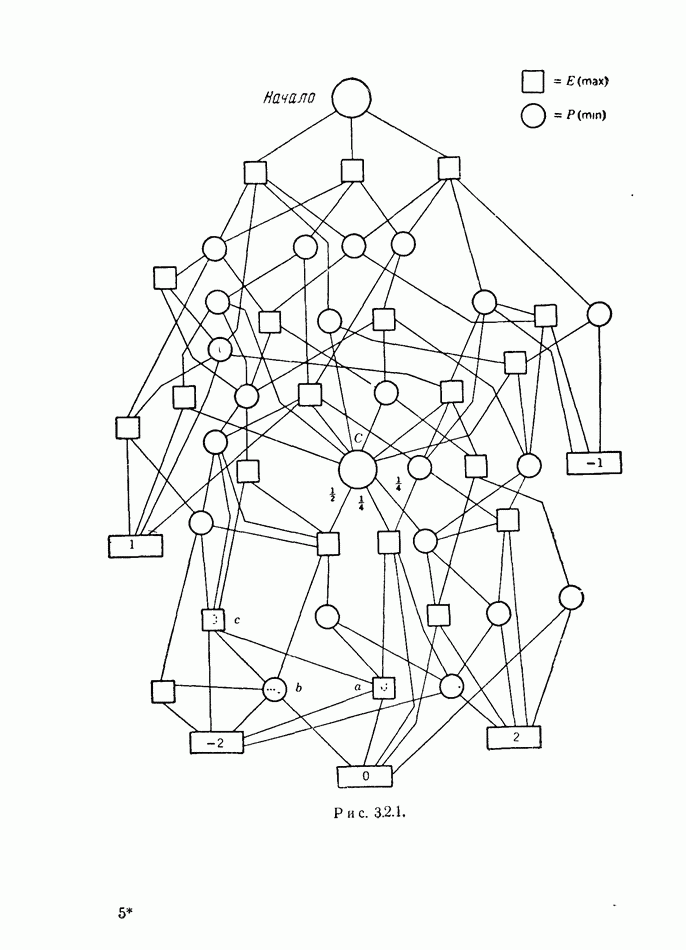
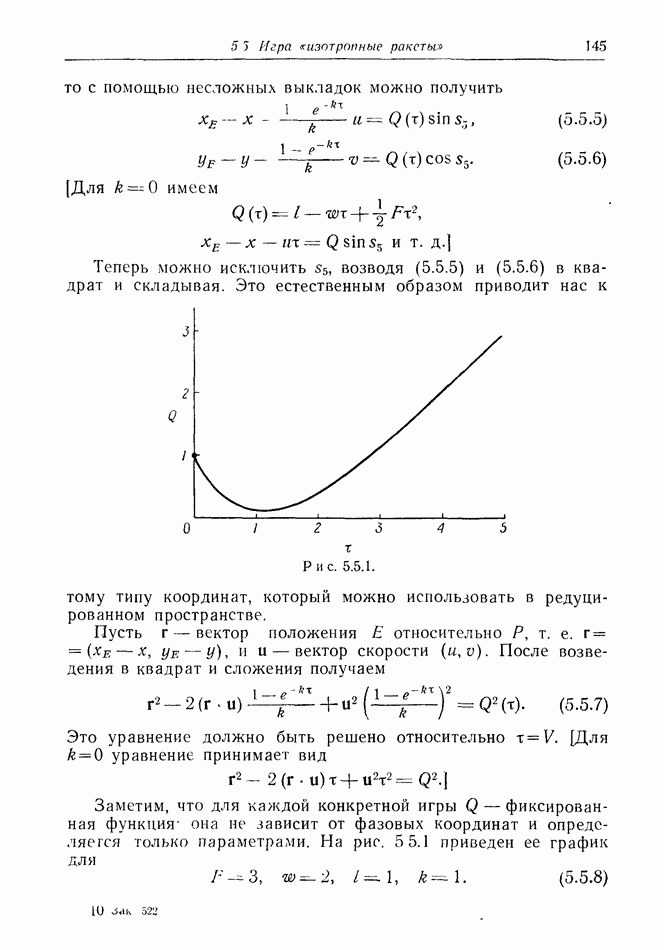
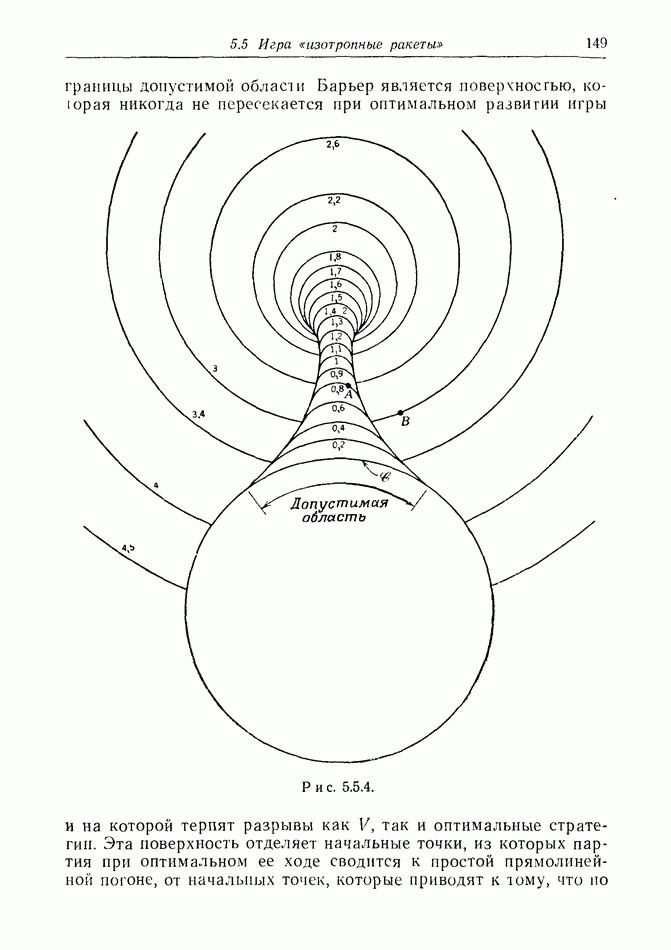
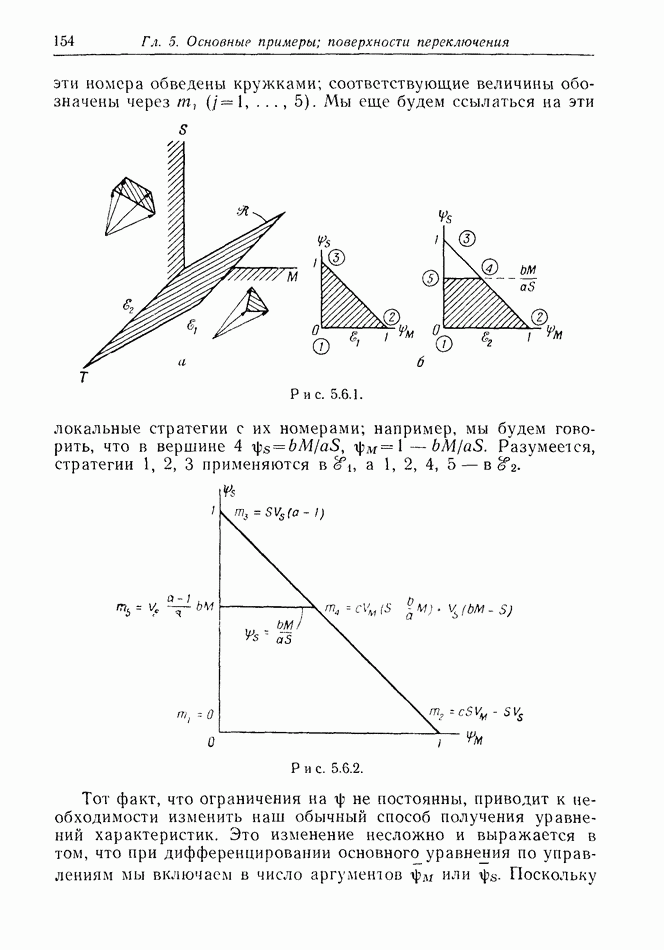
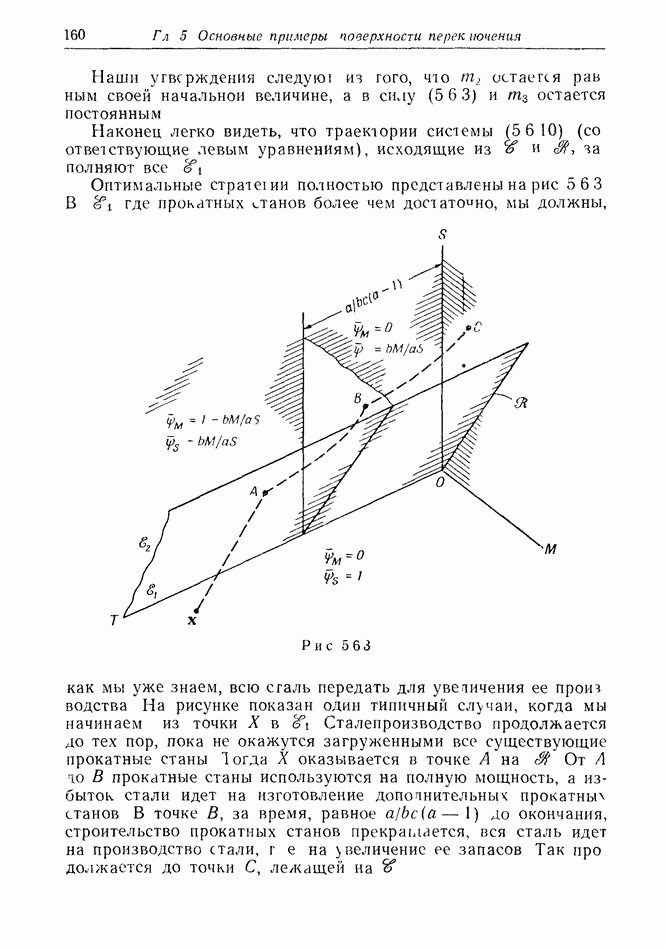
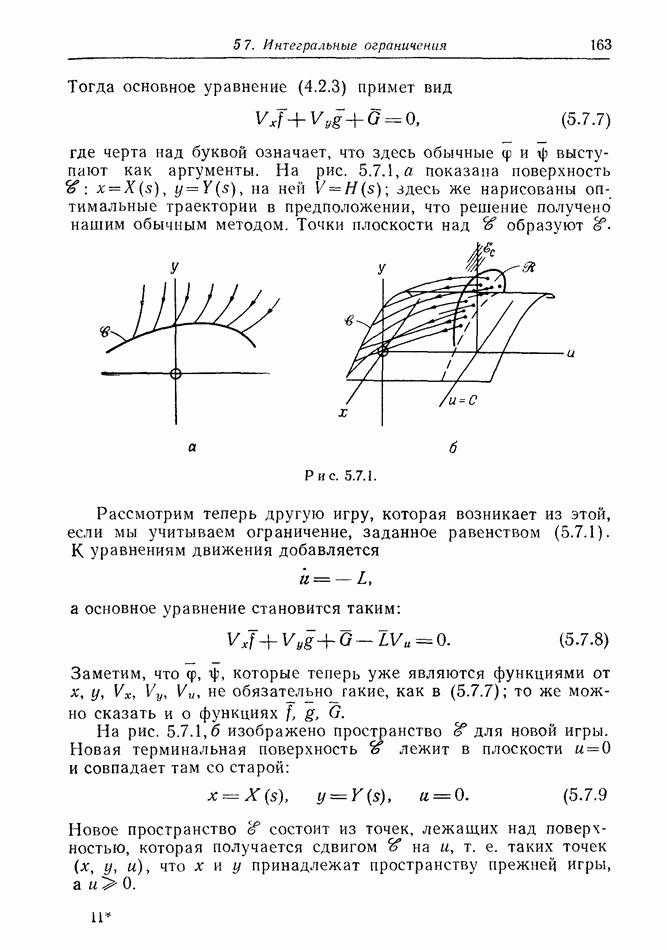
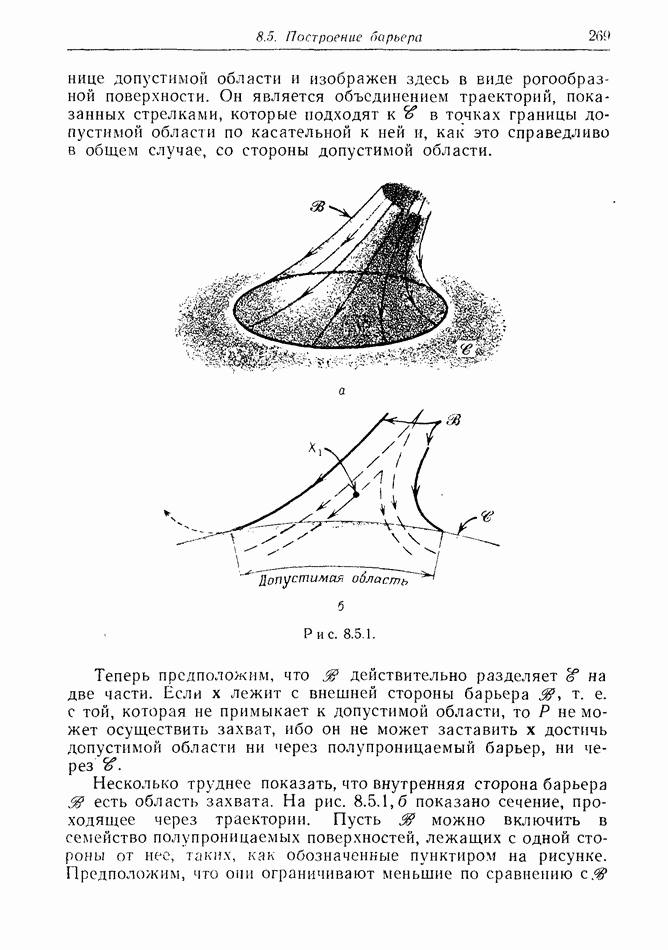
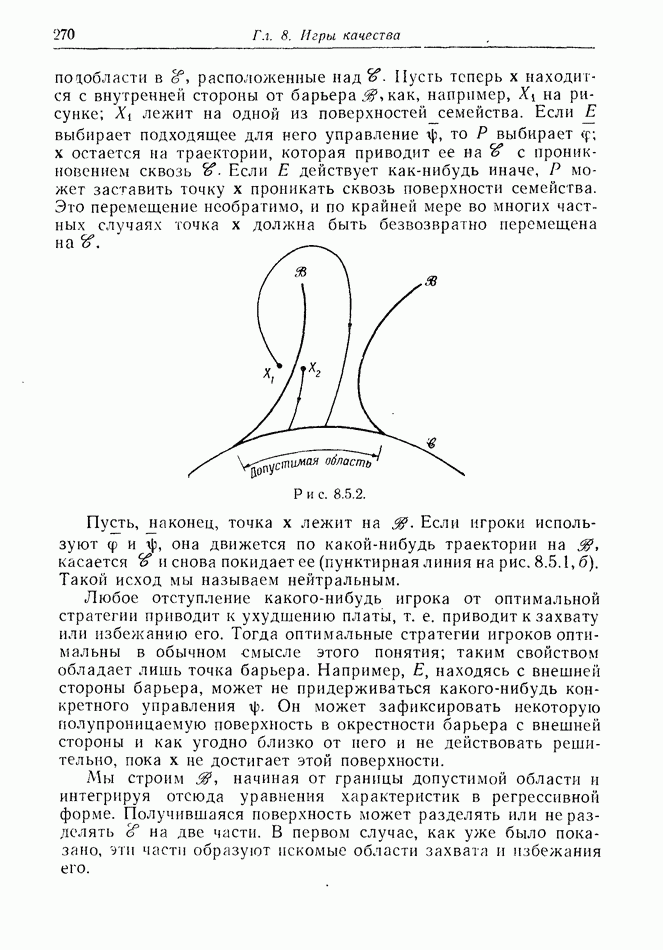
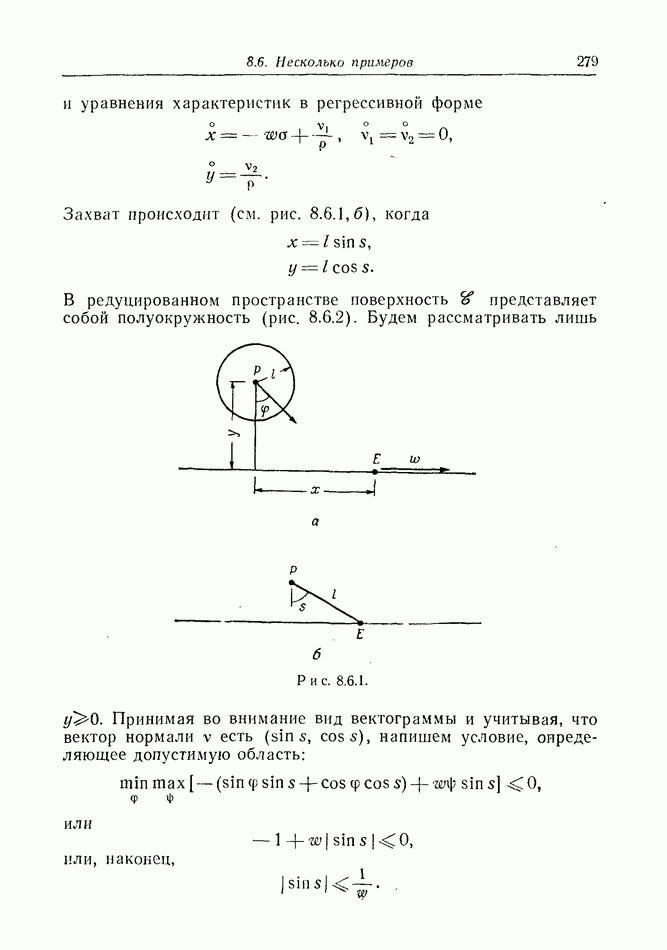
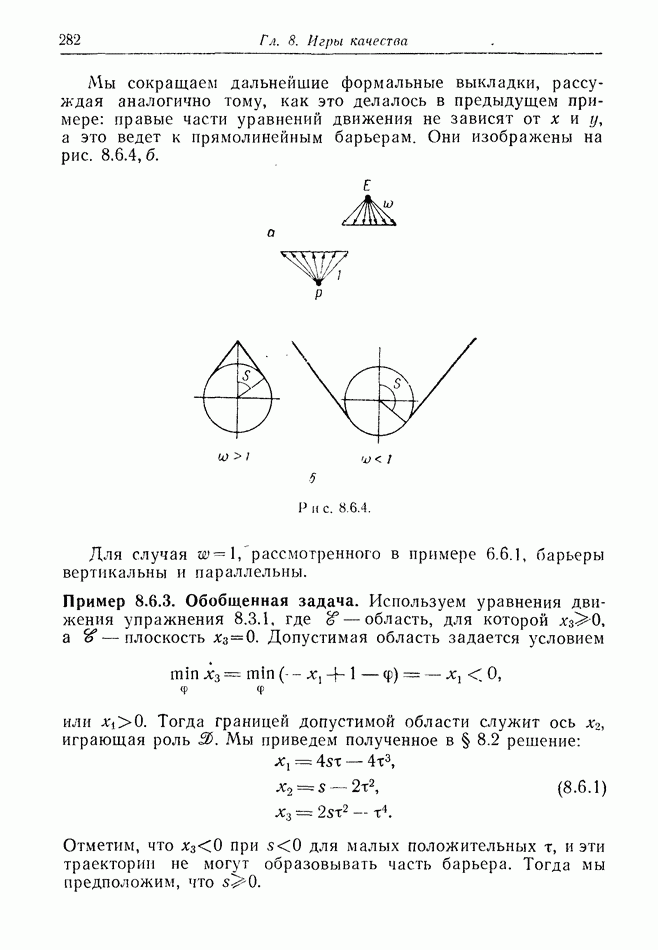
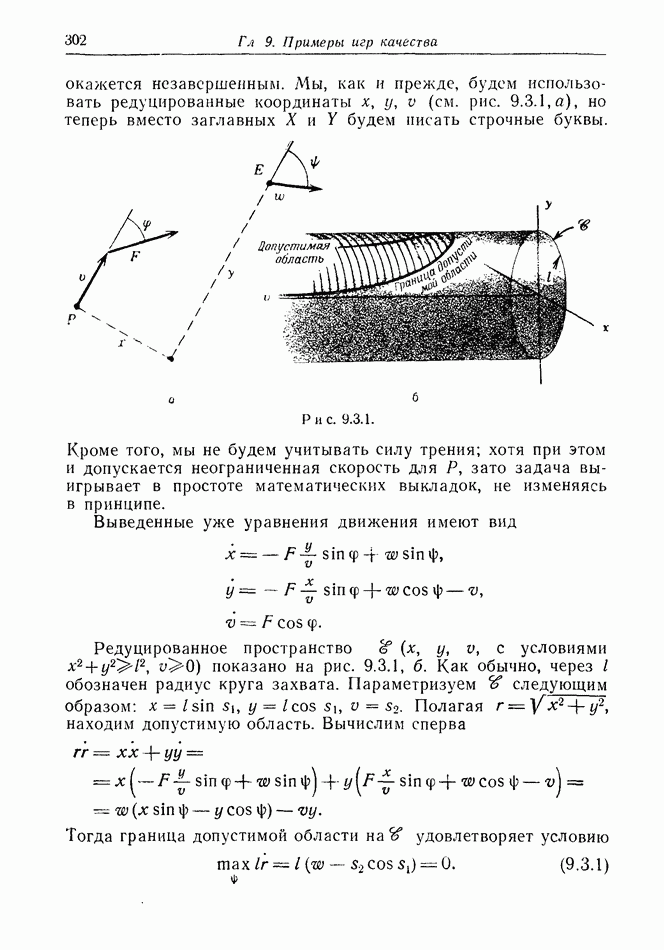
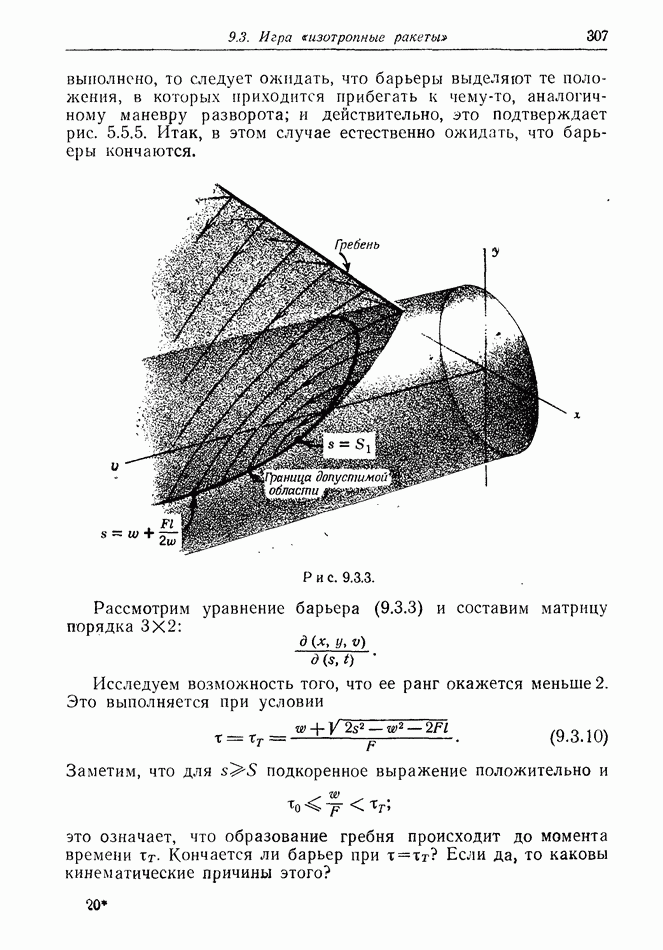
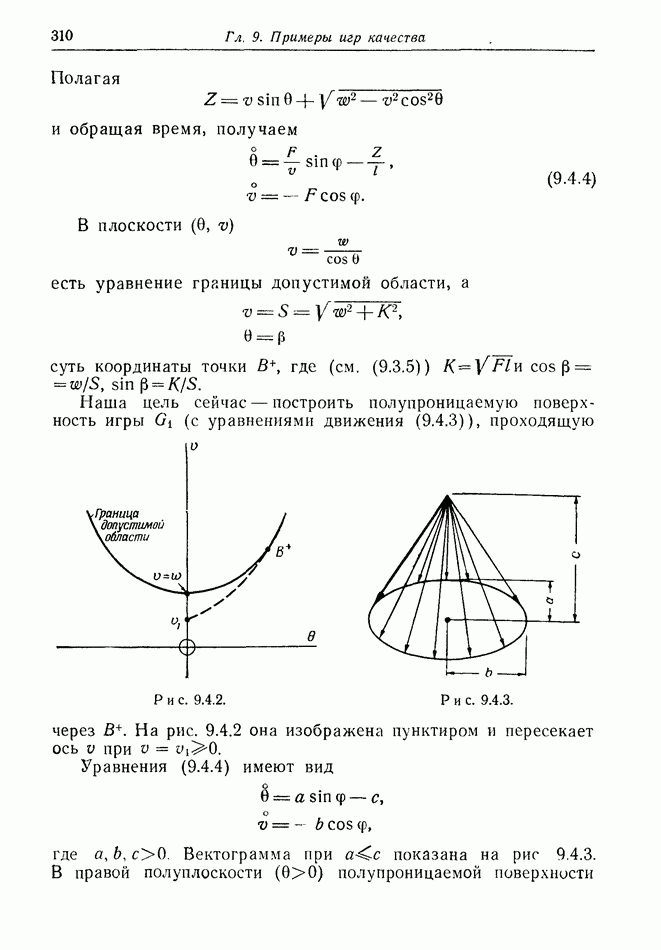
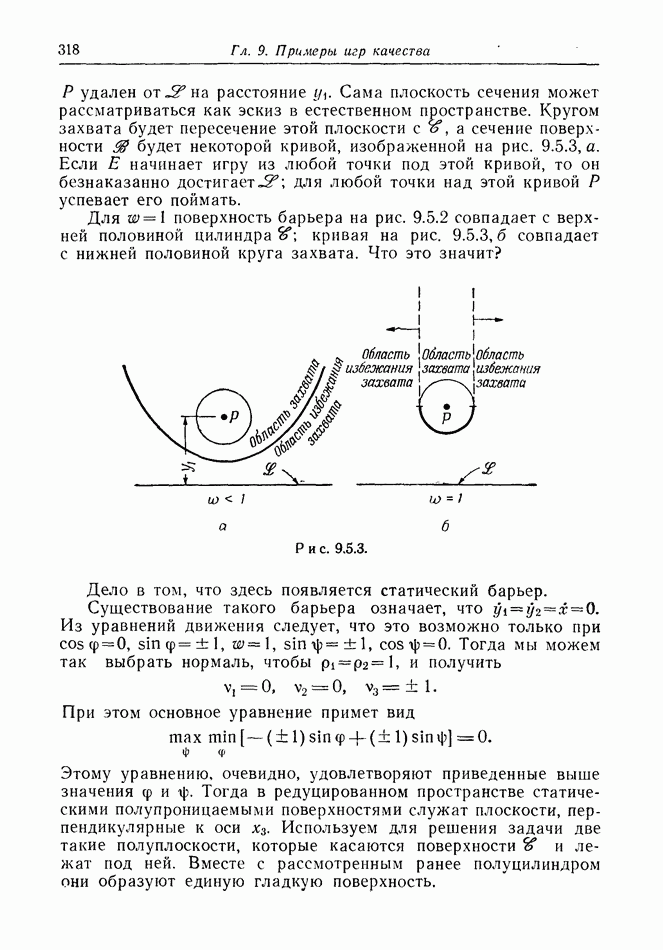
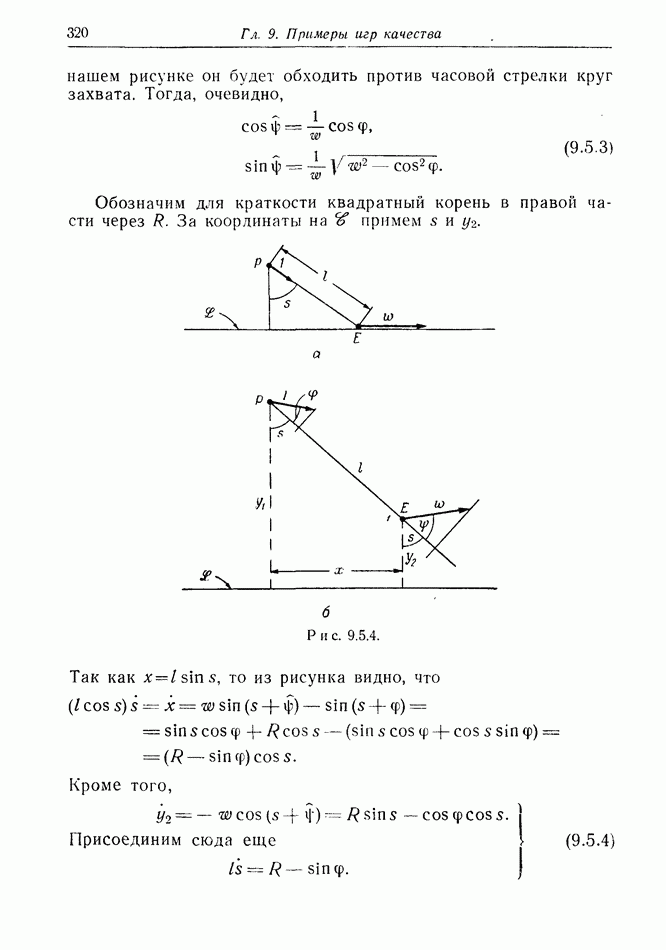
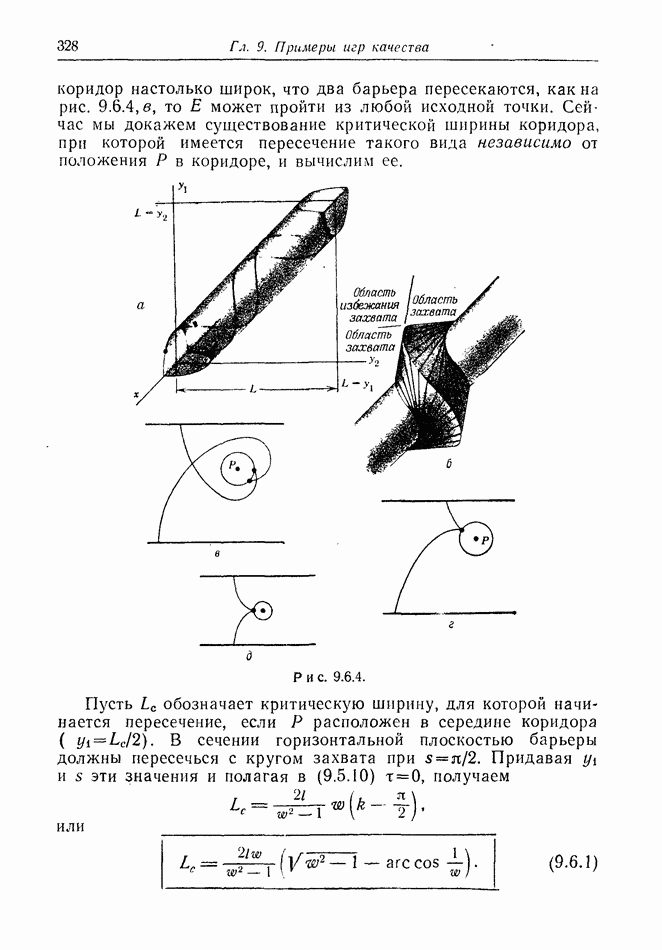
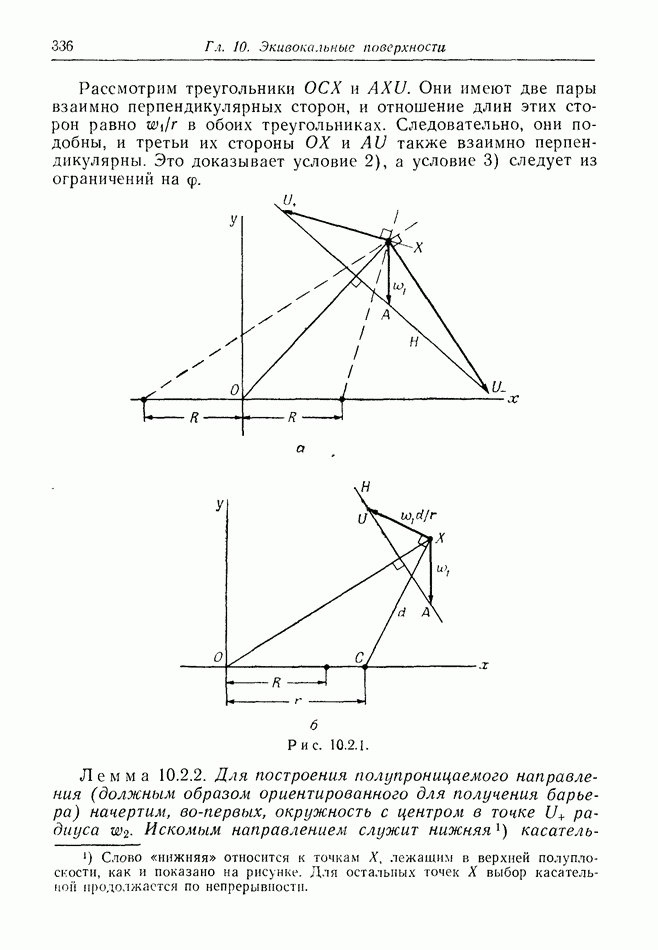
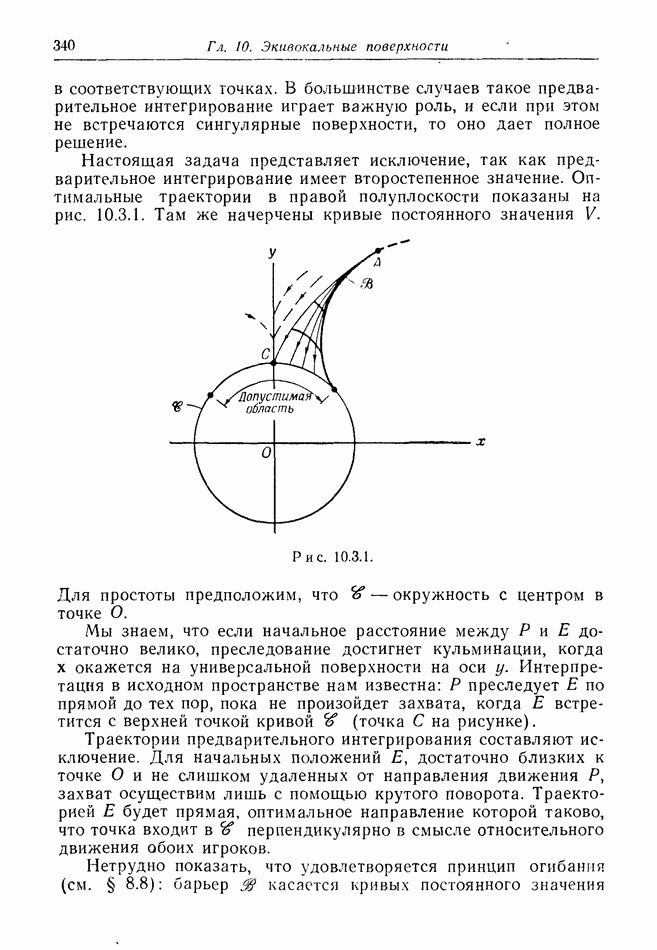
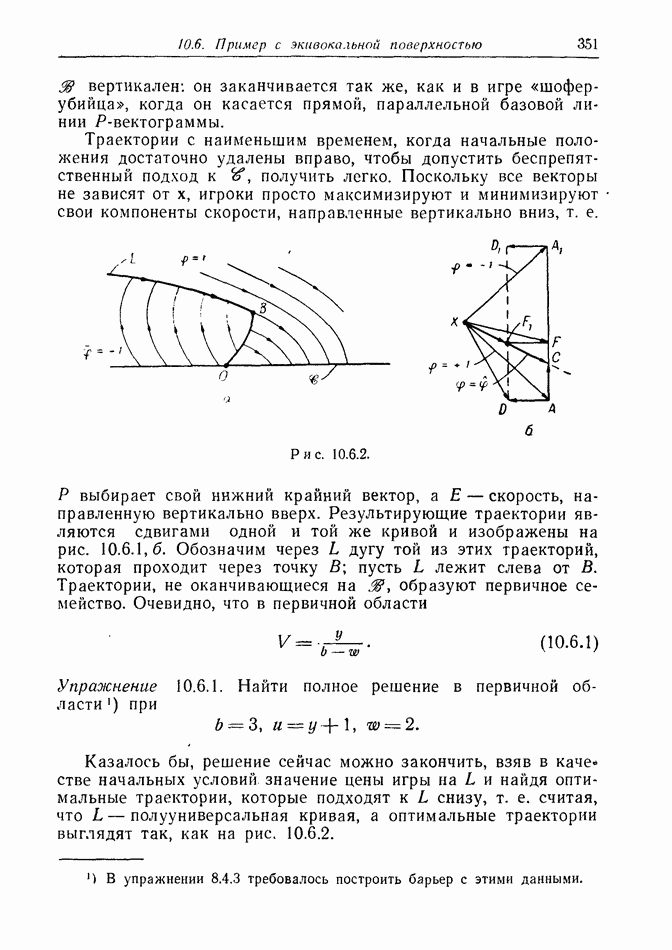
