Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
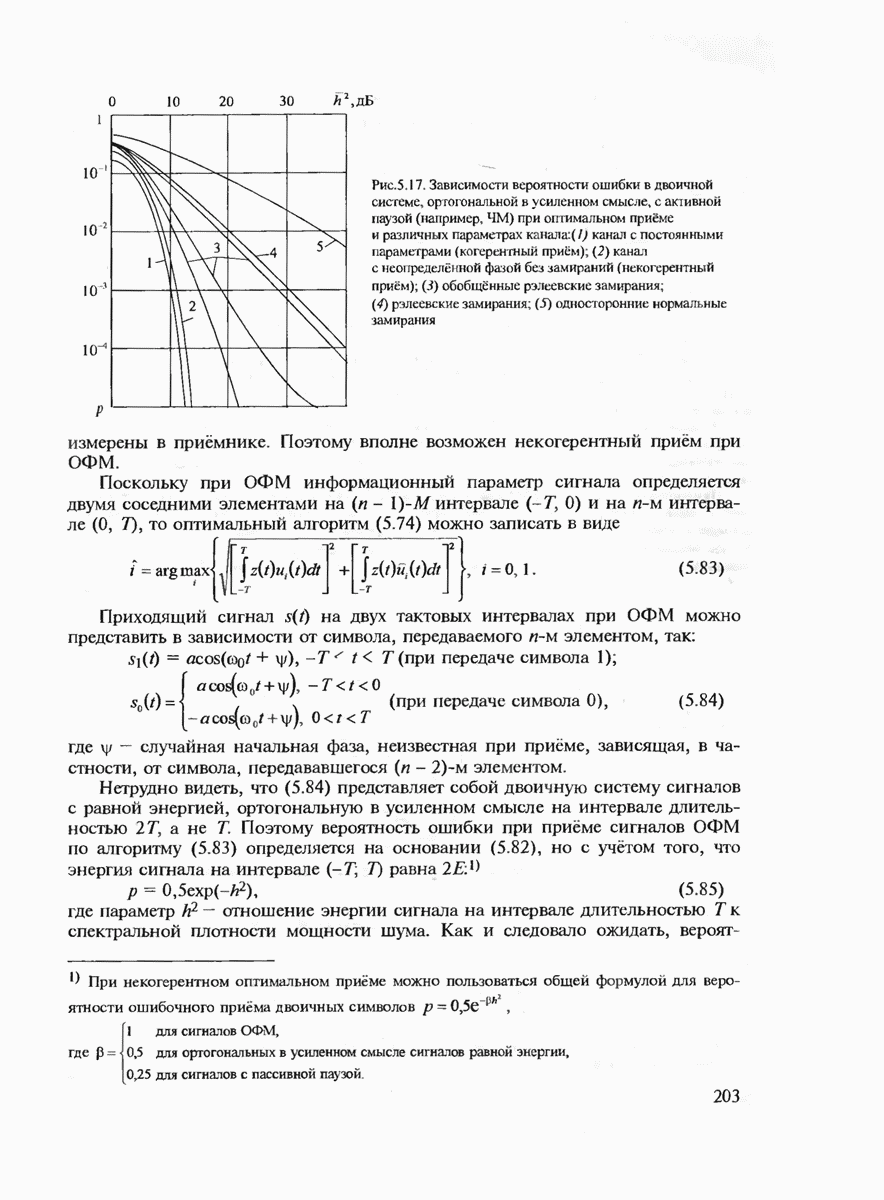
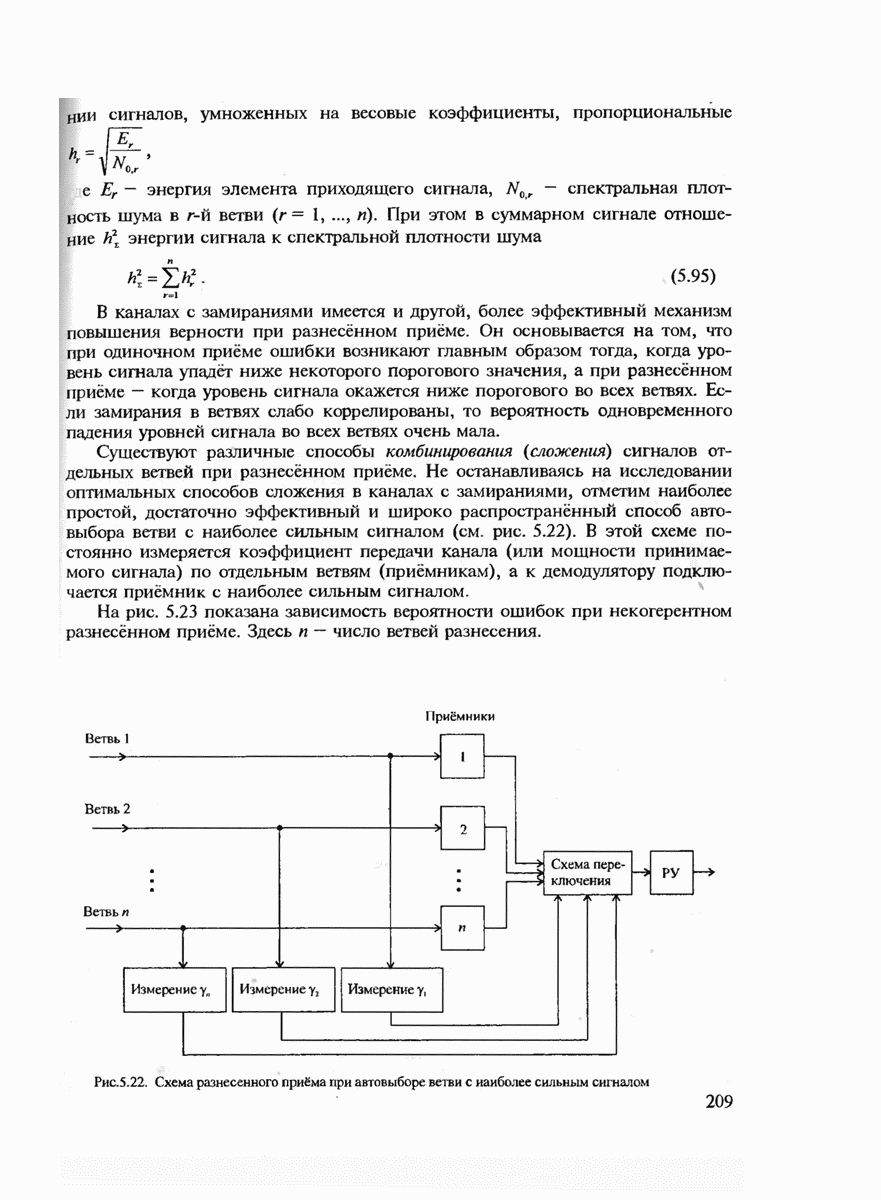
7.3.1. ВЕРОЯТНОСТЬ ОШИБКИ ОПТИМАЛЬНОГО ДЕКОДИРОВАНИЯ ДЛЯ КОДОВ С ФИКСИРОВАННОЙ ДЛИНОЙ БЛОКОВ (ЭКСПОНЕНТЫ ВЕРОЯТНОСТЕЙ ОШИБОК)Пусть имеется некоторый канал связи, который описывается условными переходными вероятностями Теорема 7.2. Существует блоковый код V длины
где Для доказательства теоремы потребуется следующая простая лемма. Лемма. Пусть
Доказательство леммы. Используя известную аддитивную границу (неравенство Буля) и тривиальную границу для вероятности любого события, получаем
Если Доказательство теоремы Верхняя граница (7.8) выводится с помошью рассмотрения так называемого ансамбля кодов, а не одного "хорошего" кода. Ансамбль блоковых кодов задаётся следующим образом. Определим сначала произвольное распределение вероятностей Среднюю по ансамблю кодов величину
где При заданных
Если в (7.13) имеет место строгое неравенство, то декодер максимального правдоподобия примет решение о передаче сообщения
Согласно определению события
