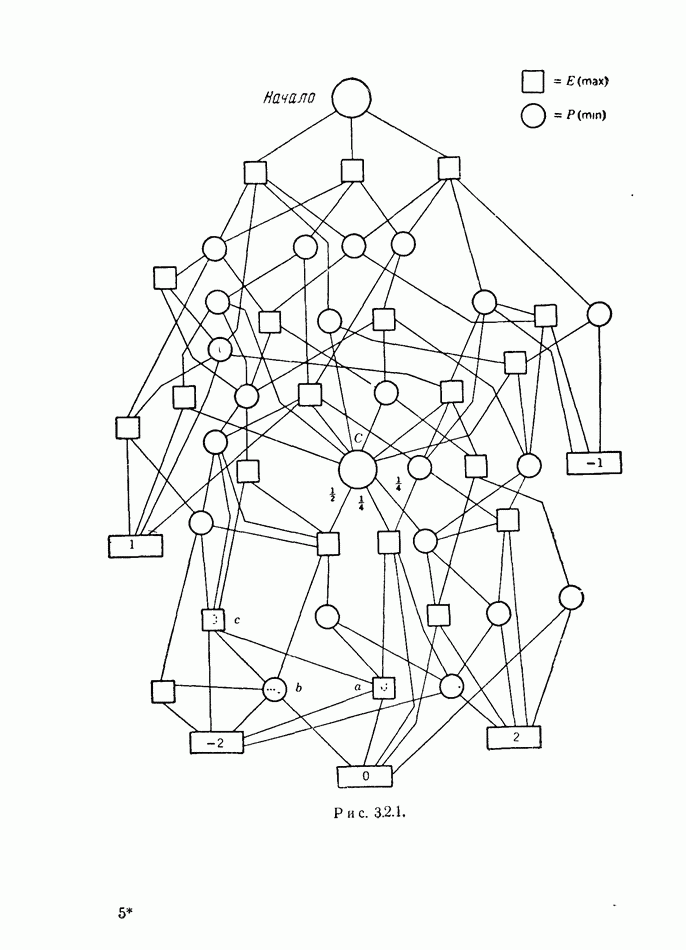
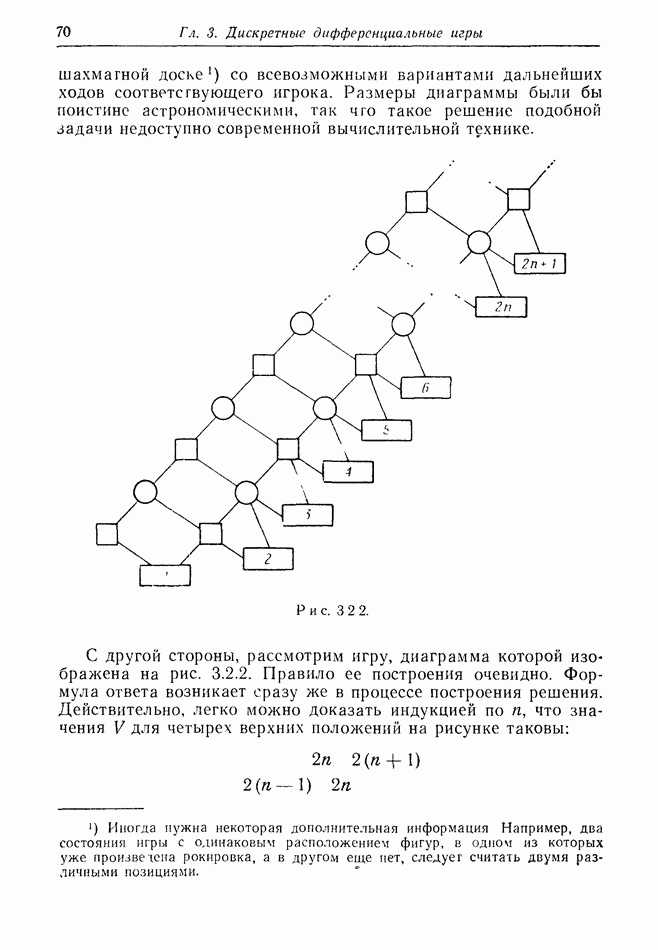
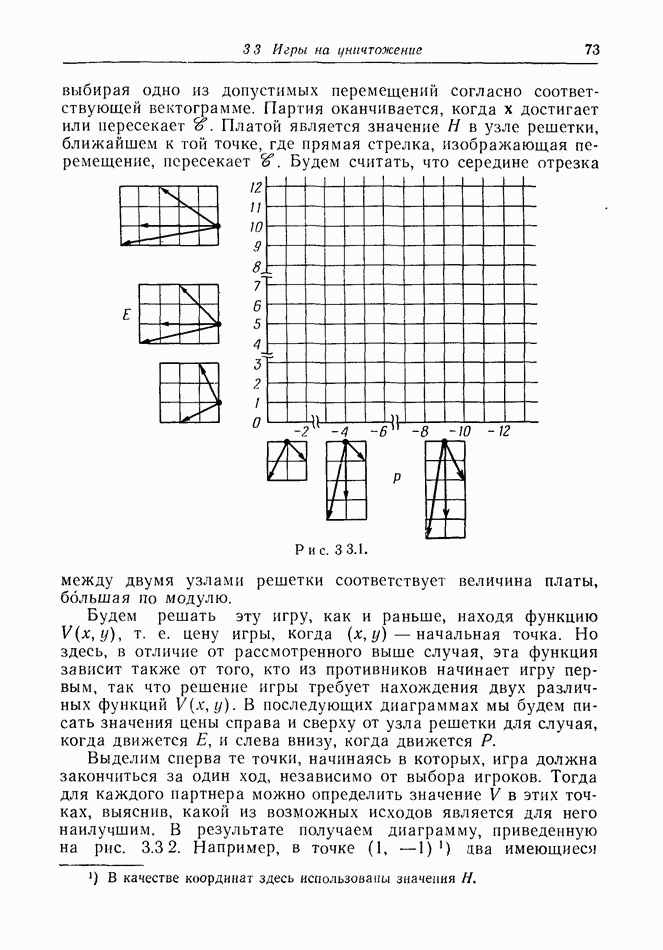
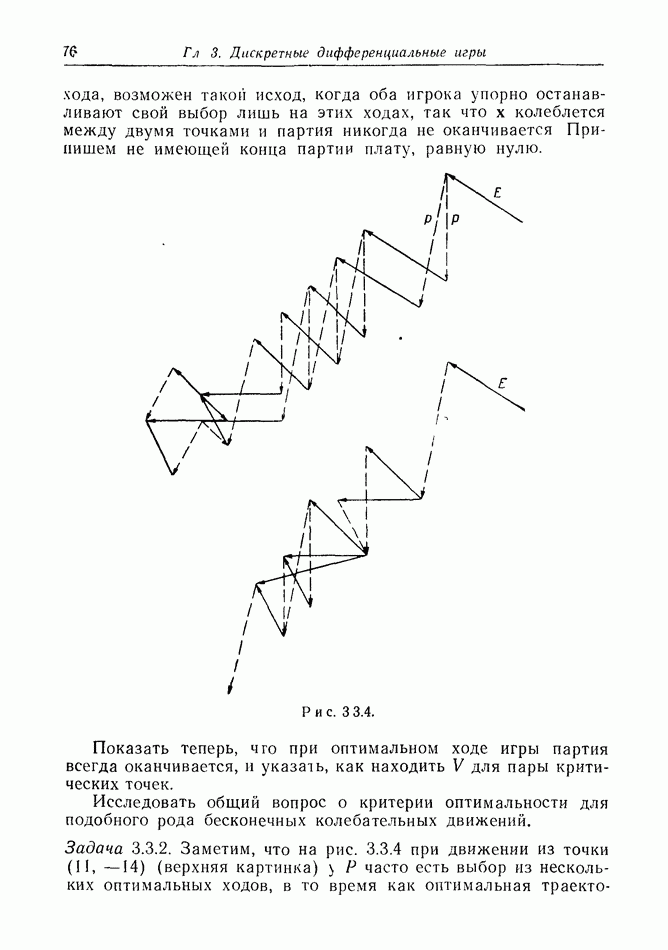
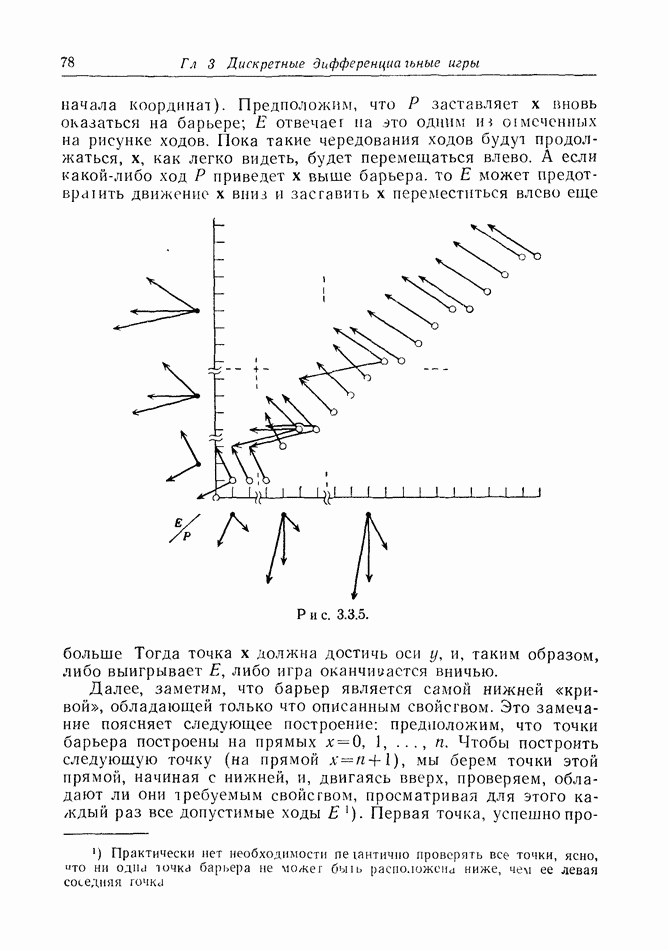
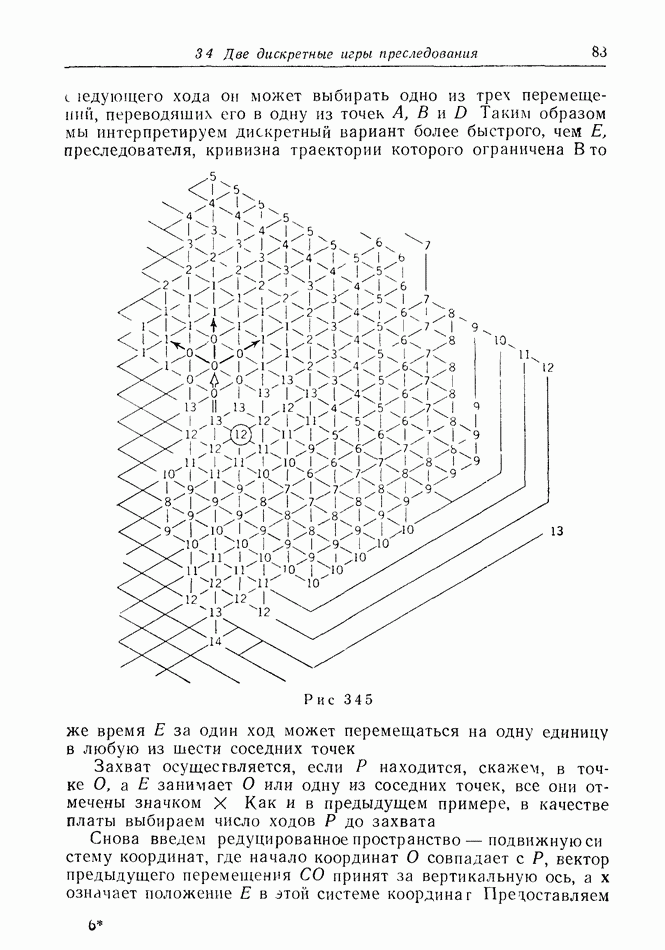
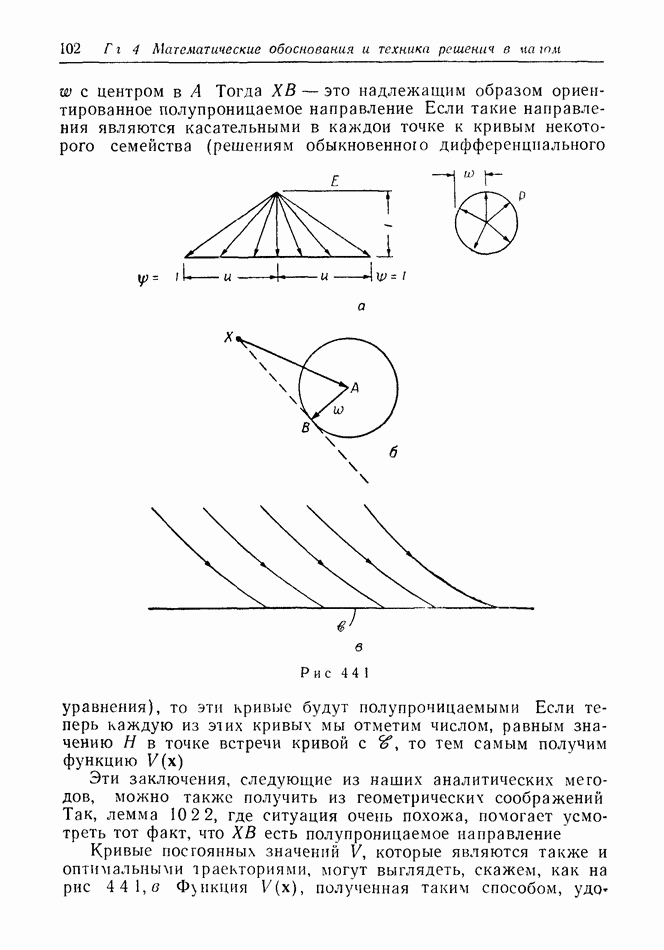
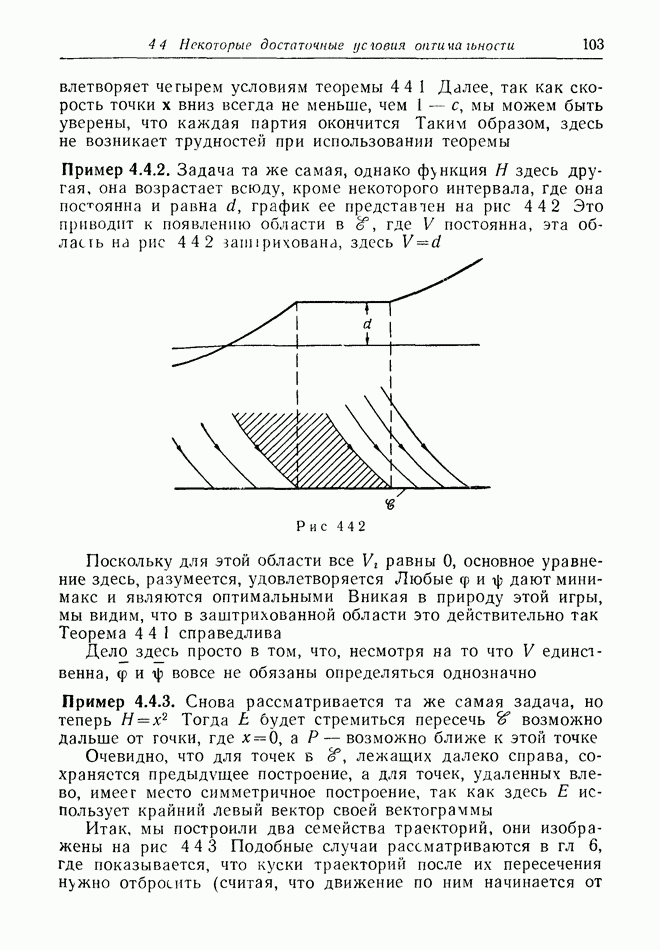
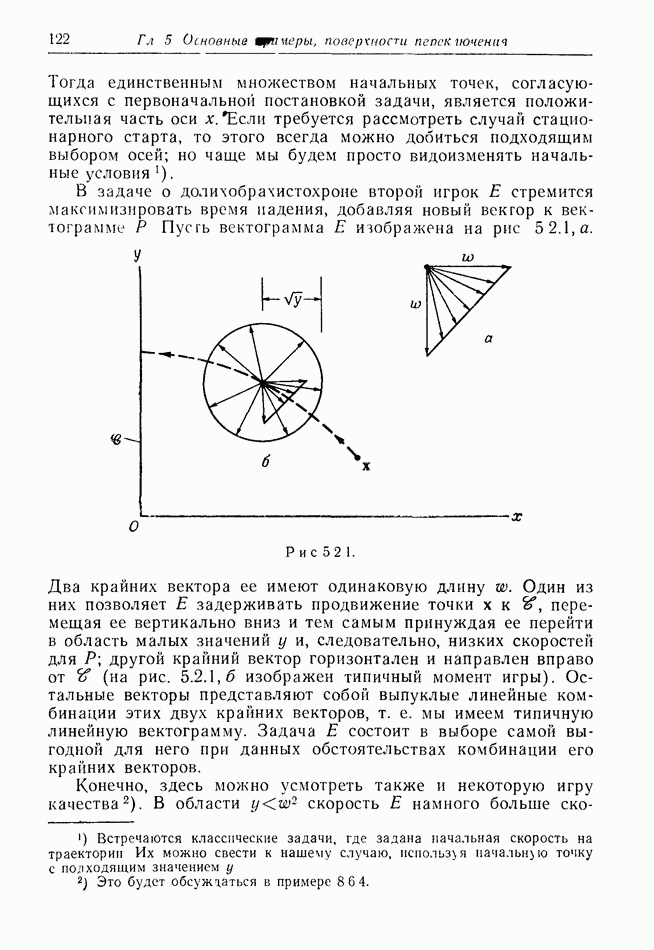
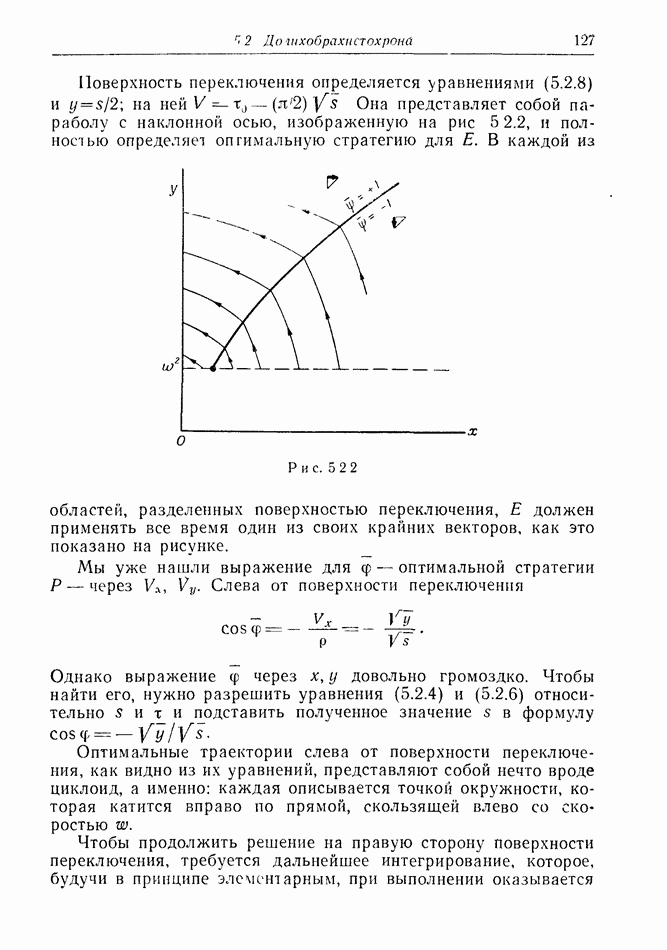
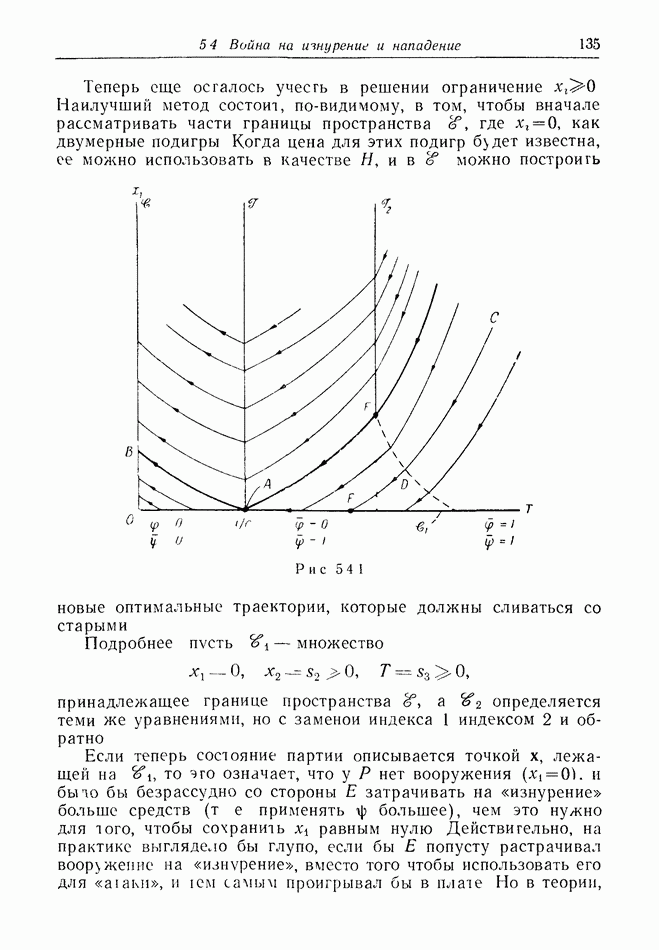
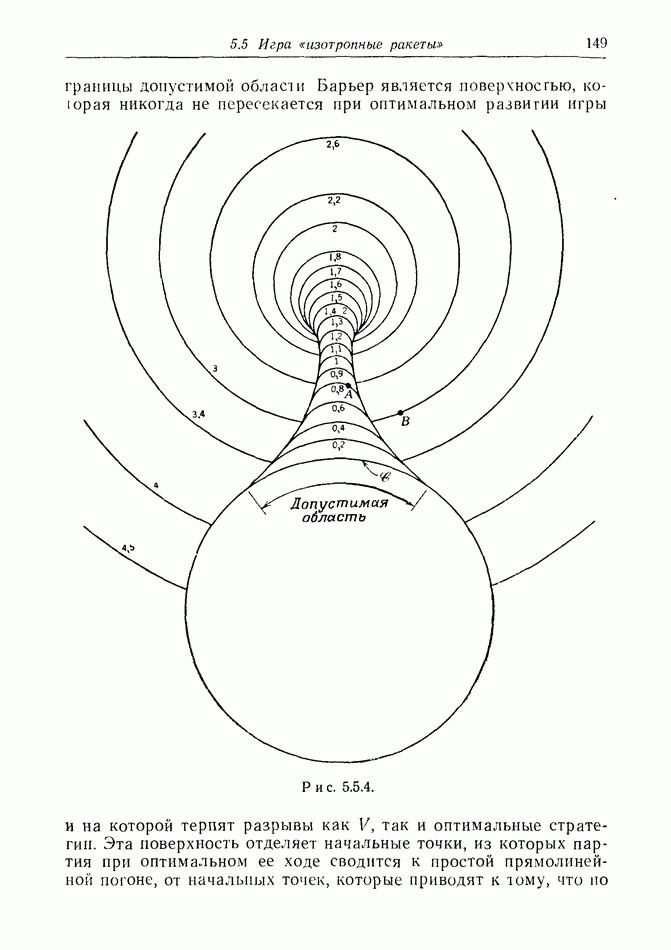
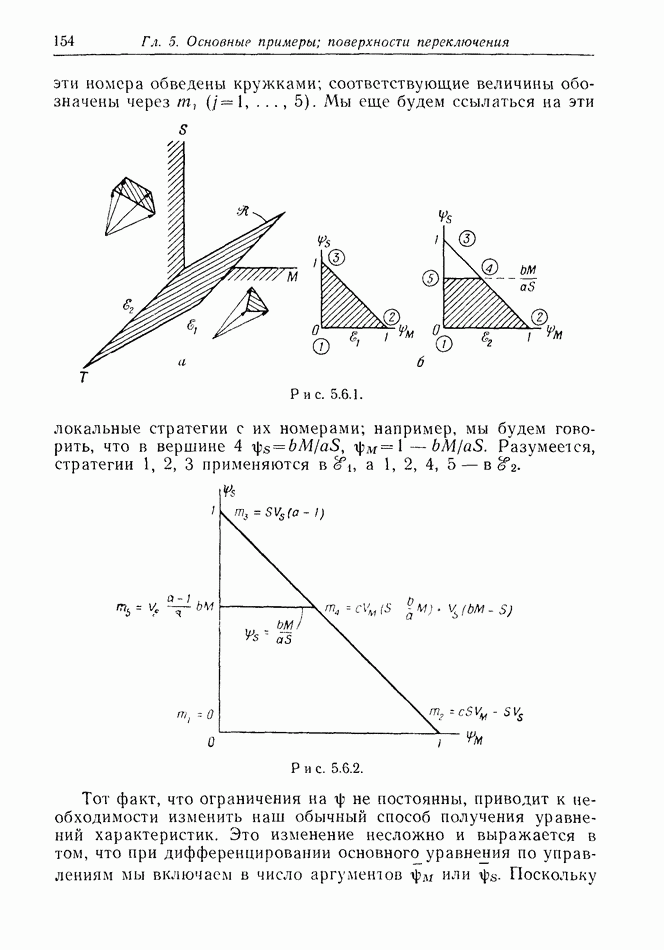
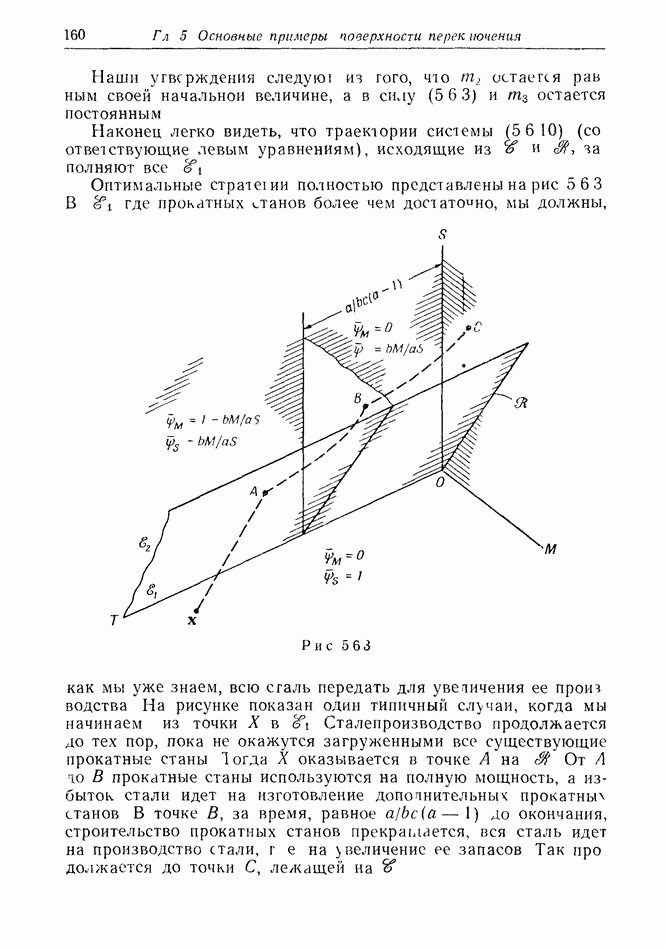
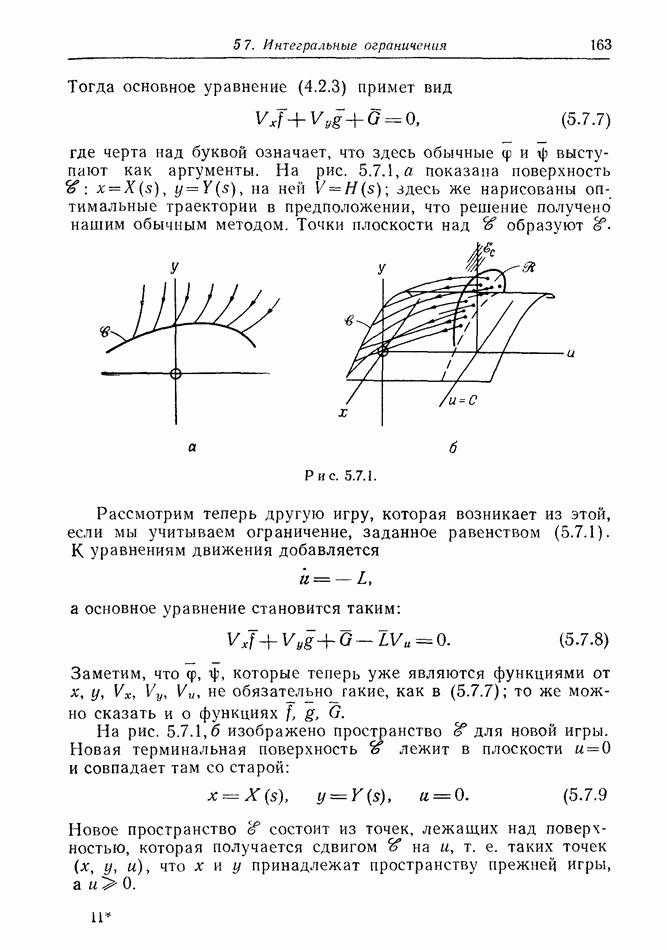
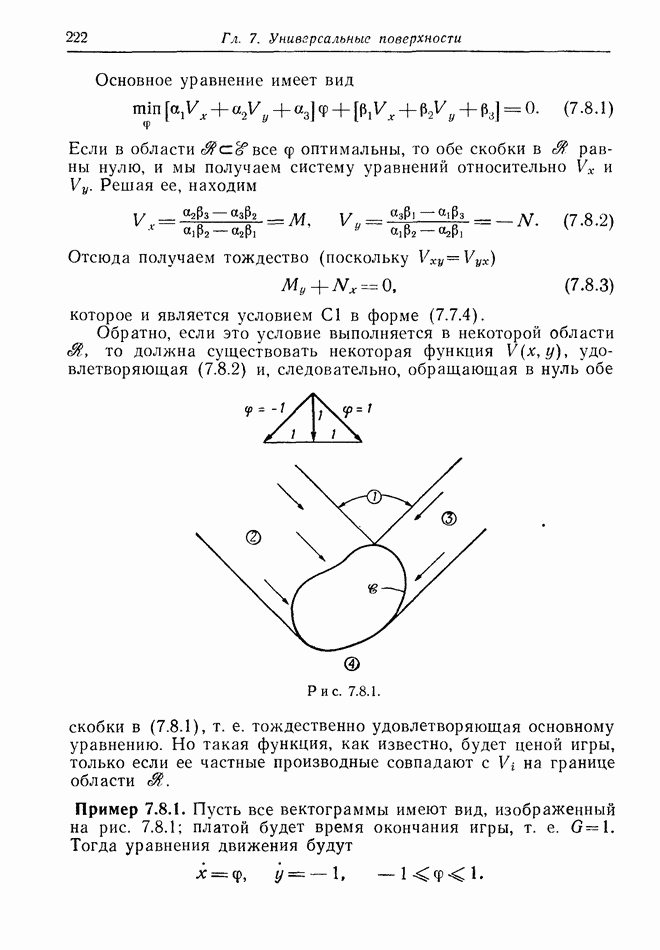
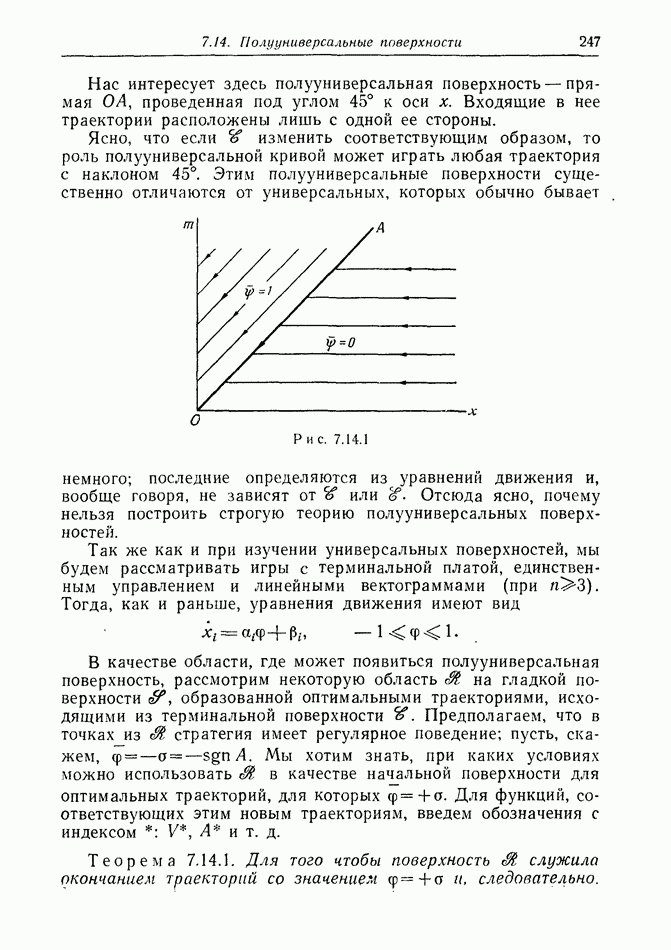
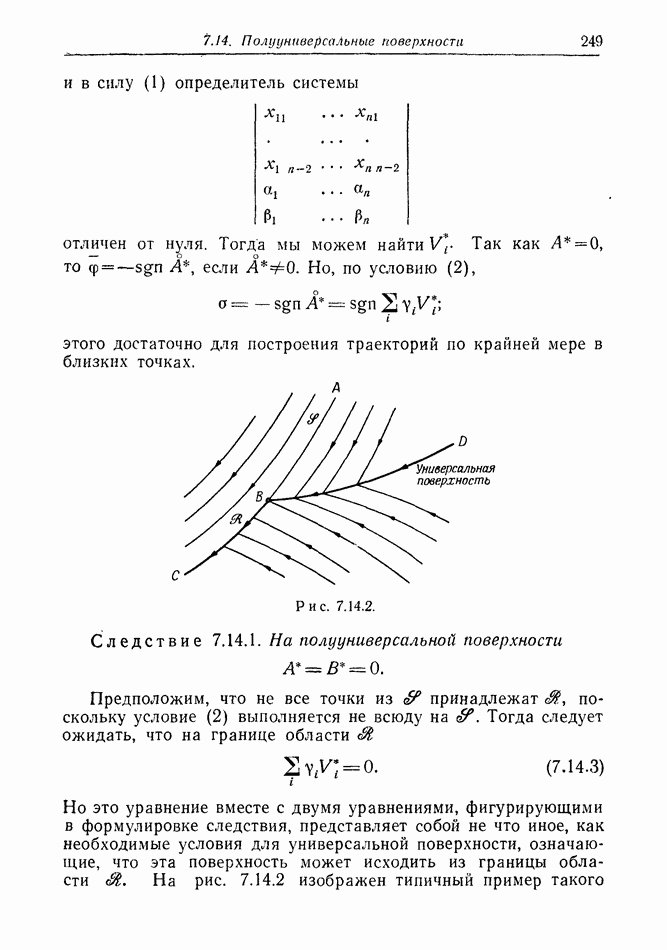
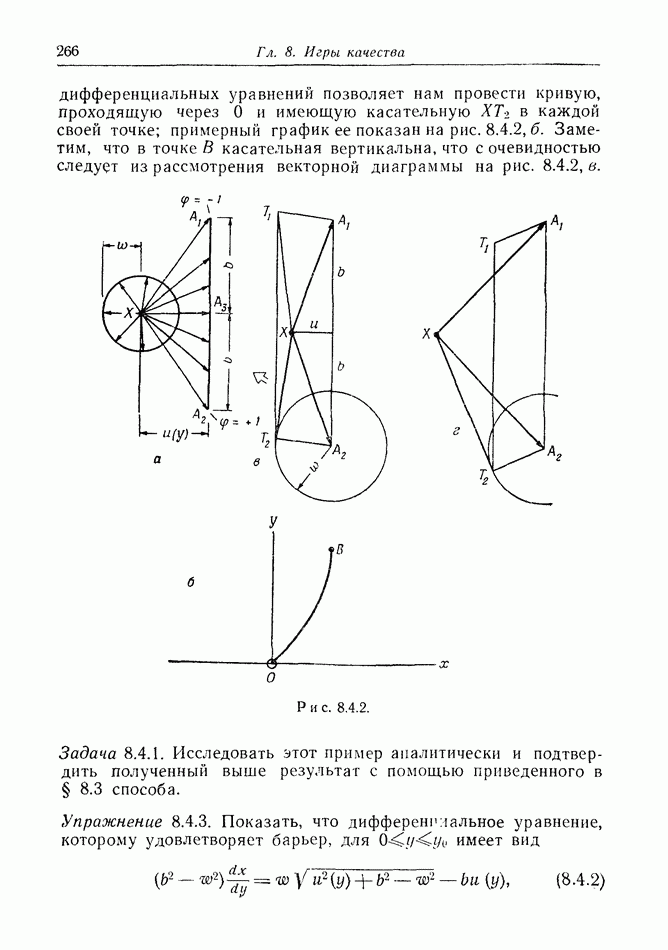
