Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
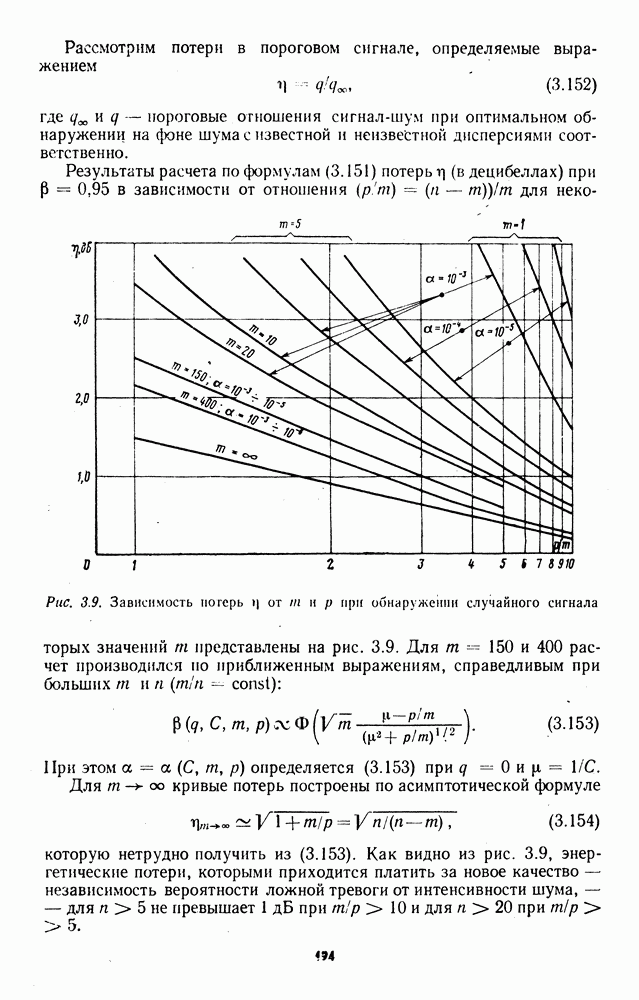
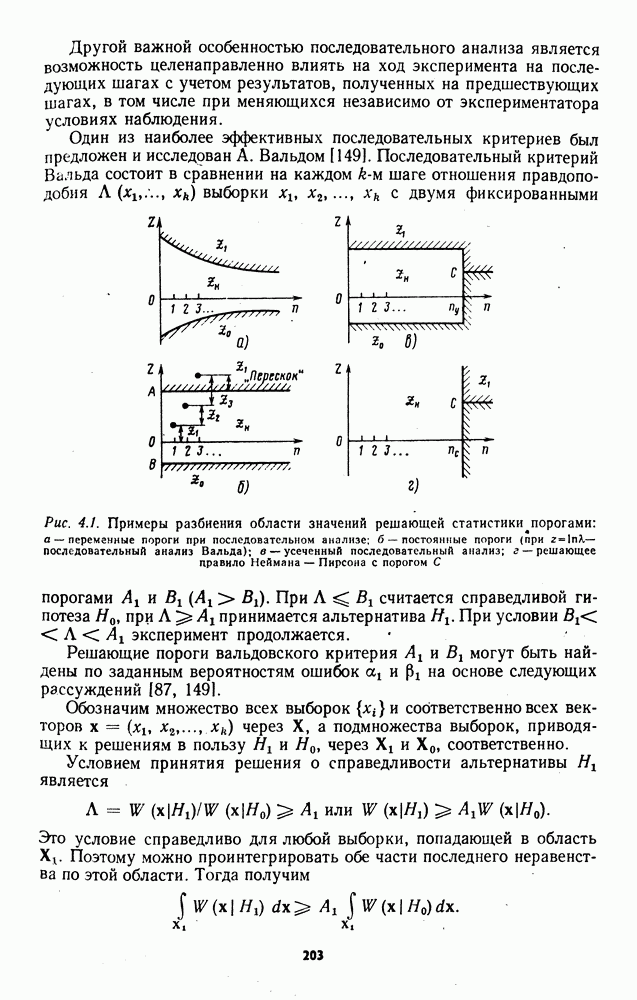
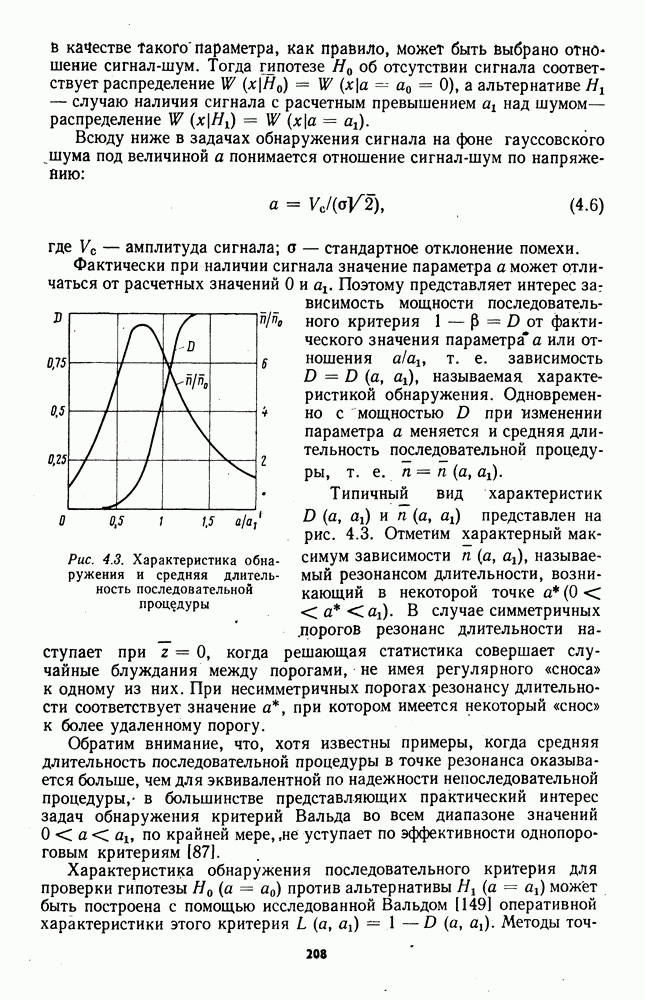
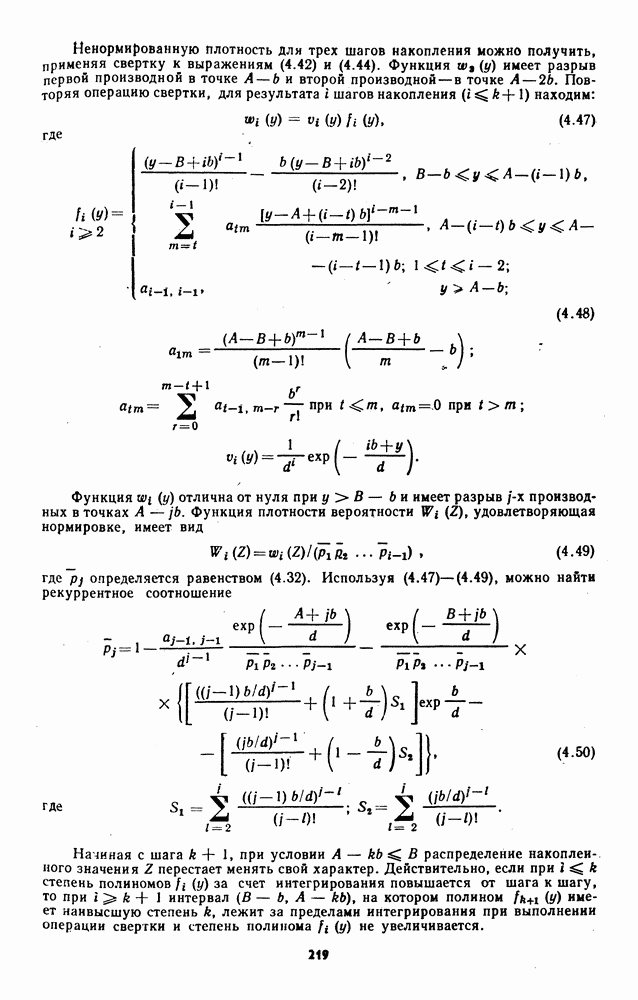
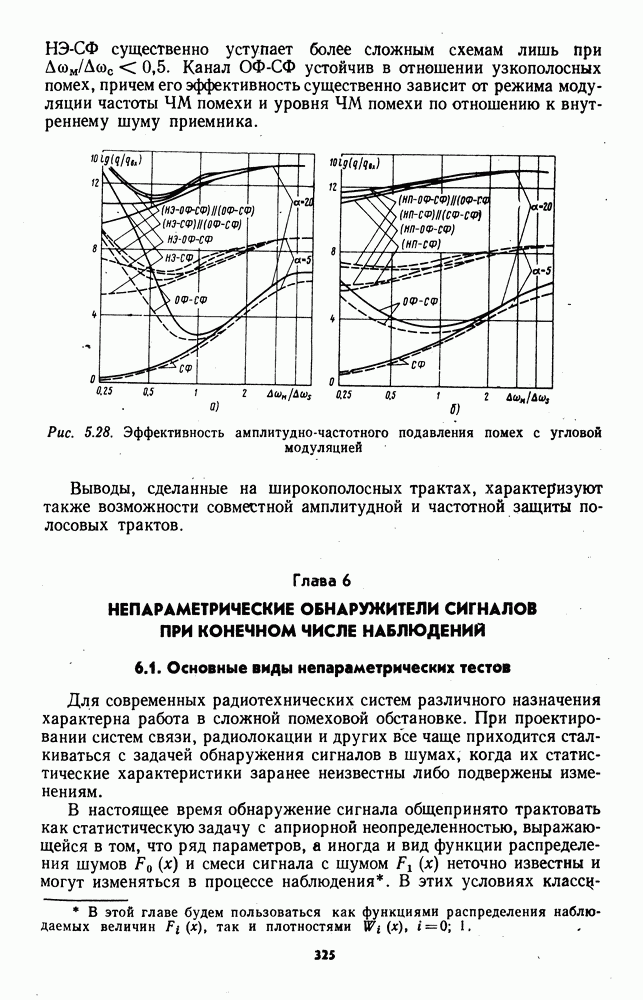
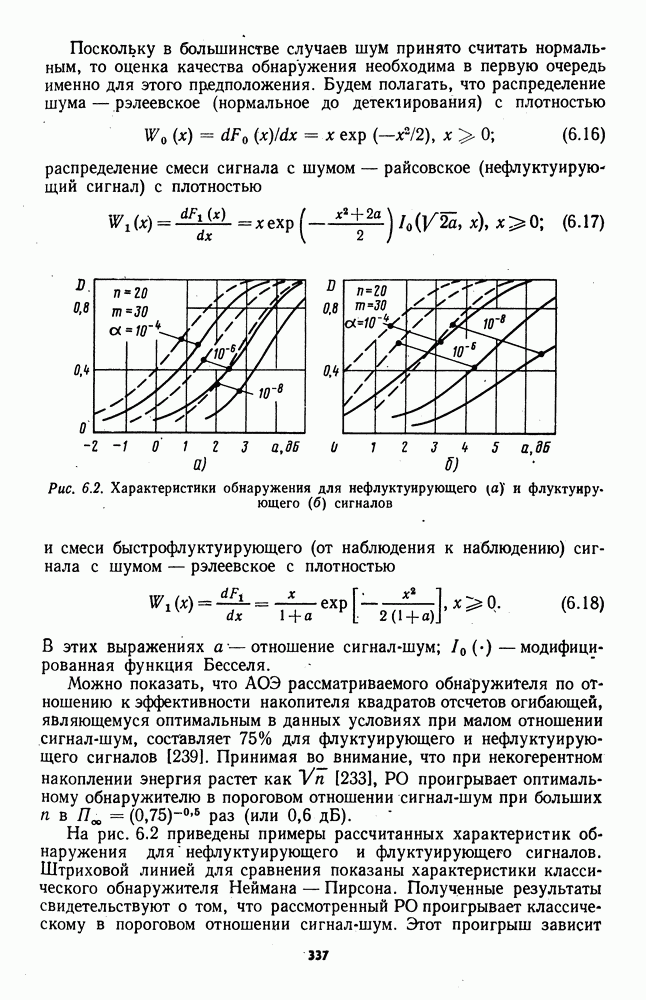
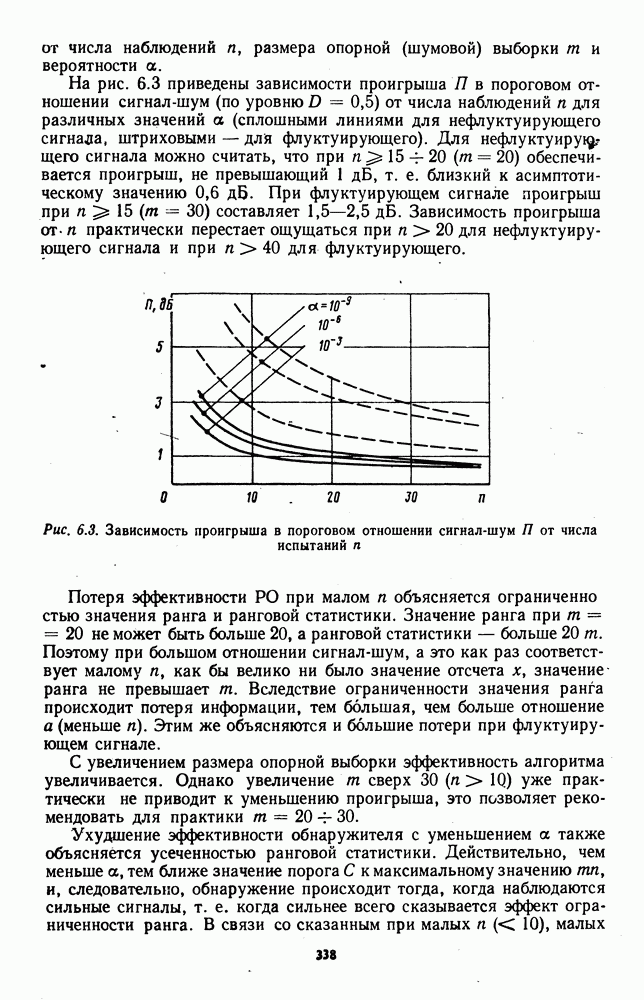
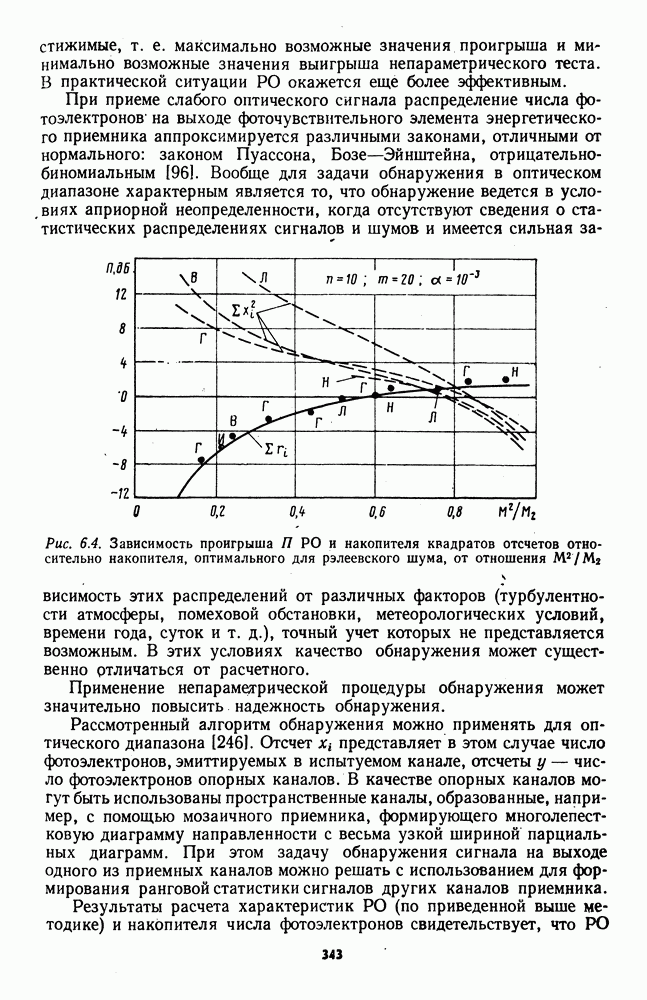
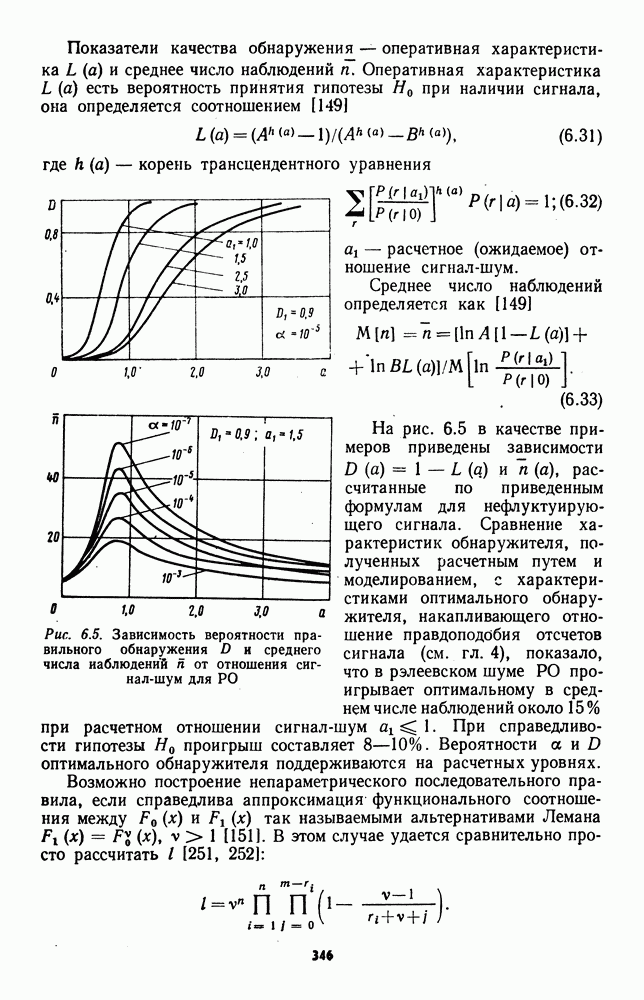
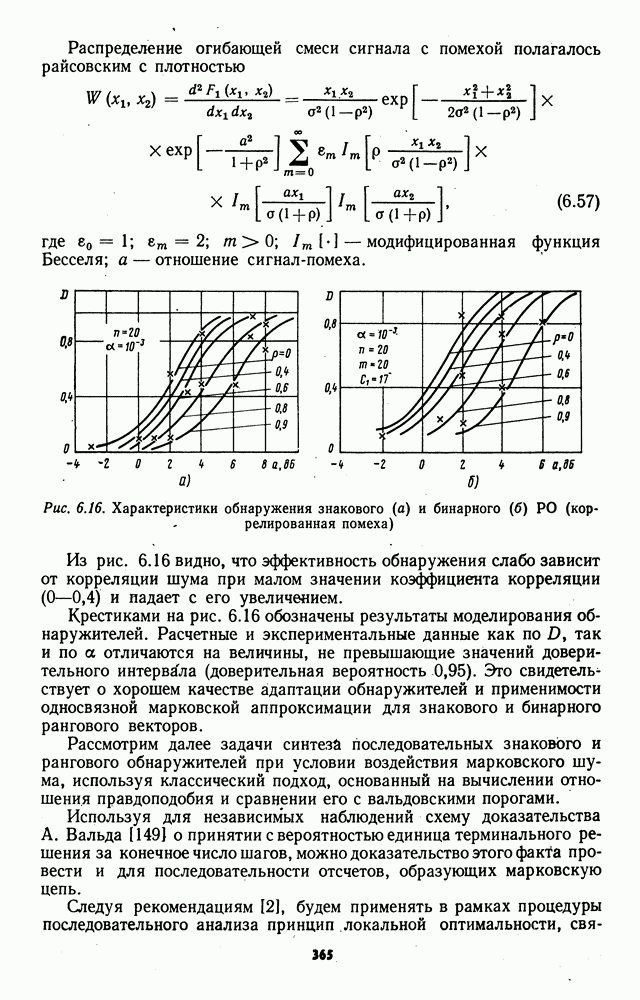
7.6. Влияние отклонений от принятых допущений на характеристики обнаружителейЗависимые выборки. Если шумовые элементы выборки образуют совокупность зависимых случайных величин с плотностью совместного распределения
соответствующем независимым выборкам, то рассмотренные ранговые и знаково-ранговые обнаружители теряют свои непараметрические свойства по следующим причинам: предельные распределения статистик обнаружителей могут отличаться от нормального ввиду несоблюдения в общем случае условий применимости центральной предельной теоремы; параметры предельного нормального распределения при соблюдении условий применимости центральной предельной теоремы для зависимых случайных величин в значительной мере определяются характером и степенью статистической зависимости между элементами выборки. В некоторых специальных случаях статистической зависимости, когда выборка может быть разбита на ряд независимых множеств, непараметрические обнаружители все же могут быть построены. Так, рассмотренный в § 7.4 обнаружитель на перемешанных статистиках, действующий по выборке (7.76), сохранит непараметрические свойства, если между элементами
где Вывод формулы (7.102) основан на непосредственном вычислении среднего значения и дисперсии промежуточных статистик. Нетрудно видеть, что В [1] рассматривалось применение знакового и знаково-рангового алгоритмов для обнаружения постоянного сигнала на фоне коррелированного шума, значения которого образуют случайную стационарную последовательность авторегрессии первого порядка. Полученные в этой работе результаты дают возможность количественно оценивать эффективность обнаружителей, которые, к сожалению, теряют свои непараметрические свойства в силу второй из вышеназванных причин. Нестационарность шума.Если значения слагаемых шума в элементах выборки (7.4) независимы и соответствуют нестационарному процессу, то следует поло жить
где плотности распределения элементов, вообще говоря, не равны друг другу, т. е. Плотность (7.103), в отличие от плотности (7.101), не является в общем случае инвариантной относительно перестановок аргументов. Отсутствие инвариантности означает, что вероятности появления возможных реализаций рангового вектора при отсутствии сигнала не равны друг другу. Отсюда сразу следует вывод о потере непараметрических свойств ранговыми и знаково-ранговыми обнаружителями при нестационарном шуме. Исключение составляет знаковый обнаружитель, сохраняющий непараметрические свойства при плотности (7.103), если плотности элементов удовлетворяют условию
Этому условию удовлетворяют все распределения с нулевой медианой и, в частности, симметричные относительно нуля распределения. Асимметрия плотности шума.Если плотность шума асимметрична относительно нуля, то условию инвариантности к перестановкам не удовлетворяет плотность совместного распределения абсолютных значений наблюдений при отсутствии сигнала; эта плотность имеет форму, подобную (7.103). Отсюда следует вывод об утрате непараметрических свойств знаково-ранговым обнаружителем при асимметричных относительно нуля распределениях. Конечно, при асимметричных плотностях сохраняются непараметрические свойства ранговбго обнаружителя, а при нулевой медиане — также и знакового. Разрывные плотности распределения шума.