Пред.
След.
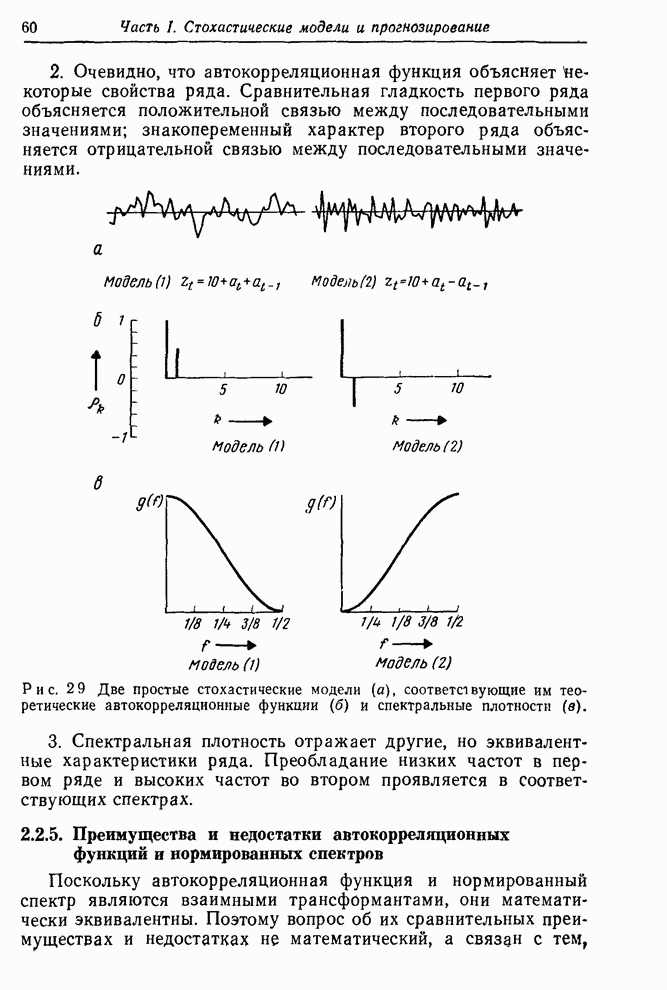
Макеты страниц
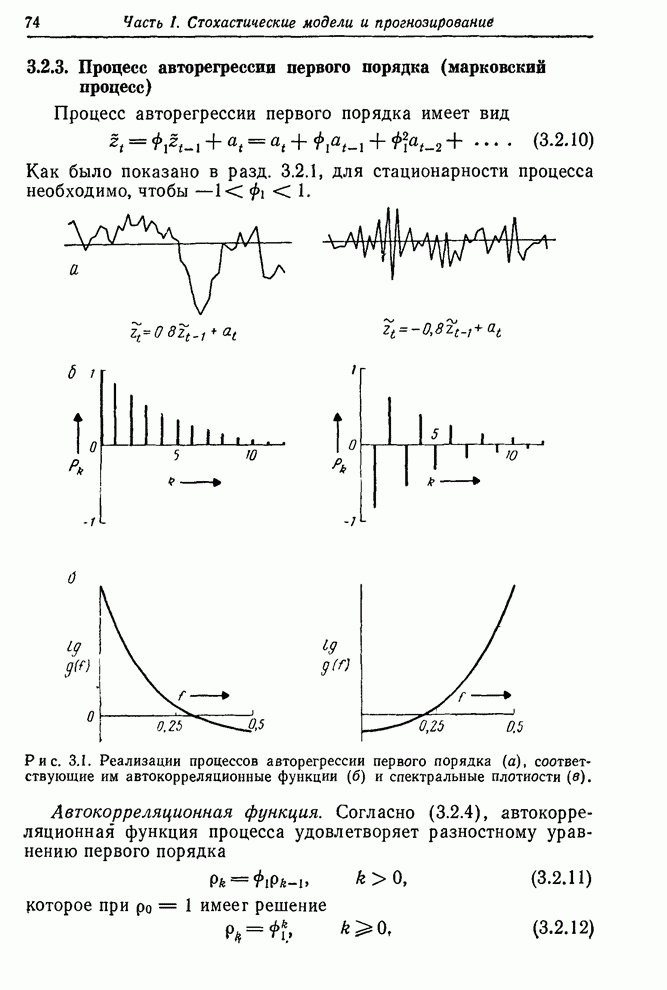
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Приложение П5.3. Прогнозирование при помощи общего проинтегрированного представленияП5.3.1. Общий метод получения проинтегрированного представления
Подчеркнем еще раз, что для практического
вычисления прогнозов использование разностного уравнения — наиболее простой
путь. Нижеследующее общее рассмотрение проинтегрированного представления нужно,
чтобы совершенствовать уже полученные прогнозы. В этом рассмотрении вместо
того, чтобы получить явное выражение для функции прогноза, как мы делали в
примерах из разд. 5.4, будет удобнее выписать общее выражение для эвентуальной
прогнозирующей функции, включающее Поскольку очевидно,
что
Эвентуальная прогнозирующая функция — это решение последнего уравнения и может быть представлена как
Когда Как пример такой модели с
так что
где
Если
где
в которой
Кроме того, (П5.3.1) дает
так что из (П5.3.4) имеем
и, следовательно,
и отсюда, пользуясь (П5.3.4), имеем
что приводит к
Следовательно, прогнозирующая функция будет
П5.3.2. Коррекция общего проинтегрированного представленияКоррекцию формул для коэффициентов можно
осуществить, используя тождество (5.2.5) с
Тогда для
Решив
Заметим, что коррекция каждого коэффициента функции
прогноза зависит только от ошибки прогноза на один шаг
В разд. П5.3.1 было показано, что прогнозирующая функция для этого примера равна
Удобно использовать тождество коррекции (П5.3.5) для
частных значений
Первые три уравнения легко решить
относительно
что дает требуемую формулу коррекции для каждого из 5
коэффициентов П5.3.3. Сравнение с методом взвешенных наименьших квадратов БраунаХотя проинтегрированное представление приводит к усложнению вычисления прогнозов, оно позволяет нам сравнить рассмотренный здесь прогноз с наименьшей среднеквадратичной ошибкой с другим достаточно известным типом прогноза. Запишем
Тогда, пользуясь (П5.3.5) для
что дает
или