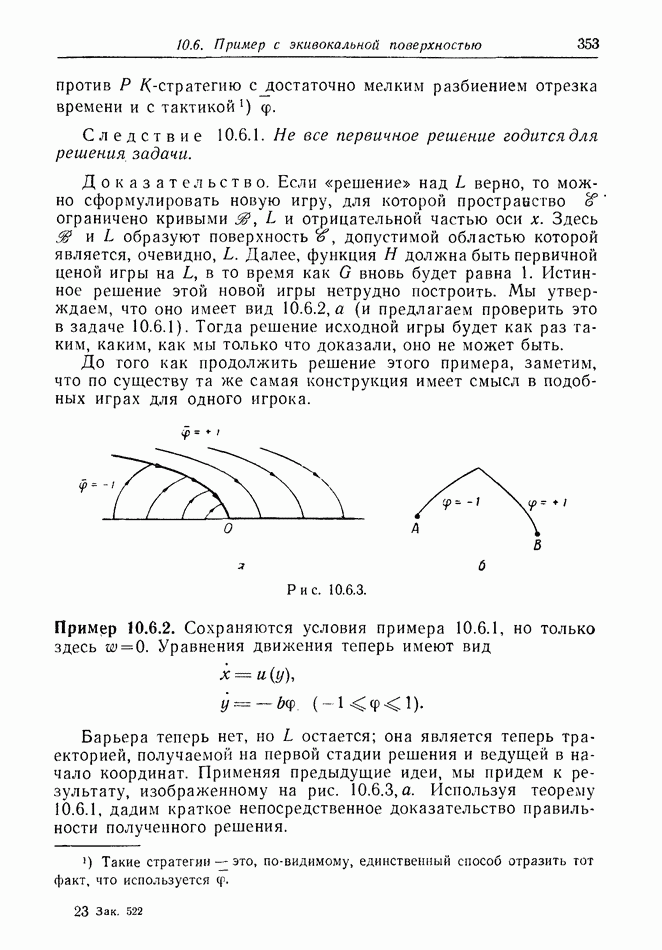
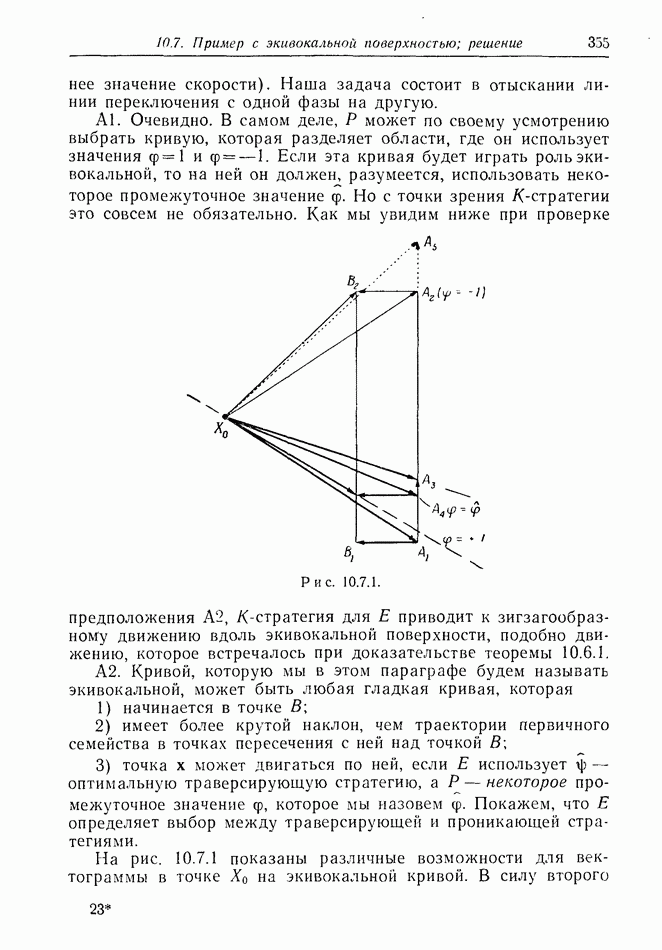
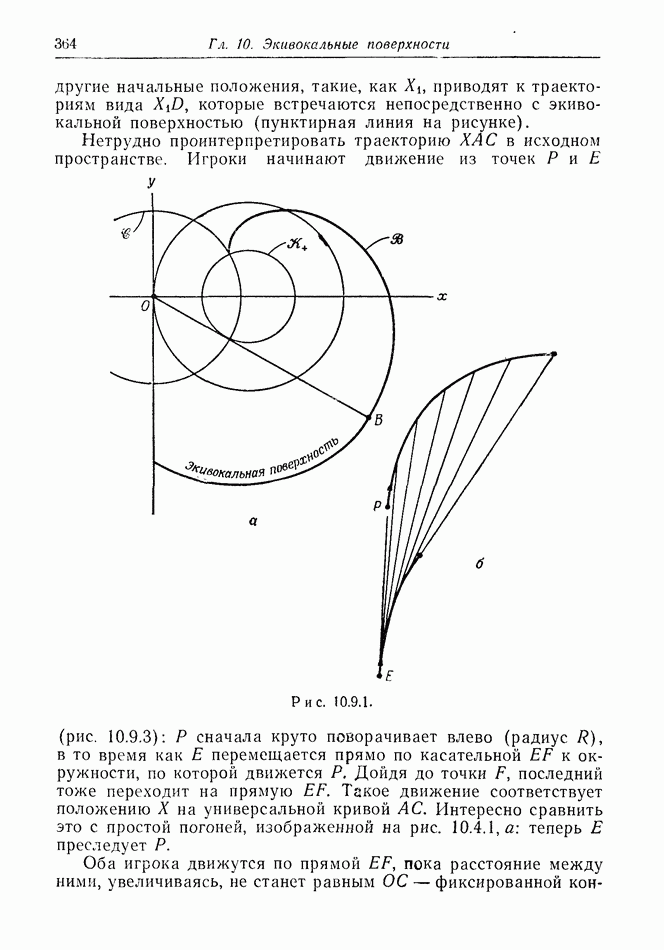
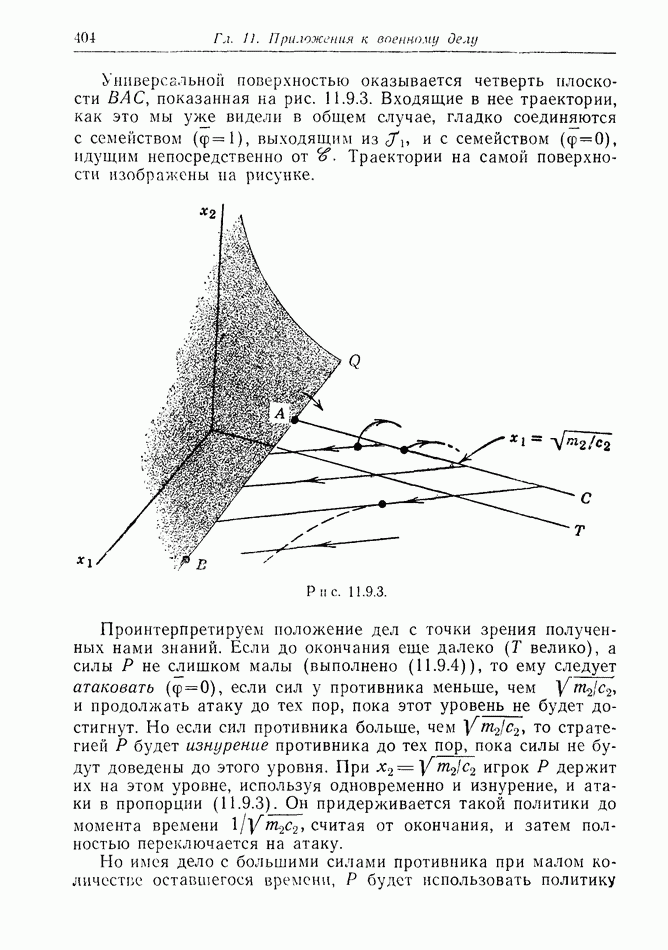
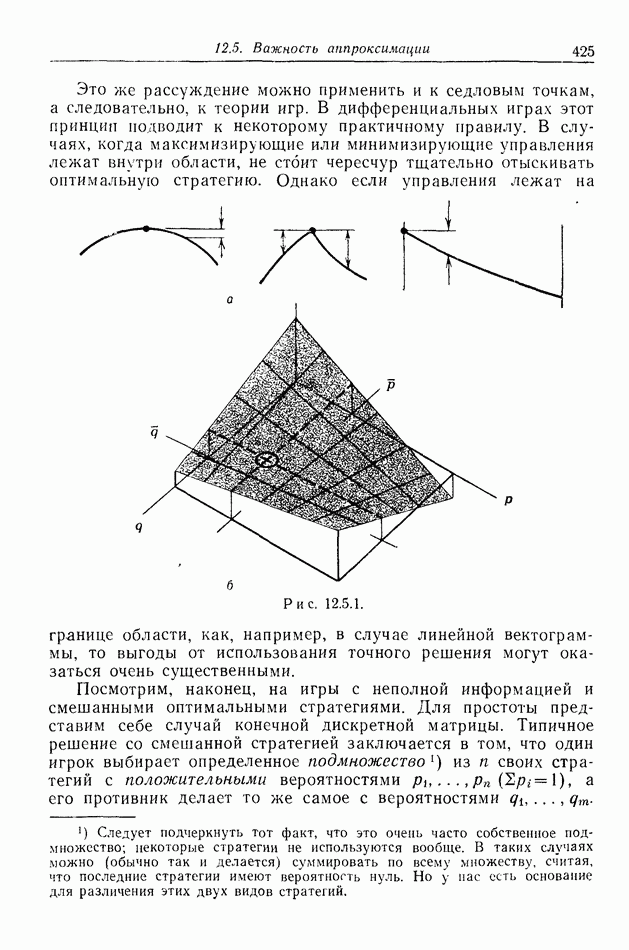
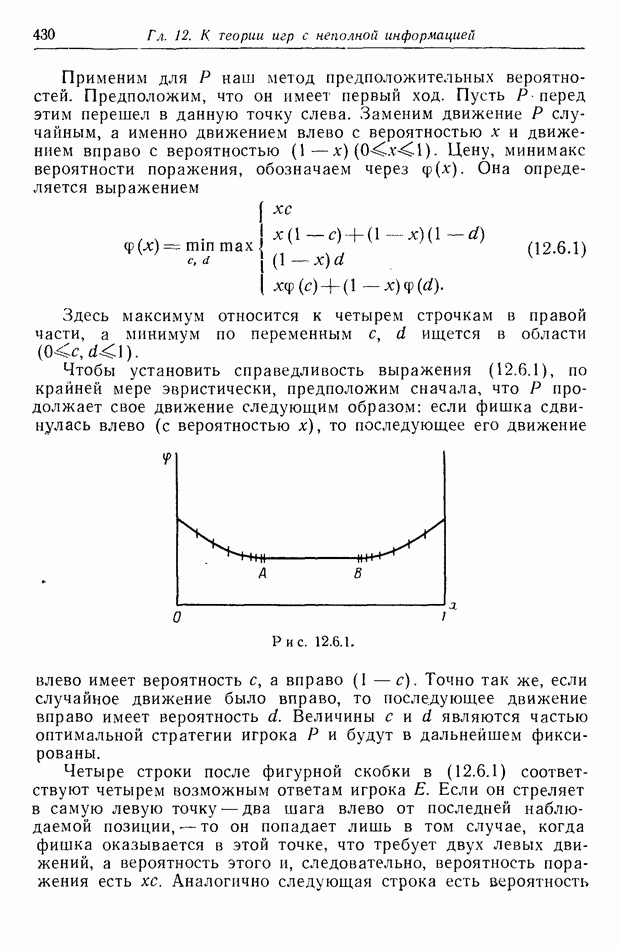
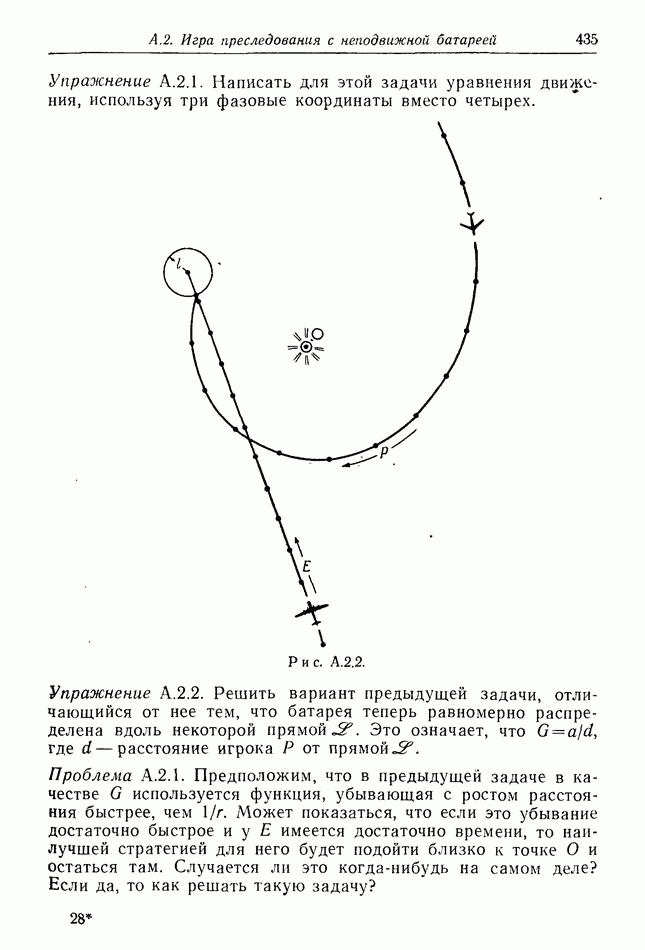
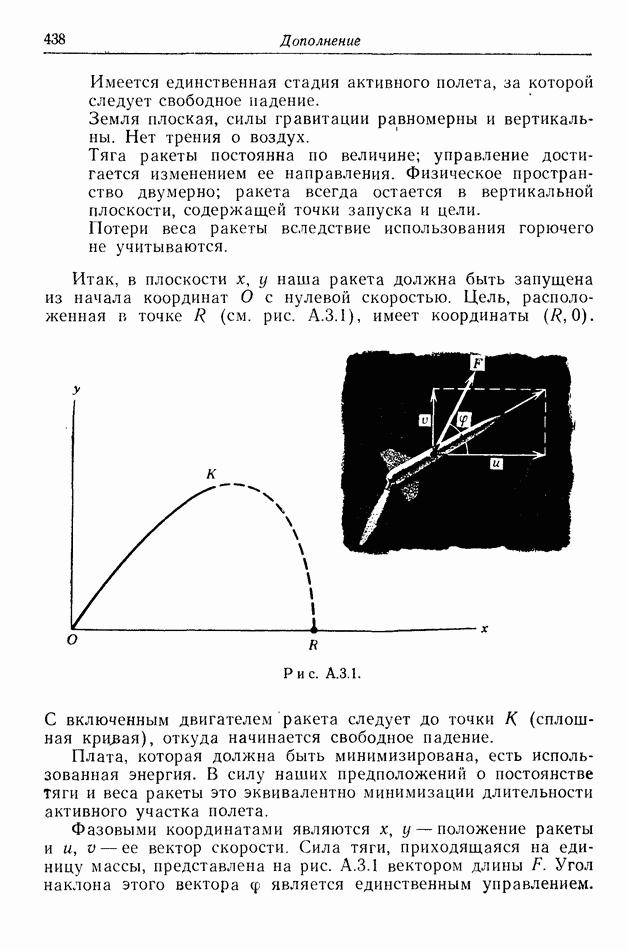
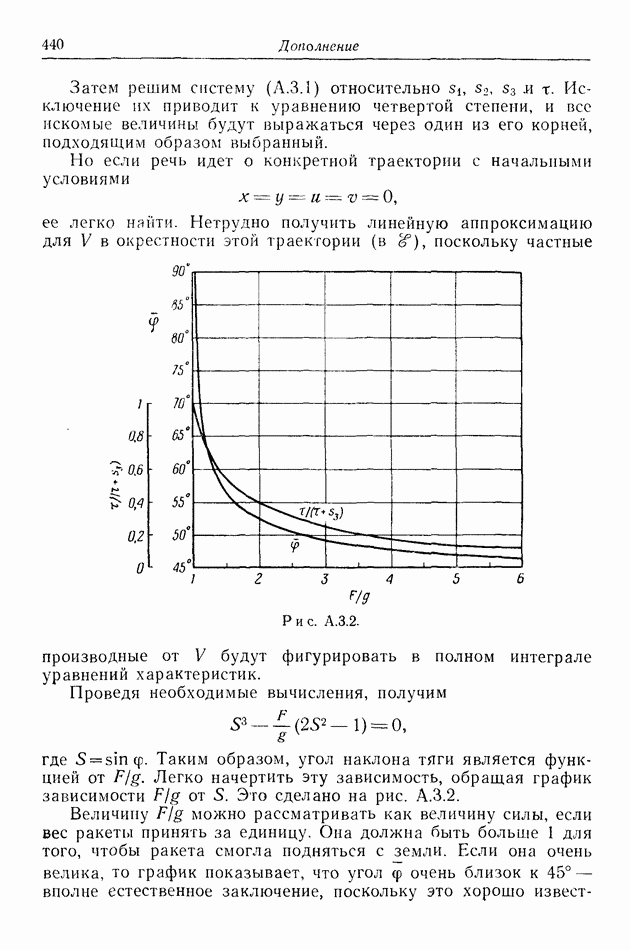
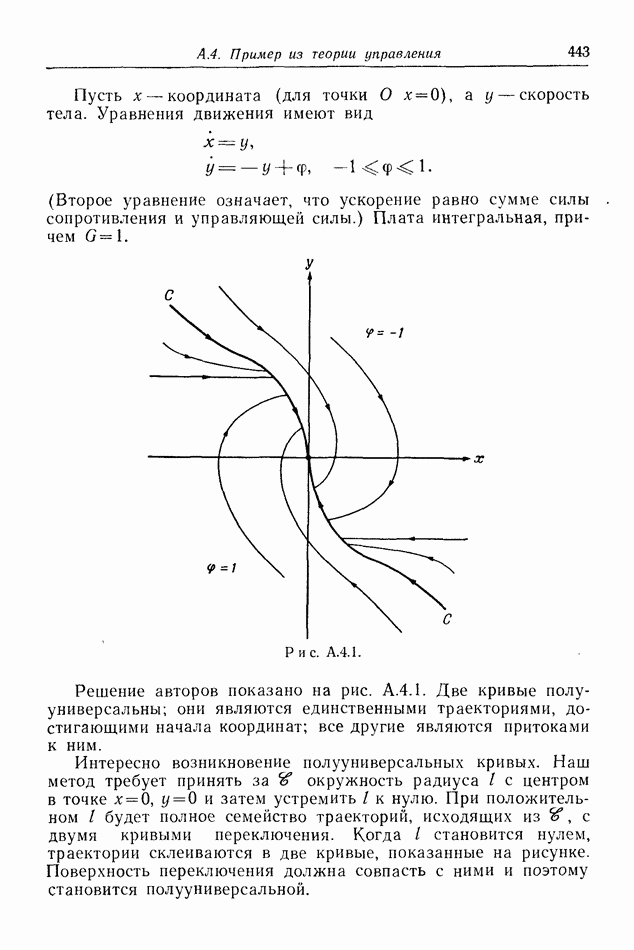
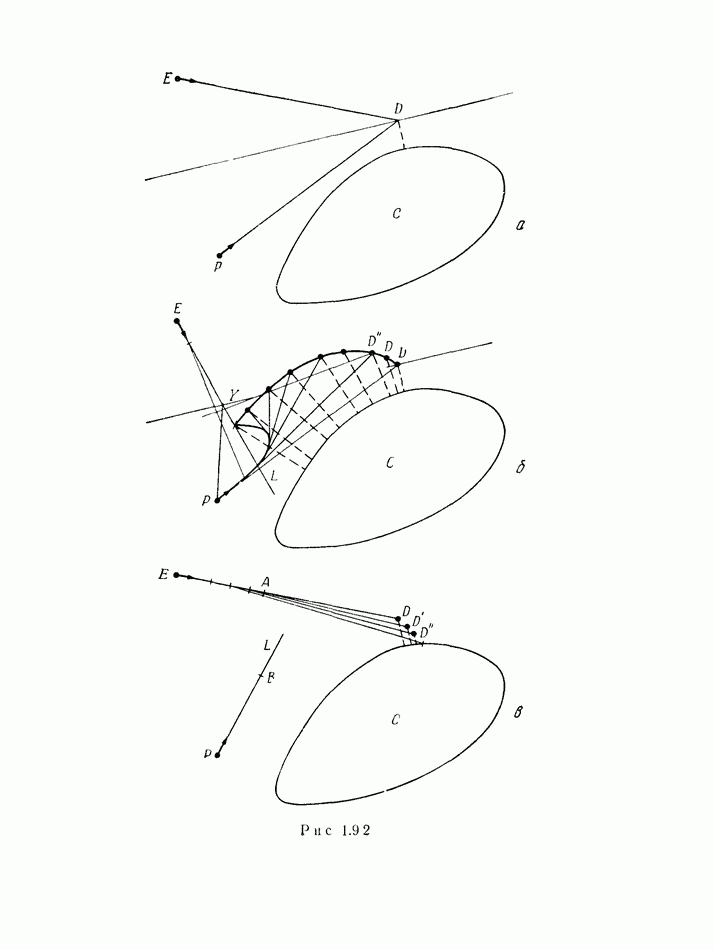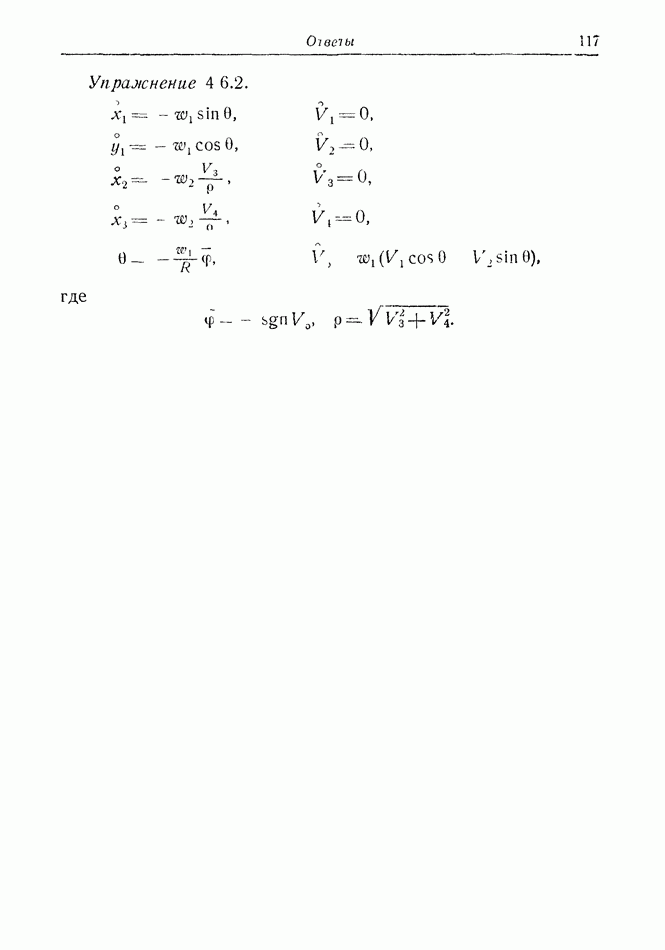12.2. ОБЩАЯ ПОСТАНОВКА ЗАДАЧ
Одна из основных трудностей в теории дифференциальных игр с неполной информацией состоит в том, что оптимальная игра в существенных случаях потребует применения смешанных стратегий. Какую форму они примут в дифференциальной игре? Смешанная стратегия обычно означает статистическое