§ 2.6. Методы нелинейного и стохастического программирования
Основные трудности при попытках аналитического решения рекуррентных уравнений оптимизации возникают из-за того, что нельзя аналитически найти условные плотности вероятностей  если динамическая система описывается нелинейным дифференциальным уравнением (1.1), не удается получить аналитические
если динамическая система описывается нелинейным дифференциальным уравнением (1.1), не удается получить аналитические
выражения для функций минимальных условных рисков  или
или  и найти векторы
и найти векторы  минимизирующие многомерные интегралы в рекуррентных уравнениях главы 1.
минимизирующие многомерные интегралы в рекуррентных уравнениях главы 1.
Поэтому далее рассматриваются два возможных метода численного решения задачи синтеза: метод, основанный на сочетании цифрового моделирования динамической системы и стохастического программирования (в частном случае — стохастических аппроксимаций), и метод, основанный на нелинейном программировании.
Изложим вкратце основы нелинейного и стохастического программирования в виде, используемом в дальнейшем. Пусть дана скалярная функция  зависящая от
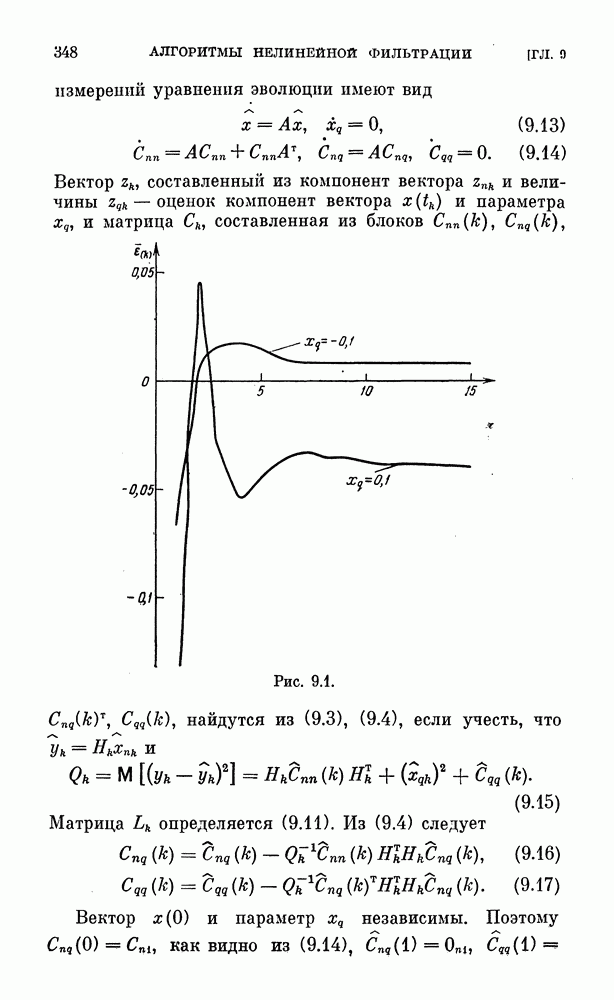
зависящая от  переменных — элементов вектора и, и необходимо найти вектор
переменных — элементов вектора и, и необходимо найти вектор 

где  выпуклая область,
выпуклая область,  строго выпуклая вниз дифференцируемая функция. Задачу (2.48) называют задачей нелинейного (выпуклого) программирования. Если
строго выпуклая вниз дифференцируемая функция. Задачу (2.48) называют задачей нелинейного (выпуклого) программирования. Если  то необходимое и достаточное условие экстремума имеет вид
то необходимое и достаточное условие экстремума имеет вид

где  градиент
градиент  в точке и. Последовательность векторов
в точке и. Последовательность векторов  сходящихся к вектору
сходящихся к вектору  строят с помощью градиентного алгоритма
строят с помощью градиентного алгоритма

