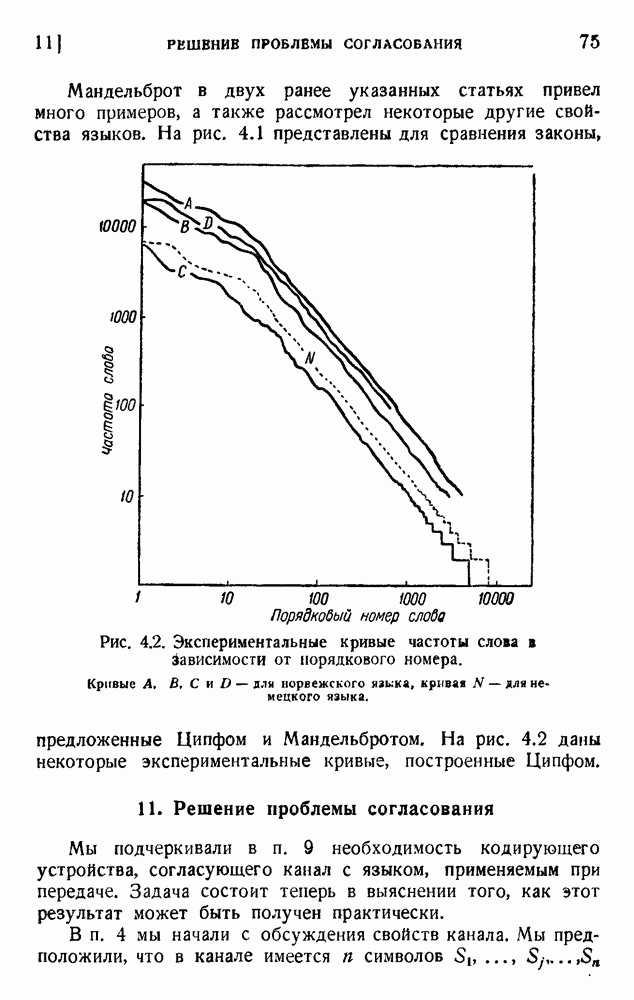
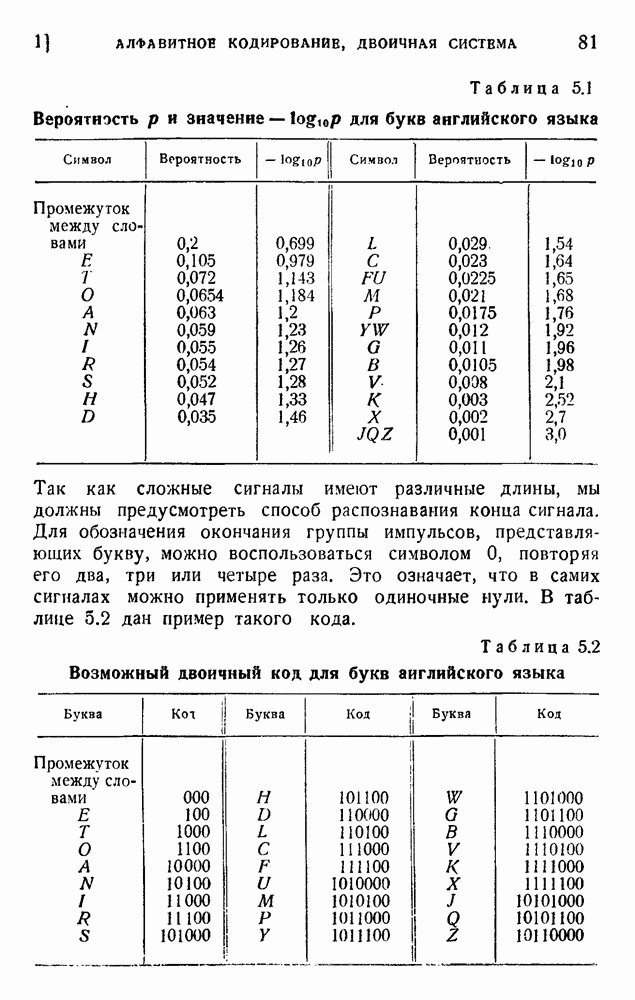
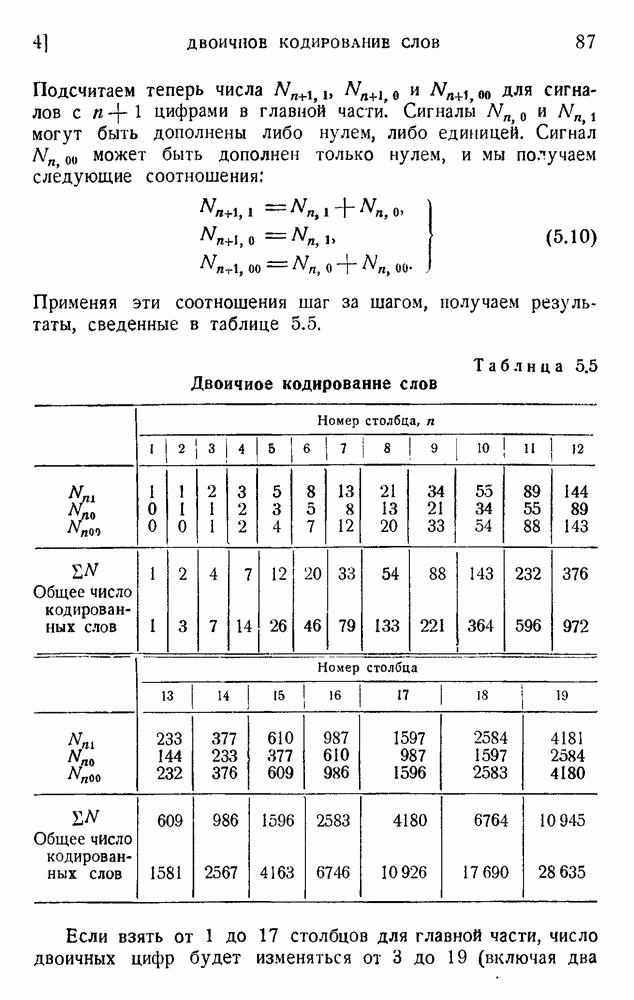
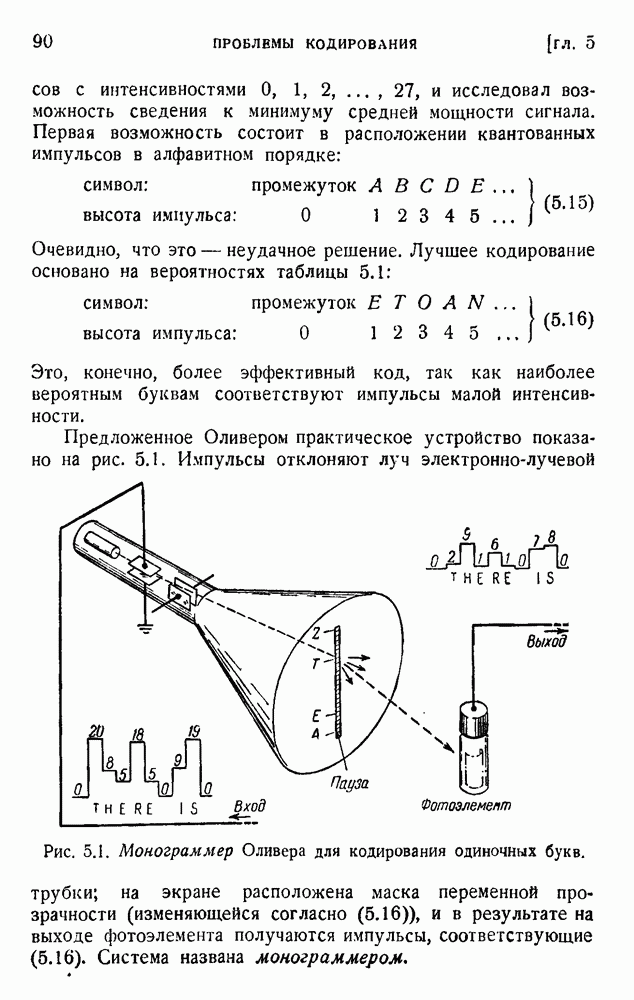
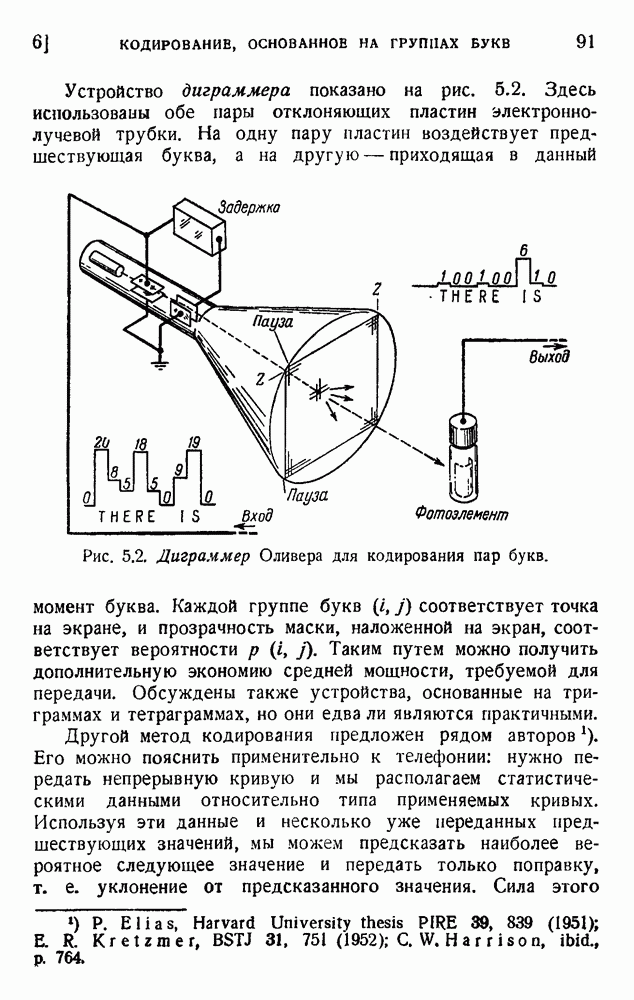
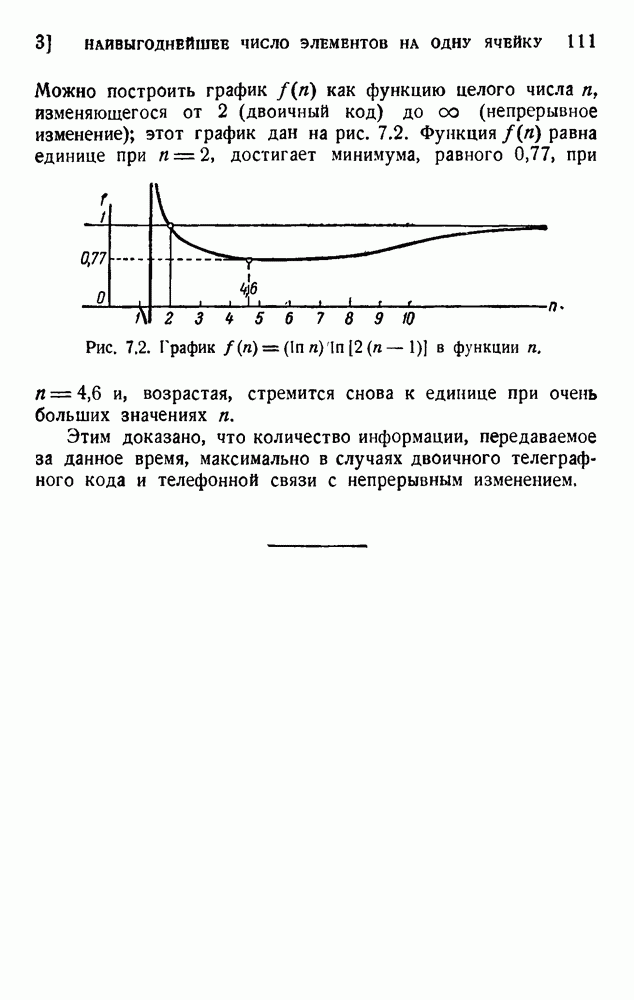
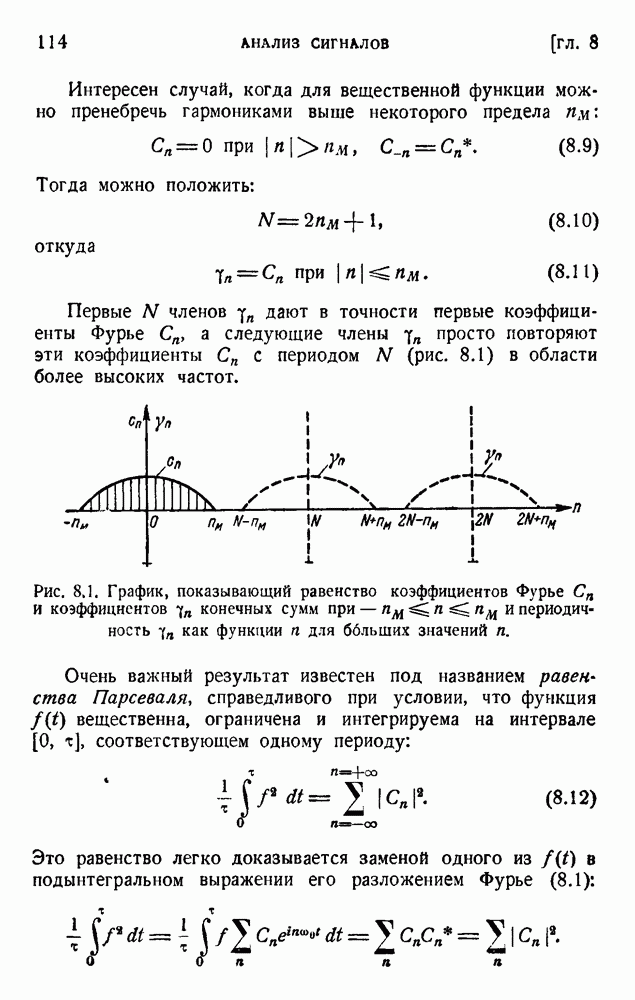
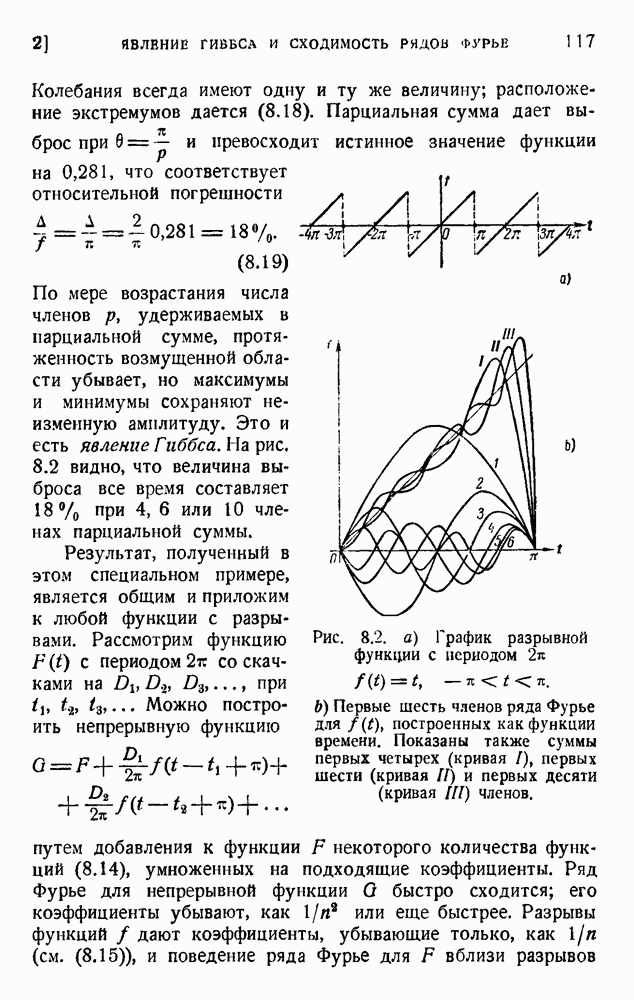
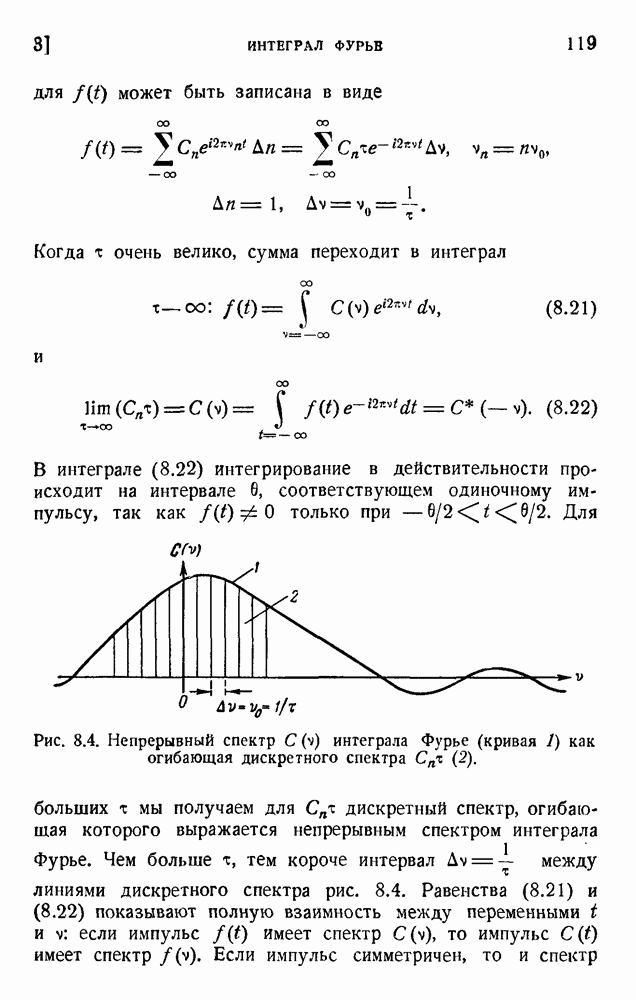