осреднение решений игроков в соответствии с некоторым вероятностным законом. Но как же игрок должен осреднять управления, значения которых он выбирает непрерывно?
Но и помимо различия в природе стратегий, игры с неполной информацией имеют существенную особенность. В общем случае здесь нельзя считать, что выбрать стратегии — это значит выбрать управления как функции от фазовых координат: решения игрока зависят теперь не только от текущих значений координат. В случае частичной информации знание прошлых состояний, вообще говоря, должно мотивировать текущее решение.
Вид информации, которую игрок может использовать, — это вероятностное распределение на пространстве фазовых координат в каждый момент времени. Поскольку полное знание является при этом частным случаем, обсуждавшиеся до сих пор игры с полной информацией являются частным случаем игр с неполной информацией.
Есть два источника такой информации. Один — это заданная информация, т. е. то, что предусмотрено правилами игры, сформулированными для этой цели. Например, если игра моделирует физическую ситуацию, в которой один игрок получает сведения о противнике с помощью несовершенной аппаратуры, правила могут быть подобраны так, чтобы в них отражалась неточность поступающей информации. Каждому игроку должны быть также известны какие-то данные о начальном состоянии; наиболее общей формой здесь является задание вероятностного распределения на 
Существует еще приобретаемая информация. Игрок знает всю историю своей собственной игры, и из нее он может вывести больше сведений, чем содержится в заданной информации.
