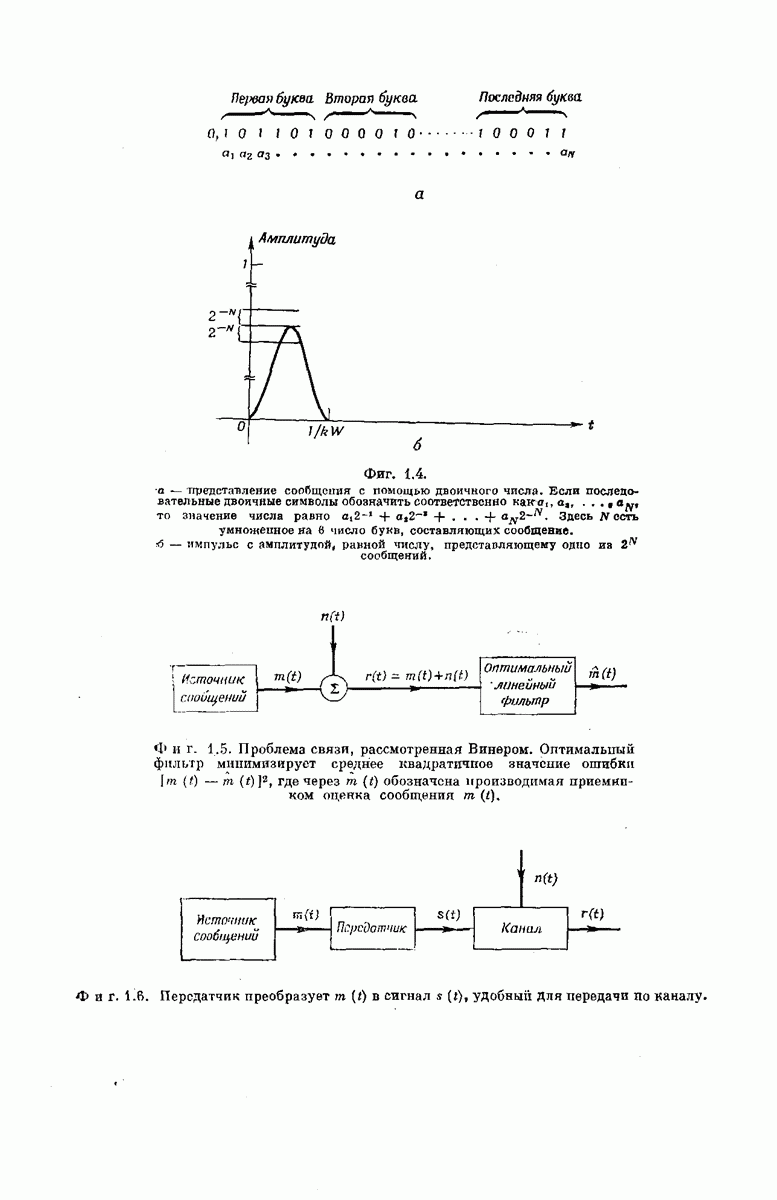
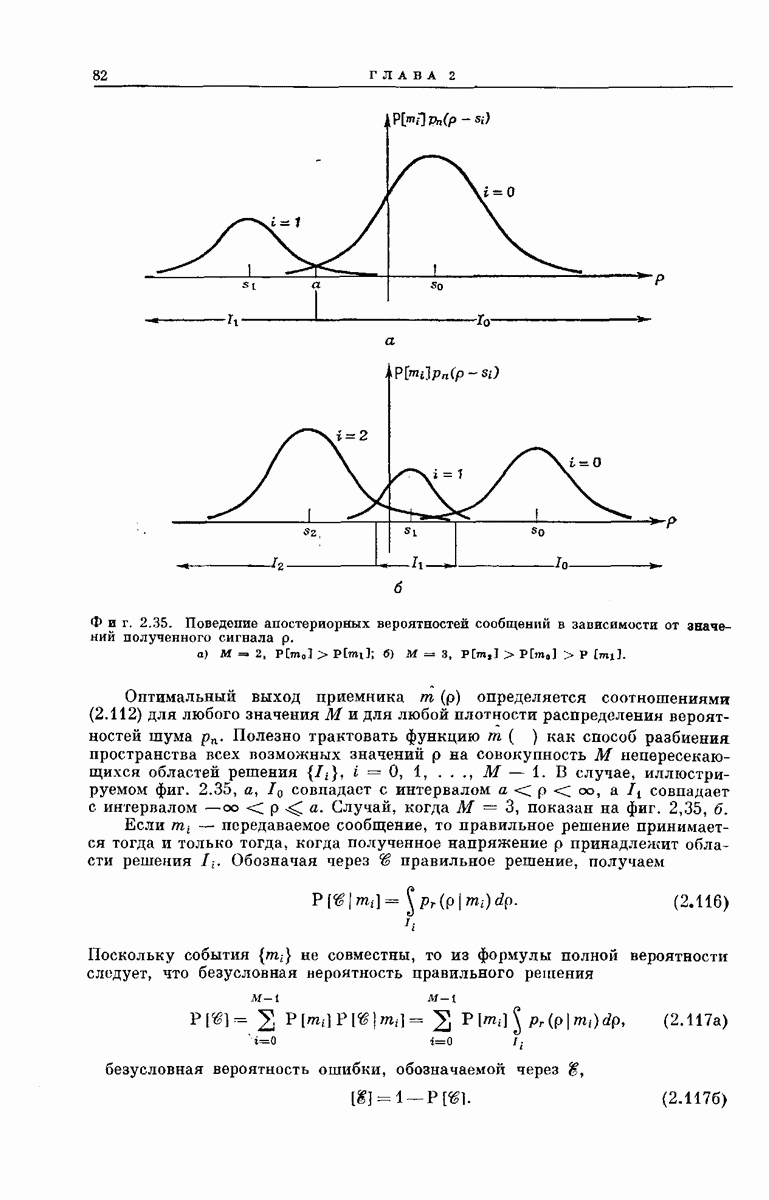
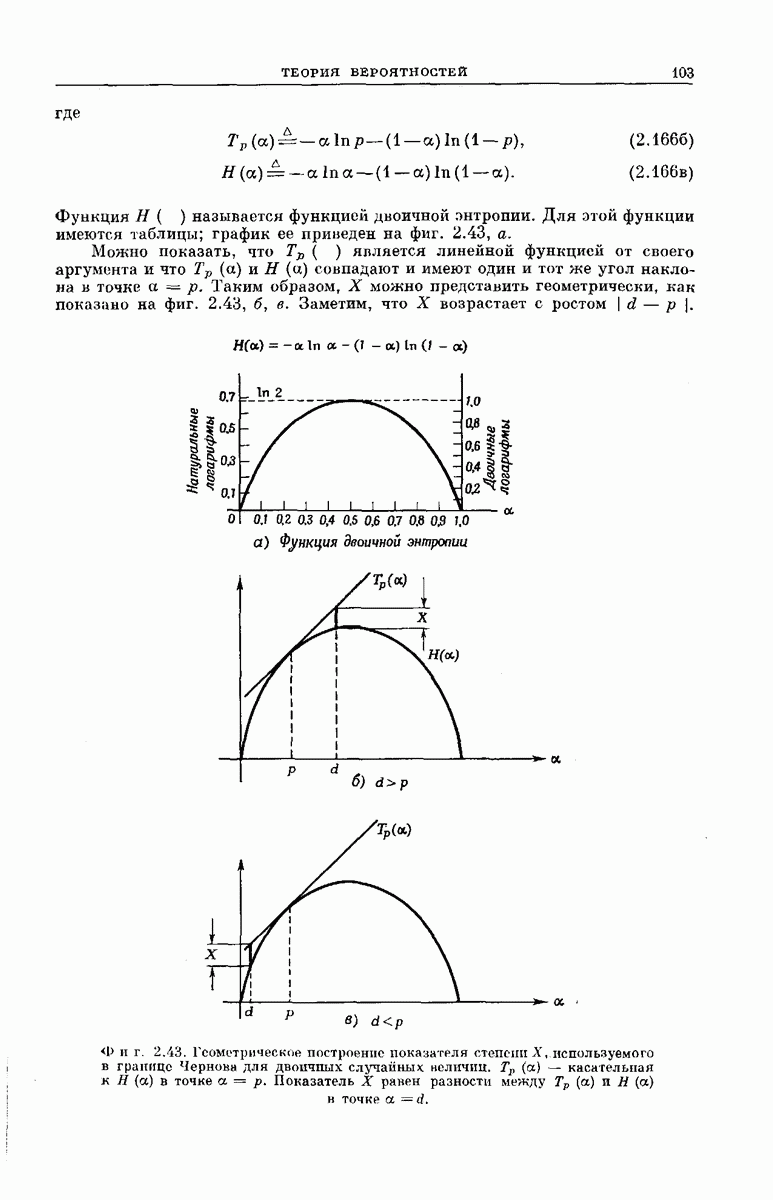
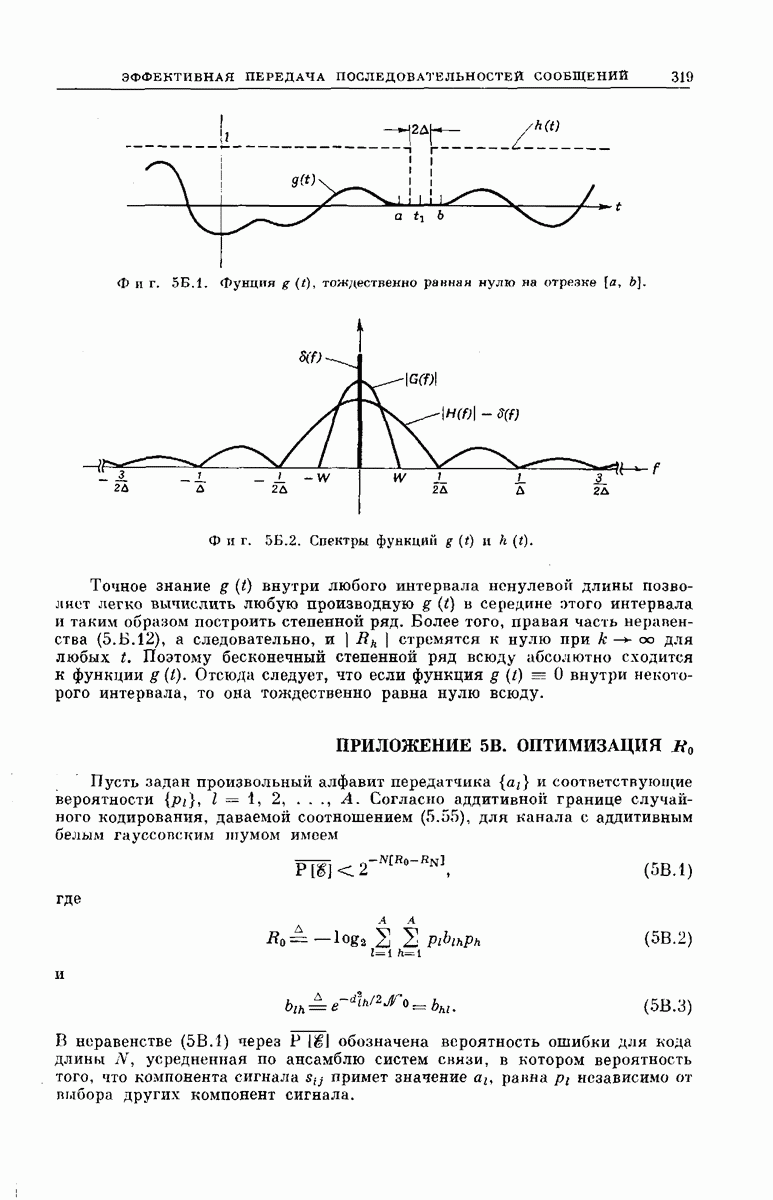
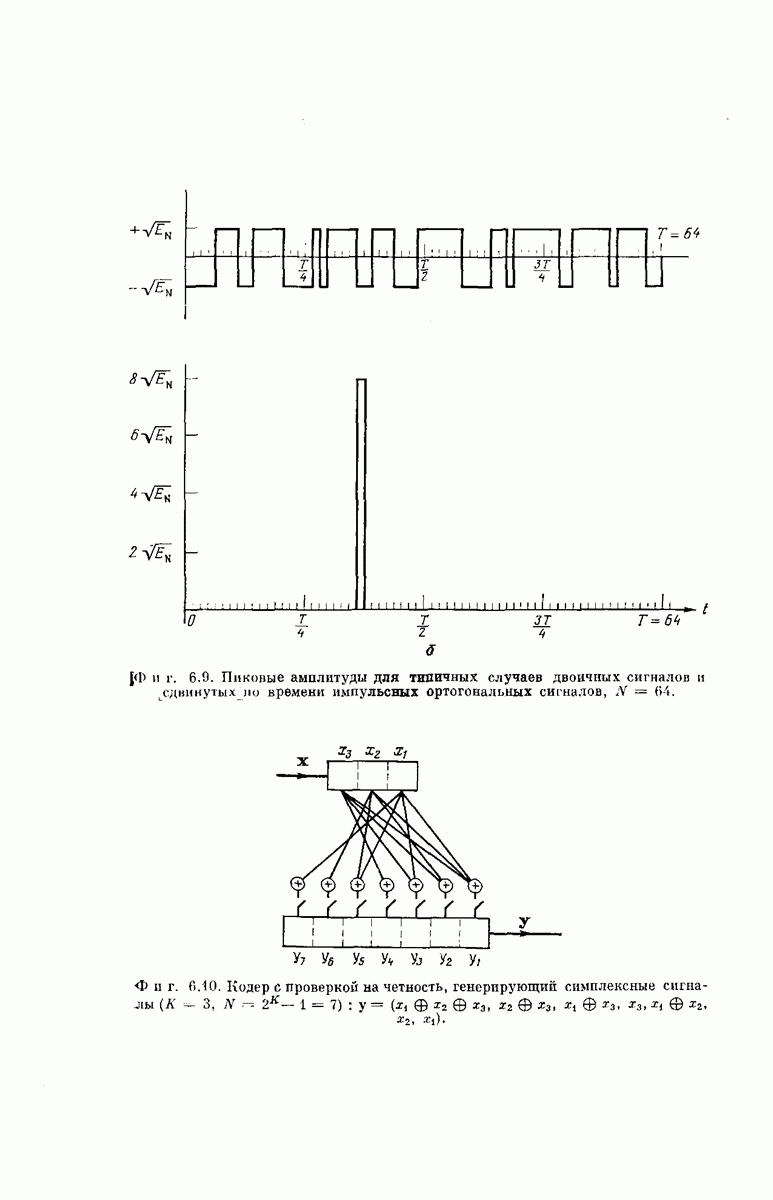
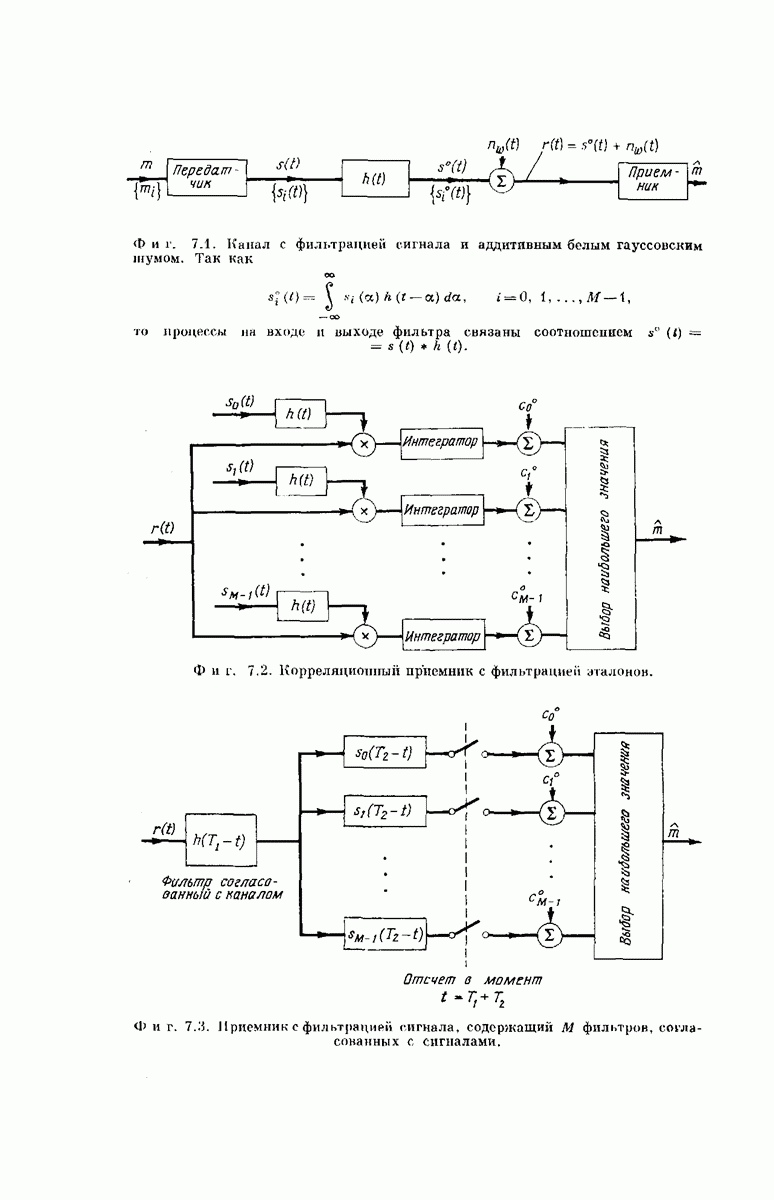
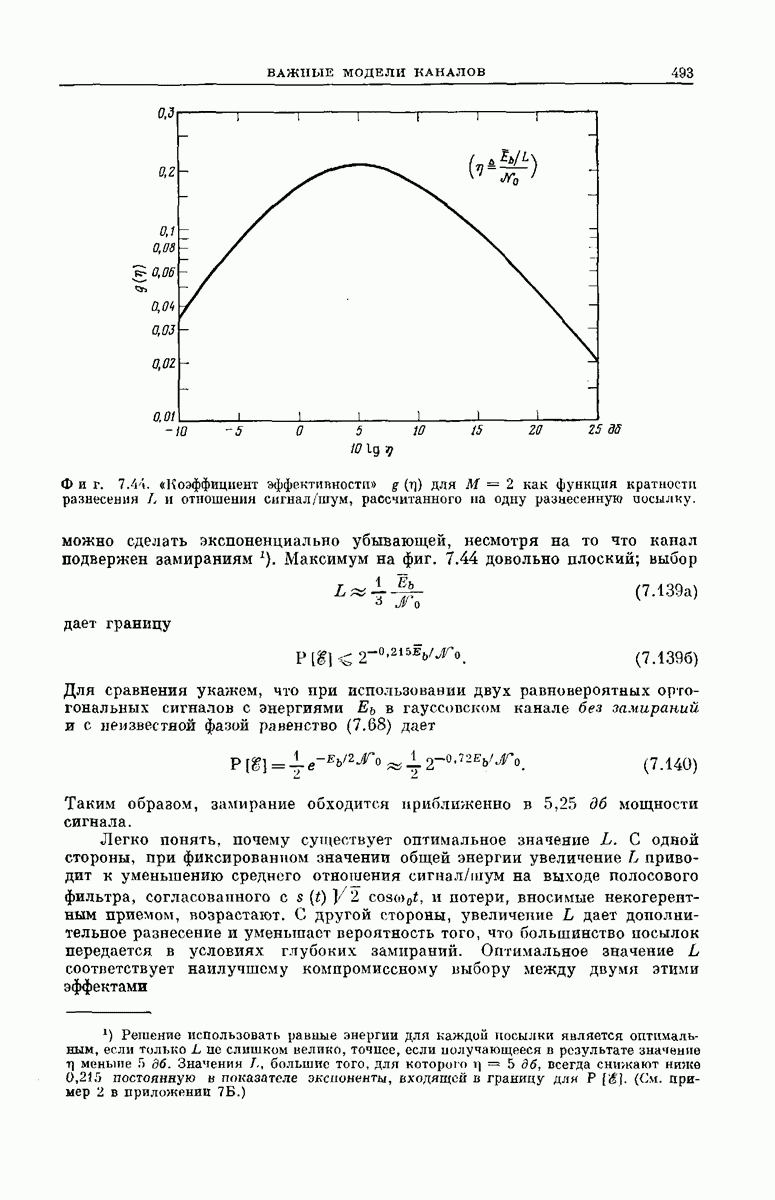
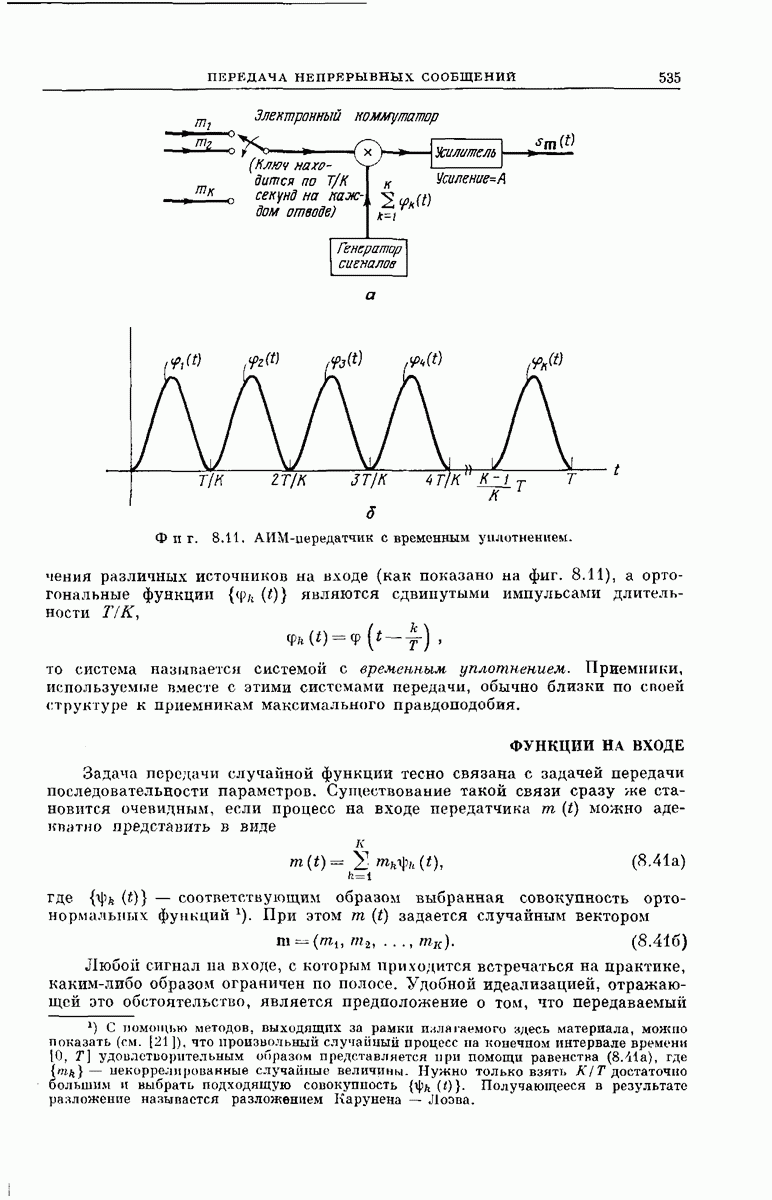
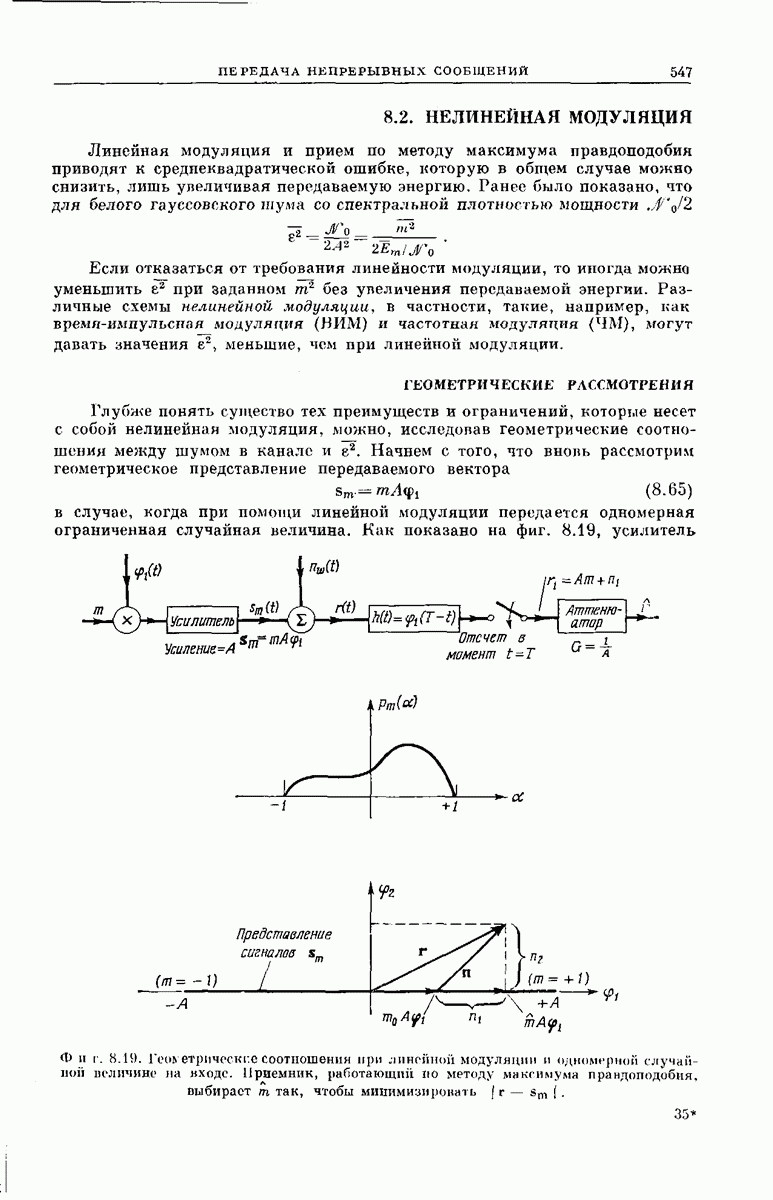
СВЕРТОЧНЫЕ КОДИРУЮЩИЕ УСТРОЙСТВА
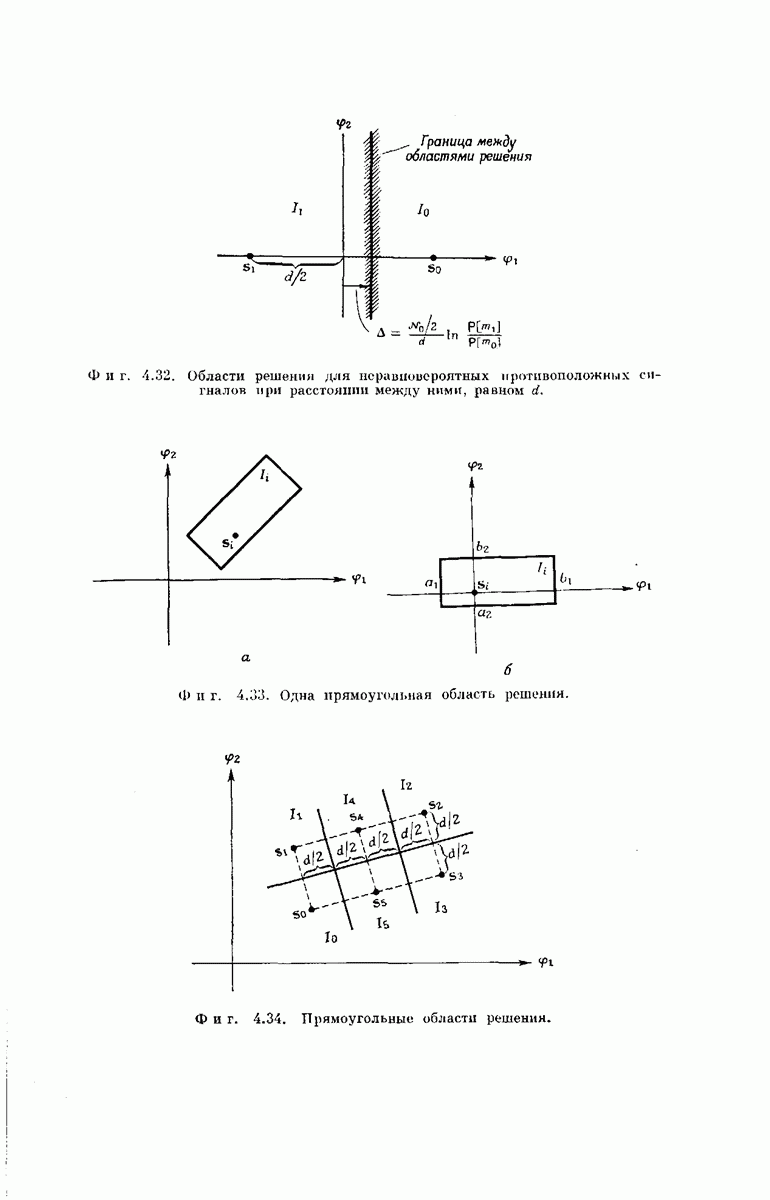
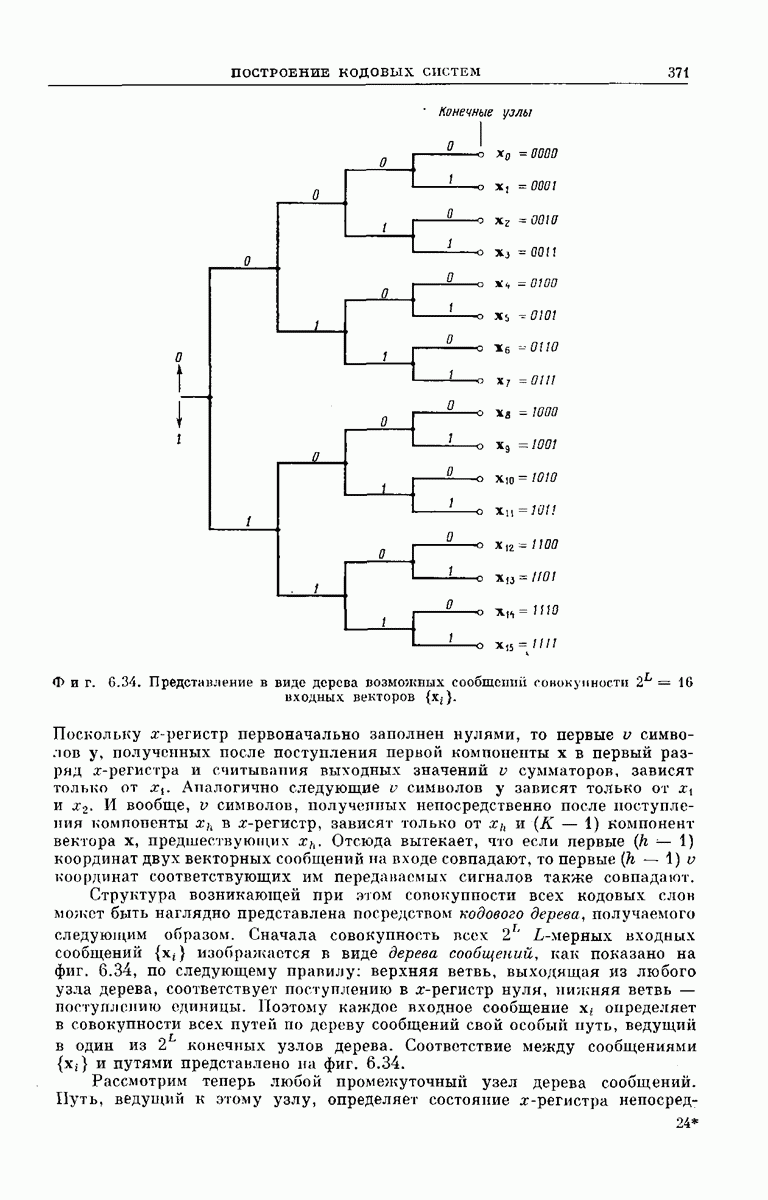
Сверточные коды для использования в ДСК можно получить кодирующими устройствами, подобными изображенным на фиг. 6.32; эти устройства несколько проще, чем блоковые кодеры. Так же как блоковый кодер, изображенный на фиг. 6.6, рассматриваемый кодер имеет  -регистр на К разрядов. Однако у-регистр отсутствует, а вместо
-регистр на К разрядов. Однако у-регистр отсутствует, а вместо  сумматоров по модулю 2 имеется только
сумматоров по модулю 2 имеется только  сумматоров, где
сумматоров, где  обычно невелико.
обычно невелико.
Устройство кодера определяют коэффициенты  Как и в блоковых кодерах, равенство
Как и в блоковых кодерах, равенство  означает, что 1-й разряд
означает, что 1-й разряд  -регистра связан с
-регистра связан с  сумматором, а равенство
сумматором, а равенство  означает, что эти разряд и сумматор не связаны. Как и ранее, удобно представить совокупность связей
означает, что эти разряд и сумматор не связаны. Как и ранее, удобно представить совокупность связей  разряда
разряда  -регистра в виде вектора, который обозначим через
-регистра в виде вектора, который обозначим через

