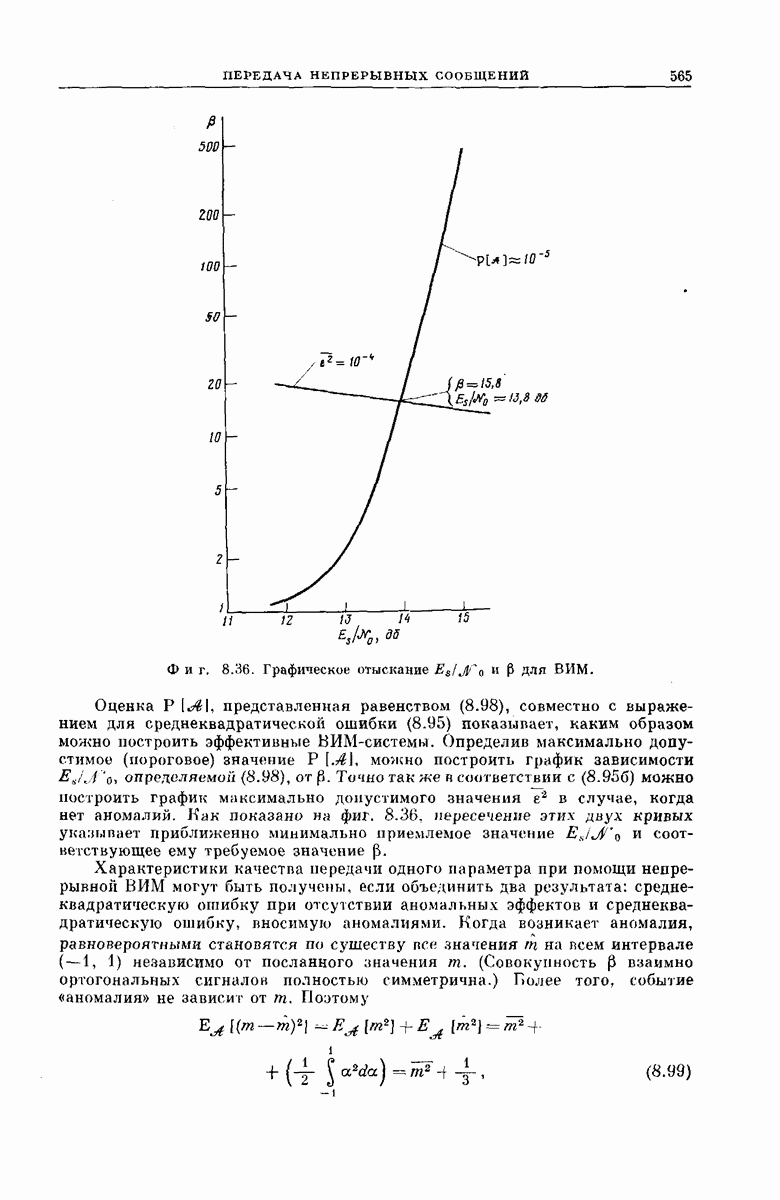
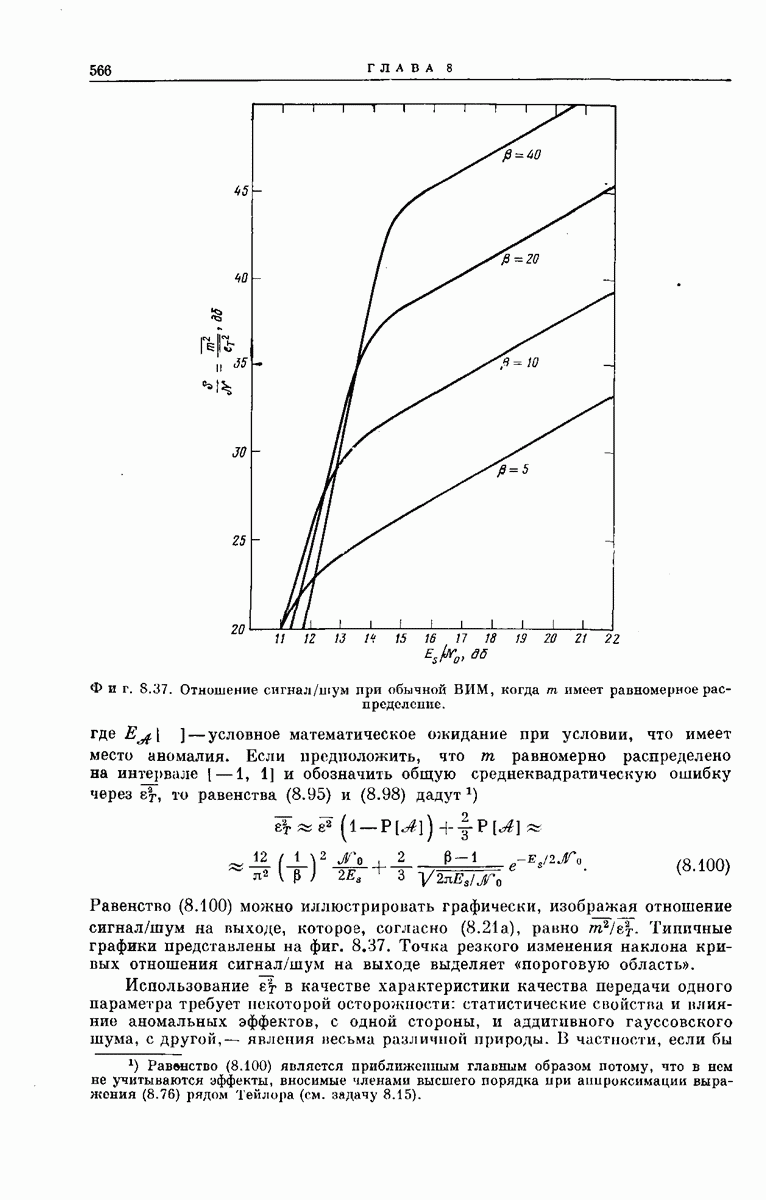
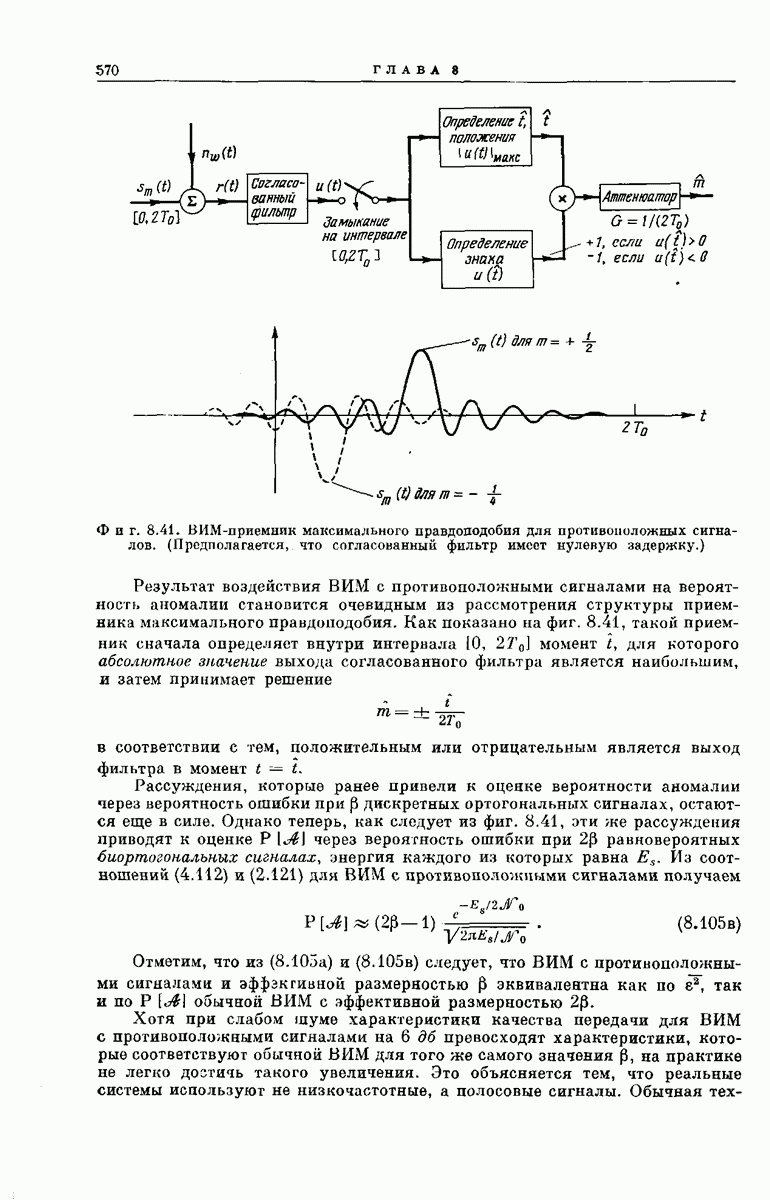
Затем подробно рассмотрим конкретный алгоритм декодирования, предложенный Фано [28]. Этот алгоритм может быть распространен на широкий класс каналов. Математический анализ этого алгоритма проведен в приложении  Его технические приложения рассмотрены в разд. 6.5.
Его технические приложения рассмотрены в разд. 6.5.
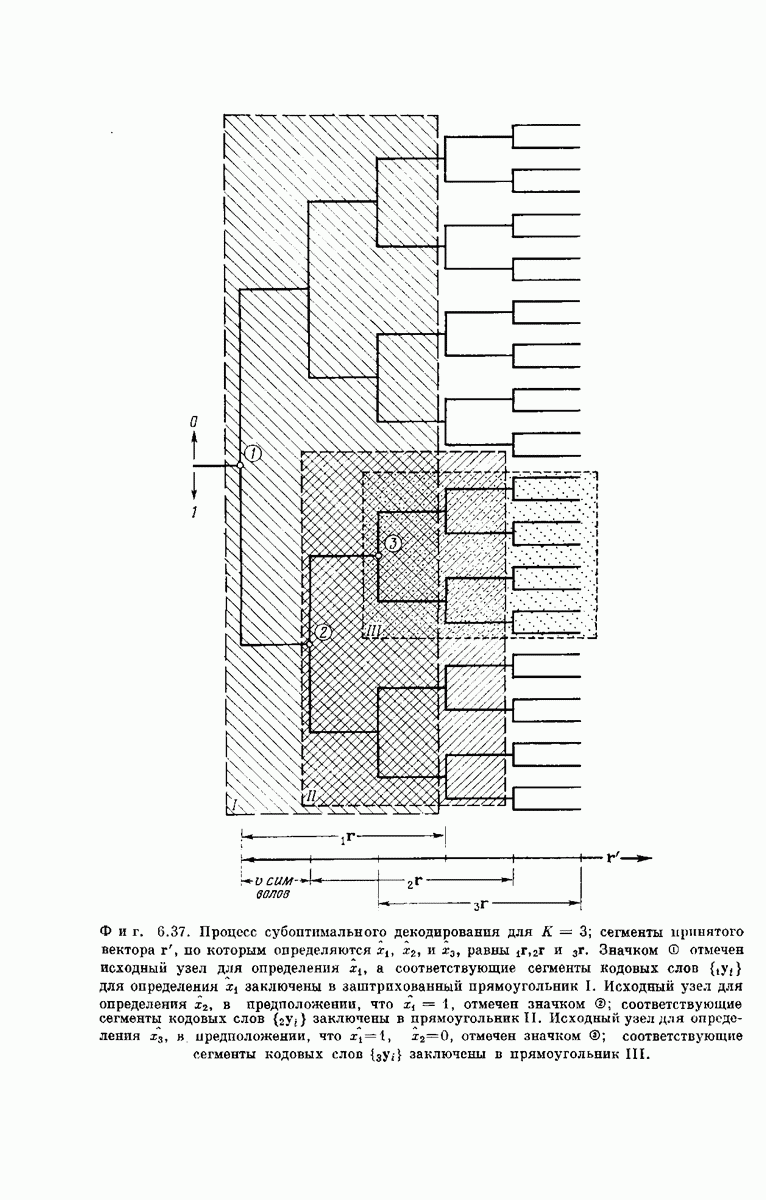
В своей простейшей форме последовательный декодер работает во многом аналогично рассмотренному нами субоптимальному декодеру. Оба декодера принимают решения о каждом из последовательных входных двоичных символов сообщения по очереди, одно за другим, как показано на фиг. 6.37. И для того, и для другого декодера задача декодирования символа  при условии, что правильно найден
при условии, что правильно найден  исходный узел, эквивалентна задаче декодирования символа х. Однако эти декодеры существенно по-разному принимают решения относительно
исходный узел, эквивалентна задаче декодирования символа х. Однако эти декодеры существенно по-разному принимают решения относительно 
ПОИСК ПО ДЕРЕВУ
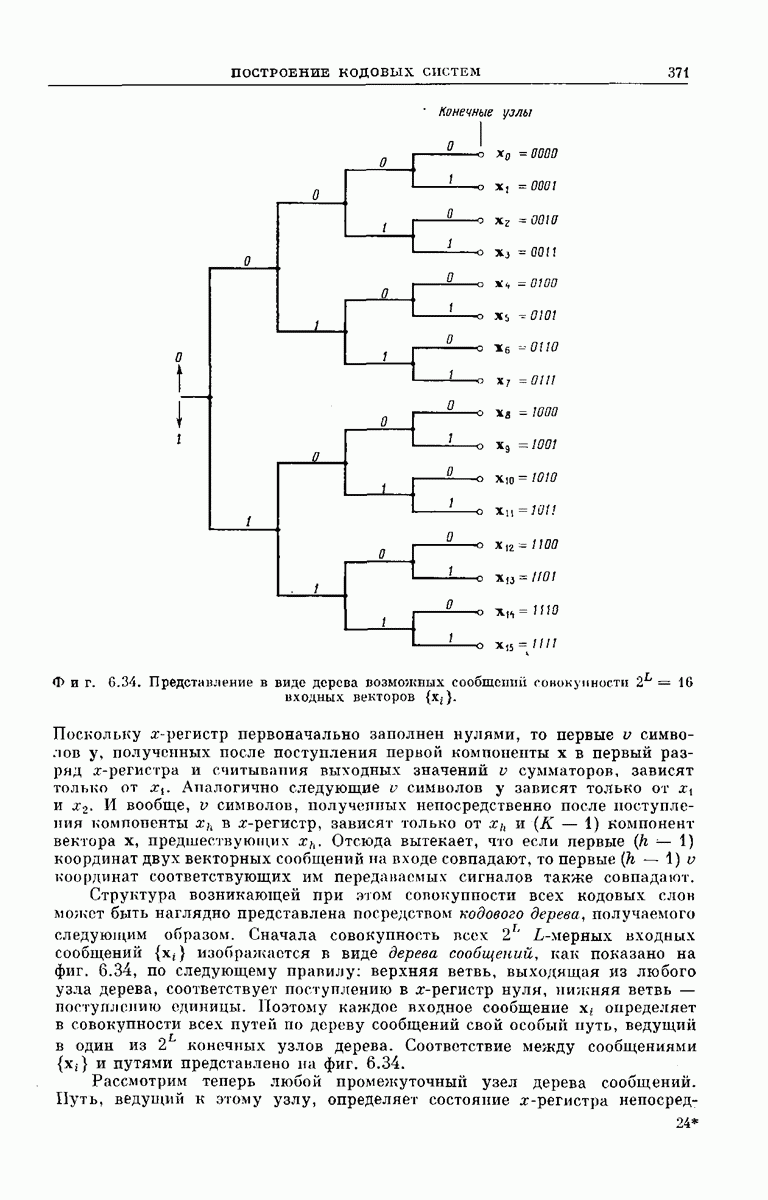
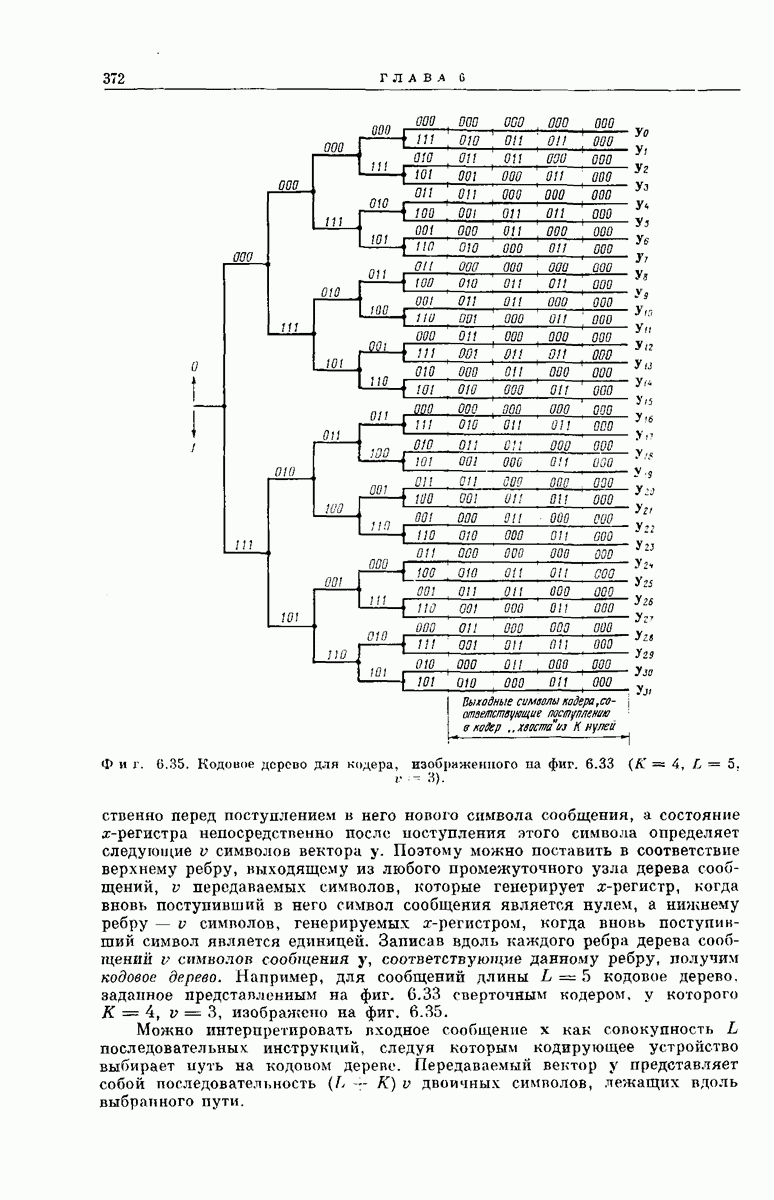
Мы уже отмечали, что сигнал  поступивший в сверточный кодер, может рассматриваться как совокупность указаний, следуя которым передатчик выбирает некоторый путь по кодовому дереву. Пусть у представляет собой вектор из
поступивший в сверточный кодер, может рассматриваться как совокупность указаний, следуя которым передатчик выбирает некоторый путь по кодовому дереву. Пусть у представляет собой вектор из  начальных символов, расположенных вдоль этого пути, а через
начальных символов, расположенных вдоль этого пути, а через  обозначены первые
обозначены первые  символов шума. Если бы мы с самого начала предположили, что ДСК является бесшумным, так что
символов шума. Если бы мы с самого начала предположили, что ДСК является бесшумным, так что  то
то  . В этом тривиальном случае декодер, содержащий точный аналог сверточного кодера, находящегося на передающем конце, может легко выделить первые К ребер пути, соответствующего вектору
. В этом тривиальном случае декодер, содержащий точный аналог сверточного кодера, находящегося на передающем конце, может легко выделить первые К ребер пути, соответствующего вектору  Декодер начинает процесс декодирования из первого узла кодового дерева. Он генерирует оба ребра, выходящих из первого узла, и следует по тому ребру, которое соответствует первым
Декодер начинает процесс декодирования из первого узла кодового дерева. Он генерирует оба ребра, выходящих из первого узла, и следует по тому ребру, которое соответствует первым  символам
символам  Выделив таким образом направление к одному из узлов на втором уровне кодового дерева, декодер вновь генерирует два ребра, исходящих из второго узла, и продолжает движение по тому ребру, которое соответствует