Это выражение имеет ту же алгебраическую форму, что и корректирующая функция, предлагаемая в
методике «взвешенных наименьших квадратов» Брауна [2, 50]. Для сравнения, если
мы обозначим ошибку прогноза, даваемую этим методом,
где
где
где В общем матрица Метод прогнозирования Брауна 1) Прогнозирующая функция выбирается из общего класса линейных комбинаций и произведений полиномов, экспонент, синусов и косинусов. 2) Выбранная прогнозирующая функция подгоняется к прошлым значениям при помощи методики «взвешенных наименьших квадратов». В этой методике коэффициенты оцениваются и корректируются так, что минимизируется сумма
взвешенных квадратов расхождения прошлых
значений ряда и значений, даваемых для соответствующих времен в прошлом
прогнозирующей функцией. Весовая функция Различие между прогнозами с минимальной среднеквадратичной ошибкой и прогнозами Брауна. Чтобы проиллюстрировать эти замечания, рассмотрим прогнозирование цен акций IВМ, обсуждавшееся Брауном [2, стр. 141]. В этом исследовании он использовал квадратичную модель, которая в обозначениях этой книги может быть представлена как
Он применил к этой модели свой метод «взвешенных наименьших квадратов», чтобы предсказать биржевые цены на три дня вперед. Результаты, полученные его методом, показаны для участка ряда IВМ на рис. П5.2, где они сравниваются с прогнозами с минимальной среднеквадратичной ошибкой. Метод «взвешенных наименьших квадратов» можно подвергнуть критике на следующих основаниях: 1) Вид прогнозирующей функции должен определяться
оператором авторегрессии Наиболее общий линейный процесс, для
которого квадратичная функция давала бы прогнозы с наименьшей среднеквадратичной
ошибкой при любом упреждении
которая на основании тех же рассуждений, что и в разд. 4.3.3, может быть представлена в виде
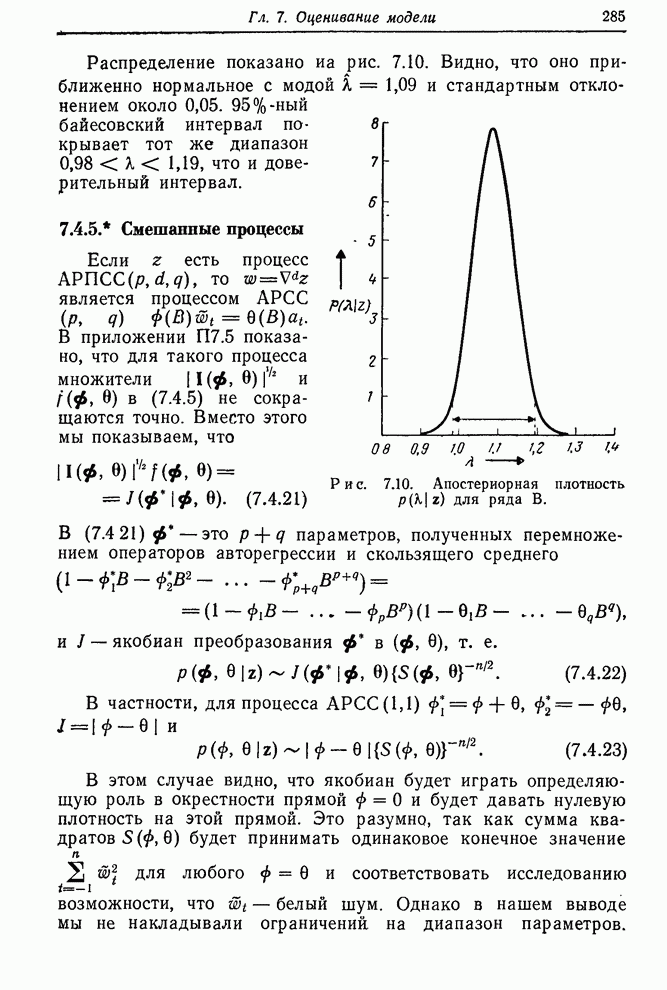
Однако в гл. 7 будет показано, что если
правильно подогнать эту модель, оценки ее параметров, полученные методом
наименьших квадратов, окажутся равными 2) Выбор весовой функции а) процесс имел порядок (0,1,1), так что б) подгонялся полином нулевой степени; в) константа сглаживания
