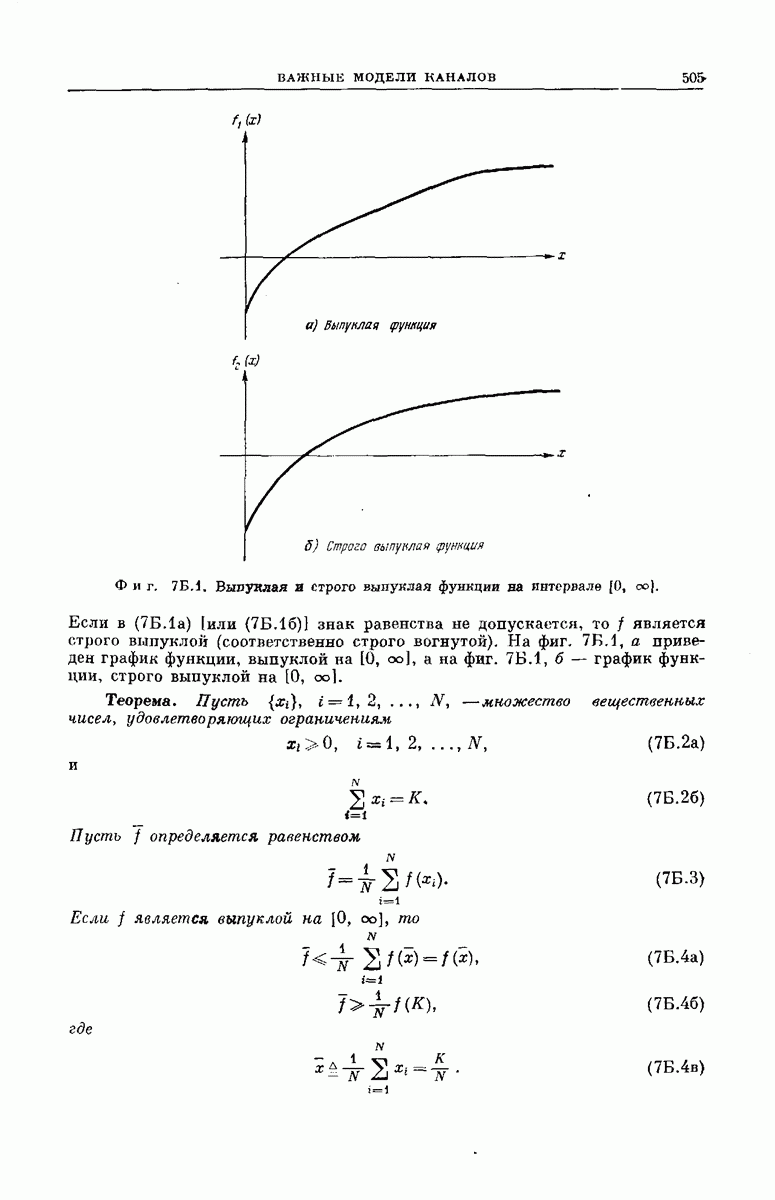
ПРИЛОЖЕНИЕ 6А. ОБОБЩЕНИЯ И ИССЛЕДОВАНИЕ АЛГОРИТМА ФАНО
В этом приложении мы получим неравенства, ограничивающие сверху величины, которые оценивают среднее количество вычислений и вероятность ошибки алгоритма последовательного декодирования Фано. Прежде чем перейти к их выводу, полезно показать, что этот алгоритм после несущественных изменений может быть применен к каналам, более общим, чем ДСК, и к древовидным кодам, у которых из каждого узла исходят не 2, а и ребер. Мы ограничимся здесь рассмотрением дискретных каналов без памяти
где  совокупность неотрицательных чисел, сумма которых равна 1. Позднее мы перейдем к рассмотрению случайного кодирования; при этом под
совокупность неотрицательных чисел, сумма которых равна 1. Позднее мы перейдем к рассмотрению случайного кодирования; при этом под  будет подразумеваться совокупность вероятностей, которые имеют буквы канала, входящие в кодовые слова. Через
будет подразумеваться совокупность вероятностей, которые имеют буквы канала, входящие в кодовые слова. Через  обозначена априорная вероятность появления на выходе канала буквы
обозначена априорная вероятность появления на выходе канала буквы  Отметим, что
Отметим, что

ВЕРОЯТНОСТЬ ОШИБКИ
Обобщение алгоритма Фано на класс случаев, рассмотренных здесь, никоим образом не меняет ни логические схемы алгоритма, представленные на фиг. 6.44 и 6.46, ни блок-схему декодера, изображенную на фиг. 6.48, хотя каждый разряд  -регистра должен теперь запоминать одну из
-регистра должен теперь запоминать одну из  букв
букв  Однако, как уже указывалось в разд. 6.5, анализ реального декодера затрудняется возможностью того, что алгоритм потребует возвращения к ранее обследованным ребрам в кодовом дереве, находящимся на большей глубине, чем это позволяет объем
Однако, как уже указывалось в разд. 6.5, анализ реального декодера затрудняется возможностью того, что алгоритм потребует возвращения к ранее обследованным ребрам в кодовом дереве, находящимся на большей глубине, чем это позволяет объем  -регистра при заданных скорости поступления данных и вычислительной скорости декодера. Эту трудность можно обойти, предполагая, что
-регистра при заданных скорости поступления данных и вычислительной скорости декодера. Эту трудность можно обойти, предполагая, что  -регистр бесконечен.
-регистр бесконечен.
Второе затруднение вытекает из статистической зависимости ветвей, возникающей из-за сдвига порождающей последовательности сверточного кода. Эта трудность устраняется при помощи различных аналитических ухищрений, с которыми мы уже знакомы. Отметим, что ошибкой мы будем считать событие  аналогичное обозначенному тем же символом событию, изученному в разд. 6.3 при рассмотрении субоптимального декодера. Как и ранее, назовем
аналогичное обозначенному тем же символом событию, изученному в разд. 6.3 при рассмотрении субоптимального декодера. Как и ранее, назовем  исходным узлом узел кодового дерева, определяемый последовательностью решений декодера
исходным узлом узел кодового дерева, определяемый последовательностью решений декодера  При определении мы предполагаем, что некий магический джин устанавливает указатель исследуемого узла на правильный
При определении мы предполагаем, что некий магический джин устанавливает указатель исследуемого узла на правильный  исходный узел и что декодер Фано действует так, как будто бы этот узел находится в начале кодового дерева. Поэтому декодеру разрешено исследовать ребра, расположенные спереди от этого узла, но запрещено исследовать ребра, расположенные позади этого исходного узла. Далее, назовем событием событие, заключающееся в том, что решение принятое в момент, когда указатель исследуемого узла впервые достигнет одного из
исходный узел и что декодер Фано действует так, как будто бы этот узел находится в начале кодового дерева. Поэтому декодеру разрешено исследовать ребра, расположенные спереди от этого узла, но запрещено исследовать ребра, расположенные позади этого исходного узла. Далее, назовем событием событие, заключающееся в том, что решение принятое в момент, когда указатель исследуемого узла впервые достигнет одного из  узлов, находящихся на глубине К ребер от
узлов, находящихся на глубине К ребер от  исходного узла, будет неправильным. Мы оценим сверху среднюю вероятность
исходного узла, будет неправильным. Мы оценим сверху среднюю вероятность  события в ансамбле сверточных кодов. Значение этой оценки применительно к реальному декодеру обсуждается в конце этого раздела.
события в ансамбле сверточных кодов. Значение этой оценки применительно к реальному декодеру обсуждается в конце этого раздела.
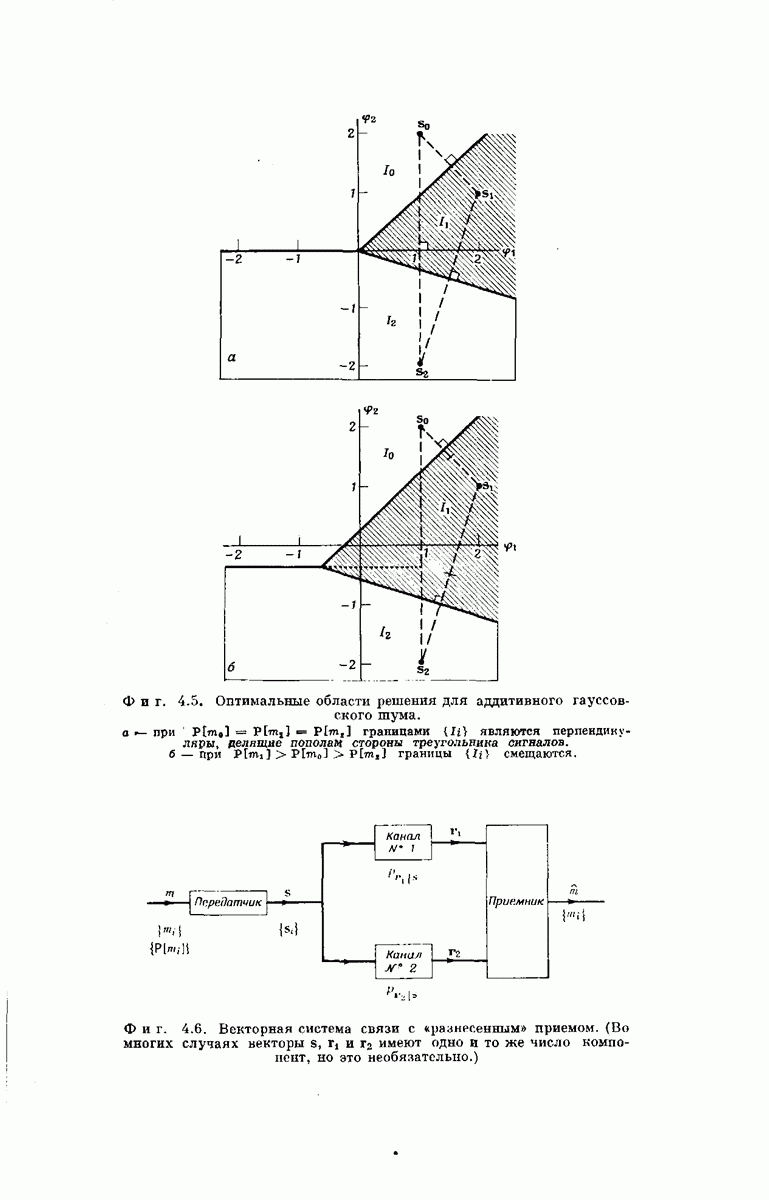
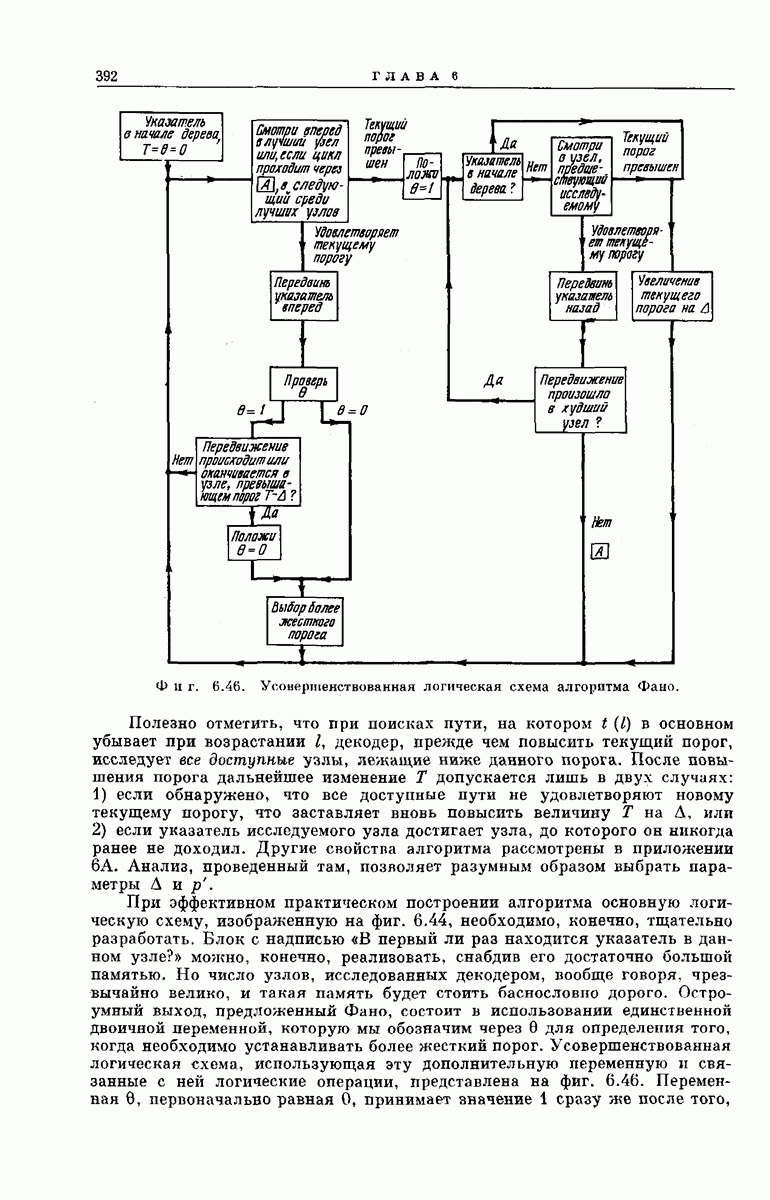
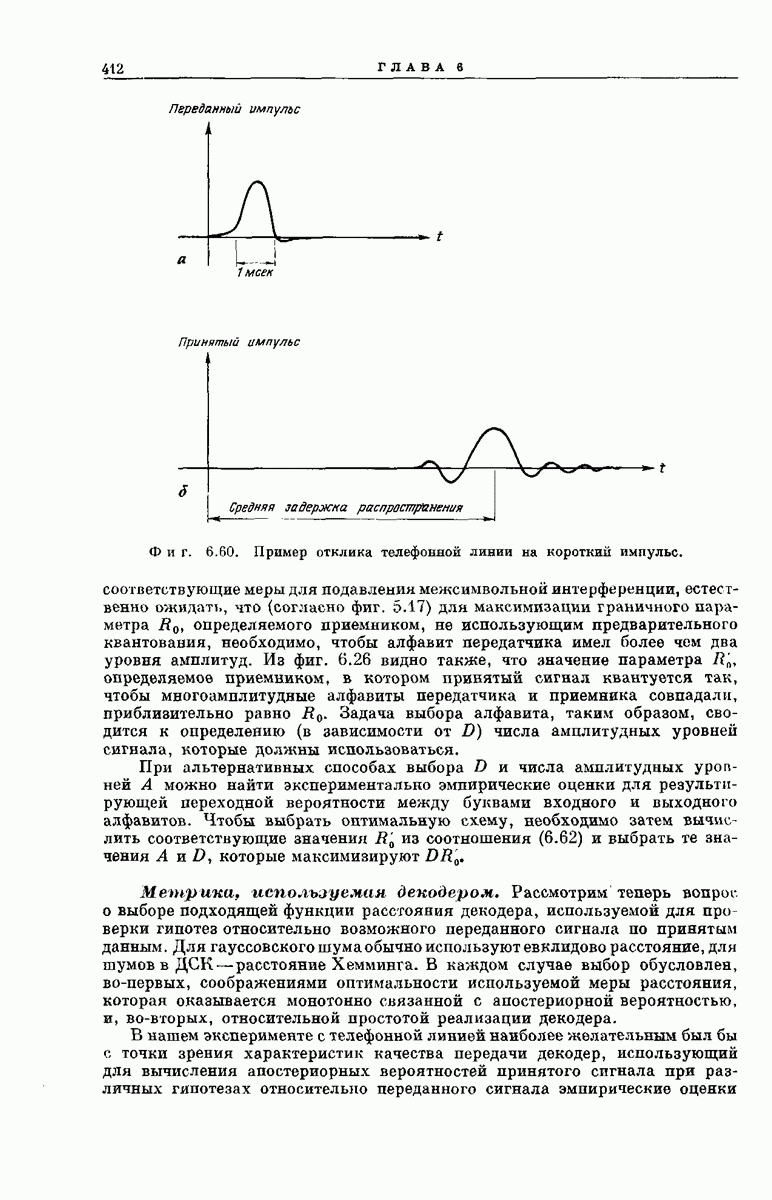
Обозначение узлов в неправильном подмножестве для  В приведенном ниже выводе воспользуемся методом анализа, предложенным и использованным Стиглитцем и Юдкиным для получения более общих результатов 1). Мы упростим вы под, введя несколько дополнительных обозначений. Во-первых, назовем неправильным подмножеством для
В приведенном ниже выводе воспользуемся методом анализа, предложенным и использованным Стиглитцем и Юдкиным для получения более общих результатов 1). Мы упростим вы под, введя несколько дополнительных обозначений. Во-первых, назовем неправильным подмножеством для  совокупность, состоящую из всех узлов, снизанных с правильным
совокупность, состоящую из всех узлов, снизанных с правильным  исходным узлом путями, проходящими через какое-либо из и
исходным узлом путями, проходящими через какое-либо из и  неправильных ребер, выходящих из исходного узла, и самого исходного узла (фиг.
неправильных ребер, выходящих из исходного узла, и самого исходного узла (фиг.  Будем говорить, что узел в неправильном подмножестве для
Будем говорить, что узел в неправильном подмножестве для  имеет глубину если он связан с
имеет глубину если он связан с  исходным узлом путем, содержащим 4 ребер. Поэтому глубину 0 имеет 1 узел (исходный узел), глубину 1 имеют
исходным узлом путем, содержащим 4 ребер. Поэтому глубину 0 имеет 1 узел (исходный узел), глубину 1 имеют  узлов, глубину 2 имеют
узлов, глубину 2 имеют  и узлов и глубину
и узлов и глубину  при любых
при любых  имеют
имеют  и
и

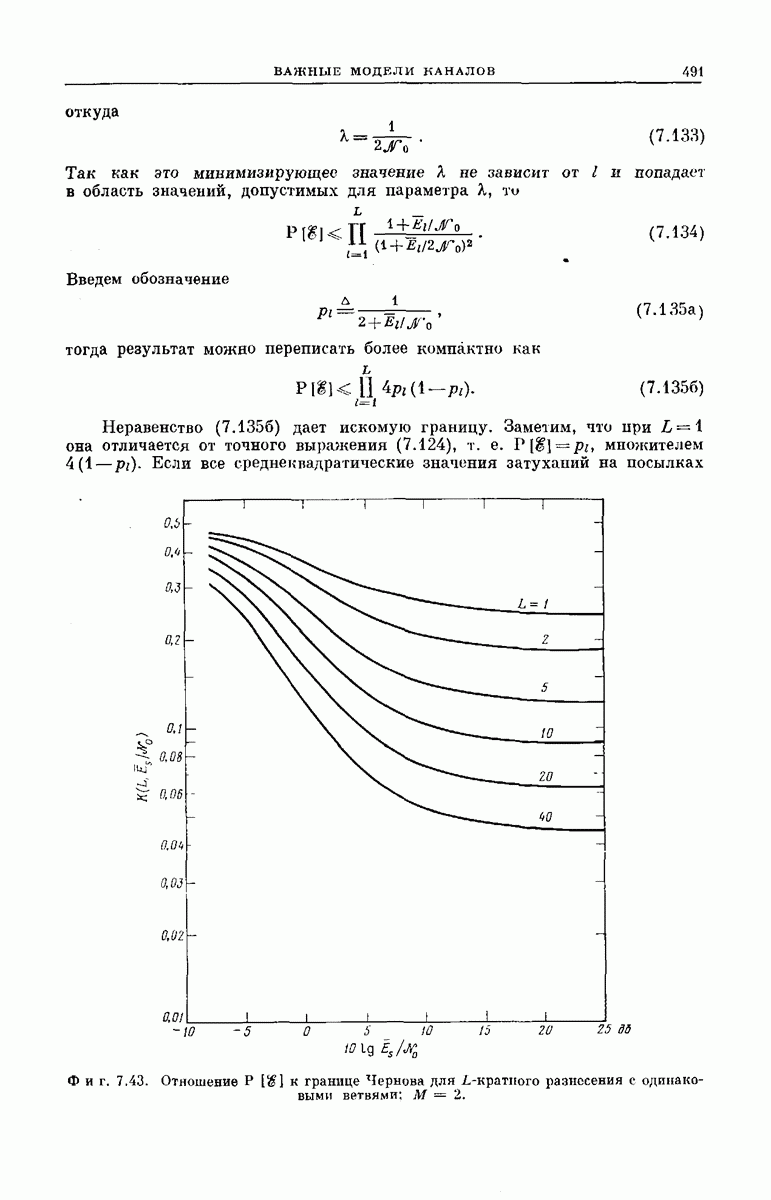
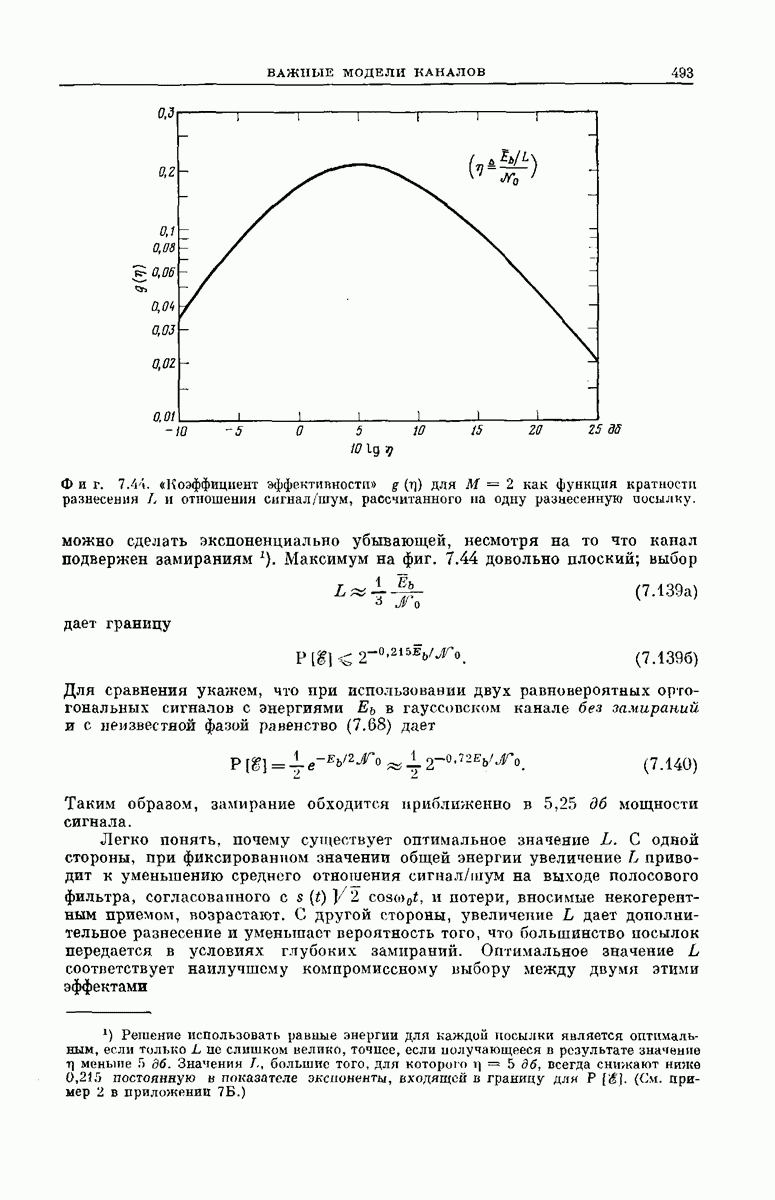
(кликните для просмотра скана)
узлов. Из соотношения  следует, что число узлов
следует, что число узлов  глубины
глубины  в неправильном подмножестве удовлетворяет неравенству
в неправильном подмножестве удовлетворяет неравенству

