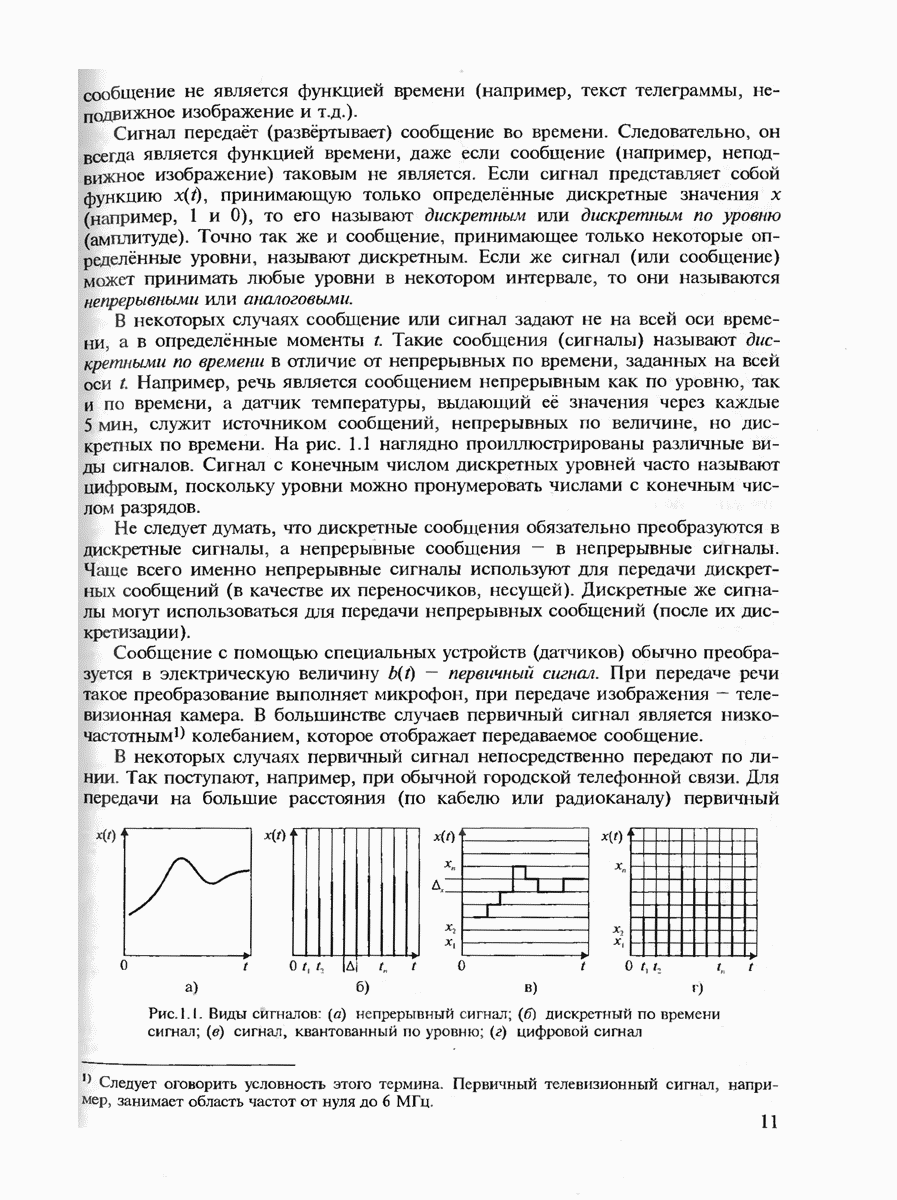
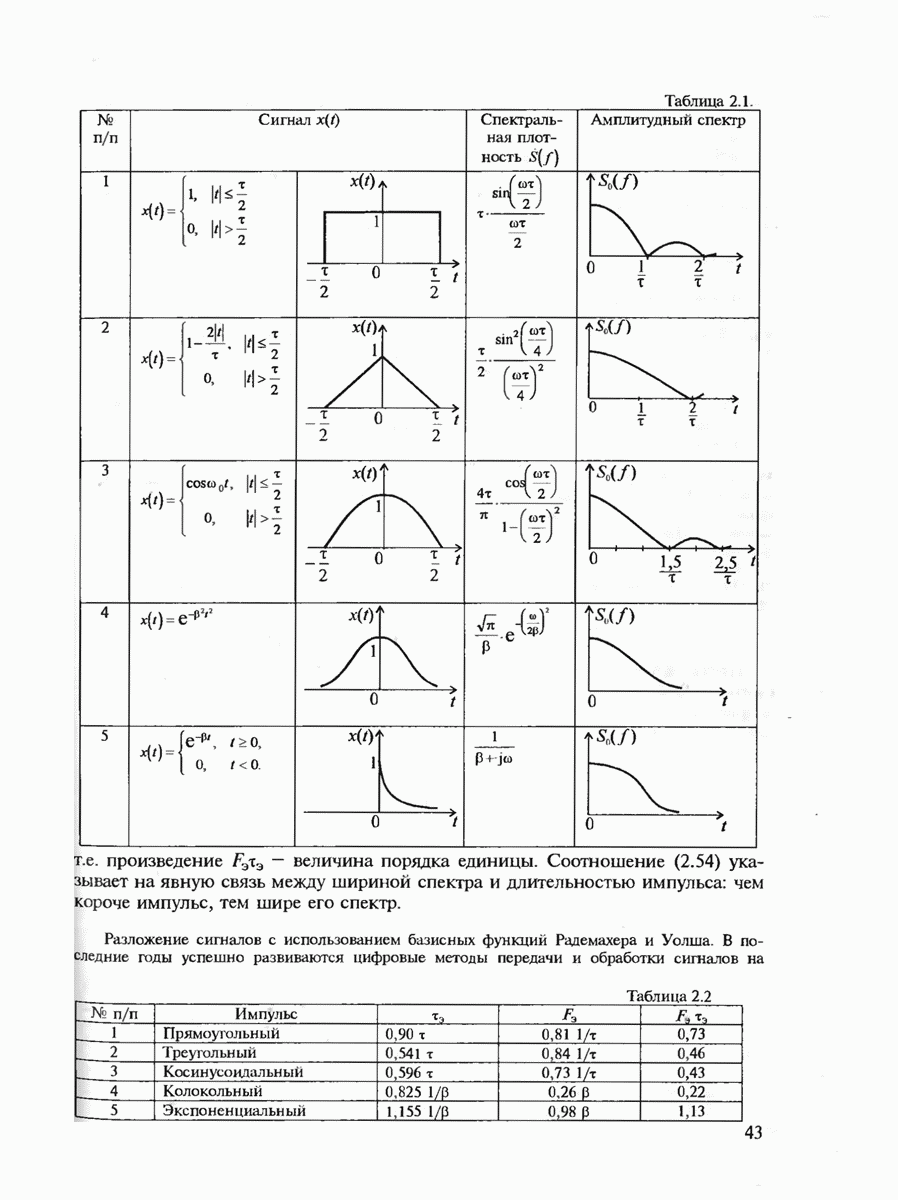