где  последовательность матриц, выбираемая из условия достижения возможно большей скорости сходимости алгоритма. Так, например, быстрая сходимость обеспечивается, если
последовательность матриц, выбираемая из условия достижения возможно большей скорости сходимости алгоритма. Так, например, быстрая сходимость обеспечивается, если  матрица, обратная матрице вторых производных функции
матрица, обратная матрице вторых производных функции  при
при  (многомерный аналог метода Ньютона). В этом случае вектор
(многомерный аналог метода Ньютона). В этом случае вектор  определяется за одну итерацию, если
определяется за одну итерацию, если  квадратичная функция компонент вектора и. Однако обычно эту матрицу найти сложно (или невозможно).
квадратичная функция компонент вектора и. Однако обычно эту матрицу найти сложно (или невозможно).
Простейший градиентный алгоритм получим, положив  равным
равным  постоянному, достаточно малому числу. Известно (см., например, [3], [42]), что обеспечится линейная сходимость
постоянному, достаточно малому числу. Известно (см., например, [3], [42]), что обеспечится линейная сходимость  (в функции
(в функции  убывает как член некоторой геометрической прогрессии:
убывает как член некоторой геометрической прогрессии:
 если величину
если величину  определить формулой
определить формулой

где  и
и  соответственно максимальное и минимальное собственные числа матрицы вторых производпых строго выпуклой вниз функции
соответственно максимальное и минимальное собственные числа матрицы вторых производпых строго выпуклой вниз функции  максимум и минимум собственных чисел определятся на некоторой области, окружающей
максимум и минимум собственных чисел определятся на некоторой области, окружающей  При выполнении (2.51)
При выполнении (2.51)

Для увеличения быстроты сходимости и для ликвидации незатухающих колебаний элементов векторов  (зацикливания) в [42] рекомендуются градиентные алгоритмы, в которых реализуется принцип обратной связи: величины (или матрицы)
(зацикливания) в [42] рекомендуются градиентные алгоритмы, в которых реализуется принцип обратной связи: величины (или матрицы)  делаются функциями
делаются функциями  Однако в задачах, имеющих прикладное значение, часто функция
Однако в задачах, имеющих прикладное значение, часто функция  задается алгоритмически, вычислить элементы вектора градиента
задается алгоритмически, вычислить элементы вектора градиента  не представляется возможным и градиентный алгоритм в виде (2.50) нереализуем. В этом случае градиент определяется приближенно с помощью конечных разностей. Пусть
не представляется возможным и градиентный алгоритм в виде (2.50) нереализуем. В этом случае градиент определяется приближенно с помощью конечных разностей. Пусть  орт, направленный по
орт, направленный по  оси системы координат в
оси системы координат в  Тогда вектор приближенного градиента (квазиградиента) определяется формулой
Тогда вектор приближенного градиента (квазиградиента) определяется формулой

В [42] описаны градиентные алгоритмы, использующие векторы  и определенную логику последовательного уменьшения величин
и определенную логику последовательного уменьшения величин  и доказана их сходимость. Уменьшение величип
и доказана их сходимость. Уменьшение величип  может привести к увеличению случайных ошибок реальных вычислений из-за деления друг на друга малых величии в (2.52). Если
может привести к увеличению случайных ошибок реальных вычислений из-за деления друг на друга малых величии в (2.52). Если  гладкая функция, аппроксимируемая в окрестности
гладкая функция, аппроксимируемая в окрестности  квадратичной функцией, то, начиная с некоторого
квадратичной функцией, то, начиная с некоторого  далее, их величины уменьшать не надо при использовании вместо (2.52) формулы
далее, их величины уменьшать не надо при использовании вместо (2.52) формулы

Легко показать, что  если
если  квадратичная функция. Действительно, допуская
квадратичная функция. Действительно, допуская
соответствующую диффереыцируемость  получим
получим