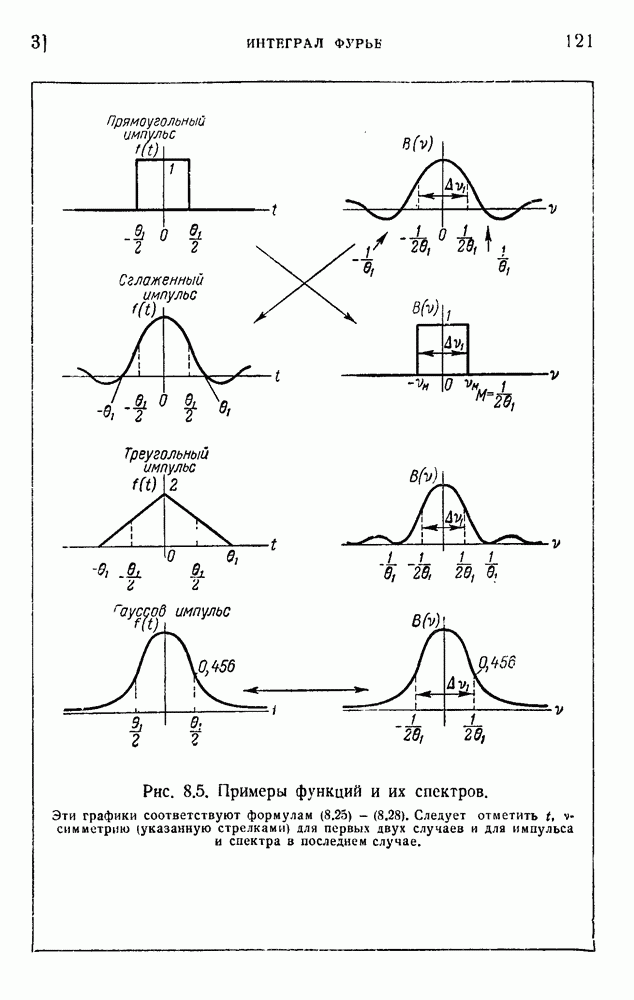
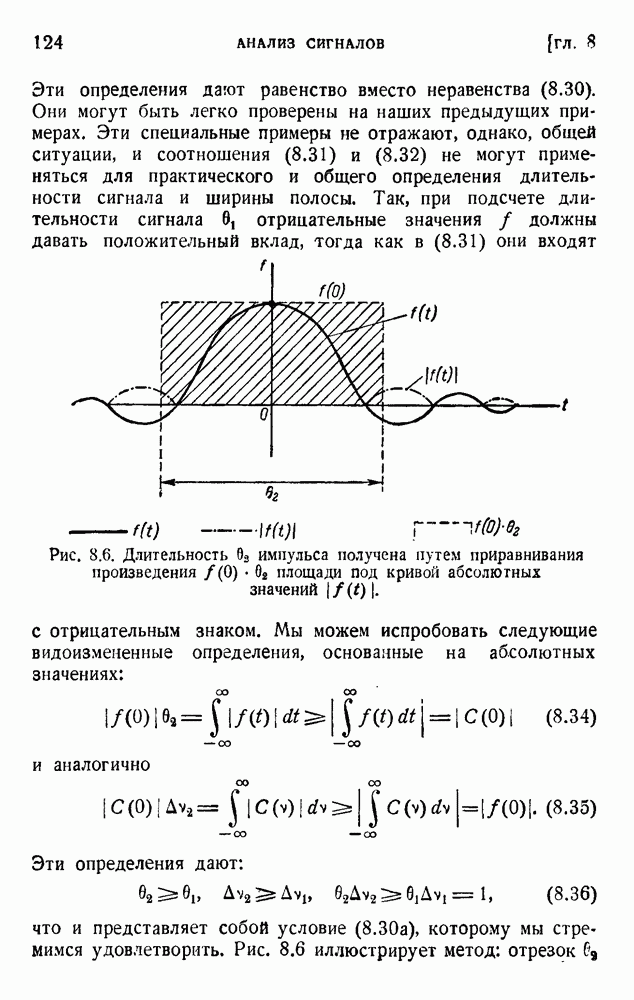
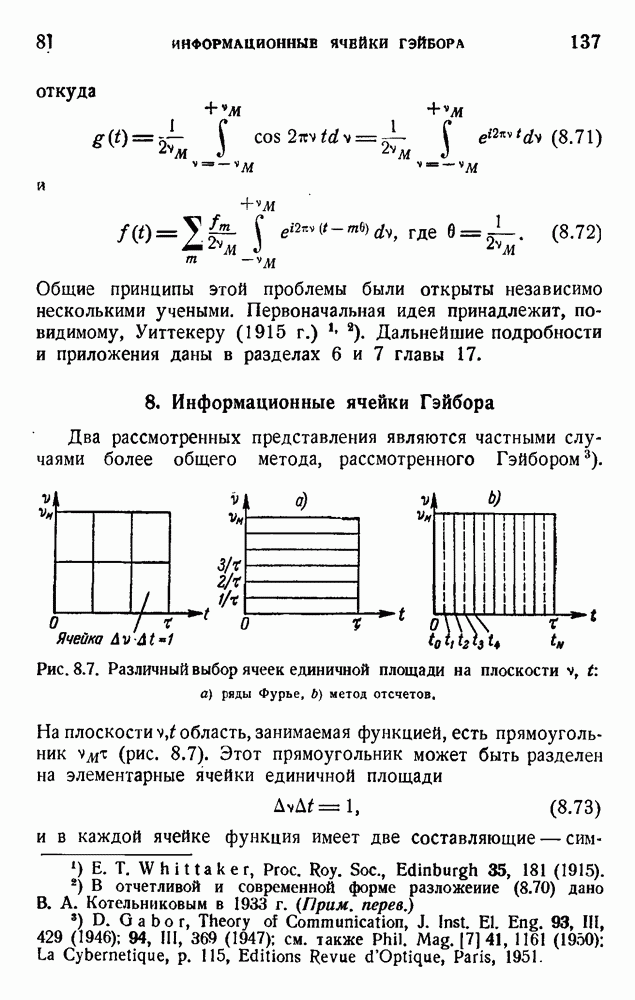
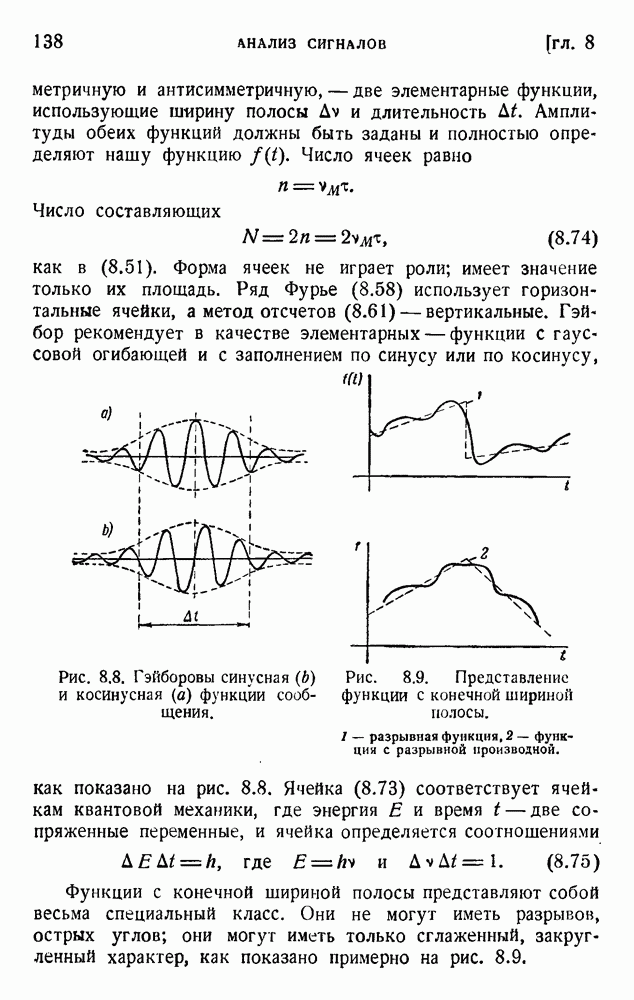
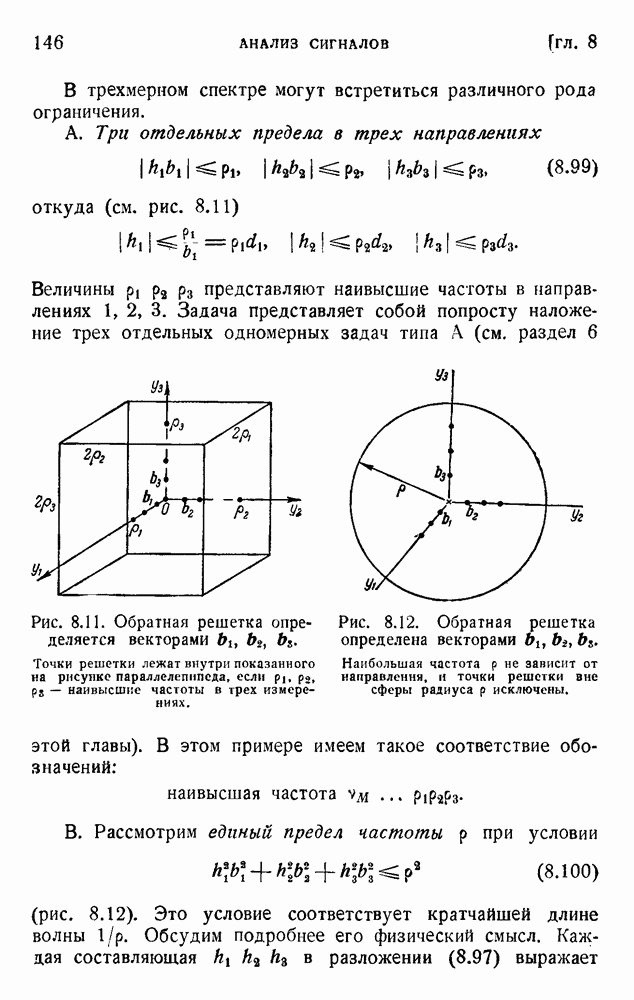
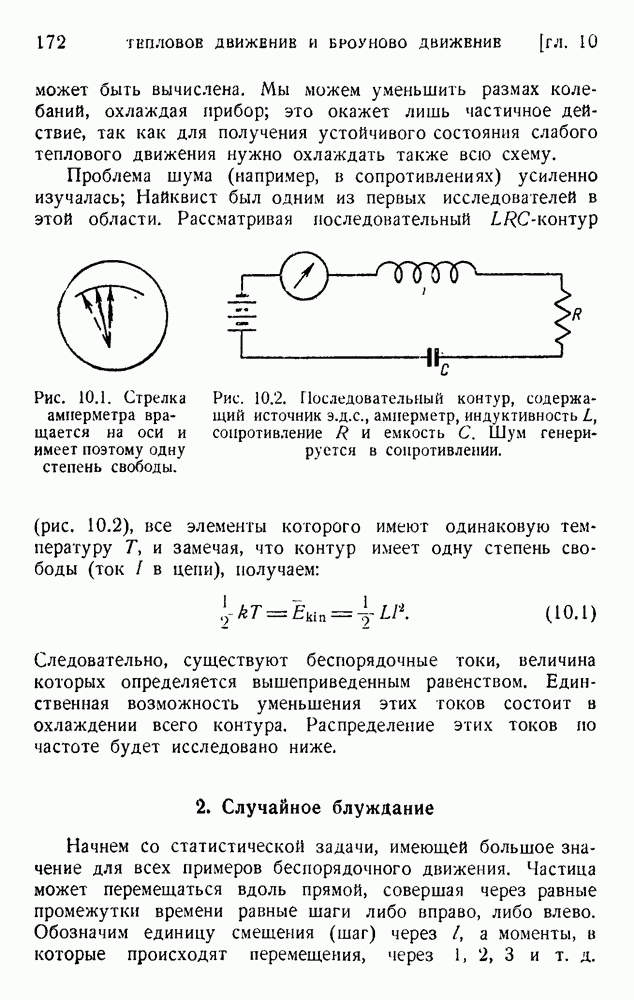
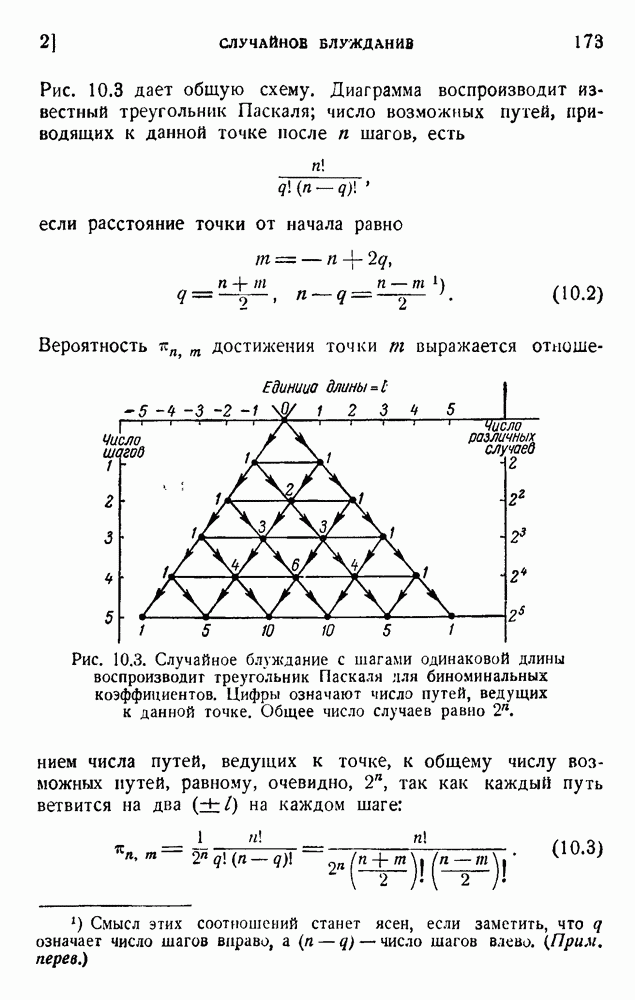
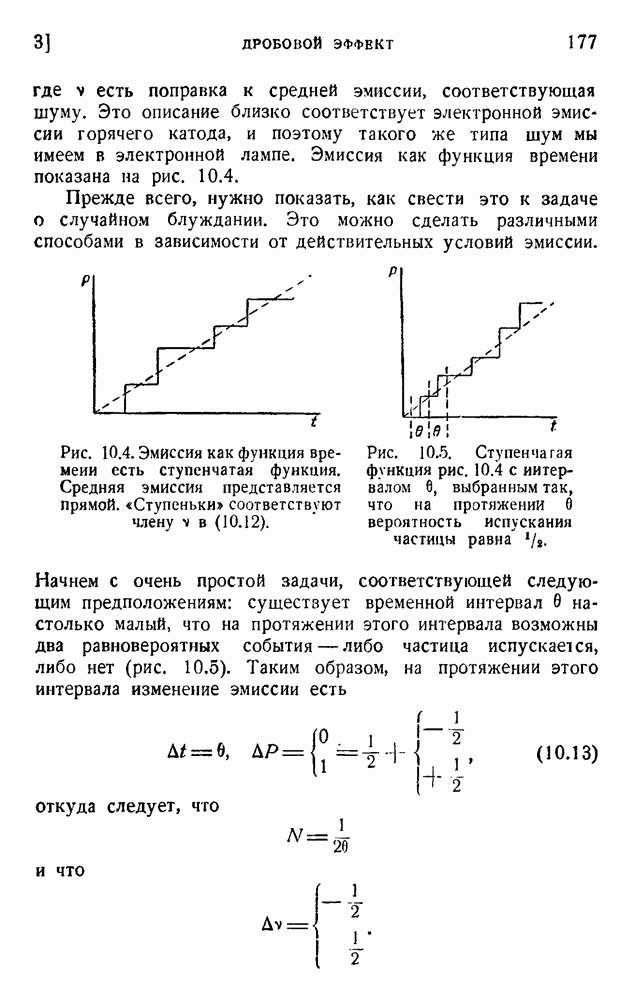
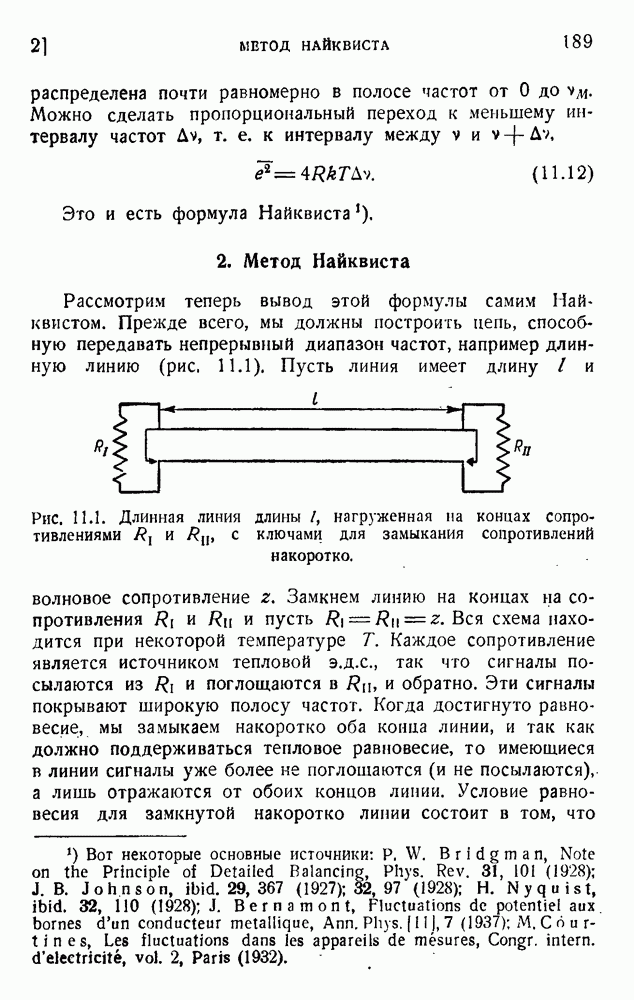