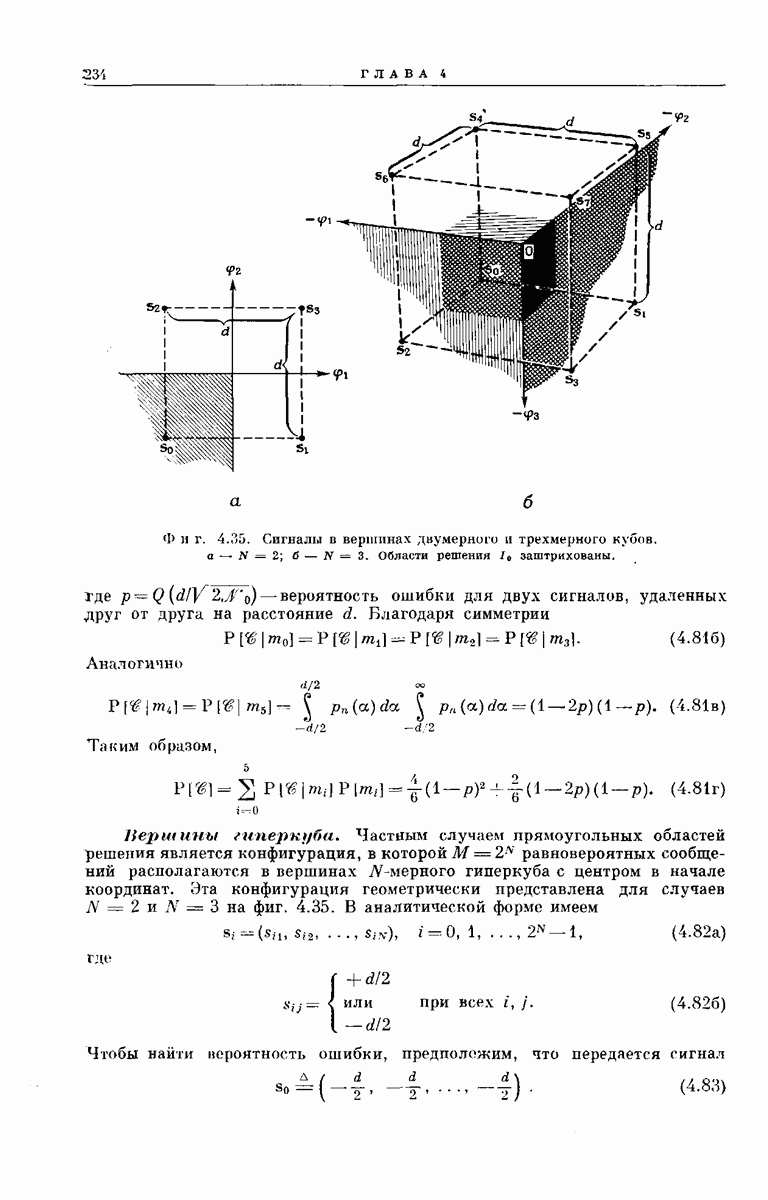
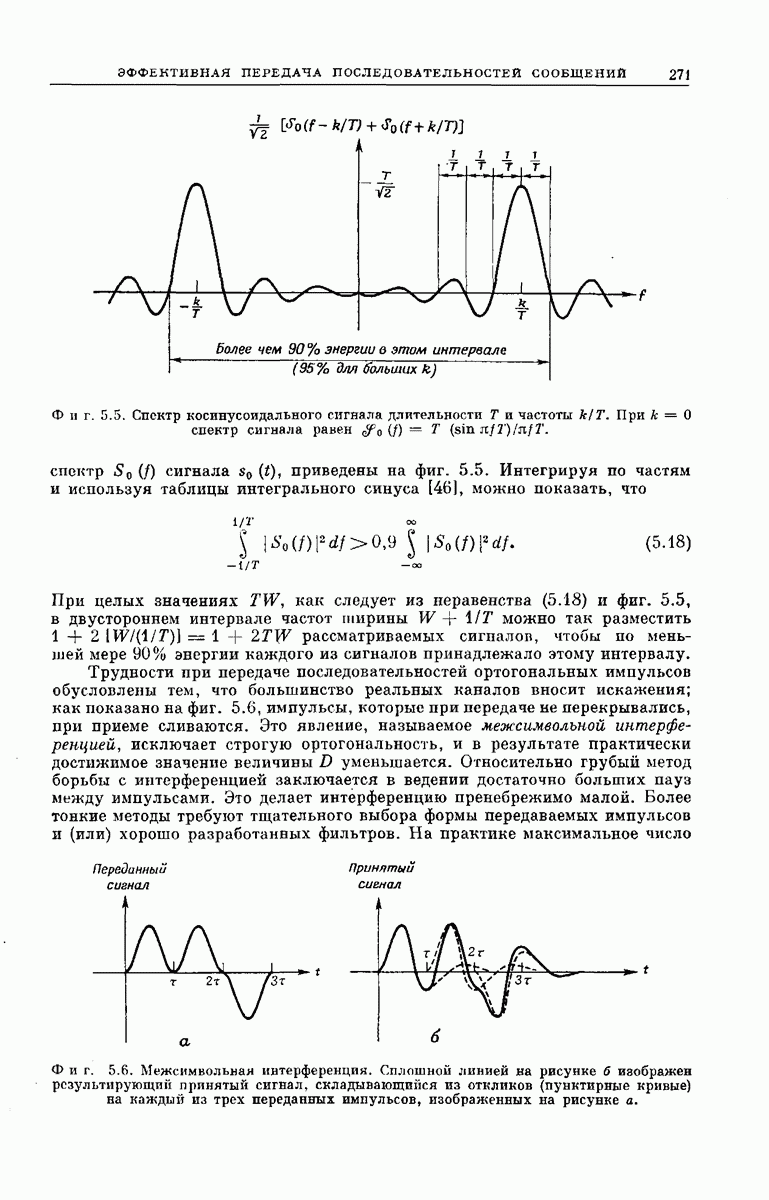
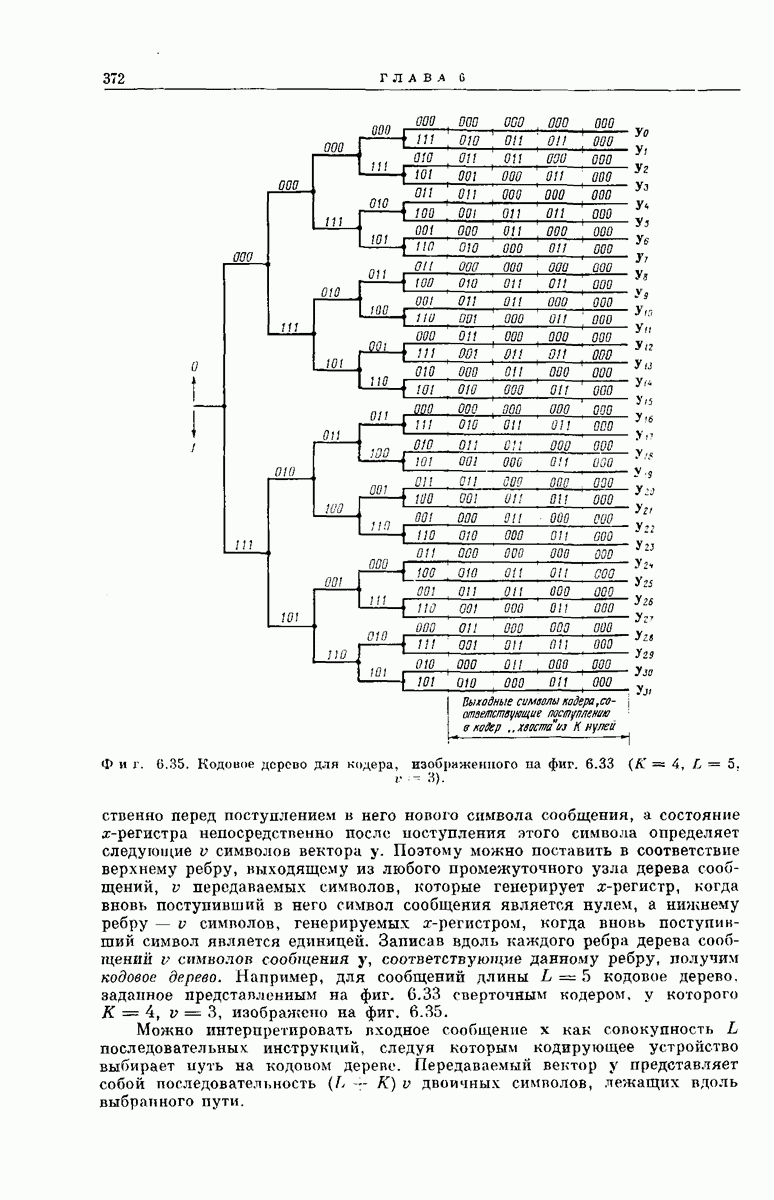
Например, кодирующее устройство, изображенное на фиг. 6.33, у которого  определяется коэффициентами
определяется коэффициентами


(кликните для просмотра скана)
Сверточный кодер действует следующим образом. Допустим, что мы хотим передать сообщение, содержащее  информационных двоичных символов,
информационных двоичных символов,

где  может быть больше К. До передачи все К разрядов
может быть больше К. До передачи все К разрядов  -регистра заполнены нулями. Затем первый символ
-регистра заполнены нулями. Затем первый символ  вектора
вектора  сдвигается в первый разряд
сдвигается в первый разряд  -регистра. Коммутатор, изображенный на фиг. 6.32, считывает один за другим выходные значения
-регистра. Коммутатор, изображенный на фиг. 6.32, считывает один за другим выходные значения  сумматоров по модулю 2 и образует из них сигнал для передачи по
сумматоров по модулю 2 и образует из них сигнал для передачи по  После считывания и передачи выходного значения
После считывания и передачи выходного значения  сумматора второй символ сообщения
сумматора второй символ сообщения  сдвигается в первый разряд
сдвигается в первый разряд  -регистра, а первый символ
-регистра, а первый символ  во второй разряд этого регистра. Выходные значения
во второй разряд этого регистра. Выходные значения  сумматоров снова считываютсн и передаются. Эта процедура продолжается до тех пор, пока последний символ
сумматоров снова считываютсн и передаются. Эта процедура продолжается до тех пор, пока последний символ  вектора
вектора  не сдвинется в первый разряд
не сдвинется в первый разряд  -регистра. После этого в
-регистра. После этого в  -регистр последовательно поступают К нулей, тем самым возвращая его в первоначальное положение. Каждый сдвиг сопровождается считыванием и передачей выходных значений
-регистр последовательно поступают К нулей, тем самым возвращая его в первоначальное положение. Каждый сдвиг сопровождается считыванием и передачей выходных значений  сумматоров; после каждого сдвига число, покидающее
сумматоров; после каждого сдвига число, покидающее  разряд
разряд  -регистра, сбрасывается
-регистра, сбрасывается 
Выходная последовательность кодера, соответствующая входному вектору длины  состоит из
состоит из  символов. Обозначим эту последовательность вектором у.
символов. Обозначим эту последовательность вектором у.
Чтобы проиллюстрировать процедуру сверточпого кодирования, вернемся к кодеру, изображенному на фиг.  Легко проверить, что передаваемому сообщению, содержащему 5 двоичных символов информации:
Легко проверить, что передаваемому сообщению, содержащему 5 двоичных символов информации:

соответствует следующая последовательность на выходе кодирующего устройства:

(Занятые введены здесь для наглядности как указания на сдвиги регистра; они будут опускаться в дальнейшем.)
Обычно в приложениях длина сообщения  гораздо больше числа разрядов в
гораздо больше числа разрядов в  -регистре, т. е.
-регистре, т. е.  Так как при этом «хвост» из нулей, вводимых в
Так как при этом «хвост» из нулей, вводимых в  -регистр после сообщения
-регистр после сообщения  гораздо короче самого вектора
гораздо короче самого вектора  то отношение числа символов сообщения к числу передаваемых символов приблизительно равно
то отношение числа символов сообщения к числу передаваемых символов приблизительно равно  Следовательно, скорость передачи сообщений
Следовательно, скорость передачи сообщений  двоичным сверточпым кодом описанного тина 2) определяется формулой
двоичным сверточпым кодом описанного тина 2) определяется формулой

