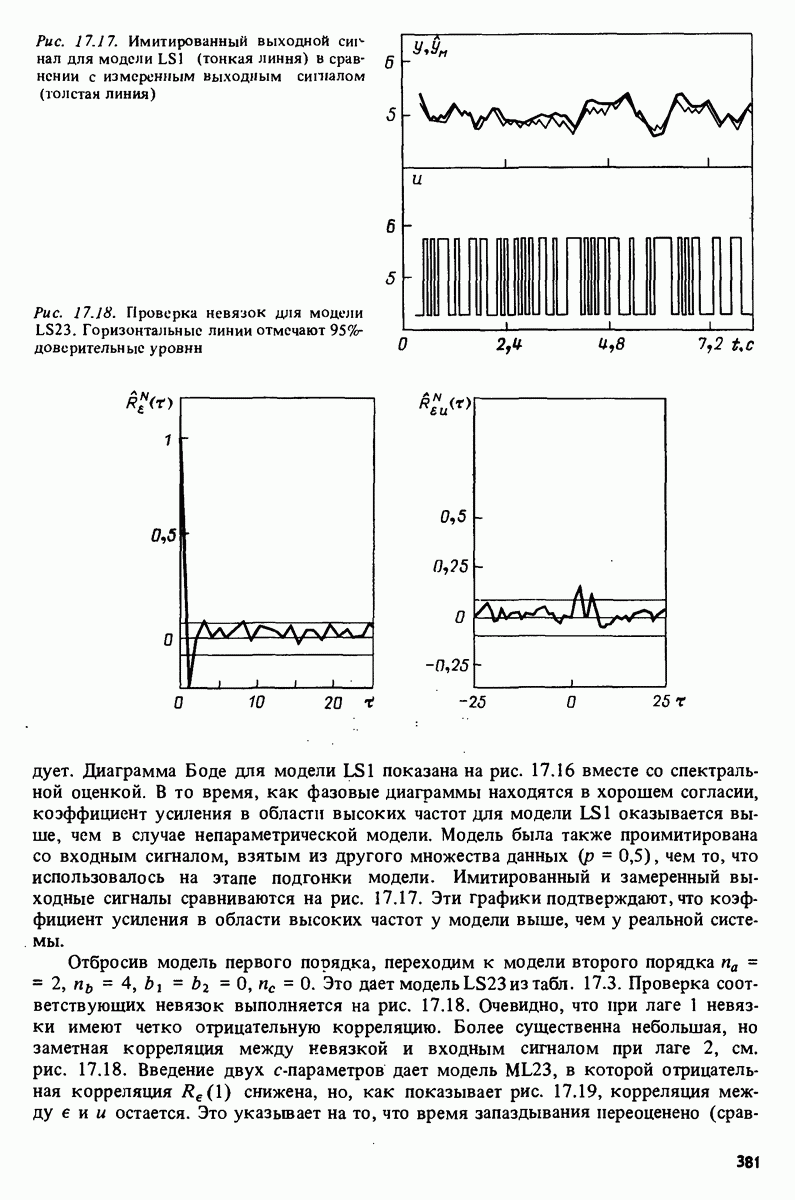














































 Например, зависимая переменная у могла бы представлять собой величину урожая, в то время как независимые переменные
Например, зависимая переменная у могла бы представлять собой величину урожая, в то время как независимые переменные  (регрессоры) давали бы информацию о количестве выпавших осадков, солнечных дней, качестве почвы и т.п. Известно огромное количество таких ситуаций во всех областях человеческой деятельности. Динамические системы, рассмотренные в части 1, образуют, очевидно, другой пример применения понятия регрессии, в которому — выходная величина
(регрессоры) давали бы информацию о количестве выпавших осадков, солнечных дней, качестве почвы и т.п. Известно огромное количество таких ситуаций во всех областях человеческой деятельности. Динамические системы, рассмотренные в части 1, образуют, очевидно, другой пример применения понятия регрессии, в которому — выходная величина
 а содержат информацию о прошлом поведении. Обозначим
а содержат информацию о прошлом поведении. Обозначим 

 такой, чтобы разность
такой, чтобы разность

 было хорошим предсказанием для
было хорошим предсказанием для  Если у и описываются как случайные величины, можно, например, стремиться к минимизации
Если у и описываются как случайные величины, можно, например, стремиться к минимизации

 минимизирующая (11.1), представляет собой условное математическое ожидание у при данных
минимизирующая (11.1), представляет собой условное математическое ожидание у при данных 


 имеющей максимальную корреляцию
имеющей максимальную корреляцию  По существу ответом является функция регрессии. См. задачу
По существу ответом является функция регрессии. См. задачу 
 априори невозможно. Ее приходится оценивать по данным и, следовательно, она должна быть удобным образом параметризована. Наиболее интенсивно изучался случай линейной параметризации. При этому приближается линейной комбинацией величин
априори невозможно. Ее приходится оценивать по данным и, следовательно, она должна быть удобным образом параметризована. Наиболее интенсивно изучался случай линейной параметризации. При этому приближается линейной комбинацией величин 