где

Для квадратичной функции  следовательно, квазиградиент равен градиенту.
следовательно, квазиградиент равен градиенту.
Заметим, что, используя разности более высоких порядков и усложняя вид правой части (2.52), можно получить точный градиент, если  полиномиальная функция любой заданной степени от компонент вектора и (см. [28]). Если
полиномиальная функция любой заданной степени от компонент вектора и (см. [28]). Если  число элементов вектора и велико, а расчет функции
число элементов вектора и велико, а расчет функции  в каждой точке осуществляется сложным алгоритмом, то определение вектора
в каждой точке осуществляется сложным алгоритмом, то определение вектора  по формуле (2.52) или (2.53) может требовать большого объема вычислений на ЦВМ. В этом случае при определении вектора квазиградиента целесообразно пользоваться методом случайного поиска, определив случайный вектор
по формуле (2.52) или (2.53) может требовать большого объема вычислений на ЦВМ. В этом случае при определении вектора квазиградиента целесообразно пользоваться методом случайного поиска, определив случайный вектор  соотношением
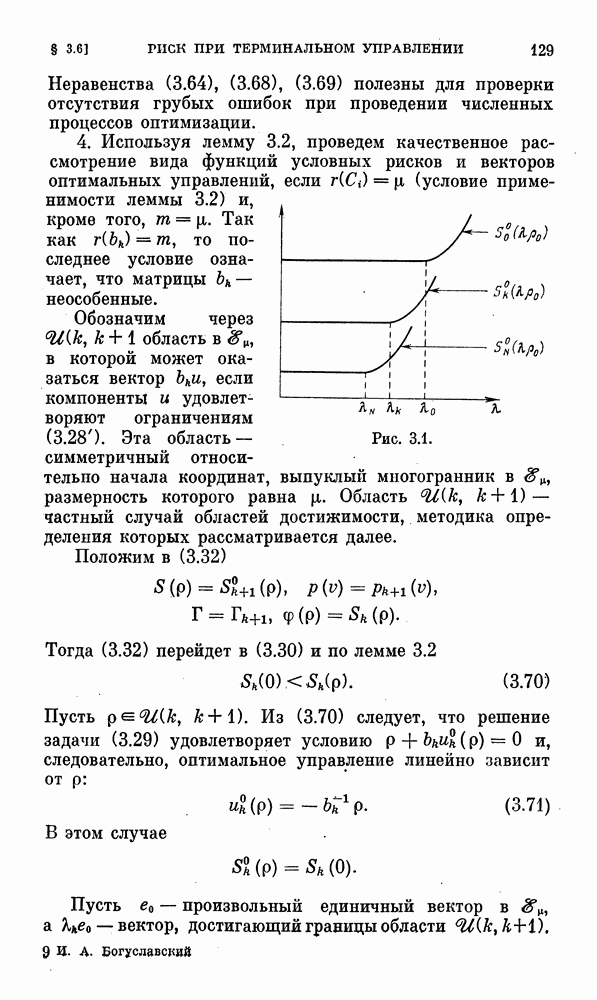
соотношением

где  случайные векторы, элементы которых являются независимыми случайными величинами
случайные векторы, элементы которых являются независимыми случайными величинами  каждая из которых равномерно распределена на отрезке
каждая из которых равномерно распределена на отрезке  число независимых статистических испытаний на
число независимых статистических испытаний на  шаге итерационного процесса (для сокращения объема вычислений число
шаге итерационного процесса (для сокращения объема вычислений число  должно быть заметно меньше числа
должно быть заметно меньше числа 
Используя в (2.56) первые три члена разложения функции  в ряд и учитывая, что
в ряд и учитывая, что

нетрудно показать [25], что

где  вектор, элементы которого зависят от вторых частных производных функции
вектор, элементы которого зависят от вторых частных производных функции  Из (2.57) видно, что вектор
Из (2.57) видно, что вектор  является случайным вектором, условное м. о. которого линейно связано с градиентом
является случайным вектором, условное м. о. которого линейно связано с градиентом  минимизируемой функции
минимизируемой функции  Такие случайные векторы называются далее стохастическими квазиградиентами [25]. Если условное м. о. вектора совпадает с градиентом минимизируемой функции, то этот вектор называется стохастическим градиентом (общее определение стохастического квазиградиента, используемого, если минимизируемая выпуклая вниз функция не имеет непрерывных производных, дано в [25]). Алгоритм минимизации функции
Такие случайные векторы называются далее стохастическими квазиградиентами [25]. Если условное м. о. вектора совпадает с градиентом минимизируемой функции, то этот вектор называется стохастическим градиентом (общее определение стохастического квазиградиента, используемого, если минимизируемая выпуклая вниз функция не имеет непрерывных производных, дано в [25]). Алгоритм минимизации функции  имеет вид (2.50) после замены векторов градиентов
имеет вид (2.50) после замены векторов градиентов  на случайные векторы стохастических квазиградиентов
на случайные векторы стохастических квазиградиентов  Условия сходимости к
Условия сходимости к  в некотором статистическом смысле случайных векторов
в некотором статистическом смысле случайных векторов  приводятся ниже.
приводятся ниже.
Учтем теперь ограниченность области допустимых векторов и: и  и для определенности примем, что квазиградиент дается формулой (2.52). Алгоритм выпуклого программирования [25], [42] имеет вид
и для определенности примем, что квазиградиент дается формулой (2.52). Алгоритм выпуклого программирования [25], [42] имеет вид