Пример 12.2.1. Пусть уравнения движения имеют вид

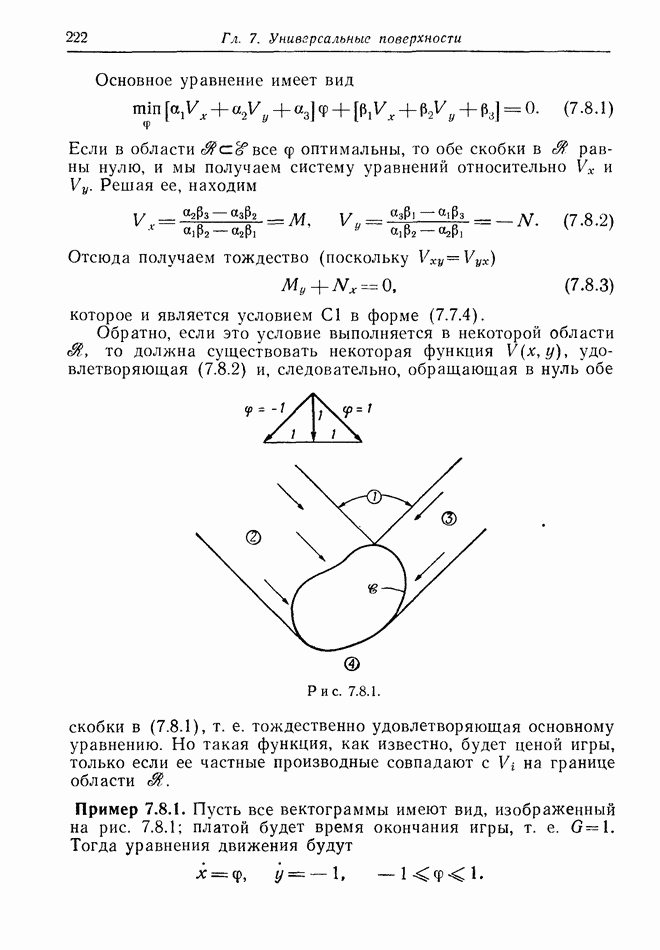
Здесь  управляющий выбором
управляющий выбором  всегда знает текущее значение х, если он знает его начальное значение
всегда знает текущее значение х, если он знает его начальное значение  (интегрируя первое из уравнений движения); это и есть приобретаемая информация. Если у него есть лишь вероятностное распределение для
(интегрируя первое из уравнений движения); это и есть приобретаемая информация. Если у него есть лишь вероятностное распределение для  то в каждый последующий момент времени он будет знать, что распределение осталось то же, оно лишь перенесено на фиксированное расстояние, которое он может с помощью интегрирования получить, зная
то в каждый последующий момент времени он будет знать, что распределение осталось то же, оно лишь перенесено на фиксированное расстояние, которое он может с помощью интегрирования получить, зная 
Но если он знает  начальное значение у, — то все, что он может сказать об у в момент
начальное значение у, — то все, что он может сказать об у в момент  это
это

Могут существовать и другие правила игры, которые снабжают его более подробными знаниями; это будет заданная информация.
Разумеется, и в случае частичной информации могут появиться оптимальные чистые стратегии. Но во многих важных примерах, основанных на реальности, интуитивно ясна необходимость смешанных стратегий.
Проблема 12.2.1. Предположим, что в игре с неполной информацией у каждого игрока имеется лишь по одному управлению и что вектограммы линейны. В решении соответствующей игры с полной информацией  и почти всюду на
и почти всюду на  принимают свои крайние значения. Обозначим через
принимают свои крайние значения. Обозначим через  те подмножества множества
те подмножества множества  где
где  Возвращаемся к исходной игре. В некоторый момент времени, исходя из заданной, приобретенной или составной информации,
Возвращаемся к исходной игре. В некоторый момент времени, исходя из заданной, приобретенной или составной информации,  знает вероятностное распределение для точки х на
знает вероятностное распределение для точки х на  Следовательно, он всегда может подсчитать вероятности попадания
Следовательно, он всегда может подсчитать вероятности попадания  Весьма правдоподобно, что надо использовать
Весьма правдоподобно, что надо использовать  или
или  в зависимости от того, какая из этих вероятностей больше. При каких условиях такая стратегия будет оптимальной? (Можно использовать пример 12.2.1 с различными
в зависимости от того, какая из этих вероятностей больше. При каких условиях такая стратегия будет оптимальной? (Можно использовать пример 12.2.1 с различными  для экспериментирования в этом направлении.)
для экспериментирования в этом направлении.)
Рассмотрим игру преследования в качестве менее абстрактного примера. Как обычно,  преследует
преследует  убегает от
убегает от  но каждый (или, может быть, один из них) имеет неполные сведения о положении другого. Практические рассмотрения, особенно существующие ограничения чувствительности приборов, подсказывают много форм такой неполноты (для определенности мы будем говорить об имеющейся в распоряжении
но каждый (или, может быть, один из них) имеет неполные сведения о положении другого. Практические рассмотрения, особенно существующие ограничения чувствительности приборов, подсказывают много форм такой неполноты (для определенности мы будем говорить об имеющейся в распоряжении  информации об игроке
информации об игроке  но, разумеется, следует учитывать равные возможности и противной стороны).
но, разумеется, следует учитывать равные возможности и противной стороны).
1. Р может (довольно) хорошо знать положение  но при этом плохо знать другие фазовые координаты (если они есть), такие, как направление и величину скорости.
но при этом плохо знать другие фазовые координаты (если они есть), такие, как направление и величину скорости.
2. Следящие приборы  дают ему лишь вероятностное распределение положения
дают ему лишь вероятностное распределение положения 
3. Р может знать лишь относительный пеленг  т. е. направление линии
т. е. направление линии 
4. Может существовать запаздывание во времени;  знает лишь то положение
знает лишь то положение  в котором тот находился некоторое фиксированное время
в котором тот находился некоторое фиксированное время  назад.
назад.
5. Р получает свою информацию в дискретные моменты времени. (Например, вращающийся радар, но этот случай имеет теоретико-игровой интерес лишь тогда, когда интервалы между сигналами достаточно велики, чтобы позволить  совершить существенный маневр в промежутке между ними.)
совершить существенный маневр в промежутке между ними.)
Если оба игрока не имеют никакой информации, то мы будем говорить об играх поиска.
Мы обсудим некоторые возможности, перечисленные в приведенных выше пяти пунктах. Примем простую версию пункта 2, считая, что в каждый момент времени  знает
знает  лишь то, что он с равной вероятностью может находиться внутри шара радиуса
лишь то, что он с равной вероятностью может находиться внутри шара радиуса  В дискретной модели, если игроки поочередно передвигаются скачками, мы будем считать, что происходит случайный сдвиг перед каждым скачком
В дискретной модели, если игроки поочередно передвигаются скачками, мы будем считать, что происходит случайный сдвиг перед каждым скачком  Это означает, что центр сферы обнаружения с равной вероятностью может находиться в любой точке шара радиуса