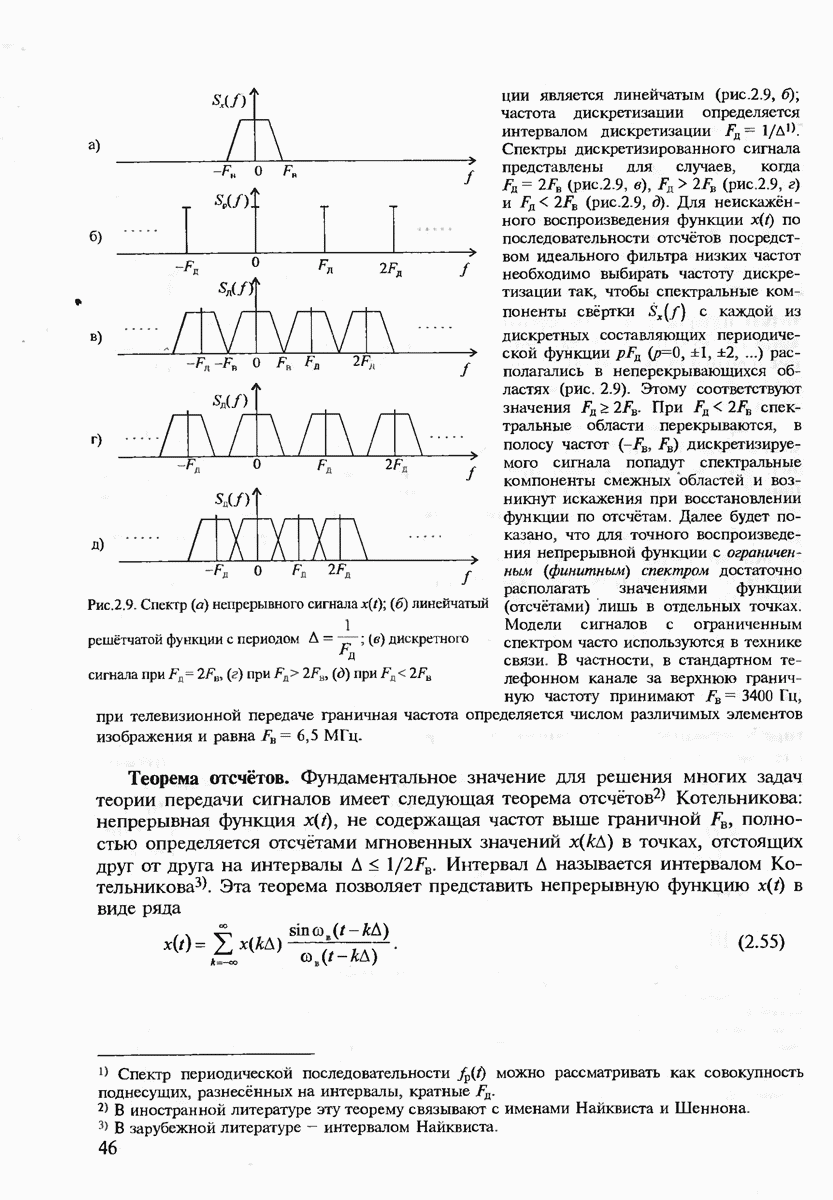
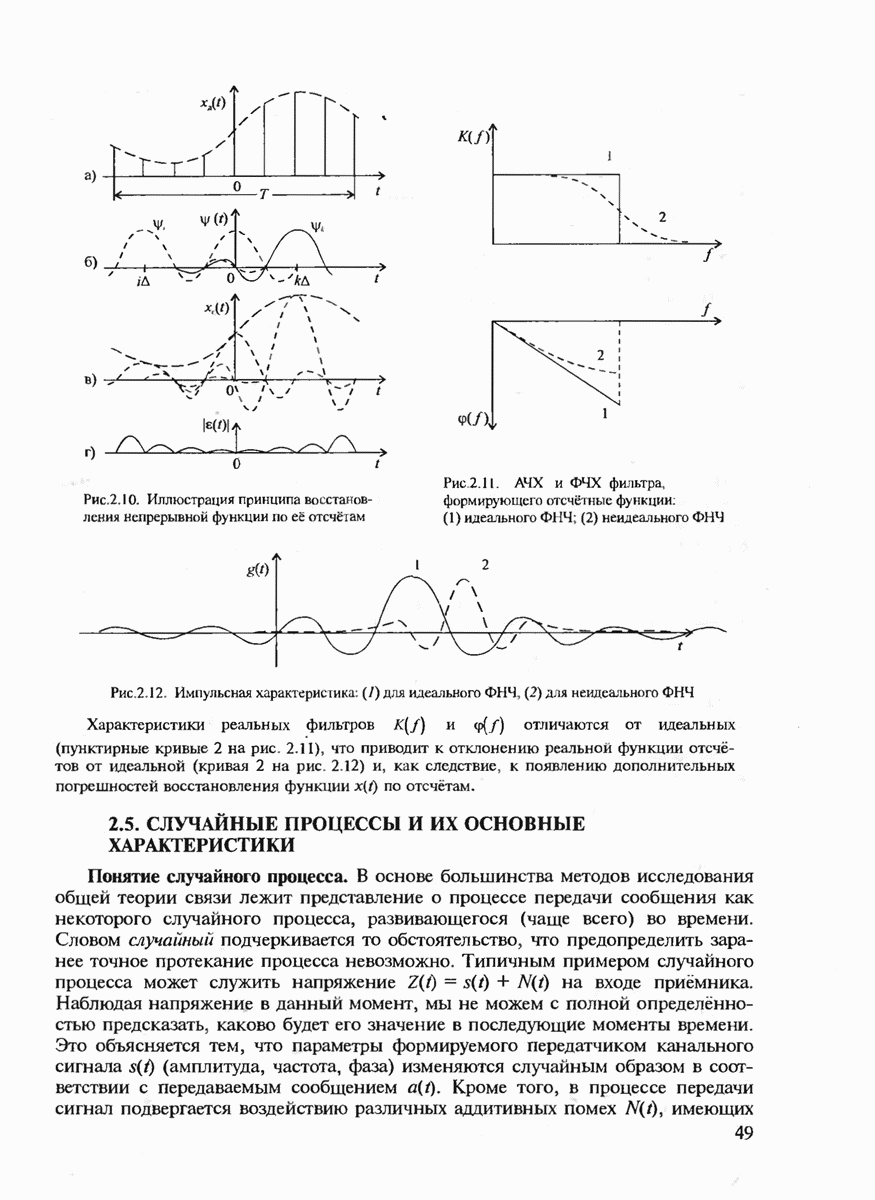
