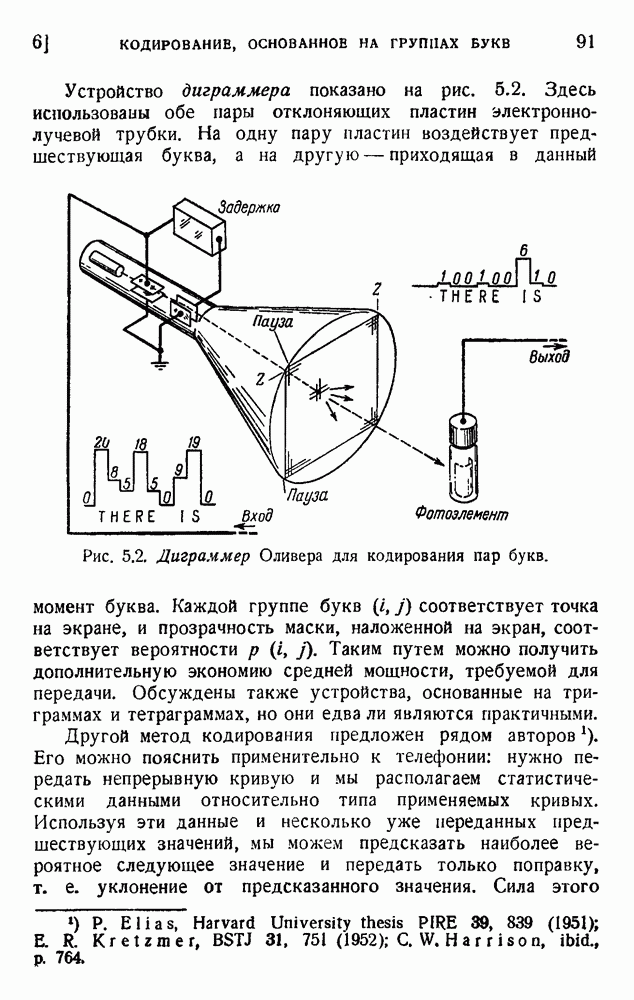
4. Эффективность исправляющих кодов
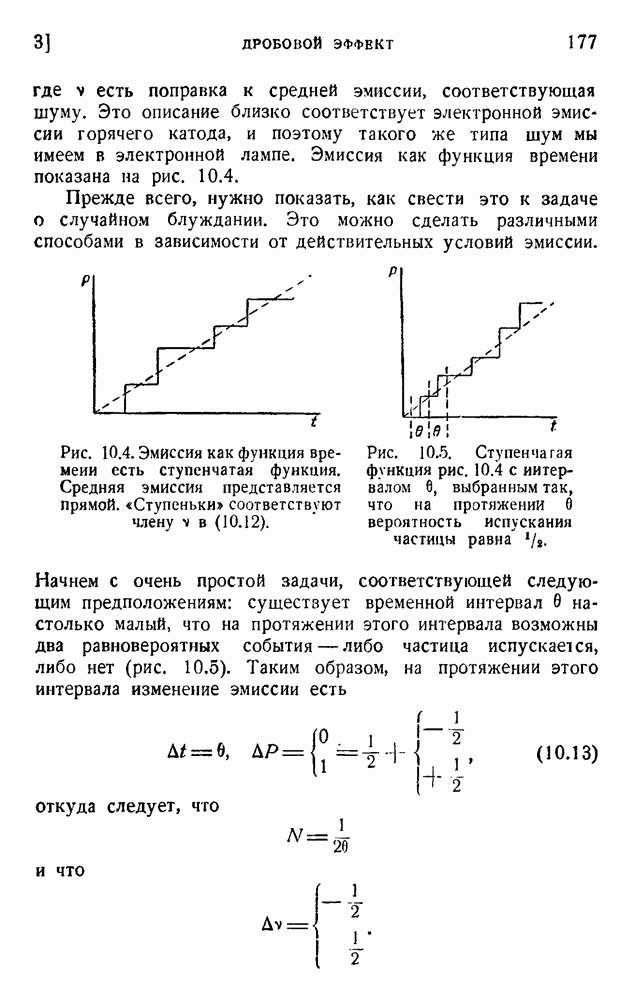
Исправляющие коды, описанные в предыдущих разделах, могут быть использованы следующим образом. Возьмем в качестве примера код «4 из 7» (см. таблицу 6.3). Начнем с некоторого сообщения, кодированного двоичными цифрами, например:
 (6.5)
(6.5)
и разделим его на группы по четыре цифры в каждой:
 (6.6)
(6.6)
Дополним теперь каждую из этих четырехзначных групп еще тремя знаками, соответствующими проверкам на четность, согласно (6.2):
 (6.7)
(6.7)
Это сообщение передается, приемник применяет проверки на четность для исправления ошибок, затем устраняет излишние последние три знака в каждой семизначной группе и восстанавливает исходное сообщение в виде (6.6) и (6.5).
Этот метод годится в том случае, если на я символов никогда не приходится больше одной ошибки (в нашем примере  ). Это условие никогда в точности не выполняется. Обычно имеется совокупность случайных ошибок со средней вероятностью р. Мы покажем, что исправляющий код может
). Это условие никогда в точности не выполняется. Обычно имеется совокупность случайных ошибок со средней вероятностью р. Мы покажем, что исправляющий код может
значительно уменьшить число ошибок и дать малую вероятность Р неисправленных ошибок.
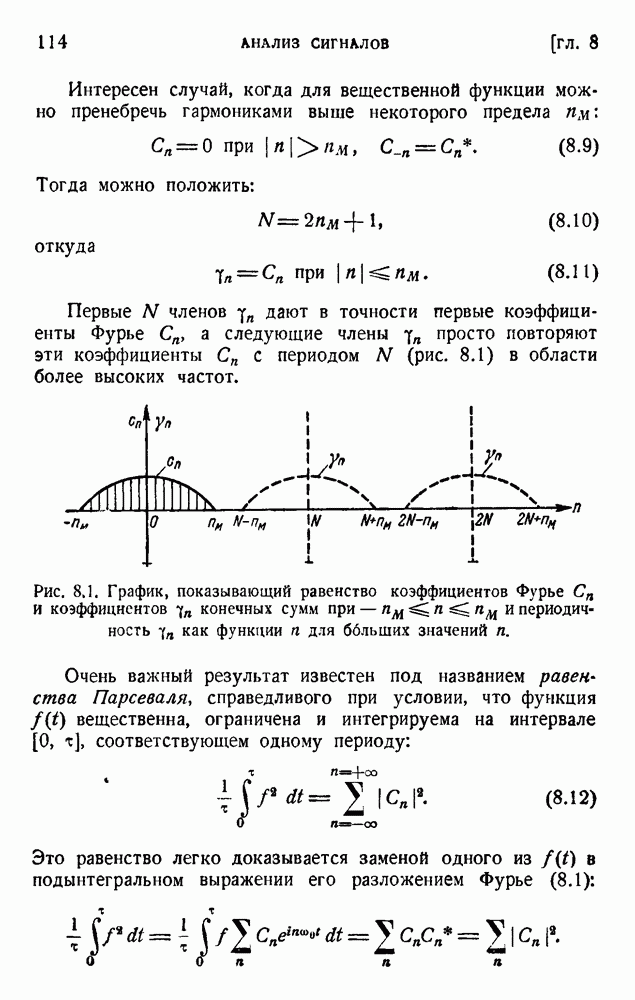
Пусть р означает вероятность ошибки в некотором определенном знаке. Это означает переход 0 в 1 или 1 в 0. Влзьмем код  , т. е. код с k проверочными знаками и m информационными позициями, а всего с n двоичными позициями, согласно таблице 6.1. В данной последовательности из n двоичных цифр имеем следующие вероятности:
, т. е. код с k проверочными знаками и m информационными позициями, а всего с n двоичными позициями, согласно таблице 6.1. В данной последовательности из n двоичных цифр имеем следующие вероятности:

Рассмотрим случай одной ошибки, чтобы показать, как получаются величины  . В этом случае имеем
. В этом случае имеем  правильных знаков с вероятностью
правильных знаков с вероятностью  и один неверный знак (с вероятностью р), который может находиться в любой из n позиций. Это дает приведенное выше значение
и один неверный знак (с вероятностью р), который может находиться в любой из n позиций. Это дает приведенное выше значение  .
.
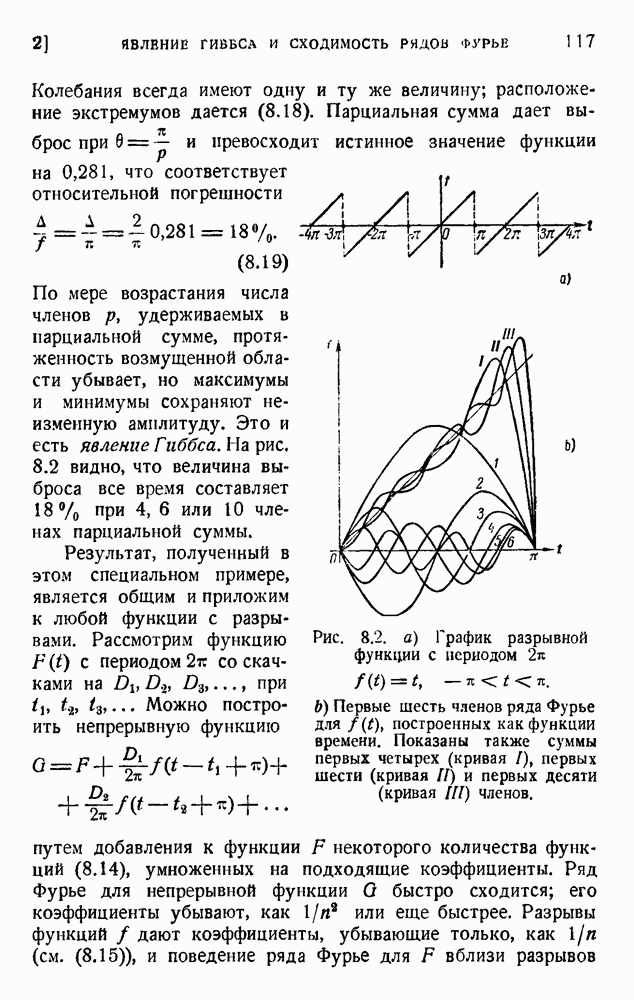
Дальнейшие вероятности вычисляются в предположении, что ошибки встречаются всегда в разных позициях. Это предположение оправдывается тем, что две ошибки, наложенные друг на друга, взаимно компенсируются и не оставляют следа: если мы имеем 1, которая в результате ошибки перешла в 0, то вторая ошибка снова дает нам 1. Таким образом, наложенные ошибки уменьшают число видимых ошибок.
Величины и, действительно являются вероятностями, так как их сумма равна единице:

(по формуле бинома).
Если ошибок нет или если имеется одна ошибка на всю последовательность, то сообщение будет принято правильно, но если будет иметься  ошибок то окончательчая последовательность будет неверна. Вероятность неправильной последовательности равна поэтому
ошибок то окончательчая последовательность будет неверна. Вероятность неправильной последовательности равна поэтому

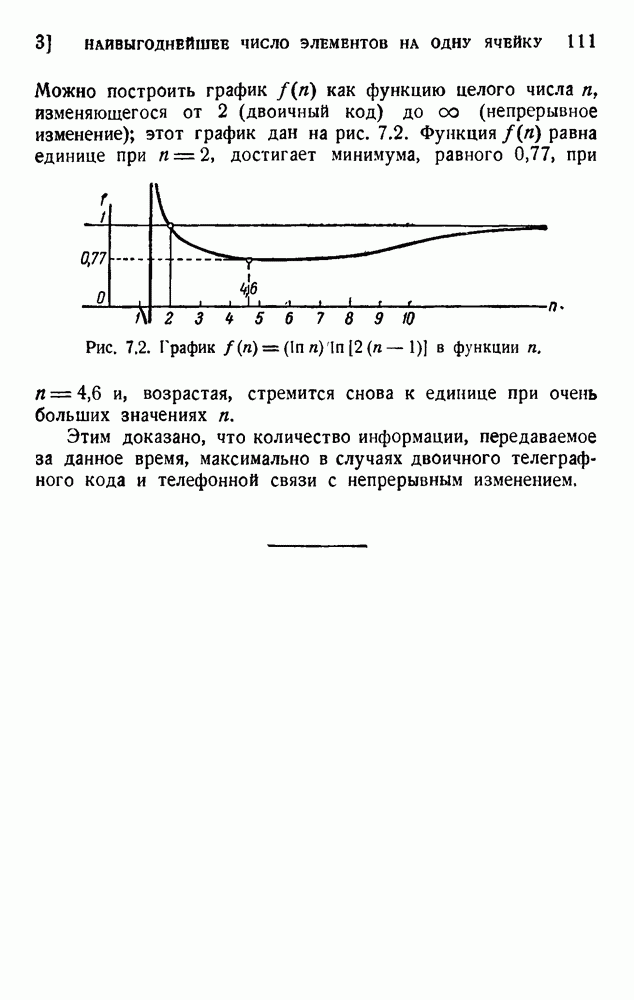
Пусть р мало; пренебрежем членами с  . Преобладающий член в выражении для Р зависит от
. Преобладающий член в выражении для Р зависит от

и эту величину нужно сравнить с ожидаемым числом ошибок без применения проверок. Это означало бы применение только m информационных позиций с вероятностью ошибки

Отношение  может служить мерой качества кода. Можно также ввести
может служить мерой качества кода. Можно также ввести  , что означает новую вероятность ошибки в одном исходном знаке после исправления. В таблице 6.5 даны значения
, что означает новую вероятность ошибки в одном исходном знаке после исправления. В таблице 6.5 даны значения  и р для нескольких кодов.
и р для нескольких кодов.
Таблица 6.5. Различные исправляющие коды и их характеристики