В соответствии с введенным в § 7.1 определением принадлежность плотности действующей помехи W непараметрическому классу Если плотность распределения описывается функцией, обращающейся в бесконечность хотя бы в одной из точек разрыва, то эта плотность называется разрывной, а соответствующее ей количество информации Фишера Разрывные плотности можно приближенно аппроксимировать последовательностью непрерывных функций Используя результаты п. 7.3.4, можно убедиться, что значения асимптотической мощности Рост асимптотической мощности при приближении плотности действующего шума к разрывной функции позволяет сделать вывод о возможности построения сингулярных правил принятия решения при разрывных плотностях, позволяющих безошибочно обнаруживать сколь угодно слабый ненулевой сигнал. Примеры подобных плотностей легко привести. Так, для шума, который с вероятностями
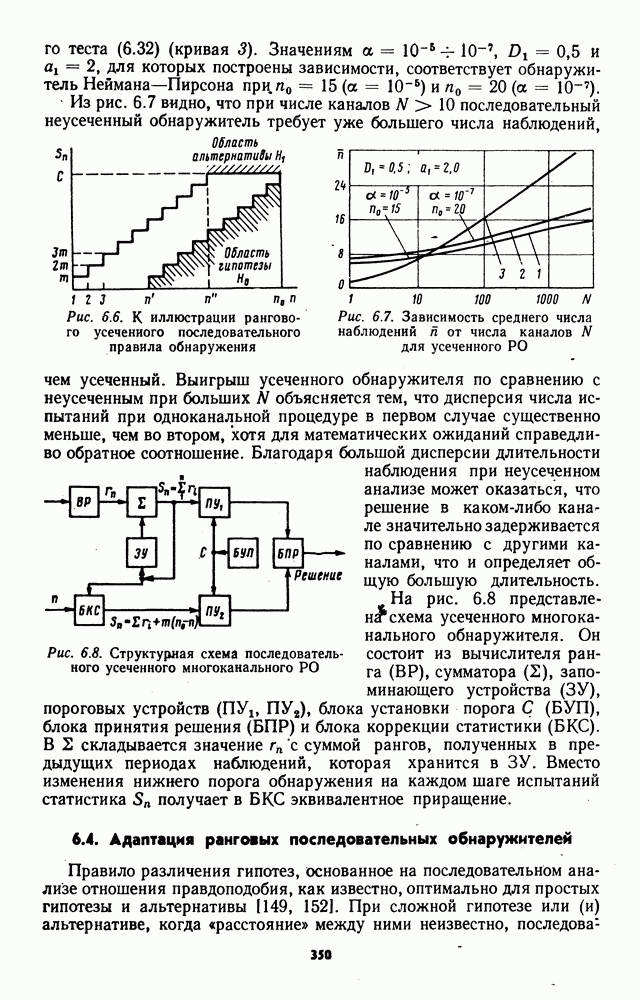
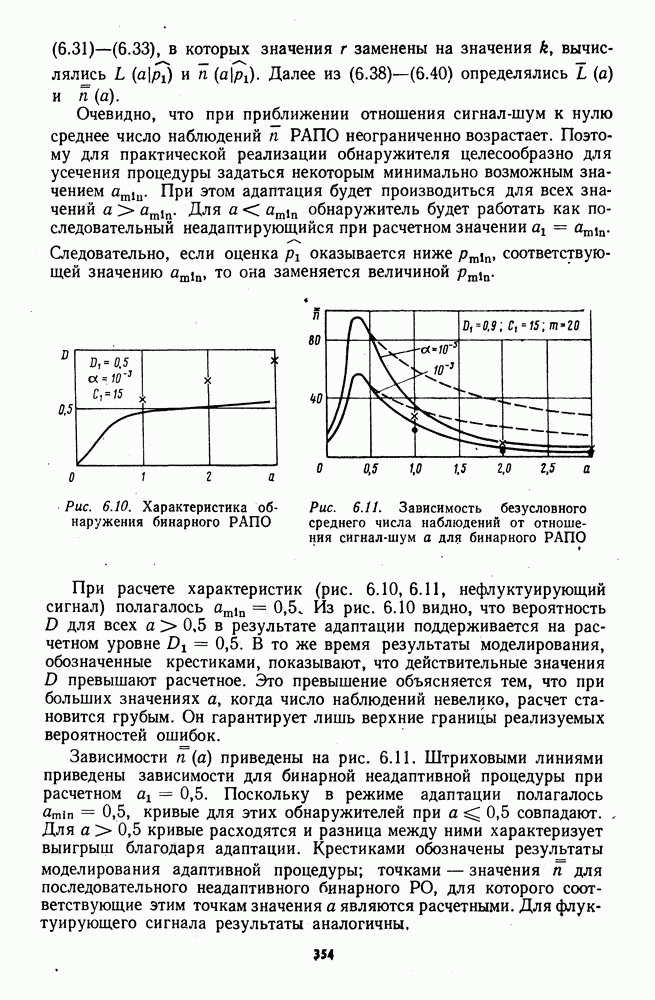
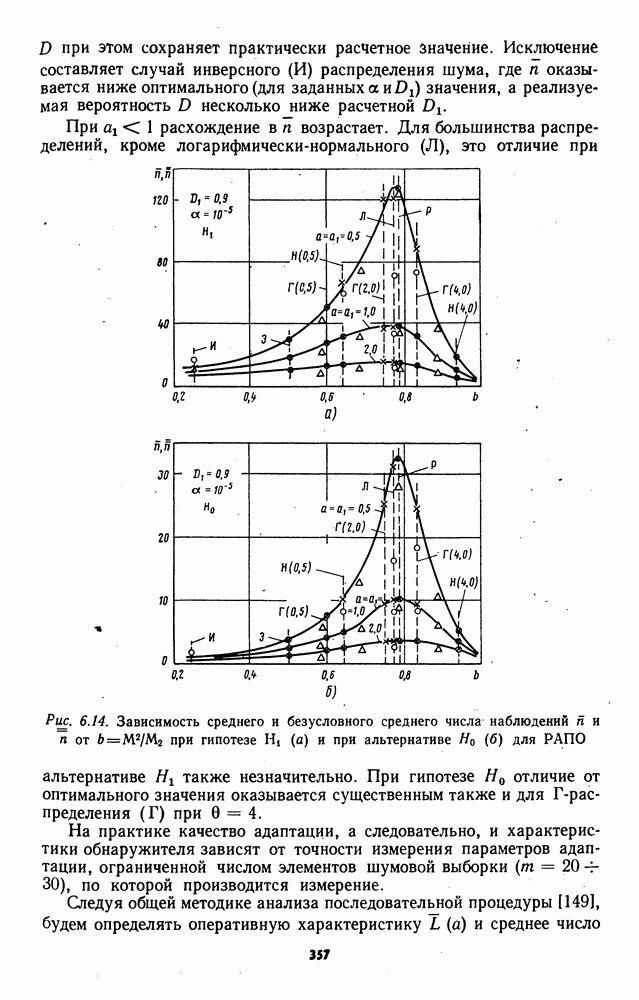
может быть построено сингулярное решающее правило, основанное на сравнении значений элементов выборки (7.4) с возможными значениями шума Выполнение условий В реальных системах передачи информации разрывные плотности помех практически не встречаются в силу ряда причин, среди которых в первую очередь следует отметить непременное наличие собственных шумов приемных устройств. Поэтому принятое в § 7.1 условие (7.5) практически всегда выполняется и, кроме того, оказывается полезным при теоретическом анализе для преодоления трудностей, связанных с появлением сингулярности. Нули и совпадения выборочных значений.При теоретическом анализе не учитывались возможности появления нулевых или совпадающих элементов выборки, поскольку вероятности их появления равны нулю в силг абсолютной непрерывности плотностей из класса Появление нулей и совпадений связано с некоторой дополнительной потерей информации при формировании выборки и поэтому приводит в общем случае к снижению эффективности обнаружителей. Степень этого снижения будет зависеть от принятого алгоритма обработки нулей и совпадений. Поэтому задание конкретного способа обработки нулей и совпадений является важным для практики, поскольку от выбора этого способа зависят непараметрические свойства, уровень фиксации ложных тревог и вероятность обнаружения сигнала. Известны рандомизированные и нерандомизированные процедуры обработки нулей и совпадений. При использовании рандомизированных процедур знаки нулевым наблюдениям и ранги совпавшим элементам присваиваются на основе результатов дополнительного статистического эксперимента, не связанного с наблюдаемым процессом; нерандомизированные процедуры предполагают использование жестких правил обработки нулей и совпадений без использования дополнительных статистических экспериментов. В статистической литературе рассмотрен ряд процедур обработки нулей и совпадений; здесь мы ограничимся описанием некоторых из известных процедур, применение которых представляется наиболее приемлемым в практически реализуемых устройствах обнаружения сигналов. Сокращение объема выборки.