Каждый символ сообщения находится в  -регистре и течение К действий сумматоров и, следовательно, влияет на К и передаваемых символов. Величину К назовем длиной кодовых ограничений (измеряемую в битах входного сообщения) сверточного кода.
-регистре и течение К действий сумматоров и, следовательно, влияет на К и передаваемых символов. Величину К назовем длиной кодовых ограничений (измеряемую в битах входного сообщения) сверточного кода.
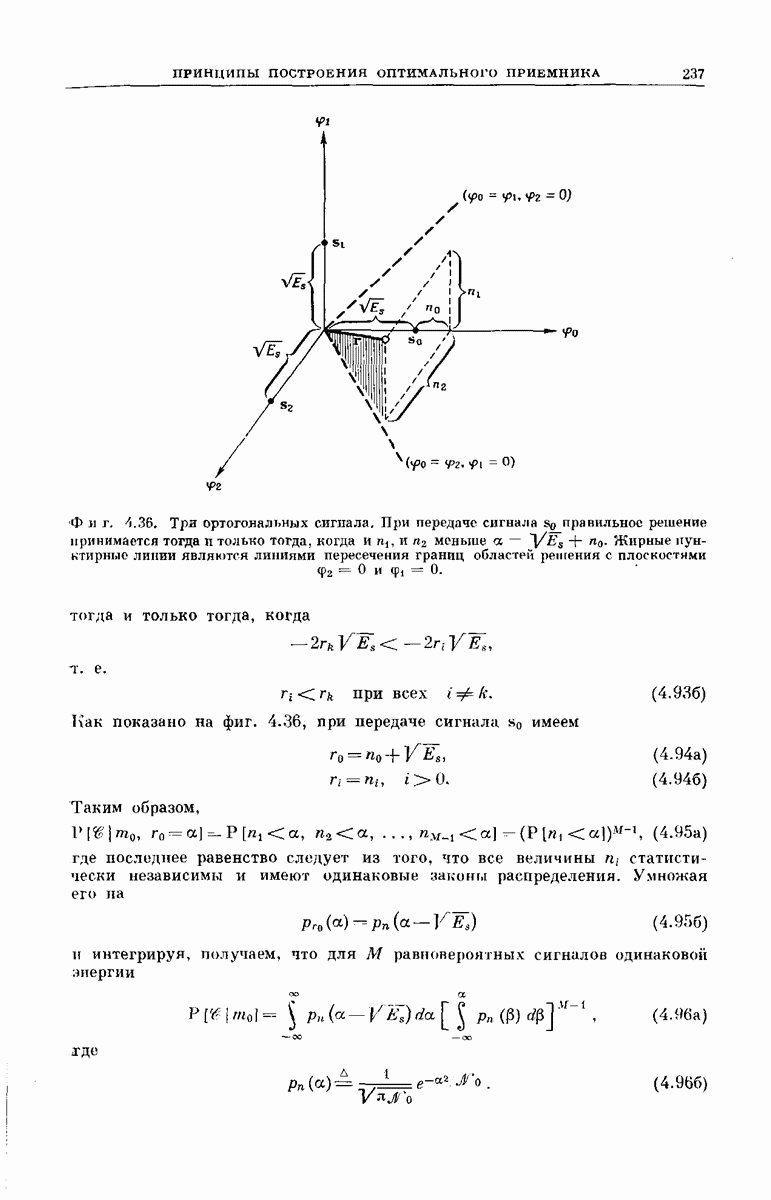
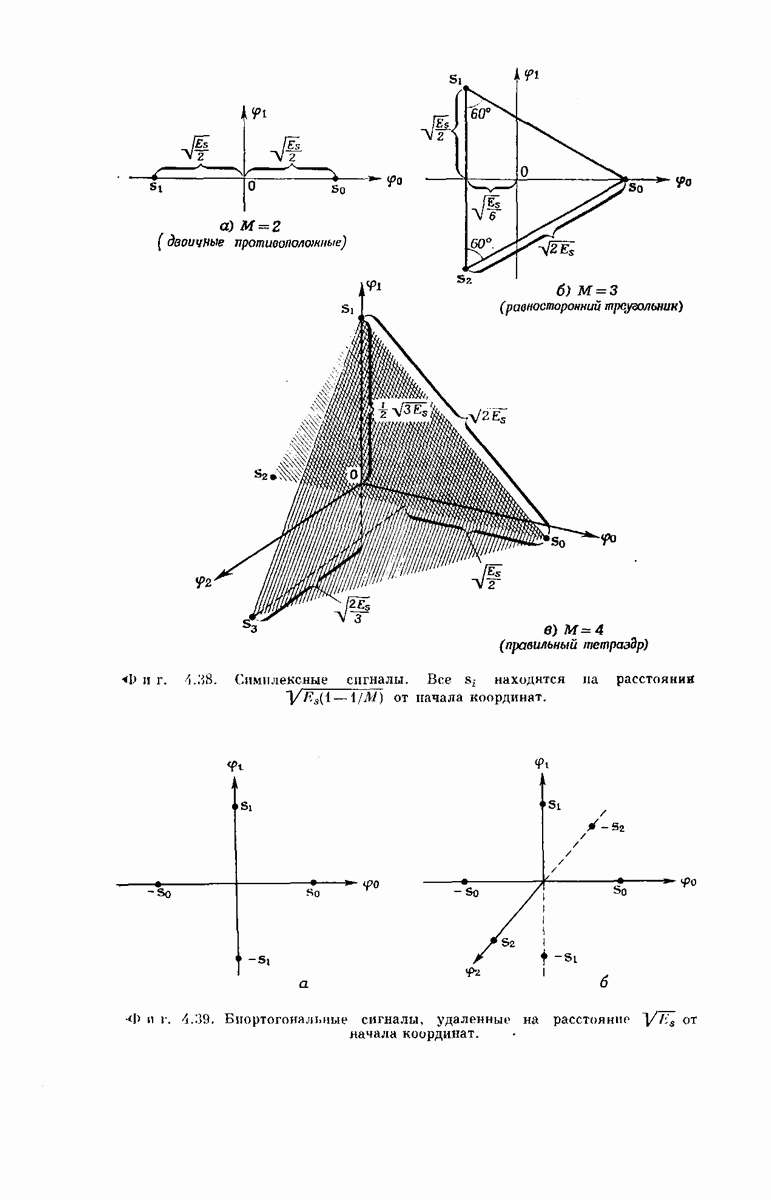
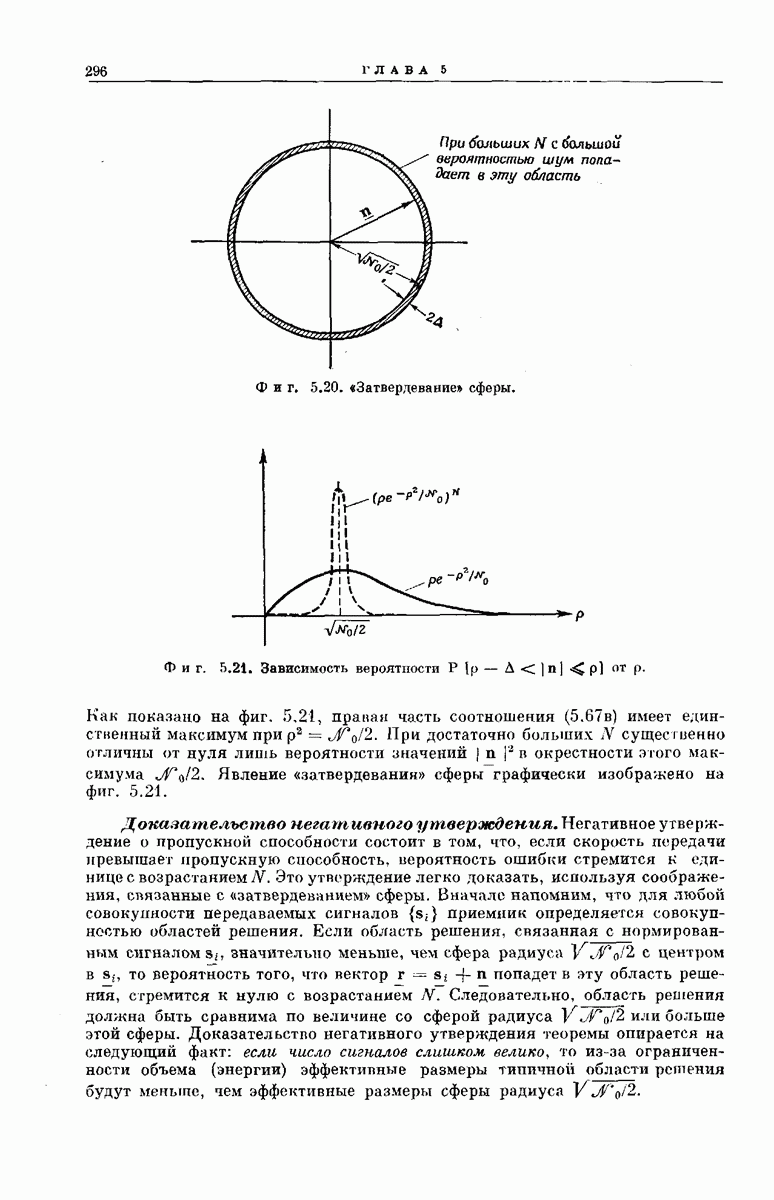
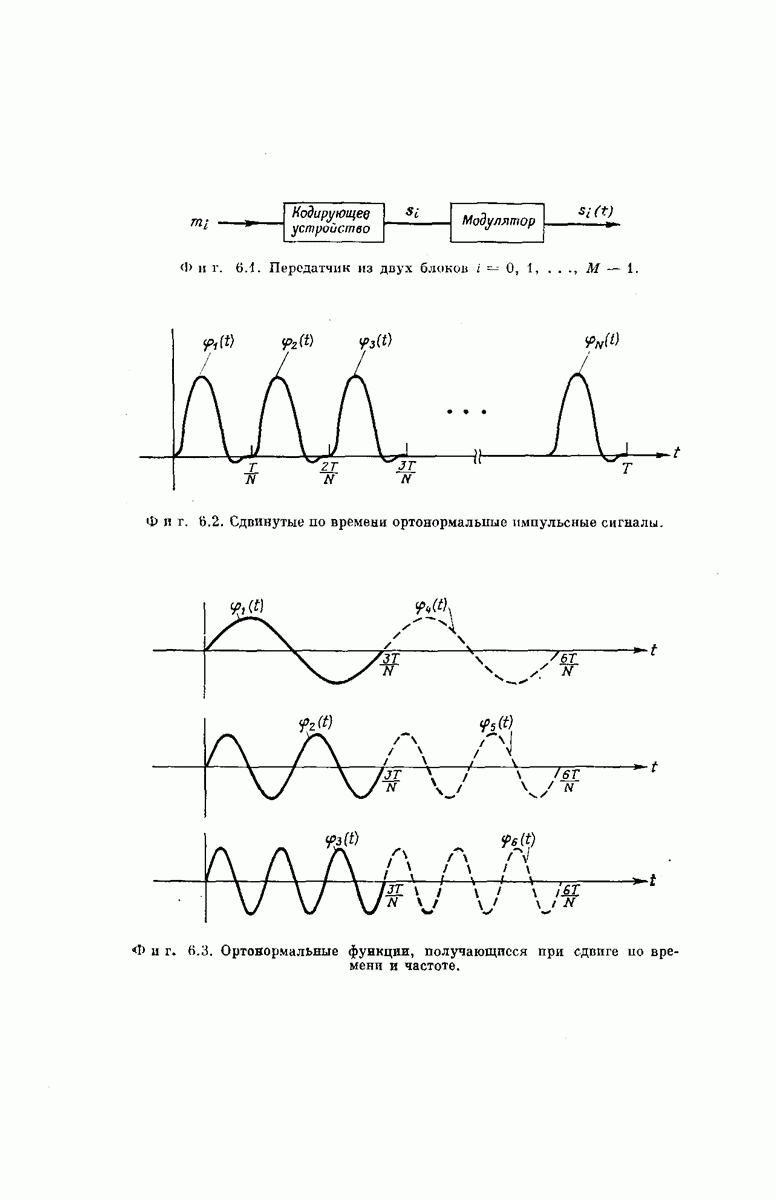
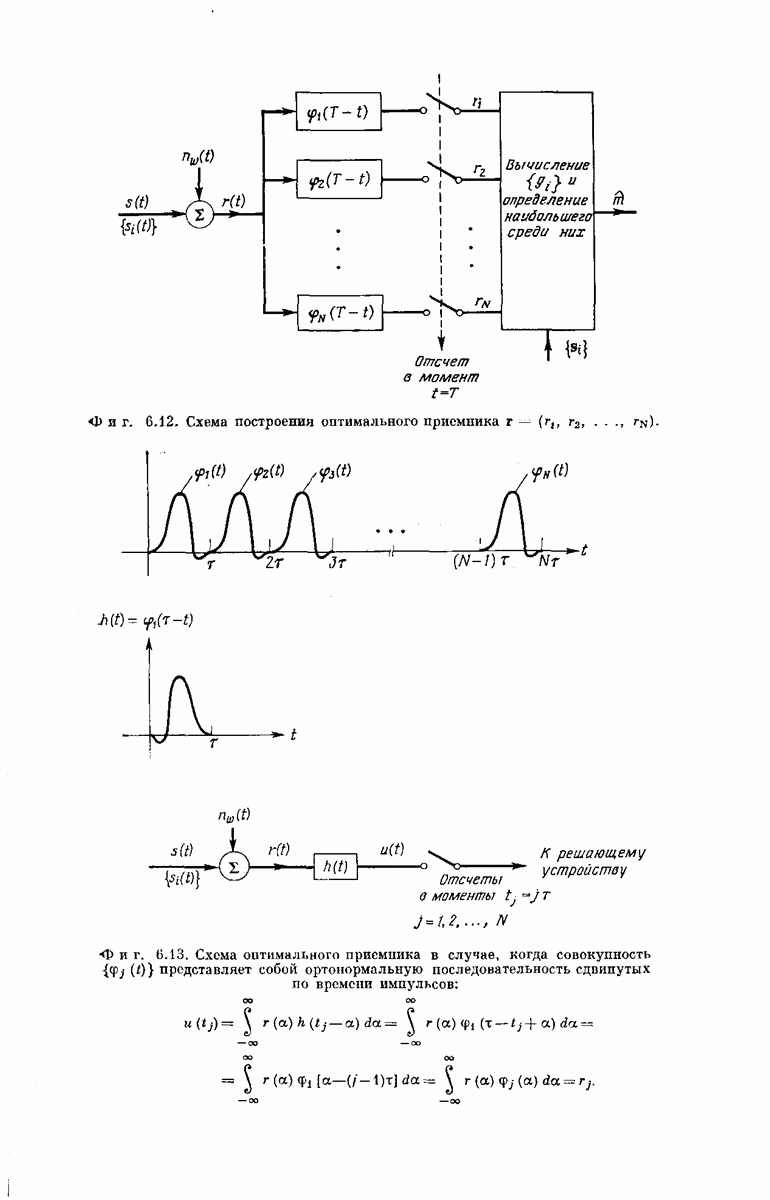
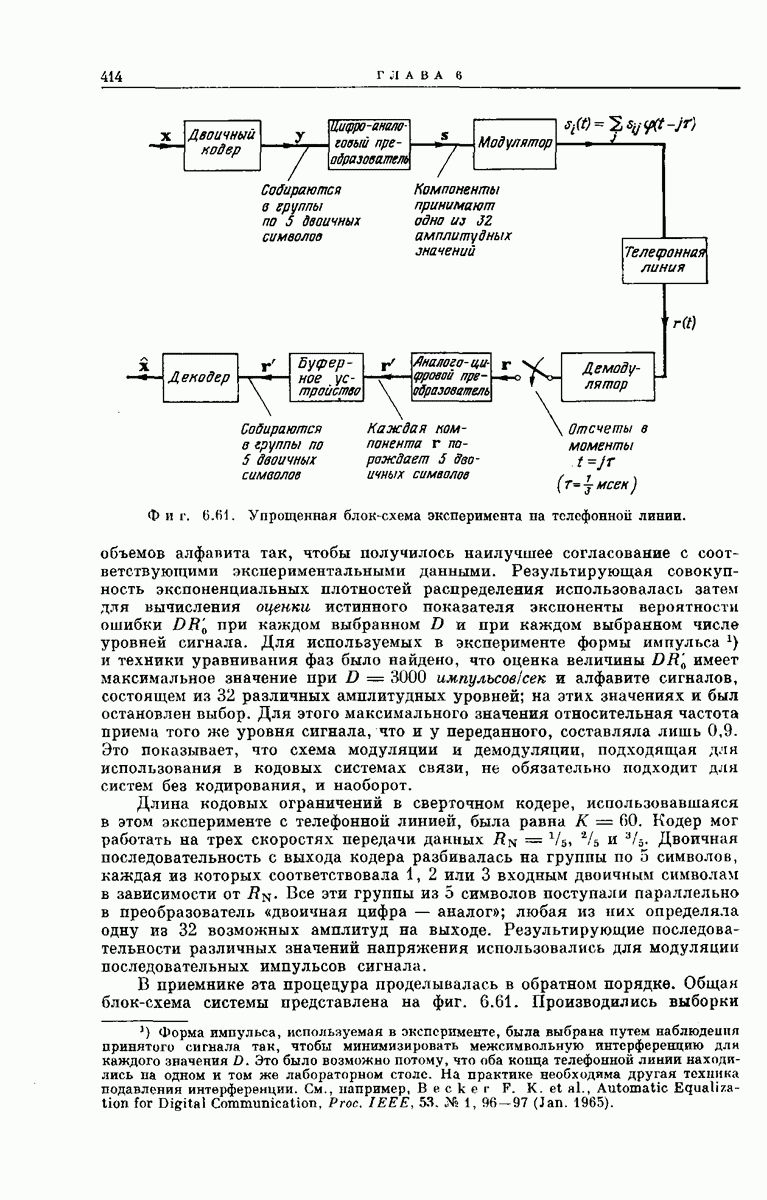
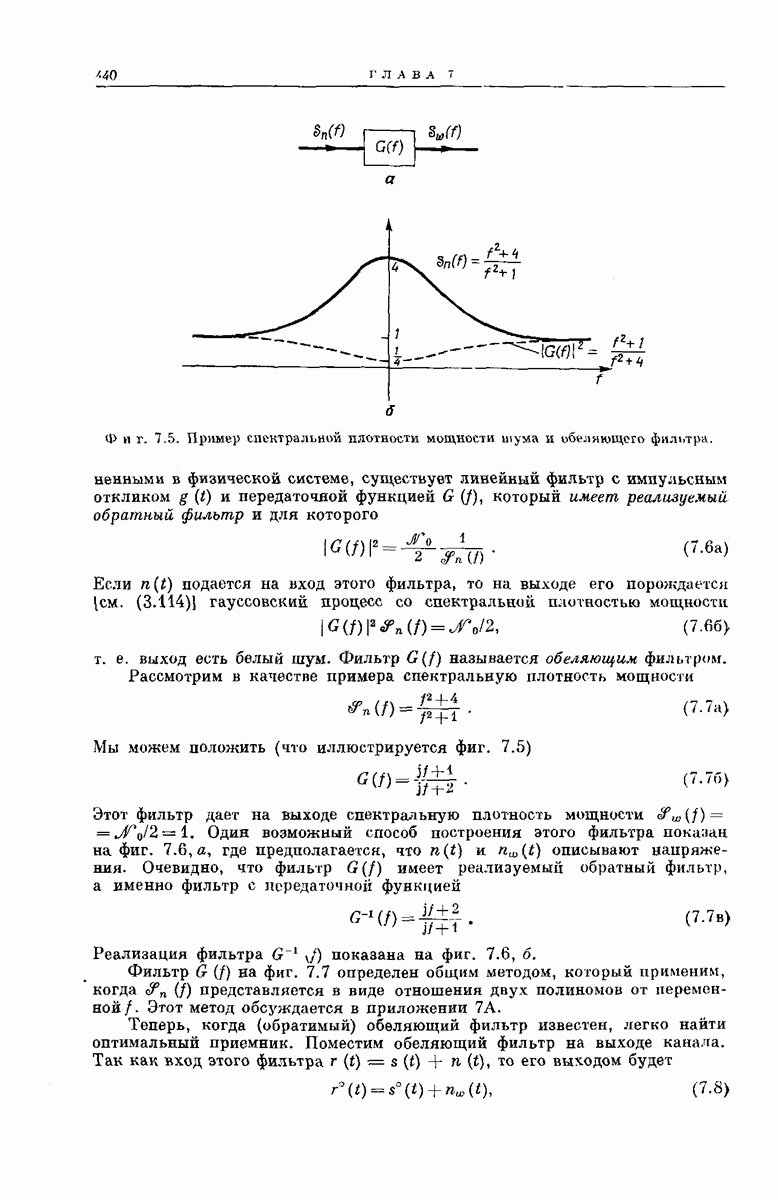
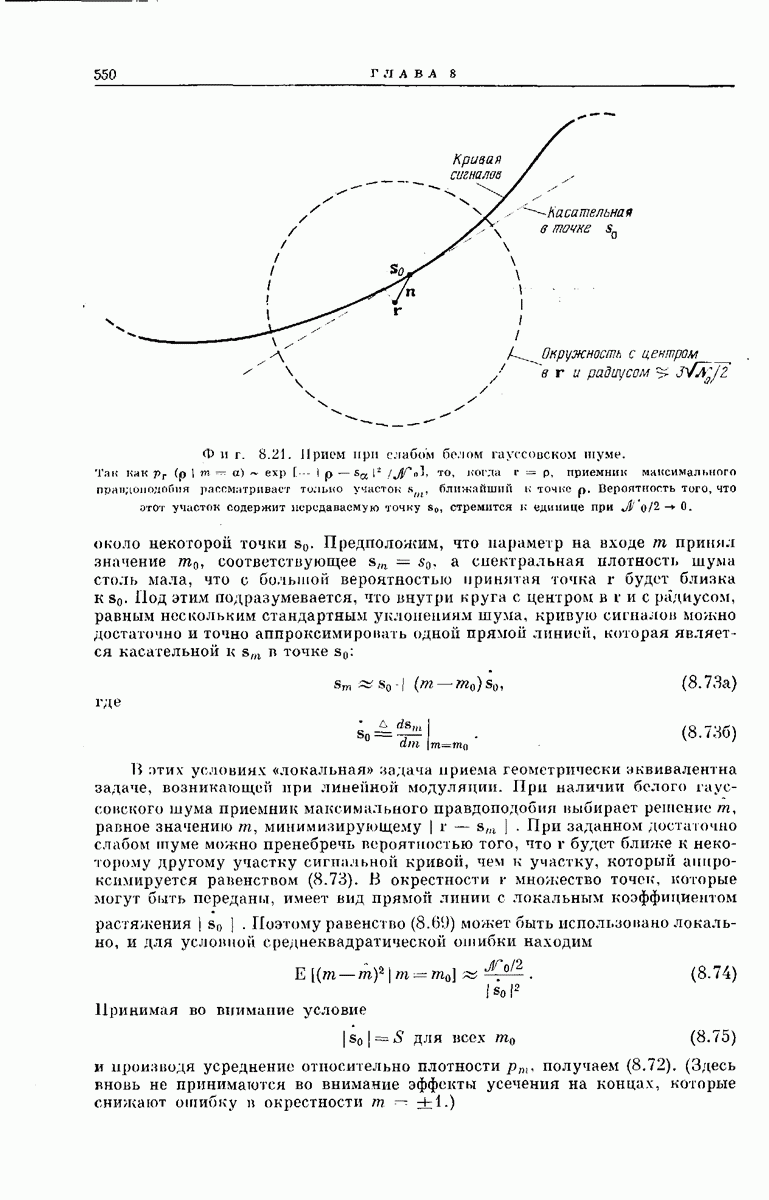
Древовидная структура. Теперь рассмотрим более детально процесс построения выходного кодового слова у по входному сообщению:


Фиг. 6.34. Представление в виде дерева возможных сообщений совокупности  входных векторов
входных векторов 
Поскольку  -регистр первоначально заполнен нулями, то первые
-регистр первоначально заполнен нулями, то первые  символов у, полученных после поступления первой компоненты
символов у, полученных после поступления первой компоненты  в первый разряд
в первый разряд  -регистра и считывания выходных значений
-регистра и считывания выходных значений  сумматоров, зависят только от
сумматоров, зависят только от  Аналогично следующие и символов у зависят только от
Аналогично следующие и символов у зависят только от  . И вообще,
. И вообще,  символов, полученных непосредственно после поступления компопенты
символов, полученных непосредственно после поступления компопенты  в
в  -регистр, зависят только от
-регистр, зависят только от  и
и  компонент вектора
компонент вектора  предшествующих
предшествующих  Отсюда вытекает, что если первые
Отсюда вытекает, что если первые  координат двух векторных сообщений на входе совпадают, то первые
координат двух векторных сообщений на входе совпадают, то первые  и координат соответствующих им передаваемых сигналов также совпадают.
и координат соответствующих им передаваемых сигналов также совпадают.
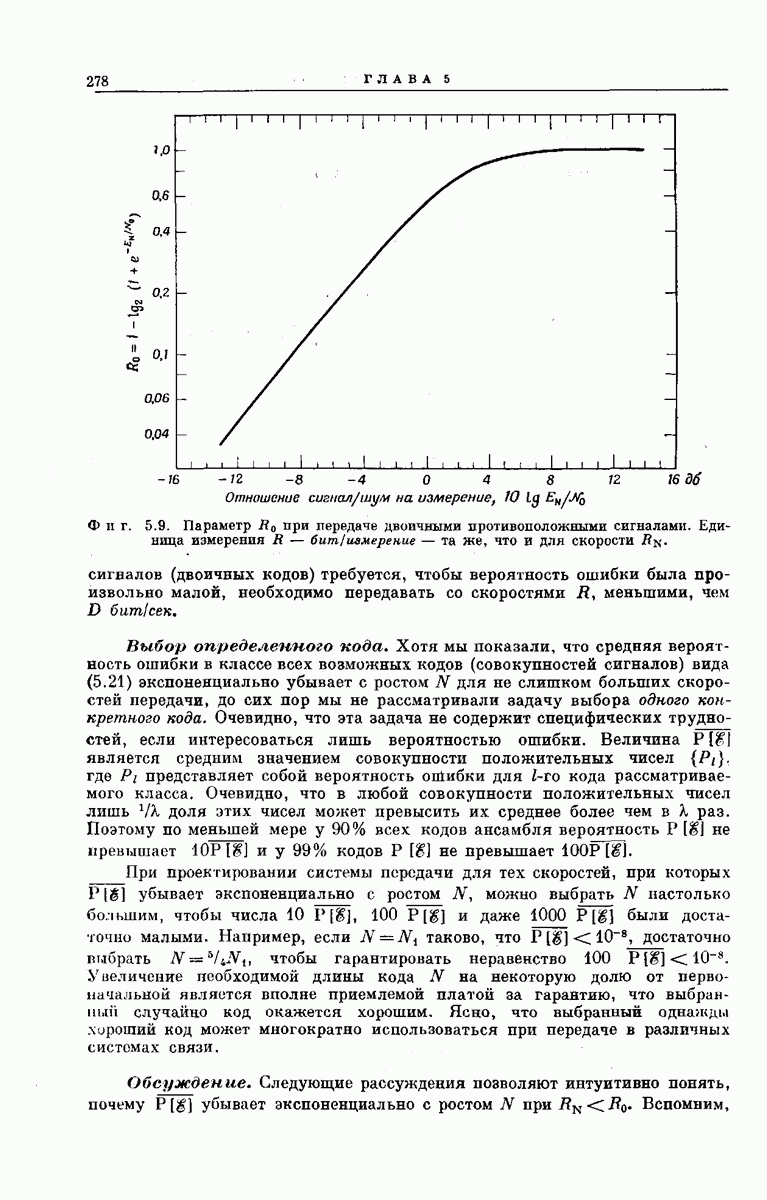
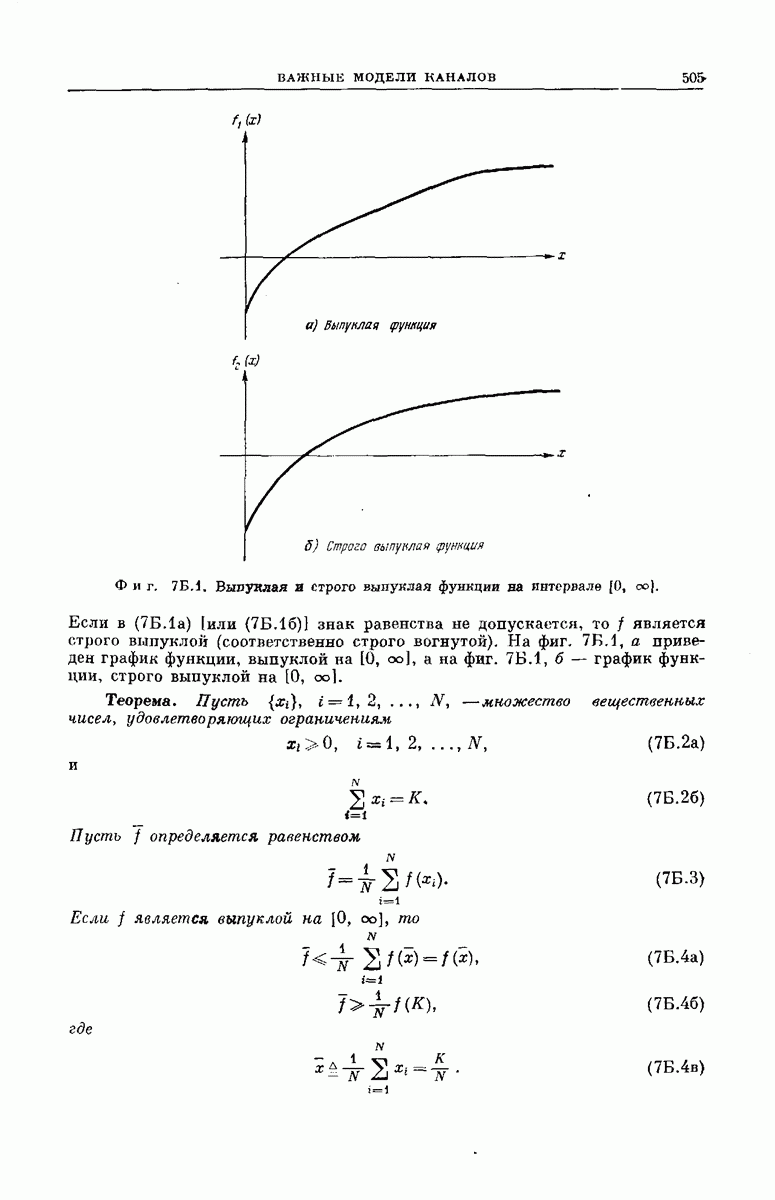
Структура возникающей при этом совокупности всех кодовых слон может быть наглядно представлена посредством кодового дерева, получаемого следующим образом. Сначала совокупность всех  -мерных входных сообщений
-мерных входных сообщений  изображается в виде дерева сообщений, как показано на фиг. 6.34, по следующему правилу: верхняя ветвь, выходящая из любого узла дерева, соответствует поступлению в
изображается в виде дерева сообщений, как показано на фиг. 6.34, по следующему правилу: верхняя ветвь, выходящая из любого узла дерева, соответствует поступлению в  -регистр нуля, нижняя ветвь — поступлению единицы. Поэтому каждое входное сообщение
-регистр нуля, нижняя ветвь — поступлению единицы. Поэтому каждое входное сообщение  определяет в совокупности всех путей по дереву сообщений свой особый путь, ведущий в один из 2 конечных узлов дерева. Соответствие между сообщениями
определяет в совокупности всех путей по дереву сообщений свой особый путь, ведущий в один из 2 конечных узлов дерева. Соответствие между сообщениями  и путями представлено на фиг. 6.34.
и путями представлено на фиг. 6.34.
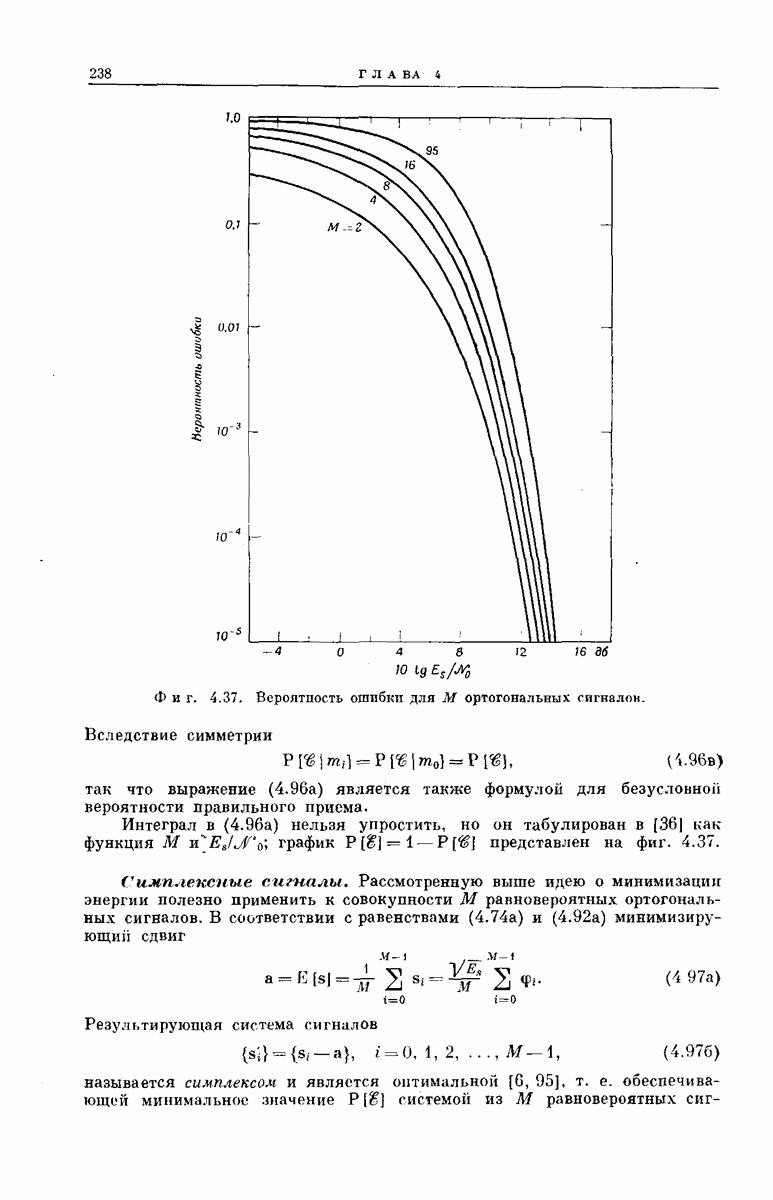
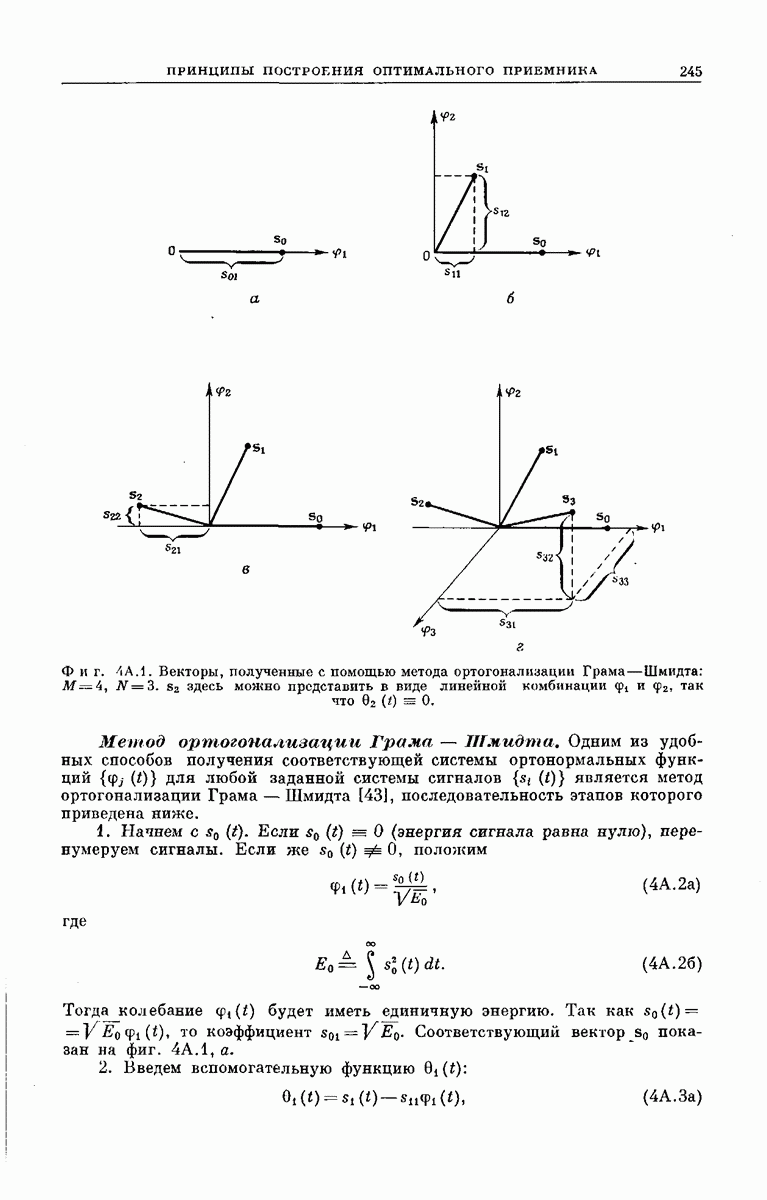
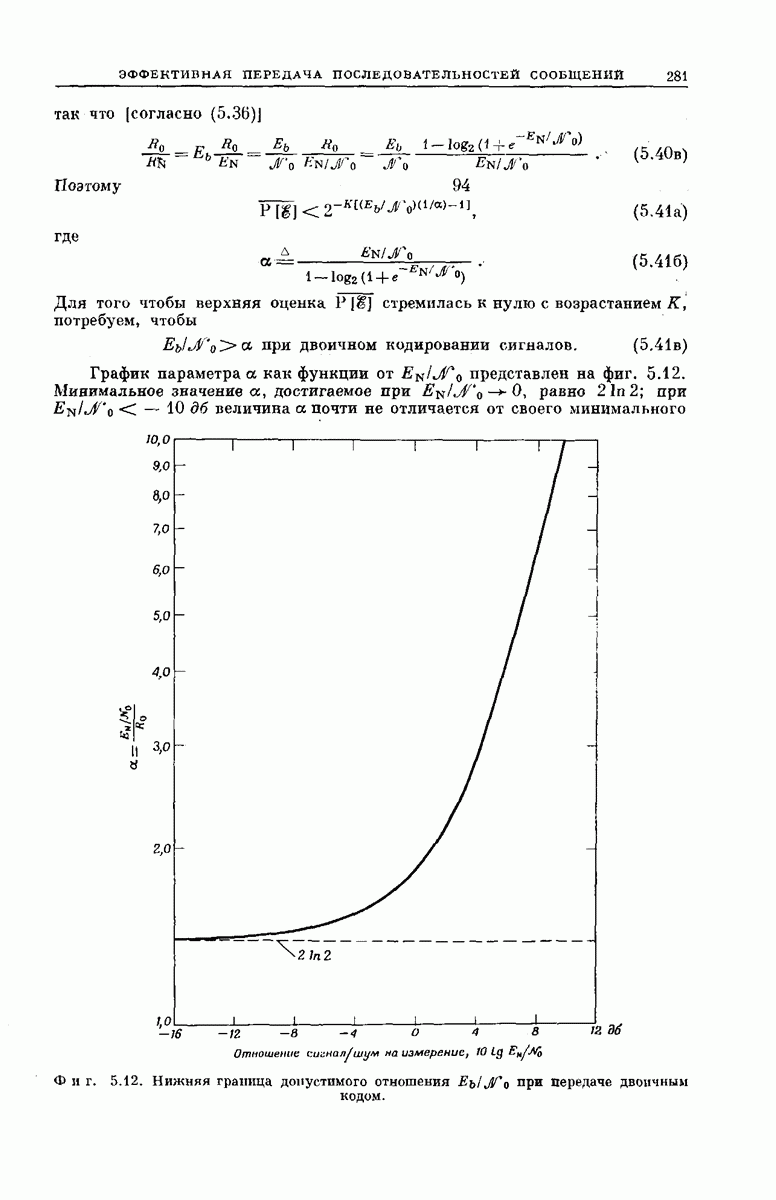
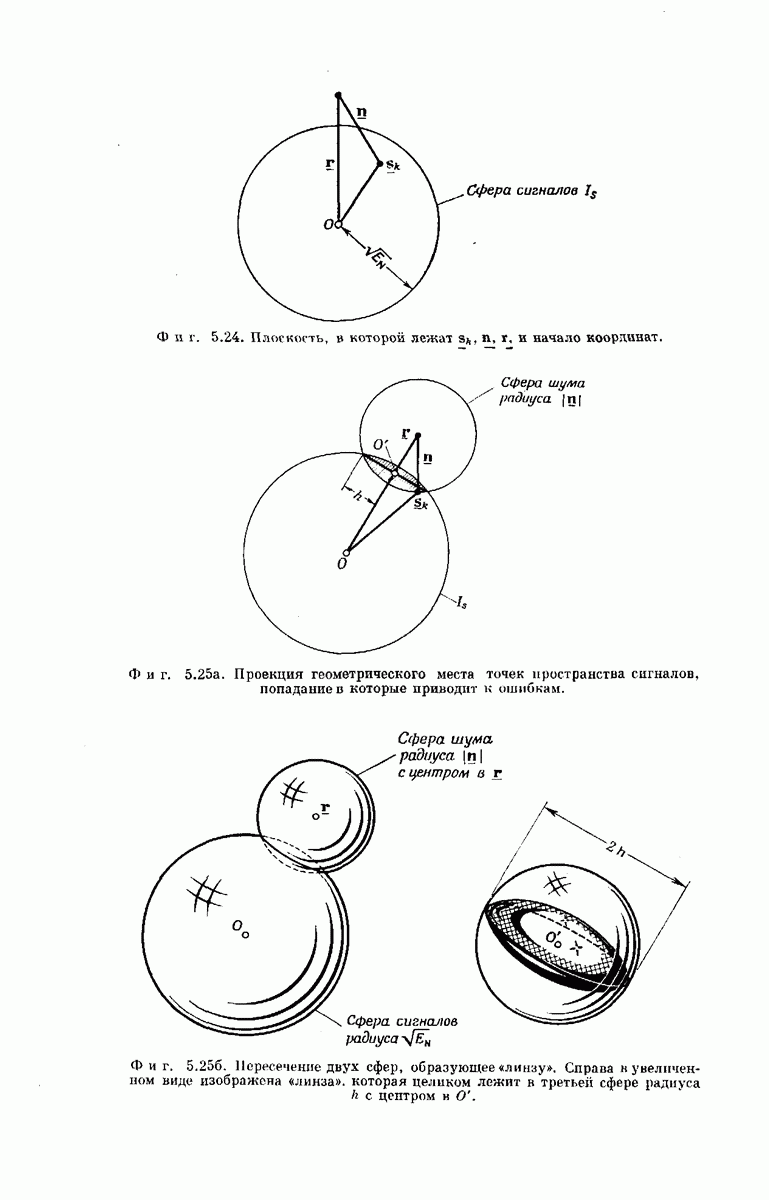
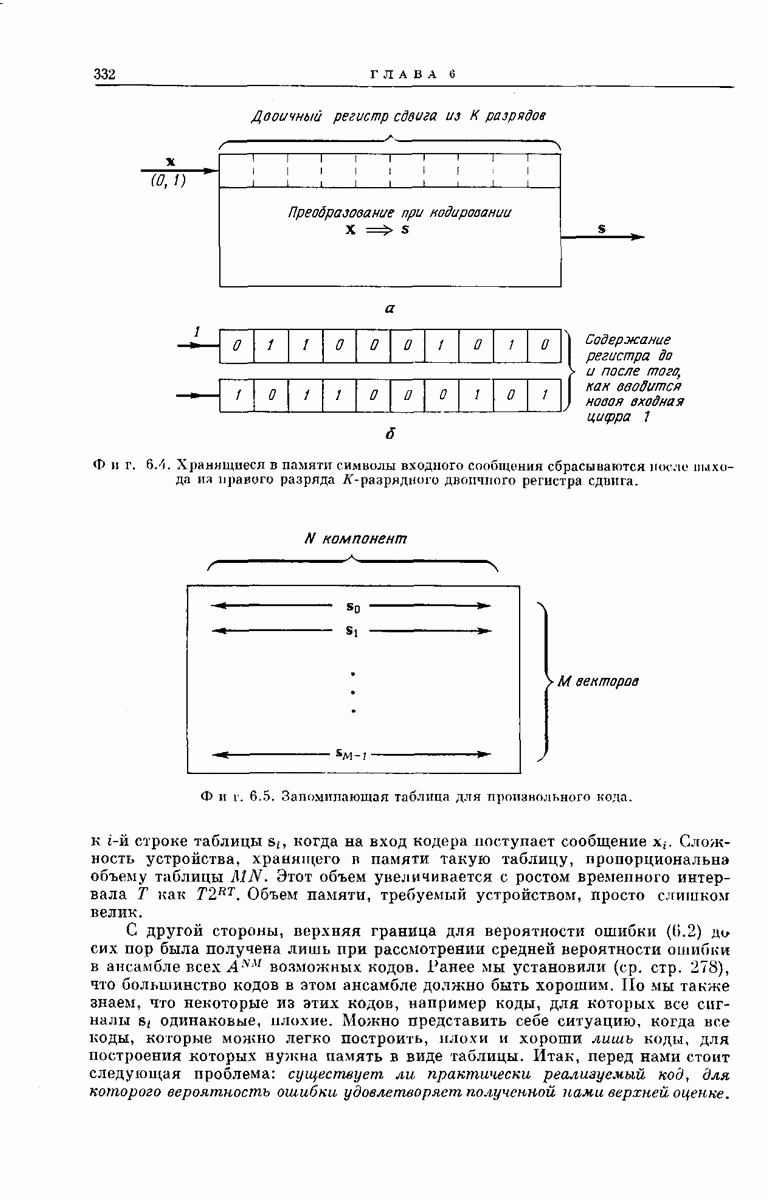
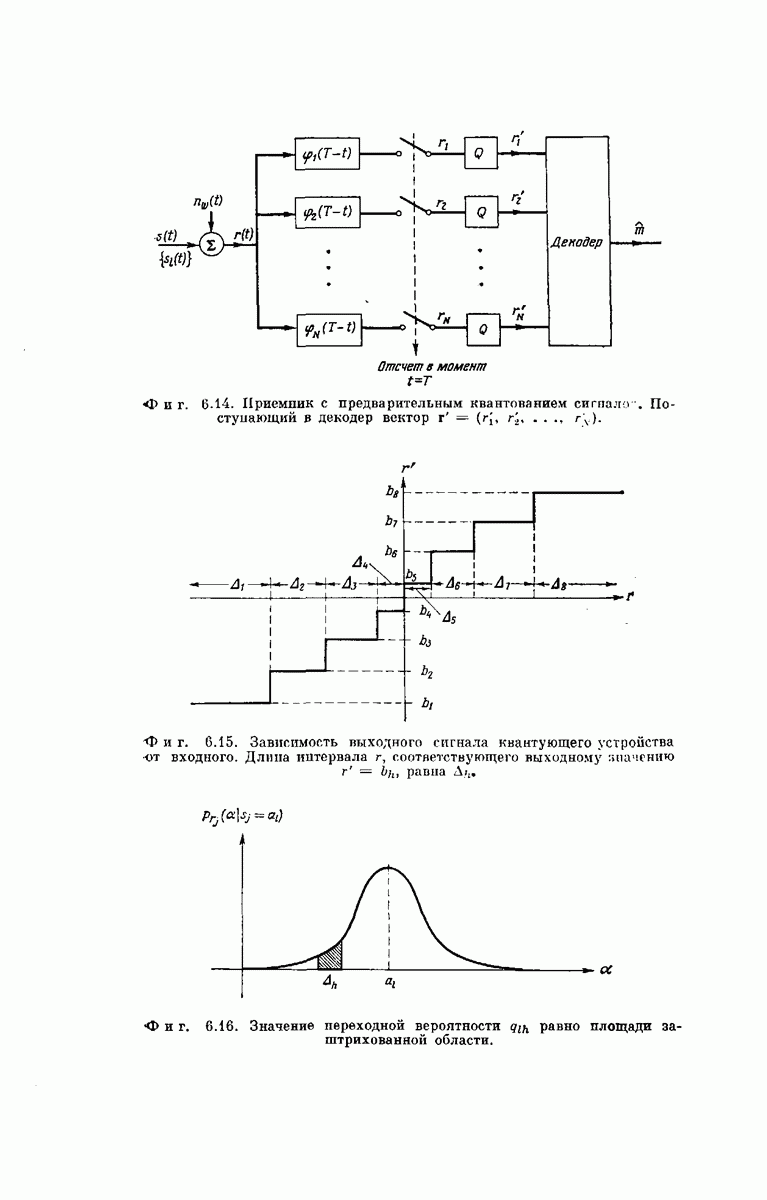
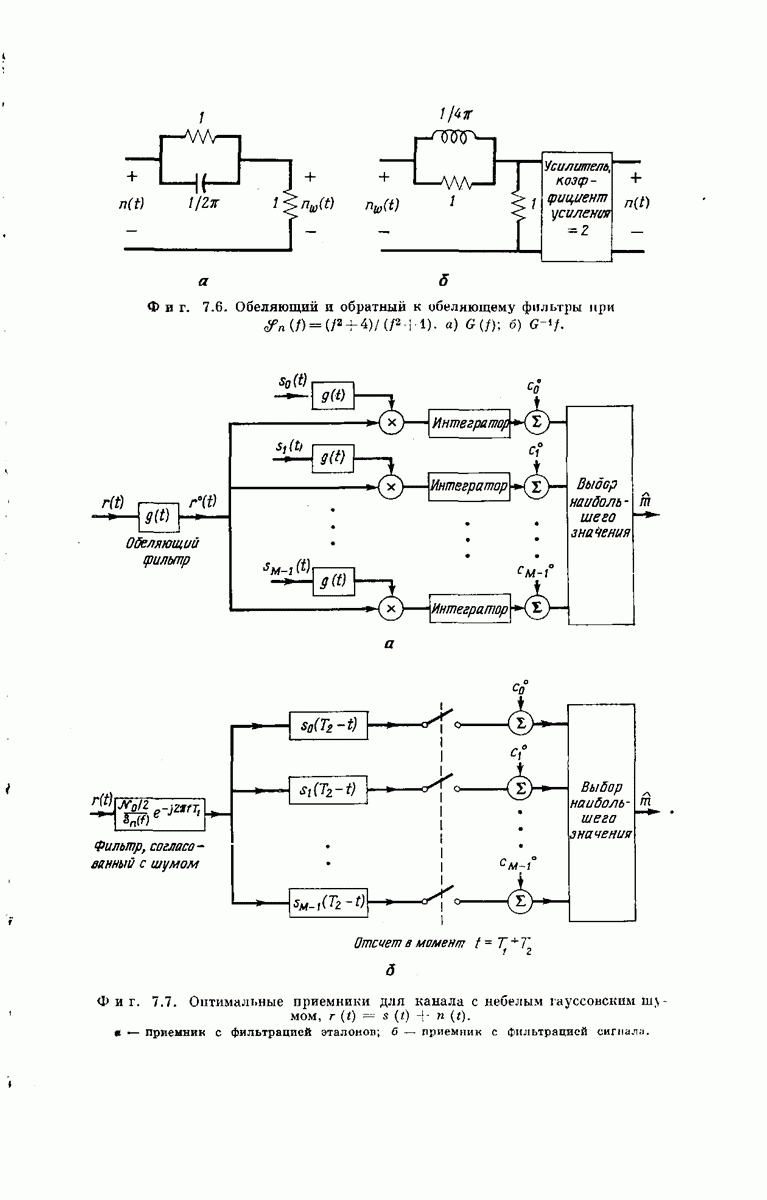
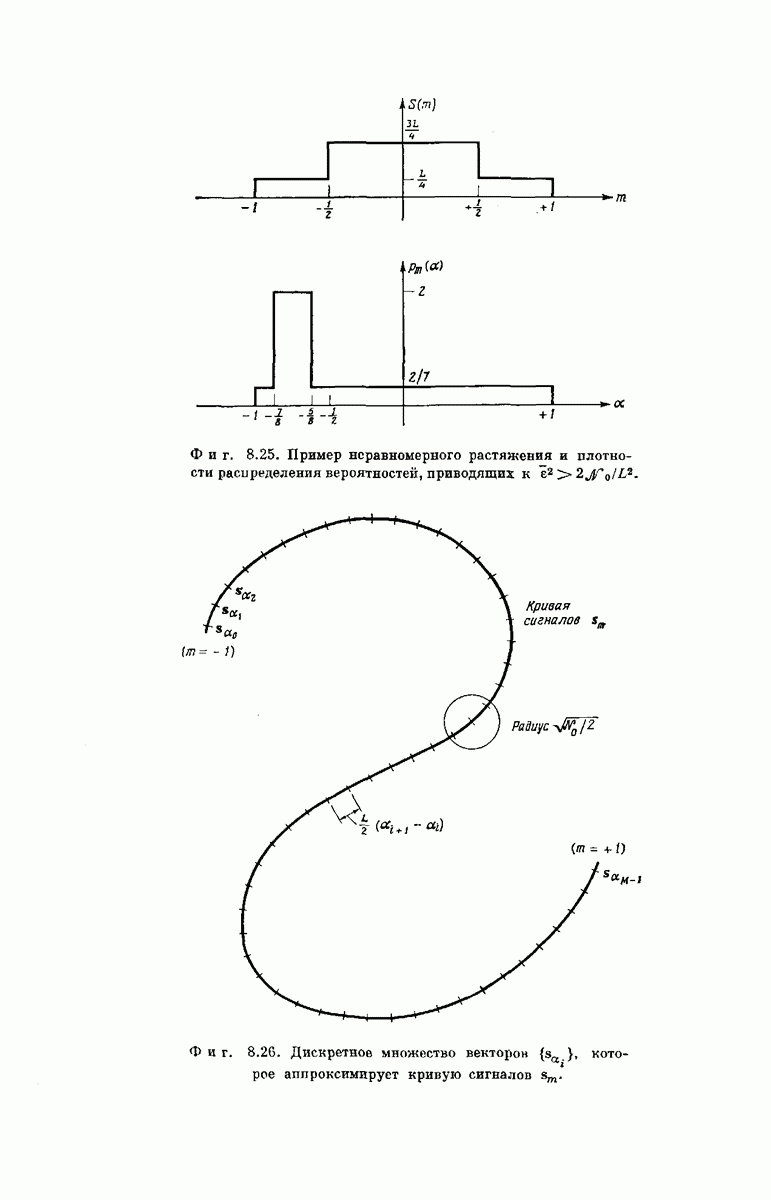
Рассмотрим теперь любой промежуточный узел дерева сообщений. Путь, ведущий к этому узлу, определяет состояние  -регистра непосредственно
-регистра непосредственно

Фиг. 6.35. Кодовое дерево для кодера, изображенного на фиг. 6.33  .
.
перед поступлением в него нового символа сообщения, а состояние  -регистра непосредственно после поступления этого символа определяет следующие
-регистра непосредственно после поступления этого символа определяет следующие  символов вектора у. Поэтому можно поставить в соответствие верхнему ребру, выходящему из любого промежуточного узла дерева сообщений,
символов вектора у. Поэтому можно поставить в соответствие верхнему ребру, выходящему из любого промежуточного узла дерева сообщений,  передаваемых символов, которые генерирует х-регистр, когда вновь поступивший в него символ сообщения является нулем, а нижнему ребру —
передаваемых символов, которые генерирует х-регистр, когда вновь поступивший в него символ сообщения является нулем, а нижнему ребру —  символов, генерируемых
символов, генерируемых  -регистром, когда вновь поступивший символ является единицей. Записав вдоль каждого ребра дерева сообщений и символов сообщения у, соответствующие данному ребру, получим кодовое дерево. Например, для сообщений длины
-регистром, когда вновь поступивший символ является единицей. Записав вдоль каждого ребра дерева сообщений и символов сообщения у, соответствующие данному ребру, получим кодовое дерево. Например, для сообщений длины  кодовое дерево, заданное представленным на фиг. 6.33 сверточным кодером, у которого
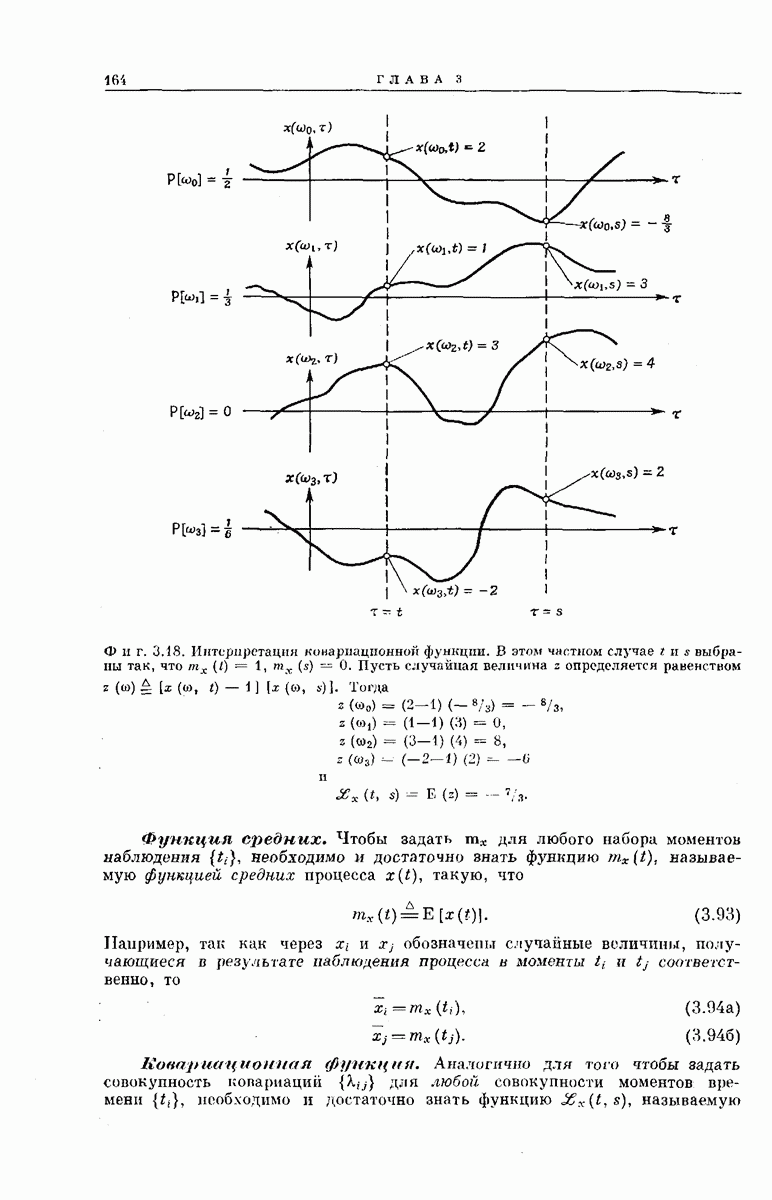
кодовое дерево, заданное представленным на фиг. 6.33 сверточным кодером, у которого  изображено на фиг. 6.35.
изображено на фиг. 6.35.
Можно интерпретировать входное сообщение  как совокупность
как совокупность  последовательных инструкций, следуя которым кодирующее устройство выбирает путь на кодовом дереве. Передаваемый вектор у представляет собой последовательность
последовательных инструкций, следуя которым кодирующее устройство выбирает путь на кодовом дереве. Передаваемый вектор у представляет собой последовательность  и двоичных символов, лежащих вдоль выбранного пути.
и двоичных символов, лежащих вдоль выбранного пути.
Линейность. Чтобы лучше понять структуру кодового дерева, используем тот факт, что сверточный кодер, изображенный на фиг. 6.32, является устройством проверки на четность; в любой момент времени выходное значение каждого из сумматоров по модулю 2 равно нулю, если число единиц в разрядах  -регистра, с которыми он связан, четно и равно единице, если это число единиц нечетно. Так же как и блоковые кодеры с проверкой на четность, сверточные кодеры линейны в том смысле, что передаваемый сигнал, соответствующий входному сообщению кодера
-регистра, с которыми он связан, четно и равно единице, если это число единиц нечетно. Так же как и блоковые кодеры с проверкой на четность, сверточные кодеры линейны в том смысле, что передаваемый сигнал, соответствующий входному сообщению кодера  может быть записан в виде
может быть записан в виде

