Пред.
След.
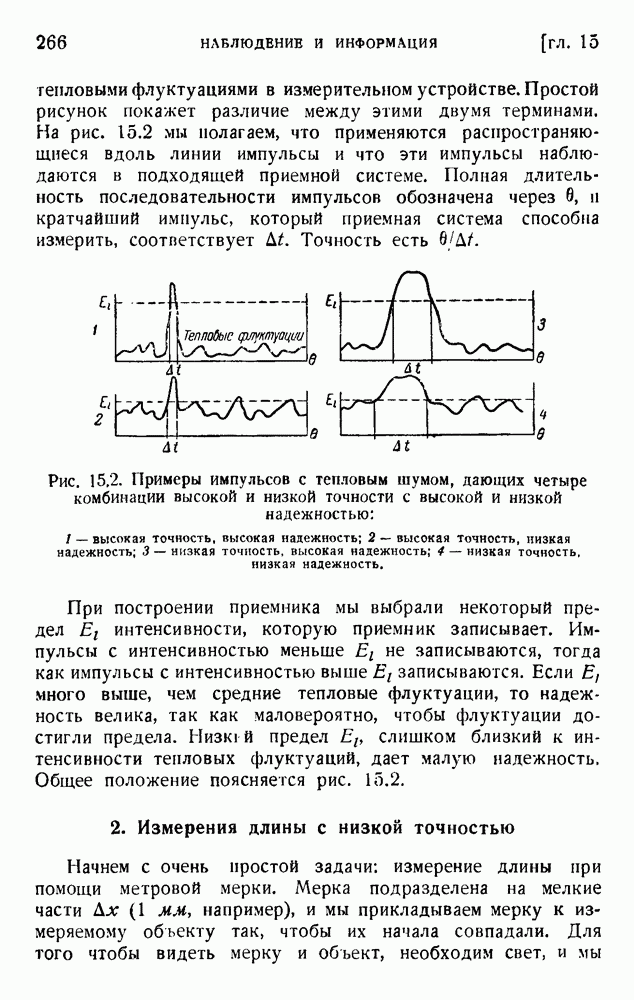
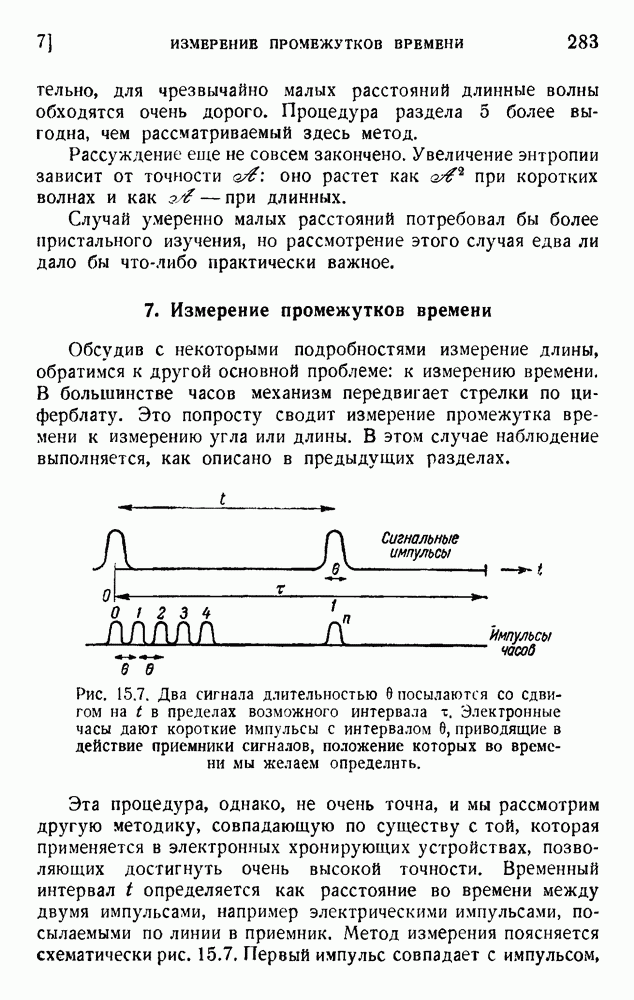
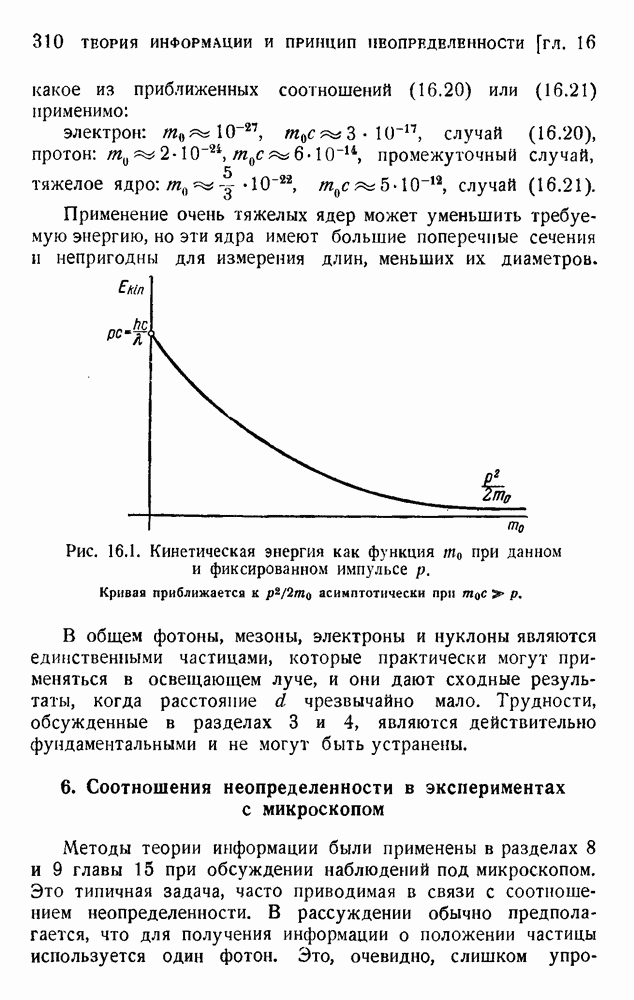
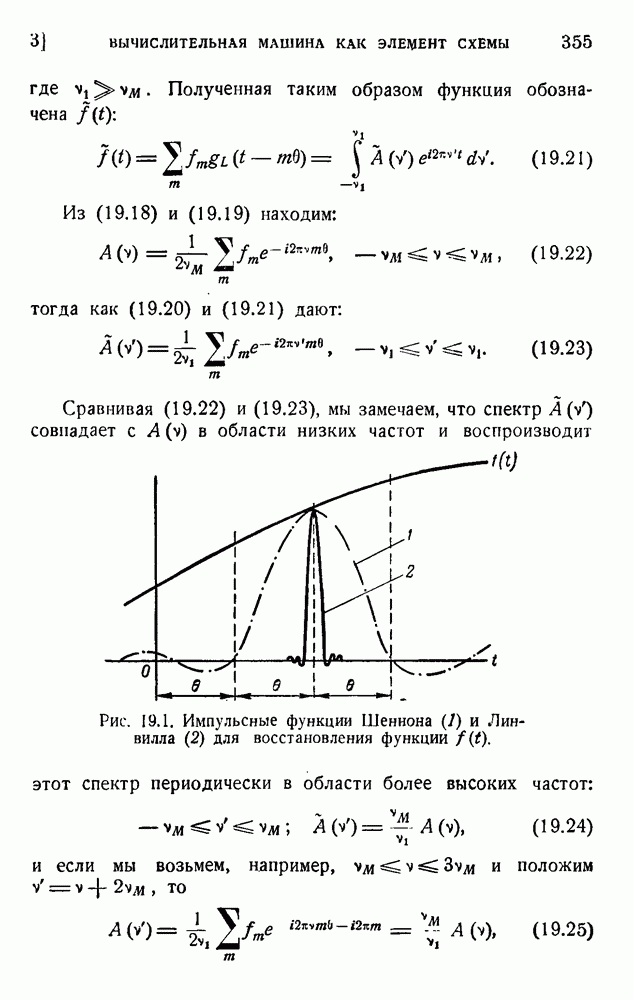
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
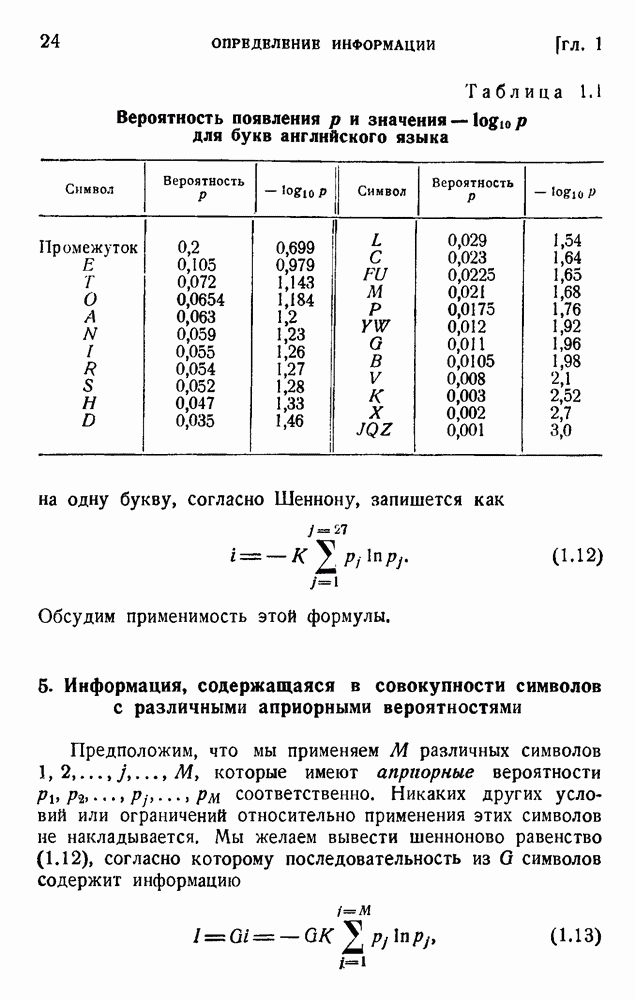
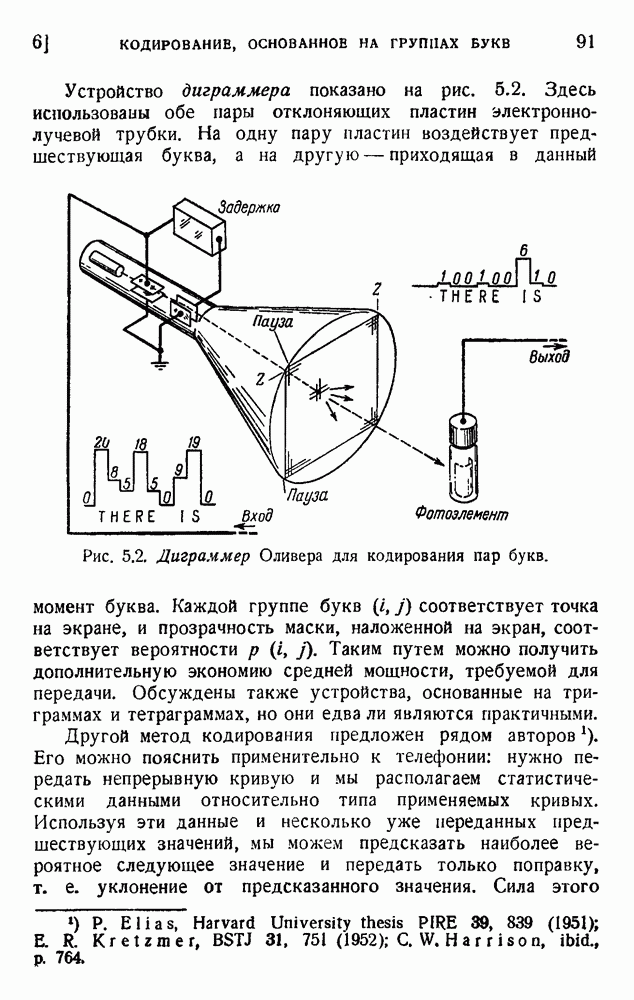
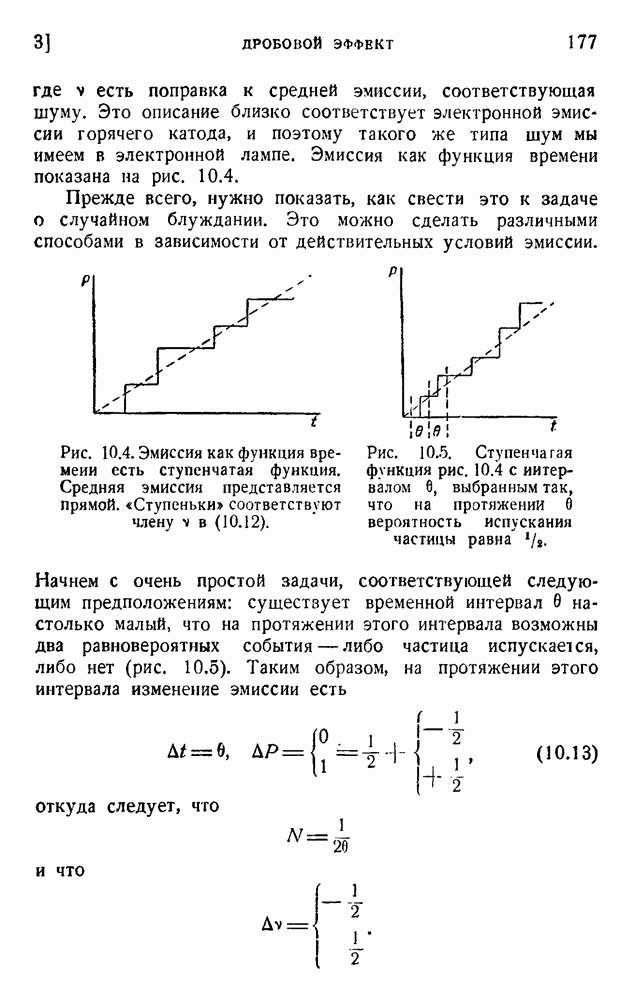
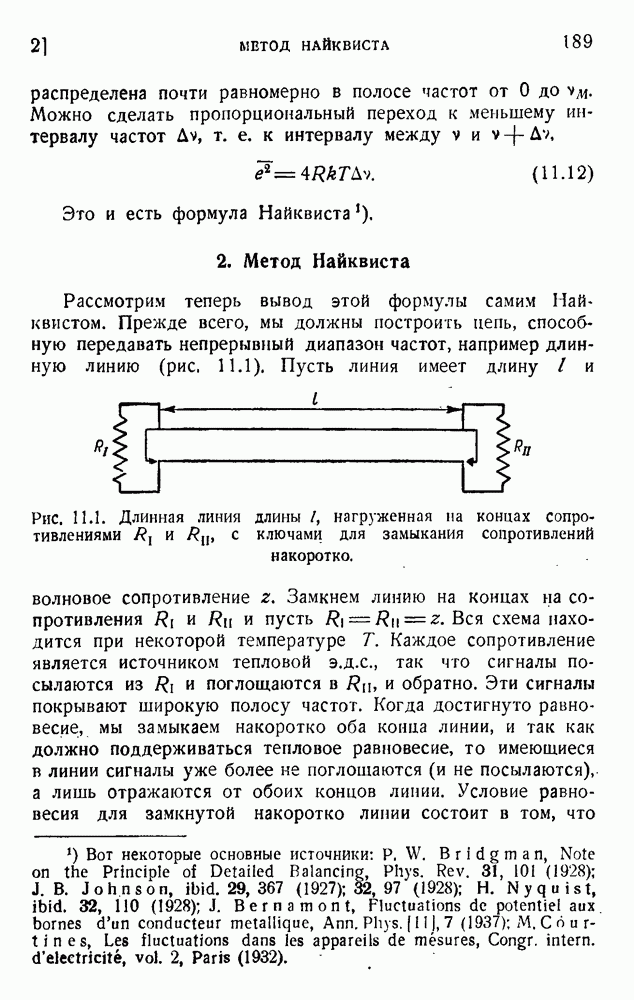
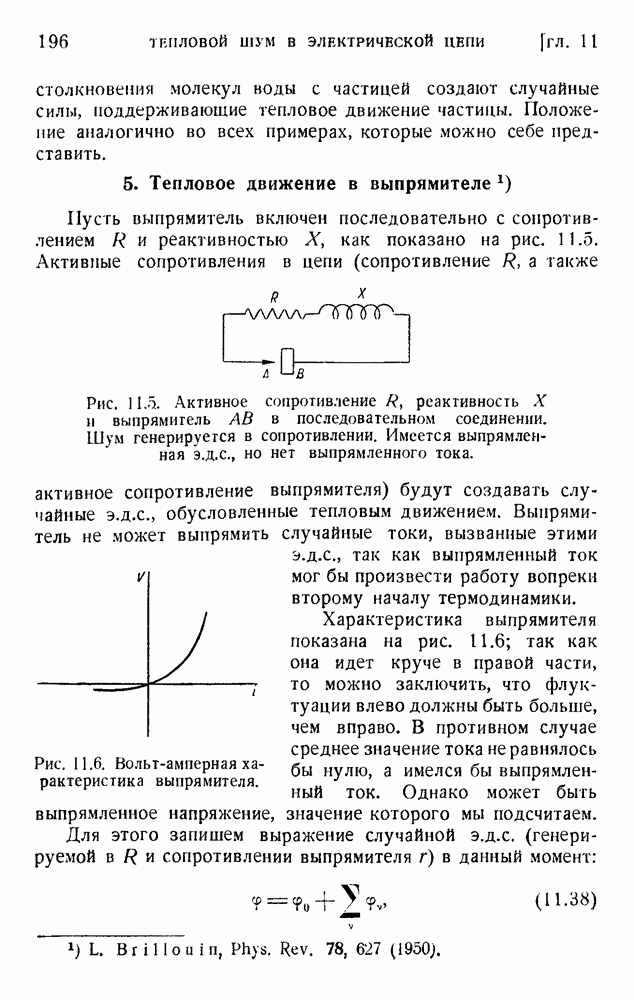
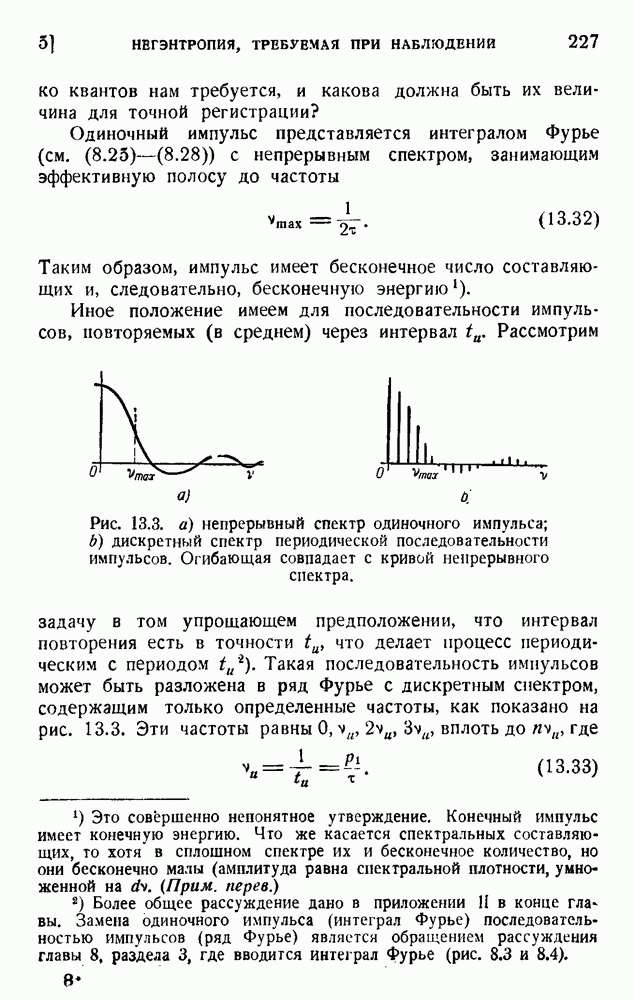
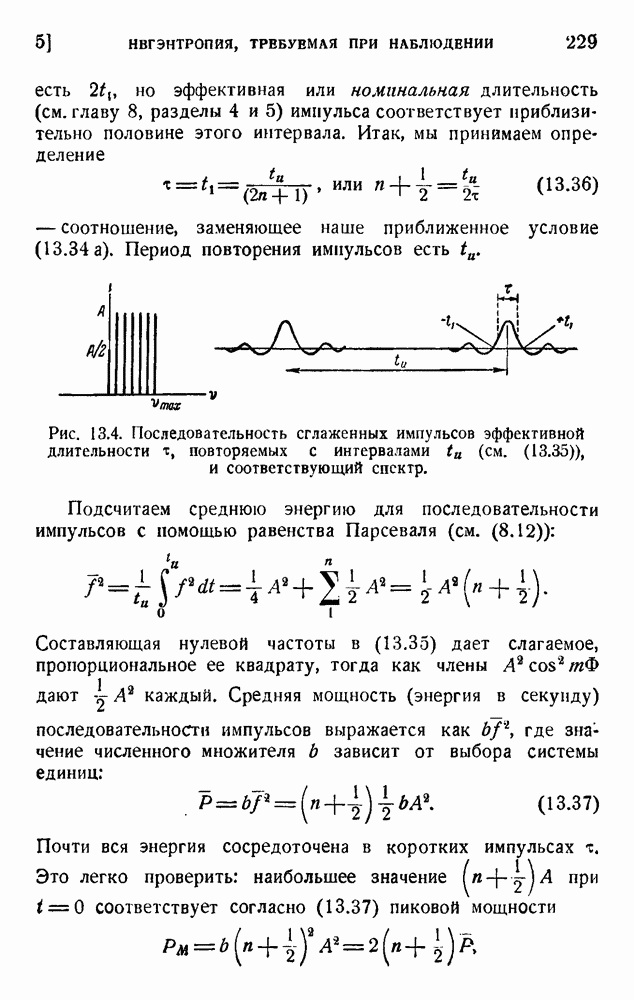
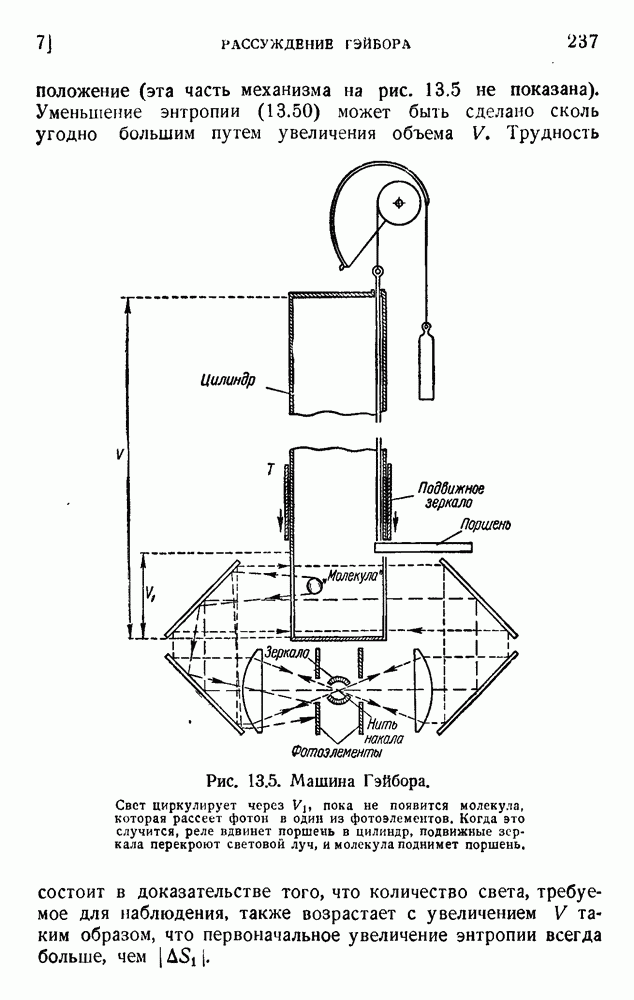
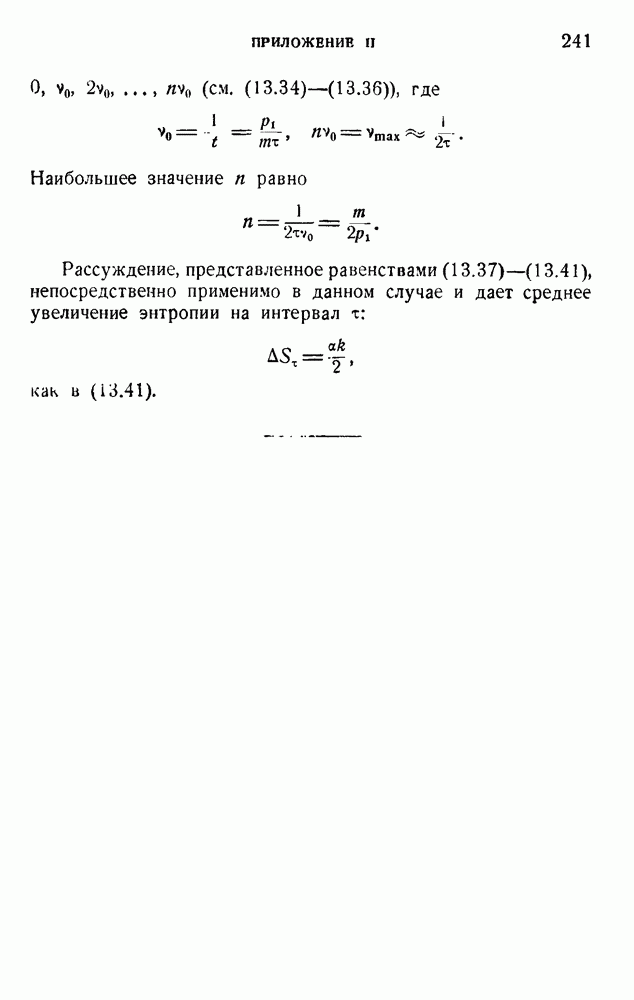
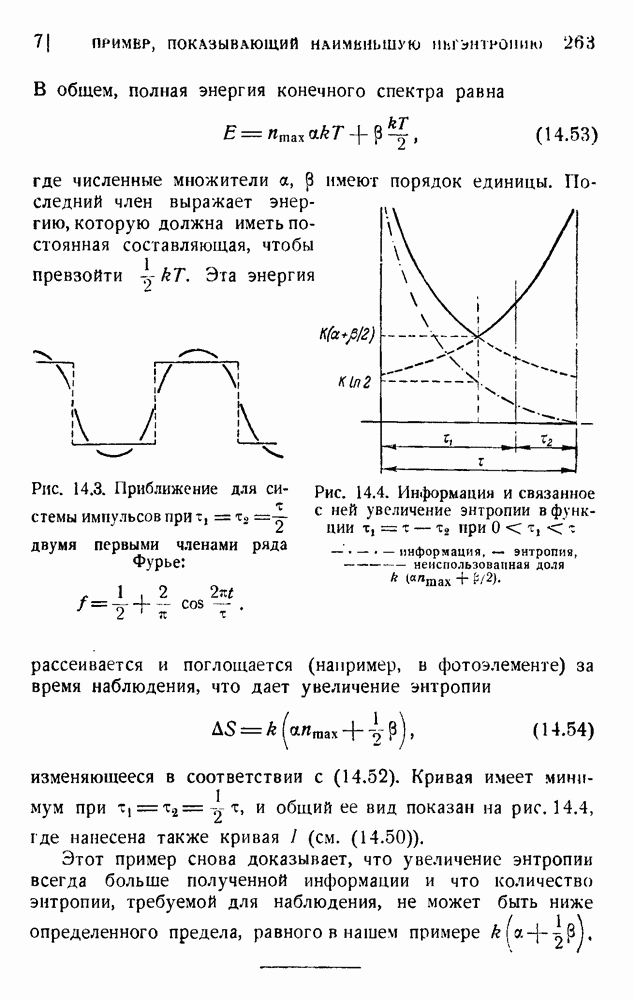
4. Двоичное кодирование словВ главе 3 мы обсуждали исследование Шеннона избыточности английского языка. В одном из своих примеров Шеннон рассматривал частоту различных слов в языке и указал закон
