Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
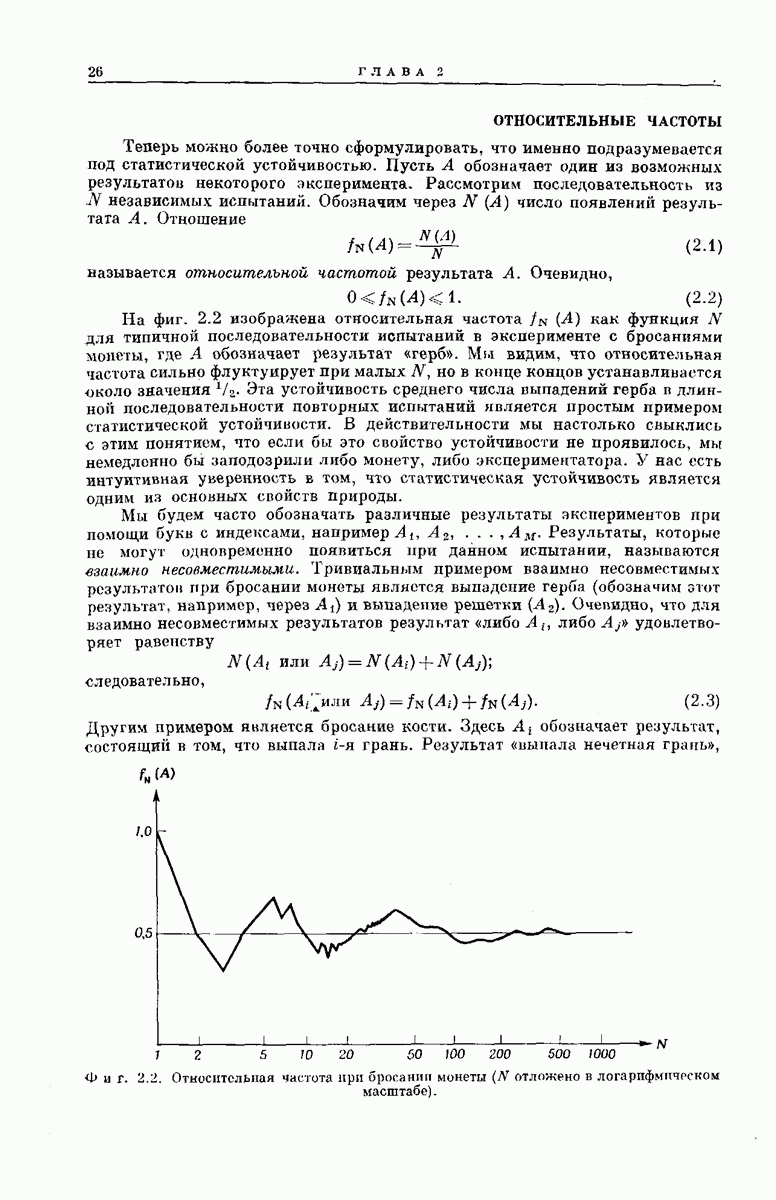
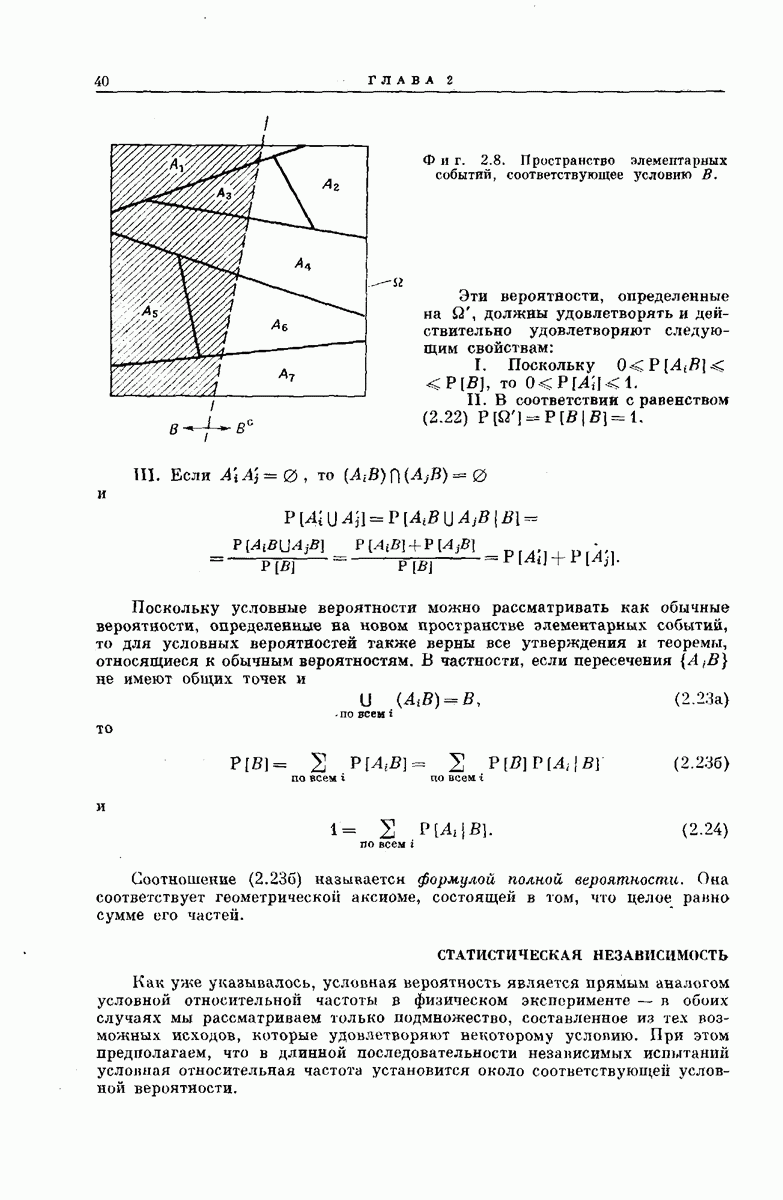
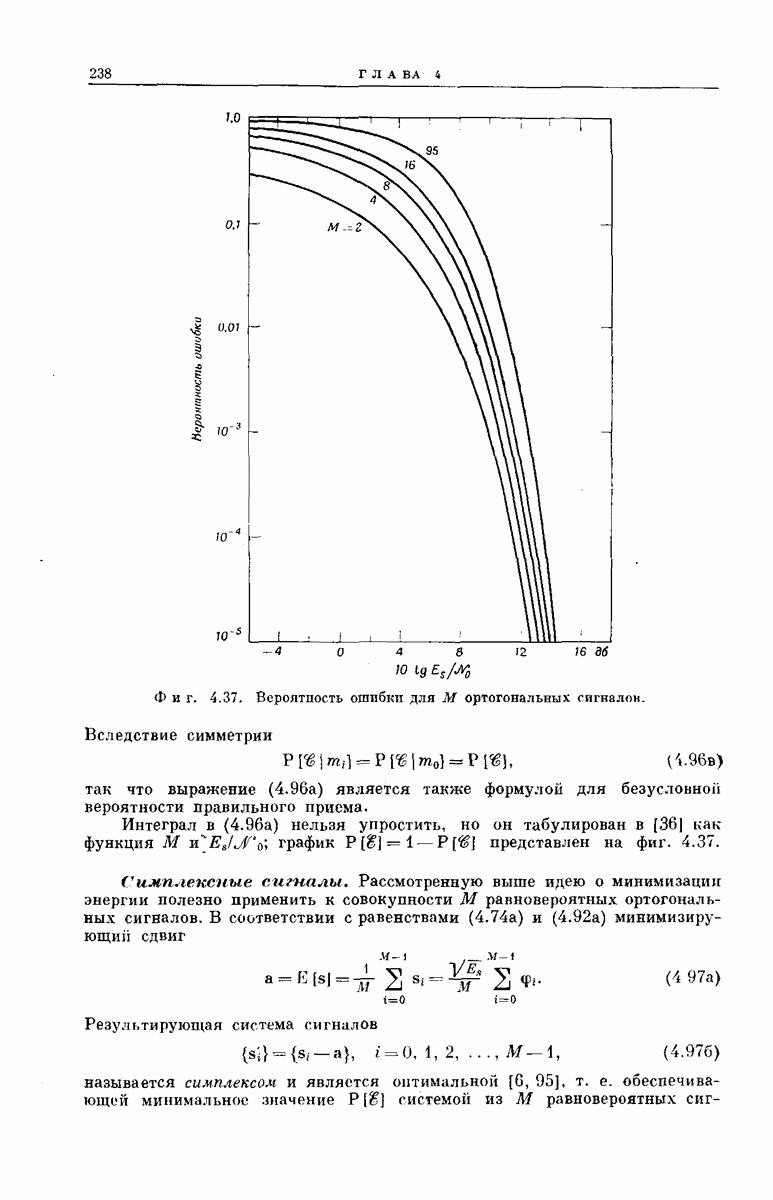
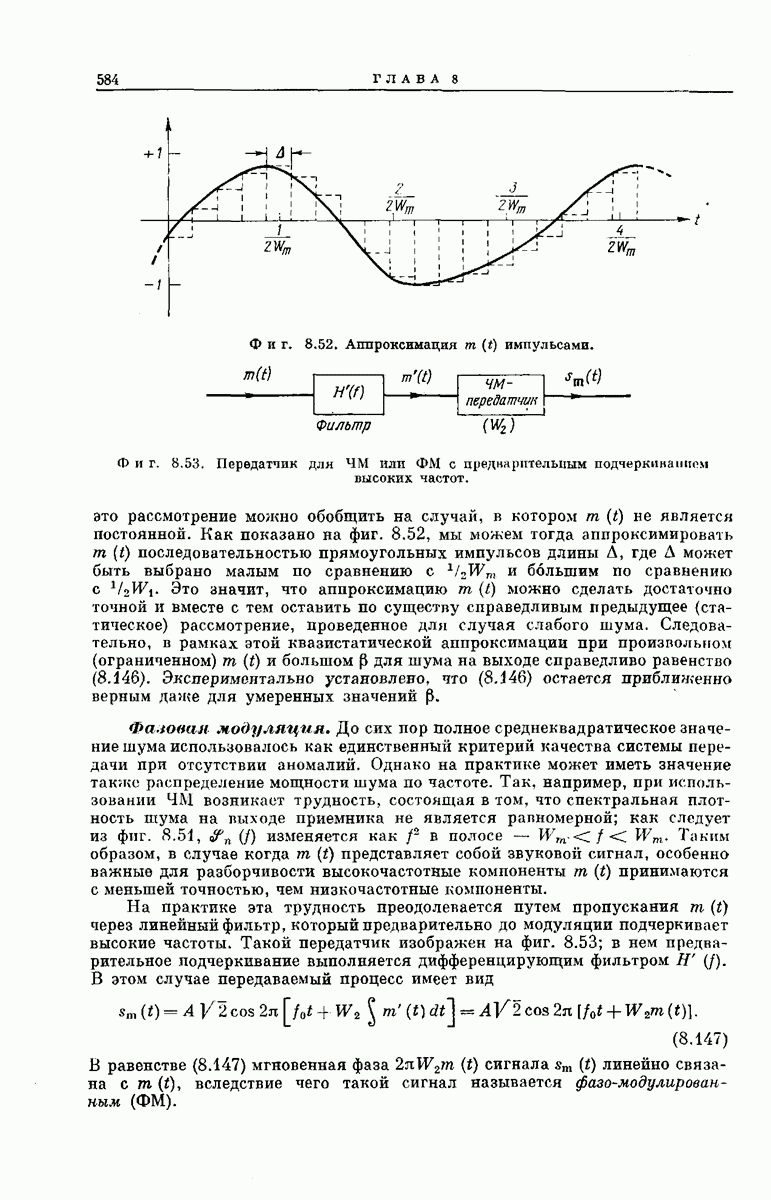
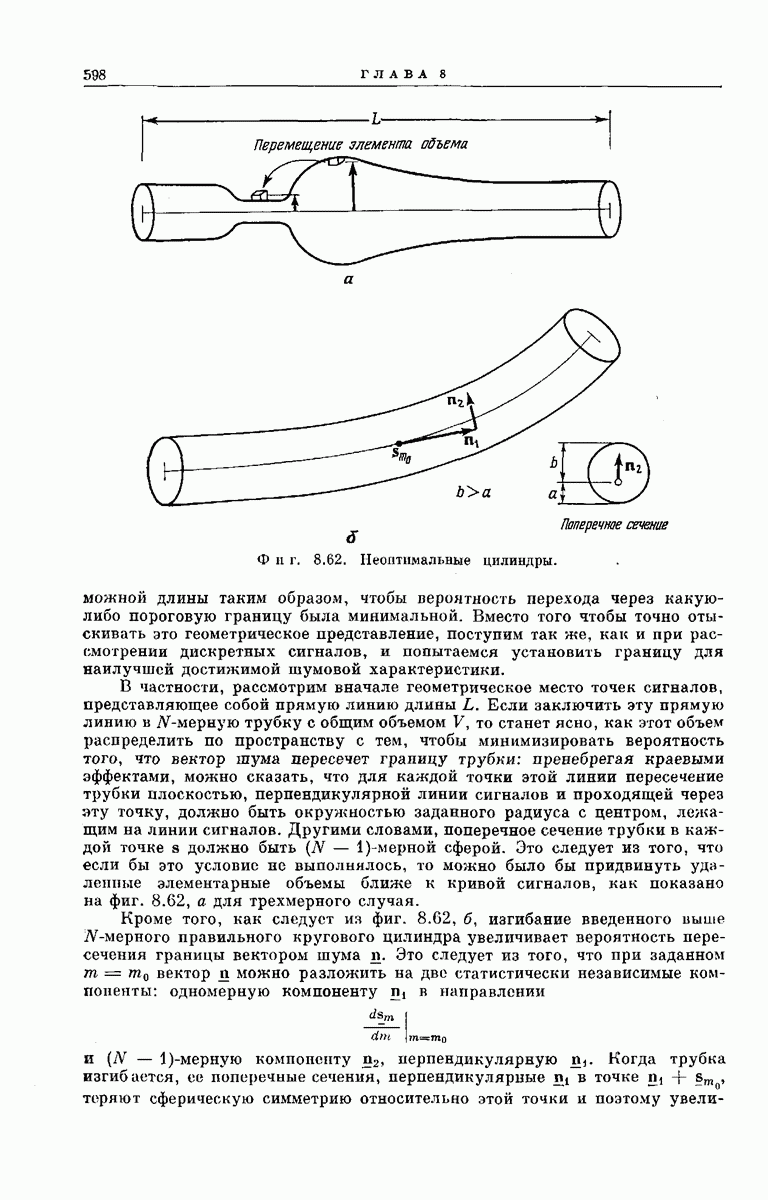
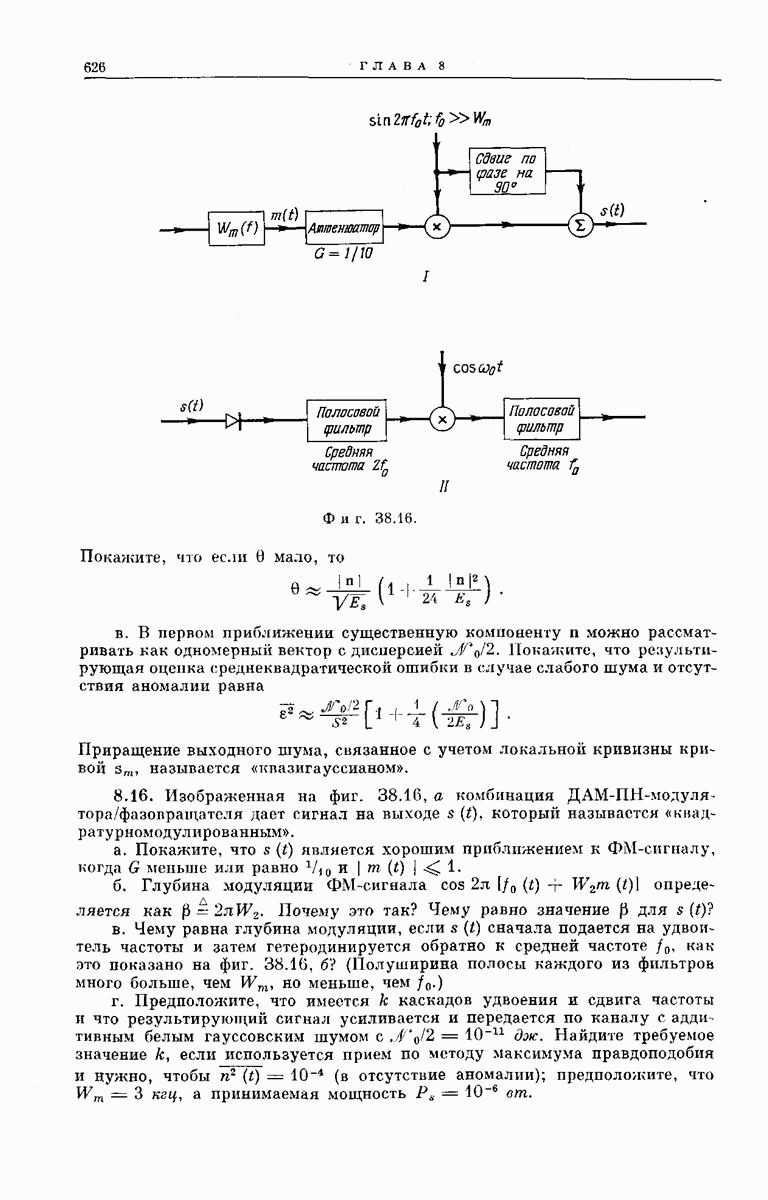
6.5. СВОДКА РЕЗУЛЬТАТОВВ этом разделе мы изложим некоторые аспекты математического анализа метода последовательного декодирования и обсудим основные полученные экспериментальные результаты. АНАЛИТИЧЕСКИЕ РЕЗУЛЬТАТЫТо обстоятельство, что объем
где значение коэффициента
а В тех же условиях из соотношения
Эта оценка сложности не зависит от К и при
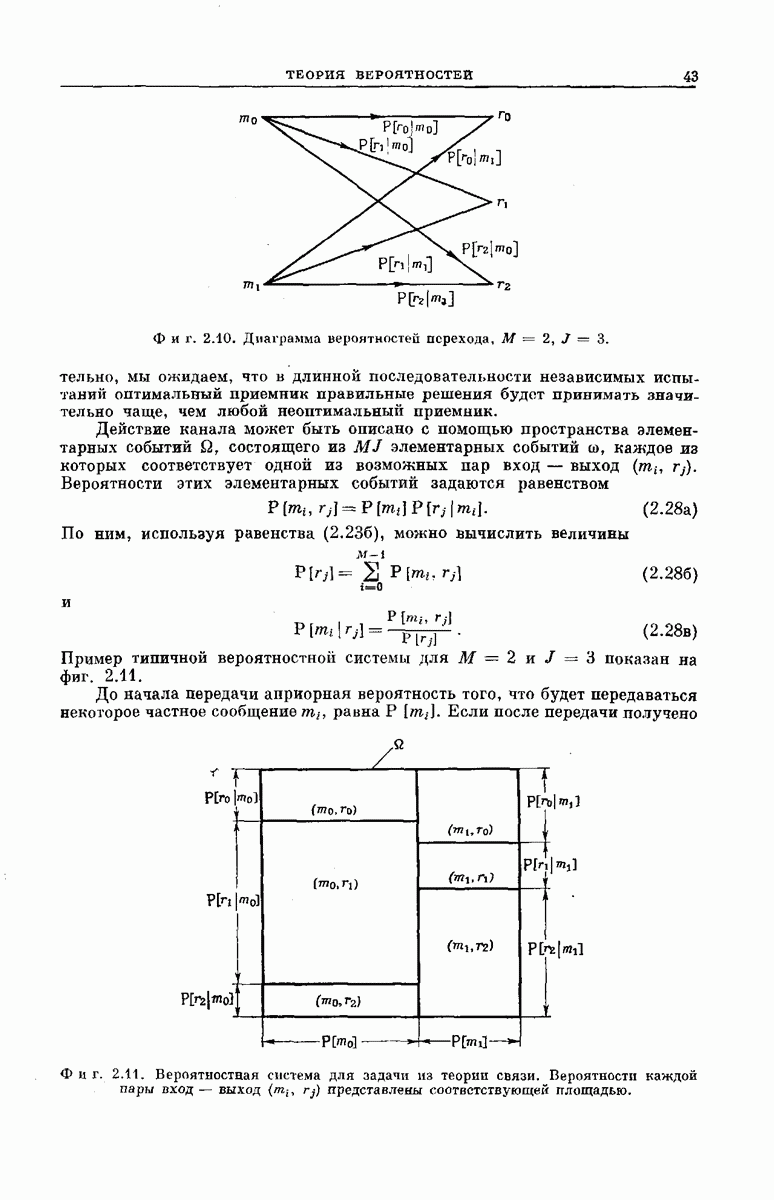
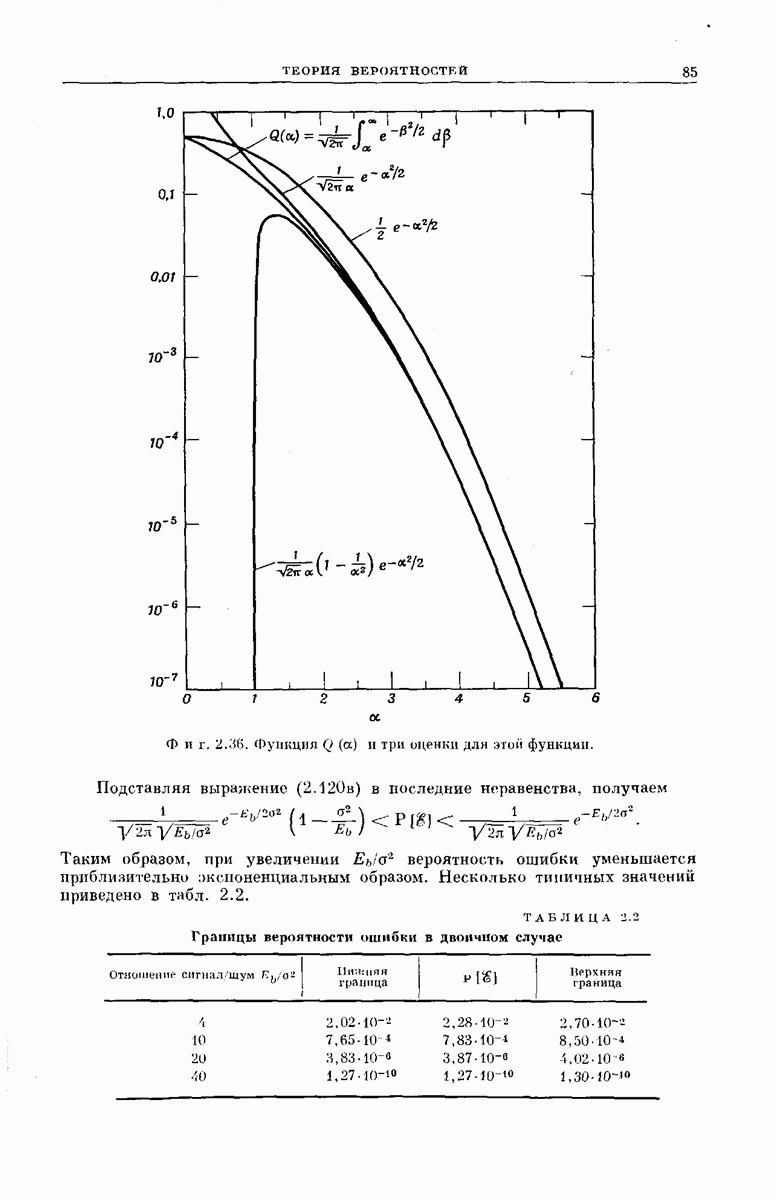
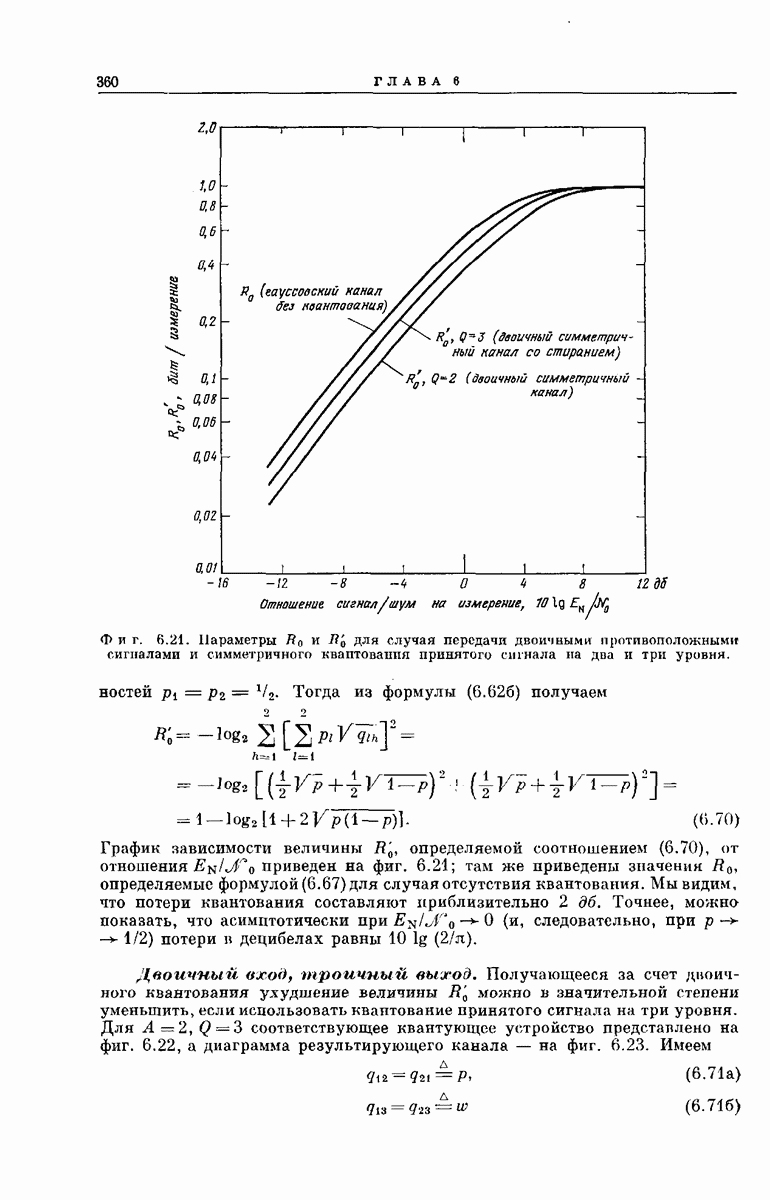
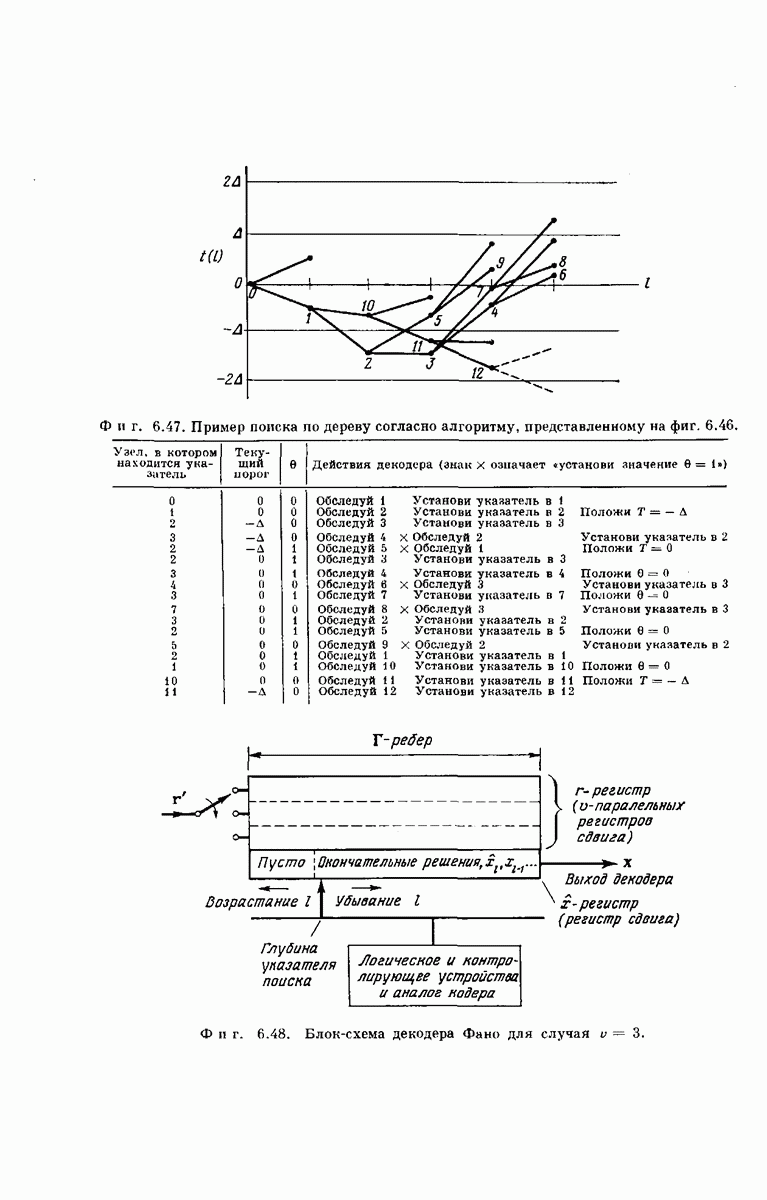
Хотя представленные здесь оценки носят частный характер и выбраны скорее из соображений простоты их вывода и формы, а не из-за их точности, они все же позволяют установить три следующих важных свойства последовательного декодирования: 1. При 2. При 3. Хотя поведение величин Таким образом, увеличивая Можно предполагать, что этими тремя свойствами обладают все процедуры последовательного декодирования; они проявляются во всех полученных до сих пор оценках и во всех опубликованных к настоящему времени экспериментальных результатах [48, 78, 91]. ПРЕИМУЩЕСТВА И НЕДОСТАТКИ СИСТЕМЫНеожиданный и основополагающий результат Шеннона, доказавшего, что шумы в канале устанавливают окончательную границу не для точности передачи, а для ее скорости, был впервые опубликован в 1948 г. С тех пор на решение задачи реального повышения надежности передачи было затрачено очень много усилий; предложено много интересных схем кодирования и декодирования. Большинство из них подробно описаны Желание иметь несколько различных решений одной и той же проблемы техники связи обусловлено главным образом инженерными соображениями. Например, рассмотрим гауссовский канал с ограниченной полосой и вычисленный Шенноном для этого канала показатель экспоненты верхней оценки надежности, график которого приведен на фиг. 5.18. Если достаточны умеренная точность и малые скорости передачи данных Чрезвычайно интересным классом кодов, применимым при больших К, являются коды Боуз — Чоудхури — Хоквенгема [15], которые в дальнейшем сокращенно называются БЧХ-кодами. При любом целом числе В качестве примера одного из возможных способов сравнения различных схем декодирования рассмотрим характеристики передачи по гауссовскому каналу с аддитивным белым шумом при применении двоичных БЧХ-кодов и в случае двоичных сверточных кодов при использовании метода последовательного декодирования. Предполагается, что применяются передача противоположными сигналами и симметричное квантование принятого сигнала на два уровня. Результирующая переходная вероятность ДСК равна
где С помощью вычислительной машины можно найти минимальное значение отношения Чтобы сравнить эти результаты с результатами последовательного декодирования, можно использовать соотношение Хотя кривые, приведенные на фиг. 6.49, и поучительны, с точки зрения проектировщика системы связи они никоим образом не могут служить сами по себе основой для решения в пользу того или иного сравниваемого устройства. Следует учитывать также, что разные схемы декодирования обладают различными преимуществами и недостатками в эксплуатации и реализации. Например, до сих пор мы рассматривали лишь среднее количество вычислений, необходимое для последовательного декодирования. В одном из следующих подразделов рассматриваются также флуктуации количества вычислений. Хотя, вообще говоря, БЧХ-коды требуют при декодировании в среднем большего числа операций, чем последовательное декодирование, количество вычислений, которое необходимо провести в случае БЧХ-кодов, гораздо меньше подвержено флуктуациям; во многих приложениях это является ценным преимуществом. Одно из главных достоинств последовательного декодирования — широта области его применимости. Мы уже отмечали, что процедуры последовательного декодирования применимы к широкому классу каналов связи. Характерно, что этот класс включает в себя, в частности, все стационарные дискретные каналы без памяти, т. е. все каналы, у которых статистические связи между используемыми в канале входными и выходными символами могут быть представлены в виде фиксированной диаграммы переходных вероятностей, изображенной, например, на фиг. 6.17. Для любого такого
(кликните для просмотра скана) канала оценки, эквивалентные оценкам (6.110) — (6.112), но со значением параметра Отсюда сразу следует, что если в канале с аддитивным белым гауссовским шумом применять не двоичное квантование сигнала на выходе согласованного фильтра, а квантование с очень малым шагом, то можно увеличить предельно достижимую для случая двоичного сверточного кодирования величину
до значений, как угодно близких показателю экспоненты вероятности ошибки в случае отсутствия квантования
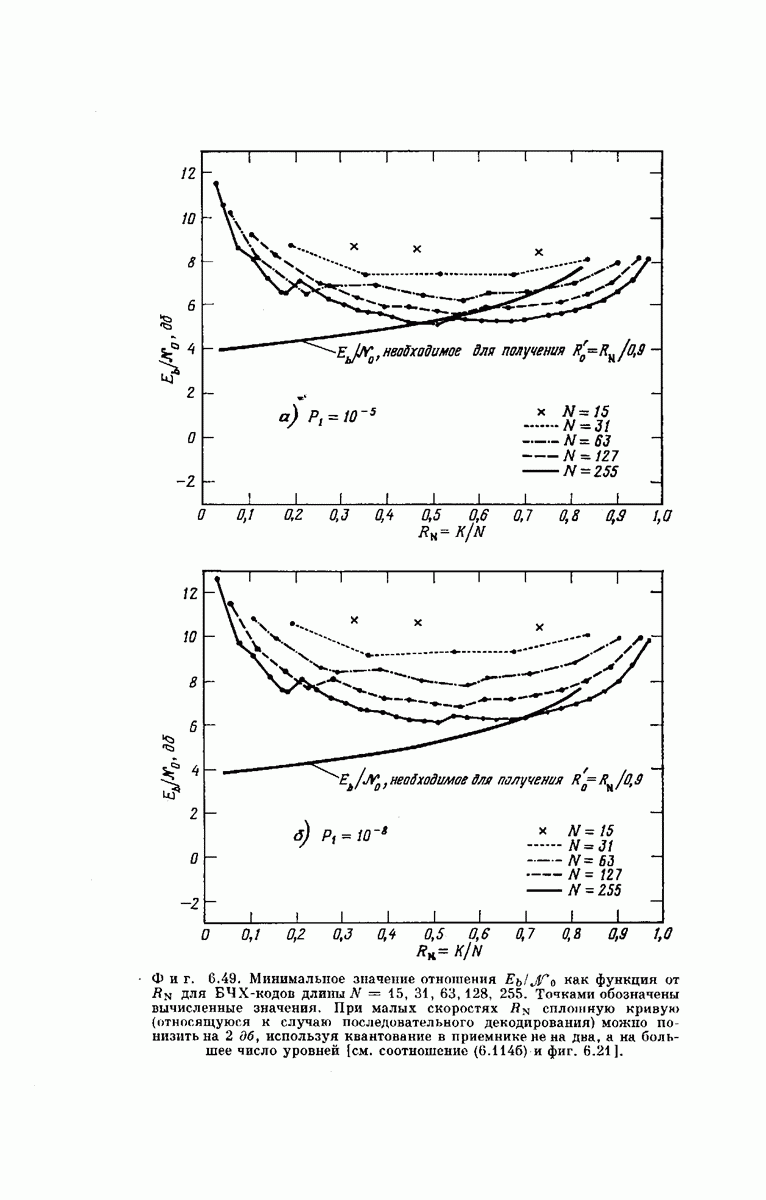
При этом улучшается эффективность использования энергии. Если, кроме того, не ограничиваться рассмотрением двоичной передачи, а использовать в передатчике многоамплитудную схему модуляции, получим, как уже отмечалось в гл. 5, значение РЕЗУЛЬТАТЫ МОДЕЛИРОВАНИЯАналитические трудности при исследовании методов последовательного декодирования таковы, что численная точность даже самых сильных из полученных оценок не достаточна для инженерных целей. В этом и в следующем подразделах будут приведены некоторые результаты моделирования на вычислительной машине алгоритма Фано, проведенного в лаборатории Линкольна Массачусетского технологического института [13]. Работа декодера при передаче по ДСК длинной входной последовательности На фиг. 6.50 приведен график зависимости наблюденного значения Экспериментальные данные, представленные на фиг. 6.50, получены для значений параметра наклона
(кликните для просмотра скана) перемещения порога представлено на фиг. 6.51, а, б. Нетрудно заметить, что необходимости в точной минимизации по этим параметрам нет. В заключение следует отметить, что первые символы порождающих последовательностей ДИНАМИКА ПОВЕДЕНИЯ ДЕКОДЕРАХотя из графиков фиг. 6.50 видно, что среднее количество вычислений
Аналитическую оценку Проектирование и оценка систем последовательного декодирования существенно осложняется тем обстоятельством, что количество вычислений подвержено большим флуктуациям. Например, Для сообщений, закодированных соответствующим образом выбранным сверточным кодом, естественно ожидать, что, если не считать редких исключений, искажения символов при передаче по ДСК, как правило, не приводят к тому, что расстояние Хемминга принятой последовательности от действительно переданной будет
Фиг. 6.53. Пример такого изменения меньше, чем от какой-либо из других возможных выходных последовательностей кодера. При этом декодер Фано обычно очень быстро отыскивает правильный путь по кодовому дереву; этим и объясняется малость значения Изредка, однако, искажения символов в канале могут привести к тому, что на значительном протяжении вдоль правильного пути перекошенное расстояние будет увеличиваться с возрастанием Действие шумов в канале, правда, очень редко может привести к тому, что принятая последовательность будет очень близка к одной из возможны
Фиг. где С точки зрения работы декодера необходимо различать ошибки и переполнения. Для наглядности установим разницу между этими явлениями геометрически, рассмотрев фиг. 6.54. Пусть на вход кодирующего устройства поступило в действительности сообщение Для того чтобы последовательный декодер был практически использован, его нужно рассчитать таким образом, чтобы вероятность переполнения и вероятность ошибки били малы. Получение малой вероятности переполнения является более трудной задачей, и мы обсудим ее в первую очередь. Нероятность переполнения. Вероятность переполнения определяется главным образом объемом памяти и вычислительной скоростью декодера. Аналогично величине Чтобы лучше понять поведение вероятности переполнения для алгоритма Фано, рассмотрим процесс декодирования нового символа сообщения, предполагая, что в начале этого декодирования указатель глубины поиска находится в крайнем левом разряде запоминающего устройства, как показано
Фиг. 6.55. Исходное положение декодера, вводимое для упрощения исследования вероятности переполнения. на фиг. 6.55. Пусть максимальное число ребер принятого сигнала, которое может храниться в памяти декодера, равно
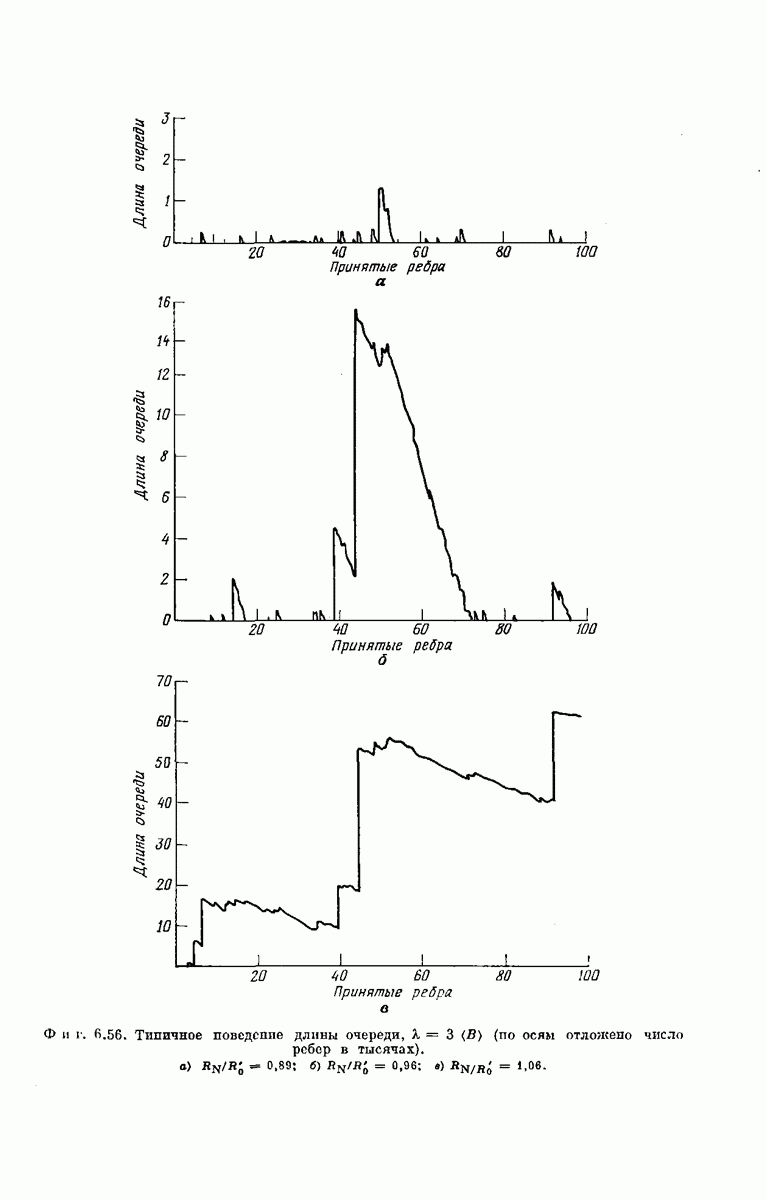
В процессе поиска декодер может двигаться назад по кодовому дереву, так что переполнение может наступить раньше, чем будут обследованы На фиг. 6.56, а — в показано типичное поведение длины очереди в случае, когда Малая вероятность переполнения при разумных значениях
(кликните для просмотра скана) сообщения и соотношение (6.117) для вероятности переполнения справедливо. Для малых значений вероятности В качестве примера рассмотрим ДСК, для которого
Согласно соотношению (6.117), потребуем, чтобы
или
Если принять, что специализированная декодирующая вычислительная машина затрачивает на обработку одного ребра 7,5 мксек, то получим
что, согласно графику фиг. 6.50, удовлетворяет условию
В этом примере для запоминания каждого принятого ребра требуется 3 двоичных разряда памяти Вероятность ошибки. Так как вероятность переполнения определяется объемом памяти декодера и скоростью вычислений, то ее трудно сделать чрезвычайно малой. Совершенно иначе обстоит дело с вероятностью необнаружимой ошибки. В соответствии с соотношением (6.110) вероятность необнаружимой ошибки для декодера Фано убывает экспоненциально с ростом длины кодовых ограничений К. При условии, что Чтобы лучше почувствовать относительную малость значимости вероятности необнаружимой ошибки, обратимся к фиг. 6.54, где дана геометрическая интерпретация процесса декодирования. Отмеченные продольной штриховкой области, которые соответствуют необнаружимым ошибкам, как правило, включают в себя лишь малую часть из общего числа точек в пространстве принятых сигналов. Кроме того, заштрихованные области
Фиг. 6.57. Геометрическое объяснение того, что полученная нами оценка вероятности ошибки оказывается слабой. Необнаружимая ошибка происходит при передаче вектора обычно далеко удалены друг от друга в смысле расстояния Хемминга и окружены незаштрихованными областями, соответствующими явлению переполнения. Поэтому разумно ояшдать, что если вероятность переполнения мала, то вероятность необнаружимой ошибки ничтожна. Это утверждение было доказано аналитически [28, 78]. Отметим, что убывание вероятности необнаружимой ошибки с ростом К происходит с показателем экспоненты, существенно большим (по абсолютной величине), чем в оценке (6.110), основанной на случайном кодировании. Причина относительной слабости этой последней оценки заключается в том, что теперь мы пренебрегаем возможностью переполнения. На фиг. 6.57 это интерпретируется геометрически. Имеется еще одно до сих пор не обсуждавшееся явление, которое вносит свой вклад в общую вероятность ошибки. Это явление состоит в том, что иногда декодер может принять неправильную гипотезу Избавиться от обнаружимых ошибок можно путем следующей простой модификации декодера: необходимо лишь увеличить длину