Удобно обозначить узлы в неправильном подмножестве для  упорядоченными парами делых чисел
упорядоченными парами делых чисел  Число
Число  означает глубину узла; число
означает глубину узла; число  номер вертикального уровня узла в кодовом дереве относительна всех
номер вертикального уровня узла в кодовом дереве относительна всех  неправильных узлов, имеющих глубину
неправильных узлов, имеющих глубину  Эти обозначения проиллюстрированы на фиг. 6А.2.
Эти обозначения проиллюстрированы на фиг. 6А.2.
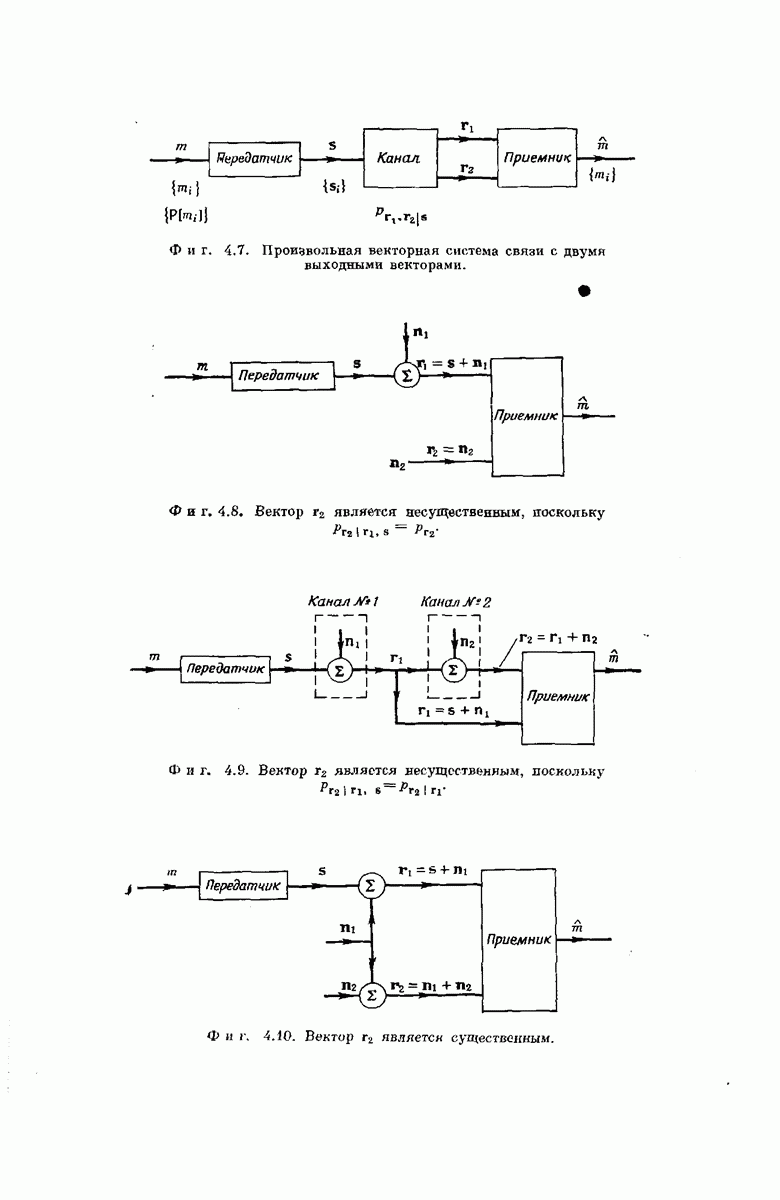
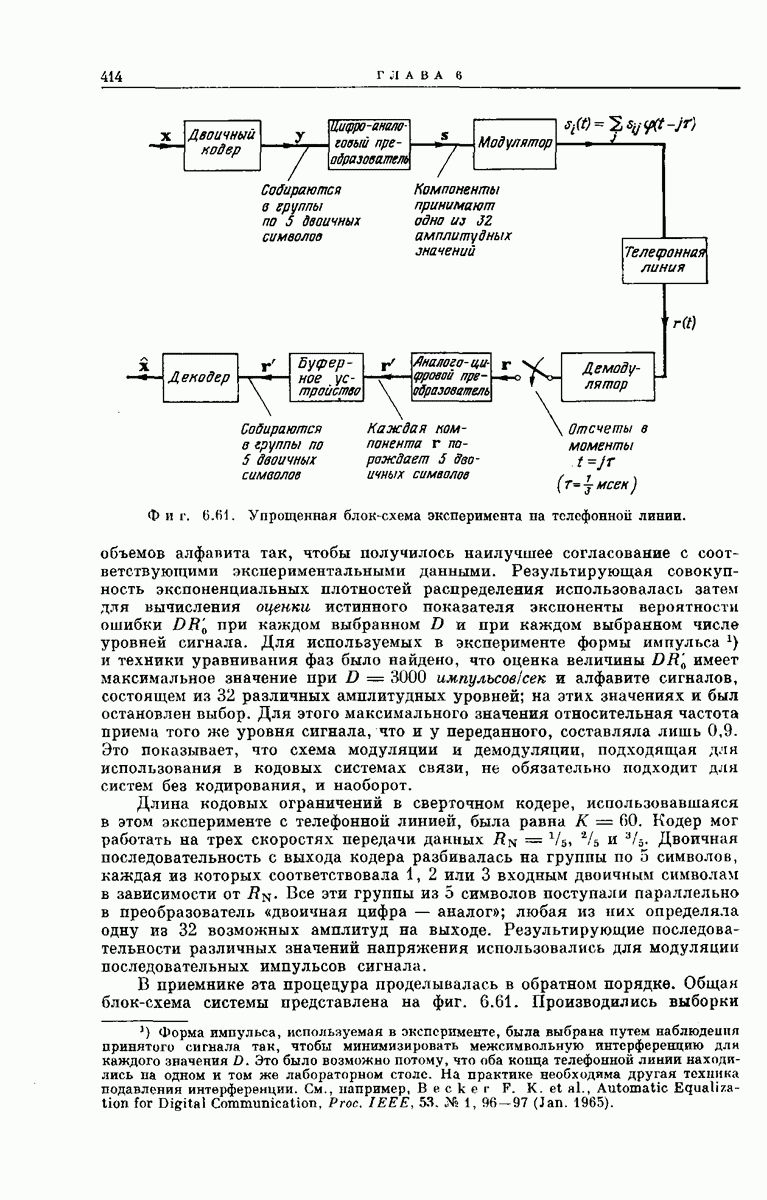
Оценка для  Определим величину
Определим величину  для любого конкретного кода и любого переданного пути как условную вероятность того, что в момент первого достижения узла, удаленного от
для любого конкретного кода и любого переданного пути как условную вероятность того, что в момент первого достижения узла, удаленного от  исходного узла на К ребер, решение
исходного узла на К ребер, решение  неправильно при условии, что первоначально наш джин установил указатель исследуемого узла в правильном исходном узле и что исследование узлов., расположенных сзади исходного, запрещено. Рассмотрение фиг. 6А.3 показывает, что из начальных условий (ниже мы будем считать их всегда выполняющимися) вытекает, что событие может наступить только в том случае, если некоторый узел на глубине К в неправильном подмножестве для
неправильно при условии, что первоначально наш джин установил указатель исследуемого узла в правильном исходном узле и что исследование узлов., расположенных сзади исходного, запрещено. Рассмотрение фиг. 6А.3 показывает, что из начальных условий (ниже мы будем считать их всегда выполняющимися) вытекает, что событие может наступить только в том случае, если некоторый узел на глубине К в неправильном подмножестве для  имеет
имеет  -значение, удовлетворяющее некоторому порогу, который мы обозначим через
-значение, удовлетворяющее некоторому порогу, который мы обозначим через  Порог
Порог  это самый нижний из порогов, которым одновременно удовлетворяют все узлы вдоль отрезка правильного пути из К ребер, исходящего из
это самый нижний из порогов, которым одновременно удовлетворяют все узлы вдоль отрезка правильного пути из К ребер, исходящего из  исходного узла. Иначе говоря, алгоритм требует, чтобы декодер следовал по правильному пути, предпочитая его любому из неправильных путей, превышающих
исходного узла. Иначе говоря, алгоритм требует, чтобы декодер следовал по правильному пути, предпочитая его любому из неправильных путей, превышающих 
Чтобы выразить эти соображения математически, обозначим сначала разность между  -значением узла
-значением узла  и максимальным значением функции
и максимальным значением функции  вдоль отрезка правильного пути из К ребер через
вдоль отрезка правильного пути из К ребер через  Обозначим число ребер, отделяющих этот максимум от исходного узла, через
Обозначим число ребер, отделяющих этот максимум от исходного узла, через  приращение
приращение  -функции в узле
-функции в узле  через
через  приращение
приращение  -функции вдоль правильного пути через
-функции вдоль правильного пути через  Из соотношения
Из соотношения  следует, что
следует, что

где  значение
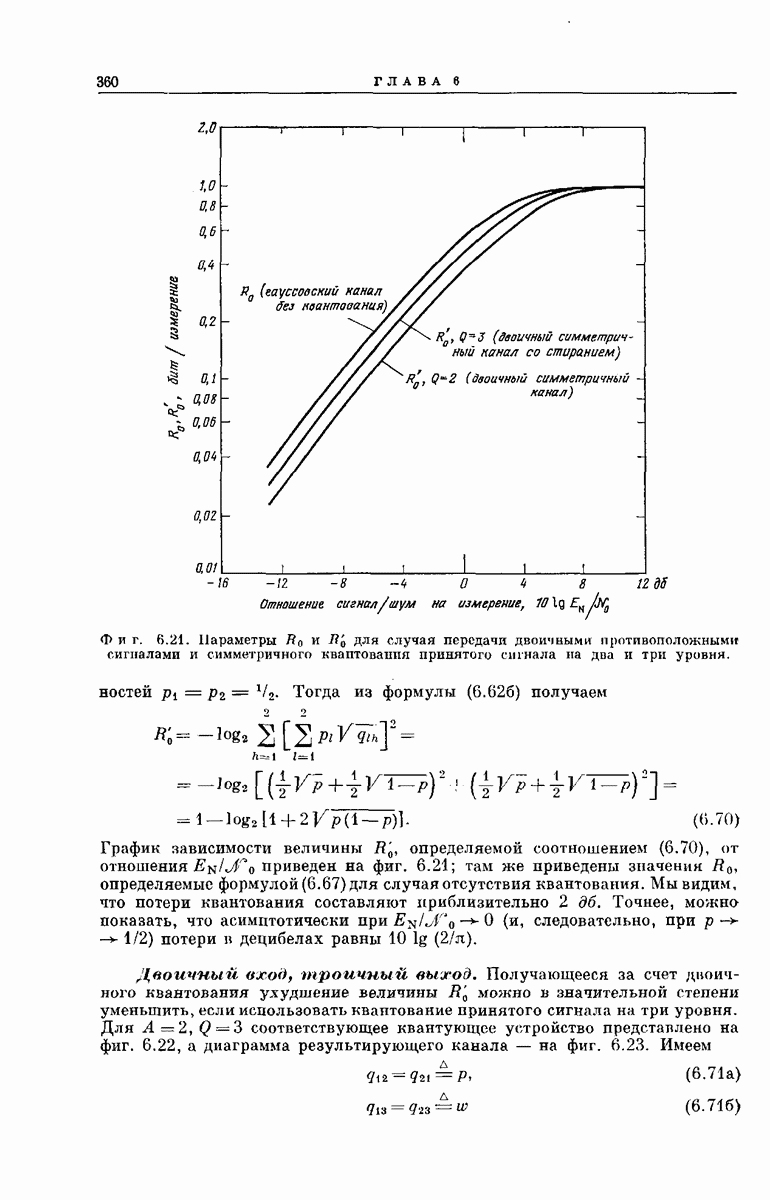
значение  -функции в исходном узле;
-функции в исходном узле;  пробегает множество индексов, соответствующих символам, расположенным справа от этого узла. Величина
пробегает множество индексов, соответствующих символам, расположенным справа от этого узла. Величина  заключена в пределах
заключена в пределах  [если
[если  вторая сумма в правой части соотношения
вторая сумма в правой части соотношения  тождественно равна нулю].
тождественно равна нулю].
Из фиг. 6А.3 ясно, что некоторый узел, принадлежащий множеству  неправильных узлов глубины К, который обозначим как узел
неправильных узлов глубины К, который обозначим как узел  может удовлетворять порогу
может удовлетворять порогу  если только выполняется неравенство
если только выполняется неравенство  Используя обычную аддитивную оценку, получим
Используя обычную аддитивную оценку, получим

Оценка величины  . В качестве первого шага при нахождении оценки сверху правой части неравенства
. В качестве первого шага при нахождении оценки сверху правой части неравенства  выясним, почему конкретное значение
выясним, почему конкретное значение  несущественно при определении
несущественно при определении  [см.
[см.  ]. Обозначим через
]. Обозначим через  величину
величину  определяемую соотношением
определяемую соотношением  при условии, что На принимает значение
при условии, что На принимает значение  . Тогда
. Тогда

где введено обозначение

Верхнюю оценку  можно получить, используя одновременно два метода: неравенство Чернова и случайное кодирование, с которыми мы уже знакомы. Обозначая символом
можно получить, используя одновременно два метода: неравенство Чернова и случайное кодирование, с которыми мы уже знакомы. Обозначая символом  функцию единичного скачка [так же как в (6.55а) и последующих соотношениях], получим из
функцию единичного скачка [так же как в (6.55а) и последующих соотношениях], получим из 

Усреднение в соотношении  производится по ансамблю шумовых последовательностей в канале. Чтобы далее упростить это выражение, используем случайное кодирование и оценим среднее значение
производится по ансамблю шумовых последовательностей в канале. Чтобы далее упростить это выражение, используем случайное кодирование и оценим среднее значение  величины
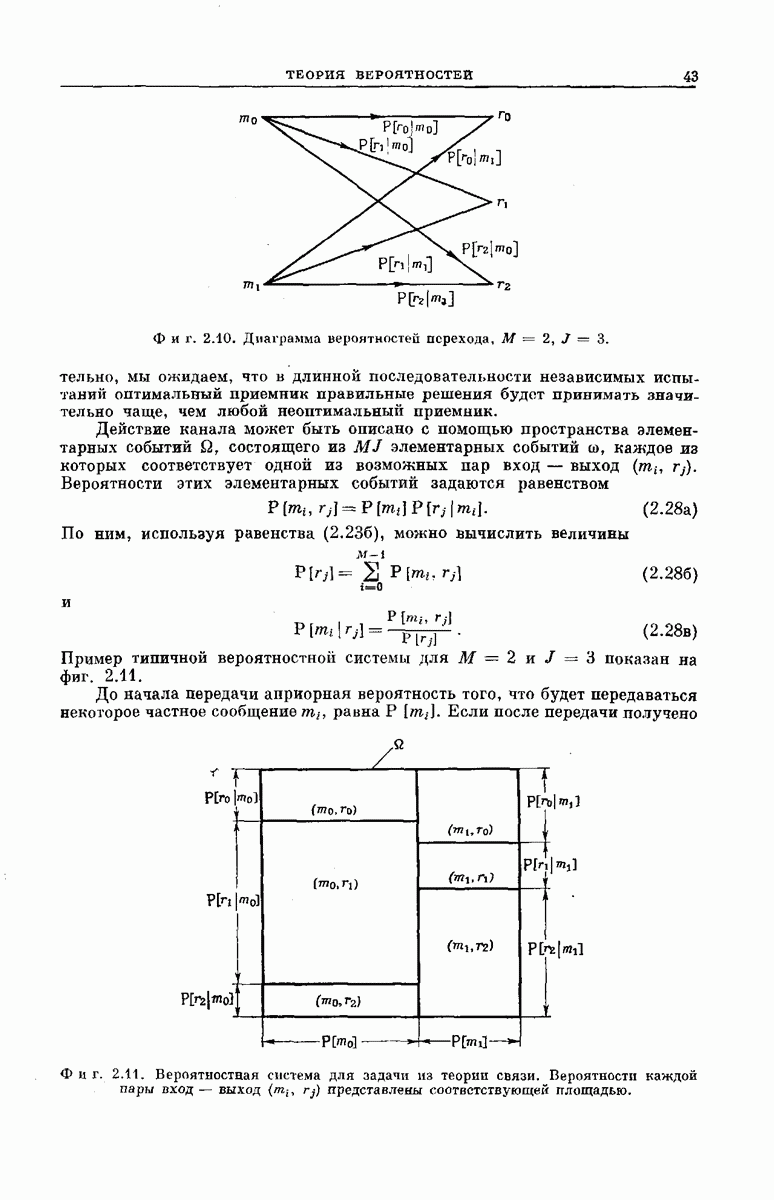
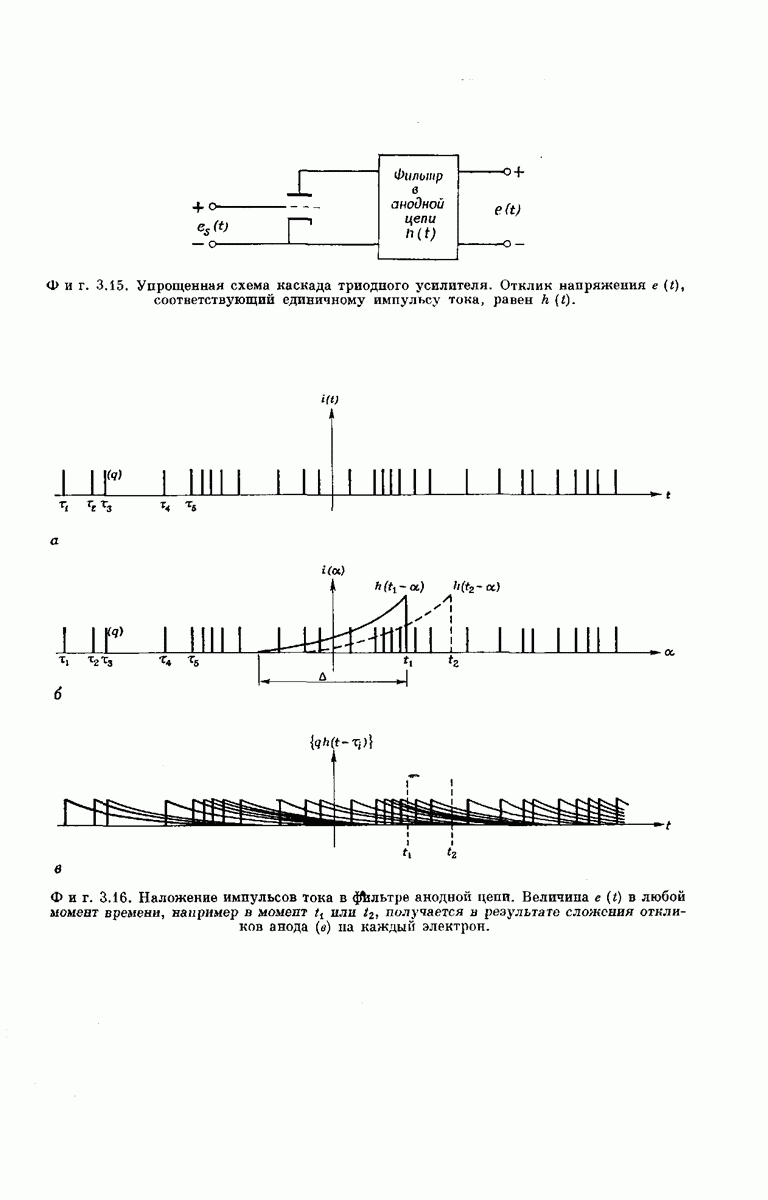
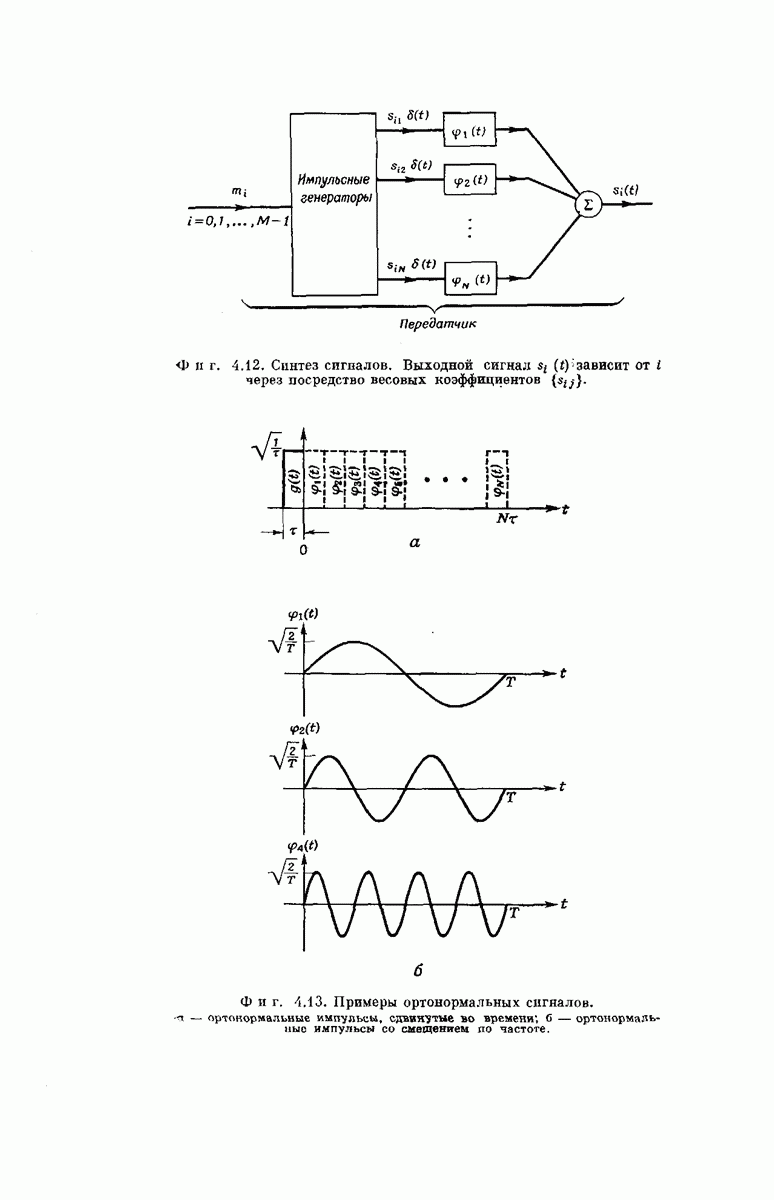
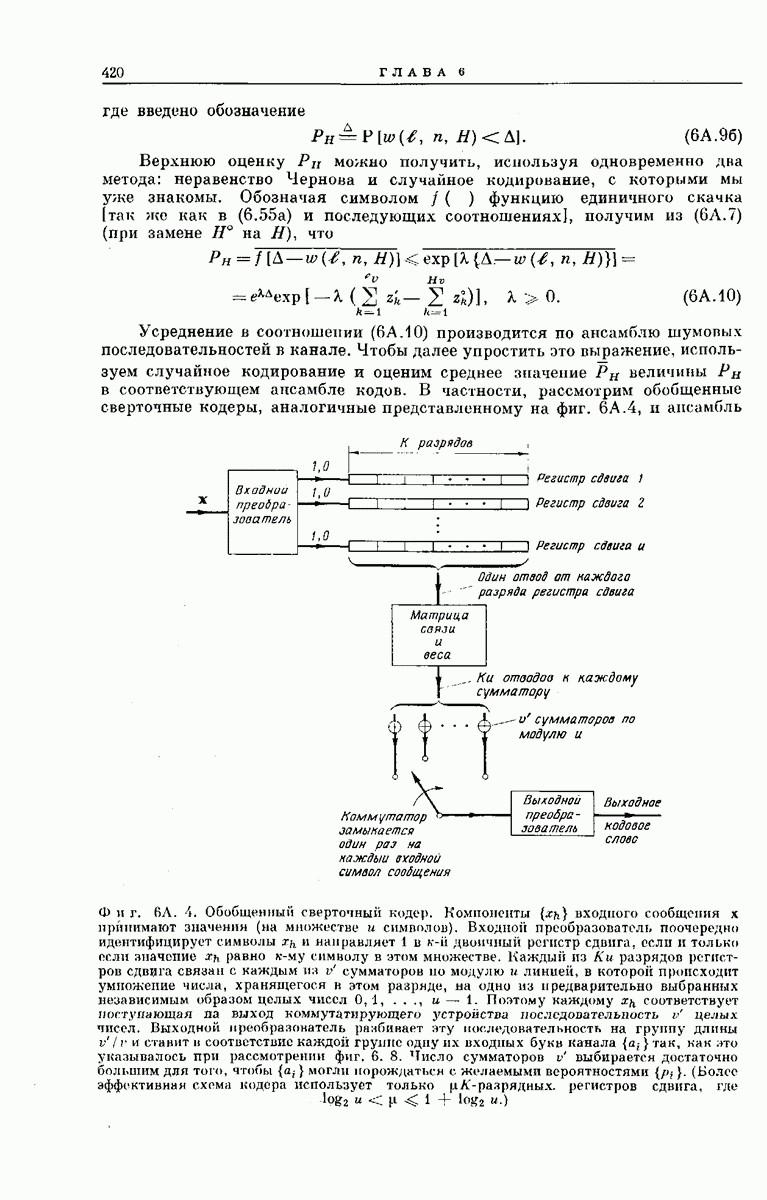
величины  в соответствующем ансамбле кодов. В частности, рассмотрим обобщенные сверточные кодеры, аналогичные представленному на фиг. 6А.4, и ансамбль
в соответствующем ансамбле кодов. В частности, рассмотрим обобщенные сверточные кодеры, аналогичные представленному на фиг. 6А.4, и ансамбль