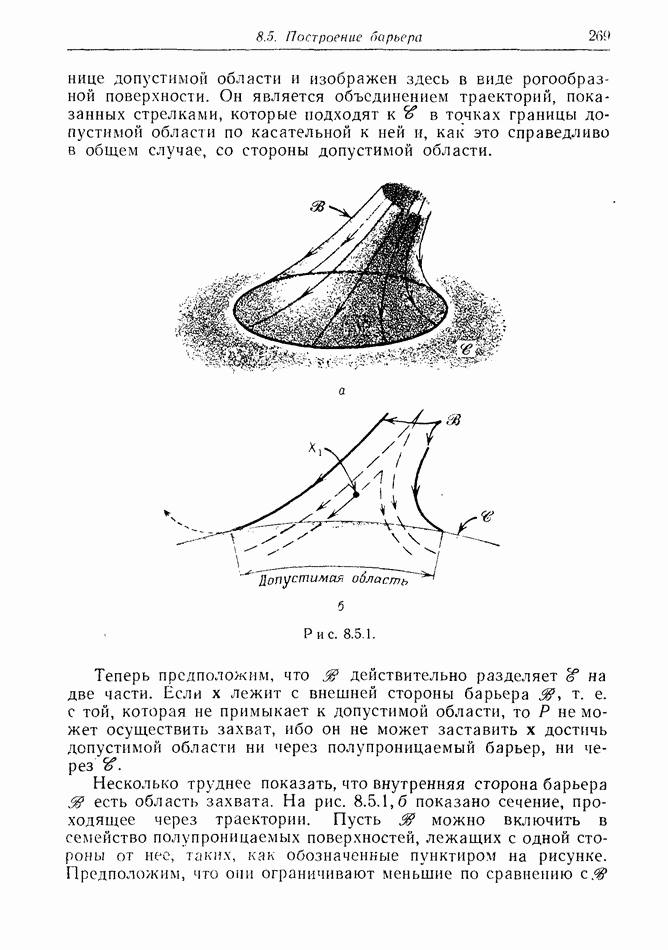
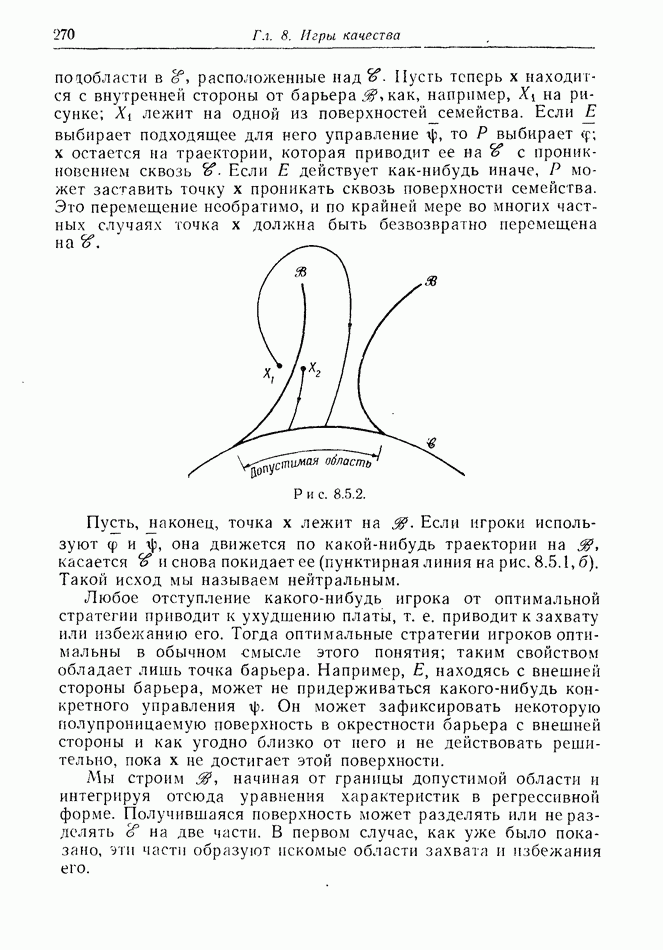
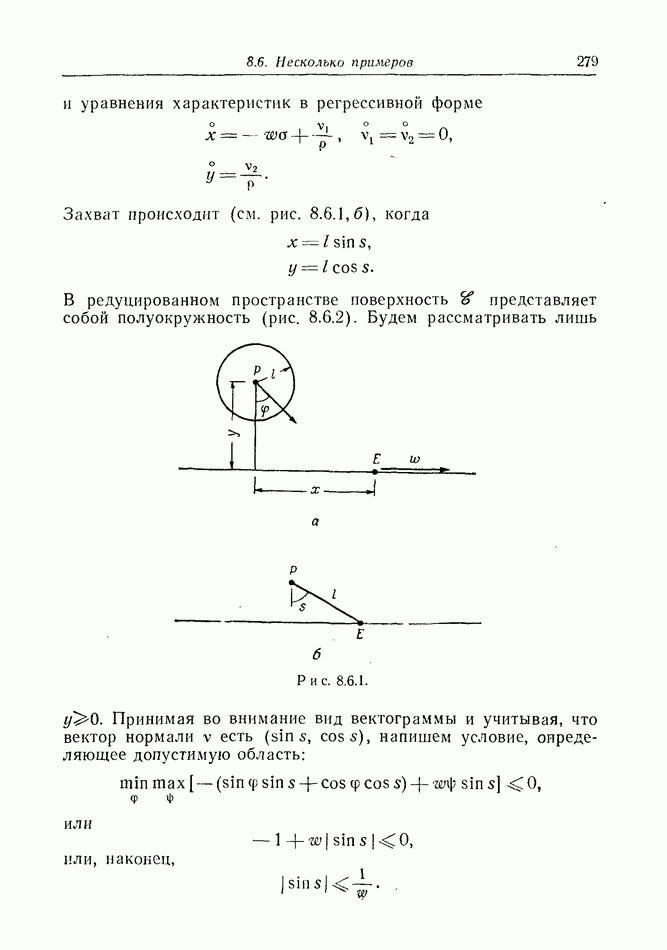
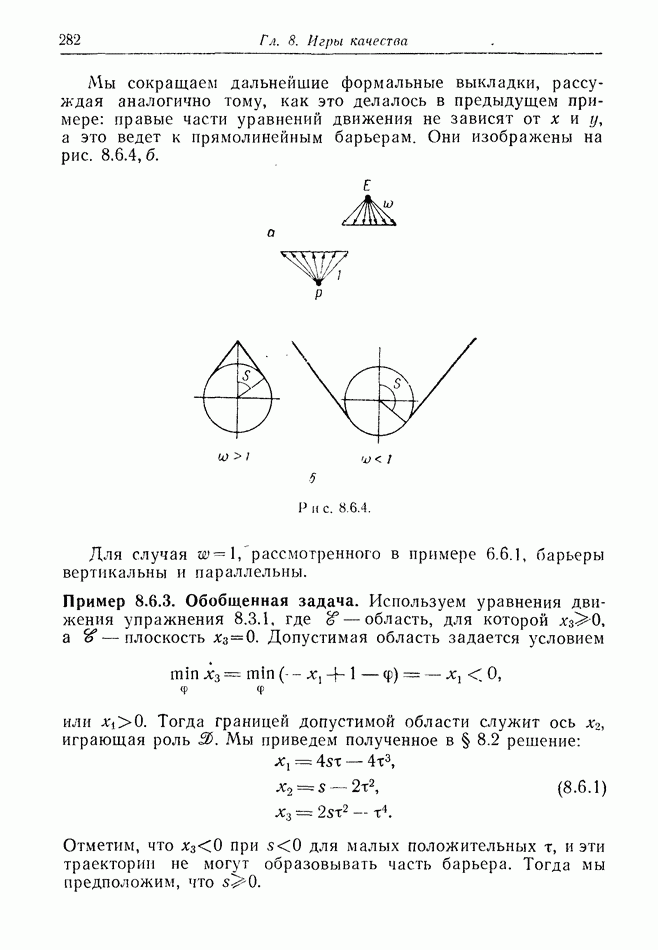
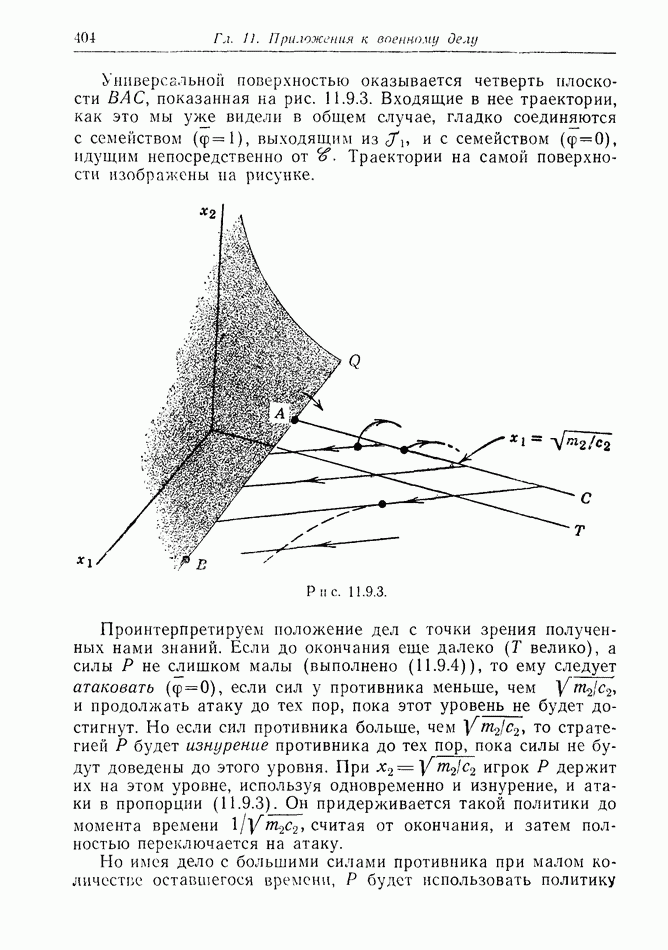
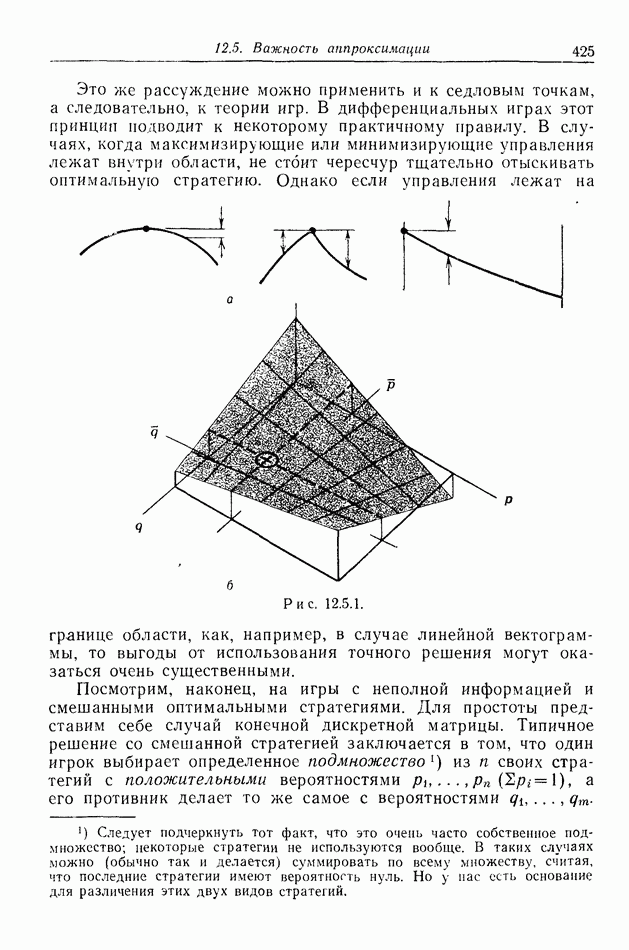
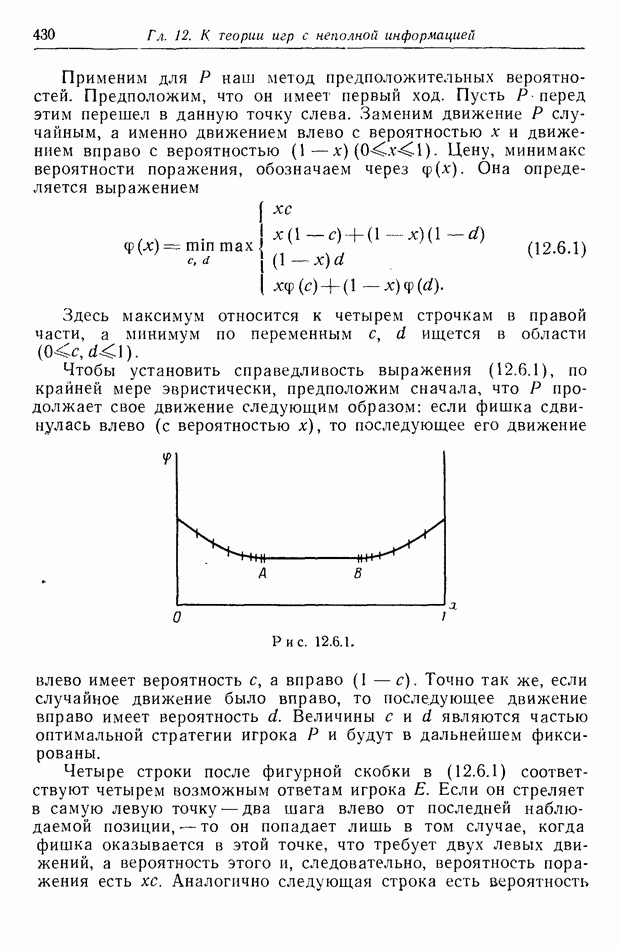
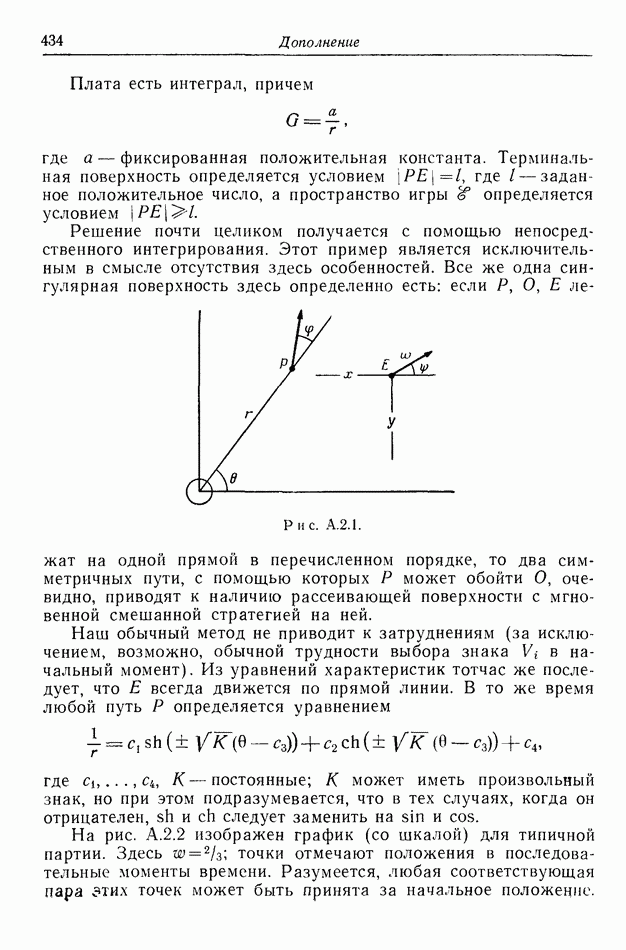
2.6. СТРАТЕГИИ
В теории дискретных игр стратегия определяется как множество решений игрока, каждое из которых однозначно соответствует возникшему положению. Если каждый из игроков выбрал стратегию, то партия, а следовательно, и плата однозначно определены.
В теории дифференциальных игр существуют аналогичные обстоятельства. Выбор решения в каждом возможном положении
состоит в определении каждым игроком своего управления как функции фазовых координат. Если игроки выбрали  и эти функции подставлены в уравнения движения, последние становятся дифференциальными уравнениями. Так как данные, определяющие игру, должны включать в себя начальное значение х, ясно, что это значение играет роль начального условия. Таким образом, мы можем надеяться, что в реальных условиях траектория, а следовательно, и плата определяются однозначно.
и эти функции подставлены в уравнения движения, последние становятся дифференциальными уравнениями. Так как данные, определяющие игру, должны включать в себя начальное значение х, ясно, что это значение играет роль начального условия. Таким образом, мы можем надеяться, что в реальных условиях траектория, а следовательно, и плата определяются однозначно.
Как и в общей теории игр, цена есть минимакс платы. Обозначим ее