Соотношение  по форме аналогично соотношению
по форме аналогично соотношению  для блоковых кодов с проверкой на четность
для блоковых кодов с проверкой на четность

где каждый из  -мерных векторов
-мерных векторов  описывает связь между
описывает связь между  сумматорами по модулю
сумматорами по модулю  разрядом
разрядом  -разрядпого х-регистра (фиг. 6.6). Однако для снерточных кодов интерпретация
-разрядпого х-регистра (фиг. 6.6). Однако для снерточных кодов интерпретация  иная — они не являются векторами связей.
иная — они не являются векторами связей.
Смысл векторов для сверточных кодов легко установить следующим образом. Согласно соотношению  вектор на выходе декодера у равен
вектор на выходе декодера у равен  если все компоненты
если все компоненты  -мерного двоичного входного вектора
-мерного двоичного входного вектора  кроме компоненты
кроме компоненты  равны нулю,
равны нулю,  частности, полагая
частности, полагая

и учитывая, что, согласно соотношению  вектор
вектор  определяет связи
определяет связи  разряда
разряда  -регистра с
-регистра с  сумматорами по модулю 2, получим, согласно фиг. 6.32, в качестве результирующего выходного вектора вектор
сумматорами по модулю 2, получим, согласно фиг. 6.32, в качестве результирующего выходного вектора вектор 

Здесь символ 0 используется для обозначения  -мерного вектора, каждая компонента которого равна нулю. Как и выше, запятые используются для обозначения моментов, когда происходит сдвиг вправо
-мерного вектора, каждая компонента которого равна нулю. Как и выше, запятые используются для обозначения моментов, когда происходит сдвиг вправо  -регистра.
-регистра.
Из фиг. 6.32 и описания операций сверточного кодирования легко понять, что сигнал у, соответствующий сообщению  у которого все символы, кроме второго, равны 0, а второй символ равен 1, получается простым сдвигом сигнала, соответствующего сообщению, у которого все символы, кроме первого, равны 0, а первый равен 1. Поэтому сообщению
у которого все символы, кроме второго, равны 0, а второй символ равен 1, получается простым сдвигом сигнала, соответствующего сообщению, у которого все символы, кроме первого, равны 0, а первый равен 1. Поэтому сообщению

соответствует сигнал

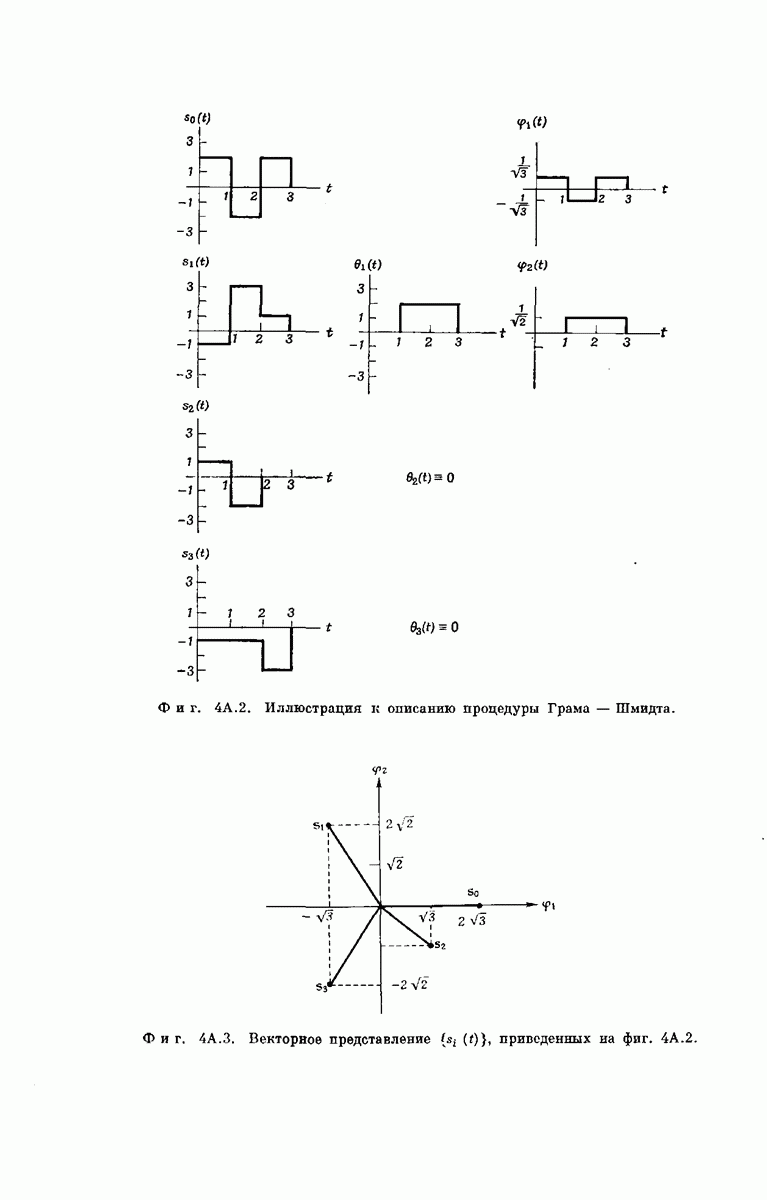
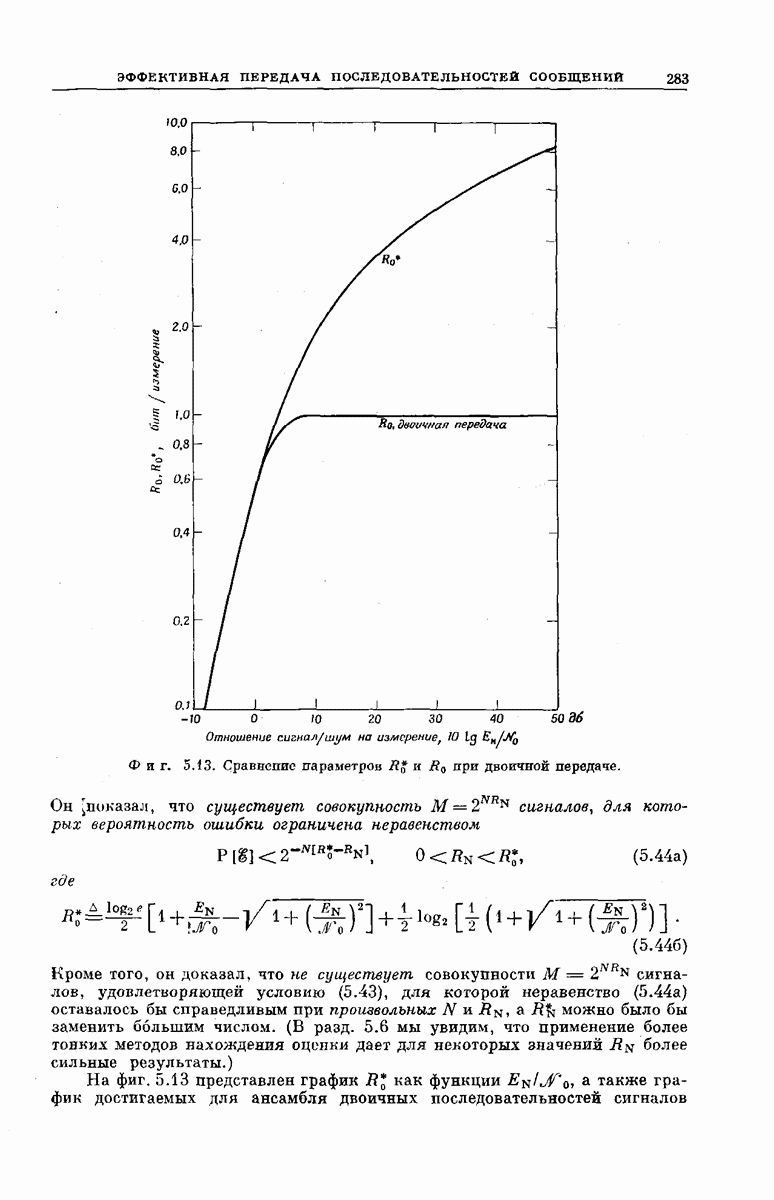
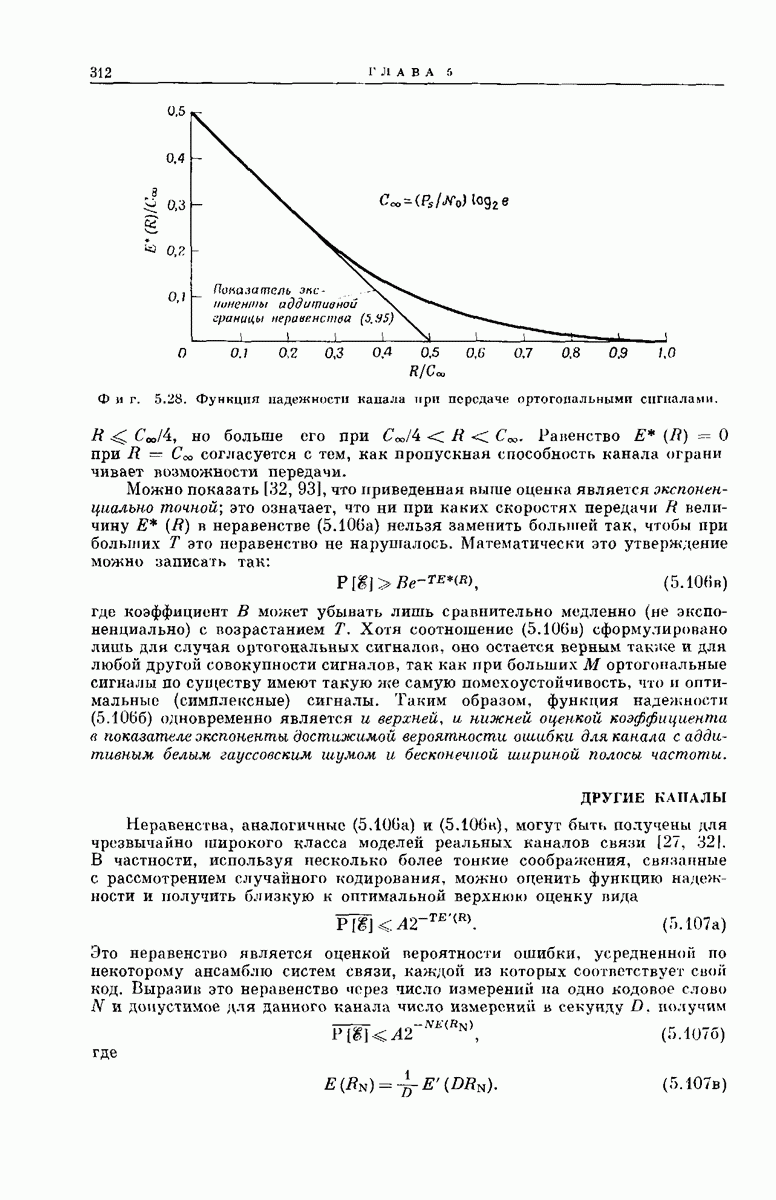
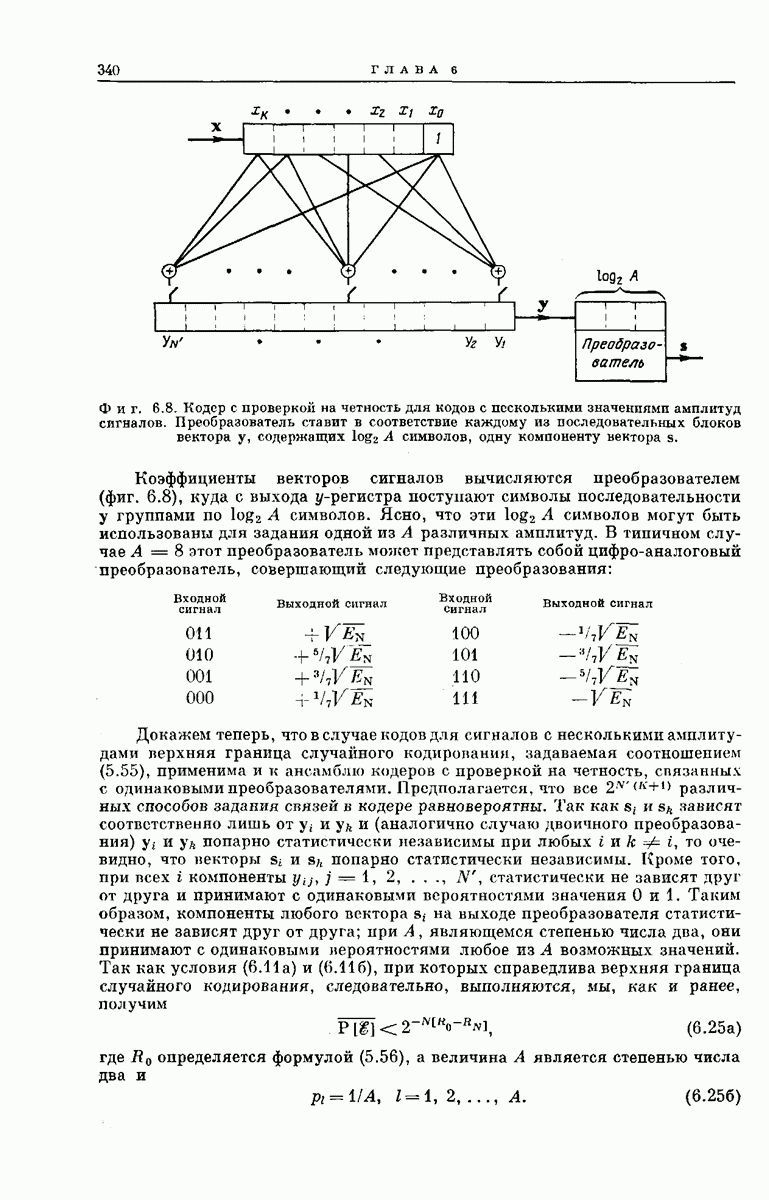
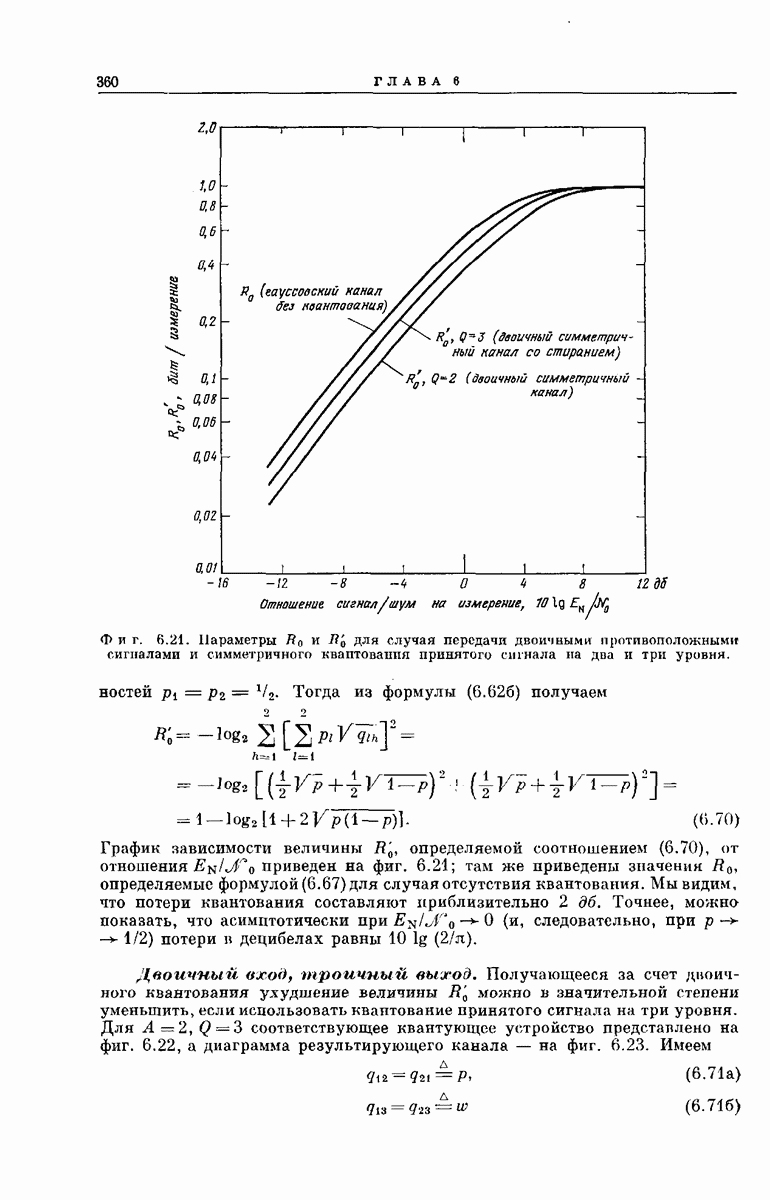
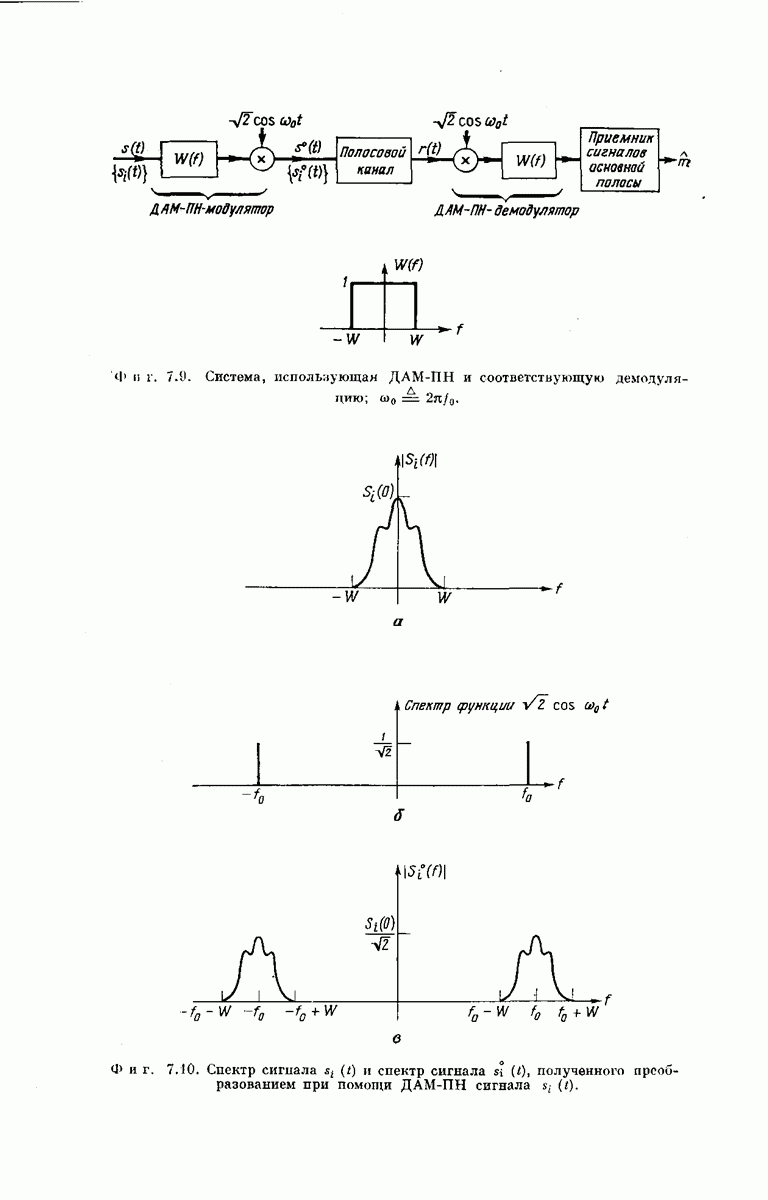
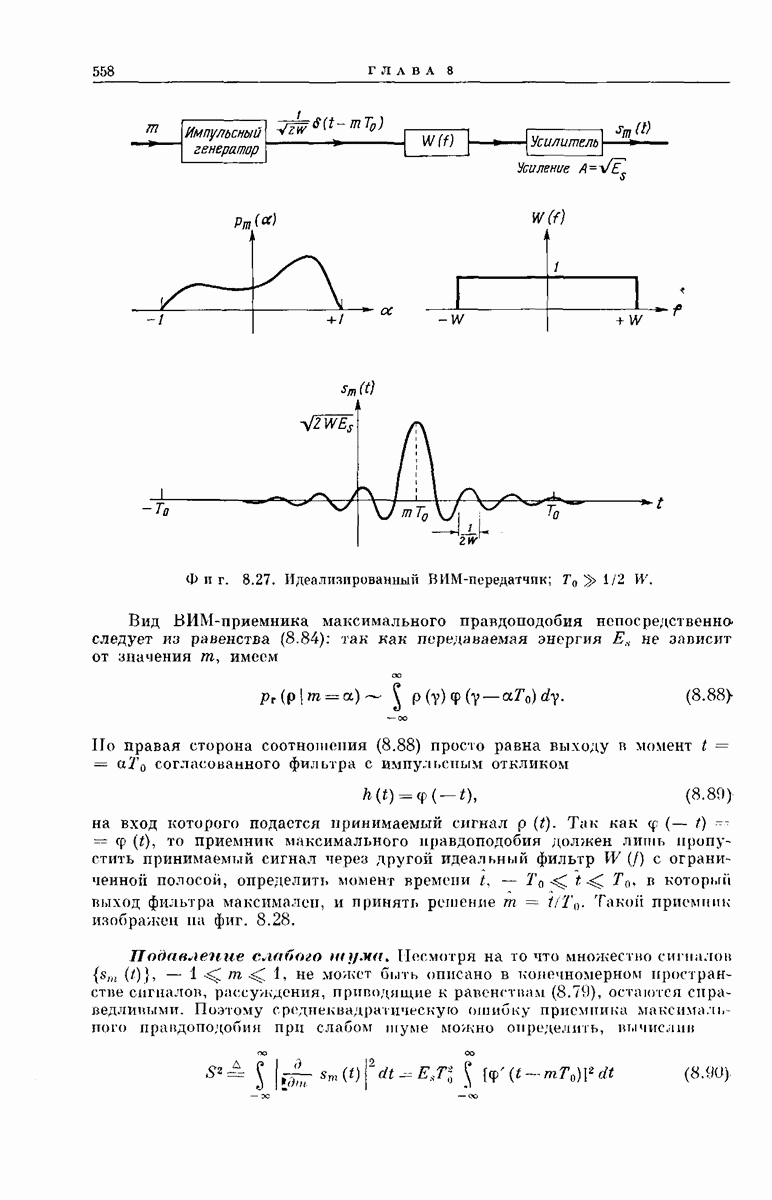
Опустив векторы  можно наглядно представить совокупность
можно наглядно представить совокупность  в случае
в случае  как показано на фиг. 6.36. Из рассмотрения
как показано на фиг. 6.36. Из рассмотрения  столбца этой диаграммы ясно, что
столбца этой диаграммы ясно, что  символов сигнала у, поступающих на выход декодера после подачи в х-регистр символа
символов сигнала у, поступающих на выход декодера после подачи в х-регистр символа  могут быть представлены в виде
могут быть представлены в виде

здесь индексы имеют тот же вид, как и в обычном выражении для свертки. (По определению полагаем  при всех
при всех  )
)
Принято называть  -мерный вектор
-мерный вектор


