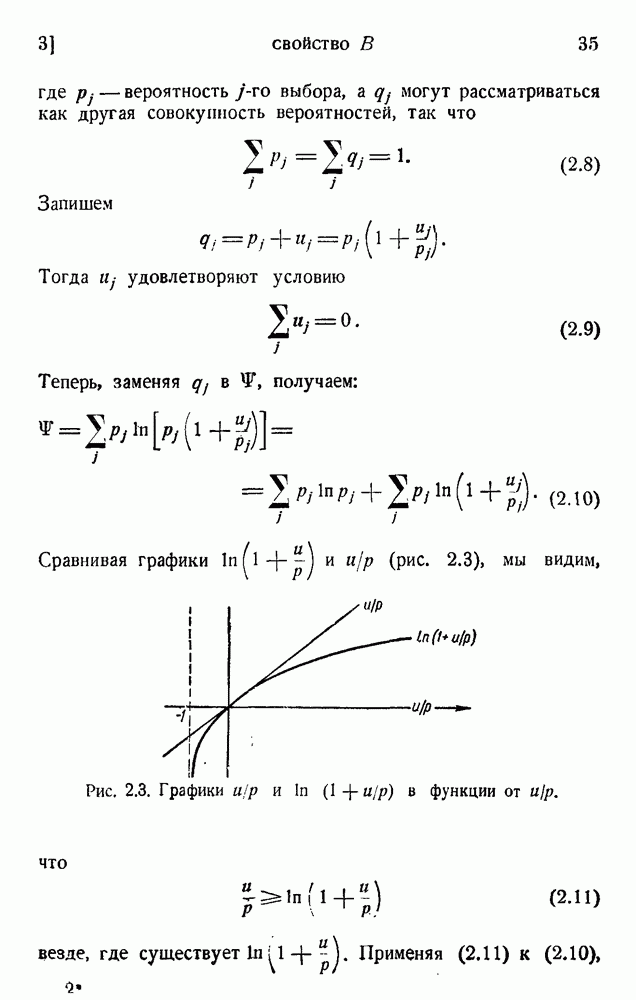
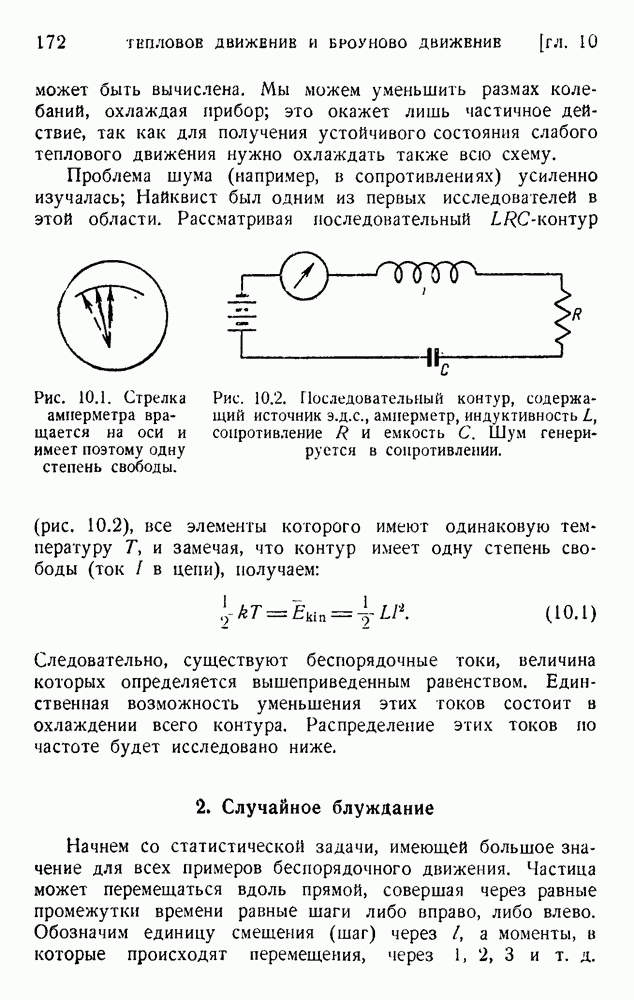
где i — средняя информация на символ и

