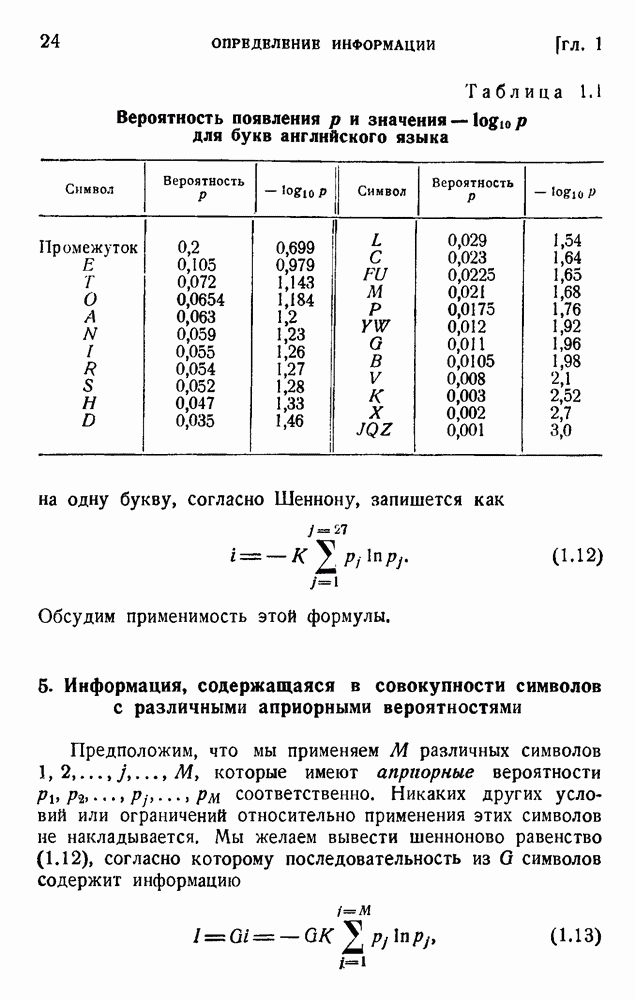
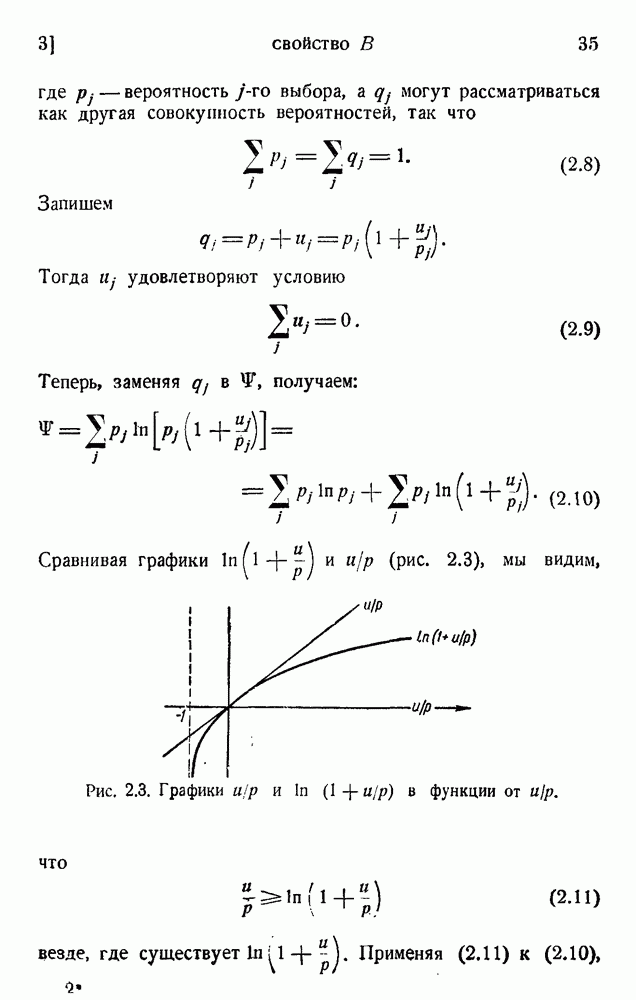
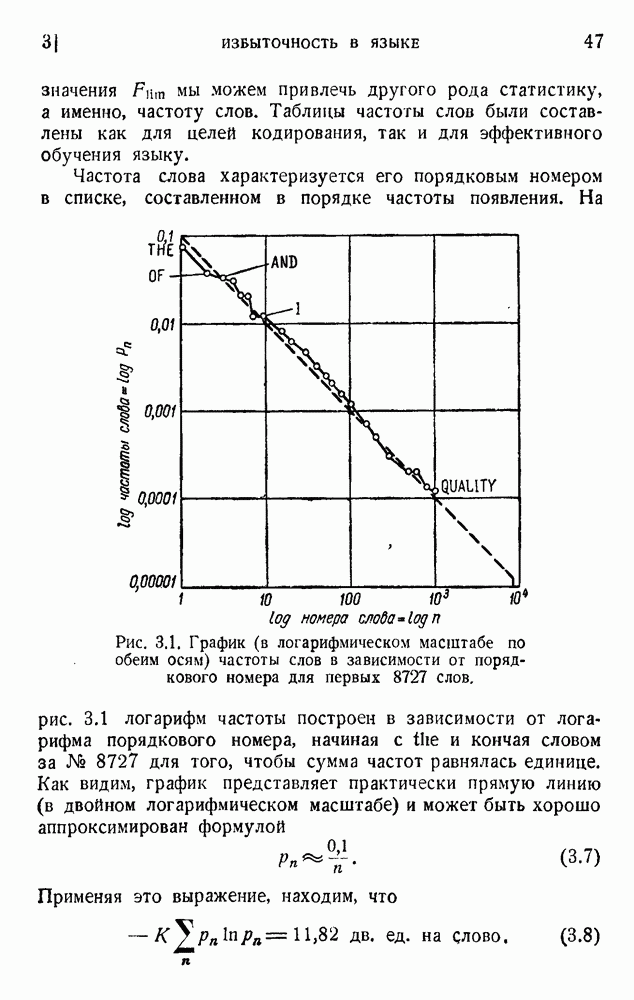
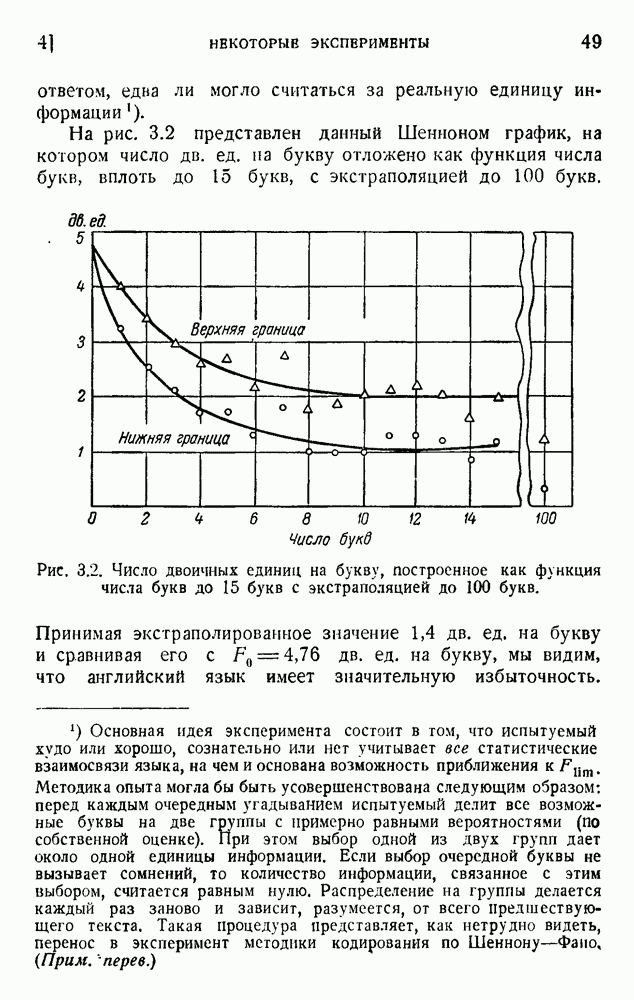
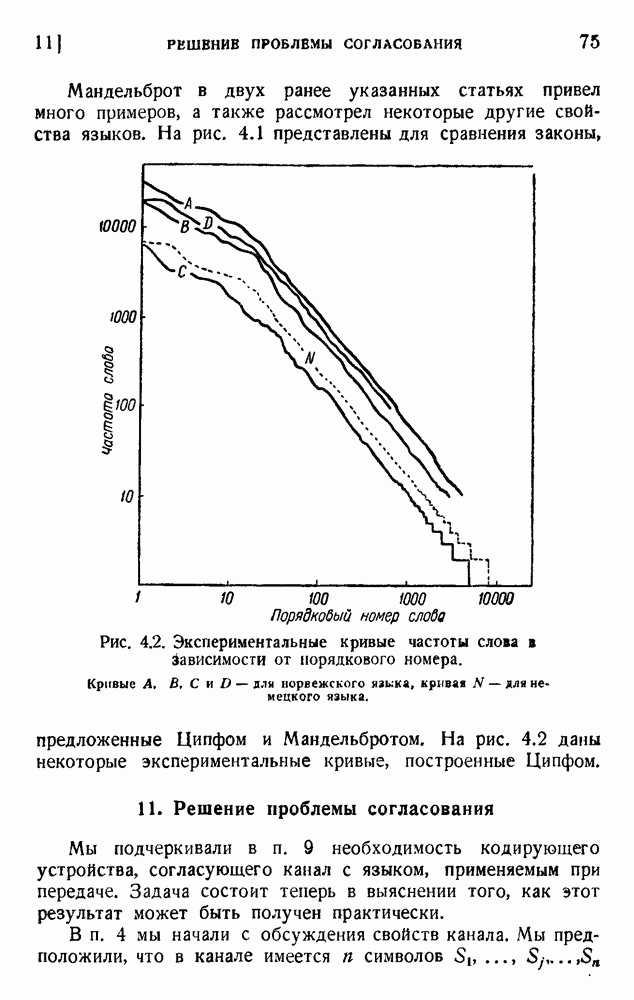
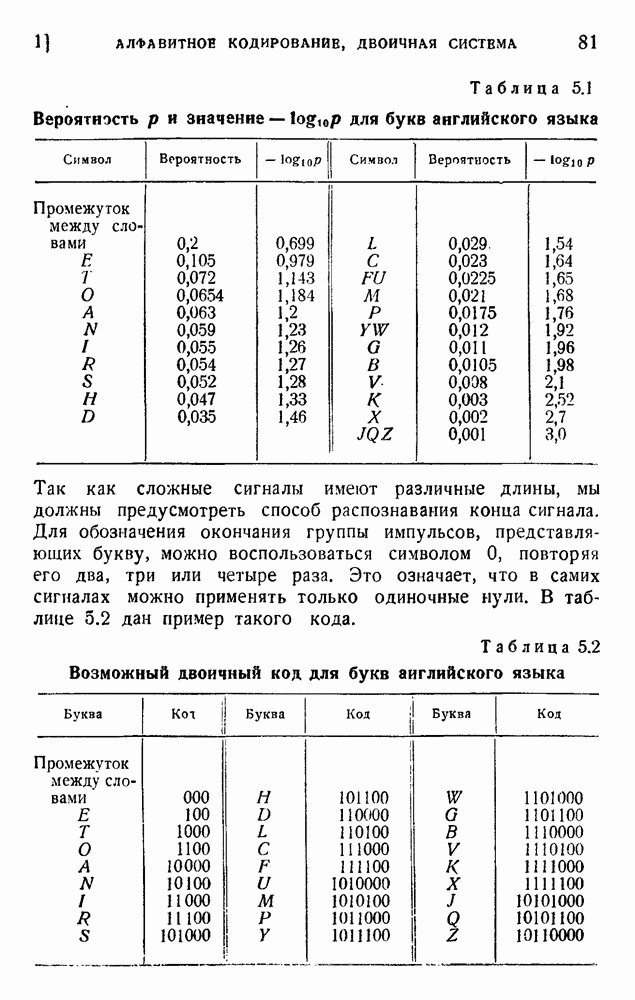
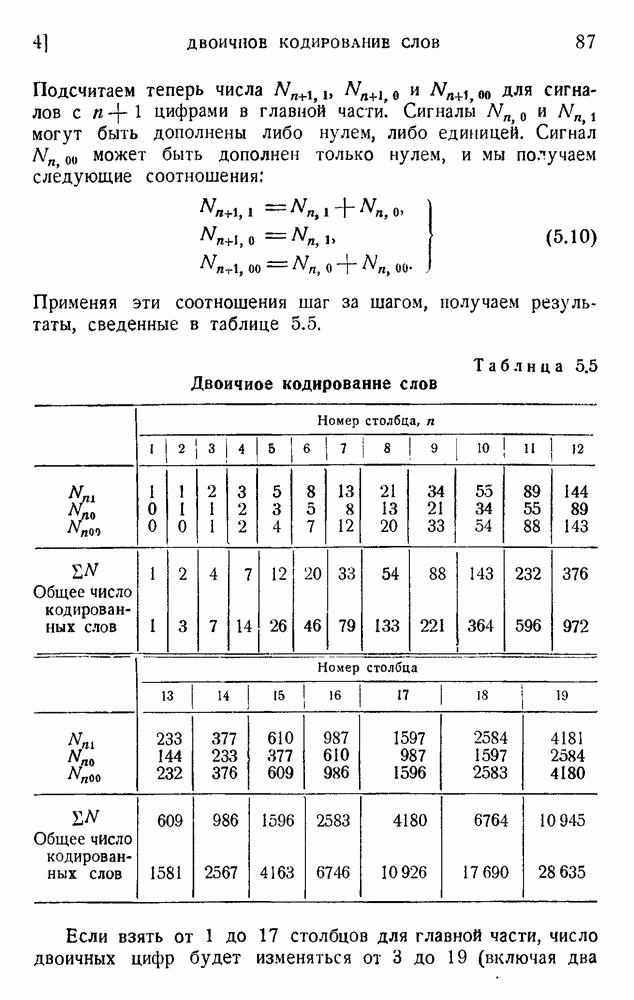
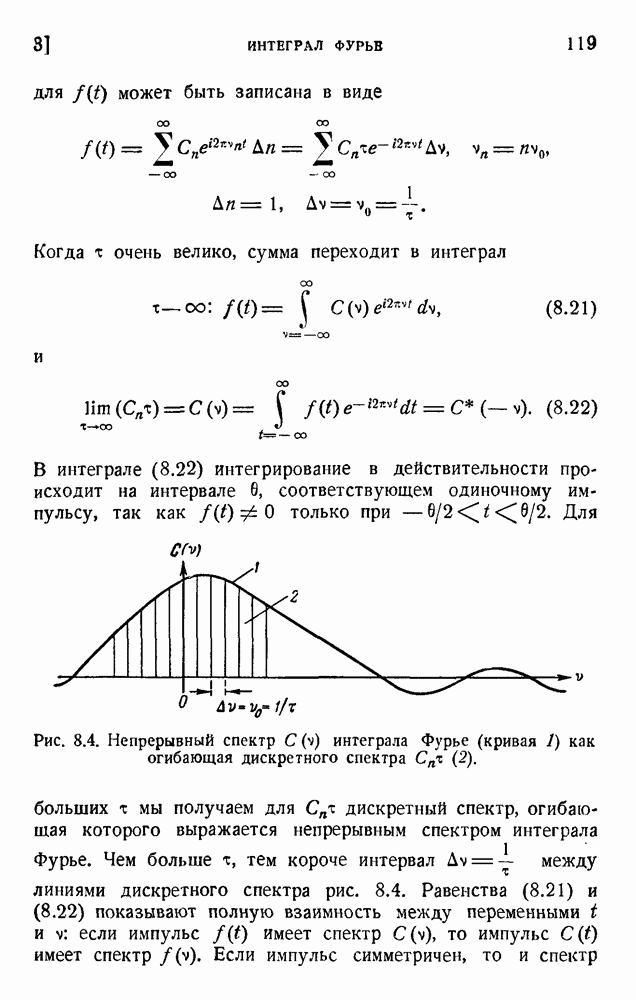