Здесь  берется по всем допустимым стратегиям
берется по всем допустимым стратегиям  Мы будем считать, что
Мы будем считать, что  эквивалентен
эквивалентен  и это допущение, основанное на «предположении о минимаксе» (§ 2.4), в дальнейшем оправдывается.
и это допущение, основанное на «предположении о минимаксе» (§ 2.4), в дальнейшем оправдывается.
Цена игры V есть функция от начального состояния х, она будет играть основную роль в дальнейших исследованиях.
В каждый момент в течение хода игры игроки сталкиваются с полной вектограммой. Если мы представим себе, что каждый из них выбирает значение своего управления, то получим, что в результате он выбирает в каждый момент времени значение вектора скорости. Таким образом, выбору хода в дискретных играх соответствует здесь происходящий каждое мгновение непрерывный выбор  Читатель может возразить, что мы требуем от игроков подвигов, превышающих человеческие возможности, а от математических задач — чрезмерной строгости. Мы постараемся его успокоить.
Читатель может возразить, что мы требуем от игроков подвигов, превышающих человеческие возможности, а от математических задач — чрезмерной строгости. Мы постараемся его успокоить.
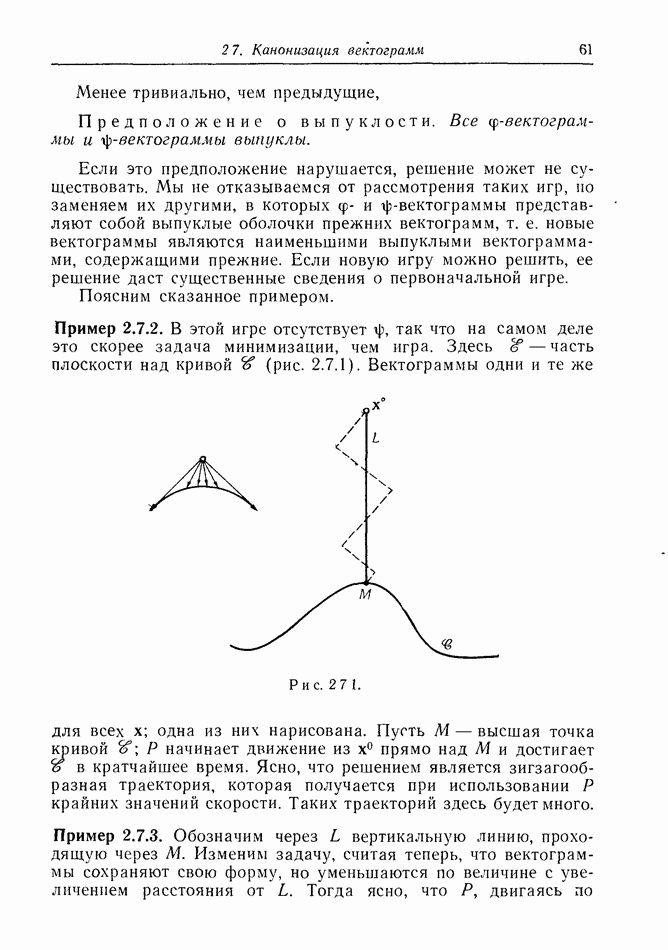
Попытка определить стратегии в форме  немедленно приводит к затруднениям. Во-первых, мы должны быть уверены, что дифференциальные уравнения, к которым свелись уравнения движения, интегрируемы. Напоминаем, что в их левых частях стоят производные по возрастающему аргументу. Далее, критерий существования решения для таких уравнений здесь должен быть гораздо шире, чем в классической теории, а ограничения носят совершенно иной характер Действительно, рассмотрим систему
немедленно приводит к затруднениям. Во-первых, мы должны быть уверены, что дифференциальные уравнения, к которым свелись уравнения движения, интегрируемы. Напоминаем, что в их левых частях стоят производные по возрастающему аргументу. Далее, критерий существования решения для таких уравнений здесь должен быть гораздо шире, чем в классической теории, а ограничения носят совершенно иной характер Действительно, рассмотрим систему