Фиг. 6.58. Модификация декодера Фано, позволяющая обнаруживать ошибки. В том случае, когда разряд декодера, из которого выходит гипотетический двоичный символ сообщения, достаточно далеко удален от разряда, при переходе в который указателя глубины поиска происходит переполнение, вероятность того, что переполнение произойдет раньше, чем будет выдана неправильная гипотеза, теперь окажется сравнимой с вероятностью необнаружимой ошибки. Если останавливать декодирование в момент переполнения, то при наличии удлиненного х-регистра общая вероятность ошибки будет настолько мала, что ею можно с уверенностью пренебрегать. ДВУХСТОРОННИЕ СТРАТЕГИИ ПЕРЕДАЧИДля нормальной работы системы последовательного декодирования недостаточно, конечно, чтобы вероятность ошибки была пренебрежимо малой; необходимо также обеспечить, чтобы декодирование возобновлялось автоматически после каждого переполнения. В односторонних системах связи можно достичь этого, периодически прерывая поток символов сообщения на вход кодера передатчика, скажем после каждого блока из С одной стороны, при В случае двухсторонней связи имеется более привлекательная возможность избежать неприятностей, связанных с переполнением. Через определенные
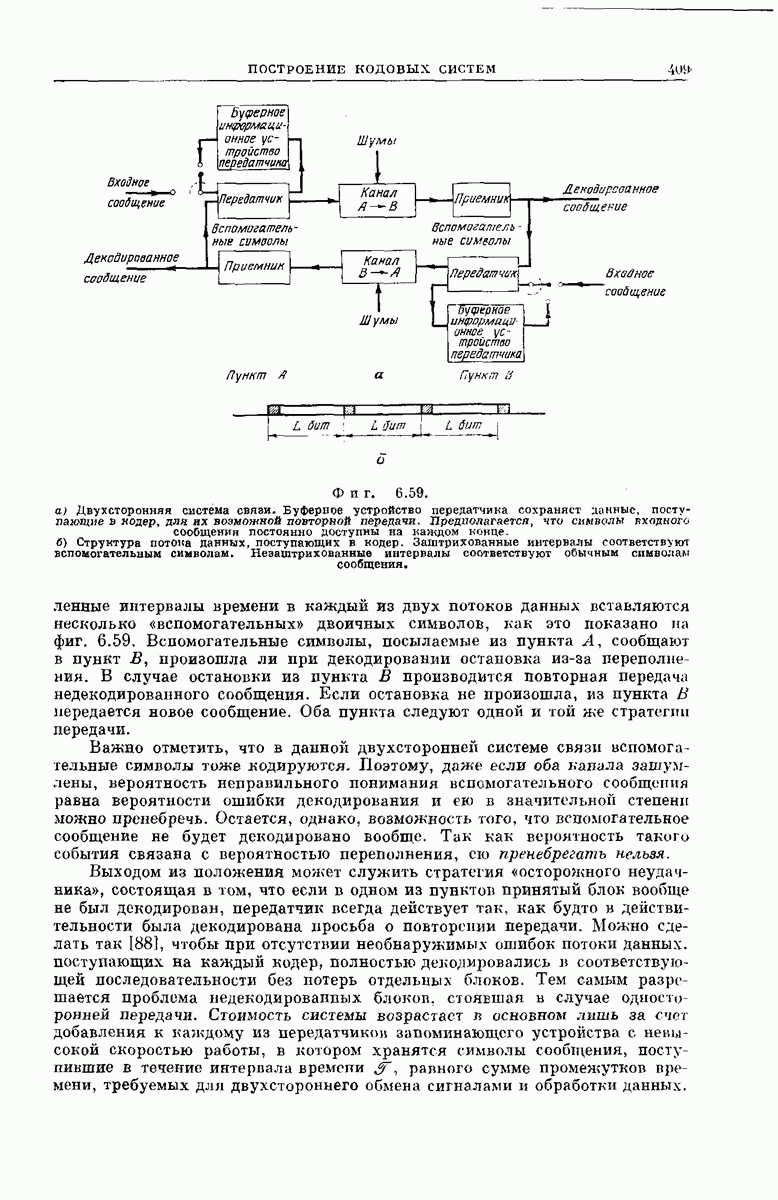
Фиг. 6.59. а) Двухсторонняя система связи. Буферное устройство передатчика сохраняет данные, поступающие в кодер, для их возможной повторной передачи. Предполагается, что символы входного сообщении постоянно доступны на каждом конце. б) Структура потока данных, поступающих в кодер. Заштрихованные интервалы соответствуют вспомогательным символам. Неэаштрихованные интервалы соответствуют обычным символам сообщения. интервалы времени в каждый из двух потоков данных вставляются несколько «вспомогательных» двоичных символов, как это показано на фиг. 6.59. Вспомогательные символы, посылаемые из пункта Важно отметить, что в данной двухсторонней системе связи вспомогательные символы тоже кодируются. Поэтому, даже если оба капала зашум-лены, вероятность неправильного понимания вспомогательного сообщения равна вероятности ошибки декодирования и ею в значительной степени можно пренебречь. Остается, однако, возможность того, что вспомогательное сообщение не будет декодировано вообще. Так как вероятность такого события связана с вероятностью переполнения, ею пренебрегать нельзя. Выходом из положения может служить стратегия «осторожного неудачника», состоящая в том, что если в одном из пунктов принятый блок вообще не был декодирован, передатчик всегда действует так, как будто в действительности была декодирована просьба о повторении передачи. Можно сделать так [88], чтобы при отсутствии необнаружимых ошибок потоки данных, поступающих на каждый кодер, полностью декодировались в соответствующей последовательности без потерь отдельных блоков. Тем самым разрешается проблема недекодированпых блоков, стоявшая в случае односторонней передачи. Стоимость системы возрастает в основном лишь за счет добавления к каждому из передатчиков запоминающего устройства с невысокой скоростью работы, в котором хранятся символы сообщения, поступившие в течение интервала времепи равного сумме промежутков времени, требуемых для двухстороннего обмена сигналами и обработки данных. Каждый цикл «переспрос — повторение» включает в себя «потери» (с точки зрения задачи передачи информации) времени, равные продолжительности двухстороннего обмена сигналами. Иначе говоря, передатчик вновь передает все данные, поступившие и переданные в предыдущий интервал времени, равный Если требуется, чтобы по реальным каналам поддерживалась точная и эффективная связь, необходимость прибегать к двухсторонним системам кажется неизбежной. Параметры большинства каналов меняются во времени, так что их функции надежности флуктуируют. Системы без обратной связи должны быть спроектированы в расчете на эффективную передачу со скоростью, соответствующей наихудшим условиям в канале, поэтому, если условия передачи хорошие, связь становится неэффективной. В случае двухсторонней стратегии, однако, могут быть использованы вспомогательные двоичные символы для того, чтобы потребовать изменения скорости передачи данных. Пример такой системы рассмотрен в следующем подразделе. СХЕМА ЭКСПЕРИМЕНТАЛЬНОЙ СИСТЕМЫВ гл. 5 и 6 мы рассмотрели, как выбор схем модуляции и демодуляции, кодирования и декодирования влияет на помехоустойчивость и сложность системы. Для случая декодирования блоковых кодов по принципу наибольшего правдоподобия это исследование (не включающее вопрос о сложности оборудования) привело нас к оценке
где Для каналов с ограниченной полосой мы обычно измеряли скорость передачи данных в битах за секунду. Если через
где Когда мы рассматривали последовательное декодирование и включили вопрос о сложности декодера в формулировку задачи выбора схемы двухсторонней системы, наши представления о выборе параметров схемы несколько изменились. Выбирая достаточно большое В этой связи отметим также, что допустимую скорость передачи данных определяет величина
то оценку (6.117) для частоты переполнений можно переписать в виде
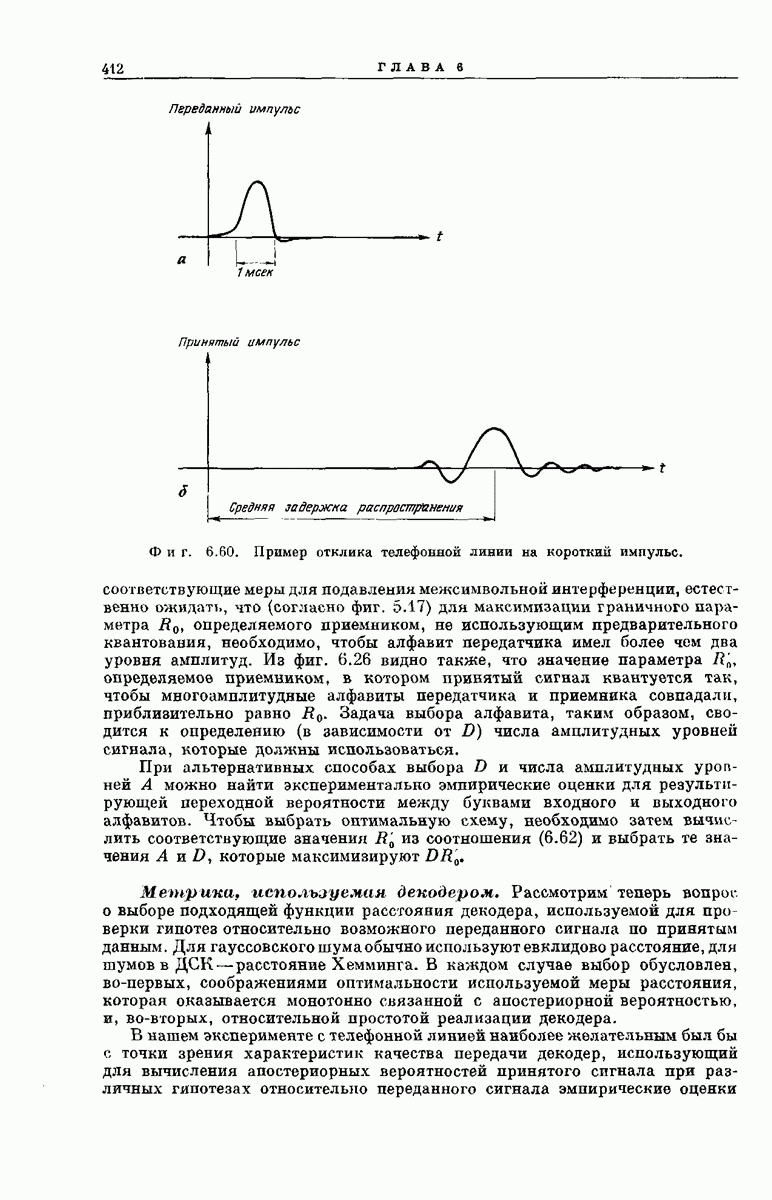
Поэтому величина При использовании систем последовательного декодирования фундаментальной мерой эффективности схем модуляции и демодуляции является определяемое ими значение параметра Максимизация Межсимвольная интерференция. Искажения сигнала при прохождении по междугородным телефонным линиям в основном вызываются не аддитивным гауссовским шумом, а межсимвольной интерференцией. Если мы попытаемся передать узкий импульс (фиг. 6.60, а), то в действительности примем размазанный импульс большей длительности (фиг. 6.60, б) 1). Размазанность в основном объясняется тем, что фазовая составляющая передаточной функции телефонной линии не является линейной функцией частоты. В результате различные частотные составляющие передаваемого сигнала распространяются с различными скоростями и поэтому достигают приемника с различными задержками. Хотя ширина полосы на уровне 3 дб амплитудной характеристики используемого в эксперименте канала составляла Межсимвольная интерференция может быть в некоторой степени уменьшена путем тщательного выравнивания фаз в линии и формирования передаваемого импульса. Однако, даже если это сделано, при сужении длительности импульса и возрастании частоты повторений импульсов неизбежно возрастает остаточная межеимвольпая интерференция. Если трактовать эту интерференцию как шум, то можно сказать, что увеличение Сигнальные алфавиты. Междугородные телефонные линии обычно характеризуются высоким отношением сигнал/шум. Поэтому, если приняты
Фиг. 6.60. Пример отклика телефонной линии на короткий импульс. соответствующие меры для подавления межсимвольной интерференции, естественно ожидать, что (согласно фиг, 5.17) для максимизации граничного параметра При альтернативных способах выбора Метрика, используемая декодером. Рассмотрим теперь вопрос о выборе подходящей функции расстояния декодера, используемой для проверки гипотез относительно возможного переданного сигнала по принятым данным. Для гауссовского шума обычно используют евклидово расстояние, для шумов в ДСК—расстояние Хемминга. В каждом случае выбор обусловлен, во-первых, соображениями оптимальности используемой меры расстояния, которая оказывается монотонно связанной с апостериорной вероятностью, и, во-вторых, относительной простотой реализации декодера. В нашем эксперименте с телефонной линией наиболее желательным был бы с точки зрения характеристик качества передачи декодер, использующий для вычисления апостериорных вероятностей принятого сигнала при различных гипотезах относительно переданного сигнала эмпирические оценки переходных вероятностей. Значение К счастью, для получения хороших результатов нет необходимости использовать оптимальную систему; в инженерной практике ищут не столько оптимальные решения, сколько стараются избежать вопиющих отклонений от оптимальности. В частности, для рассматриваемого нами каскада, состоящего из модулятора, телефонной линии и демодулятора, результирующий шум характеризуется в первую очередь тем, что вероятности больших искажений амплитуды принятого сигнала гораздо меньше, чем малых. Поэтому интуитивно ясно, что куммулятивная сумма абсолютных разностей напряжений принятого и гипотетического сигналов может служить подходящей, хотя, конечно, и не оптимальной, функцией расстояний при декодировании. Например, если квантованные амплитуды принятого сигнала равны
а гипотетический сигнал
можно определить расстояние между
Функция расстояния, определяемая соотношением (6.121в), монотонно зависит от логарифма апостериорной вероятности, если все сигналы равновероятны и помеха в канале представляет собой аддитивный вектор шума
Конечно, такая модель не может точно описать рассматриваемый нами каскад, состоящий из модулятора, телефонной линии и демодулятора. Однако экспериментальная проверка, выполненная для нескольких различных значений Экспериментальные результаты. После выбора подходящей декодирующей функции расстояния удобный и разумный компромиссный метод оценкисостоит в согласовании функции плотпости, соответствующей этой функции расстояния, с эмпирическими данными, а не в подстановке эмпирических данных непосредственно в соотношение
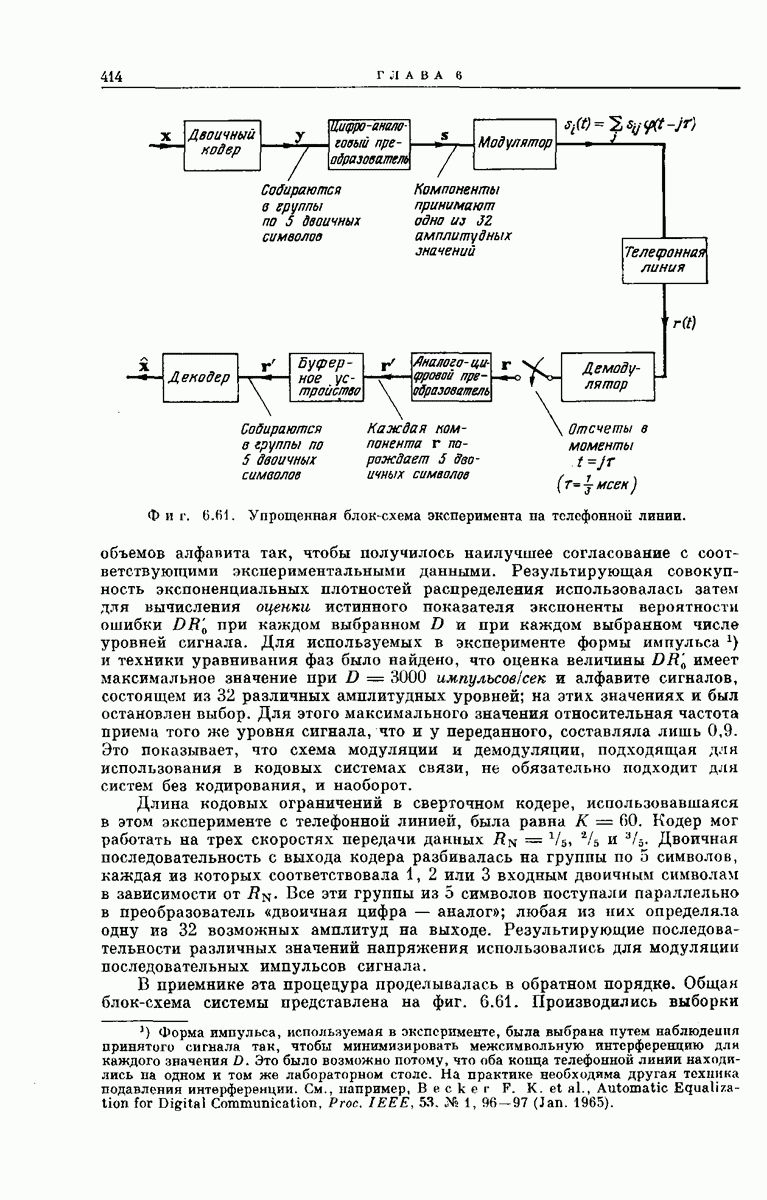
Фиг. 6.61. Упрощенная блок-схема эксперимента на телефонной линии. объемов алфавита так, чтобы получилось наилучшее согласование с соответствующими экспериментальными данными. Результирующая совокупность экспоненциальных плотностей распределения использовалась затем для вычисления оценки истинного показателя экспоненты вероятности ошибки Длина кодовых ограничений в сверточном кодере, использовавшаяся в этом эксперименте с телефонной линией, была равна В приемнике эта процедура проделывалась в обратном порядке. Общая блок-схема системы представлена на фиг. 6.61. Производились выборки принятого сигнала В этом эксперименте последовательный декодер использовал алгоритм поиска, предложенный ранее алгоритма Фано, и буферное устройство было отделено от самого декодера. Как только каждая из групп, состоящая из 5 символов, декодировалась и выводилась из Скорость передачи данных Вся аппаратура работала круглосуточно в общей сложности 40 час. Средняя скорость передачи во время работы составляла приблизительно 7500 декодированных двоичных символов в секунду. Первая ошибка в декодировании произошла после декодирования более чем 109 двоичных символов сообщения, и эта ошибка была обнаружена после вывода из регистра небольшого числа следующих декодированных символов. Так как задержка между моментом декодирования и моментом выхода двоичного символа из регистра составила всего лишь К бит, то и эта ошибка декодирования не была бы сделана, если бы к х-регистру декодера была добавлена дополнительная задержка, рассчитанная на По-видимому, кодирование лучше всего применять в каналах, в которых обеспечить хорошие условия передачи дорого (или невозможно); описанный выше эксперимент был проведен на телефонной линии главным образом из-за относительной легкости его выполнения. Несмотря на это. экспериментальное изучение использованной нами процедуры позволило лучше понять компромиссы, которые неизбежны при техническом осуществлении кодовых систем связи.
|
 |
Оглавление
|




