устанавливающий вероятность появления слова, имеющего порядковый номер
В этих предположениях была подсчитана информация, оказавшаяся равной
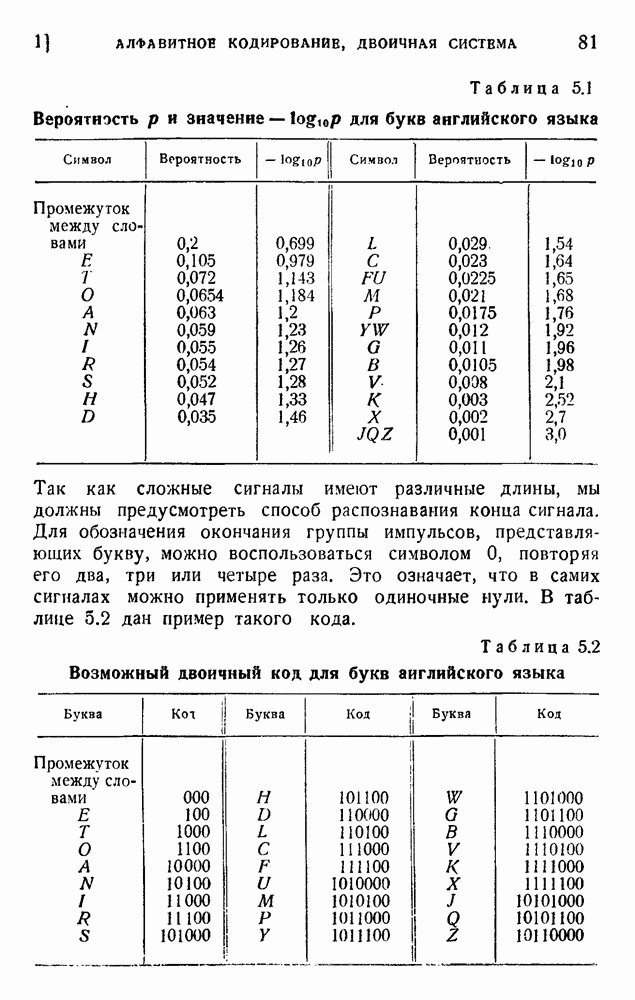
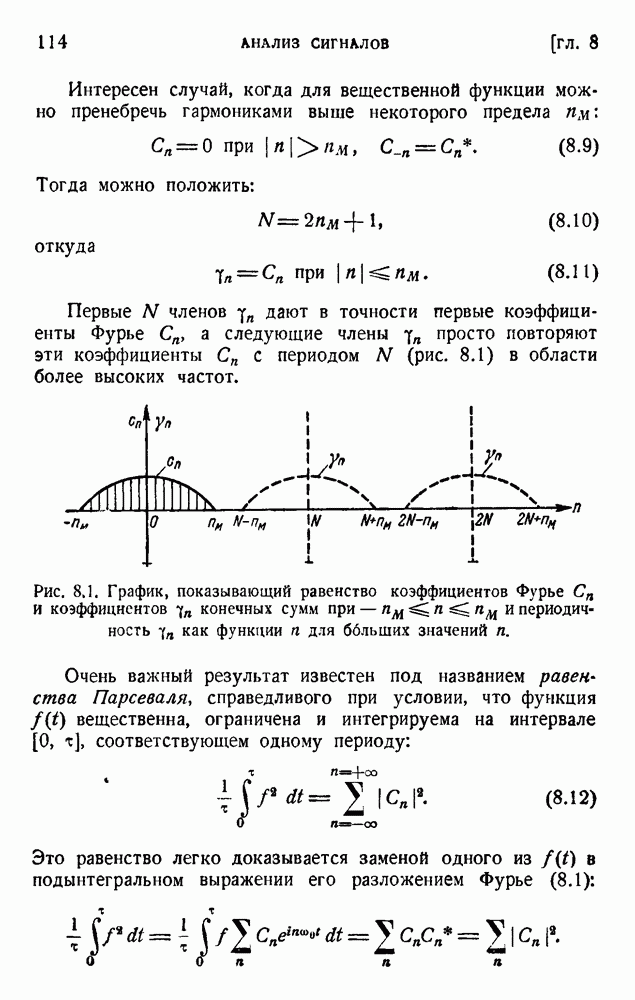
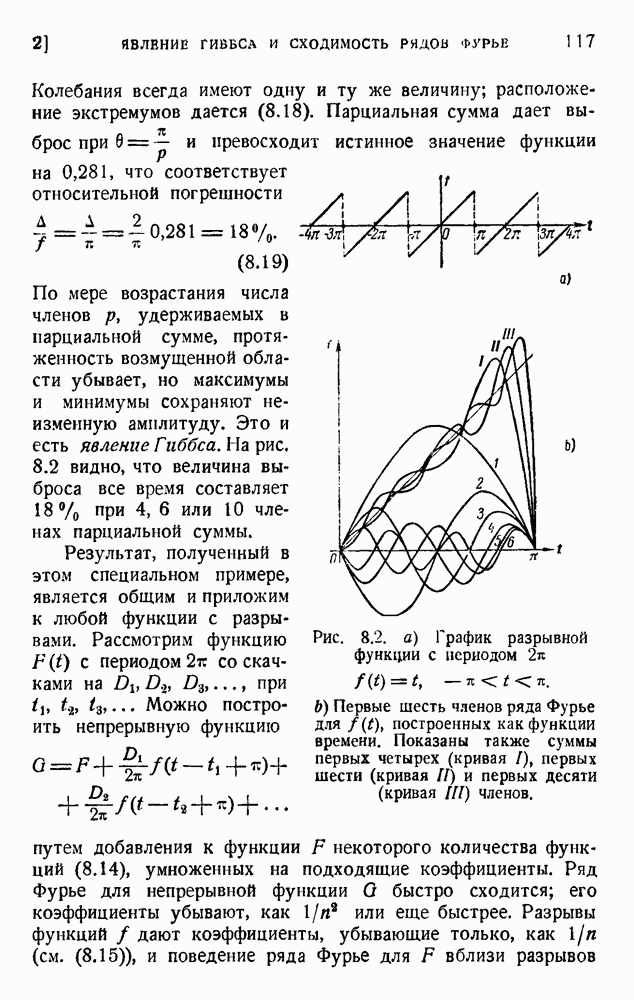
так как среднее слово содержит 5,5 буквы при алфавите из 27 букв (26 букв плюс промежуток между словами). Цифра 2,14 дв. ед. на букву представляет значительную экономию по сравнению с обычным алфавитным кодированием, которое требует около 5 дв. ед. на букву. Посмотрим, как можно использовать это преимущество. Рассмотрим сначала сигналы одинаковой длины. Применяя двоичные цифры 0 и 1 и беря постоянную длину, равную 13 цифрам, можем составить букву, что уже очень близко к теоретическому пределу (см. (5.9)). Можно получить лучший результат, применяя метод, обсужденный в п. 1 