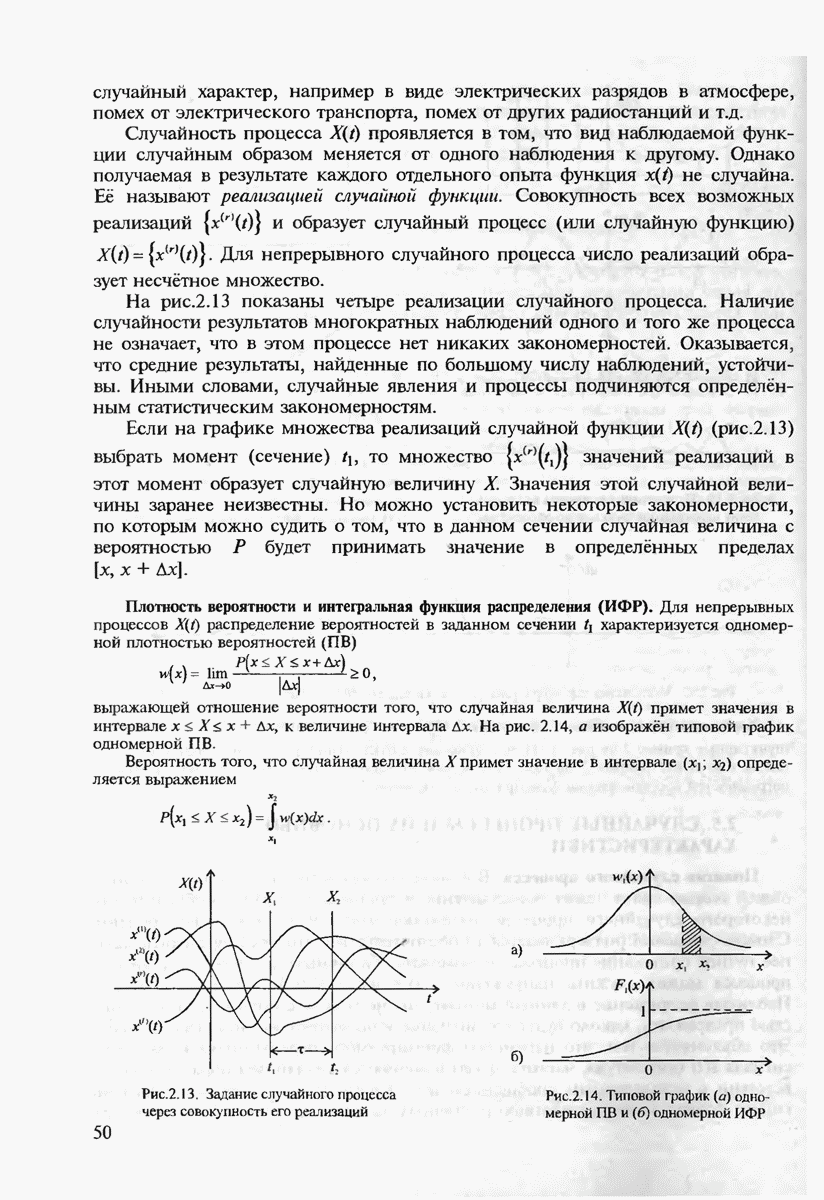
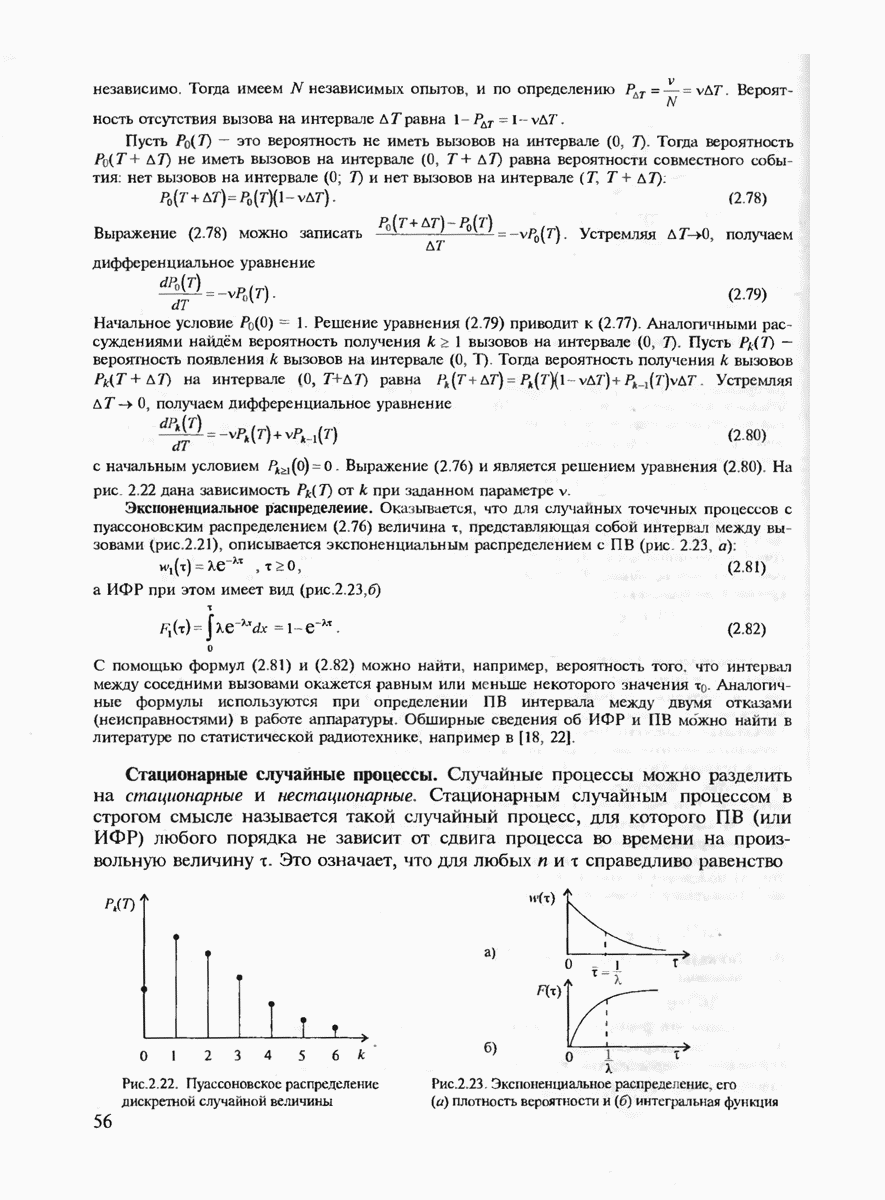
