Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
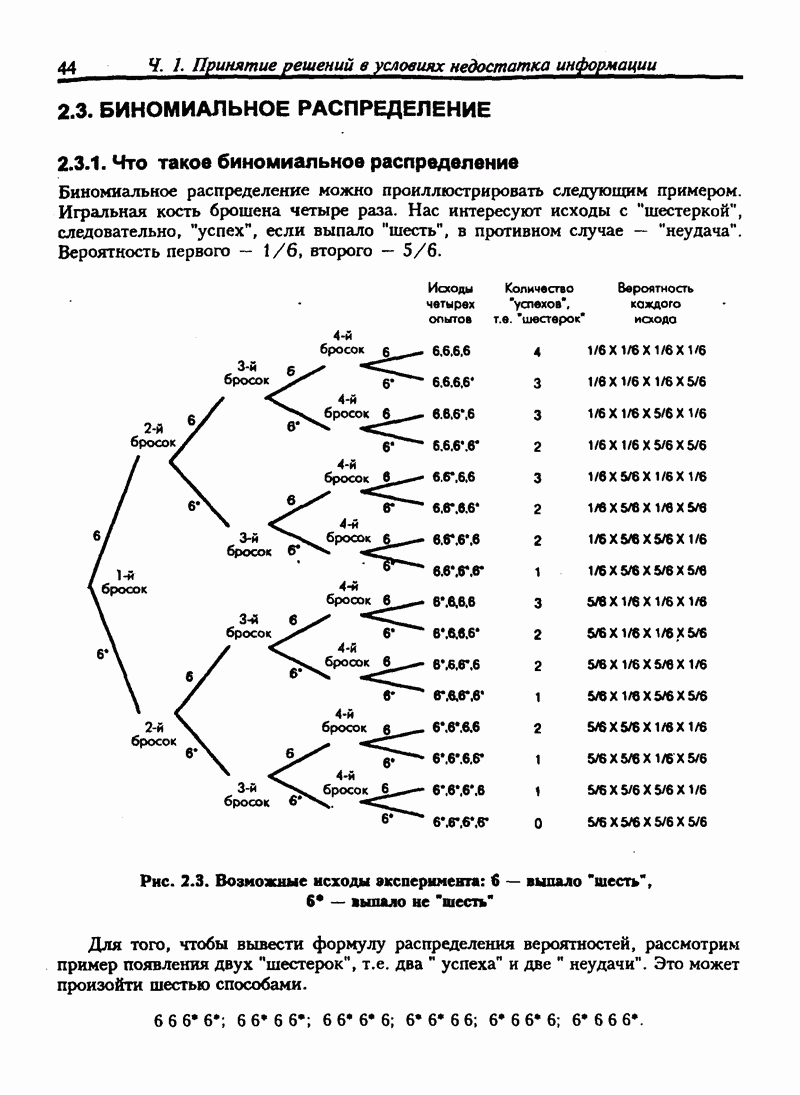
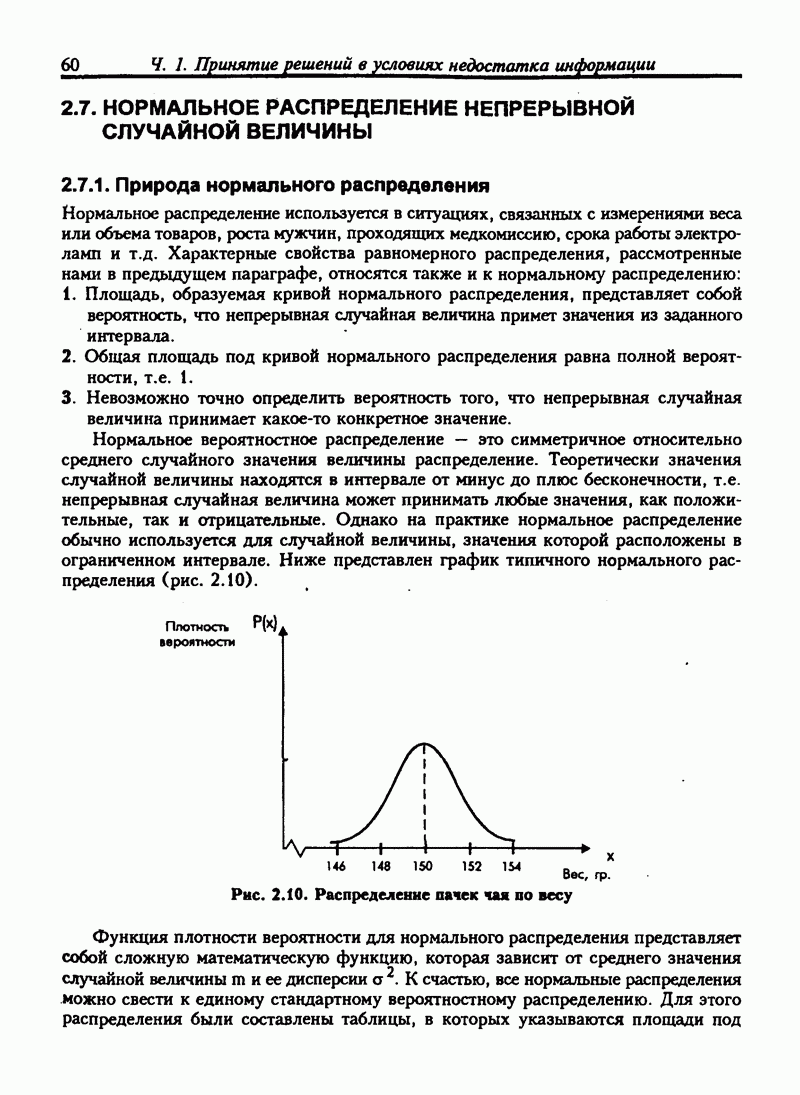
8.6. МОДЕЛИ МНОЖЕСТВЕННОЙ РЕГРЕССИИВ предыдущих разделах было упомянуто о том, что вряд ли выбранная независимая переменная является единственным фактором, который повлияет на зависимую переменную. В большинстве случаев мы можем идентифицировать более одного фактора, способного влиять каким-то образом на зависимую переменную. Так, например, разумно предположить, что расходы цеха будут определяться количеством отработанных часов, использованного сырья, количеством произведенной продукции. По видимому, нужно использовать все факторы, которые мы перечислили для того, чтобы предсказать расходы цеха. Мы можем собрать данные об издержках, отработанном времени, использованном сырье и т.д. за неделю или за месяц Но мы не сможем исследовать природу связи между издержками и всеми другими переменными посредством корреляционной диаграммы. Начнем с предположений о линейной связи, и только если это предположение будет неприемлимо, попробуем использовать нелинейную модель. Линейная модель для множественной регрессии:
Вариация у объясняется вариацией всех независимых переменных, которые в идеале должны быть независимы друг от друга. Например, если мы решим использовать пять независимых переменных, то модель будет следующей:
Как и в случае простой линейной регрессии мы получаем по выборке оценки
Коэффициент а и коэффициенты регрессии
2. Дисперсия 3. Ошибки независимы друг от друга. Эти предположения те же, что и в случае простой регрессии. Однако в ШАГ 1. ПОДГОТОВКА ИСХОДНЫХ ДАННЫХПервый шаг обычно предполагает обдумать, как зависимая переменная быть связана с каждой из независимых переменных. Нет смысла ШАГ 2. ОПРЕДЕНИЕ ВСЕХ СТАТИСТИЧЕСКИ ЗНАЧИМЫХ МОДЕЛ Мы можем исследовать линейную связь между у и любой комбинацией Мы можем оценить значимость модели в целом, используя Полная процедура заключается в том, чтобы установить множествениу нейную регрессионную модель для всех комбинаций независимых переме. Оценим каждую модель, используя F-критерий для модели в целом и модели исключаются из рассмотрения. Этот процесс занимает очень много времени. Например, если у нас имеются пять независимых переменных, то возможно построение 31 модели: одна модель со всеми пятью переменными, пять моделей, включающие четыре из пяти переменных, десять — с тремя переменными, десять — с двумя переменными и пять моделей с одной. Можно получить множественную регрессию не исключая последовательно независимые переменные, а расширяя их круг. В в этом случае мы начинаем с построения простых регрессий для каждой из независимых переменных поочередно. Мы выбираем лучшую из этих регрессий, т.е. с наивысшим коэффициентом корреляции, затем добавляем к этому, наиболее приемлемому значению переменной у вторую переменную. Этот метод построения множественной регрессии называется прямым. Обратный метод начинается с исследования модели, включающей все независимые переменные; в нижеприведенном примере их пять. Переменная, которая дает наименьший вклад в общую модель, исключается из рассмотрения, остается только четыре переменных. Для этих четырех переменных определяется линейная модель. Если же эта модель не верна, исключается еще одна переменная, дающая наименьший вклад, остается три переменных. И этот процесс повторяется со следующими переменными. Каждый раз, когда исключается новая переменная, нужно проверять, чтобы