Фиг. 6А. 4. Обобщенный сверточный кодер. Компоненты  входного сообщения
входного сообщения  принимают значения (на множестве и символов). Входной преобразователь поочередно идентифицирует символы
принимают значения (на множестве и символов). Входной преобразователь поочередно идентифицирует символы  и направляет 1 в
и направляет 1 в  двоичный регистр сдвига, еелн и только если значение
двоичный регистр сдвига, еелн и только если значение  равно
равно  символу в этом множестве. Каждый из К и разрядов регистров сдвига связан с каждым ни
символу в этом множестве. Каждый из К и разрядов регистров сдвига связан с каждым ни  сумматоров по модулю и линией, в которой происходит умножение числа, хранящегося в этом разряде, на одно из предварительно выбранных независимым образом целых чисел
сумматоров по модулю и линией, в которой происходит умножение числа, хранящегося в этом разряде, на одно из предварительно выбранных независимым образом целых чисел  . Поэтому каждому
. Поэтому каждому  соответствует поступающая на выход коммутатирующего устройства последовательность
соответствует поступающая на выход коммутатирующего устройства последовательность  целых чисел. Выходной преобразователь разбивает эту последовательность на группу длины
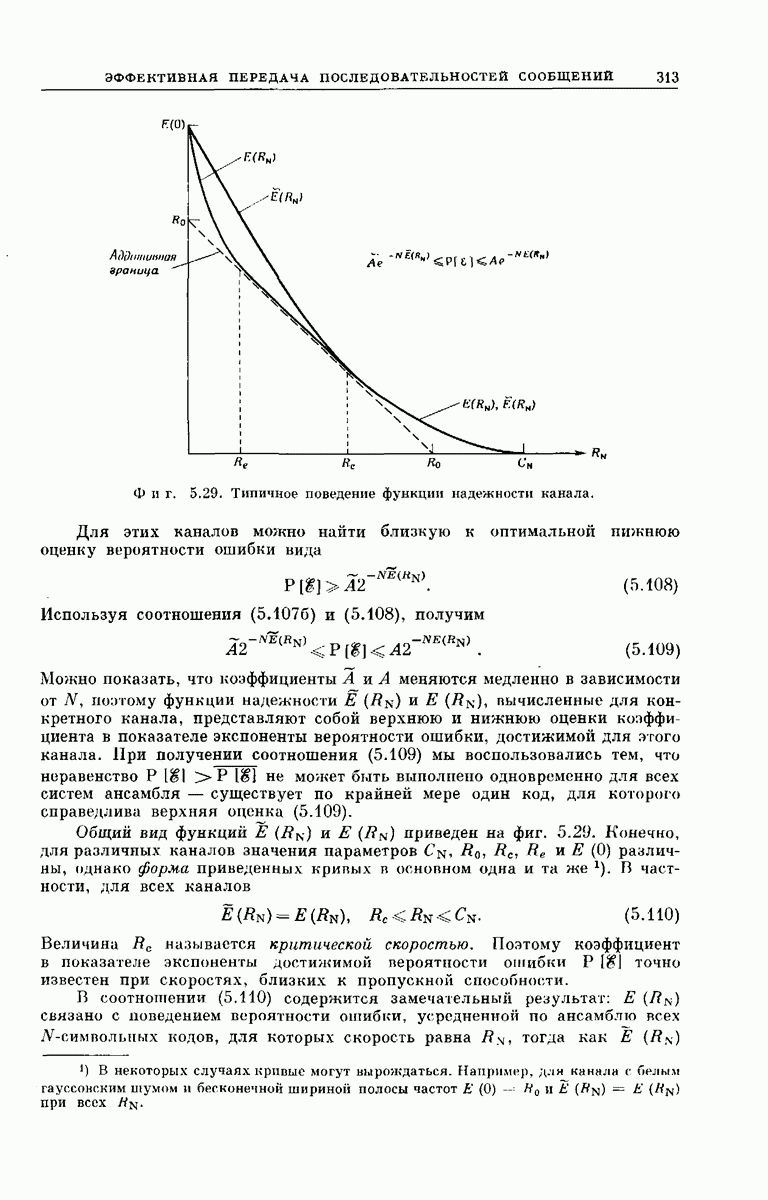
целых чисел. Выходной преобразователь разбивает эту последовательность на группу длины  и станит в соответствие каждой группе одну их входных букв канала
и станит в соответствие каждой группе одну их входных букв канала  гак, как это указывалось при рассмотрении фиг. 6. 8. Число сумматоров
гак, как это указывалось при рассмотрении фиг. 6. 8. Число сумматоров  выбирается достаточно большим для того, чтобы
выбирается достаточно большим для того, чтобы  могли порождаться с желаемыми вероятностями
могли порождаться с желаемыми вероятностями  (Более эффективная схема кодера использует только
(Более эффективная схема кодера использует только  -раярядных. регистров сдвига, где
-раярядных. регистров сдвига, где
кодов, для которого сопоставленные отводам матрицы связи и веса, на которые умножается проходящий по ним сигнал, статистически независимы и с одинаковыми вероятностями принимают значения  . Мы предполагаем, что на выходе кодеров в ансамбле стоят идентичные преобразователи, выбранные так, что входные буквы канала
. Мы предполагаем, что на выходе кодеров в ансамбле стоят идентичные преобразователи, выбранные так, что входные буквы канала  используются с вероятностями
используются с вероятностями  Для этого ансамбля правильный путь и любое подмножество неправильных путей глубины
Для этого ансамбля правильный путь и любое подмножество неправильных путей глубины  статистически независимы. Кроме того, обозначив
статистически независимы. Кроме того, обозначив  символ вдоль правильного пути через
символ вдоль правильного пути через  принятый символ — через
принятый символ — через  символ вдоль (неправильного) пути, ведущего в узел
символ вдоль (неправильного) пути, ведущего в узел  через
через  получим
получим

независимо от значения  . Условившись, что черта сверху (здесь и ниже) означает усреднение также и по указанному ансамблю кодов, найдем
. Условившись, что черта сверху (здесь и ниже) означает усреднение также и по указанному ансамблю кодов, найдем

Перейдя в соотношении  от суммы в показателе к произведению экспонент, мы использовали то обстоятельство, что в силу
от суммы в показателе к произведению экспонент, мы использовали то обстоятельство, что в силу  значения
значения  при различных к статистически независимы.
при различных к статистически независимы.
Оценка сомножителей. Получить оценку отдельных средних значений в соотношении  нетрудно. Используя соотношение
нетрудно. Используя соотношение  и определение перекошенного расстояния
и определение перекошенного расстояния  найдем
найдем

Дальнейшее рассмотрение упростится, если положить величину X равной положительному числу  Получим
Получим

где  — показатель экспоненциальной оценки, определенный соотношением (6.62б).
— показатель экспоненциальной оценки, определенный соотношением (6.62б).
Остальные сомножители в  оцениваются в основном аналогично. Во-первых,
оцениваются в основном аналогично. Во-первых,

Непосредственно применяя неравенство Шварца  к многомерным векторам а и
к многомерным векторам а и  получим
получим

Таким образом,

где использовалось то обстоятельство, что, согласно соотношению 
Последние сомножители в соотношении  оцениваются с помощью
оцениваются с помощью  Имеем
Имеем

Применяя неравенство Шварца, получим

Подстановки. Требуемая оценка  получается после нескольких подстановок одних соотношений в другие. Вначале, подставляя соотношения
получается после нескольких подстановок одних соотношений в другие. Вначале, подставляя соотношения  в
в  (при значении
(при значении  ), получим
), получим

Следовательно,

Усредняя  по ансамблю кодов и подставляя туда неравенство
по ансамблю кодов и подставляя туда неравенство  получим
получим

Ослабим оценку, просуммировав до бесконечности. Тогда

где коэффициент  равен
равен

Полагая  и подставляя в
и подставляя в  получим окончательный результат
получим окончательный результат

В силу  это неравенство можно переписать в виде
это неравенство можно переписать в виде

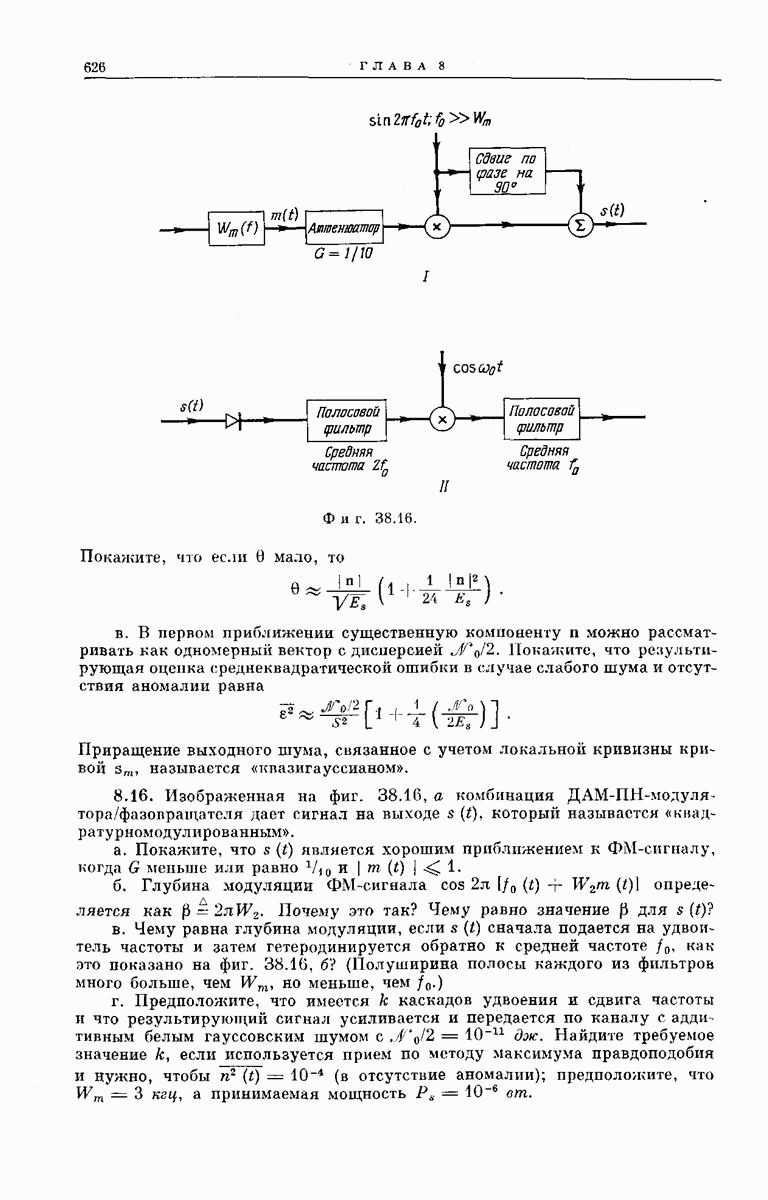
Мы установили, что при  средняя но ансамблю вероятность события «в момент, когда впервые исследуется ребро, удаленное от правильного исходного узла на К ребер, решение
средняя но ансамблю вероятность события «в момент, когда впервые исследуется ребро, удаленное от правильного исходного узла на К ребер, решение  неправильно» убывает экспоненциально с возрастанием длины кодовых ограничений К. Стиглитц и Юдкин, используя более тонкие методы, получили более точные оценки.
неправильно» убывает экспоненциально с возрастанием длины кодовых ограничений К. Стиглитц и Юдкин, используя более тонкие методы, получили более точные оценки.
Интерпретация. Выясним связь оценки  с вероятностью ошибки для реального декодера Фано. Как и в случае субоптимального декодера, рассмотренного в разд. 6.3, мы предполагаем, что на вход кодера поступает длинная последовательность символов
с вероятностью ошибки для реального декодера Фано. Как и в случае субоптимального декодера, рассмотренного в разд. 6.3, мы предполагаем, что на вход кодера поступает длинная последовательность символов  и что ошибка происходит, если не все
и что ошибка происходит, если не все  символов декодированы правильно. Так как оценка, даваемая соотношением
символов декодированы правильно. Так как оценка, даваемая соотношением  не зависит от
не зависит от  и передаваемого пути, то средняя вероятность ошибки при посимвольном декодировании входной последовательности с помощью управляемого джином декодера ограничена сверху величиной
и передаваемого пути, то средняя вероятность ошибки при посимвольном декодировании входной последовательности с помощью управляемого джином декодера ограничена сверху величиной  Поэтому, выбирая соответствующие значения
Поэтому, выбирая соответствующие значения  можно сделать вероятность ошибки произвольно малой. Для облегчения изложения обозначим декодер, управляемый джином, символом
можно сделать вероятность ошибки произвольно малой. Для облегчения изложения обозначим декодер, управляемый джином, символом  .
.
Теперь рассмотрим второй декодер  почти полностью идентичный
почти полностью идентичный  и отличающийся лишь тем, что
и отличающийся лишь тем, что  исходный узел,
исходный узел,  определяется предыдущими решениями декодера
определяется предыдущими решениями декодера  а не указывается джином. Так как
а не указывается джином. Так как  определяет
определяет  правильно, если и только если
правильно, если и только если  определяет
определяет  правильно, то величина
правильно, то величина  служит верхней оценкой вероятности ошибки декодера
служит верхней оценкой вероятности ошибки декодера  несмотря на то что джин теперь уволен в отставку
несмотря на то что джин теперь уволен в отставку
Следующее утверждение наиболее тонкое. Рассмотрим третий декодер  который, подобно и
который, подобно и  имеет бесконечный
имеет бесконечный  -регистр, но использует более близкий к реальному алгоритм поиска. Единственное отличие декодера
-регистр, но использует более близкий к реальному алгоритм поиска. Единственное отличие декодера  от декодера, использующего алгоритм Фано, состоит в том, что для каждого
от декодера, использующего алгоритм Фано, состоит в том, что для каждого  после того как указатель исследуемого узла продвинется до узла на глубине
после того как указатель исследуемого узла продвинется до узла на глубине  ребер от начала кодового дерева, запрещается изменять решения
ребер от начала кодового дерева, запрещается изменять решения  Таким образом,
Таким образом,  помнит тот путь, по которому дальше всего углублялся в кодовое дерево, и в любой момент трактует узел, от которого точка самого большого углубления в дерево удалена на
помнит тот путь, по которому дальше всего углублялся в кодовое дерево, и в любой момент трактует узел, от которого точка самого большого углубления в дерево удалена на  ребер, как начало кода. Отличие декодера
ребер, как начало кода. Отличие декодера  от декодера
от декодера  заключается в том, что он не возвращается в следующий исходный узел поело каждого принятого решения. Мы увидим, однако, что эти два декодера всегда принимают одни и те же решения, даже когда они декодируют неправильно.
заключается в том, что он не возвращается в следующий исходный узел поело каждого принятого решения. Мы увидим, однако, что эти два декодера всегда принимают одни и те же решения, даже когда они декодируют неправильно.
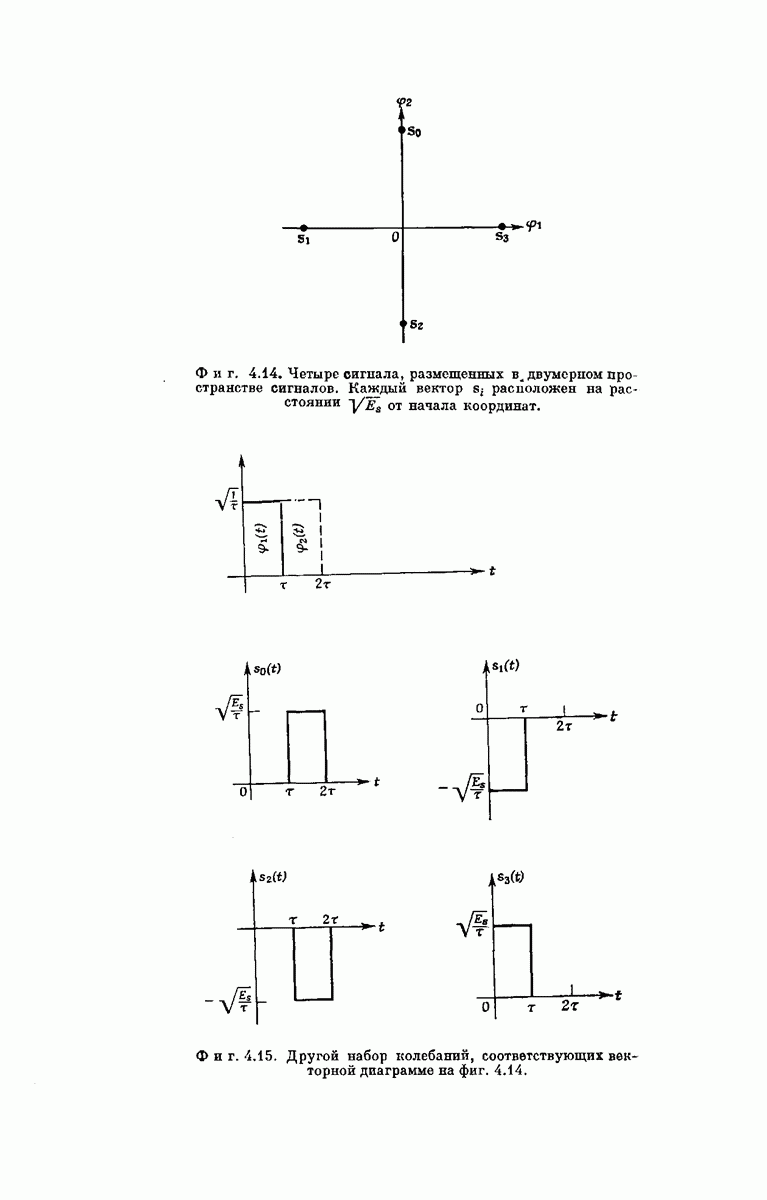
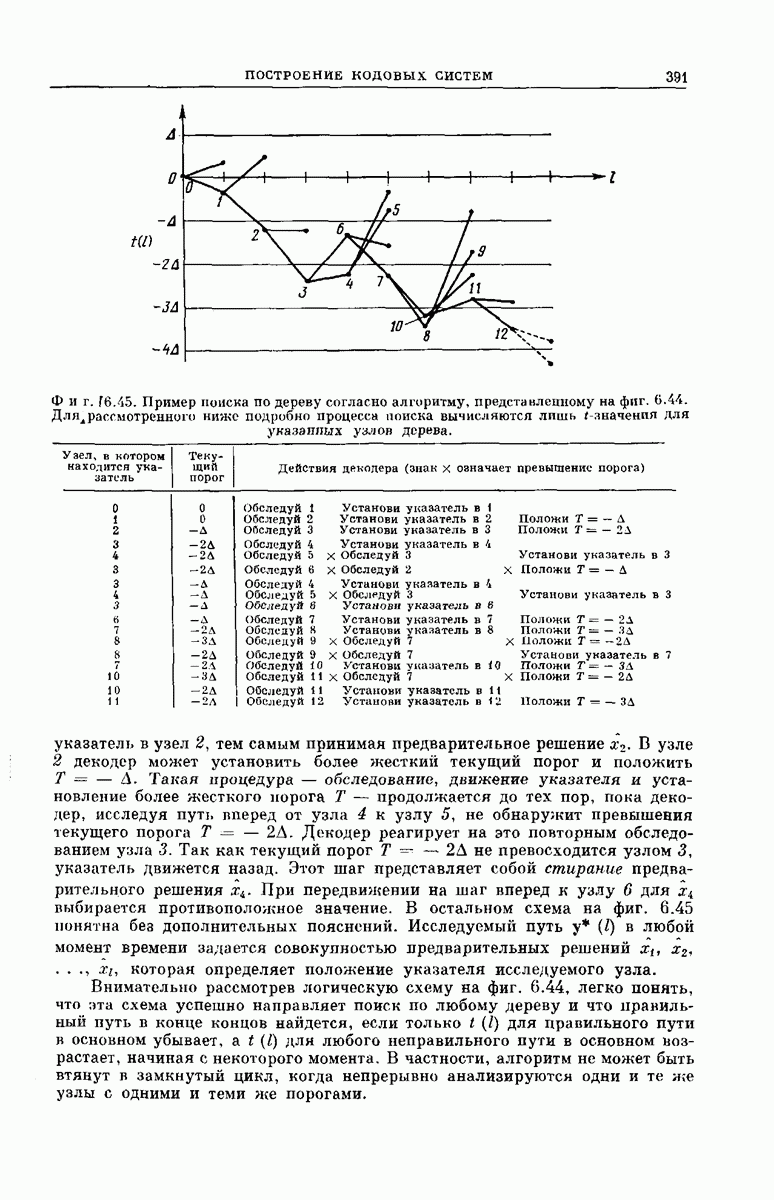
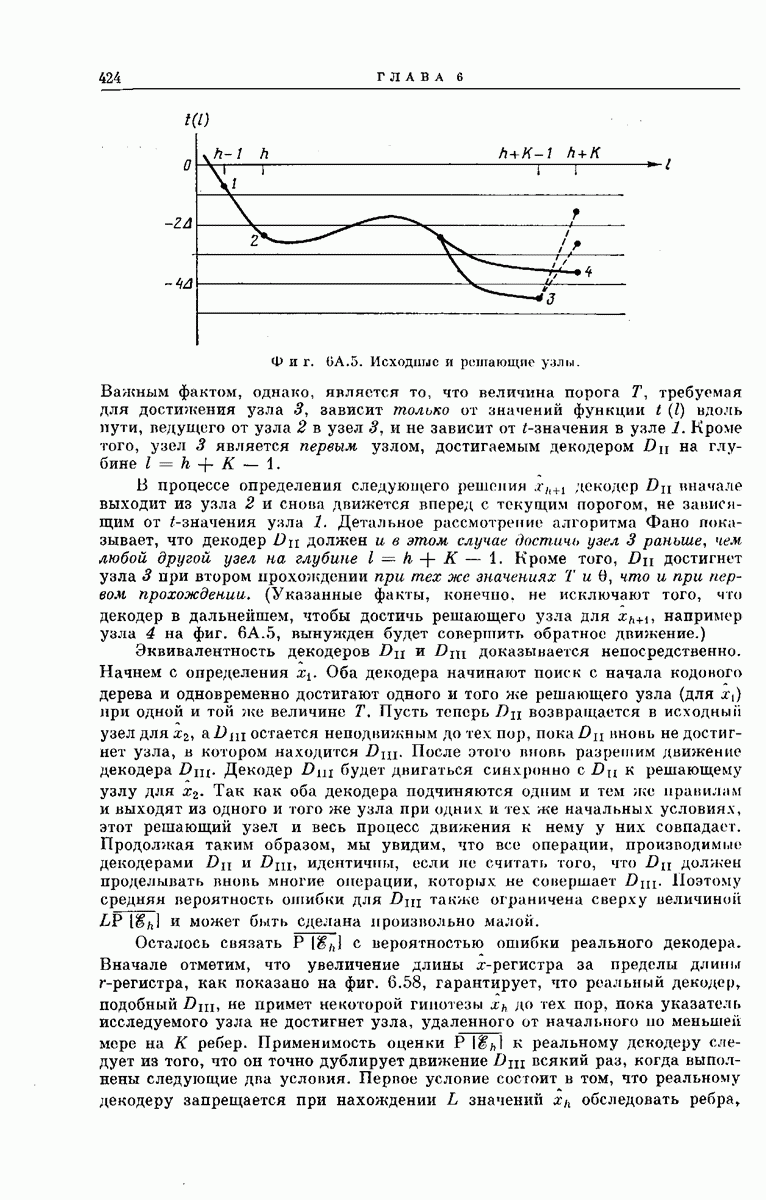
Чтобы показать эквивалентность  обратимся к фиг. 6А.5. Рассмотрим декодер пусть узел 1 является исходным узлом и пусть узел 3 является «рзтающим узлом» для
обратимся к фиг. 6А.5. Рассмотрим декодер пусть узел 1 является исходным узлом и пусть узел 3 является «рзтающим узлом» для  Решающим узлом для
Решающим узлом для  будем называть первый ерзди просмотренных декодером
будем называть первый ерзди просмотренных декодером  узлов на уровне, удаленном от
узлов на уровне, удаленном от  исходного узла на К ребер. Поэтому узел 2 в случае использования
исходного узла на К ребер. Поэтому узел 2 в случае использования  является исходным узлом для
является исходным узлом для  . В процессе определения
. В процессе определения  может потребоваться многократное прохождение декодера
может потребоваться многократное прохождение декодера  через узел 2 каждый раз с более высоким значением текущего порога
через узел 2 каждый раз с более высоким значением текущего порога 

