Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
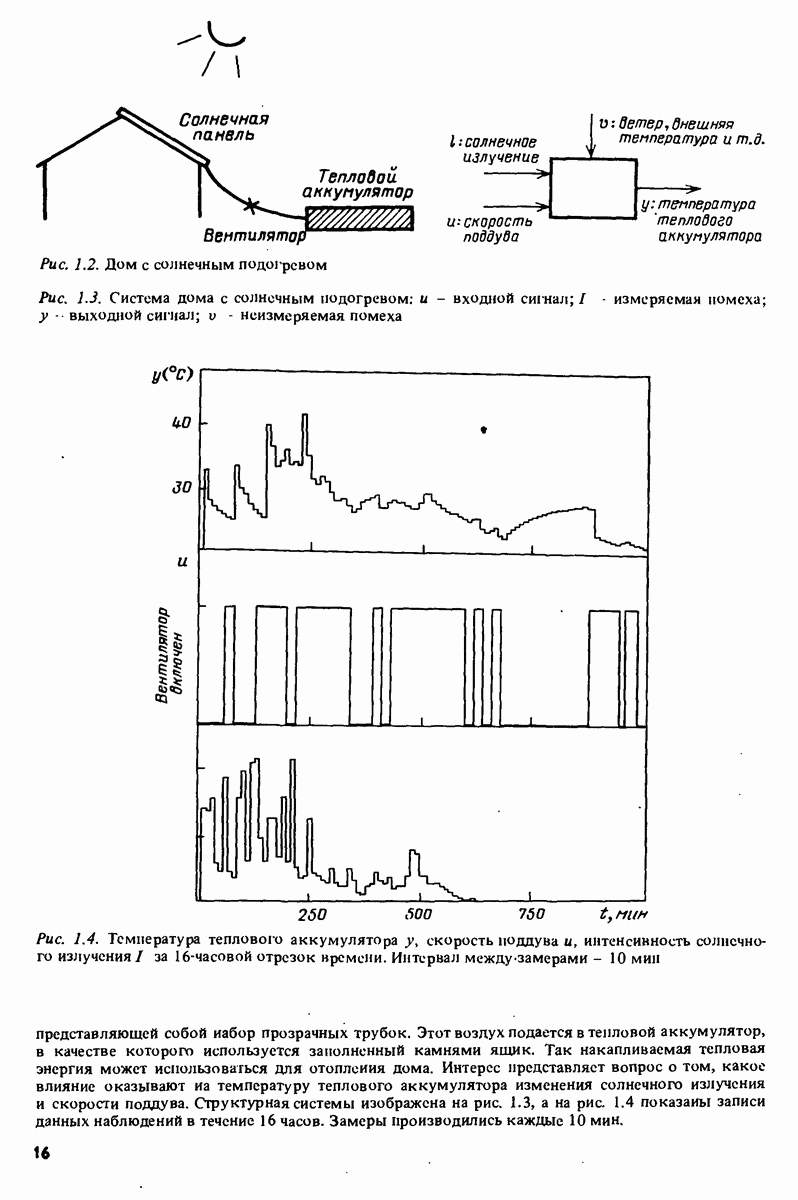
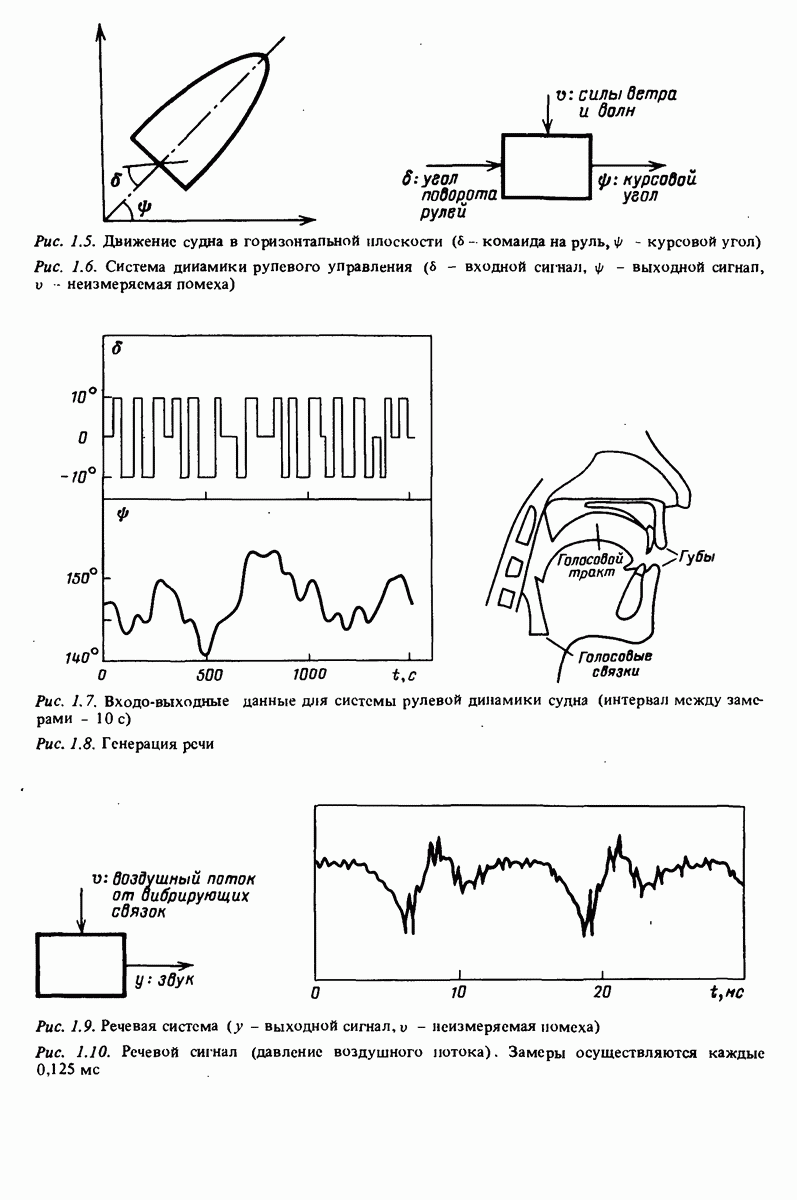
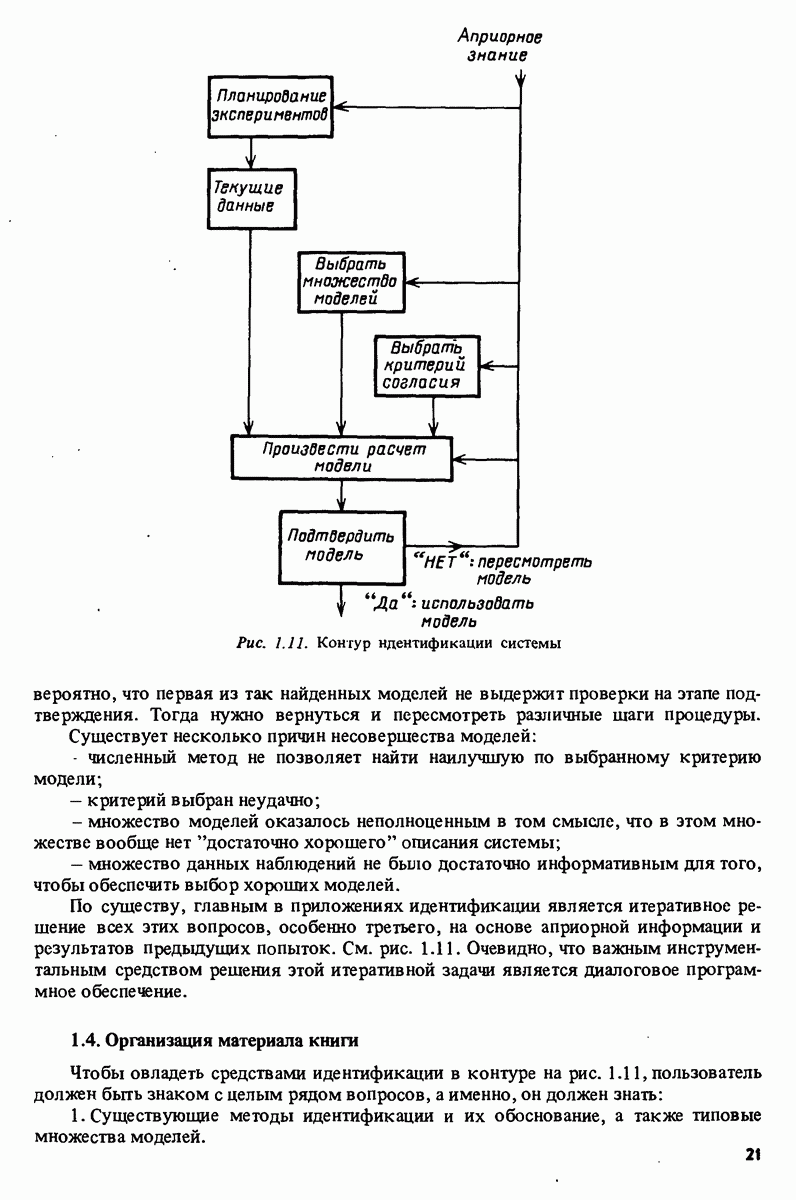
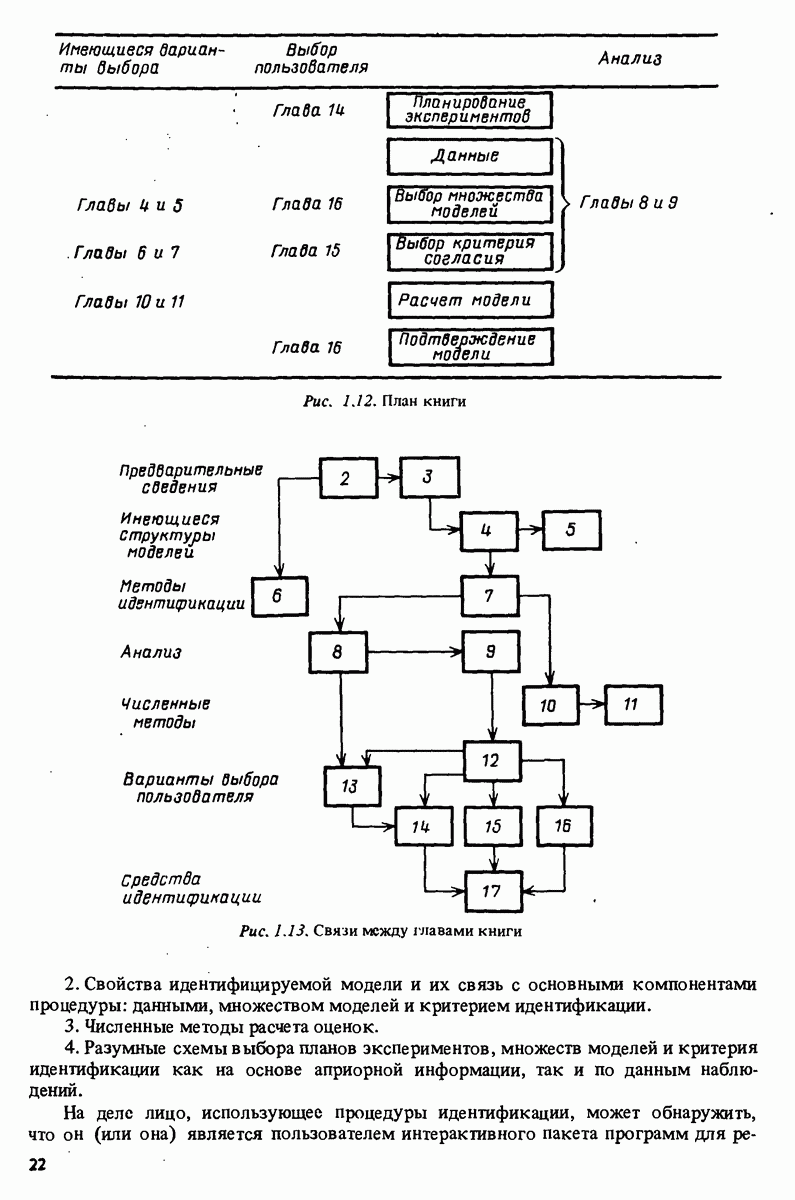
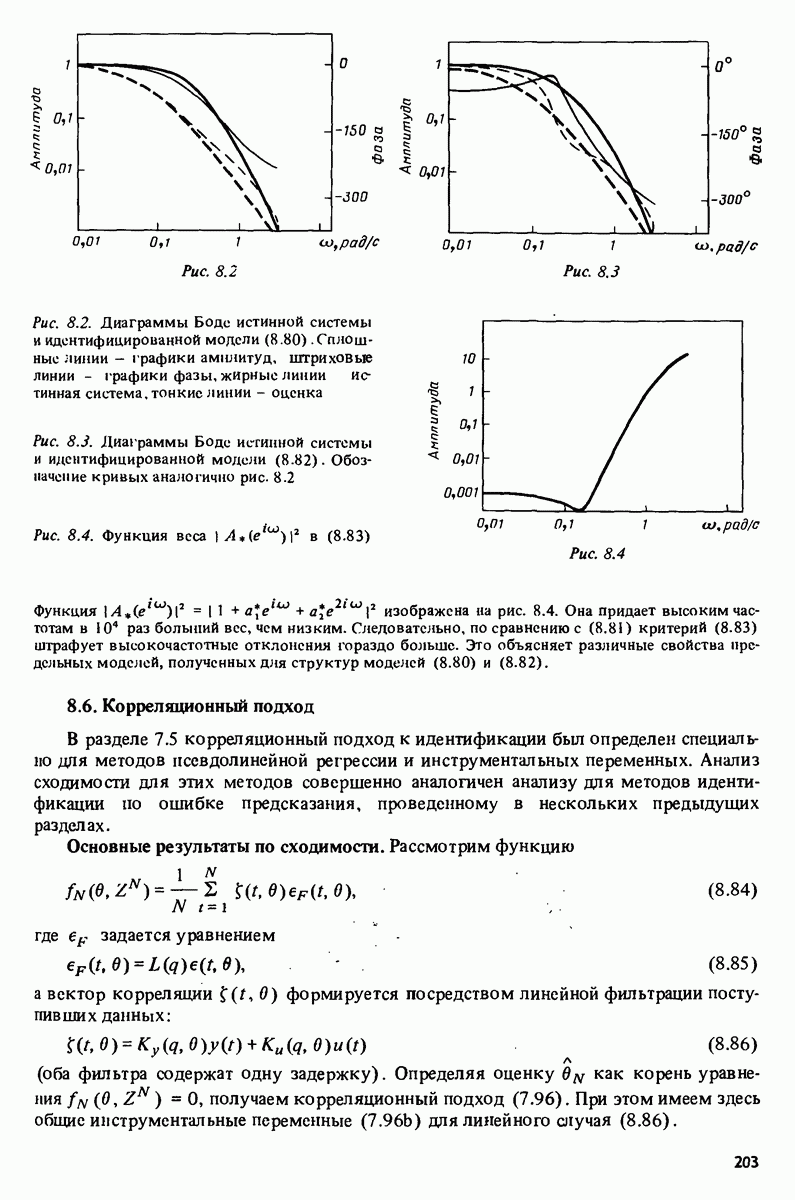
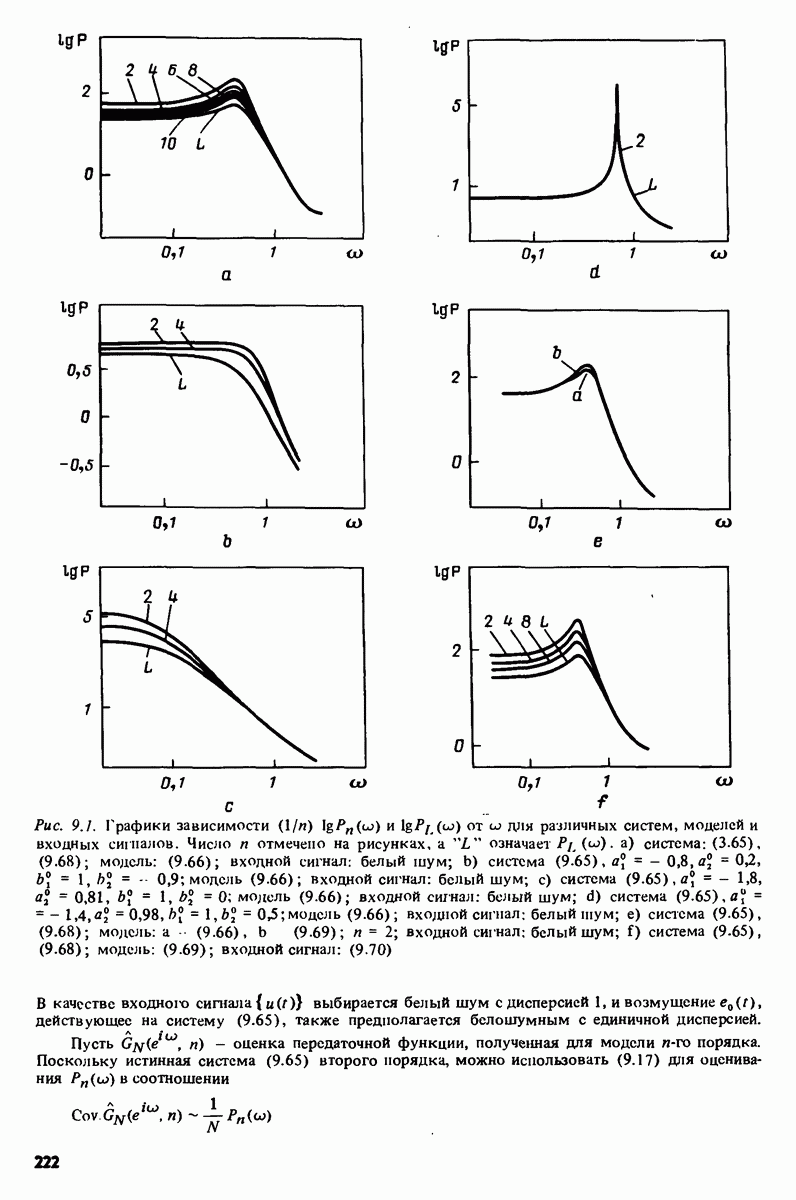
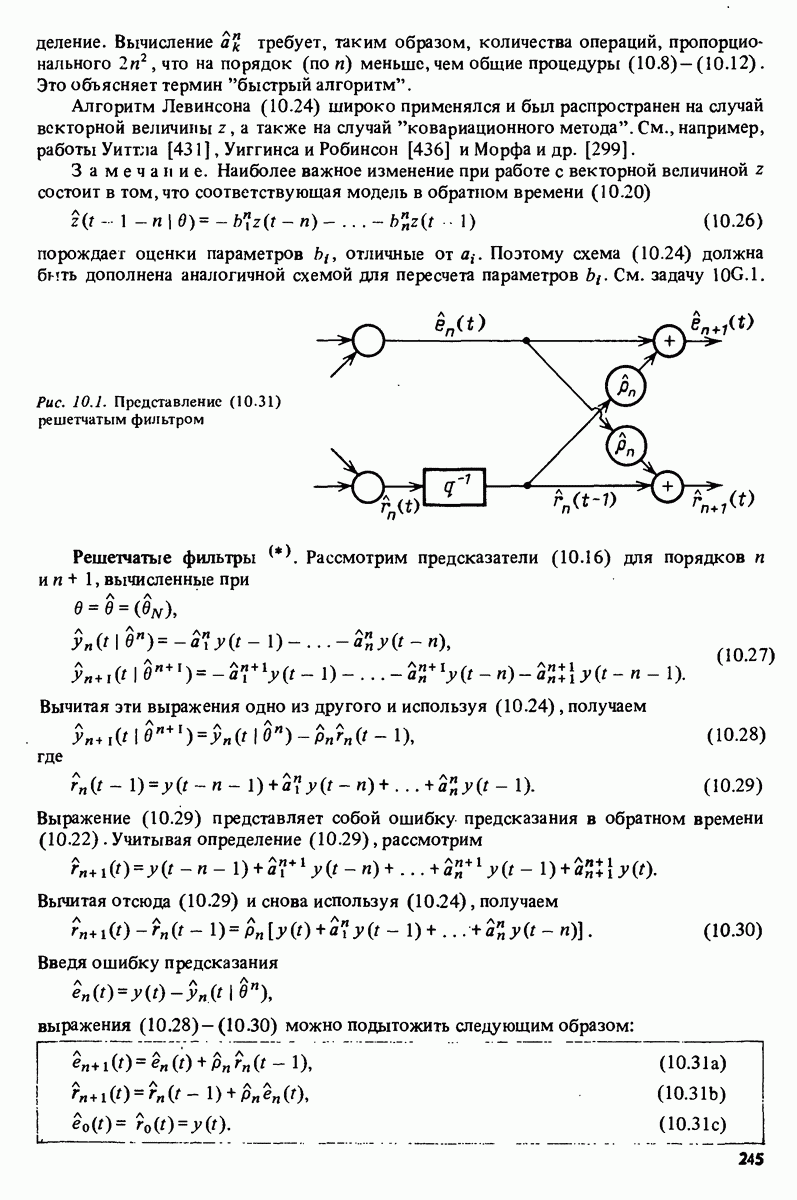
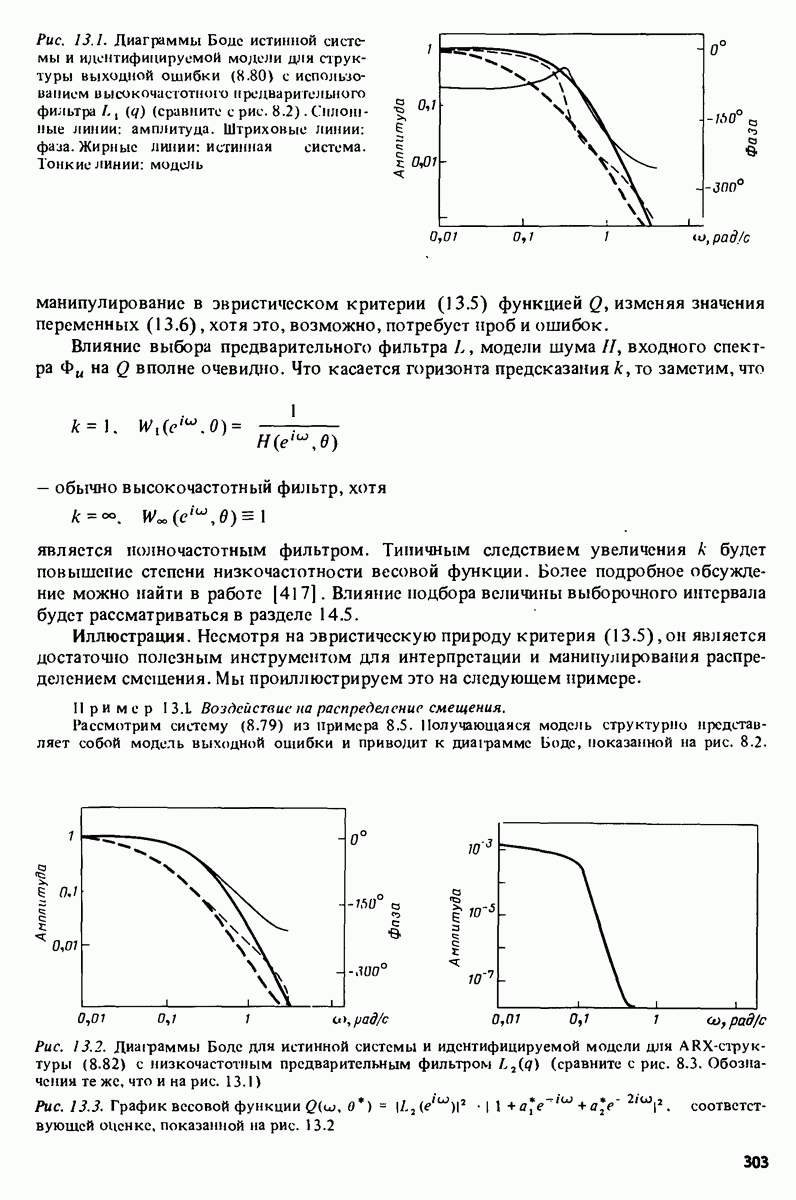
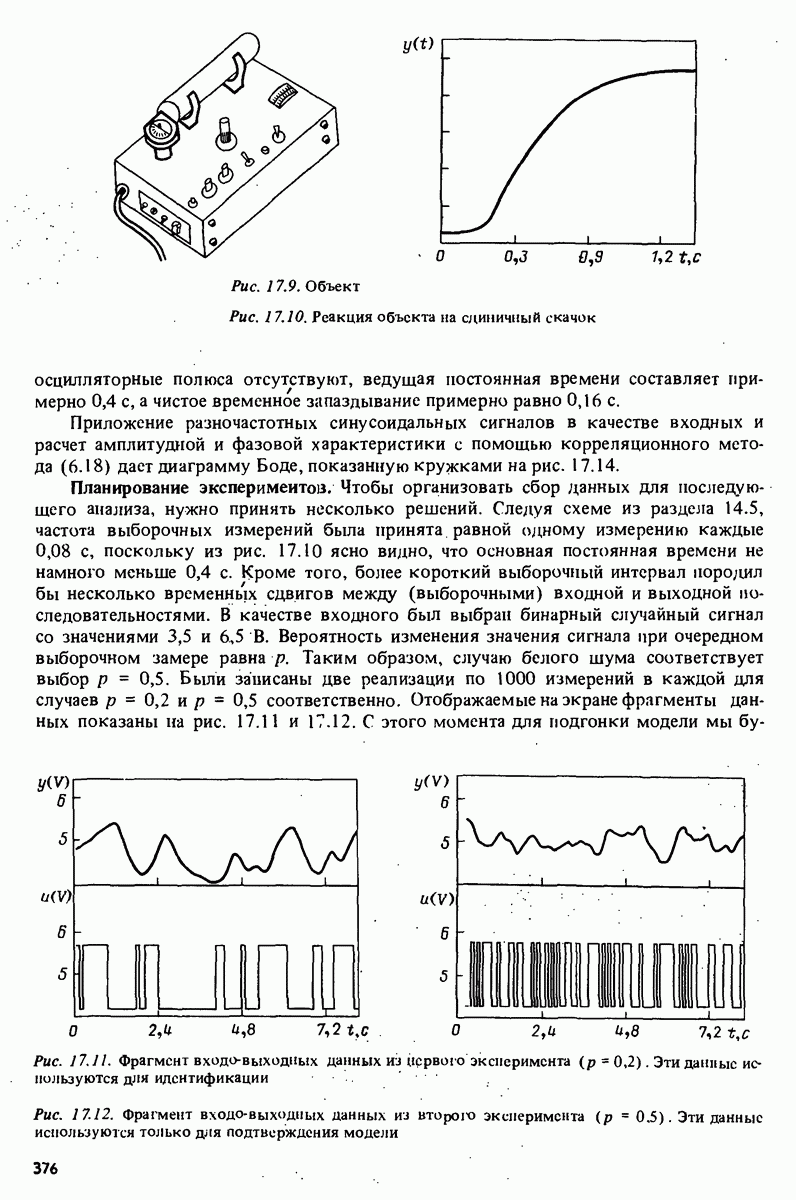
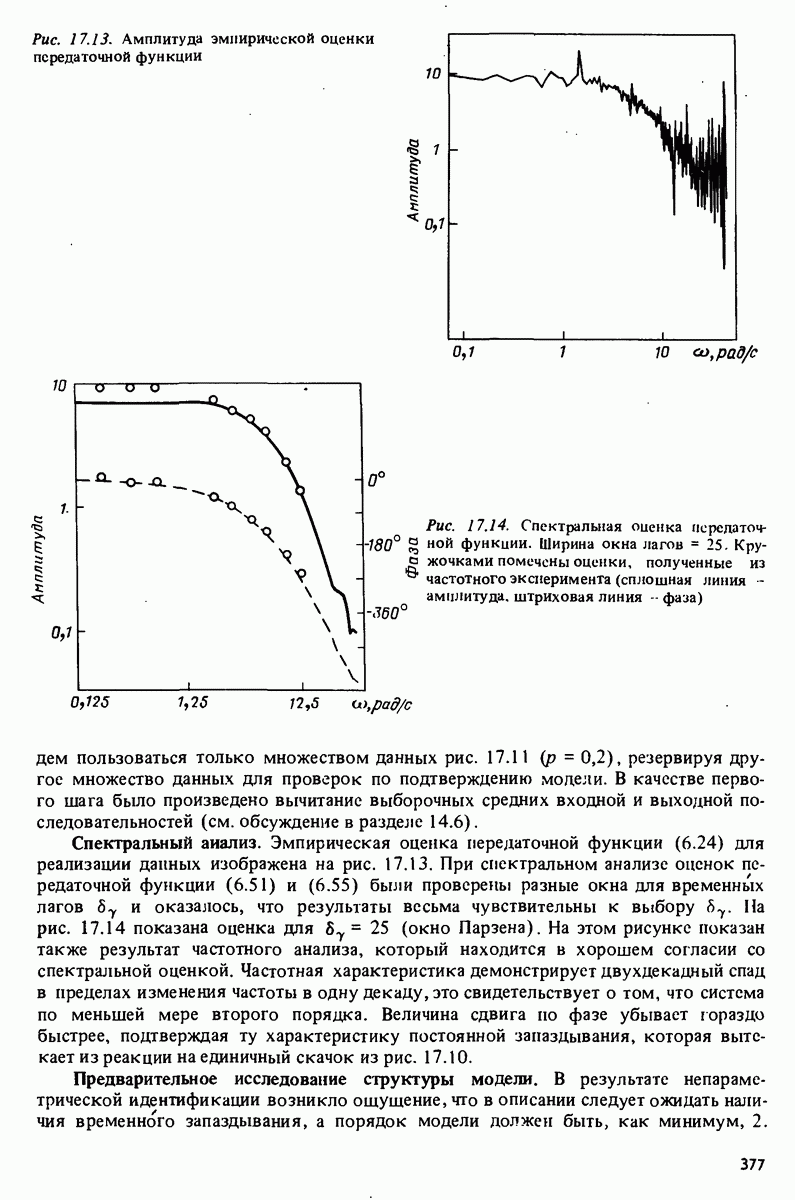
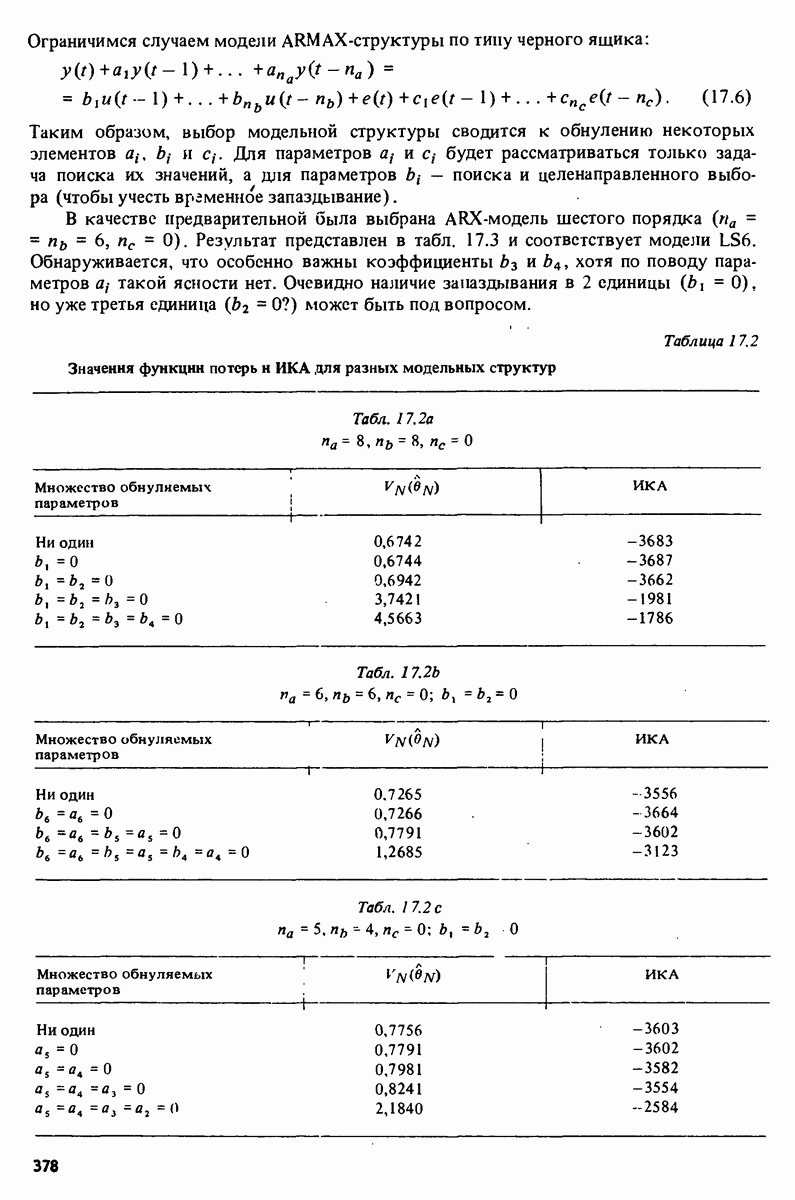
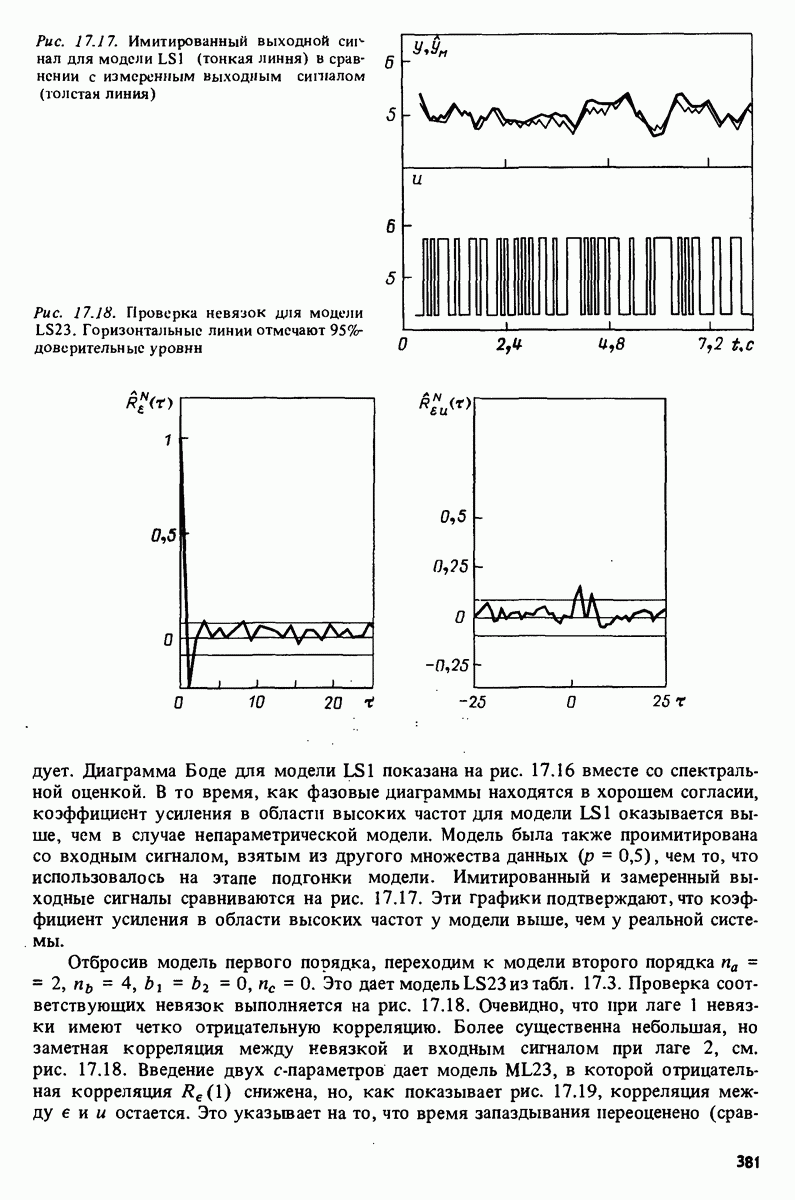
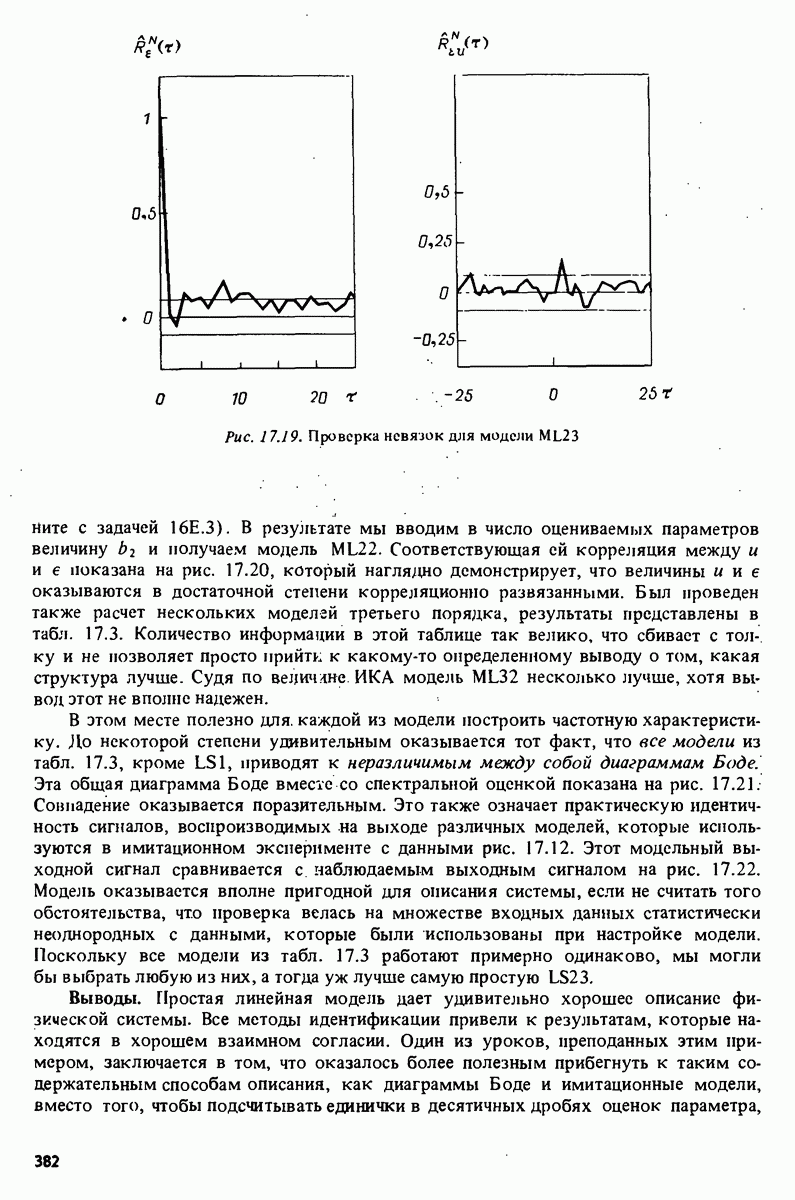
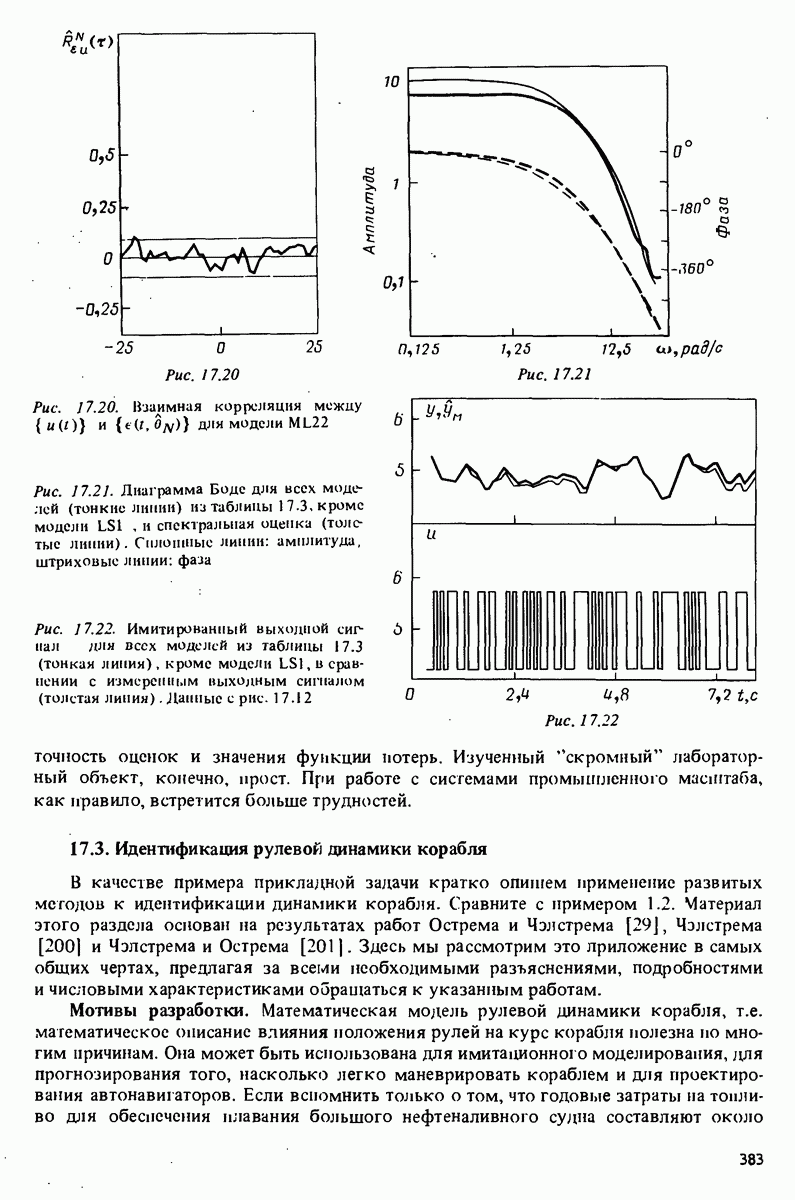
Глава 17. ИДЕНТИФИКАЦИЯ СИСТЕМ НА ПРАКТИКЕВ этой книге рассматривалась теория идентификации систем. Практическое решение вопросов идентификации вносит в предмет элемент искусства. Начинают играть важную рель опыт, интуиция и содержательные соображения, В этой главе мы обсудим методы идентификации систем как набор инструментов исследования, осмысления и создания реальных систем. В разделе 17.1 мы начнем с описания одного из доступных пользователю