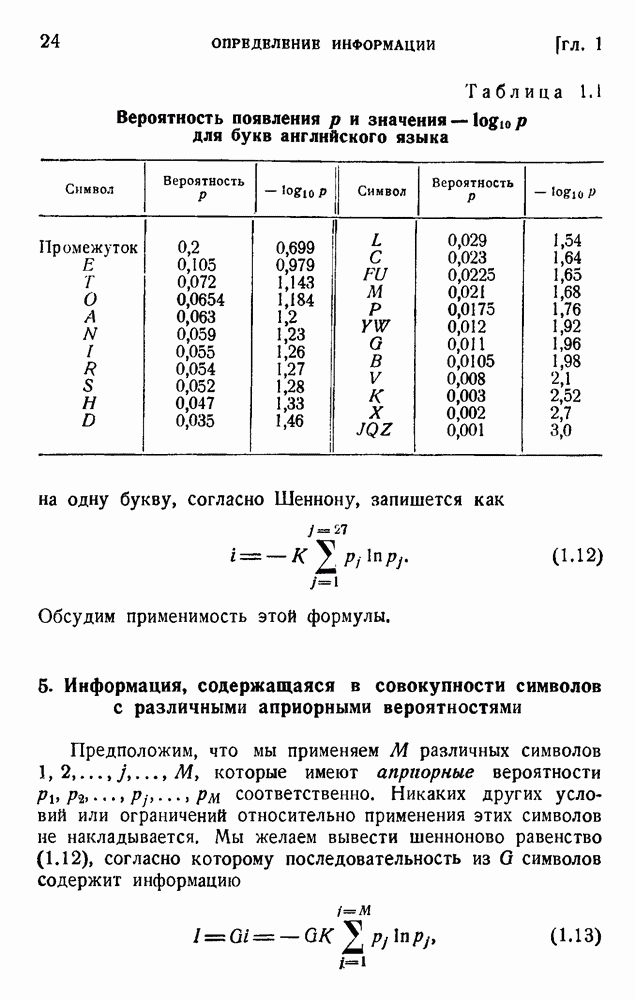
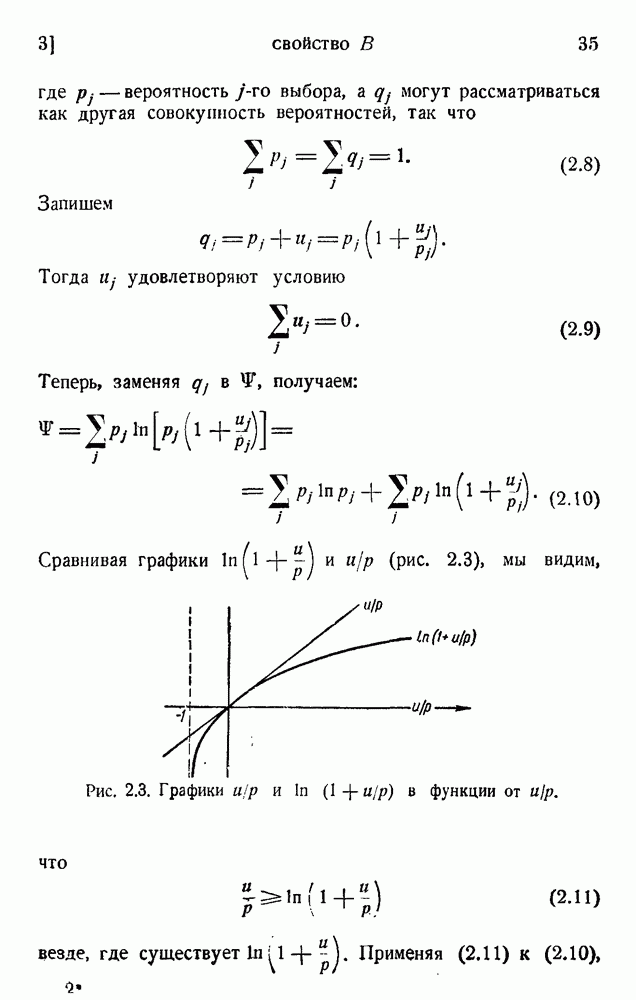
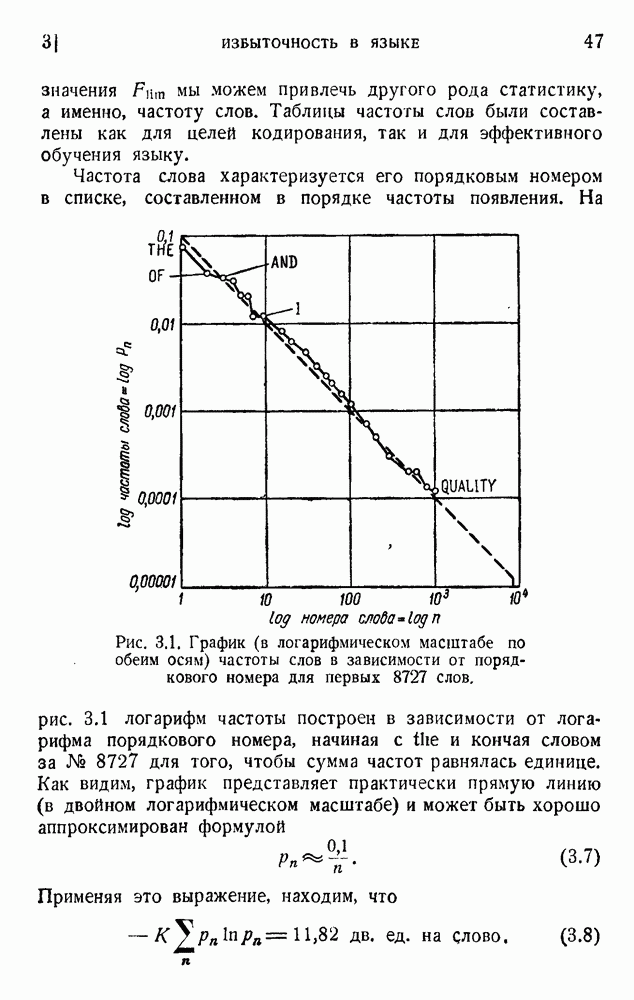
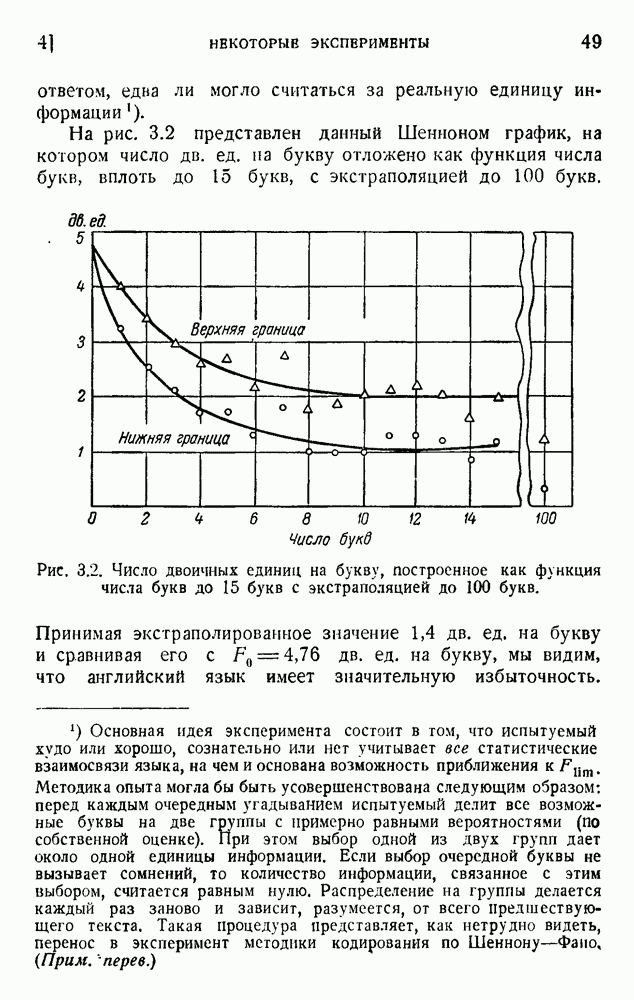
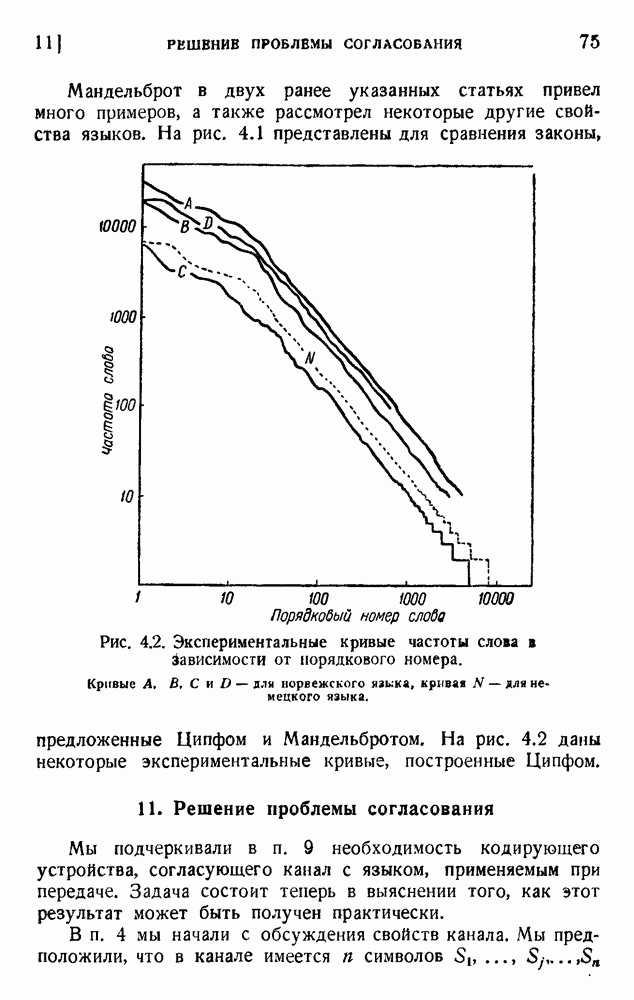
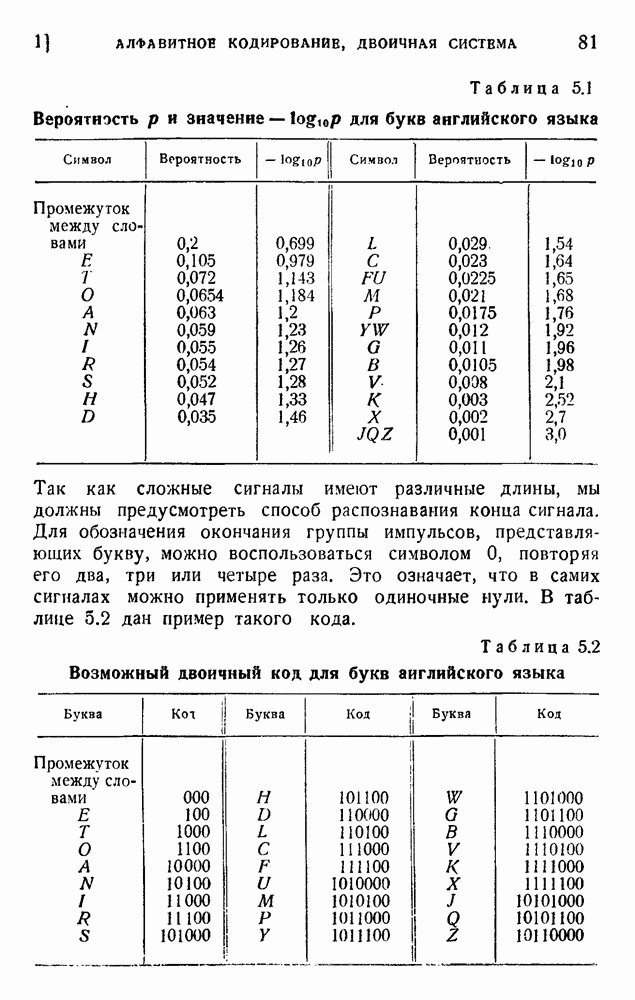
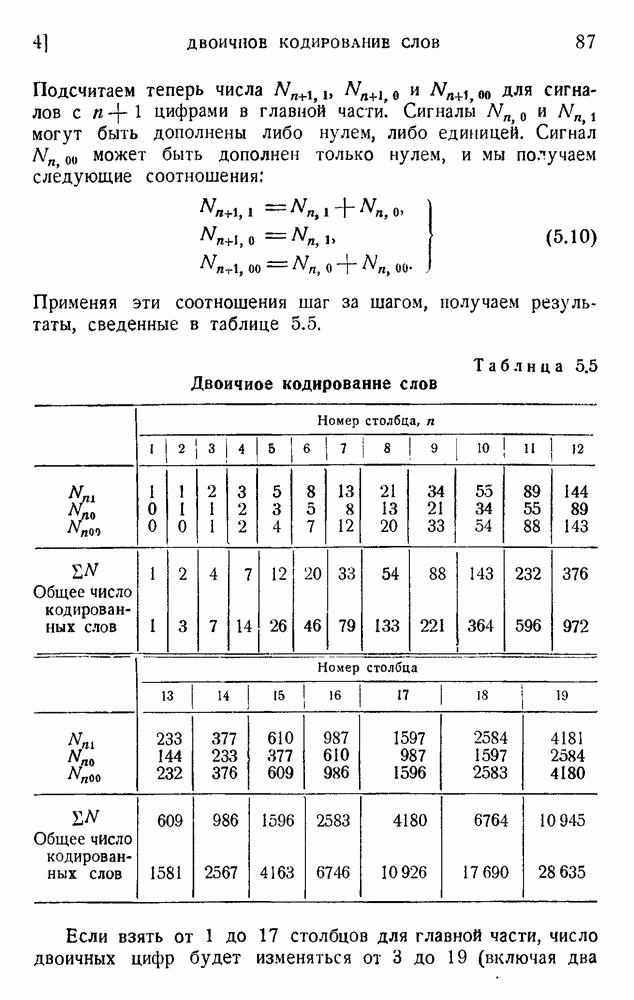
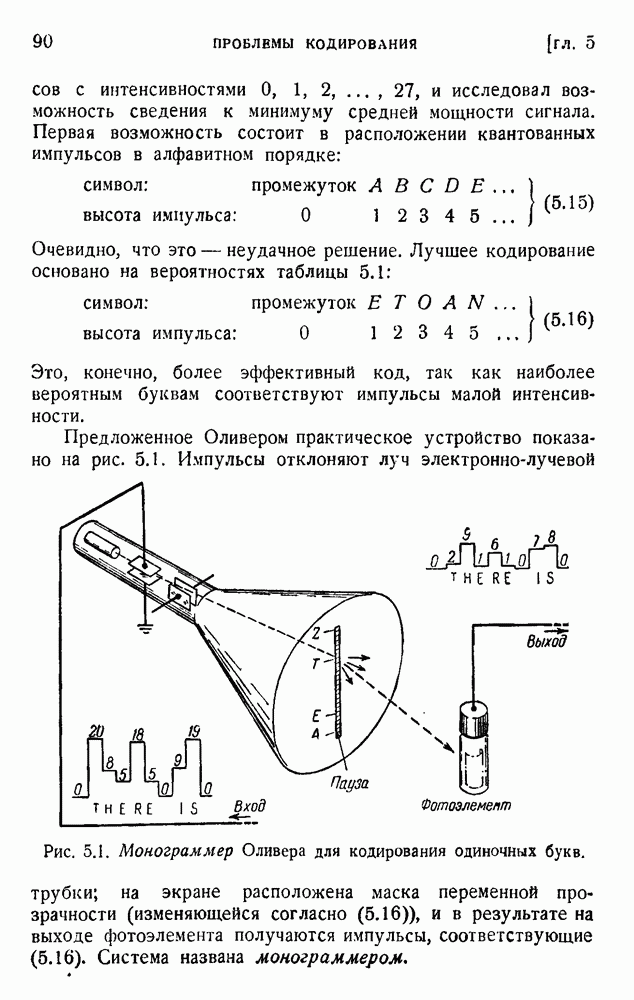
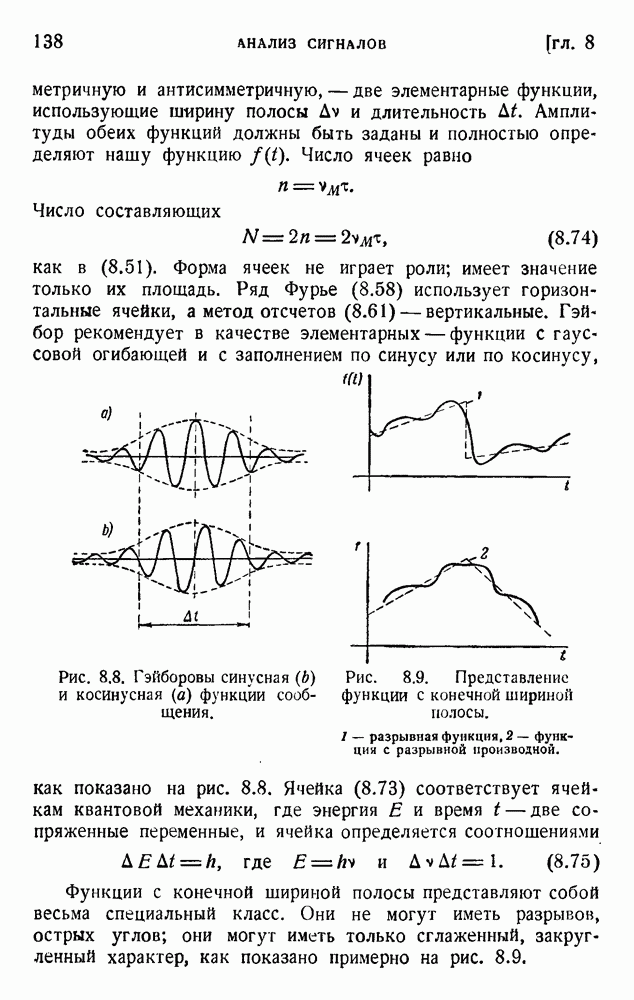
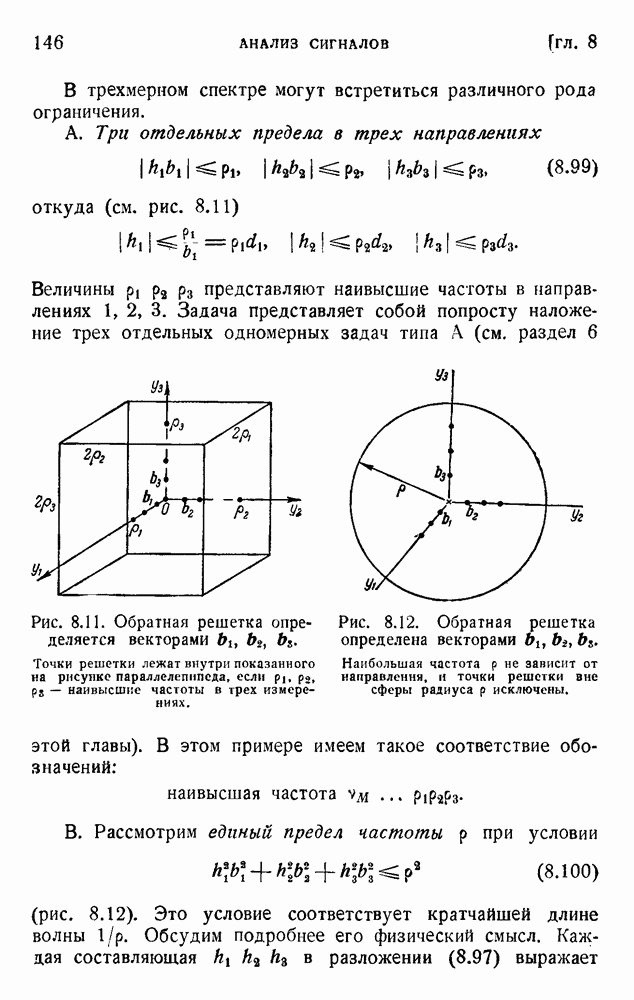
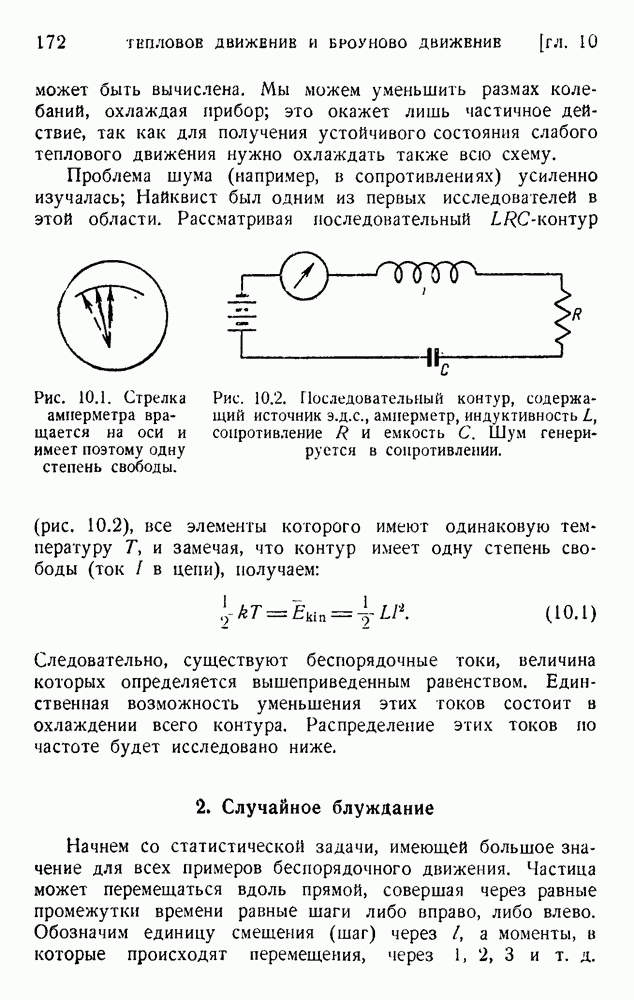