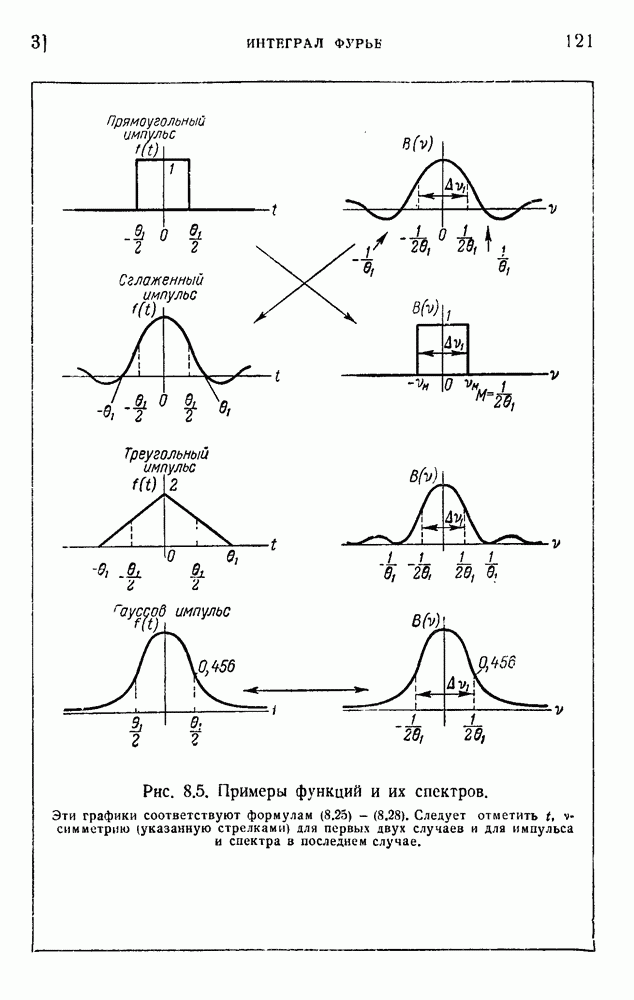
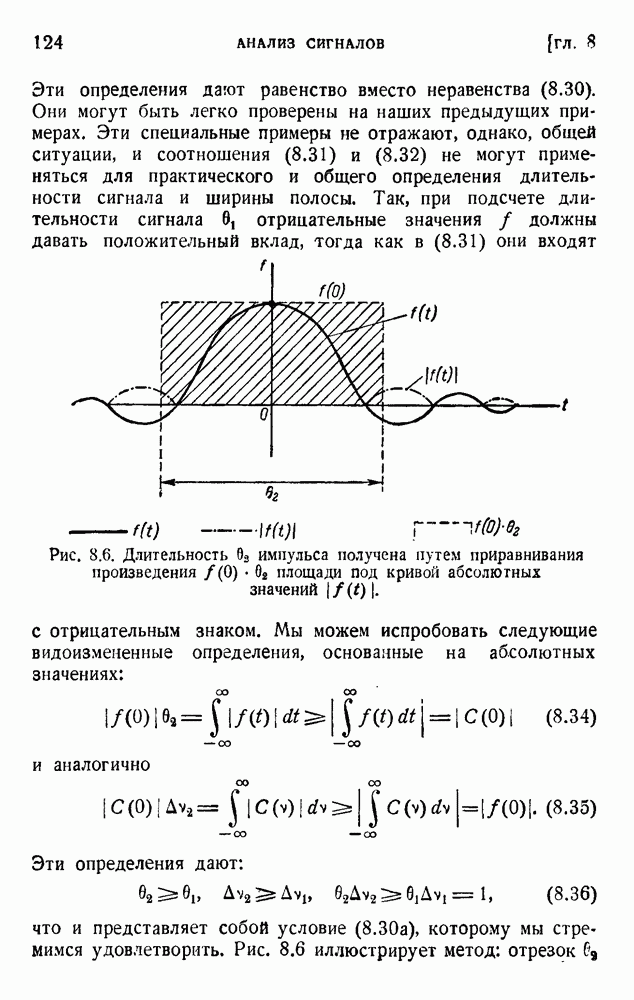
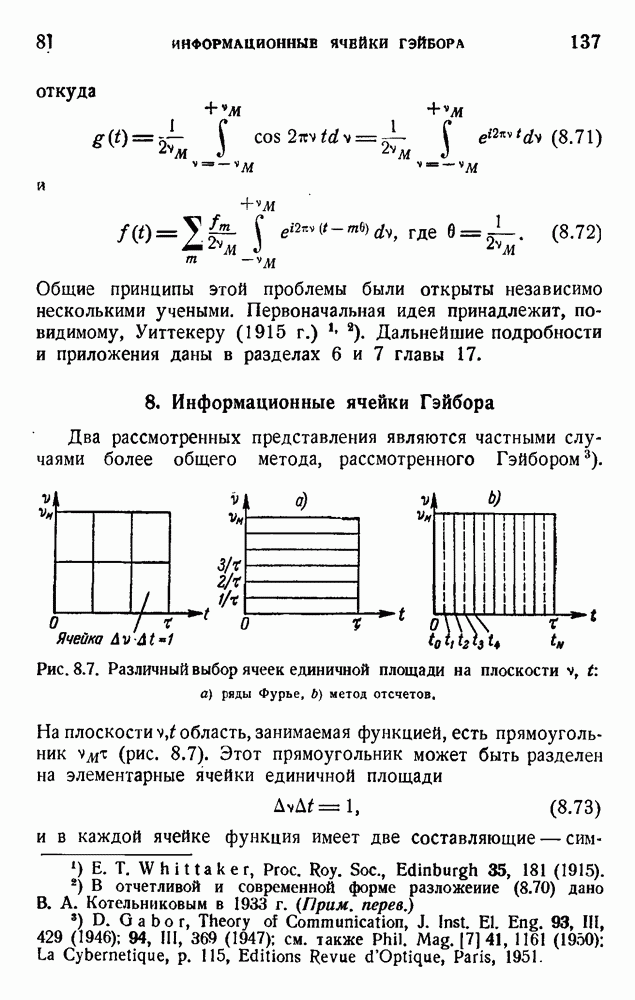
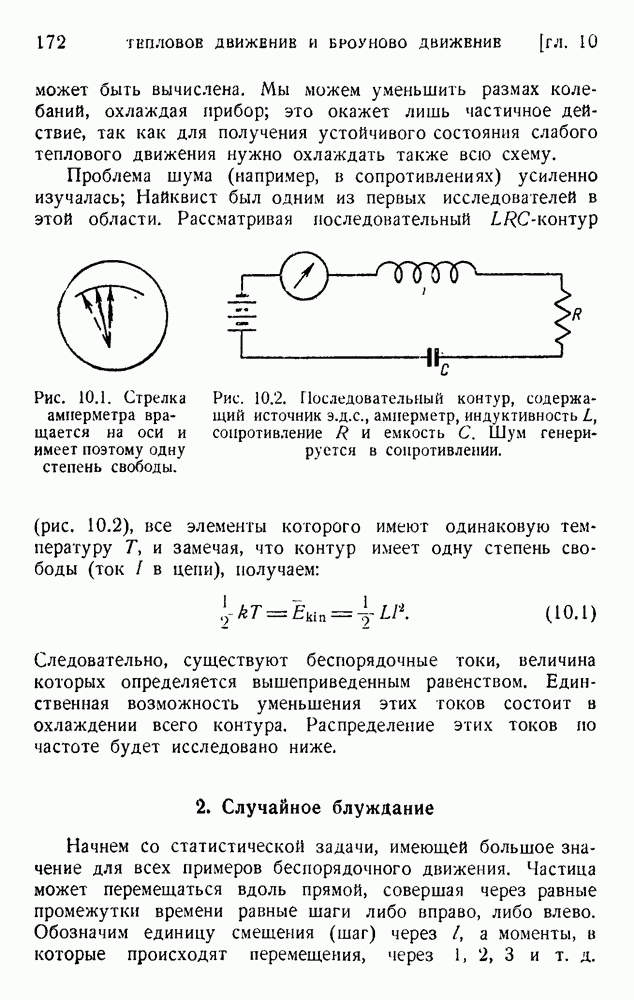
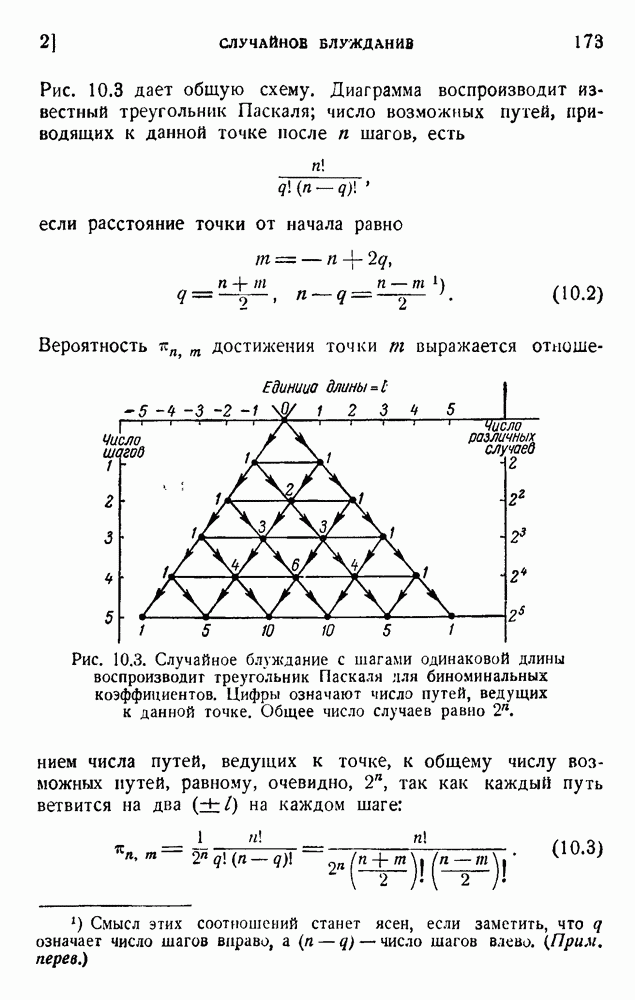
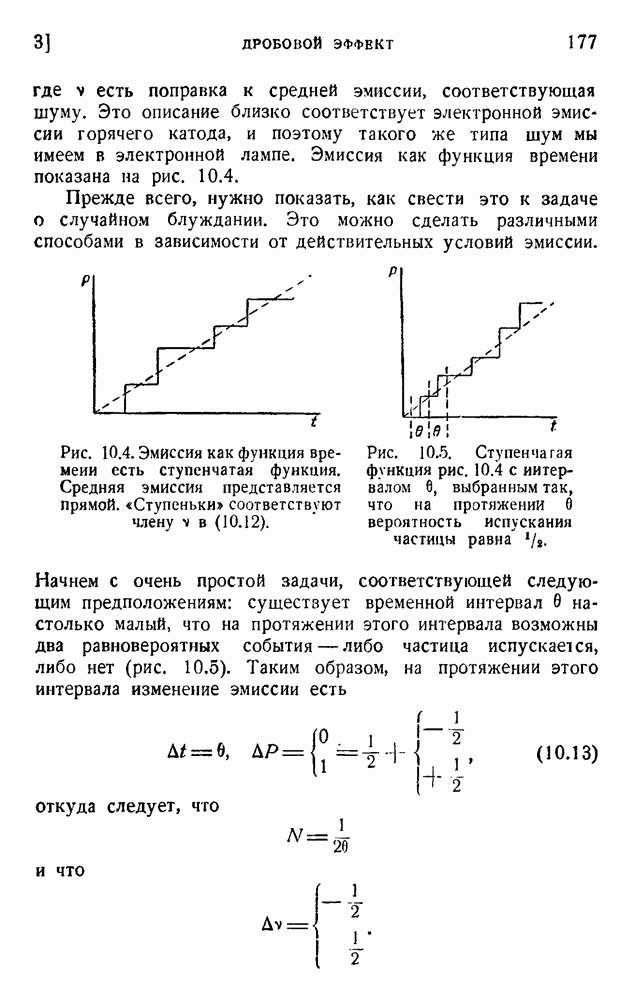
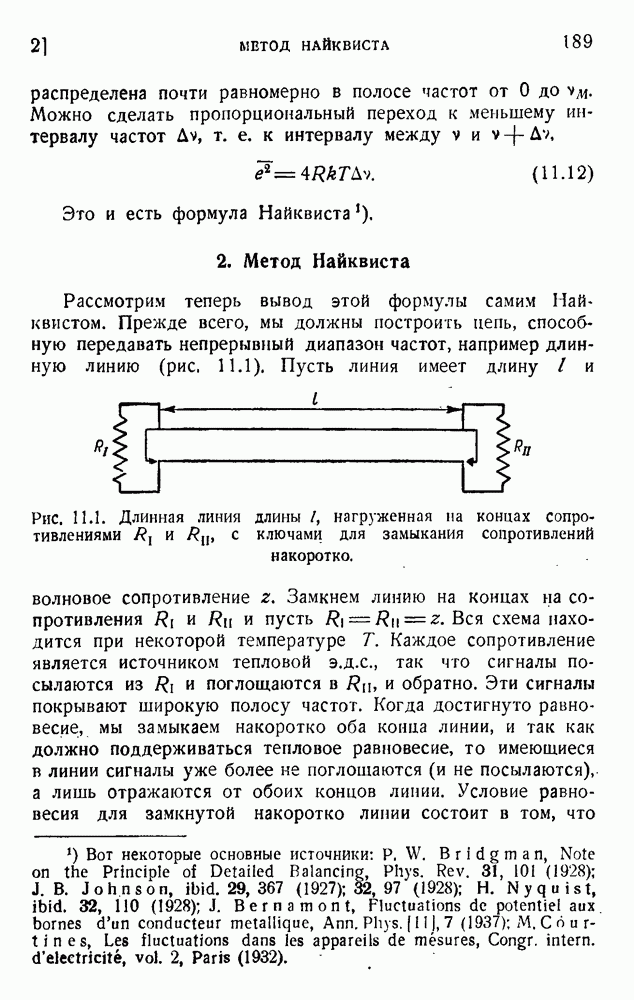
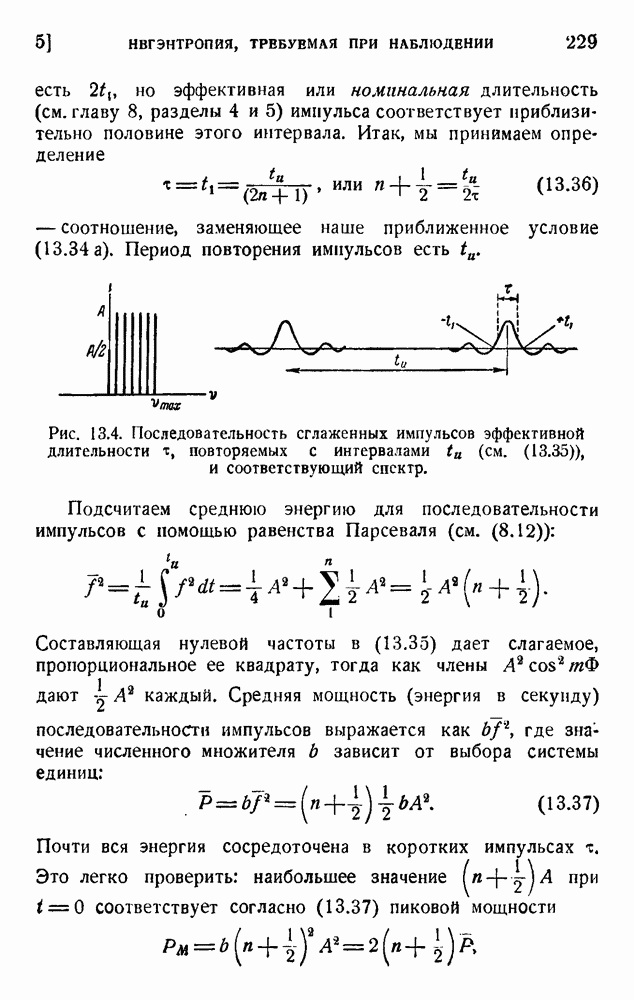