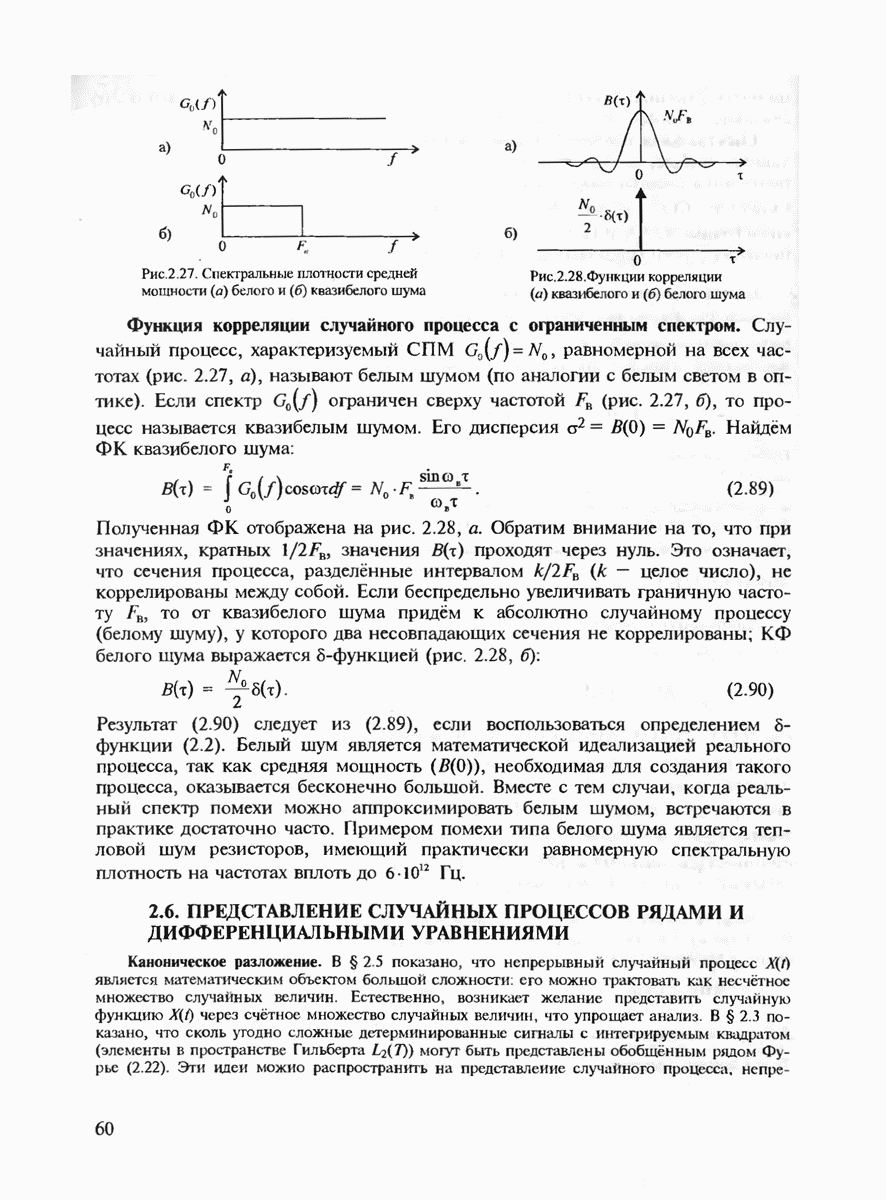
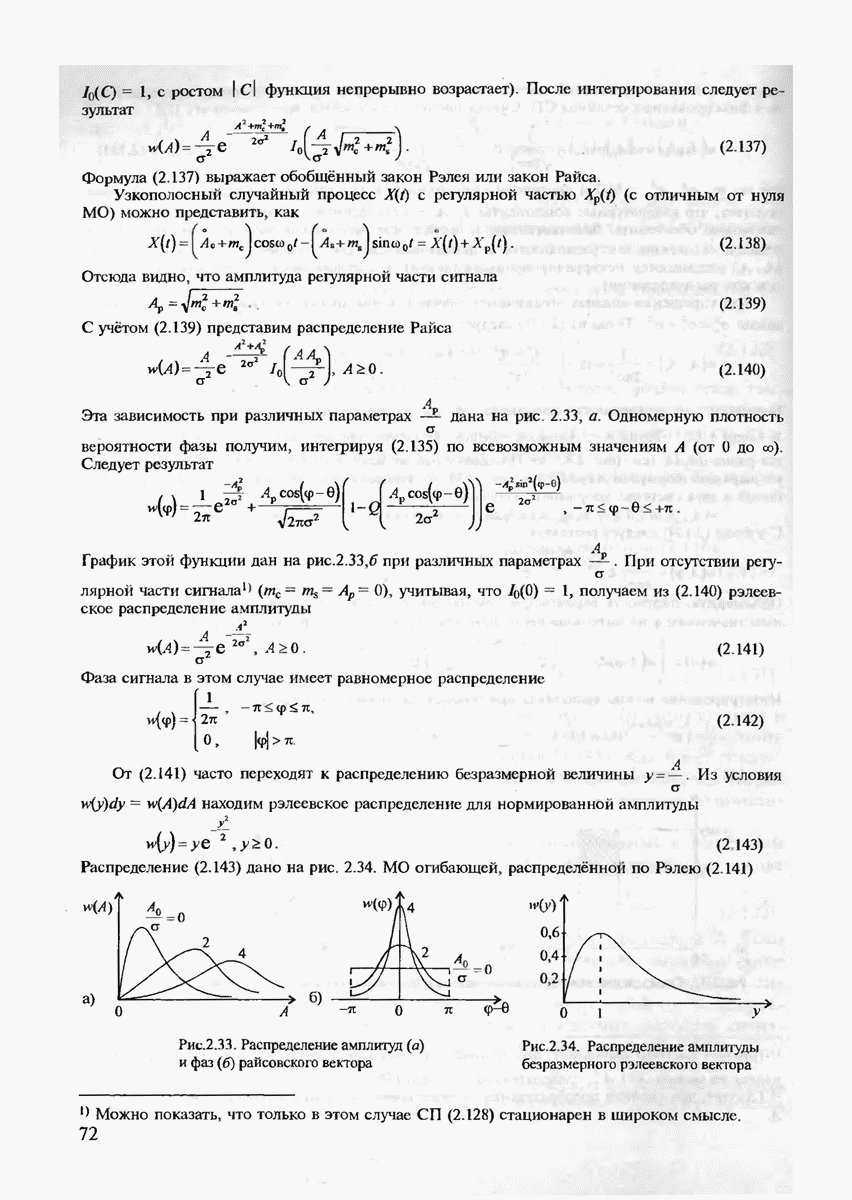