Фиг. 6.36. Представление векторов  для сверточного кодера с
для сверточного кодера с  Пустым клеткам соответствуют
Пустым клеткам соответствуют  нулей. (Десятый столбец, целиком состоящий из нулей, опущен.)
нулей. (Десятый столбец, целиком состоящий из нулей, опущен.)
порождающей последовательностью сверточного кода; ясно, что этот вектор полностью определяет кодовые связи. Ненулевые сегменты векторов  как раз представляют собой последовательные сдвиги вектора
как раз представляют собой последовательные сдвиги вектора  на
на  символов.
символов.
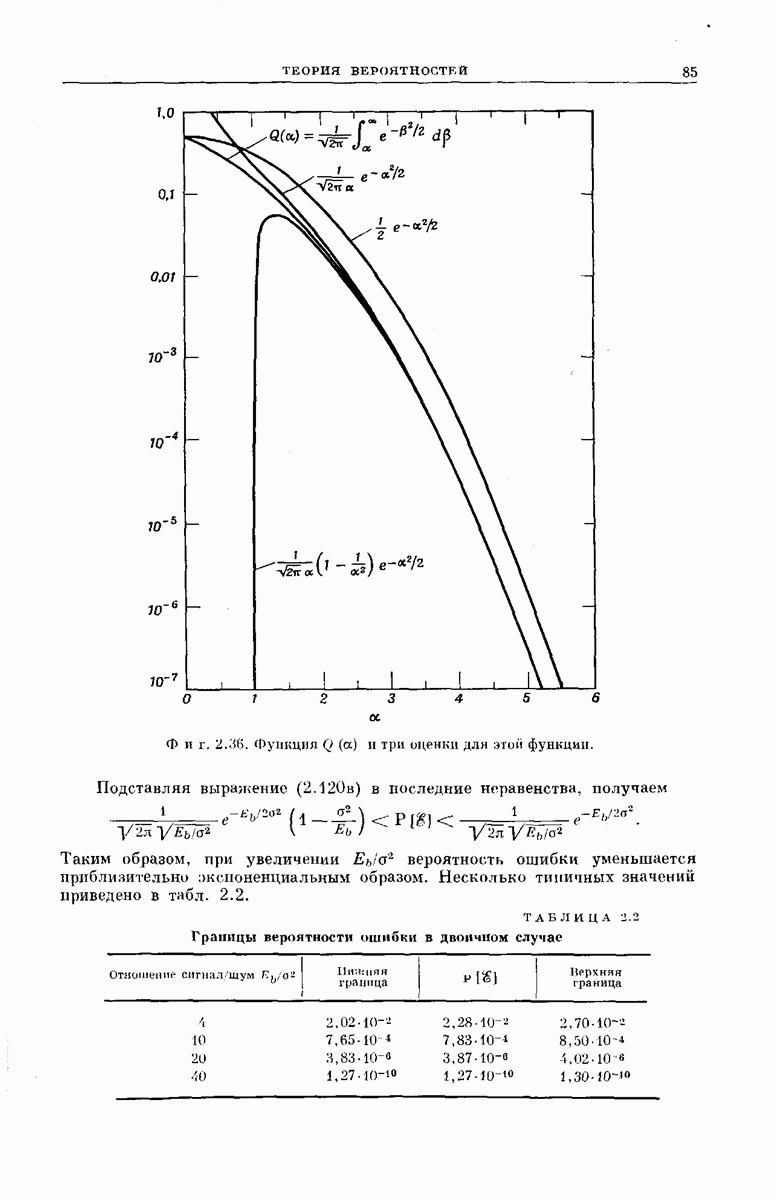
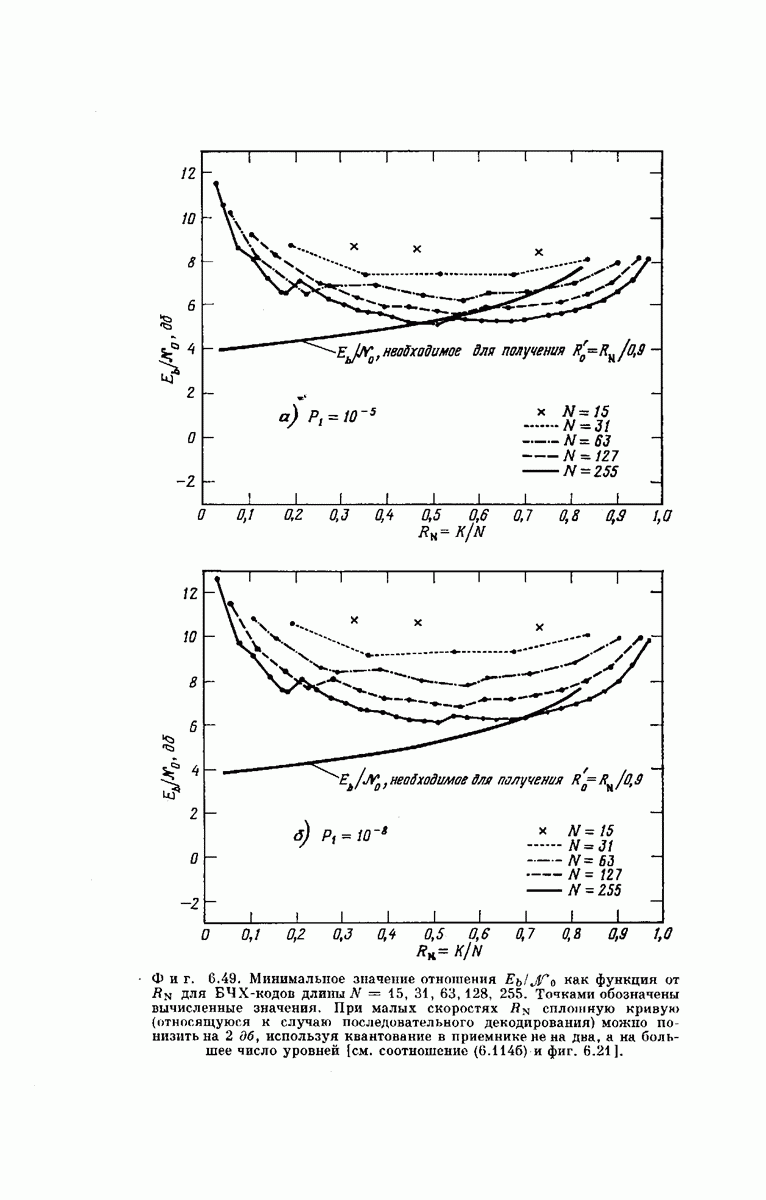
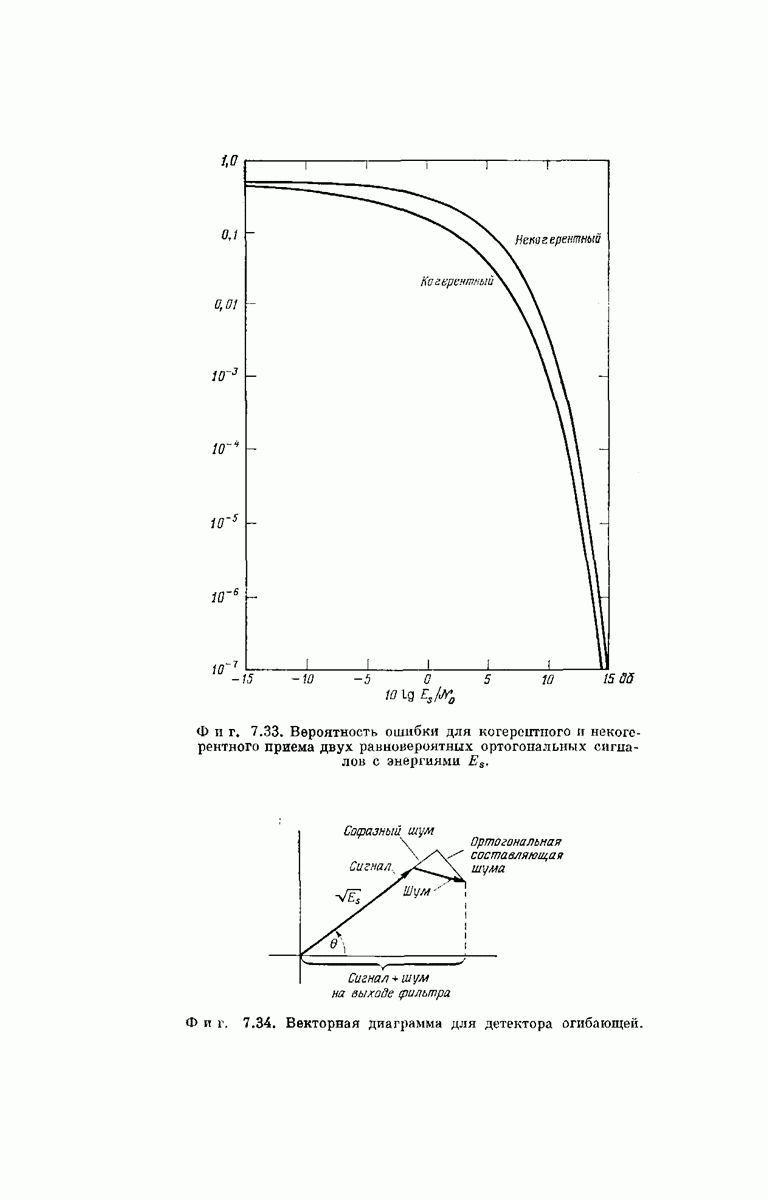
ВЕРОЯТНОСТЬ ОШИБКИ
При любых конкретных значениях порождающей последовательности  формула
формула  выражает выходной вектор у сверточного кодера через значения
выражает выходной вектор у сверточного кодера через значения  и входную последовательность
и входную последовательность  Поэтому совокупность
Поэтому совокупность  возможных выходных векторов
возможных выходных векторов  может порождаться не только рассмотренным нами сверточным кодером, но и [согласно соотношению
может порождаться не только рассмотренным нами сверточным кодером, но и [согласно соотношению  ] блоковым кодером с проверкой на четность, в который поступает входной вектор длины
] блоковым кодером с проверкой на четность, в который поступает входной вектор длины  и который генерирует выходной вектор длины
и который генерирует выходной вектор длины  Определяющая сверточный кодер совокупность
Определяющая сверточный кодер совокупность  (фиг. 6.36) для этого эквивалентного блокового кодера будет являться множеством векторов связей.
(фиг. 6.36) для этого эквивалентного блокового кодера будет являться множеством векторов связей.
Хотя сверточные коды, применяемые к входным векторам фиксированной длины  можно считать частным видом
можно считать частным видом  -разрядных блоковых кодов, из этого не следует, что существуют сверточные коды, для которых достижимая вероятность ошибки подчиняется неравенству
-разрядных блоковых кодов, из этого не следует, что существуют сверточные коды, для которых достижимая вероятность ошибки подчиняется неравенству  полученному для ансамбля блоковых кодов,
полученному для ансамбля блоковых кодов,

где  Доказательство справедливости этого неравенства для блоковых кодов с проверкой на четность существенно основано на возможности произвольного пьтбора для них векторов связей; в случае когда совокупность векторов
Доказательство справедливости этого неравенства для блоковых кодов с проверкой на четность существенно основано на возможности произвольного пьтбора для них векторов связей; в случае когда совокупность векторов  должна быть такой, как в сверточном коде, такой свободы нет. Для блоковых кодов, не обязательно носящих сверточный характер, любая компонента входного вектора
должна быть такой, как в сверточном коде, такой свободы нет. Для блоковых кодов, не обязательно носящих сверточный характер, любая компонента входного вектора  может влиять на все компоненты выходного вектора у, тогда как для сверточных кодов каждая компонента
может влиять на все компоненты выходного вектора у, тогда как для сверточных кодов каждая компонента  может влиять лишь на
может влиять лишь на  компонент у.
компонент у.
Так как свобода выбора векторов  ограничена, нет основания надеяться на то, что вероятность ошибки для сверточных кодов стремится к нулю экспоненциально с показателем экспоненты, пропорциональным
ограничена, нет основания надеяться на то, что вероятность ошибки для сверточных кодов стремится к нулю экспоненциально с показателем экспоненты, пропорциональным  . В самом деле, интуиция правильно подсказывает, что вероятность по меньшей мере одной ошибки для блока из
. В самом деле, интуиция правильно подсказывает, что вероятность по меньшей мере одной ошибки для блока из  входных символов стремится к 1, а не к 0, если
входных символов стремится к 1, а не к 0, если  возрастает, а К фиксировано. В то же время представляется естественным экспоненциальное стремление к нулю границы вероятности ошибки с ростом длины кодового ограничения К.
возрастает, а К фиксировано. В то же время представляется естественным экспоненциальное стремление к нулю границы вероятности ошибки с ростом длины кодового ограничения К.
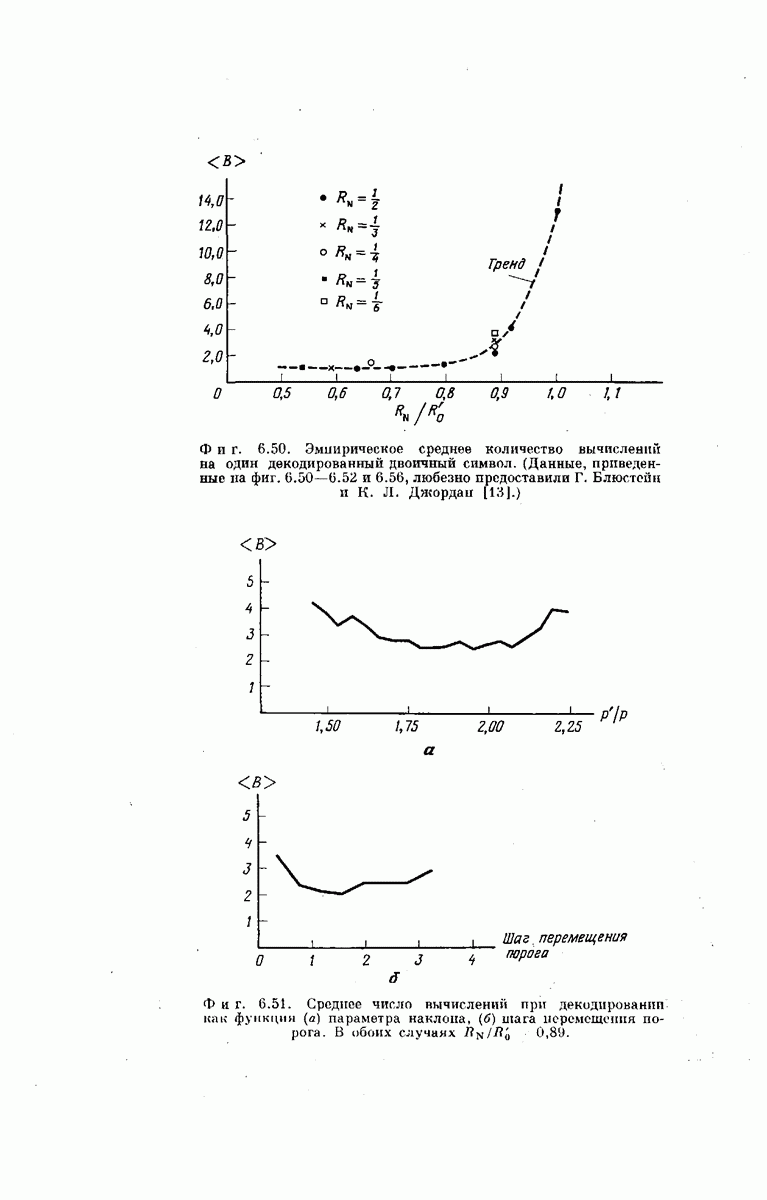
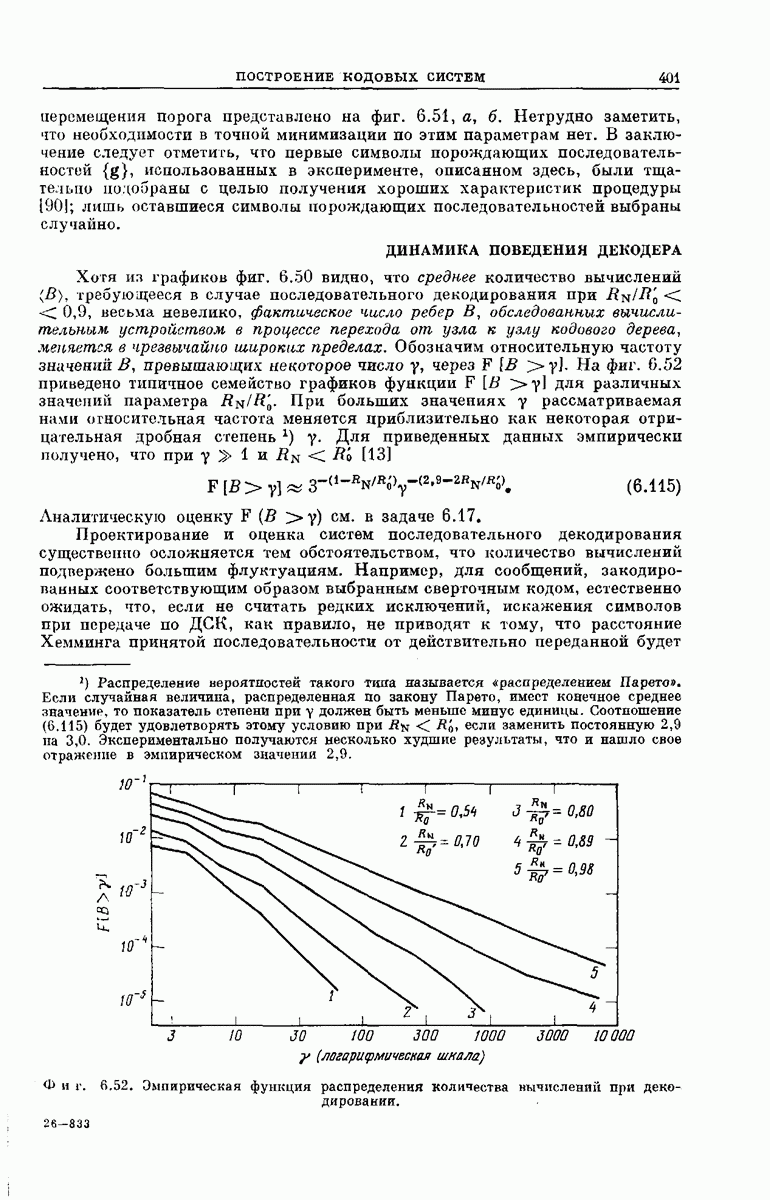
Для сверточных кодов трудно (а может быть, и невозможно) использовать при анализе оптимального декодера те же рассуждения, что и при рассмотрении случайного кодирования; это объясняется тем, что последовательные символы  влияют на перекрывающиеся сегменты вектора у. Поэтому вместо оптимального мы рассмотрим субоптимальный декодер. Для этого декодера найдем оценку средней по ансамблю вероятности ошибки, которая действительно будет экспоненциально убывать с ростом К. Знакомство с субоптимальной процедурой декодирования послужит введением к пониманию методов последовательного декодирования.
влияют на перекрывающиеся сегменты вектора у. Поэтому вместо оптимального мы рассмотрим субоптимальный декодер. Для этого декодера найдем оценку средней по ансамблю вероятности ошибки, которая действительно будет экспоненциально убывать с ростом К. Знакомство с субоптимальной процедурой декодирования послужит введением к пониманию методов последовательного декодирования.
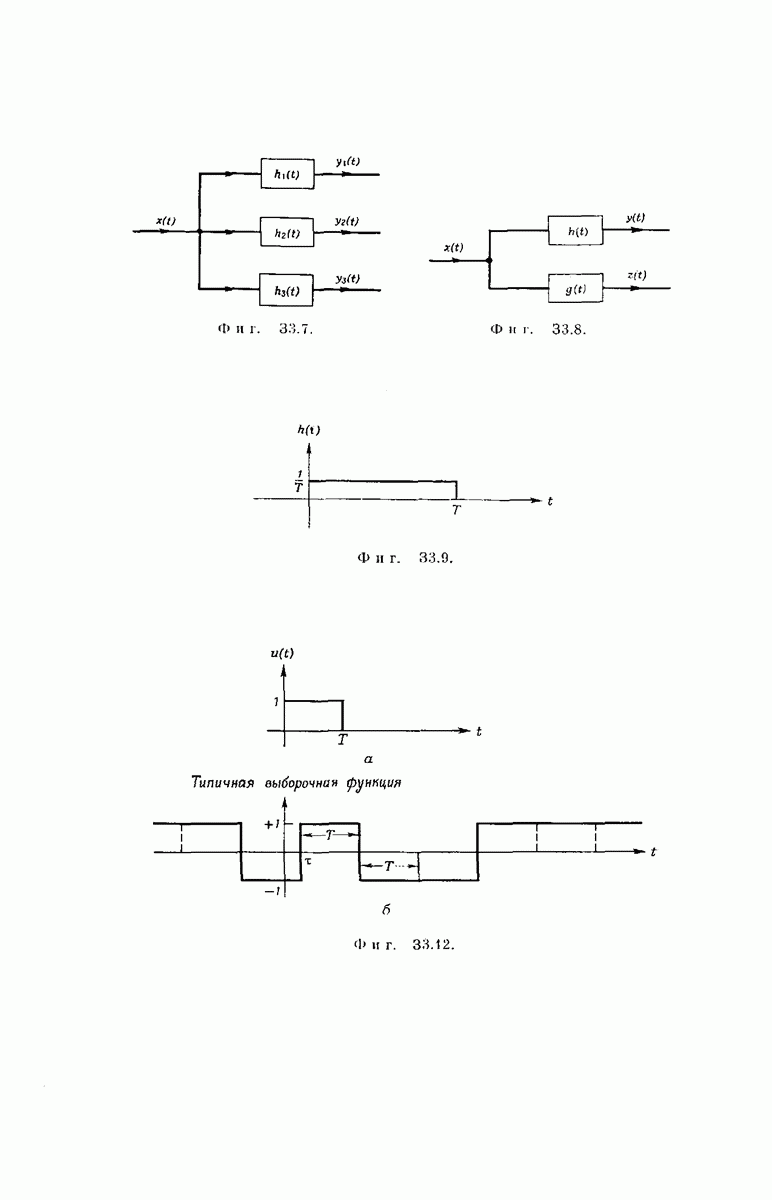
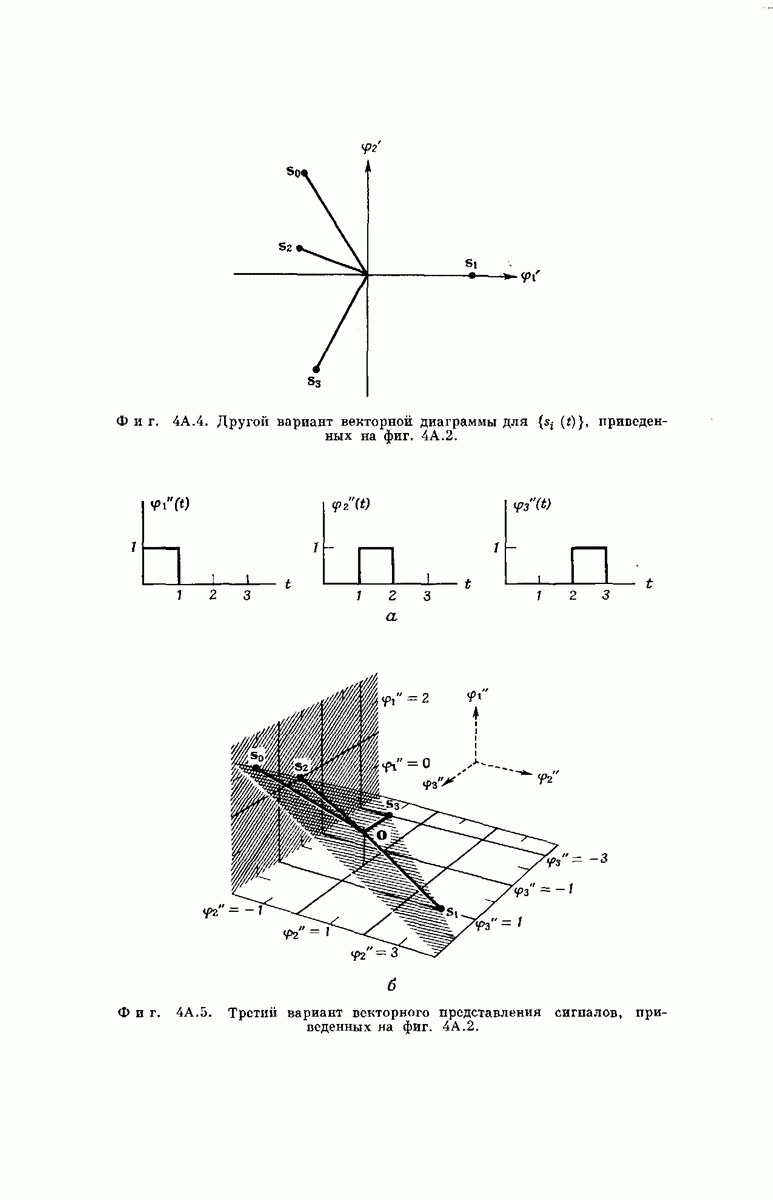
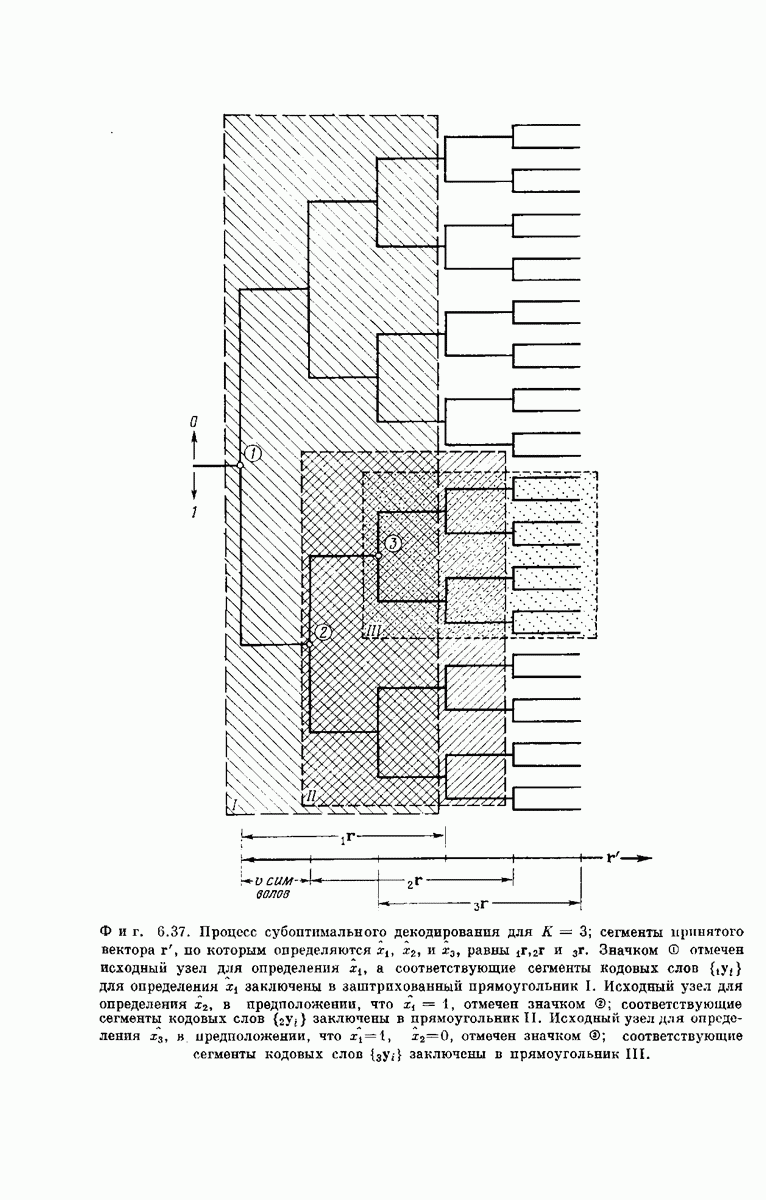
Субоптимальное декодирование. Рассмотрим процедуру декодирования сообщений, закодированных сверточным кодером (предполагается, что число двоичных сообщений  передаваемых по ДСК, равно
передаваемых по ДСК, равно  Декодер последовательно принимает решения
Декодер последовательно принимает решения  относительно
относительно  компонент
компонент  вектора, поступившего в кодер. Каждое решение
вектора, поступившего в кодер. Каждое решение  зависит только от: а) предыдущих решений
зависит только от: а) предыдущих решений  и б) отрезка, состоящего из
и б) отрезка, состоящего из  символов принятого вектора сигнала, который непосредственно определяется компонентой
символов принятого вектора сигнала, который непосредственно определяется компонентой  Этот отрезок принятых символов обозначим как
Этот отрезок принятых символов обозначим как  -мерный вектор
-мерный вектор  а промежуточпыи узел кодового дерева, определяемый числами
а промежуточпыи узел кодового дерева, определяемый числами  назовем
назовем  исходным узлом. Каждый символ
исходным узлом. Каждый символ  декодируется в свою очередь путем определения, для какого из
декодируется в свою очередь путем определения, для какого из  выходящих из
выходящих из  исходного узла сегментов кодового слона из К ребер вероятность перехода в
исходного узла сегментов кодового слона из К ребер вероятность перехода в  максимальна. Для этого, согласно соотношению
максимальна. Для этого, согласно соотношению  декодер вычисляет расстояние Хемминга между каждым из таких сегментов кодового слова, состоящих из
декодер вычисляет расстояние Хемминга между каждым из таких сегментов кодового слова, состоящих из  символов, и
символов, и  Если первое ребро сегмента кодового слова, начинающегося в
Если первое ребро сегмента кодового слова, начинающегося в  исходном узле и имеющего минимальное расстояние от оказывается верхним, декодер полагает
исходном узле и имеющего минимальное расстояние от оказывается верхним, декодер полагает  в противном случае декодер полагает
в противном случае декодер полагает  Типичный процесс декодирования для сверточного кода с
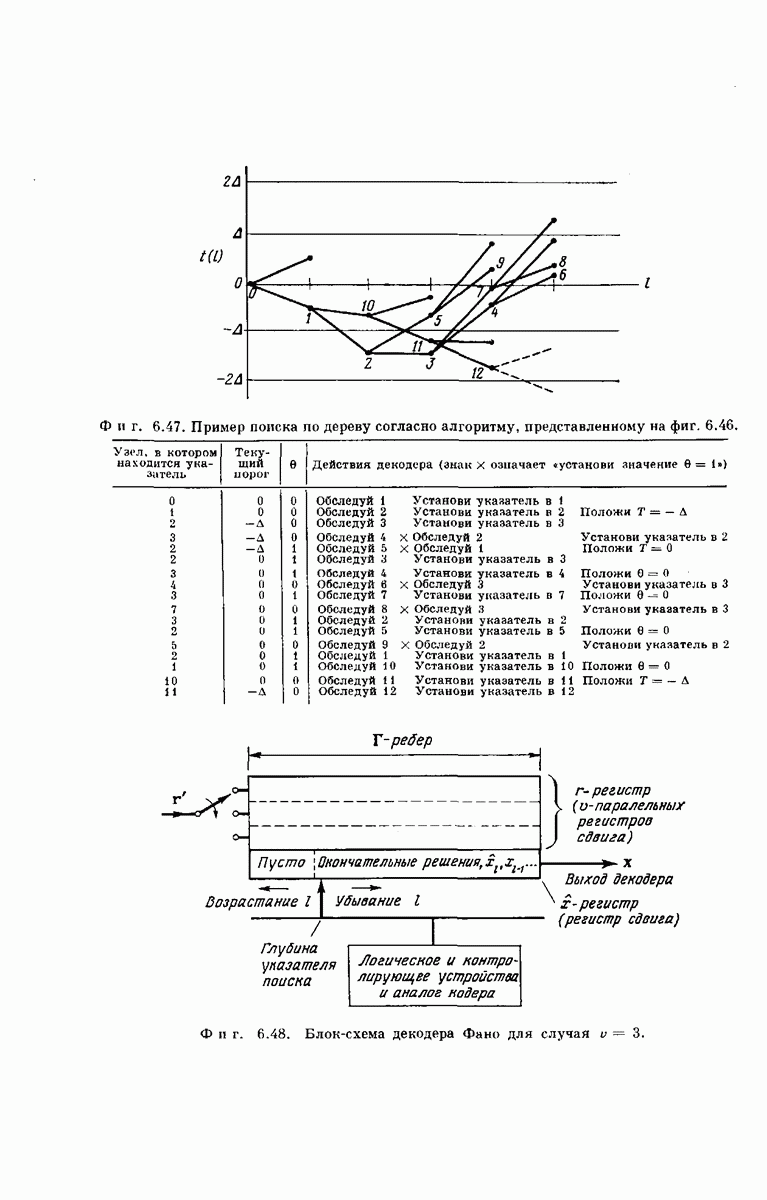
Типичный процесс декодирования для сверточного кода с  показан на фиг. 6.37.
показан на фиг. 6.37.
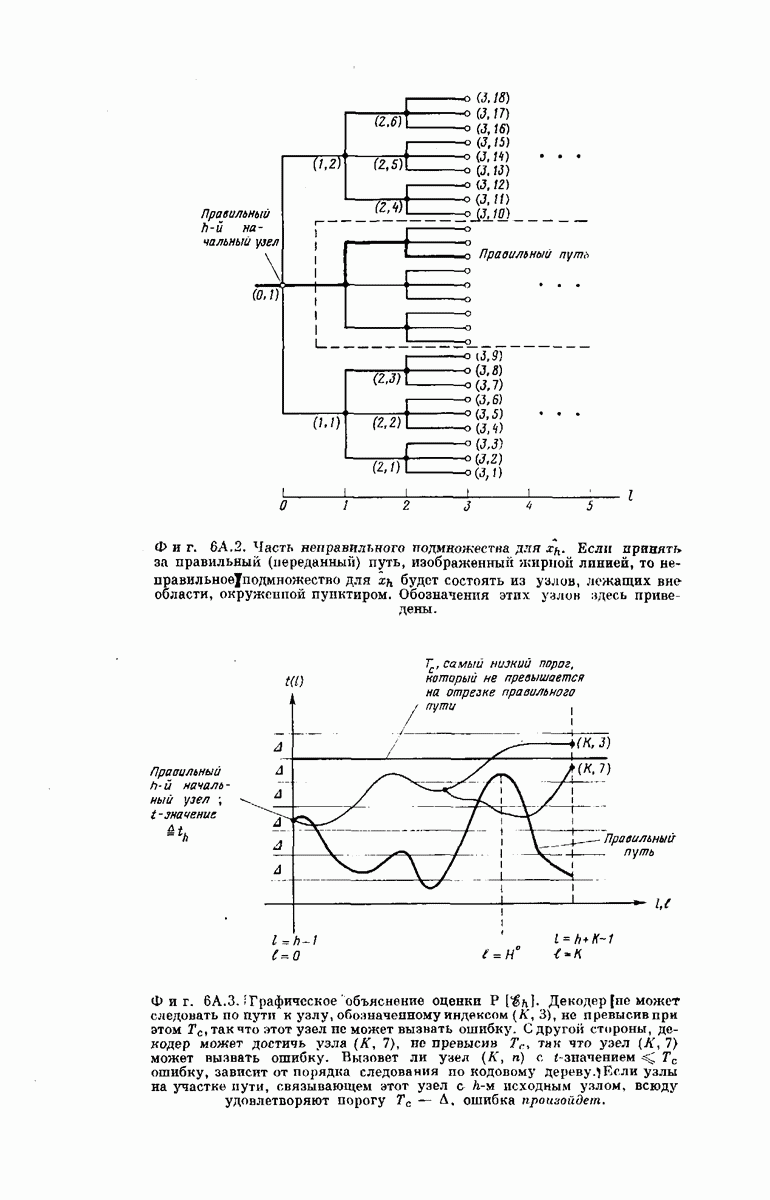
Рассмотрим вначале какой-либо сверточный код; последующие подразделы посвящены нахождению оценки для  вероятности того, что в последовательности решений
вероятности того, что в последовательности решений  субоптимальный декодер сделает по меньшей мере одну ошибку. Обозначим через
субоптимальный декодер сделает по меньшей мере одну ошибку. Обозначим через  вероятность ошибки в
вероятность ошибки в  решении при условии, что
решении при условии, что  исходный узел найдеп правильно. Оценку (безусловной) вероятности
исходный узел найдеп правильно. Оценку (безусловной) вероятности  найдем, используя следующую цепочку соотношений:
найдем, используя следующую цепочку соотношений:

где величина  в правой части равенства III означает, что вероятность ошибки вычисляется при условии, что передана последовательность, целиком состоящая из нулей. Отсюда непосредственно следует, что
в правой части равенства III означает, что вероятность ошибки вычисляется при условии, что передана последовательность, целиком состоящая из нулей. Отсюда непосредственно следует, что


(кликните для просмотра скана)
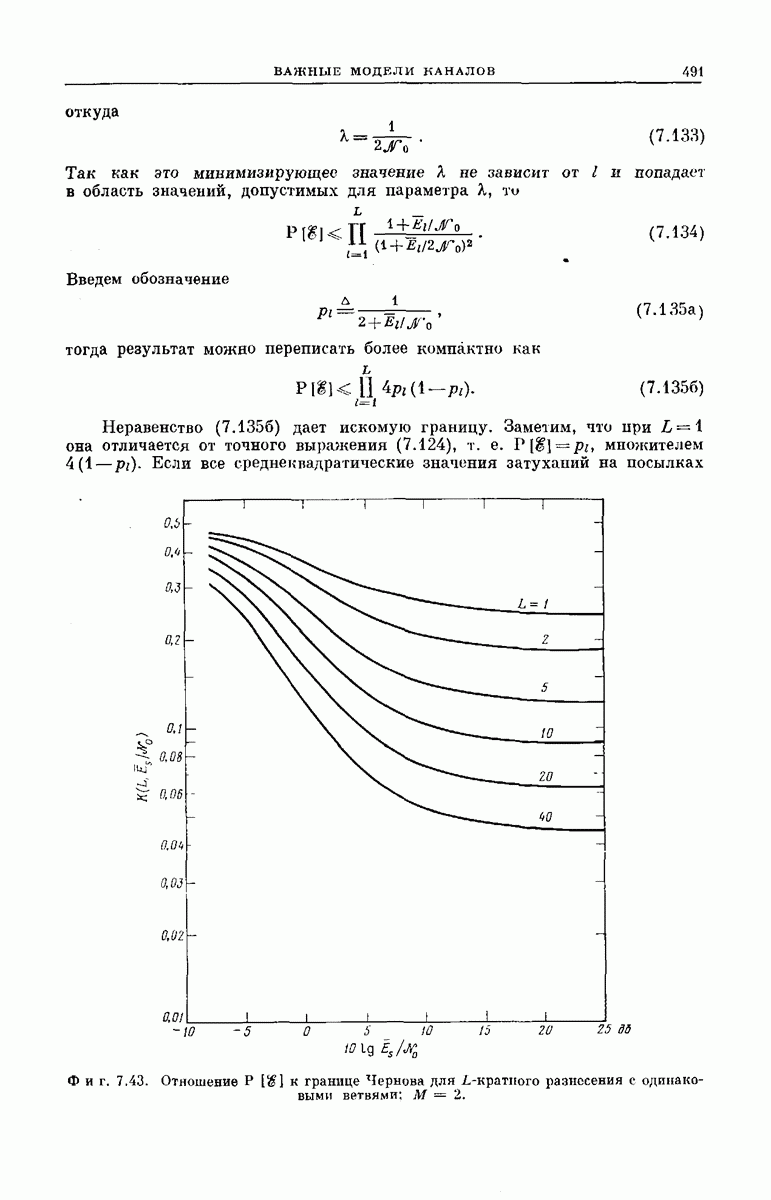
Наконец, усредняя обе части этого неравенства по ансамблю систем связи, каждая из которых использует особый сверточный код, получим неравенство

Соотношение IV представляет собой верхнюю оценку для средней вероятности того, что при декодировании информационной последовательности из  двоичных символов, закодированной сверточным кодером и переданной по ДСК, описанный выше субоптимальный декодер сделает одну или более ошибок. Длина кодовых ограничений равна
двоичных символов, закодированной сверточным кодером и переданной по ДСК, описанный выше субоптимальный декодер сделает одну или более ошибок. Длина кодовых ограничений равна  параметр
параметр  представляет собой показатель экспоненты вероятности ошибки ДСК, определяемый соотношением
представляет собой показатель экспоненты вероятности ошибки ДСК, определяемый соотношением 

Рассматриваемая вероятность ошибок оказывается, таким образом, сравнимой по величине с достижимой вероятностью ошибки блокового кода длины К при оптимальном декодировании; аддитивная граница для вероятности неправильного декодирования хотя бы одного из  последовательных блоков удовлетворяет неравенству
последовательных блоков удовлетворяет неравенству

Разница в точности этих двух оценок не отражается в их показателях. Это становится очевидным, если переписать соотношение IV для сверточного кодирования в виде

Если  увеличивается,
увеличивается,  стремится к нулю и неравенства (6.87а) и (6.87б) по существу становятся эквивалентными
стремится к нулю и неравенства (6.87а) и (6.87б) по существу становятся эквивалентными 
Доказательство соотношений I, II, III, IV, которое приведено ниже, несколько перегружено деталями и может быть опущено при первом чтении.
• Доказательство соотношения  . При доказательстве соотношения
. При доказательстве соотношения  предположим вначале, что некий магический джин указывает декодеру правильный исходный узел для нахождения каждого
предположим вначале, что некий магический джин указывает декодеру правильный исходный узел для нахождения каждого  По определению вероятность того, что в этом случае
По определению вероятность того, что в этом случае  будет найдено неправильно, равна
будет найдено неправильно, равна  Используя известное аддитивное неравенство, найдем, что вероятность одной или более ошибок в последовательности
Используя известное аддитивное неравенство, найдем, что вероятность одной или более ошибок в последовательности  решений, принятых руководимым джином декодером, ограничена сверху величиной
решений, принятых руководимым джином декодером, ограничена сверху величиной  .
.
Заметим теперь, что если ошибки декодирования отсутствуют, то для каждого  исходный узел точно определяется предыдущими решениями декодера. Если руководимый джином декодер не сделает ни одной ошибки, то и декодер, которому джин не помогает, также не сделает ни одной ошибки! Так как обратное также верно, то вероятность появления по крайней мере одной ошибки декодирования не зависит от того, руководит или нет декодером джин, и
исходный узел точно определяется предыдущими решениями декодера. Если руководимый джином декодер не сделает ни одной ошибки, то и декодер, которому джин не помогает, также не сделает ни одной ошибки! Так как обратное также верно, то вероятность появления по крайней мере одной ошибки декодирования не зависит от того, руководит или нет декодером джин, и

• Доказательство соотношения II. Чтобы доказать, что вероятность неправильного декодирования символа  при правильно найденном
при правильно найденном 
Аналогично обозначим через  совокупность сегментов кодового слова из
совокупность сегментов кодового слова из  символов, входящих в определение
символов, входящих в определение  при условии, что правильный исходный узел задан. Если вектор
при условии, что правильный исходный узел задан. Если вектор  представляет собой двоичную запись числа к, то передается, как и ранее, сегмент
представляет собой двоичную запись числа к, то передается, как и ранее, сегмент 

Для любого  как это видно из рассмотрения фиг. 6.38, б,
как это видно из рассмотрения фиг. 6.38, б,

где двоичный вектор  не зависящий от
не зависящий от  определяется входными символами кодера, предшествующими
определяется входными символами кодера, предшествующими  . Значение вектора
. Значение вектора  определяется
определяется  исходным узлом.
исходным узлом.
Теперь рассмотрим решение  получаемое при условии, что известен правильный исходный узел. Пусть передается
получаемое при условии, что известен правильный исходный узел. Пусть передается  сегмент. Субоптимальный приемник сравнивает принятый сегмент
сегмент. Субоптимальный приемник сравнивает принятый сегмент

с каждым из сегментов, которые могут быть переданы:

Здесь совокупность  символов шума в канале, накладывающихся на
символов шума в канале, накладывающихся на  мы обозначили как вектор
мы обозначили как вектор  Но решение
Но решение  не изменится, если к
не изменится, если к  и к каждому из векторов
и к каждому из векторов  прибавить по модулю 2 вектор
прибавить по модулю 2 вектор  (обратимая операция!). Прибавим этот вектор. Из соотношений (6.93а) и (6.936) видно, что решение
(обратимая операция!). Прибавим этот вектор. Из соотношений (6.93а) и (6.936) видно, что решение  основанное на сравнении
основанное на сравнении  с каждым из векторов
с каждым из векторов  имеет ту же вероятность ошибки, что и решение
имеет ту же вероятность ошибки, что и решение  для случая переданного сигнала у. Это следует из того, что шумы в канале стационарны, т. е.
для случая переданного сигнала у. Это следует из того, что шумы в канале стационарны, т. е.

Отсюда получим

Если все векторы на входе кодера равновероятны, то

Отсюда, усредняя обе части соотношения  получим
получим

Это равенство и представляет собой соотношение II. В следующем подразделе мы покажем, что вероятность

не зависит от к. Следовательно, обе части соотношения  не зависят от к и соотношение
не зависят от к и соотношение  остается верным, даже если сообщения
остается верным, даже если сообщения  не равновероятны.
не равновероятны.
Вывод соотношения  существенно опирается на предположение о том, что правильный исходный узел для определения
существенно опирается на предположение о том, что правильный исходный узел для определения  а следовательно, и вектор а известны. Если
а следовательно, и вектор а известны. Если  исходный узел определен неправильно, то истинное значение
исходный узел определен неправильно, то истинное значение  не может быть вычислено и вероятность того, что решение
не может быть вычислено и вероятность того, что решение  будет неправильным, становится большой. В конце главы мы обсудим этот случай.
будет неправильным, становится большой. В конце главы мы обсудим этот случай.
• Доказательство соотношения III. Покажем теперь, что для нашего субоптимального приемника

Доказательство этого факта основано на свойстве замкнутости совокупности усеченных сегментов кодового слова  Как и в случае блоковых кодов с проверкой на четность, в силу линейности соотношения (6.90а)
Как и в случае блоковых кодов с проверкой на четность, в силу линейности соотношения (6.90а)

так что сумма по модулю 2 любых двух векторов множества 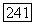 также принадлежит
также принадлежит 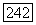 Однако для сверточных кодов мы получаем также следующее более сильное свойство замкнутости:
Однако для сверточных кодов мы получаем также следующее более сильное свойство замкнутости:
Пусть 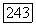 подмножество, состоящее из всех
подмножество, состоящее из всех  векторов
векторов 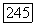 соответствующих
соответствующих  и пусть
и пусть  подмножество, состоящее из векторов, соответствующих
подмножество, состоящее из векторов, соответствующих  Таким образом,
Таким образом,  состоит из всех векторов разложение которых содержит
состоит из всех векторов разложение которых содержит 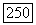 состоит из всех векторов
состоит из всех векторов 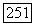 разложение которых его не содержит, Так как
разложение которых его не содержит, Так как 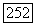 то получим
то получим

тогда как

Кроме того, если вектор 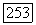 принадлежит.
принадлежит. 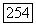 при и, принимающем значения на множестве векторов
при и, принимающем значения на множестве векторов  вектор
вектор 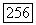 также принимает значения на множестве векторов
также принимает значения на множестве векторов 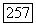 . С другой стороны, если принадлежит
. С другой стороны, если принадлежит 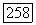 то при V, принимающем значения на множестве векторов
то при V, принимающем значения на множестве векторов 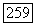 вектор
вектор 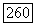 также принимает значения на множестве векторов
также принимает значения на множестве векторов 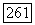
Субоптимальный декодер определяет, какой из векторов совокупности 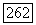 имеет минимальное расстояние Хемминга от и полагает
имеет минимальное расстояние Хемминга от и полагает 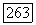 если этот вектор принадлежит
если этот вектор принадлежит 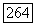 и если он принадлежит
и если он принадлежит 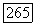
Поэтому если переданный в действительности сигнал 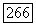 принадлежит то решение
принадлежит то решение 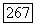 будет правильным, если в множестве
будет правильным, если в множестве 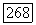 не существует вектора
не существует вектора 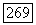 для которого
для которого

Здесь, так же как и в соотношении 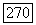 через
через 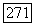 обозначено расстояние Хемминга. Но
обозначено расстояние Хемминга. Но 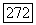 принадлежит
принадлежит 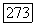 принимает значения на множестве Поэтому эквивалентное, но более простое утверждение состоит в том, что
принимает значения на множестве Поэтому эквивалентное, но более простое утверждение состоит в том, что 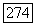 определяется правильно, если для любого переданного вектора, принадлежащего в множестве
определяется правильно, если для любого переданного вектора, принадлежащего в множестве 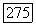 не существует вектора
не существует вектора 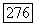 такого, что
такого, что

С другой стороны, когда передаваемый сигнал 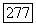 принадлежит
принадлежит 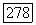 решение
решение 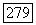 оказывается правильным, если в множестве
оказывается правильным, если в множестве 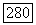 не существует вектора и, для которого
не существует вектора и, для которого

Но 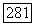 принадлежит
принадлежит 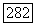 , тогда
, тогда  принимает значении на множестве векторов
принимает значении на множестве векторов  Поэтому соотношение (6.100) снова является условием появления ошибки. Вероятность того, что наличие шума приведет
Поэтому соотношение (6.100) снова является условием появления ошибки. Вероятность того, что наличие шума приведет
к выполнению соотношения (0.100) и, следовательно, к ошибке в решении  не зависит от к; тем самым доказательство соотношения III завершено.
не зависит от к; тем самым доказательство соотношения III завершено.
• Доказательство соотношения IV. Из результатов предыдущих трех подразделов следует неравенство

справедливое для общей вероятности ошибки при использовании любого фиксированного сверточного кодера и рассматриваемого нами субоптимального декодера. Осталось определить в экспоненциальном приближении поведение достижимой вероятности 
Число сегментов кодового слова  на которых основывается решение
на которых основывается решение  равно
равно 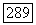 при больших К это число становится все же очень большим. Как обычно, мы избежим необходимости вычисления вероятности ошибки для каждого частного сверточного кода, прибегнув к рассуждениям, основанным на случайном кодировании. Рассмотрим ансамбль систем связи, каждая из которых использует свой сверточный код, и вычислим оценку среднего значения
при больших К это число становится все же очень большим. Как обычно, мы избежим необходимости вычисления вероятности ошибки для каждого частного сверточного кода, прибегнув к рассуждениям, основанным на случайном кодировании. Рассмотрим ансамбль систем связи, каждая из которых использует свой сверточный код, и вычислим оценку среднего значения 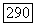 по этому ансамблю. Большинство систем в ансамбле должно обладать вероятностью
по этому ансамблю. Большинство систем в ансамбле должно обладать вероятностью  не на много большей, чем ее среднее значение.
не на много большей, чем ее среднее значение.
Мы уже отметили, что сверточный кодер определяется порождающей последовательностью 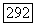 При вычислении
При вычислении 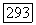 удобно рассмотреть ансамбль, в котором
удобно рассмотреть ансамбль, в котором 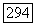 с одинаковыми вероятностями принимает каждое значение из совокупности
с одинаковыми вероятностями принимает каждое значение из совокупности 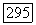 возможных двоичных последовательностей длины
возможных двоичных последовательностей длины 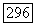 Другими словами, в ансамбле систем связи вектор
Другими словами, в ансамбле систем связи вектор 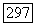 является РР-вектором.
является РР-вектором.
При оценке  вначале покажем, что в ансамбле порождающих последовательностей любое кодовое слово, принадлежащее подмножеству также является РР-вектором. Доказательство этого факта основано на том утверждении, что если порождающая последовательность, определяемая соотношением
вначале покажем, что в ансамбле порождающих последовательностей любое кодовое слово, принадлежащее подмножеству также является РР-вектором. Доказательство этого факта основано на том утверждении, что если порождающая последовательность, определяемая соотношением  в виде
в виде

является РР-вектором, то  -мерные векторы [определяемые соотношением также обязательно являются РР-векторами и статистически независимы. Но любое кодовое слово, принадлежащее например соответствует вектору на входе кодера, для которого Следовательно, согласно соотношению (6.90а) и фиг. 6.36, вектор можно записать в виде
-мерные векторы [определяемые соотношением также обязательно являются РР-векторами и статистически независимы. Но любое кодовое слово, принадлежащее например соответствует вектору на входе кодера, для которого Следовательно, согласно соотношению (6.90а) и фиг. 6.36, вектор можно записать в виде

где

Каждый из векторов представляет собой сумму по модулю 2 РР-вектора и вектора (заключенного в скобки), статистически независимого от
В соответствии с этим векторы также являются РР-векторами и статистически независимы, откуда и следует, что любое кодовое слово принадлежащее есть РР-вектор.
Если сообщением является так что то правильное решение принимается в тех системах ансамбля, для которых вероятность перехода в по крайней мере одного кодового слова, принадлежащего больше, чем вероятность перехода в любого из кодовых слов, принадлежащих . В частности, ошибок не будет в тех системах, для которых

Пренебрегая тем, что может быть декодировано правильно, даже если соотношение (6.103) не удовлетворяется (из-за наличия в векторов, отличных от мы найдем верхнюю оценку для вероятности для каждой системы в ансамбле, а следовательно, и для Поэтому не превышает вероятности того, что по крайней мере для одного из РР-векторов, принадлежащих переход в более вероятен, чем переход в переданного сегмента
Осталось показать, что эта последняя вероятность тесно связана с полученной нами оценкой средней вероятности ошибки при передаче по равновероятных сообщений, закодированных блоковым кодом с проверкой на четность, содержащим разрядов. С математической точки зрения единственная разница состоит в том, что в сверточных кодах имеется лишь РР-векторов, которые могут привести к ошибке, тогда как в случае блоковых кодов их Не останавливаясь больше на этом вопросе, запишем

где

и в силу соотношения

Доказательство соотношения IV закончено.
















































































































































































