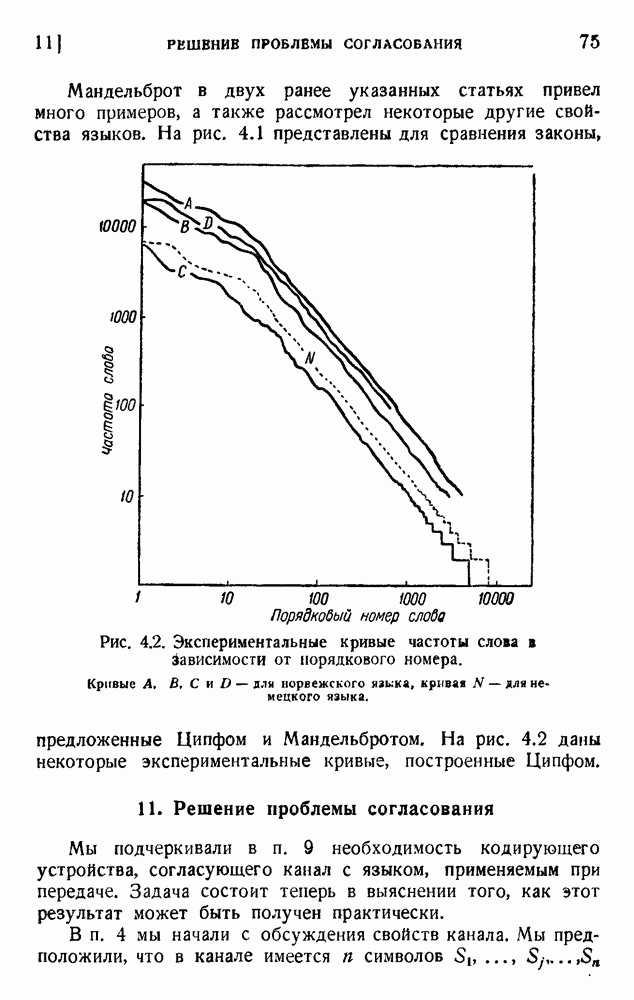
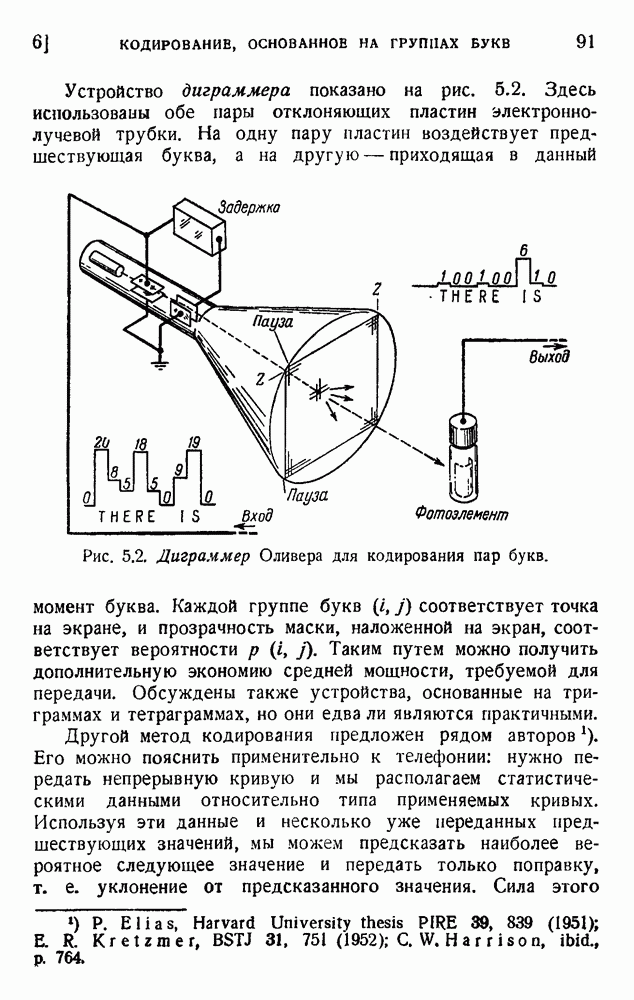
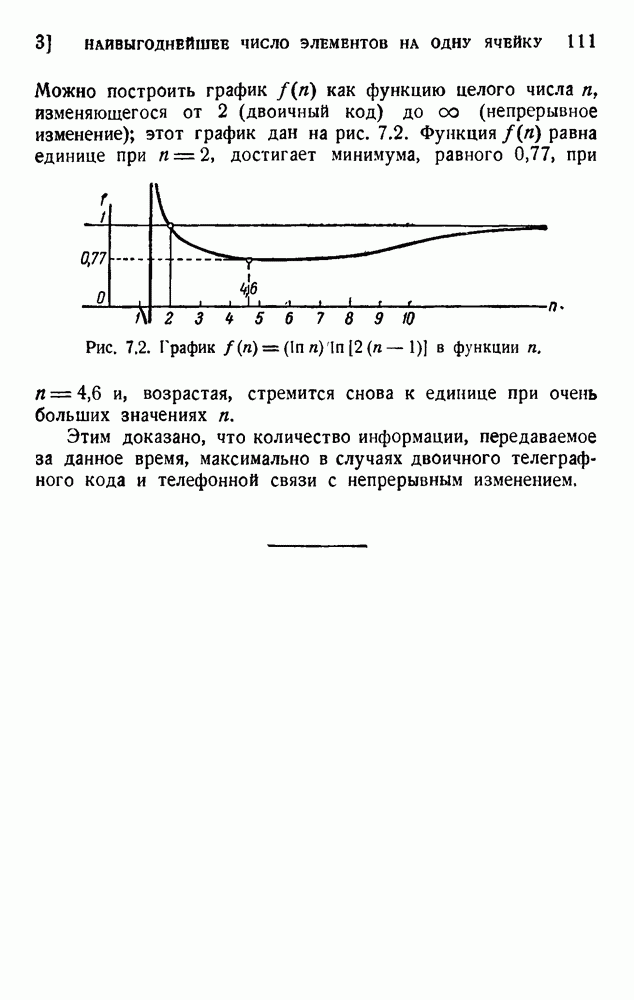
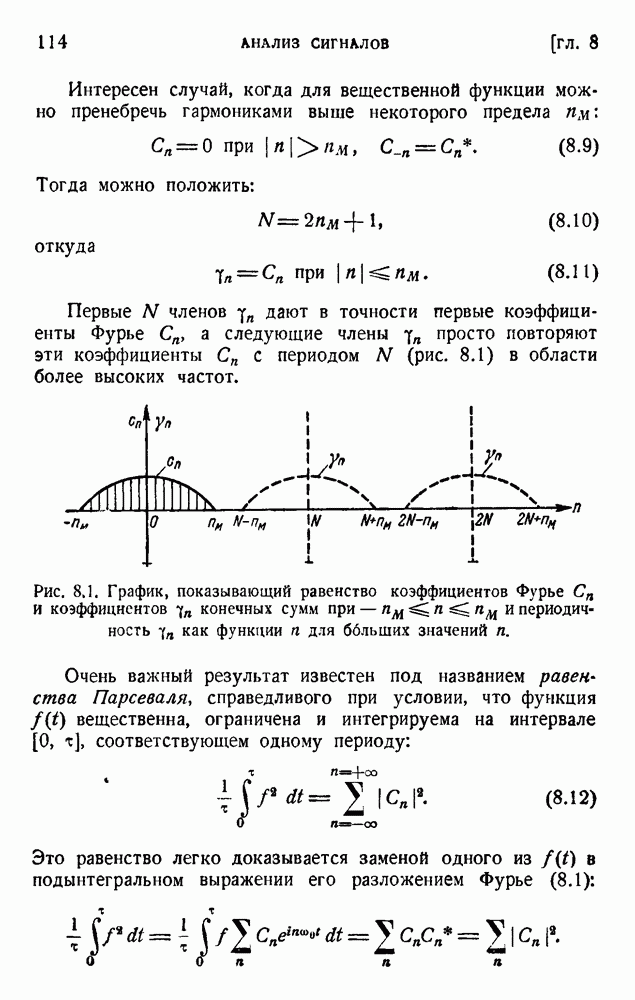
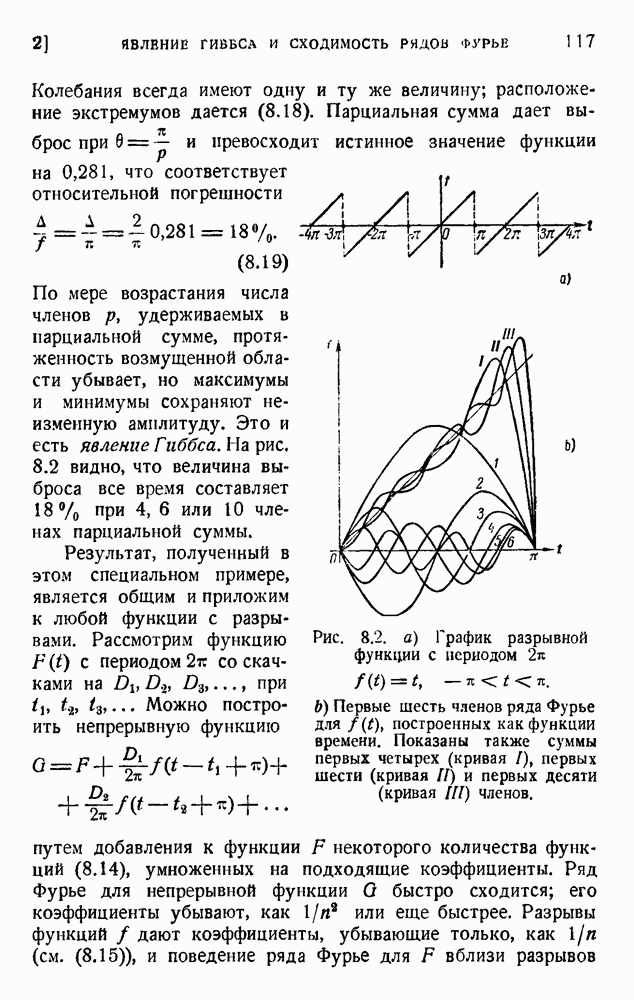
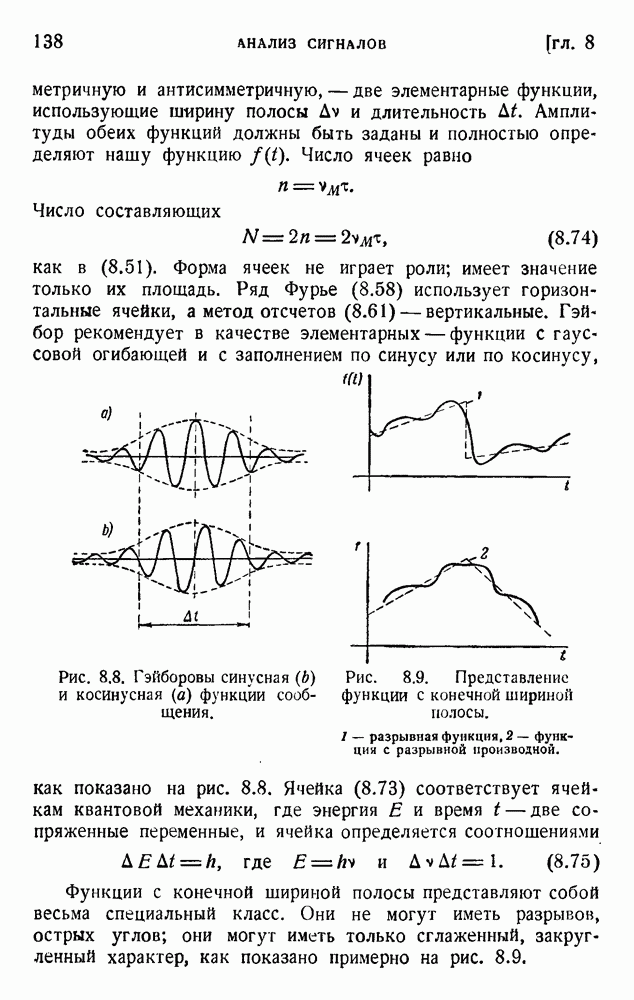
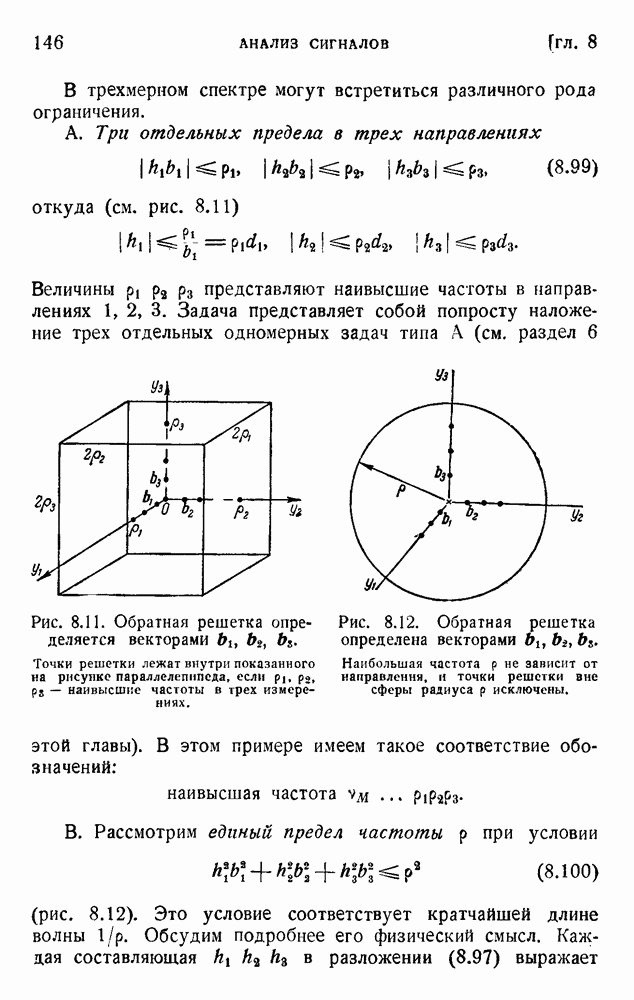
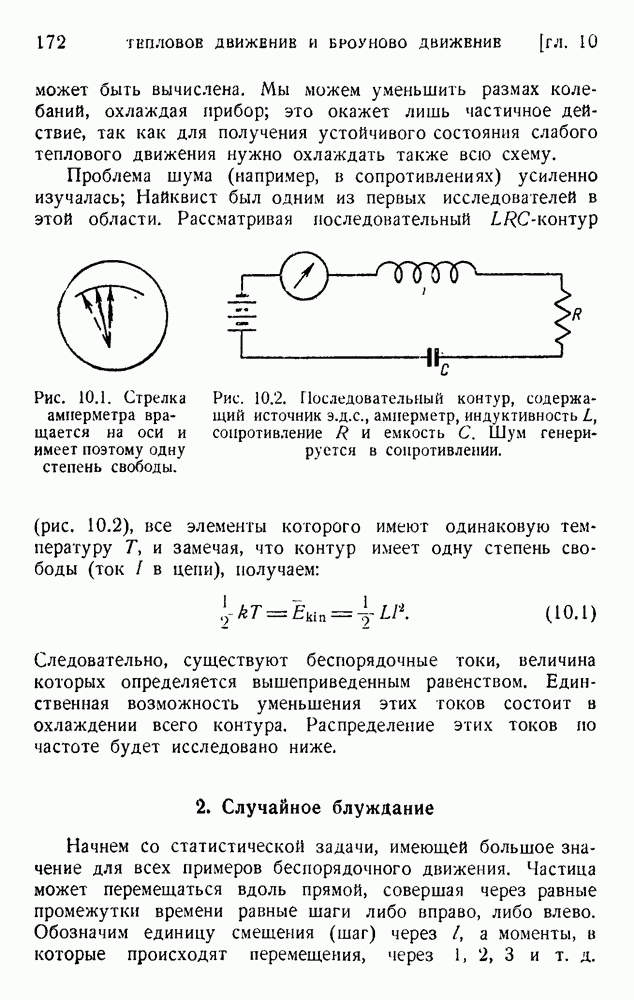
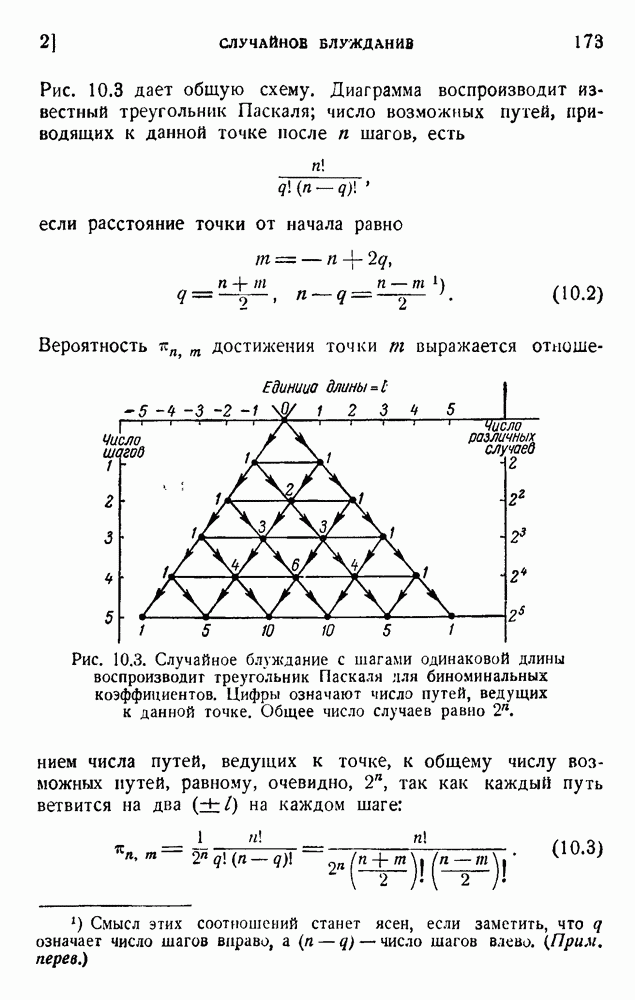
