Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
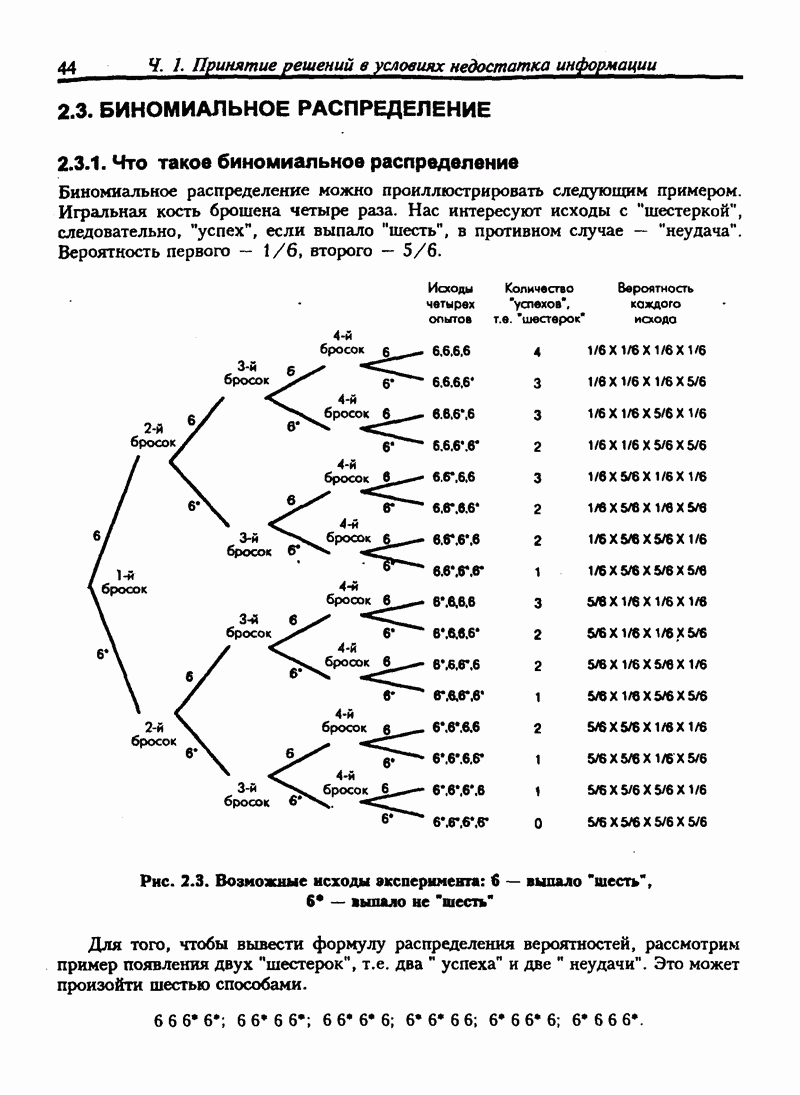
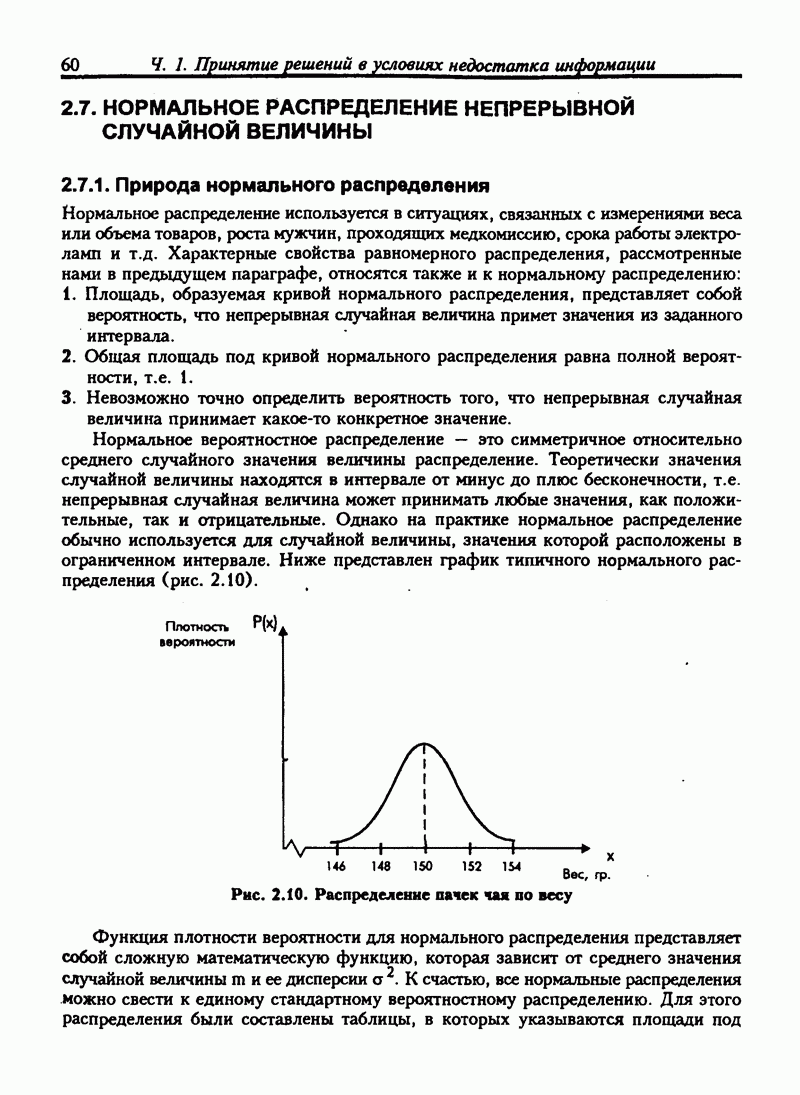
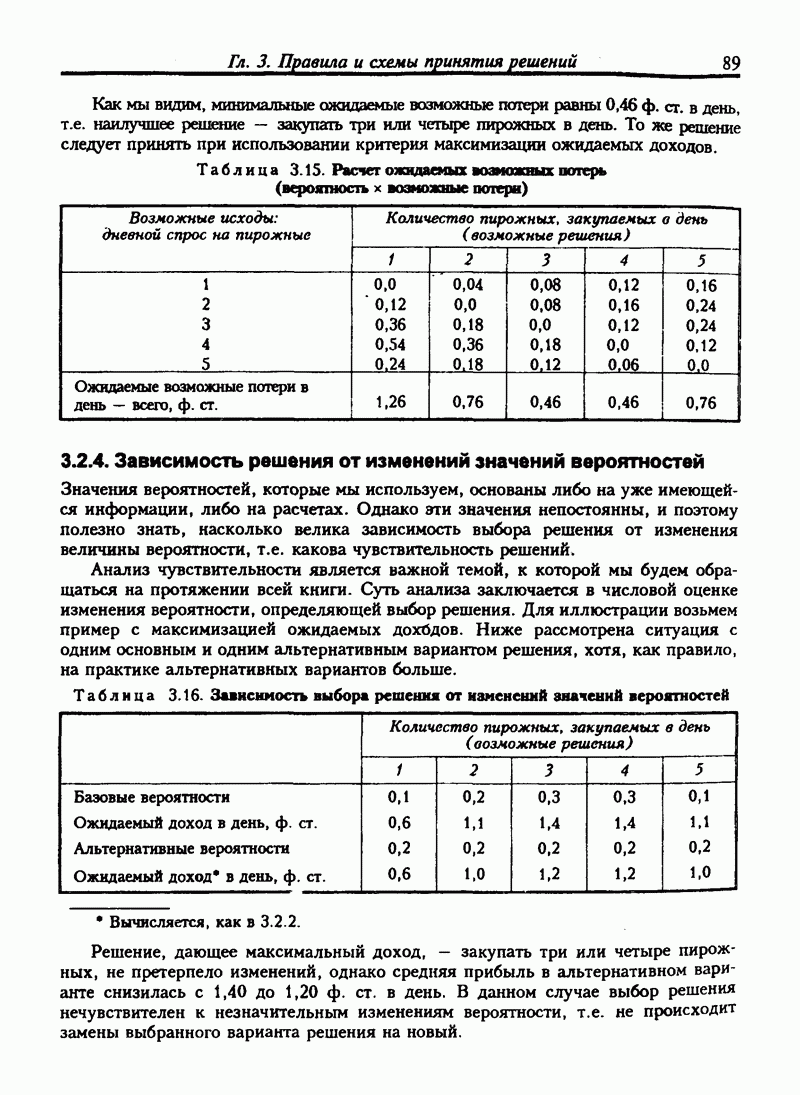
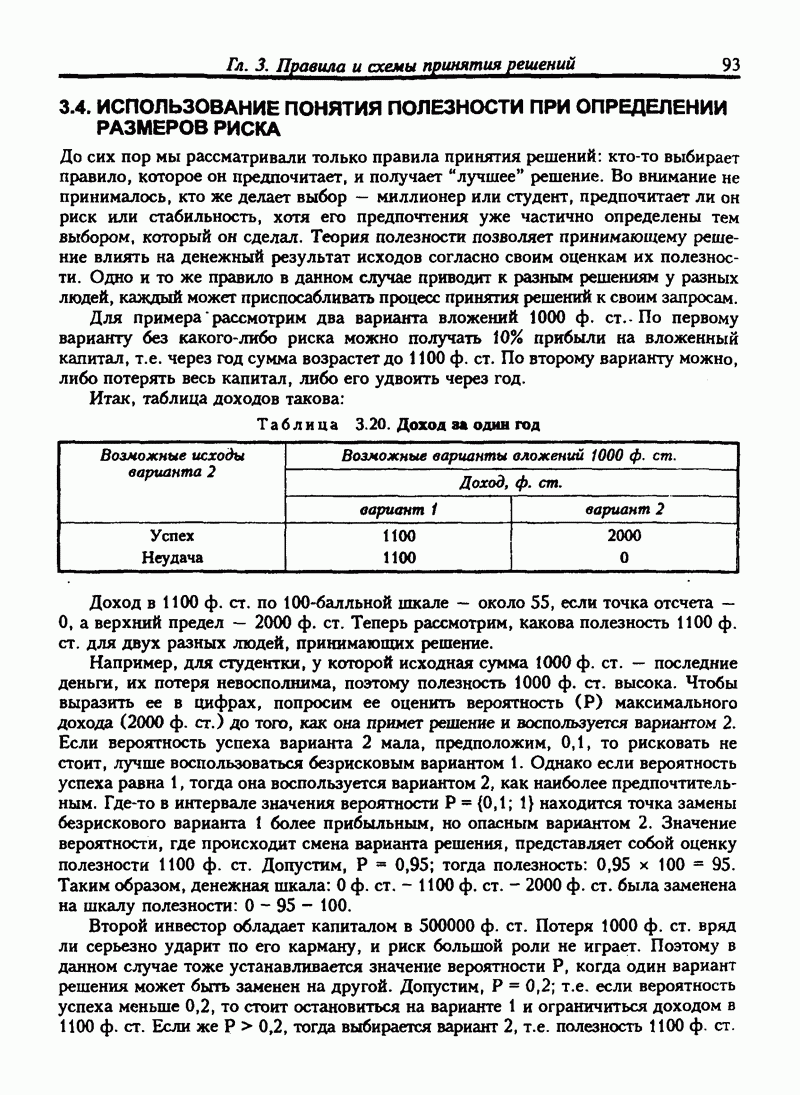
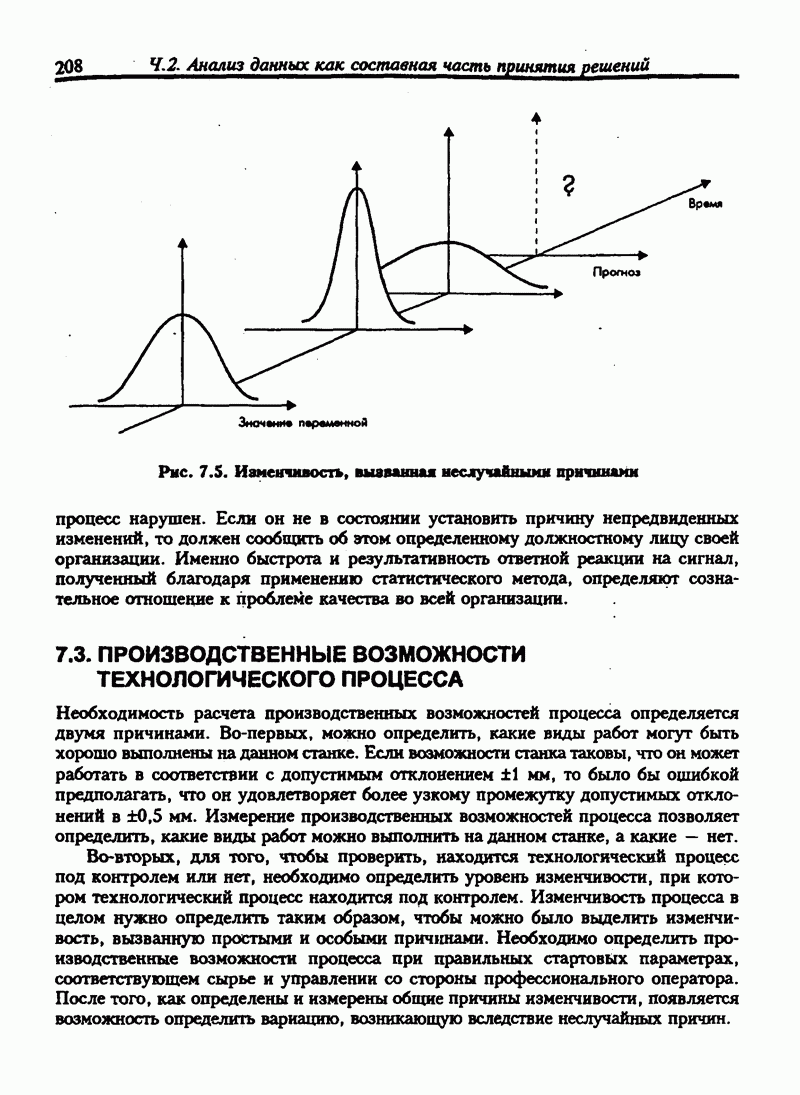
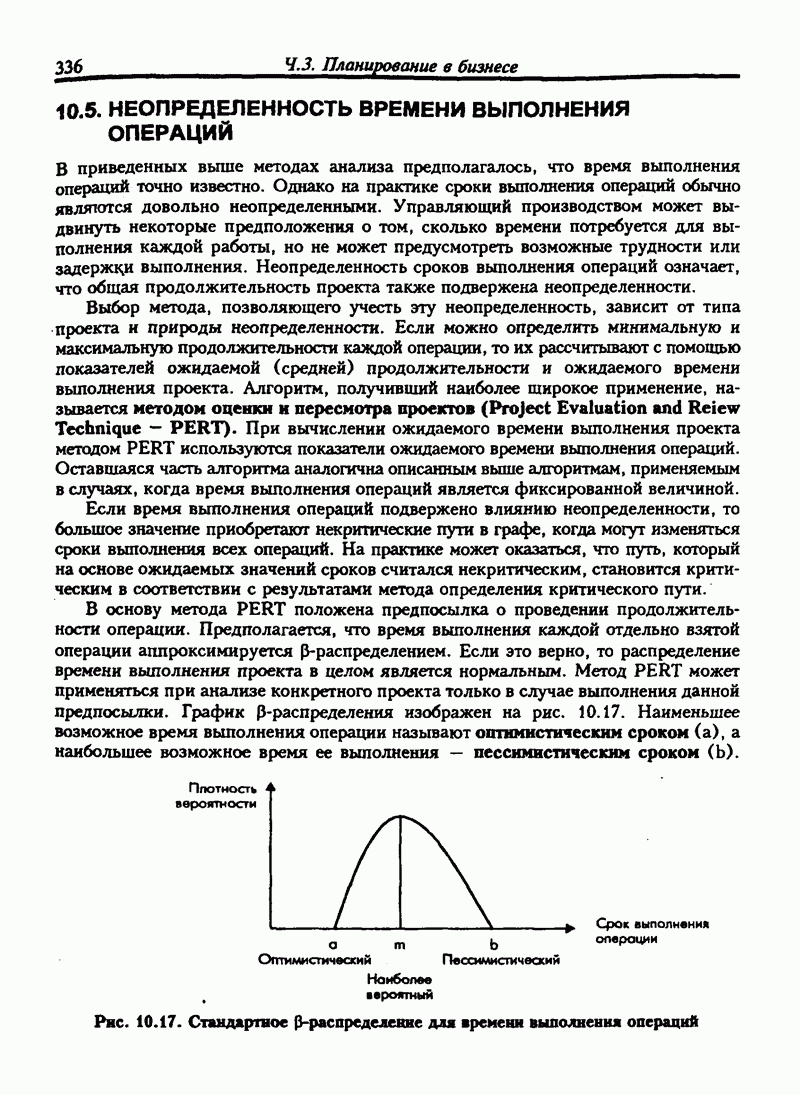
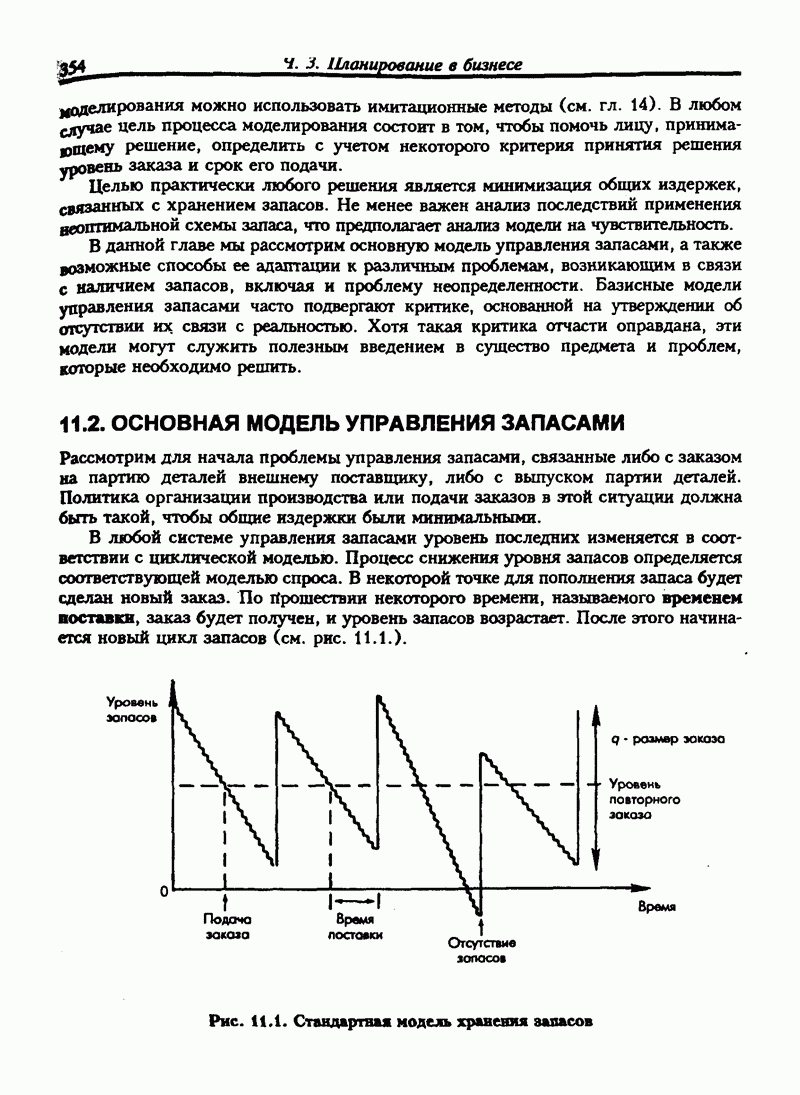
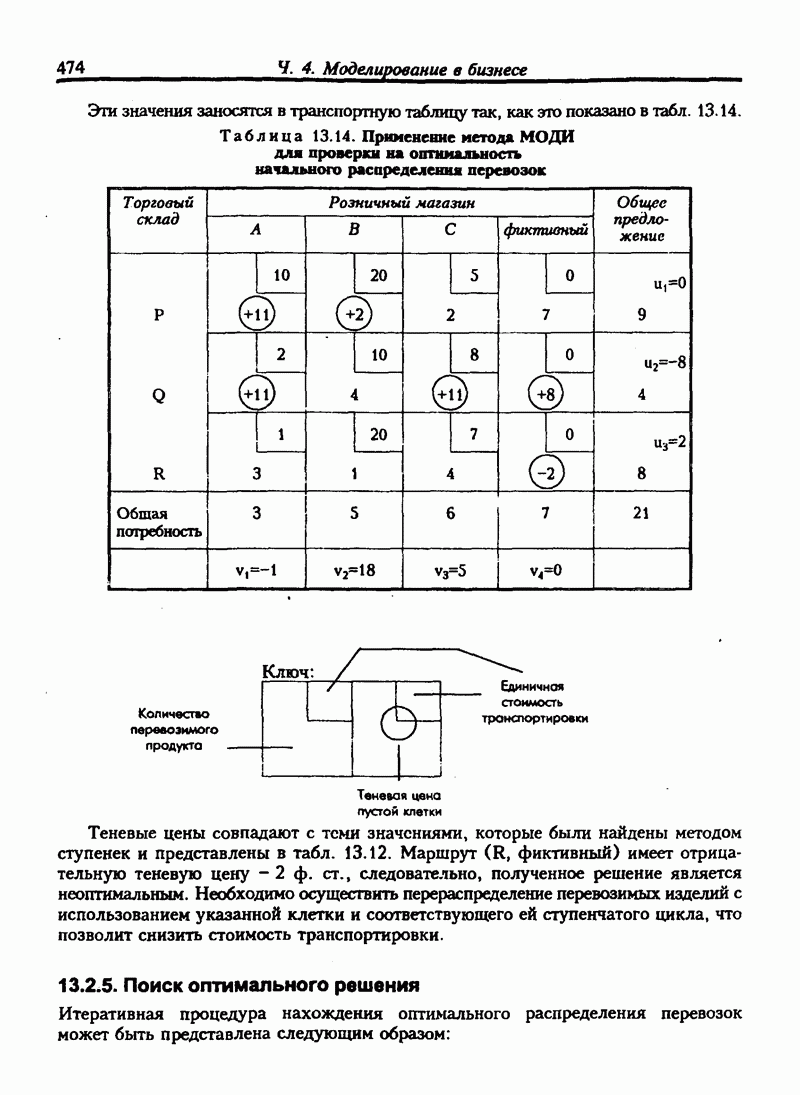
6.11. НЕПАРАМЕТРИЧЕСКИЕ ИСПЫТАНИЯ ГИПОТЕЗ-КРИТЕРИЙ ХИ-КВАДРАТВ прошлых разделах испытание касалось сравнения выборочной статистики с соответствующими генеральными параметрами. Для больших выборочных совокупностей мы предпологали, что генеральные совокупности нормальны или приблизительно нормальны. Теперь мы будем рассматривать примеры испытаний гипотез, которые не требуют ни этого предположения, ни использования генеральных параметров. Эта группа испытаний относится к непараметрическим испытаниям. Общая процедура испытания гипотез та же, что и для