Выделив таким образом направление к одному из узлов на втором уровне кодового дерева, декодер вновь генерирует два ребра, исходящих из второго узла, и продолжает движение по тому ребру, которое соответствует  символам вектора
символам вектора  ведущим от второго узла к одному из узлов на третьем уровне кодового дерева. Продолжая декодирование таким образом, декодер быстро определяет первые К символов вектора
ведущим от второго узла к одному из узлов на третьем уровне кодового дерева. Продолжая декодирование таким образом, декодер быстро определяет первые К символов вектора  Эта процедура легко осуществляется, если два ребра, выходящих из любого узла кодового дерева, отличаются хотя бы одним символом. Из фиг. 6.32 ясно, что, связав первую ячейку
Эта процедура легко осуществляется, если два ребра, выходящих из любого узла кодового дерева, отличаются хотя бы одним символом. Из фиг. 6.32 ясно, что, связав первую ячейку  -регистра с первым сумматором но модулю 2, т. е. положив
-регистра с первым сумматором но модулю 2, т. е. положив  мы гарантируем несовпадение этих ребер.
мы гарантируем несовпадение этих ребер.
Если ДСК является каналом с шумами, то вектор  вообще говоря, не равен 0, и только что описанная процедура будет неэффективной даже при декодировании первого символа сообщения
вообще говоря, не равен 0, и только что описанная процедура будет неэффективной даже при декодировании первого символа сообщения  Однако привлекательна простая модификация этой процедуры, которая хможет быть использована для декодирования символа
Однако привлекательна простая модификация этой процедуры, которая хможет быть использована для декодирования символа  с высокой надежностью. Если ни одно из ребер, исходящих из промежуточного узла, не совпадает с соответствующими и символами вектора то декодер следует вначале по ребру, у которого число совпадающих символов больше. Ясно, что, если исказилось более чем
с высокой надежностью. Если ни одно из ребер, исходящих из промежуточного узла, не совпадает с соответствующими и символами вектора то декодер следует вначале по ребру, у которого число совпадающих символов больше. Ясно, что, если исказилось более чем  символов передаваемой ветви, такой декодер вначале проследует к неправильному узлу. Однако маловероятно, чтобы, сделав однажды такую ошибку, декодер при сравнении следующих ребер нашел хоть какой-нибудь путь, исходящий из этого неправильного узла, который хорошо согласовывался бы с оставшимися символами вектора
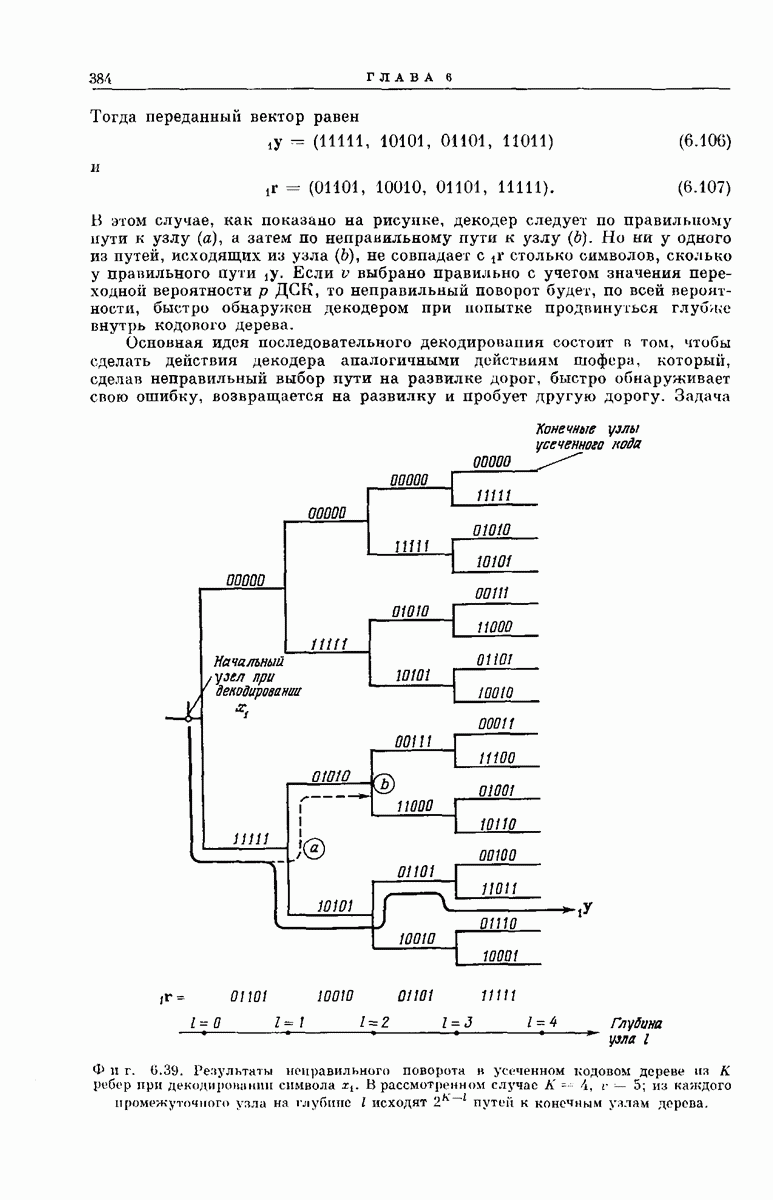
символов передаваемой ветви, такой декодер вначале проследует к неправильному узлу. Однако маловероятно, чтобы, сделав однажды такую ошибку, декодер при сравнении следующих ребер нашел хоть какой-нибудь путь, исходящий из этого неправильного узла, который хорошо согласовывался бы с оставшимися символами вектора  Рассмотрим, например, усеченное кодовое дерево, изображенное на фиг. 6.39, с
Рассмотрим, например, усеченное кодовое дерево, изображенное на фиг. 6.39, с  Предположим, что
Предположим, что

