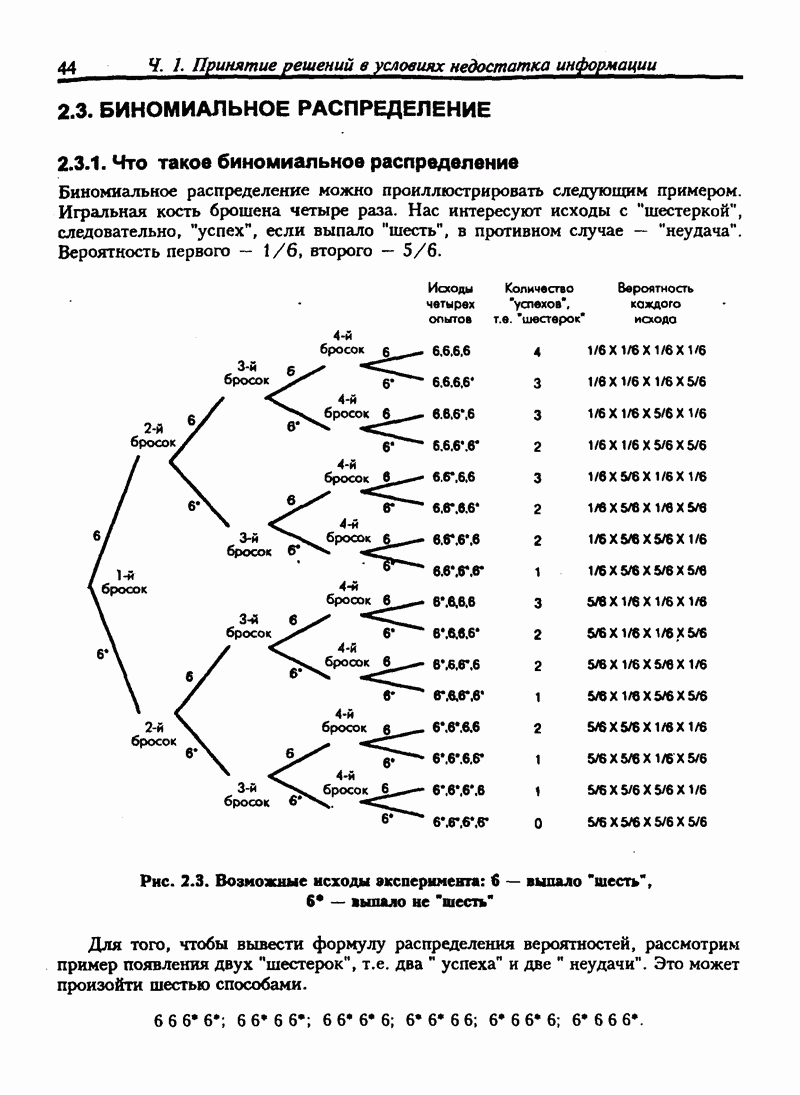
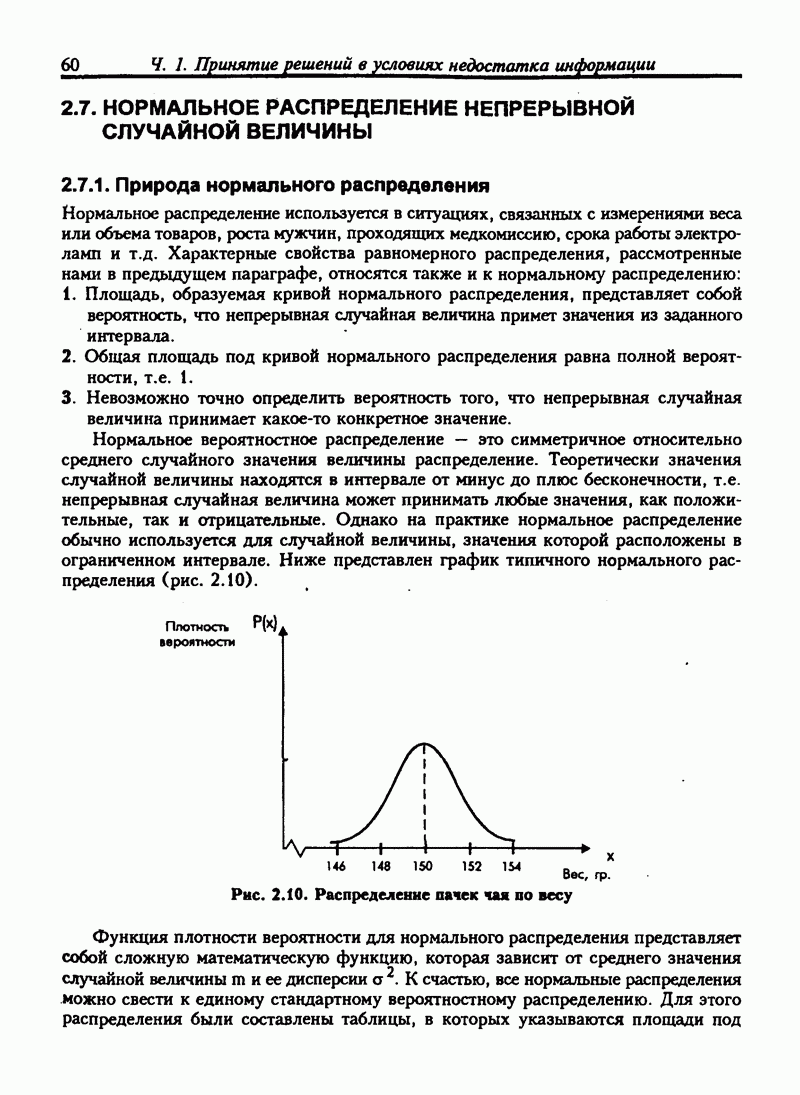
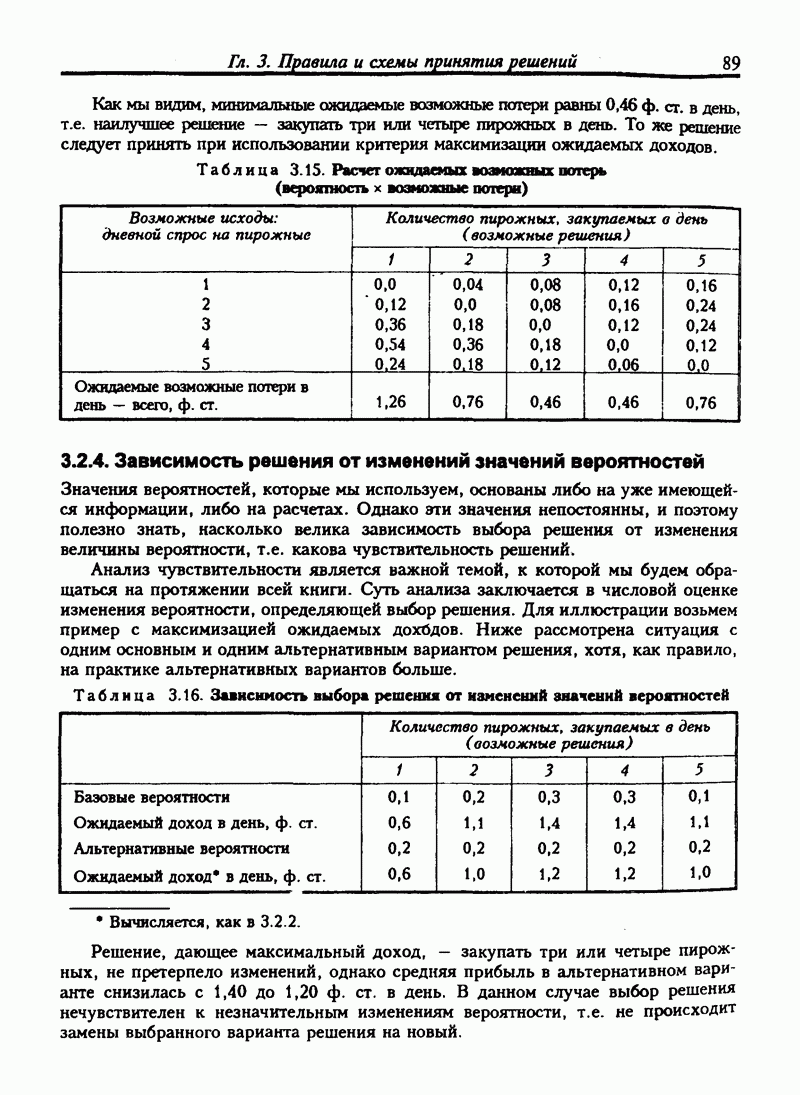
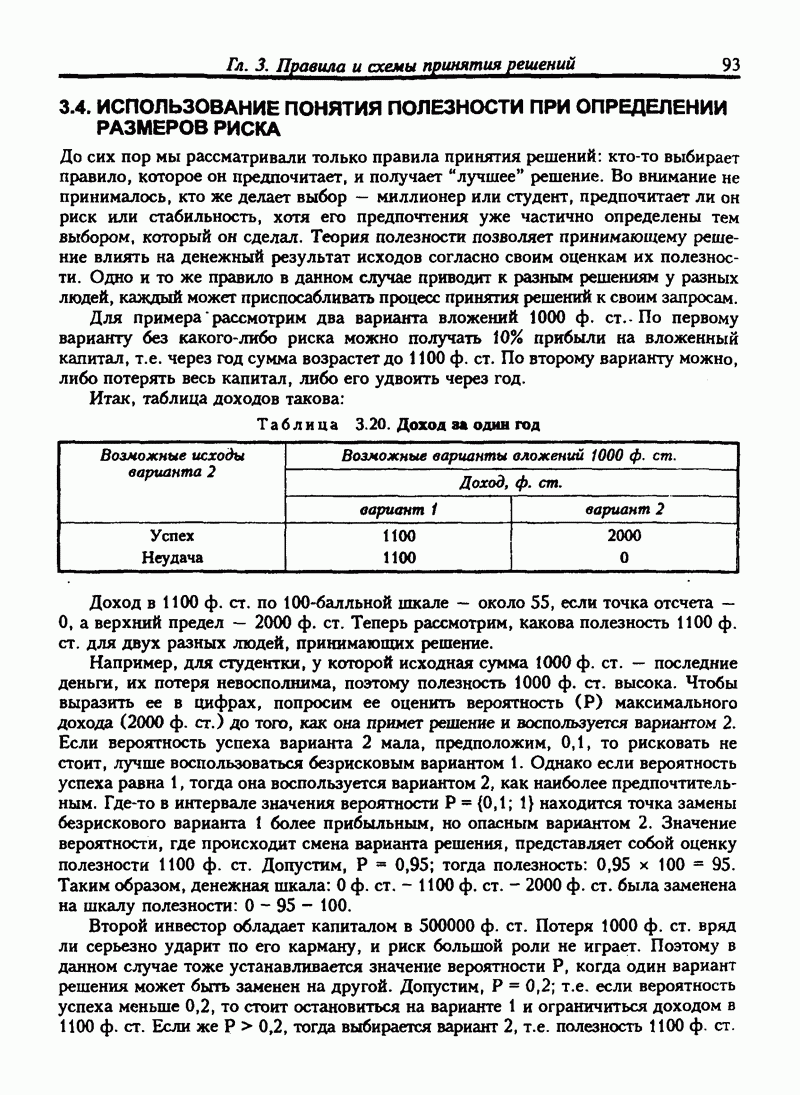
8.4. ПРЕДСКАЗАНИЯ И ПРОГНОЗЫ НА ОСНОВЕ ЛИНЕЙНОЙ МОДЕЛИ РЕГРЕССИИ
8.4.1. Прогнозы с упорядоченными данными
Мы можем использовать модель для прогноза времени поездки на любые расстояния. Если расстояние равно 4,0 мили, то среднее время поставки:

В расчетах такого рода требуется осторожность: не рекомендуется использовать модель для прогноза при тех значениях независимой переменной, которые не входят в исходные данные. В нашем случае расстояние изменяется от 1,0 мили до 4,9 мили. Не очевидно, что модель подойдет для данных, не входящих в этот интервал.
Связь между временем и расстоянием может изменяться по мере увеличения расстояния. Например, дальняя поездка может включать использование скоростных шоссе, тогда как наша модель описывала связь с учетом медленных городских поездок. Дальние перевозки должны включать остановки на отдых или перекус, которые безусловно изменяют затраченное время.