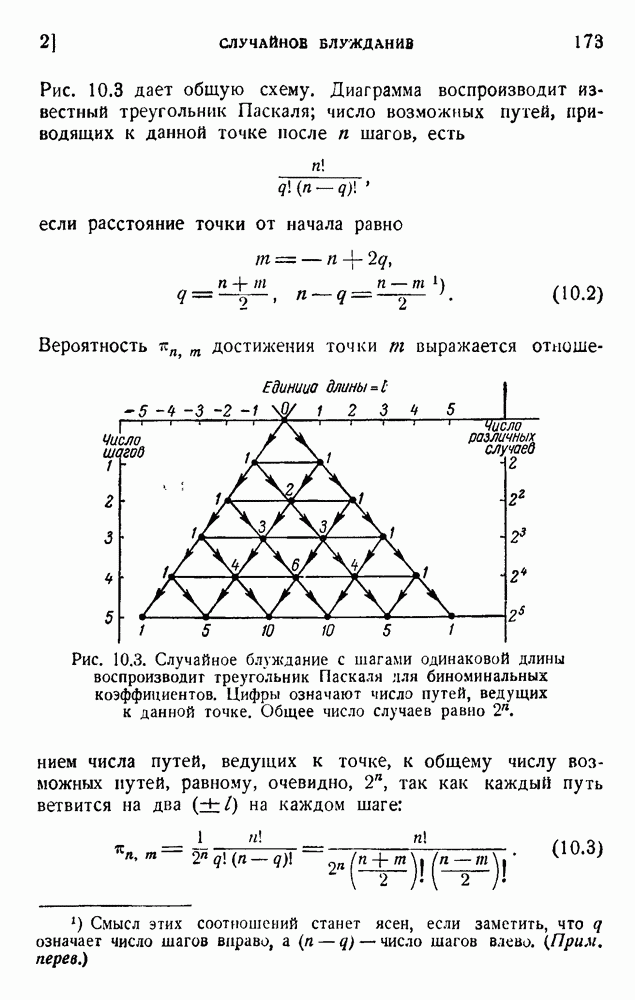
Начнем с простой задачи, которую затем легко обобщить. Рассмотрим алфавит из двух «букв» — точки и тире, как в телеграфии, или 0 и 1. Рассмотрим G позиций (cells — ячеек), и пусть  позиций содержат
позиций содержат  содержат 1, так что
содержат 1, так что  . Таким образом, все позиции заполнены. Тогда вероятность позиции, содержащей 0, будет
. Таким образом, все позиции заполнены. Тогда вероятность позиции, содержащей 0, будет

и вероятность того, что позиция содержит 1, есть

причем

так как вероятность того, что в некоторой позиции содержится либо 0, либо 1, равна единице.
Теперь найдем число способов заполнения каждой из G позиций либо 0, либо 1 (но никоим образом не обоими символами одновременно). Эта задача в точности та же, что в статистике Ферми. Число способов заполнения G позиций равно числу способов заполнения позиций нулями, так как, если мы уже распределили  нулей, то остальные
нулей, то остальные  позиций должны содержать по единице каждая. Но число способов заполнения
позиций должны содержать по единице каждая. Но число способов заполнения  позиций нулями равно числу перестановок (с повторяющимися элементами) из G по
позиций нулями равно числу перестановок (с повторяющимися элементами) из G по  :
:

Это есть число сообщений из G символов двухбуквенного алфавита, один из которых встречается  раз, а другой —
раз, а другой —  раз. Для одного из таких сообщений согласно (1.1) информация равна
раз. Для одного из таких сообщений согласно (1.1) информация равна

Если сообщение длинно и  и
и  достаточно велики, то логарифмы факториалов могут быть выражены приближенно на основании формулы Стирлинга:
достаточно велики, то логарифмы факториалов могут быть выражены приближенно на основании формулы Стирлинга:

Эта формула дает, как известно, очень хорошее приближение для  . Итак, если
. Итак, если  , то
, то