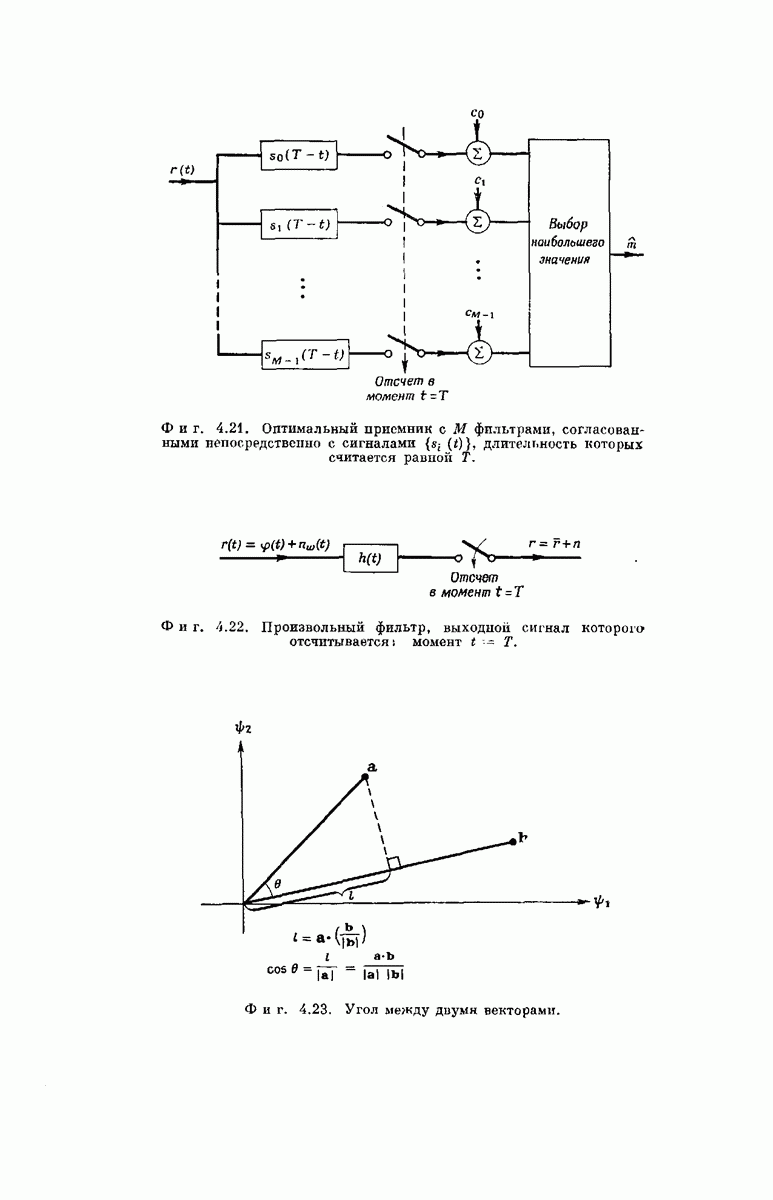





















































































































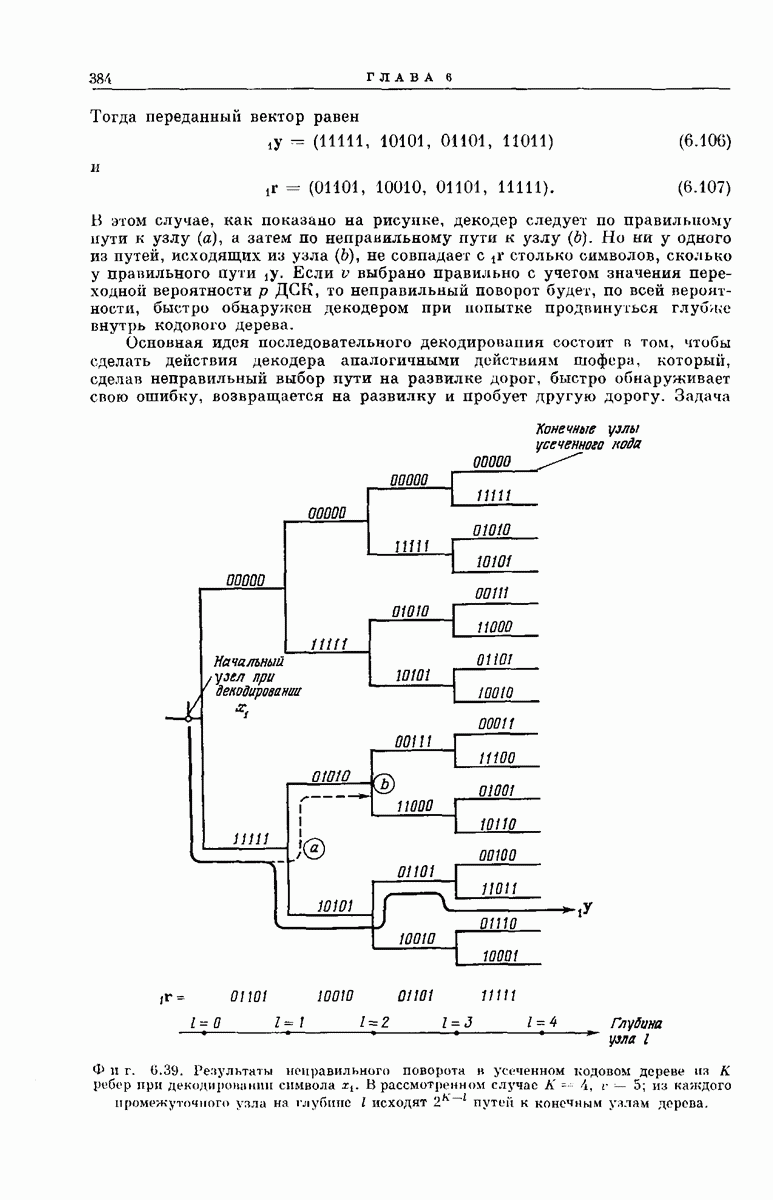
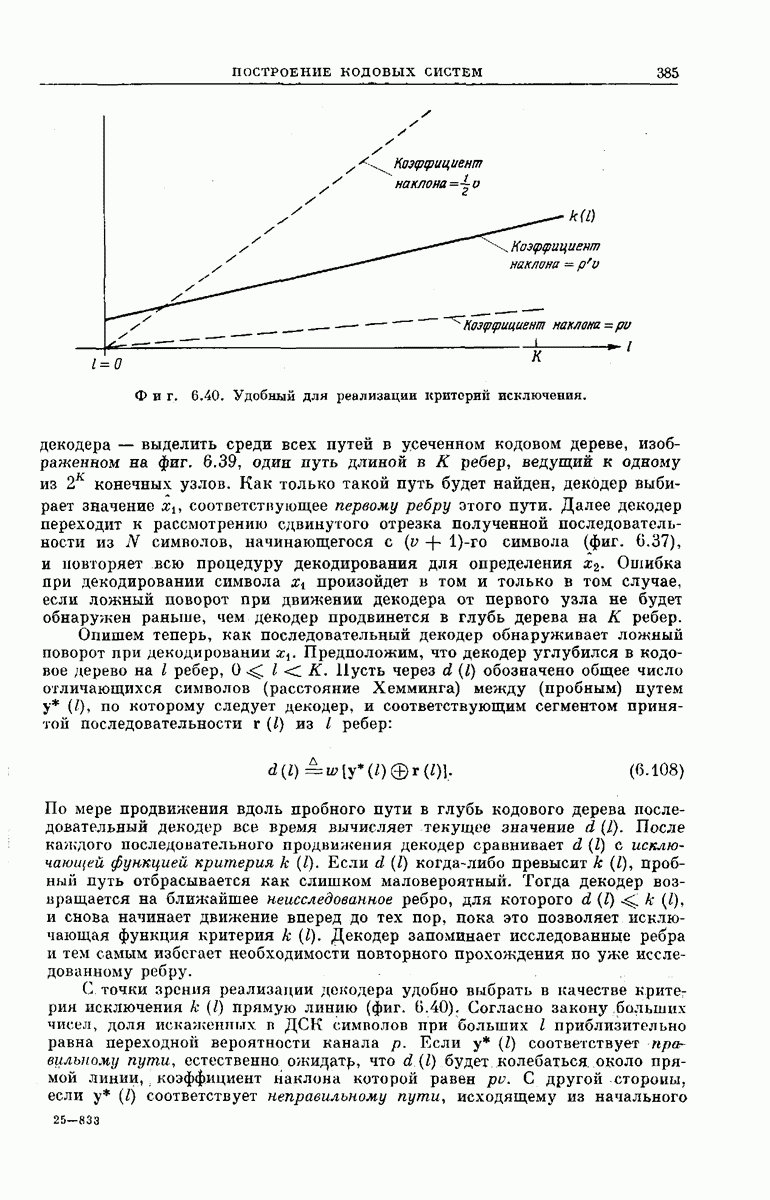


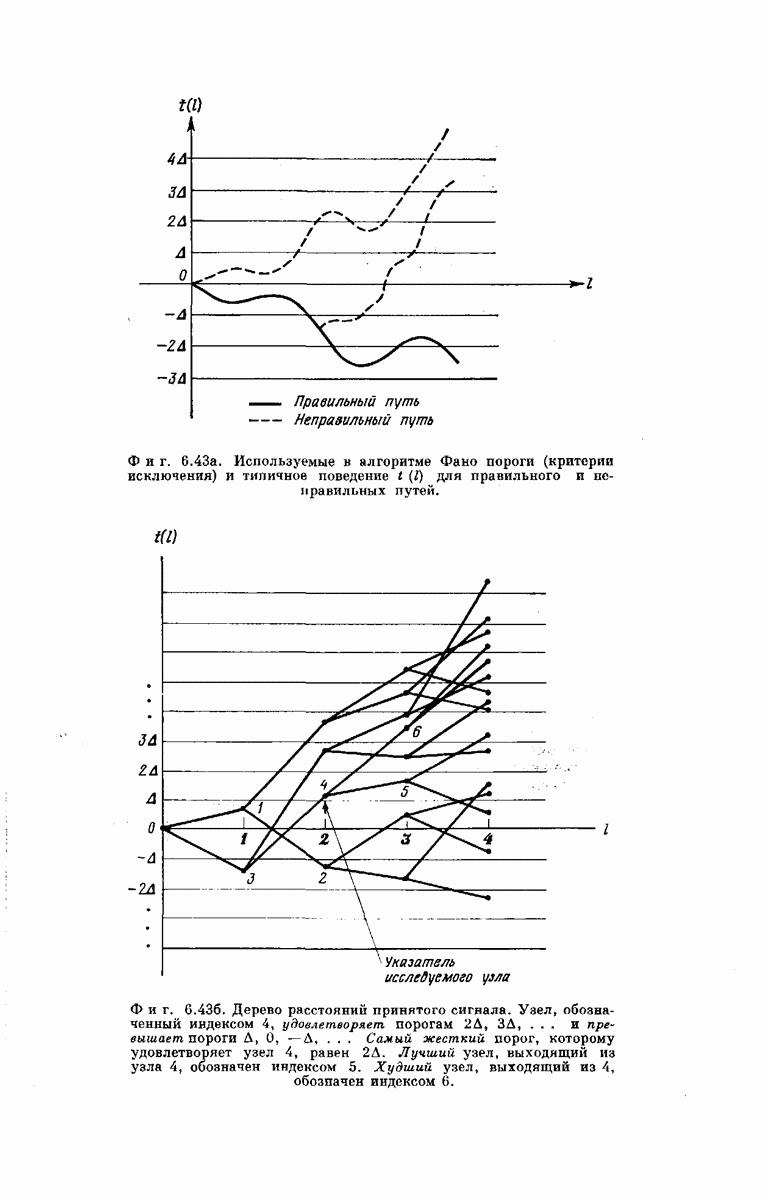
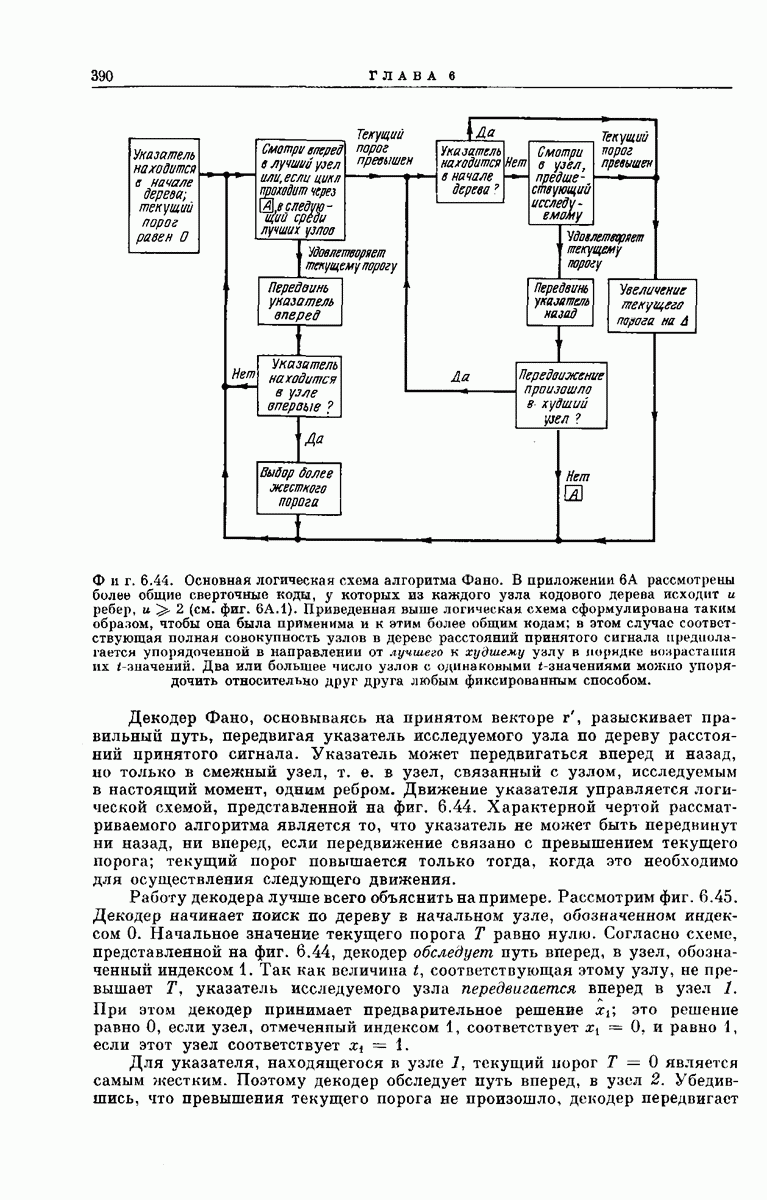
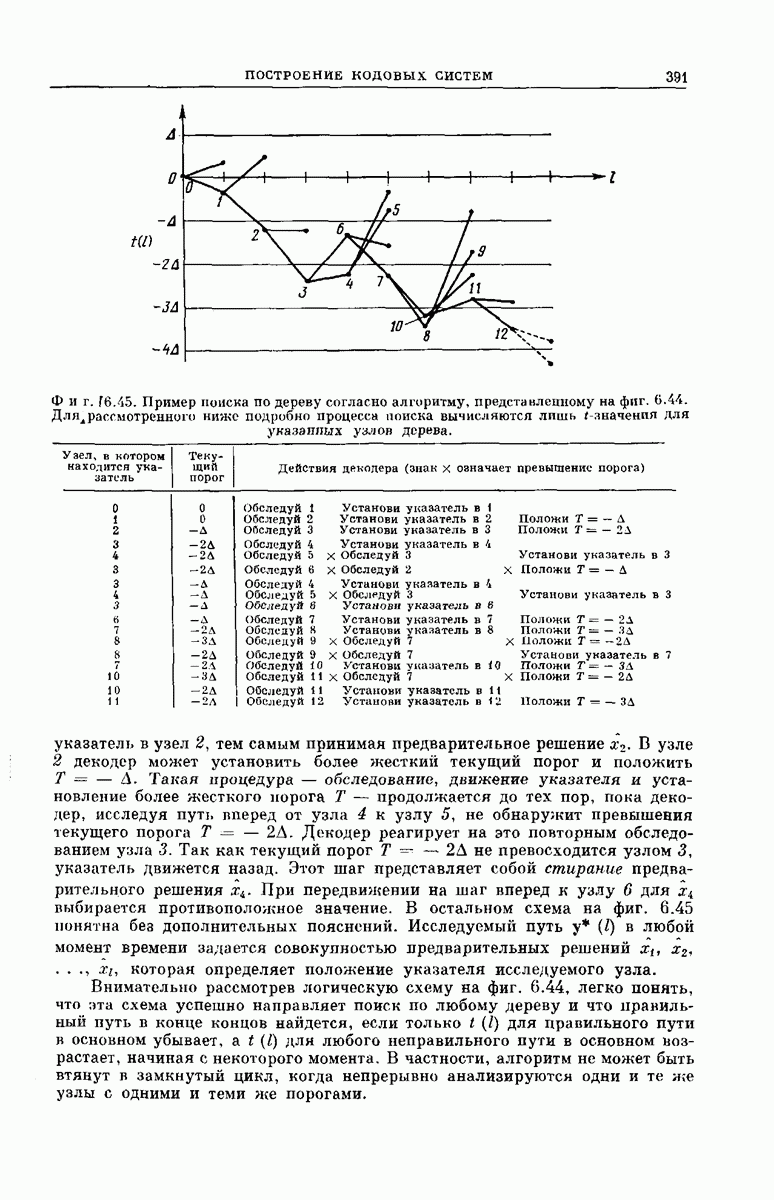
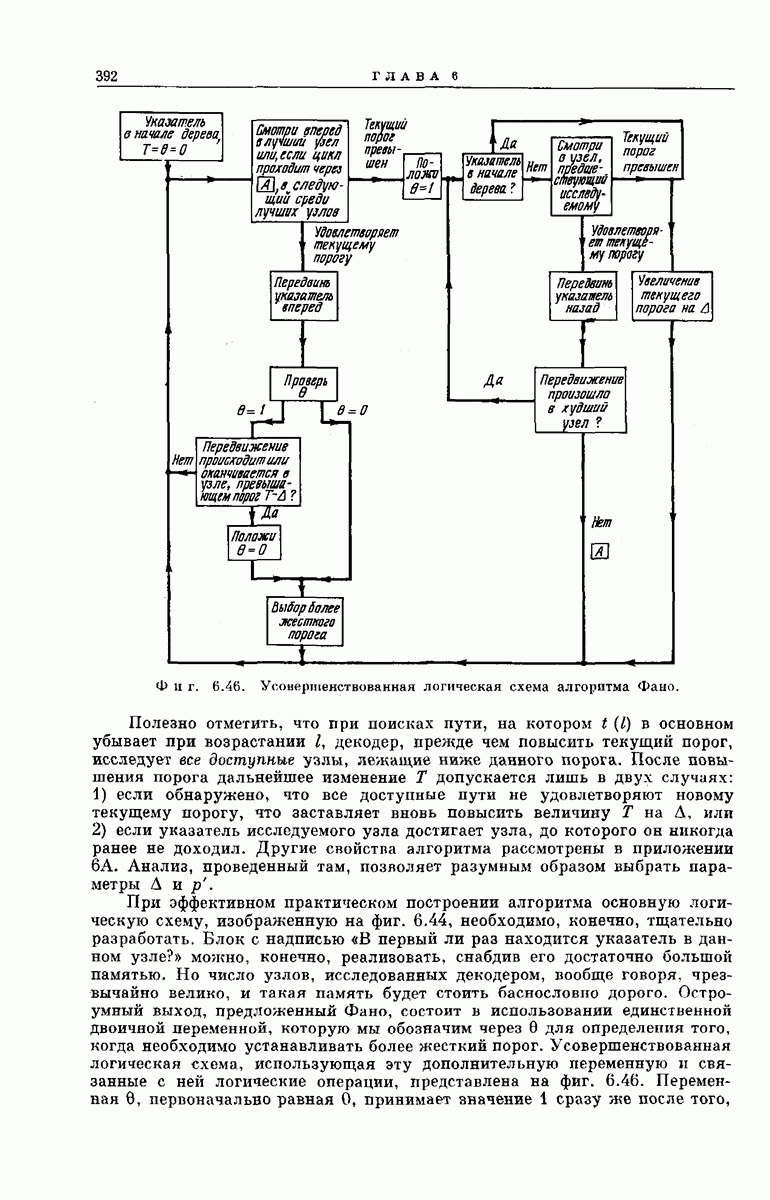


















































































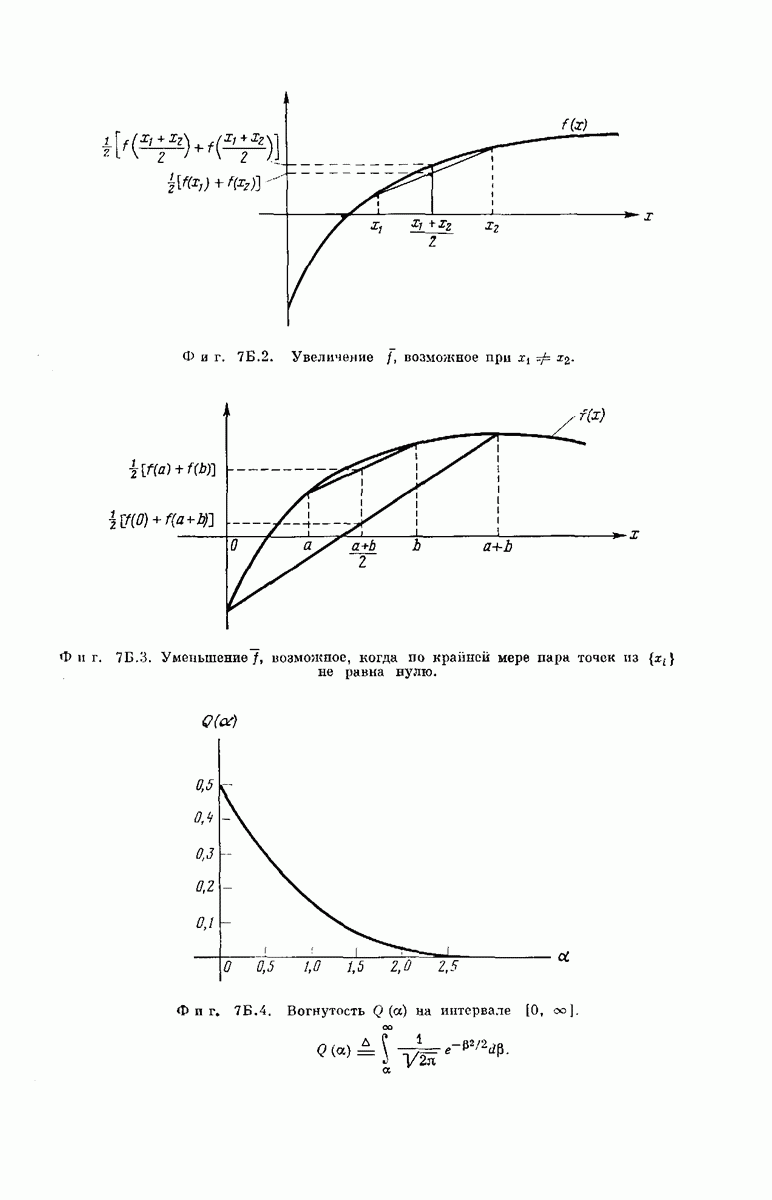
























































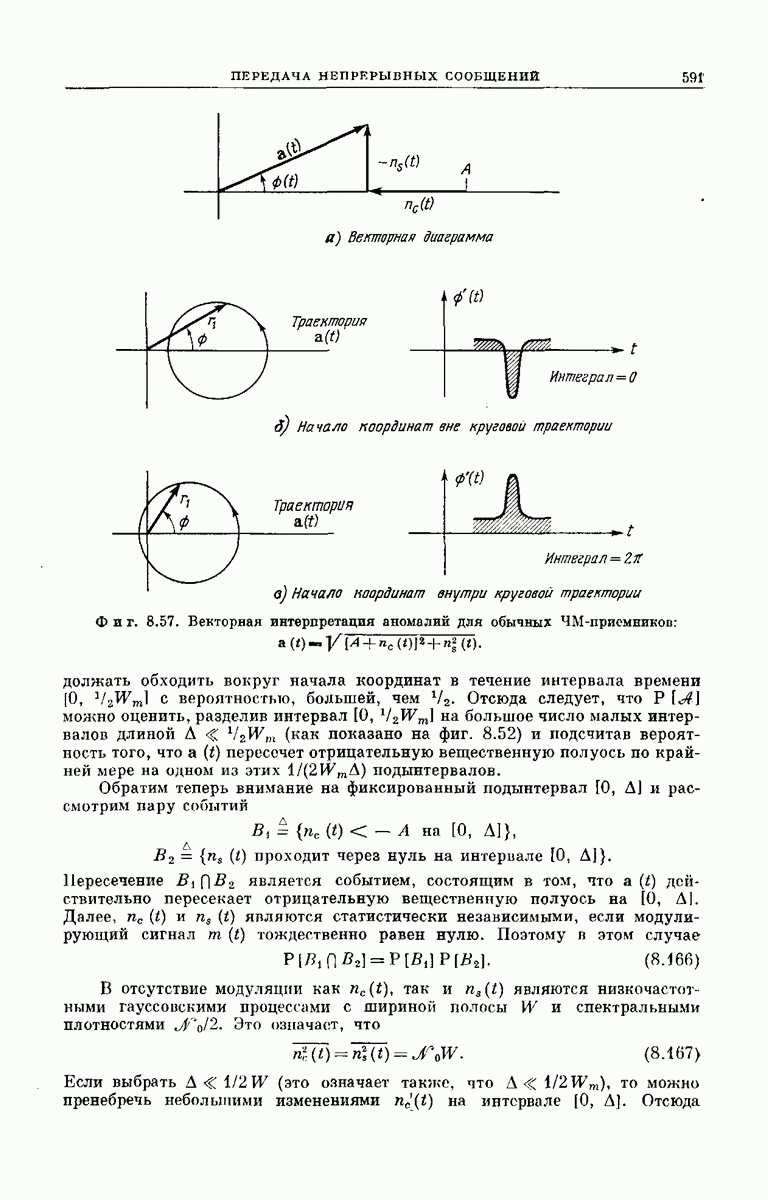




































 рассмотрим подробпее структуру кодового дерева. Обозначим сегменты кодового слова из
рассмотрим подробпее структуру кодового дерева. Обозначим сегменты кодового слова из  символов, определяющие решение
символов, определяющие решение  особыми символами
особыми символами  Если сообщением является последовательность
Если сообщением является последовательность  представляющая собой двоичную запись числа к, то передается
представляющая собой двоичную запись числа к, то передается  сегмент кодового слова
сегмент кодового слова  поэтому запишем
поэтому запишем

 из
из  символов можно описать, как это следует из фиг. 6.38, а, формулой
символов можно описать, как это следует из фиг. 6.38, а, формулой


 если «усечь» обе части равенства а следовательно, и каждый из векторов
если «усечь» обе части равенства а следовательно, и каждый из векторов  до
до  символов. Легко видеть, что
символов. Легко видеть, что  где
где  порождающая последовательность сверточного кодера.
порождающая последовательность сверточного кодера.