средств системной идентификации интерактивных вычислений. В разделе 17.2 рассматривается хотя реальный, но лабораторный процесс, на котором демонстрируются реализуемость и полезность предложенных методов. В разделе 17.3 описывается прикладная задача о динамике корабля. Наконец, в разделе 17.4 мы делаем попытку дать ответ на главный вопрос: что же все-таки теория идентификации, как часть прикладной науки, дает для решения практических задач? 17.1. Инструмент идентификации: интерактивное программное обеспечениеДля процесса идентификации характерно проведение поиска: поиска приемлемой модельной структуры, поиска представительной модели в рамках структуры и т.д. По существу процесс является итеративным - прежде чем сформировать приемлемую модель, несколько моделей приходится, перебрав, отбросить. Этот процесс не может быть полностью автоматизирован; решения, принимаемые человеком, будут переплетены с формальными выкладками, строгими численными расчетами. Таким образом, в целях достижения достаточной эффективности процесса идентификации необходимо процесс вычислений осуществлять в диалоге. Можно указать следующие типовые составляющие пакета прикладных программ для идентификации: 1. Обработка данных, фильтрация, построение графиков и т.д. 2. Непараметрические методы идентификации: расчет корреляций, спектров, быстрого преобразования Фурье. 3. Методы параметрической идентификации для различных модельных структур. 4. Отображение свойств модели: диаграммы Боде, имитационное моделирование. 5. Процедуры подтверждения. В процессе проведения идентификации может совершаться много переходов между программными средствами пп. 3—5 и необходимо, чтобы вопросы, связанные с заменами и проверкой различных модельных структур, решались просто. Кроме того, нужно отметить проблему реализации программных средств п. 3. Здесь хотелось бы иметь полный набор средств в виде многомерных моделей, моделей черного ящика, физически параметризованных модельных структур. Но это стоит больших средств. Решения разбросанных но этой книге Пакет IDPAC. Сейчас имеется много интерактивных пакетов программ. В основном, они различаются структурой команд и меню, предлагаемыми пользователю по и. 3. Здесь мы раскажем об интерактивном пакете программ IDPAC, предназначенном для решения задач идентификации и разработанном на факультете автоматического управления Института технологии университета Лунда. Это один из самым первых и широко используемых пакетов. Подробности можно найти в работах Висландера [435] и Острема [24]. В рамках пункта (17.3) пакет IDPAC предлагает структуры ARMAX-моделей по типу черного ящика с одним выходным и несколькими входными сигналами, причем для согласования с данными наблюдений используется "робастизированный” квадратичный критерий ошибки предсказания. Рассматривается также частный случай ARX-моделей при таком способе применения алгоритмов метода наименьших квадратов, что удается организовать эффективную проверку различных подструктур (см. раздел 16.4). Процедуры подтверждения моделей (17.5) используют корреляционные критерии для ошибок предсказания и сравнения значений функции потерь (см. раздел 16.5). Пакет командно управляем, что великолепно иллюстрируется следующим примером.