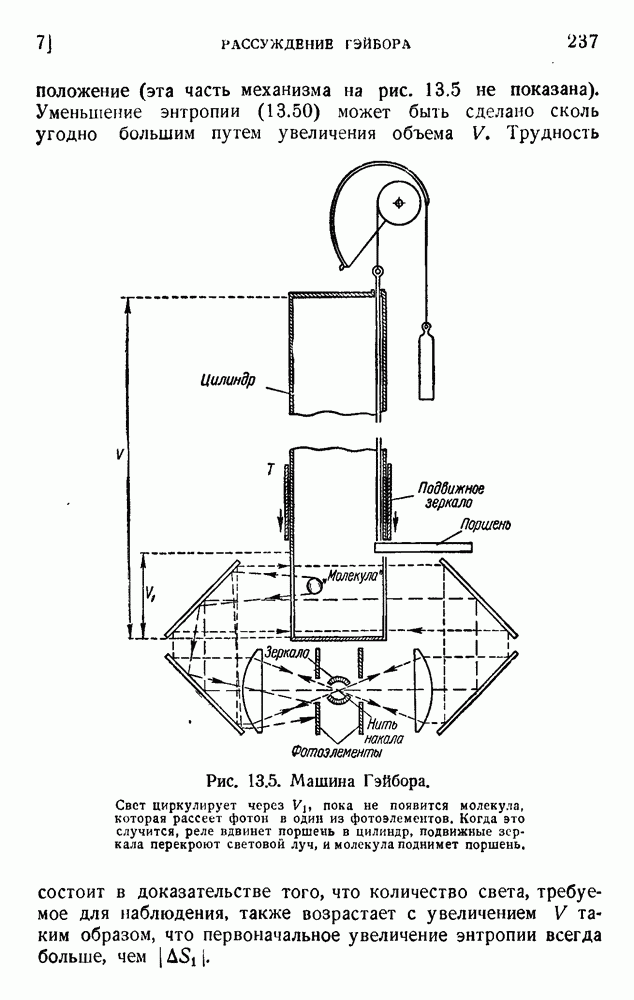
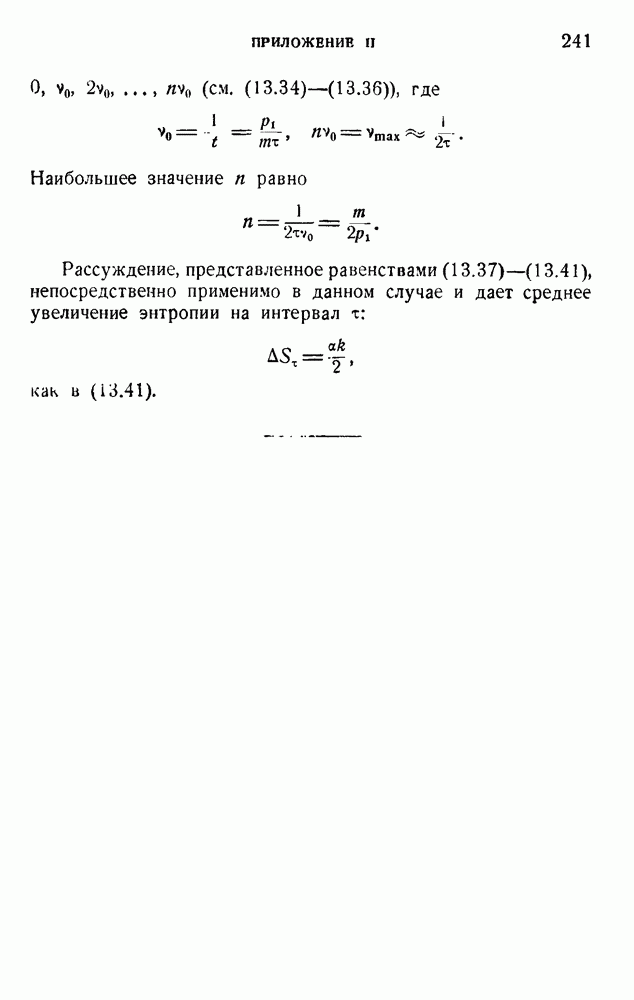
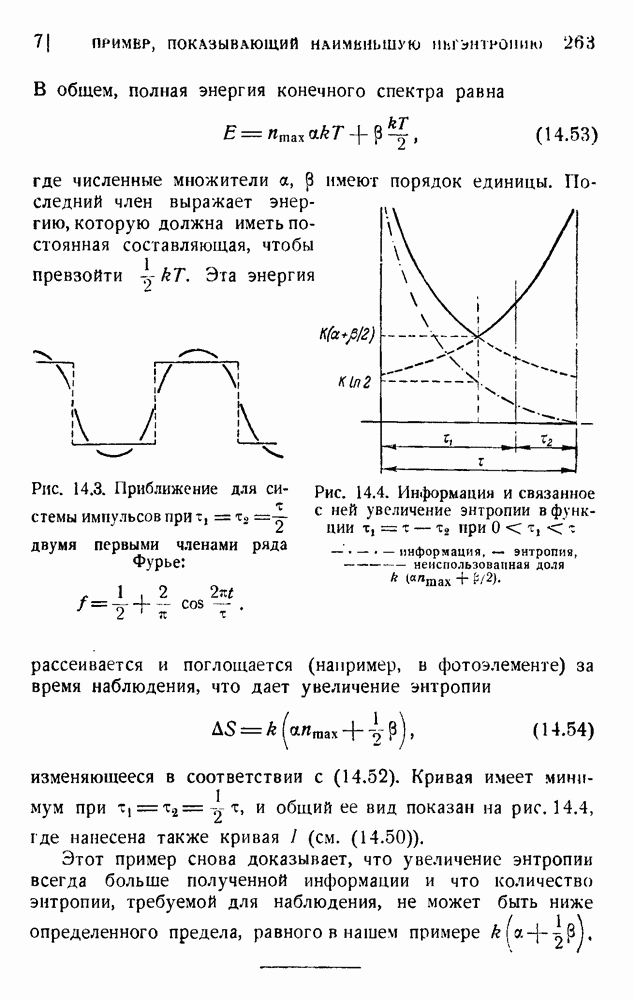
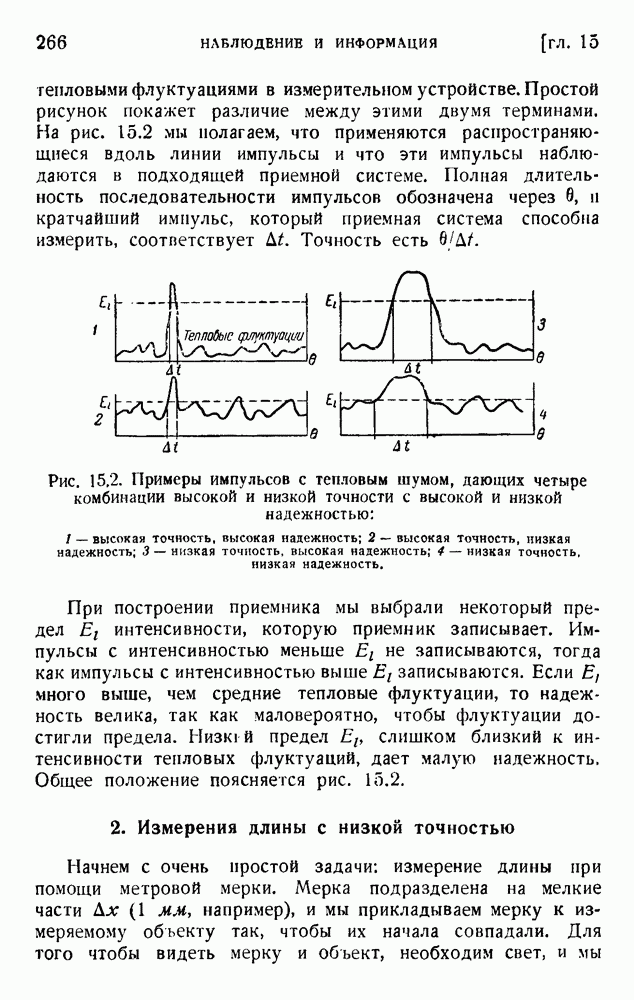
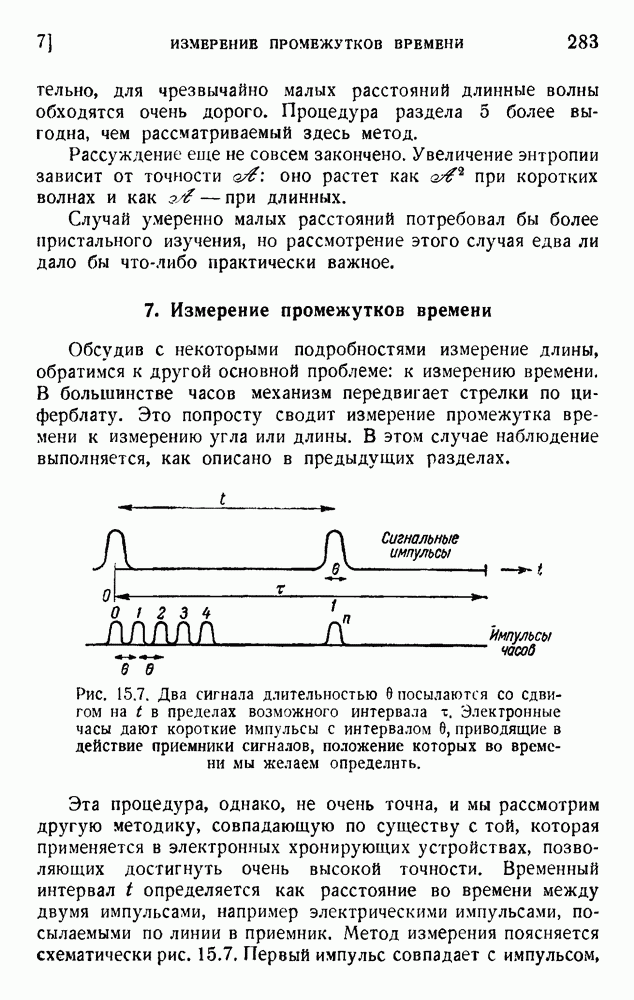
6. Кодирование, основанное на группах букв и на корреляции
В конце главы 3 упоминалась общая процедура кодирования, предложенная Шенноном. Метод