Если бы нам нужно было экстраполировать расчеты для расстояния, выходящего за указанные пределы, мы должны были бы собрать больше данных. Если бы мы решили не делать этого, то должны быть предельно осторожны при использовании прогнозных значений времени поездок. Но эти прогнозы были бы, вероятно, ненадежны.
8.4.2. Оценки, ошибки и остатки
Насколько точными должны быть наши прогнозы? В следующей части мы рассмотрим вопросы, связанные с доверительными интервалами. Однако также полезно оценить надежность, сравнив значения зависимой переменной у и предсказанные значения у для каждого значения независимой переменной х. Эти ошибки, или остатки  — необъясненная часть каждого наблюдаемого значения у, являются чрезвычайно важными по двум причинам. Во-первых, они позволяют проверить, применима ли данная модель и те предположения, на которых она основана. Во-вторых, мы можем использовать их для того, чтобы дать грубую оценку вероятных ошибок прогнозов, сделанных на основе линейкой модели.
— необъясненная часть каждого наблюдаемого значения у, являются чрезвычайно важными по двум причинам. Во-первых, они позволяют проверить, применима ли данная модель и те предположения, на которых она основана. Во-вторых, мы можем использовать их для того, чтобы дать грубую оценку вероятных ошибок прогнозов, сделанных на основе линейкой модели.
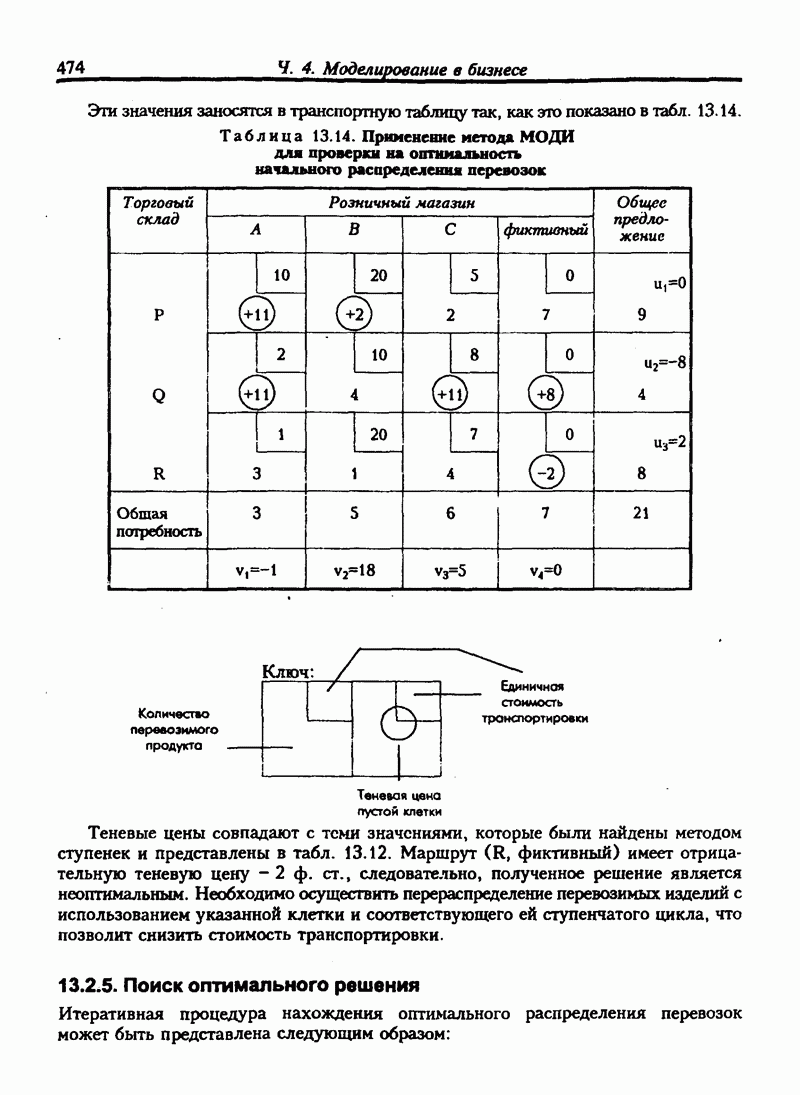
Табл. 8.3 содержит значения остатков для примера 8.1.