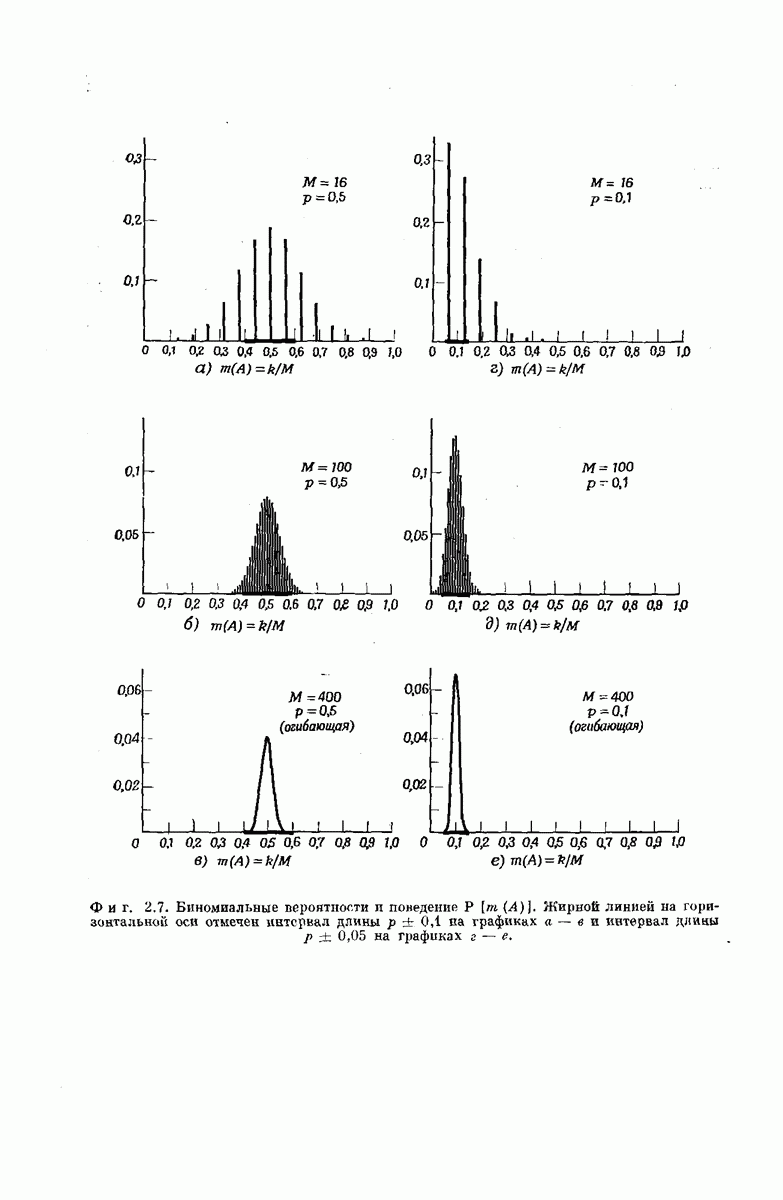

































































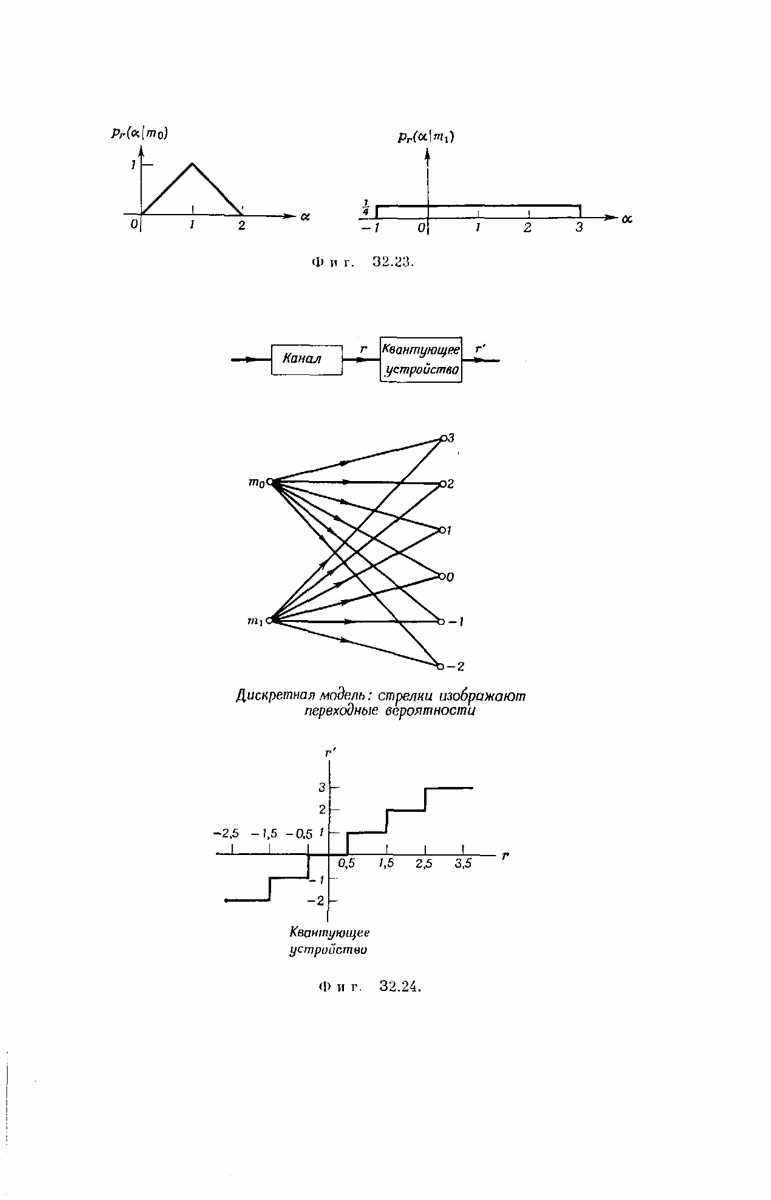












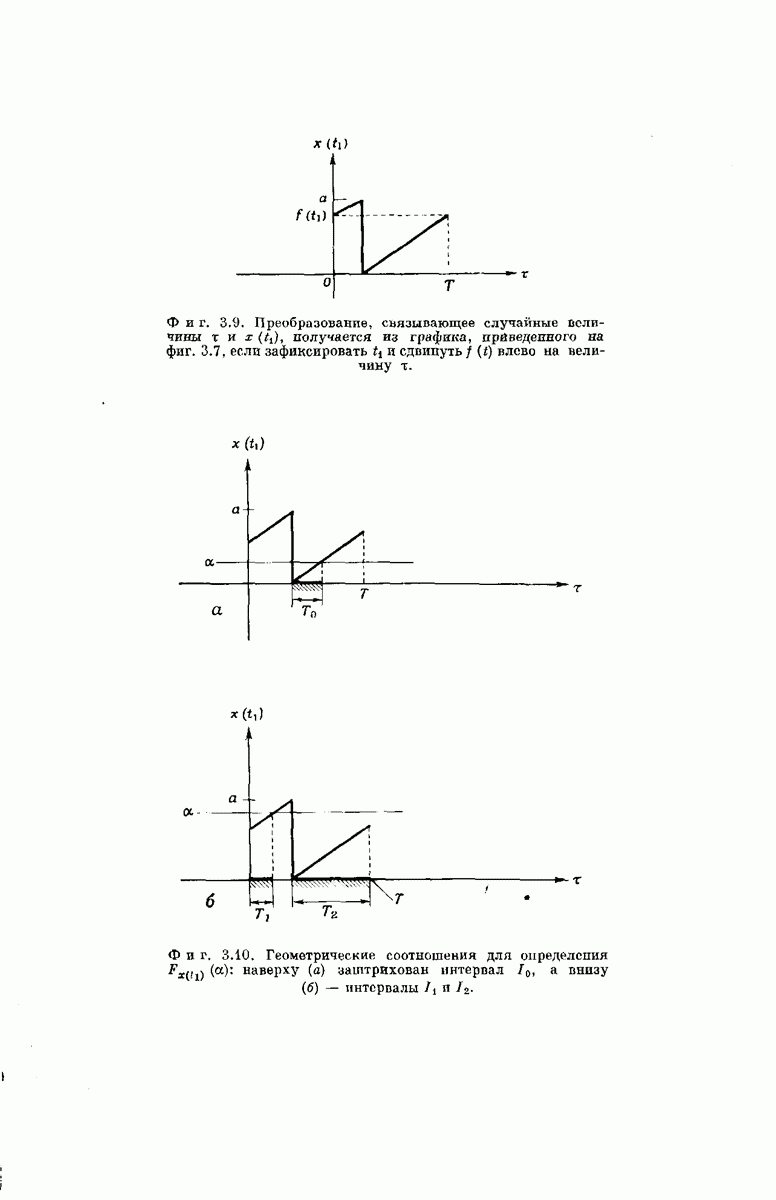



































































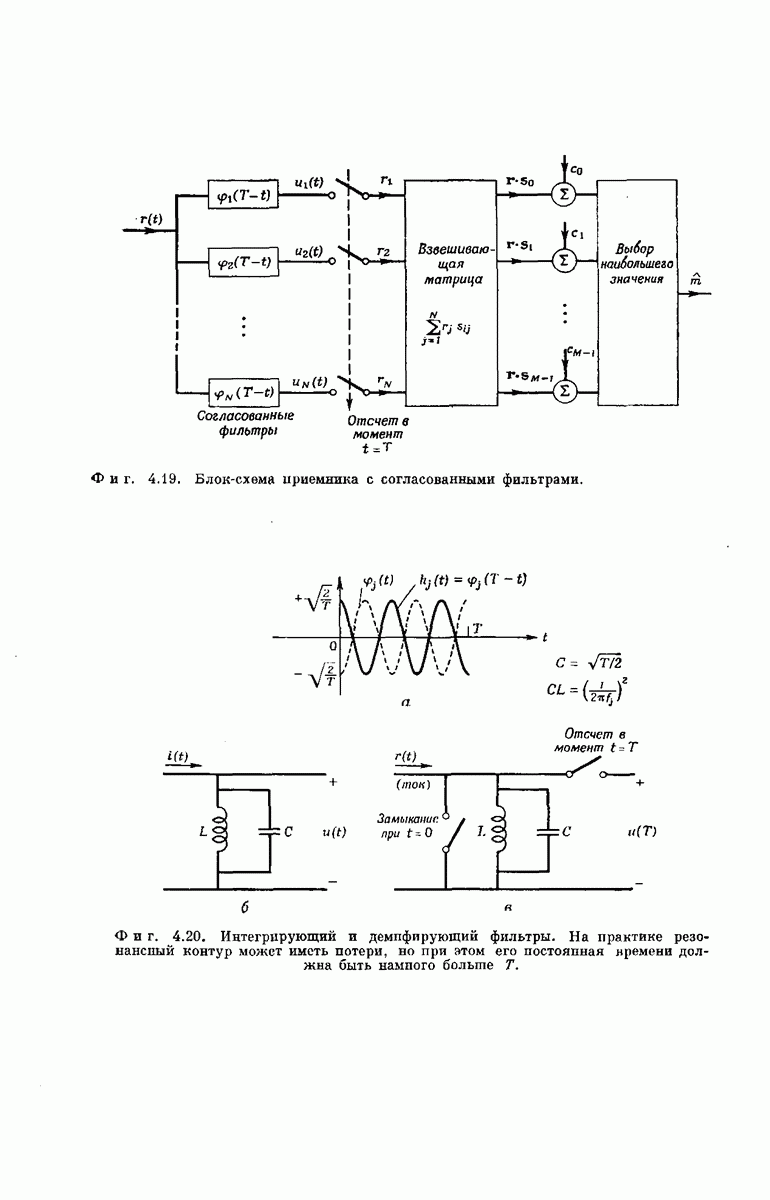



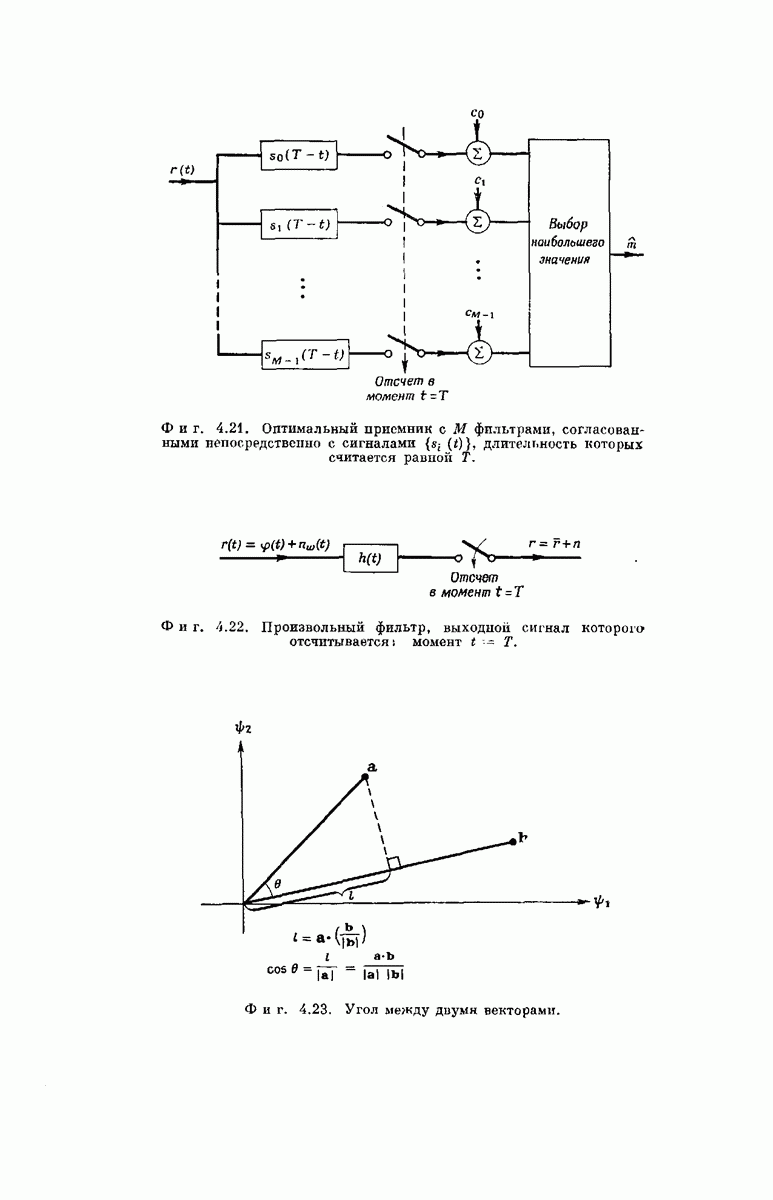

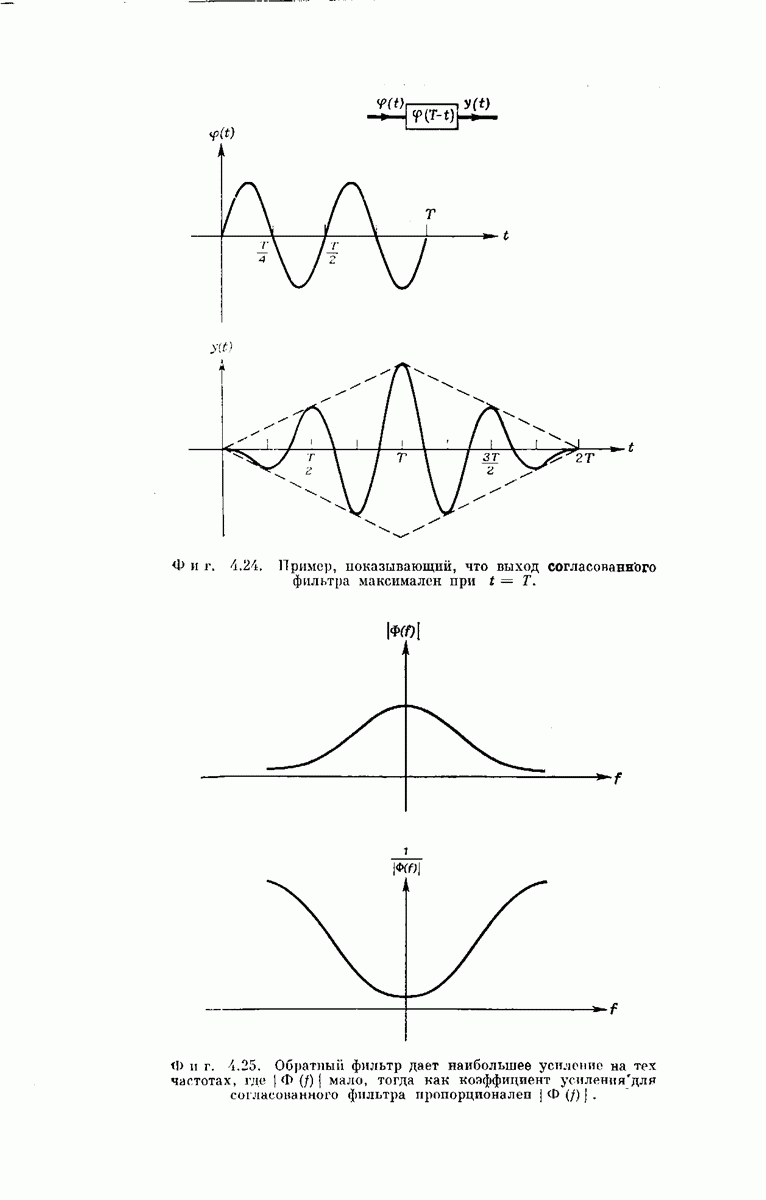



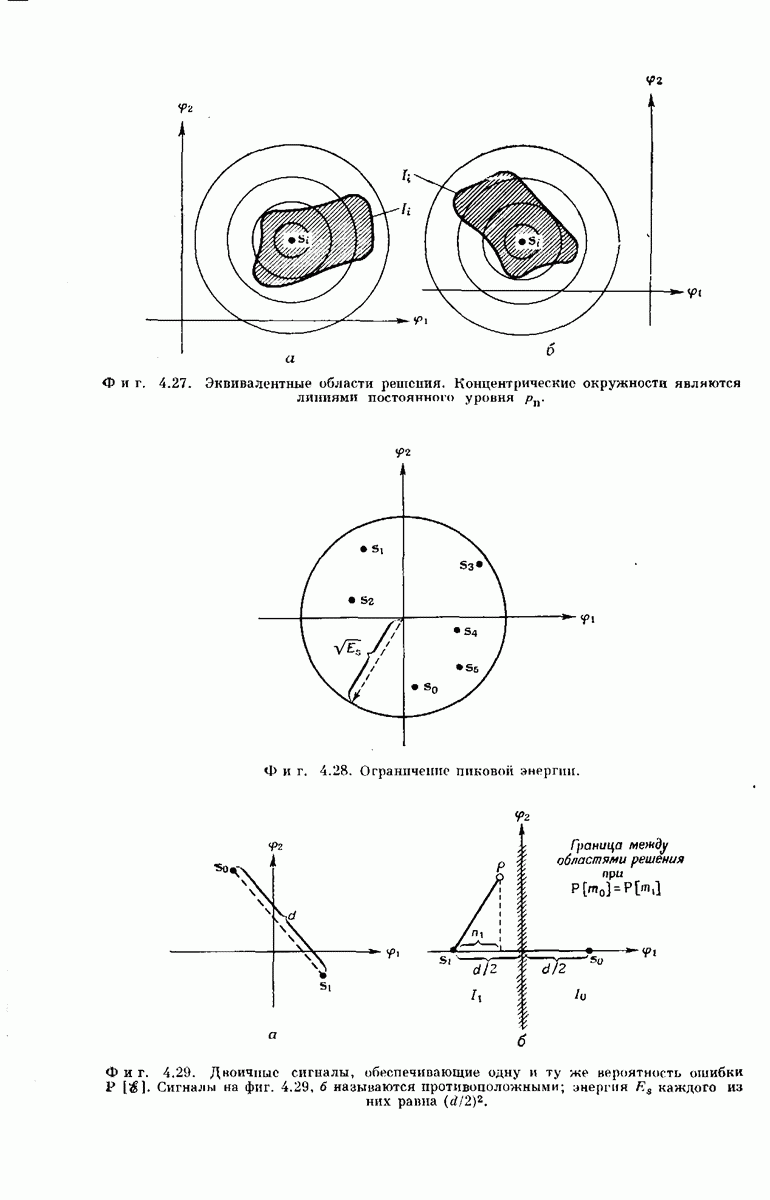














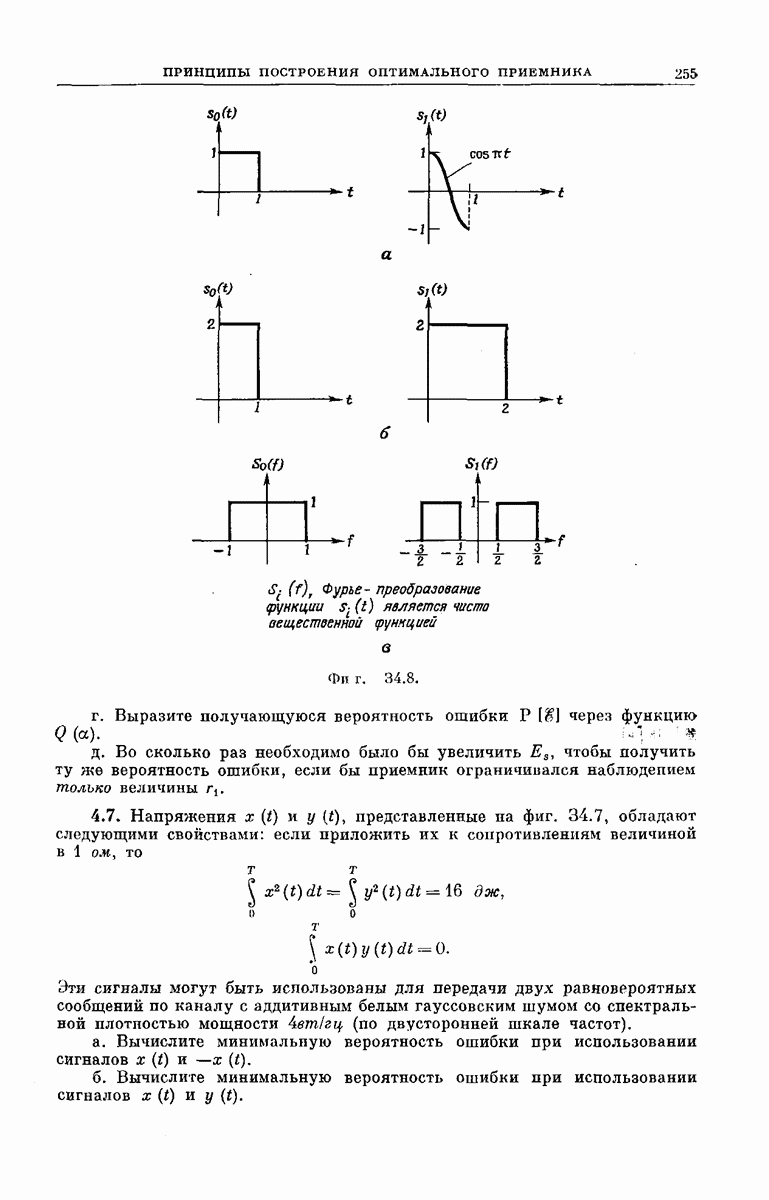










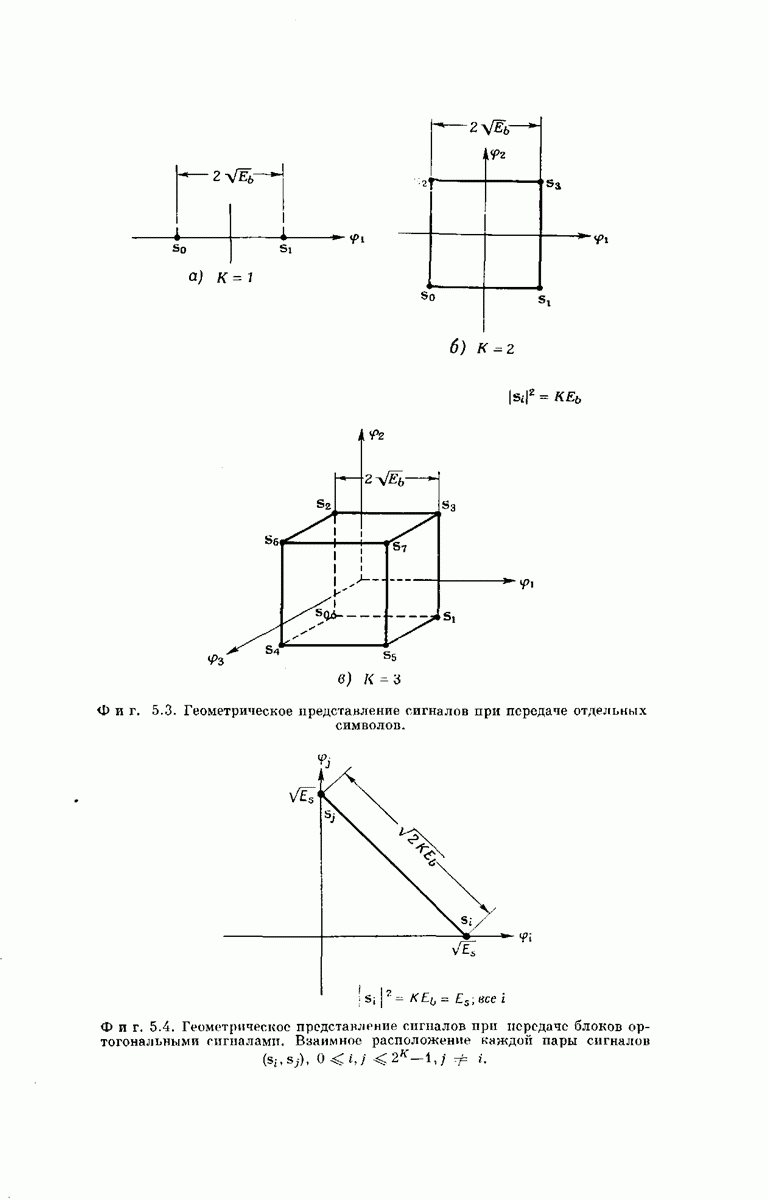

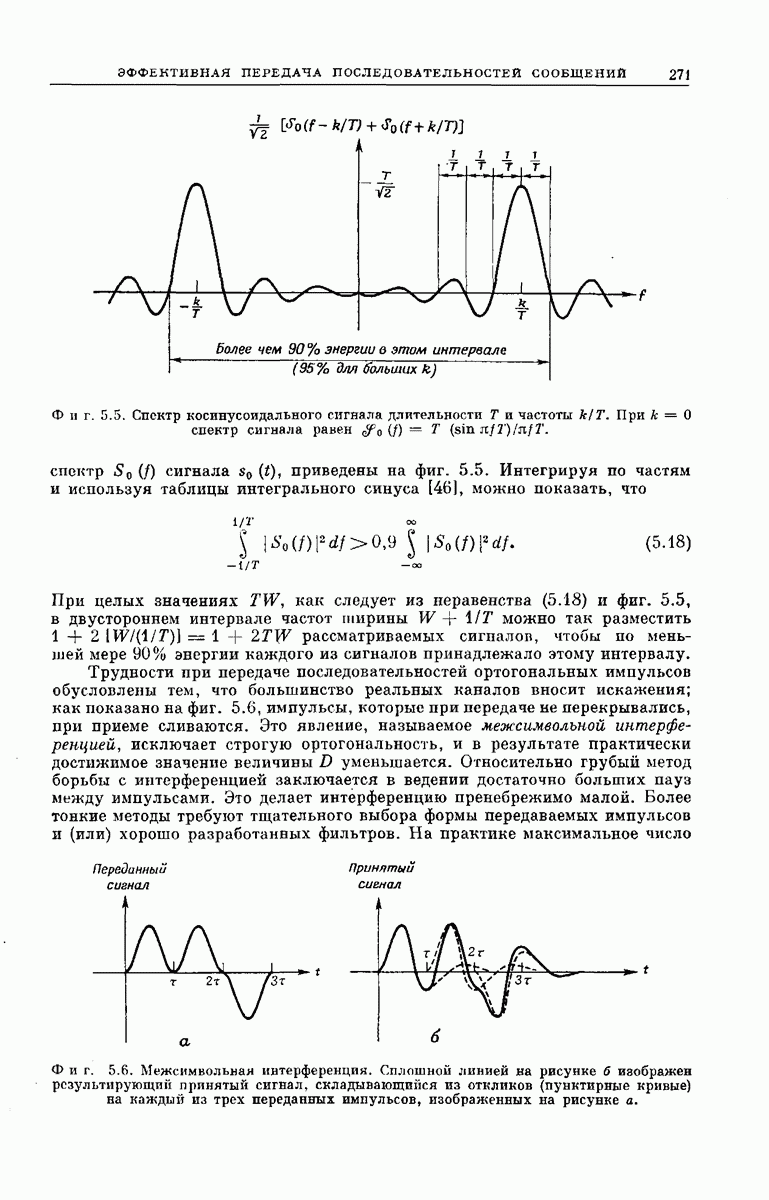






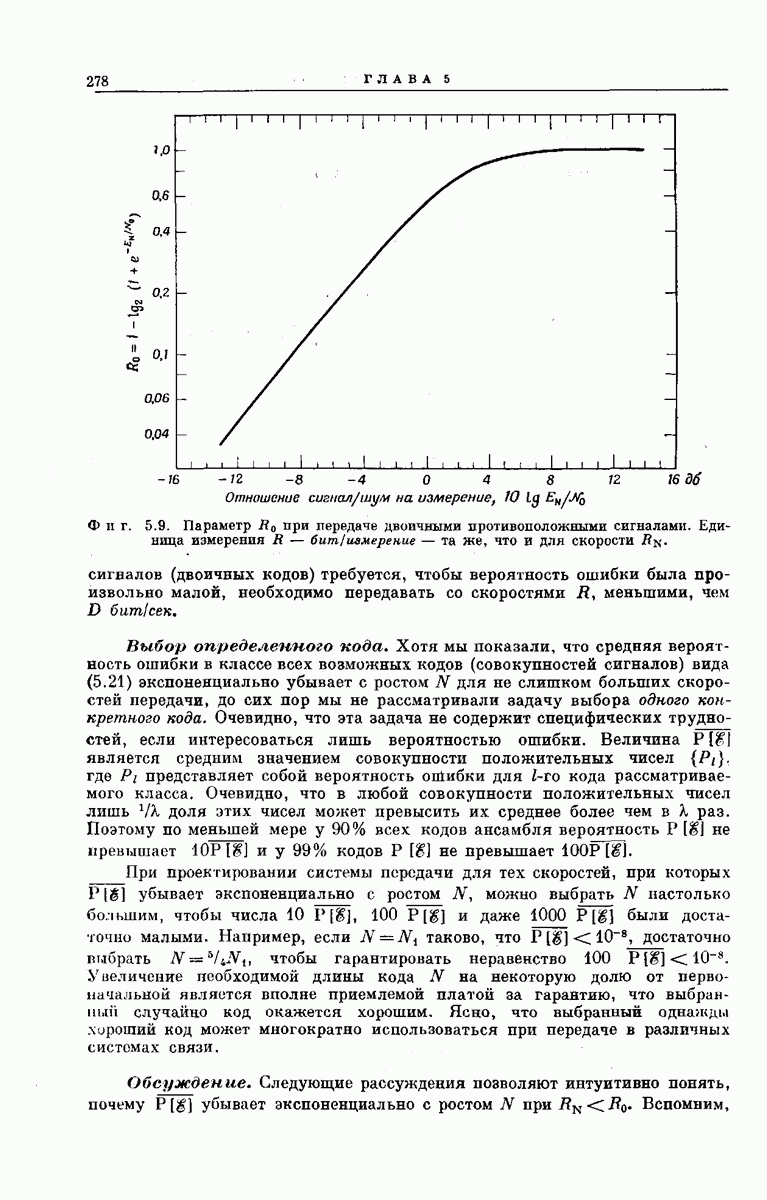