здесь  производная по возрастающему аргументу, а
производная по возрастающему аргументу, а

Легко проверить, что эта система имеет единственное решение для каждой начальной точки плоскости Позднее мы увидим, что функции такого рода вовсе не редкость в решении дифференциальных игр.
Пусть теперь

Мы оказываемся в затруднении, если решение начинается или приходит в точку, для которой 
Теории подобных дифференциальных уравнений посвящен целый ряд работ, см., например, [16]; но здесь мы не используем этих методов.
Впоследствии мы разработаем методы решения дифференциальных игр. Результаты будут включать в себя значения  которые мы будем называть оптимальными; обозначим их
которые мы будем называть оптимальными; обозначим их  После подстановки их в уравнения движения последние становятся по крайней мере кусочно-интегрируемыми (или интегрируемыми в смысле дифференциальных уравнений с производными по возрастающему аргументу). Тогда решения (траектории, плата и т. д.) можно вычислить, и они оказываются оптимальными в смысле достижения минимаксной платы
После подстановки их в уравнения движения последние становятся по крайней мере кусочно-интегрируемыми (или интегрируемыми в смысле дифференциальных уравнений с производными по возрастающему аргументу). Тогда решения (траектории, плата и т. д.) можно вычислить, и они оказываются оптимальными в смысле достижения минимаксной платы
Но остается еще вторая трудность. Утверждение, что  скажем, оптимально, требует знания хода игры для некоторого класса противодействующих управлений
скажем, оптимально, требует знания хода игры для некоторого класса противодействующих управлений  Каков этот класс? Он должен включать в себя такие функции
Каков этот класс? Он должен включать в себя такие функции  чтобы пара
чтобы пара  всегда приводила к интегрируемым уравнениям движения, а все
всегда приводила к интегрируемым уравнениям движения, а все  представляли собой реальные действия оппонента.
представляли собой реальные действия оппонента.
С. Карлин выдвинул идею, которая устраняет эту трудность. Стратегия для  определяется теперь выбором не только функции
определяется теперь выбором не только функции  теперь уже не подчиненной никаким условиям, кроме ограничений на область значений, но и возрастающей последовательности
теперь уже не подчиненной никаким условиям, кроме ограничений на область значений, но и возрастающей последовательности  значений времени, стремящейся к бесконечности. Такая стратегия будет названа
значений времени, стремящейся к бесконечности. Такая стратегия будет названа  -стратегией. Предположим, что
-стратегией. Предположим, что  придерживается ее и что в момент
придерживается ее и что в момент  состояние игры описывается точкой
состояние игры описывается точкой  начальное состояние). Пусть в полуинтервале
начальное состояние). Пусть в полуинтервале  он сохраняет постоянное значение
он сохраняет постоянное значение  равное
равное 
Предположим, что К-стратегия,т. е.  , определена также и для
, определена также и для  Таким образом, мы имеем две
Таким образом, мы имеем две
последовательности значений времени  и в каждом подинтервале обе функции
и в каждом подинтервале обе функции  и постоянны. Тогда уравнения движения очевидно интегрируемы. Мы строим траекторию, используя для каждого интервала в качестве начального значения конечное значение х в предыдущем интервале.
и постоянны. Тогда уравнения движения очевидно интегрируемы. Мы строим траекторию, используя для каждого интервала в качестве начального значения конечное значение х в предыдущем интервале.
Итак, для каждой начальной точки и каждой пары К-стратегий траектория точки  следовательно, плата однозначно определены. Назовем ценой игры
следовательно, плата однозначно определены. Назовем ценой игры  платы, где
платы, где  соответственно берутся по классам К-стратегий игроков. Таков естественный аналог минимакса, определение которого было дано выше в этом параграфе.
соответственно берутся по классам К-стратегий игроков. Таков естественный аналог минимакса, определение которого было дано выше в этом параграфе.
В мире действительности нелегко отыскать пример, где последовательность принимаемых решений не была бы дискретной. Таким образом, К-стратегия несколько приближает нас к реальности.
Мы будем называть функцию  которая составляет К-стратегию игрока, его тактикой.
которая составляет К-стратегию игрока, его тактикой.
Ясно, что, вообще говоря, К-стратегии реализуют не оптимальные, а лишь  -оптимальные стратегии, т. е. такие стратегии, для которых плата отличается от V не более чем на
-оптимальные стратегии, т. е. такие стратегии, для которых плата отличается от V не более чем на  (этого можно достичь с помощью все более мелкого разбиения оси
(этого можно достичь с помощью все более мелкого разбиения оси  последовательностями
последовательностями 
Можно ли утверждать, что описанные стратегии определяют все наилучшие способы развития игры? Давайте на мгновение отбросим ухищрения и примем введенное ранее определение стратегии. Предположим, что один из игроков, скажем  действует согласно правилу
действует согласно правилу  которое не является стратегией. Например,
которое не является стратегией. Например,  может задавать как функцию от
может задавать как функцию от  высших производных от
высших производных от  (и каким-нибудь способом — в тех точках, где эти производные не существуют), от предшествующих значений
(и каким-нибудь способом — в тех точках, где эти производные не существуют), от предшествующих значений  интеграла от этих значений и т. д. Если
интеграла от этих значений и т. д. Если  действуя согласно
действуя согласно  противостоит оптимальной стратегии игрока
противостоит оптимальной стратегии игрока  то можно ли сказать, что он не добьется для себя лучшего значения платы, чем
то можно ли сказать, что он не добьется для себя лучшего значения платы, чем 
Мы попытаемся найти ответ на этот вопрос двумя способами. Первый из них — эвристический. Он основан на том, что фазовые координаты полностью описывают состояние в том смысле, как это обсуждалось в § 2.1.
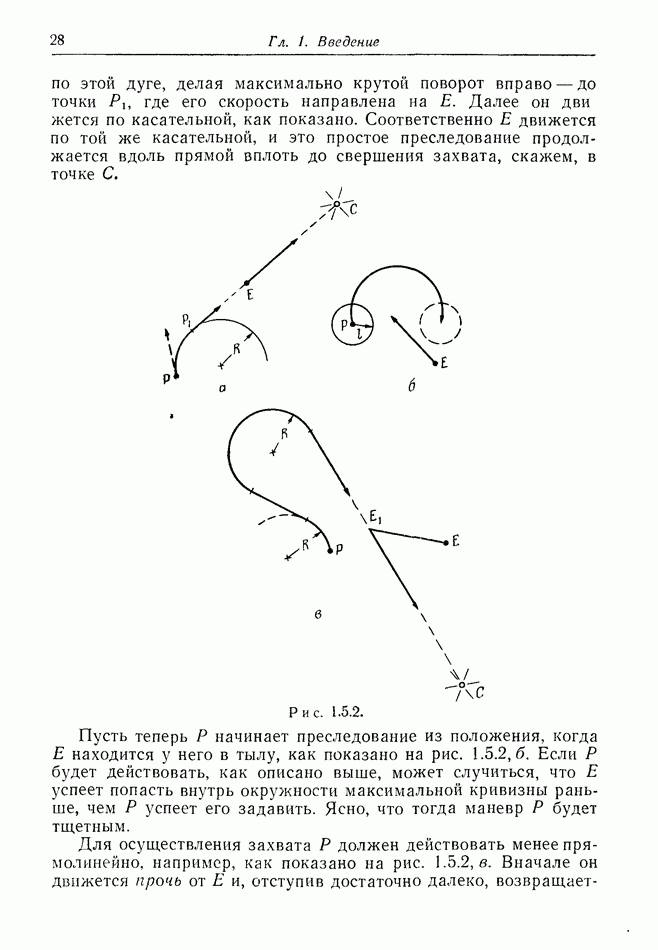
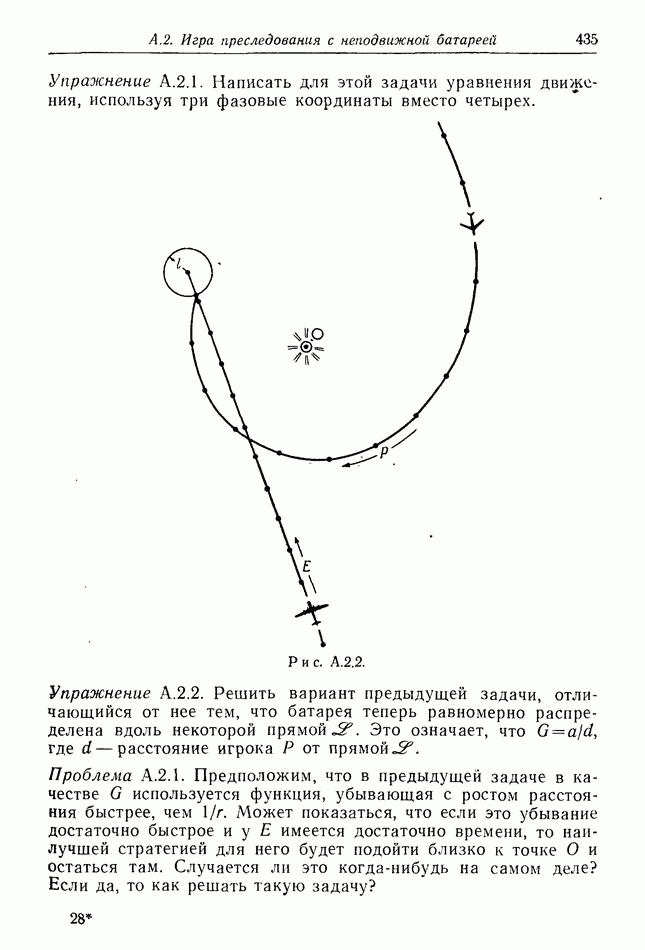
Чтобы проиллюстрировать это, рассмотрим игру преследования, в которой  есть движущаяся на плоскости точка. Обозначим ее координаты через
есть движущаяся на плоскости точка. Обозначим ее координаты через  Пусть
Пусть  обладает простым движением, уравнения которого имеют вид
обладает простым движением, уравнения которого имеют вид

Мы утверждаем, что для  целесообразнее всего основывать свои действия только на знании значений
целесообразнее всего основывать свои действия только на знании значений  Эти действия могут, конечно, зависеть от
Эти действия могут, конечно, зависеть от  прошлых значений
прошлых значений  как, например, в случае, когда
как, например, в случае, когда  пытается экстраполировать будущее положение
пытается экстраполировать будущее положение  Но скорость
Но скорость  в соответствии с постановкой задачи может в каждый момент резко изменяться, и эти изменения невозможно предугадать. Поэтому
в соответствии с постановкой задачи может в каждый момент резко изменяться, и эти изменения невозможно предугадать. Поэтому  не может полагаться на какие-либо предсказания или строить свое поведение, исходя из каких-либо других величин, кроме значений
не может полагаться на какие-либо предсказания или строить свое поведение, исходя из каких-либо других величин, кроме значений 
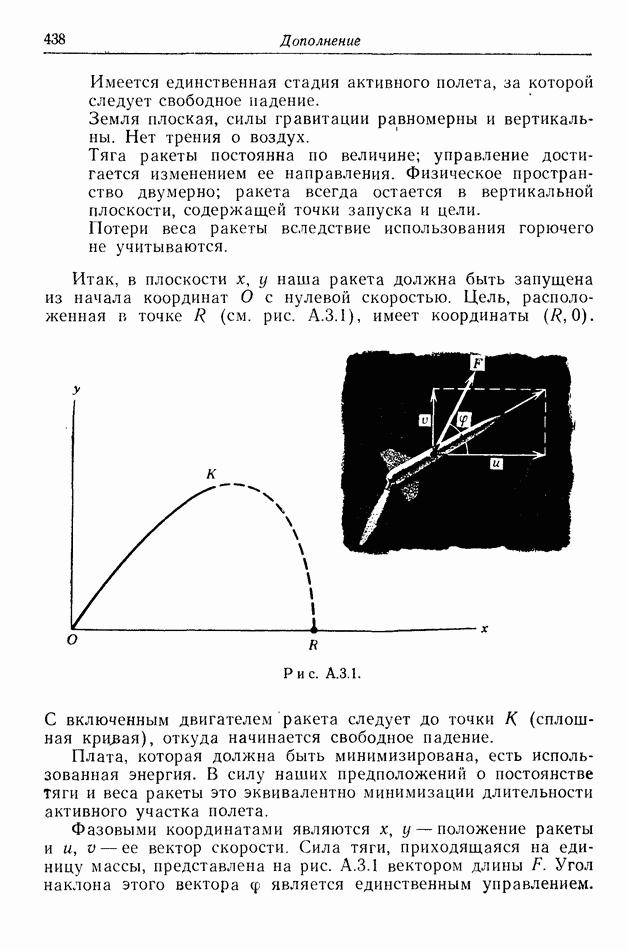
Теперь предположим, что движение  несколько усложнилось. Пусть теперь он регулирует свои ускорения
несколько усложнилось. Пусть теперь он регулирует свои ускорения  (подчиненные некоторым условиям, что пока не имеет значения). Уравнениями движения
(подчиненные некоторым условиям, что пока не имеет значения). Уравнениями движения  будут
будут

Сейчас  уже не может допускать резких скачков скорости, и потому
уже не может допускать резких скачков скорости, и потому  в соответствии со здравым смыслом мог бы основывать свое поведение на знании значений
в соответствии со здравым смыслом мог бы основывать свое поведение на знании значений  Но эти значения теперь равны
Но эти значения теперь равны  и также входят в число фазовых координат. Однако те же рассуждения, что и выше, показывают, что если бы
и также входят в число фазовых координат. Однако те же рассуждения, что и выше, показывают, что если бы  действовал, исходя из ускорений
действовал, исходя из ускорений  он мог бы быть введен в заблуждение.
он мог бы быть введен в заблуждение.
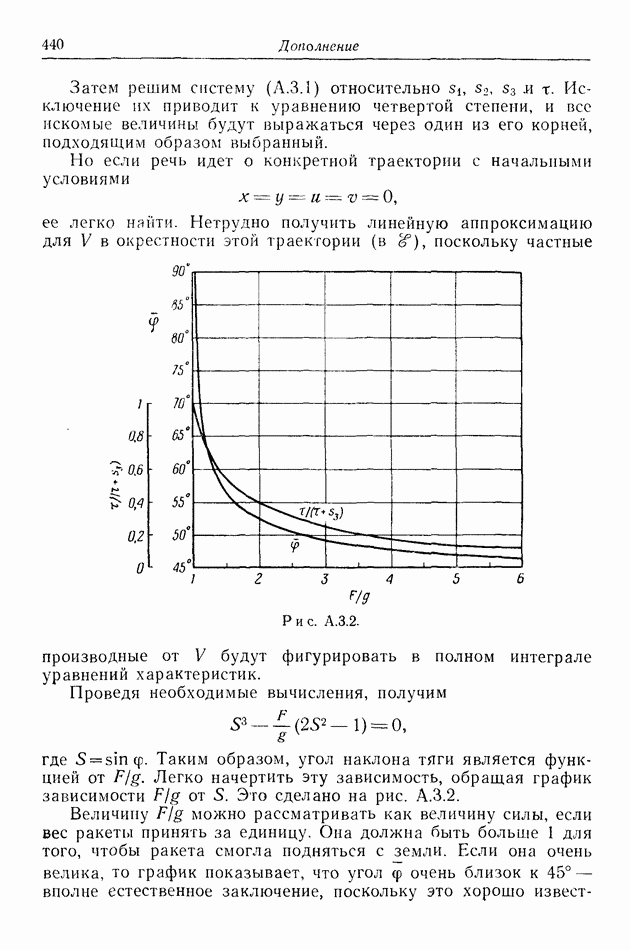
Можно продолжить подобные рассуждения, создавая цепь все более и более сложных типов движения  и получая при этом много вариантов. В каждом случае, отбирая те данные, на основании которых
и получая при этом много вариантов. В каждом случае, отбирая те данные, на основании которых  мог бы строить свое разумное поведение при выборе решения, мы обнаруживаем, что все они входят в число фазовых координат.
мог бы строить свое разумное поведение при выборе решения, мы обнаруживаем, что все они входят в число фазовых координат.
Второй способ математический. Предположим, что игра начинается из некоторой фиксированной точки,  применяет оптимальную стратегию
применяет оптимальную стратегию  а
а  действует согласно
действует согласно  В результате управление
В результате управление  заданное правилом
заданное правилом  определено как функция
определено как функция






































































