(кликните для просмотра скана)
(кликните для просмотра скана) Даны входо-выходные данные в виде двух последовательностей
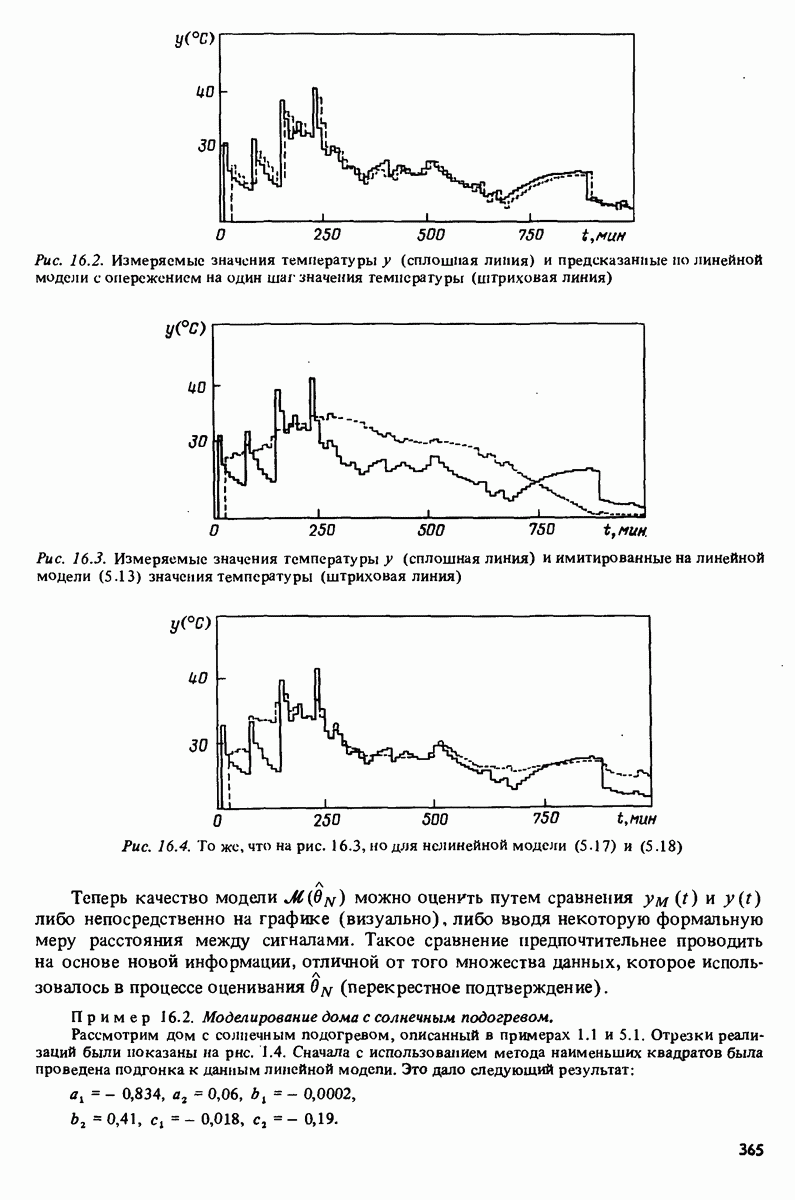
показанный на рис. 17.1 (здесь
осуществляют оценку спектральных характеристик методами раздела 6.4, результаты - на рис. 17.2. FROP - это акроним функционирования в частотной области, а число 50 обозначает число лагов, исиользованных в окнах дня расчета спектров и взаимных спектров. Затем данные собираются в двухстолбцовый файл данных
Команда
производит расчет ARMAX-модели первого порядка, параметры которой хранятся в файле
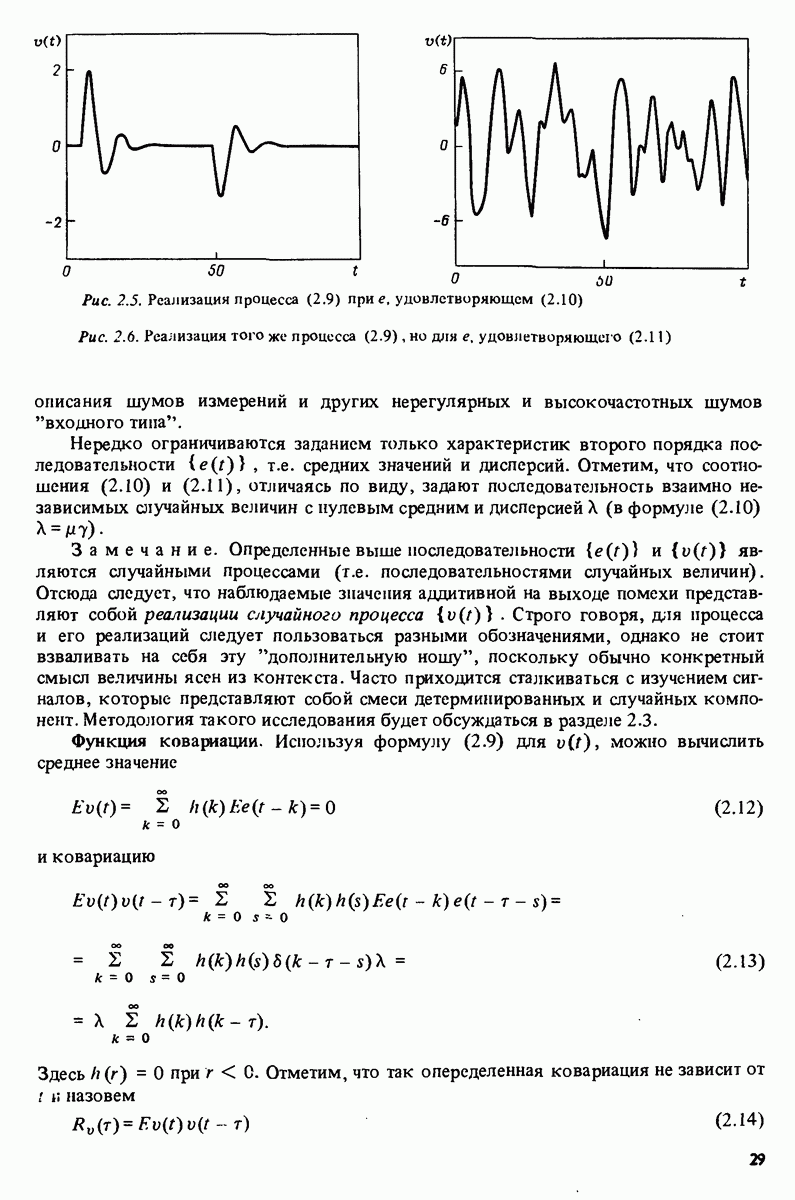
Эта команда, по которой создается файл
Параметры различных моделей приводятся в табл. 17.1 вместе с соответствующими значениями функций потерь
с последующей командой
которая осуществляет сравнение с истинным выходным сигналом системы. Это приводит к картинке, показанной на рис. 17.7 (сравните с Таблица 17А (см. скан) характеристика модели рассчитывается