значимая переменная не была удалена. Все эти действия нужно производить с большим вниманием, так как можно неосторожно исключить нужную, значимую модель из рассмотрения. Не важно, какой именно метод используется, может быть несколько значимых моделей и каждая из них может иметь огромное значение. ШАГ 3. ВЫБОР ЛУЧШЕЙ МОДЕЛИ ИЗ ВСЕХ ЗНАЧИМЫХ МОДЕЛЕЙЭта процедура может бьгть рассмотрена с помощью примера, в котором определились три важнейших модели. Первоначально было пять независимых переменных Поэтому значимыми моделями оказались: Модель 1: у прогнозируется только Модель 2: у прогнозируется только Модель 3: у прогнозируется Для того, чтобы сделать выбор из этих моделей, проверим значения коэффициента корреляции и стандартного отклонения остатков В данном примере мы просто выбираем модель с наибольшим значением Пример 8.2. Руководство большой шоколадной фабрики заинтересовано в построении модели для того, чтобы предсказать реализацию одной из своих уже долго существующих торговых марок. Были собраны следующие данные. Таблица 8.5. Построение модели для прогноза объема реализации (см. скан) Определим "лучшую" модель для прогноза объема реализации. Решение. Шаг 1. Просмотр данных. Реализация за шесть месяцев — зависимая переменная у. У нас пять независимых переменных х, четыре из них — расходы на рекламу, цена товара, конкурентная цена и индекс потребительских затрат. Пятая переменная — время, которое может быть обозначено для первого периода — Январь-июнь 19X0- период 1, следующий период - 2 и т.д., до 16 — последнего периода, июль-декабрь 19X7. Вычислим коэффициенты корреляции, Воспользуемся процедурой проверки гипотез для определения значимости этих коэффициентов. - коэффициент корреляции в генеральной совокупности равен нулю. Между парой переменных не существует никакой линейной связи. В идеале это должно выполняться для всех пар независимых переменных.
Это должно выполняться для пар, образованных зависимой переменной с каждой независимымой переменной. Проверим эти гипотезы на 5%-ном и 1%-ном уровнях значимости, используя двусторонний критерий. Из таблиц
а на
Формула критерия:
Коэффициенты корреляции и соответствующий уровень значимости приведены ниже: Таблица 8.6. Коэффициенты корреляции
Зависимая переменная, т.е. объем реализации, имеет невероятно сильную линейную связь со временем, расходами на рекламу товара и индексом потребительских расходов. К сожалению, независимые переменные, время и индекс потребительских расходов, очень высоко коррелированы. Маловероятно, что обе переменные должны быть включены в окончательную модель. Это же верно и для двух ценовых переменных с коэффициентом корреляции 0,70. Будем иметь это в виду в ходе выполнения шага 2. Шаг 2. Нахождение всех статистически значимых моделей. Будем использовать обратный метод для нахождения значимых моделей. Начнем с рассмотрения всех переменных в модели и затем придем к четырем переменным вместо пяти и так далее, пока не будут определены значимые модели. Модель для пяти переменных имеет вид:
Установим сначала общую значимость модели, используя F-критерий. Компьютер производит обычно табличный анализ дисперсии, в котором общая вариация реализации разделена на две части: часть, которая объясняется моделью, и часть, которая не объясняется моделью, т.е. на вариацию, объясненную регрессией и необъясненную, или остаточную вариацию. Компьютер рассчитывает два показателя:
эта величина измеряет вариацию, объясненную регрессионной моделью.