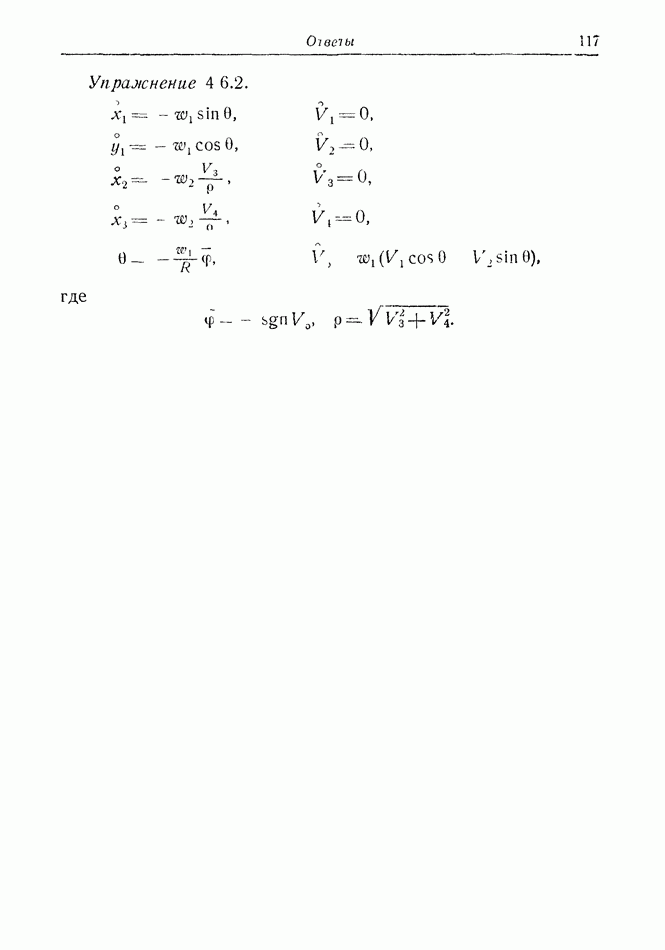















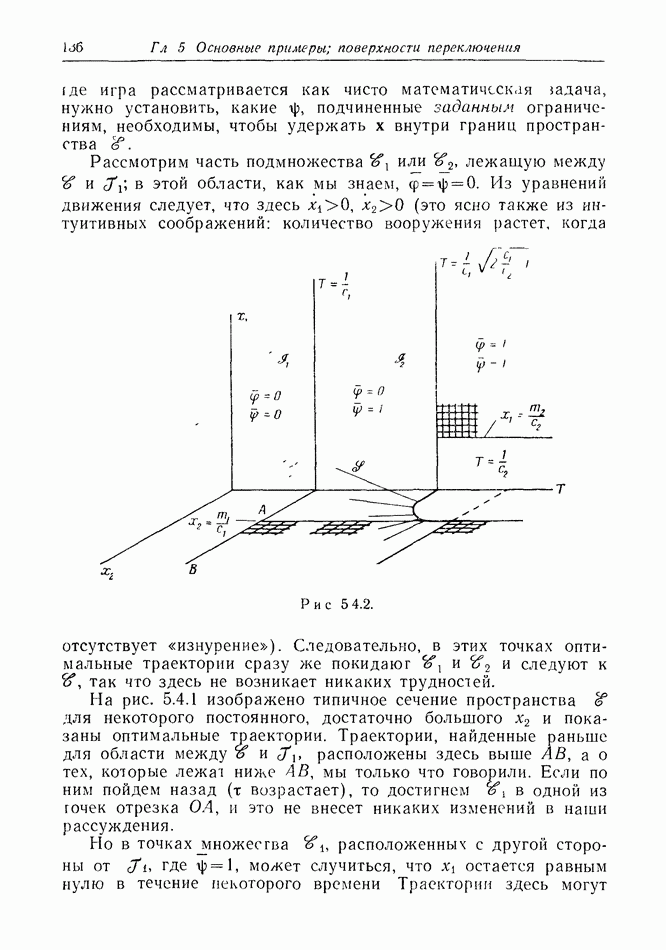








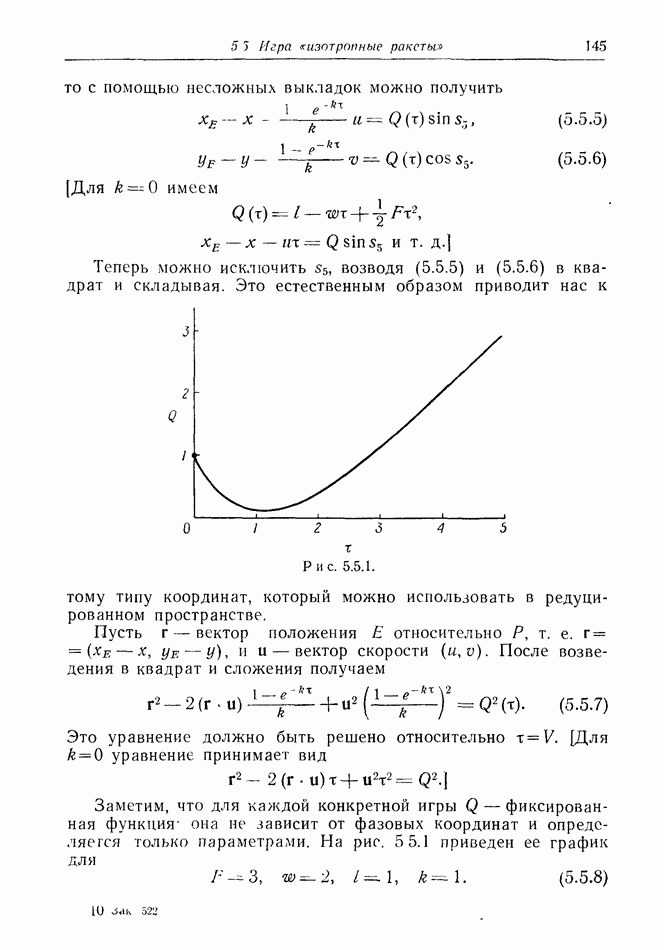

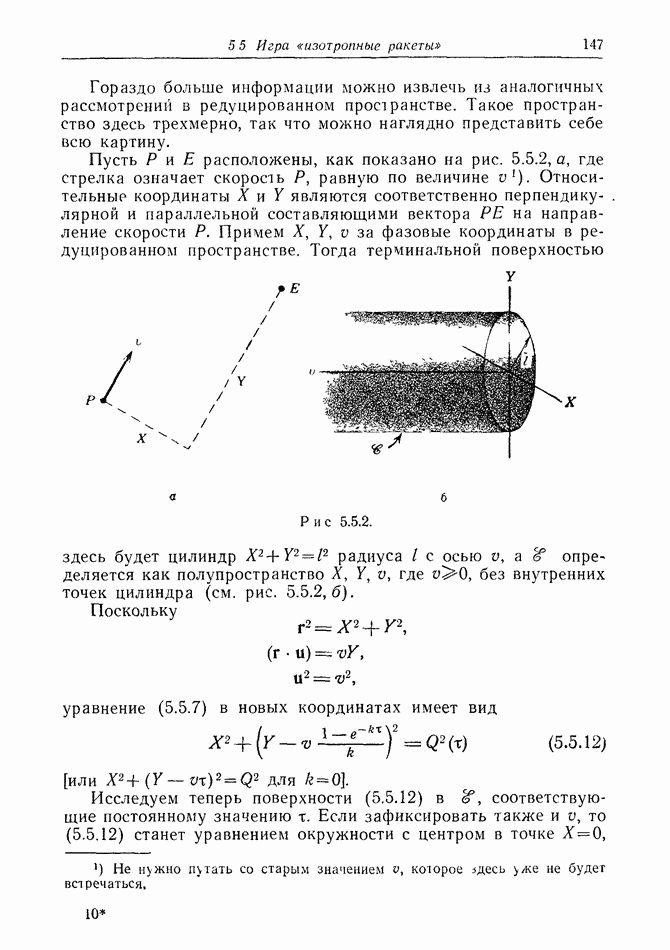
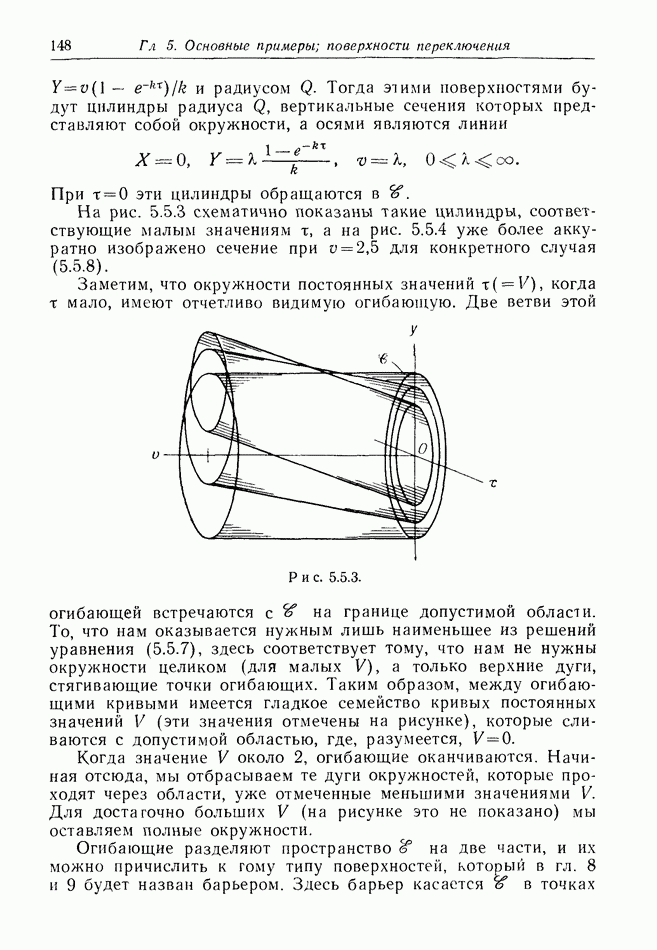















