В знаковых алгоритмах обработка нулей может быть основана на сокращении объема выборки за счет исключения нулевых элементов. Для практической реализации этого принципа достаточно при вычислении знаковых статистик положить Сокращение объема выборки ведет к некоторой потере мощности, которая может еще увеличиться за счет снижения вероятности ложной тревоги относительно заданного уровня, если коррекция порога при исключении нулевых наблюдений не производится. Д. Путтер в [274] проводит сравнение мощности нерандомизированного знакового критерия, использующего исключение нулей из выборки, с мощностью рандомизированного критерия, основанного на случайном присвоении нулевым наблюдениям знаков плюс или минус с вероятностью 1/2, в задаче обнаружения постоянного положительного сдвига при симметричном распределении шума. В этой работе показано, что мощность нерандомизированного критерия равна или больше мощности рандомизированного, а асимптотическая относительная эффективность нерандомизированного критерия по сравнению с рандомизированным всегда больше единицы, если имеют место нулевые наблюдения. Средние ранги.Определим средний ранг элементов группы с одинаковыми значениями как среднее арифметическое значение рангов, которые имели бы эти элементы при отличии их значений друг от друга и сохранении отношений типа строгих неравенств с элементами выборки, не входящими в группу. Очевидно, что при наличии в группе только одного элемента его средний ранг совпадает с рангом в обычном определении. Средние ранги
где Распространенный способ обработки совпадений при вычислении ранговых и знаково-ранговых статистик состоит в присвоении средних рангов совпавшим элементам. Такое присвоение будет обеспечиваться автоматически, если при ранжировке всех элементов выборки использовать алгоритм (7.104). Для практических целей этот алгоритм удобнее представить в форме
выражающей средние ранги непосредственно через значения элементов выборки, при этом функцию единичного скачка следует определить соотношениями: Можно ожидать, что во многих практически важных случаях процедуры, использующие средние ранги, будут эффективнее процедур, основанных на сокращении объема выборки. Исключение совпавших ненулевых элементов при вычислении ранговых статистик может повлечь чрезмерное снижение вероятности обнаружения, так как в отброшенных элементах, имеющих большую величину, велика вероятность наличия сигналов. Сравнение нерандомизированной процедуры обработки совпадений, использующей средние ранги, с рандомизированной процедурой присвоения рангов совпавшим элементам, выполненное в [274] для обнаружителя Манна—Уитни, показывает, что асимптотическая относительная эффективность нерандомизированного правила по отношению к рандомизированному при наличии совпадений оказывается больше единицы. Влияние нулей и совпадений на свойства обнаружителя Вилкоксона рассмотрено в работе Д. Пратта [275]. Применение рандомизации, усредненных статистик и других методов обработки совпадений рассмотрены в [107, 276, 277 и др.] Выборки конечного объема.Результаты синтеза структуры асимптотически оптимальных обнаружителей и оценки их эффективности в различных условиях функционирования справедливы асимптотически при неограниченном возрастании объема выборки и стремлении к нулю величины сигнала. В практически реализуемых системах объем выборки всегда ограничен, а интенсивность сигнала, при которой достигаются заданные показатели качества обнаружения, превосходит определенный фиксированный уровень. Можно ожидать, что асимптотически оптимальные структуры будут близки к оптимальным и при конечном объеме выборки, если этот объем велик При малом объеме выборки (n — несколько единиц) достигнуть заданное качество обнаружения обычно оказывается возможным лишь при сильных сигналах В соответствии с фундаментальной леммой Неймана—Пирсона структура оптимального алгоритма обнаружения сигнала при конечном объеме выборки определяется однозначно (в отличие от асимптотически оптимальных алгоритмов) как процедура сравнения