а ее сравнение со спектральной оценкой осуществляется командой
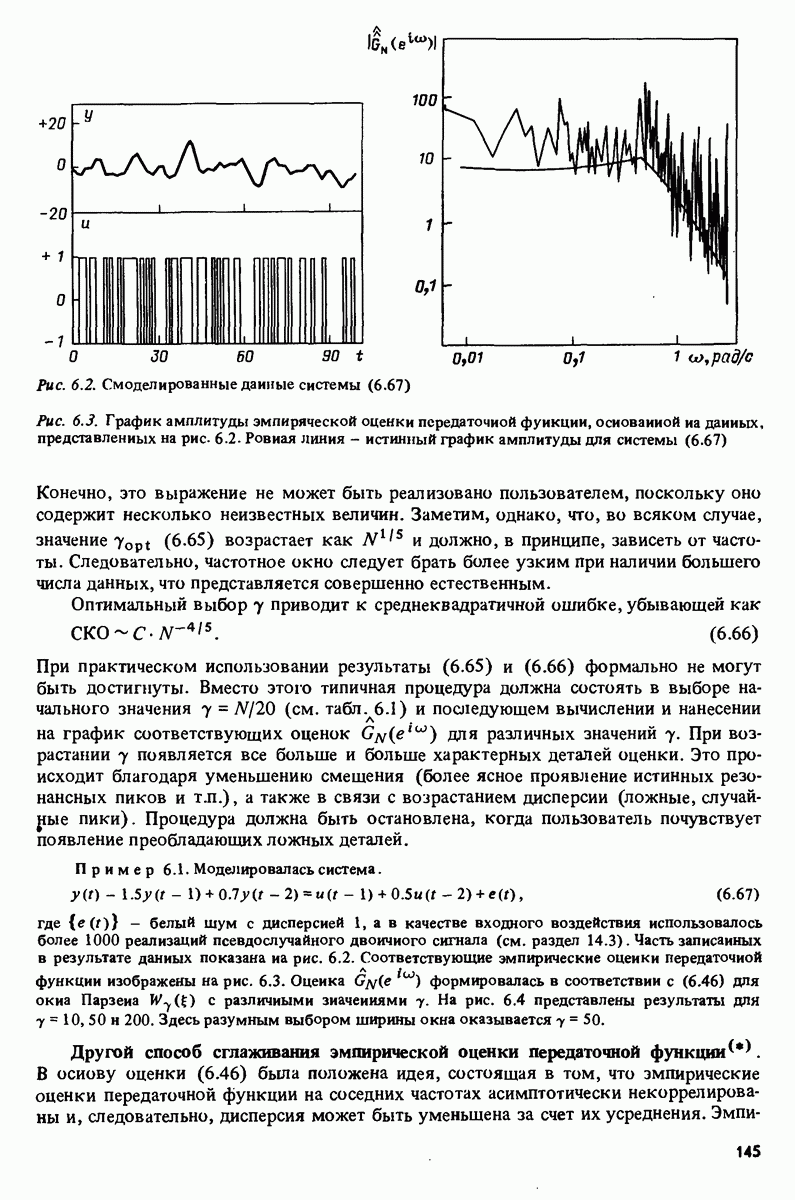
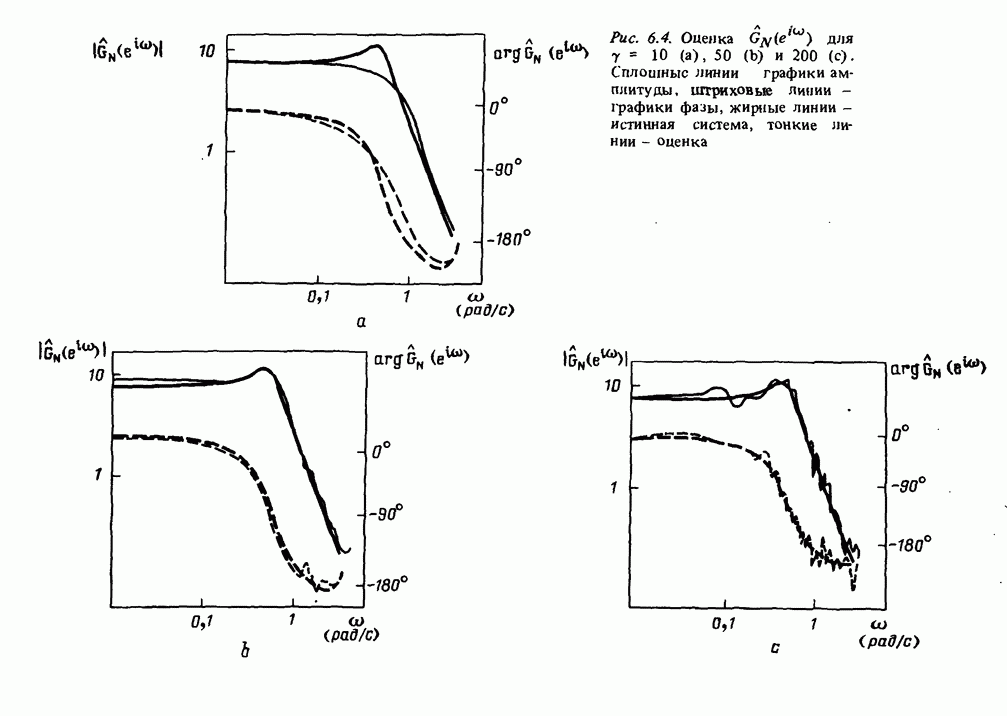
в результате которой воспроизводится картинка рис. 17.8. Замечание. Приведенные данные были сгенерированы в результате моделирования системы вида
где Дальнейшее развитие. Очевидно, что в будущем по мере развития вычислительных систем, средств отображения и программного обеспечения мы будем получать все более тонкие и сложные средства для решения задач идентификации. Особый интерес представляют попытки автоматизировать на основе экспертных систем субъективные компоненты, связанные с принятием решений в процессе идентификации.
|
 |
Оглавление
|















































































































































































































































































