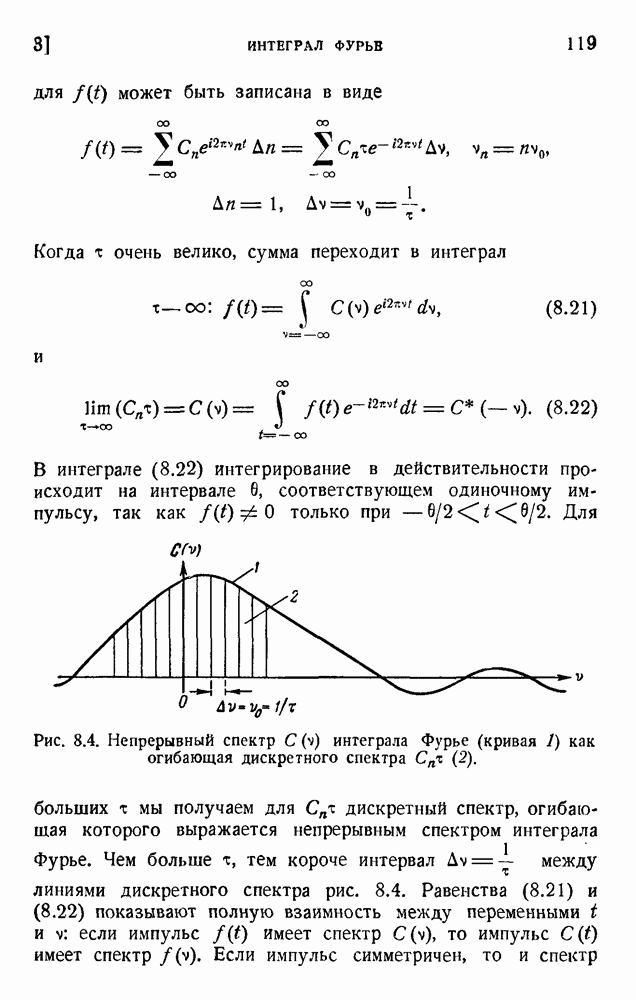
или, учитывая, что 

Снова применяя равенство  перепишем (1.20) в виде
перепишем (1.20) в виде

Подставляя (1.14) и (1.15) и деля на G, получаем:

где i — информация на символ сообщения. Это и есть формула Шеннона для случая двух символов. Заметим, что  меньше единицы, их логарифмы отрицательны, а потому формула (1.22) дает положительное значение для
меньше единицы, их логарифмы отрицательны, а потому формула (1.22) дает положительное значение для  .
.
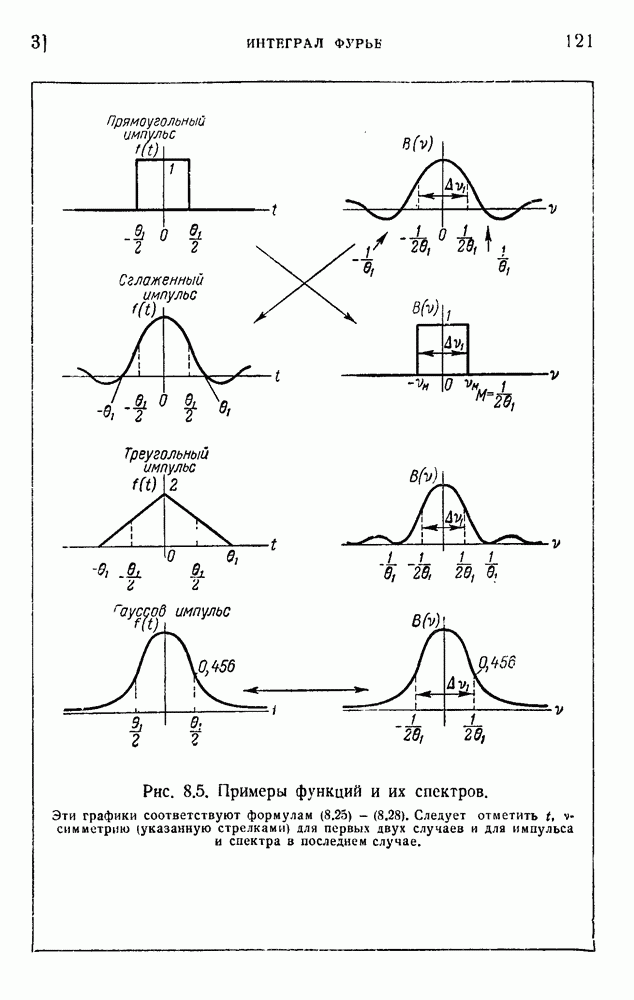
Обобщение на случай более чем двух символов получается легко. Обозначим через  числа символов М различных типов и выберем число позиций
числа символов М различных типов и выберем число позиций