этой главы и иллюстрированный таблицей 5.2. Исключим кратные нули в главном сигнале и используем их только в окончании. Каждый сигнал начинается единицей и кончается группой 00,000, 0000,... Несколько таких комбинаций дано в таблице 5.4. Таблица 5.4
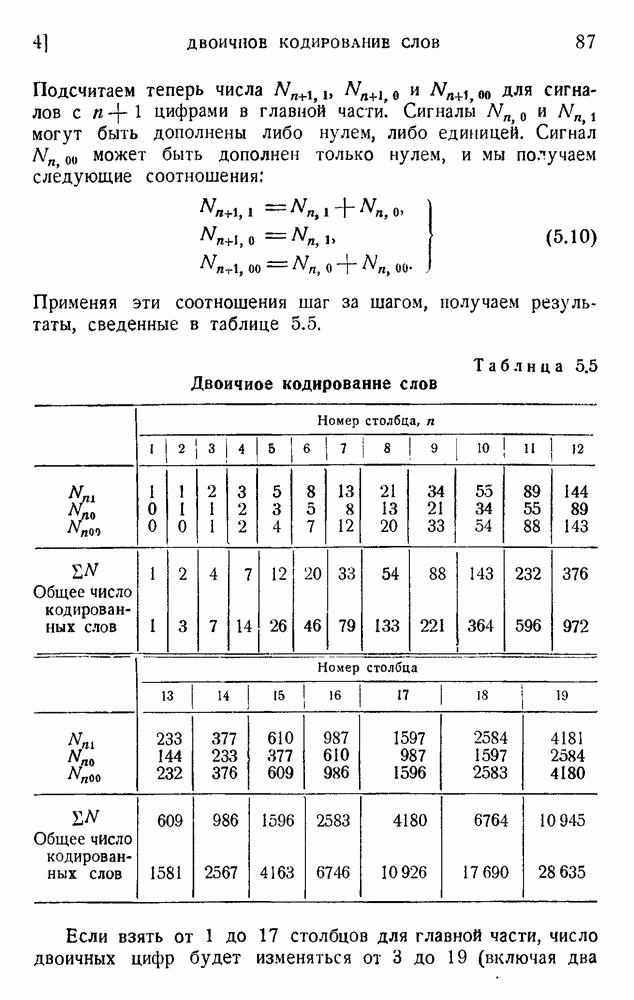
В четвертом столбце комбинация 1001 опущена, так как она содержит два нуля подряд. По этой же причине опущены комбинации 10001.00; 10010.00; 10011.00 и 11001.00 в пятом столбце. В последующем рассуждении мы опустим последние два нуля, появляющиеся в конце каждого сигнала. Предположим, что мы нашли все сигналы некоторого столбца (например, семь сигналов четвертого столбца с четырьмя цифрами в главной части каждого сигнала). Введем следующие обозначения: n — номер столбца,
Например, для четвертого столбца (не считая последних двух нулей после точки)