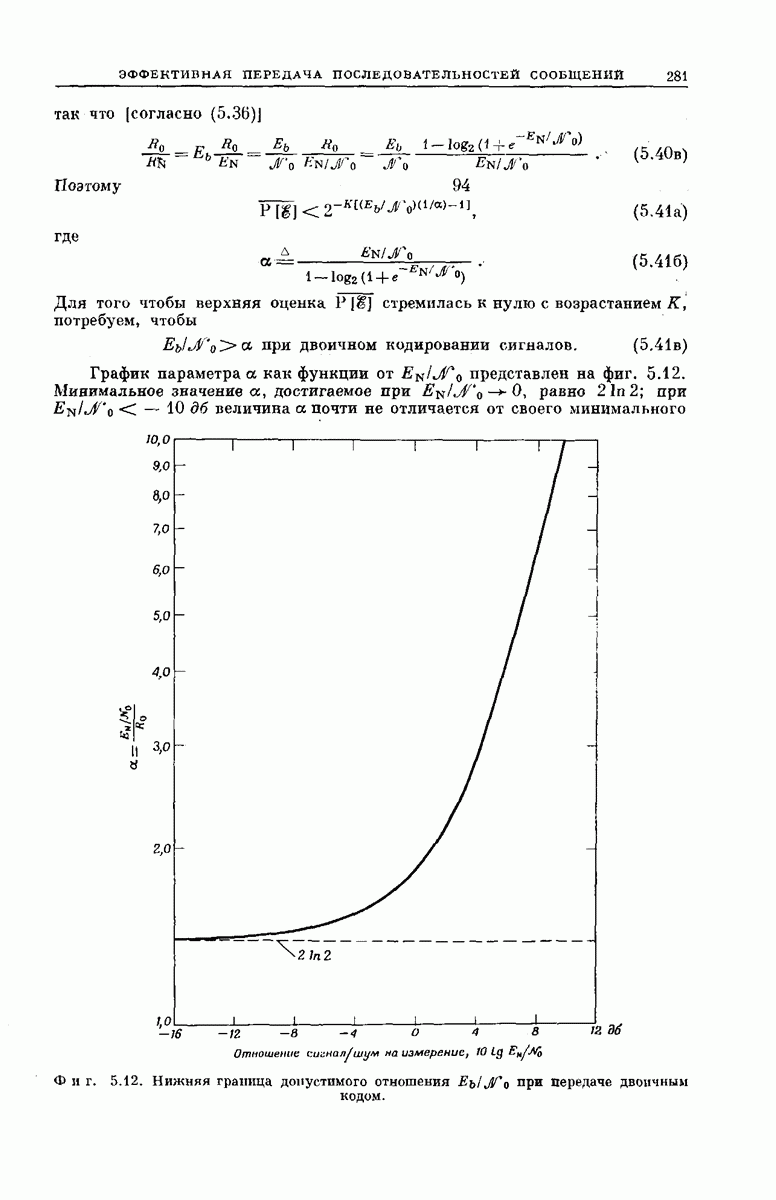

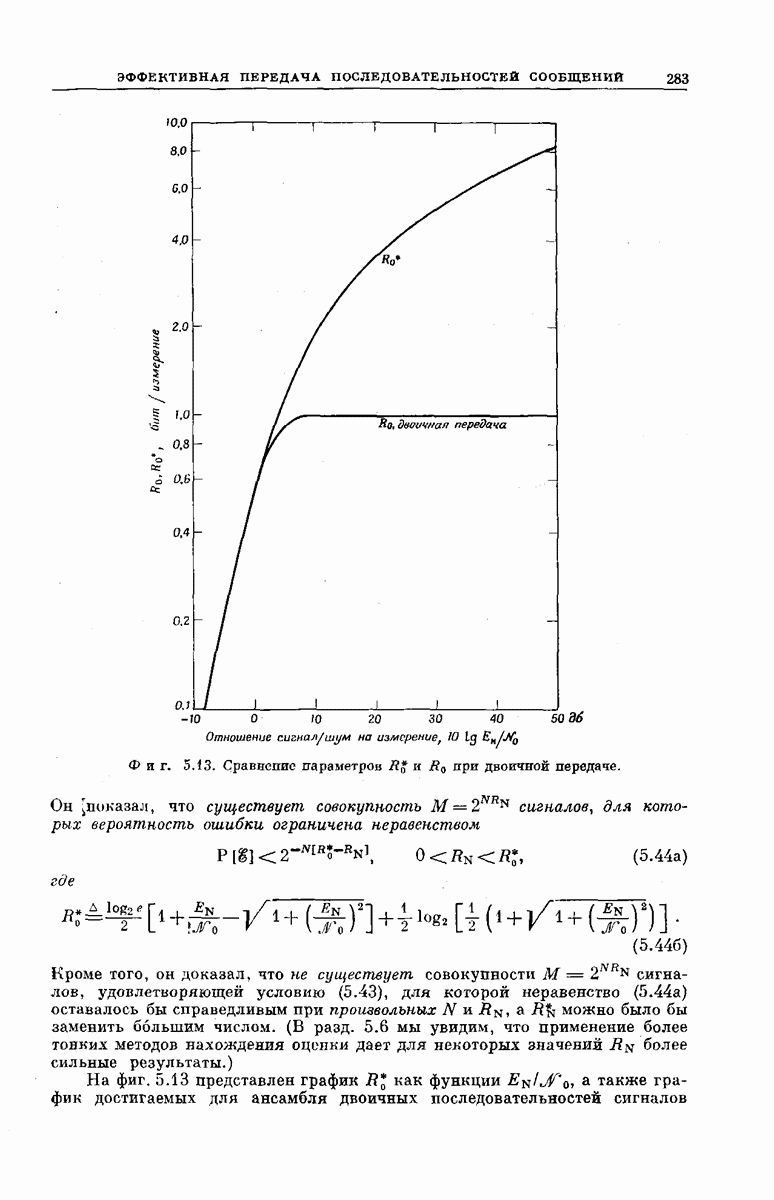

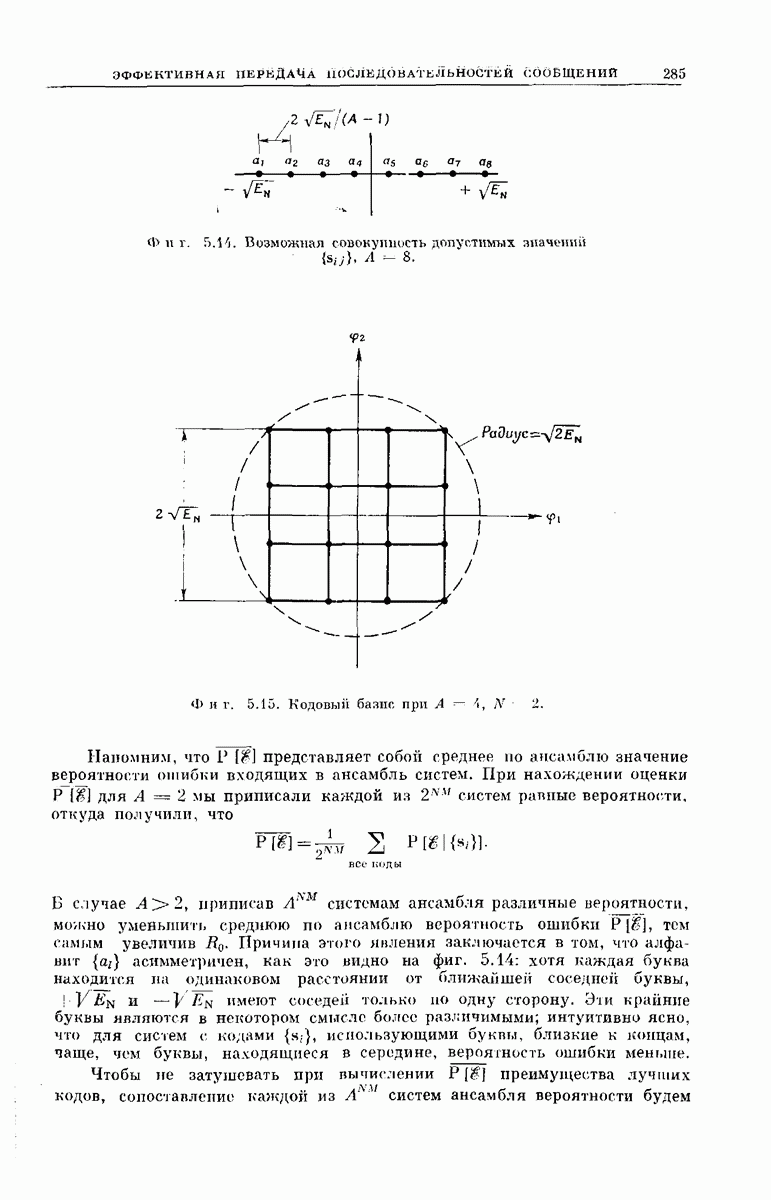



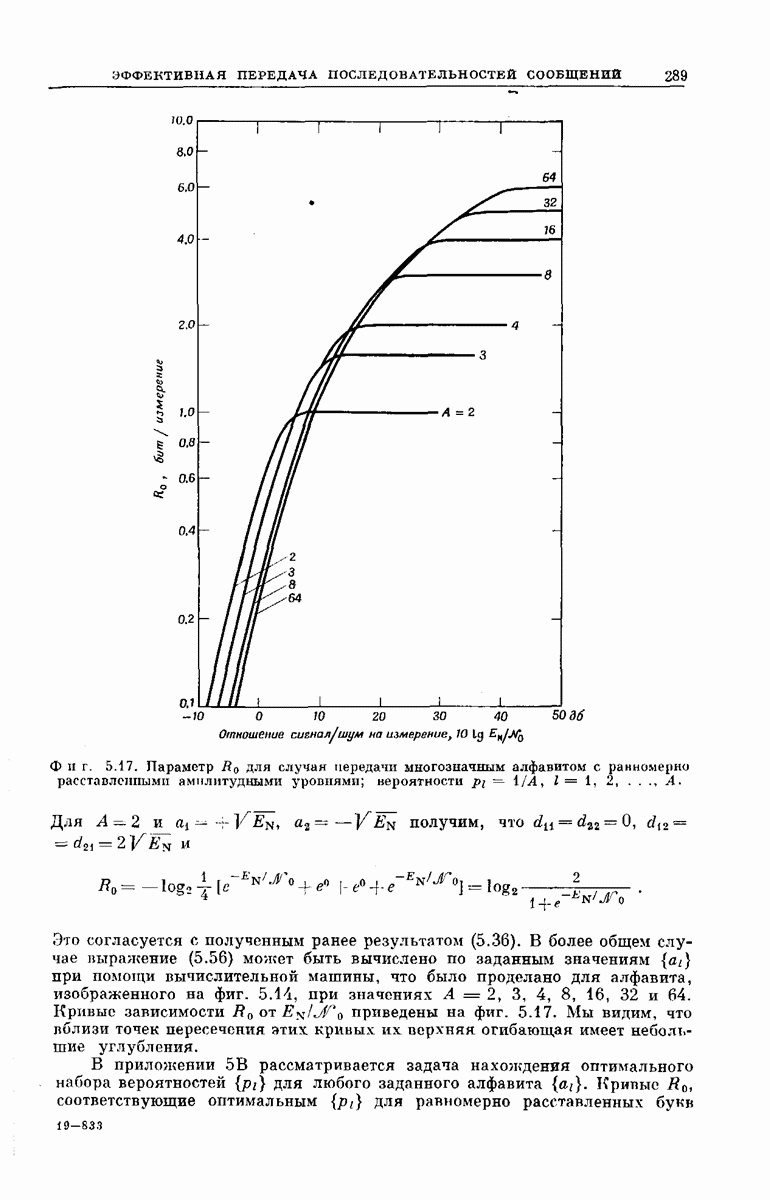
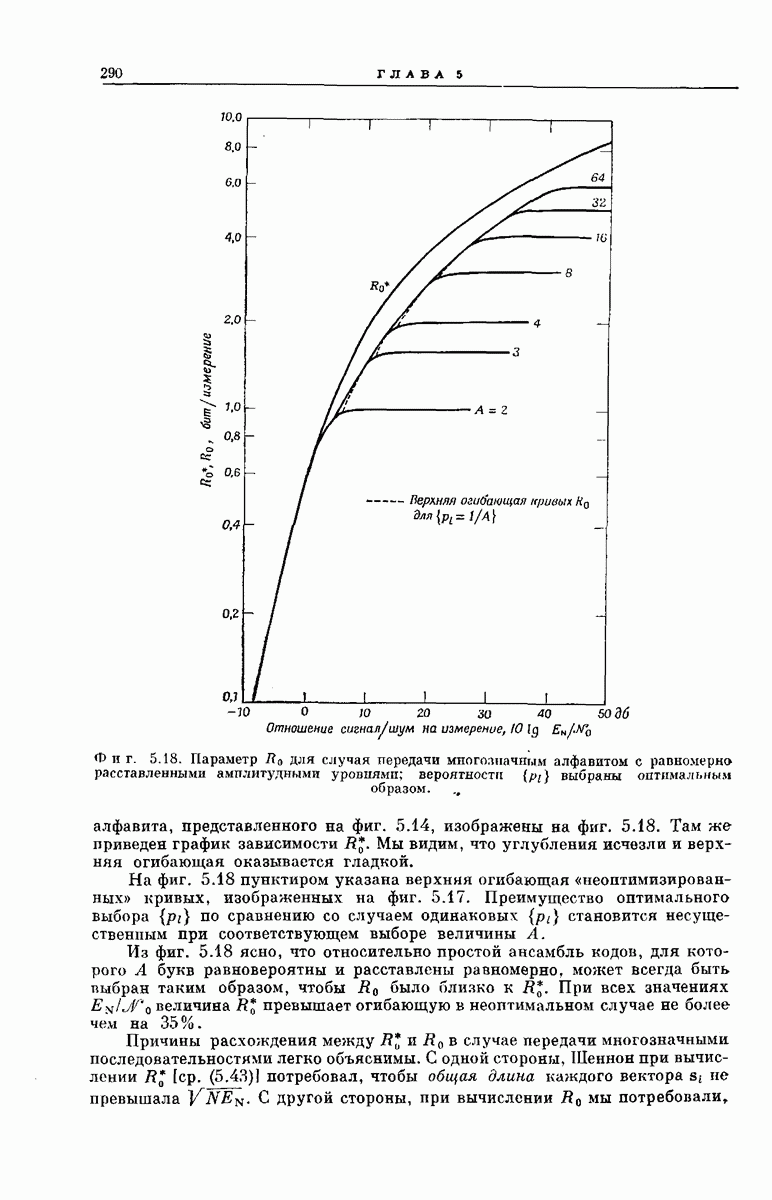









































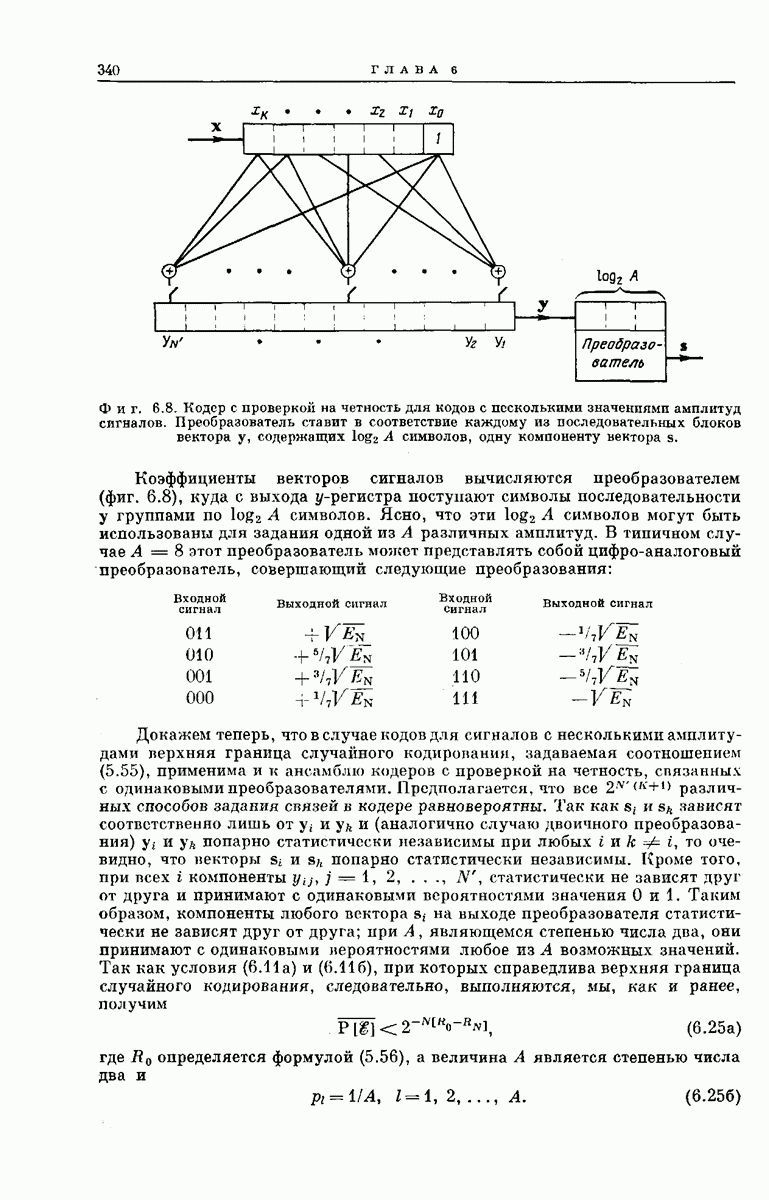





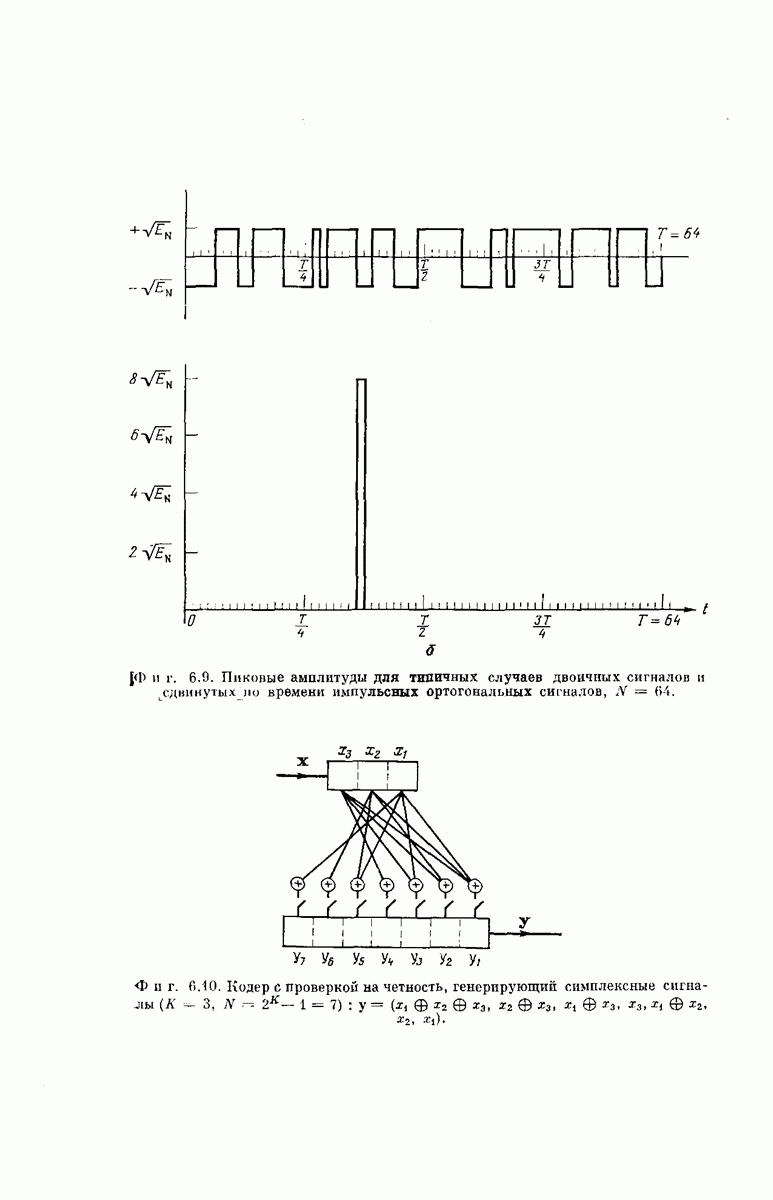


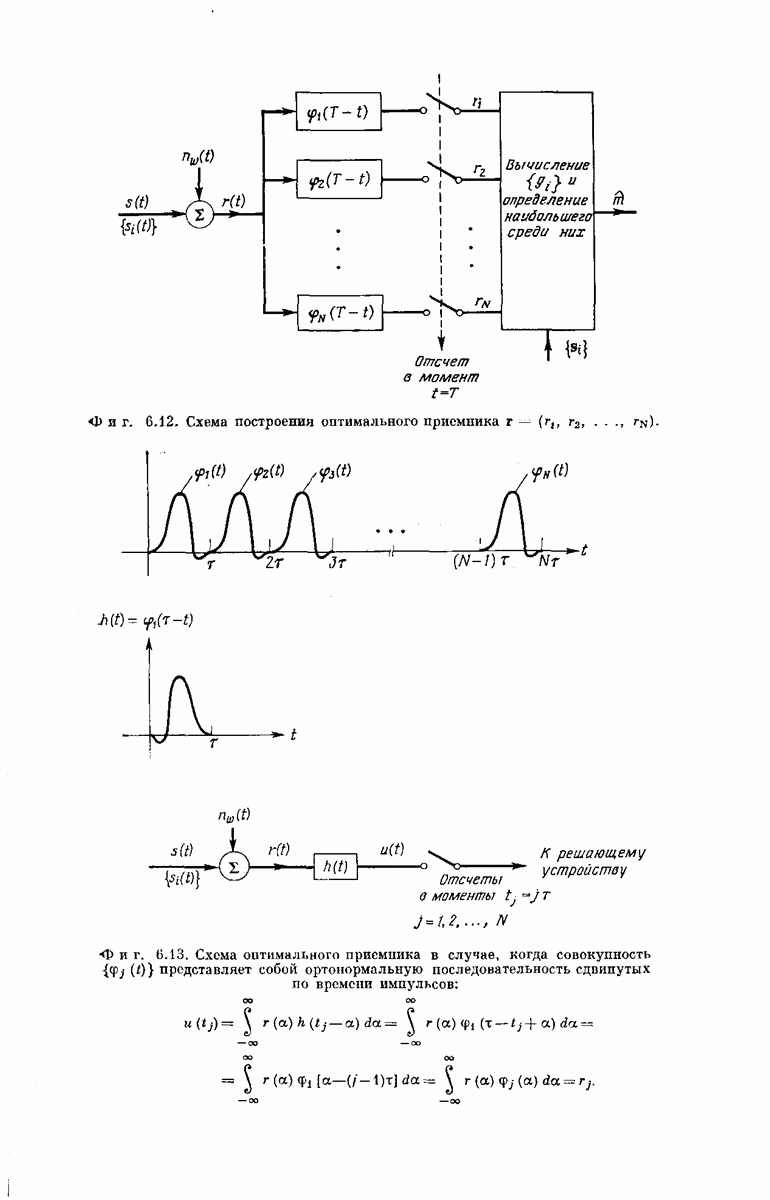


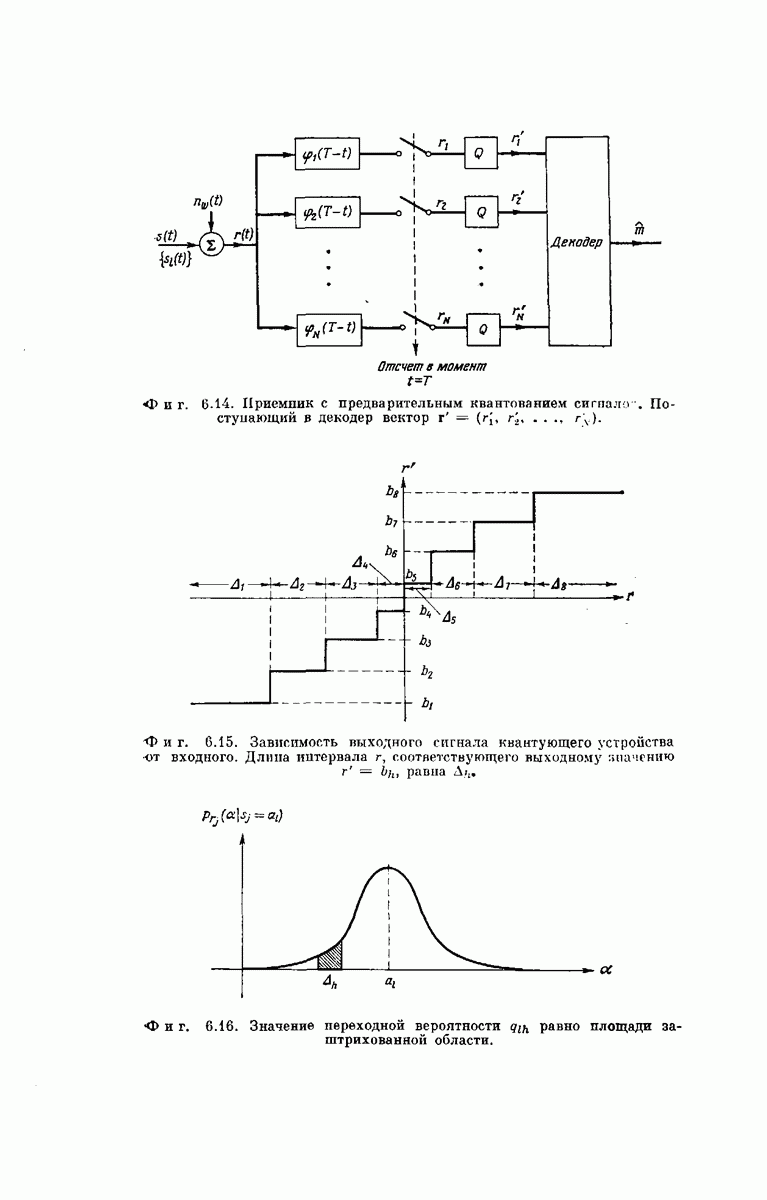















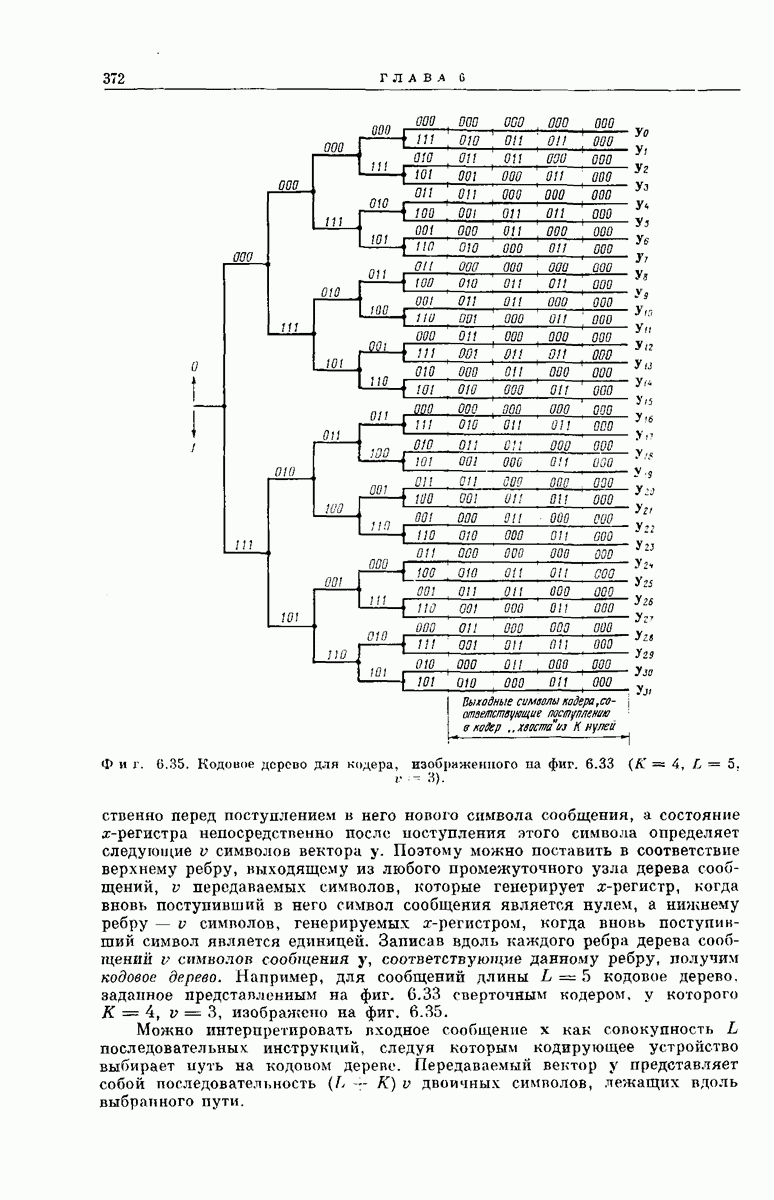



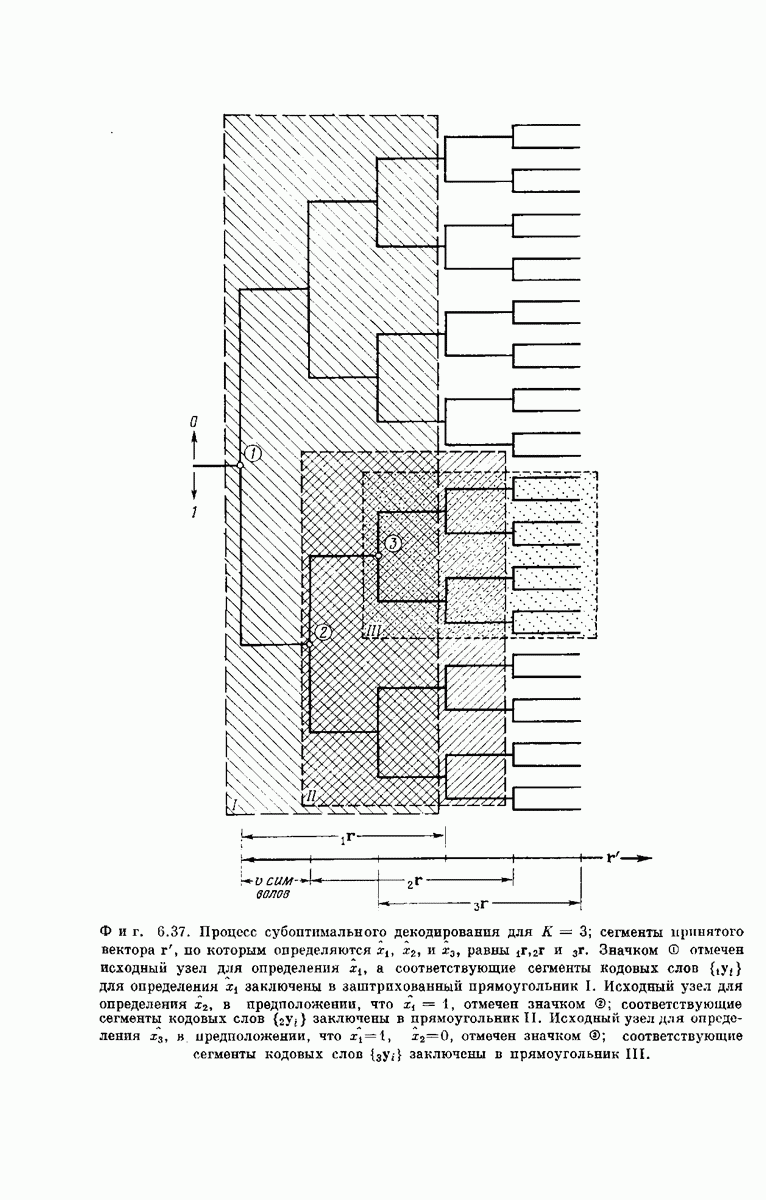







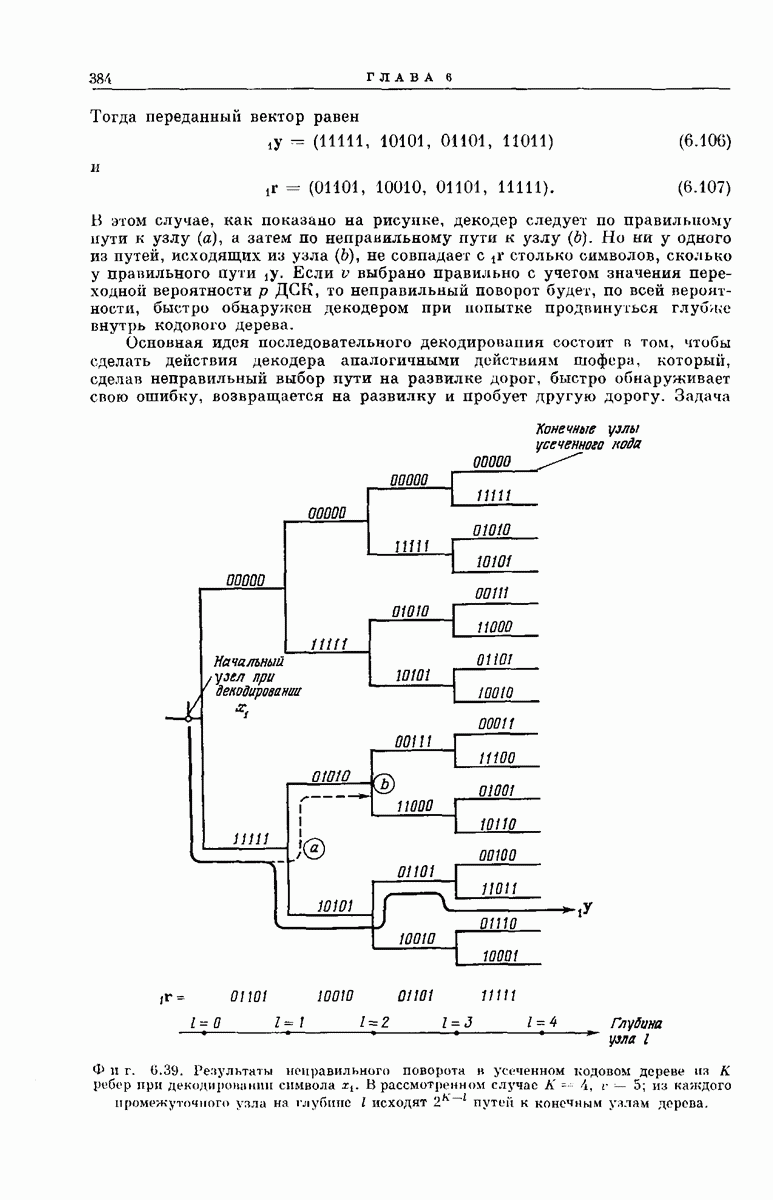
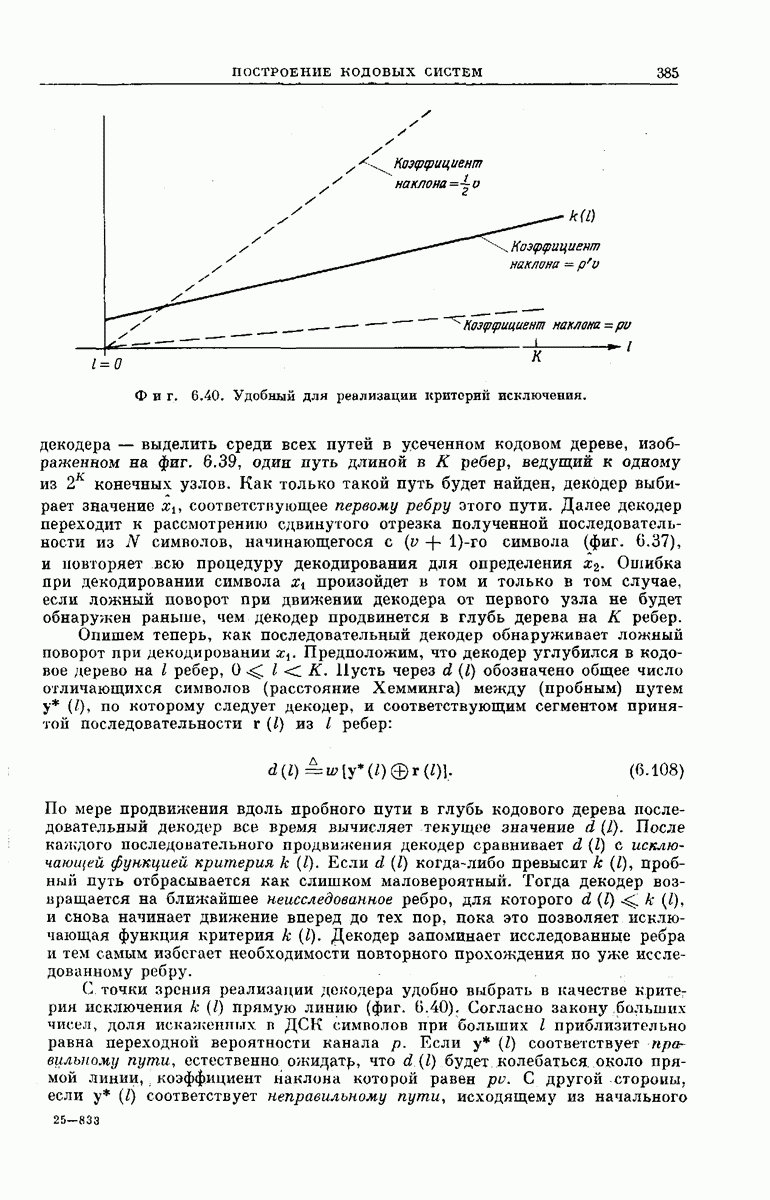