основан на применении запоминающегося устройства и на использовании корреляционных связей при кодировании следующих друг за другом букв. Эта процедура является прямым приложением математического анализа главы 3, но он может применяться только к языку, в котором вероятности диграмм и триграмм (т. е. групп из двух, трех и более букв) известны из предшествующего статистического исследования языка.
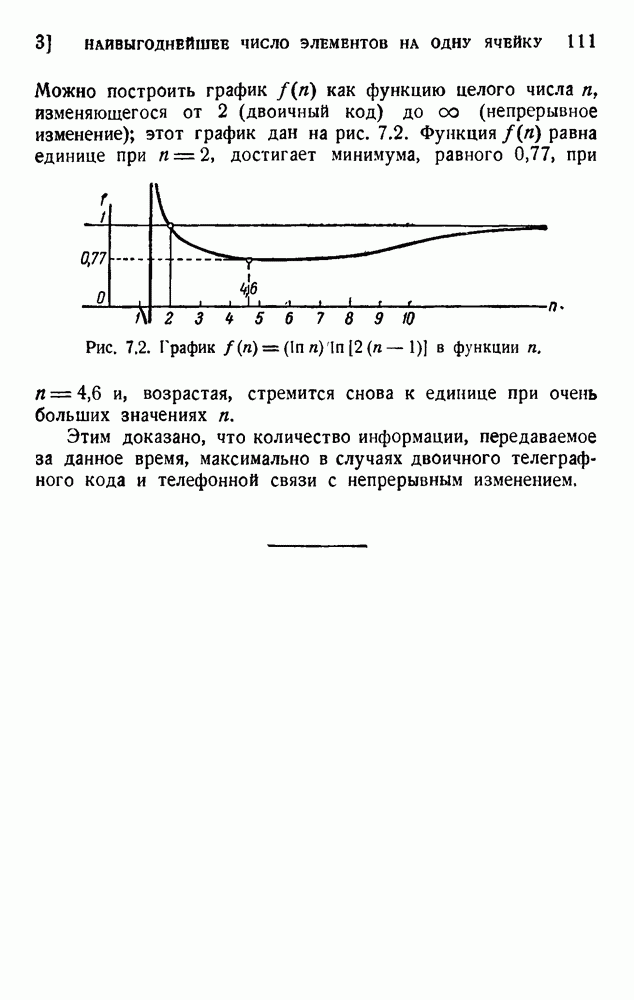
Оливер 2) недавно рассмотрел практические методы этого рода. Он полагал, что при передаче применяются 27 импульсов
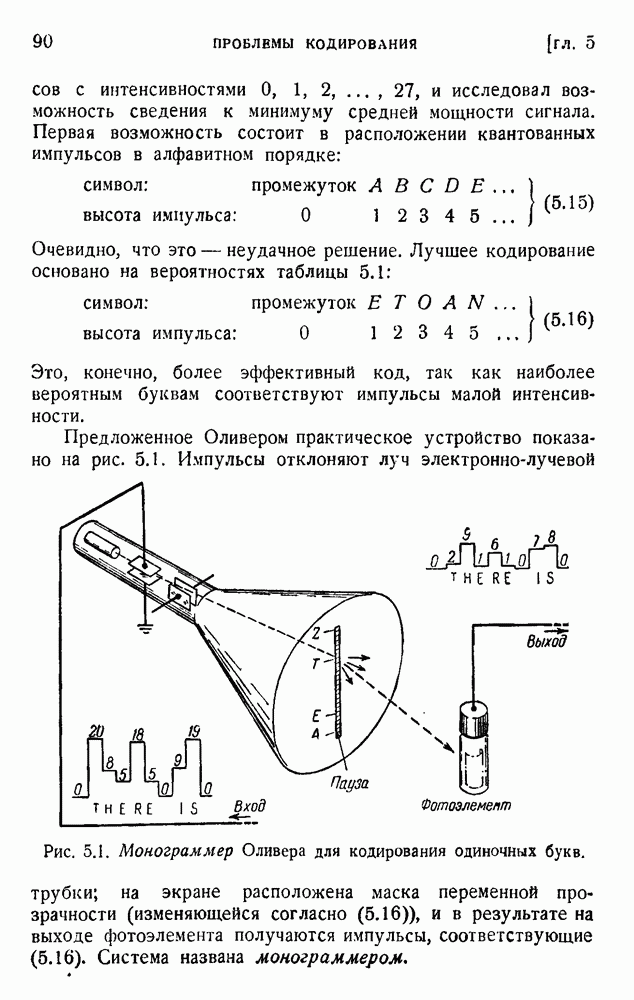
с интенсивностями 0, 1, 2,... , 27, и исследовал возможность сведения к минимуму средней мощности сигнала. Первая возможность состоит в расположении квантованных импульсов в алфавитном порядке:

Очевидно, что это — неудачное решение. Лучшее кодирование основано на вероятностях таблицы 5.1:

Это, конечно, более эффективный код, так как наиболее вероятным буквам соответствуют импульсы малой интенсивности.