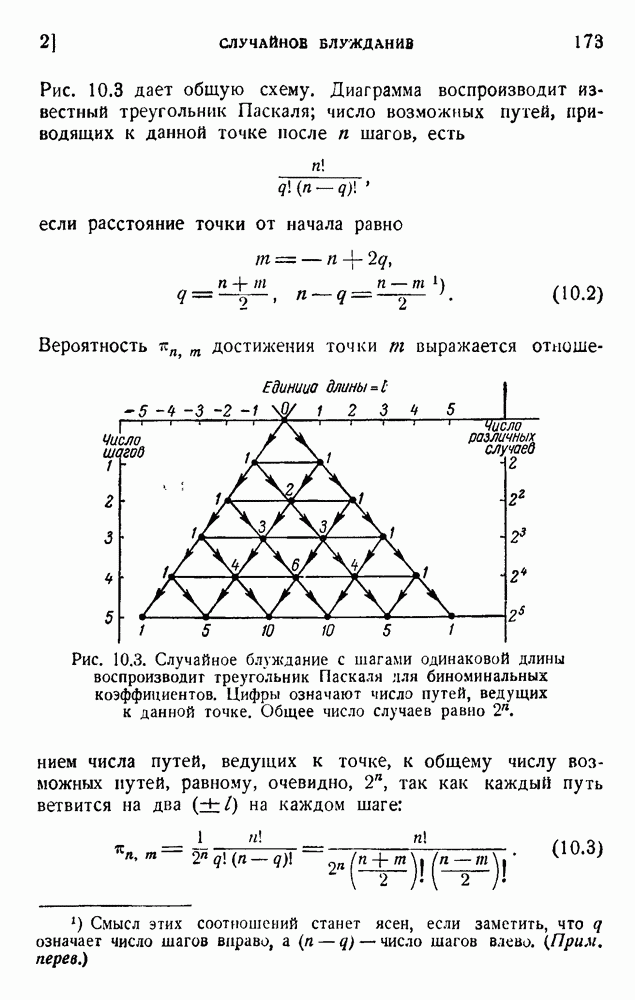
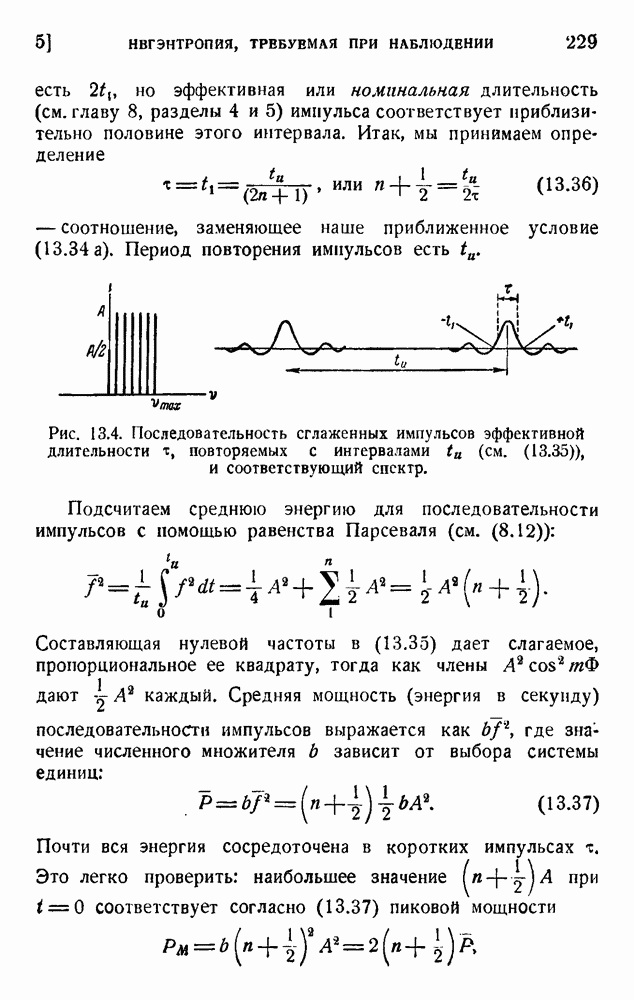
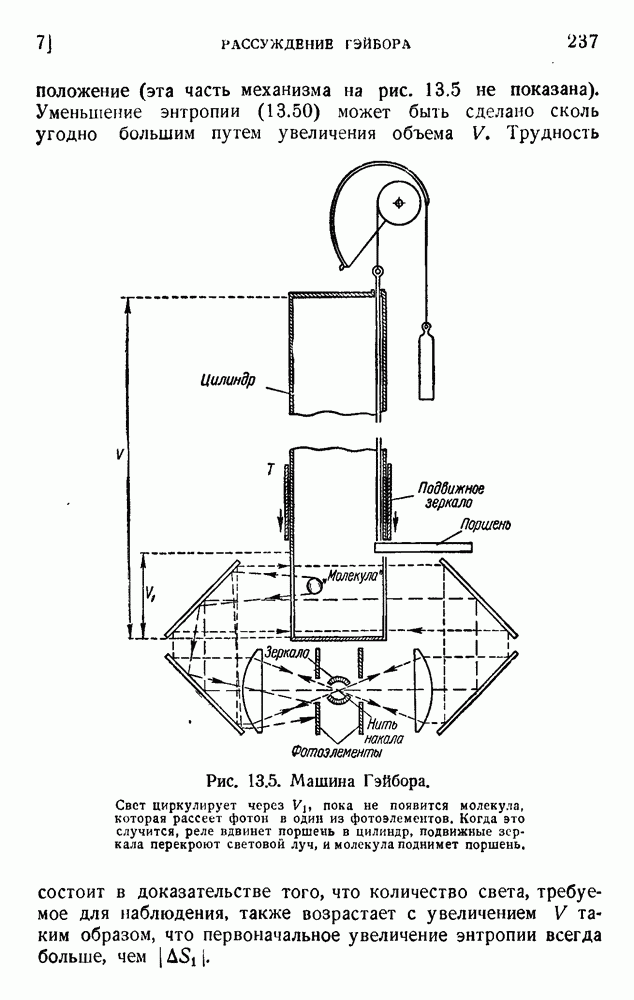
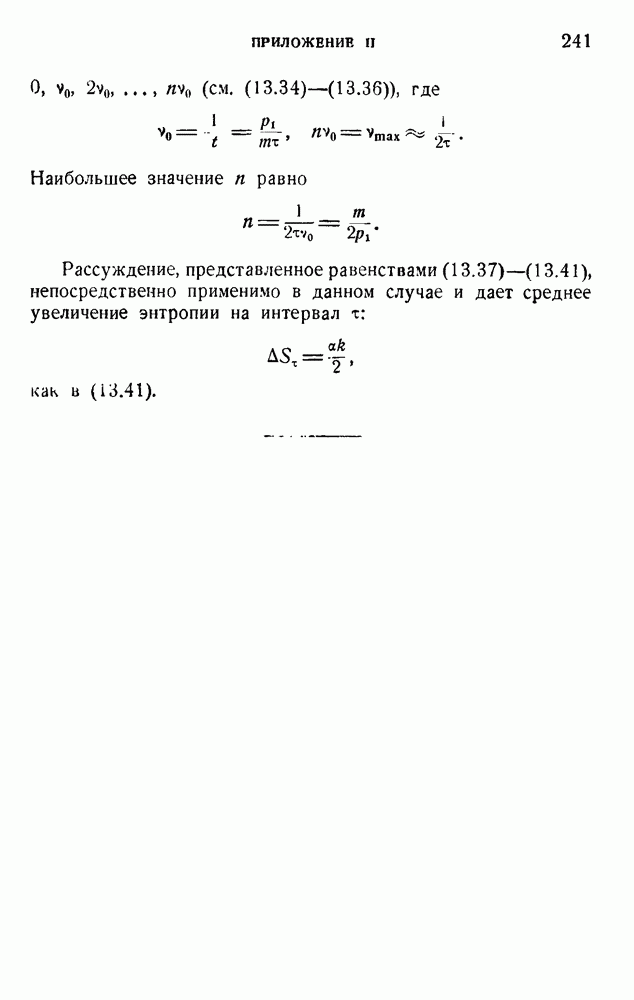
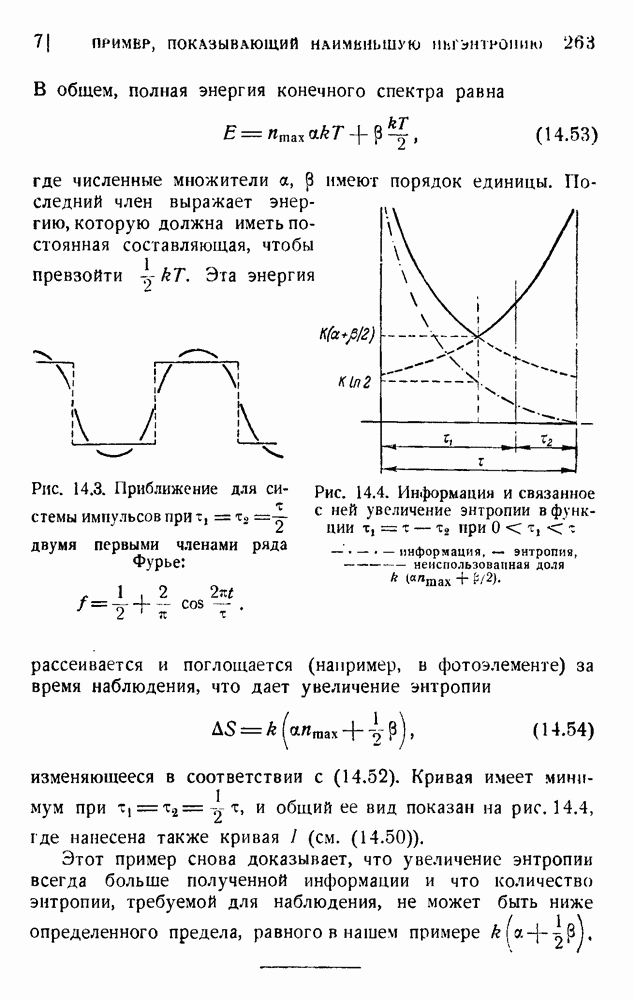
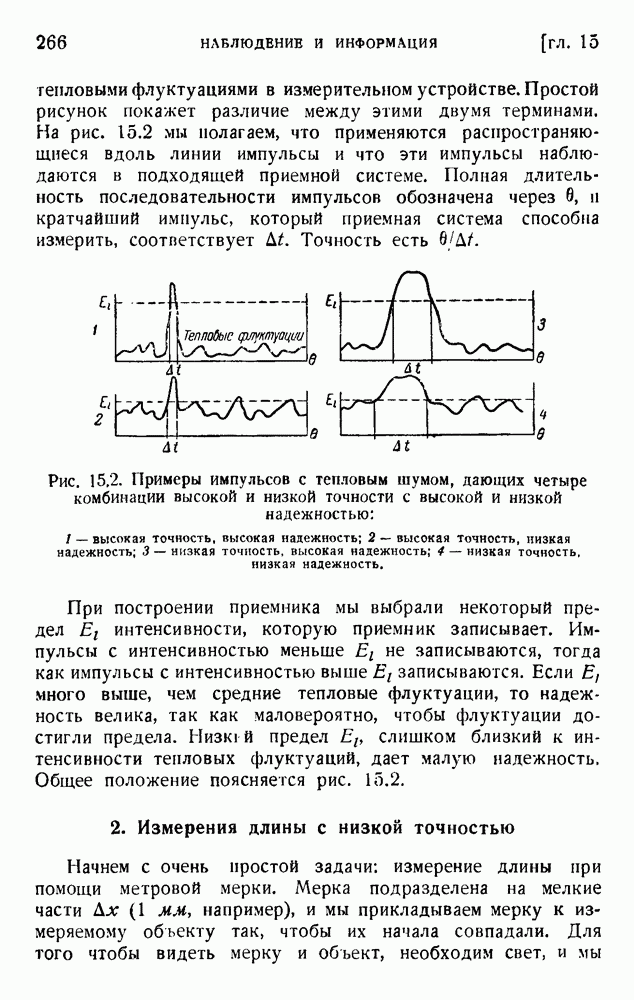
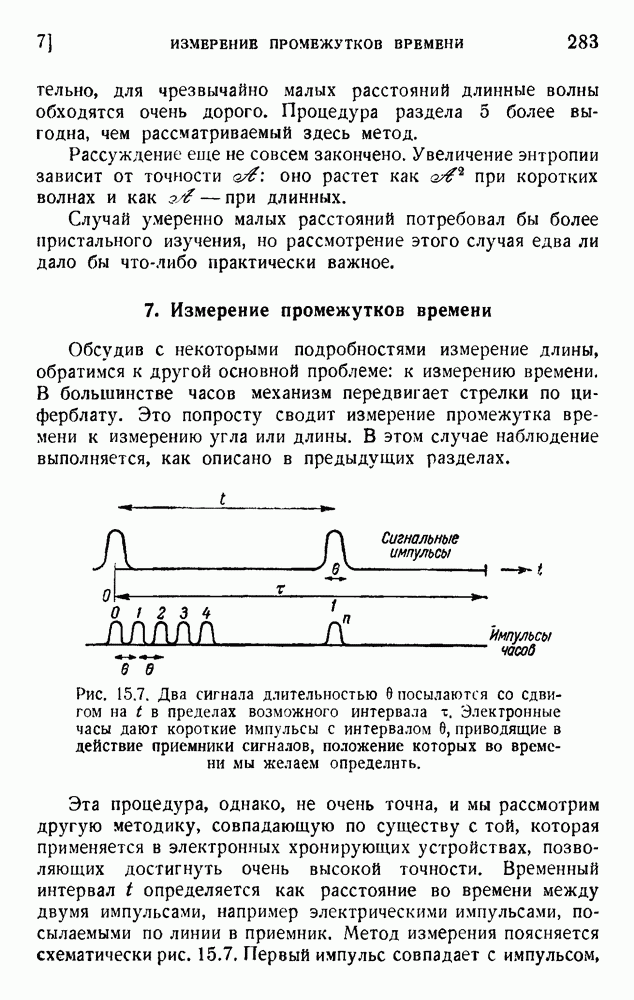
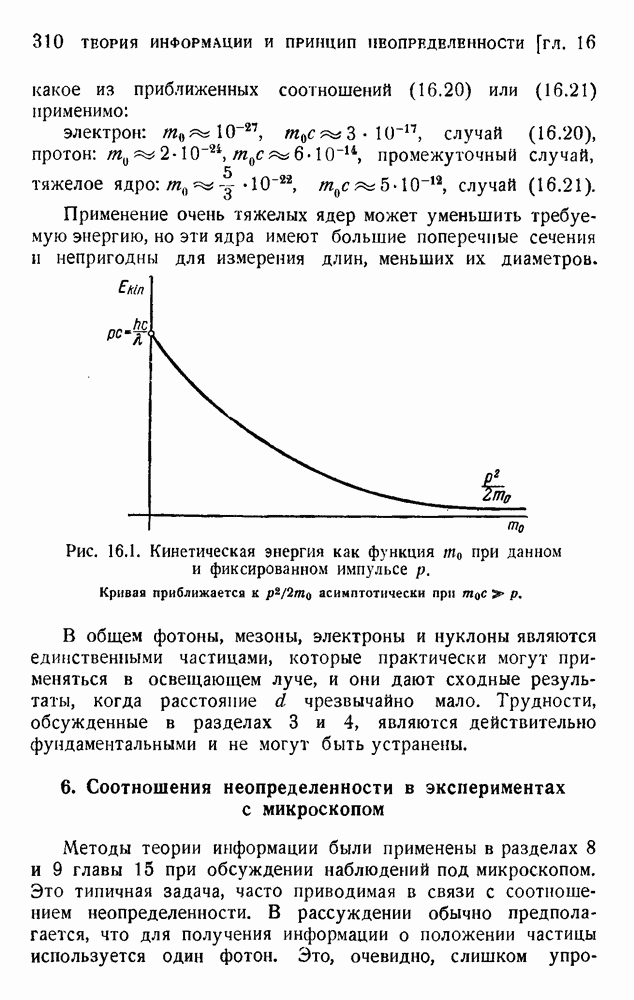
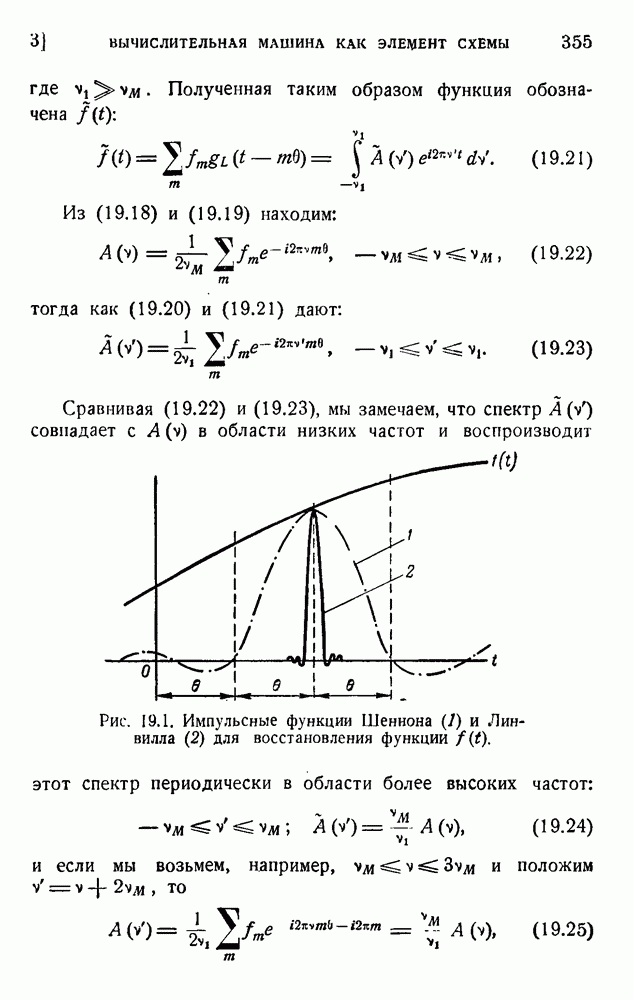
2. Корреляция в языке
Корреляция имеется во всех  так как, если появляется некоторая буква, то