Таблица 8.3. Расчет остатков 

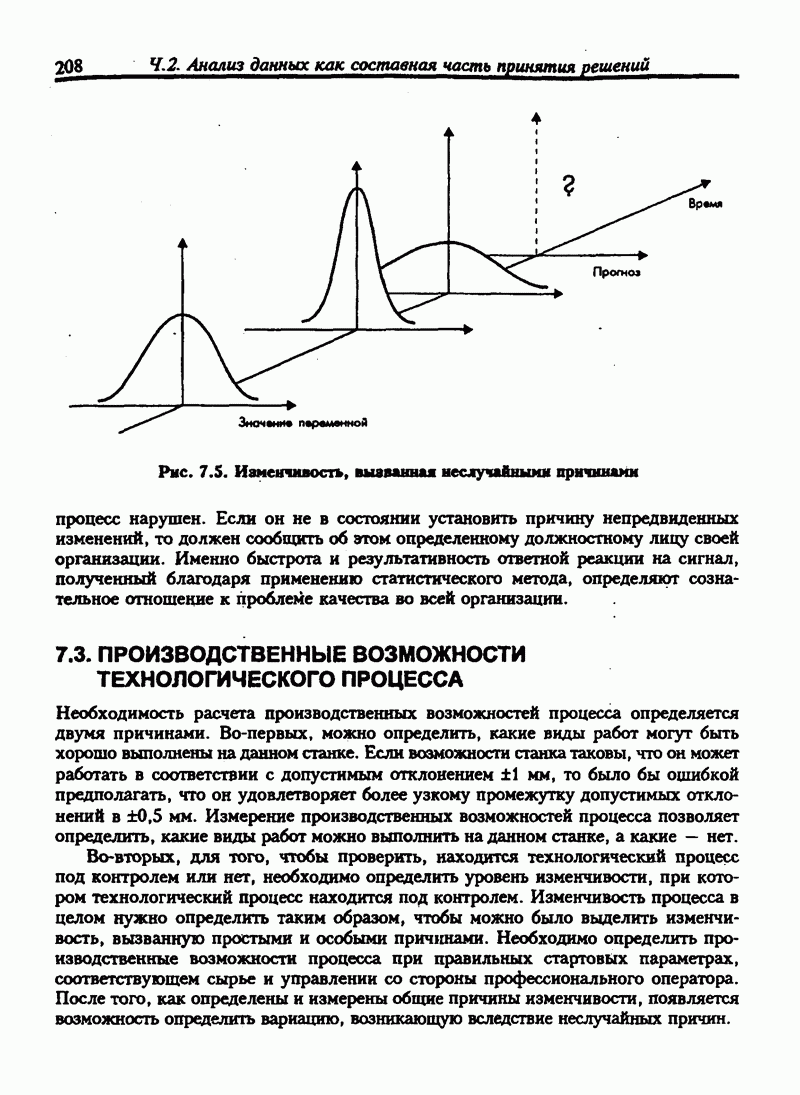
Мы можем проверить удовлетворительность модели, нанося остатки  на ось ординат против вычисленных значений у, с учетом значений х. Эта процедура очень важна при построении множественной регрессии, когда исходные данные не могут быть нанесены на исходную диаграмму, т. е. линейность предположенной связи может быть оценена в полной мере только через анализ остатков. Если линейная модель является точной, разности, или остатки, будут носить случайный характер и их сумма будет близка к нулю. Изображение разностей, или остатков, для данного примера дано на рис. 8.10.
на ось ординат против вычисленных значений у, с учетом значений х. Эта процедура очень важна при построении множественной регрессии, когда исходные данные не могут быть нанесены на исходную диаграмму, т. е. линейность предположенной связи может быть оценена в полной мере только через анализ остатков. Если линейная модель является точной, разности, или остатки, будут носить случайный характер и их сумма будет близка к нулю. Изображение разностей, или остатков, для данного примера дано на рис. 8.10.

Рис. 8.10. График остатков  против вычисленных значений у
против вычисленных значений у
Если бы связь была нелинейной, то рисунок показал бы это очень четко. Пример эффекта линейной модели показан на рис. 8.11 и 8.12.