Фиг. 6A.5. Исходные и решающие узлы.
Важным фактом, однако, является то, что величина порога  требуемая для достижения узла 3, зависит только от значений функции
требуемая для достижения узла 3, зависит только от значений функции  вдоль пути, ведущего от узла 2 в узел 3, и не зависит от Означения в узле 1. Кроме того, узел 3 является первым узлом, достигаемым декодером
вдоль пути, ведущего от узла 2 в узел 3, и не зависит от Означения в узле 1. Кроме того, узел 3 является первым узлом, достигаемым декодером  на глубине
на глубине  .
.
В процессе определения следующего решения  декодер
декодер  вначале выходит из узла 2 и снова движется вперед с текущим порогом, не зависящим от Означения узла 1. Детальное рассмотрение алгоритма Фано показывает, что декодер
вначале выходит из узла 2 и снова движется вперед с текущим порогом, не зависящим от Означения узла 1. Детальное рассмотрение алгоритма Фано показывает, что декодер  должен и в этом случае достичь узел 3 раньше, чем любой другой узел на глубине
должен и в этом случае достичь узел 3 раньше, чем любой другой узел на глубине  Кроме того,
Кроме того,  достигнет узла 3 при втором прохождении при тех же значениях
достигнет узла 3 при втором прохождении при тех же значениях  и 6, что и при первом прохождении. (Указанные факты, конечно, не исключают того, что декодер в дальнейшем, чтобы достичь решающего узла для
и 6, что и при первом прохождении. (Указанные факты, конечно, не исключают того, что декодер в дальнейшем, чтобы достичь решающего узла для  например узла 4 на фиг.
например узла 4 на фиг.  вынужден будет совершить обратное движение.)
вынужден будет совершить обратное движение.)
Эквивалентность декодеров  доказывается непосредственно. Начнем с определения
доказывается непосредственно. Начнем с определения  Оба декодера начинают поиск с начала кодоного дерева и одновременно достигают одного и того же решающего узла (для
Оба декодера начинают поиск с начала кодоного дерева и одновременно достигают одного и того же решающего узла (для  одной и той же величине
одной и той же величине  Пусть теперь
Пусть теперь  возвращается в исходный узел для
возвращается в исходный узел для  остается неподвижным до тех пор, покажи вновь не достигнет узла, в котором находится
остается неподвижным до тех пор, покажи вновь не достигнет узла, в котором находится  После этого вновь разрешим движение декодера
После этого вновь разрешим движение декодера  Декодер
Декодер  будет двигаться синхронно с
будет двигаться синхронно с  к решающему узлу для
к решающему узлу для  Так как оба декодера подчиняются одним и тем
Так как оба декодера подчиняются одним и тем  правилам и выходят из одного и того же узла при одних и тех же начальных условиях, этот решающий узел и весь процесс движения к нему у них совпадает. Продолжая таким образом, мы увидим, что все операции, производимые декодерами
правилам и выходят из одного и того же узла при одних и тех же начальных условиях, этот решающий узел и весь процесс движения к нему у них совпадает. Продолжая таким образом, мы увидим, что все операции, производимые декодерами  и идентичны, если не считать того, что
и идентичны, если не считать того, что  должен проделывать вновь многие операции, которых не совершает
должен проделывать вновь многие операции, которых не совершает  Поэтому средняя вероятность ошибки для
Поэтому средняя вероятность ошибки для  также ограничена сверху величиной и может быть сделана произвольно малой.
также ограничена сверху величиной и может быть сделана произвольно малой.
Осталось связать  с вероятностью ошибки реального декодера. Вначале отметим, что увеличение длины
с вероятностью ошибки реального декодера. Вначале отметим, что увеличение длины  -регистра за пределы длины
-регистра за пределы длины  -регистра, как показано на фиг. 6.58, гарантирует, что реальный декодер, подобный
-регистра, как показано на фиг. 6.58, гарантирует, что реальный декодер, подобный  не примет некоторой гипотезы
не примет некоторой гипотезы  до тех пор, пока указатель исследуемого узла не достигнет узла, удаленного от начального но меньшей мере на К ребер. Применимость оценки
до тех пор, пока указатель исследуемого узла не достигнет узла, удаленного от начального но меньшей мере на К ребер. Применимость оценки  к реальному декодеру следует из того, что он точно дублирует движение
к реальному декодеру следует из того, что он точно дублирует движение  всякий раз, когда выполнены следующие два условия. Перпое условие состоит в том, что реальному декодеру запрещается при нахождении
всякий раз, когда выполнены следующие два условия. Перпое условие состоит в том, что реальному декодеру запрещается при нахождении  значений
значений 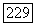 обследовать ребра,
обследовать ребра,
от которых узел наибольшего углубления удален на 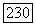 или более ребер; второе условие состоит в том, что (конечный)
или более ребер; второе условие состоит в том, что (конечный) 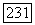 -регистр должен не переполняться. Так как число ребер, обычно исследованных декодером в процессе поиска, очень велико, естественно ожидать, что второе условие на практике доминирует. Поэтому можно интерпретировать оценку
-регистр должен не переполняться. Так как число ребер, обычно исследованных декодером в процессе поиска, очень велико, естественно ожидать, что второе условие на практике доминирует. Поэтому можно интерпретировать оценку 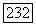 как грубую оценку средней вероятности необнаружимой ошибки на декодированный символ сообщения. Это объясняется тем, что мы пренебрегаем возможностью того, что, до того как на выходе х-регистра появится ошибочное решение, произойдет переполнение. Если
как грубую оценку средней вероятности необнаружимой ошибки на декодированный символ сообщения. Это объясняется тем, что мы пренебрегаем возможностью того, что, до того как на выходе х-регистра появится ошибочное решение, произойдет переполнение. Если  -регистр удлинен более чем на К разрядов, как показано на фиг. 6.58, естественно ожидать, что эта оценка должна быть очень грубой.
-регистр удлинен более чем на К разрядов, как показано на фиг. 6.58, естественно ожидать, что эта оценка должна быть очень грубой.
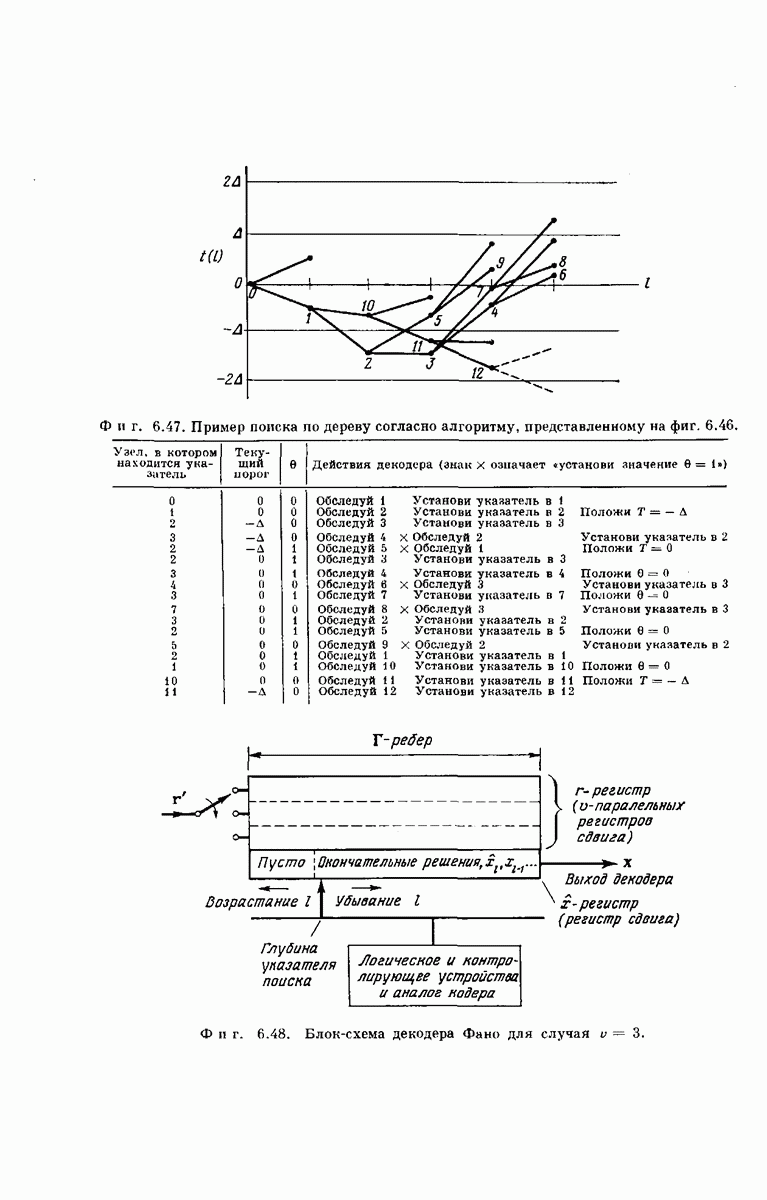
СРЕДНЕЕ КОЛИЧЕСТВО ВЫЧИСЛЕНИЙ
Теперь оценим среднее количество вычислений (по ансамблю сверточных кодов), выполняемых декодером  при декодировании символов
при декодировании символов  Так как мы не учитываем повторные вычислении при каждом новом прохождении из указанного джином исходного узла к первому из узлов, удаленных от исходного на
Так как мы не учитываем повторные вычислении при каждом новом прохождении из указанного джином исходного узла к первому из узлов, удаленных от исходного на  ребер, то полученный результат при условии, что декодер
ребер, то полученный результат при условии, что декодер  декодировал все
декодировал все  символов
символов  правильно, может служить оценкой количества вычислений, производимых декодером
правильно, может служить оценкой количества вычислений, производимых декодером  следовательно, может быть оценкой количества вычислений, производимых реальным декодером при отсутствии переполнения.
следовательно, может быть оценкой количества вычислений, производимых реальным декодером при отсутствии переполнения.
Следует отметить, что декодер производит одно вычисление каждый раз, когда обращается к блоку «смотри вперед» или блоку «смотри назад», изображенных на логической схеме фиг. 6.46, В частности, обозначим символом 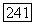 среднее общее число обращений декодера к одному из этих блоков в момент, когда указатель исследуемого узла находится на неправильном подмножестве для
среднее общее число обращений декодера к одному из этих блоков в момент, когда указатель исследуемого узла находится на неправильном подмножестве для 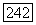 Из рассмотрения фиг.
Из рассмотрения фиг. 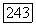 видно, что каждый узел кодового дерева принадлежит неправильпому подмножеству одного и только одного
видно, что каждый узел кодового дерева принадлежит неправильпому подмножеству одного и только одного  Поэтому среднее число вычислений на декодированный символ дается соотношением
Поэтому среднее число вычислений на декодированный символ дается соотношением

Оценим сверху величины 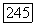 тем самым величину В, используя следующие основные свойства алгоритма поиска.
тем самым величину В, используя следующие основные свойства алгоритма поиска.
1. Максимальное число вычислений, которое можно произвести при заданном положении указателя исследуемого узла и заданном уровне порога, равно 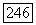 .
.
2. Максимальное число различных использованных порогов, когда указатель поиска находится в одном из узлов неправильного подмножества для 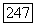 равно числу порогов, лежащих выше Означения этого узла или совпадающих с ним, но ниже
равно числу порогов, лежащих выше Означения этого узла или совпадающих с ним, но ниже 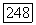 где
где 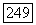 определено на фиг. 6А.3.
определено на фиг. 6А.3.
Справедливость первого свойства вытекает из того, что при данном уровне порога просмотр каждого из и ребер, выходящих вперед из данного узла, требует лишь одну операцию, просмотр ребра, несущего назад, требует также только одну операцию. Действительно, наличие переменной О в алгоритме поиска устраняет возможность просмотра некоторого ребра при одном и том же пороге более чем один раз; если бы это было не так, то декодер мог бы выйти на бесконечный замкнутый цикл.
Справедливость второго свойства вытекает из того, что указатель исследуемого узла не может быть передвинут в узел, у которого 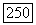 -значение не удовлетворяет текущему порогу, и что при исследовании неправильного подмножества для
-значение не удовлетворяет текущему порогу, и что при исследовании неправильного подмножества для 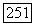 алгоритм никогда не использует порог, лежащий выше, чем
алгоритм никогда не использует порог, лежащий выше, чем 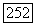

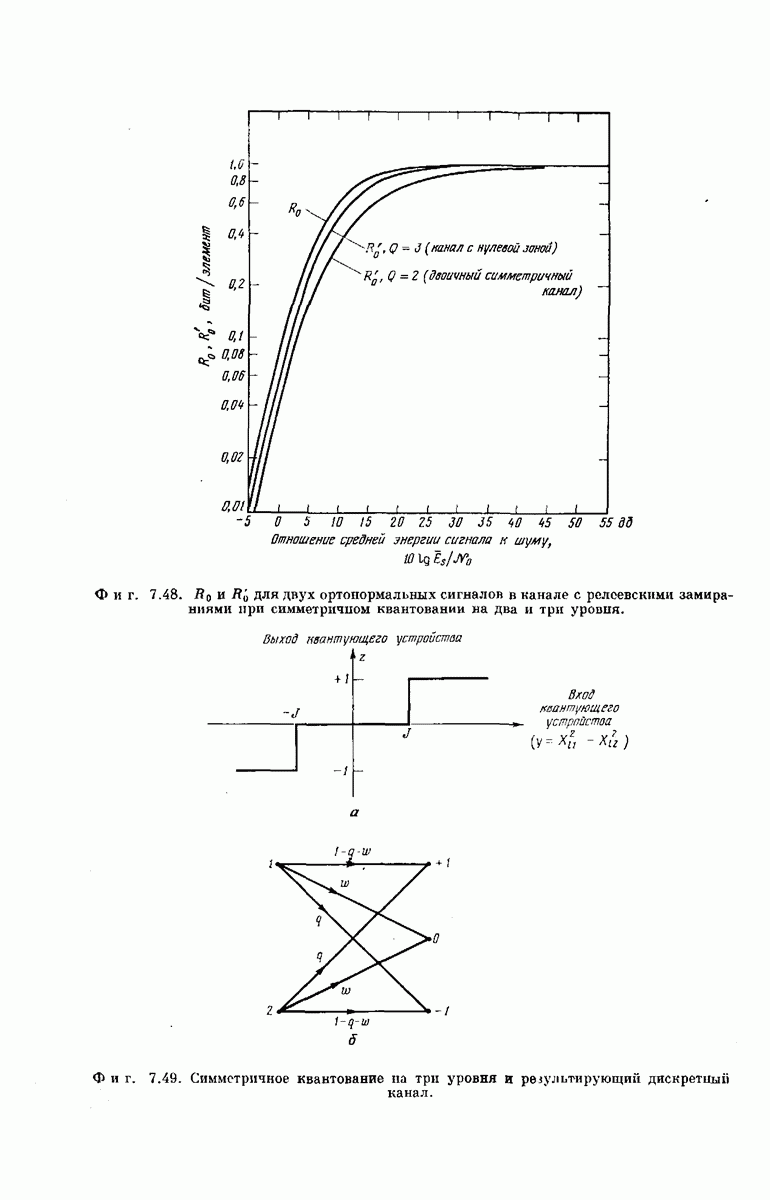
Фиг. 6A.6. Функция, ограничивающая число операций, выполняемых в узле.
При нахождении верхней оценки для 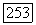 рассмотрим сначала конкретный код и определенный передаваемый путь. Из указанных двух свойств следует, что число вычислений
рассмотрим сначала конкретный код и определенный передаваемый путь. Из указанных двух свойств следует, что число вычислений 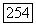 , выполняемых в узле
, выполняемых в узле  неправильного подмножества для удовлетворяет неравенству
неправильного подмножества для удовлетворяет неравенству