и

Тогда переданный вектор равен

и

В этом случае, как показано на рисунке, декодер следует по правильному пути к узлу  а затем по неправильному пути к узлу
а затем по неправильному пути к узлу  Но ни у одного из путей, исходящих из узла
Но ни у одного из путей, исходящих из узла  не совпадает с
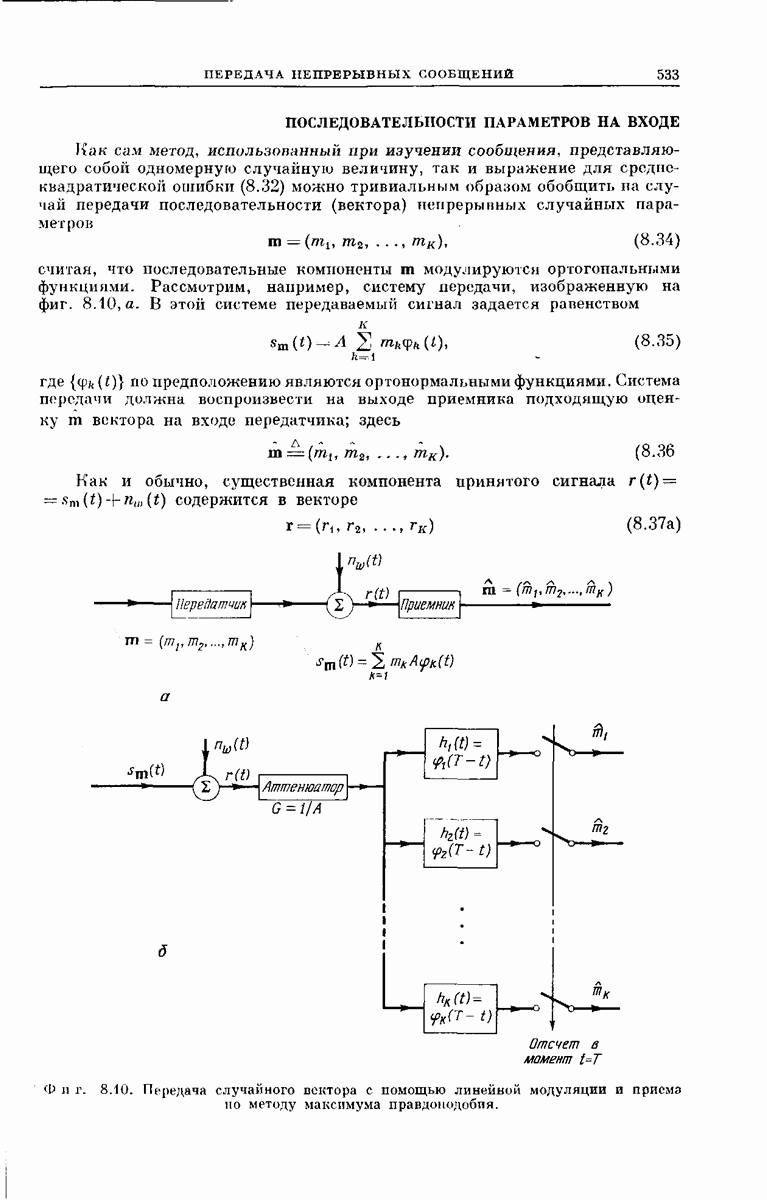
не совпадает с  столько символов, сколько у правильного пути
столько символов, сколько у правильного пути  Если
Если  выбрано правильно с учетом значения переходной вероятности
выбрано правильно с учетом значения переходной вероятности  то неправильный поворот будет, по всей вероятности, быстро обнаружен декодером при попытке продвинуться глубже внутрь кодового дерева.
то неправильный поворот будет, по всей вероятности, быстро обнаружен декодером при попытке продвинуться глубже внутрь кодового дерева.
Основная идея последовательного декодирования состоит и том, чтобы сделать действия декодера аналогичными действиям шофера, который, сделав неправильный выбор пути на развилке дорог, быстро обнаруживает свою ошибку, возвращается на развилку и пробует другую дорогу.
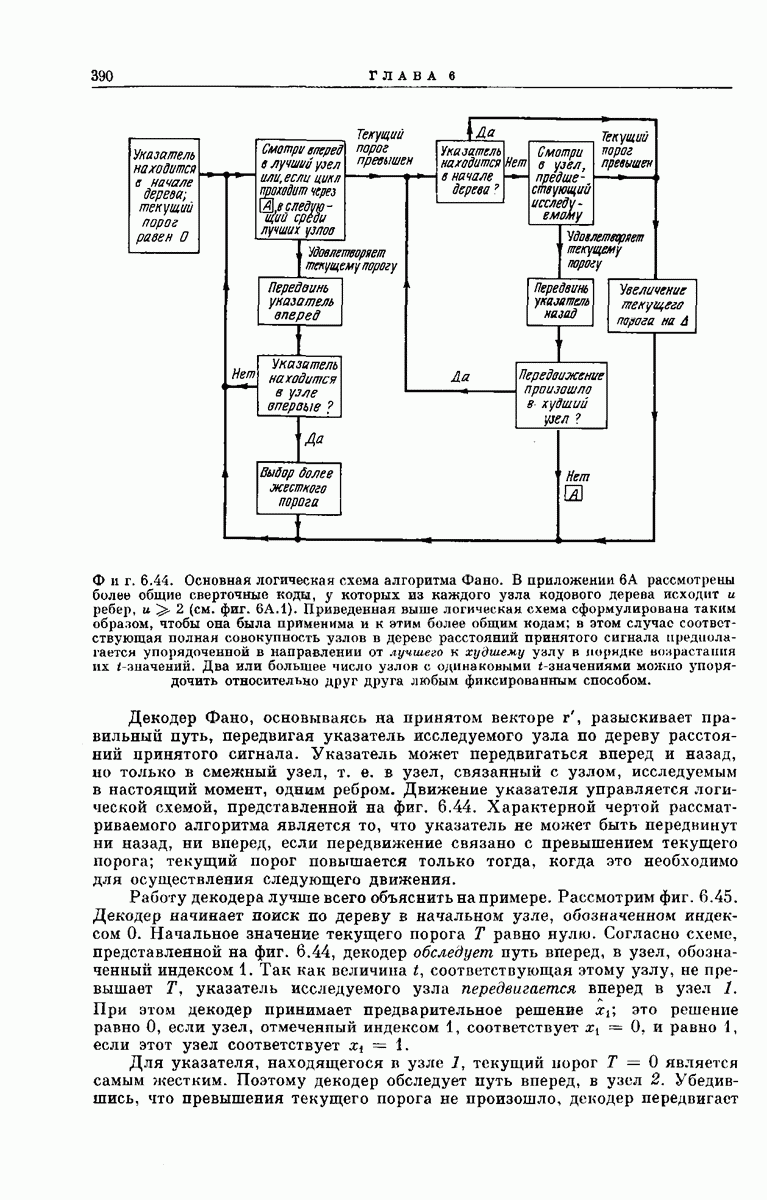
Фиг. 6.39. (см. скан) Результаты неправильного поворота в усеченном кодовом дереве из К ребер при декодировании символа  . В рассмотренном случае
. В рассмотренном случае  ; из каждого промежуточного узла на глубине I исходят путей к конечным узлам дерева.
; из каждого промежуточного узла на глубине I исходят путей к конечным узлам дерева.

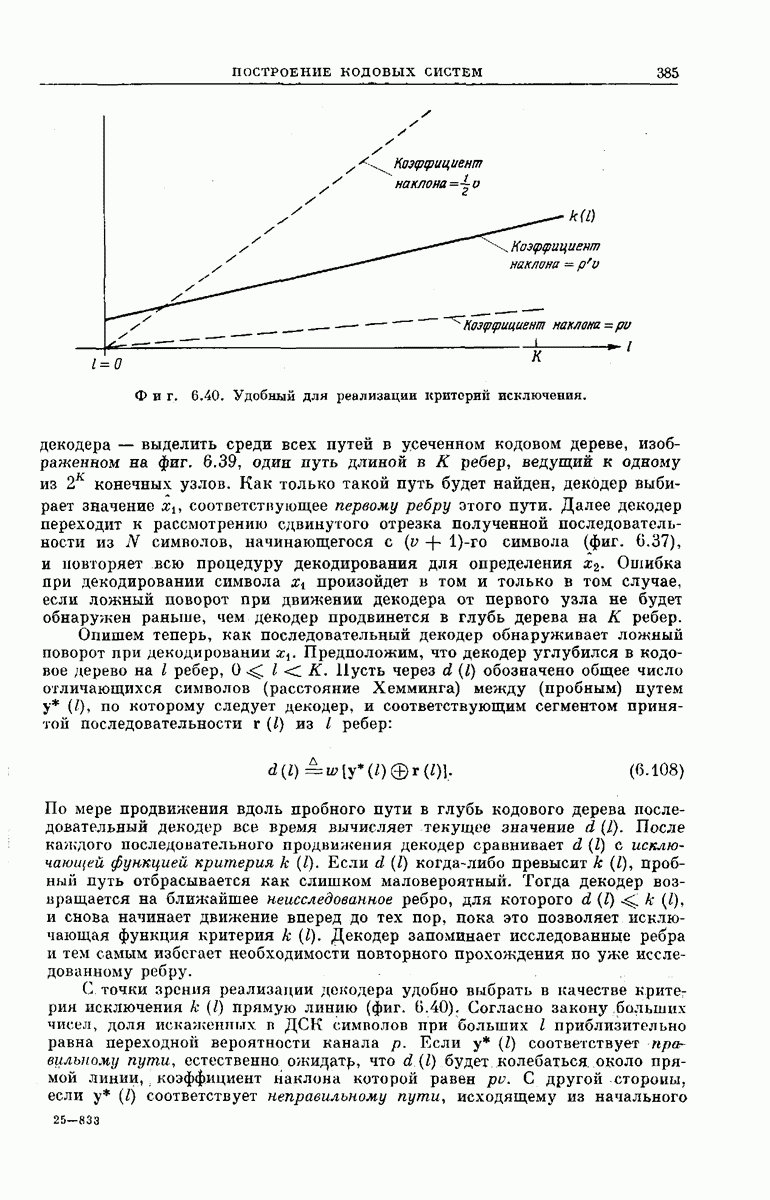
Фиг. 6.40. Удобный для реализации критерий исключения.
Задача декодера — выделить среди всех путей в усеченном кодовом дереве, изображенном на фиг. 6.39, один путь длиной в К ребер, ведущий к одному из  конечных узлов. Как только такой путь будет найден, декодер выбирает значение соответствующее первому ребру этого пути. Далее декодер переходит к рассмотрению сдвинутого отрезка полученной последовательности из
конечных узлов. Как только такой путь будет найден, декодер выбирает значение соответствующее первому ребру этого пути. Далее декодер переходит к рассмотрению сдвинутого отрезка полученной последовательности из  символов, начинающегося с
символов, начинающегося с  символа (фиг. 6.37), и повторяет всю процедуру декодирования для определения Ошибка при декодировании символа
символа (фиг. 6.37), и повторяет всю процедуру декодирования для определения Ошибка при декодировании символа  произойдет в том и только в том случае, если ложный поворот при движении декодера от первого узла не будет обнаружен раньше, чем декодер продвинется в глубь дерева на К ребер.
произойдет в том и только в том случае, если ложный поворот при движении декодера от первого узла не будет обнаружен раньше, чем декодер продвинется в глубь дерева на К ребер.
Опишем теперь, как последовательный декодер обнаруживает ложный поворот при декодировании а. Предположим, что декодер углубился в кодовое дерево на I ребер,  Пусть через
Пусть через  обозначено общее число отличающихся символов (расстояние Хемминга) между (пробным) путем
обозначено общее число отличающихся символов (расстояние Хемминга) между (пробным) путем  по которому следует декодер, и соответствующим сегментом принятой последовательности
по которому следует декодер, и соответствующим сегментом принятой последовательности  из I ребер:
из I ребер:

По мере продвижения вдоль пробного пути в глубь кодового дерева последовательный декодер все время вычисляет текущее значение  После каждого последовательного продвижения декодер сравнивает
После каждого последовательного продвижения декодер сравнивает  с исключающей функцией критерия
с исключающей функцией критерия  Если
Если  когда-либо превысит к (I), пробный путь отбрасывается как слишком маловероятный. Тогда декодер возвращается на блияайшее неисследованное ребро, для которого
когда-либо превысит к (I), пробный путь отбрасывается как слишком маловероятный. Тогда декодер возвращается на блияайшее неисследованное ребро, для которого  к (7), и снова начинает движение вперед до тех пор, пока это позволяет исключающая функция критерия к (I). Декодер запоминает исследованные ребра и тем самым избегает необходимости повторного прохождения по уже исследованному ребру.
к (7), и снова начинает движение вперед до тех пор, пока это позволяет исключающая функция критерия к (I). Декодер запоминает исследованные ребра и тем самым избегает необходимости повторного прохождения по уже исследованному ребру.
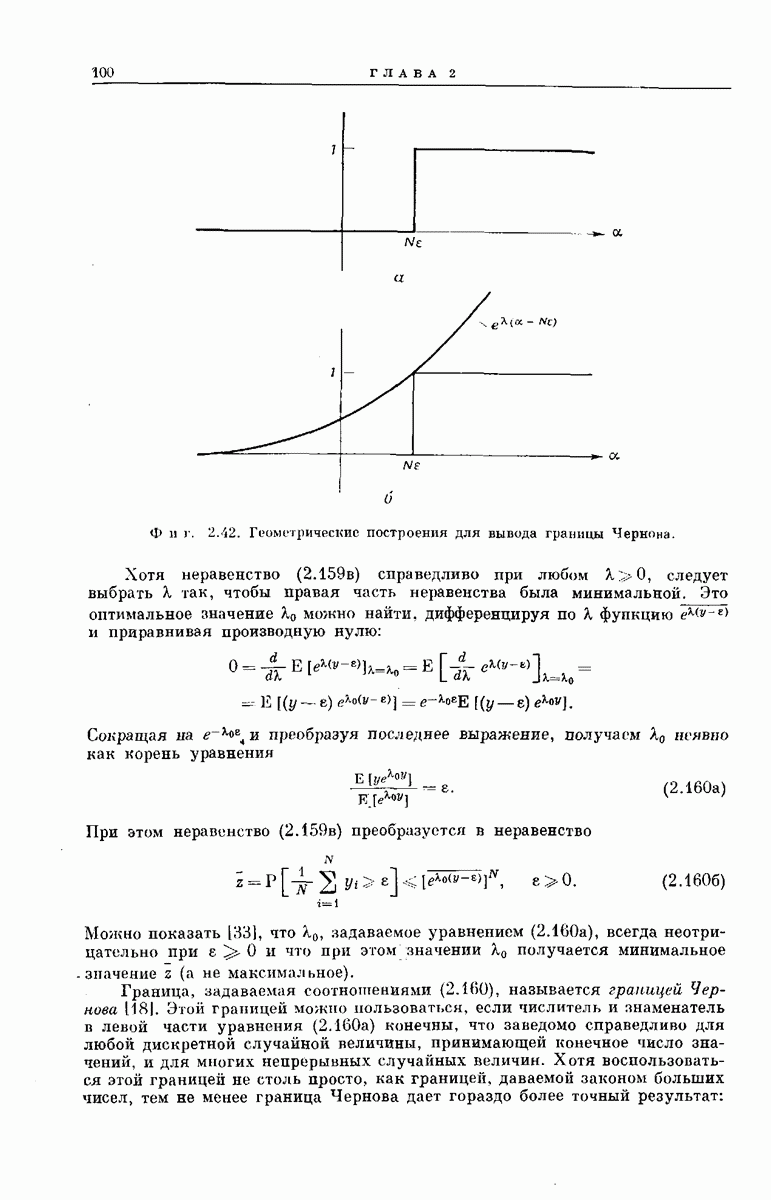
С точки зрения реализации декодера удобно выбрать в качестве критерия исключения к (I) прямую линию (фиг. 6.40). Согласно закону больших чисел, доля искаженных в ДСК символов при больших I приблизительно равна переходной вероятности канала  Если
Если  соответствует правильному пути, естественно ожицатр, что
соответствует правильному пути, естественно ожицатр, что  будет колебаться, около прямой линии,
будет колебаться, около прямой линии,  коэффициент наклона которой равен
коэффициент наклона которой равен  . С другой стороны, если
. С другой стороны, если  соответствует неправильному пути, исходящему из начального
соответствует неправильному пути, исходящему из начального
узла  естественно ожидать, что
естественно ожидать, что  будет колебаться
будет колебаться  около прямой, коэффициент наклона которой равен Выберем в качестве
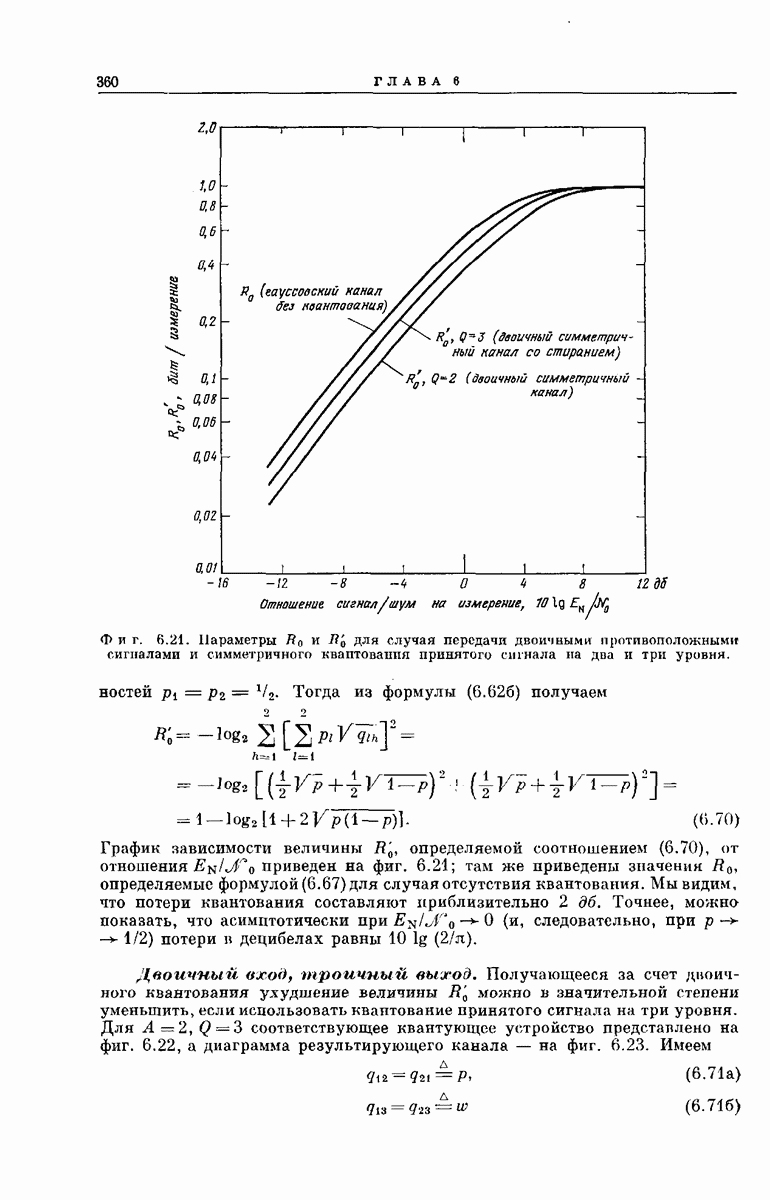
около прямой, коэффициент наклона которой равен Выберем в качестве  прямую линию, коэффициент наклона которой
прямую линию, коэффициент наклона которой  принимает промежуточное значение, так что
принимает промежуточное значение, так что  Поскольку не исключено, что паличие помех приведет к искажению большого числа начальных символов вектора
Поскольку не исключено, что паличие помех приведет к искажению большого числа начальных символов вектора  функцию
функцию  выбирают так, чтобы при
выбирают так, чтобы при  она была отлична от нуля.
она была отлична от нуля.
ОСНОВНЫЕ ПРИНЦИПЫ
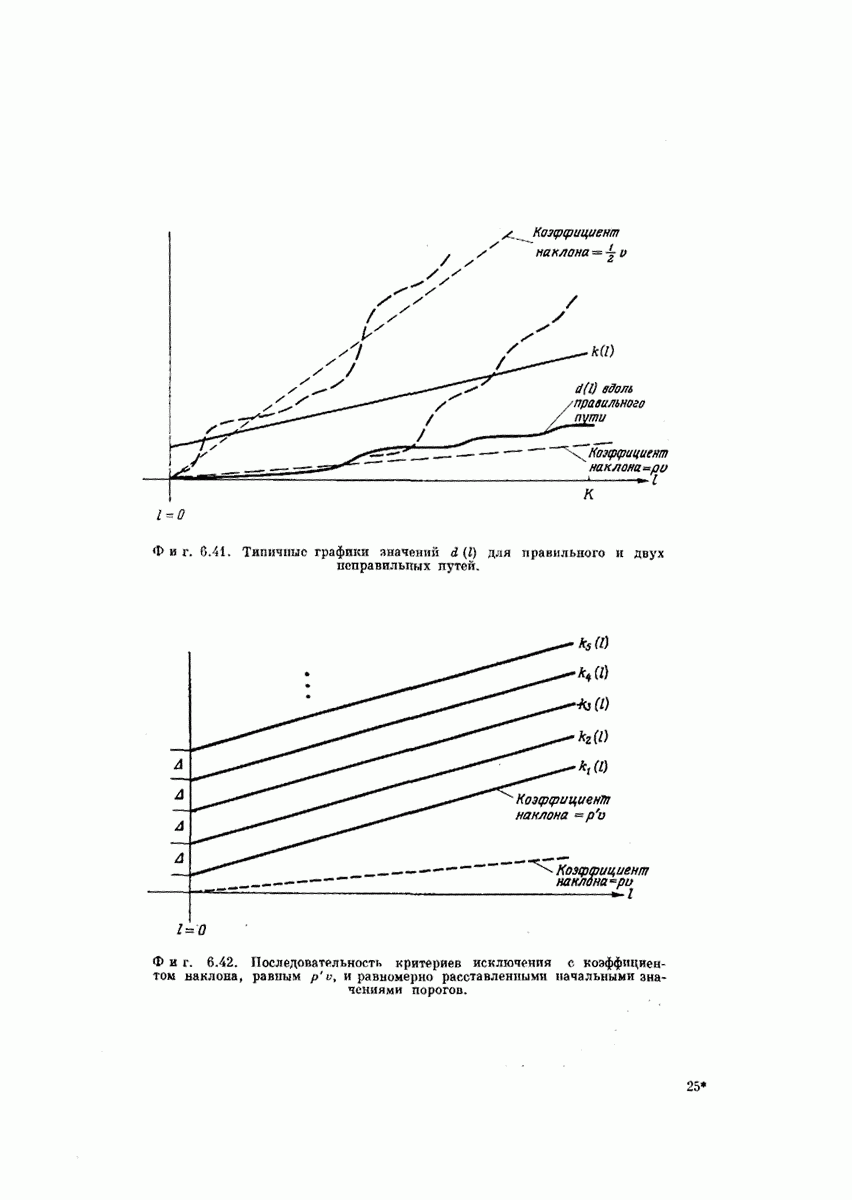
Использование при последовательном декодировании разумно подобранных критериев исключения позволяет декодеру довольно быстро обнаруживать, что он следует по неправильному пути. Например, на фиг. 6.41 показаны два неправильных пути, один из которых ответвляется от истинного в начальном узле, а другой — в некотором промежуточном узле. Оба они пересекают  вскоре после ответвления. Преимущество с вычислительной точки зрения —
вскоре после ответвления. Преимущество с вычислительной точки зрения —  этом состоит первый из основных принципов последовательного декодирования — заключается в том, что исключение некоторого пути, состоящего из I ребер, эквивалентно исключению
этом состоит первый из основных принципов последовательного декодирования — заключается в том, что исключение некоторого пути, состоящего из I ребер, эквивалентно исключению  остальных путей в усеченном дереве, которые исходят из исключенного пути (фиг. 6.39). Главное свойство сверточных кодов состоит в том, что если удается достаточно быстро обнаружить неправильный поворот, то экономия в количестве вычислений (измеряемая числом исследованных ребер) экспоненциально велика.
остальных путей в усеченном дереве, которые исходят из исключенного пути (фиг. 6.39). Главное свойство сверточных кодов состоит в том, что если удается достаточно быстро обнаружить неправильный поворот, то экономия в количестве вычислений (измеряемая числом исследованных ребер) экспоненциально велика.
Ясно, что среднее количество вычислений можно уменьшить путем более жесткого ограничения функции к  т. е. путем выбора достаточно малых коэффициентов наклона и
т. е. путем выбора достаточно малых коэффициентов наклона и  . С другой стороны, если выбрать критерий исключения слишком жестким, то каждая из последовательностей в кодовом дереве (включая и правильную) под действием шумов в канале пересечет
. С другой стороны, если выбрать критерий исключения слишком жестким, то каждая из последовательностей в кодовом дереве (включая и правильную) под действием шумов в канале пересечет  при I, меньших К. В этом случае описанный нами декодер не сможет найти путь ни к одному из конечных узлов, изображенных на фиг. 6.39, и, следовательно, не сможет декодировать
при I, меньших К. В этом случае описанный нами декодер не сможет найти путь ни к одному из конечных узлов, изображенных на фиг. 6.39, и, следовательно, не сможет декодировать 
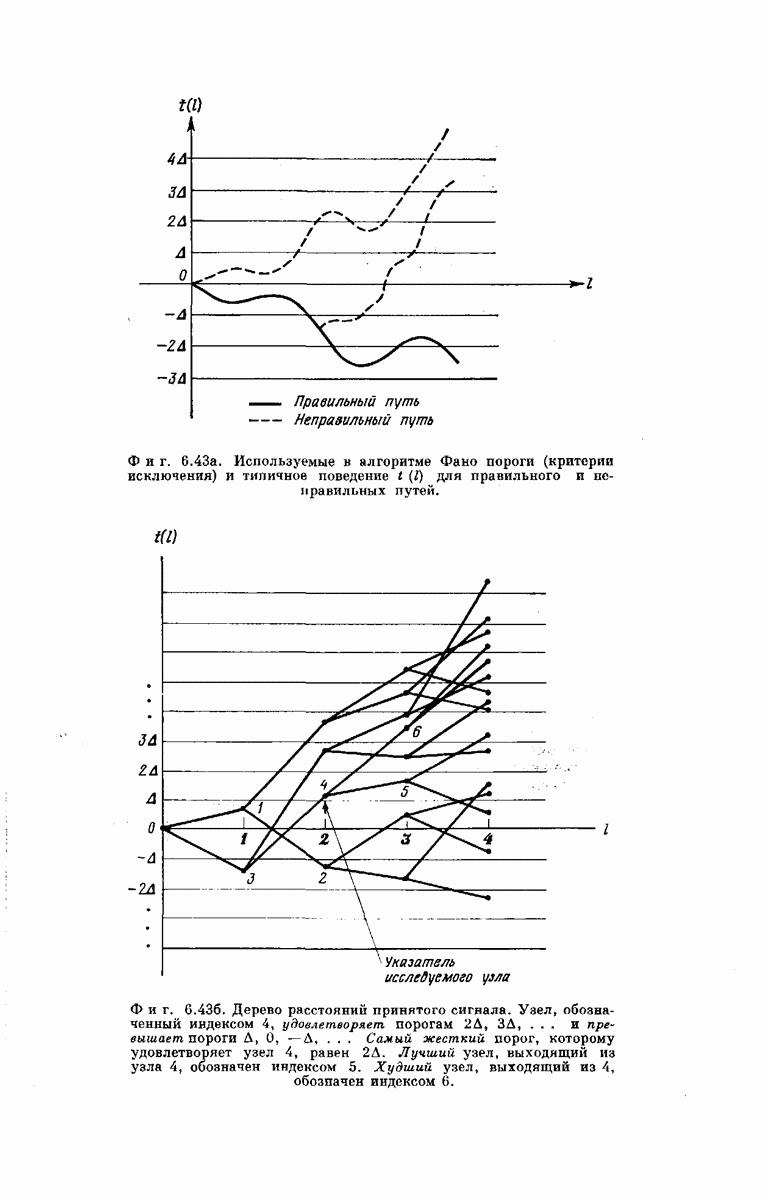
К счастью, есть путь к разрешению этой дилеммы; этот путь основан на втором основном принципе последовательного декодирования. Пусть декодирование начинается с жесткого критерия, например с такого, для которого исключающая функция  представлена на фиг. 6.42. Чаще всего правильный путь (или по крайней мере некоторый путь, у которого правильно первое ребро) не будет исключен и символ
представлена на фиг. 6.42. Чаще всего правильный путь (или по крайней мере некоторый путь, у которого правильно первое ребро) не будет исключен и символ  будет декодирован лишь малым количеством вычислений. В остальных более редких случаях, когда все пути по кодовому дереву исключаются, прибегают к менее жесткому критерию, например такому, исключающая функция которого
будет декодирован лишь малым количеством вычислений. В остальных более редких случаях, когда все пути по кодовому дереву исключаются, прибегают к менее жесткому критерию, например такому, исключающая функция которого  изображена на фиг. 6.42. Если же (а это может случиться в еще более редких случаях) все пути исключаются и при использовании критерия
изображена на фиг. 6.42. Если же (а это может случиться в еще более редких случаях) все пути исключаются и при использовании критерия  прибегают к критерию (I) и т. д.
прибегают к критерию (I) и т. д.
Последовательно смягчая критерий исключения, мы в конце концов приходим к тому, что некоторый путь из К ребер останется неисключенным; с высокой вероятностью первое ребро этого пути будет правильным. Конечно, более мягкий критерий требует большего числа вычислений, чем  но, так как более мягкие критерии используются редко, рост вычислительной нагрузки, который они вызывают, может и не привести к катастрофическому увеличению требуемого среднего количества вычислений, измеряемого снова числом исследованных ребер.
но, так как более мягкие критерии используются редко, рост вычислительной нагрузки, который они вызывают, может и не привести к катастрофическому увеличению требуемого среднего количества вычислений, измеряемого снова числом исследованных ребер.