параметрических испытаний. Но расчет проверочной статистики другой. Рассмотрим самый общий непараметрический критерий хи-квадрат. Это — метод сравнения ряда наблюдаемых частот с ожидаемыми частотами, если верна нулевая гипотеза. Мы будем использовать этот метод для проверки взаимосвязи признаков. Признак — это характеристика переменной. Характеристики обычно относят к категории. Например цвет глаз — это признак человека, может быть отнесен к категориям: карие, голубые, серые или зеленые. Положение счетов клиентов в банке может быть отнесено к категориям: “всегда в кредите”, “обычно в кредите”, “часто превышает кредит”, "постоянно в долгу". Месячные суммы выручки от продажи товаров могут быть описаны как “высокие”, “средние”, "низкие”. Предположим, нас интересуют две разные характеристики переменной и мы хотим знать существует ли между ними какие-либо связи. Например, у нас имеются данные по оценкам, полученным группой студентов на экзамене по бухгалтерскому учету и на экзамене по математике. Нас интересует, существует ли связь между оценками, полученными на экзамене по бухучету и тем, сдали ли студенты или провалили экзамен по математике. Могут быть следующие категории: Таблица 6.5. Пример таблицы сопряженности
Число или частота студентов, которые сдали экзамен по математике и получили оценку А по бухгалтерскому учету, записано в верхней левой части таблицы. Число студентов, не сдавших математику и получивших оценку А по бухгалтерскому учету, записывается в нижней левой части таблицы и т.д. Такой тип таблицы называется таблицей сопряженности. Таблица 6.5. имеет две строки и четыре столбца, т.е. является таблицей Если обозначить наблюдаемую частоту события
Возведение в квадрат разницы
Если одна или более ожидаемых частот меньше, чем 5, то категории должны быть скомбинированны до тех пор, пока частота не превысит установленного значения. Для таблиц сопряженности