с порогом отношения правдоподобия наблюдаемой выборки. Отношение правдоподобия определяется статистическими характеристиками значений наблюдаемого процесса, информация о которых частично утрачивается при редукции данных до знаков и рангов. Следовательно, в общем случае в силу однозначности оптимального решающего правила при выборках ограниченного объема невозможно построение оптимального обнаружителя, использующего только знаки и ранги элементов наблюдаемой выборки. Однако та же лемма Неймана—Пирсона позволяет в принципе строить решающие правила, наилучшие в классах ранговых или знаково-ранговых алгоритмов. Построение таких правил требует выполнения сложных и громоздких расчетов, основанных на использовании распределений ранговых или знаковоранговых статистик при гипотезах и альтернативах [107]. Следует ожидать, что преодоление вычислительных трудностей даст в этом случае громоздкие решающие алгоритмы, техническая реализация которых окажется весьма затруднительной. Поэтому на практике описанный метод синтеза непараметрических алгоритмов не получил распространения, и при выборках ограниченного объема используются асимптотически оптимальные алгоритмы или алгоритмы с простыми статистиками, структура которых устанавливается на эвристической основе с учетом удобства технической реализации. Для оценки эффективности непараметрических алгоритмов при выборках малого объема широко используется математическое моделирование на вычислительных машинах. Для аналитической оценки эффективности обнаружителей при выборках малого объема можно использовать определения относительной эффективности, не требующие контигуальности гипотезы и альтернативы [133, 278]. Многочисленные публикации, содержащие исследования непараметрических обнаружителей с конкретными структурами, показывают, что при малых объемах выборок эффективность обнаружителей может значительно отличаться от асимптотических значений; сравнительная оценка эффективности обнаружителей свидетельствует о том, что лучшими обычно при малом объеме выборки оказываются те обнаружители, которые лучше и асимптотически. Подробный анализ структуры и свойств ряда непараметрических алгоритмов при выборках конечного объема содержится в гл. 6. Усложнение моделей регрессии.При синтезе асимптотически оптимальных непараметрических алгоритмов предполагалось, что альтернатива отличается от гипотезы наличием регрессии в сдвиге. Это предположение соответствует аддитивному взаимодействию сигнала и помехи, которое наиболее часто имеет место в реальной обстановке. Тем не менее на практике возможно возникновение ситуаций, в которых взаимодействие сигнала и помехи принимает другие формы. В частности, действие мультипликативной помехи соответствует появлению регрессии в масштабном коэффициенте; использование амплитудных и фазовых детекторов, а также других устройств нелинейной обработки наблюдаемого процесса для формирования промежуточных статистик может вызывать регрессию не только в сдвиге и масштабном коэффициенте, но и в форме плотности распределения. Поэтому для практики представляет интерес исследование возможностей построения непараметрических алгоритмов для сложных моделей регрессии, не сводящихся к регрессии в сдвиге распределения при действии сигнала. В книге Я. Гаека и 3. Шидака [107] содержится исследование асимптотически оптимальных критериев для альтернатив с регрессией в масштабе распределения. Другие сложные модели регрессии рассматривались в работах Д. М. Чибисова [279], А. Ф. Кушнира [280] и Б. Р. Левина [1].
|
 |
Оглавление
|





































