(кликните для просмотра скана)

























































































































































































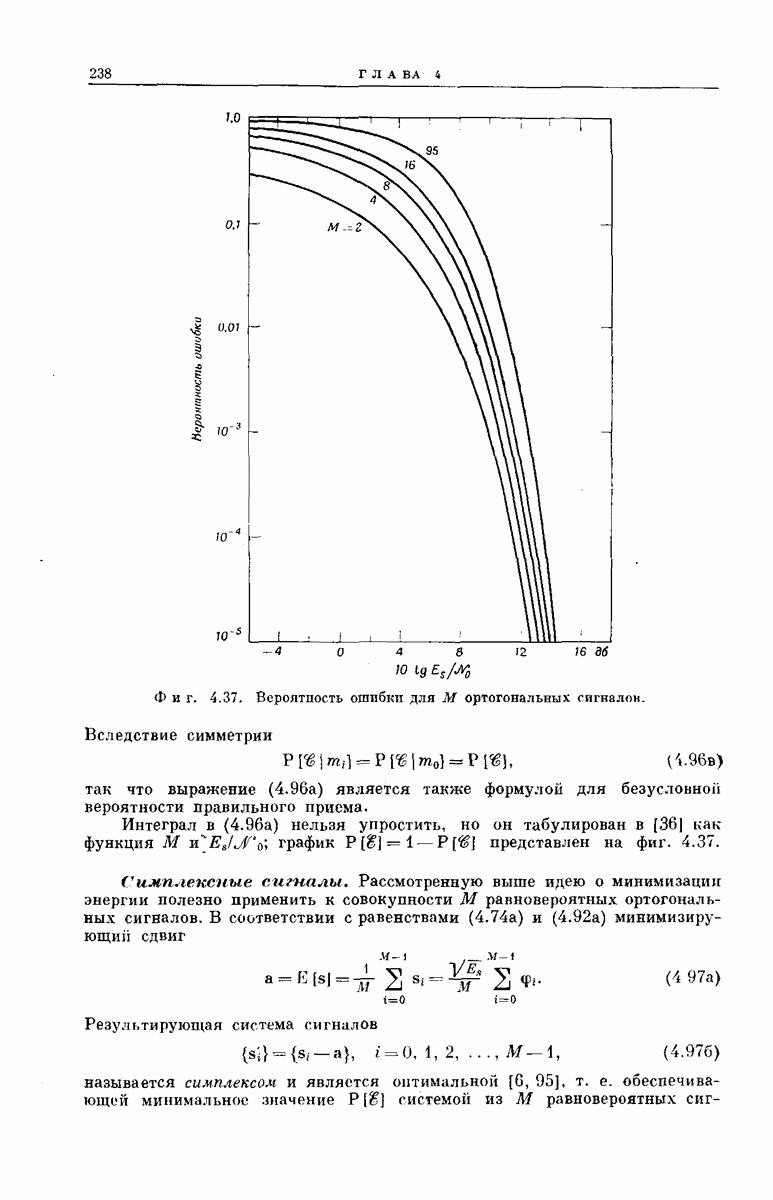

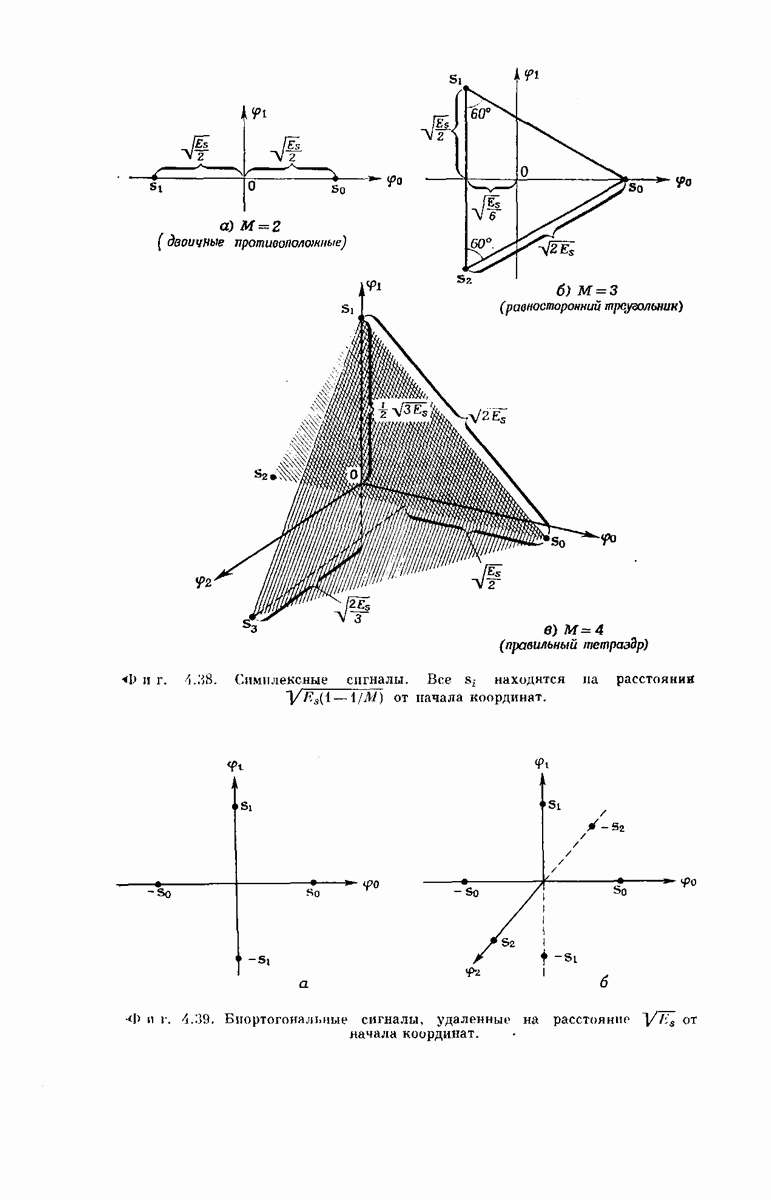