ГЛАВА 5. ПРОБЛЕМЫ КОДИРОВАНИЯ
1. Алфавитное кодирование, двоичная система
В предыдущих главах были обсуждены условия наиболее эффективного кодирования; мы пришли к заключению, что идеальная процедура кодирования выражается условием

где  — априорная вероятность символа
— априорная вероятность символа  имеющего длительность
имеющего длительность  — постоянная.
— постоянная.
Условие (5.1) легко объяснить: наиболее вероятные символы имеют вероятность, близкую к единице, а следовательно,  является малой положительной величиной, и соответствующие символы, согласно (5.1), имеют относительно малую длительность. Другими словами, наиболее вероятные сигналы должны быть короткими, тогда как маловероятные сигналы могут быть длинными. Этот результат почти очевиден, и (5.1) выражает идеальное условие, к которому следует по возможности стремиться. Это условие может быть применено к алфавитным кодам, если использовать хорошо известные вероятности различных букв в языке.
является малой положительной величиной, и соответствующие символы, согласно (5.1), имеют относительно малую длительность. Другими словами, наиболее вероятные сигналы должны быть короткими, тогда как маловероятные сигналы могут быть длинными. Этот результат почти очевиден, и (5.1) выражает идеальное условие, к которому следует по возможности стремиться. Это условие может быть применено к алфавитным кодам, если использовать хорошо известные вероятности различных букв в языке.