Такая поправка проводится потому, что Как мы установили в гл. 4, форма
где Пример 6.17. Компания “Autosure pic” (товарищество с ограниченной ответственностью) является крупной страховой компанией, специализирующейся на страховании автомобилей. Обычной политикой компании является начисление различных премий в соответствии с размером машины, которая страхуется. Чем больше машина, тем больше выплаты. Однако такая политика оказывается неправильной, поскольку руководители отделов сообщают о большой частоте заявлений о случаях личного ущерба для машин меньших размеров. Один из аналитиков компании исследовал данные из 566 недавно поступивших заявлений. Собранные данные представлены в таблице 6.6. Таблица 6.6. Данные 566 заявителей
Указывают ли данные на то, что частота заявлений о личном ущербе связана с размером страхуемой машины? Решение Для начала мы должны установить нулевую гипотезу. Если нет связи между типом страхового случая и размером машины, то будем предполагать, что частота заявлений в таблице зависимости будет пропорциональна итоговым данным по каждой категории:
Будем испытывать гипотезу на Для расчета проверочной статистики Таблица 6.7. Наблюдаемые частоты
Имеется 566 заявлений, из которых в 219 фигурирует личный ущерб; доля таких заявлений составляет: 219/566. Охвачено всего 269 маленьких машин, и если нет связи между двумя факторами, то можно ожидать, что 219/566 из 269 относится к категории “маленький автомобиль”. Таким образом, ожидаемая частота в первой клетке таблицы равна:
Подобно этому можно рассчитать ожидаемое число заявлений в других категориях. Все результаты показаны в ниже представленных таблицах. Ожидаемые частоты записаны слева в десятичных дробях. Поскольку они являются средними величинами, то не могут быть округлены до целого значения. Таблица 6.8. Расчет ожидаемых частот
Ожидаемые частоты представлены в табл. 6.9. Таблица 6.9. Ожидаемые частоты
Критерий х находится по формуле:
Расчет х приведен в табл. 6.10 Таблица 6.10. Расчет
Найденное значение
Рис. Поскольку
результат статистически значим на 5%-ном уровне. Мы отклоняем Таблица 6.11. Различил между наблюдаемыми и ожидаемыми частотами
Таблица подтверждает подозрения компании: число заявлений о личном ущербе больше, от владельцев маленьких машин. Учитывая сверхзатраты на заявления о личном ущербе, компания должна пересмотреть свою политику начислений. Пример 6.18. Международная фирма подготовки бухгалтеров принимает 150 выпускников школ для обучения бухгалтерским методам по результатам персональной беседы с каждым кандидатом. Управляющий хочет сравнить результаты обучения во время первого года обучения со школьным аттестатом, чтобы выяснить, есть ли между ними связь. Собранные данные приведены ниже: Таблица 6.12. Наблюдаемые частоты
Решение Для начала мы должны установить подходящую нулевую гипотезу.