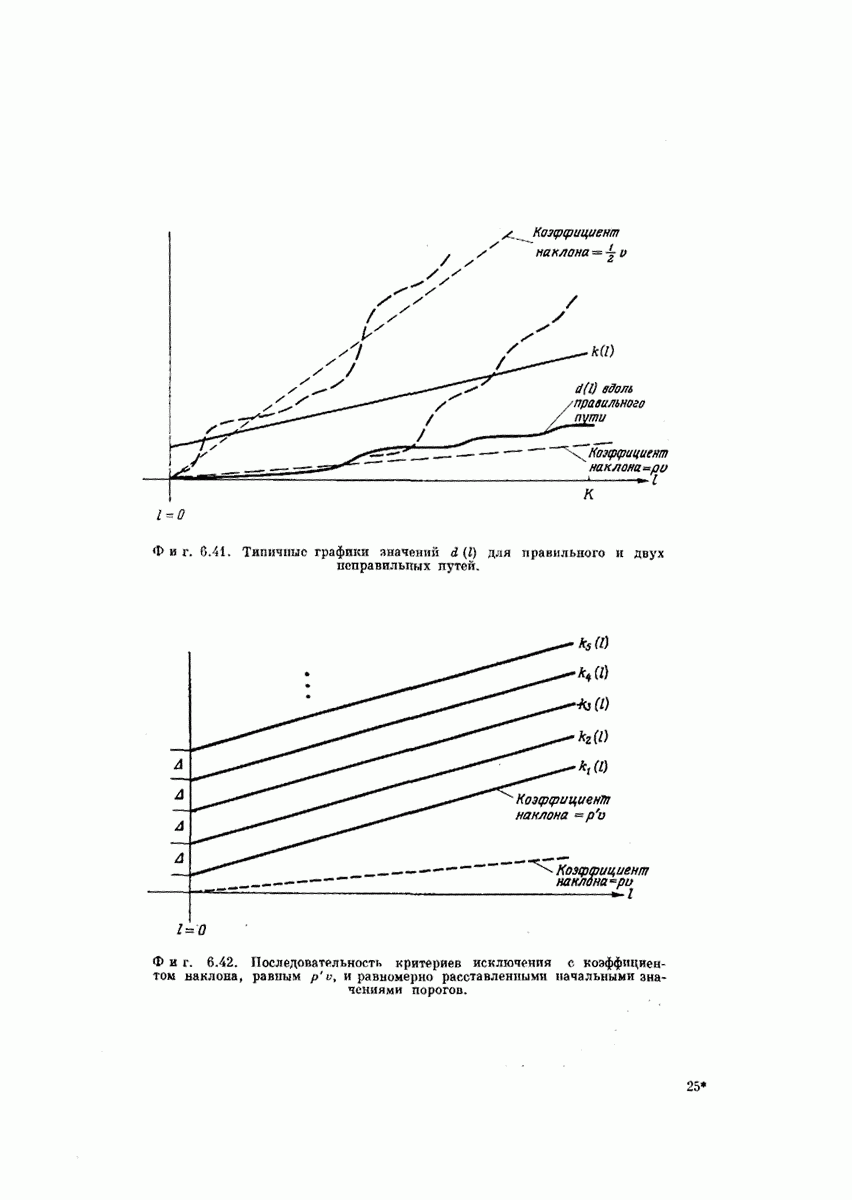

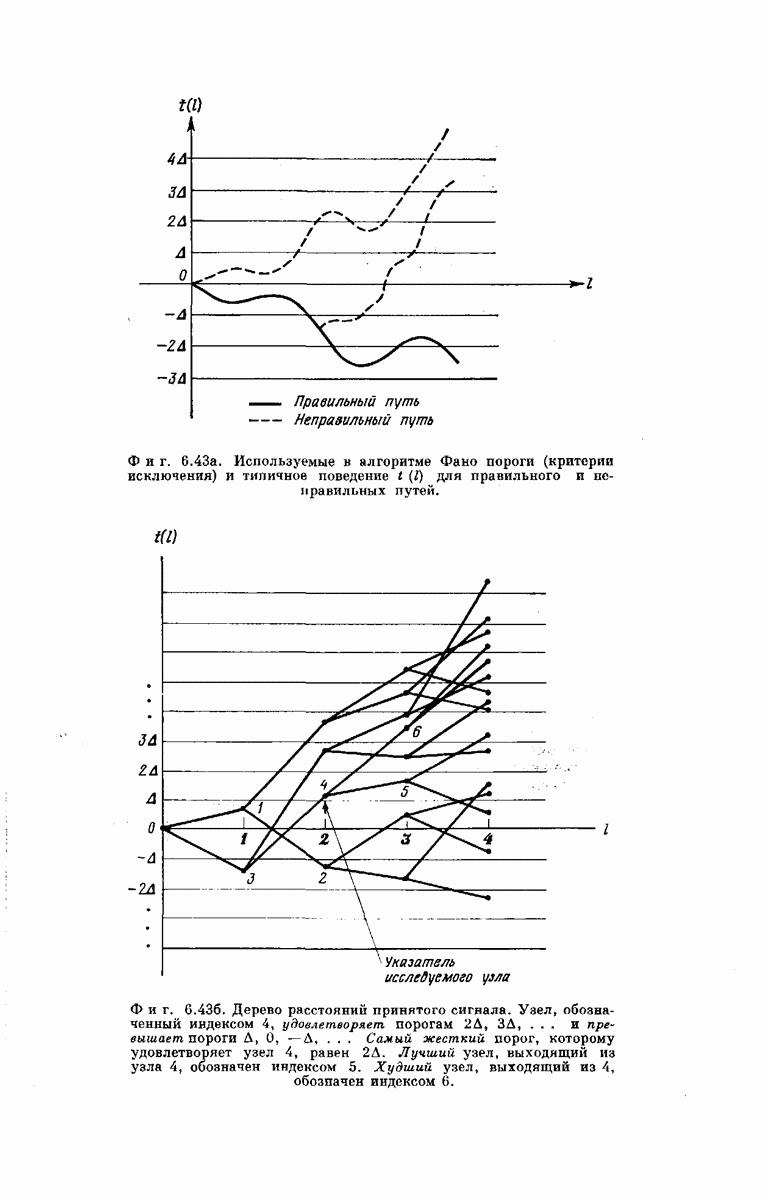
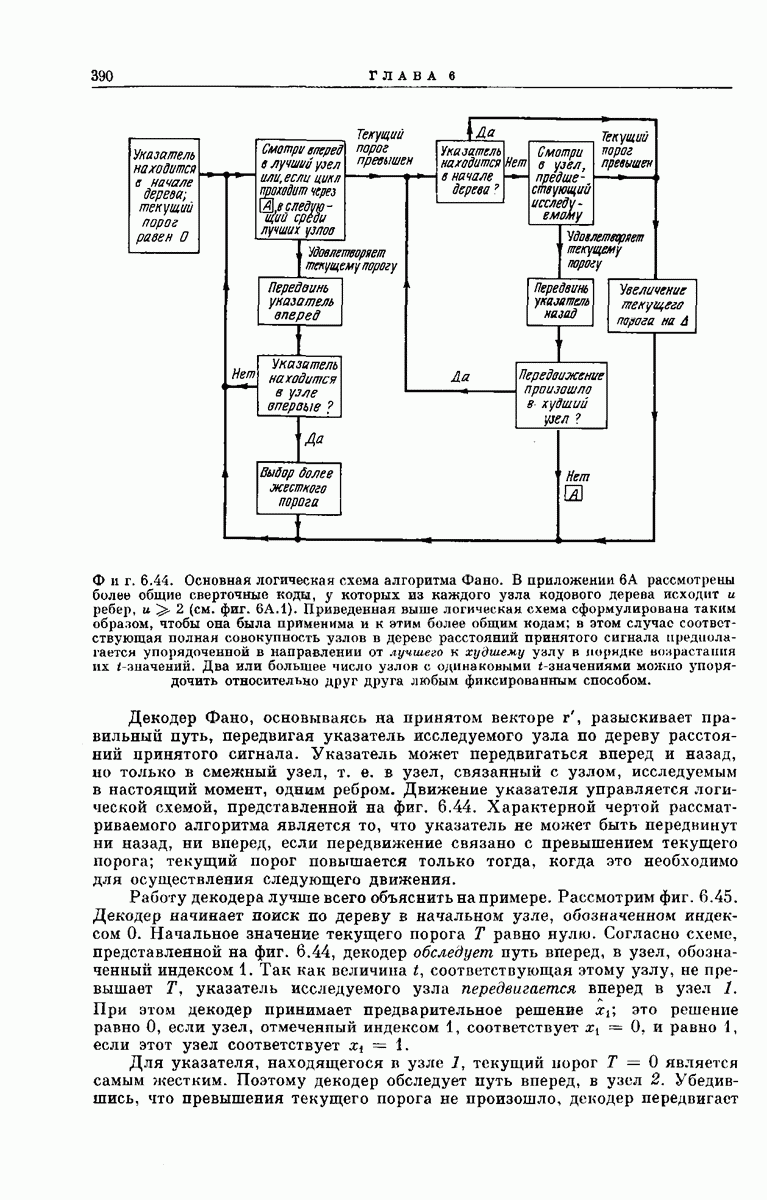
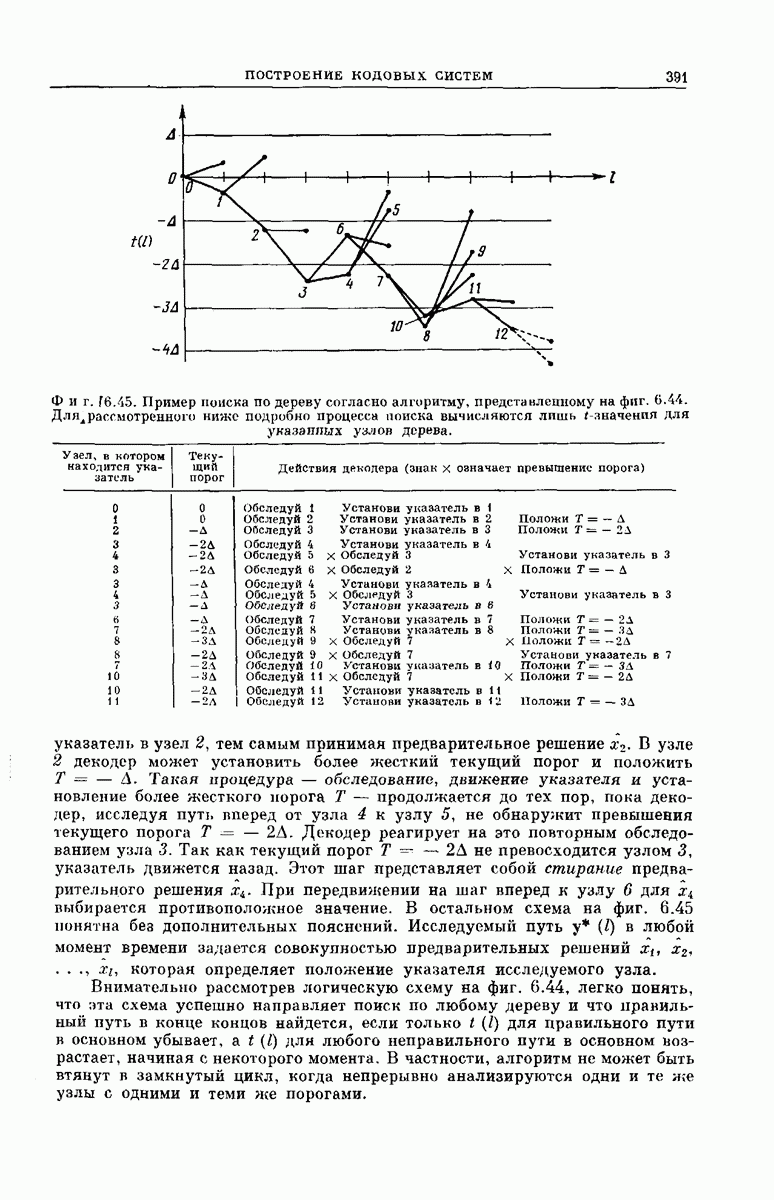
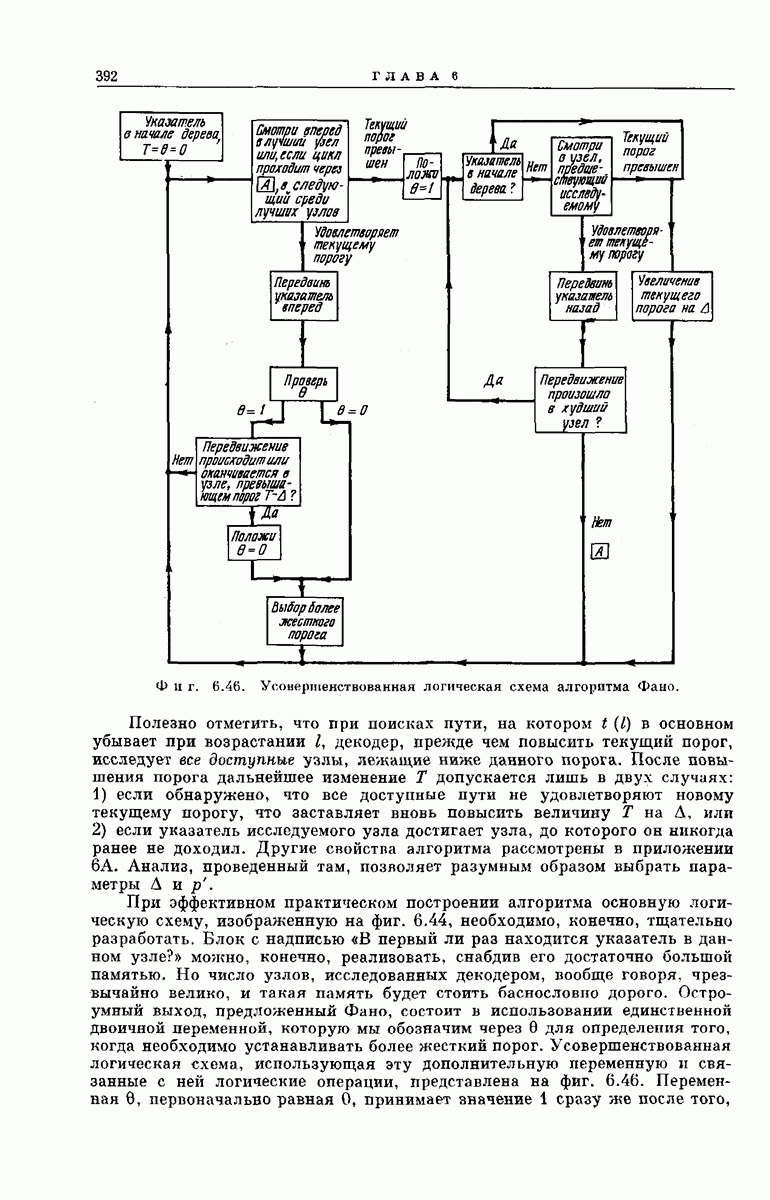




