которая измеряет вариацию, не объясненную регрессией. Замечание: Общее число степеней свободы равно
В данном примере Если модель описывает связь между у и всеми независимыми переменными х, то величина остаточной вариации будет очень малой. Для всей модели в целом: Для того чтобы модель была полезной и имела силу, мы должны отвергнуть Но и принять
Этот критерий с одним хвостом (односторонний), потому, что средний квадрат, обусловленный регрессией, должен быть больше, чтобы мы могли принять
Из таблиц стандартного распределения F-критерия:
В нашем примере значение критерия:
Проверим каждое из значений коэффициентов регрессии. Предположим, что компьютер сосчитал все необходимые
Проведем испытание гипотезы на
Граничные значения на данном уровне:
Значение критерия:
Рассчитанные значения Так как все независимые переменные подчиняются этому правилу, то результаты проверки значимости для пяти переменных в данной модели обобщены в следующей таблице: Таблица 8.7. Проверка значимости коэффициентов регрессии для пяти переменных
Сейчас мы видим, что наша модель не достоверна, потому что четыре коэффициента регрессии не значимо отличны от нуля. Нам нужно решить, какую переменную следует исключить из модели. В табл. 8.8 представлены шаги, предпринятые по мере того, как мы сокращаем число переменных в модели от 5 до 4, затем до 3, до 2 и, наконец, до 1 независимой переменной. Прочерки показывают, что переменная не включена в модель. Пользуясь результатами наших исследований, можно решить, какая переменная должна быть исключена из рассмотрения. Для каждой модели мы испытываем всю регрессию и отдельные коэффициенты регрессии. Если модель подходит по всем критериям, то Таблица 8.8. Исследование различных моделей регрессии
Шаг 3. Какую из значимых моделей нужно использовать? В нашем примере значение модели появились лишь тогда, когда количество переменных сократилось до двух. Сравнение моделей необходимо проводить через сопоставление стандартных отклонений остатков. Отклонение должно быть предельно малым числом. Первая модель с расходами на рекламу и индексом потребительских расходов является наилучшей, так как
Коэффициенты регрессии для расходов на рекламу и индекса потребительских расходов положительны, как мы и предполагали. Постоянная - Этот пример хорошо показывает все сложности объяснения и расчета каждой отдельной величины многофакторной модели. Цель статистической модели — объяснить вариацию продаж, а не предоставить особую информацию по изолированному влиянию рекламы или индекса потребительских цен на реализацию. По данным выборки модель дает некоторое представление о таких эффектах. В выборочной совокупности всегда возникает противоречие между теми или иными переменными. Поэтому коэффициенты регрессии при отдельных переменных должны использоваться с особым вниманием. Наконец, при анализе мы должны проверить структуру и размер ошибок, а потому мы должны заранее предполагать большие ошибки. Ошибки рассчитываются следующим образом:
Таблица 8.9. Размер ошибок (млн. ф. ст.)
Рис. 8.20. Распределение остатков для модели с двумя переменными Оказалось восемь ошибок с отклонениями 10% или более от фактического объема продаж. Наибольшая из них — 27%. Будет ли размер ошибки принят компанией при планировании деятельности? Ответ на этот вопрос будет зависеть от степени надежности других методов. 8.7. НЕЛИНЕЙНЫЕ СВЯЗИВернемся к ситуации, когда у нас всего две переменные, но связь между ними нелинейная. На практике многие связи между переменными являются криволинейными. Например, связь может быть выражена уравнением:
или:
или:
или
Если связь между переменными сильная, т.е. отклонение от криволинейной модели относительно небольшое, то мы сможем догадаться о природе наилучшей модели по диаграмме (полю корреляции). Однако трудно применить нелинейную модель к выборочной совокупности. Было бы легче, если бы мы могли манипулировать нелинейной моделью в линейной форме. В первых двух записанных моделях функциям
лучше всего описывает связь между у и х, то перепишем нашу модель, используя независимые переменные
где Эти переменные рассматриваются как обыкновенные независимые переменные, даже если мы знаем, что Третья и четвертая модели рассматриваются по-другому. Тут мы уже встречаемся с необходимостью так называемой линейной трансформации. Например, если связь
то на графике это будет изображено кривой линией. Все необходимые действия могут быть представлены следующим образом: Таблица 8.10. Расчет
Рис. 8.21. Нелинейная связь Линейная модель, при трансформированной связи:
где
Рис. 8.22. Линейная трансформация связи В общем, если исходная диаграмма показывает, что связь может быть изображена в форме: Четвертая модель, приведенная выше, включает трансформацию у с использованием натурального логарифма:
Взяв логарифмы по
поэтому: Если Таким образом, метод линейной регрессии может быть применен к нелинейным связям. Однако в этом случае требуется алгебраическое преобразование при записи исходной модели. Пример 8.3. Следующая таблица содержит данные об общем годовом объеме производства промышленной продукции в определенной стране за период Таблица 8.11. Годовой объем продукции
Требуется: 1. Нарисовать диаграмму, прокомментировать ее. 2. Нарисовать новую диаграмму за следующий год. 3. Предположим, что связь между общей годовой продукцией и временем может быть описана как:
где у — общий объем годовой продукции их — число лет с Используйте выборочную совокупность для оценки а и 4. Используйте модель, описанную в Решение 1. Диаграмма по указанным данным.
Рис. 8.23. Диаграмма общего объема производства Рисунок показывает, что между у и х существует некая связь, но она может быть криволинейной. 2. Трансформируем для начала значения объема производства в логарифмической форме. Таблица 8.12. Логарифмы значений объема производства
Линейная связь между
где:
Рис. 8.24. Изображение 3. Предполагаемая модель:
Пролагорифмируем обе части:
Отсюда:
Пусть
Для оценки А и В используем технику простой линейной регрессии: Таблица 8.13. Расчеты для модели регрессии
Для выявления наилучшей модели применяется метод наименьших квадратов в выборочной совокупности:
Коэффициент А находится как:
т.е.
Поэтому линейная модель:
так как Связь между общим объемом годовой продукции и числом лет с
Интерпретация
Нужно быть предельно внимательными, когда мы расширяем рамки
|
 |
Оглавление
|




























































































































































































































































































































































































































































































































































