Используемая в этом соотношении ступенчатая функция 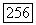 график которой представлен на фиг. 6А.6, ограничивает сверху максимальное число порогов, которое можно использовать при обследовании узла
график которой представлен на фиг. 6А.6, ограничивает сверху максимальное число порогов, которое можно использовать при обследовании узла 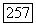 Заметив, что
Заметив, что

где 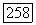 функция единичного скачка, ранее использованная при выводе соотношения
функция единичного скачка, ранее использованная при выводе соотношения 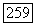 получим
получим

Усредняя обе части этого неравенства в соответствии с распределением вероятностей 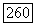 находим
находим

Заметим, что из вывода соотношения 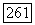 следует, что эта оценка верна независимо от конкретного значения параметра
следует, что эта оценка верна независимо от конкретного значения параметра 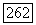 Заменяя в соотношении
Заменяя в соотношении 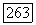 величиной
величиной 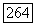 и подставляя результат в неравенство
и подставляя результат в неравенство 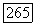 получим при
получим при 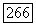

где коэффициент 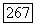 равен
равен

Минимум правой части этой оценки достигается при выборе расстояния между порогами 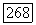 равным 2. При таком выборе
равным 2. При таком выборе

Среднее число вычислений 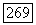 равно по определению декодера
равно по определению декодера 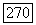 общему среднему числу неповторяющихся вычислений, произведенных в узлах неправильного подмножества для
общему среднему числу неповторяющихся вычислений, произведенных в узлах неправильного подмножества для  на глубине, меньшей или равной К. Так как среднее суммы равно сумме средних,
на глубине, меньшей или равной К. Так как среднее суммы равно сумме средних,

Таким образом, вновь обращаясь к  получим
получим

Правая часть неравенства  не зависит от
не зависит от  Поэтому, согласно
Поэтому, согласно 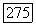 правая часть неравенства
правая часть неравенства 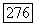 также является верхней оценкой В. Если
также является верхней оценкой В. Если 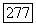 , среднее количество вычислений на декодированный символ сообщения ограничено величиной, не зависящей от длины кодовых ограничений А.
, среднее количество вычислений на декодированный символ сообщения ограничено величиной, не зависящей от длины кодовых ограничений А.
Таким образом, мы установили, что при скоростях передачи 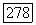 использовании декодера
использовании декодера 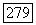 величина В и общая средняя вероятность одной или более ошибок
величина В и общая средняя вероятность одной или более ошибок 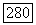 по отдельности ограничены в ансамбле сверточных кодов соответственно постоянной и экспоненциально убывающей с ростом К функциями [оценка для
по отдельности ограничены в ансамбле сверточных кодов соответственно постоянной и экспоненциально убывающей с ростом К функциями [оценка для 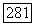 следует из соотношения
следует из соотношения 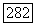 и неравенства
и неравенства 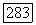 ]. Осталось показать, что существуют сверточные коды, для которых обе оценки выполняются одновременно. При доказательстве того, что такие коды существуют, можно использовать рассуждения, несколько более общие, чем те, с которыми мы уже знакомы. Мы знаем, что неравенство
]. Осталось показать, что существуют сверточные коды, для которых обе оценки выполняются одновременно. При доказательстве того, что такие коды существуют, можно использовать рассуждения, несколько более общие, чем те, с которыми мы уже знакомы. Мы знаем, что неравенство

может выполняться не более чем для  доли кодов ансамбля и что количество вычислений, подчиняющееся неравенству
доли кодов ансамбля и что количество вычислений, подчиняющееся неравенству

может потребоваться не более чем 1/b-й доле кодов; здесь левые части неравенств 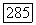 означают величины, усредненные только по шумам в канале. Самый худший случай — это когда совокупность кодов, которая имеет большую вероятность ошибки, не совпадает с совокупностью кодов, требующих большое количество вычислений. Отсюда следует, что по меньшей мере
означают величины, усредненные только по шумам в канале. Самый худший случай — это когда совокупность кодов, которая имеет большую вероятность ошибки, не совпадает с совокупностью кодов, требующих большое количество вычислений. Отсюда следует, что по меньшей мере 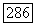 доля кодов в ансамбле одновременно удовлетворяет неравенствам, обратным неравенствам
доля кодов в ансамбле одновременно удовлетворяет неравенствам, обратным неравенствам 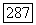
Таким образом, по крайней мере для 80% сверточных кодов

ЗАДАЧИ
(см. скан)