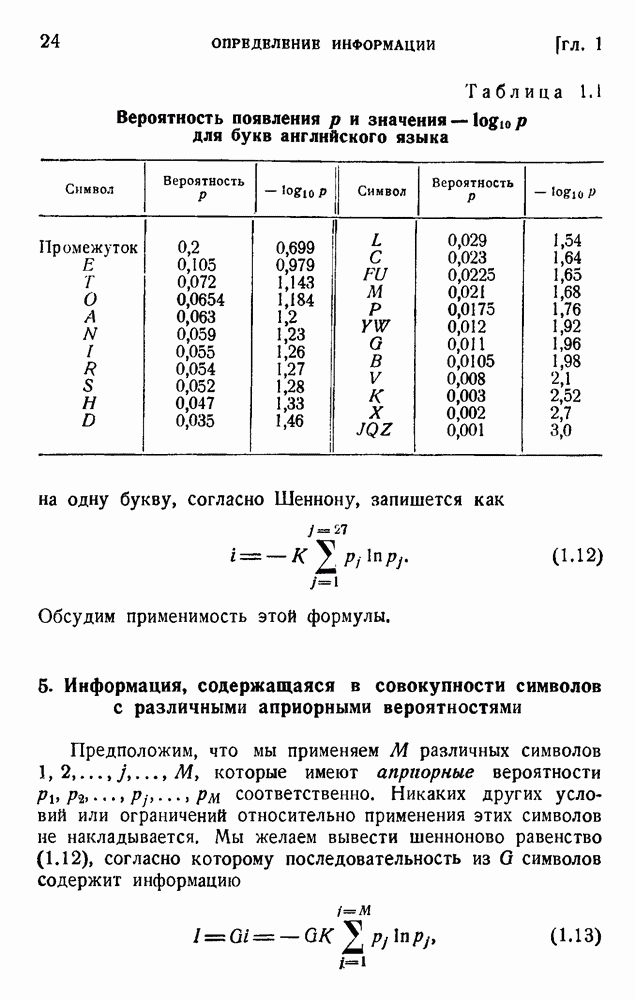










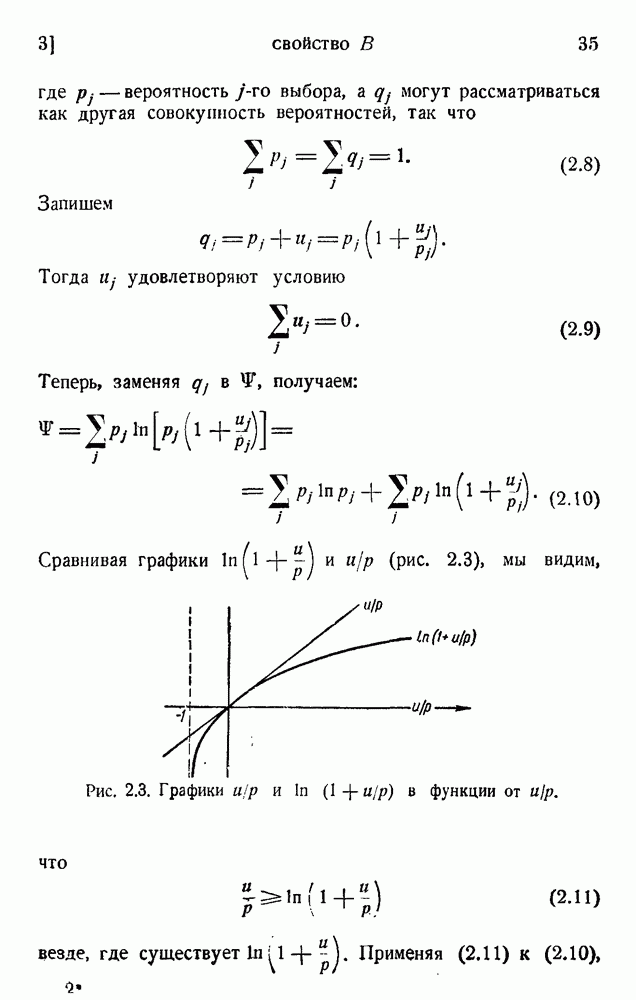











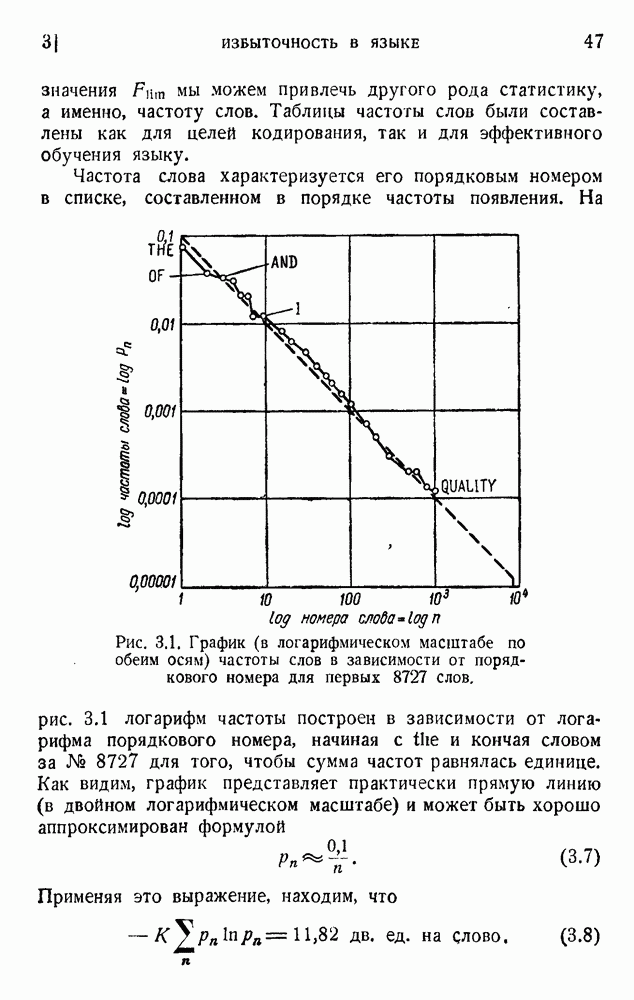

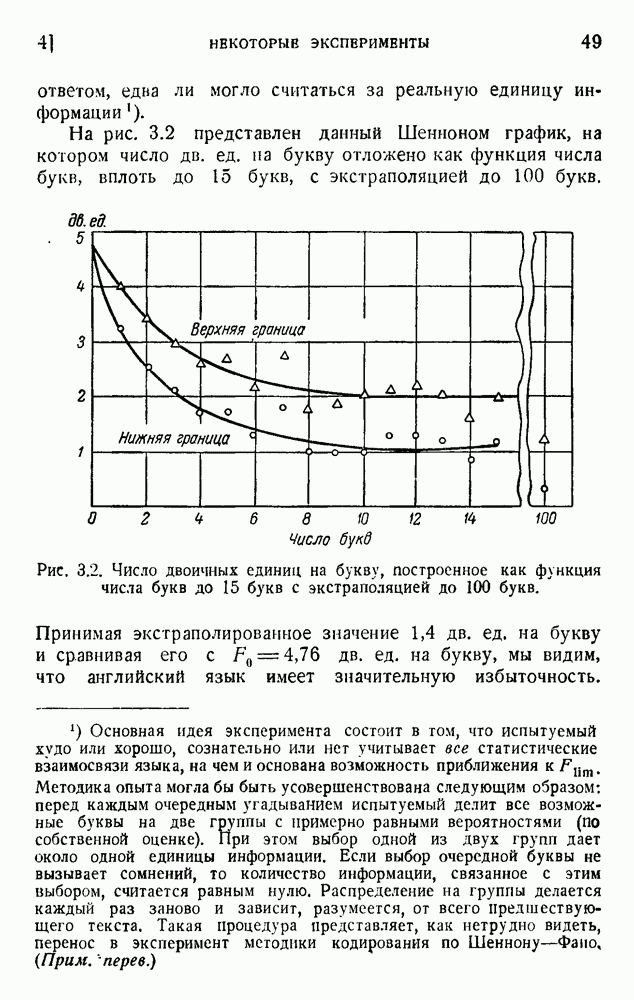

