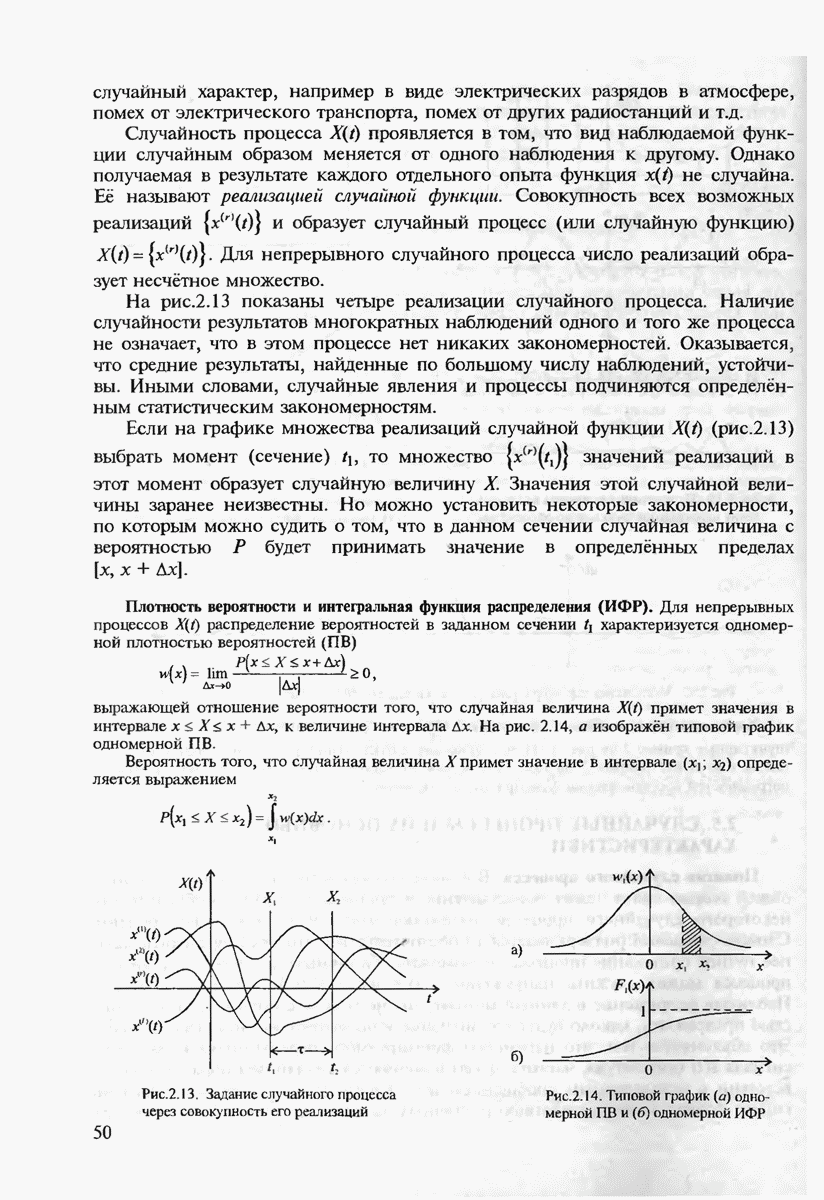
Легко убедиться, что правую часть (7.15) можно ограничить сверху, если умножить каждое слагаемое в нём на
Видно, что
Далее, подставляя (7.17) в (7.12), будем иметь
Подставляя Используем неравенство (7.8) для оценки
Тогда (7.8) преобразуется к виду
где Границу (7.19) можно представить в экспоненциальной форме, заменив
где Чтобы найти наилучшую верхнюю границу, необходимо максимизировать
Решение этой задачи для произвольных дискретных каналов представляет определённые трудности. Однако для
где
при
и
где
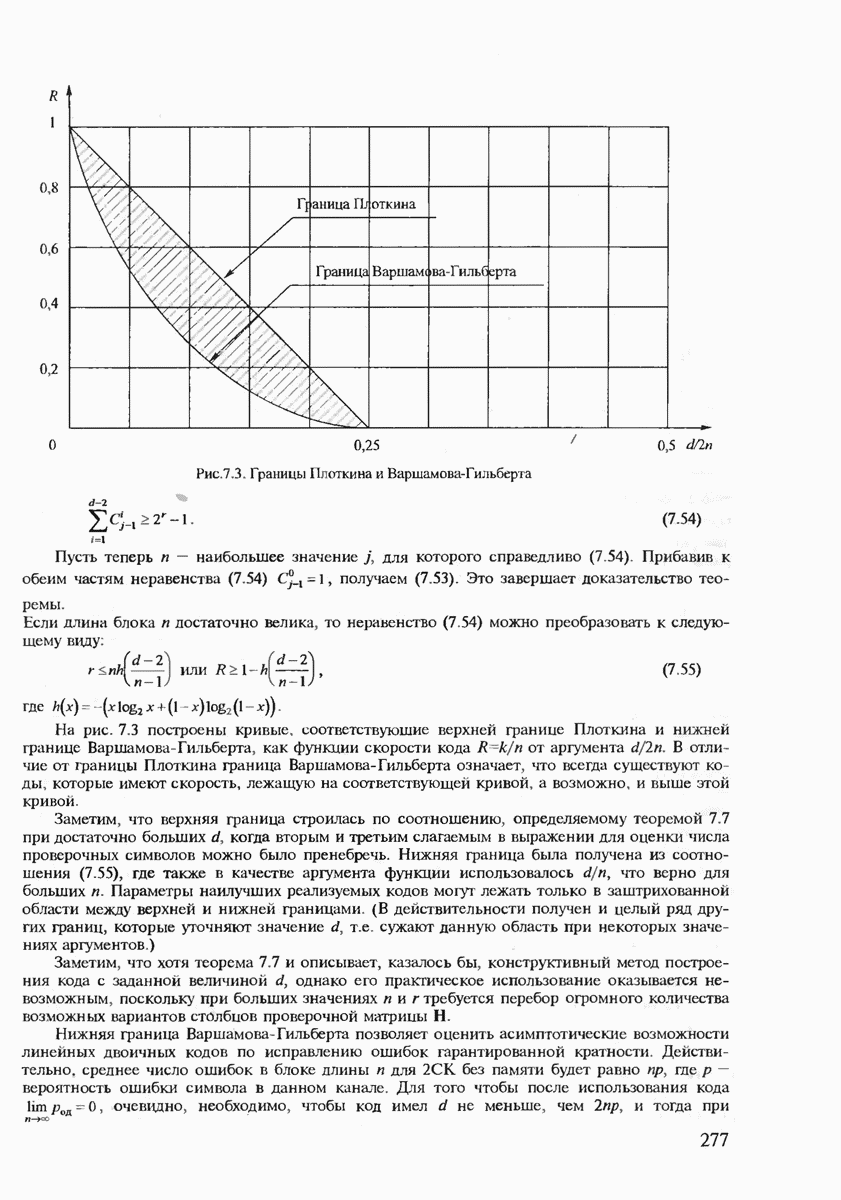
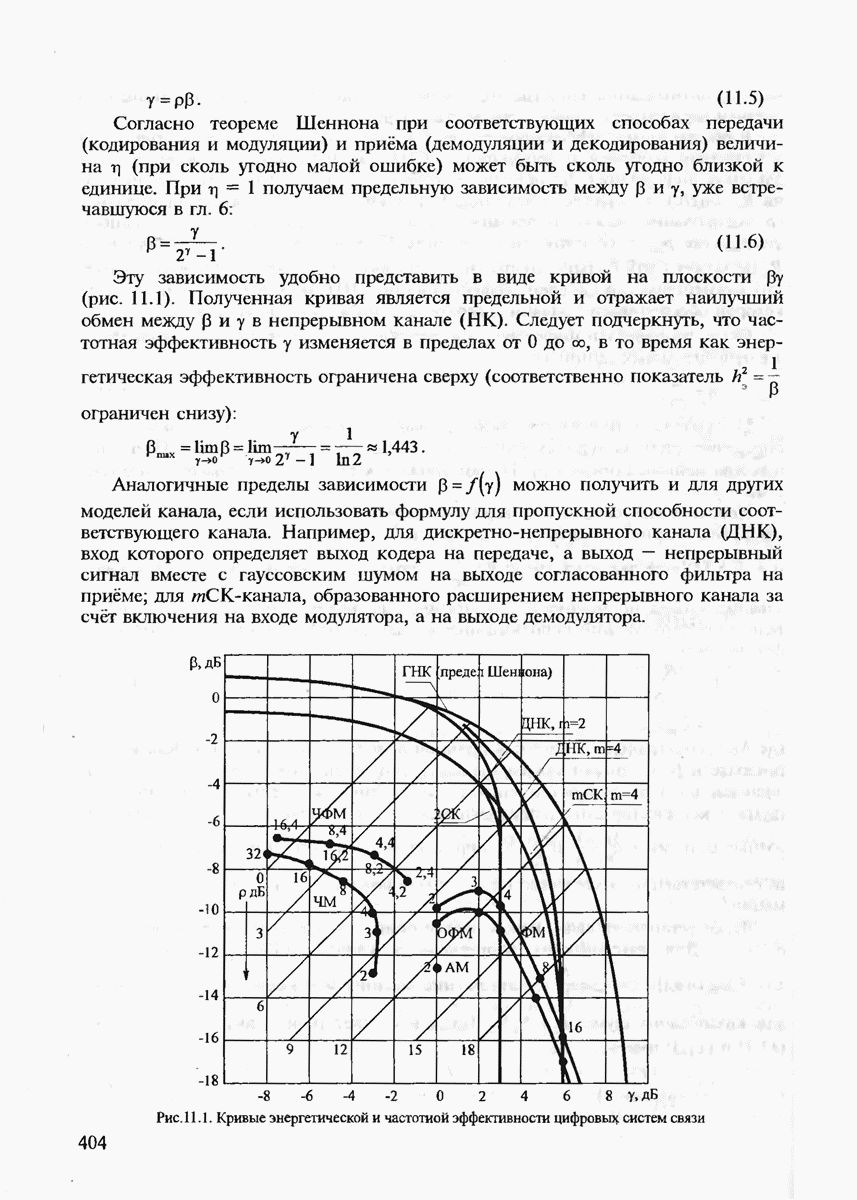
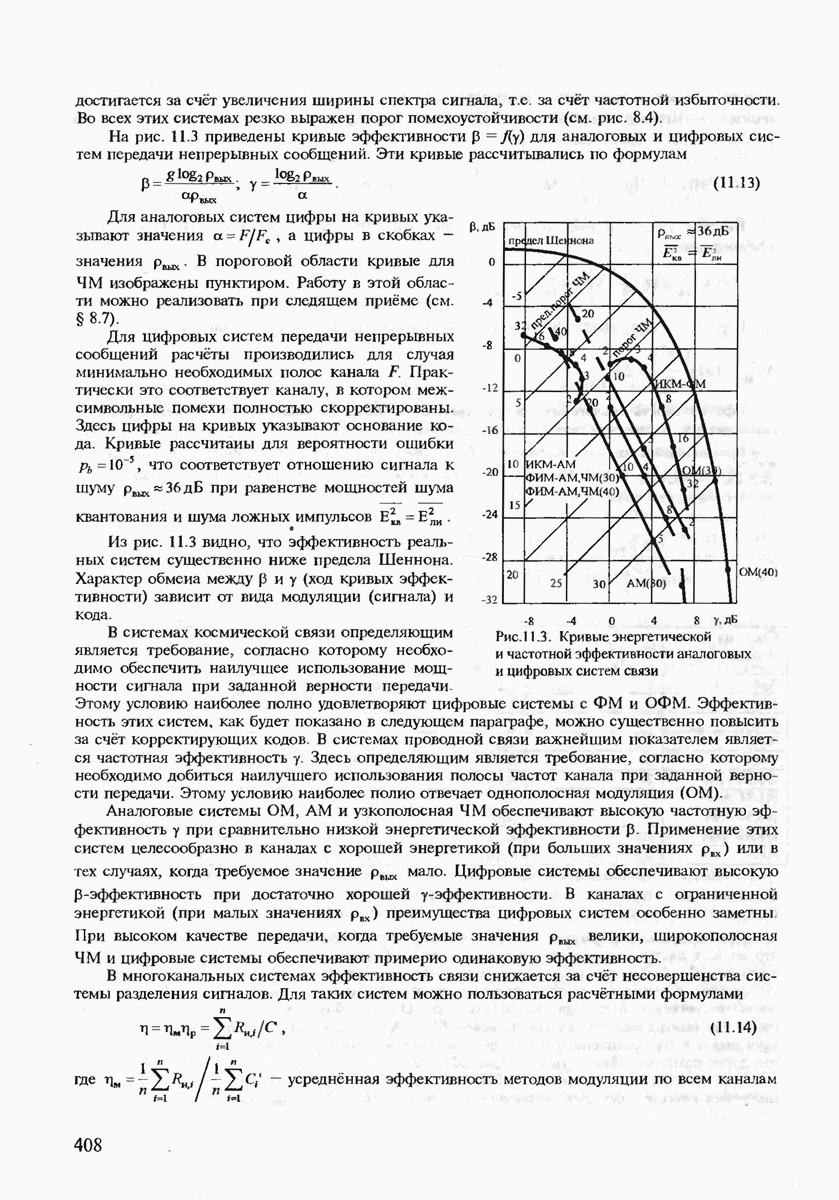
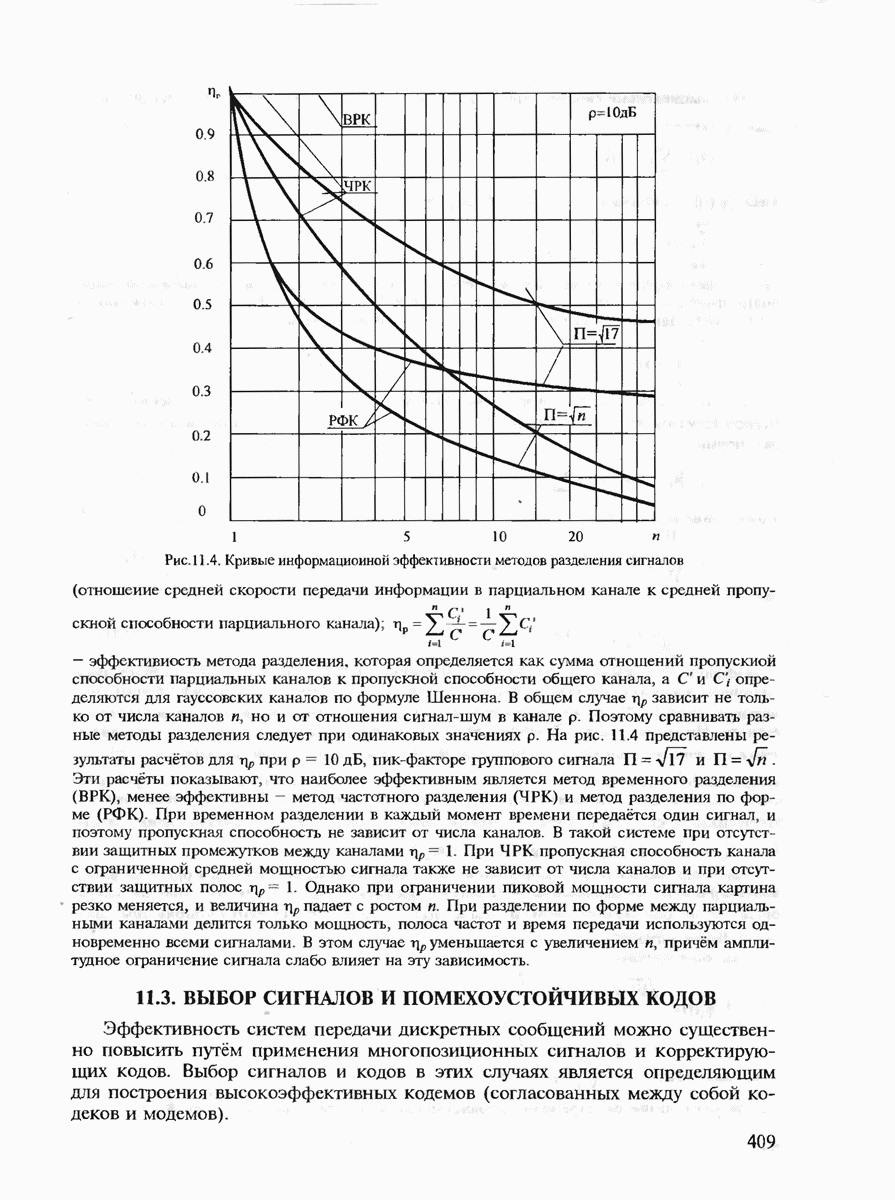
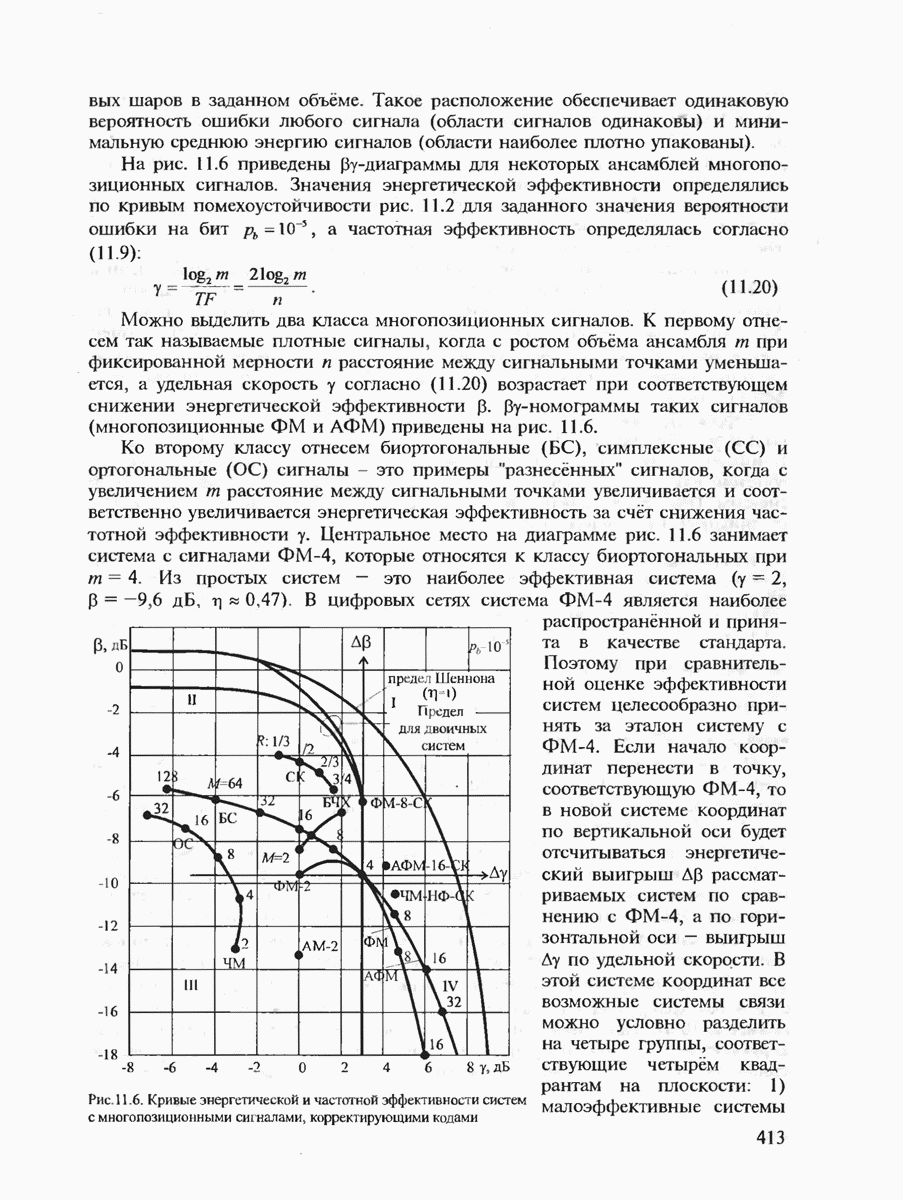
Неравенство (7.21) позволяет сделать важный вывод, что при Для доказательства обратной части теоремы кодирования, очевидно, необходимо использовать нижнюю границу Экспоненты вероятностей (7.20), (7.21) позволяют рассчитать энергетический выигрыш от применения кодирования (ЭВК) как функцию заданной верности длины и, состоящего из