Определим вероятность j-го символа

Имеем:

Общее число сообщений Р, которые можно получить, распределяя символы случайным образом по G позициям (так чтобы на одной позиции никогда не оказывалось более одного символа), составляет:

Формула (1.26) является прямым обобщением (1.17). Мы получаем для информации, содержащейся в одном из сообщений:

Равенства в этом выражении соответствуют (1.18), (1.19) и (1.20), полагая по-прежнему, что G и  достаточно велики, так что применима формула Стирлинга. Метод, при помощи которого получены (1.21) и (1.22), дает теперь:
достаточно велики, так что применима формула Стирлинга. Метод, при помощи которого получены (1.21) и (1.22), дает теперь:

а это и есть формула Шеннона.
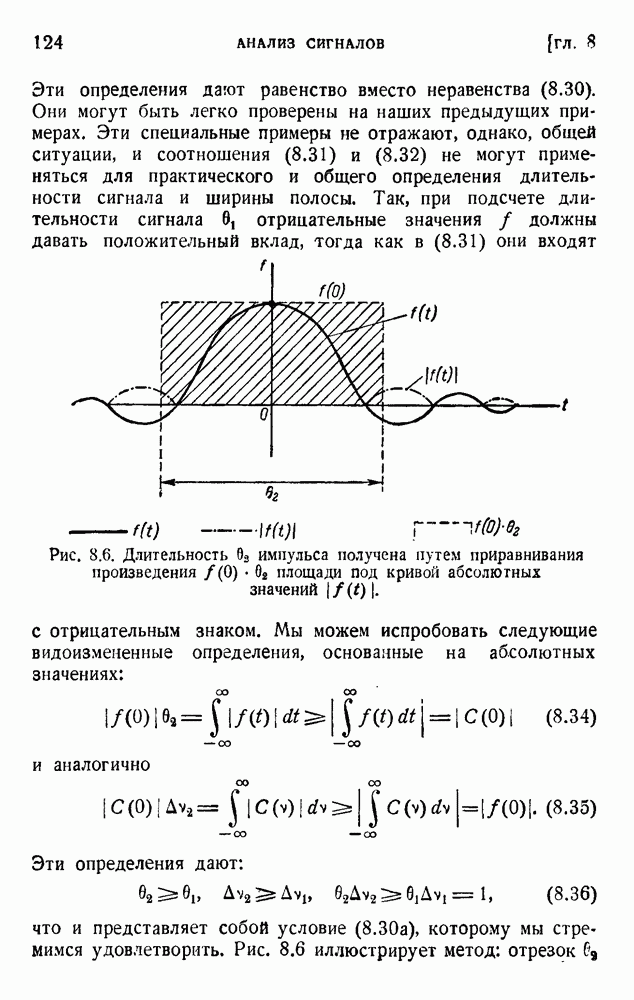
В качестве примера рассмотрим сообщение из 10 000 букв 27-буквенного алфавита, выбранных, случайным образом с
одинаковыми априорными вероятностями. Тогда

и

Если, однако, мы составим сообщение такой же длины, но выберем буквы в соответствии с их действительными априорными вероятностями, то нужно воспользоваться (1.28):