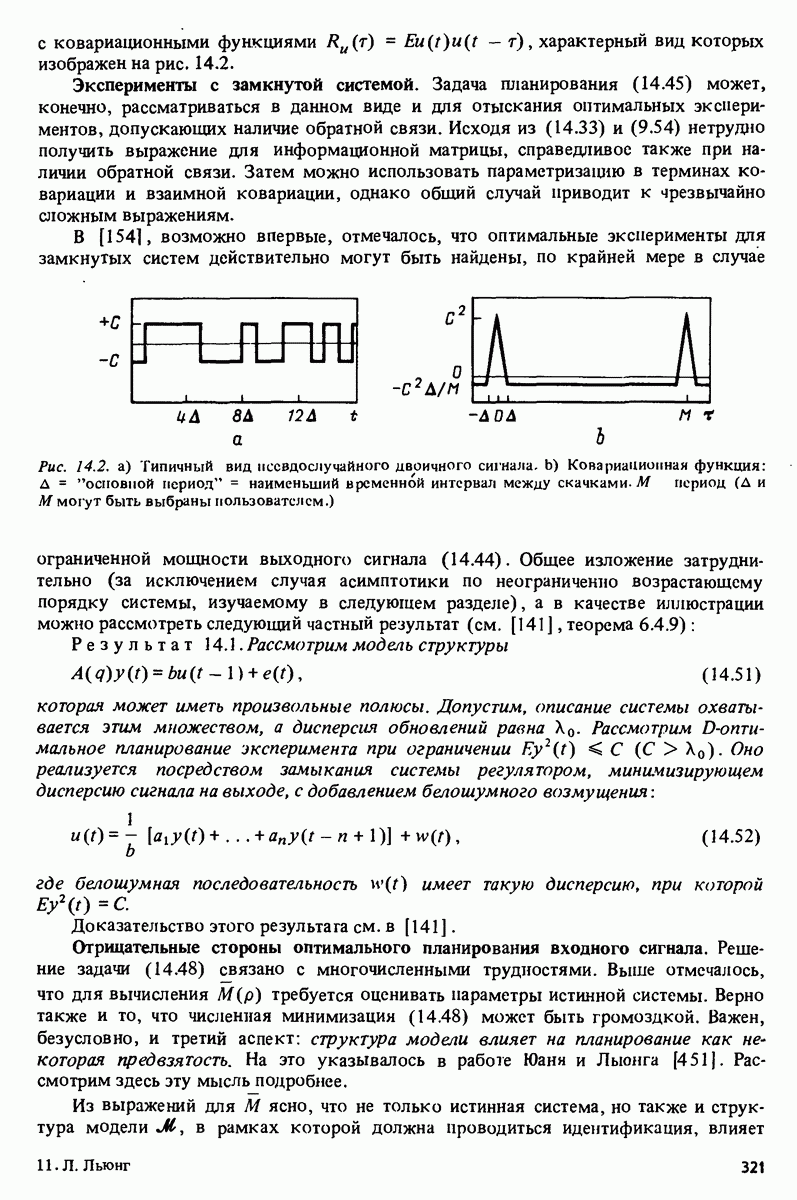









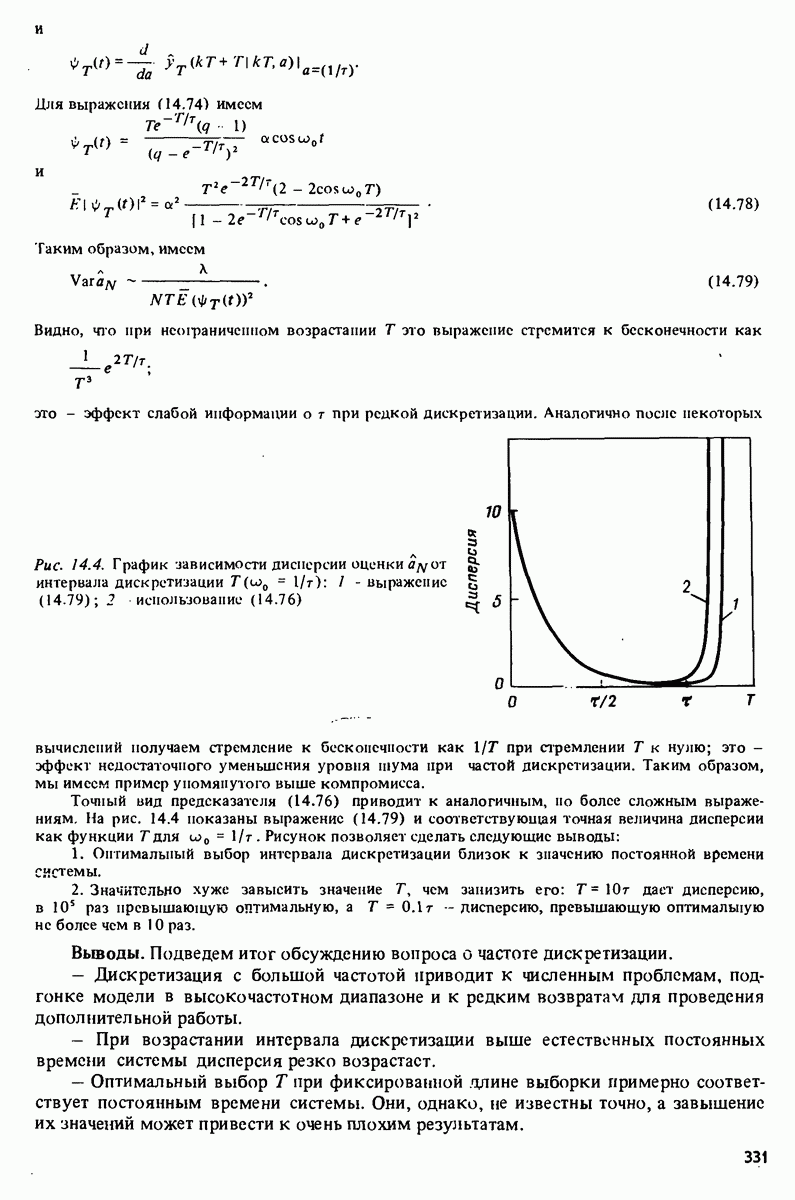









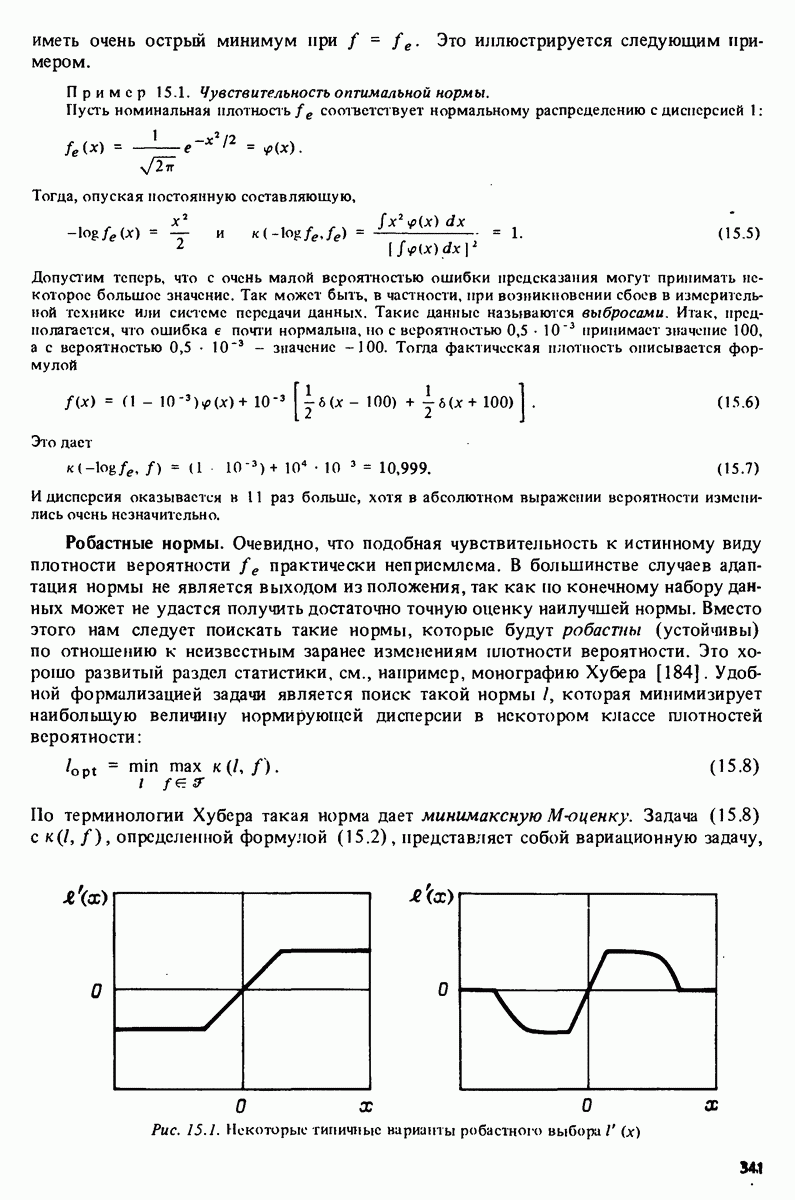














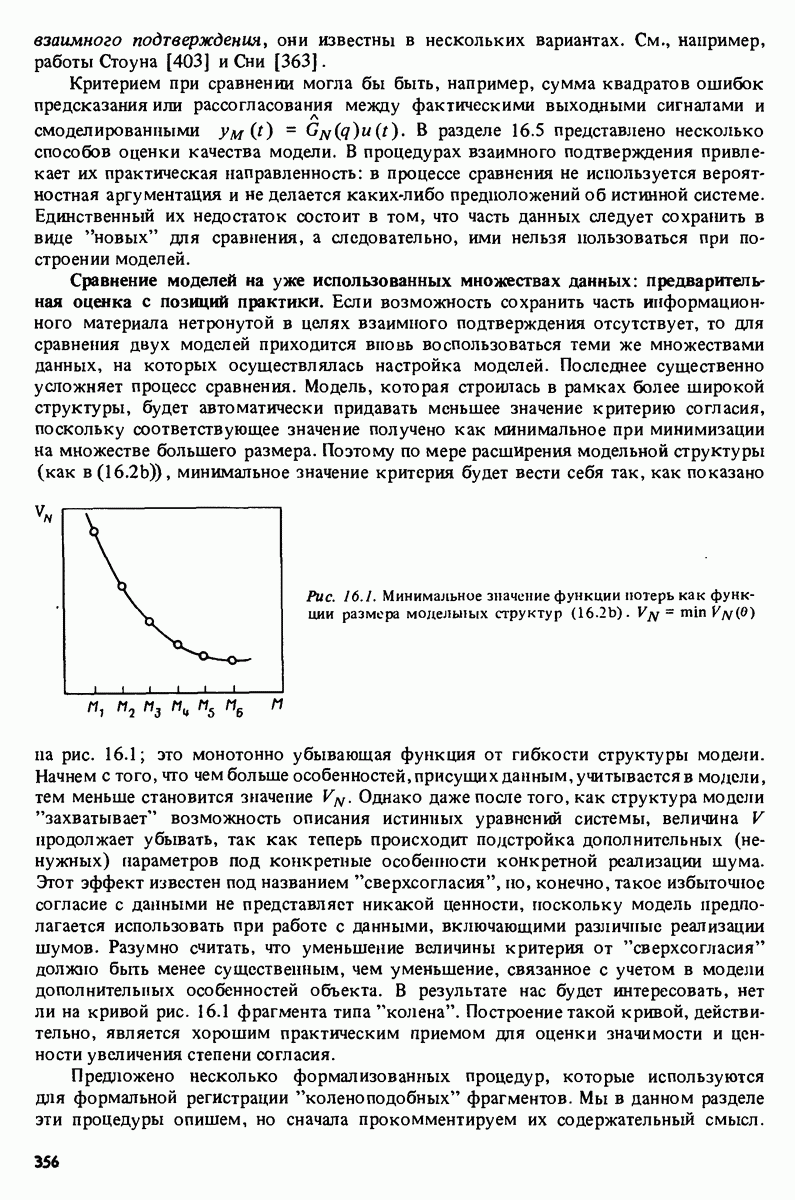






























































 -задач образуют простой интерактивный пакет, концентрирующийся вокруг общей входо-выходной модели (4.34). Заметим, однако, что со структурой модели связаны только макропроцедуры
-задач образуют простой интерактивный пакет, концентрирующийся вокруг общей входо-выходной модели (4.34). Заметим, однако, что со структурой модели связаны только макропроцедуры  и
и  стало быть, модифицировав или переписав эти три макроироцедуры, можно без особого труда распространить этот пакет на новые, более специальные структуры моделей.
стало быть, модифицировав или переписав эти три макроироцедуры, можно без особого труда распространить этот пакет на новые, более специальные структуры моделей.