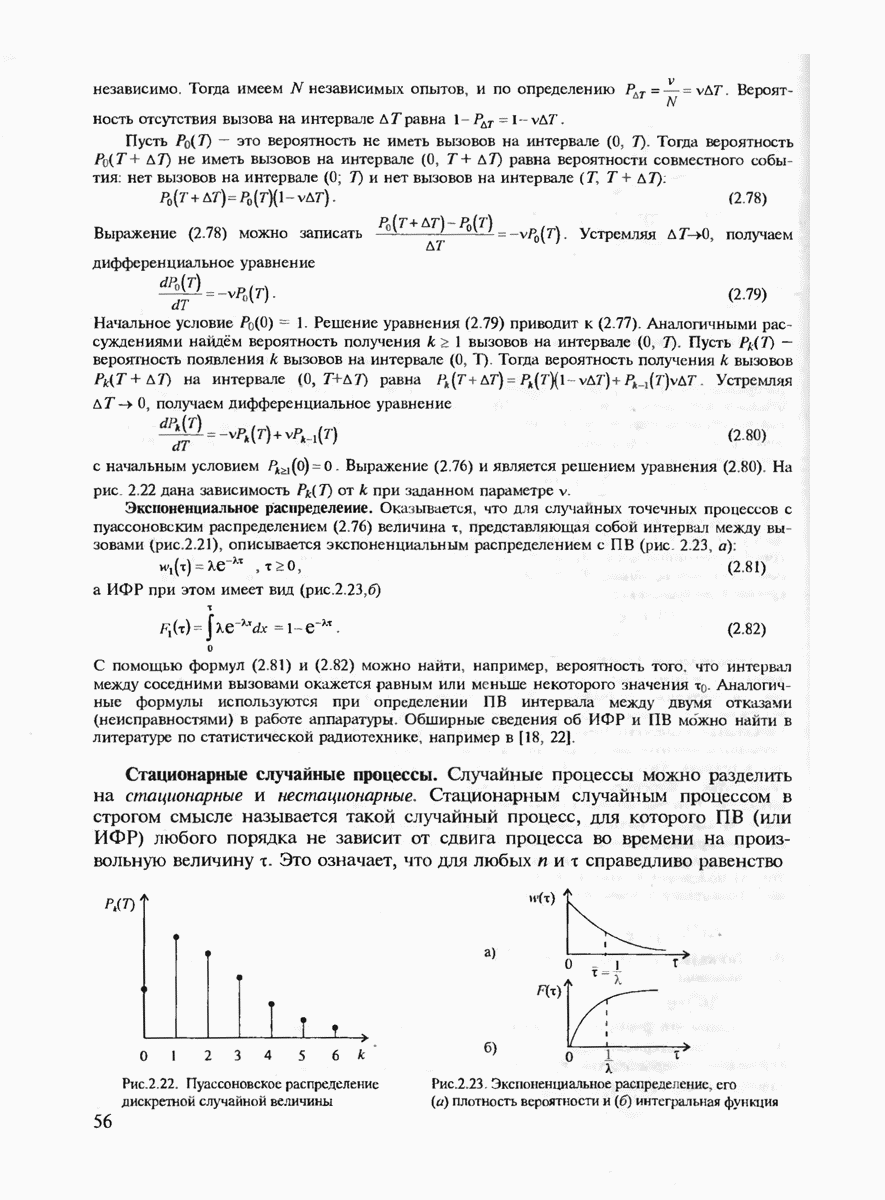
где Теперь ясно, что если два кода имеют одинаковые скорости, но разные длины, то код с большей длиной блока будет иметь большее число кодовых комбинаций
для которой сделанный выше вывод также оказывается справедливым.) Для того чтобы сравнивать коды различной мощности, воспользуемся понятием эквивалентной вероятности ошибки
Преобразуя (7.27), получаем
(Видно, что Если
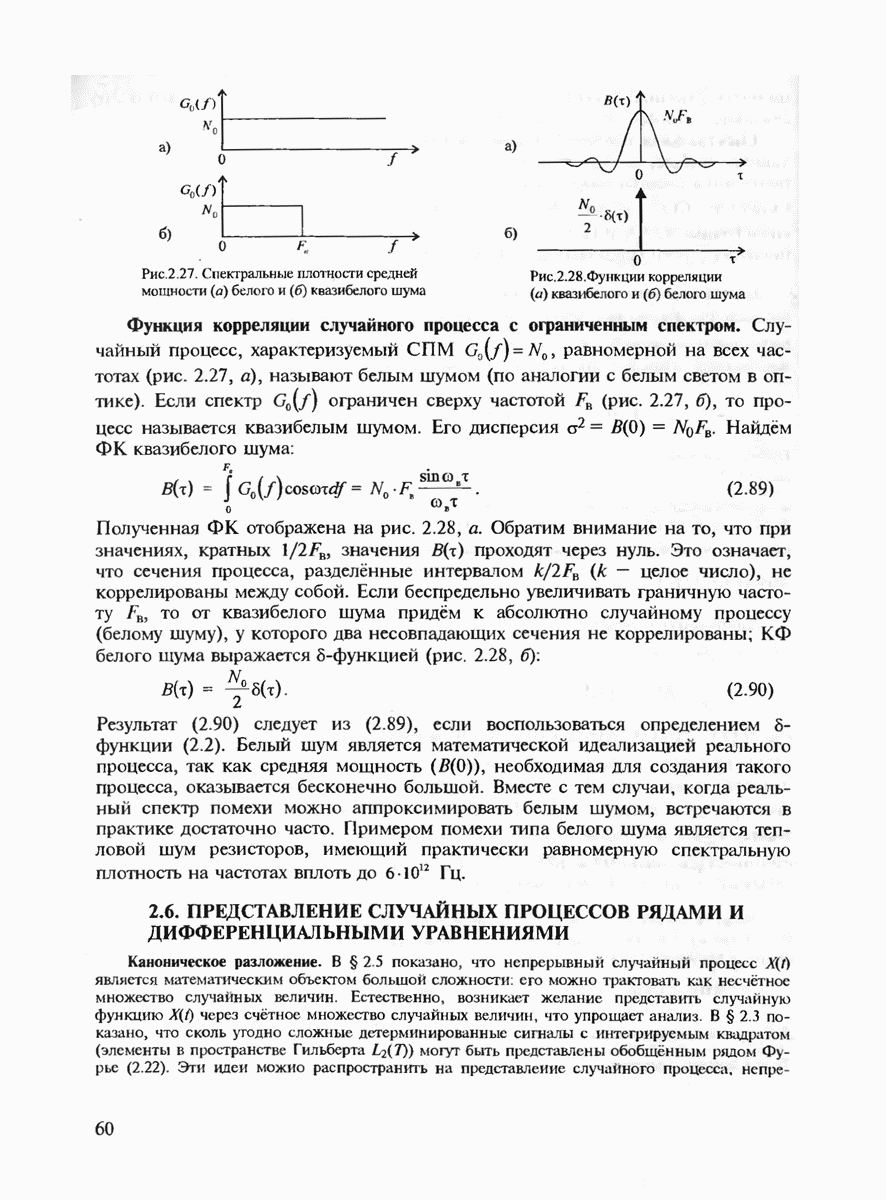
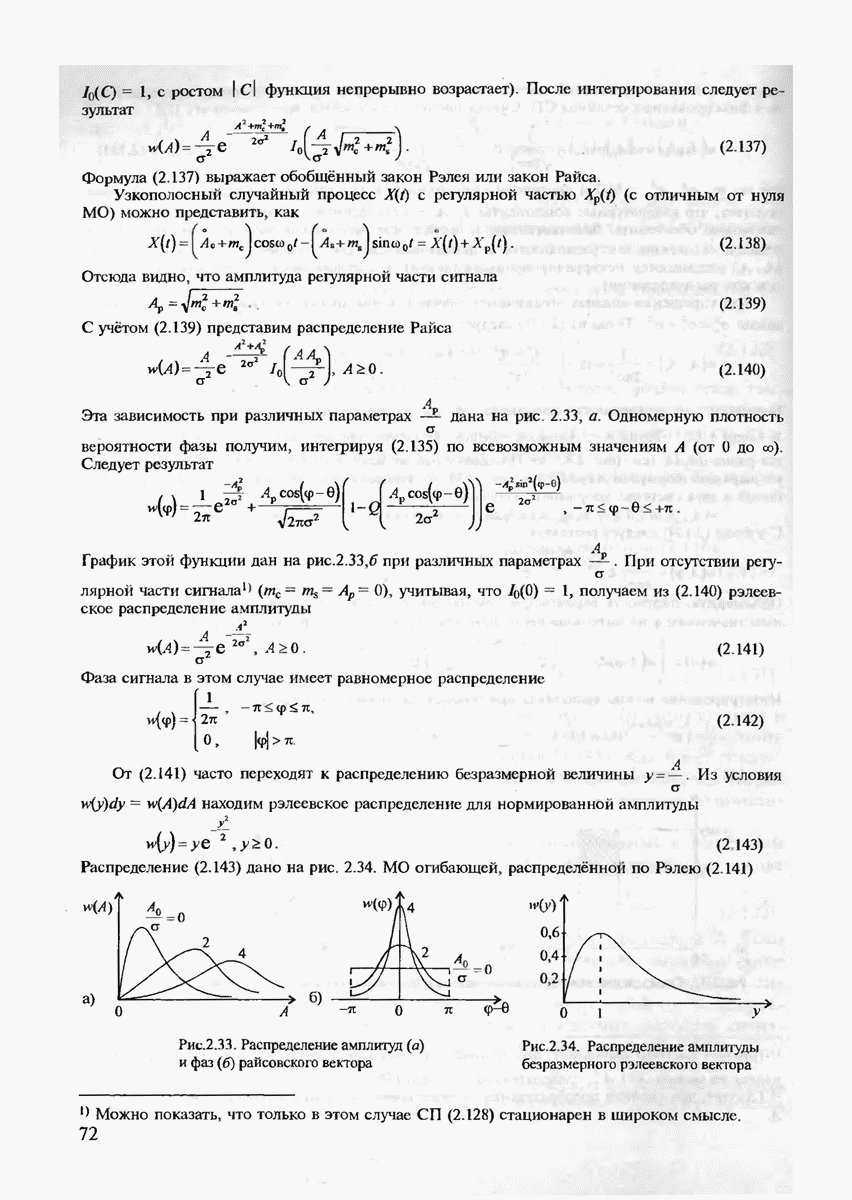
Величину Расчёт энергетического выигрыша одной дискретной системы передачи над другой (ЭВС) можно в общем случае вычислить при Предположение о том, что получатель сообщений не является критичным к количеству ошибок, типично для передачи данных, но вряд ли оправдано для таких сообщений, как оцифрованная речь, печатный текст или факсимильные сообщения. Для этих источников более естественно оценивать качество передачи сообщений средним числом ошибочных бит или средним числом ошибочных передач некоторых элементов сообщений. Экспоненты вероятностей ошибок являются значительным продвижением в теории кодирования по сравнению с теоремами кодирования, поскольку они определяют верхнюю границу для наилучшего кода как функцию длины кодового блока. Однако это верно лишь для наилучшего кода, тогда как способ его построения является пока неизвестным. Можно, правда, попытаться действительно случайно выбрать некоторый код и зафиксировать его для работы по данному каналу связи. (При неудачном выборе можно повторить эксперимент. проверяя эффективность кода при помощи расчёта реализуемой им частости ошибочного декодирования.) Однако, как будет показано в дальнейшем, сложность алгоритма декодирования для случайно выбранного кода также экспоненциально возрастает с ростом длины кодового блока и поэтому целесообразно указать некоторый регулярный выбор если не наилучшего кода, то по крайней мере кода, гарантирующего определённую величину
|
 |
Оглавление
|



































































































































