Причем все наблюдаемые частоты не менее 5. Для расчета проверочной величины х мы определяем общее число обучающихся каждой категории и используем это для нахождения ожидаемых частот. Таблица 6.3. Общее число обучающихся в каждой категории
Имеется 150 обучающихся, 35 из них имеют хороший результат обучения во время первого года. Поэтому доля получения хорошего результата 35/150. Мы используем это для расчета ожидаемых частот для верхней строки таблицы. Имеется 63 обучающихся с хорошим дипломом об окончании школы, и если нет связи между двумя факторами, то будем предполагать, что 35/150 из 63 относится к первой категории в среднем. Ожидаемой частотой в первой клетке является:
Подобно этому, ожидаемое число обучающихся с хорошими результатами среди получивших средний школьный диплом равно:
в то время как ожидаемое число обучающихся с хорошими результатами среди тех, кто имеет плохой школьный диплом равно:
Следует отметить, что эти три ожидаемые частоты при суммировании дают итог строки:
Ожидаемые частоты в других строках таблицы вычисляются подобным образом. Доля обучающихся со средними результатами первого года обучения равняется 91/150, поэтому ожидаемое число обучающихся среди имеющих хороший школьный аттестат равняется:
Остающиеся ожидаемые частоты рассчитываются таким же образом. Окончательное распределение показано в табл. 6.14. Таблица 6.14. Ожидаемые частоты
Все строки и столбцы таблицы ожидаемых частот должны иметь такие же итоги, как и в исходной таблице сопряженности. Мы имеем только одну ожидаемую частоту, которая меньше 5 в клетке (3,3). Для того, чтобы использовать распределение, мы должны соединить две категории. С точки зрения испытания не важно, сокращаем ли мы число категорий школьного аттестата или результатов обучения. Нужно выбрать самое значительное для задачи. Предположим в этом случае, мы определим школьный аттестат как “хорошо" или “не хорошо", т.е. объединим столбцы “средне” и “плохо” в таблице. Тогда таблица сопряженности будет следующей: Таблица 6.15. Исправленные наблюдаемые частоты.
Соответствующие ожидаемые частоты представлены в табл. 6.16: Таблица 6.16. Исправленные ожидаемые частоты
Ожидаемые частоты теперь превышают
степенями свободы вместо 4. Из таблицы в Приложении 2 находим:
Это значение рассчитано в табл. 6.17:
Таблица 6.17. Расчет
Поскольку:
результат не значим на уровне 5%. Мы вполне уверены, что наши наблюдения согласуются с
|
 |
Оглавление
|



























































































































































































































































































































































































































































































































































































 (два на четыре). Используя соответствующую нулевую гипотезу, мы можем рассчитать число студентов, которое ожидается в каждой клетке. Если нулевая Гипотеза верна, различия между наблюдаемыми и ожидаемыми частотами будут небольшие. Будем использовать те же правила для решения, как и в прошлом испытании. Проверочная статистика рассчитывается на основе разницы между наблюдаемыми и ожидаемыми частотами для всех клеток таблицы.
(два на четыре). Используя соответствующую нулевую гипотезу, мы можем рассчитать число студентов, которое ожидается в каждой клетке. Если нулевая Гипотеза верна, различия между наблюдаемыми и ожидаемыми частотами будут небольшие. Будем использовать те же правила для решения, как и в прошлом испытании. Проверочная статистика рассчитывается на основе разницы между наблюдаемыми и ожидаемыми частотами для всех клеток таблицы.