где вектор  определяется формулой
определяется формулой

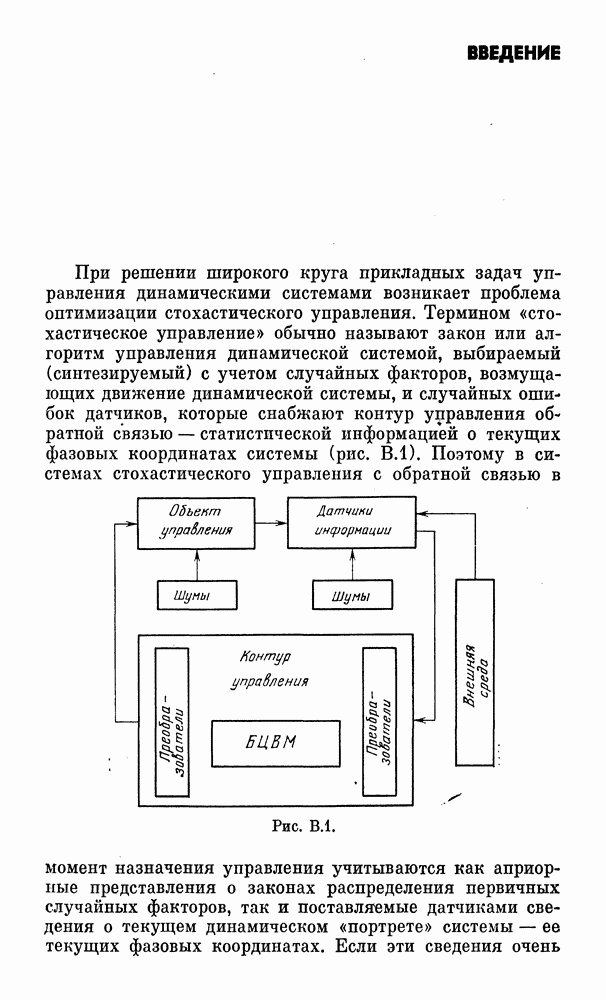
Соотношение (2.59) описывает операцию проектирования произвольного вектора z на оболочку выпуклой области  точка на
точка на  расстояние которой до произвольной точки z минимально. Ясно,
расстояние которой до произвольной точки z минимально. Ясно,  если
если  (рис. 2.1). В приложениях часто область
(рис. 2.1). В приложениях часто область  прямоугольный параллелепипед. Тогда
прямоугольный параллелепипед. Тогда

где  элемент вектора
элемент вектора  заданные числа. Тогда (2.59) запишем в виде
заданные числа. Тогда (2.59) запишем в виде

откуда

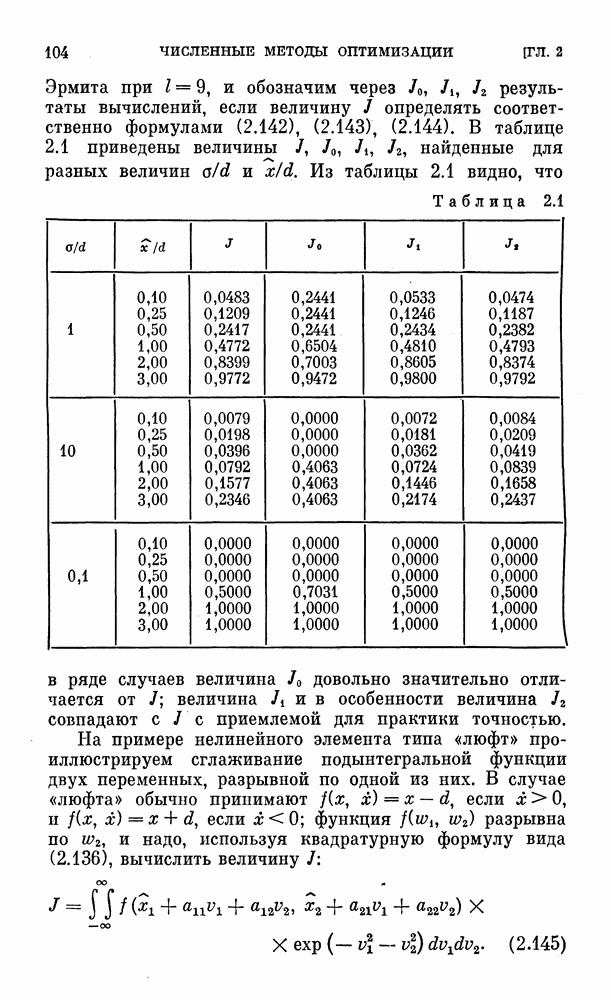
Алгоритм выпуклого программирования вида (2.58) называется методом проектирования градиента (или квазиградиента). Метод проектирования стохастического квазиградиента описывается алгоритмом