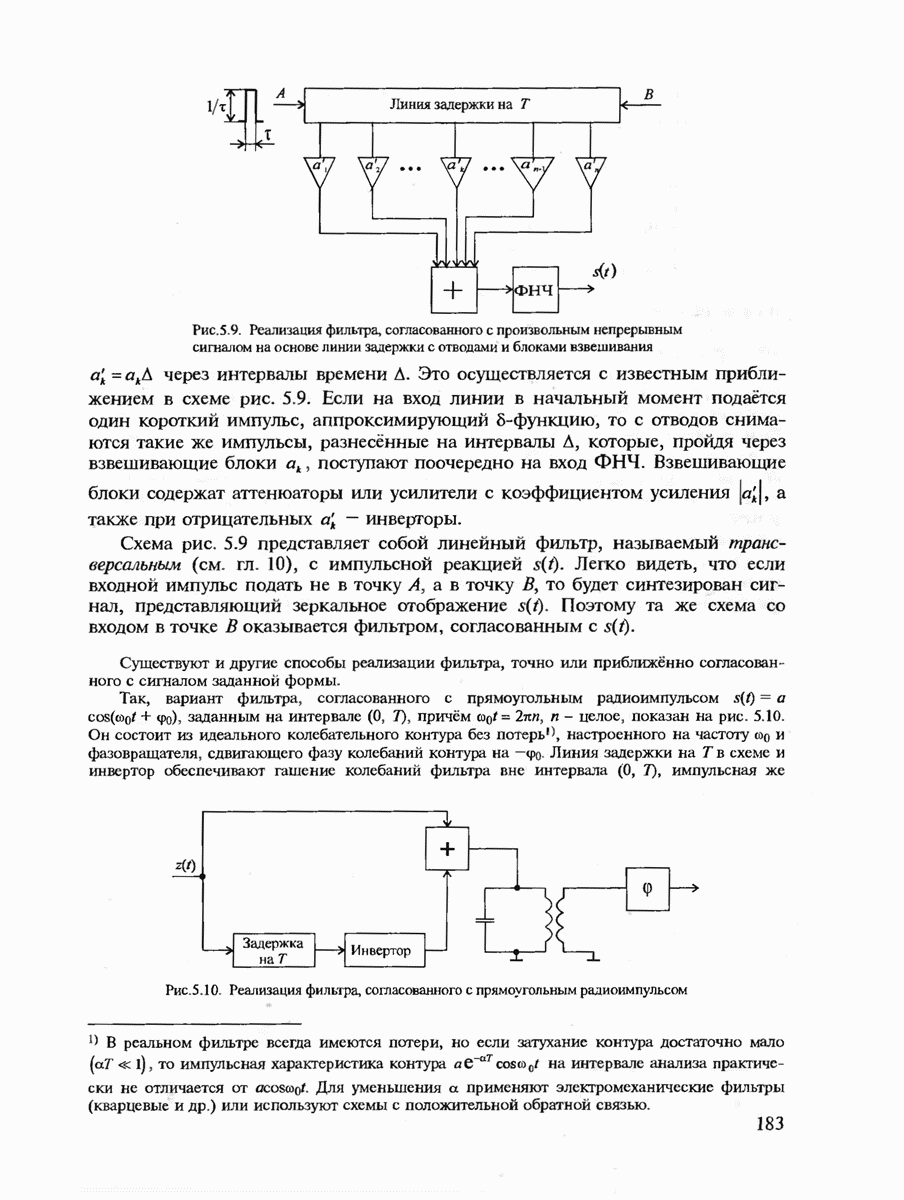
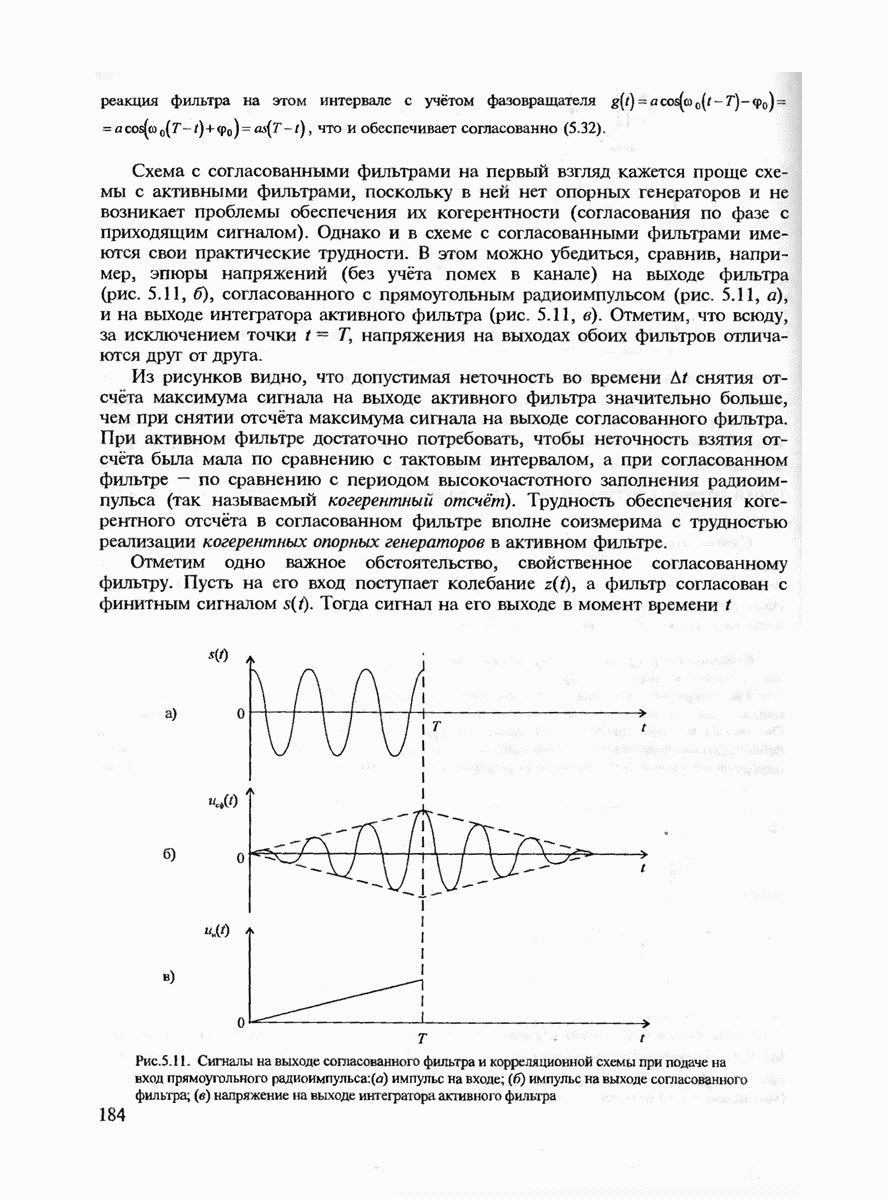