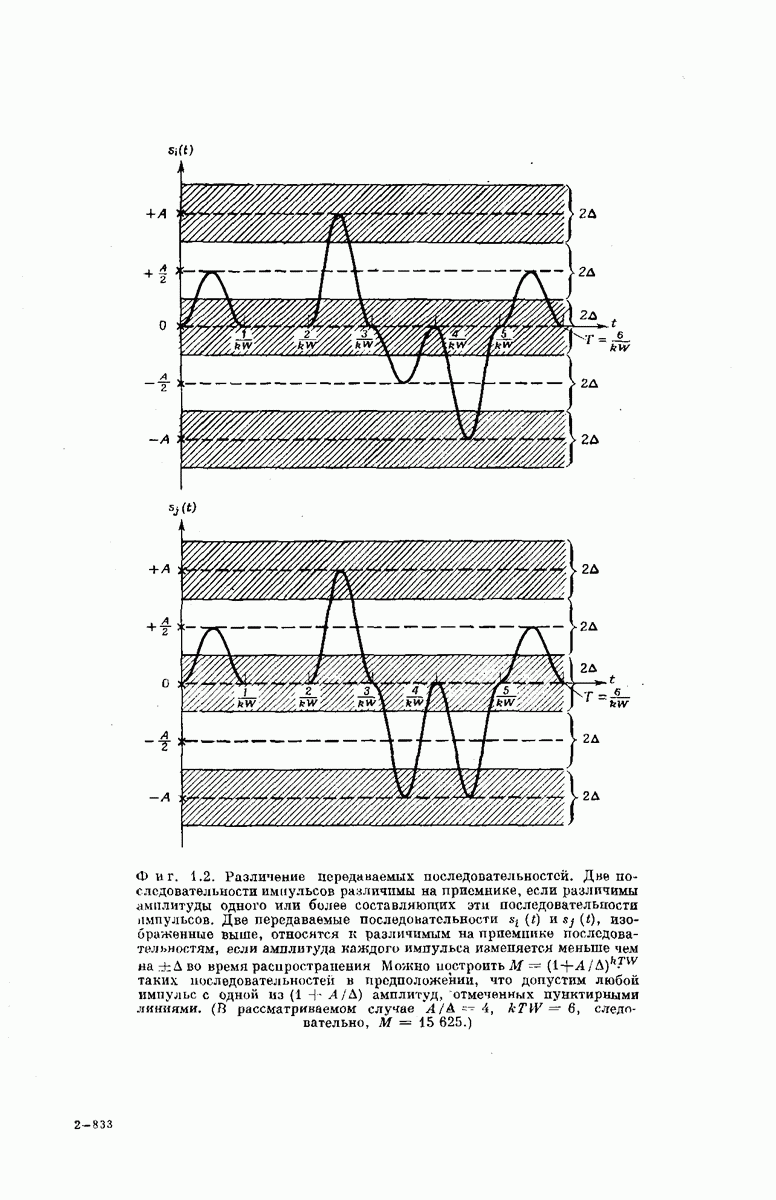


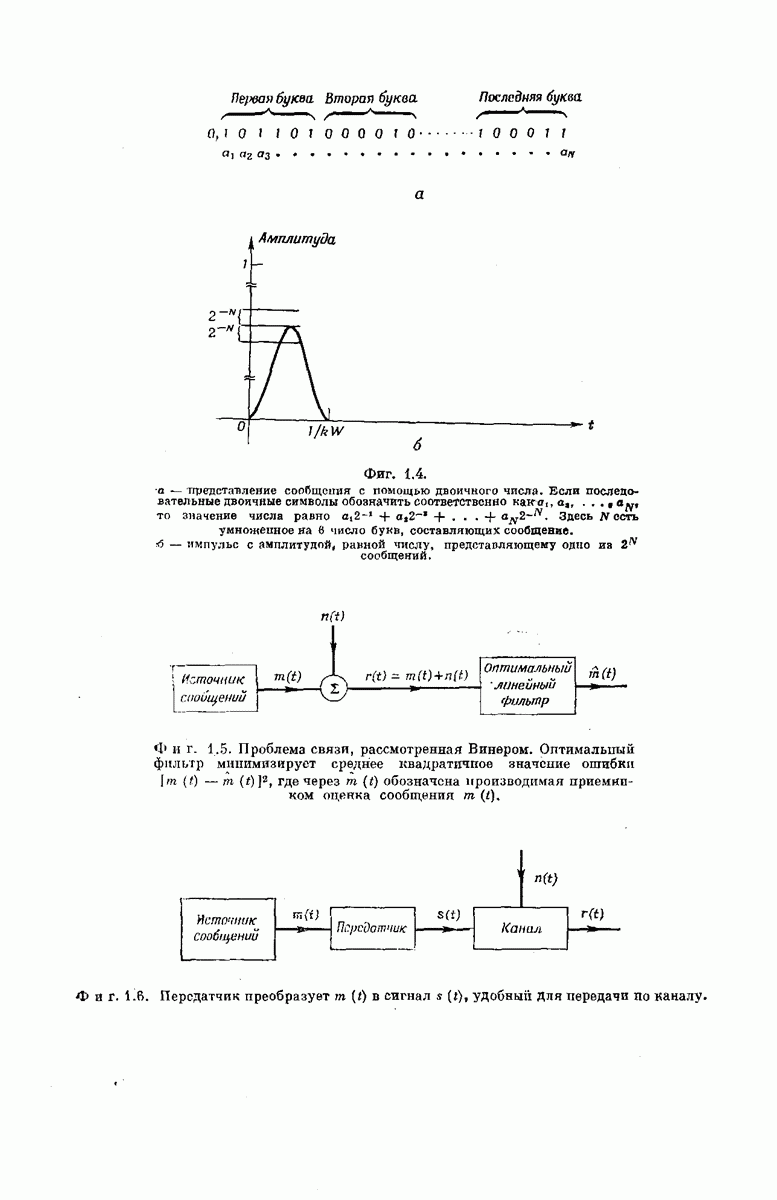





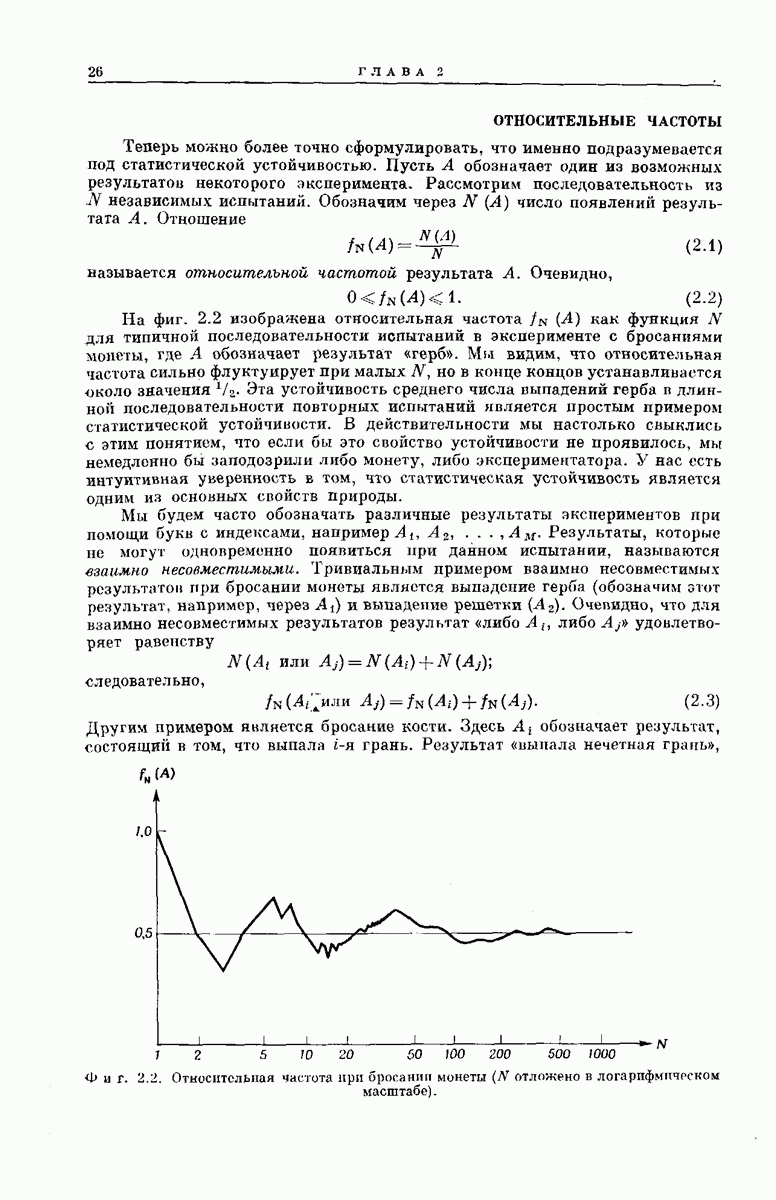



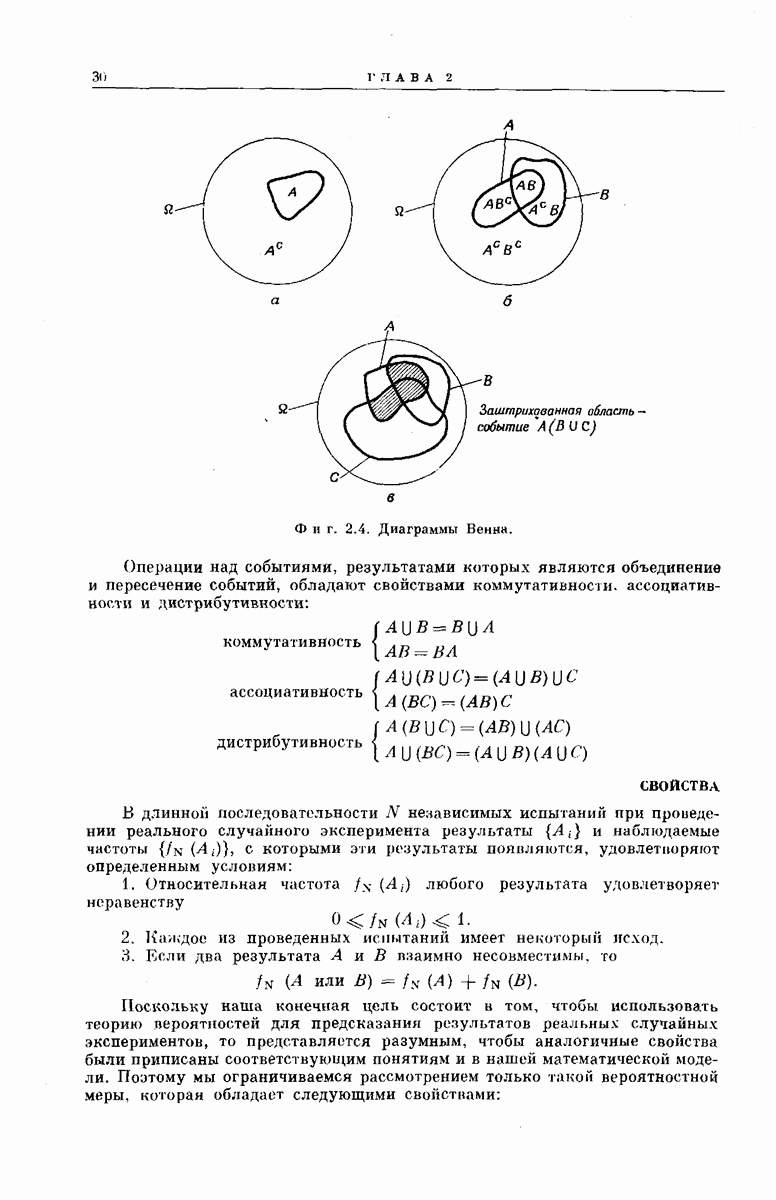







































































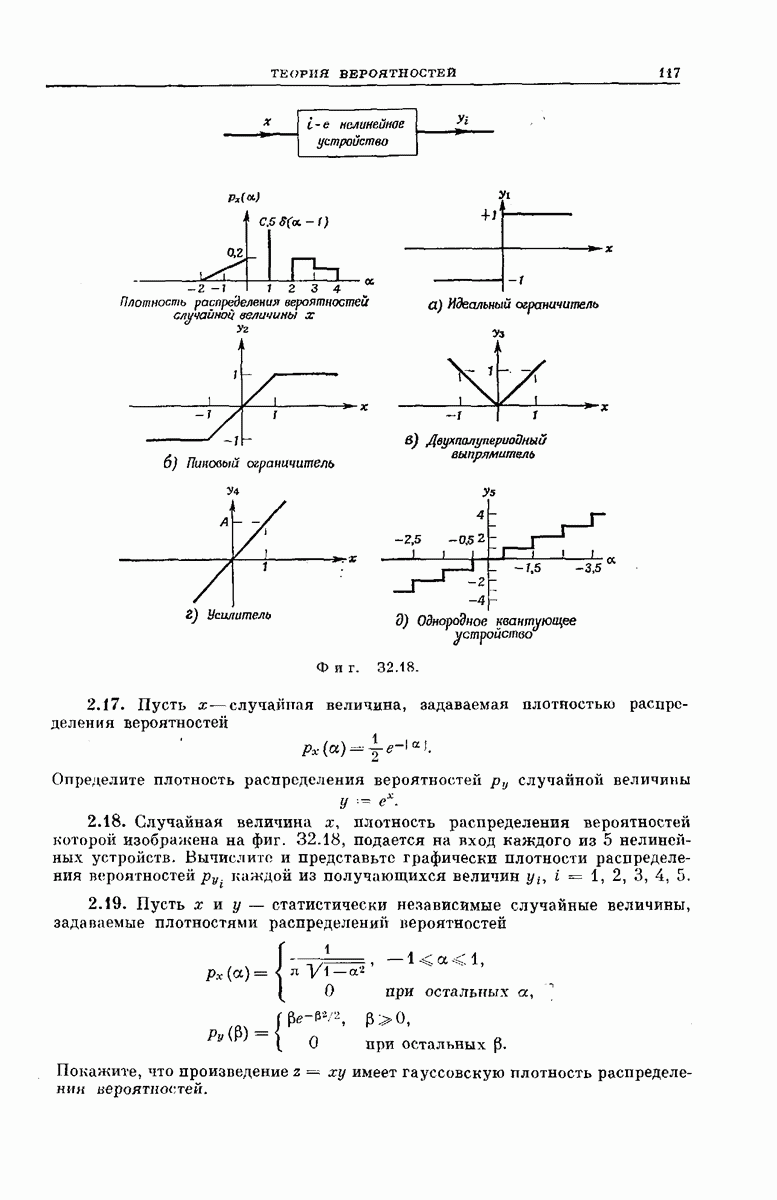

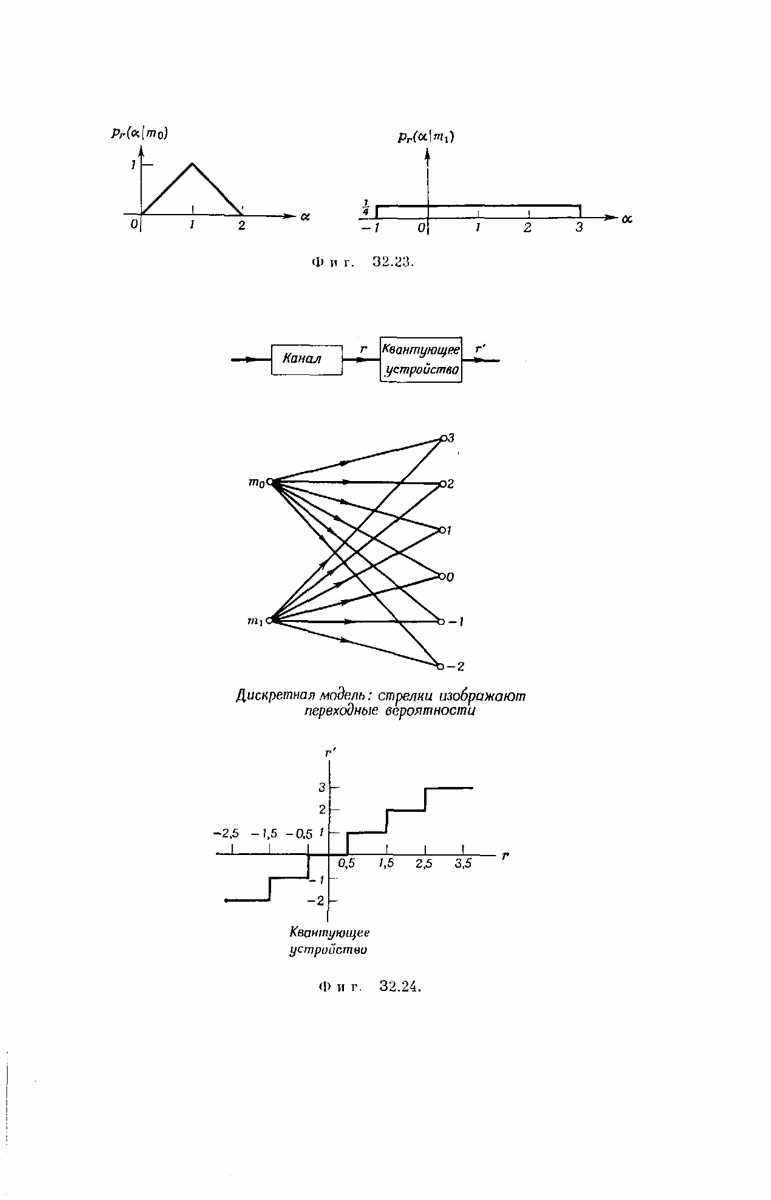


































































































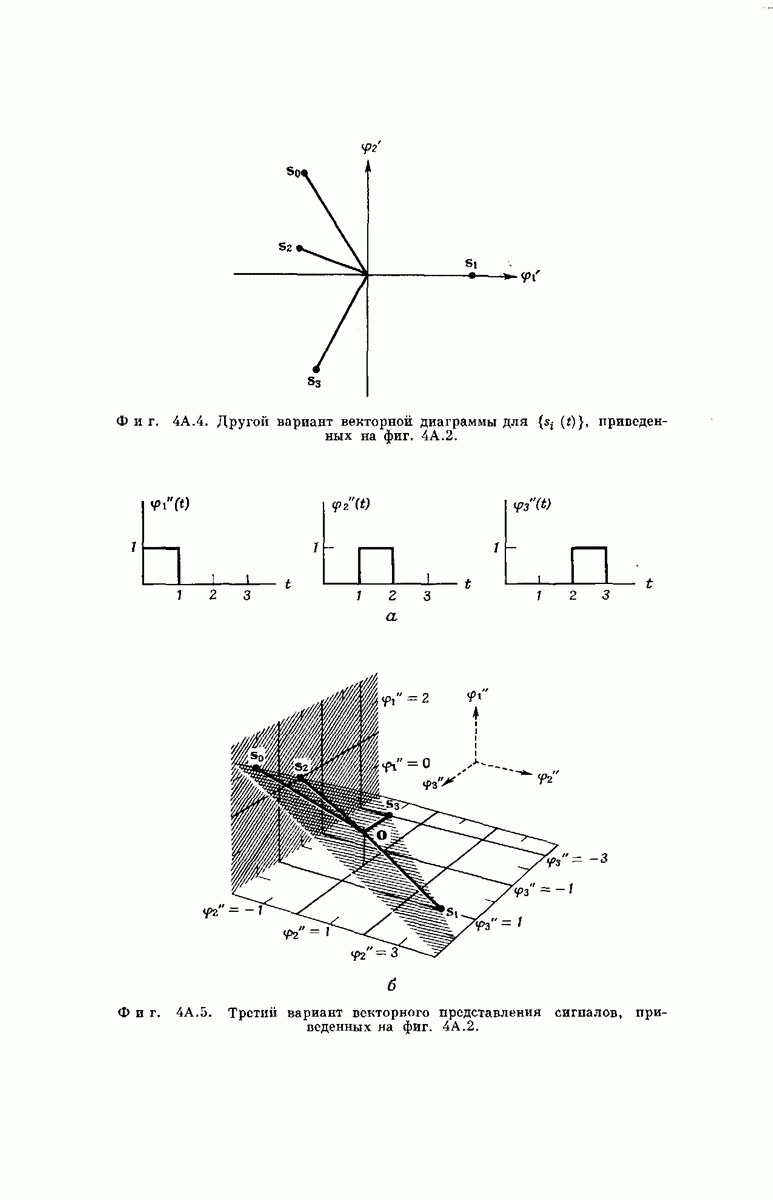

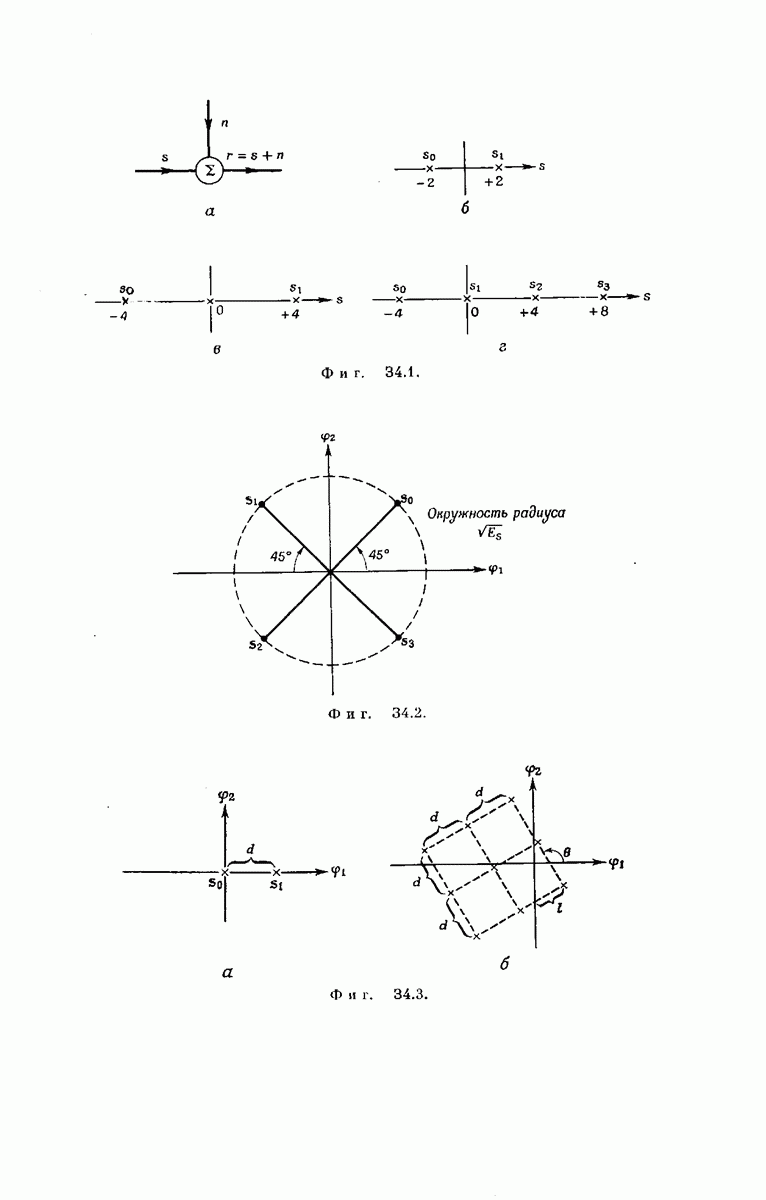

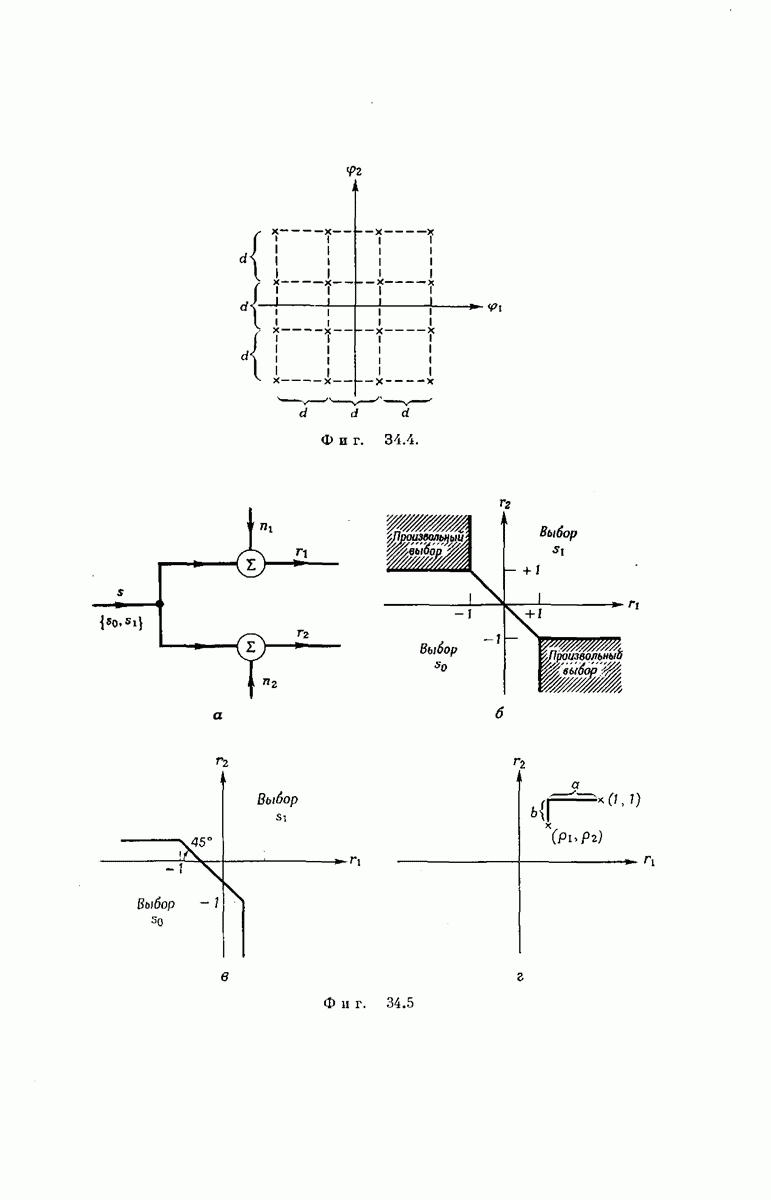
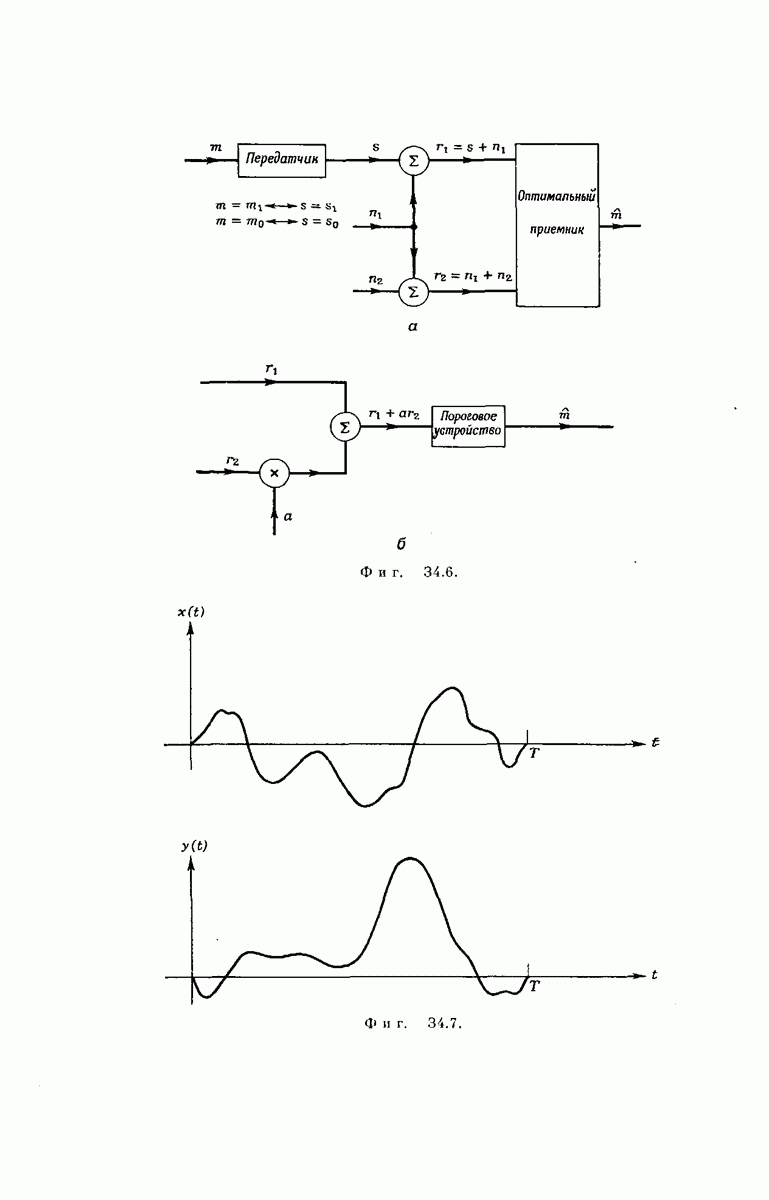




















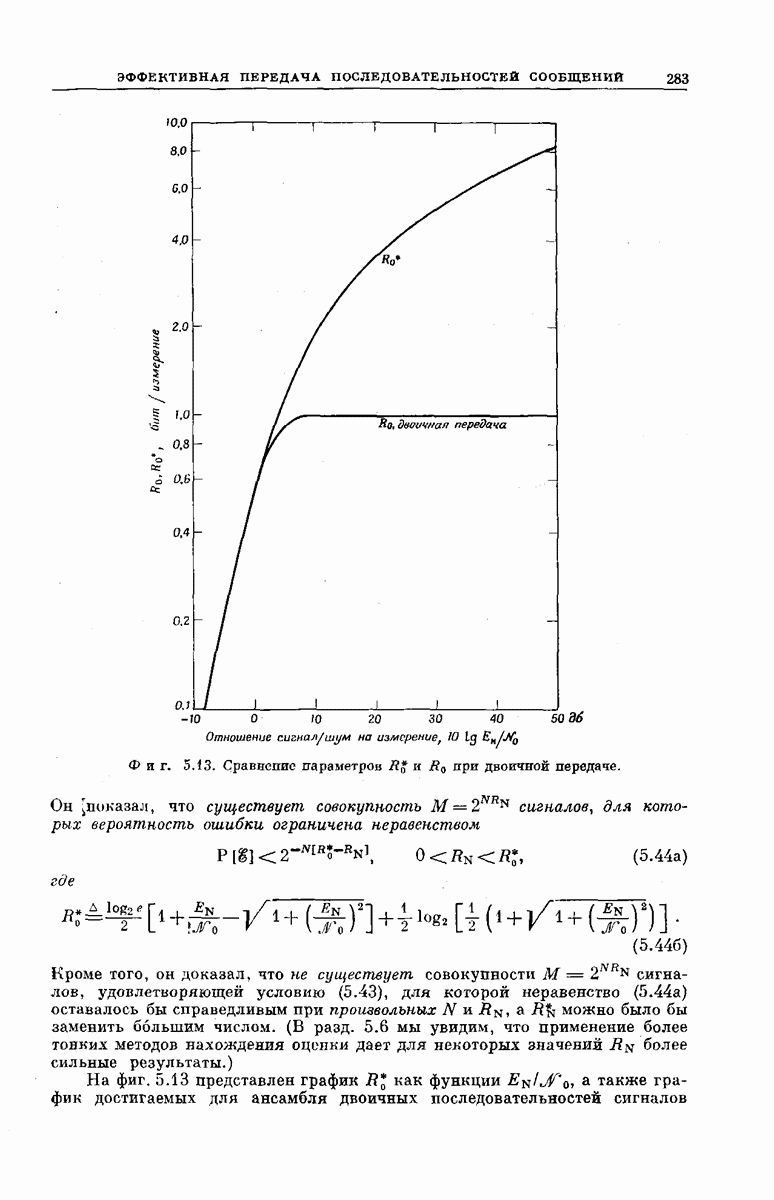




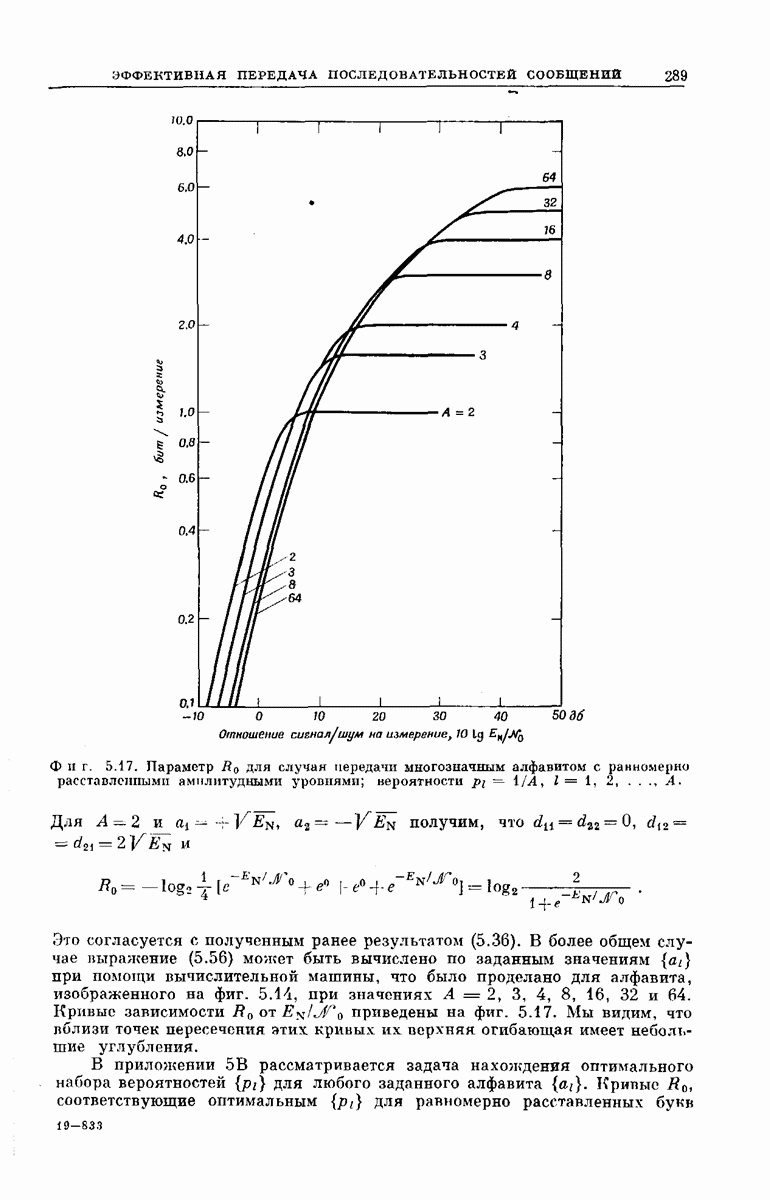
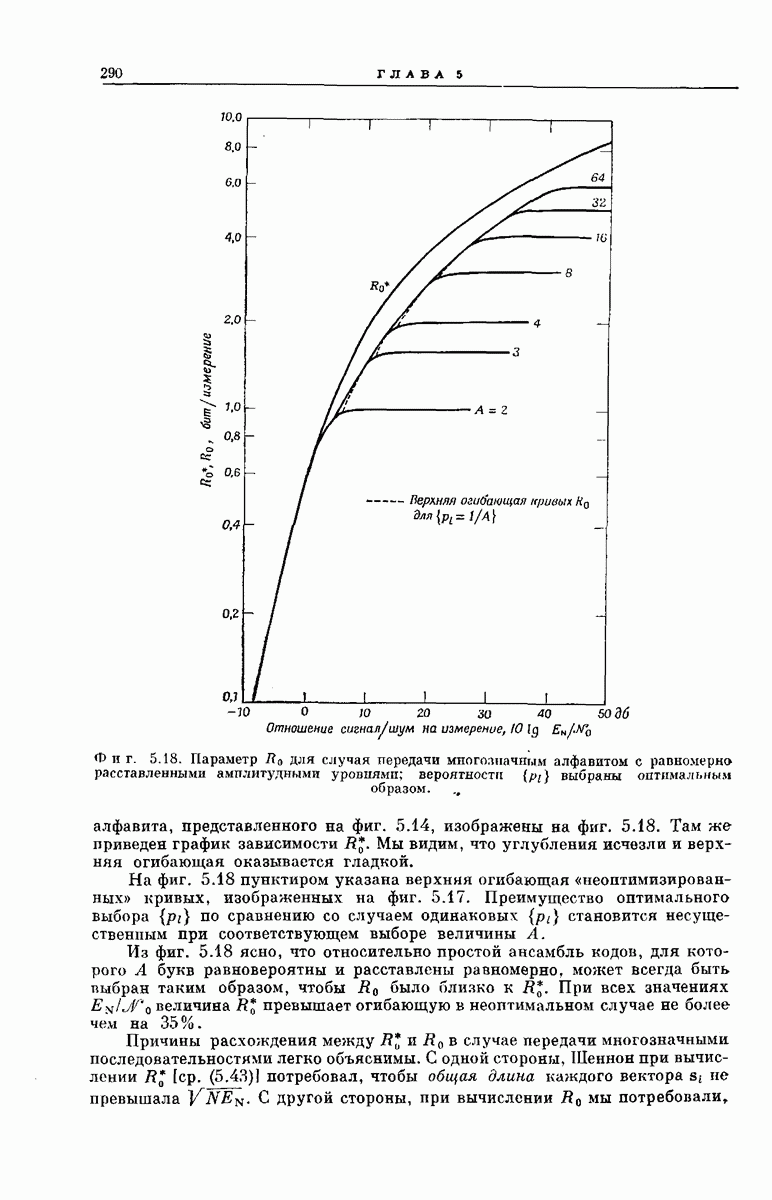









