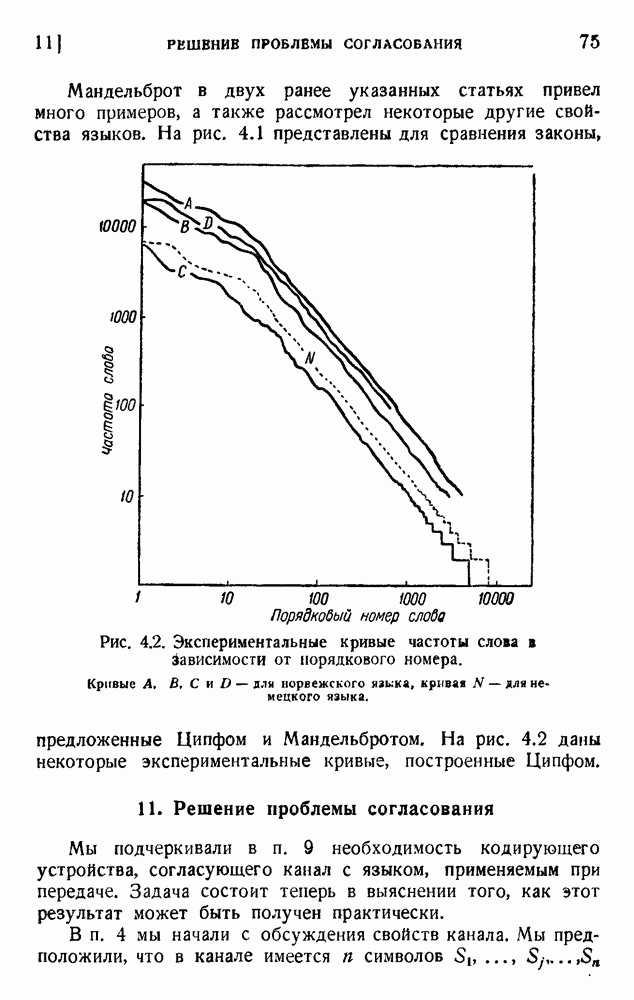





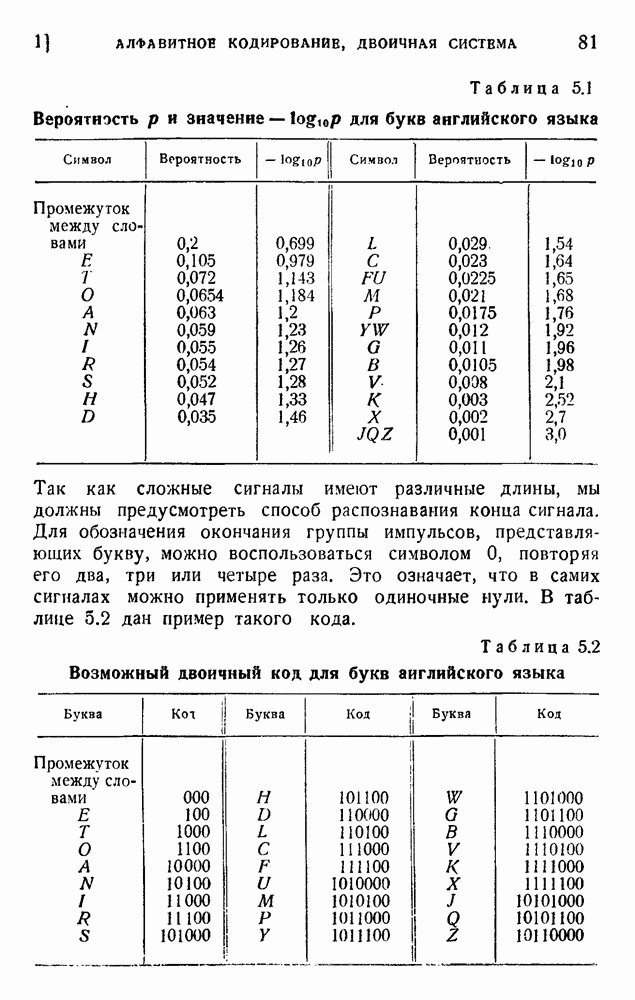





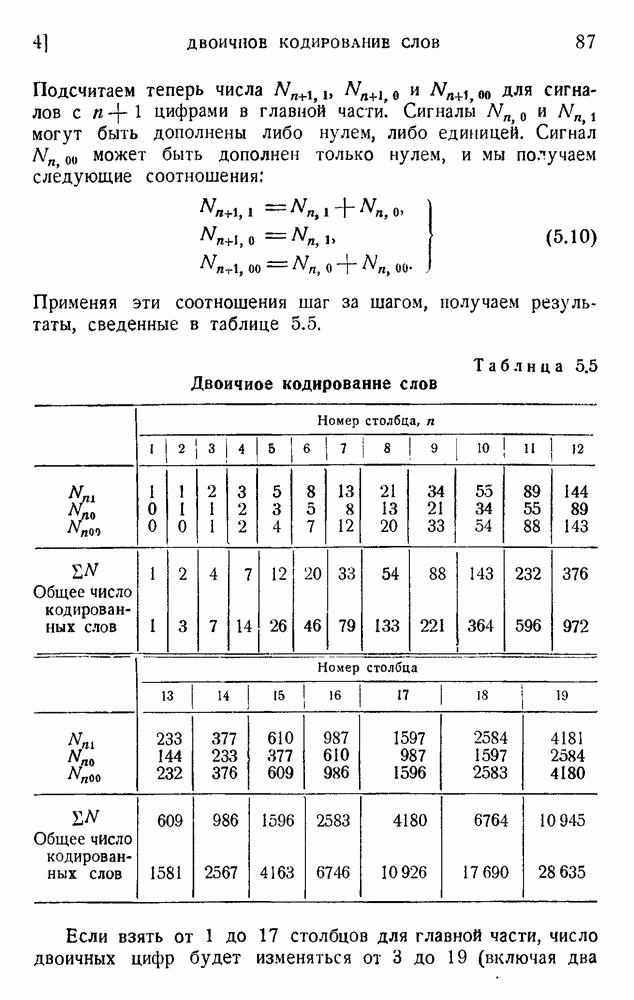


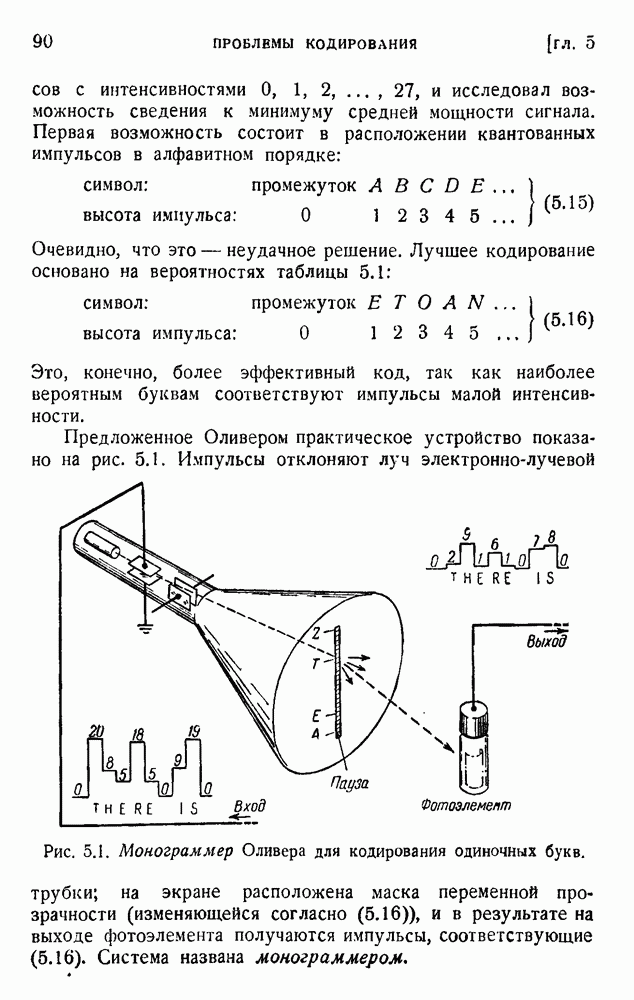
