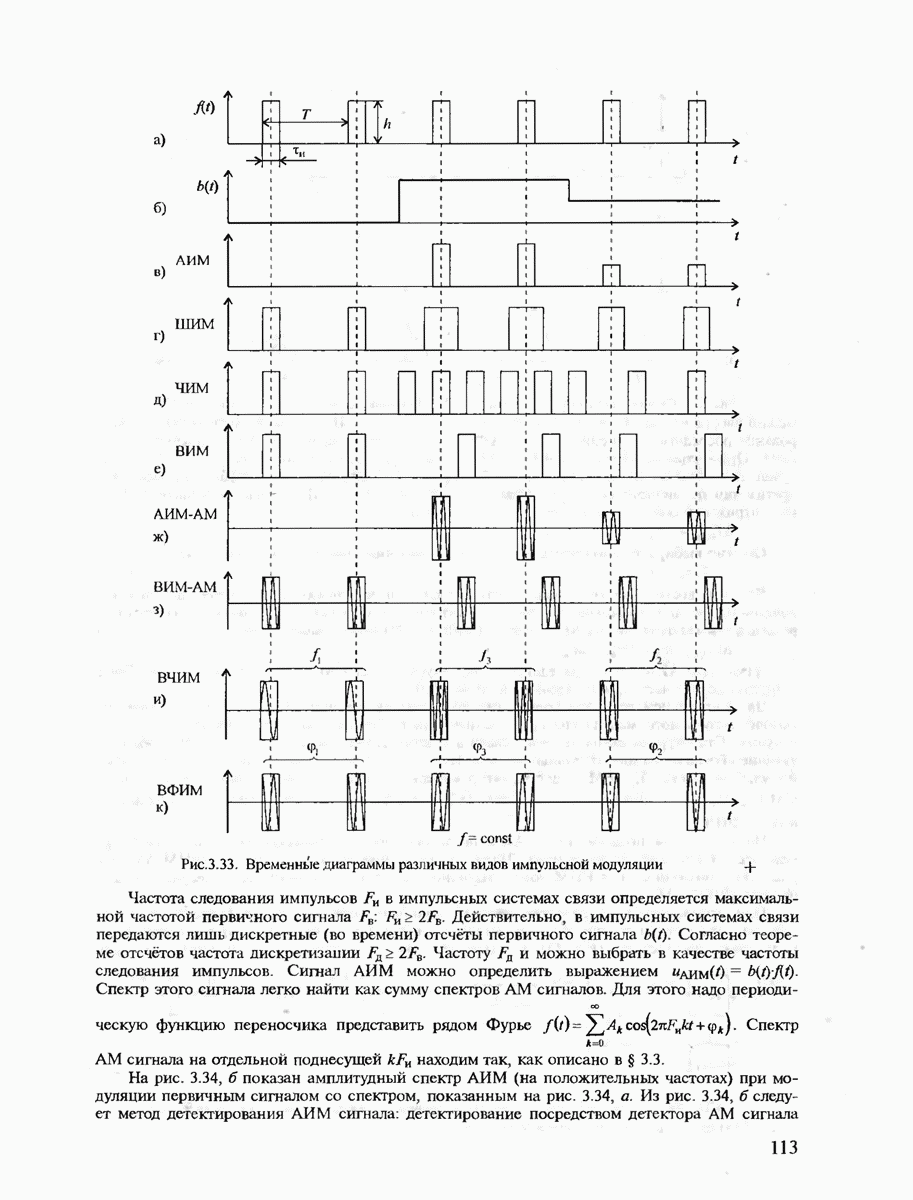
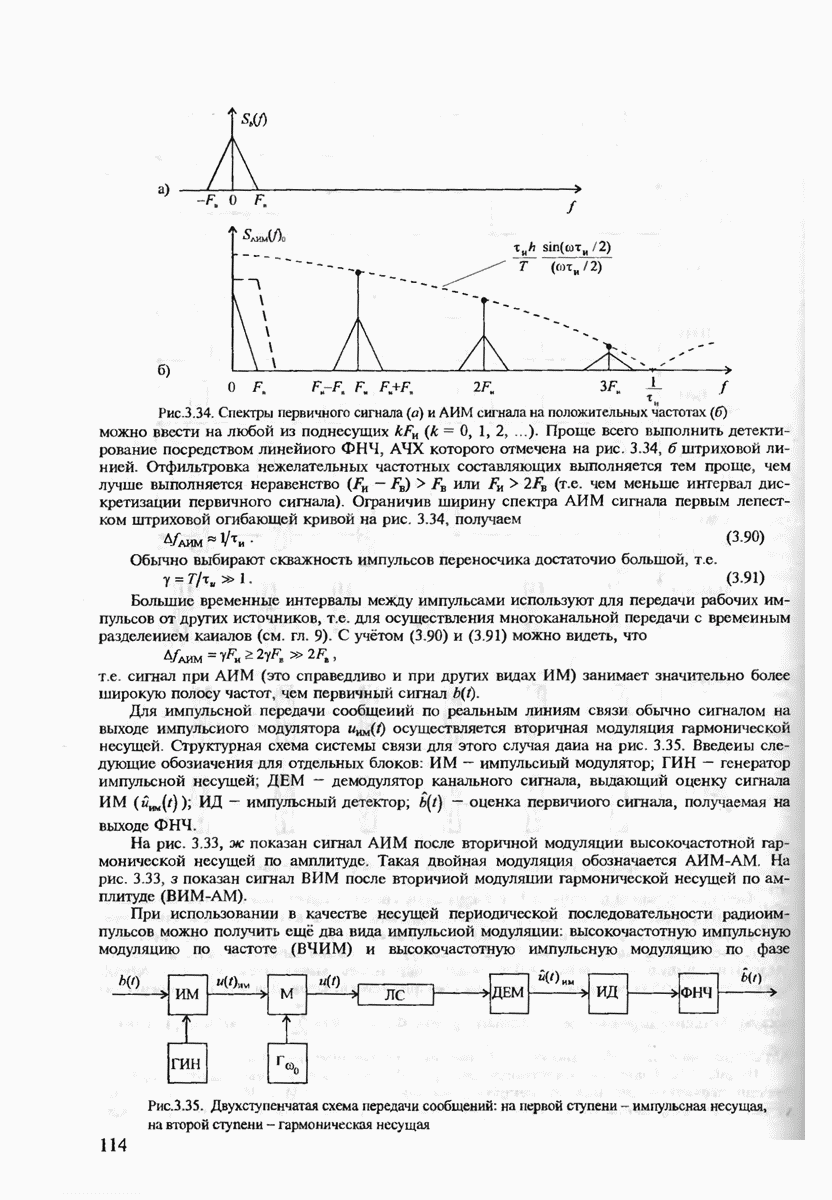
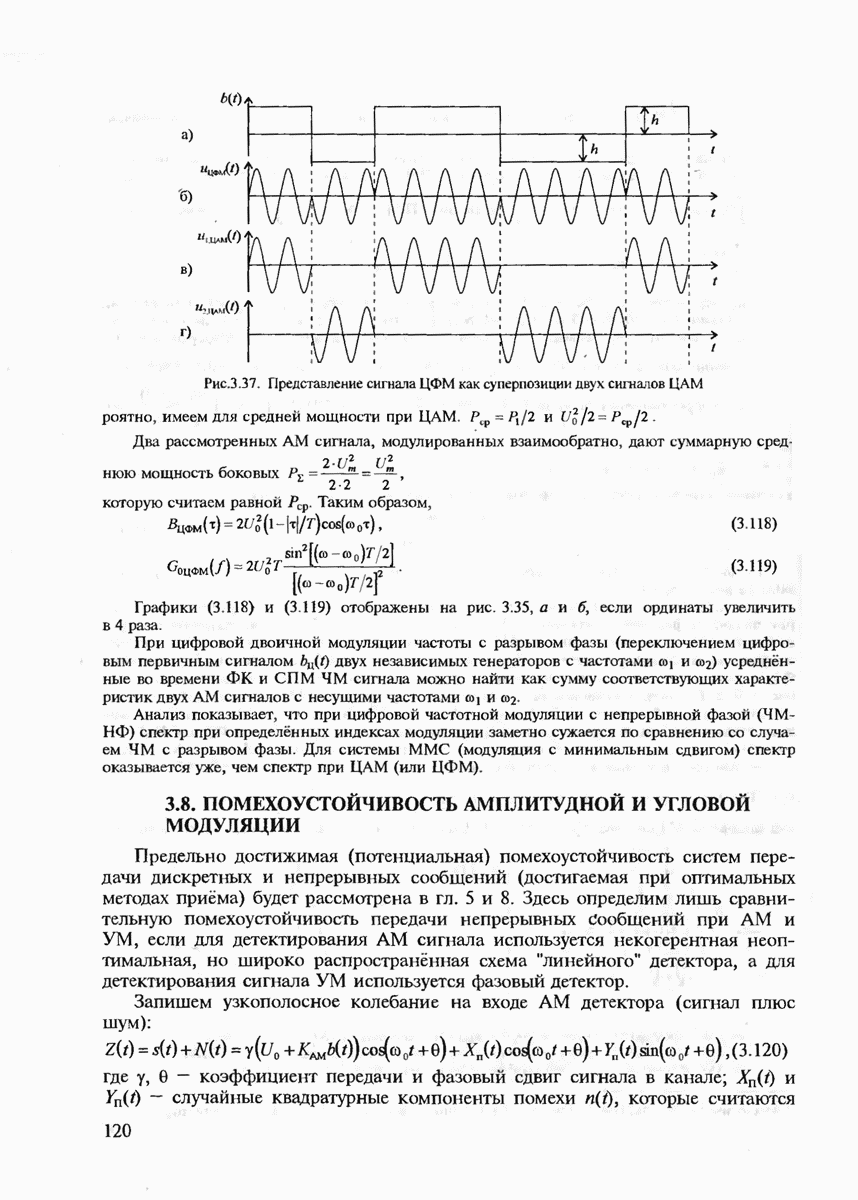