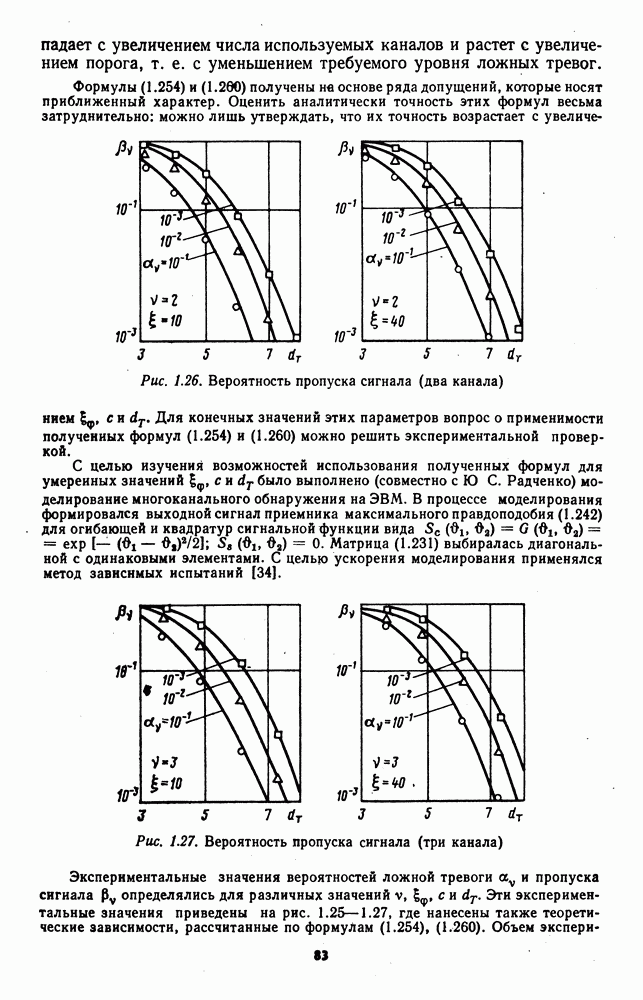























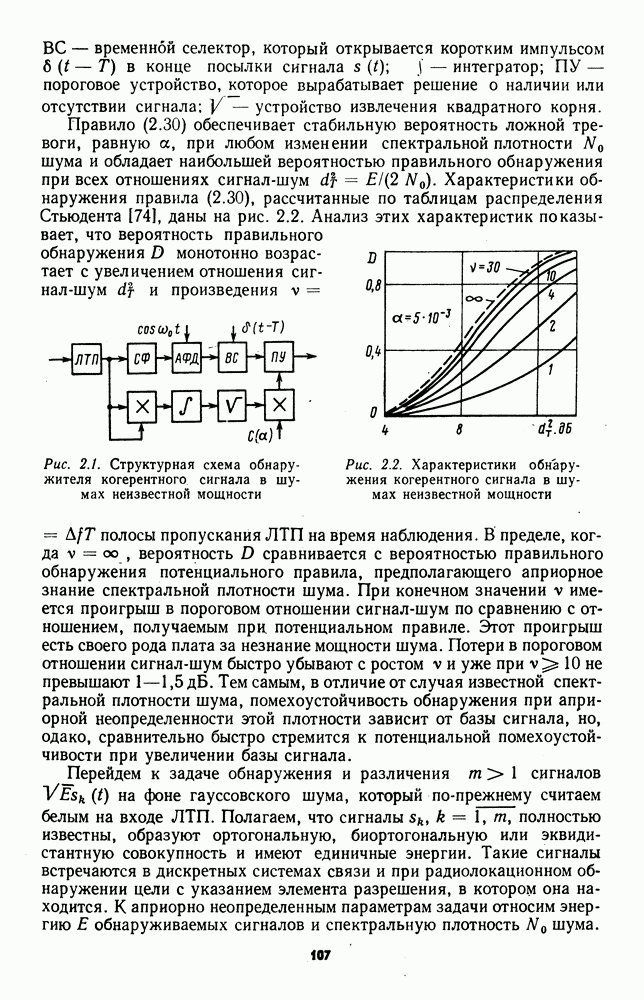



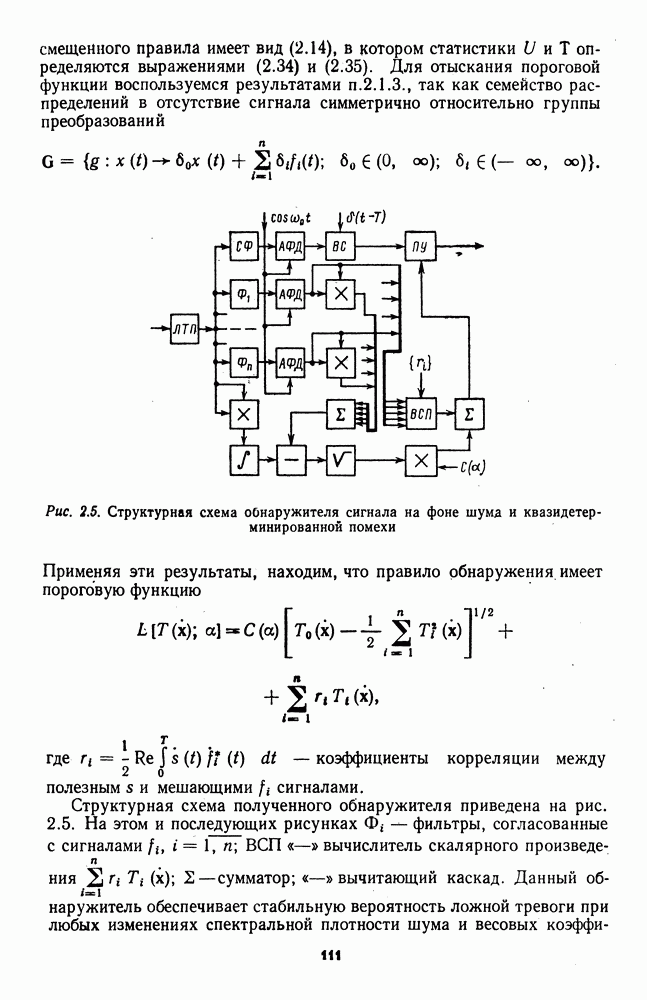



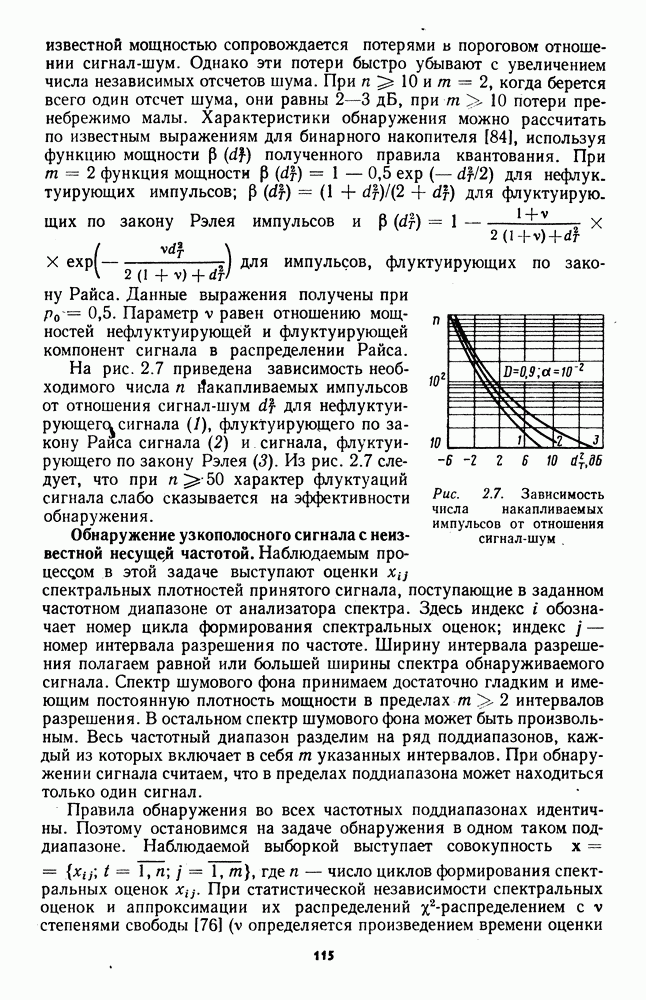











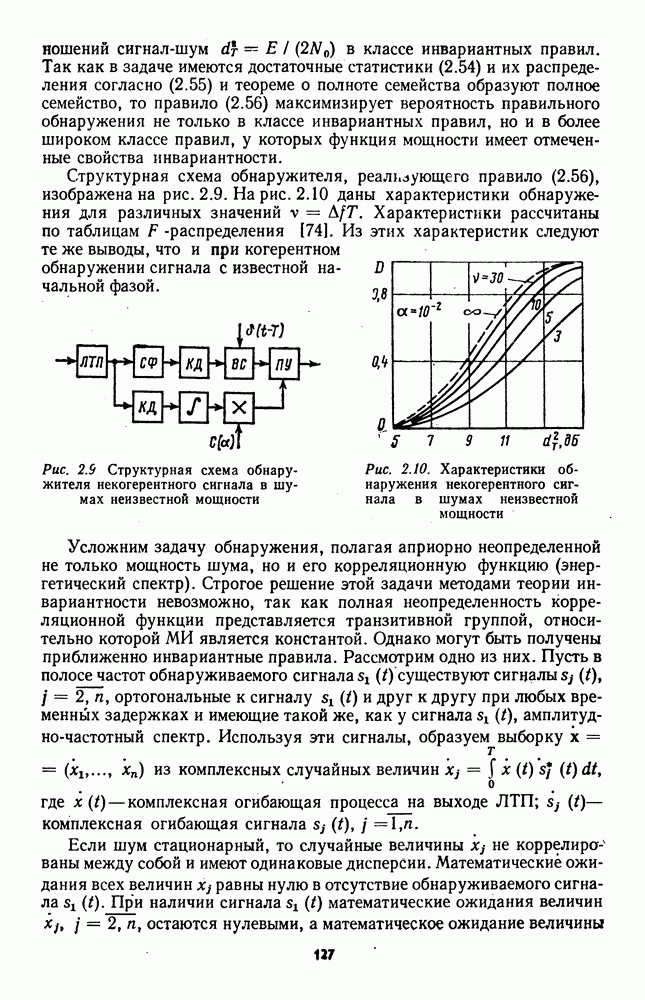