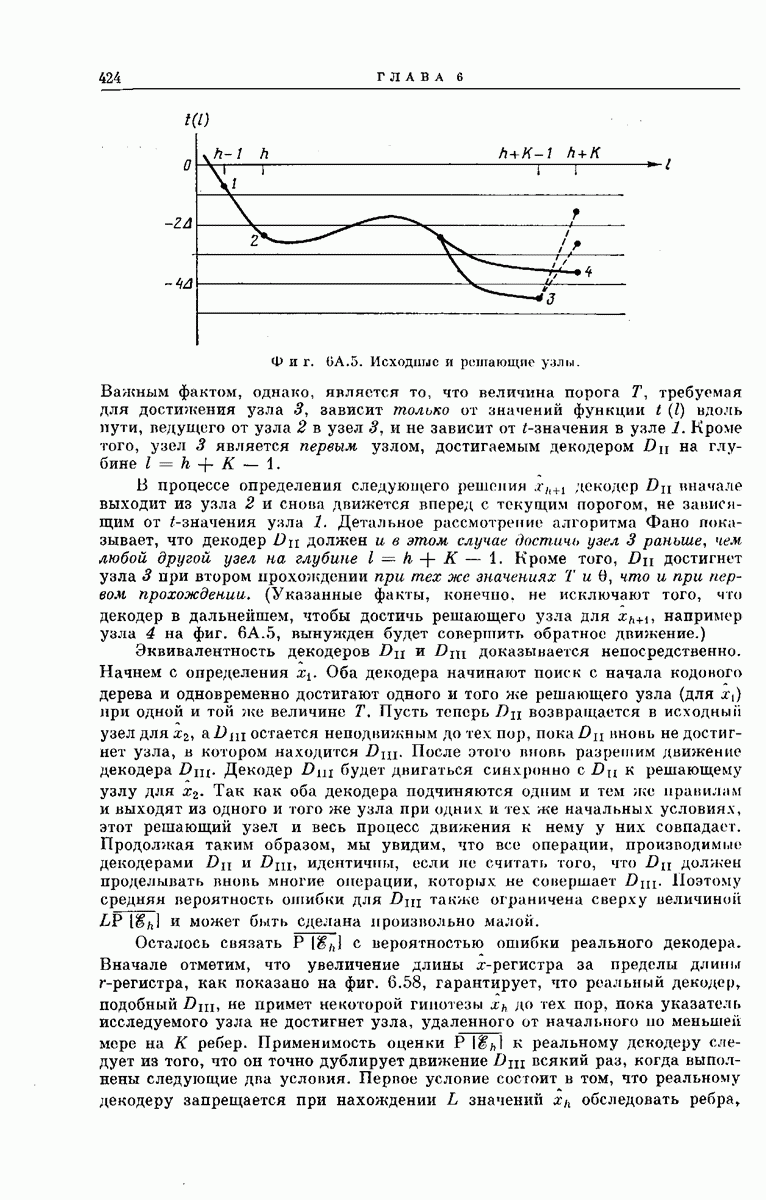













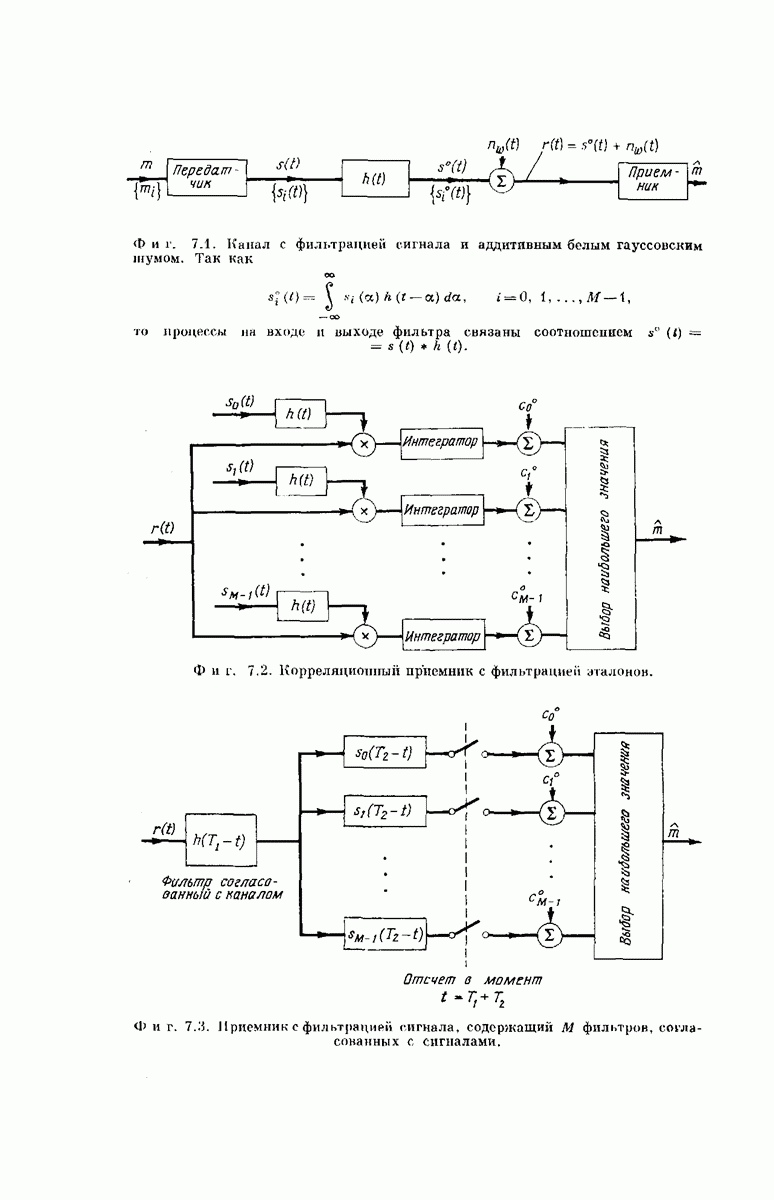

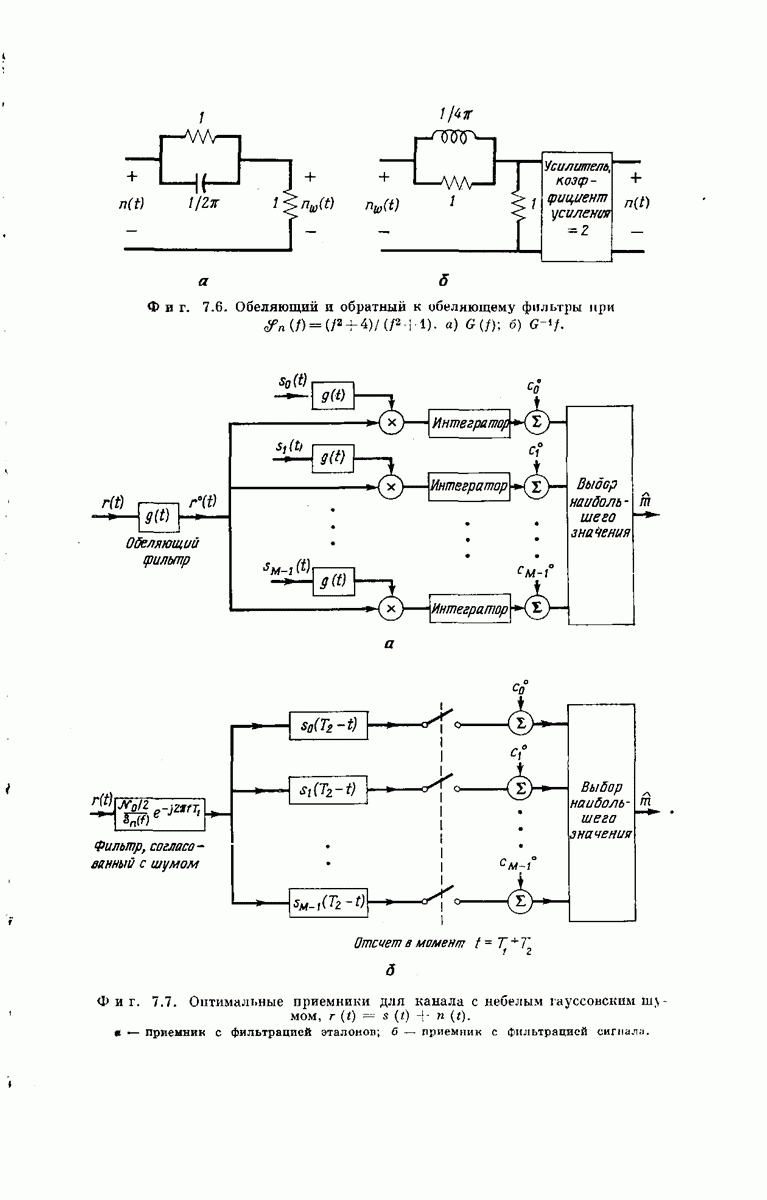


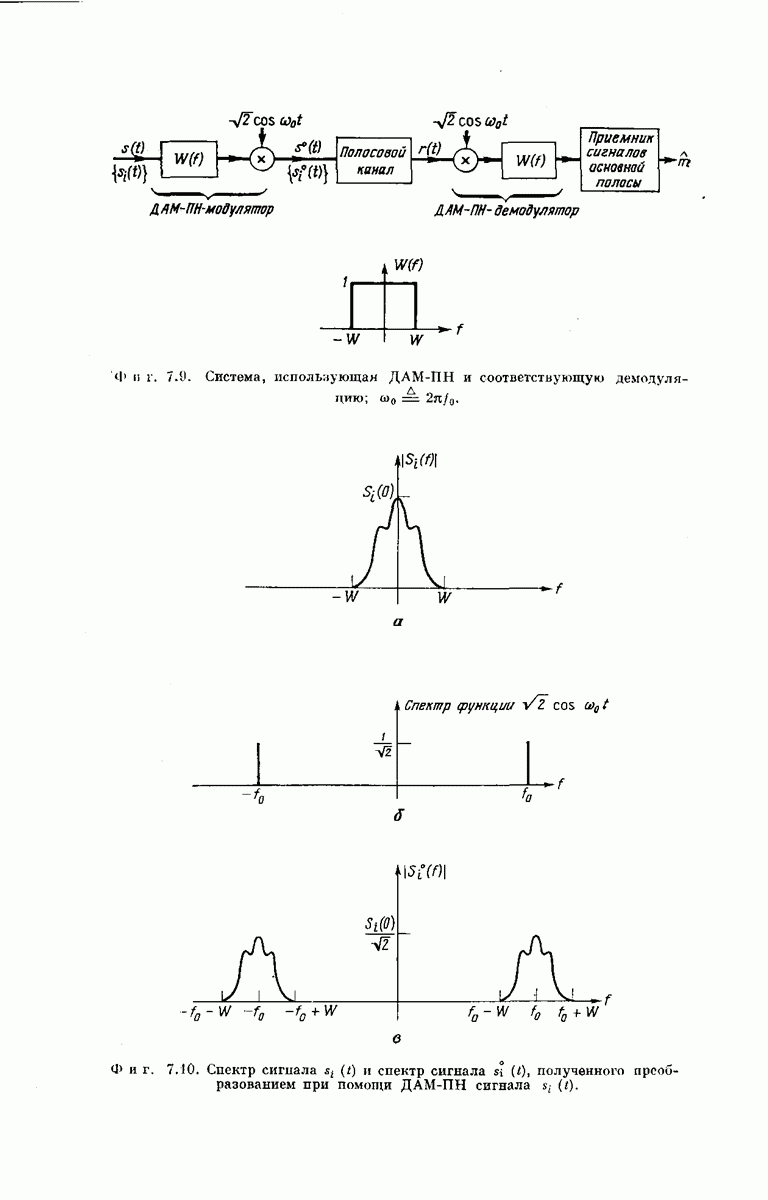















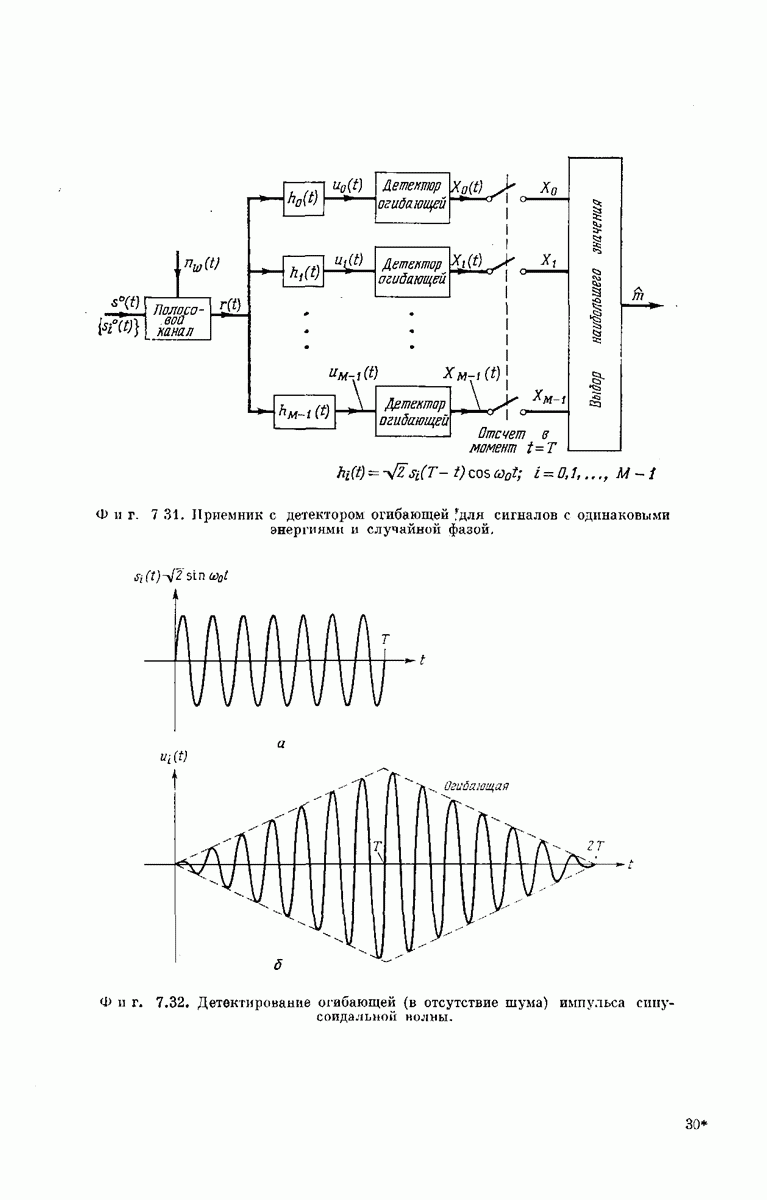


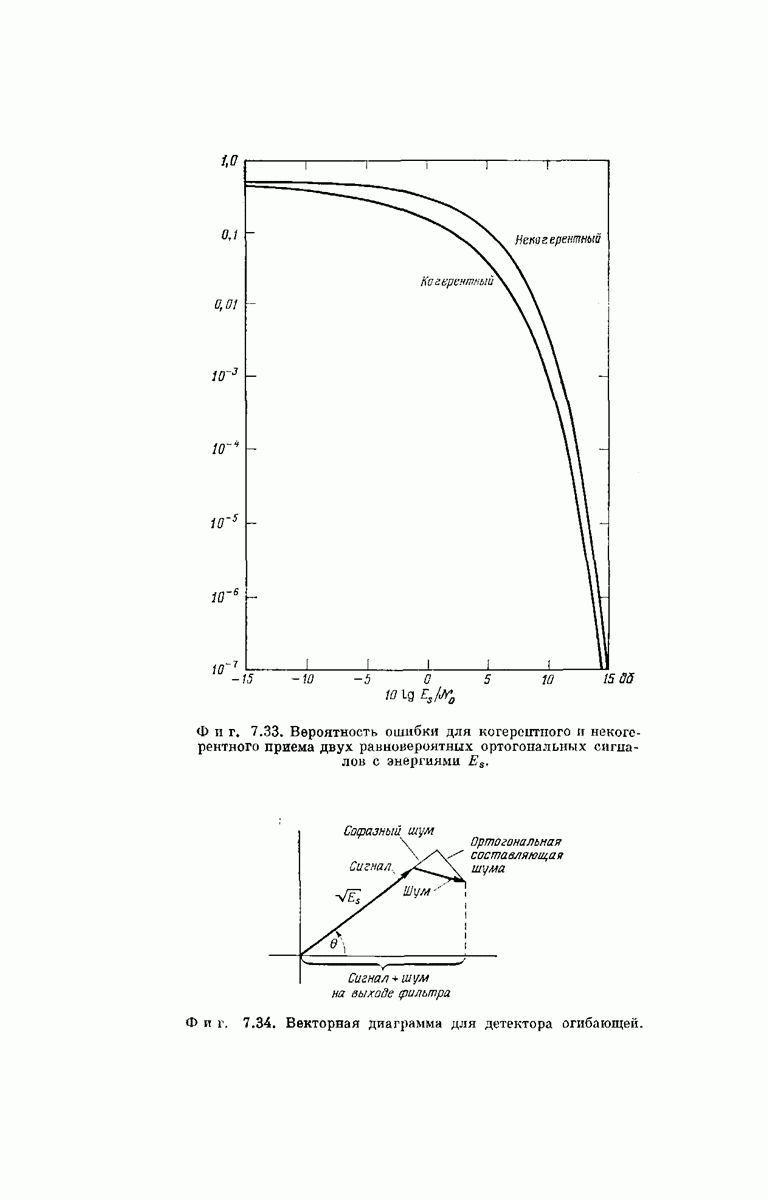

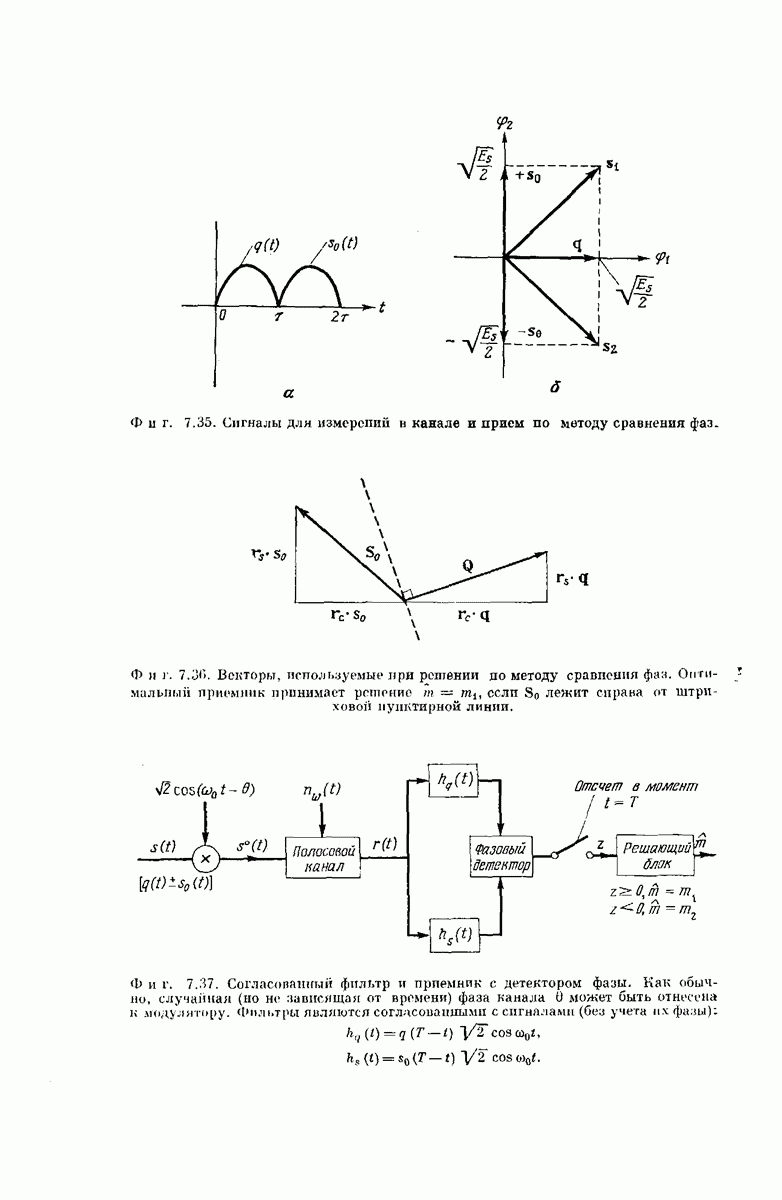

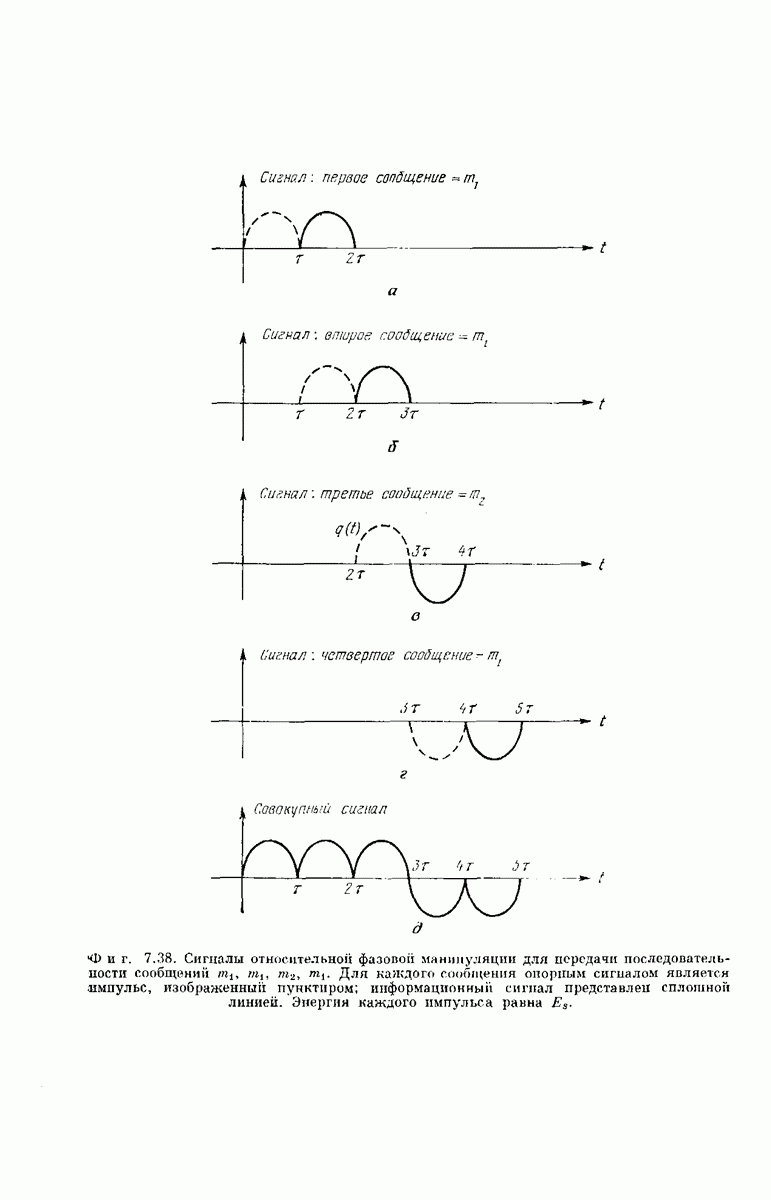
















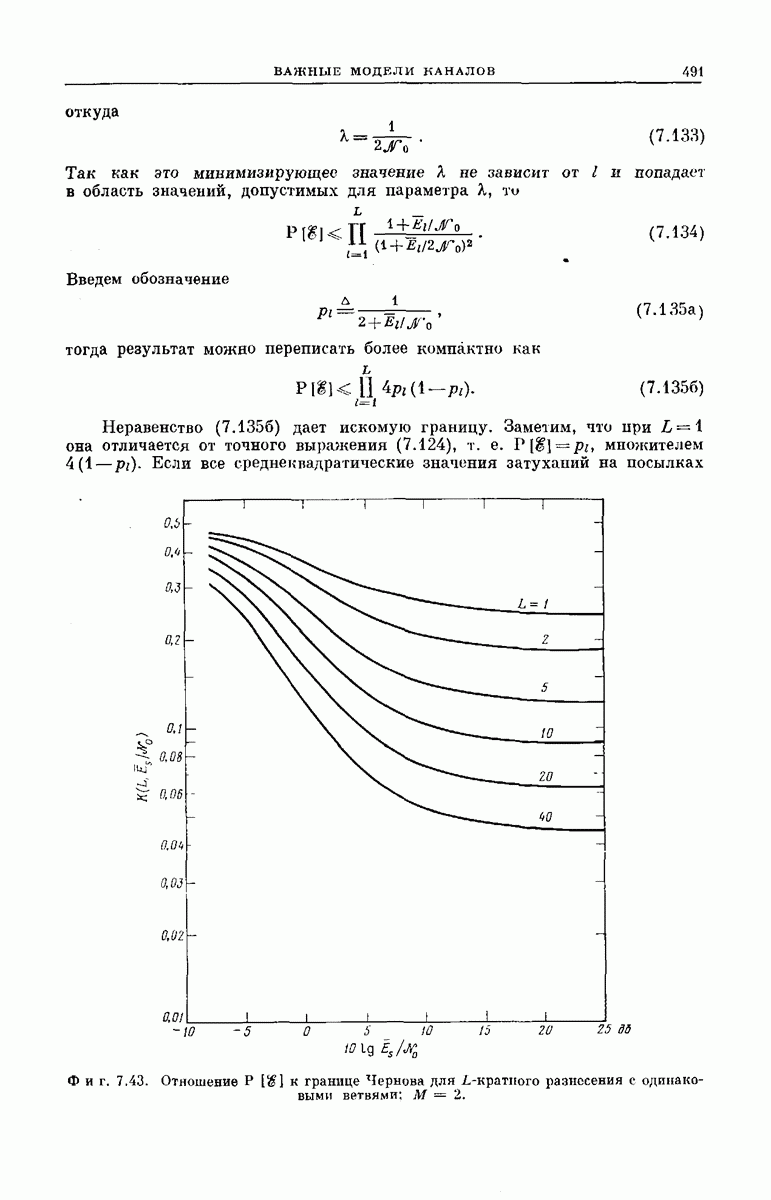













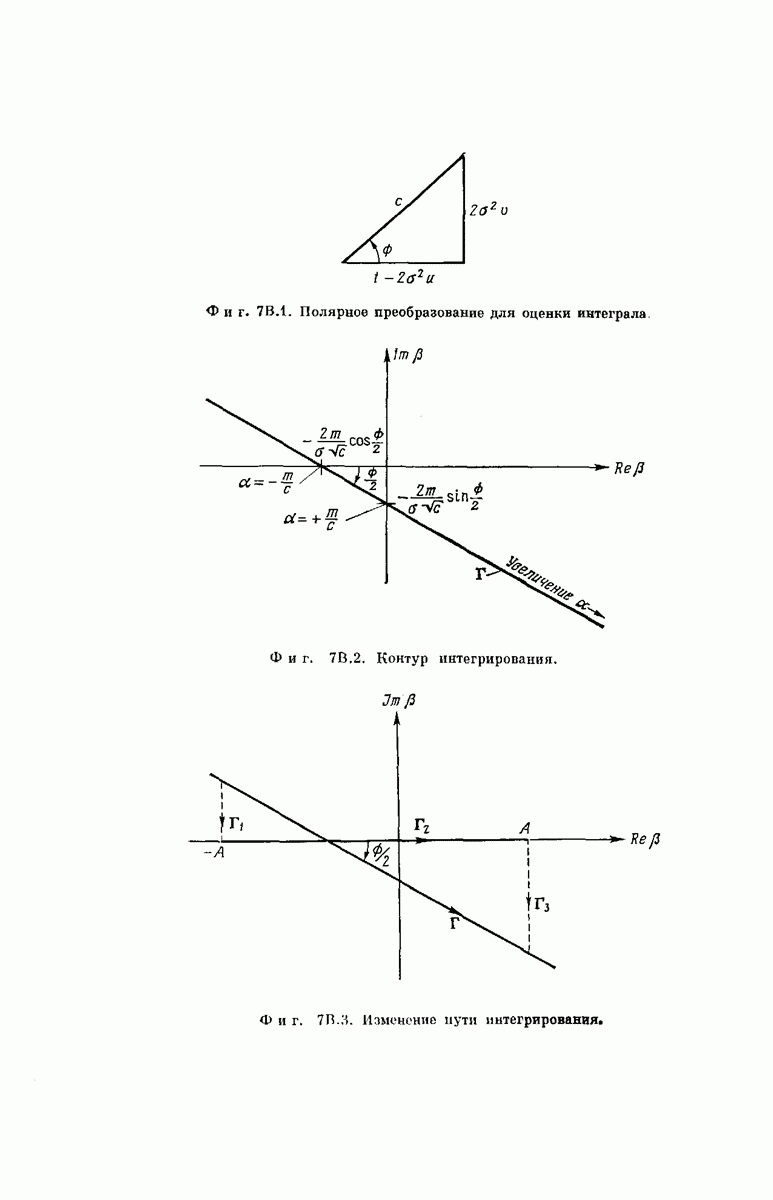











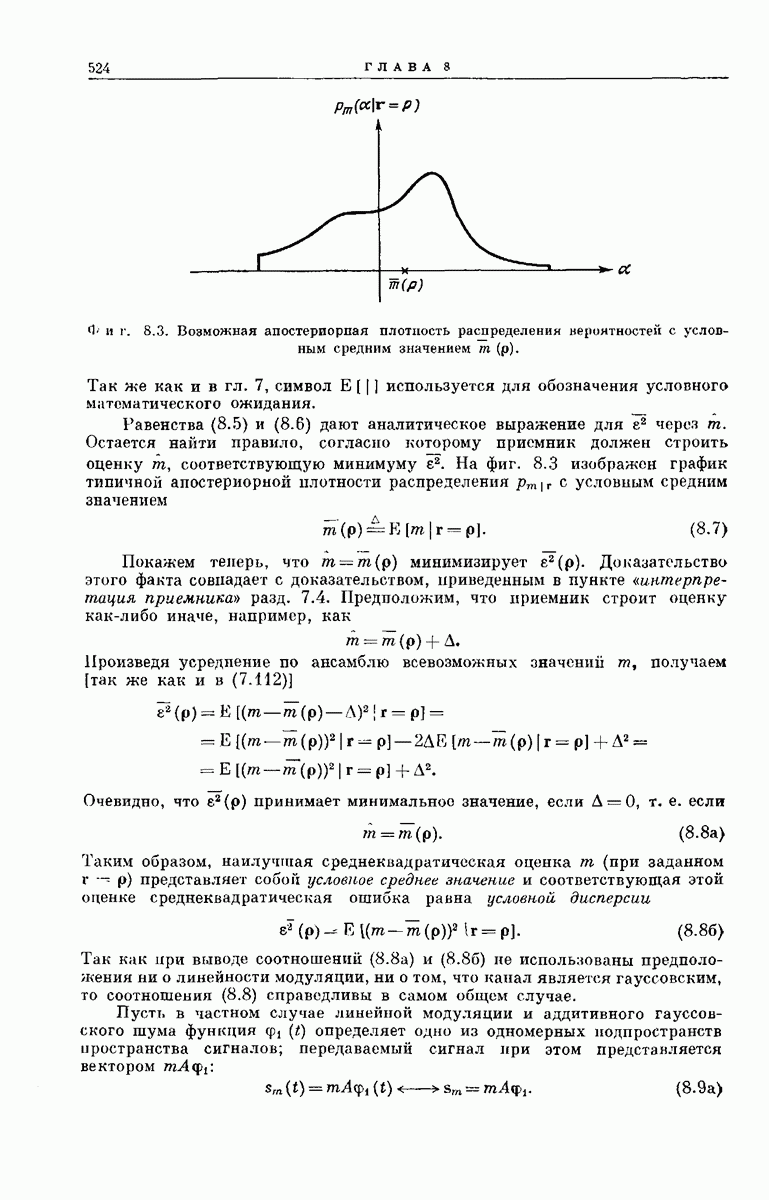






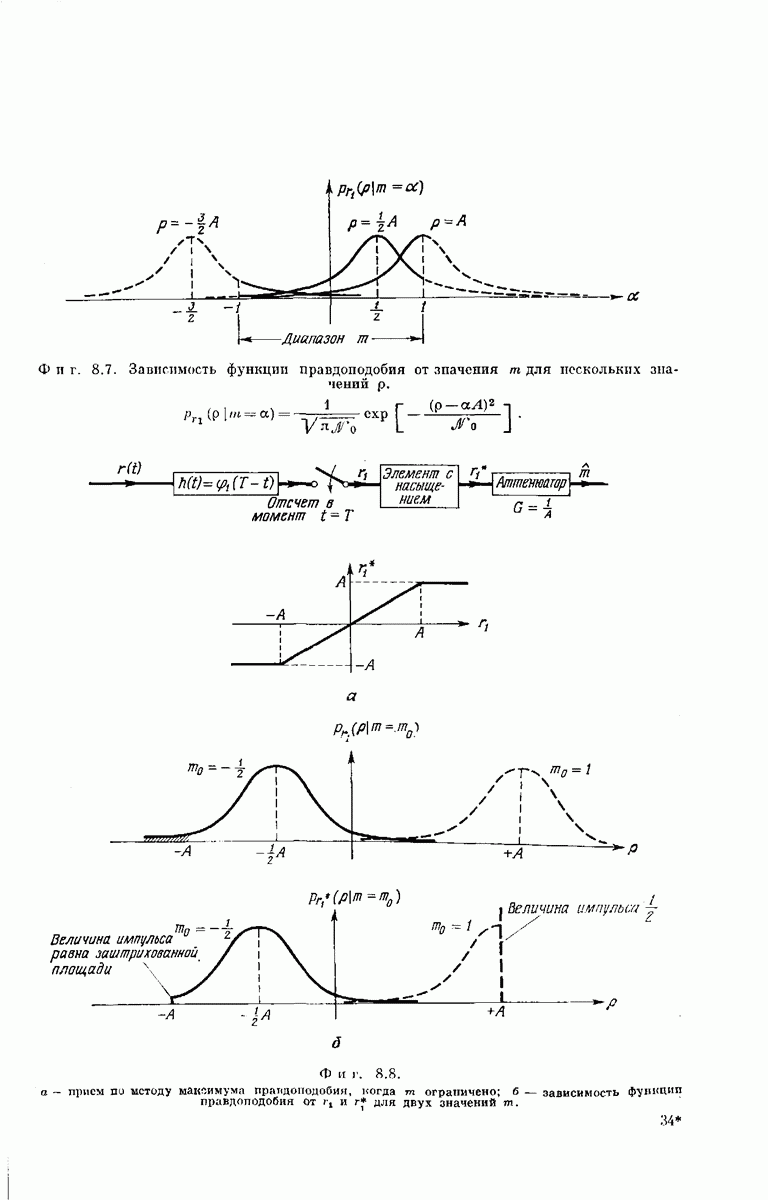
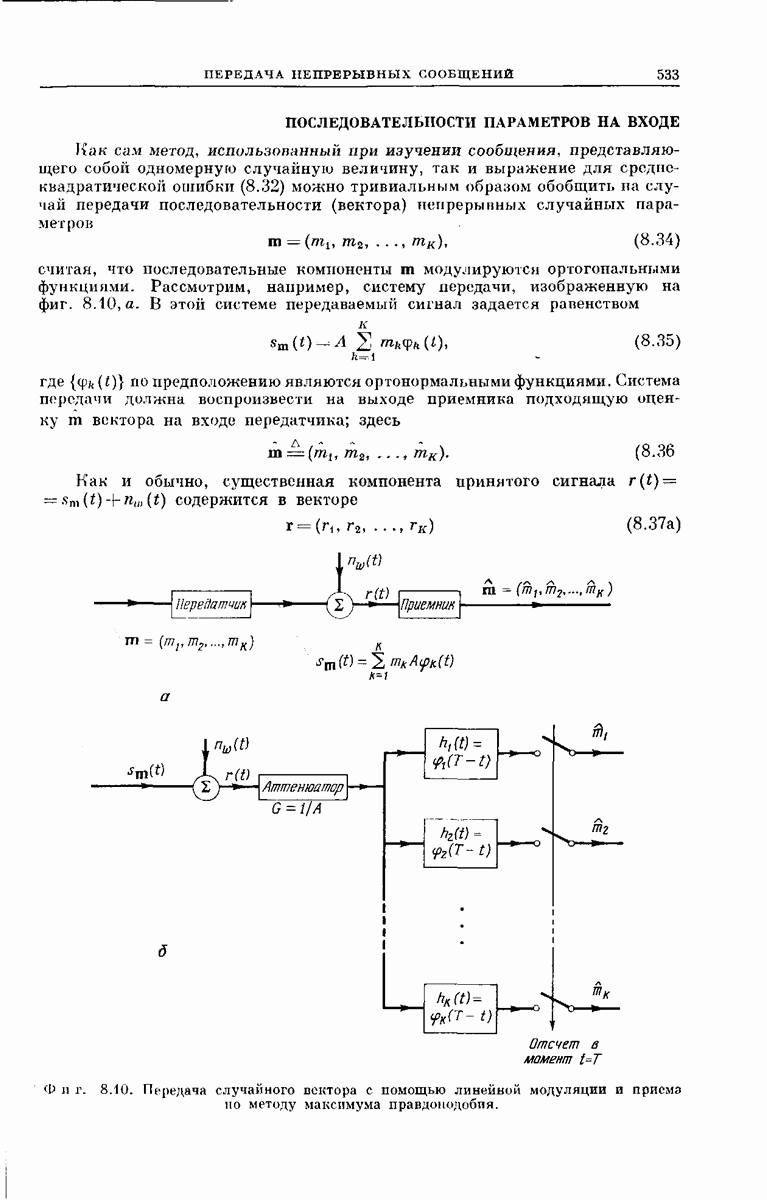

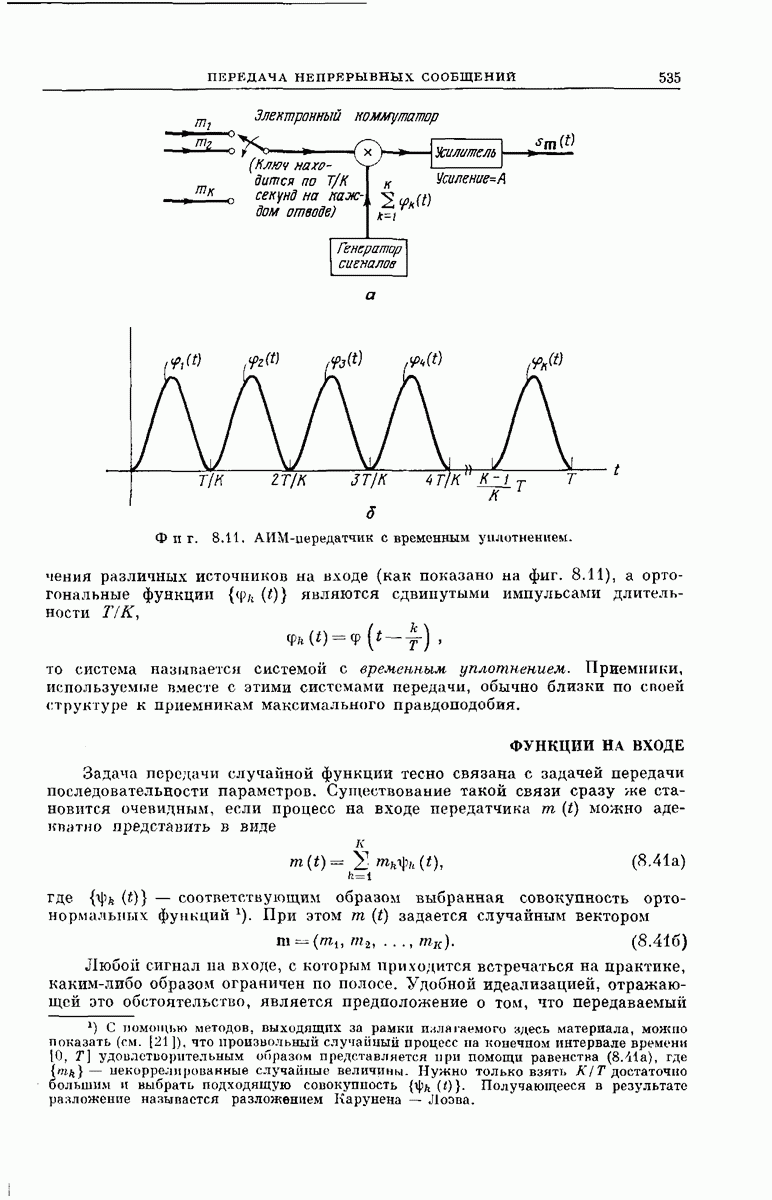

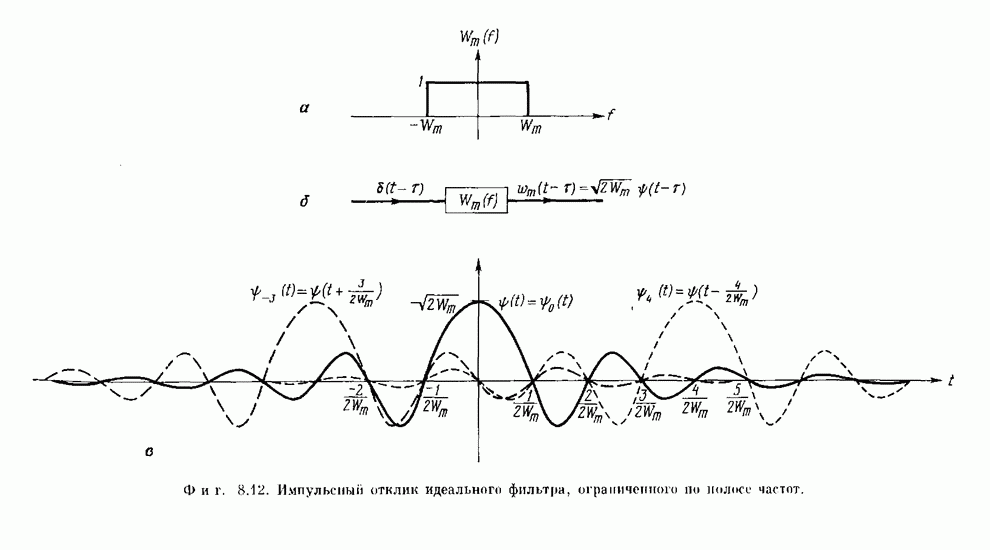



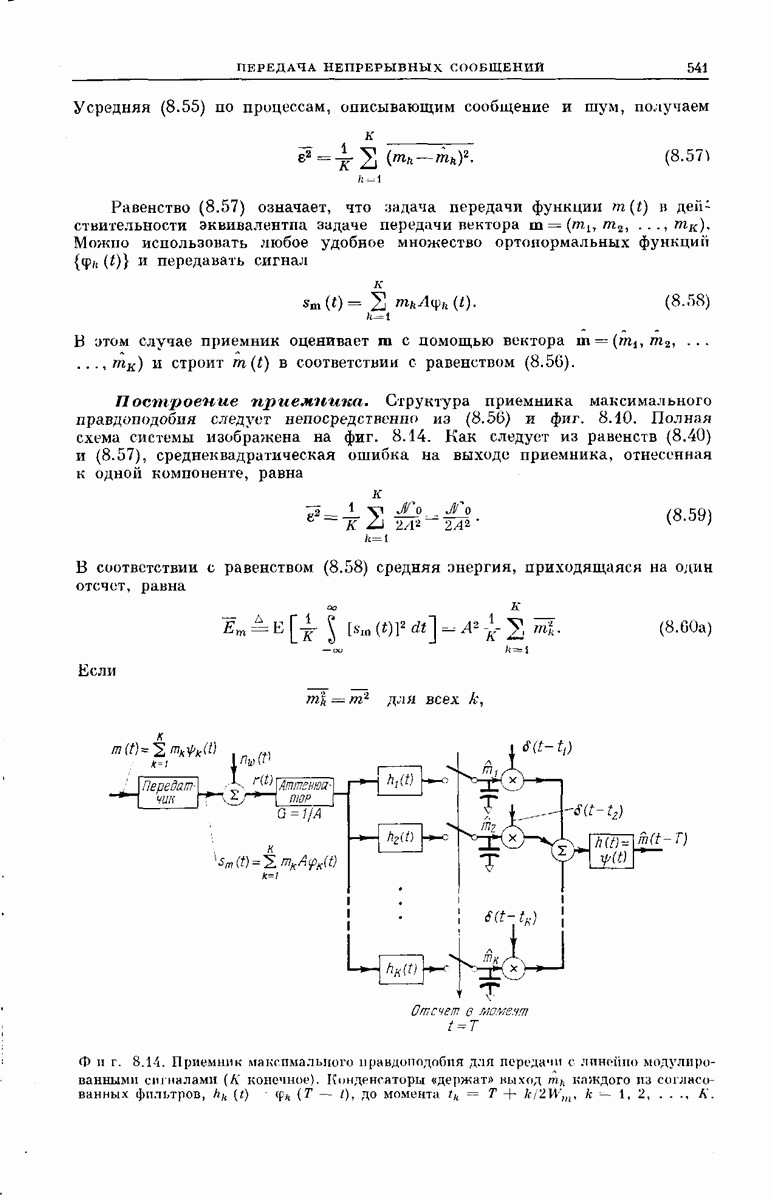












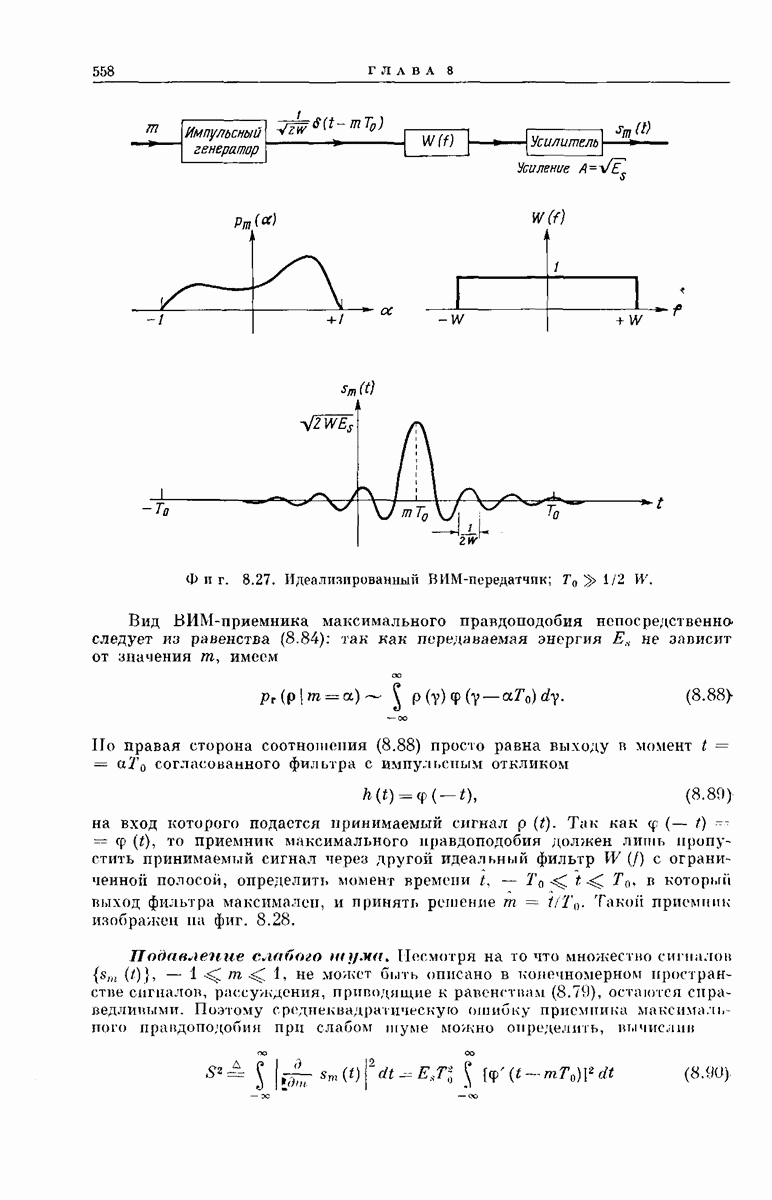



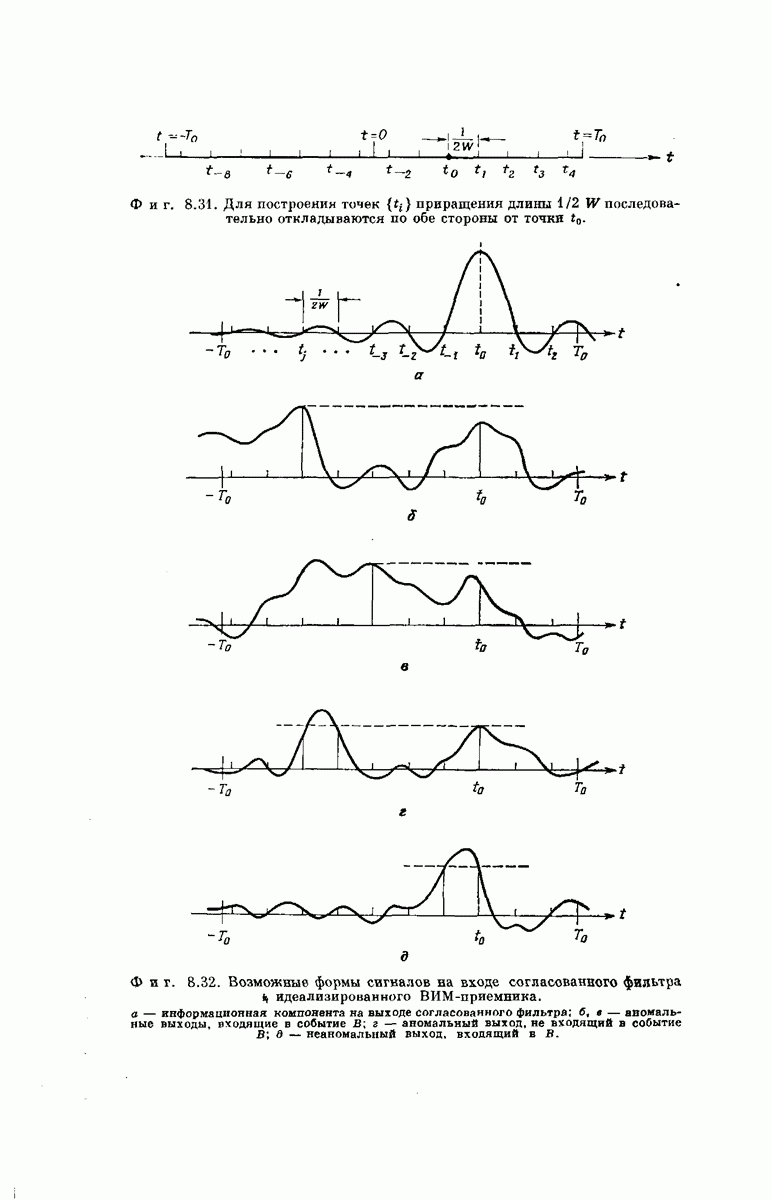
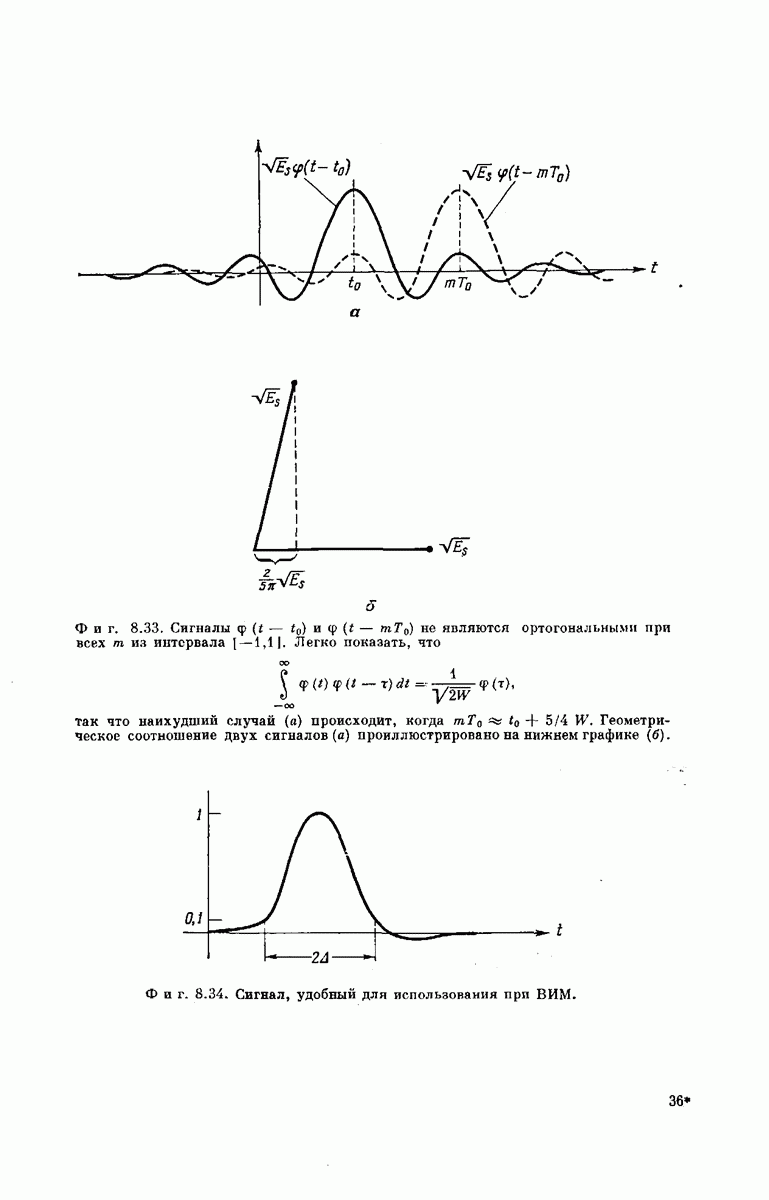





















