Из общих теорем, приведенных в [25], следует (теорема 1 на стр. 97), что при получении векторов  из (2.56) случайные векторы
из (2.56) случайные векторы  из (2.60) сходятся к
из (2.60) сходятся к  почти наверное (с вероятностью 1), если выполнены условия
почти наверное (с вероятностью 1), если выполнены условия

и ограничены вторые частные производные минимизируемой выпуклой вниз функции  Последнее условие обеспечивает ограниченность компонент векторов
Последнее условие обеспечивает ограниченность компонент векторов  в (2.57) и ограниченность условных (при фиксированных
в (2.57) и ограниченность условных (при фиксированных  дисперсий случайных величин
дисперсий случайных величин  Условия (2.61) выполнятся, если, например,
Условия (2.61) выполнятся, если, например,


Рис. 2.1.
Требуемую (2.61) интенсивность уменьшения величин можно сделать менее значительной (это целесообразно для уменьшения ошибок реальных вычислений), если вместо (2.56) определить вектор  формулой
формулой

После разложения в ряд найдем 

В (2.64) и  векторы, зависящие от третьих частных производных функции
векторы, зависящие от третьих частных производных функции  - компоненты которых считаем ограниченными. При использовании стохастического квазиградиента в форме (2.63) последнее условие в (2.61) можно заменить условием
- компоненты которых считаем ограниченными. При использовании стохастического квазиградиента в форме (2.63) последнее условие в (2.61) можно заменить условием

В этом случае сходимость почти наверное обеспечится, если в (2.62) условие  заменить условием
заменить условием

Заметим, что если считать  функцией, достаточно точно аппроксимируемой в окрестности
функцией, достаточно точно аппроксимируемой в окрестности  квадратичной функцией, то в
квадратичной функцией, то в  стохастический квазиградиент не зависит от
стохастический квазиградиент не зависит от  и совпадает со стохастическим градиентом. В этом случае, начиная с некоторого
и совпадает со стохастическим градиентом. В этом случае, начиная с некоторого  величины
величины  можно не уменьшать.
можно не уменьшать.
Следует отметить, что метод проектирования градиента — лишь один из большого числа эффективных численных методов выпуклого программирования, прошедших апробацию при решении широкого круга задач практики. Выше изложен именно этот метод из-за его тесной связи с рассматриваемым далее методом стохастического программирования.
Пусть Ли) — функция вектора  определяемая формулой
определяемая формулой

где  случайный вектор,
случайный вектор,  функция соответствующего числа переменных. Распределение вектора
функция соответствующего числа переменных. Распределение вектора  может моделироваться — существует программа ЦВМ, которая при каждом фиксированном векторе и выдает независимые случайные векторы, имеющие условную плотность вероятности
может моделироваться — существует программа ЦВМ, которая при каждом фиксированном векторе и выдает независимые случайные векторы, имеющие условную плотность вероятности  Функцию
Функцию  обычно считают строго выпуклой вниз по и (что обеспечивает существование единственного минимума) и имеющей непрерывные и ограниченные вторые производные.
обычно считают строго выпуклой вниз по и (что обеспечивает существование единственного минимума) и имеющей непрерывные и ограниченные вторые производные.
Надо построить последовательность случайных векторов  которая в некотором статистическом смысле сходится к
которая в некотором статистическом смысле сходится к  вектору, доставляющему минимум функции Ли):
вектору, доставляющему минимум функции Ли):