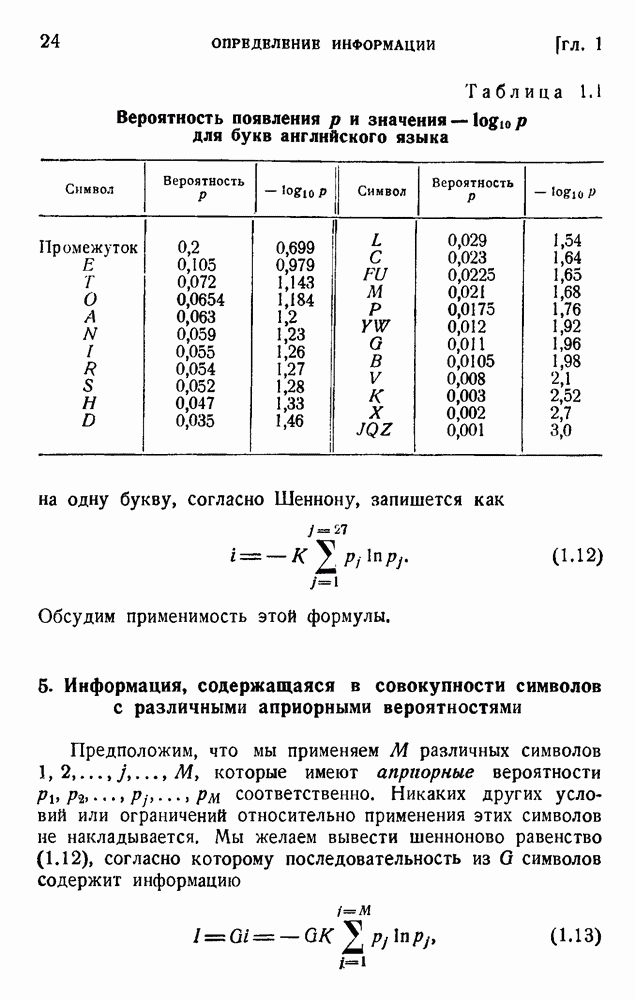
Последнее значение легко подсчитать по данным таблицы 1.1.
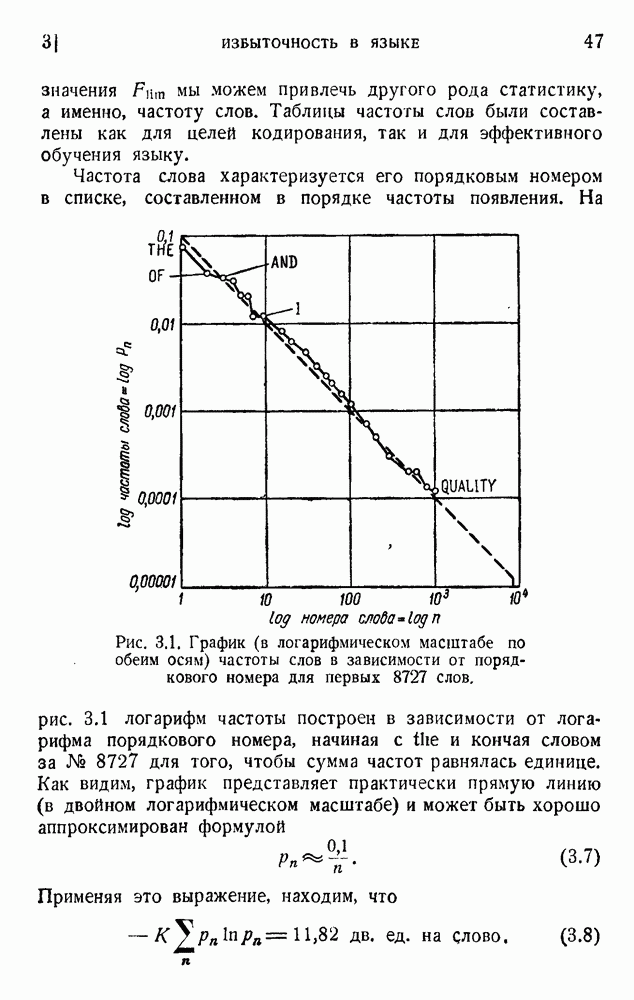
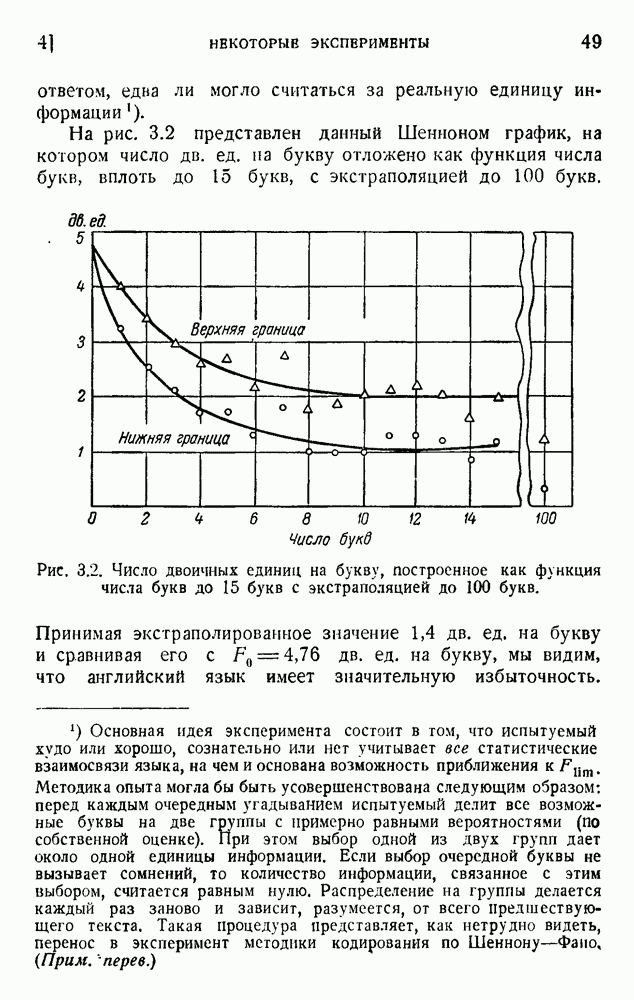
Более подробный анализ структуры языка будет дан в следующих разделах. Будет показано, что вышеприведенное значение представляет собой верхнюю грань и что действительное количество информации на одну букву много меньше 4, вероятно, между 1 и 2 дв. ед. на букву.




































































































































































































