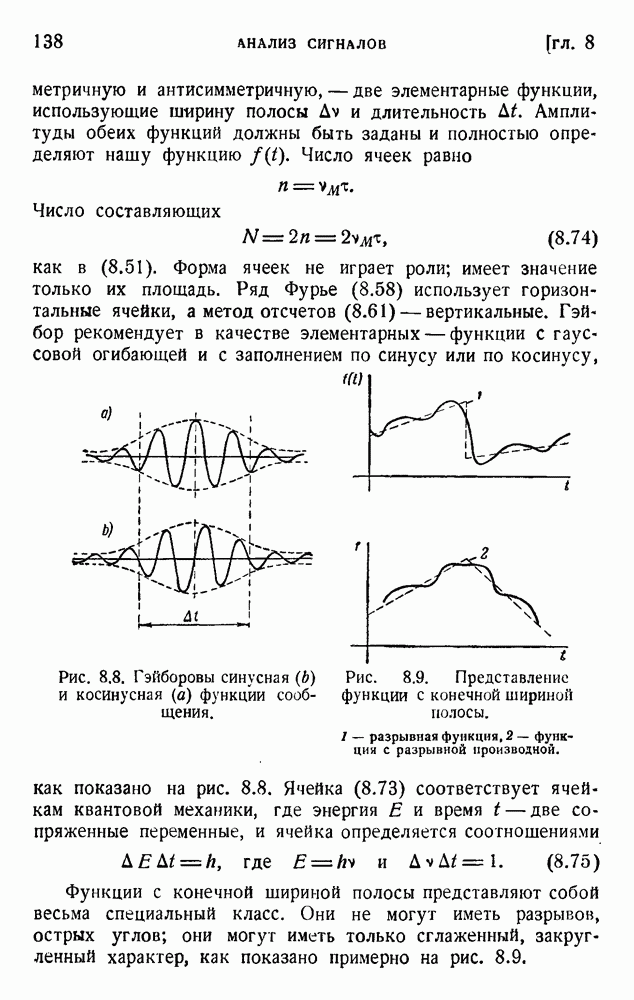
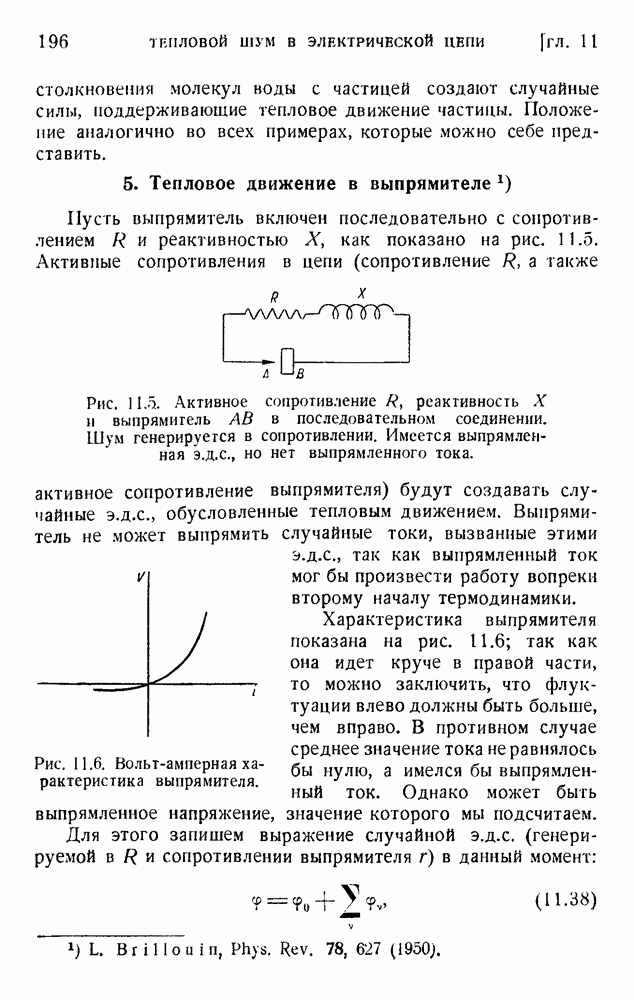
Рис. 5.1. Монограммер Оливера для кодирования одиночных букв.
Предложенное Оливером практическое устройство показано на рис. 5.1. Импульсы отклоняют луч электронно-лучевой трубки; на экране расположена маска переменной прозрачности (изменяющейся согласно (5.16)), и в результате на выходе фотоэлемента получаются импульсы, соответствующие (5.16). Система названа монограммером.
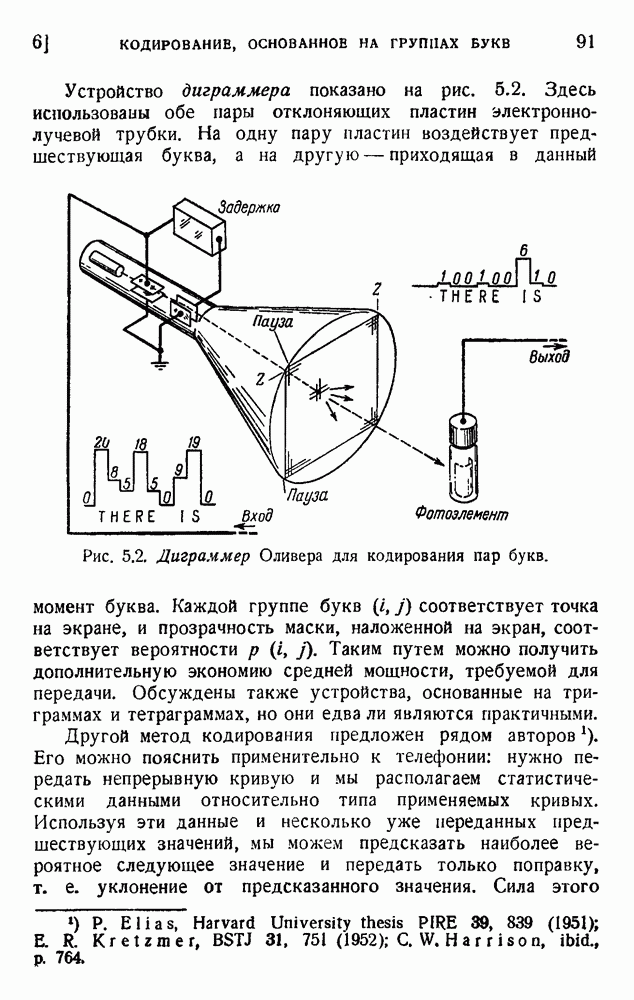
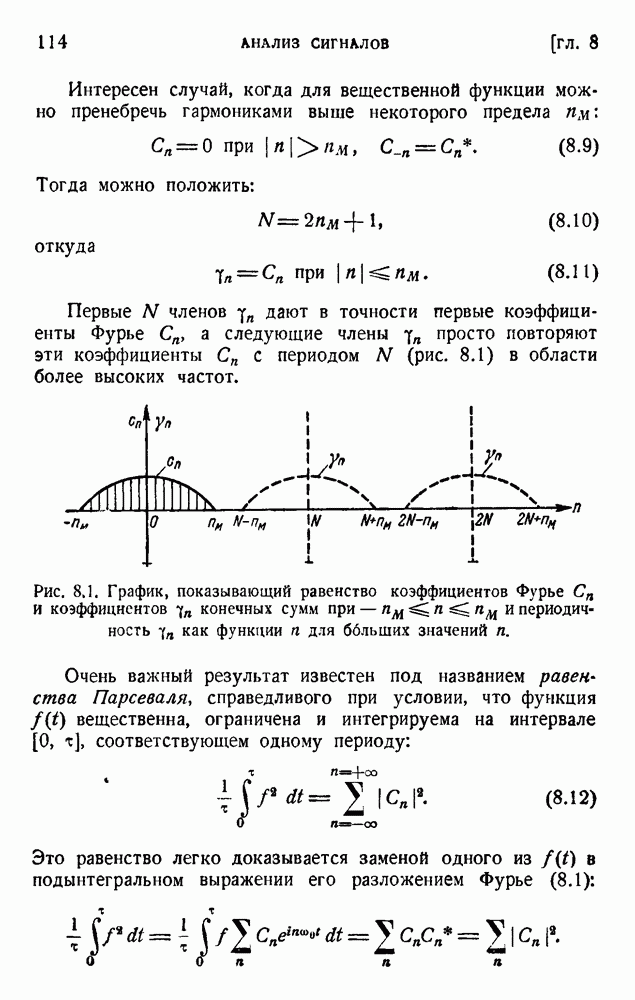
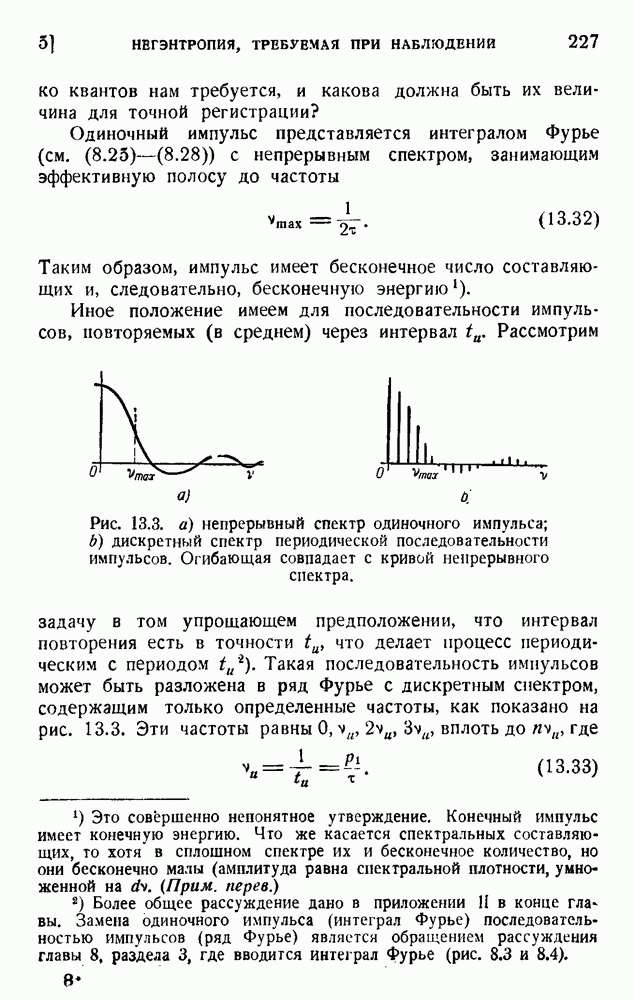
Устройство диграмжра показано на рис. 5.2. Здесь использованы обе пары отклоняющих пластин электроннолучевой трубки. На одну пару пластин воздействует предшествующая буква, а на другую — приходящая в данный момент буква.