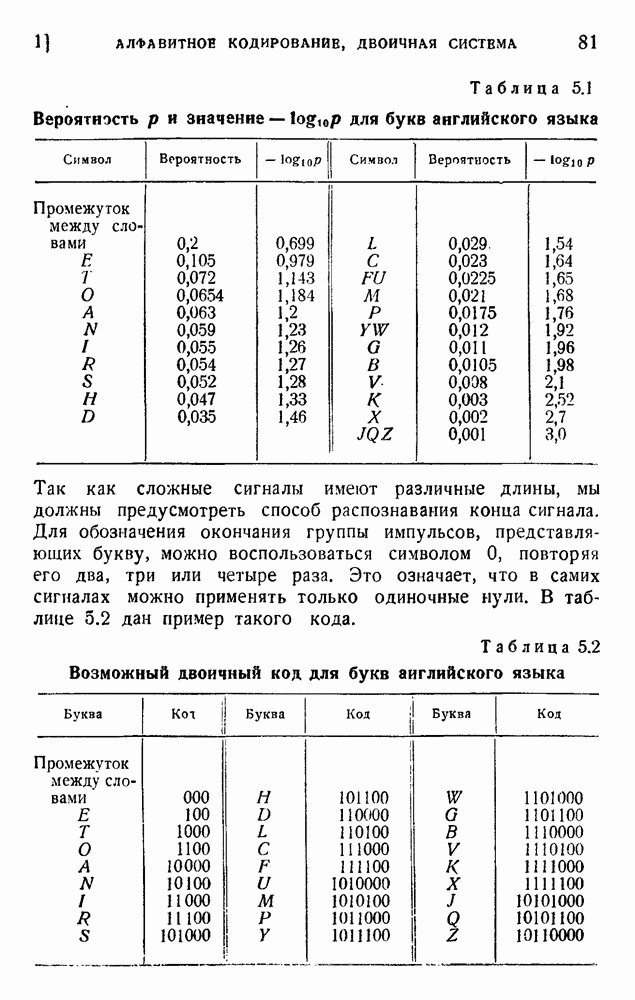
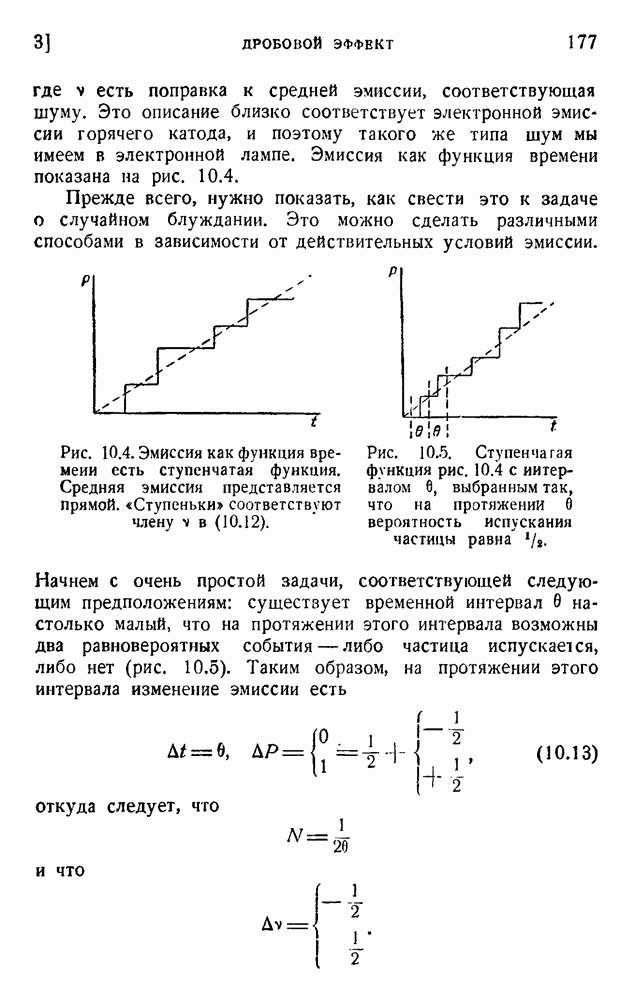
В таблице 5.1, повторяющей таблицу 1.1, даны вероятности  и их отрицательные логарифмы для букв английского алфавита. Неважно, какие логарифмы мы применяем; изменение основания логарифма приводит лишь к умножению константы р на постоянный множитель. Рассматривая таблицу 5.1, можно отметить, что логарифмы вероятностей букв алфавита лежат между 0,7 и 3. Мы можем построить двоичный код с таким же интервалом длин сигналов. Это относится к каналу, способному передавать только один вид импульса: отсутствие импульса означает 0, наличие импульса означает 1.