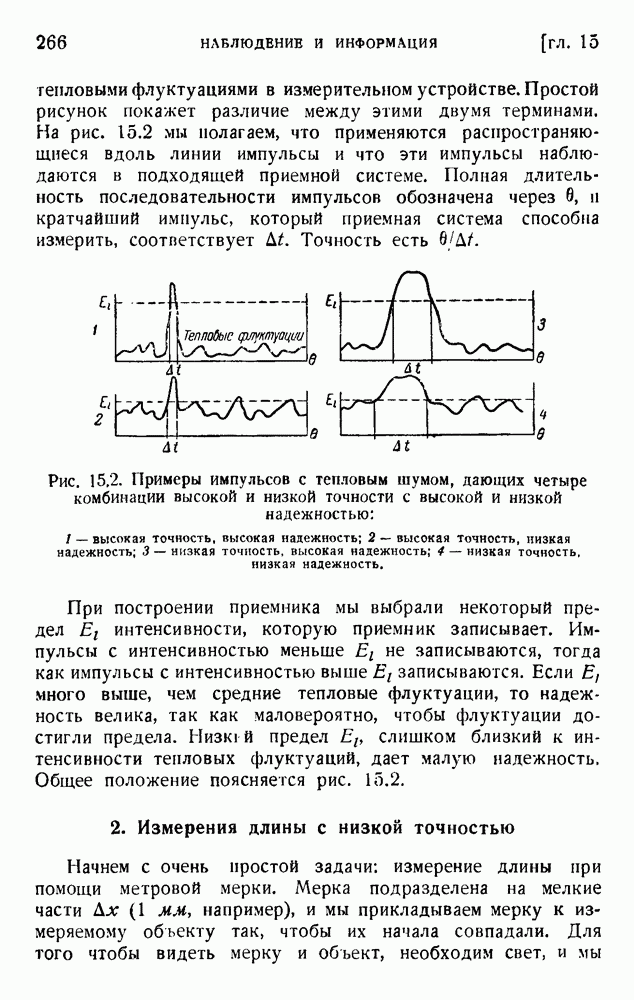
























































































































 , которые имеют априорные вероятности
, которые имеют априорные вероятности  соответственно. Никаких других условий или ограничений относительно применения этих символов не накладывается. Мы желаем вывести шенноново равенство (1.12), согласно которому последовательность из
соответственно. Никаких других условий или ограничений относительно применения этих символов не накладывается. Мы желаем вывести шенноново равенство (1.12), согласно которому последовательность из  символов содержит информацию
символов содержит информацию