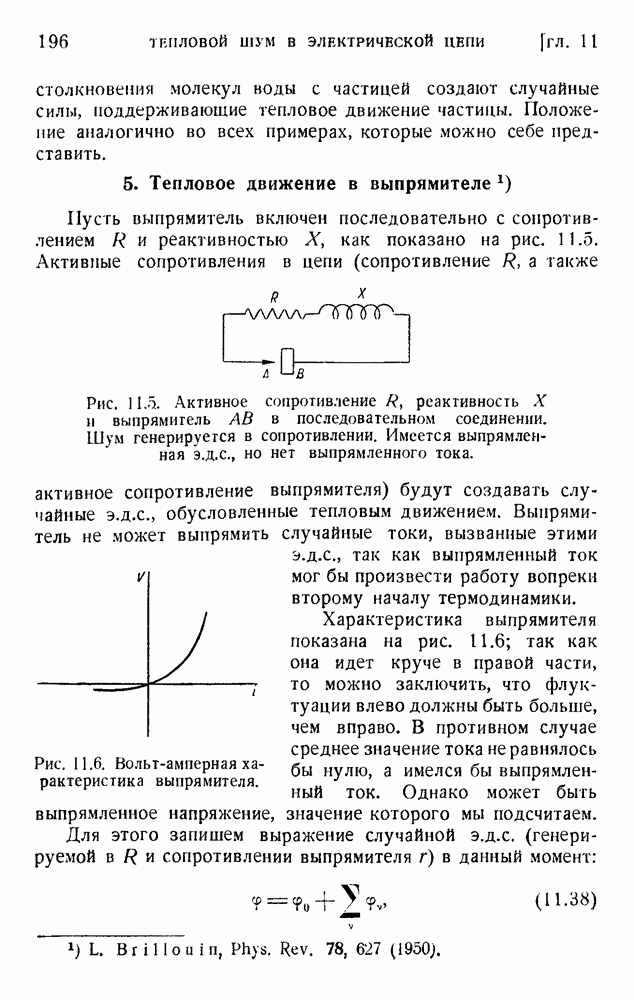
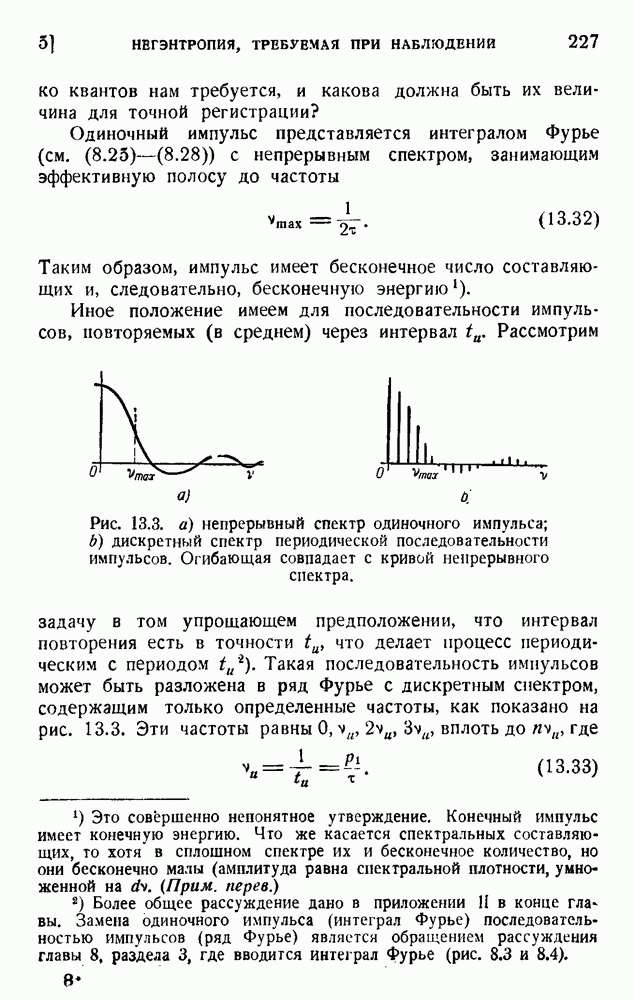
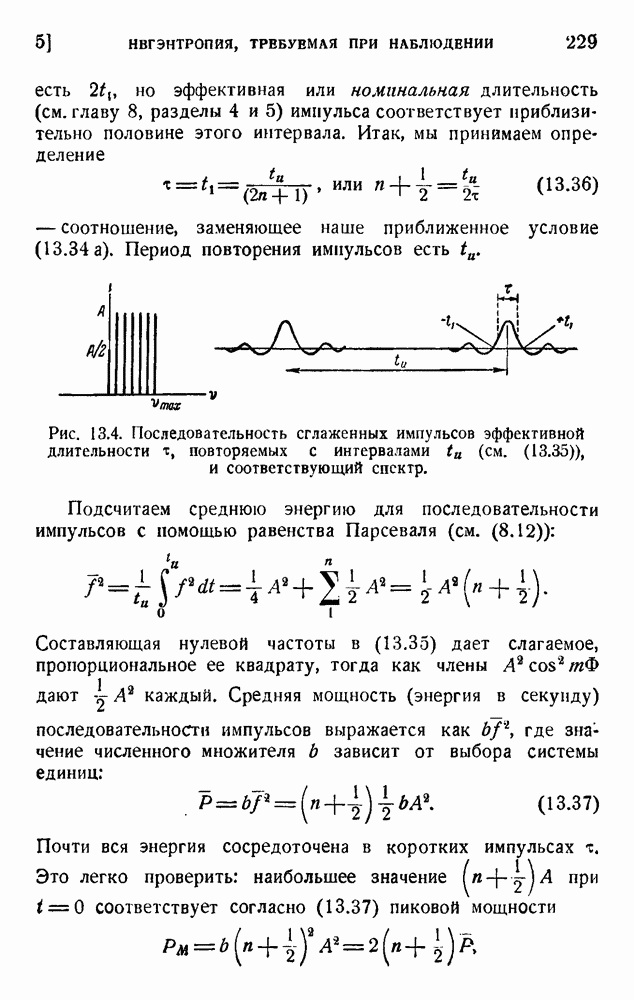
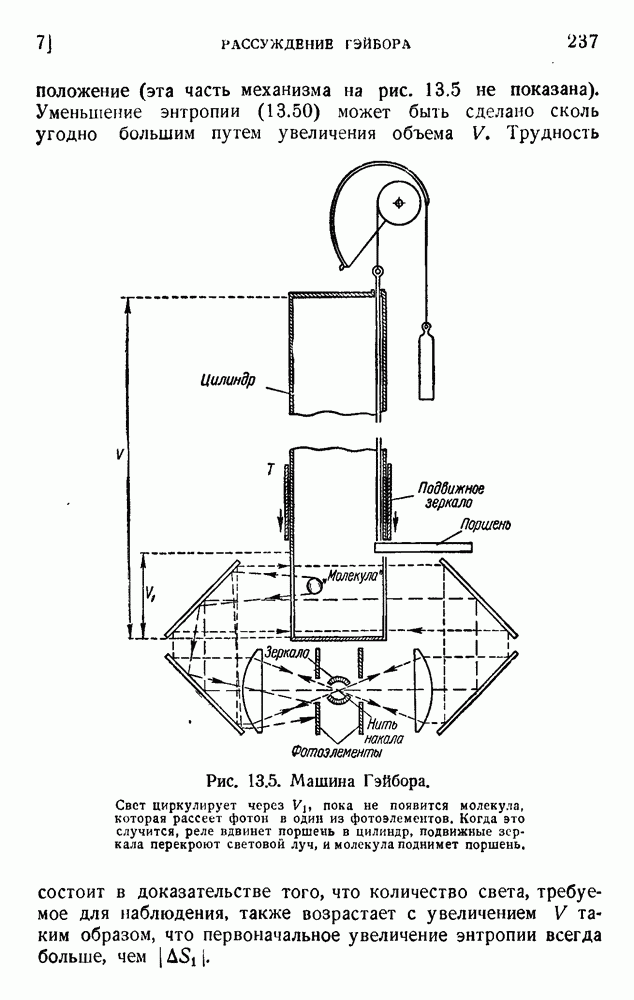
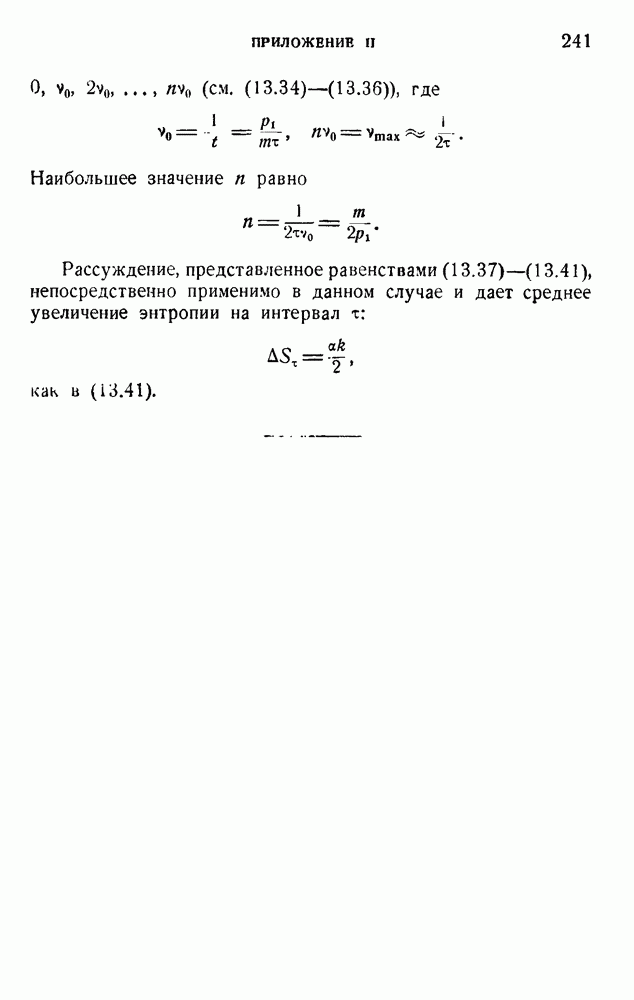
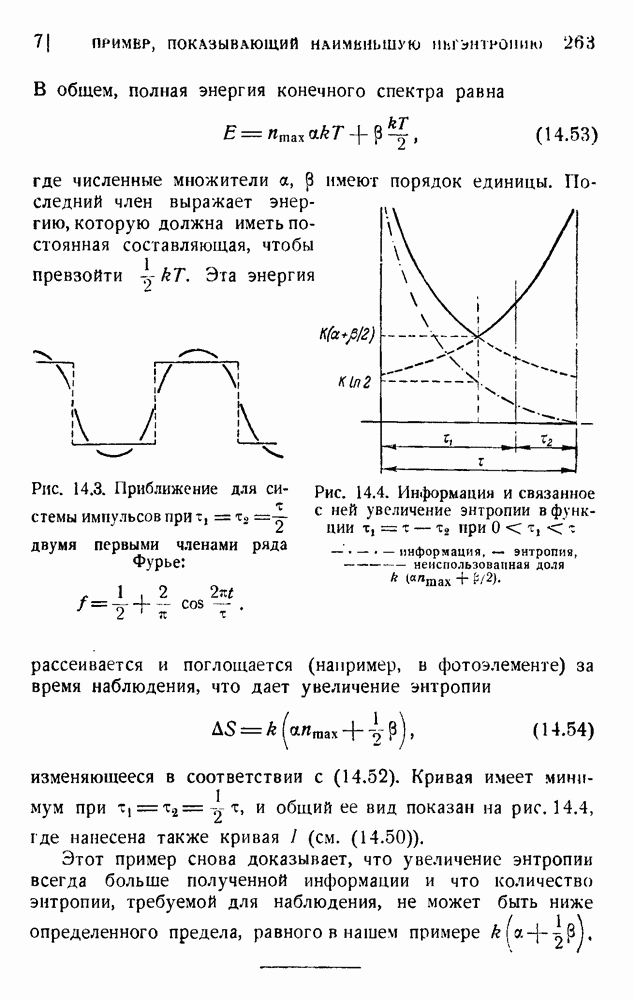
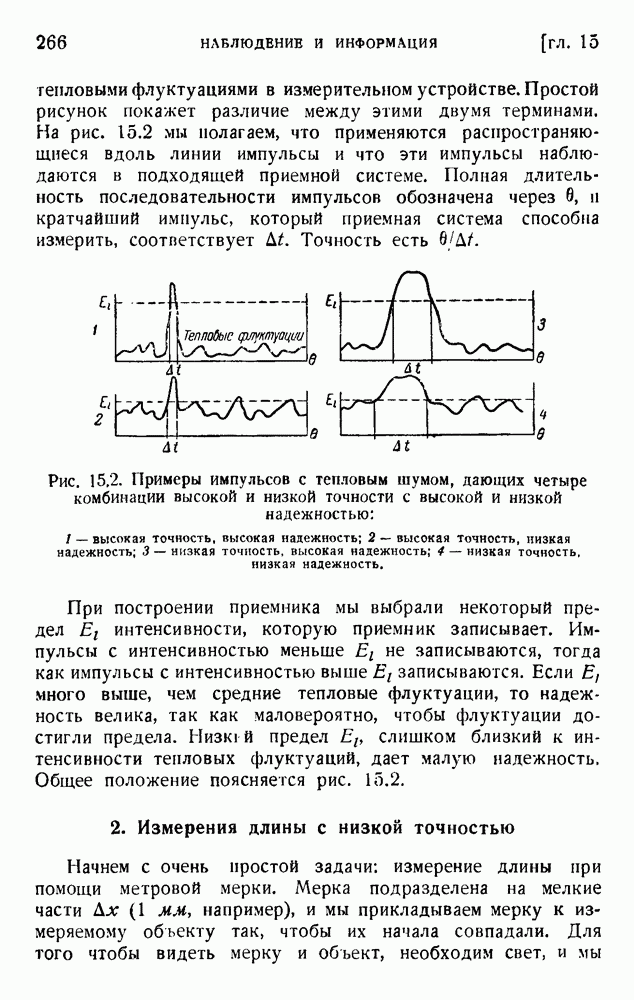
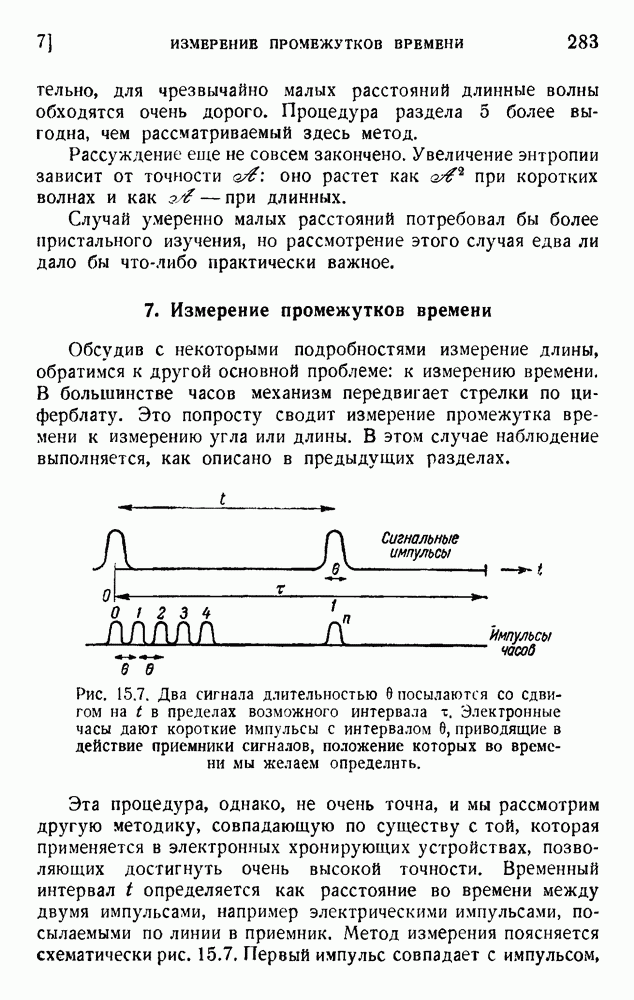
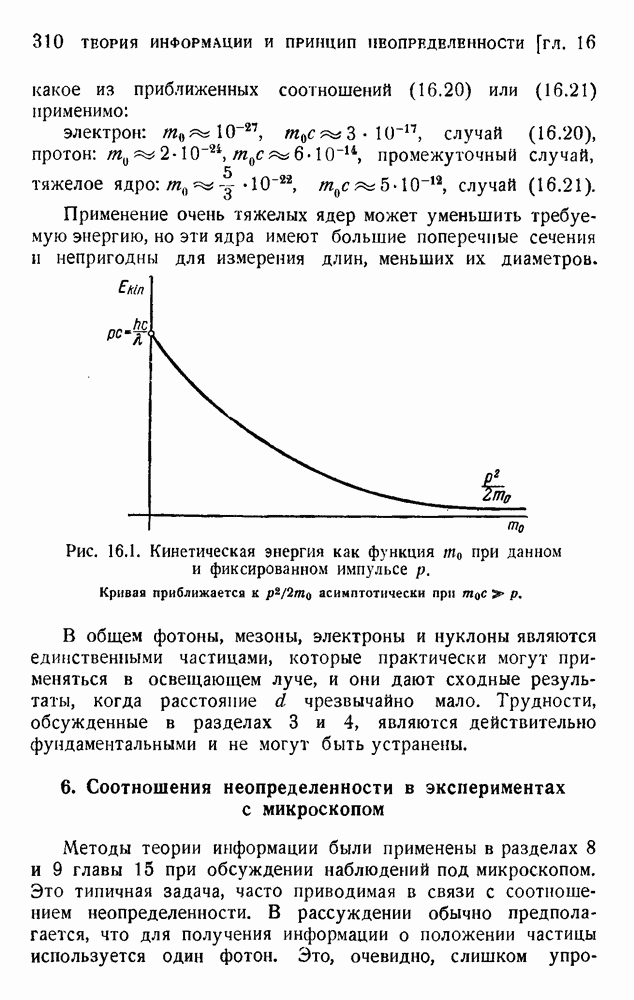