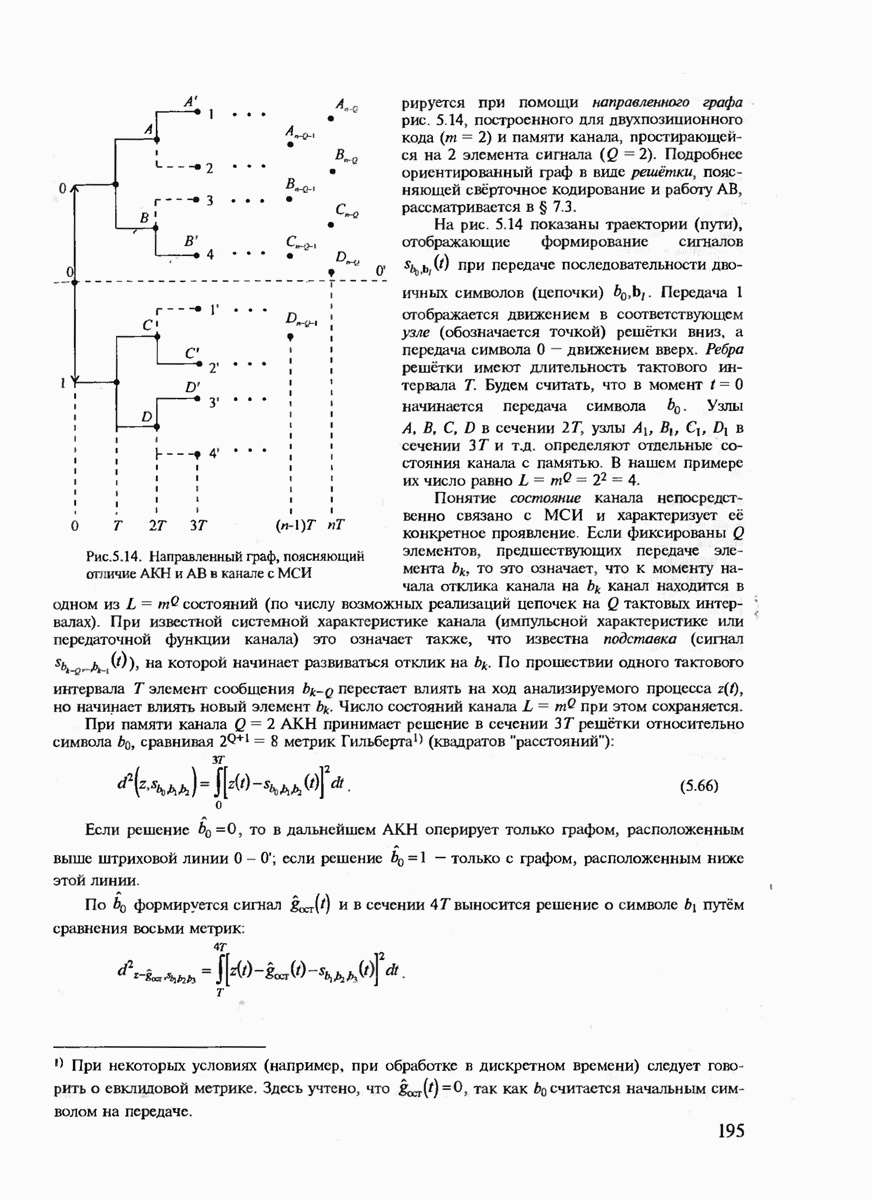



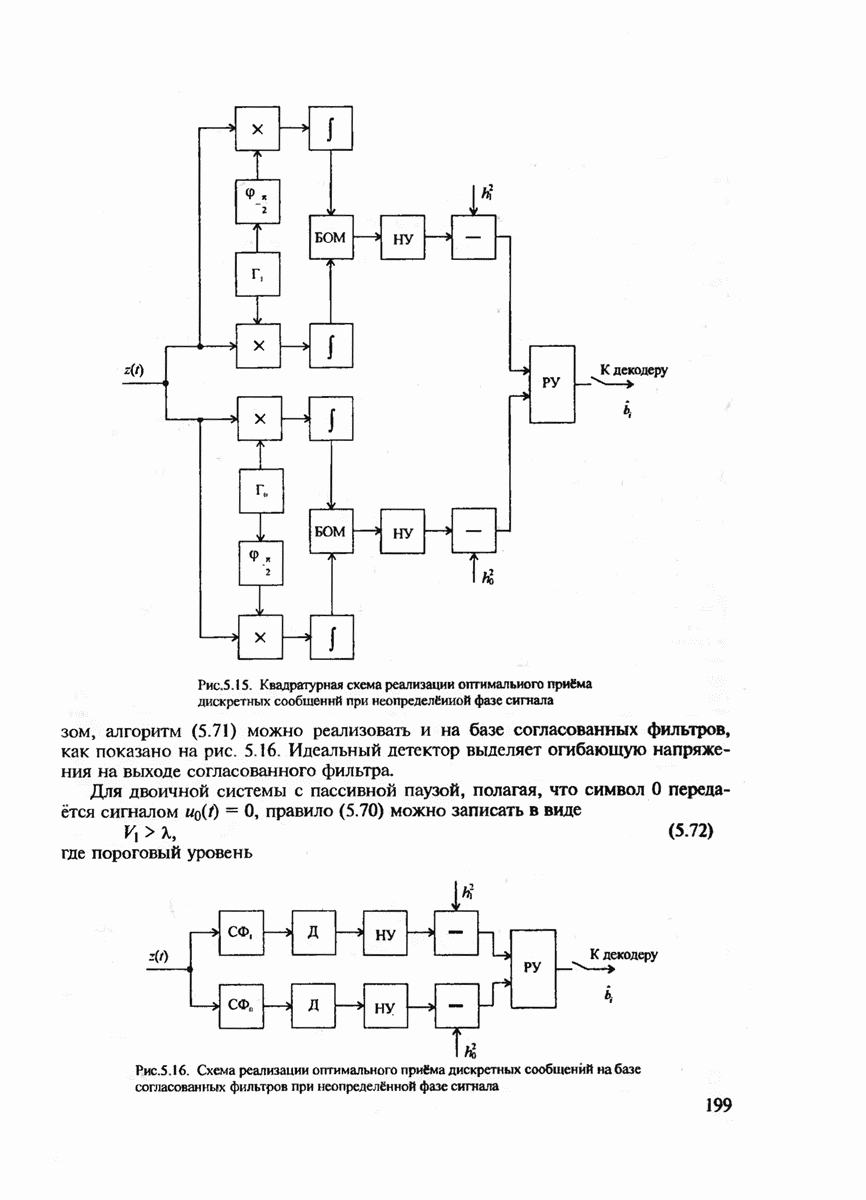



























































































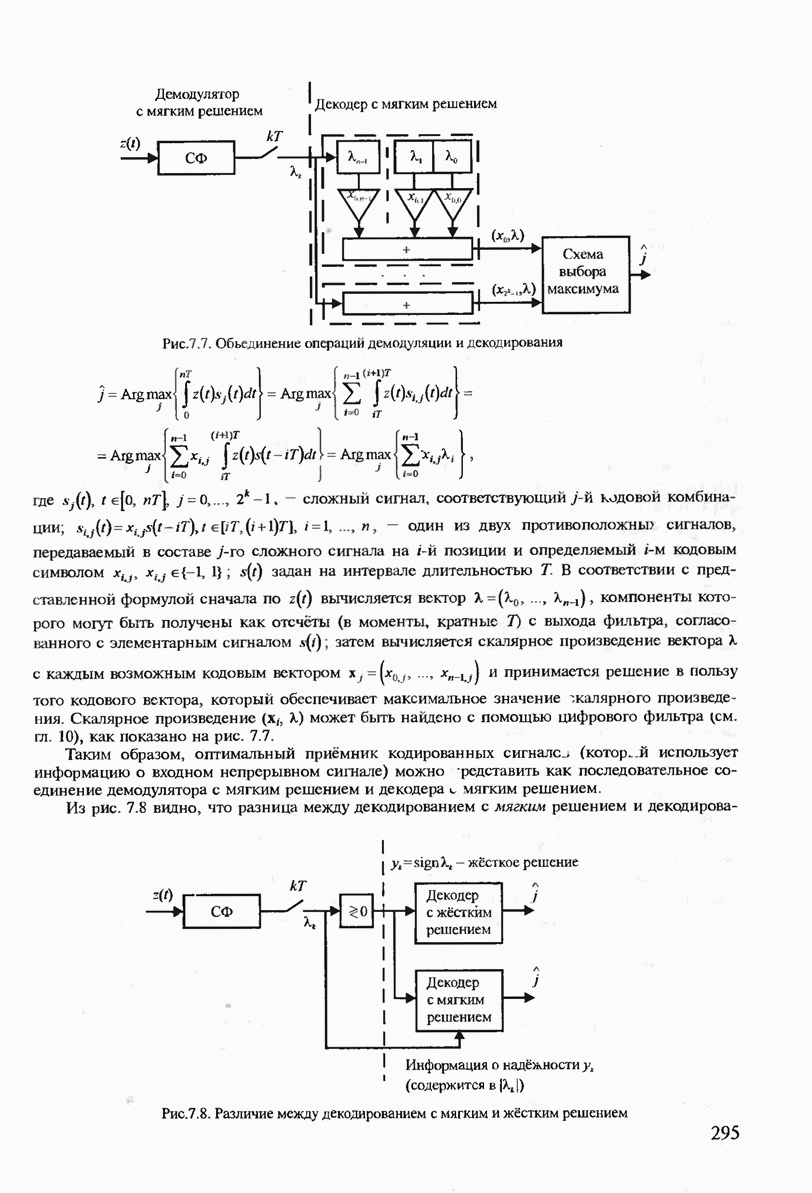



























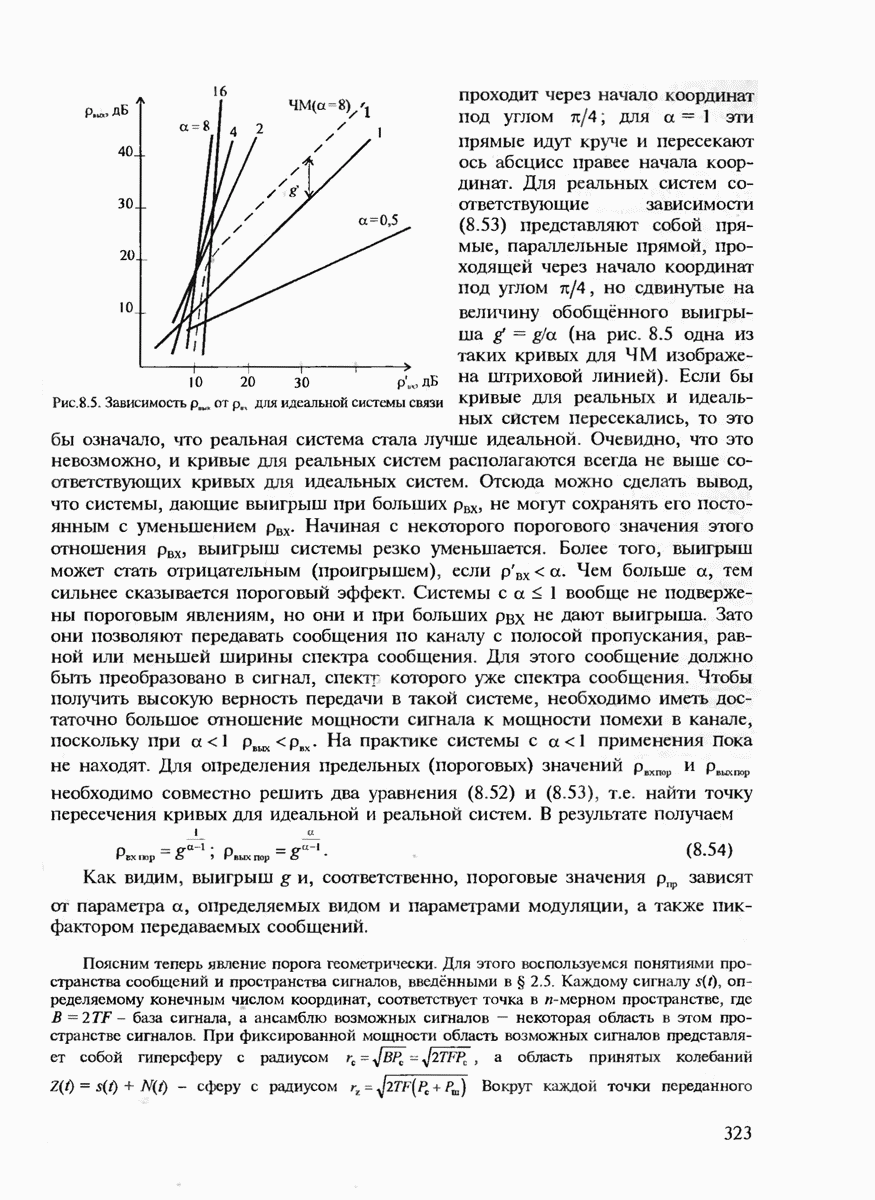













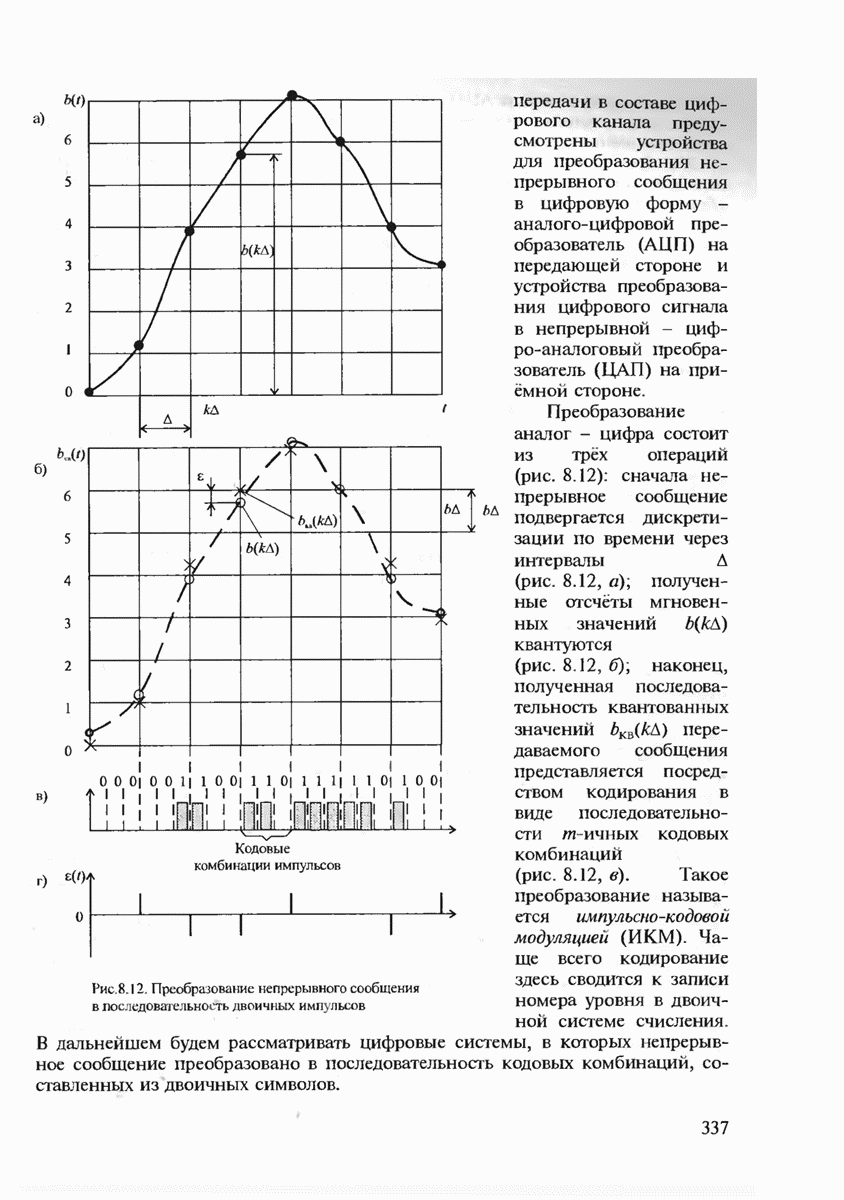


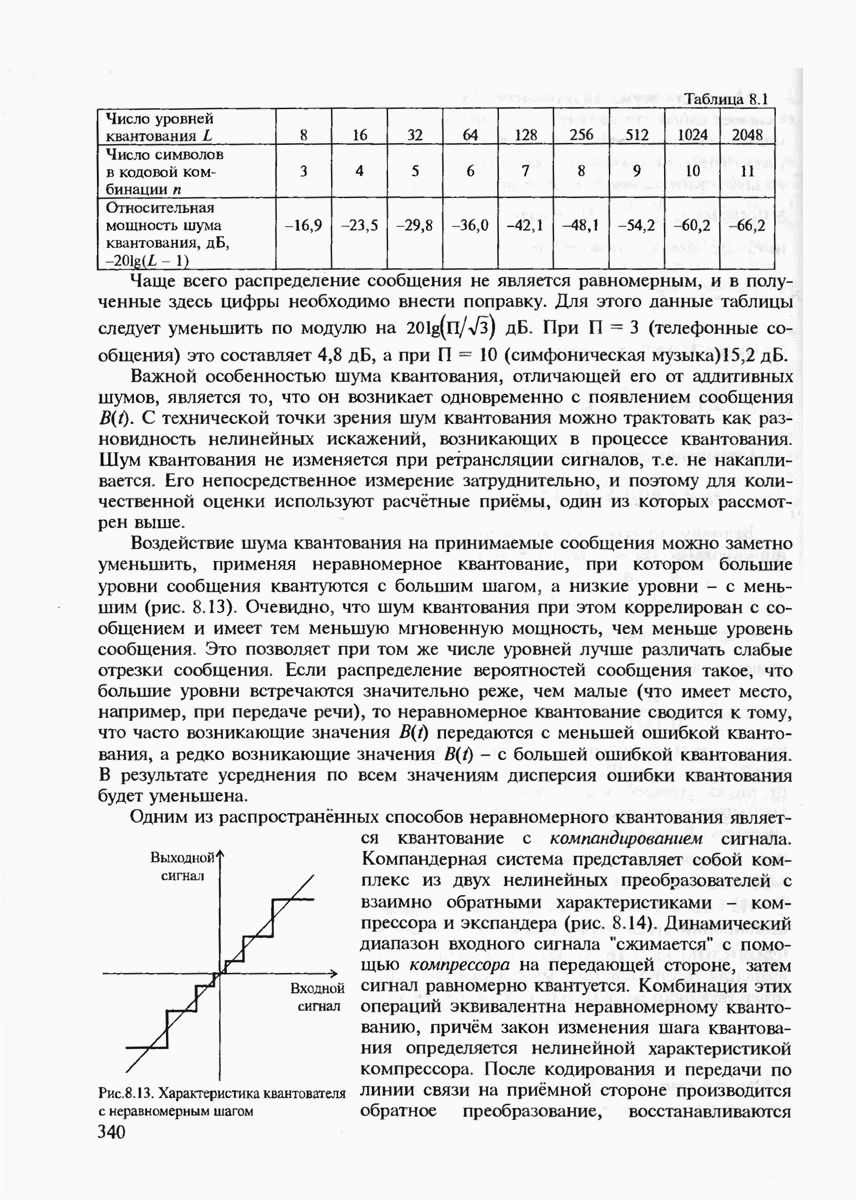














































































 где
где  его входной и выходной алфавиты, а
его входной и выходной алфавиты, а  и
и  означают всевозможные последовательности длины
означают всевозможные последовательности длины  из алфавитов
из алфавитов  соответственно. Обозначим через
соответственно. Обозначим через  вероятность ошибочного декодирования в таком канале при использовании некоторого кода V, состоящего из
вероятность ошибочного декодирования в таком канале при использовании некоторого кода V, состоящего из  комбинаций, и алгоритма декодирования по максимуму правдоподобия, если передаётся сообщение
комбинаций, и алгоритма декодирования по максимуму правдоподобия, если передаётся сообщение  Достаточно общая верхняя граница для
Достаточно общая верхняя граница для  при наилучшем выборе кода V была получена
при наилучшем выборе кода V была получена  Галлагером [8]. Сформулируем её в виде теоремы.
Галлагером [8]. Сформулируем её в виде теоремы.
 состоящий из
состоящий из  комбинаций, для которого при передаче произвольного сообщения
комбинаций, для которого при передаче произвольного сообщения 