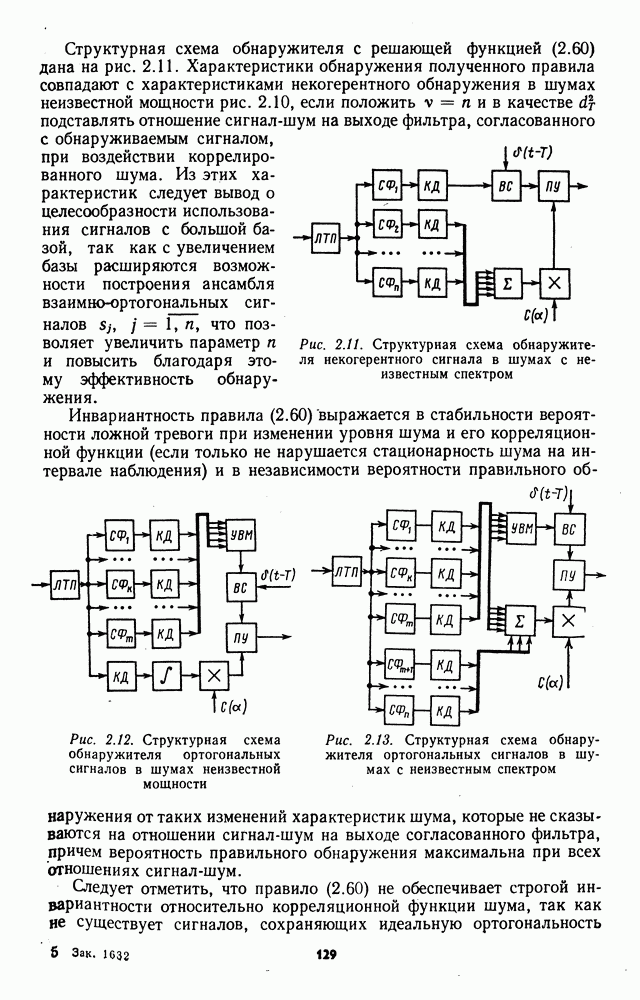





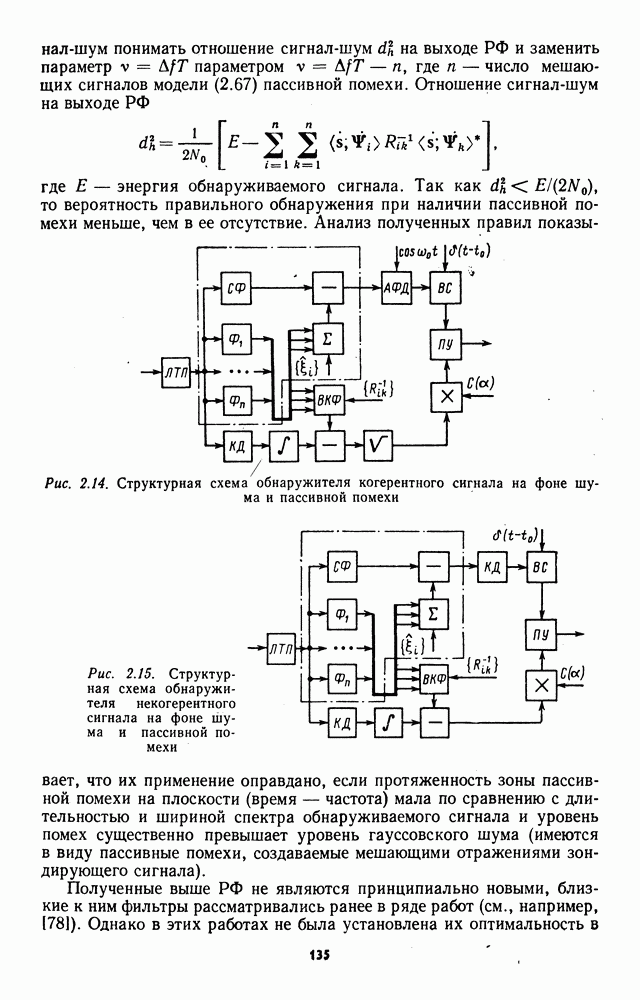

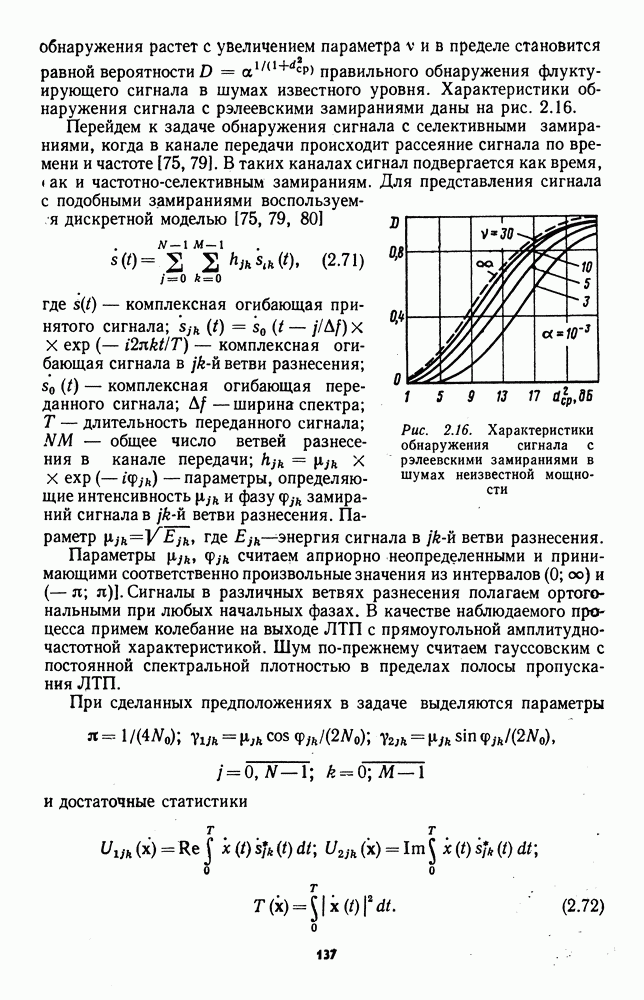


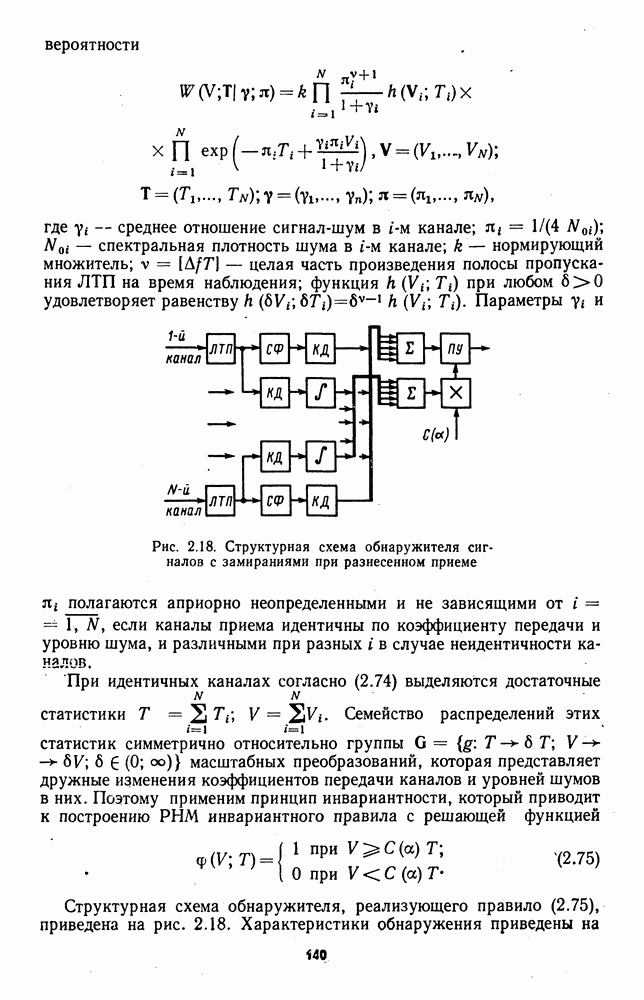
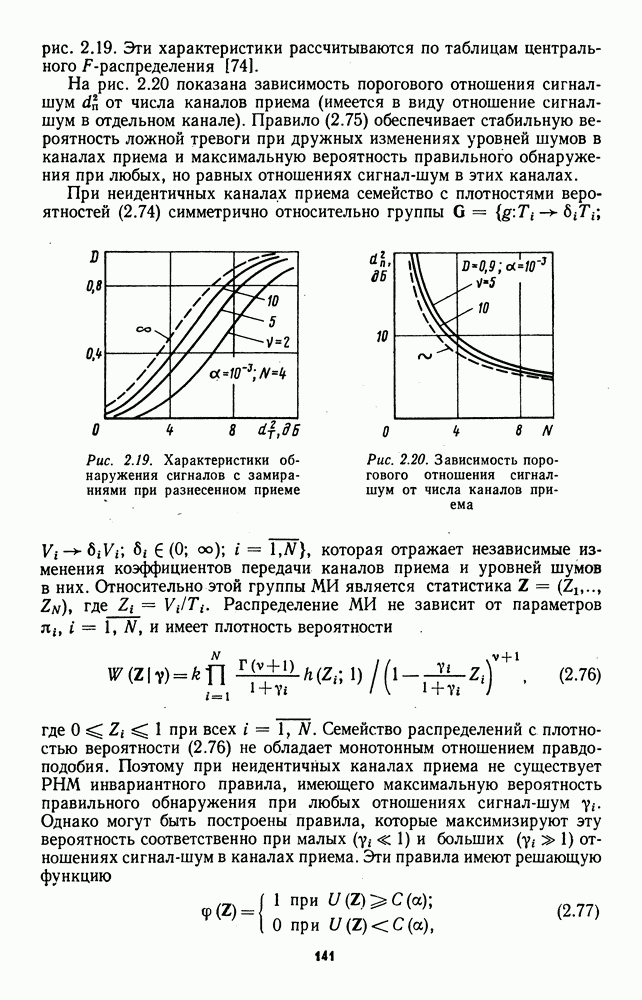











