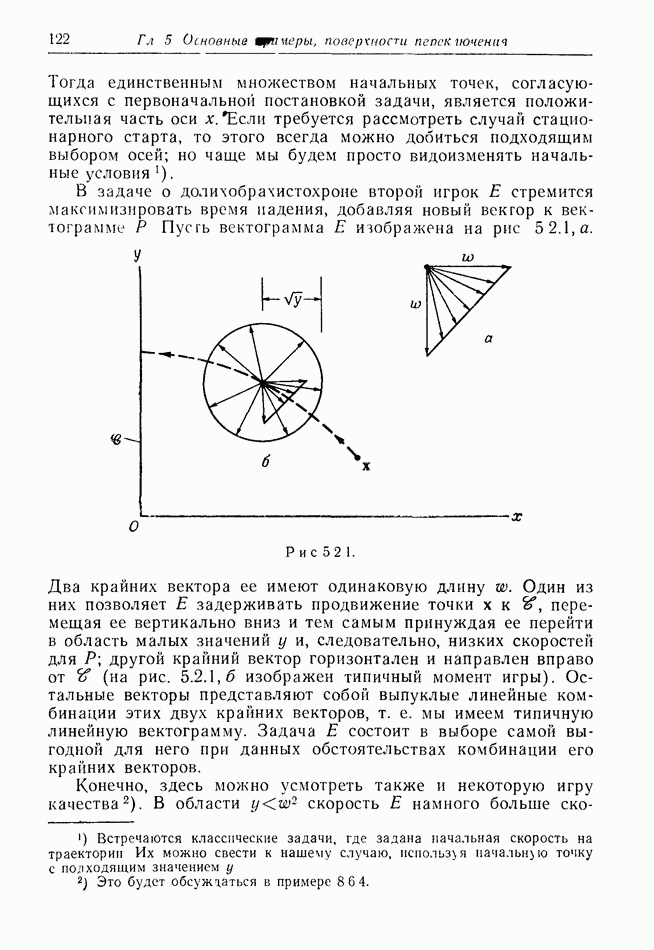
Это означает, что центр сферы обнаружения с равной вероятностью может находиться в любой точке шара радиуса  с центром в
с центром в 
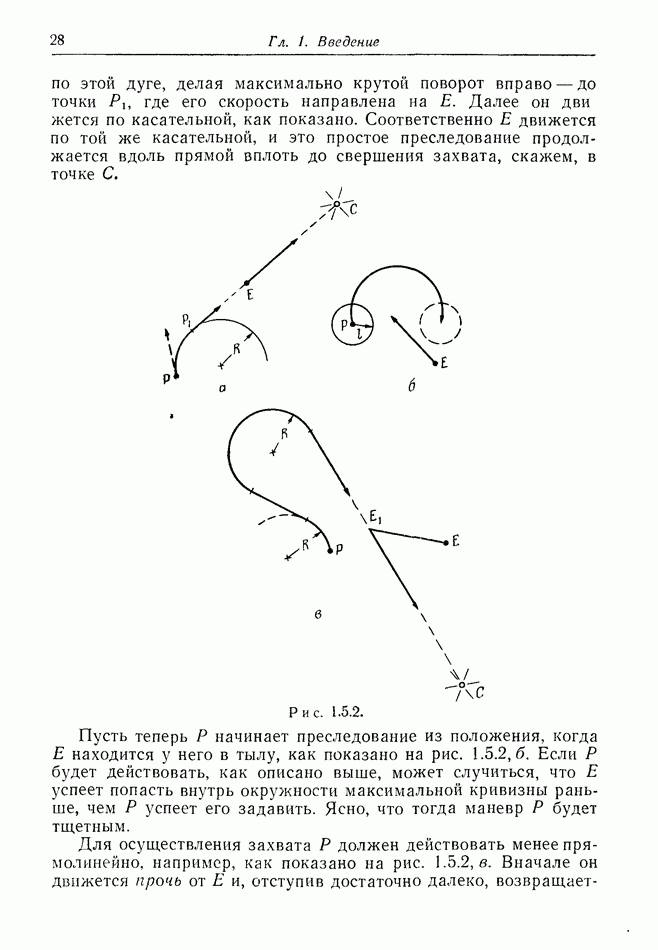
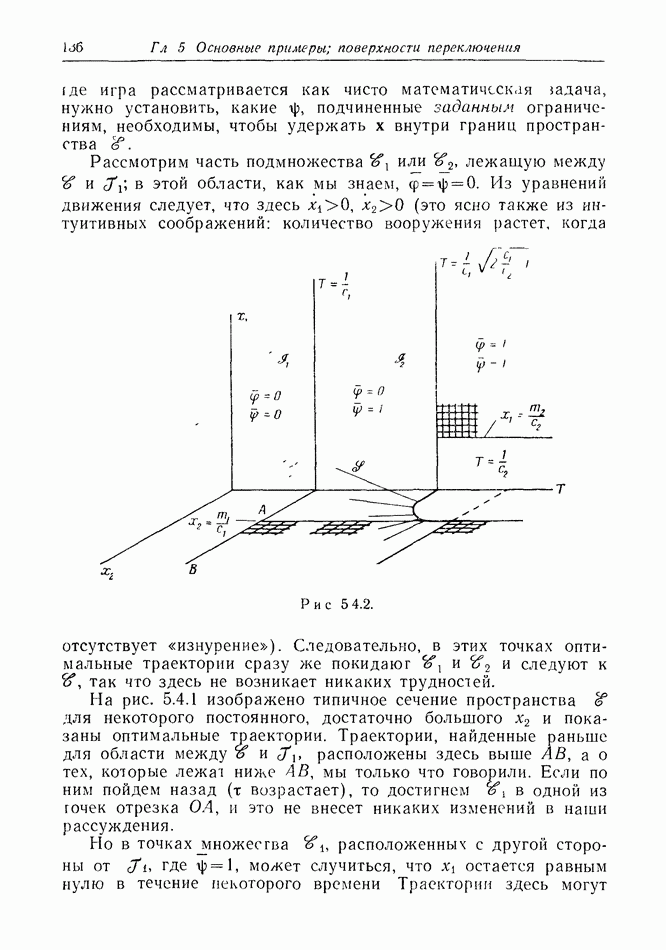
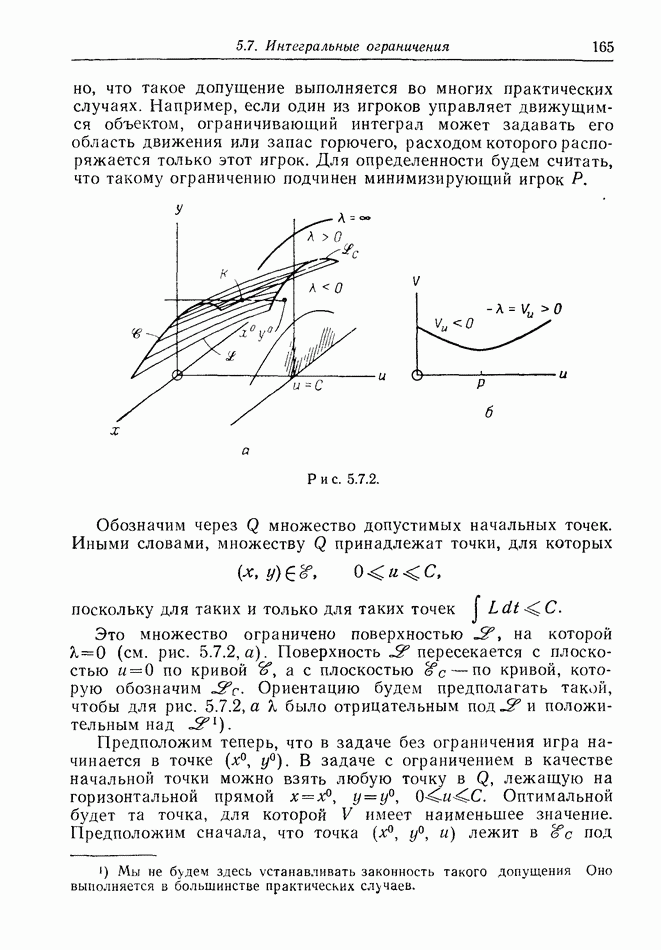
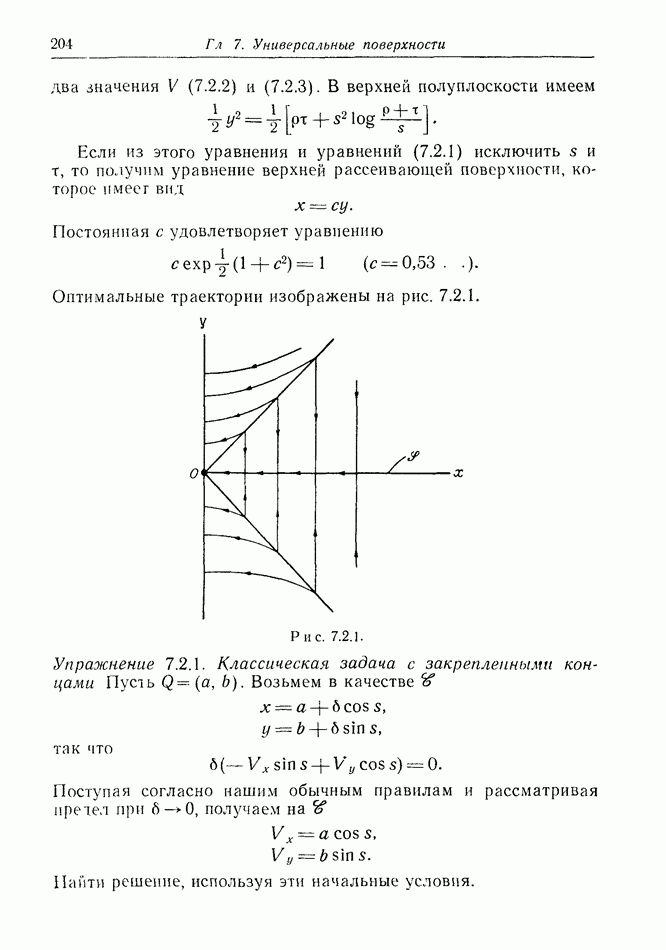
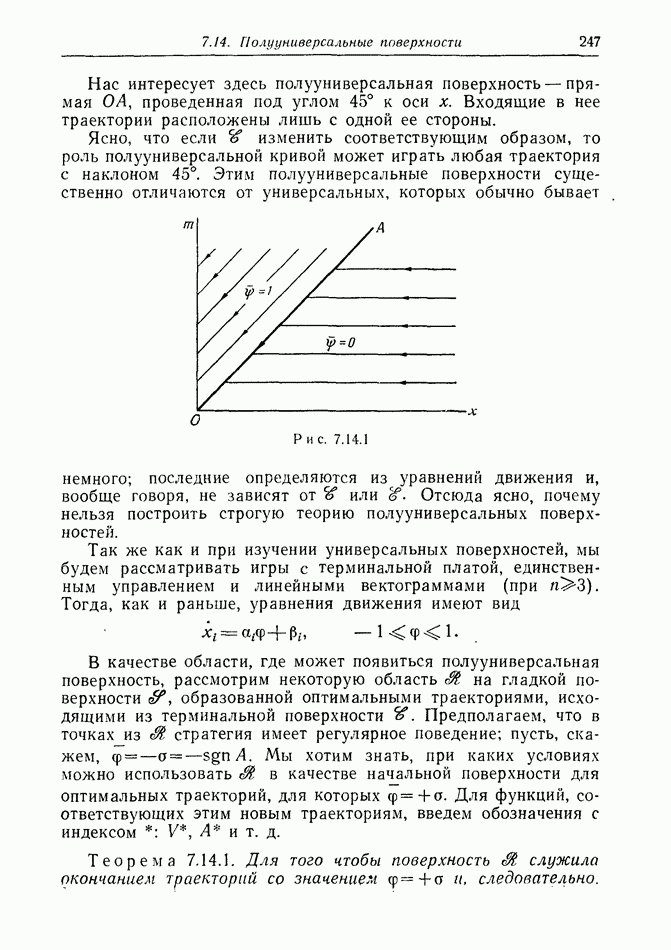
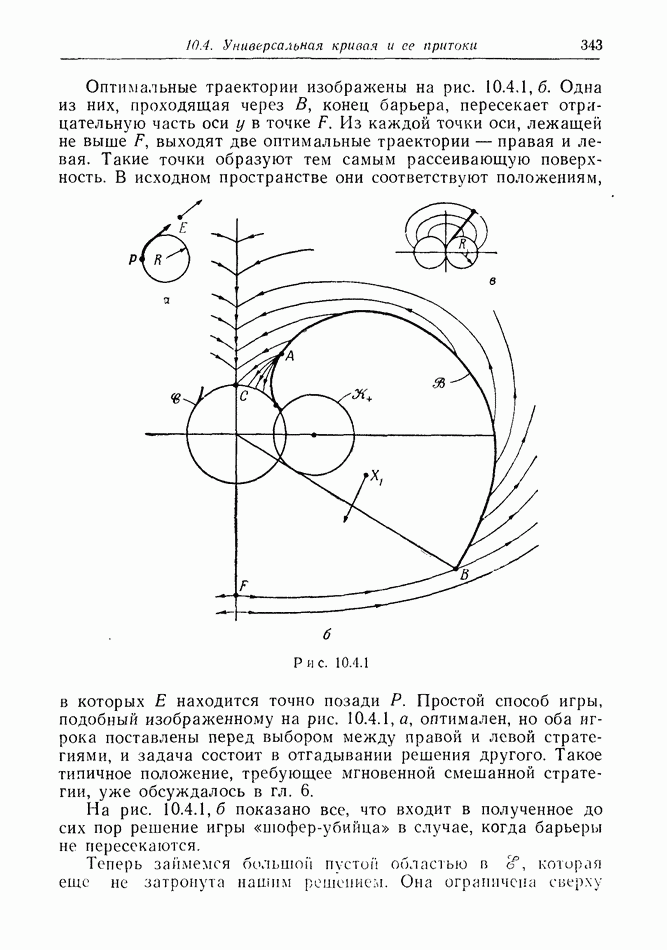
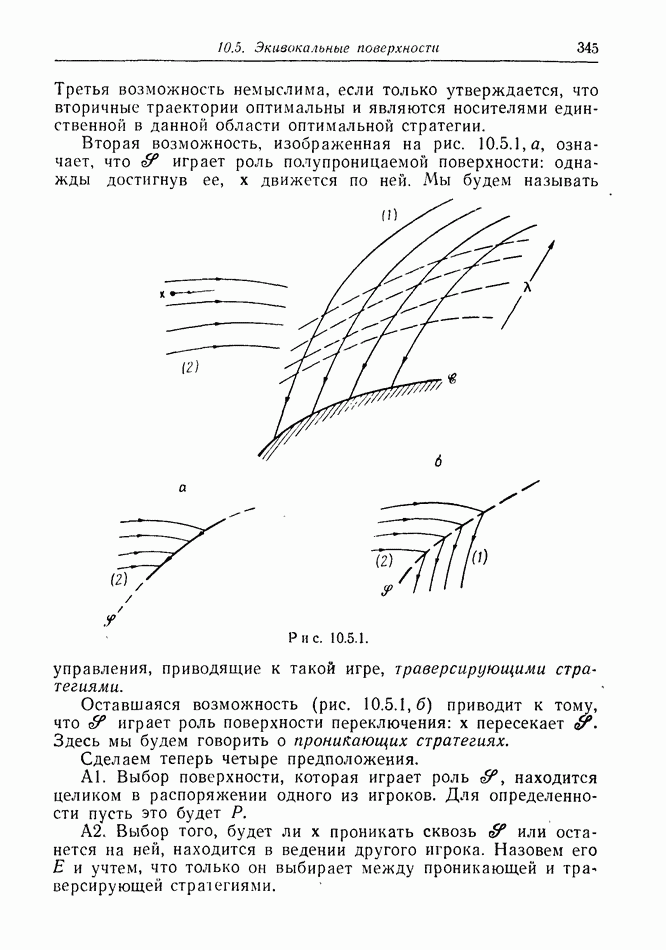
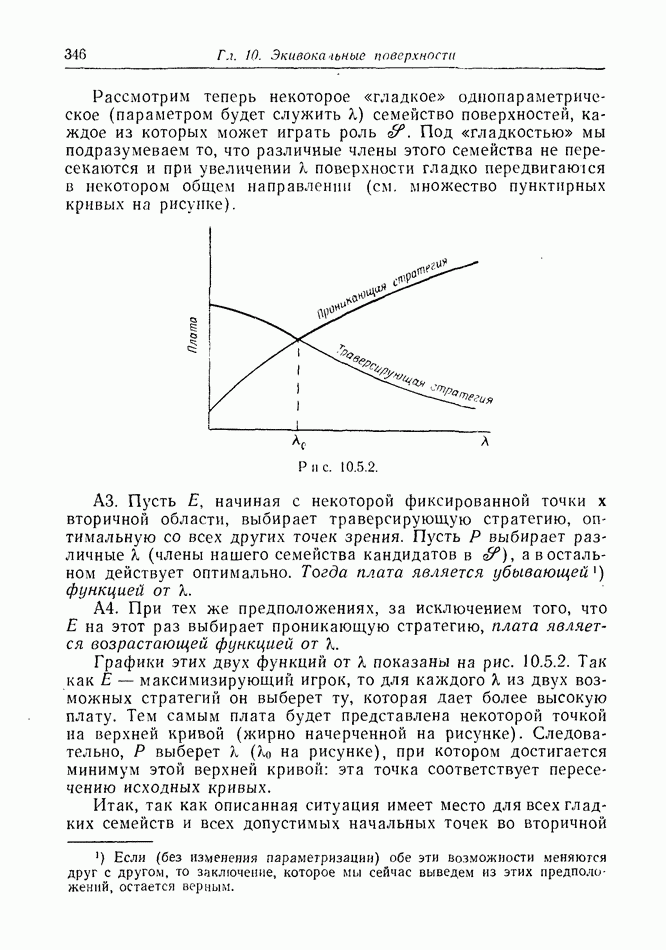
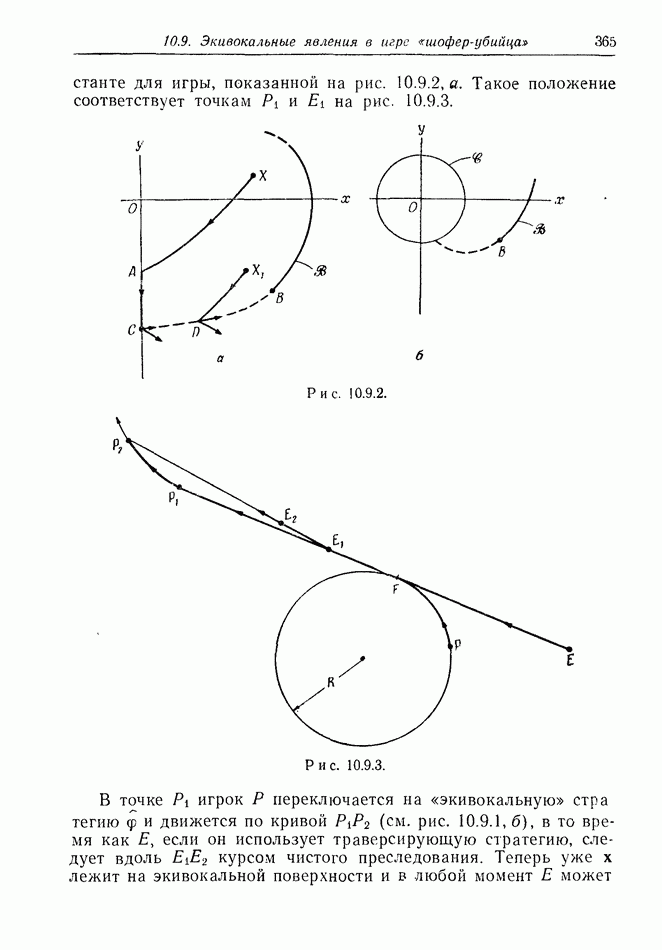
Остановимся ненадолго на дискретной модели. Один из возможных случаев получаемой  информации показан на рис. 12.2.1, а. Точками обозначены последовательные положения
информации показан на рис. 12.2.1, а. Точками обозначены последовательные положения
Е, но  знает только, что каждое из них с равной вероятностью лежит внутри содержащего его круга.
знает только, что каждое из них с равной вероятностью лежит внутри содержащего его круга.
Предположим, что наступит момент, когда два последовательных круга расположены, как на рис. 12.2.1, б, где расстояние  лишь немного меньше, чем путь, который может пройти
лишь немного меньше, чем путь, который может пройти  при своем последнем движении. Тогда
при своем последнем движении. Тогда  может заключить, что
может заключить, что  должен находиться очень близко к В. Такая ситуация не является исключительной. В частном случае, когда
должен находиться очень близко к В. Такая ситуация не является исключительной. В частном случае, когда  неподвижен, результат имеет вид, показанный на рис. 12.2.1, в.
неподвижен, результат имеет вид, показанный на рис. 12.2.1, в.

Рис. 12.2.1.
Если  подождет достаточно долго, то с вероятностью, равной единице, он сможет получить сколь угодно точную информацию.
подождет достаточно долго, то с вероятностью, равной единице, он сможет получить сколь угодно точную информацию.
Итак, накопление заданной информации может дать гораздо больше, чем ее текущее значение. Эти явления вновь объясняют, почему хорошая стратегия должна зависеть от прошлых состояний.
Полное перекрытие сфер на рис. 12.2.1, в отчасти вызвано тем, что мы предположили их статистическую независимость. Но что случится, если мы будем выбирать дискретизацию с более мелким шагом, пытаясь приблизиться к непрерывной игре? Мы подойдем еще ближе к некоторой определенности за более короткий интервал времени, что в конце концов равносильно полному отсутствию ошибок или игре с полной информацией.
Абсурдность этого вывода проявляется, если взглянуть на существующие измерительные приборы непрерывного действия и на науку об их ошибках — часть теории стохастических процессов. Общим в таких рассмотрениях являются автокорреляционные функции: вероятность большого изменения при
малых значениях аргумента мала. Очевидно, что учет ограничений такого типа необходим для реального подхода к непрерывной игре.
Существует аналогичная нереальность, относящаяся к стратегиям. По-видимому, ясно, что оптимальная стратегия должна быть смешанной в играх с существенными ограничениями на информацию. Как же может быть достигнуто осреднение управлений? Разрешить каждому игроку в каждый момент времени выбрать значения из независимых вероятностных распределений было бы так же нелепо, как и в предыдущем случае. Действительно, любая реальная модель с непрерывным выбором, скажем, положения руля, требует, чтобы близкие последовательные позиции были коррелированы независимо от того, является ли исполнителем человек или механизм. По-видимому, здесь мы вновь должны говорить со стохастическим акцентом.
У. Гренандер в великолепной работе на 84-х страницах указал путь прогресса. Он рассматривал игру преследования, которая имела установившийся характер, а решения игроков описывались стохастическими средствами, как в теории прогнозирования.
Вернемся к игре преследования и подумаем, какой вид должно иметь полное решение. Для иллюстрации возникающих возможностей примем искусственное предположение, что  — радиус сферы обнаружения — постоянен и велик по сравнению с радиусом зоны захвата.
— радиус сферы обнаружения — постоянен и велик по сравнению с радиусом зоны захвата.
Если партия начинается с расстояния  большего, чем
большего, чем  то следует ожидать, что в ранней стадии игра будет похожа на игру с полной информацией. Игрок
то следует ожидать, что в ранней стадии игра будет похожа на игру с полной информацией. Игрок  будет преследовать относительно маленькую сферу, как он преследовал бы
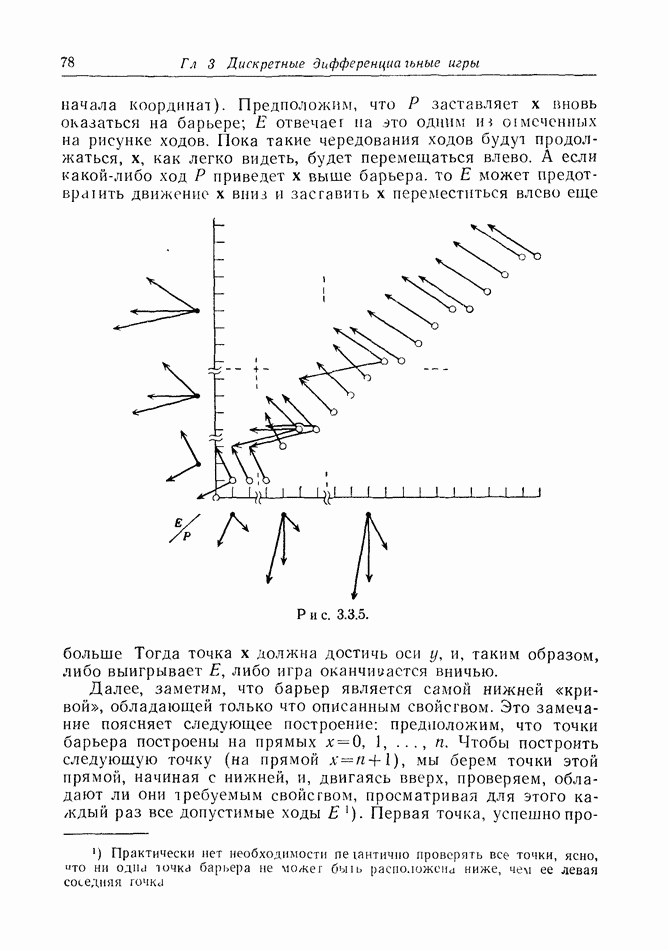
будет преследовать относительно маленькую сферу, как он преследовал бы  а
а  будет применять соответствующую тактику убегания. Но со сближением и особенно после того, как
будет применять соответствующую тактику убегания. Но со сближением и особенно после того, как  войдет внутрь сферы обнаружения, недостаток информации приведет к положению, возникающему в играх поиска. Если предположить наличие большой автокорреляции, то сфера обнаружения будет фактически стационарной и, однажды войдя внутрь нее,
войдет внутрь сферы обнаружения, недостаток информации приведет к положению, возникающему в играх поиска. Если предположить наличие большой автокорреляции, то сфера обнаружения будет фактически стационарной и, однажды войдя внутрь нее,  останется там, не проявляя особой ловкости. Последующая игра на самом деле будет игрой поиска с пространством игры У, роль которого выполняет внутренность шара.