и их отрицательные логарифмы для букв английского алфавита. Неважно, какие логарифмы мы применяем; изменение основания логарифма приводит лишь к умножению константы р на постоянный множитель. Рассматривая таблицу 5.1, можно отметить, что логарифмы вероятностей букв алфавита лежат между 0,7 и 3. Мы можем построить двоичный код с таким же интервалом длин сигналов. Это относится к каналу, способному передавать только один вид импульса: отсутствие импульса означает 0, наличие импульса означает 1.
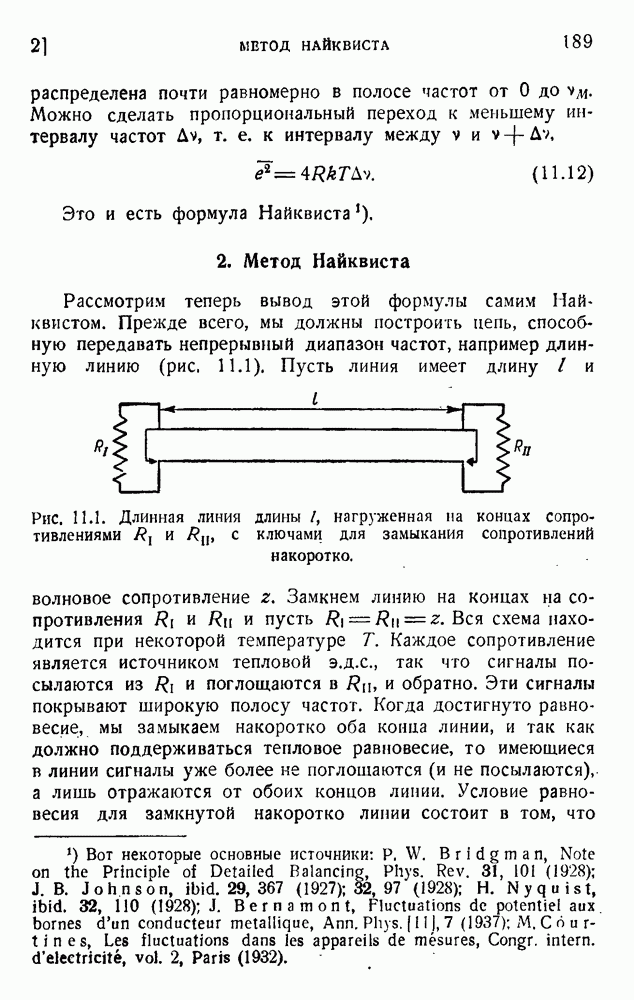
Таблица 5.1. Вероятность р и значение  для букв английского языка
для букв английского языка

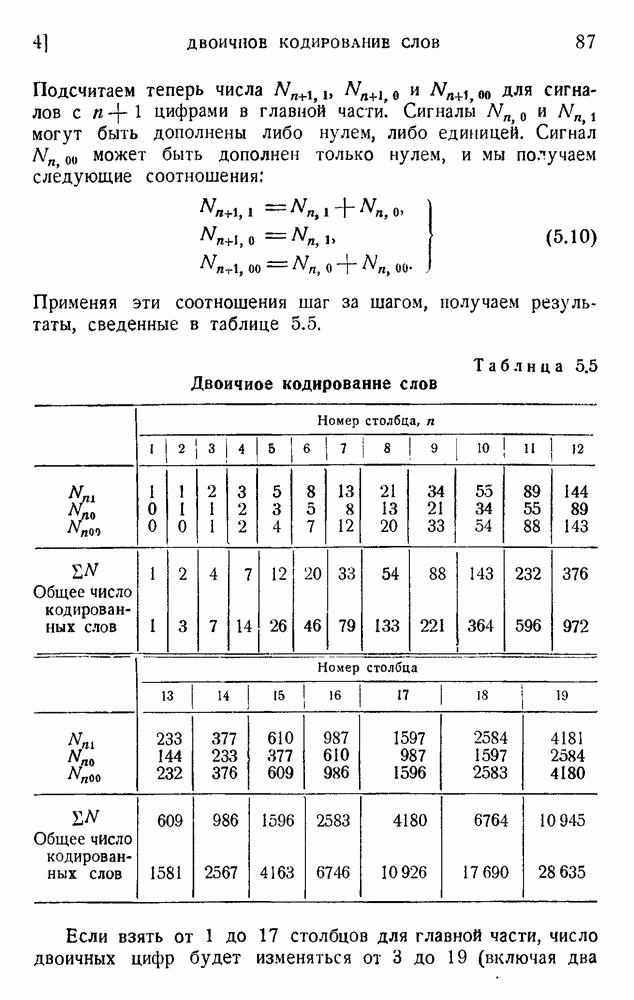
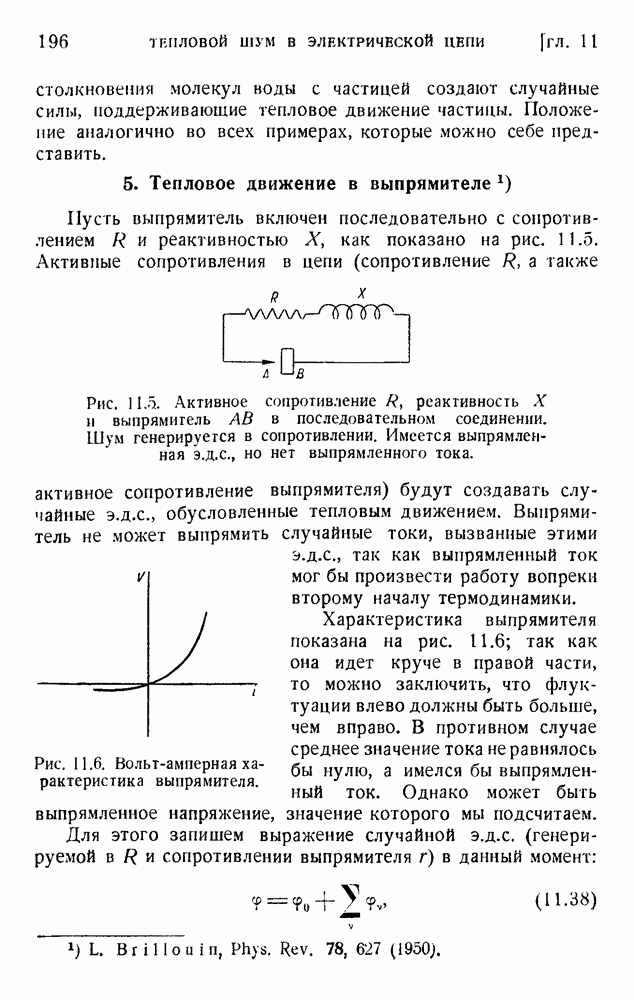
Так как сложные сигналы имеют различные длины, мы должны предусмотреть способ распознавания конца сигнала. Для обозначения окончания группы импульсов, представляющих букву, можно воспользоваться символом 0, повторяя его два, три или четыре раза. Это означает, что в самих сигналах можно применять только одиночные нули. В таблице 5.2 дан пример такого кода.
Таблица 5.2. Возможный двоичный код для букв английского языка

Длина кодовой комбинации составляет от трех до восьми символов на букву, что является, в общем, подходящим соотношением. В длинном сообщении средняя длина на букву получается умножением длительности  на ее вероятность
на ее вероятность  и суммированием:
и суммированием:

где значения  берутся из таблицы 5.1. Значение 4,65 является также средним числом символов на букву, и для применяемой нами двоичной системы имеем:
берутся из таблицы 5.1. Значение 4,65 является также средним числом символов на букву, и для применяемой нами двоичной системы имеем:
информация на букву  (информация на символ) X (символов на букву) = 4,65 X log2 2 = 4,65.
(информация на символ) X (символов на букву) = 4,65 X log2 2 = 4,65.
Сравним этот результат с некоторыми другими кодами. Если взять символы одинаковой длины, то потребуется пять двоичных цифр для получения 32 комбинаций, из которых можно выбрать 27 для обозначения букв алфавита. Символы одинаковой длины, равной 5, несколько хуже, чем наша система переменных длин. Однако полученная нами величина все еще слишком велика, так как она превосходит теоретическое значение 4,03 дв. ед. на букву (см. (1.30)). Код, представленный в таблице 5.2, много лучше обычного кода Морзе, применяемого в телеграфии.