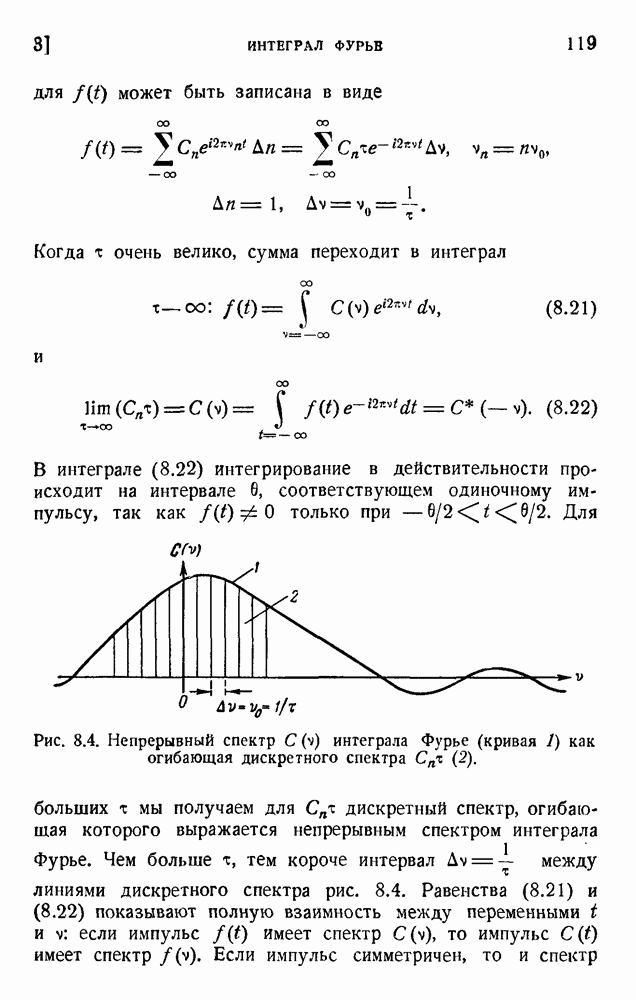

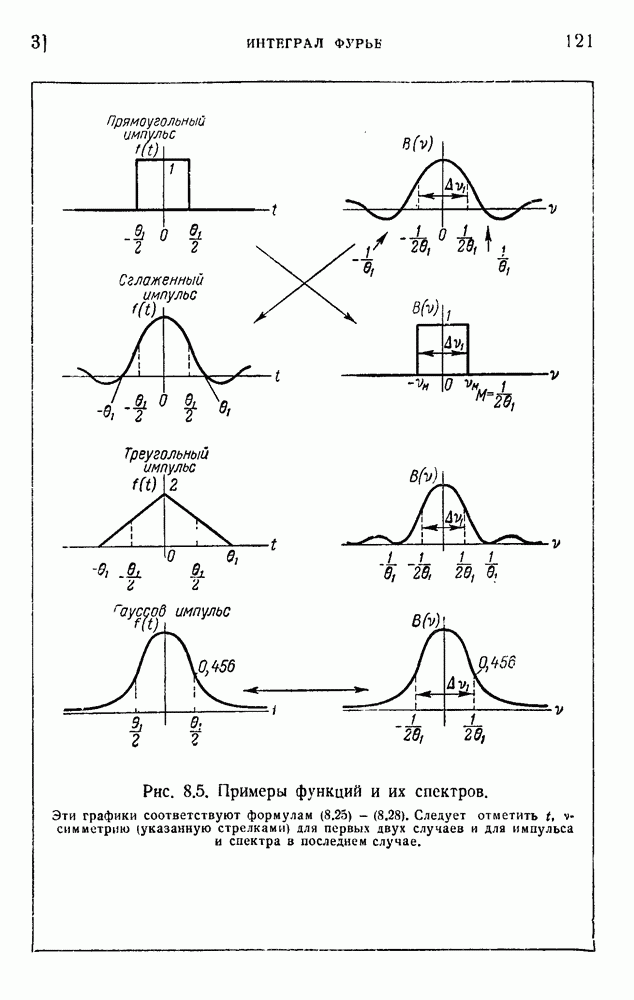


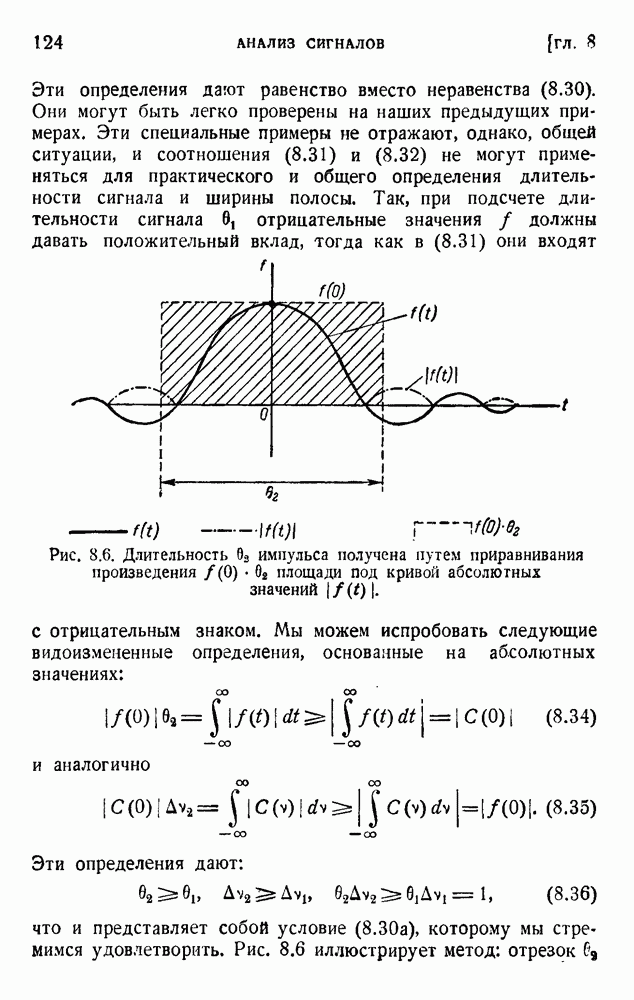












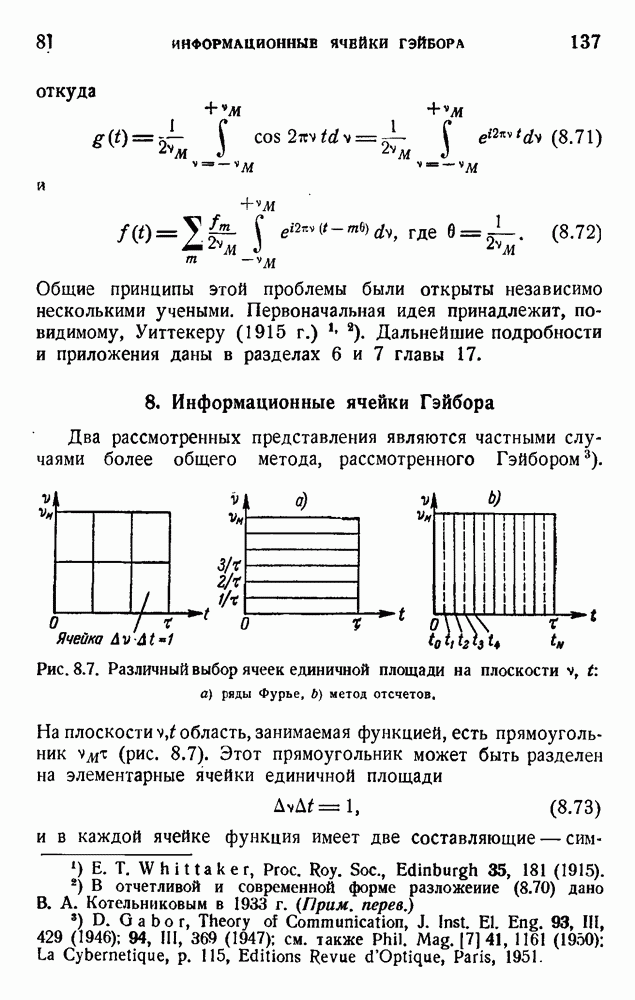
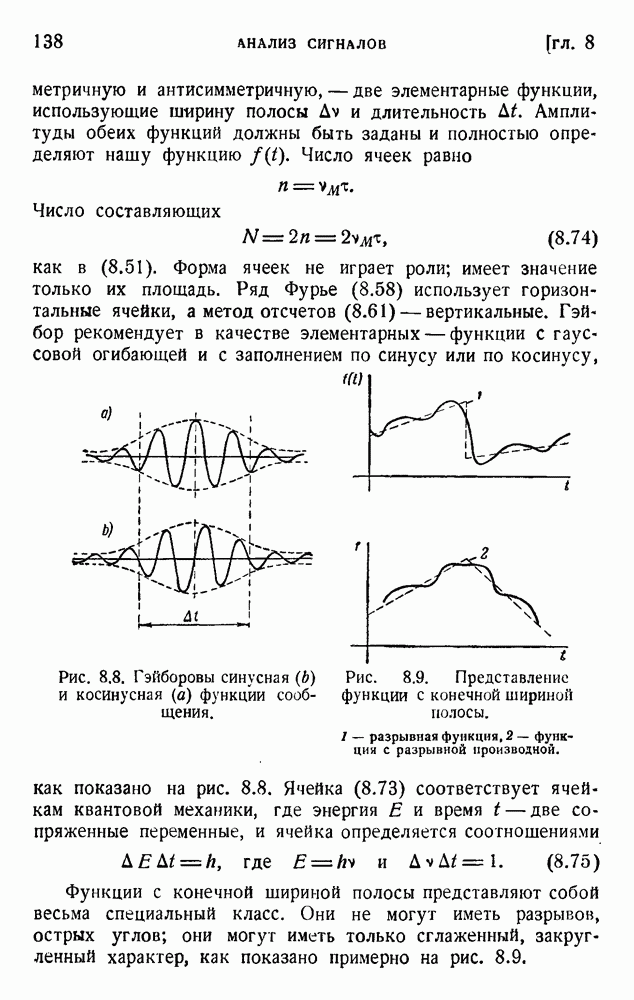