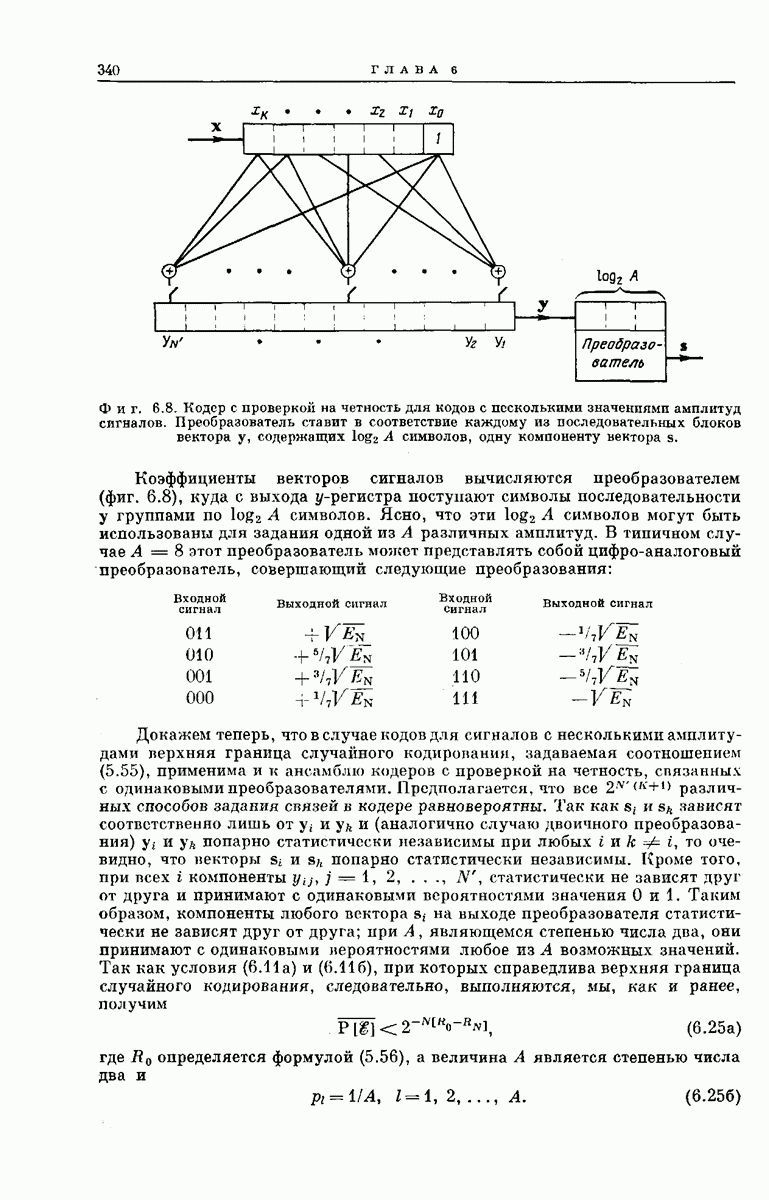





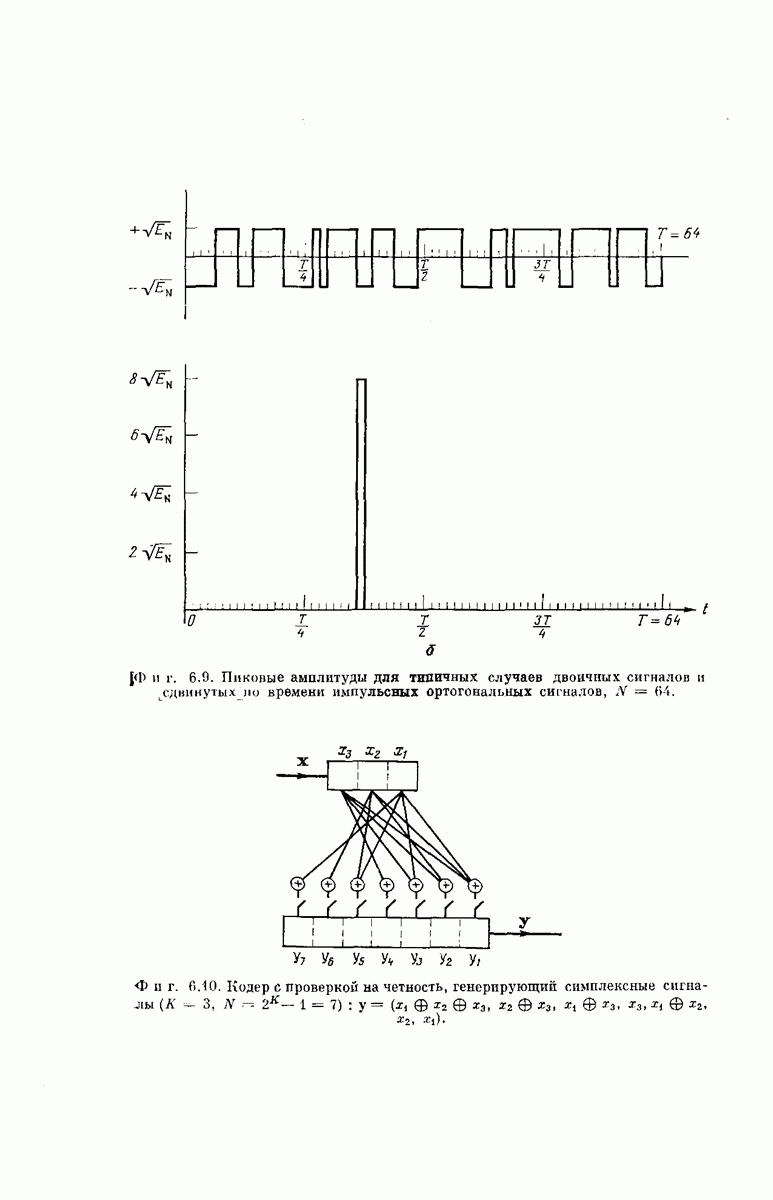


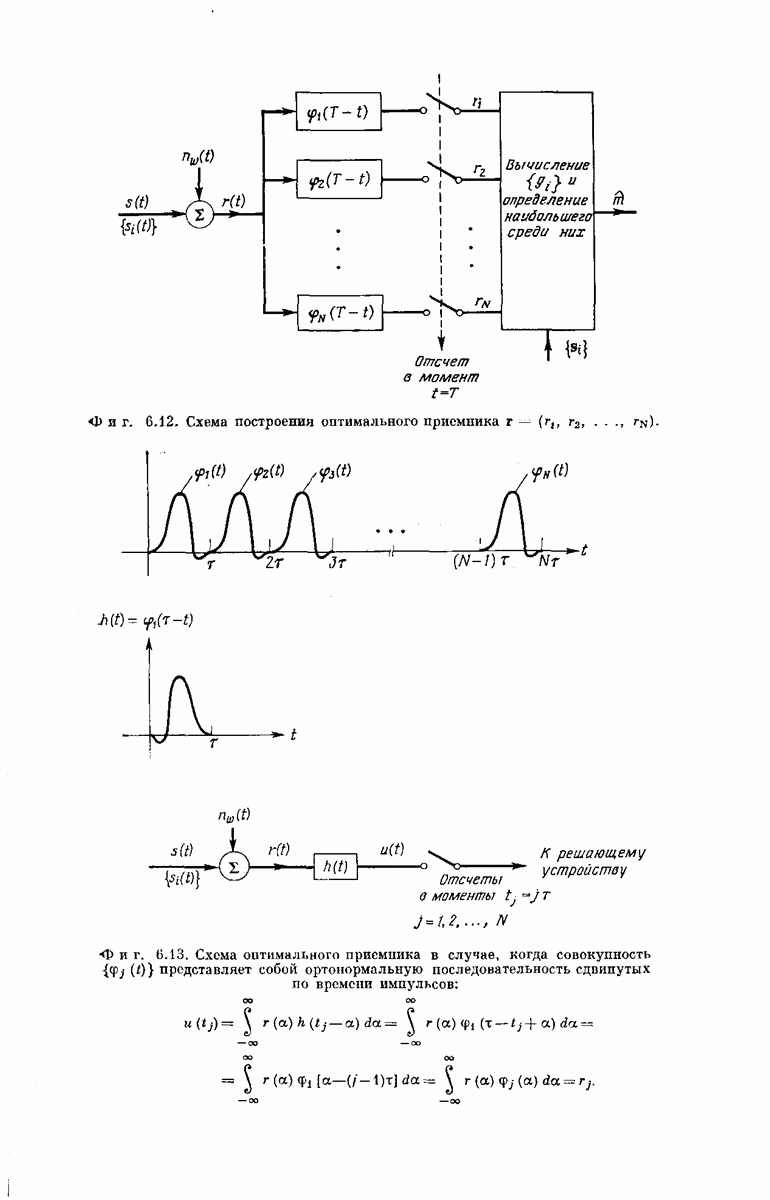


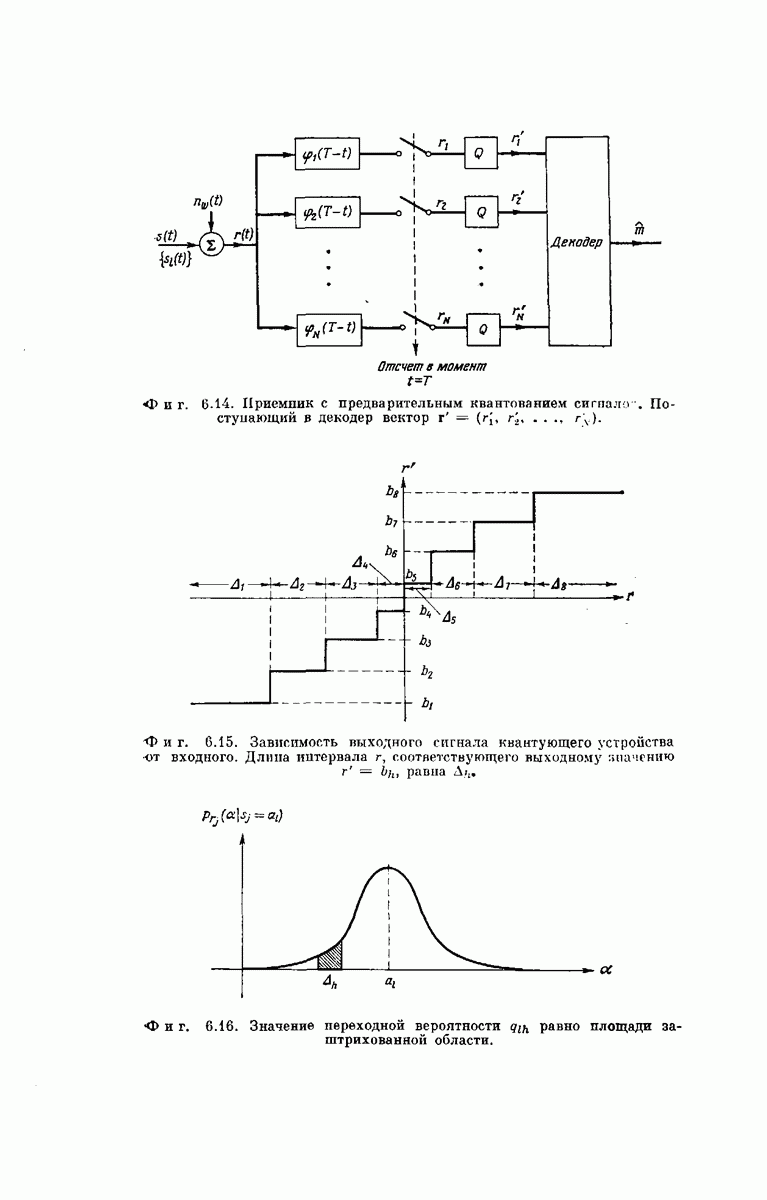






































































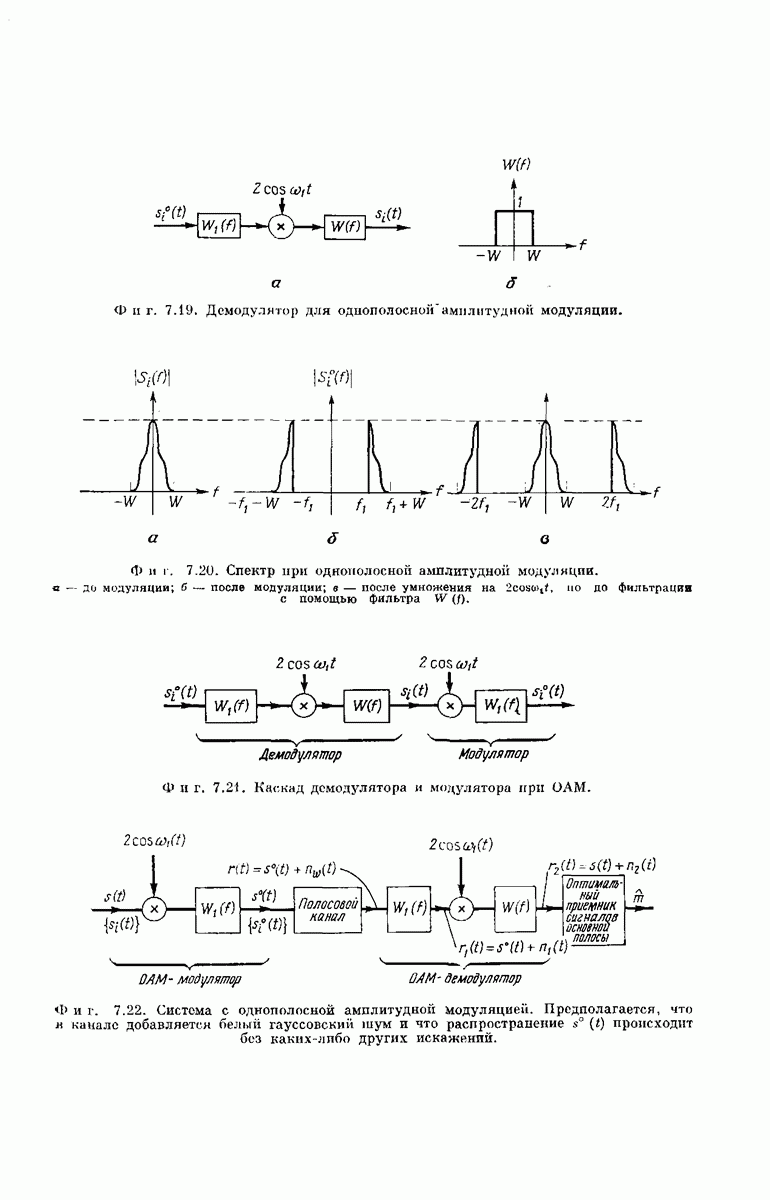










































































































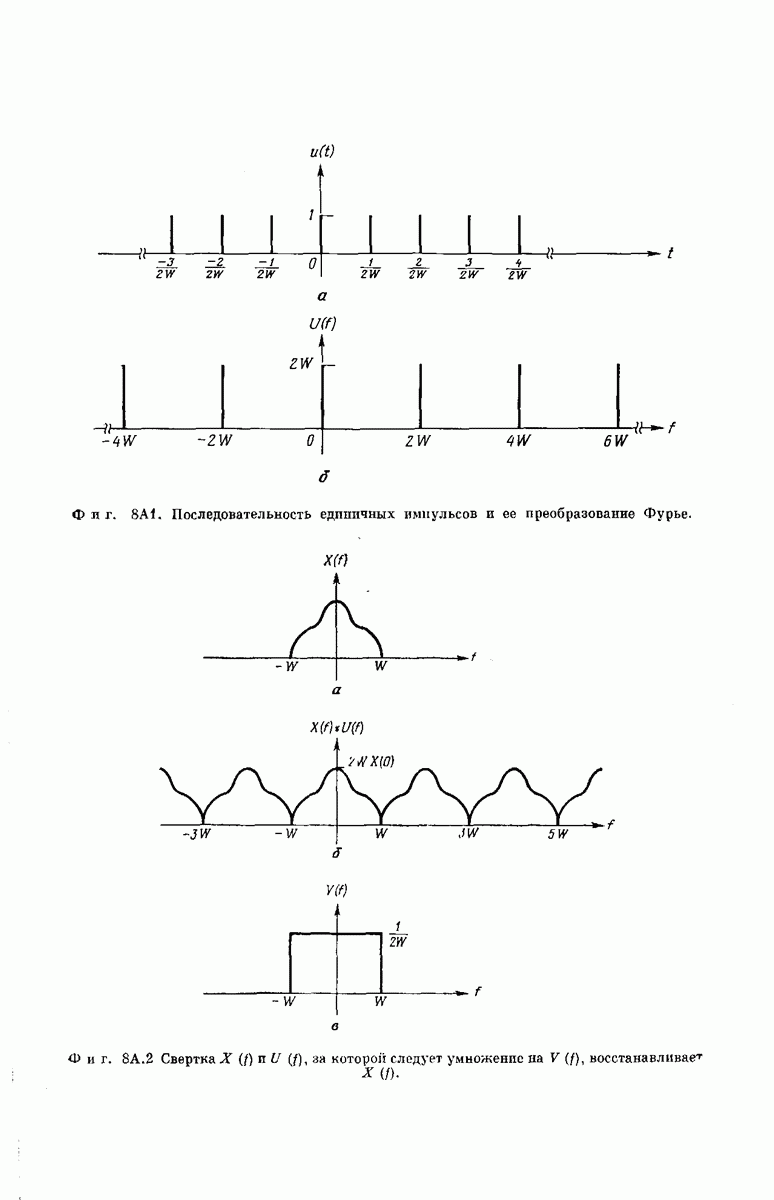

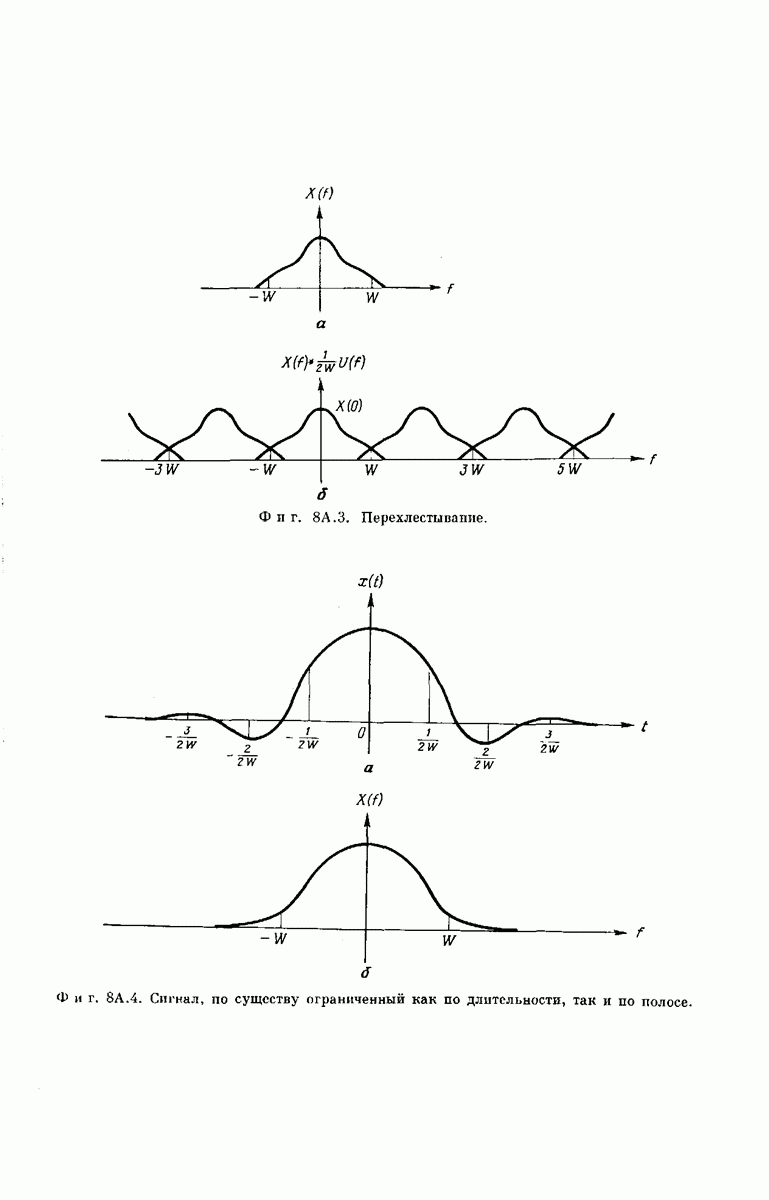






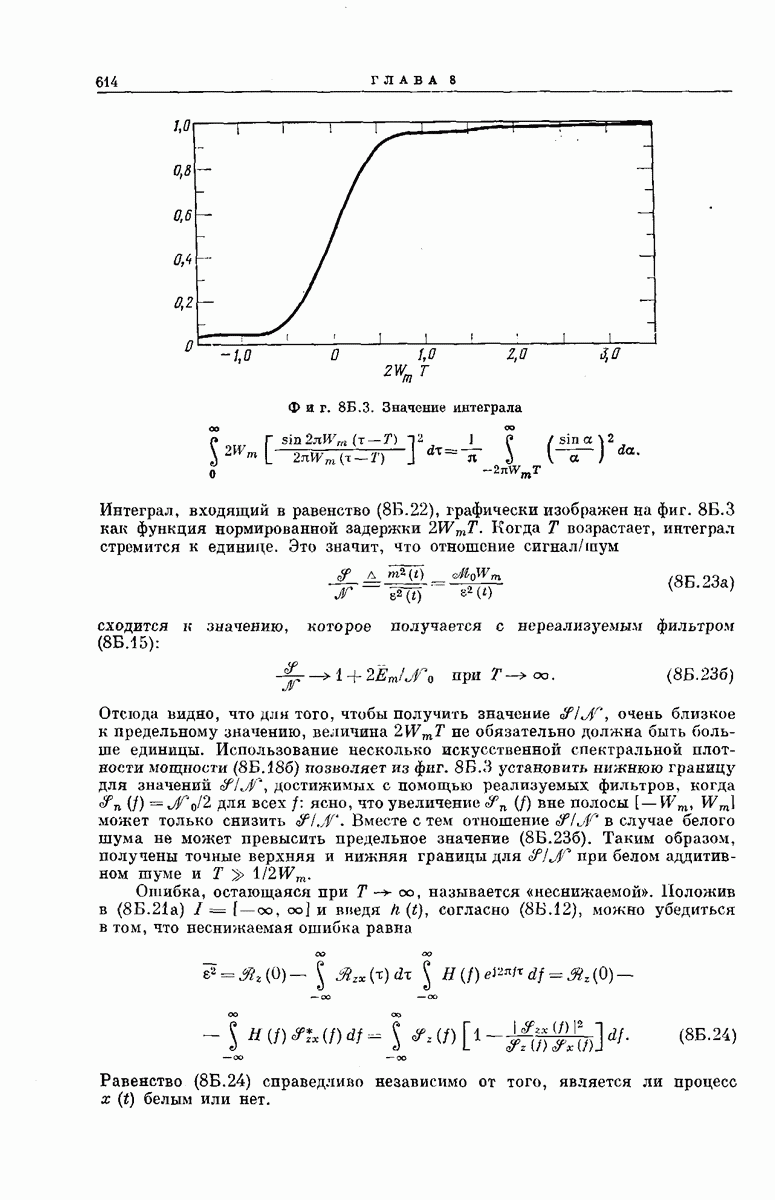




















 выходными буквами
выходными буквами  и переходными вероятностями
и переходными вероятностями 
 входных букв канала. Скорость передачи
входных букв канала. Скорость передачи  для дерева, в котором из каждого узла выходят и ребер и каждое ребро состоит из
для дерева, в котором из каждого узла выходят и ребер и каждое ребро состоит из  символов канала, равна
символов канала, равна