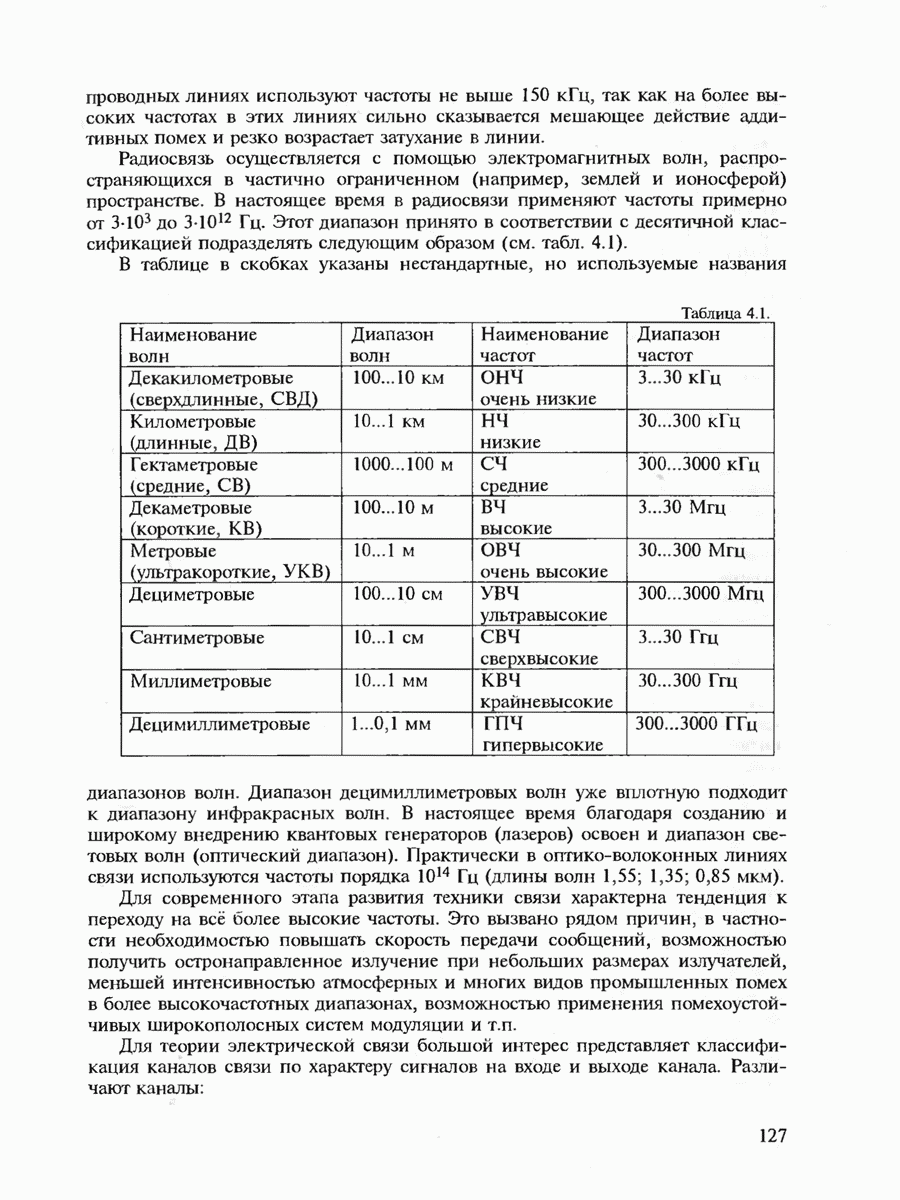
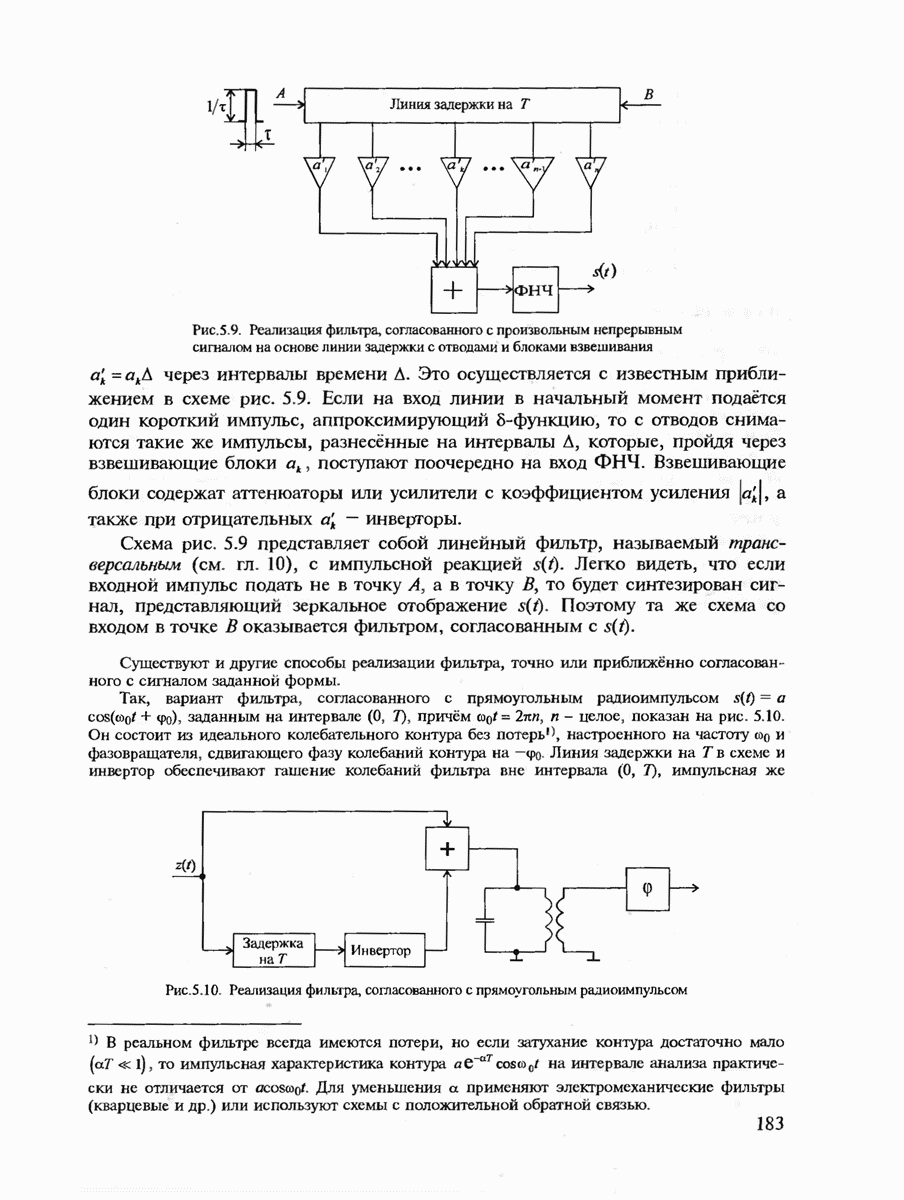