 и т.д. Наилучшая линия для выборки:
и т.д. Наилучшая линия для выборки:

 вычисляются с помощью
вычисляются с помощью  минимальности суммы квадратов ошибок
минимальности суммы квадратов ошибок  Для дальнейшего
Для дальнейшего  регрессионной модели используют следующие предположения об ошибка любого данного
регрессионной модели используют следующие предположения об ошибка любого данного 

 равна
равна  и одинакова для всех х.
и одинакова для всех х.
 случае они ведут к очень сложным вычислениям. К счастью,
случае они ведут к очень сложным вычислениям. К счастью,  выполня вычисления, позволяя нам сосредоточиться на интерпретации и оценке
выполня вычисления, позволяя нам сосредоточиться на интерпретации и оценке  торной модели. В следующем разделе мы определим шаги, которые необх предпринять в случае множественной регрессии, но в любом случае мы полагаться на компьютер.
торной модели. В следующем разделе мы определим шаги, которые необх предпринять в случае множественной регрессии, но в любом случае мы полагаться на компьютер.
 нительные переменные х, если они не дают возможность объяснения вариа Вспомним, что наша задача состоит в
нительные переменные х, если они не дают возможность объяснения вариа Вспомним, что наша задача состоит в  объяснить вариацию
объяснить вариацию  изменения независимой переменкой х. Нам необходимо рассчитать коэффид корреляции
изменения независимой переменкой х. Нам необходимо рассчитать коэффид корреляции  для всех пар переменных при условии независимости наблк друг от друга. Это даст нам возможность определить, связаны х с у линей! же нет, независимы ли
для всех пар переменных при условии независимости наблк друг от друга. Это даст нам возможность определить, связаны х с у линей! же нет, независимы ли  между собой. Это важно в множественной регр Мы можем вычислить каждый из коэффициентов корреляции, как пока: разделе 8.5, чтобы посмотреть, насколько их значения отличны от нуля нужно выяснить, нет ли высокой корреляции между значениями незавю переменных. Если мы обнаружим высокую корреляцию, например, между х то маловероятно, что обе эти переменные должны быть включены в оконч
между собой. Это важно в множественной регр Мы можем вычислить каждый из коэффициентов корреляции, как пока: разделе 8.5, чтобы посмотреть, насколько их значения отличны от нуля нужно выяснить, нет ли высокой корреляции между значениями незавю переменных. Если мы обнаружим высокую корреляцию, например, между х то маловероятно, что обе эти переменные должны быть включены в оконч  модель.
модель.
 переменных. Но модель имеет силу только в том случае, если
переменных. Но модель имеет силу только в том случае, если  значимая линейная связь между у и всеми х и если каждый коэффи регрессии
значимая линейная связь между у и всеми х и если каждый коэффи регрессии  значимо отличен от нуля.
значимо отличен от нуля.
 того, мы должны использовать
того, мы должны использовать  -критерий для каждого коэффициента регр
-критерий для каждого коэффициента регр  чтобы определить, значимо ли он отличен от нуля. Если коэффициент
чтобы определить, значимо ли он отличен от нуля. Если коэффициент  сии не значимо отличается от нуля, то соответствующая независимая перем не помогает в прогнозе значения у и модель не имеет силы.
сии не значимо отличается от нуля, то соответствующая независимая перем не помогает в прогнозе значения у и модель не имеет силы.
 -кри для каждого коэффициента регрессии. Если F-критерий или любой из
-кри для каждого коэффициента регрессии. Если F-критерий или любой из  -кря! незначимы, то эта модель не имеет силы и не может быть использована.
-кря! незначимы, то эта модель не имеет силы и не может быть использована.
 но три из них —
но три из них —  — исключены из всех моделей. Эти переменные не помогают в прогнозировании у.
— исключены из всех моделей. Эти переменные не помогают в прогнозировании у.