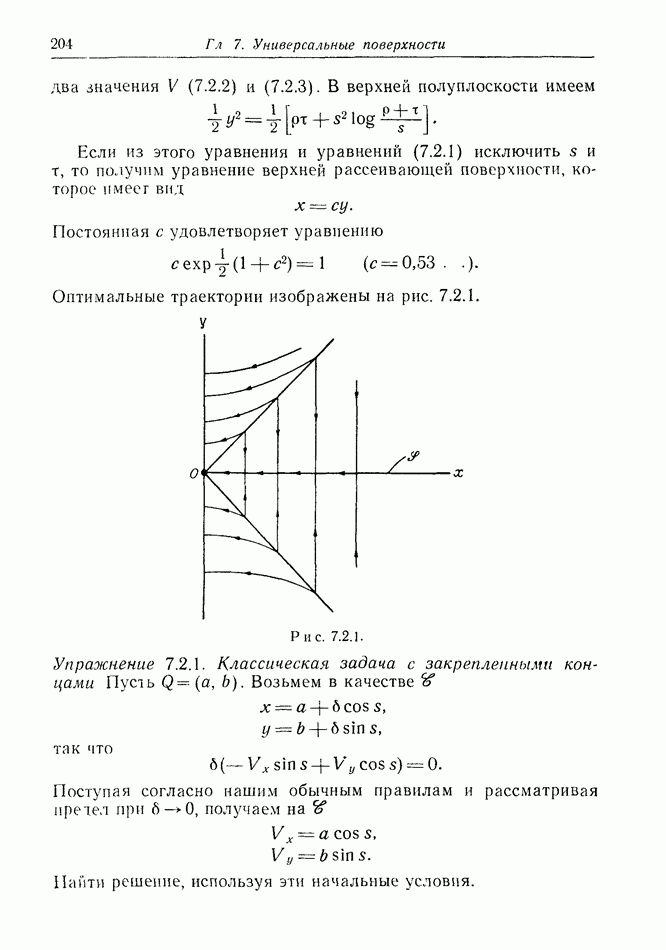











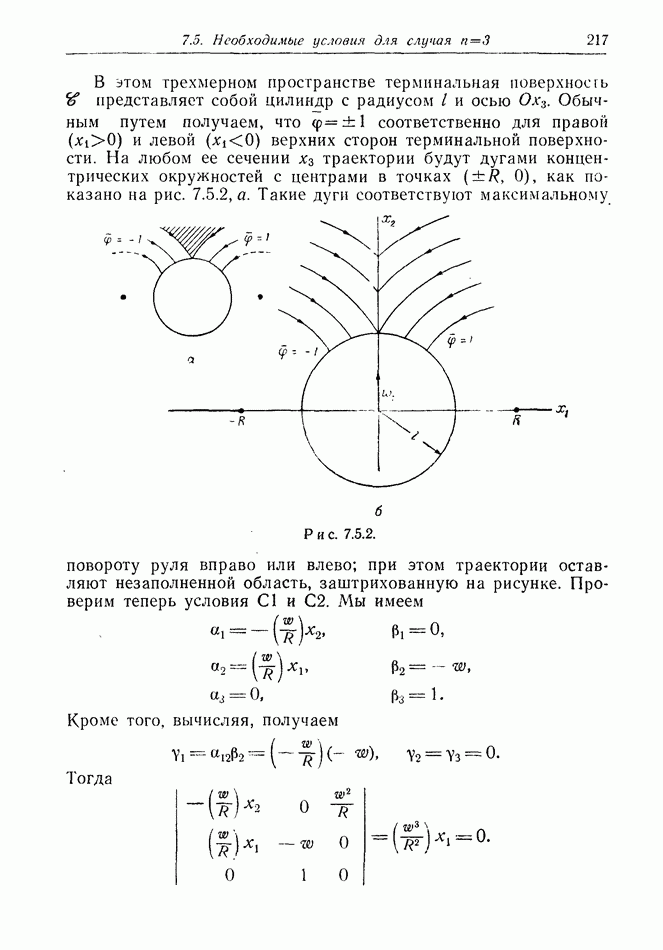







































































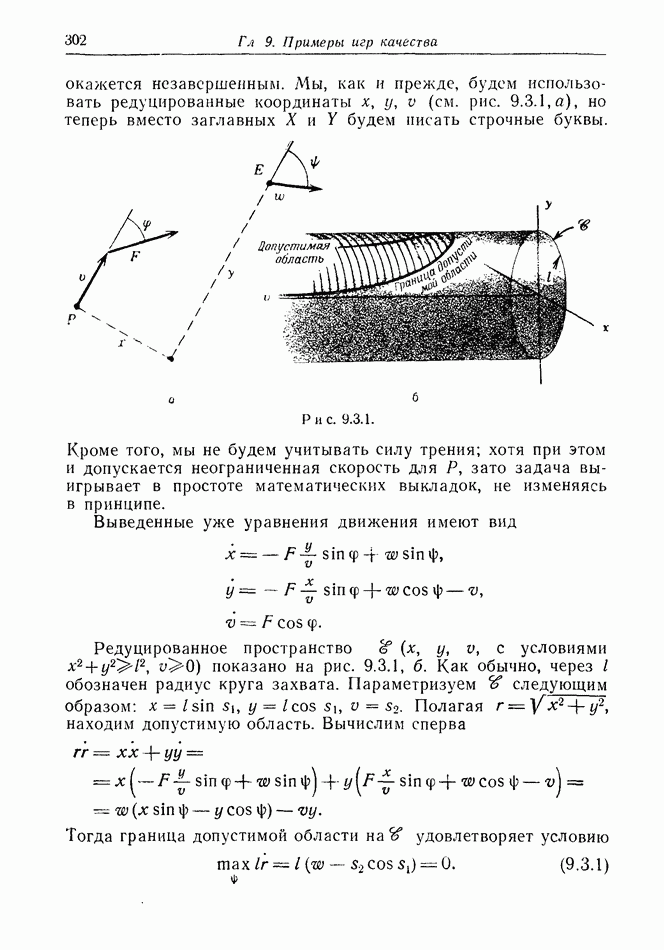




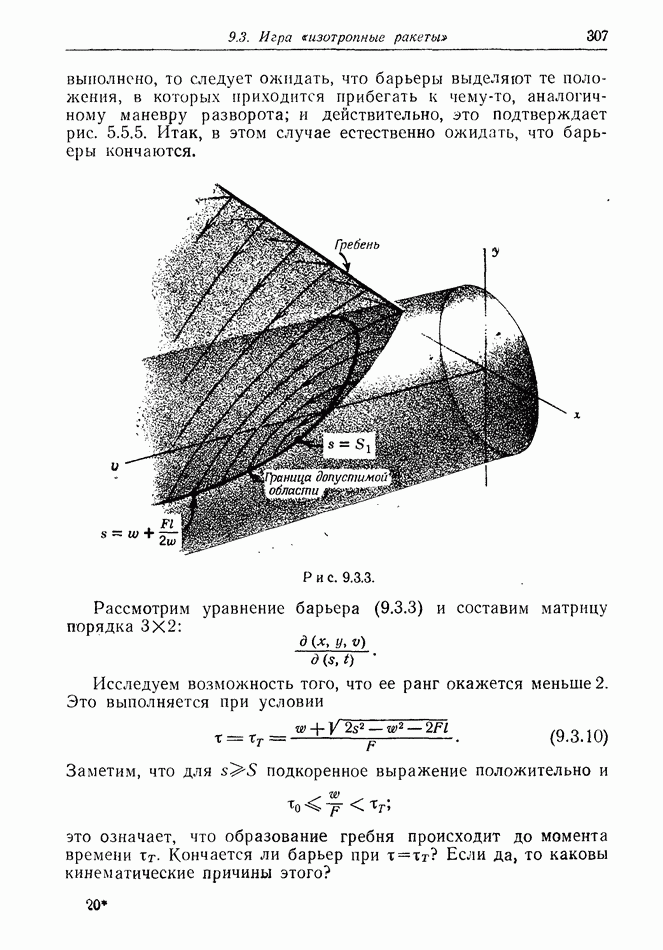


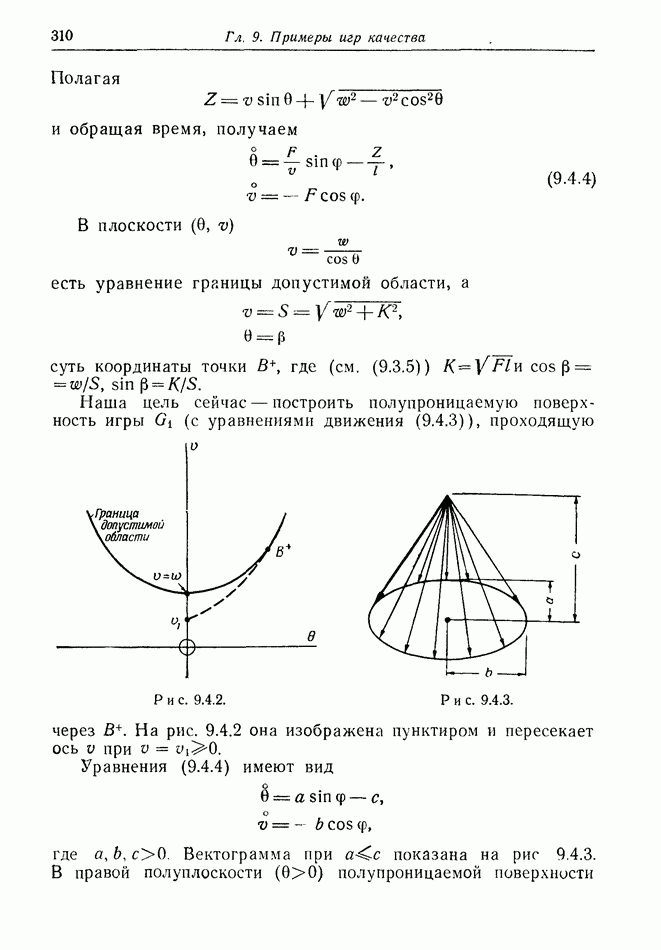







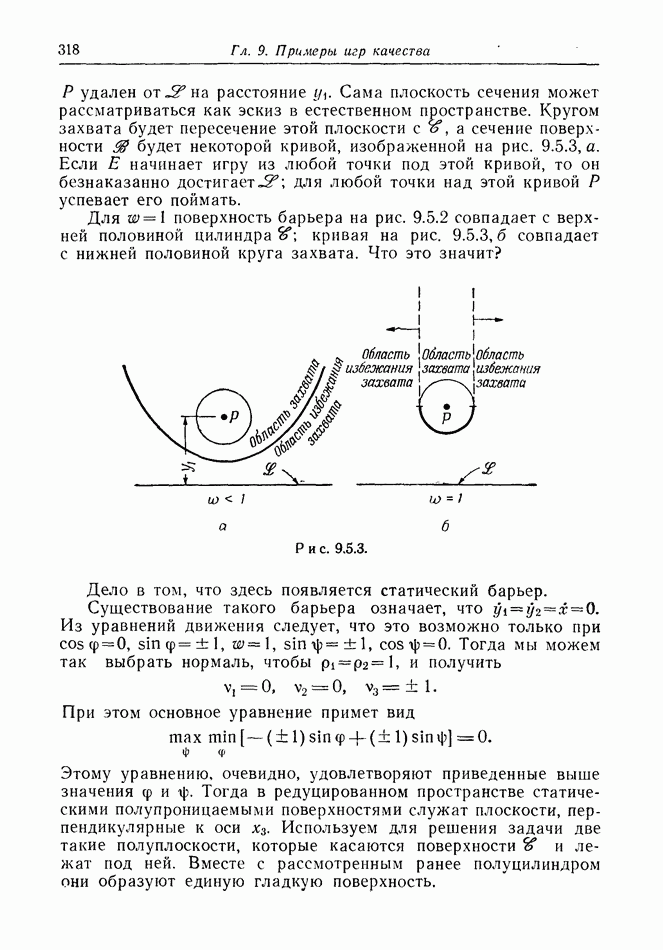




















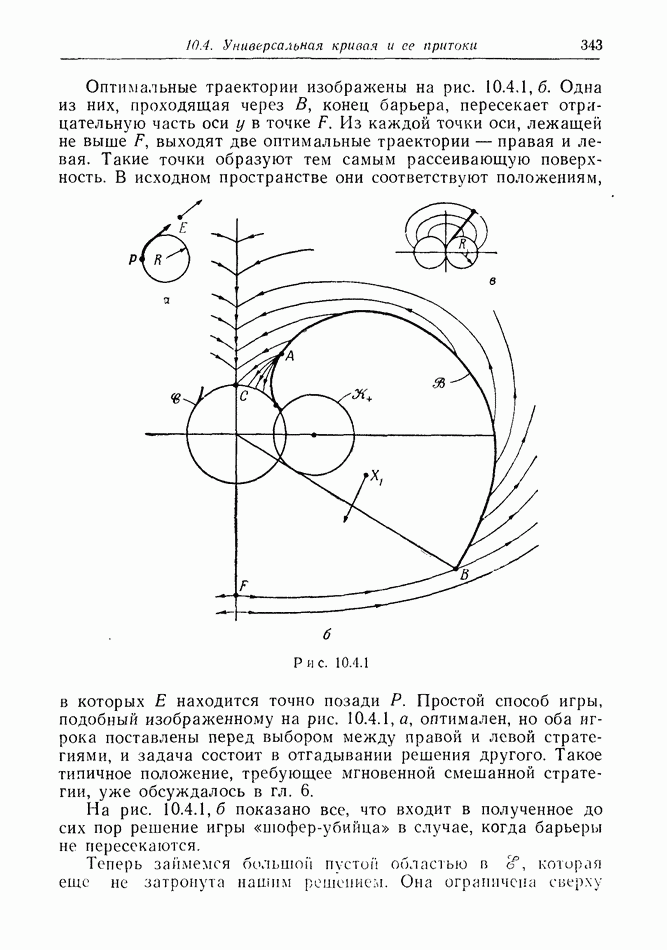

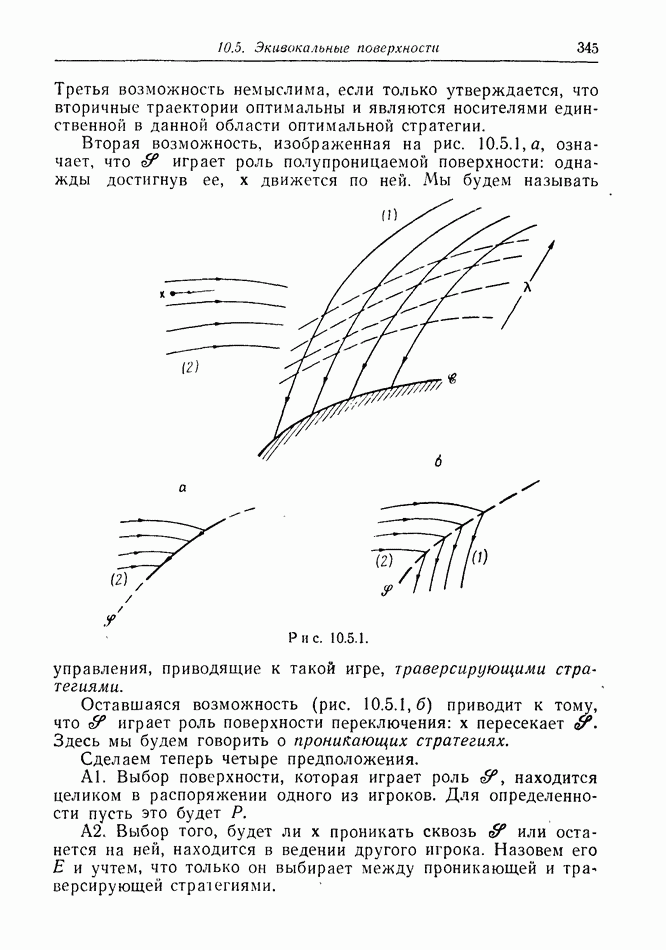
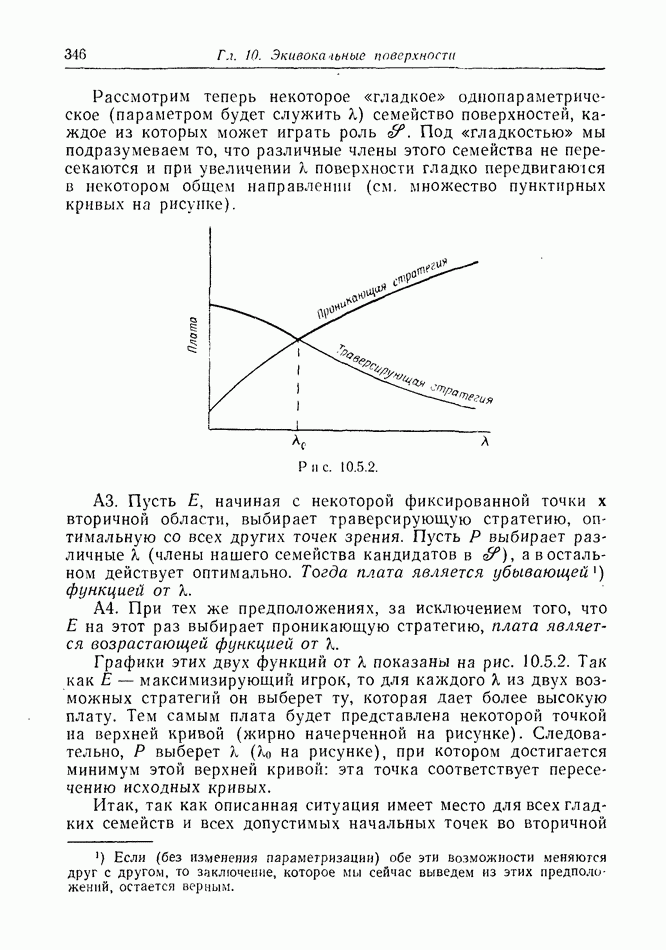