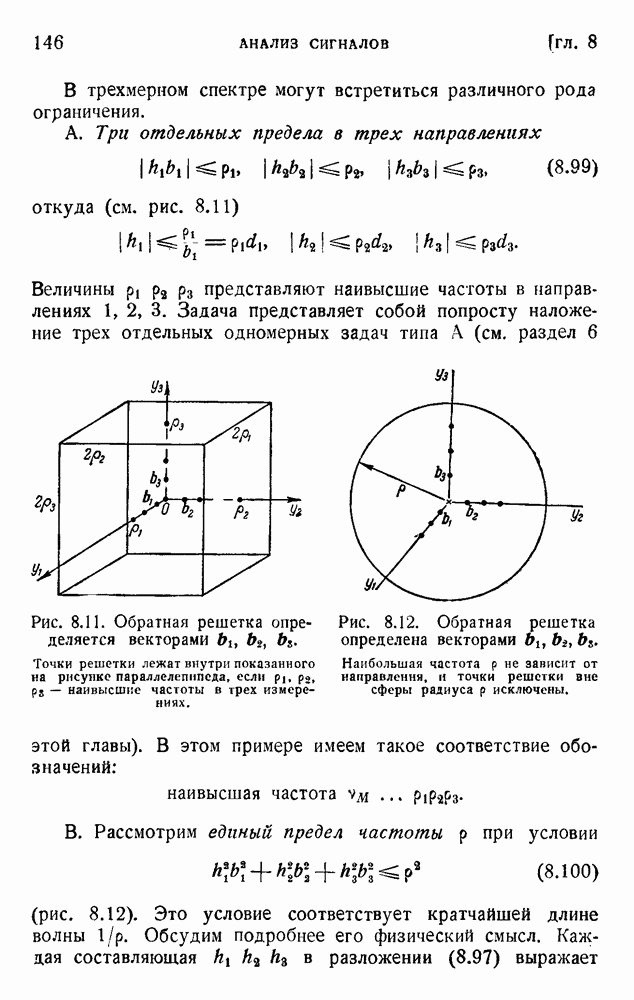

























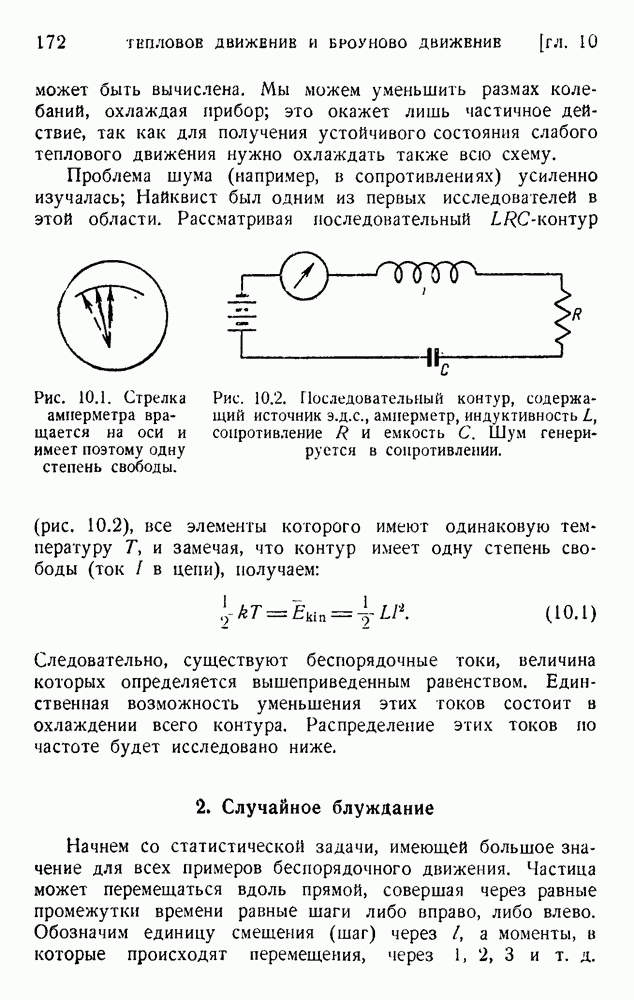
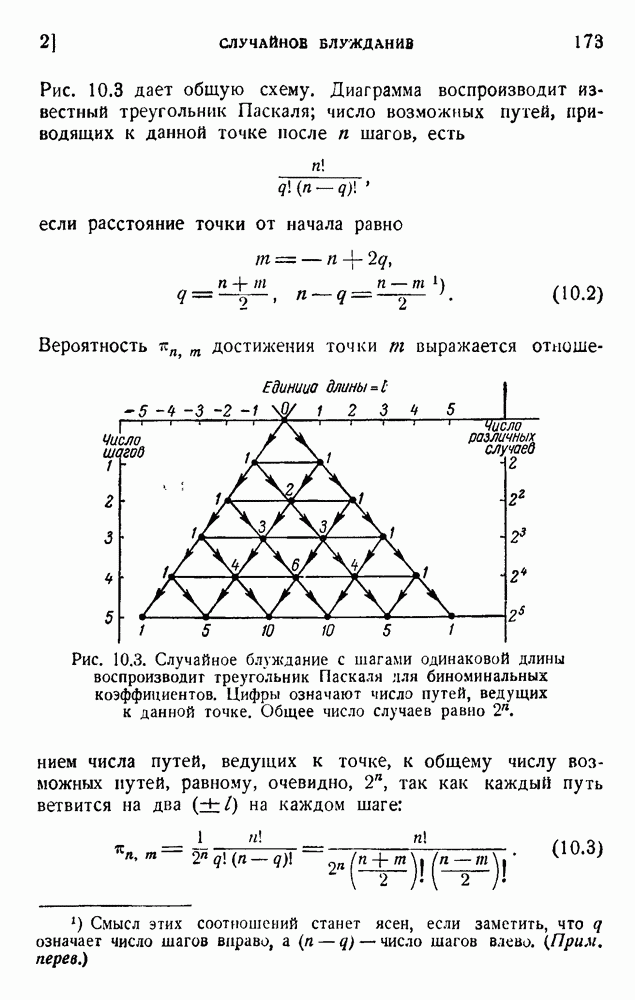



















