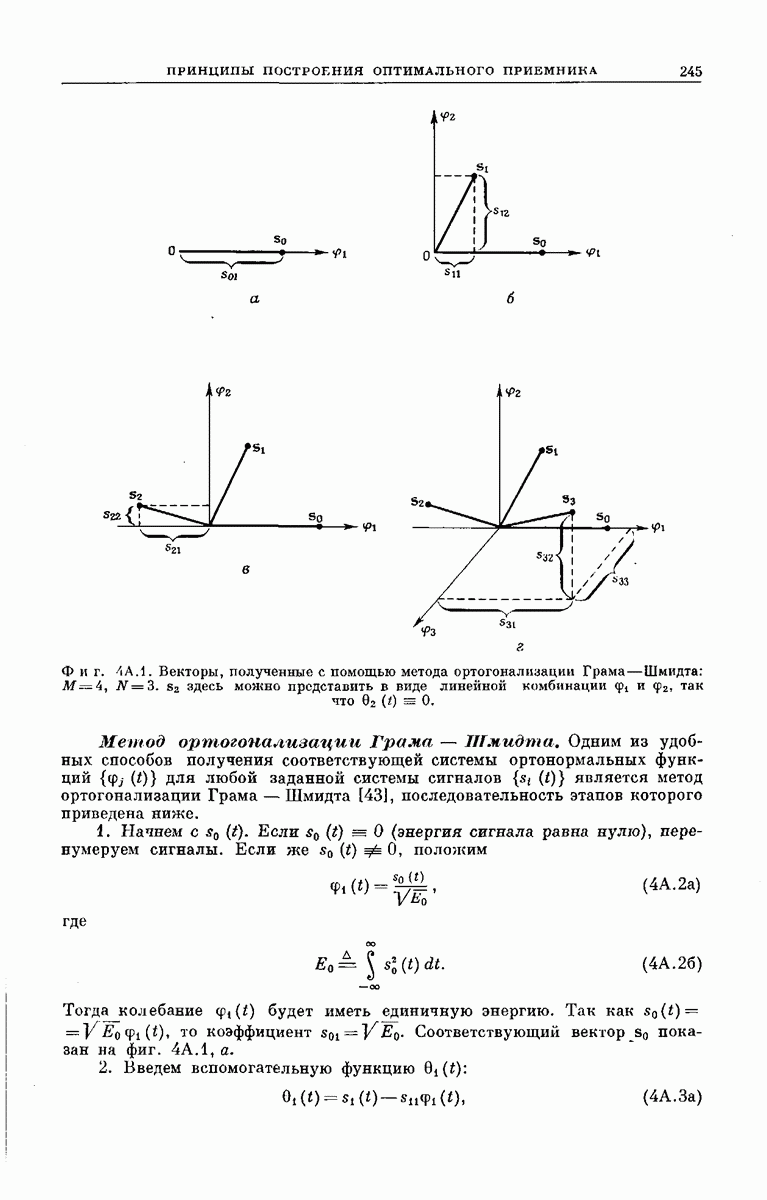


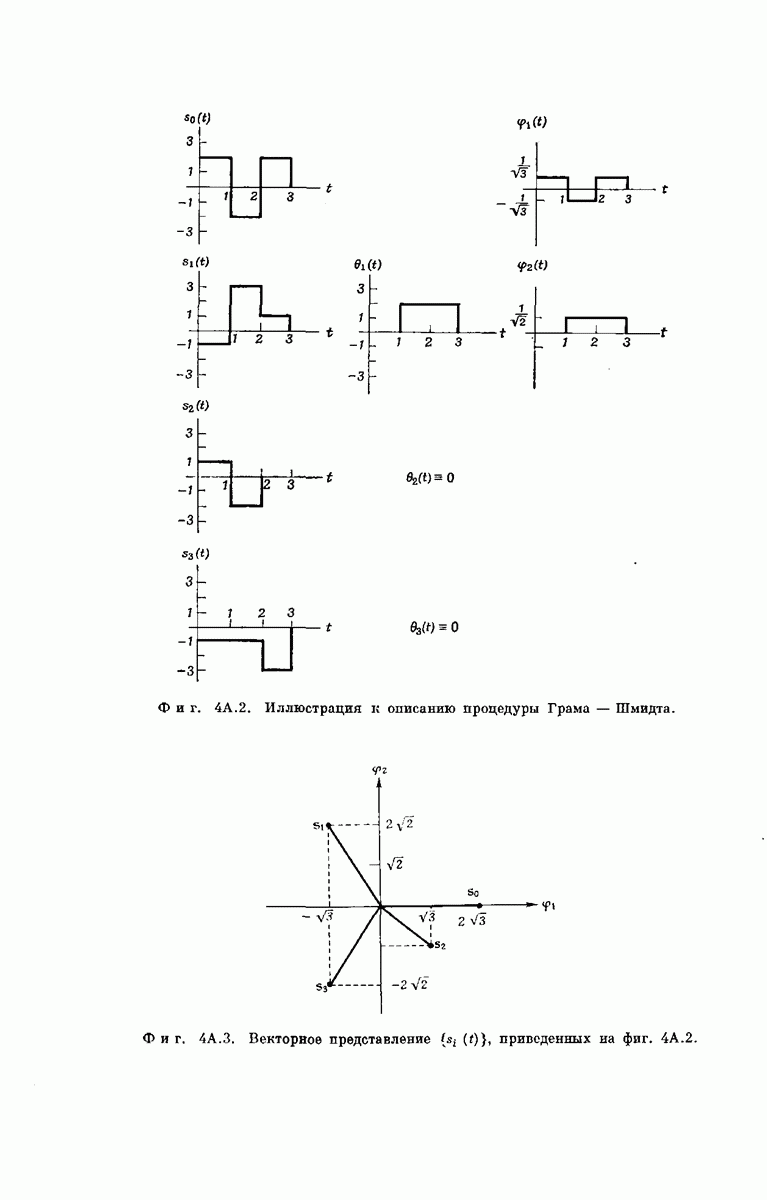






















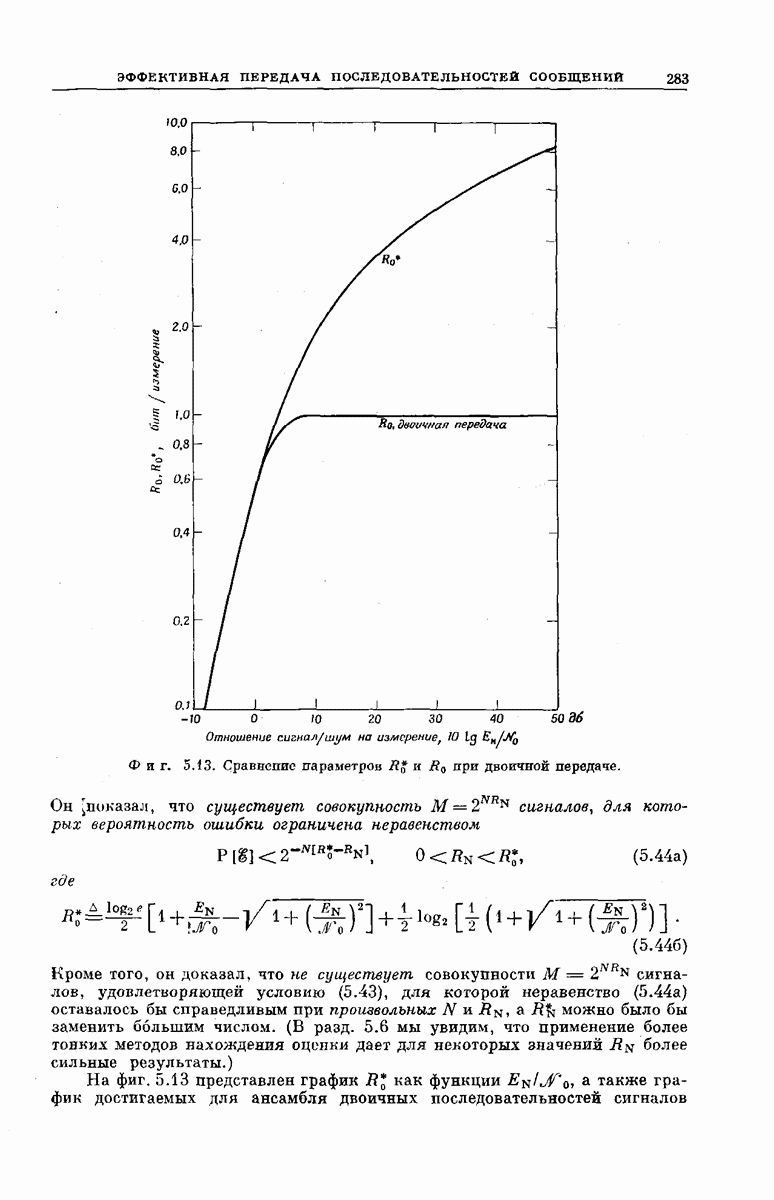

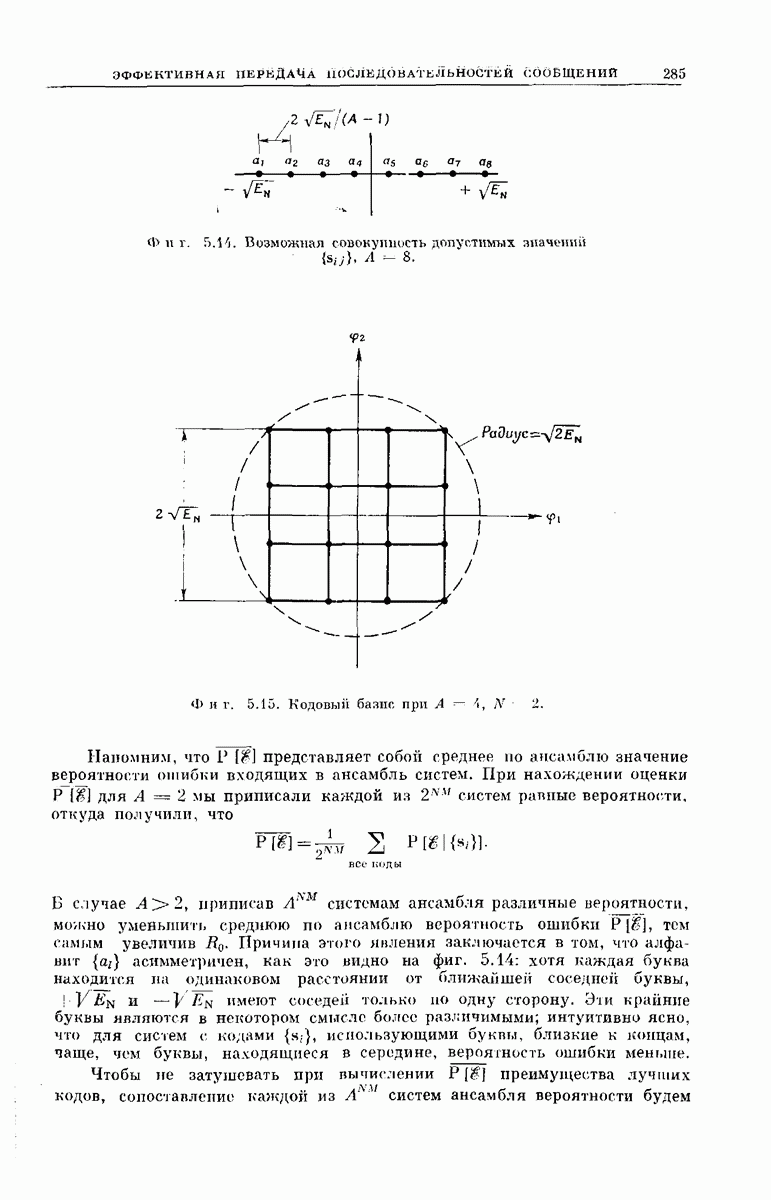



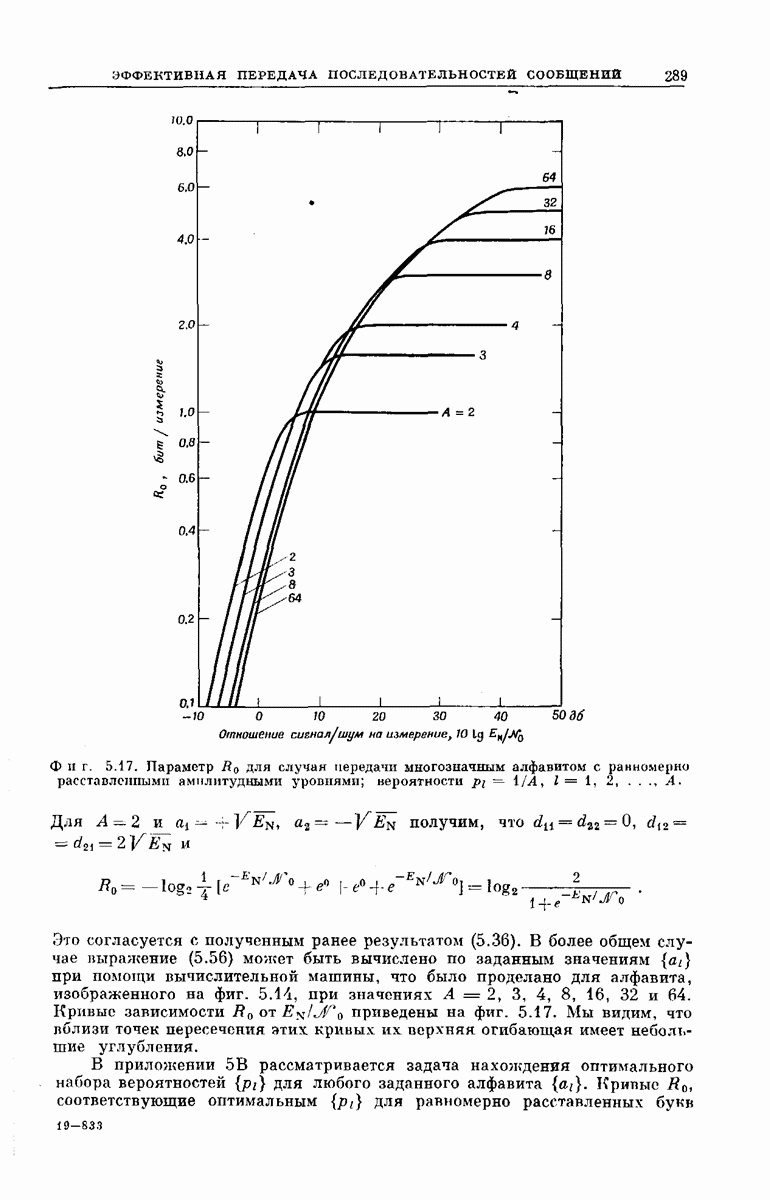
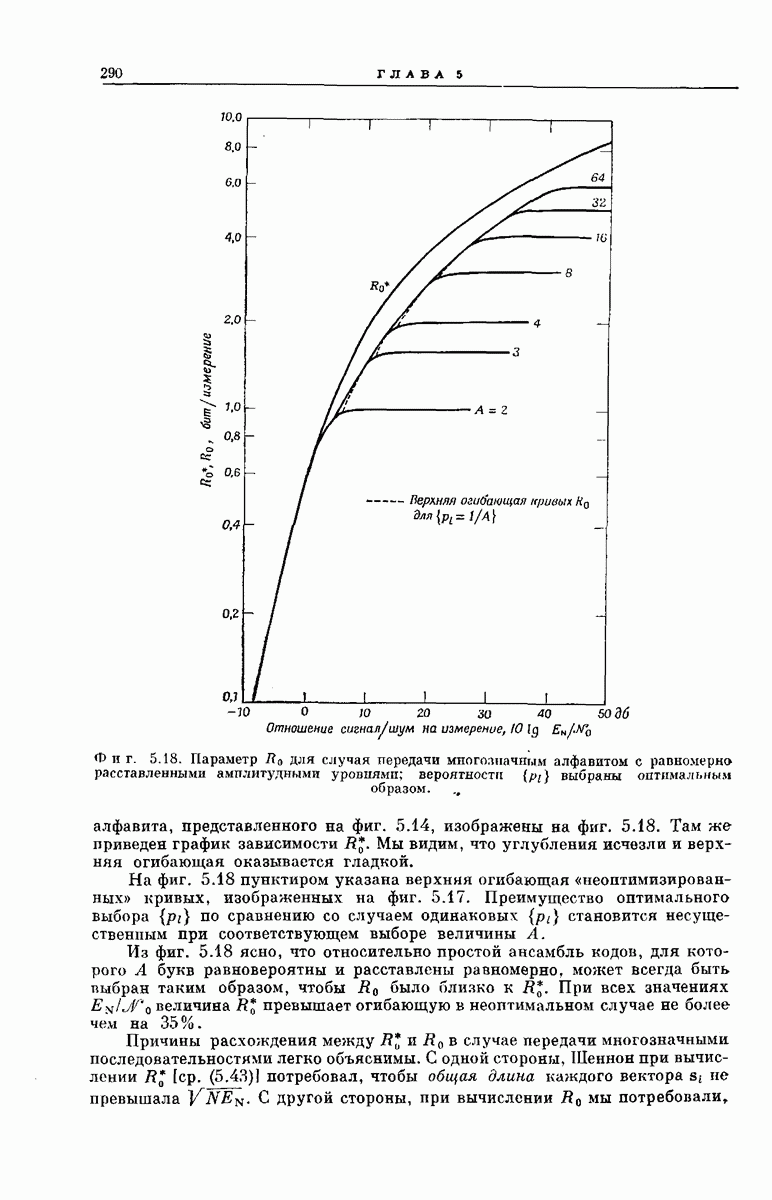



























