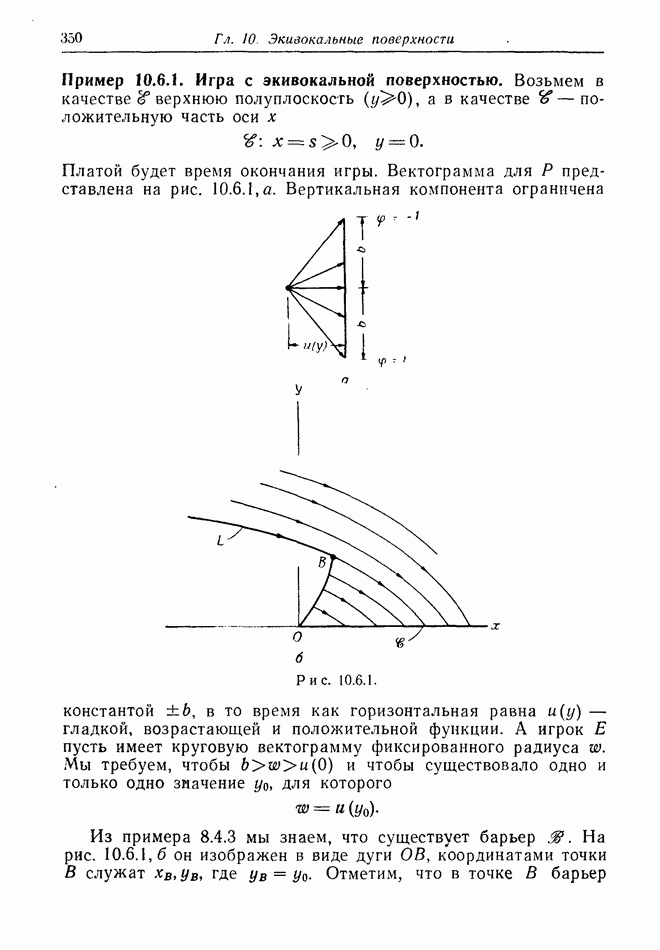
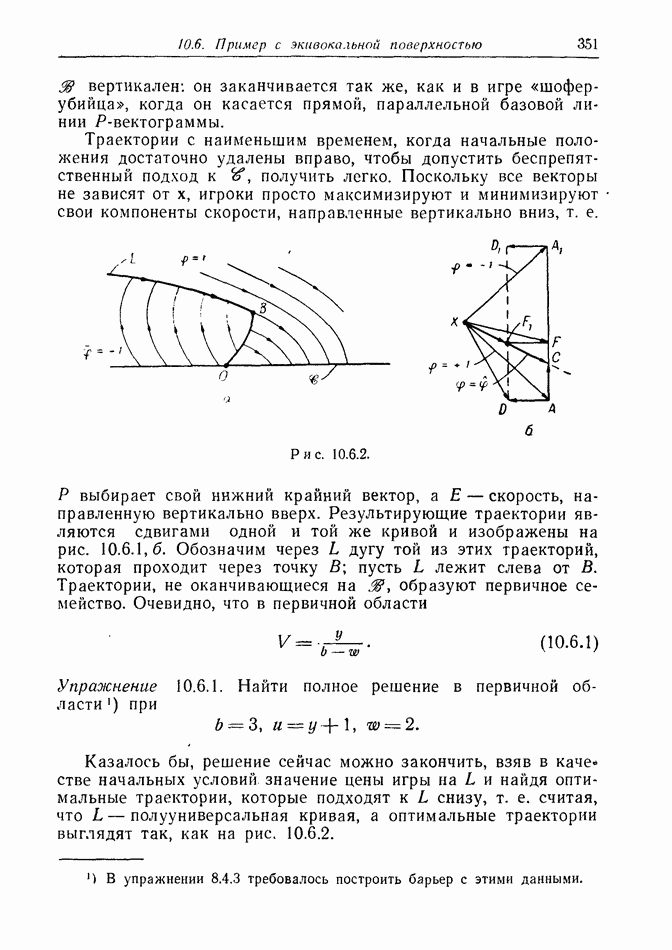










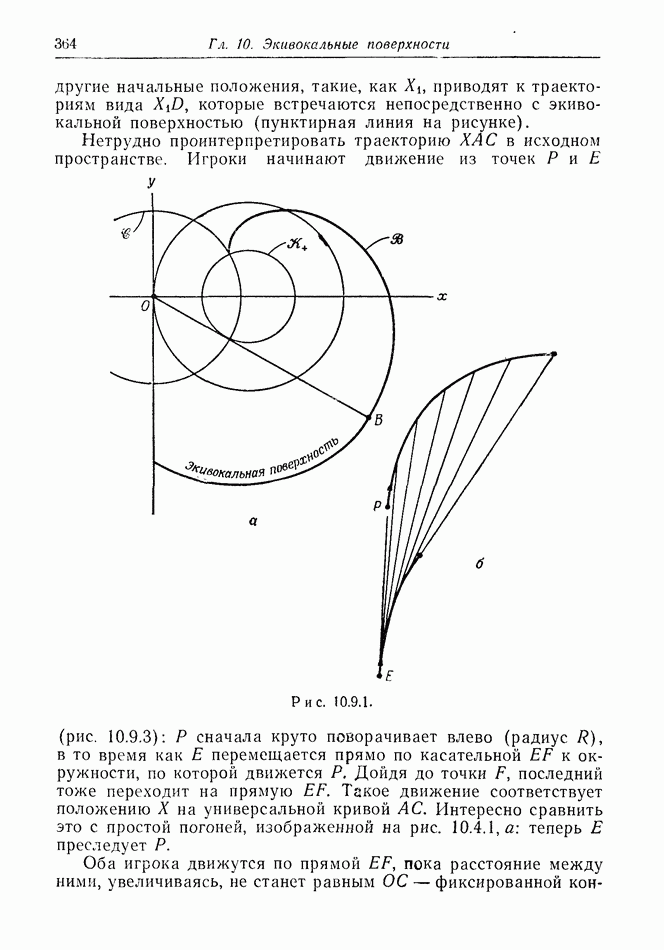
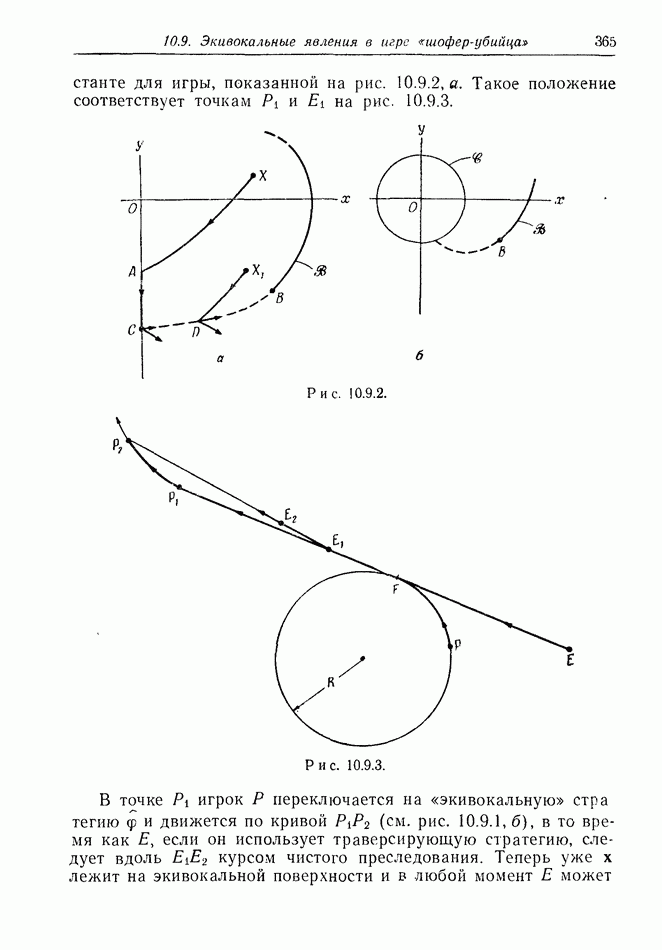
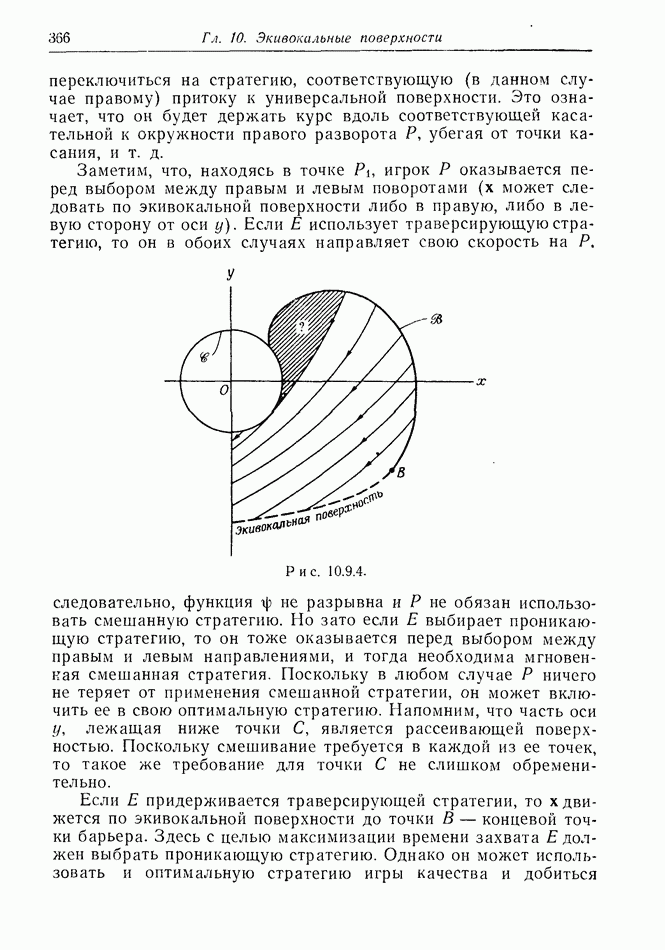



































































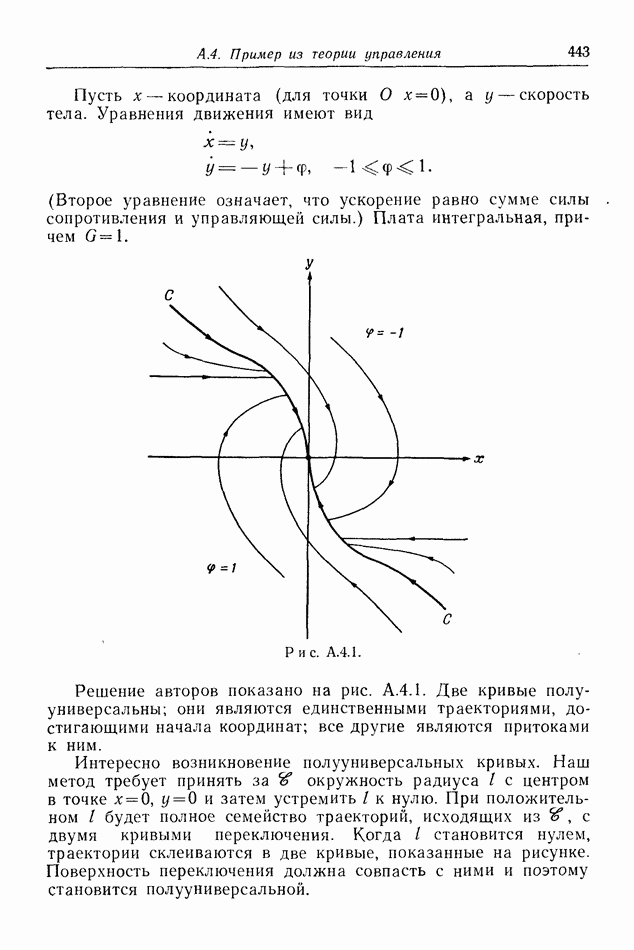





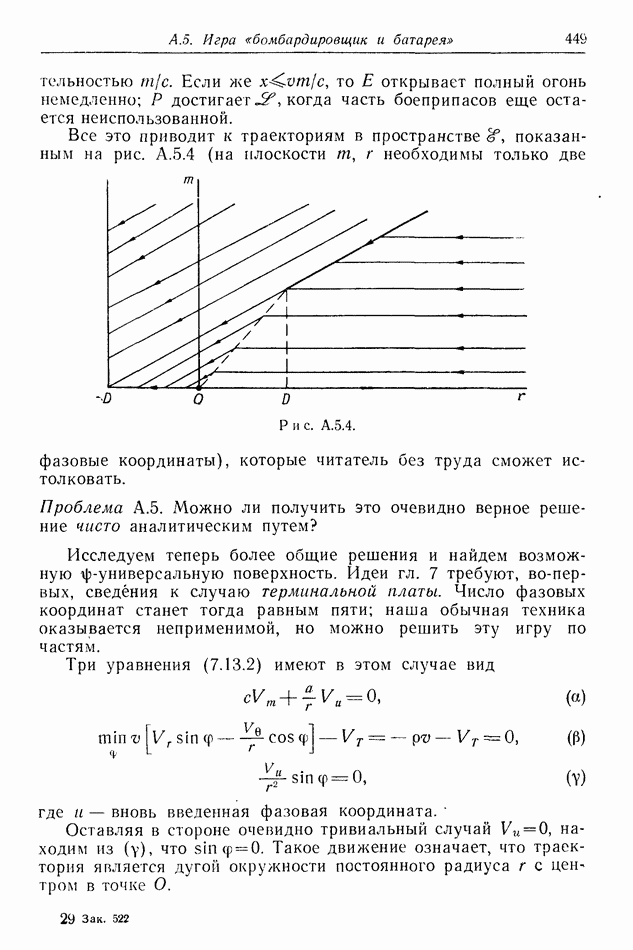





















 найдется стратегия
найдется стратегия  которая будет соответствовать
которая будет соответствовать  всякий раз, когда партия сводится к той же самой траектории. Таким образом, до тех пор пока
всякий раз, когда партия сводится к той же самой траектории. Таким образом, до тех пор пока  применяет стратегию
применяет стратегию  выигрывает одно и то же, действует ли он в соответствии с
выигрывает одно и то же, действует ли он в соответствии с  или
или  Поскольку стратегия
Поскольку стратегия  оптимальна,
оптимальна,  не может добиться для себя лучшего значения платы, чем
не может добиться для себя лучшего значения платы, чем 