Подсчитаем теперь числа
Применяя эти соотношения шаг за шагом, получаем результаты, сведенные в таблице 5.5. Таблица 5.5. Двоичное кодирование слов
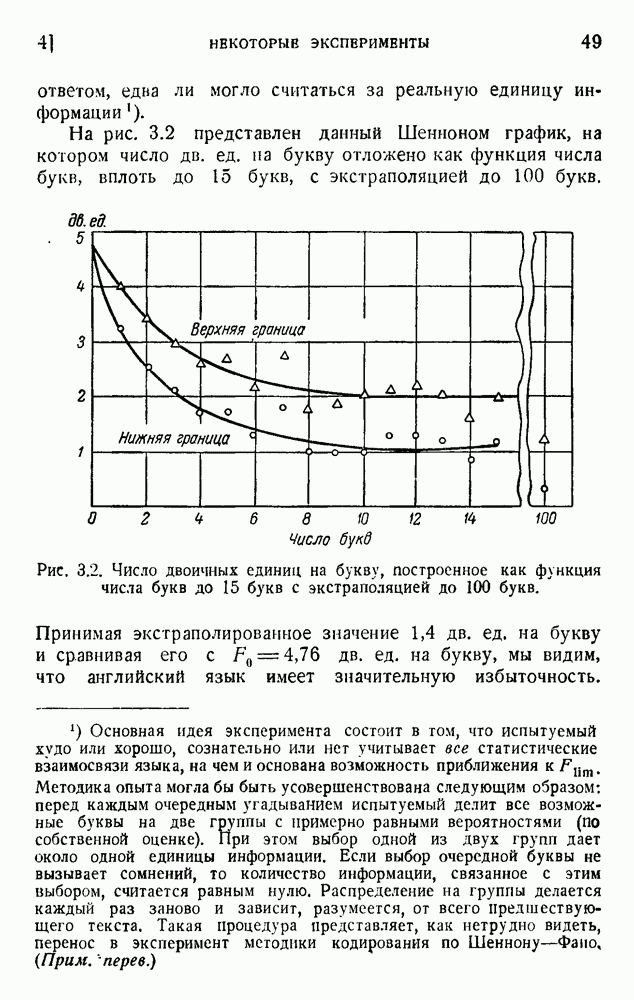
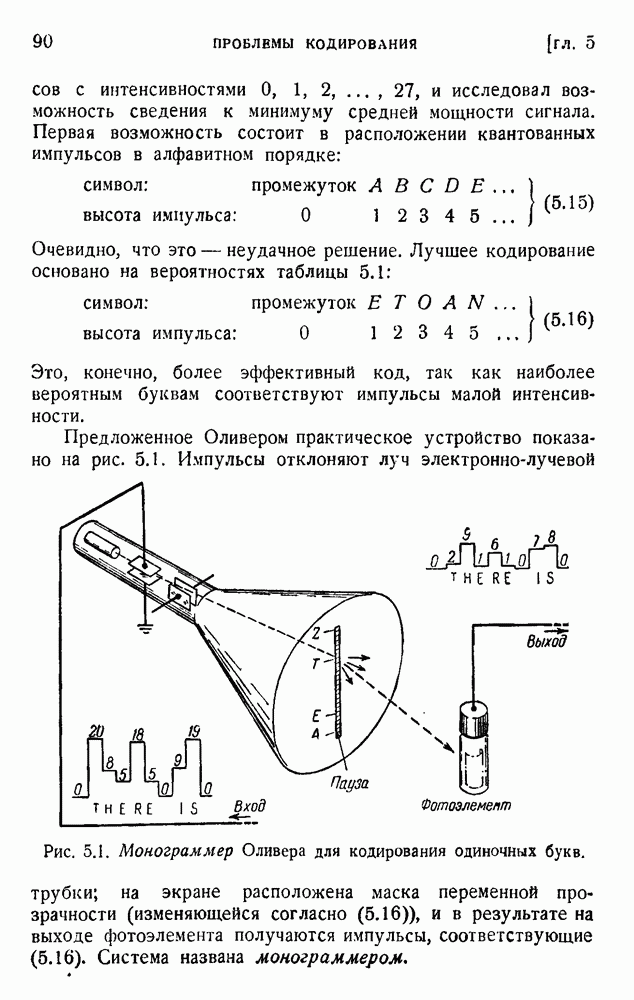
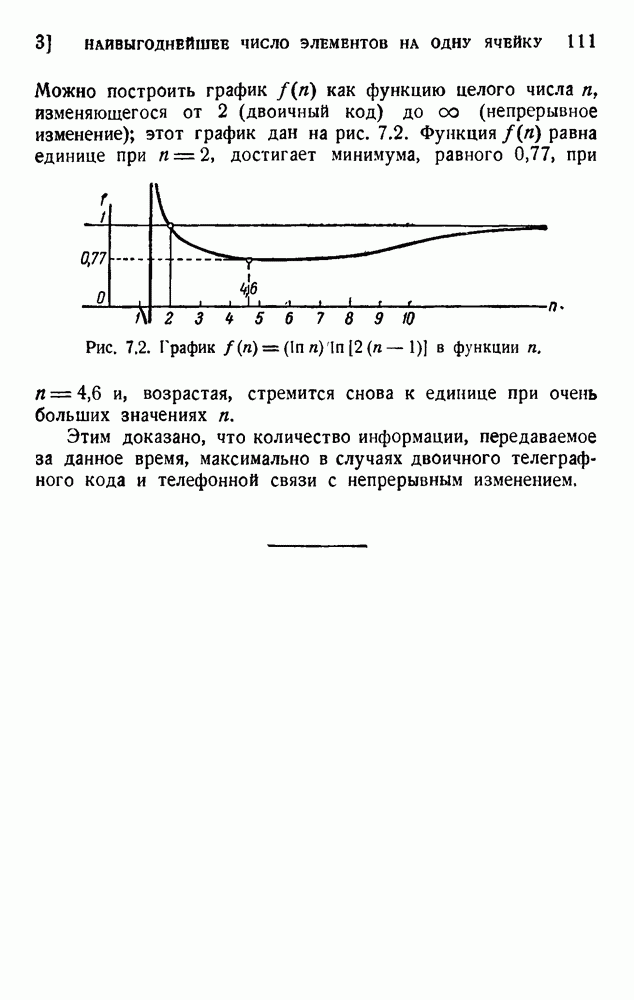
Если взять от 1 до 17 столбцов для главной части, число двоичных цифр будет изменяться от 3 до 19 (включая два нуля, которые должны быть добавлены в конце каждого сигнала), что даст словарь, содержащий около 11 000 слов. Подсчет среднего числа двоичных единиц на слово может быть выполнен без особых трудностей, если принять результаты Шеннона для вероятности последовательных слов. Такой подсчет дает около 12 дв. ед. на слово, что очень близко к теоретическому пределу 11,82. Такого родз кодирование является, по-видимому, наиболее экономичным из числа практически