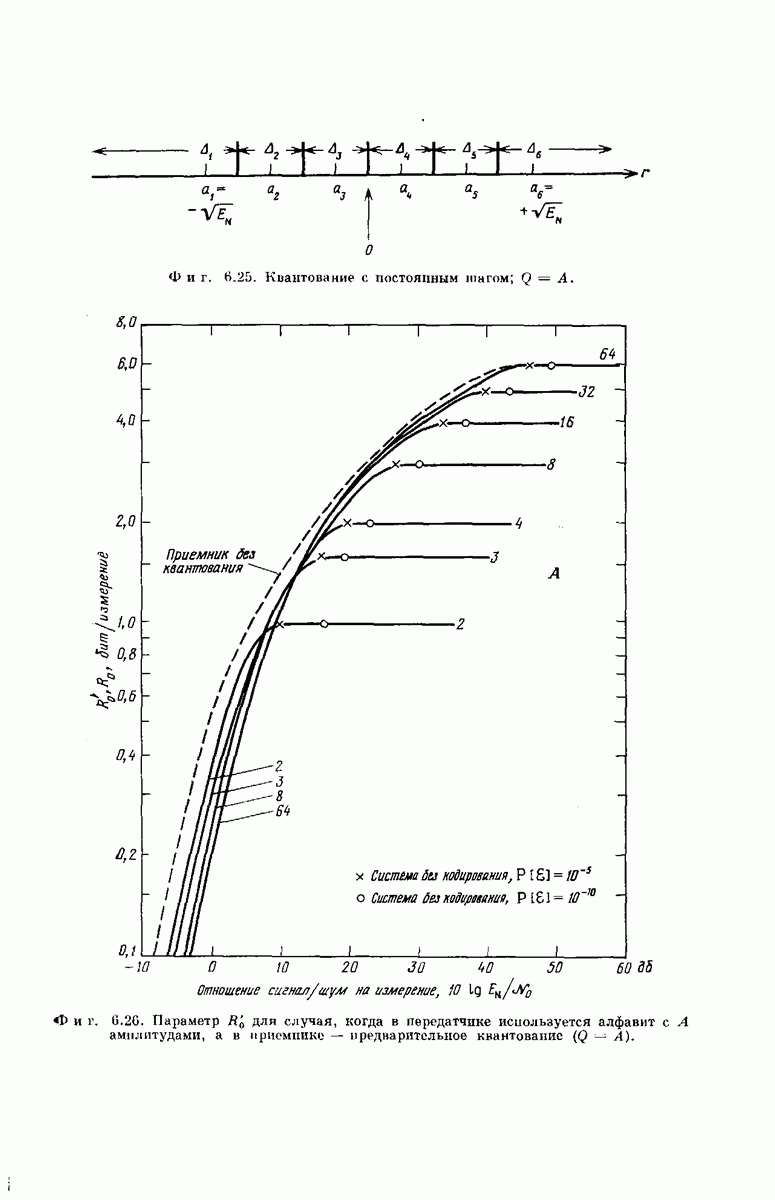


















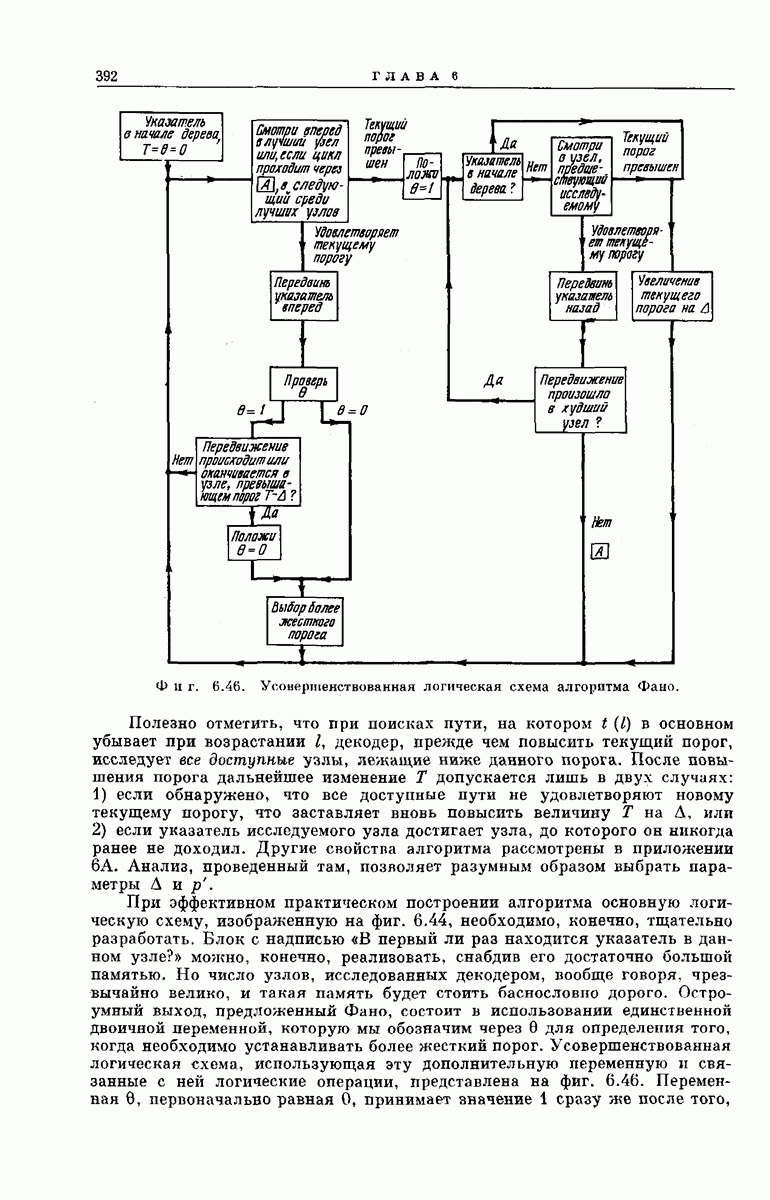

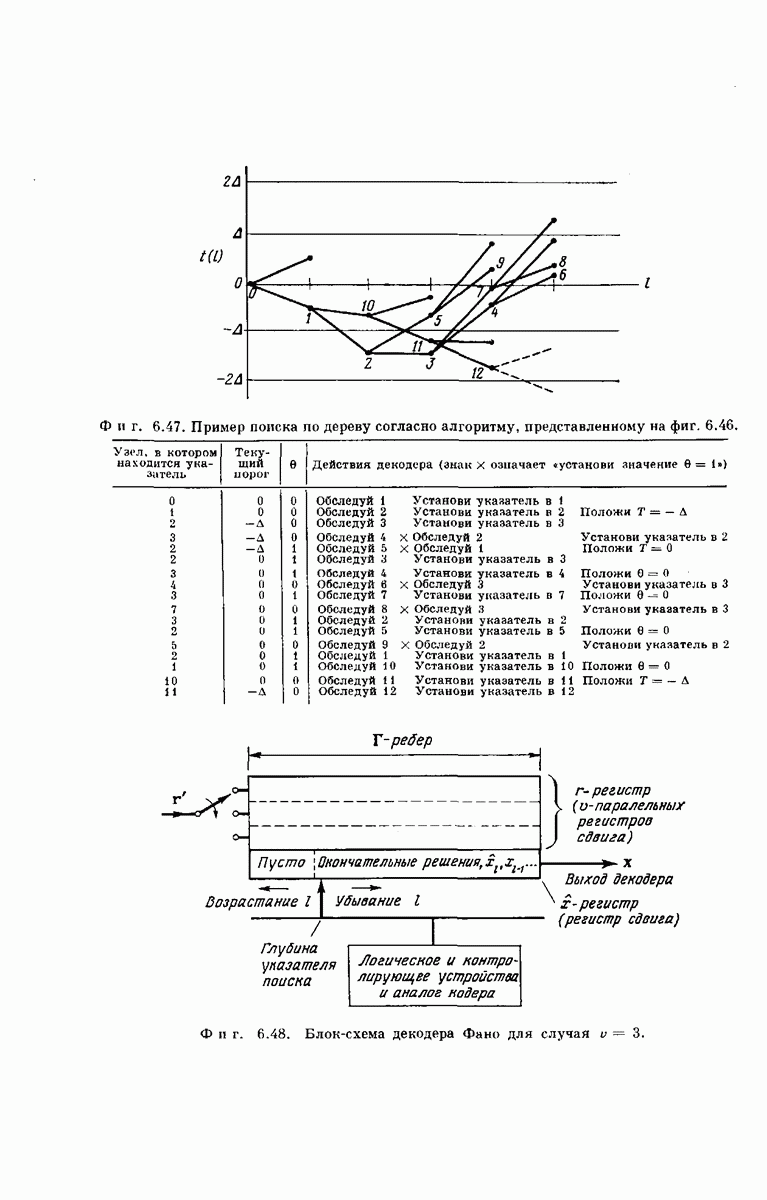



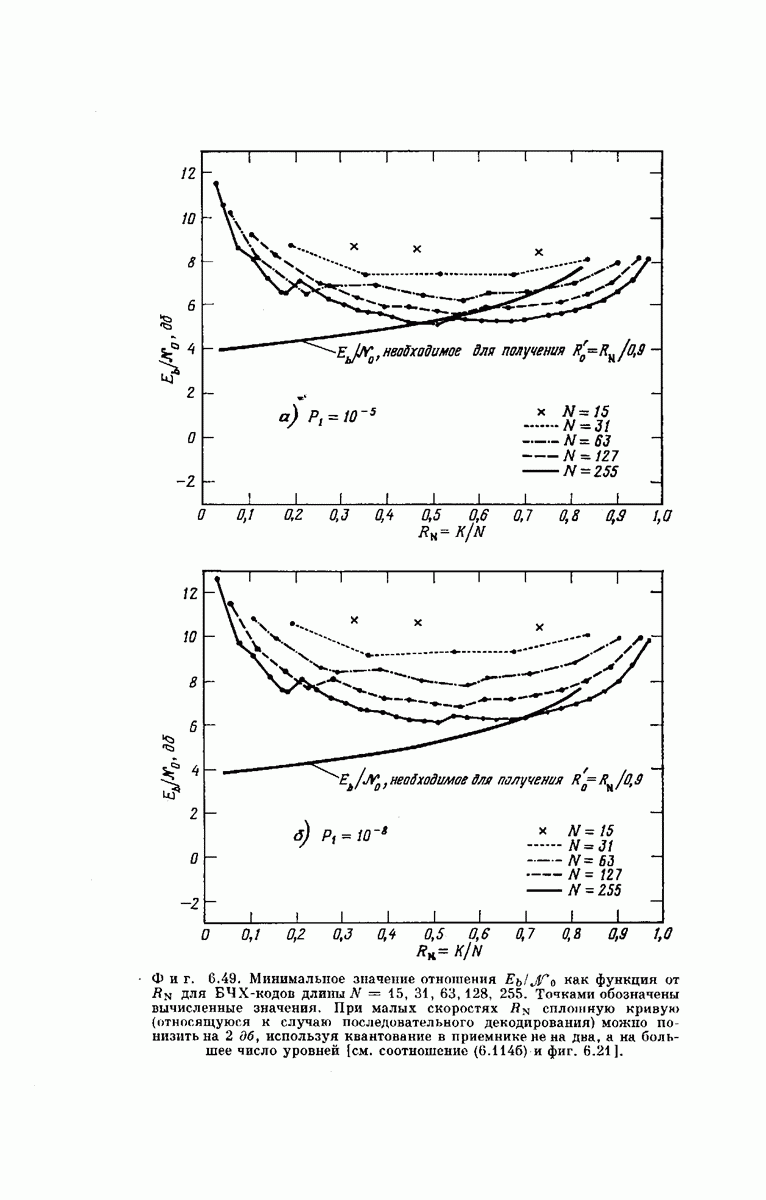

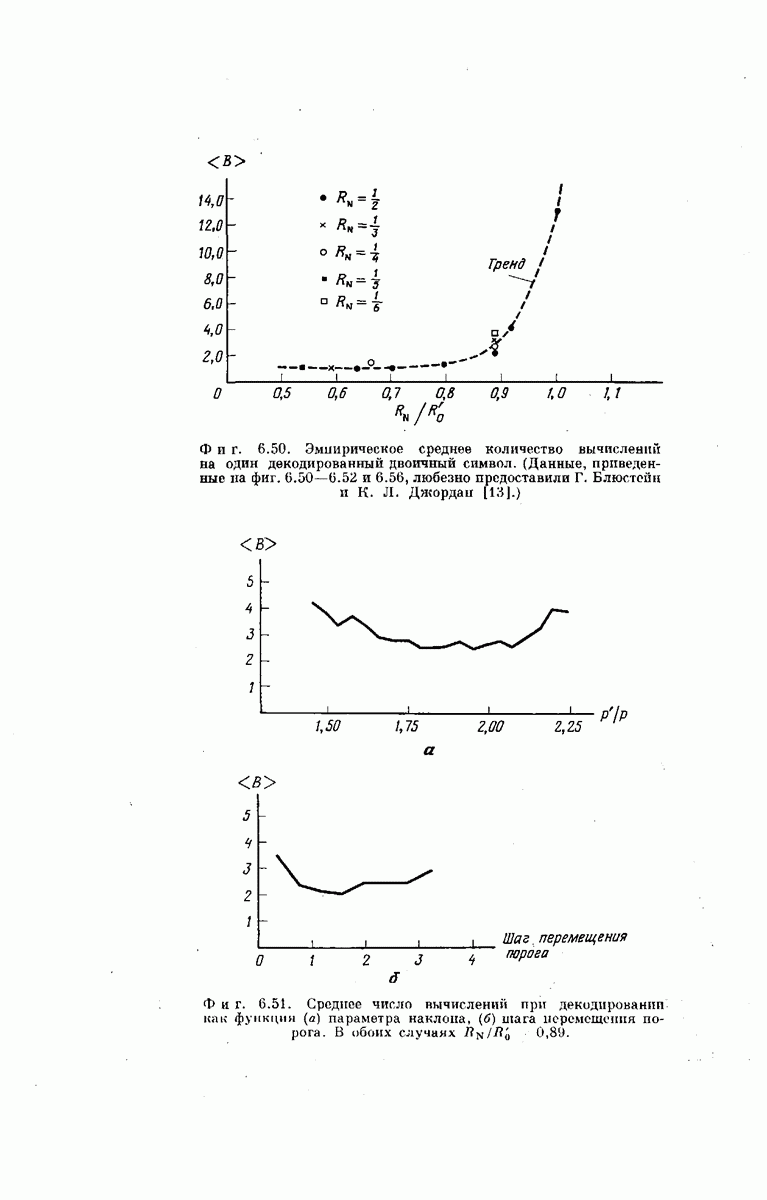

































































































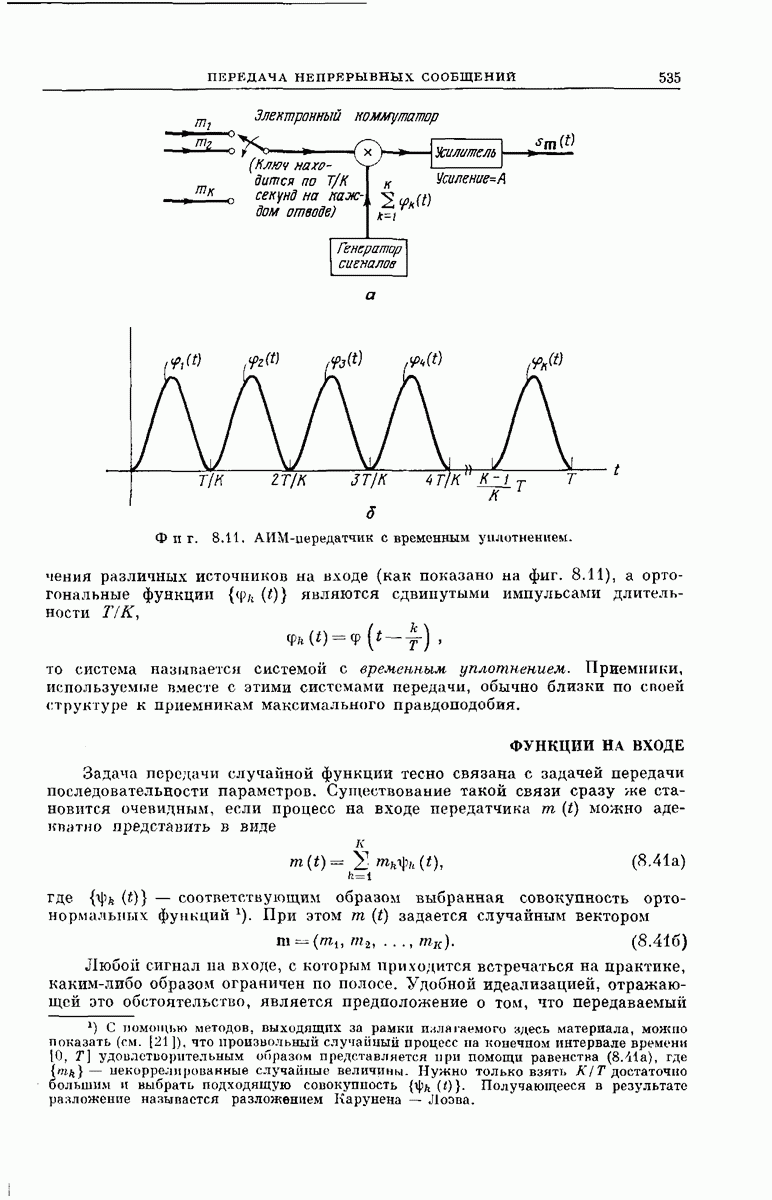




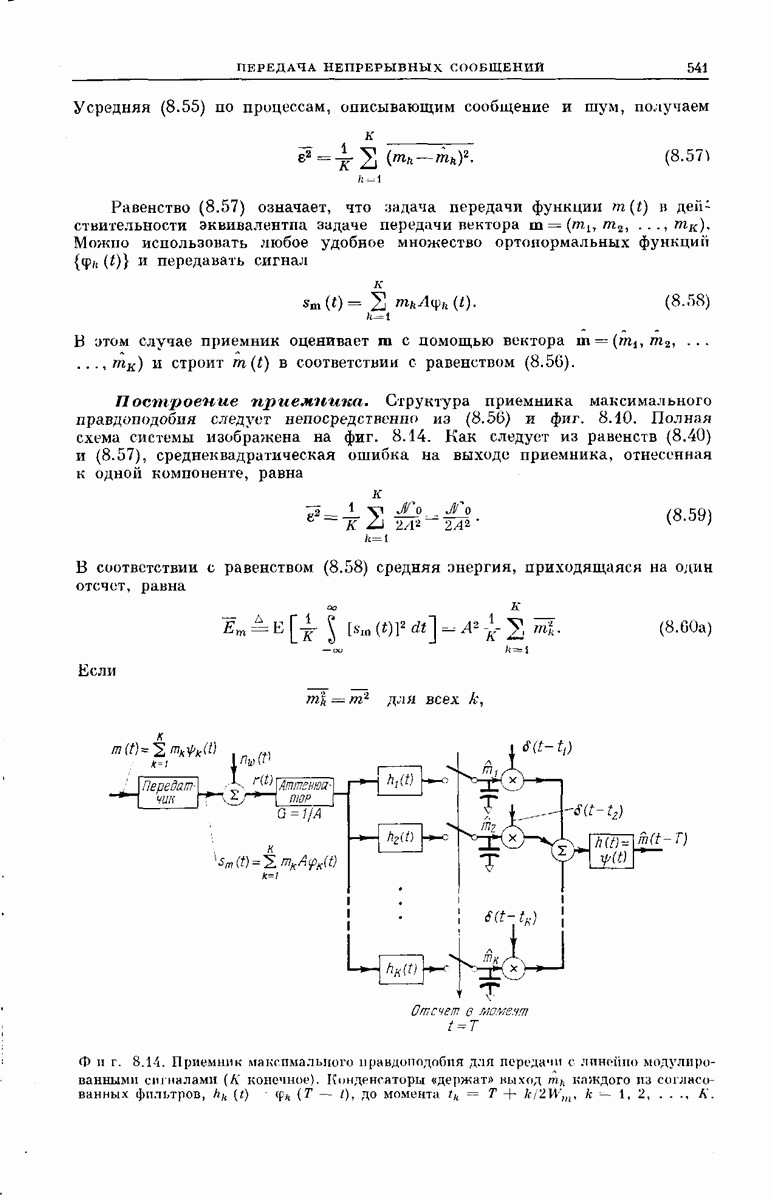


























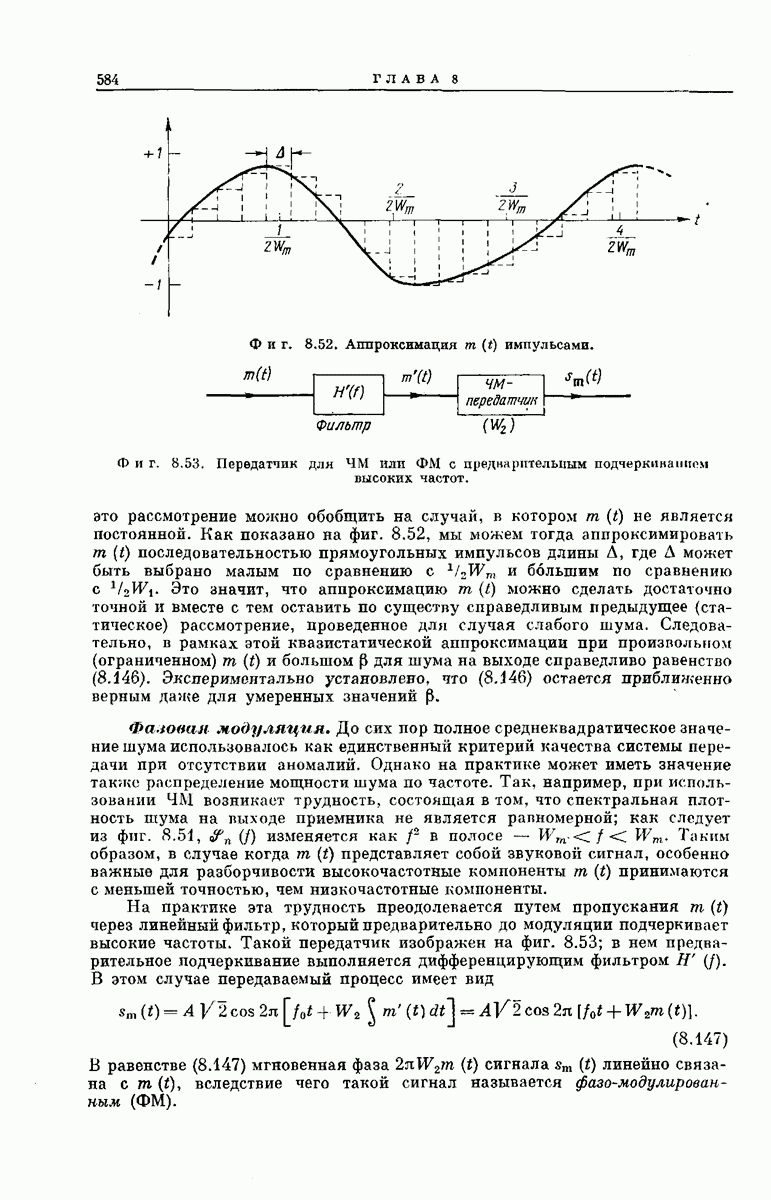






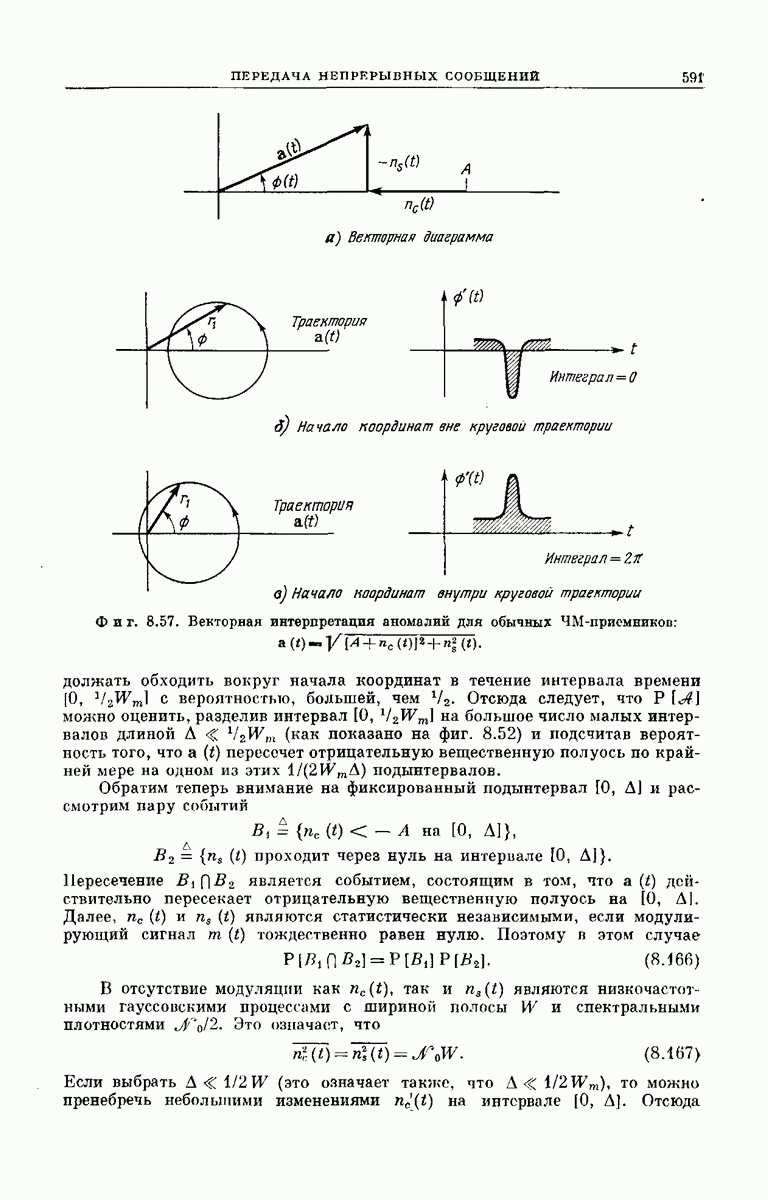



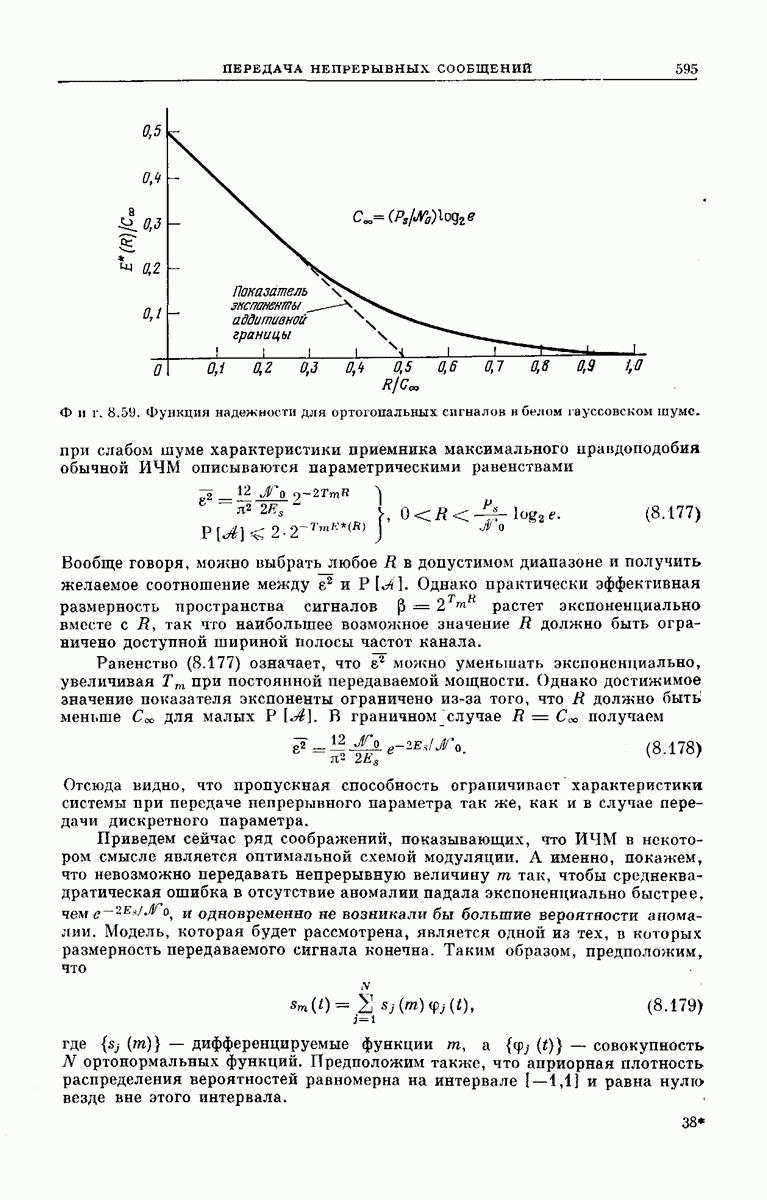


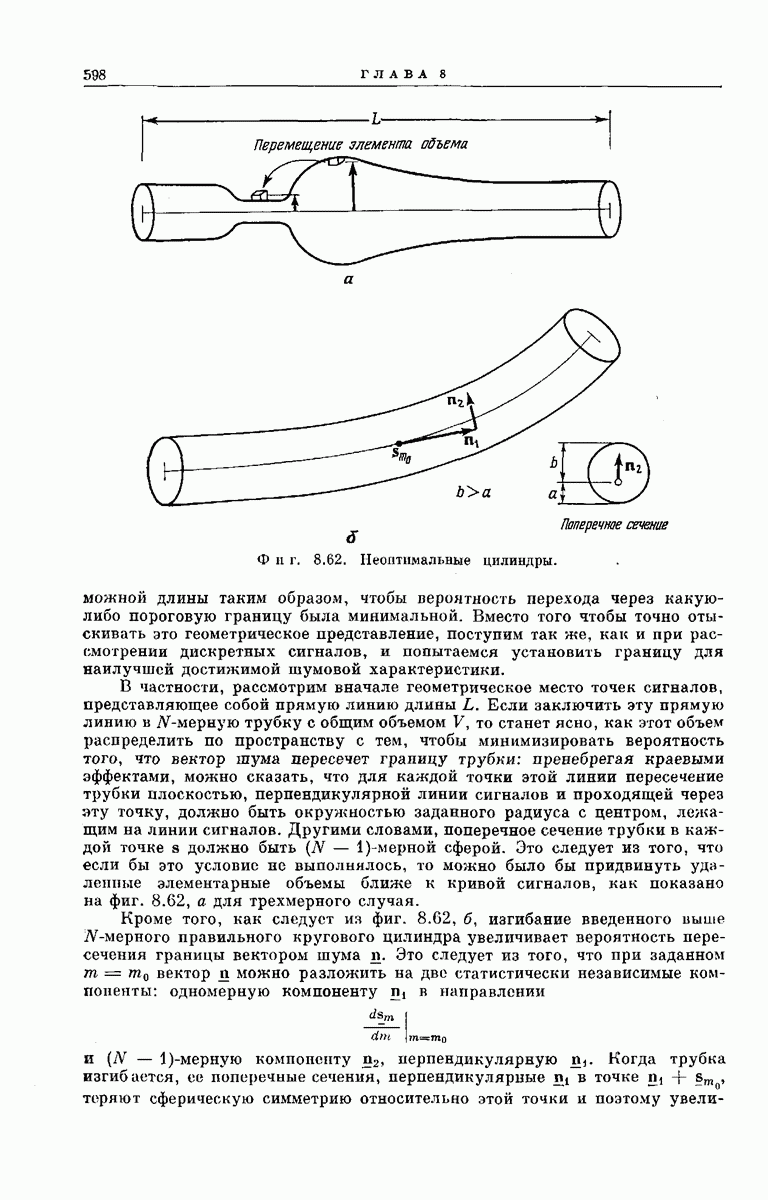































 главная проблема — проблема конструктивного построения декодеров, обладающих такой помехоустойчивостью, — остается пока не затронутой. Точнее говоря, рассматривавшийся до сих пор субоптимальный декодер нельзя реализовать при больших
главная проблема — проблема конструктивного построения декодеров, обладающих такой помехоустойчивостью, — остается пока не затронутой. Точнее говоря, рассматривавшийся до сих пор субоптимальный декодер нельзя реализовать при больших  так как процедура декодирования каждого из последовательных входных диоичных символов
так как процедура декодирования каждого из последовательных входных диоичных символов  включает в себя сравнение отрезка полученпого сообщения
включает в себя сравнение отрезка полученпого сообщения  с сегментами кодового слова, каждый из которых состоит из К ребер. Использование «последовательной» процедуры для определения каждого из