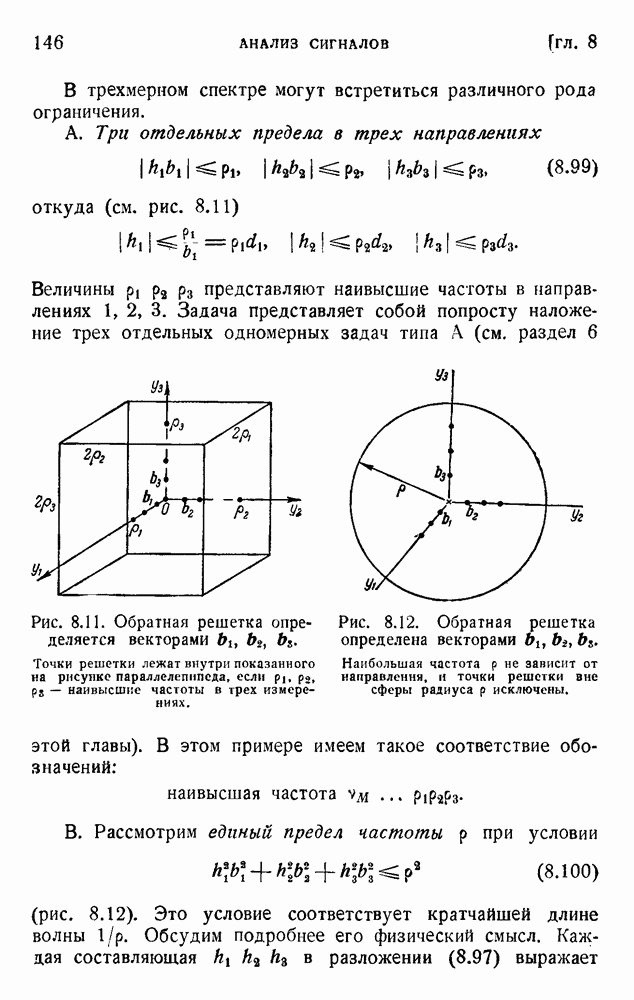
Рис. 5.2. Диграммер Оливера для кодирования пар букв.
Каждой группе букв (i, j) соответствует точка на экране, и прозрачность маски, наложенной на экран, соответствует вероятности  . Таким путем можно получить дополнительную экономию средней мощности, требуемой для передачи. Обсуждены также устройства, основанные на триграммах и тетраграммах, но они едва ли являются практичными.
. Таким путем можно получить дополнительную экономию средней мощности, требуемой для передачи. Обсуждены также устройства, основанные на триграммах и тетраграммах, но они едва ли являются практичными.
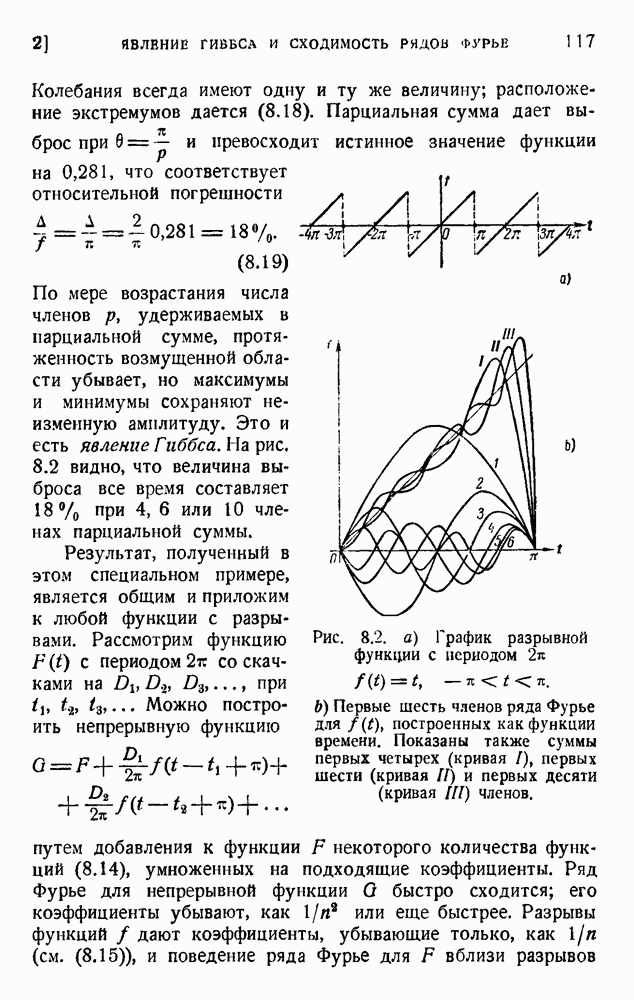
Другой метод кодирования предложен рядом авторов). Его можно пояснить применительно к телефонии: нужно передать непрерывную кривую и мы располагаем статистическими данными относительно типа применяемых кривых. Используя эти данные и несколько уже переданных предшествующих значений, мы можем предсказать наиболее вероятное следующее значение и передать только поправку, т. е. уклонение от предсказанного значения. Сила этого
метода состоит в том, что он может быть применен в двух измерениях (телевидение) при условии, что имеются соответствующие статистические данные. Применительно к телевидению рассмотрим систему, применяющую  уровней квантования. Если все уровни равновероятны, нам потребуется 6 дв. ед. на каждый элемент изображения. Однако различные уровни имеют различную вероятность, и это простое обстоятельство сразу уменьшает информацию до 5 дв. ед. на элемент. Используя корреляцию между соседними элементами, можно снизить эту величину до 2,4 — 2,6 дв. ед. на элемент. Это представляет потенциальную возможность сокращения пропускной способности телевизионного канала вдвое. Как и в других аналогичных проблемах, нужно, однако, заметить, что передача с малой избыточностью в значительно большей мере страдает от помех, так как устранение избыточности уменьшает также возможность предсказания и исправления ошибок при приеме.
уровней квантования. Если все уровни равновероятны, нам потребуется 6 дв. ед. на каждый элемент изображения. Однако различные уровни имеют различную вероятность, и это простое обстоятельство сразу уменьшает информацию до 5 дв. ед. на элемент. Используя корреляцию между соседними элементами, можно снизить эту величину до 2,4 — 2,6 дв. ед. на элемент. Это представляет потенциальную возможность сокращения пропускной способности телевизионного канала вдвое. Как и в других аналогичных проблемах, нужно, однако, заметить, что передача с малой избыточностью в значительно большей мере страдает от помех, так как устранение избыточности уменьшает также возможность предсказания и исправления ошибок при приеме.