 длины 500 каждая. Сначала строится график данных
длины 500 каждая. Сначала строится график данных

 означает построение гистограммы). После этого команды
означает построение гистограммы). После этого команды

 с помощью команд
с помощью команд


 представленном в табл. 17.1. Ошибки предсказания, или невязки, связанные параметрами модели из файла
представленном в табл. 17.1. Ошибки предсказания, или невязки, связанные параметрами модели из файла  вычисляются по команде
вычисляются по команде

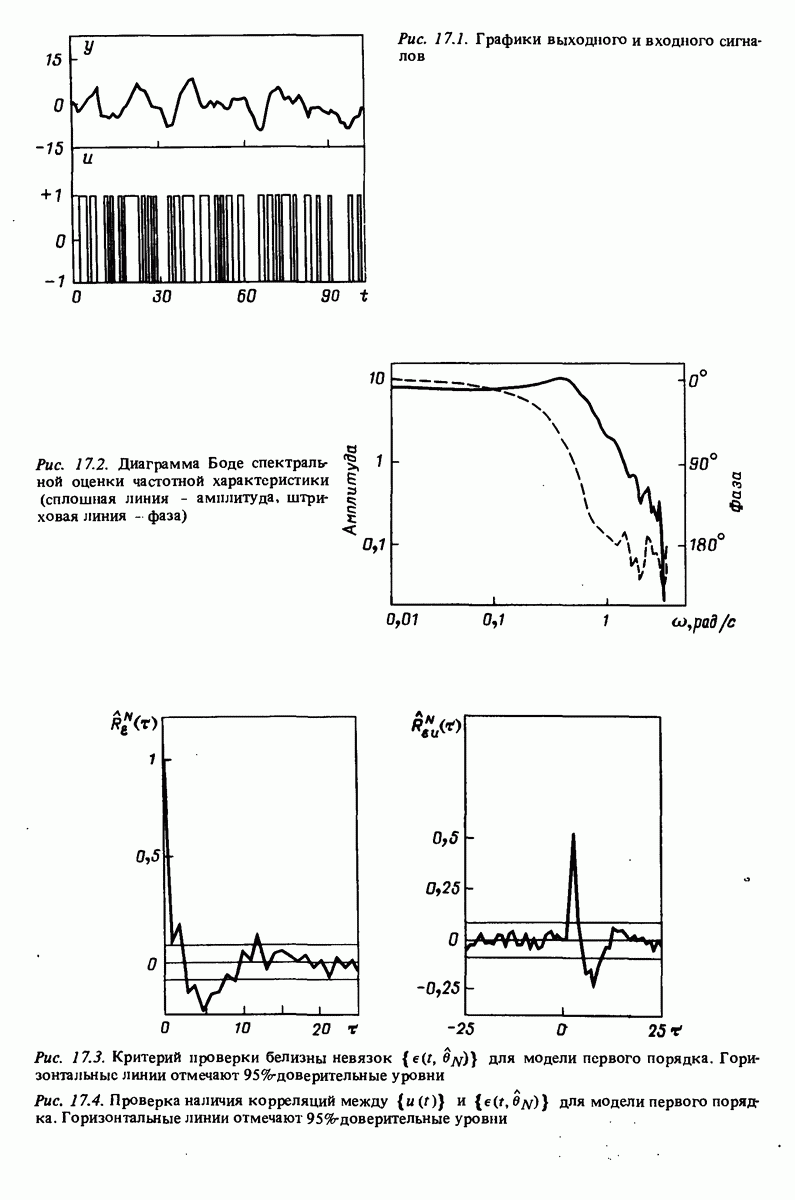
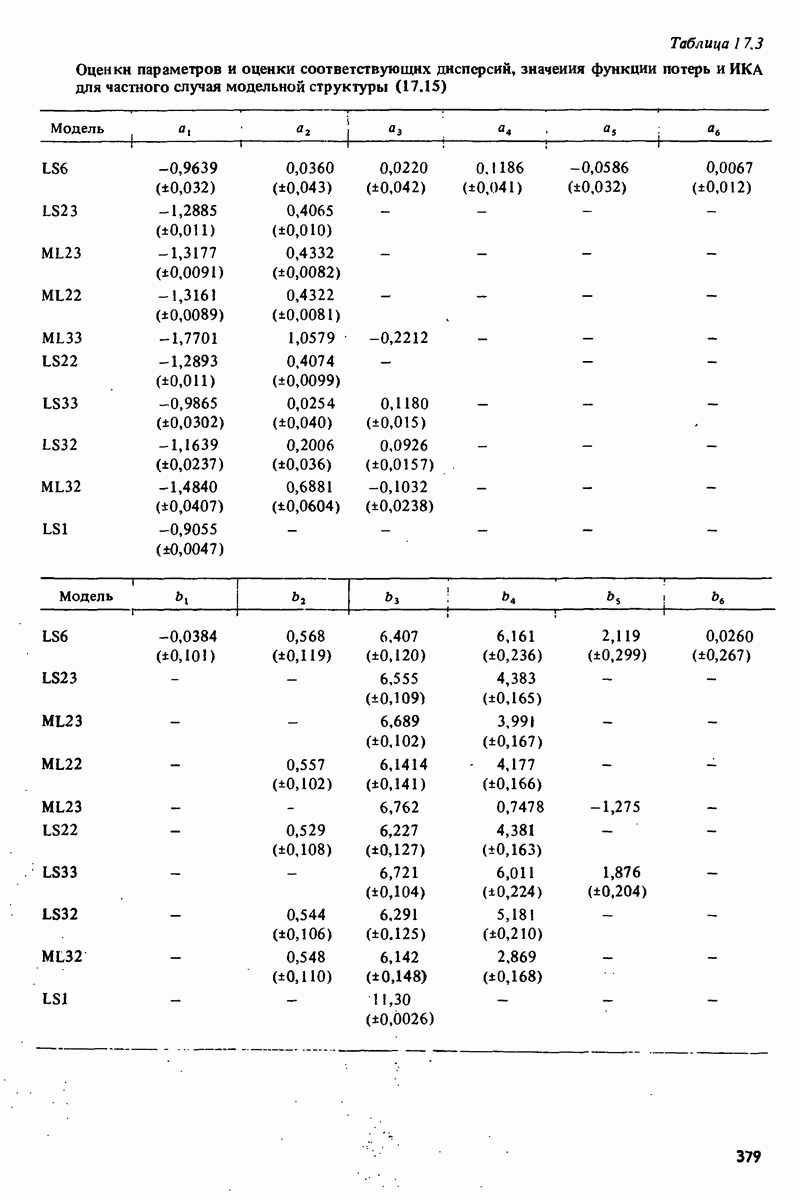
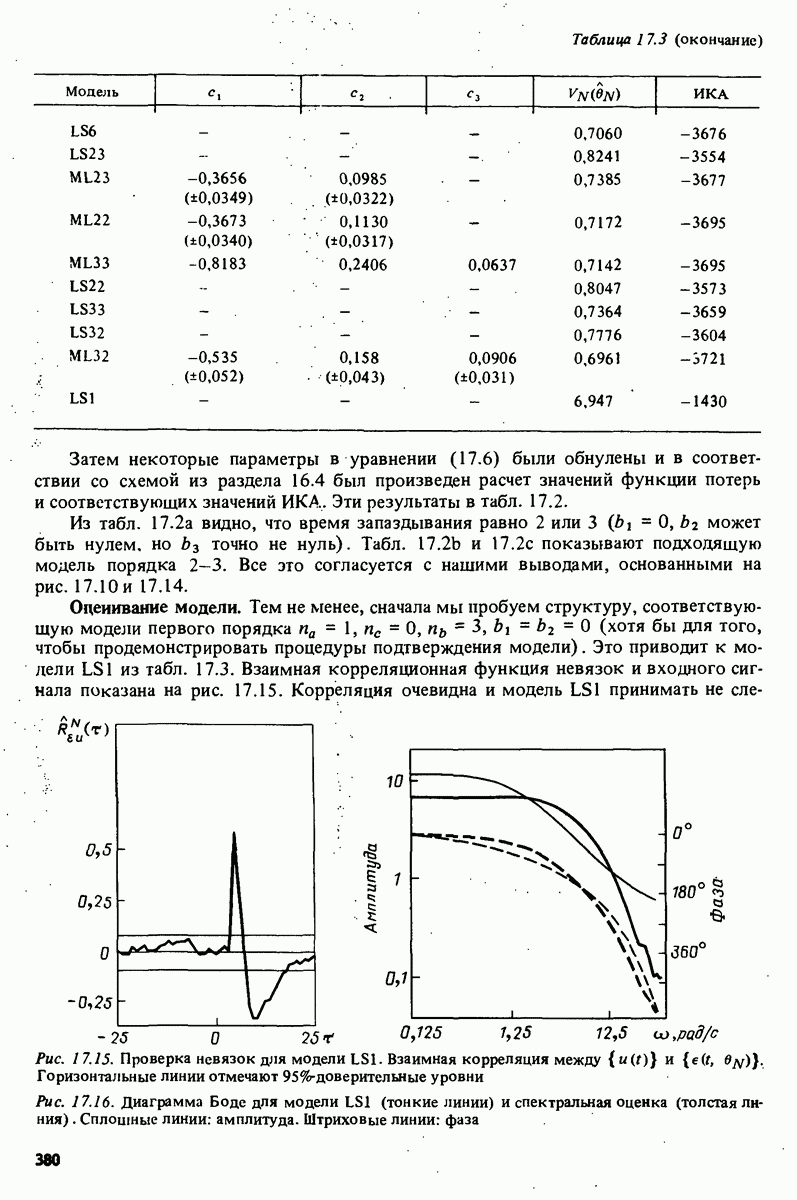
 невязок, осуществляет также расчет и демонстрацию на экране значений автокорреляционной функции невязок и взаимной корреляционной функции невязок и входного сигнала при 25 лагах. Результаты приведены на рис. 17.3 и 17.4. Невязки оказываются коррелированными и тогда подаются команды на проверку моделей более высокого порядка
невязок, осуществляет также расчет и демонстрацию на экране значений автокорреляционной функции невязок и взаимной корреляционной функции невязок и входного сигнала при 25 лагах. Результаты приведены на рис. 17.3 и 17.4. Невязки оказываются коррелированными и тогда подаются команды на проверку моделей более высокого порядка

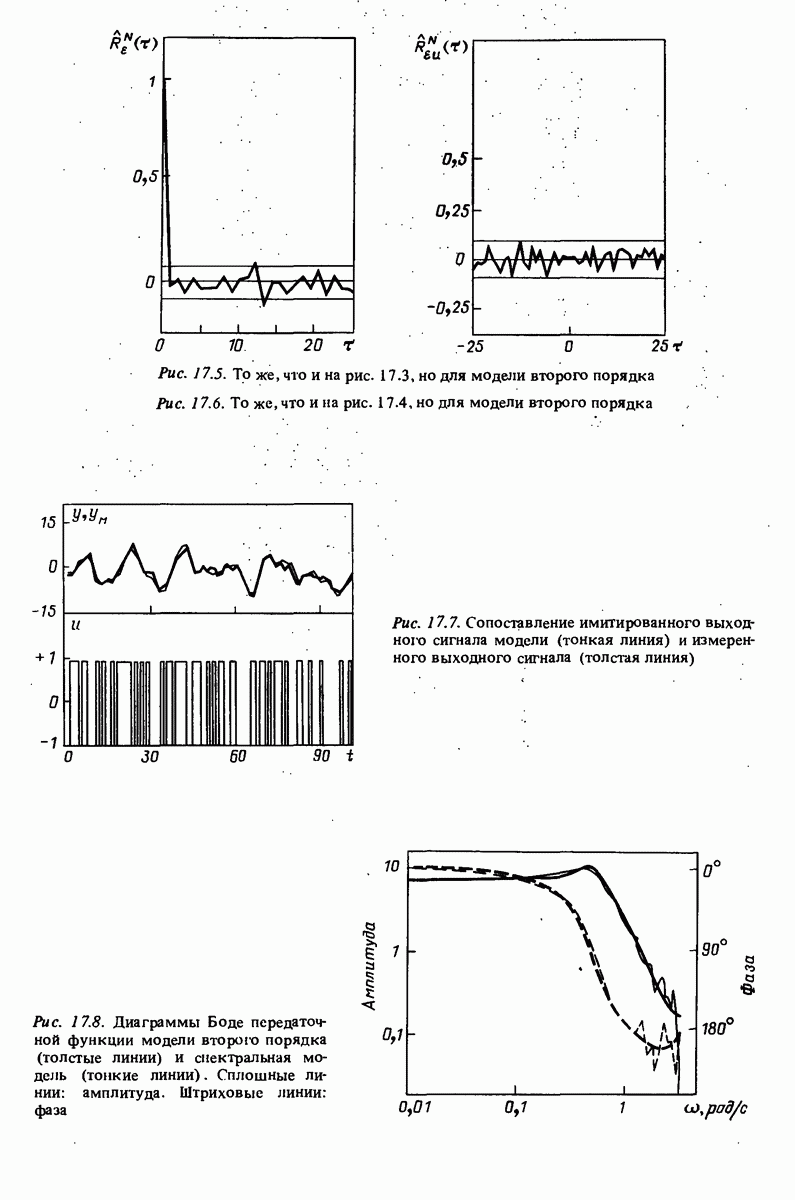
 и информационного критерия Акаике (16.29). Проверка невязок
и информационного критерия Акаике (16.29). Проверка невязок  показана на рис. 17.5 и 17.6. Из приведенных картинок ясно, что можно принять модель второго порядка
показана на рис. 17.5 и 17.6. Из приведенных картинок ясно, что можно принять модель второго порядка  В качестве следующей проверки проводится расчет имитированного на модели
В качестве следующей проверки проводится расчет имитированного на модели  выходного сигнала при подаче реального входного сигнала
выходного сигнала при подаче реального входного сигнала  Это делается командой
Это делается командой


 Частотная
Частотная
 команде
команде



 белый шум с единичной дисперсией.
белый шум с единичной дисперсией.