останется там, не проявляя особой ловкости. Последующая игра на самом деле будет игрой поиска с пространством игры У, роль которого выполняет внутренность шара.
Этот чисто поисковый аспект годится для нашей игры преследования только в том случае, когда  имеет столь большие кинематические преимущества над
имеет столь большие кинематические преимущества над  что последний может рассматриваться как относительно неподвижный. Но в другом, по-видимому, более общем случае
что последний может рассматриваться как относительно неподвижный. Но в другом, по-видимому, более общем случае  обязан отвлечь часть своих сил на попытку удержаться внутри движущегося шара. Тогда его стратегия будет смешанной стратегией преследования
обязан отвлечь часть своих сил на попытку удержаться внутри движущегося шара. Тогда его стратегия будет смешанной стратегией преследования  (скажем, с помощью преследования центра шара) и случайных поисков, как и выше. Подобным же образом
(скажем, с помощью преследования центра шара) и случайных поисков, как и выше. Подобным же образом  должен перемешать стратегию убегания со своим случайным прятаньем.
должен перемешать стратегию убегания со своим случайным прятаньем.
В любом случае игра поиска будет составляющей частью. Мы рассматриваем ее в двух следующих параграфах.
Является ли переход между этими фазами — ранней фазой чистого преследования и поздней, с частичным (или полным) смешанным поиском, — постепенным или резким?
Теперь обратимся к некоторым другим из пяти случаев частичной информации, упоминавшимся ранее в этом параграфе.
Если выполнен пункт 3, т. е.  знает лишь относительный пеленг то вновь знания о положении
знает лишь относительный пеленг то вновь знания о положении  накапливаются с течением времени. Если
накапливаются с течением времени. Если  неподвижен, то
неподвижен, то  глядя на него с двух различных позиций, может определить его точное положение с помощью триангуляции. В случае если
глядя на него с двух различных позиций, может определить его точное положение с помощью триангуляции. В случае если  подвижен,
подвижен,  приходится гораздо труднее, но насколько именно — это зависит от его знания кинематических ограничений
приходится гораздо труднее, но насколько именно — это зависит от его знания кинематических ограничений  особенно ограничений на скорость.
особенно ограничений на скорость.
Имеет смысл рассмотреть стратегии  намеренно предназначенные для того, чтобы разрушить планы накопления информации игрока
намеренно предназначенные для того, чтобы разрушить планы накопления информации игрока  Они должны быть, конечно, случайными, поскольку (еще раз) если
Они должны быть, конечно, случайными, поскольку (еще раз) если  может предсказать действия
может предсказать действия  то его местоположение можно найти с помощью триангуляции и в том случае, когда
то его местоположение можно найти с помощью триангуляции и в том случае, когда  меняет свое положение.
меняет свое положение.
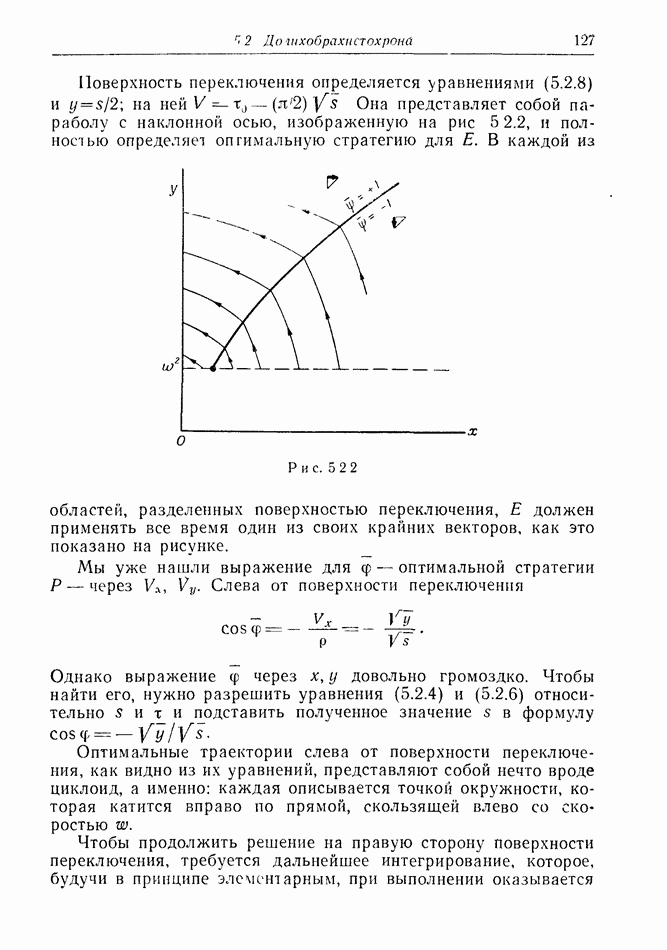
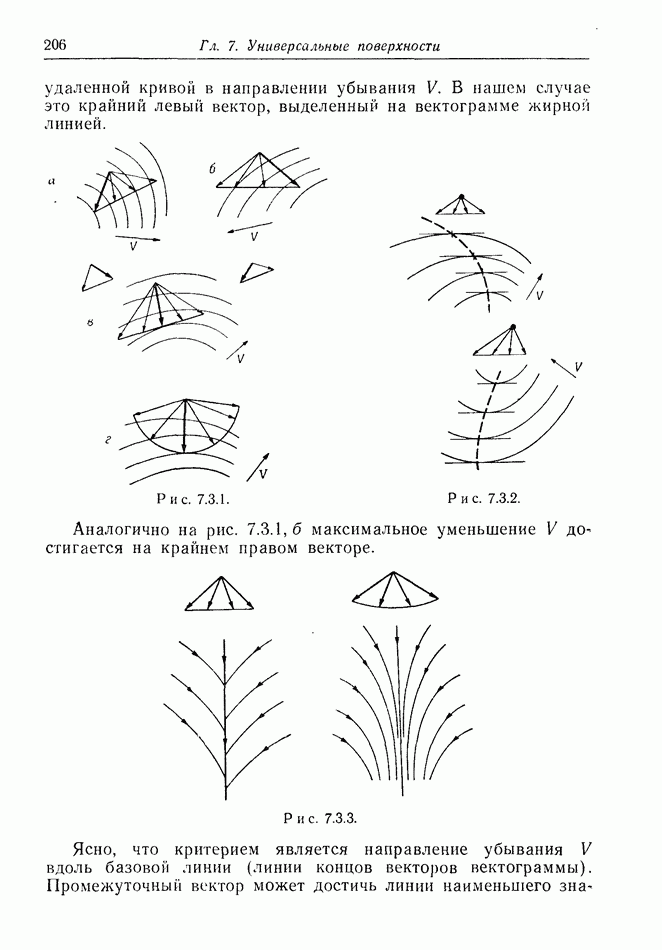
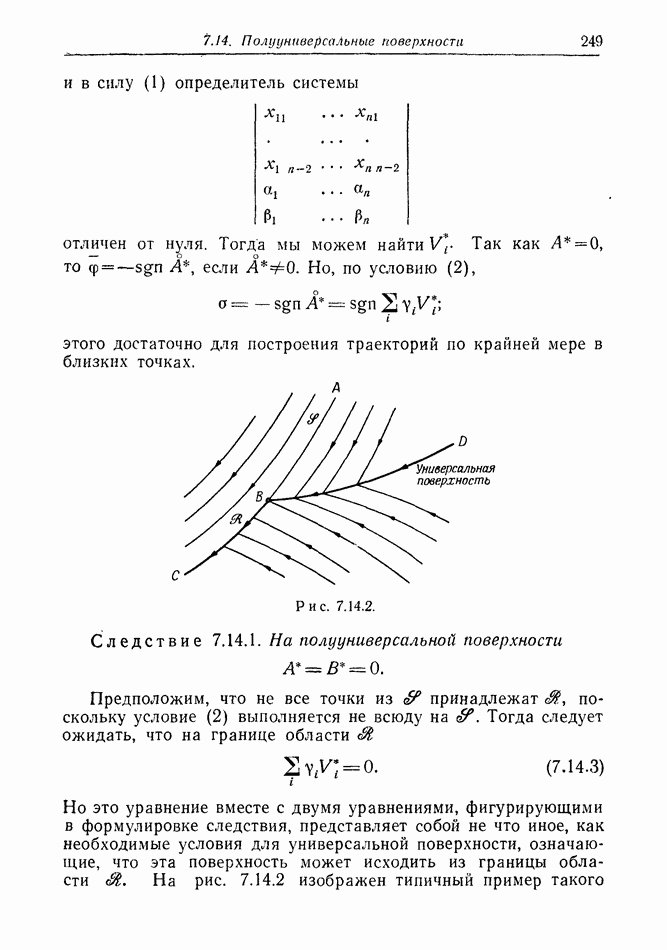
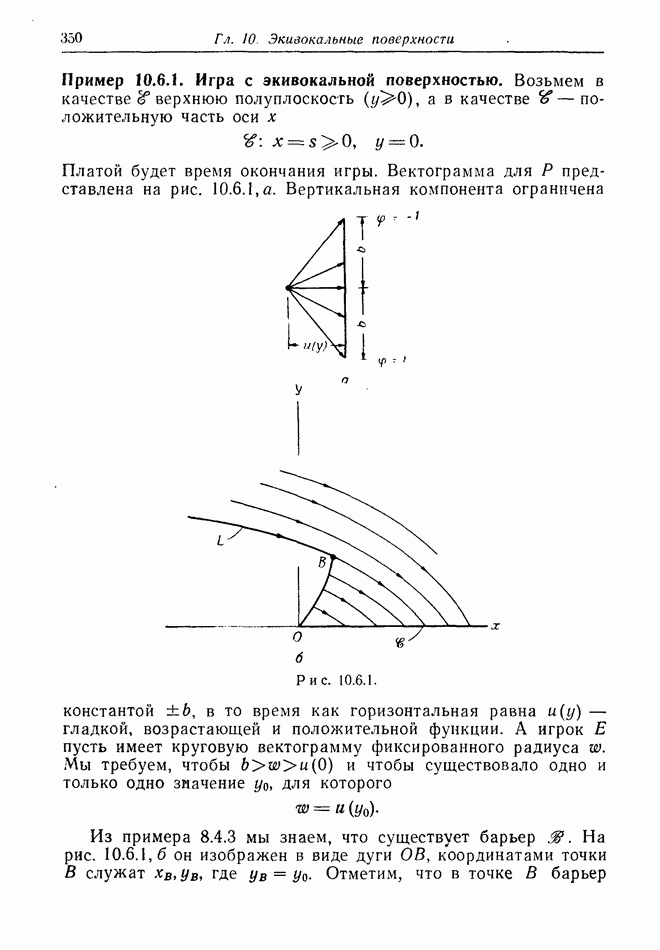
В случае 5, когда  получает информацию дискретно, периодически из относительно большой области пространства, стоит подумать о желательности для
получает информацию дискретно, периодически из относительно большой области пространства, стоит подумать о желательности для  использовать изменения курса с периодом, совпадающим с периодом поступления информации к
использовать изменения курса с периодом, совпадающим с периодом поступления информации к  как показано на рис. 12.2.2. Этот обман приводит к тому, что
как показано на рис. 12.2.2. Этот обман приводит к тому, что  замечает лишь положения
замечает лишь положения  отмеченные точками.
отмеченные точками.
Ситуация 4 с запаздыванием во времени банальна. Например, ложные маневры эффективны лишь в том случае, если существует запаздывание между наблюдением противника и его активным ответом. Вернемся к примеру с футболом, когда игрок В, владеющий мячом, противостоит защитнику  Финты со стороны
Финты со стороны  такие, как выпад влево с последующим быстрым обходом вокруг
такие, как выпад влево с последующим быстрым обходом вокруг  справа, будут тщетными попытками сбить
справа, будут тщетными попытками сбить  столку, если он обладает достаточно быстрой реакцией.
столку, если он обладает достаточно быстрой реакцией.
Мы обсудили ряд действий, предпринимаемых игроками ради информации, —  старается ее собрать,
старается ее собрать,  старается помешать этому; эти действия почти всегда включают элемент случайности. В рассматриваемой игре преследования оптимальная стратегия должна состоять из комбинации случайных движений и движений, непосредственной целью которых служат захват и убегание, похожих (по крайней мере) на используемые в играх с полной информацией.
старается помешать этому; эти действия почти всегда включают элемент случайности. В рассматриваемой игре преследования оптимальная стратегия должна состоять из комбинации случайных движений и движений, непосредственной целью которых служат захват и убегание, похожих (по крайней мере) на используемые в играх с полной информацией.

Рис. 12.2.2.
В общем случае такие рассуждения не всегда верны. Первый тип движений, касающийся информации, вообще говоря, ставит в невыгодное положение второй тип — непосредственное преследование и убегание. Иногда возникающие здесь потери оказываются чересчур большими — следующие далее примеры являются в этом отношении крайними случаями, — и новой важной стороной нашей общей задачи является нахождение критерия применимости того или другого типа движений.
Пример 12.2.2. Простая игра преследования. Вернемся к примеру 1.9.1, в котором  движутся по плоскости, каждый обладает простым движением и
движутся по плоскости, каждый обладает простым движением и  имеет большую скорость. Платой является время захвата, и мы знаем, что оптимальная игра состоит в погоне по прямой линии, проходящей через начальные положения
имеет большую скорость. Платой является время захвата, и мы знаем, что оптимальная игра состоит в погоне по прямой линии, проходящей через начальные положения  Предположим теперь, что
Предположим теперь, что  имеет лишь информацию типа 3. Он знает только относительный угол отклонения
имеет лишь информацию типа 3. Он знает только относительный угол отклонения  и не знает расстояния до него. Но угол отклонения — это все, что ему нужно, для того чтобы применять свою оптимальную стратегию в игре с полной информацией. Очевидно, что такая стратегия здесь также оптимальна. Ни один из игроков не будет использовать смешанной стратегии.
и не знает расстояния до него. Но угол отклонения — это все, что ему нужно, для того чтобы применять свою оптимальную стратегию в игре с полной информацией. Очевидно, что такая стратегия здесь также оптимальна. Ни один из игроков не будет использовать смешанной стратегии.
Возможно, что для  окажется желательным менять курс в целях триангуляции, но это произойдет только в том случае,
окажется желательным менять курс в целях триангуляции, но это произойдет только в том случае,
если игра будет изменена так, что ему потребуется большая информация. Предоставляем читателю самому придумать такое видоизменение.
Подобные, но в менее крайней форме идеи применимы и в других наших случаях. Например, осциллирующий путь на рис. 12.2.2 сократит эффективную скорость убегания  При такой плате, как время захвата, сомнительно, будет ли он его использовать.
При такой плате, как время захвата, сомнительно, будет ли он его использовать.