Рис. 8.11. Исходные данные и вычисленная линия регрессии

Рис. 8.12. Остатки, свидетельствующие о криволннейности связи
Остатки позволяют оценить рассеяние ошибок. Одним из основных предположений в методе наименьших квадратов является то, что рассеяние данных возле линии регрессии одинаково при всех значениях х (см. рис. 8.13 и рис. 8.14):

Рис. 8.13. Постоянная вариация для всех значений х

Рис. 8.14. Вариация, изменяющаяся со значениями х
Варьирующие данные постоянно пересекают линию, следовательно, для подбора наилучшей линии может быть использован метод наименьших квадратов (рис. 8.13).
На рис. 8.14 показан пример данных, которые распределяются вдоль линии регрессии неравномерно, в этом случае метод наименьших квадратов непригоден для подбора "наилучшей" линии.
Если остатки распределяются так, как на рис. 8.15, то мы делаем вывод, что вариация у изменяется с изменениями х.
В нашем примере выделяются два значения остатка  и 1,63). Они свидетельствуют, что данные не соответствуют предположениям о едином характере вариации. Следовательно, доверительный интервал, описанный в следующей части, не будет применим.
и 1,63). Они свидетельствуют, что данные не соответствуют предположениям о едином характере вариации. Следовательно, доверительный интервал, описанный в следующей части, не будет применим.