 и ожидаемую частоту —
и ожидаемую частоту —  то
то  — различия между наблюдаемой и ожидаемой частотами. Проверочной статистикой будет служить:
— различия между наблюдаемой и ожидаемой частотами. Проверочной статистикой будет служить:

 необходимо для того, чтобы избежать нулевого эффекта при суммировании отрицательных и положительных величин. К тому же, чтобы достичь независимости от значения фактических частот, квадраты отклонений делятся на ожидаемые частоты. Это нормализует все величины. Получаемая статистика подчиняется
необходимо для того, чтобы избежать нулевого эффекта при суммировании отрицательных и положительных величин. К тому же, чтобы достичь независимости от значения фактических частот, квадраты отклонений делятся на ожидаемые частоты. Это нормализует все величины. Получаемая статистика подчиняется  -распределению при достаточно больших значениях ожидаемых частот. Ориентиром обычно служит условие:
-распределению при достаточно больших значениях ожидаемых частот. Ориентиром обычно служит условие:


 в которых сумма частот меньше или равна 100, иногда применяется корректировка — поправка Йетса. Тогда проверочная статистика вычисляется по следующей формуле:
в которых сумма частот меньше или равна 100, иногда применяется корректировка — поправка Йетса. Тогда проверочная статистика вычисляется по следующей формуле:

 является непрерывным распределением, а данные выборки - дискретные. В гл. 2 мы обсуждали необходимость такой корректировки при использовании нормального распределения для аппроксимации дискретного распределения. Для больших выборок разница между исправленными и неисправленными величинами
является непрерывным распределением, а данные выборки - дискретные. В гл. 2 мы обсуждали необходимость такой корректировки при использовании нормального распределения для аппроксимации дискретного распределения. Для больших выборок разница между исправленными и неисправленными величинами  является небольшой и в таких случаях корректировка не требуется.
является небольшой и в таких случаях корректировка не требуется.
 -распределения зависит от числа степеней свободы в данной задаче. При использовании таблиц сопряженности число степеней свободы равняется:
-распределения зависит от числа степеней свободы в данной задаче. При использовании таблиц сопряженности число степеней свободы равняется:

 и с — число строк и столбцов в таблице сопряженности. Если таблица имеет только одну строку, то чисдо степеней свободы: (с - 1).
и с — число строк и столбцов в таблице сопряженности. Если таблица имеет только одну строку, то чисдо степеней свободы: (с - 1).


 -иом уровне значимости используя
-иом уровне значимости используя  критерий с
критерий с  степенями свободы. Из таблиц в Приложении 2 находим, что:
степенями свободы. Из таблиц в Приложении 2 находим, что: 
 мы должны определить ожидаемые частоты из итоговых данных по каждой категории.
мы должны определить ожидаемые частоты из итоговых данных по каждой категории.







 показано на рис. 6.13.
показано на рис. 6.13.

 критическое значение на
критическое значение на  -ном уровне значимости при двух степенях свободы
-ном уровне значимости при двух степенях свободы

 на этом уровне и принимаем
на этом уровне и принимаем  Мы можем быть вполне уверены, что данные указывают на связь между заявлениями, в которых отмечается личный ущерб, и размером страхуемой машины. На этой ступени мы не знаем, какой это вид связи. Компания считает, что она получает больше заявлений о личном ущербе при страховке машин маленьких размеров. Чтобы убедиться так ли это, покажем составляющие
Мы можем быть вполне уверены, что данные указывают на связь между заявлениями, в которых отмечается личный ущерб, и размером страхуемой машины. На этой ступени мы не знаем, какой это вид связи. Компания считает, что она получает больше заявлений о личном ущербе при страховке машин маленьких размеров. Чтобы убедиться так ли это, покажем составляющие  (табл. 6.11.).
(табл. 6.11.).


 должна быть так выбрана, что бы мы смогли рассчитать ожидаемые частоты. Если мы предполагаем, что нет связи между результатами обучения в первом году и школьным аттестатом, то будем ожидать частоты обучающихся в таблице сопряженности пропорционально общим числам в каждой категории.
должна быть так выбрана, что бы мы смогли рассчитать ожидаемые частоты. Если мы предполагаем, что нет связи между результатами обучения в первом году и школьным аттестатом, то будем ожидать частоты обучающихся в таблице сопряженности пропорционально общим числам в каждой категории.
 Нет связи между результатами обучающихся первый год и их конечными оценками в школе.
Нет связи между результатами обучающихся первый год и их конечными оценками в школе.
 Имеется некоторая связь между результатом обучения и аттестатом. Будем испытывать гипотезу на
Имеется некоторая связь между результатом обучения и аттестатом. Будем испытывать гипотезу на  -ном уровне значимости, используя
-ном уровне значимости, используя  критерий с
критерий с  степенями свободы.
степенями свободы.









 испытание может быть продолжено как и раньше, но с
испытание может быть продолжено как и раньше, но с






 и мы принимаем ее на атом уровне. Мы заключаем, что не существует связи между результатами обучения во время первого года и школьным аттестатом.
и мы принимаем ее на атом уровне. Мы заключаем, что не существует связи между результатами обучения во время первого года и школьным аттестатом.