выполнимых. Для практического применения код должен быть дополнен буквенным кодом. Буквы во всяком случае будут нужны для всех слов, не вошедших в словарь, в особенности для имен, географических названий и т. д. Если такие слова встречаются редко, можно оставить последние 27 символов кода для алфавита. Если же специальные слова встречаются очень часто, кодирование слов становится невыгодным. Воспользуемся соотношениями (5.10) для вычисления вероятностей
Равенства (5.10) и (5.11), взятые совместно, определяют последовательные значения вероятностей. Когда
и равенства (5.10) принимают вид:
откуда
где
|
 |
Оглавление
|



































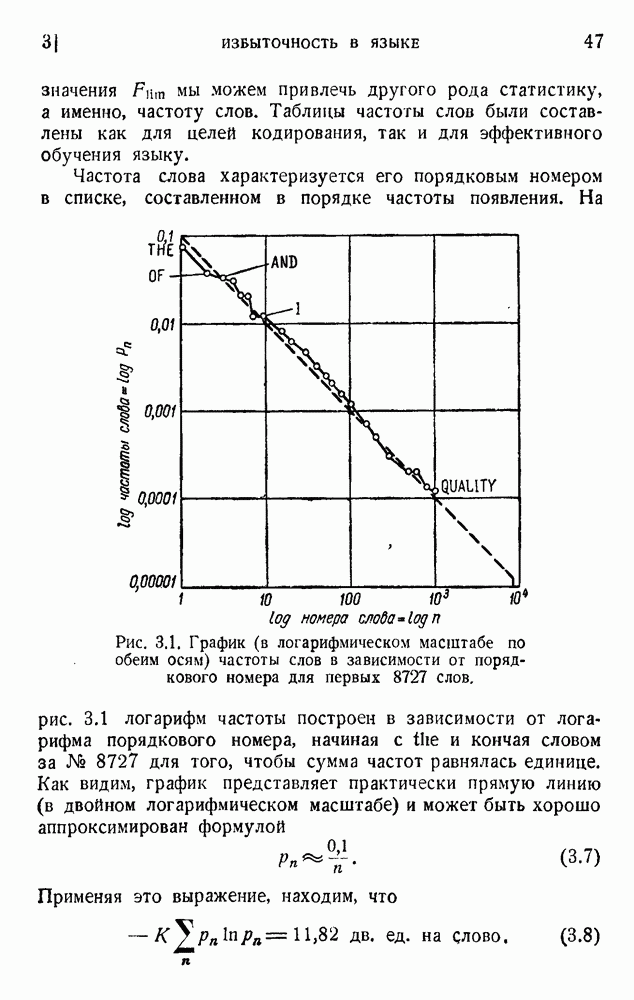


