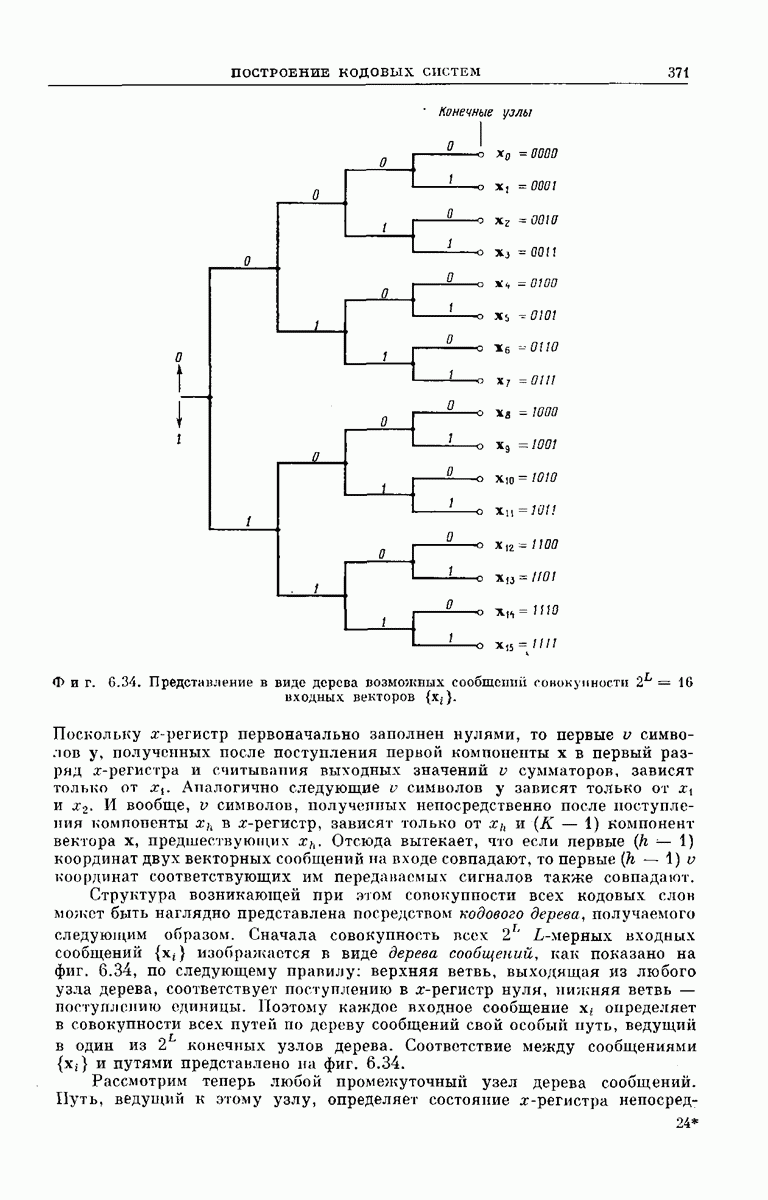
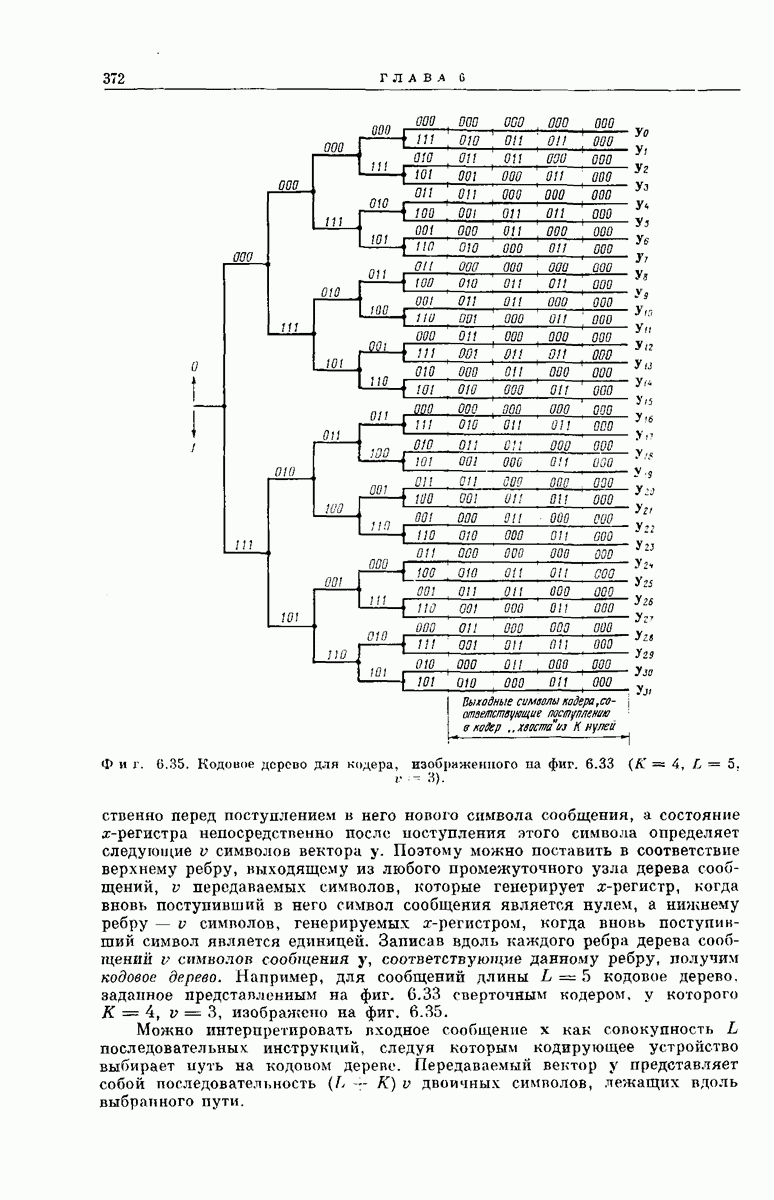
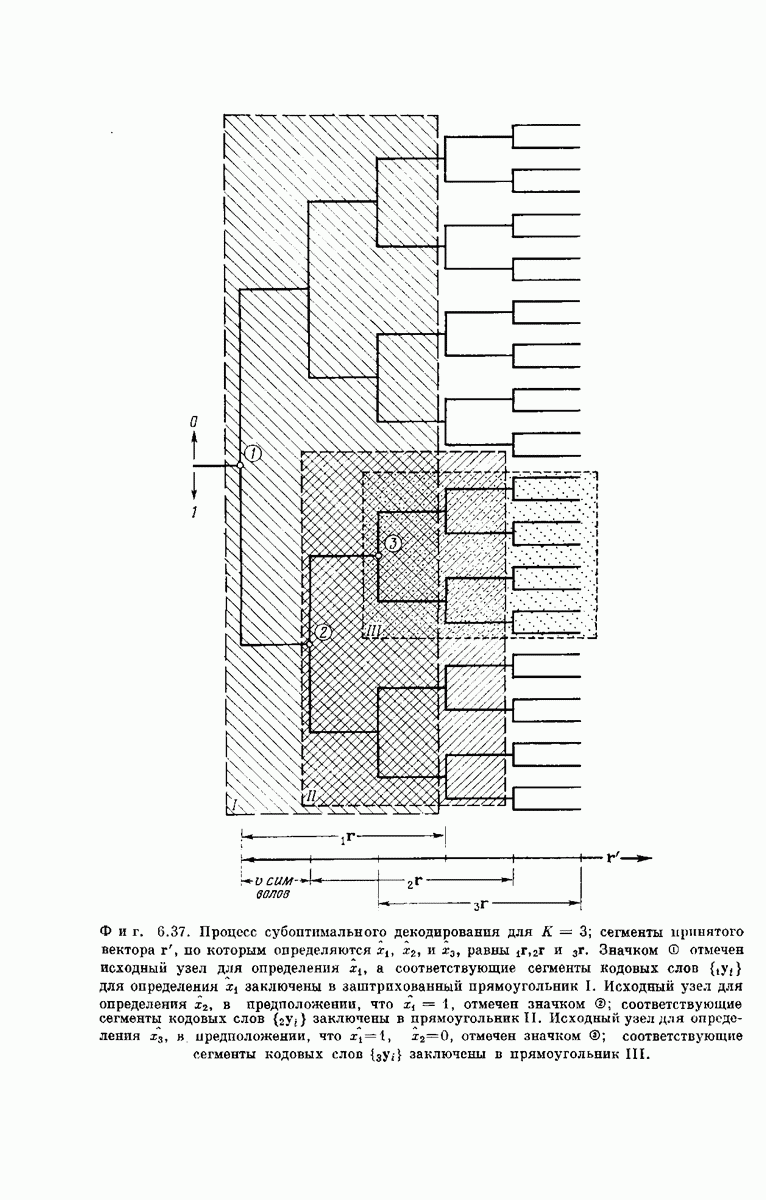
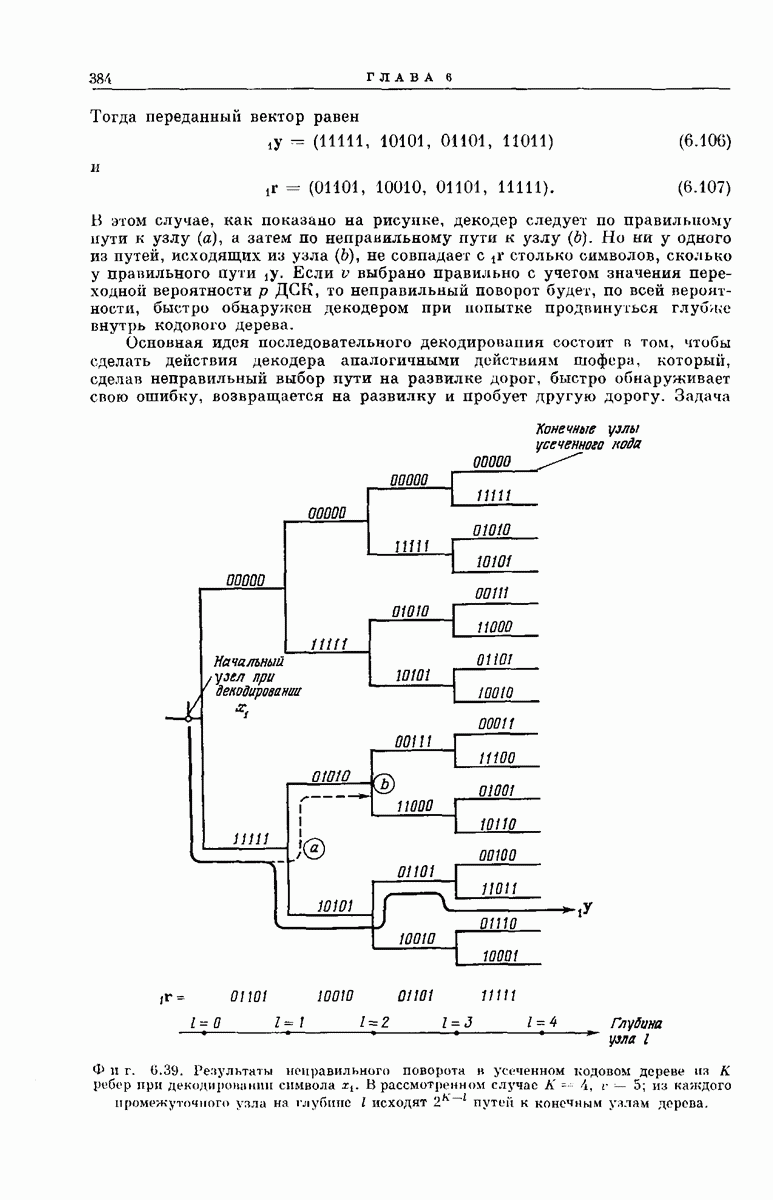
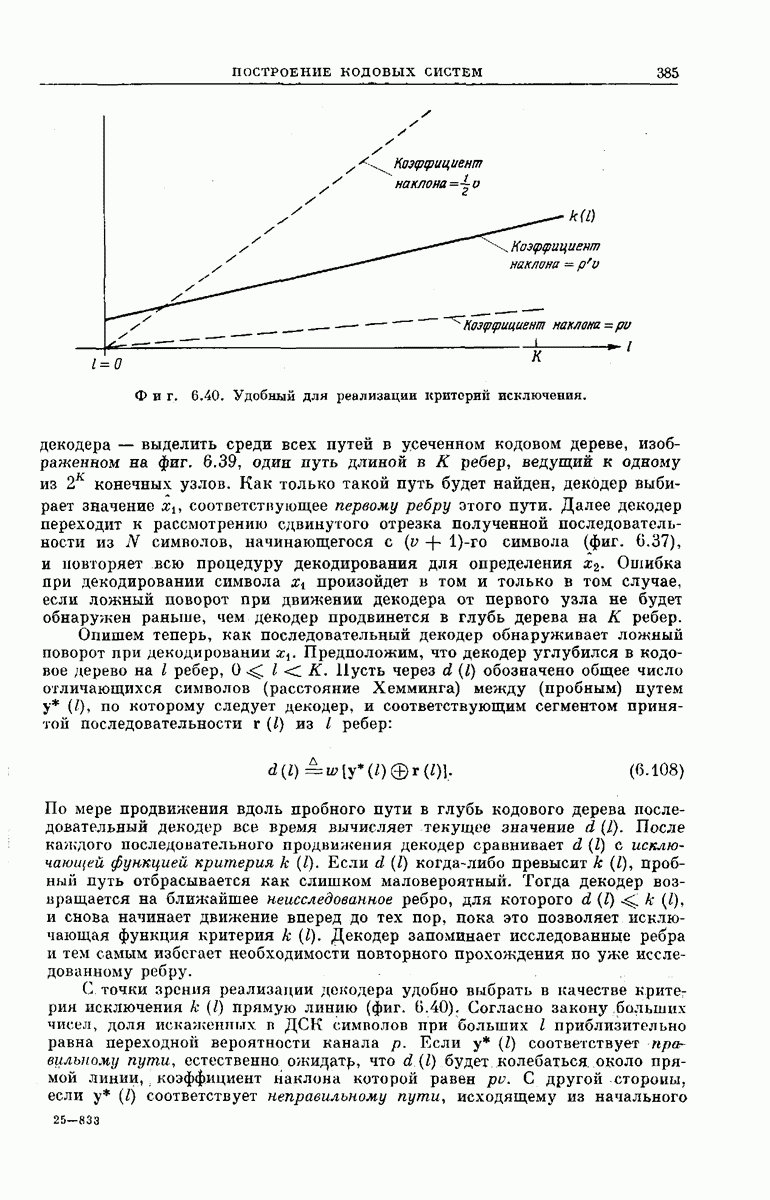
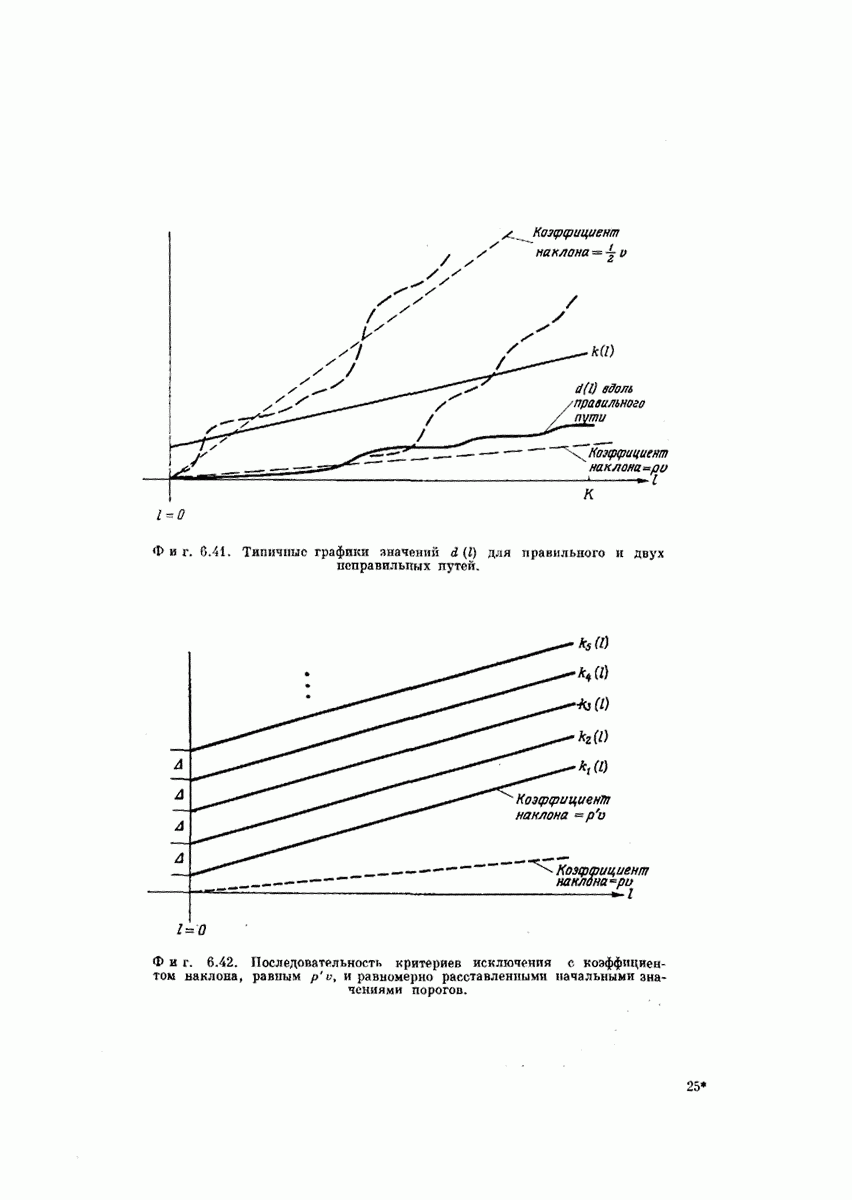
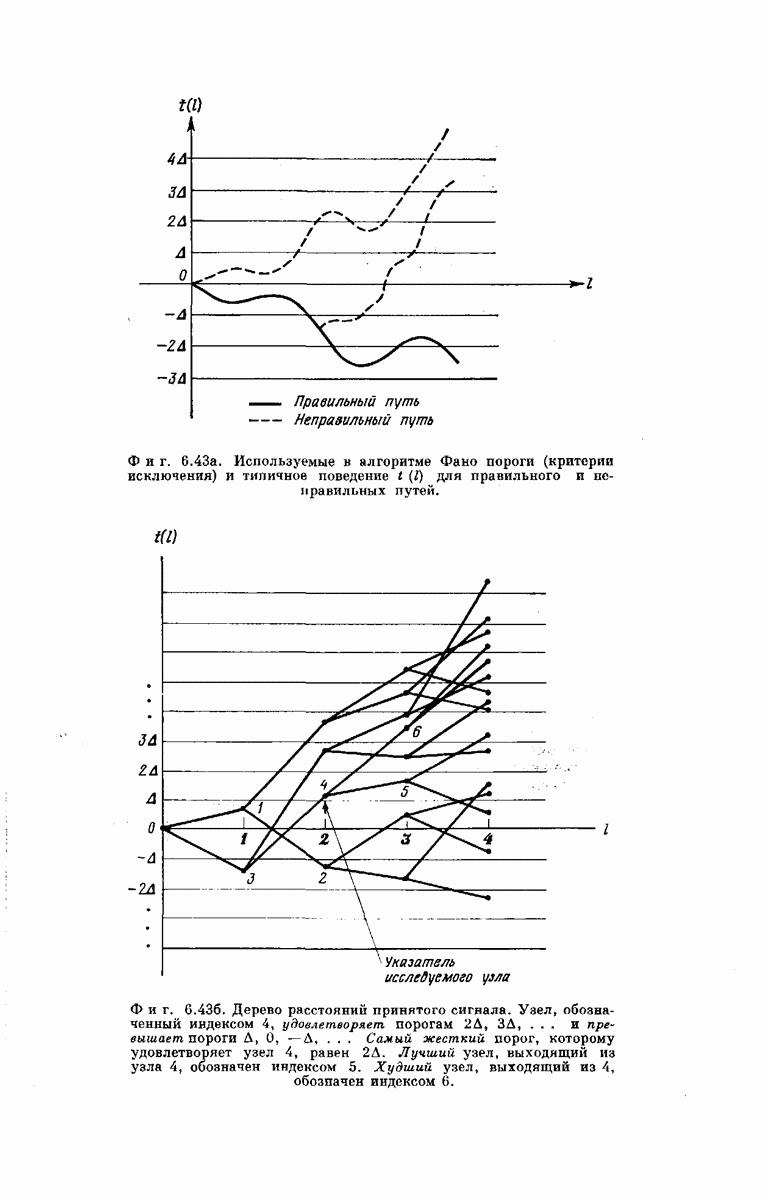
 Длина кодовых ограничений уже определялась выше как число ребер кодового дерева, зависящих от одного и того же символа на входе кодера. Примеры кодовых деревьев такого вида представлены на фиг.
Длина кодовых ограничений уже определялась выше как число ребер кодового дерева, зависящих от одного и того же символа на входе кодера. Примеры кодовых деревьев такого вида представлены на фиг. 
 символ гипотетической передаваемой последовательности, состоящей из
символ гипотетической передаваемой последовательности, состоящей из  входных символов канала, через
входных символов канала, через  и соответствующий символ на выходе канала через
и соответствующий символ на выходе канала через  заново определим (позднее мы убедимся в целесообразности этого) перекошенное расстояние
заново определим (позднее мы убедимся в целесообразности этого) перекошенное расстояние  формулой
формулой


 служит здесь нормирующим множителем; при
служит здесь нормирующим множителем; при  она определяется равенством
она определяется равенством