Наиболее естественный и «добротный» способ нахождения вектора  состоит в приближенном определении методом статистических испытаний (методом Монте-Карло) величины
состоит в приближенном определении методом статистических испытаний (методом Монте-Карло) величины  — среднего значения случайной величины
— среднего значения случайной величины  для каждого фиксированного и и применении, далее, градиентного алгоритма, в котором
для каждого фиксированного и и применении, далее, градиентного алгоритма, в котором  заменен на
заменен на  вектор квазиградиента функции
вектор квазиградиента функции  при
при  Однако в этом «прямолинейном» способе очень велик объем вычислений на ЦВМ. Действительно, для осуществления одной итерации надо определить вектор
Однако в этом «прямолинейном» способе очень велик объем вычислений на ЦВМ. Действительно, для осуществления одной итерации надо определить вектор  который, например, в соответствии с формулой
который, например, в соответствии с формулой

требует применения метода Монте-Карло  раз (для определения значения Ли) и в
раз (для определения значения Ли) и в  точках).
точках).
Экономию объема вычислений дает метод стохастического программирования, в котором несколько сотен статистических испытаний, нужных для уверенного определения Ли) при данном векторе и, заменяются одним испытанием — вычислением одной из реализаций случайной величины 
Ранее подчеркивалось, что в изложенном варианте метода случайного поиска применяется градиентный алгоритм (или алгоритм проектирования градиента) при замене вектора градиента вектором стохастического квазиградиента — случайным вектором, условное м. о. которого линейно зависит от вектора градиента минимизируемой функции. Та же идея используется и в методе стохастического программирования: для минимизации функции Ли), заданной (2.68), применяется тот или иной вариант градиентного алгоритма, в котором вместо квазиградиента  определяемого в результате большого объема вычислений, используется стохастический квазиградиент функции Ли).
определяемого в результате большого объема вычислений, используется стохастический квазиградиент функции Ли).
Допустим вначале, что  гладкая по и функция и имеет соответствующее число производных и при дифференцировании по и равенства (2.68) операции дифференцирования и осреднения перестановочны (производная по параметру интеграла, подынтегральная функция которого зависит от параметра, равна интегралу от производной этой функции по параметру). Тогда
гладкая по и функция и имеет соответствующее число производных и при дифференцировании по и равенства (2.68) операции дифференцирования и осреднения перестановочны (производная по параметру интеграла, подынтегральная функция которого зависит от параметра, равна интегралу от производной этой функции по параметру). Тогда

где  градиент по и функции
градиент по и функции  следовательно,
следовательно,  стохастический градиент функции Ли). Если вектор
стохастический градиент функции Ли). Если вектор  не может быть найден точно (функция
не может быть найден точно (функция  задается алгоритмически), то в градиентном алгоритме на итерации с номером
задается алгоритмически), то в градиентном алгоритме на итерации с номером  используется его приближенное выражение — квазиградиент, например, вида (2.53) (вектор
используется его приближенное выражение — квазиградиент, например, вида (2.53) (вектор  фиксирован):
фиксирован):

где  случайная реализация вектора
случайная реализация вектора  имеющего плотность вероятности
имеющего плотность вероятности 
Вместо одного вектора  можно в (2.72) использовать и независимую выборку
можно в (2.72) использовать и независимую выборку  Аналогично (2.54) получим
Аналогично (2.54) получим

и

где  вектор, компоненты которого ограничены, если допустить ограниченность третьих частных производных функции
вектор, компоненты которого ограничены, если допустить ограниченность третьих частных производных функции  по
по  . Аналогичные выражения для стохастического градиента получим при использовании процедуры случайного поиска в описанном выше варианте.
. Аналогичные выражения для стохастического градиента получим при использовании процедуры случайного поиска в описанном выше варианте.
Алгоритм метода стохастического программирования имеет вид

где  последовательность случайных, независимых векторов с плотностями вероятностей
последовательность случайных, независимых векторов с плотностями вероятностей 
Векторы  из алгоритма (2.75) сходятся к
из алгоритма (2.75) сходятся к  почти наверное, если выполнены условия (2.61) с заменой последнего из них менее жестким условием (2.66) и справедливо представление (2.73), а условные дисперсии случайных величин
почти наверное, если выполнены условия (2.61) с заменой последнего из них менее жестким условием (2.66) и справедливо представление (2.73), а условные дисперсии случайных величин  и
и  ограничены [25].
ограничены [25].
Однако часто функция  недифференцируема по и и представления (2.73), (2.74) не существуют. Такая ситуация возникает, если, например,
недифференцируема по и и представления (2.73), (2.74) не существуют. Такая ситуация возникает, если, например,  характеристическая функция некоторого множества элементарных событий (равна 0 или 1) и Ли) — вероятность
характеристическая функция некоторого множества элементарных событий (равна 0 или 1) и Ли) — вероятность
выполнения некоторого сложного события. Поэтому обычно требуют лишь ограниченности условий дисперсии величины  Тогда из (2.72) для условной дисперсии случайной величины
Тогда из (2.72) для условной дисперсии случайной величины  следует лишь оценка
следует лишь оценка