с сегментами кодового слова, каждый из которых состоит из К ребер. Использование «последовательной» процедуры для определения каждого из  исключает такой катастрофический экспоненциальный рост нагрузки и позволяет указать декодер, который приводит к экспоненциально малой вероятности ошибки и в то же время может быть реализован даже при больших К.
исключает такой катастрофический экспоненциальный рост нагрузки и позволяет указать декодер, который приводит к экспоненциально малой вероятности ошибки и в то же время может быть реализован даже при больших К.
 предложен в работе [90] и проверен в
предложен в работе [90] и проверен в  . Хотя эта модификация не поддается математическому анализу, экспериментальная проверка
. Хотя эта модификация не поддается математическому анализу, экспериментальная проверка  результаты обсуждаются в разд. 6.5) доказала эффективность получающегося алгоритма. Более тонкий алгоритм, использующий всю сущность этой модификации и обобщающий ее интуитивно ясным образом, предложен Фано [28]. Алгоритм Фано не только более гибок и эффективен при реализации, но также может быть подробно проанализирован (см. приложение
результаты обсуждаются в разд. 6.5) доказала эффективность получающегося алгоритма. Более тонкий алгоритм, использующий всю сущность этой модификации и обобщающий ее интуитивно ясным образом, предложен Фано [28]. Алгоритм Фано не только более гибок и эффективен при реализации, но также может быть подробно проанализирован (см. приложение  Мы детально рассмотрим этот алгоритм.
Мы детально рассмотрим этот алгоритм.