 соответственно, вектор параметров в, случай
соответственно, вектор параметров в, случай  сводим к
сводим к 
 и
и  Вместо этого мы имеем данные истории, набор предыдущих наблюдений соответствующих друг другу величину и
Вместо этого мы имеем данные истории, набор предыдущих наблюдений соответствующих друг другу величину и  Удобно перенумеровать эти величины, используя аргумент
Удобно перенумеровать эти величины, используя аргумент 

 выборочной
выборочной

 имеем, таким образом, вместо
имеем, таким образом, вместо 




 является то, что эта функция квадратична по в. Следовательно, ее можно минимизировать аналитически (см. задачу
является то, что эта функция квадратична по в. Следовательно, ее можно минимизировать аналитически (см. задачу  Находим, что любая оценка
Находим, что любая оценка  удовлетворяющая уравнению
удовлетворяющая уравнению

 Эта система линейных уравнений известна как нормальные уравнения. Если матрица в левой части этого уравнения обратима, получаем выражение оценки наименьших квадратов
Эта система линейных уравнений известна как нормальные уравнения. Если матрица в левой части этого уравнения обратима, получаем выражение оценки наименьших квадратов

 более удобно записывать в матричной форме. Определимых
более удобно записывать в матричной форме. Определимых  -вектор-столбец
-вектор-столбец

 -матрицу
-матрицу

 можно переписать как
можно переписать как



 (по
(по  матрицу:
матрицу:

 дает псевдообратное решение для переопределенной
дает псевдообратное решение для переопределенной  системы линейных уравнений
системы линейных уравнений


 как векторы в пространстве
как векторы в пространстве  Задача, выраженная соотношением (11.17), состоит в нахождении линейной комбинации векторов
Задача, выраженная соотношением (11.17), состоит в нахождении линейной комбинации векторов  приближающей
приближающей  наилучшим образом.
наилучшим образом.


 -мерное подпространство, натянутое на векторы
-мерное подпространство, натянутое на векторы  Если оказывается, что вектор
Если оказывается, что вектор  принадлежит этому подпространству, его можно описать как единственную линейную комбинацию векторов
принадлежит этому подпространству, его можно описать как единственную линейную комбинацию векторов  В противном случае, наилучшим приближением
В противном случае, наилучшим приближением  в подпространстве
в подпространстве  является такой вектор в
является такой вектор в  который имеет наименьшее расстояние от
который имеет наименьшее расстояние от  т. е., как хорошо известно, ортогональная проекция
т. е., как хорошо известно, ортогональная проекция  на
на  См. рис.
См. рис.  А
А
 Так как это ортогональная проекция, имеем
Так как это ортогональная проекция, имеем


 имеем для некоторых координат
имеем для некоторых координат



 различным наблюдениям придан одинаковый вес. Иногда приходится рассматривать взвешенный критерий
различным наблюдениям придан одинаковый вес. Иногда приходится рассматривать взвешенный критерий




 При этом предыдущая формула (11.24) по-прежнему верна. Чтобы понять, что происходит, в терминах исходных измерений, удобно произвести факторизацию
При этом предыдущая формула (11.24) по-прежнему верна. Чтобы понять, что происходит, в терминах исходных измерений, удобно произвести факторизацию 

 нижняя треугольная матрица с единицами на диагонали:
нижняя треугольная матрица с единицами на диагонали:

 диагональная матрица, как в
диагональная матрица, как в  Тогда
Тогда  принимает вид
принимает вид



 в (11.23) сводится к тому, что исходные наблюдения должны обрабатываться фильтром
в (11.23) сводится к тому, что исходные наблюдения должны обрабатываться фильтром 


 не являющиеся диагональными, соответствуют суммам квадратов профильтрованных ошибок предсказания, аналогично
не являющиеся диагональными, соответствуют суммам квадратов профильтрованных ошибок предсказания, аналогично 


 Обозначим вектор невязки
Обозначим вектор невязки


 ортогональны. Значит,
ортогональны. Значит,





 среднее значение у вычитают из у и у.
среднее значение у вычитают из у и у.
 допустим, что действительные измерения
допустим, что действительные измерения  могут быть описаны равенством
могут быть описаны равенством

 некоторая последовательность возмущений или ошибок пока еще неуказанной природы. Если эта последовательность имеет некоторые приятные (описанные ниже) свойства, естественно называть
некоторая последовательность возмущений или ошибок пока еще неуказанной природы. Если эта последовательность имеет некоторые приятные (описанные ниже) свойства, естественно называть  "истинным параметром”. Если обозначить
"истинным параметром”. Если обозначить


 получаем
получаем


 записывается также в виде
записывается также в виде 

 Если и
Если и  квазистационарны, видно, что при
квазистационарны, видно, что при  стремящемся к бесконечности,
стремящемся к бесконечности,  стремится к
стремится к

 имеет полный ранг), а
имеет полный ранг), а  равна нулю (что соответствует определенной независимости между
равна нулю (что соответствует определенной независимости между
 будет стремиться к истинному значению
будет стремиться к истинному значению  с ростом числа наблюдений.
с ростом числа наблюдений.
 естественно описывать последовательность возмущений с вероятностных позиций. Это будет сделано в следующем разделе.
естественно описывать последовательность возмущений с вероятностных позиций. Это будет сделано в следующем разделе.