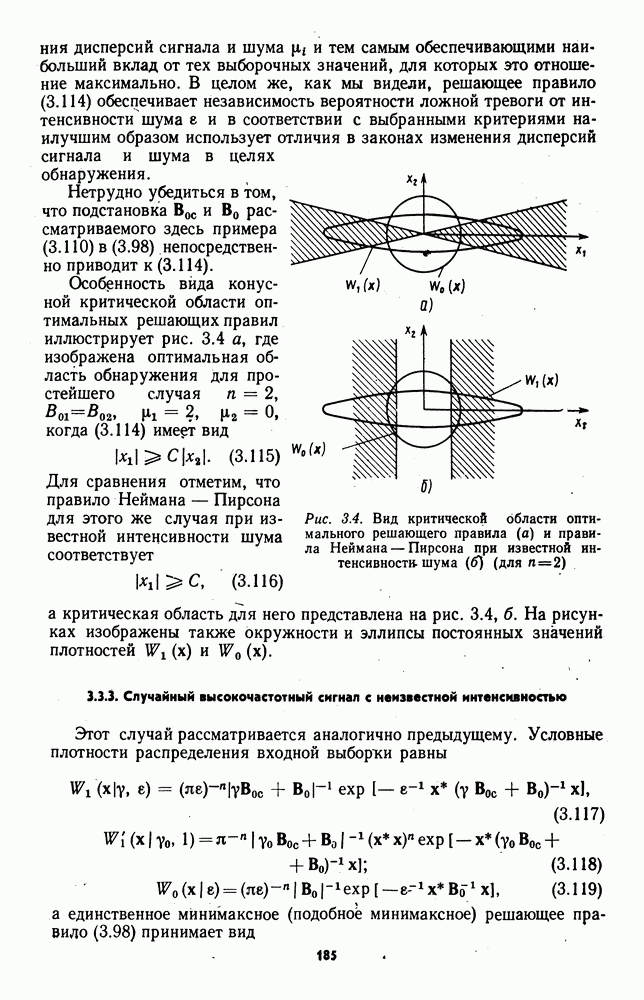






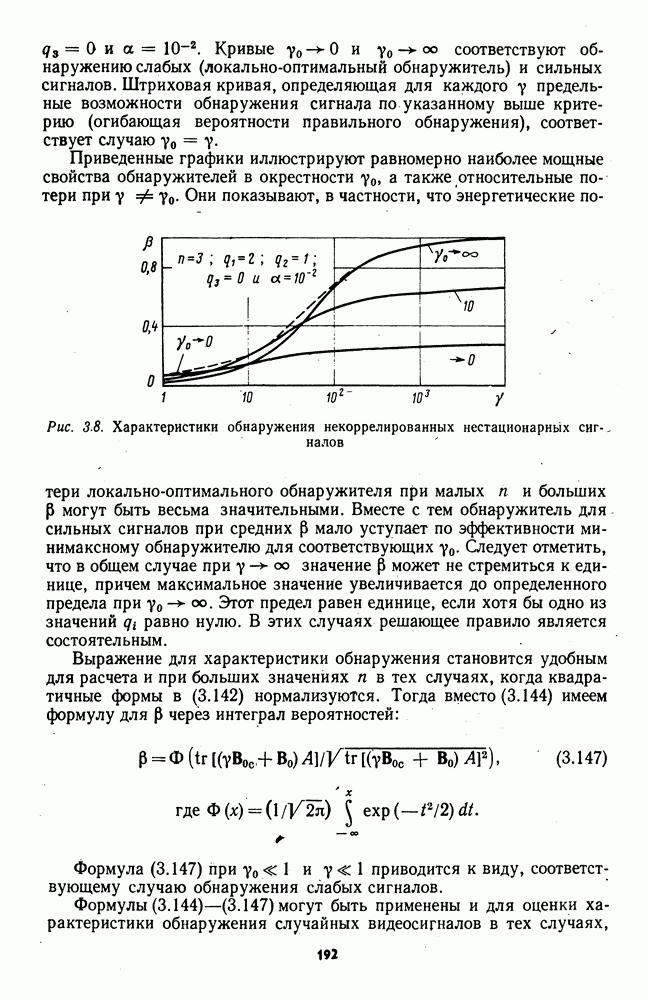
































































































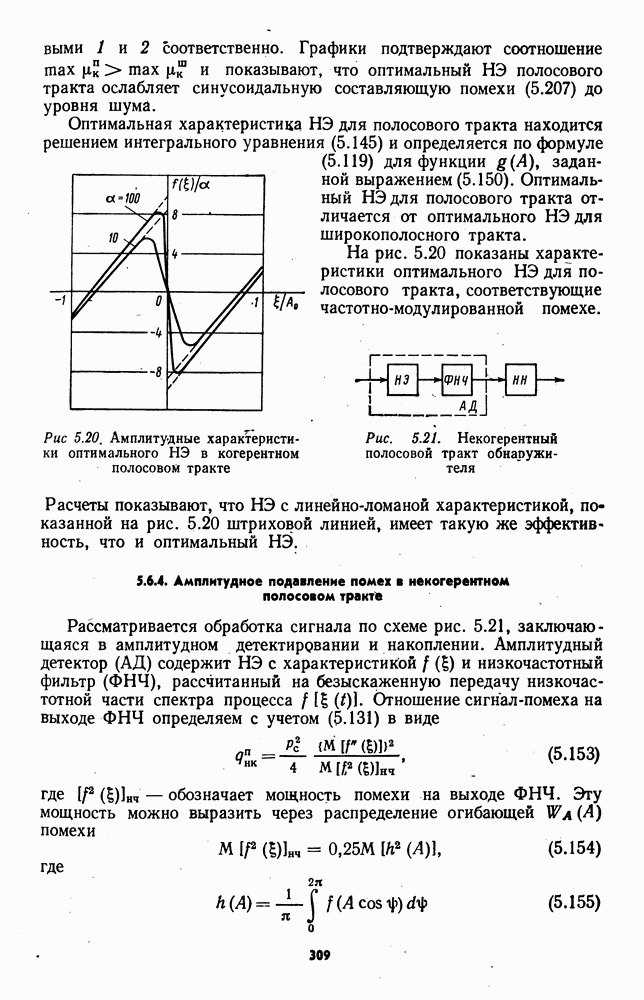




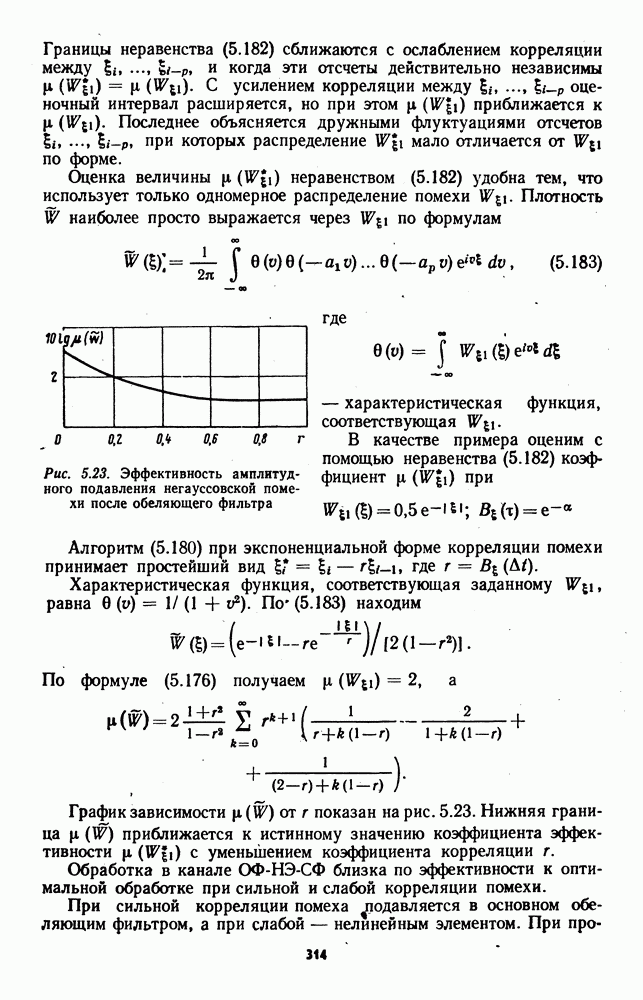


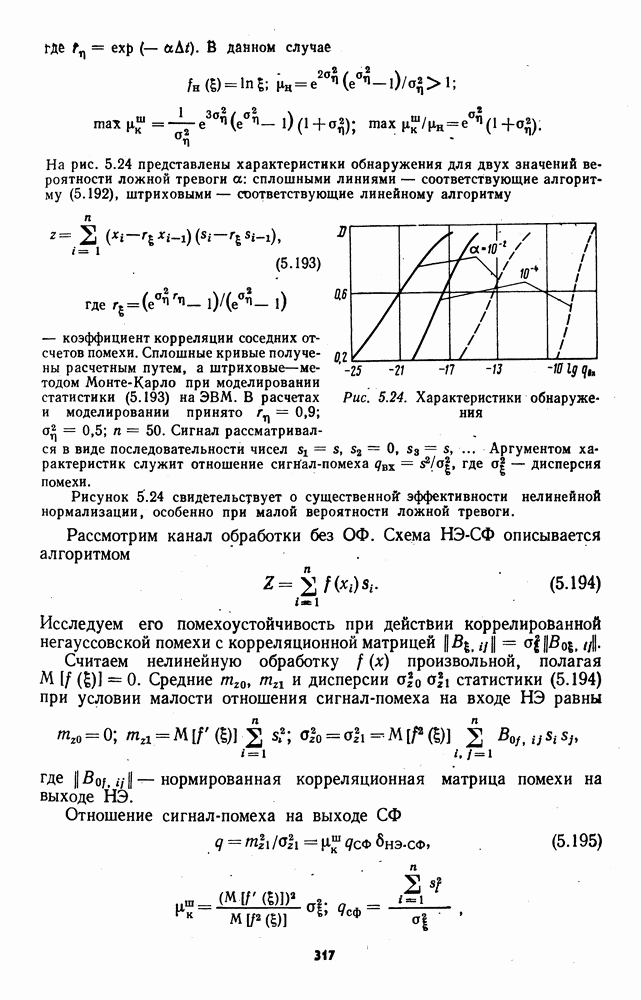



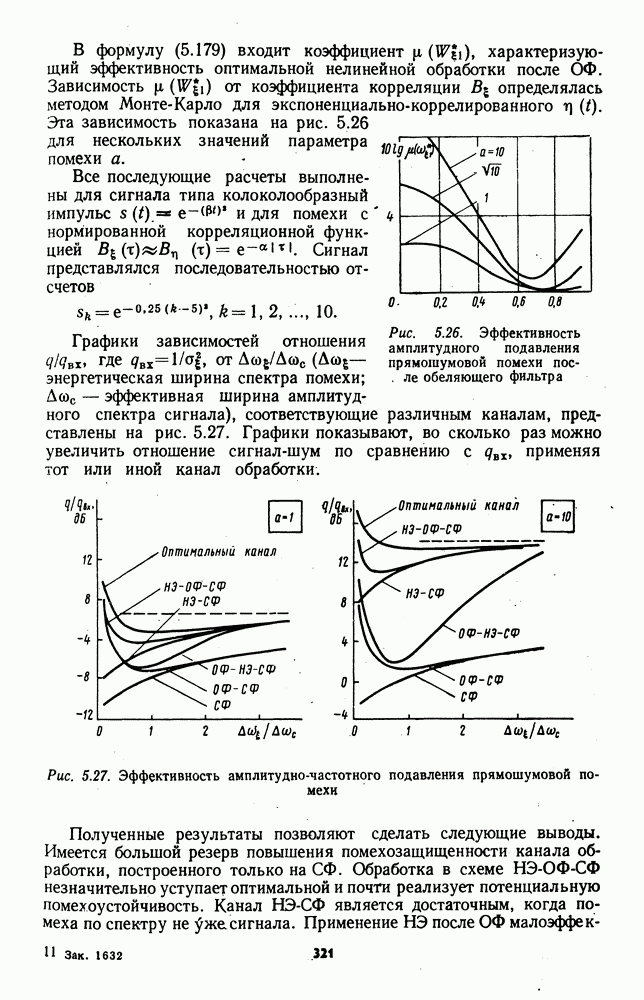








































































































 которая не может быть представлена в виде
которая не может быть представлена в виде

 принадлежащими одному блоку, будет иметь место статистическая зависимость, а между элементами
принадлежащими одному блоку, будет иметь место статистическая зависимость, а между элементами  принадлежащими разным блокам, — не будет, что следует из очевидной независимости промежуточных статистик. При наличии статистической зависимости между значениями помехи
принадлежащими разным блокам, — не будет, что следует из очевидной независимости промежуточных статистик. При наличии статистической зависимости между значениями помехи  ту которой соответствует известная корреляционная матрица
ту которой соответствует известная корреляционная матрица  одинаковая для всех
одинаковая для всех  при каждом фиксированном
при каждом фиксированном  и независимости шумовых значений, принадлежащих разным блокам (с разными
и независимости шумовых значений, принадлежащих разным блокам (с разными  ), эффективность обнаружителя на перемешанных статистиках составит
), эффективность обнаружителя на перемешанных статистиках составит

 определяется из формулы (7.89).
определяется из формулы (7.89).
 причем знак равенства имеет место только при
причем знак равенства имеет место только при  для всех k и
для всех k и  что соответствует статистической независимости элементов. Таким образом, статистическая зависимость между элементами в блоках снижает эффективность непараметрических обнаружителей на перемешанных статистиках.
что соответствует статистической независимости элементов. Таким образом, статистическая зависимость между элементами в блоках снижает эффективность непараметрических обнаружителей на перемешанных статистиках.

 при
при  для всех или некоторых
для всех или некоторых 

 определяется количеством информации Фишера (7.5), которое должно быть ограничено. Ограниченность количества информации Фишера означает, что плотности из класса
определяется количеством информации Фишера (7.5), которое должно быть ограничено. Ограниченность количества информации Фишера означает, что плотности из класса  описываются функциями, абсолютно непрерывными почти всюду на интервале
описываются функциями, абсолютно непрерывными почти всюду на интервале  Такйечфункции могут иметь ограниченное число конечных разрывов, которые характеризуются существованием в точках разрыва конечных пределов справа и слева.
Такйечфункции могут иметь ограниченное число конечных разрывов, которые характеризуются существованием в точках разрыва конечных пределов справа и слева.