 вместе.
вместе.
 Коэффициент множественной корреляции — есть отношение "объясненной" вариации у к общей вариации у и вычисляется так же, как и коэффициент парной корреляции для простой регрессии при двух переменных. Модель, которая описывает связь между у и несколькими значениями х, имеет множественный коэффициент корреляции
Коэффициент множественной корреляции — есть отношение "объясненной" вариации у к общей вариации у и вычисляется так же, как и коэффициент парной корреляции для простой регрессии при двух переменных. Модель, которая описывает связь между у и несколькими значениями х, имеет множественный коэффициент корреляции  который близок к
который близок к  и значение
и значение  очень мало. Коэффициент детерминации
очень мало. Коэффициент детерминации  который часто предлагается в ППП, описывает процент изменяемости у, которая обменяется моделью. Модель имеет значение в том случае, когда
который часто предлагается в ППП, описывает процент изменяемости у, которая обменяется моделью. Модель имеет значение в том случае, когда  близко к 100%.
близко к 100%.
 и наименьшим значением
и наименьшим значением  Предпочтительной моделью оказалась модель
Предпочтительной моделью оказалась модель  следующем шаге необходимо сравнить модели 1 и 3. Различие между этими моделями состоит во включении переменной
следующем шаге необходимо сравнить модели 1 и 3. Различие между этими моделями состоит во включении переменной  в модель 3. Вопрос в том повышает ли значительно
в модель 3. Вопрос в том повышает ли значительно  точность предсказания значения у или же нет! Следующий критерий поможет ответить нам на этот вопрос — это частный F-критерий. Рассмотрим пример, иллюстрирующий всю процедуру построения множественной регрессии.
точность предсказания значения у или же нет! Следующий критерий поможет ответить нам на этот вопрос — это частный F-критерий. Рассмотрим пример, иллюстрирующий всю процедуру построения множественной регрессии.
 для всех шести переменных.
для всех шести переменных.