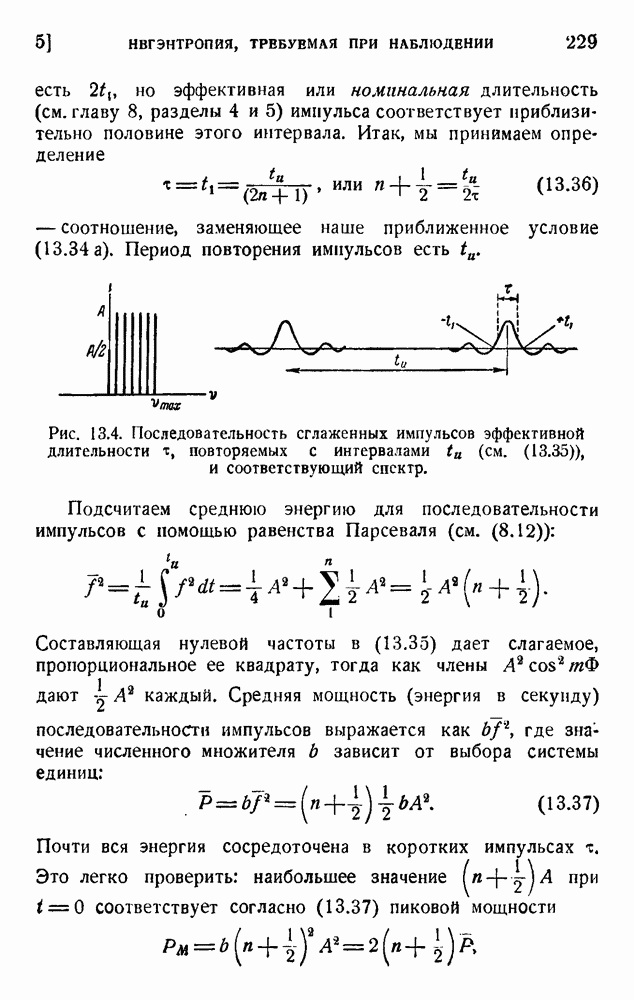







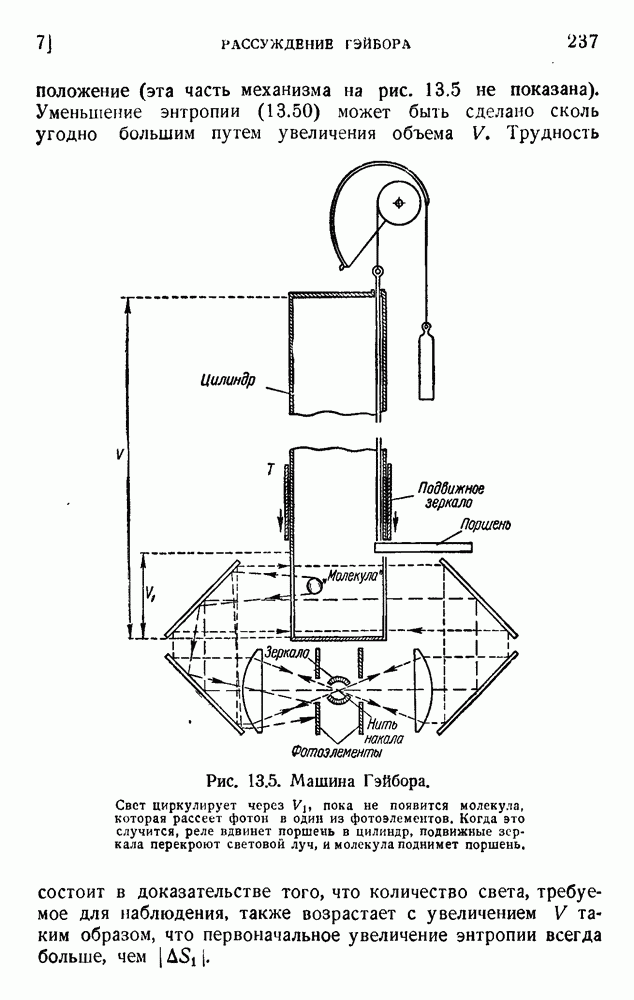



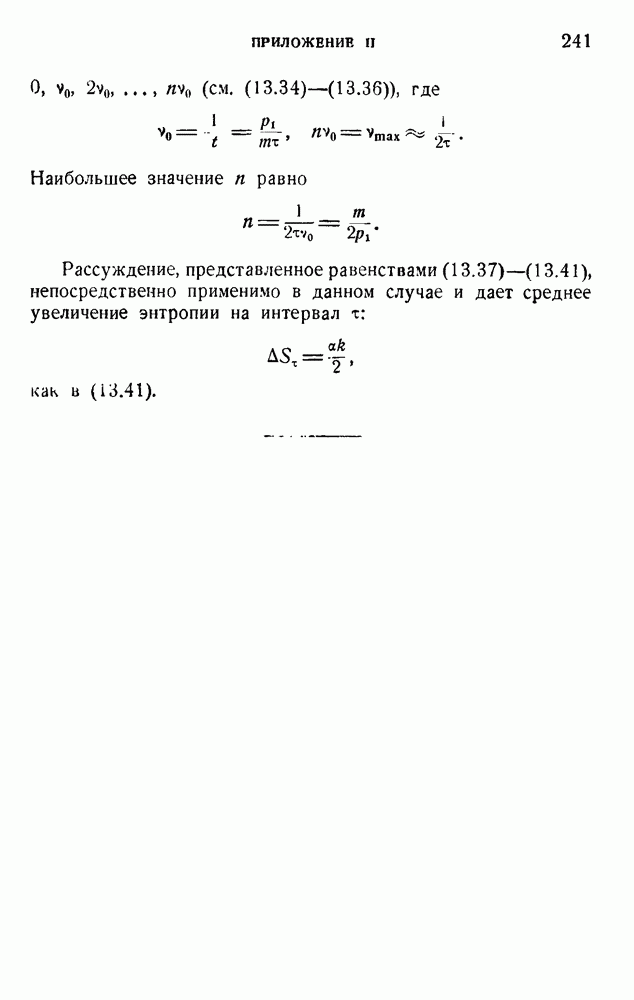





















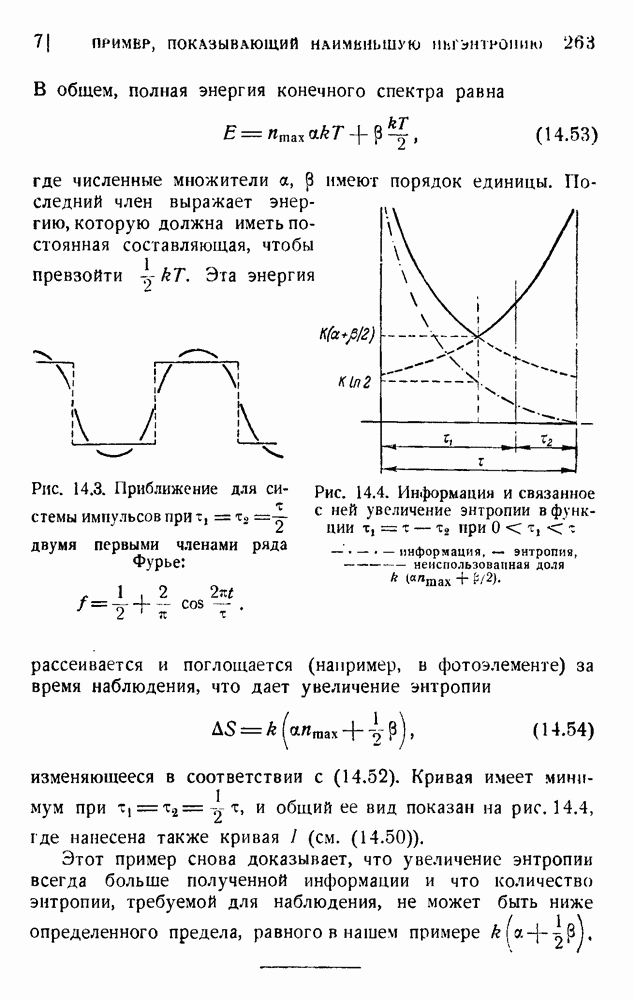


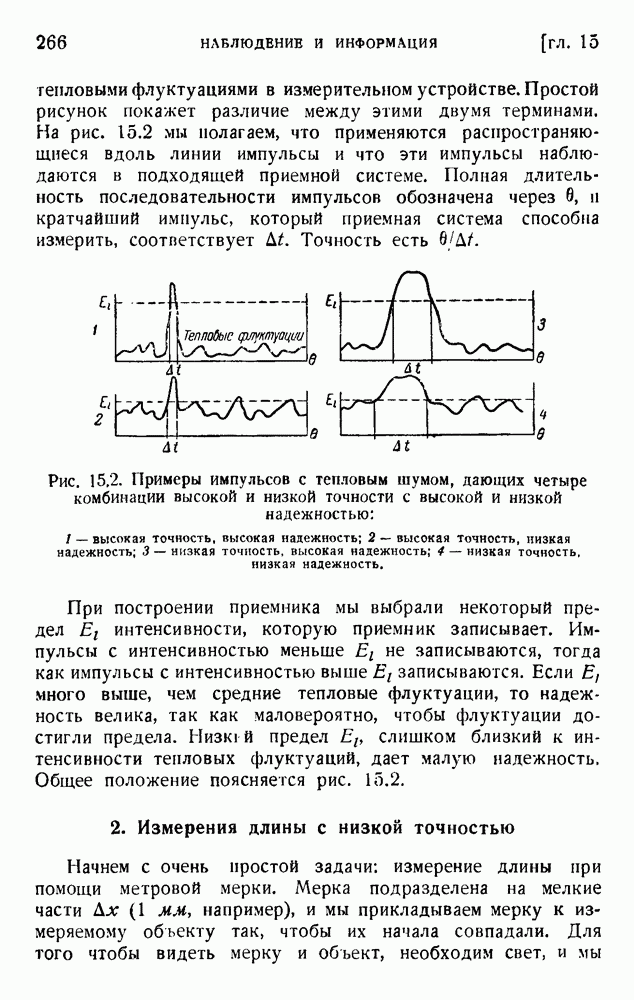
















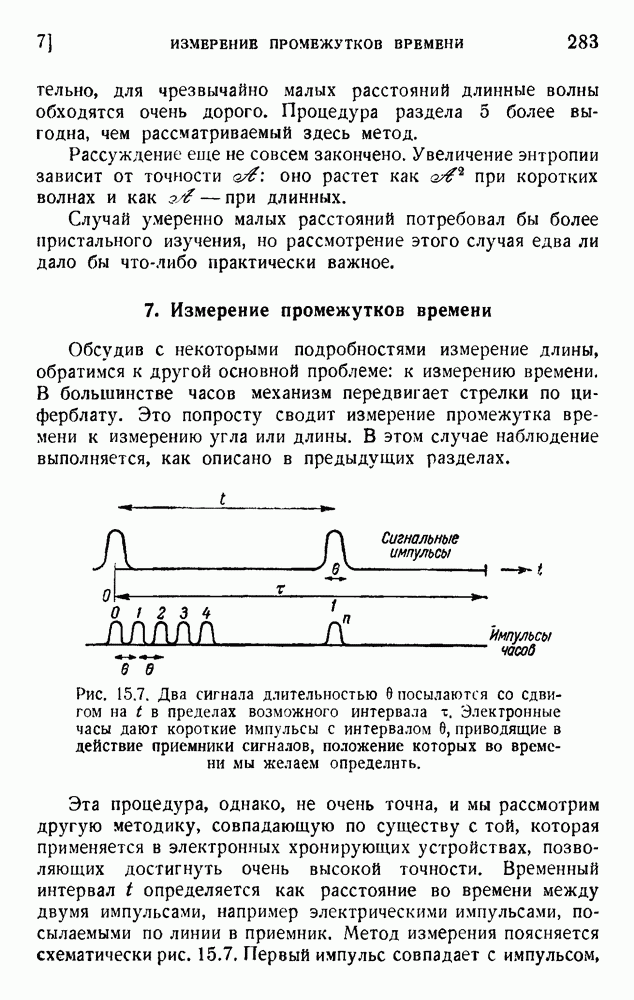


























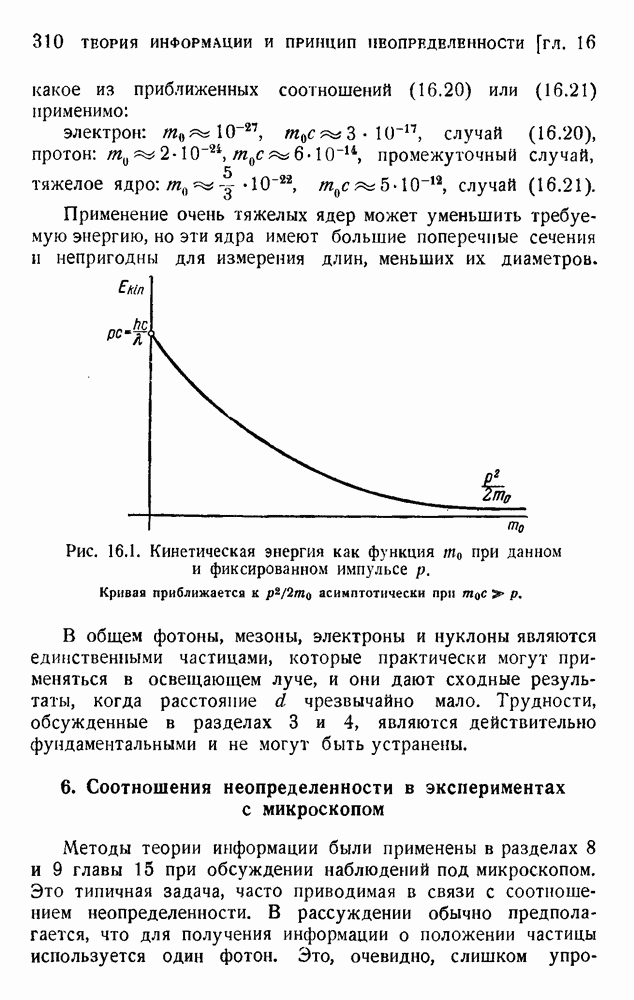












