Рис. 8.15. График остатков для данных, вариация которых не является постоянной для всех значений х
Единственным способом продолжать статистический анализ доверительных интервалов и испытание гипотез в таком случае является трансформация данных (часто используются логарифмы значений  до тех пор, пока график остатков не покажет случайное рассеяние точек относительно
до тех пор, пока график остатков не покажет случайное рассеяние точек относительно  при небольших значениях остатков.
при небольших значениях остатков.
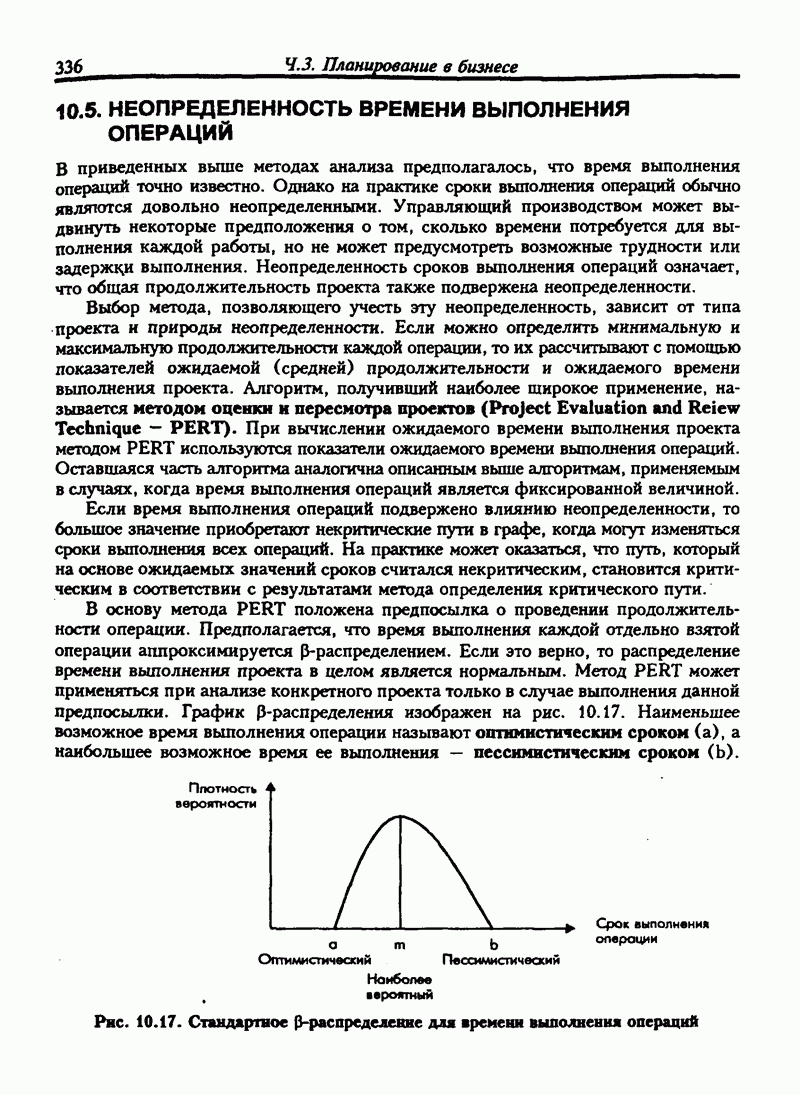
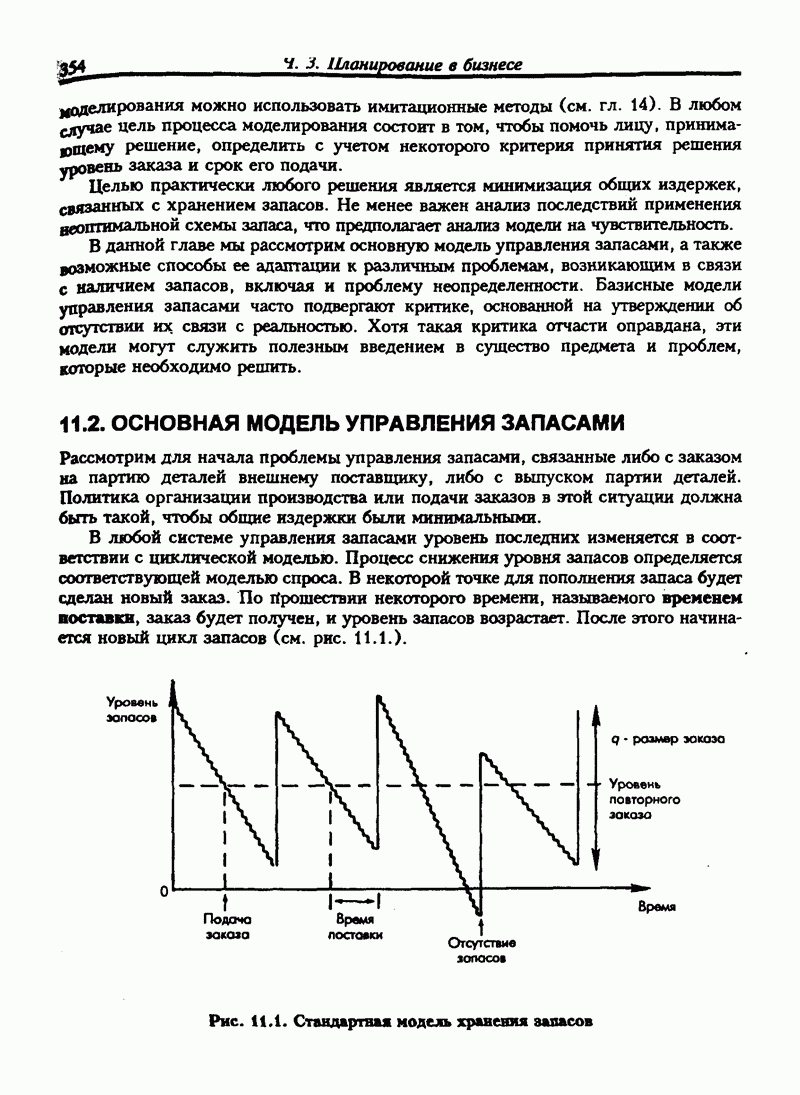
Оценка устойчивости и колеблемости линейной модели регрессии может быть длительной процедурой, особенно если ряд данных увеличивается не постоянно, а с замедлением. Существует множество  для статистической обработки. Может показаться, что дело обстоит просто: нужно собрать данные и ввести их в компьютер. Программа рассчитывает линейную модель, не обращая внимание на то, годится она или нет. В следующем разделе мы рассмотрим, как установить и оценить линейную регрессионную модель.
для статистической обработки. Может показаться, что дело обстоит просто: нужно собрать данные и ввести их в компьютер. Программа рассчитывает линейную модель, не обращая внимание на то, годится она или нет. В следующем разделе мы рассмотрим, как установить и оценить линейную регрессионную модель.