вероятность появления за ней некоторой другой буквы не равна ее априорной вероятности. Так, в английском языке, если дана буква t, то вероятность того, что непосредственно последующей буквой будет h, гораздо больше вероятности, что следующей буквой будет n. Аналогично, если дано сочетание
так как, если появляется некоторая буква, то вероятность появления за ней некоторой другой буквы не равна ее априорной вероятности. Так, в английском языке, если дана буква t, то вероятность того, что непосредственно последующей буквой будет h, гораздо больше вероятности, что следующей буквой будет n. Аналогично, если дано сочетание  то вероятность появления n в качестве следующей буквы очень велика. Корреляция подобного рода определяется
то вероятность появления n в качестве следующей буквы очень велика. Корреляция подобного рода определяется  как избыточность (redundancy).
как избыточность (redundancy).
Применим теперь соотношения предыдущего раздела к исследованию информационного содержания сообщения. Эти соотношения могут применяться, если корреляция имеется
только между соседними символами. Для каждой пары букв мы связываем переменную х с первой буквой, а у — со второй. Тогда средняя информация на символ (или букву) будет условная информация

Мы предполагаем, что условия стационарны и что вероятности не меняются с течением времени.
Если между буквами нет корреляции, то, так как  (3.1) переходит в обычную формулу:
(3.1) переходит в обычную формулу:

Рассмотрение корреляции между отдельными буквами может быть легко распространено на сочетания букв, вроде упомянутого выше сочетания  . Мы обозначаем сочетание (N-1) букв как
. Мы обозначаем сочетание (N-1) букв как  , а вероятность появления этого сочетания как
, а вероятность появления этого сочетания как  . Обсудим теперь вероятность того, что за этим сочетанием последует некоторая буква j, иначе говоря, образуем новое сочетание из N букв:
. Обсудим теперь вероятность того, что за этим сочетанием последует некоторая буква j, иначе говоря, образуем новое сочетание из N букв:

Обозначим вероятность появления этого нового сочетания, рассматриваемого как целое, через

Условная вероятность  есть вероятность того, что j последует за данным сочетанием
есть вероятность того, что j последует за данным сочетанием  . Это определение сходно с примененным в предыдущем разделе, и мы имеем аналогичную связь между вероятностями:
. Это определение сходно с примененным в предыдущем разделе, и мы имеем аналогичную связь между вероятностями:

Определим теперь среднюю информацию на символ
в последовательности, в которой учитывается корреляция на расстоянии до N символов:

Эта формула аналогична (3.1). Суммирование по i распространяется на все возможные сочетания из (N-1) букв.