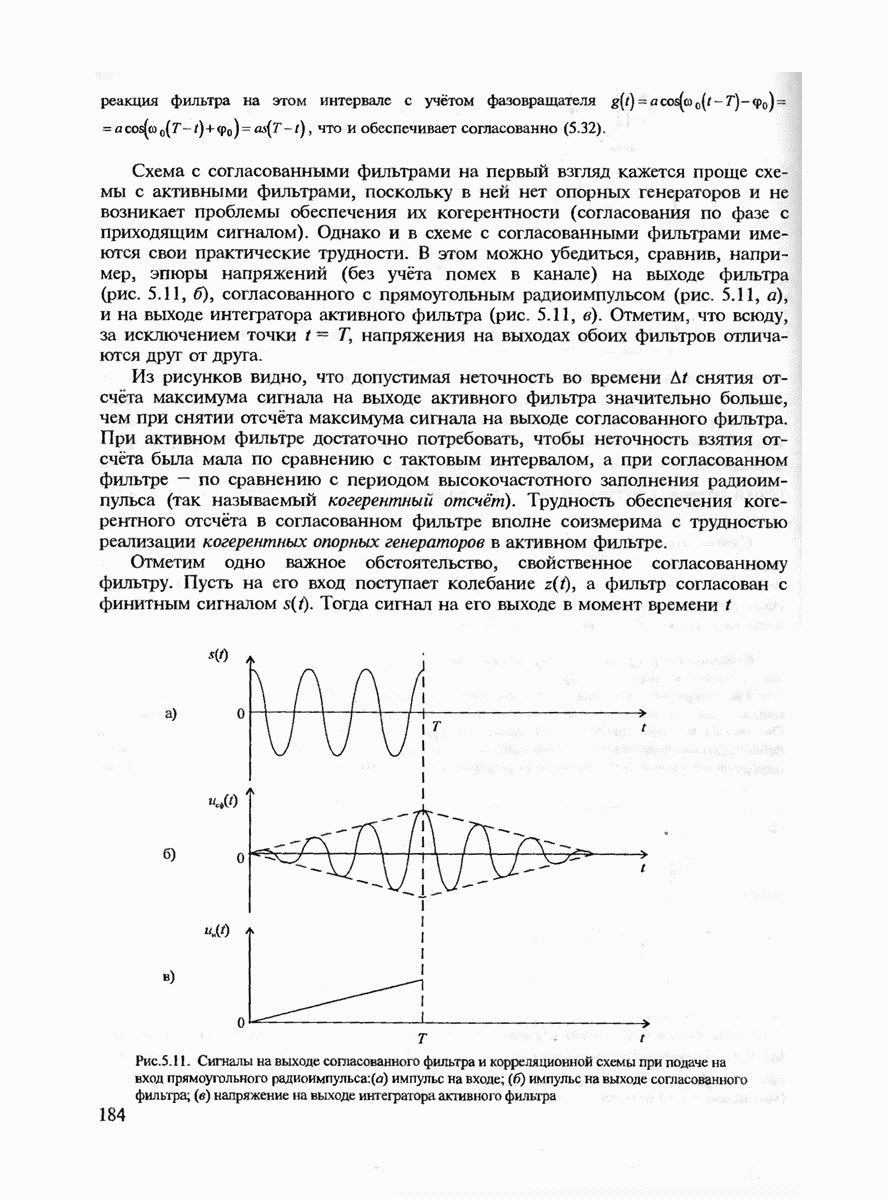
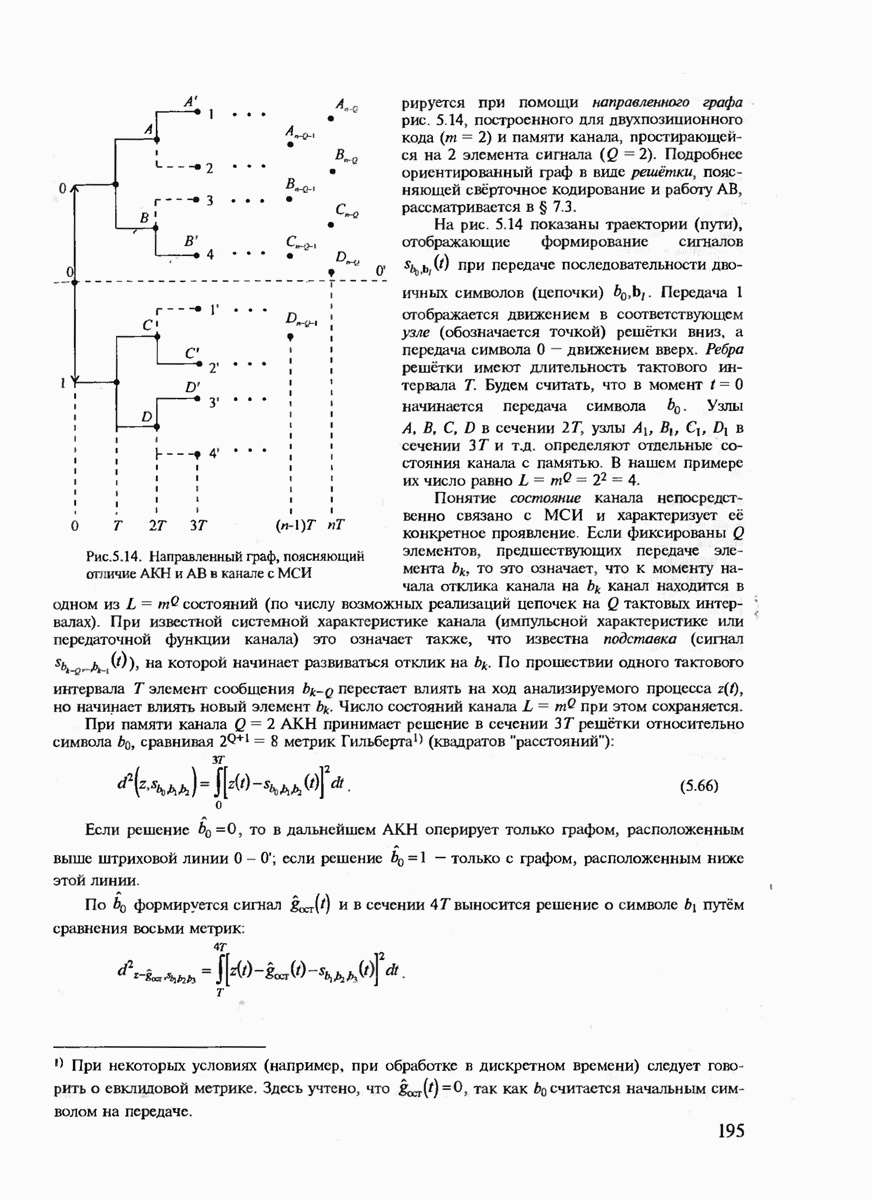