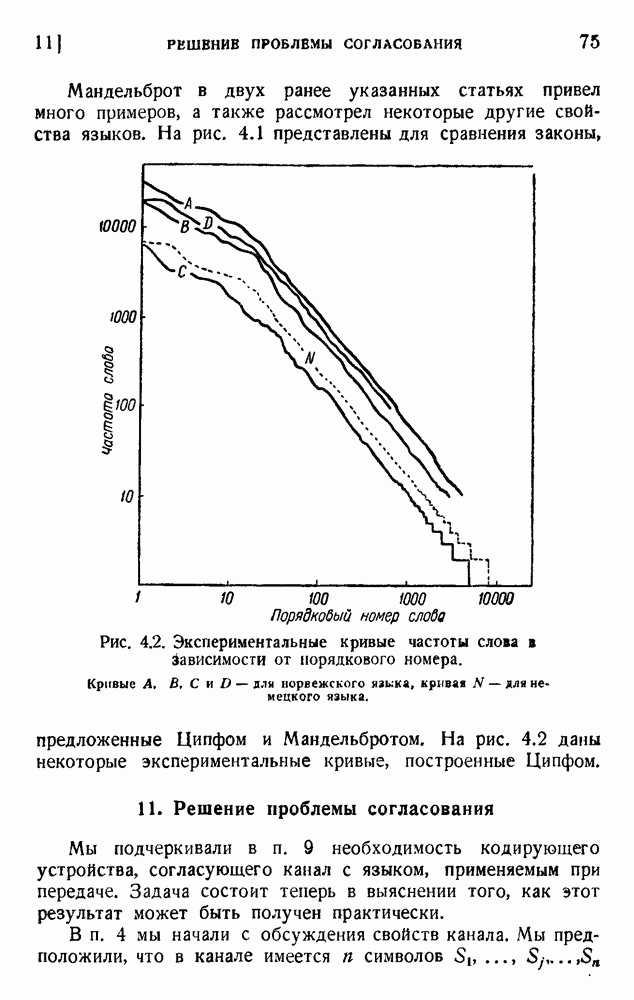
































































































































































































































































































 . в списке, составленном в порядке убывающей частоты. Этот закон нельзя применять до бесконечности, так как сумма будет расходиться, и Шеннон предположил, что применяется только 8727 слов. Это число выбрано так, чтобы сумма вероятностей равнялась единице):
. в списке, составленном в порядке убывающей частоты. Этот закон нельзя применять до бесконечности, так как сумма будет расходиться, и Шеннон предположил, что применяется только 8727 слов. Это число выбрано так, чтобы сумма вероятностей равнялась единице):


 различных сигналов, которыми можно закодировать 8192 слова, образующих словарь, достаточный для многих применений. Этот очень простой код дает 13 дв. ед. на слово или 2,36 дв. ед. на