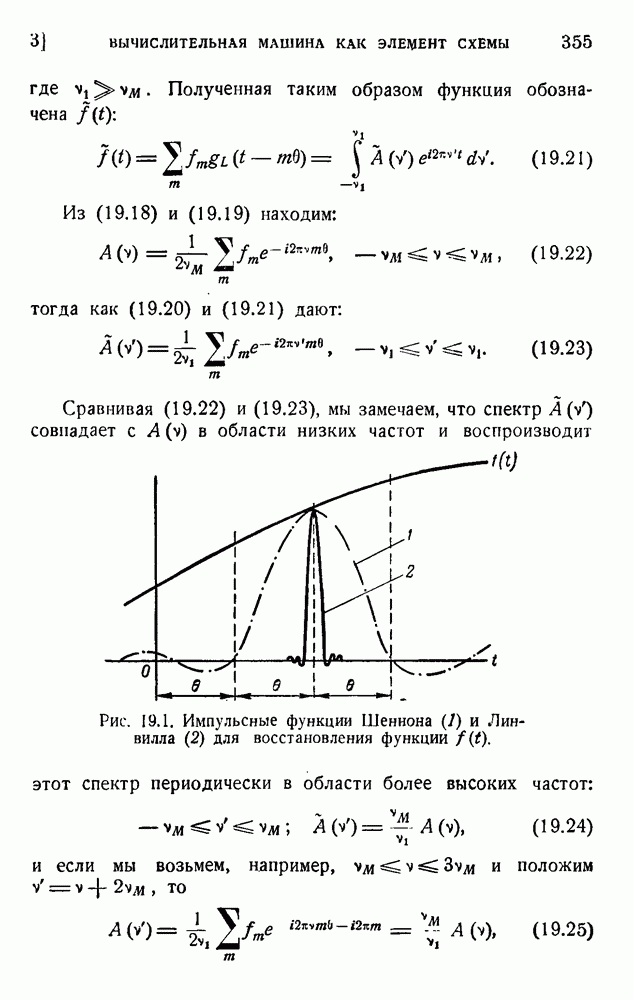
ГЛАВА 6. КОДЫ, ОБНАРУЖИВАЮЩИЕ И ИСПРАВЛЯЮЩИЕ ОШИБКИ
1. Коды, обнаруживающие ошибки
В предыдущих главах обсуждались методы устранения избыточности и построения кодов, требующих наименьшего числа двоичных единиц на букву. Те же методы могут применяться не только к буквам, но и к любого рода символам в более общих задачах теории информации.