 для которых
для которых  при
при  а точность приближения возрастает с увеличением
а точность приближения возрастает с увеличением 
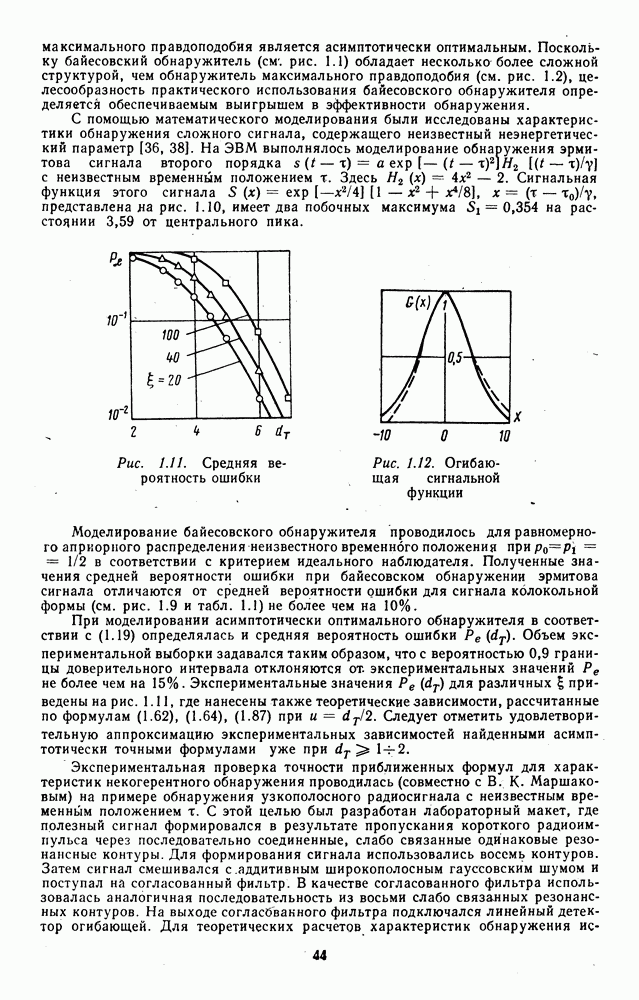
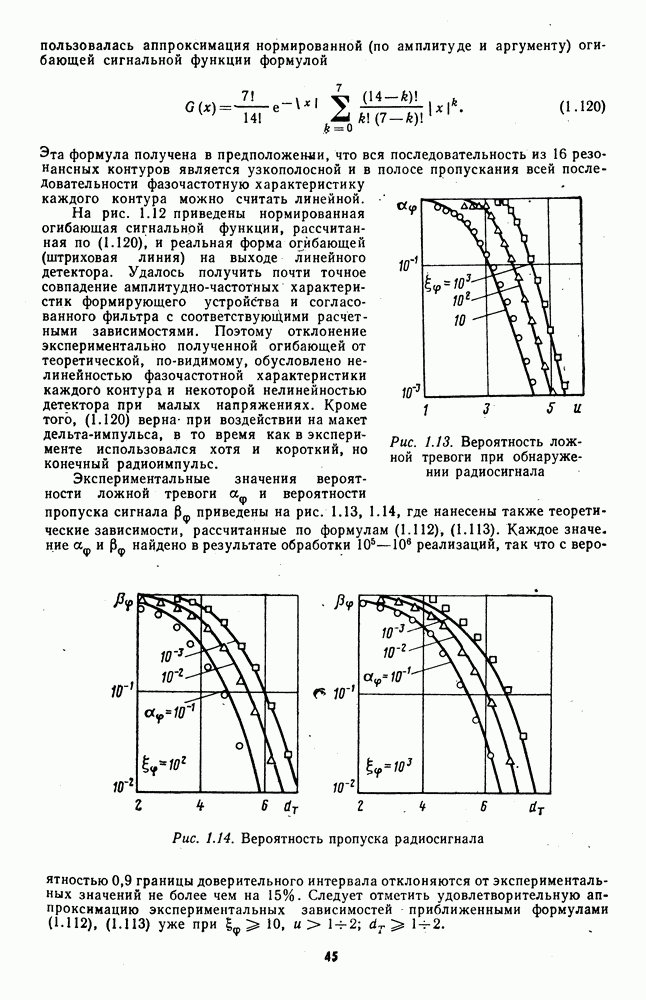
 последовательности критериев, асимптотически оптимальных для последовательности плотностей
последовательности критериев, асимптотически оптимальных для последовательности плотностей  возрастает с увеличением
возрастает с увеличением 
 может принять только одно из заданного множества дискретных значений
может принять только одно из заданного множества дискретных значений  и описывается соответствующей разрывной плотностью
и описывается соответствующей разрывной плотностью

 при
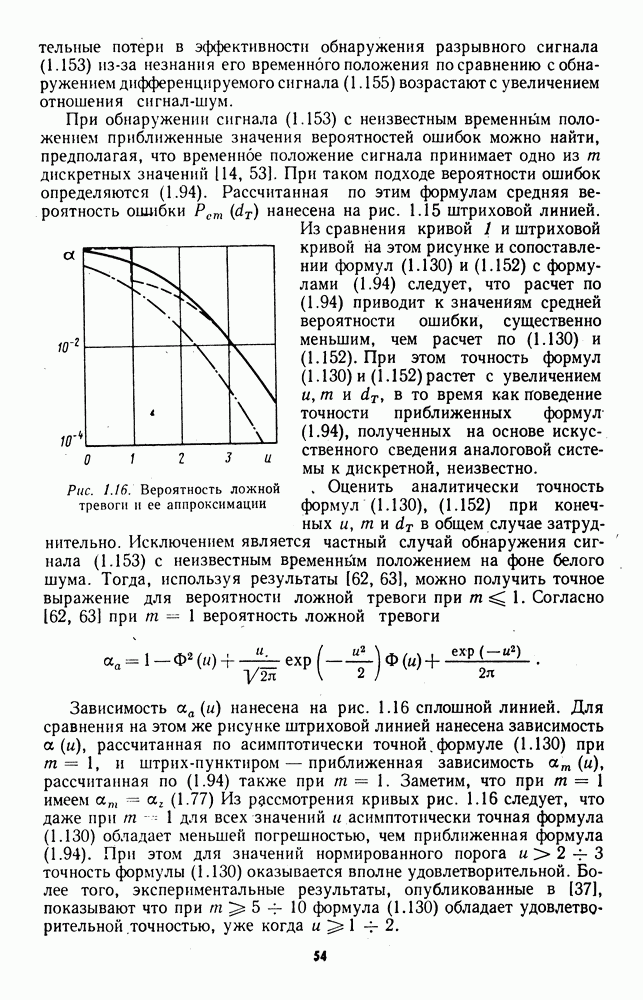
при  вероятностью единица свидетельствует о наличии в выборке ненулевого сигнала.
вероятностью единица свидетельствует о наличии в выборке ненулевого сигнала.
 почти всюду на числовой прямой
почти всюду на числовой прямой  Однако на практике ввиду ограниченной точности измерительных приборов, а также вследствие дискретизации наблюдаемых значений, применяемой в цифровых устройствах обработки сигналов, появление нулевых или совпадающих элементов может иметь конечные вероятности и оказывать заметное влияние на характеристики обнаружителей. Поэтому в реальных устройствах должна предусматриваться специальная обработка нулей и совпадений.
Однако на практике ввиду ограниченной точности измерительных приборов, а также вследствие дискретизации наблюдаемых значений, применяемой в цифровых устройствах обработки сигналов, появление нулевых или совпадающих элементов может иметь конечные вероятности и оказывать заметное влияние на характеристики обнаружителей. Поэтому в реальных устройствах должна предусматриваться специальная обработка нулей и совпадений.
 при
при  и произвести коррекцию порога в соответствии с фактическим объемом выборки, полученной после исключения из исходной выборки нулевых элементов.
и произвести коррекцию порога в соответствии с фактическим объемом выборки, полученной после исключения из исходной выборки нулевых элементов.
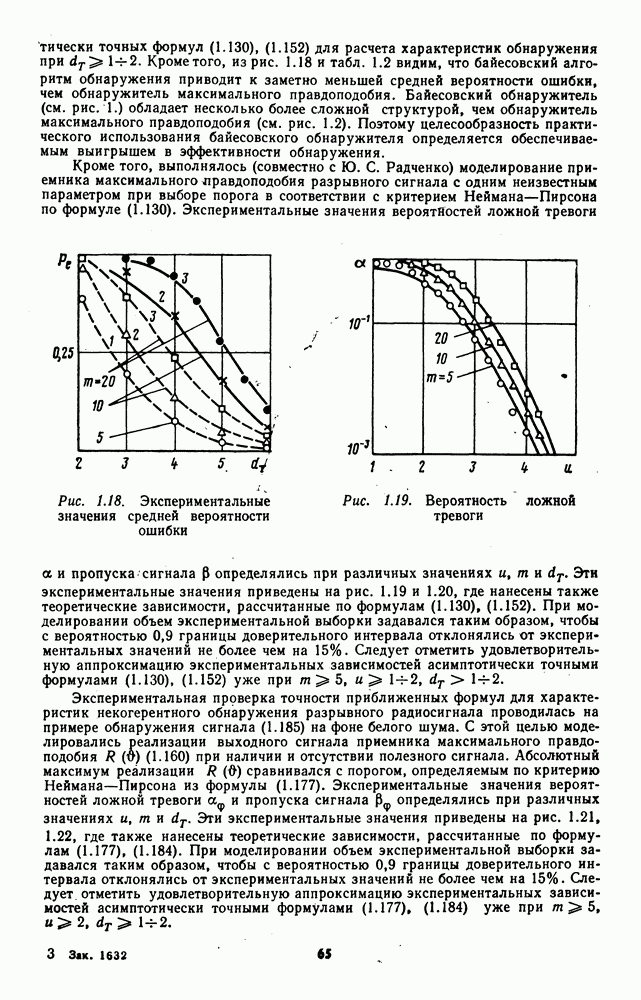
 элементов выборки
элементов выборки  могут быть получены с помощью алгоритма [274]
могут быть получены с помощью алгоритма [274]

 — число элементов выборки, строго меньших
— число элементов выборки, строго меньших  число элементов выборки, меньших или равных
число элементов выборки, меньших или равных 

 при
при  .
.
 а заданные показатели качества обнаружения достигаются при слабых сигналах
а заданные показатели качества обнаружения достигаются при слабых сигналах 
 . В этом случае асимптотически оптимальные структуры могут оказаться неоптимальными, а получаемые при их использовании значения эффективности могут отличаться от значений, определенных по асимптотическим формулам.
. В этом случае асимптотически оптимальные структуры могут оказаться неоптимальными, а получаемые при их использовании значения эффективности могут отличаться от значений, определенных по асимптотическим формулам.