различных сигналов, которыми можно закодировать 8192 слова, образующих словарь, достаточный для многих применений. Этот очень простой код дает 13 дв. ед. на слово или 2,36 дв. ед. на

 — число сигналов, оканчивающихся единицей,
— число сигналов, оканчивающихся единицей,
 — число сигналов, оканчивающихся одним нулем,
— число сигналов, оканчивающихся одним нулем,
 — число сигналов, оканчивающихся группой нулей.
— число сигналов, оканчивающихся группой нулей.

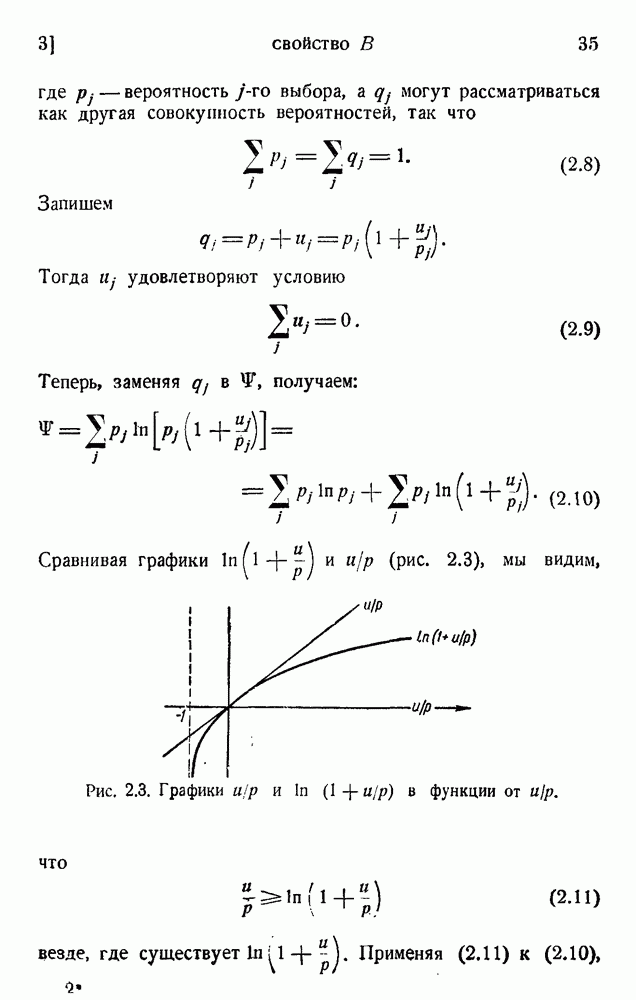
 и
и  для сигналов с
для сигналов с  цифрами в главной части. Сигналы
цифрами в главной части. Сигналы  могут быть дополнены либо нулем, либо единицей. Сигнал
могут быть дополнены либо нулем, либо единицей. Сигнал  может быть дополнен только нулем, и мы получаем следующие соотношения:
может быть дополнен только нулем, и мы получаем следующие соотношения:


 сигналов, главная часть которых имеет окончание 1, 0 или 00. Имеем:
сигналов, главная часть которых имеет окончание 1, 0 или 00. Имеем:

 велико (например,
велико (например,  ), эти вероятности делаются независимыми от n, и легко получить
), эти вероятности делаются независимыми от n, и легко получить
 (5.12)
(5.12)


 . Сравнение с точными цифрами таблицы 5.5 показывает, что эти соотношения дают хорошее приближение при
. Сравнение с точными цифрами таблицы 5.5 показывает, что эти соотношения дают хорошее приближение при  . При помощи этих формул можно провести более детальное исследование кода, предложенного в данном разделе,
. При помощи этих формул можно провести более детальное исследование кода, предложенного в данном разделе,