 -регистра
-регистра  (фиг. 6.48) конечен, затрудняет математическое исследование реального декодера Фано. Однако довольно полное представление о характеристиках декодера можно получить, если при расчетах предполагать, что величина
(фиг. 6.48) конечен, затрудняет математическое исследование реального декодера Фано. Однако довольно полное представление о характеристиках декодера можно получить, если при расчетах предполагать, что величина  достаточно велика и указатель глубины поиска никогда не выходит на выходной конец
достаточно велика и указатель глубины поиска никогда не выходит на выходной конец  -регистра. Используя это предположение, мы находим в приложении
-регистра. Используя это предположение, мы находим в приложении  оценку величины, аналогичной средней вероятности
оценку величины, аналогичной средней вероятности  рассмотренной в разд. 6.3 при изучении субоптимального декодера. Черта сверху, как обычно, означает математическое ожидание в соответствующем ансамбле кодов. В частности, для используемых в двоичном симметричном канале кодеров, аналогичных рассмотренному на фиг. 6.32, из соотношения
рассмотренной в разд. 6.3 при изучении субоптимального декодера. Черта сверху, как обычно, означает математическое ожидание в соответствующем ансамбле кодов. В частности, для используемых в двоичном симметричном канале кодеров, аналогичных рассмотренному на фиг. 6.32, из соотношения  следует
следует  что
что

 дается формулой
дается формулой

 — показатель экспоненциальной оценки, вычисленной для ДСК [см.
— показатель экспоненциальной оценки, вычисленной для ДСК [см.  ]. Как показано в приложении, величина может служить для декодера Фано, использующего бесконечный
]. Как показано в приложении, величина может служить для декодера Фано, использующего бесконечный  -регистр, оценкой вероятности одной или более ошибок при декодировании последовательности
-регистр, оценкой вероятности одной или более ошибок при декодировании последовательности  символов сообщения.
символов сообщения.
 следует после соответствующей подстановки нужных параметров, что величина В, интерпретируемая в приложении как верхняя оценка характеризующего данный алгоритм среднего числа исследованных ребер, приходящихся на декодированный символ сообщения, ограничена неравенством
следует после соответствующей подстановки нужных параметров, что величина В, интерпретируемая в приложении как верхняя оценка характеризующего данный алгоритм среднего числа исследованных ребер, приходящихся на декодированный символ сообщения, ограничена неравенством

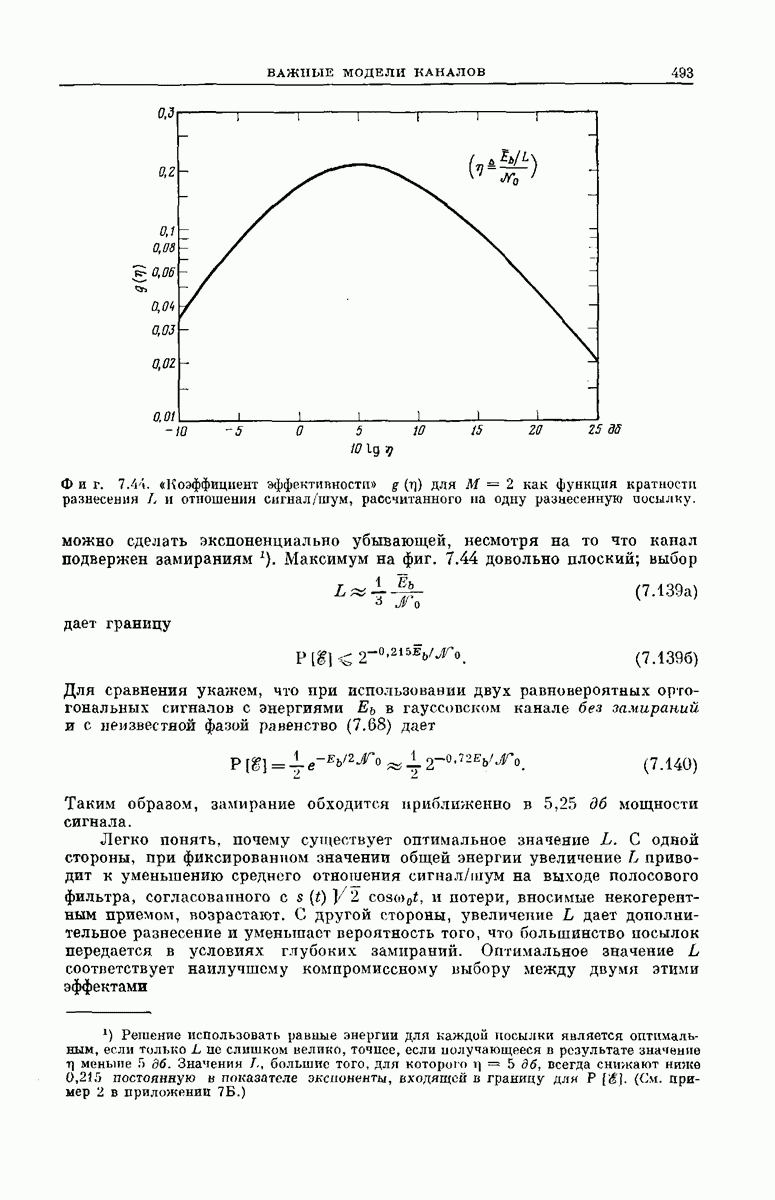
 несколько меньших
несколько меньших  приближенно определяется как
приближенно определяется как

 длина кодовых ограничений К может быть увеличена без одновременного увеличения оценки В.
длина кодовых ограничений К может быть увеличена без одновременного увеличения оценки В.
 величина
величина  экспоненциально убывает с ростом К.
экспоненциально убывает с ростом К.
 с возрастанием К удовлетворяет требованиям, предъявляемым к последовательному декодированию, обе оценки катастрофически возрастают при стремлении
с возрастанием К удовлетворяет требованиям, предъявляемым к последовательному декодированию, обе оценки катастрофически возрастают при стремлении 
 можно получить как угодно малую вероятность ошибки без одновременного увеличения средней вычислительной скорости декодера; однако для каждого канала существует верхний предел скоростей
можно получить как угодно малую вероятность ошибки без одновременного увеличения средней вычислительной скорости декодера; однако для каждого канала существует верхний предел скоростей  при которых он ведет себя таким образом.
при которых он ведет себя таким образом.
 , и мы не будем их здесь рассматривать.
, и мы не будем их здесь рассматривать.
 , то проблема передачи может быть решена соответствующим выбором модулятора и детектора — в кодировании нет необходимости. Если же мы хотим получить высокую точность при малых скоростях передачи данных, можно выбрать такую схему, как пороговое декодирование [57], отличающуюся простотой реализации. Наиболее трудным является случай, когда требуется одновременно высокая точность и высокая скорость передачи данных,
, то проблема передачи может быть решена соответствующим выбором модулятора и детектора — в кодировании нет необходимости. Если же мы хотим получить высокую точность при малых скоростях передачи данных, можно выбрать такую схему, как пороговое декодирование [57], отличающуюся простотой реализации. Наиболее трудным является случай, когда требуется одновременно высокая точность и высокая скорость передачи данных,  . В этом случае необходимость применения мощных кодов
. В этом случае необходимость применения мощных кодов  и сложного передающего и приемного оборудования становится неизбежной, а задача сравнения различных методов кодирования особенно затрудняется.
и сложного передающего и приемного оборудования становится неизбежной, а задача сравнения различных методов кодирования особенно затрудняется.
 существует двоичный БЧХ-код с длиной кодового слова
существует двоичный БЧХ-код с длиной кодового слова  который содержит
который содержит  кодовых слов и который гарантирует исправление любой комбинации из
кодовых слов и который гарантирует исправление любой комбинации из  или меньшего числа искаженных символов в ДСК, причем
или меньшего числа искаженных символов в ДСК, причем  Схема декодирования этих кодов, применимая при числе искажений, меньшем или равном
Схема декодирования этих кодов, применимая при числе искажений, меньшем или равном  разработана Петерсоном [66], а также другими авторами г). Необходимое количество вычислений для этих систем растет как небольшая степень
разработана Петерсоном [66], а также другими авторами г). Необходимое количество вычислений для этих систем растет как небольшая степень 

 отношение сигнал/шум на одно измерение,
отношение сигнал/шум на одно измерение,  скорость передачи данных в битах на один символ канала.
скорость передачи данных в битах на один символ канала.
 которое требуется любому БЧХ-коду для достижения определенной вероятности ошибки на двоичный символ
которое требуется любому БЧХ-коду для достижения определенной вероятности ошибки на двоичный символ  Мы ввели величину
Мы ввели величину  где
где  есть вероятность ошибки для всего блока БЧХ-кода. Результаты вычислений для значений
есть вероятность ошибки для всего блока БЧХ-кода. Результаты вычислений для значений  представлены на фиг. 6.49, а, б в виде функций от
представлены на фиг. 6.49, а, б в виде функций от 
 и найти величину
и найти величину  которая требуется, чтобы выполнялось равенство
которая требуется, чтобы выполнялось равенство  . Эти результаты также представлены в виде кривых на фиг.
. Эти результаты также представлены в виде кривых на фиг.  Согласно соотношениям (6.110) и (6.111), при таких значениях отношения
Согласно соотношениям (6.110) и (6.111), при таких значениях отношения  выбирая достаточно большое К, можно достичь как угодно малой вероятности ошибки. Как мы увидим, если декодирование последовательное, то разумно выбирать К столь большим, чтобы вероятность ошибки была пренебрежимо малой, и использовать скорости
выбирая достаточно большое К, можно достичь как угодно малой вероятности ошибки. Как мы увидим, если декодирование последовательное, то разумно выбирать К столь большим, чтобы вероятность ошибки была пренебрежимо малой, и использовать скорости 

 определяемым соотношением (6.626), получены в приложении
определяемым соотношением (6.626), получены в приложении  Поэтому системы, использующие последовательное декодирование, могут основываться на весьма различных видах модулирующих и детектирующих схем.
Поэтому системы, использующие последовательное декодирование, могут основываться на весьма различных видах модулирующих и детектирующих схем.
 от значения
от значения


 как угодно близкое к оптимальному для данной величины
как угодно близкое к оптимальному для данной величины  Результаты соответствующего эксперимента обсуждаются в конце этой главы. Вычисление значений
Результаты соответствующего эксперимента обсуждаются в конце этой главы. Вычисление значений  для некоторых типов каналов, характеризуемых случайным сдвигом фазы и замираниями, проведено в гл. 7.
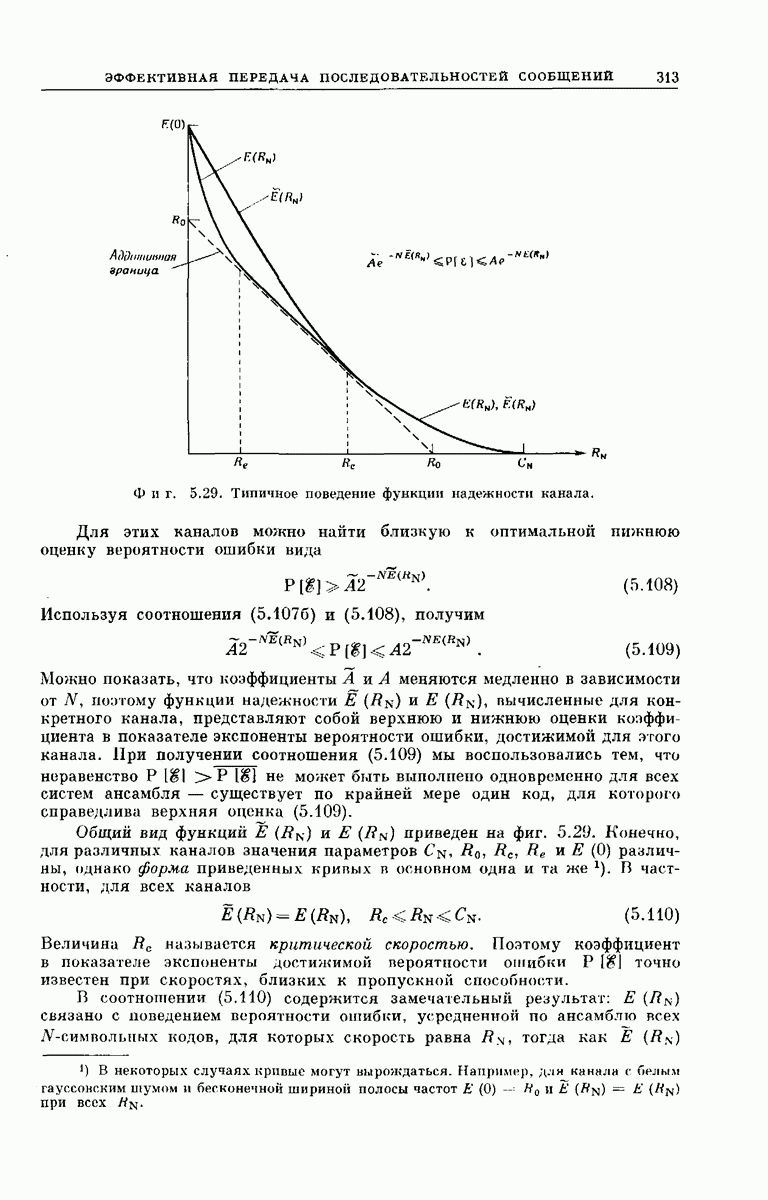
для некоторых типов каналов, характеризуемых случайным сдвигом фазы и замираниями, проведено в гл. 7.
 состоящей из
состоящей из  двоичных символов и закодированной сверточным кодером, моделировалась на цифровой вычислительной машине; при этом производился подсчет числа ребер кодового дерена, обследованных в ходе декодировании. Обозначим это число, деленное на
двоичных символов и закодированной сверточным кодером, моделировалась на цифровой вычислительной машине; при этом производился подсчет числа ребер кодового дерена, обследованных в ходе декодировании. Обозначим это число, деленное на  через
через  Таким образом,
Таким образом,  представляет собой эмпирическое среднее число обследованных ребер, приходящихся на один декодированный двоичный символ сообщения.
представляет собой эмпирическое среднее число обследованных ребер, приходящихся на один декодированный двоичный символ сообщения.
 от отношения
от отношения  Длина кодовых ограничений К при моделировании полагалась равной 60; эта величина оказалась достаточно большой, для того чтобы не произошло ни одной ошибки декодирования. При этом значении К субоптимальный декодер, рассмотренный в разд. 6.3, произведет приблизительно
Длина кодовых ограничений К при моделировании полагалась равной 60; эта величина оказалась достаточно большой, для того чтобы не произошло ни одной ошибки декодирования. При этом значении К субоптимальный декодер, рассмотренный в разд. 6.3, произведет приблизительно  сравнений ребер на декодированный символ; при
сравнений ребер на декодированный символ; при  даже из оценки (6.112) следует только, что
даже из оценки (6.112) следует только, что  Напротив, в эксперименте, результаты которого представлены на фиг. 6.50, оказалось, что
Напротив, в эксперименте, результаты которого представлены на фиг. 6.50, оказалось, что  при всех
при всех  Если
Если  то величина
то величина  быстро возрастает, что соответствует поведению оценки (6.112). Таким образом, экспериментальное рассмотрение показывает, что
быстро возрастает, что соответствует поведению оценки (6.112). Таким образом, экспериментальное рассмотрение показывает, что  существенно зависит от отношения
существенно зависит от отношения  и очень слабо — от значений этих величин по отдельности.
и очень слабо — от значений этих величин по отдельности.
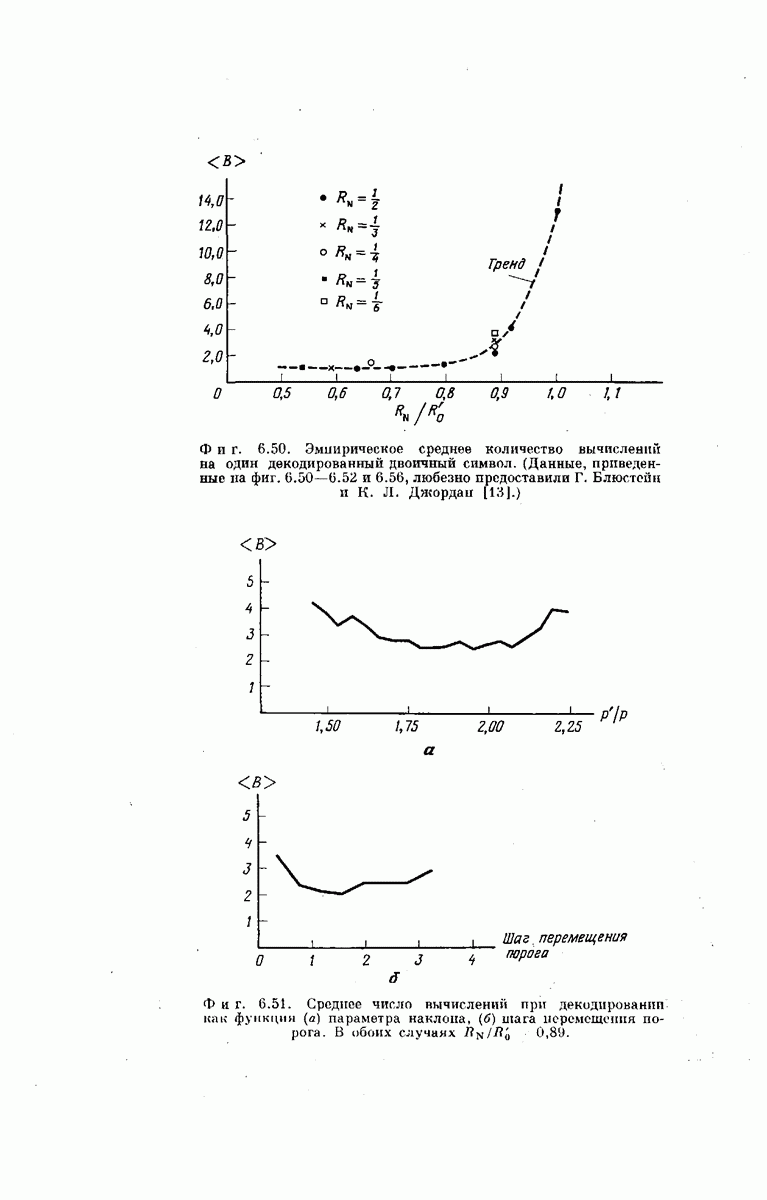
 [см. (6.109)] и шага перемещения порога
[см. (6.109)] и шага перемещения порога  подобранных эмпирически так, чтобы величина
подобранных эмпирически так, чтобы величина  была минимальной. Типичное поведение
была минимальной. Типичное поведение  как функции от параметра наклона и шага
как функции от параметра наклона и шага

 использованных в эксперименте, описанном здесь, были тщательно подобраны с целью получения хороших характеристик процедуры [90]; лишь оставшиеся символы порождающих последовательностей выбраны случайно.
использованных в эксперименте, описанном здесь, были тщательно подобраны с целью получения хороших характеристик процедуры [90]; лишь оставшиеся символы порождающих последовательностей выбраны случайно.
 требующееся в случае последовательного декодирования при
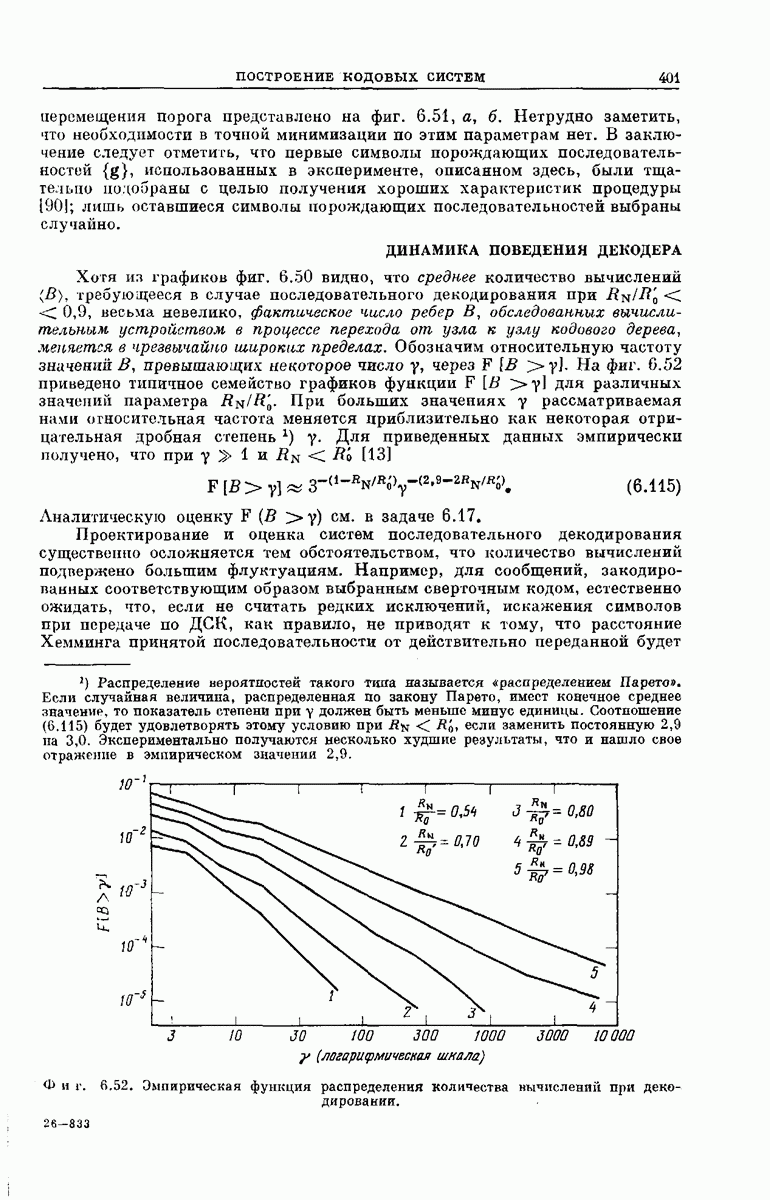
требующееся в случае последовательного декодирования при  весьма невелико, фактическое число ребер В, обследованных вычислительным устройством в процессе перехода от узла к узлу кодового дерева, меняется в чрезвычайно широких пределах. Обозначим относительную частоту значений В, превышающих некоторое число у, через
весьма невелико, фактическое число ребер В, обследованных вычислительным устройством в процессе перехода от узла к узлу кодового дерева, меняется в чрезвычайно широких пределах. Обозначим относительную частоту значений В, превышающих некоторое число у, через  На фиг. 6.52 приведено типичное семейство графиков функции
На фиг. 6.52 приведено типичное семейство графиков функции  для различных значений параметра
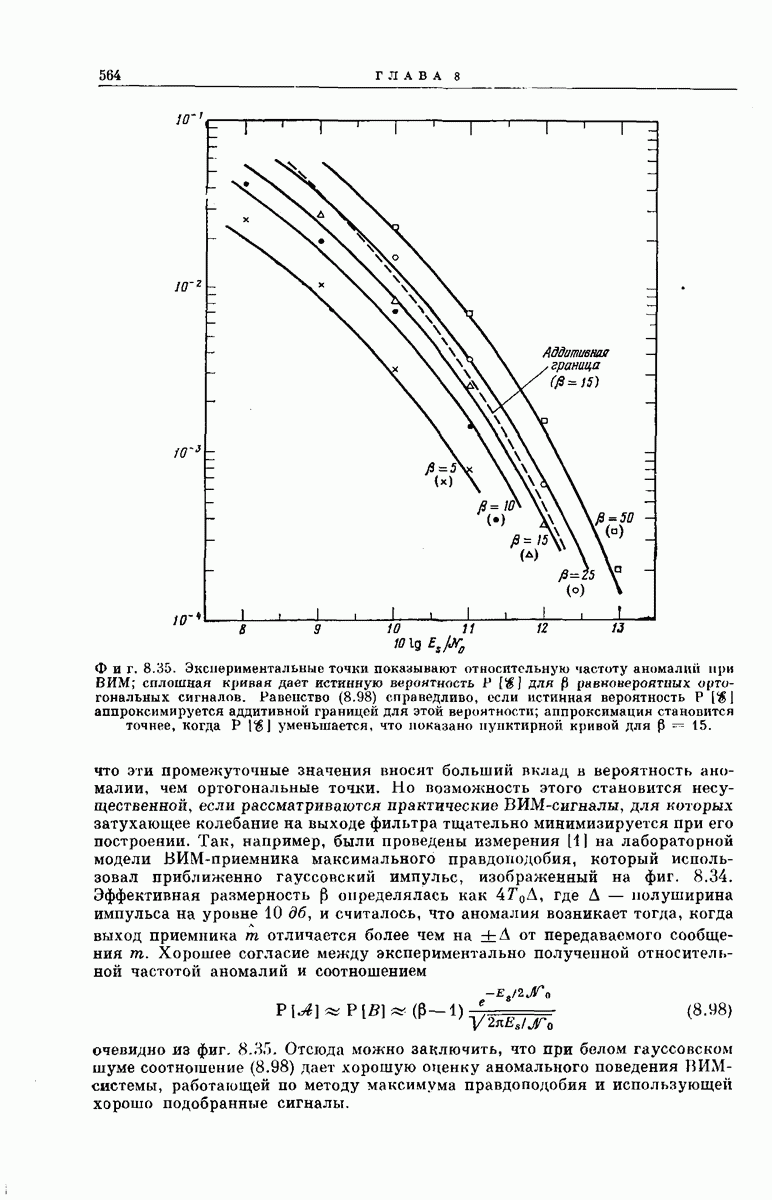
для различных значений параметра  При больших значениях у рассматриваемая нами относительная частота меняется приблизительно как некоторая отрицательная дробная степень у. Для приведенных данных эмпирически получено, что при
При больших значениях у рассматриваемая нами относительная частота меняется приблизительно как некоторая отрицательная дробная степень у. Для приведенных данных эмпирически получено, что при  [13]
[13]

 см. в задаче 6.17.
см. в задаче 6.17.