 коэффициент корреляции не равен нулю. Между парой переменных существует линейная связь.
коэффициент корреляции не равен нулю. Между парой переменных существует линейная связь.
 -распределения значение
-распределения значение  на
на  -ном уровне значимости составляет:
-ном уровне значимости составляет:

 -ном уровне:
-ном уровне:


 степенями свободы.
степенями свободы.
 (в скобках указав уровень значимости)
(в скобках указав уровень значимости)




 где
где  — число данных в совокупности, в данном примере
— число данных в совокупности, в данном примере  — число степеней свободы для регрессии, которая задана числом независимых переменных к. В данной модели
— число степеней свободы для регрессии, которая задана числом независимых переменных к. В данной модели  — число степеней свободы для остатков может быть найдено как:
— число степеней свободы для остатков может быть найдено как:


 нет линейной связи между какими-либо независимыми переменными и продажей, т.е.
нет линейной связи между какими-либо независимыми переменными и продажей, т.е.  существует линейная связь между одной или большим числом независимых переменных, т.е. по крайней мере одна величина
существует линейная связь между одной или большим числом независимых переменных, т.е. по крайней мере одна величина 
 Значение F-критерия есть соотношение двух величин, описанных выше:
Значение F-критерия есть соотношение двух величин, описанных выше:

 . В предыдущих разделах, когда мы использовали F-критерий, критерии были двусторонние, так как во главу угла ставилось большее значение вариации, каким бы оно ни было. В регрессионном анализе нет выбора — наверху (в числителе) всегда вариация у по регрессии. Если она меньше, чем вариация по остаточной величине, мы принимает Но, так как модель не объясняет изменений у. Это значение F-критерия сравнивается с табличным:
. В предыдущих разделах, когда мы использовали F-критерий, критерии были двусторонние, так как во главу угла ставилось большее значение вариации, каким бы оно ни было. В регрессионном анализе нет выбора — наверху (в числителе) всегда вариация у по регрессии. Если она меньше, чем вариация по остаточной величине, мы принимает Но, так как модель не объясняет изменений у. Это значение F-критерия сравнивается с табличным:



 поэтому мы получили результат с высокой достоверностью.
поэтому мы получили результат с высокой достоверностью.
 -критерии. Для первого коэффициента гипотезы формулируются так:
-критерии. Для первого коэффициента гипотезы формулируются так:
 время не помогает объяснить изменение продаж при условии, что остальные переменные присутствуют в модели, т.е.
время не помогает объяснить изменение продаж при условии, что остальные переменные присутствуют в модели, т.е. 
 время дает существенный вклад и должно быть включено в модель, т. е.
время дает существенный вклад и должно быть включено в модель, т. е. 
 -ном уровне, пользуясь двусторонним
-ном уровне, пользуясь двусторонним  -критерием при:
-критерием при:



 -критерия должны лежать вне указанных границ для того, чтобы мы смогли отвергнуть гипотезу
-критерия должны лежать вне указанных границ для того, чтобы мы смогли отвергнуть гипотезу 

 должно быть малым,
должно быть малым,  как можно ближе к 1.
как можно ближе к 1.