В этом случае условия сходимости алгоритма (2.75) имеют вид [25]

Нетрудно проверить, что (2.76) выполнится, если

где 
Отметим, что при отсутствии ограничений на векторы и алгоритм стохастического программирования имеет вид

и носит название метода стохастических аппроксимаций Сметод Кифера — Вольфовица); условия сходимости этого метода обычно записываются в виде (2.76) [20]. Рекомендуется использовать 
Если функция  в (2.68) задана аналитически и вектор
в (2.68) задана аналитически и вектор  в (2.71) может быть определен для любых
в (2.71) может быть определен для любых  то алгоритм стохастического программирования получим из (2.75) после замены
то алгоритм стохастического программирования получим из (2.75) после замены  на
на  Условия его сходимости почти наверное состоят из первых трех условий в (2.61).
Условия его сходимости почти наверное состоят из первых трех условий в (2.61).
Для убыстрения сходимости алгоритма (2.75) можно с методом стохастического программирования комбинировать усеченный метод Монте-Карло, осуществляемый при относительно малом числе статистических испытаний. В этом случае стохастический квазиградиент  заменяется
заменяется  его средним за
его средним за  независимых статистических испытаний:
независимых статистических испытаний:

При  и соответствующий
и соответствующий  алгоритм (2.75) переходит в детерминированный алгоритм метода проектирования градиента.
алгоритм (2.75) переходит в детерминированный алгоритм метода проектирования градиента.
Выбирая  из условия
из условия  можно ценой не очень значительного увеличения вычислений добиться улучшения сходимости итерационного процесса.
можно ценой не очень значительного увеличения вычислений добиться улучшения сходимости итерационного процесса.
Когда следует прекращать итерационный процесс? В дальнейшем всегда вектор и имеет физический смысл вектора управления динамической системой, обычно реализуемого с точностью, не превышающей 5%. Поэтому итерационный процесс можно было бы прекратить, например, после того как выполнится неравенство

В реальных ситуациях судить о близости  можно, сравнивая сглаженные каким-либо цифровым фильтром значения величин
можно, сравнивая сглаженные каким-либо цифровым фильтром значения величин 
В ряде случаев наряду с определением оптимального вектора  необходимо найти величину
необходимо найти величину  где
где  заданная функция соответствующих переменных. В частном случае может быть
заданная функция соответствующих переменных. В частном случае может быть  следовательно,
следовательно,  После того как
После того как  определен, величину
определен, величину  легко найти методом Монте-Карло:
легко найти методом Монте-Карло:

где  достаточно велико. Однако можно поступить более экономно. Построим последовательность случайных чисел, сходящихся к величине
достаточно велико. Однако можно поступить более экономно. Построим последовательность случайных чисел, сходящихся к величине  в процессе определения алгоритмом стохастического программирования вектора
в процессе определения алгоритмом стохастического программирования вектора  Именно, определим упомянутую последовательность алгоритмом
Именно, определим упомянутую последовательность алгоритмом

где  — отрезок, внутри которого из априорных соображений должно находиться число
— отрезок, внутри которого из априорных соображений должно находиться число  Обозначим
Обозначим  Тогда
Тогда

где  некоторое число. Поэтому случайные величины
некоторое число. Поэтому случайные величины  являются стохастическими градиентами по
являются стохастическими градиентами по  функций
функций  которые выпуклы вниз по
которые выпуклы вниз по  и равномерно (при
и равномерно (при  по
по  сходятся к функции
сходятся к функции  когда
когда  Тогда из [25]
Тогда из [25]