 переходная условная вероятность для блоков длины
переходная условная вероятность для блоков длины  в заданном канале связи;
в заданном канале связи;  произвольное вероятностное распределение на входных блоках длины
произвольное вероятностное распределение на входных блоках длины 
 вероятности событий
вероятности событий  Тогда при любом
Тогда при любом  вероятность объединения событий имеет границу
вероятность объединения событий имеет границу


 оказывается меньше 1, то эта величина лишь увеличивается при возведении в степень
оказывается меньше 1, то эта величина лишь увеличивается при возведении в степень  и (7.9) следует из (7.10). Если же
и (7.9) следует из (7.10). Если же  то
то  и тогда (7.9) следует из (7.11).
и тогда (7.9) следует из (7.11).
 на всех блоках длины
на всех блоках длины  составленных из входных символов канала связи, и будем считать, что все кодовые слова выбираются независимо друг от друга с этими вероятностями. Таким образом, вероятность выбора некоторого частного кода
составленных из входных символов канала связи, и будем считать, что все кодовые слова выбираются независимо друг от друга с этими вероятностями. Таким образом, вероятность выбора некоторого частного кода  в этом ансамбле равна
в этом ансамбле равна  Каждый код из ансамбля имеет свою вероятность ошибочного декодирования при декодировании по максимуму правдоподобия. Если рассчитать среднюю по всему ансамблю кодов вероятность ошибочного декодирования, то она даст верхнюю границу ров для наилучшего кола (т.е. кода с инимальной величиной
Каждый код из ансамбля имеет свою вероятность ошибочного декодирования при декодировании по максимуму правдоподобия. Если рассчитать среднюю по всему ансамблю кодов вероятность ошибочного декодирования, то она даст верхнюю границу ров для наилучшего кола (т.е. кода с инимальной величиной  .
.
 при передаче
при передаче  сообщения можно тогда определить следующим образом
сообщения можно тогда определить следующим образом

 вероятность ошибочного декодирования при условии, что, во-первых, передаётся сообщение
вероятность ошибочного декодирования при условии, что, во-первых, передаётся сообщение  во-вторых, что для передачи этого сообщения была случайно выбрана комбинация кода
во-вторых, что для передачи этого сообщения была случайно выбрана комбинация кода  в-третьих, что была принята последовательность у. Суммирование в (7.12) производится по всем входным и выходным последовательностям длины
в-третьих, что была принята последовательность у. Суммирование в (7.12) производится по всем входным и выходным последовательностям длины 
 у определим событие
у определим событие  для каждого
для каждого  как событие, состоящее в том, что выбирается такое кодовое слово
как событие, состоящее в том, что выбирается такое кодовое слово  соответствующее сообщению
соответствующее сообщению  для которого
для которого

 сделает ошибку (При наличии равенства в (7 13) ошибка произойдёт не обязательно.) Поэтому, используя лемму, получаем
сделает ошибку (При наличии равенства в (7 13) ошибка произойдёт не обязательно.) Поэтому, используя лемму, получаем

 имеем
имеем

 при любом
при любом  распространяя суммирование на все
распространяя суммирование на все  Это даёт верхнюю границу для
Это даёт верхнюю границу для 

 является "глухой" переменной суммирования в (7.16), и поэтому эта граница фактически не зависит от
является "глухой" переменной суммирования в (7.16), и поэтому эта граница фактически не зависит от  Подставляя (7.16) в (7.14), получаем
Подставляя (7.16) в (7.14), получаем


 в (7.18) и замечая, что
в (7.18) и замечая, что  является также "глухой" переменной суммирования, получаем утверждение теоремы в виде неравенства (7.8)
является также "глухой" переменной суммирования, получаем утверждение теоремы в виде неравенства (7.8)
 в дискретных каналах без памяти, описываемых переходными вероятностями
в дискретных каналах без памяти, описываемых переходными вероятностями  где
где  Определим в этом случае вероятность случайного выбора кодового слова х как
Определим в этом случае вероятность случайного выбора кодового слова х как


 объёмы алфавитов входа и выхода канала соответственно.
объёмы алфавитов входа и выхода канала соответственно.
 на среднюю по сообщениям вероятность ошибки
на среднюю по сообщениям вероятность ошибки  при произвольном наборе вероятностей этих сообщений:
при произвольном наборе вероятностей этих сообщений:



 без памяти с вероятностью ошибки символа
без памяти с вероятностью ошибки символа  получается решение в замкнутом виде
получается решение в замкнутом виде




 удовлетворяет уравнению
удовлетворяет уравнению

 вероятность ошибки при выборе наилучшего кода не только убывает к нулю при
вероятность ошибки при выборе наилучшего кода не только убывает к нулю при  но убывает и как экспонента от и. Именно поэтому границы подобного типа называются экспонентами вероятностей ошибок. Это фактически доказывает прямую часть теоремы кодирования Шеннона.
но убывает и как экспонента от и. Именно поэтому границы подобного типа называются экспонентами вероятностей ошибок. Это фактически доказывает прямую часть теоремы кодирования Шеннона.
 для наилучшего кода. Этот вопрос не будем здесь обсуждать, поскольку нижняя граница не имеет большого прикладного значения.
для наилучшего кода. Этот вопрос не будем здесь обсуждать, поскольку нижняя граница не имеет большого прикладного значения.
 скорости кода
скорости кода  и длины кодового блока
и длины кодового блока  Однако в отличие от асимптотического случая здесь возникает одна дополнительная сложность. Пусть, например, два кода с одинаковыми скоростями
Однако в отличие от асимптотического случая здесь возникает одна дополнительная сложность. Пусть, например, два кода с одинаковыми скоростями  длинами
длинами  имеют одинаковые вероятности
имеют одинаковые вероятности  Можно ли считать, что в обоих случаях обеспечивается действительно одинаковая верность передачи сообщений? Интуиция подсказывает нам, что во втором случае надёжность передачи будет, наверное, больше, чем в первом. Постараемся облечь теперь наши интуитивные ощущения в более строгую форму. Пусть передаётся информация такого типа, что количество ошибок на сеансе связи, состоящем из
Можно ли считать, что в обоих случаях обеспечивается действительно одинаковая верность передачи сообщений? Интуиция подсказывает нам, что во втором случае надёжность передачи будет, наверное, больше, чем в первом. Постараемся облечь теперь наши интуитивные ощущения в более строгую форму. Пусть передаётся информация такого типа, что количество ошибок на сеансе связи, состоящем из  информационных бит, не играет существенной роли для оценивания качества передачи. Критерием верности тогда служит вероятность
информационных бит, не играет существенной роли для оценивания качества передачи. Критерием верности тогда служит вероятность  абсолютно правильного приёма всех элементов. Очевидно, что при использовании двоичного кода
абсолютно правильного приёма всех элементов. Очевидно, что при использовании двоичного кода
 комбинаций, эта вероятность в канале связи без памяти может быть рассчитана по формуле
комбинаций, эта вероятность в канале связи без памяти может быть рассчитана по формуле

 число кодовых комбинаций на интервале анализа.
число кодовых комбинаций на интервале анализа.
 и поэтому для него
и поэтому для него  оказывается больше при равных значениях
оказывается больше при равных значениях  . (Для канала с памятью можно при
. (Для канала с памятью можно при  использовать аддитивную границу
использовать аддитивную границу

 Напомним читателю (см. § 5.11), что
Напомним читателю (см. § 5.11), что  это такая вероятность ошибки символа в
это такая вероятность ошибки символа в  без памяти, с постоянными параметрами и при отсутствии кодирования, которая обеспечивает ту же вероятность правильного приёма
без памяти, с постоянными параметрами и при отсутствии кодирования, которая обеспечивает ту же вероятность правильного приёма  информационных символов, что и данный код в данном канате. Очевидно, что можно написать
информационных символов, что и данный код в данном канате. Очевидно, что можно написать


 оказалось не зависящей от
оказалось не зависящей от 
 то для
то для  справедливо следующее приближённое выражение:
справедливо следующее приближённое выражение:

 (соответственно
(соответственно  для наилучшего кода можно найти из (7.21).
для наилучшего кода можно найти из (7.21).
 по формуле (5.108), ЭВК. для заданного кода можно находить при заданной вероятности
по формуле (5.108), ЭВК. для заданного кода можно находить при заданной вероятности  и по формуле (6.61).
и по формуле (6.61).
 в заданном канале связи. Такие классы кодов рассматриваются в следующем разделе.
в заданном канале связи. Такие классы кодов рассматриваются в следующем разделе.