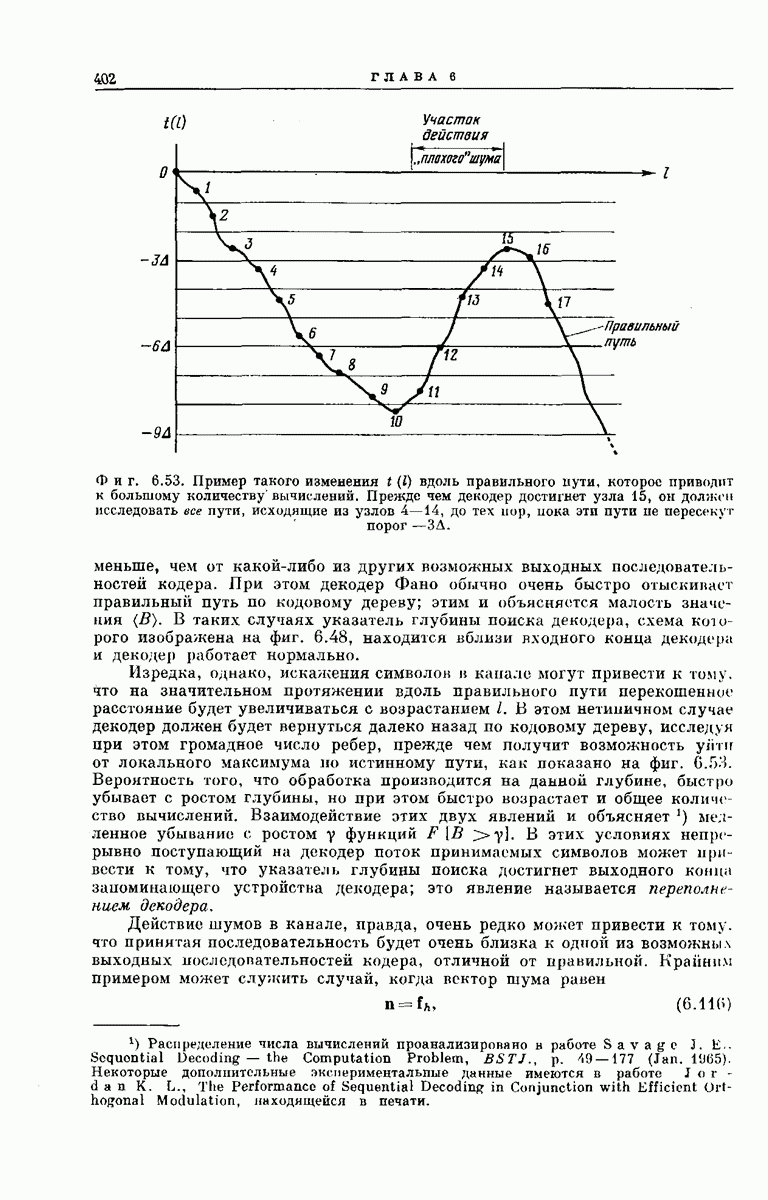
 вдоль правильного пути, которое приводит к большому количеству вычислений. Прежде чем декодер достигнет узла 15, он должен исследовать все пути, исходящие из узлов 4—14, до тех пор, пока эти пути не пересекут порог
вдоль правильного пути, которое приводит к большому количеству вычислений. Прежде чем декодер достигнет узла 15, он должен исследовать все пути, исходящие из узлов 4—14, до тех пор, пока эти пути не пересекут порог  .
.
 . В таких случаях указатель глубины поиска декодера, схема которого изображена на фиг. 6.48, находится вблизи входного конца декодера и декодер работает нормально.
. В таких случаях указатель глубины поиска декодера, схема которого изображена на фиг. 6.48, находится вблизи входного конца декодера и декодер работает нормально.
 . В этом нетипичном случае декодер должен будет вернуться далеко назад по кодовому дереву, исследуя при этом громадное число ребер, прежде чем получит возможность уйти от локального максимума но истинному пути, как показано на фиг.
. В этом нетипичном случае декодер должен будет вернуться далеко назад по кодовому дереву, исследуя при этом громадное число ребер, прежде чем получит возможность уйти от локального максимума но истинному пути, как показано на фиг.  Вероятность того, что обработка производится на данной глубине, быстро убывает с ростом глубины, но при этом быстро возрастает и общее количество вычислений. Взаимодействие этих двух явлений и объясняет 1) медленное убывание с ростом у функций
Вероятность того, что обработка производится на данной глубине, быстро убывает с ростом глубины, но при этом быстро возрастает и общее количество вычислений. Взаимодействие этих двух явлений и объясняет 1) медленное убывание с ростом у функций  В этих условиях непрерывно поступающий на декодер поток принимаемых символов может привести к тому, что указатель глубины поиска достигпет выходного конца запоминающего устройства декодера; это явление называется переполнением декодера.
В этих условиях непрерывно поступающий на декодер поток принимаемых символов может привести к тому, что указатель глубины поиска достигпет выходного конца запоминающего устройства декодера; это явление называется переполнением декодера.
 выходных последовательностей кодера, отличной от правильной. Крайним примером может служить случай, когда вектор шума равен
выходных последовательностей кодера, отличной от правильной. Крайним примером может служить случай, когда вектор шума равен


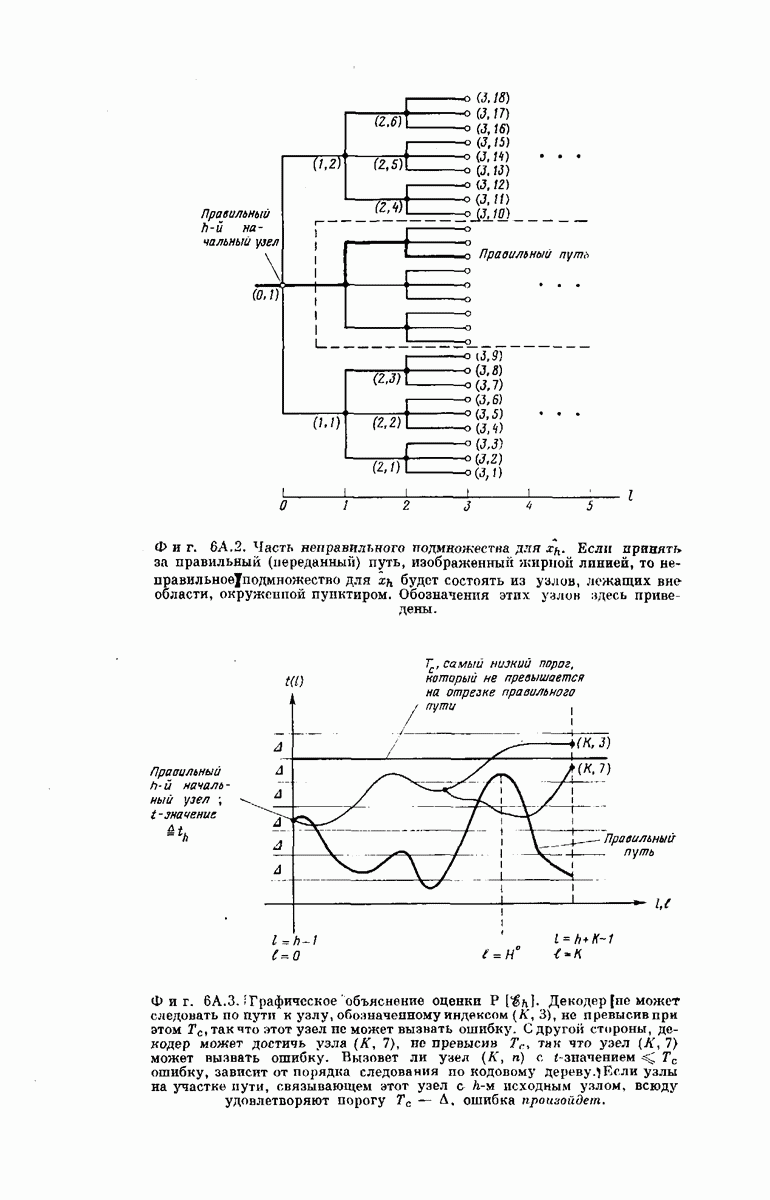
 Абстрактное представление событий «переполнение» и «ошибка» для
Абстрактное представление событий «переполнение» и «ошибка» для  Точками отмечены выходные векторы кодера
Точками отмечены выходные векторы кодера  Если принятый сигнал попадает в незаштрихованную область, он не декодируется из-за переполнения. (Близкие точки соответствуют векторам, близким в смысле «расстояния Хемминга».)
Если принятый сигнал попадает в незаштрихованную область, он не декодируется из-за переполнения. (Близкие точки соответствуют векторам, близким в смысле «расстояния Хемминга».)
 — вектор, полученный из порождающей последовательности кода
— вектор, полученный из порождающей последовательности кода  при помощи
при помощи  сдвигов вправо. Из соотношения
сдвигов вправо. Из соотношения  следует, что принятая последовательность точно совпадает с тем кодовым словом, которое необходимо было бы передать, если бы
следует, что принятая последовательность точно совпадает с тем кодовым словом, которое необходимо было бы передать, если бы  символ сообщения
символ сообщения  отличался от переданного. В этом случае
отличался от переданного. В этом случае  наверняка будет декодировано без труда, но неправильно. В принципе возможность появления на выходе
наверняка будет декодировано без труда, но неправильно. В принципе возможность появления на выходе  -регистра декодера нескольких неправильных символов, не сопровождаемое возрастанием числа исследованных ребер и сопутствующего ему перехода указателя глубины поиска вправо, не исключена и не в столь крайних случаях. Такие явления будем называть необнаружимыми ошибками.
-регистра декодера нескольких неправильных символов, не сопровождаемое возрастанием числа исследованных ребер и сопутствующего ему перехода указателя глубины поиска вправо, не исключена и не в столь крайних случаях. Такие явления будем называть необнаружимыми ошибками.
 Если действие шума в канале не приводит к выходу принятой последовательности за пределы отмеченной перекрестной штриховкой области, декодер работает правильно. Соответственно, если принятая последовательность попадает и одну из областей, отмеченных продольной штриховкой, произойдет необнаружимая ошибка. Промежуточный случай, когда принятая последовательность попадет в незаштрихованную область, приводит к переполнению.
Если действие шума в канале не приводит к выходу принятой последовательности за пределы отмеченной перекрестной штриховкой области, декодер работает правильно. Соответственно, если принятая последовательность попадает и одну из областей, отмеченных продольной штриховкой, произойдет необнаружимая ошибка. Промежуточный случай, когда принятая последовательность попадет в незаштрихованную область, приводит к переполнению.
 она практически не зависит от длины кодовых ограничений, но очень сильно зависит от отношения
она практически не зависит от длины кодовых ограничений, но очень сильно зависит от отношения 

 Если прежде, чем в декодер поступит
Если прежде, чем в декодер поступит  новых ребер, указатель не успеет продвинуться хотя бы на одно ребро в кодовом дереве, заведомо наступит переполнение. Эквивалентное утиерждение состоит в том, что если за время до следующего углубления указателя будет обследовано более чем
новых ребер, указатель не успеет продвинуться хотя бы на одно ребро в кодовом дереве, заведомо наступит переполнение. Эквивалентное утиерждение состоит в том, что если за время до следующего углубления указателя будет обследовано более чем  ребер, где Я означает число ребер, которое декодер может обследовать в течение времени, отведенного на передачу каждого ребра, то наступит переполнение. Согласно соотношению (6.115), относительная частота наступления этого события
ребер, где Я означает число ребер, которое декодер может обследовать в течение времени, отведенного на передачу каждого ребра, то наступит переполнение. Согласно соотношению (6.115), относительная частота наступления этого события  равна
равна

 ребер. Практически, однако, в случае, когда правая часть соотношения (6.117) очень мала и
ребер. Практически, однако, в случае, когда правая часть соотношения (6.117) очень мала и  величина
величина  может служить полезной оценкой вероятности переполнения
может служить полезной оценкой вероятности переполнения  Доказательство справедливости этого утверждения опирается на наблюдения за поведением длины очереди в процессе экспериментов по моделированию работы декодера. Под длиной очереди мы понимаем положение указателя глубины поиска декодера в предположении, что
Доказательство справедливости этого утверждения опирается на наблюдения за поведением длины очереди в процессе экспериментов по моделированию работы декодера. Под длиной очереди мы понимаем положение указателя глубины поиска декодера в предположении, что  бесконечно.
бесконечно.
 фиксировано,
фиксировано,  меняется. При
меняется. При  длина очереди, как правило, равна нулю, хотя шум в канале изредка приводит к продолжительному поиску и в связи с этим к появлению пульсирующей по длине очереди. При
длина очереди, как правило, равна нулю, хотя шум в канале изредка приводит к продолжительному поиску и в связи с этим к появлению пульсирующей по длине очереди. При  продолжительный поиск бывает чаще и возникает опасность того, что последствия одного появления очереди не будут ликвидированы до нового ее появления. В случае
продолжительный поиск бывает чаще и возникает опасность того, что последствия одного появления очереди не будут ликвидированы до нового ее появления. В случае  все периоды продолжительного поиска сливаются и длина очереди возрастает до бесконечности.
все периоды продолжительного поиска сливаются и длина очереди возрастает до бесконечности.
 возможна только тогда, когда поведение длины очереди аналогично представленному на фиг. 6.56, а. В таких случаях переполнение вызывается главным образом трудностями декодирования изолированных входных символов
возможна только тогда, когда поведение длины очереди аналогично представленному на фиг. 6.56, а. В таких случаях переполнение вызывается главным образом трудностями декодирования изолированных входных символов

 в интересующей нас области скоростей передачи данных необходимо, чтобы
в интересующей нас области скоростей передачи данных необходимо, чтобы  поэтому объем декодера определяет главным образом не длина кодовых ограничений К, а параметр
поэтому объем декодера определяет главным образом не длина кодовых ограничений К, а параметр 





 Следовательно, нужно выбрать
Следовательно, нужно выбрать

 а для запоминания каждой принятой гипотезы относительно символа
а для запоминания каждой принятой гипотезы относительно символа  нужен 1 двоичный разряд. Таким образом, требуется память объемом приблизительно на
нужен 1 двоичный разряд. Таким образом, требуется память объемом приблизительно на  бит. При использовании памяти на магнитных сердечниках такое запоминающее устройство вполне реально. Необходимо только отметить, что трудно существенно уменьшить вероятность переполнения, не пожертповав скоростью передачи. Например, зафиксировав
бит. При использовании памяти на магнитных сердечниках такое запоминающее устройство вполне реально. Необходимо только отметить, что трудно существенно уменьшить вероятность переполнения, не пожертповав скоростью передачи. Например, зафиксировав  0.85 и увеличив
0.85 и увеличив  в 100 раз, мы уменьшим при этом величину
в 100 раз, мы уменьшим при этом величину  лишь с
лишь с  до
до  Вероятность переполнения не убывает экспоненциально с ростом объема памяти декодера или скорости вычислений.
Вероятность переполнения не убывает экспоненциально с ростом объема памяти декодера или скорости вычислений.
 можно получить, выбрав достаточно большое К, произвольно малую вероятность ошибки. Более того, в ряде интересных случаев удается получить чрезвычайно малую величину вероятности ошибки, например
можно получить, выбрав достаточно большое К, произвольно малую вероятность ошибки. Более того, в ряде интересных случаев удается получить чрезвычайно малую величину вероятности ошибки, например  при значениях К, на порядки меньших, чем объем памяти декодера
при значениях К, на порядки меньших, чем объем памяти декодера  требуемый для достижения приемлемой вероятности переполнения, например
требуемый для достижения приемлемой вероятности переполнения, например  Поэтому уменьшение вероятности необнаружимой ошибки не связано с существенным возрастанием стоимости системы.
Поэтому уменьшение вероятности необнаружимой ошибки не связано с существенным возрастанием стоимости системы.

 тогда, когда вектор
тогда, когда вектор  попадет в одну из продольно заштрихованных областей. С другой стороны, величина
попадет в одну из продольно заштрихованных областей. С другой стороны, величина  оценивает вероятность того, что
оценивает вероятность того, что  не попадет в область решения
не попадет в область решения  эта оценка близка к вероятности необнаружимой ошибки, если только переполнений нет.
эта оценка близка к вероятности необнаружимой ошибки, если только переполнений нет.
 непосредственно перед наступлением переполнения. Для декодера Фано, схему которого мы до сих пор рассматривали, вероятность такого события сравнима с вероятностью переполнения. В самом деле, при кодовой структуре, пример которой приведен на фиг. 6.35, количество вычислений, обычно затрачиваемое на поиск при движении по кодовому дереву назад на I ребер, растет экспоненциально с ростом
непосредственно перед наступлением переполнения. Для декодера Фано, схему которого мы до сих пор рассматривали, вероятность такого события сравнима с вероятностью переполнения. В самом деле, при кодовой структуре, пример которой приведен на фиг. 6.35, количество вычислений, обычно затрачиваемое на поиск при движении по кодовому дереву назад на I ребер, растет экспоненциально с ростом  Поэтому даже при не слишком больших значениях величины I указатель глубины поиска сильно смещается вправо. Вследствие неуверенного поведения декодера при принятии гипотезы об истинном символе сообщения в момент, когда указатель находится в крайнем правом конце
Поэтому даже при не слишком больших значениях величины I указатель глубины поиска сильно смещается вправо. Вследствие неуверенного поведения декодера при принятии гипотезы об истинном символе сообщения в момент, когда указатель находится в крайнем правом конце  -регистра, наступает переполнение. Так как ошибки этого типа сопутствуют переполнению, они называются обнаружимыми.
-регистра, наступает переполнение. Так как ошибки этого типа сопутствуют переполнению, они называются обнаружимыми.
 -регистра от конца
-регистра от конца  -регистра декодера на несколько длин кодовых ограничений, допустим на
-регистра декодера на несколько длин кодовых ограничений, допустим на  разрядов, как показано на фиг. 6.58. Возможность эффективного использования этой модифицированной процедуры опирается на следующий факт; если декодеру никогда не нужно возвращаться назад к тем
разрядов, как показано на фиг. 6.58. Возможность эффективного использования этой модифицированной процедуры опирается на следующий факт; если декодеру никогда не нужно возвращаться назад к тем  которые вышли за конец
которые вышли за конец  -регистра, то
-регистра, то  должно быть либо правильным, либо соответствовать необнаружимой ошибке. С другой стороны, если декодеру необходимо вести поиск и вне границ
должно быть либо правильным, либо соответствовать необнаружимой ошибке. С другой стороны, если декодеру необходимо вести поиск и вне границ  -регистра, произойдет переполнение.
-регистра, произойдет переполнение.

 символов, и произвольным образом вставляя в передачу А нулей. Тогда после каждого переполнения декодер всегда может ресинхронизироваться в пределах блока из
символов, и произвольным образом вставляя в передачу А нулей. Тогда после каждого переполнения декодер всегда может ресинхронизироваться в пределах блока из  символов и затем продолжать работу, сбросив недекодированный блок.
символов и затем продолжать работу, сбросив недекодированный блок.
 такая односторонняя стратегия передачи приведет лишь к 10%-ному снижению эффективной скорости передачи данных, т. е. к уменьшению этой скорости в
такая односторонняя стратегия передачи приведет лишь к 10%-ному снижению эффективной скорости передачи данных, т. е. к уменьшению этой скорости в  раз. Но, с другой стороны, из аддитивной оценки для вероятности следует, что с вероятностью, приблизительно равной
раз. Но, с другой стороны, из аддитивной оценки для вероятности следует, что с вероятностью, приблизительно равной  весь блок из
весь блок из  символов сообщения (или часть его) будет сброшен, а следовательно, не будет декодирован вообще, хотя при этом блоки, которые декодированы, почти заведомо декодированы правильно. Во многих приложениях оперативные характеристики такого типа неприемлемы.
символов сообщения (или часть его) будет сброшен, а следовательно, не будет декодирован вообще, хотя при этом блоки, которые декодированы, почти заведомо декодированы правильно. Во многих приложениях оперативные характеристики такого типа неприемлемы.

 , сообщают в пункт В, произошла ли при декодировании остановка из-за переполнения. В случае остановки из пункта В производится повторная передача недекодированного сообщения. Если остановка не произошла, из пункта В передается новое сообщение. Оба пункта следуют одной и той же стратегии передачи.
, сообщают в пункт В, произошла ли при декодировании остановка из-за переполнения. В случае остановки из пункта В производится повторная передача недекодированного сообщения. Если остановка не произошла, из пункта В передается новое сообщение. Оба пункта следуют одной и той же стратегии передачи.
 сек. Так как относительная частота циклов «переспрос — повторение» равна
сек. Так как относительная частота циклов «переспрос — повторение» равна  средняя доля оставшегося полезного времени раина
средняя доля оставшегося полезного времени раина  Выбрав достаточно малое
Выбрав достаточно малое  можно добиться, чтобы
можно добиться, чтобы  поэтому эффективная скорость передачи данных (в битах в секунду) не слишком уменьшается из-за переполнений. Вспомогательные символы можно защитить от необнаружимых ошибок путем периодической ресинхронизации через каждые
поэтому эффективная скорость передачи данных (в битах в секунду) не слишком уменьшается из-за переполнений. Вспомогательные символы можно защитить от необнаружимых ошибок путем периодической ресинхронизации через каждые  или
или  символов.
символов.

 — длина кодовых ограничений, измеренная числом двоичных символов сообщения, и
— длина кодовых ограничений, измеренная числом двоичных символов сообщения, и  скорость передачи данных в битах на передаваемый символ.
скорость передачи данных в битах на передаваемый символ.
 обозначено число ортогональных сигналов в стандартном блоке, которое можно передать по каналу за 1 сек, то соотношение (6.118а) можно переписать в виде
обозначено число ортогональных сигналов в стандартном блоке, которое можно передать по каналу за 1 сек, то соотношение (6.118а) можно переписать в виде

 скорость передачи данных в битах за секунду, а
скорость передачи данных в битах за секунду, а  длительность блока в секундах. Из соотношения (6.118б) следует, что при
длительность блока в секундах. Из соотношения (6.118б) следует, что при  выбирая достаточно большое
выбирая достаточно большое  можно получить произвольно малую вероятность ошибки. Для передачи данных с высокой скоростью необходимо выбрать схемы модуляции и демодуляции с большим значением параметра
можно получить произвольно малую вероятность ошибки. Для передачи данных с высокой скоростью необходимо выбрать схемы модуляции и демодуляции с большим значением параметра 
 можно сделать вероятность ошибки декодирования настолько малой, насколько это желательно; разумно выбрать
можно сделать вероятность ошибки декодирования настолько малой, насколько это желательно; разумно выбрать  столь большим, чтобы вероятность ошибки была пренебрежимо мала. Однако главной задачей является выбор схемы с малым значением параметра
столь большим, чтобы вероятность ошибки была пренебрежимо мала. Однако главной задачей является выбор схемы с малым значением параметра  где, как и ранее,
где, как и ранее,  означает комбинированное время, требуемое для двухстороннего обмена сигналами и обработки данных,
означает комбинированное время, требуемое для двухстороннего обмена сигналами и обработки данных,  частота переполнений.
частота переполнений.
 Так как
Так как


 необходимая для получения заданного значения
необходимая для получения заданного значения  убывает, когда
убывает, когда  возрастает,
возрастает,  остается фиксированным.
остается фиксированным.
 При проектировании системы необходимо стремиться максимизировать
При проектировании системы необходимо стремиться максимизировать  при заданном ограничении на сложность оборудования. Как мы видели в гл. 5, в простом случае канала с аддитивным белым гауссовским шумом и ограниченной полосой существуют теоретические пределы для максимально достижимых значений параметров
при заданном ограничении на сложность оборудования. Как мы видели в гл. 5, в простом случае канала с аддитивным белым гауссовским шумом и ограниченной полосой существуют теоретические пределы для максимально достижимых значений параметров  Сложность оборудования возрастет, если попытаться сделать хотя бы один из этих параметров слишком близким к его теоретическому пределу. Нужно остановиться на схеме, для которой выигрыш приближается к максимальному.
Сложность оборудования возрастет, если попытаться сделать хотя бы один из этих параметров слишком близким к его теоретическому пределу. Нужно остановиться на схеме, для которой выигрыш приближается к максимальному.
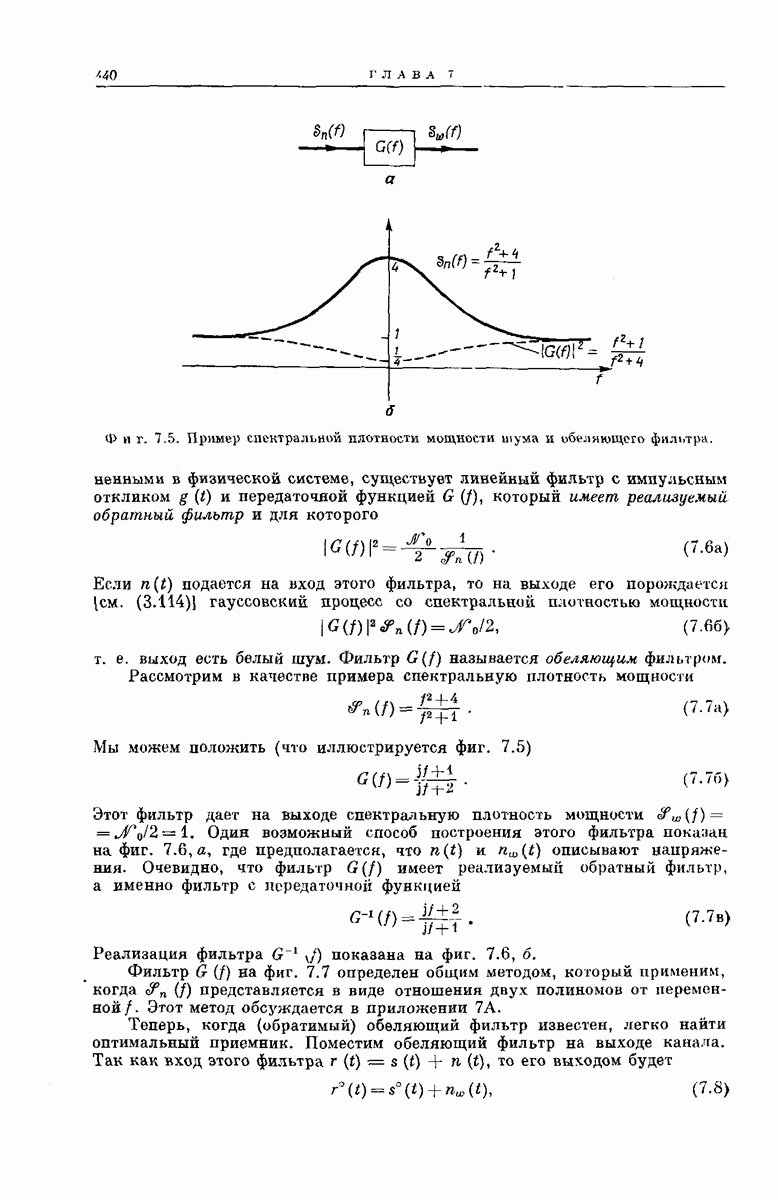
 реальных каналов связи обычно затрудняется отсутствием адекватной математической модели для помех в канале. Экспериментальные исследования шумовых процессов выполнены для дальних междугородных телефонных линий, предназначенных для передачи речи. Эксперимент, проведенный в лаборатории Линкольна Массачусетского технологического института [54], дает поучительный пример исследования взаимодействия между различными факторами, важными для построения схемы передачи, которые были введены в гл. 5 и 6.
реальных каналов связи обычно затрудняется отсутствием адекватной математической модели для помех в канале. Экспериментальные исследования шумовых процессов выполнены для дальних междугородных телефонных линий, предназначенных для передачи речи. Эксперимент, проведенный в лаборатории Линкольна Массачусетского технологического института [54], дает поучительный пример исследования взаимодействия между различными факторами, важными для построения схемы передачи, которые были введены в гл. 5 и 6.
 нескорректированная ширина полосы, в пределах которой задержка меняется менее чем на
нескорректированная ширина полосы, в пределах которой задержка меняется менее чем на  мсек, составляла лишь
мсек, составляла лишь 
 влечет за собой убивание
влечет за собой убивание  Поэтому максимизировать отдельно
Поэтому максимизировать отдельно  нельзя.
нельзя.

 определяемого приемником, не использующим предварительного квантования, необходимо, чтобы алфавит передатчика имел более чем два уровня амплитуд. Из фиг. 6.26 видно также, что значение параметра
определяемого приемником, не использующим предварительного квантования, необходимо, чтобы алфавит передатчика имел более чем два уровня амплитуд. Из фиг. 6.26 видно также, что значение параметра  определяемое приемником, в котором принятый сигнал квантуется так, чтобы многоамплитудные алфавиты передатчика и приемника совпадали, приблизительно равно
определяемое приемником, в котором принятый сигнал квантуется так, чтобы многоамплитудные алфавиты передатчика и приемника совпадали, приблизительно равно  Задача выбора алфавита, таким образом, сводится к определению (в зависимости от
Задача выбора алфавита, таким образом, сводится к определению (в зависимости от  числа амплитудных уровней сигнала, которые должны использоваться.
числа амплитудных уровней сигнала, которые должны использоваться.
 и числа амплитудных уровней А можно найти экспериментально эмпирические оценки для результирующей переходной вероятности между буквами входного и выходного алфавитов. Чтобы выбрать оптимальную схему, необходимо затем вычислить соответствующие значения
и числа амплитудных уровней А можно найти экспериментально эмпирические оценки для результирующей переходной вероятности между буквами входного и выходного алфавитов. Чтобы выбрать оптимальную схему, необходимо затем вычислить соответствующие значения  из соотношения
из соотношения  и выбрать те значения
и выбрать те значения  , которые максимизируют
, которые максимизируют 
 в этом случае дается соотношением
в этом случае дается соотношением  и в принципе мы смогли бы даже попытаться построить кодер, который использует буквы алфавита передатчика с частотами, максимизирующими
и в принципе мы смогли бы даже попытаться построить кодер, который использует буквы алфавита передатчика с частотами, максимизирующими  На практике, однако, реализовать такие кодер и декодер было бы чрезвычайно трудно. Вместо этого мы попытаемся найти приемлемое с технической точки зрения компромиссное решение.
На практике, однако, реализовать такие кодер и декодер было бы чрезвычайно трудно. Вместо этого мы попытаемся найти приемлемое с технической точки зрения компромиссное решение.


 для целей декодирования в виде
для целей декодирования в виде

 со статистически независимыми экспоненциально распределенными составляющими, т. е. с составляющими, имеющими плотность распределения вероятностей
со статистически независимыми экспоненциально распределенными составляющими, т. е. с составляющими, имеющими плотность распределения вероятностей


 и многоамплитудных алфавитов сигналов, показала, что отклонения не очень велики. Важнее всего то, что преимуществом функции расстояния (6.121 в) является простота ее реализации в декодере. Это и определило ее выбор.
и многоамплитудных алфавитов сигналов, показала, что отклонения не очень велики. Важнее всего то, что преимуществом функции расстояния (6.121 в) является простота ее реализации в декодере. Это и определило ее выбор.
 (Этот метод, вообще товоря, требует меньше эмпирических данных.) В эксперименте с телефонной линией использовалась экспоненциальная плотность распределения, даваемая соотношениями (6.122); параметр
(Этот метод, вообще товоря, требует меньше эмпирических данных.) В эксперименте с телефонной линией использовалась экспоненциальная плотность распределения, даваемая соотношениями (6.122); параметр  подбирался для различных
подбирался для различных  и разных
и разных

 при каждом выбранном
при каждом выбранном  и при каждом выбранном числе уровней сигнала. Для используемых в эксперименте формы импульса и техники уравнивания фаз было найдено, что оценка величины
и при каждом выбранном числе уровней сигнала. Для используемых в эксперименте формы импульса и техники уравнивания фаз было найдено, что оценка величины  имеет максимальное значение при
имеет максимальное значение при  и алфавите сигналов, состоящем из 32 различных амплитудных уровней; на этих значениях и был остановлен выбор. Для этого максимального значения относительная частота приема того же уровня сигнала, что и у переданного, составляла лишь 0,9. Это показывает, что схема модуляции и демодуляции, подходящая для использования в кодовых системах связи, не обязательно подходит для систем без кодирования, и наоборот.
и алфавите сигналов, состоящем из 32 различных амплитудных уровней; на этих значениях и был остановлен выбор. Для этого максимального значения относительная частота приема того же уровня сигнала, что и у переданного, составляла лишь 0,9. Это показывает, что схема модуляции и демодуляции, подходящая для использования в кодовых системах связи, не обязательно подходит для систем без кодирования, и наоборот.
 Кодер мог работать на трех скоростях передачи данных
Кодер мог работать на трех скоростях передачи данных  Двоичная последовательность с выхода кодера разбивалась на группы по 5 символов, каждая из которых соответствовала 1, 2 или 3 входным двоичным символам в зависимости от
Двоичная последовательность с выхода кодера разбивалась на группы по 5 символов, каждая из которых соответствовала 1, 2 или 3 входным двоичным символам в зависимости от  Все эти группы из 5 символов поступали параллельно в преобразователь «двоичная цифра — аналог»; любая из них определяла одну из 32 возможных амплитуд на выходе. Результирующие последовательности различных значений напряжения использовались для модуляции последовательных импульсов сигнала.
Все эти группы из 5 символов поступали параллельно в преобразователь «двоичная цифра — аналог»; любая из них определяла одну из 32 возможных амплитуд на выходе. Результирующие последовательности различных значений напряжения использовались для модуляции последовательных импульсов сигнала.
 синхронно с переданными импульсами, и результирующая последовательность выборочных значений поступала в преобразователь «двоичная цифра — аналог». Аналоговые выборочные значения квантовались на 32 уровня, и группы по 5 двоичных символов поступали параллельно в буферное запоминающее устройство.
синхронно с переданными импульсами, и результирующая последовательность выборочных значений поступала в преобразователь «двоичная цифра — аналог». Аналоговые выборочные значения квантовались на 32 уровня, и группы по 5 двоичных символов поступали параллельно в буферное запоминающее устройство.
 -регистра декодера, в него поступала группа данных, дольше всех хранящаяся в буферном устройстве. Буферное устройство и
-регистра декодера, в него поступала группа данных, дольше всех хранящаяся в буферном устройстве. Буферное устройство и  -регистр состояли соответственно из 3000 и 300 двоичных ячеек памяти.
-регистр состояли соответственно из 3000 и 300 двоичных ячеек памяти.
 с которой работало оборудование системы, контролировалась декодером. Всякий раз, когда декодирование затруднялось и наступало переполнение буферного устройства, декодер автоматически посылал вспомогательный двоичный символ, требуя уменьшить скорость поступления данных. Наоборот, когда декодирование происходило слишком легко, декодер автоматически требовал увеличить
с которой работало оборудование системы, контролировалась декодером. Всякий раз, когда декодирование затруднялось и наступало переполнение буферного устройства, декодер автоматически посылал вспомогательный двоичный символ, требуя уменьшить скорость поступления данных. Наоборот, когда декодирование происходило слишком легко, декодер автоматически требовал увеличить  . В эксперименте наблюдались флуктуации скорости передачи главным образом между
. В эксперименте наблюдались флуктуации скорости передачи главным образом между  лишь изредка скорость снижалась до
лишь изредка скорость снижалась до  Переход на другую скорость передачи происходил с частотой одно изменение в 6—7 сек.
Переход на другую скорость передачи происходил с частотой одно изменение в 6—7 сек.
 символов. Для сравнения укажем, что высококачественная стандартная система для передачи данных по телефонной линии без кодирования при работе в аналогичных каналах имеет скорость приблизительно 2400 бит/сек и вероятность ошибки равна примерно
символов. Для сравнения укажем, что высококачественная стандартная система для передачи данных по телефонной линии без кодирования при работе в аналогичных каналах имеет скорость приблизительно 2400 бит/сек и вероятность ошибки равна примерно 