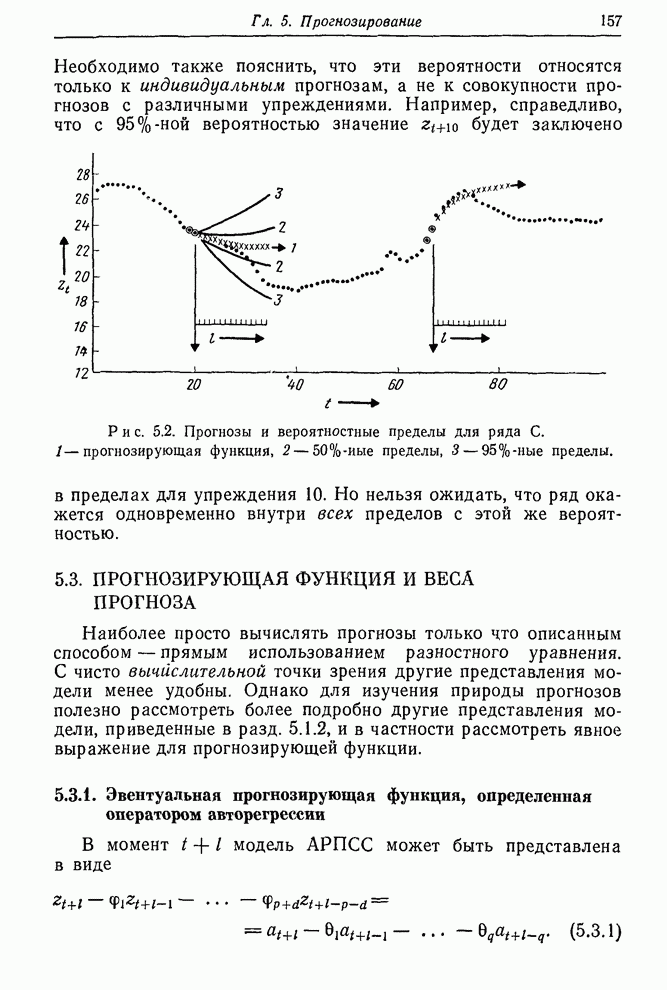
Рис. П5 2. Ряд биржевых цен акций IВМ; сравнение с прогнозом на три шага вперед, основанным на лучшей модели ПСС (0,1,1), к квадратичным прогнозом Брауна для периода, начинающегося 11 июля 1960 г.: а — квадратичный прогноз Брауна, б — прогноз с минимальной среднеквадратичной ошибкой. 1 — данные; 2 — прогнозы на три шага вперед. В данном примере, даже если бы была
выбрана правильная степень полинома (нуль), значение 3) Методика экспоненциально взвешенных
наименьших квадратов вынуждает все Итак, различия между двумя методами
нетривиальны, и интересно сравнить на данных IBM, как они
действуют. Прогноз с минимальной среднеквадратичной ошибкой равен т. е. лучший прогноз цен акций для всех будущих
моментов времени есть текущая цена. Идея, что биржевые цены ведут себя так,
конечно, не нова и восходит к Бейгельеру [51]. При Для сопоставления прогноза с минимальной
среднеквадратичной ошибкой (СКО) с квадратичными прогнозами Брауна было
проведено прямое сравнение на базе ряда цен акций IBM за период с
11 июля 1960 г. по 10 февраля 1961 г. (150 наблюдений). Для этого участка ряда
прогноз с минимальной СКО был получен для модели Среднеквадратичные ошибки прогноза при разных
упреждениях, вычисленные прямым сравнением значений ряда и их прогнозов с
упреждением Таблица П5.3. Сравнение среднеквадратичных ошибок прогнозов, полученных при различных упреждениях, по наилучшему из процессов ПСС(0,1,1) и по методике Брауна
|
 |
Оглавление
|




















































































































































































































































































































































































 (П5.3.1)
(П5.3.1)
 (П5.3.2)
(П5.3.2)

 (П5.3.3)
(П5.3.3)
 (П5.2.3)
(П5.2.3)

 (П5.3.5)
(П5.3.5)




 (П5.3.8)
(П5.3.8)