 по сравнению с
по сравнению с  для модели с расходами на рекламу и временем как независимыми переменными. Последний шаг — сравнение лучшей модели с двумя переменными с лучшей моделью с одной переменной. По величине корреляции выбираем лучшую модель с одной переменной при
для модели с расходами на рекламу и временем как независимыми переменными. Последний шаг — сравнение лучшей модели с двумя переменными с лучшей моделью с одной переменной. По величине корреляции выбираем лучшую модель с одной переменной при  . Если бы добавление еще одной независимой переменной значительно улучшило модель, то мы смогли бы применить частный F-критерий для проверки. Этог критерий показывает, что введение величины расходов на рекламу значительно улучшает модель и нам нужно использовать две переменные: индекс потребительских расходов и расходы на рекламу. Окончательная модель:
. Если бы добавление еще одной независимой переменной значительно улучшило модель, то мы смогли бы применить частный F-критерий для проверки. Этог критерий показывает, что введение величины расходов на рекламу значительно улучшает модель и нам нужно использовать две переменные: индекс потребительских расходов и расходы на рекламу. Окончательная модель:

 ст.) выглядит абсурдной, но вспомним, что модель имеет силу только для значений, входящих в выборочную совокупность. Расходы на рекламу изменяются от 3,8 млн. ф. ст. до 19,8 млн. ф. ст., а индекс — от 98,4 до 112,9.
ст.) выглядит абсурдной, но вспомним, что модель имеет силу только для значений, входящих в выборочную совокупность. Расходы на рекламу изменяются от 3,8 млн. ф. ст. до 19,8 млн. ф. ст., а индекс — от 98,4 до 112,9.







 могут быть присвоены разные имена, и тогда будет использоваться множественная модель регрессии. Например, если модель:
могут быть присвоены разные имена, и тогда будет использоваться множественная модель регрессии. Например, если модель:




 и х не могут быть независимы друг от друга. Лучшая модель выбирается так же, как и в предыдущем разделе.
и х не могут быть независимы друг от друга. Лучшая модель выбирается так же, как и в предыдущем разделе.







 то представление у против X, где
то представление у против X, где  определит прямую линию. Воспользуемся простой линейной регрессией для установления модели:
определит прямую линию. Воспользуемся простой линейной регрессией для установления модели:  Рассчитанные значения а и
Рассчитанные значения а и  — лучшие значения а и (5.
— лучшие значения а и (5.

 обеих сторон уравнения, получим:
обеих сторон уравнения, получим:

 где
где 
 , то
, то  - уравнение линейной связи между Y и х. Пусть
- уравнение линейной связи между Y и х. Пусть  — связь между у и х, тогда мы должны трансформировать каждое значение у взятием логарифма по е. Определяем простую линейную регрессию
— связь между у и х, тогда мы должны трансформировать каждое значение у взятием логарифма по е. Определяем простую линейную регрессию  по х для того, чтобы найти значения А и
по х для того, чтобы найти значения А и  Антилогарифм записан ниже.
Антилогарифм записан ниже.




 .
.
 Объяснить получение
Объяснить получение 
 для прогнозирования общего объема продукции. Прокомментируйте ваш прогноз.
для прогнозирования общего объема продукции. Прокомментируйте ваш прогноз.


 четко видна из диаграммы. Нелинейная же связь между у и х должка быть трансформирована в:
четко видна из диаграммы. Нелинейная же связь между у и х должка быть трансформирована в:



 , соответствующих значениям х
, соответствующих значениям х



 Тогда ожидаемая линейная модель:
Тогда ожидаемая линейная модель:






 , то
, то  Так как
Так как  то
то 
 быть описана:
быть описана:

 если мы перепишем эту модель таким образом:
если мы перепишем эту модель таким образом:  то природа связи станет более очевидна. Годовая про, 739
то природа связи станет более очевидна. Годовая про, 739  в
в  году при
году при  Затем мы видим, что продукция растет
Затем мы видим, что продукция растет  в год. b — отношение объема производства в текущем году к объему
в год. b — отношение объема производства в текущем году к объему  в предыдущем году. Прогноз будущего объема продукции:
в предыдущем году. Прогноз будущего объема продукции:

 построенной по выборочной совокупности. Предположим, что условия с 15
построенной по выборочной совокупности. Предположим, что условия с 15  годы остаются неизменными. Это предложение может быть оправд для прогноза на
годы остаются неизменными. Это предложение может быть оправд для прогноза на  год, но по мере того как мы будем двигаться далее,
год, но по мере того как мы будем двигаться далее,  станет все менее надежен.
станет все менее надежен.