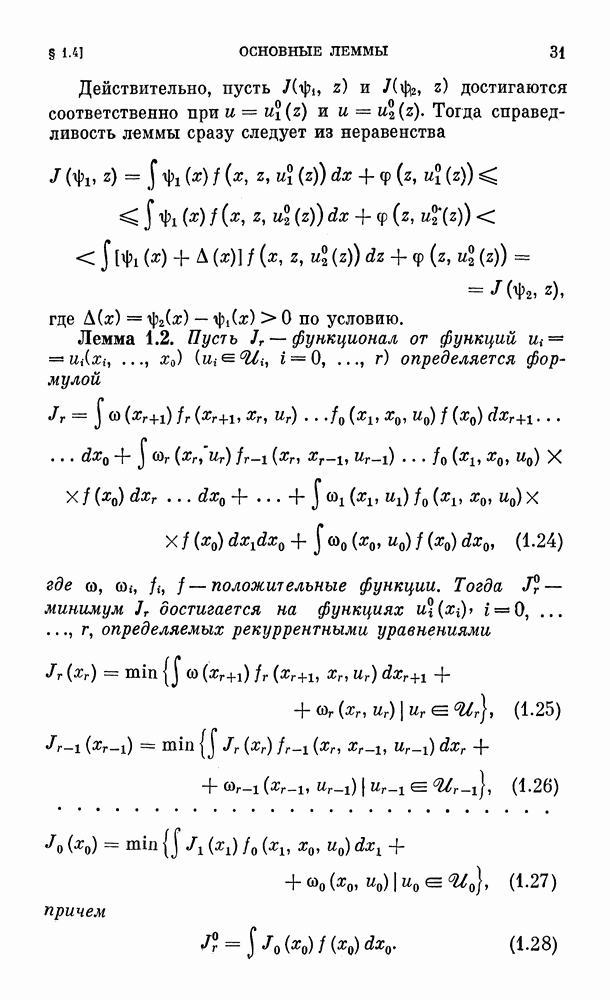


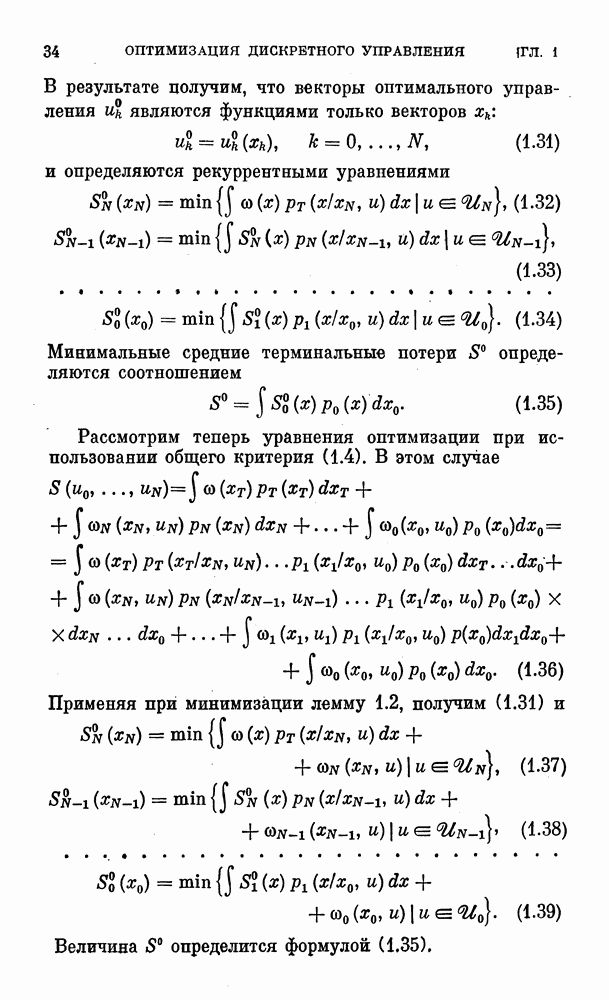





























































































































































































































































































































































 определяемая алгоритмом (2.77), почти наверное сходится в величине
определяемая алгоритмом (2.77), почти наверное сходится в величине  точке минимума функции
точке минимума функции  Поэтому одновременная реализация алгоритмов (2.75), (2.77) приведет к построению вектора
Поэтому одновременная реализация алгоритмов (2.75), (2.77) приведет к построению вектора  и величины
и величины  с помощью одной и той же последовательности случайных независимых векторов
с помощью одной и той же последовательности случайных независимых векторов 