Однако ситуация изменится, если перейти от задач преследования к задачам стрельбы. Будем считать, что  вооружен таким оружием, как пушка (торпеда, ракета), и может сделать один или несколько выстрелов по
вооружен таким оружием, как пушка (торпеда, ракета), и может сделать один или несколько выстрелов по  Будем сначала игнорировать некоторую присущую оружию неточность, так что
Будем сначала игнорировать некоторую присущую оружию неточность, так что  заведомо попадет, если он точно знает положение
заведомо попадет, если он точно знает положение  Платой является вероятность поражения.
Платой является вероятность поражения.
Тогда, поскольку единственной целью  является уменьшение информированности
является уменьшение информированности  ясно, что его стратегии здесь должны быть существенно случайными. Подобным же образом
ясно, что его стратегии здесь должны быть существенно случайными. Подобным же образом  тоже должен использовать смешанную стратегию, так как для каждой определенной стратегии — куда и когда стрелять —
тоже должен использовать смешанную стратегию, так как для каждой определенной стратегии — куда и когда стрелять —  будет способен не оказаться в этот момент в пункте цели.
будет способен не оказаться в этот момент в пункте цели.
Характерный пример такой игры, имеющий практическую важность и иллюстрирующий эти идеи, следующий.
Пример 12.2.3. Задача «прицеливание и увертывание». Пример относится к пункту 4. Здесь имеется время запаздывания между моментом, когда  видит
видит  и моментом попадания снаряда в цель. Пусть
и моментом попадания снаряда в цель. Пусть  может сделать лишь один выстрел, прицелившись в некоторое будущее положение
может сделать лишь один выстрел, прицелившись в некоторое будущее положение  Задача игрока
Задача игрока  который предполагается подвижным, состоит в таком маневрировании, чтобы осложнить предсказания игрока
который предполагается подвижным, состоит в таком маневрировании, чтобы осложнить предсказания игрока  Усреднение является здесь существом дела; ведь систематический зигзаг так же легко предсказать, как и равномерное движение. Но найти нужное движение очень трудно, поскольку, как мы предполагаем,
Усреднение является здесь существом дела; ведь систематический зигзаг так же легко предсказать, как и равномерное движение. Но найти нужное движение очень трудно, поскольку, как мы предполагаем,  ничего не знает о выстреле до момента прибытия снаряда, а
ничего не знает о выстреле до момента прибытия снаряда, а  может стрелять в любой момент. Можно минимизировать информацию, которой располагает
может стрелять в любой момент. Можно минимизировать информацию, которой располагает  к некоторому моменту времени, используя смешанную стратегию, результатом которой будет равномерное распределение положения
к некоторому моменту времени, используя смешанную стратегию, результатом которой будет равномерное распределение положения  по доступной ему площади. Однако, не зная, когда произойдет взрыв, он должен иметь равномерное распределение в любой момент времени, что невозможно.
по доступной ему площади. Однако, не зная, когда произойдет взрыв, он должен иметь равномерное распределение в любой момент времени, что невозможно.
Можно, конечно, привести много примеров игр подобного рода. Одна из них, простейшая из нетривиальных, приведена в примере 12.6.1.
Имеющие «стационарный» характер (см. § 12.6) чистые игры типа «прицеливание и увертывание», вроде описанной выше, цели которых могут быть выражены лишь в терминах информации, представляют собой область приложения теории стационарных стохастических процессов. Существующая техника оптимального прогнозирования может быть использована для  а ее обращение — для
а ее обращение — для  поскольку
поскольку  старается найти случайный курс, максимизирующий ошибку в предсказании его местоположения. Исследования Гренандера блестящи и глубоки и, по-видимому, подают надежду на то, что будущая теория окажется полной, красивой и полезной.
старается найти случайный курс, максимизирующий ошибку в предсказании его местоположения. Исследования Гренандера блестящи и глубоки и, по-видимому, подают надежду на то, что будущая теория окажется полной, красивой и полезной.
Но при отказе от стационарности наши идеи вновь закрываются тучами, даже если плата включает в себя лишь предсказание.
Например, откажемся от предположения об абсолютной точности стрельбы  и предположим, что она убывает с удалением
и предположим, что она убывает с удалением  Тогда, по-видимому, случайная стратегия
Тогда, по-видимому, случайная стратегия  должна включать в себя в некоторой степени удаление от места расположения оружия. В какой степени? Может ли скорость убывания точности с расстоянием достичь такой критической величины, что при ее дальнейшем увеличении оптимальная стратегия
должна включать в себя в некоторой степени удаление от места расположения оружия. В какой степени? Может ли скорость убывания точности с расстоянием достичь такой критической величины, что при ее дальнейшем увеличении оптимальная стратегия  является чистой и состоит в убегании?
является чистой и состоит в убегании?
Другой вариант возникает, если  есть место назначения; придя туда, он выполняет свою миссию; целью
есть место назначения; придя туда, он выполняет свою миссию; целью  является его поражение до этого момента. Модифицируем пример 12.2.3, предположив, что
является его поражение до этого момента. Модифицируем пример 12.2.3, предположив, что  имеет несколько снарядов. Если
имеет несколько снарядов. Если  достаточно близок к своей цели, то, идя туда прямо, он делает свое положение полностью предсказуемым. Если же делать случайные обманные движения, то безопасность повышается. Вновь возникает дилемма чистой и смешанной стратегии!
достаточно близок к своей цели, то, идя туда прямо, он делает свое положение полностью предсказуемым. Если же делать случайные обманные движения, то безопасность повышается. Вновь возникает дилемма чистой и смешанной стратегии!
Другим примером является следующий упрощенный вариант жизненно важного случая.
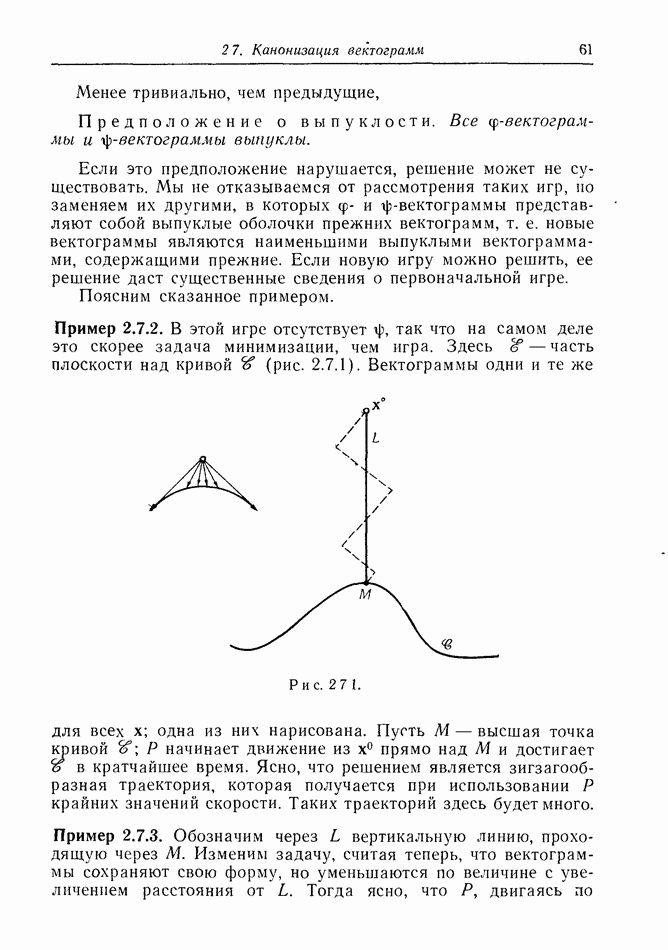
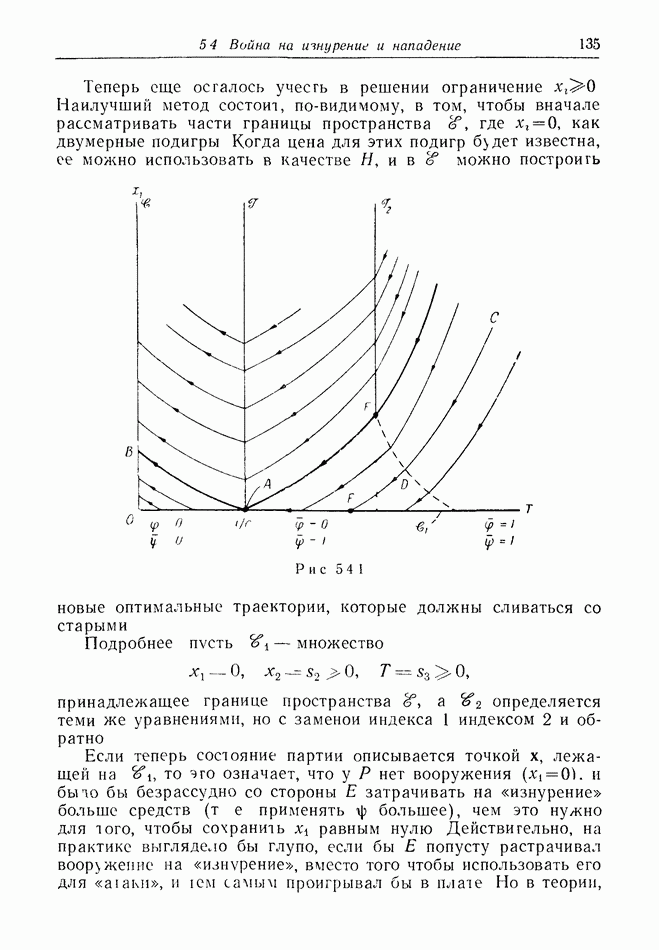
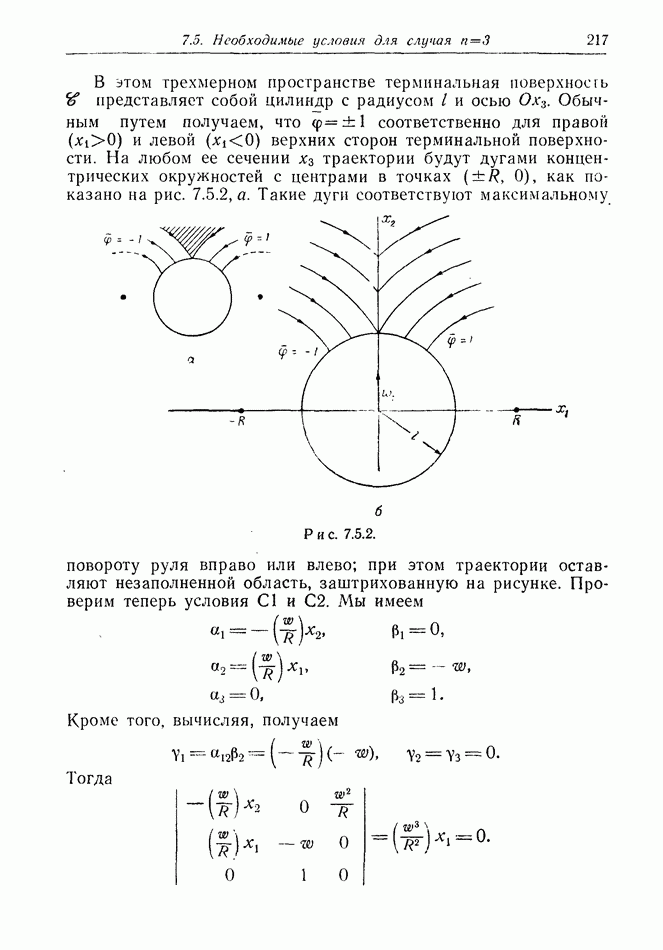
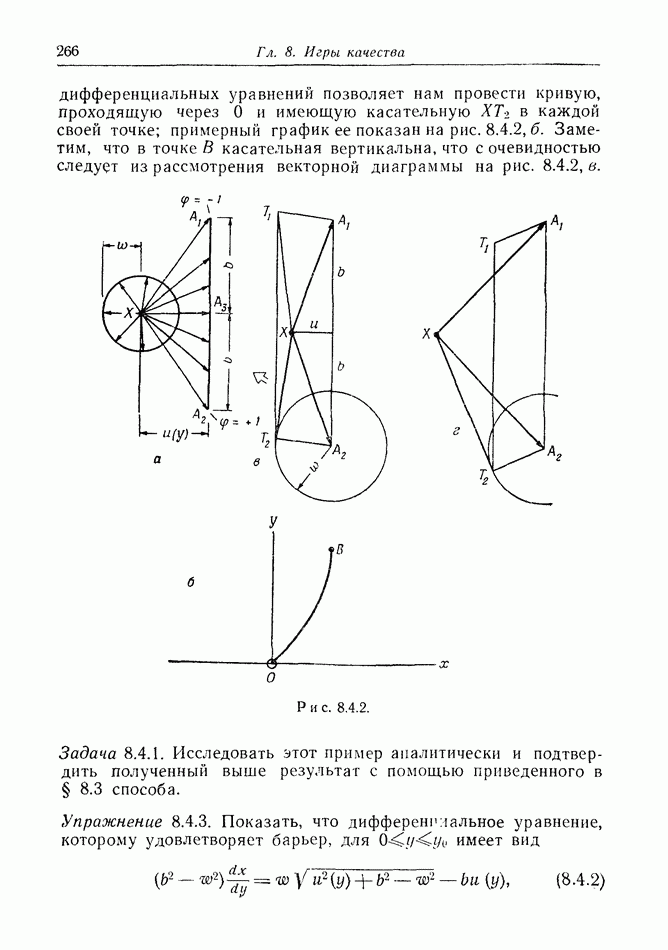
Пример 12.2.4. Перехват при раннем обнаружении. Вражеский бомбардировщик (или управляемая ракета)  обнаружен на дальних подступах к известной цели. Его скорость и направление, так же как и месторасположение, становятся известными в некоторый момент времени, как это бывает, например, при использовании линии дальнего обнаружения. Немедленно запускается защищающий перехватчик; на рис. 12.2.3 показано, что он стартует из точки
обнаружен на дальних подступах к известной цели. Его скорость и направление, так же как и месторасположение, становятся известными в некоторый момент времени, как это бывает, например, при использовании линии дальнего обнаружения. Немедленно запускается защищающий перехватчик; на рис. 12.2.3 показано, что он стартует из точки  точка обнаружения
точка обнаружения  Наивная защитная стратегия состоит в выборе прямолинейного курса,
Наивная защитная стратегия состоит в выборе прямолинейного курса,
основанного на предположении, что  движется с постоянной скоростью. Пунктирные траектории на рисунке показывают, что перехват происходит, когда
движется с постоянной скоростью. Пунктирные траектории на рисунке показывают, что перехват происходит, когда  оказывается в точке С, находящейся в центре круговой области.
оказывается в точке С, находящейся в центре круговой области.
Но что если  выберет менее прямой путь к цели? Сплошные линии на рисунке изображают некоторые возможные пути (чтобы подчеркнуть суть дела, не будем бояться фантастических уклонений).
выберет менее прямой путь к цели? Сплошные линии на рисунке изображают некоторые возможные пути (чтобы подчеркнуть суть дела, не будем бояться фантастических уклонений).

Рис. 12.2.3.
Если  производит случайный выбор из некоторого множества таких траекторий, то перехватчик по существу оказывается перед лицом игры поиска. Его цель состоит в том, чтобы обнаружить
производит случайный выбор из некоторого множества таких траекторий, то перехватчик по существу оказывается перед лицом игры поиска. Его цель состоит в том, чтобы обнаружить  перед тем, как тот достигнет цели.
перед тем, как тот достигнет цели.
Мы не можем решить этой игры, где оптимальные стратегии являются заведомо смешанными. Она представляет собой еще одну иллюстрацию трудностей, возникающих при их определении. Использование со стороны  крайних внешних траекторий делает его обнаружение очень трудным, но большая длина таких траекторий слишком увеличивает время его уязвимости и тем самым понижает вероятность успеха. Каков наилучший компромисс между чистой — идти прямо к цели — и смешанной стратегиями?
крайних внешних траекторий делает его обнаружение очень трудным, но большая длина таких траекторий слишком увеличивает время его уязвимости и тем самым понижает вероятность успеха. Каков наилучший компромисс между чистой — идти прямо к цели — и смешанной стратегиями?