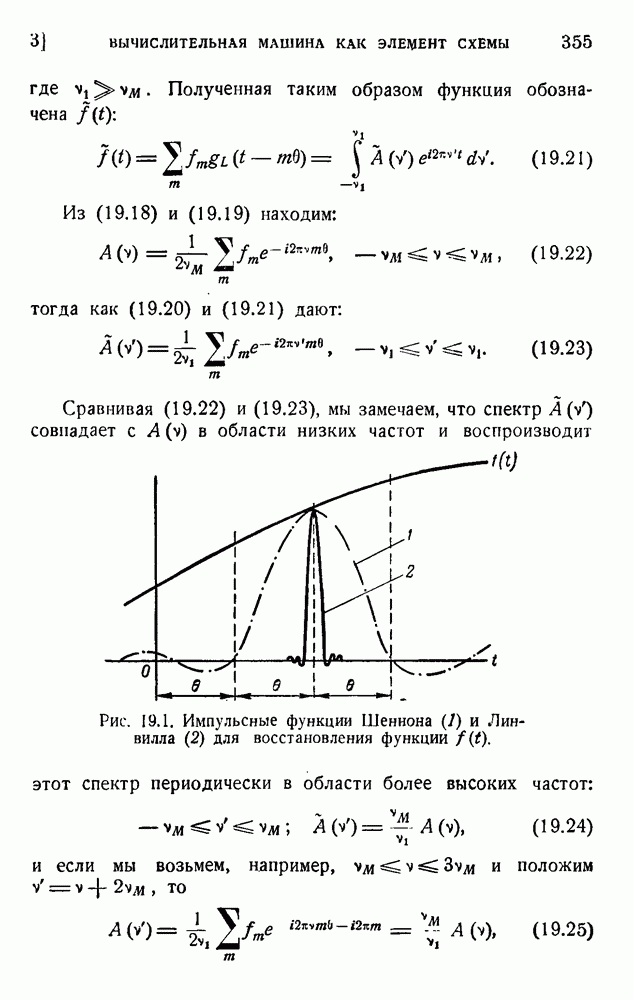


































 . Код «4 из 7» дает
. Код «4 из 7» дает  т. е. одну ошибку на последовательность из 475 знаков (после исправления). Мера качества составляет
т. е. одну ошибку на последовательность из 475 знаков (после исправления). Мера качества составляет  . Вероятность р ошибки в первоначальном знаке равна
. Вероятность р ошибки в первоначальном знаке равна  .
.