Рассмотрим теперь вопрос о том, не является ли избыточность благоприятной в некоторых практических случаях. Когда мы запасаем информацию в устройстве с высоким уровнем шума, то ложные шумовые сигналы могут вызвать ошибки, и некоторая избыточность была бы очень полезна для обнаружения и даже для исправления ошибок. Именно так обстоит дело, когда мы читаем книгу с опечатками или когда мы получаем телеграмму, в которой некоторые буквы переданы неправильно. Вместо того чтобы использовать для обнаружения ошибок высокую избыточность языка, мы можем построить специальный проверочный механизм для применения совместно с кодом малой избыточности. Таким образом мы получим более эффект иьную систему, способную (в отличие от системы, основанной на избыточности языка) обнаруживать ошибки в начертании имен, географических названий и т. п.
При применении двоичного кода простейшим методом проверки является проверка на четность. При известных условиях, мы можем быть почти уверены, что в группе из некоторого числа (например, n = 6) двоичных знаков не может быть больше одной ошибки. Для осуществления проверки на четность мы объединяем наши сигналы в группы
по шесть знаков и добавляем к каждой группе седьмой знак, выбирая его так, чтобы общее число единиц было четным. Например:

Это позволяет незамедлительно обнаружить на приемной стороне одиночную ошибку; однако узнать, в каком знаке произошла ошибка, нельзя. Двойная ошибка не будет обнаружена.