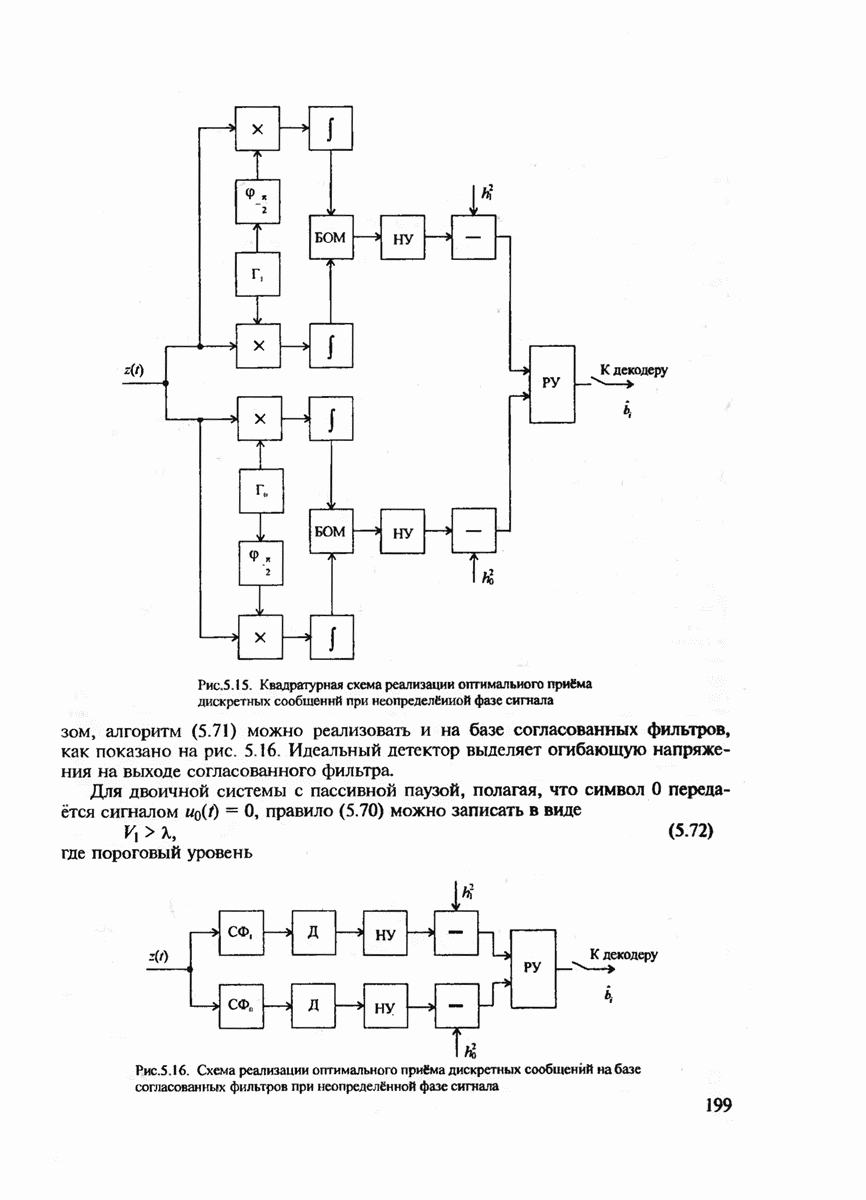
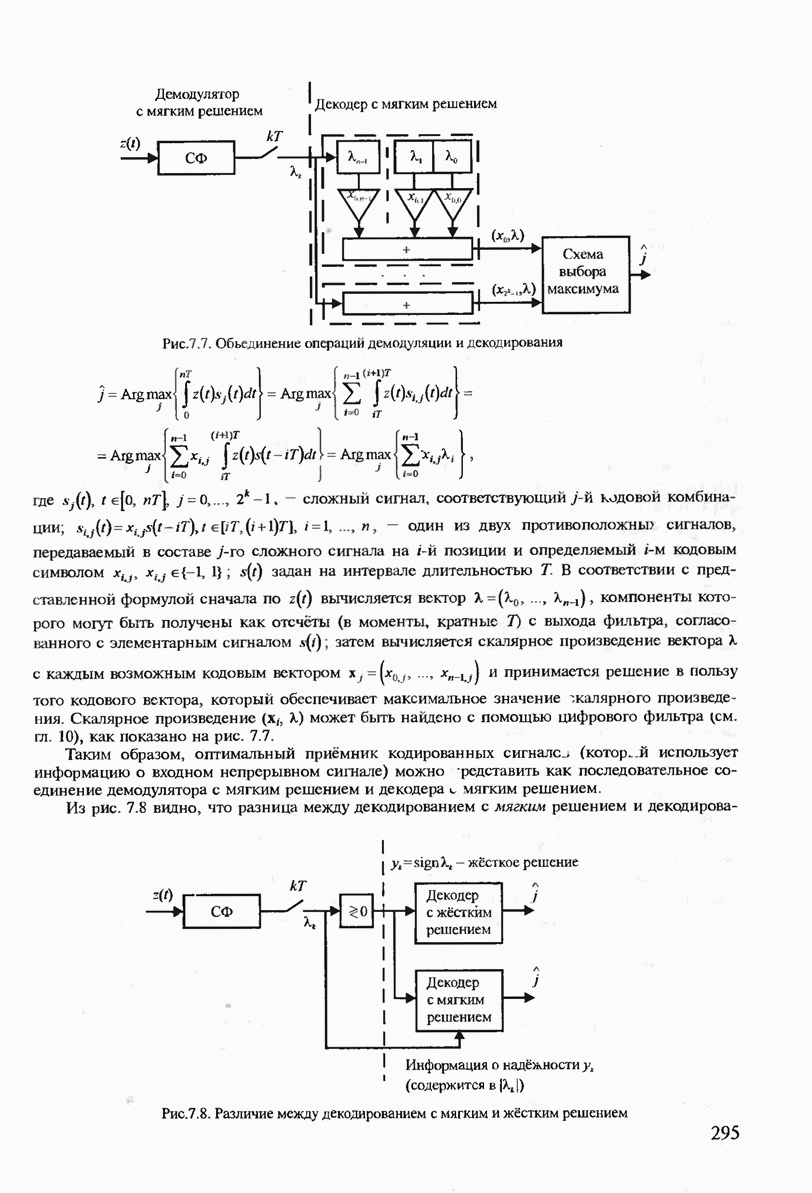
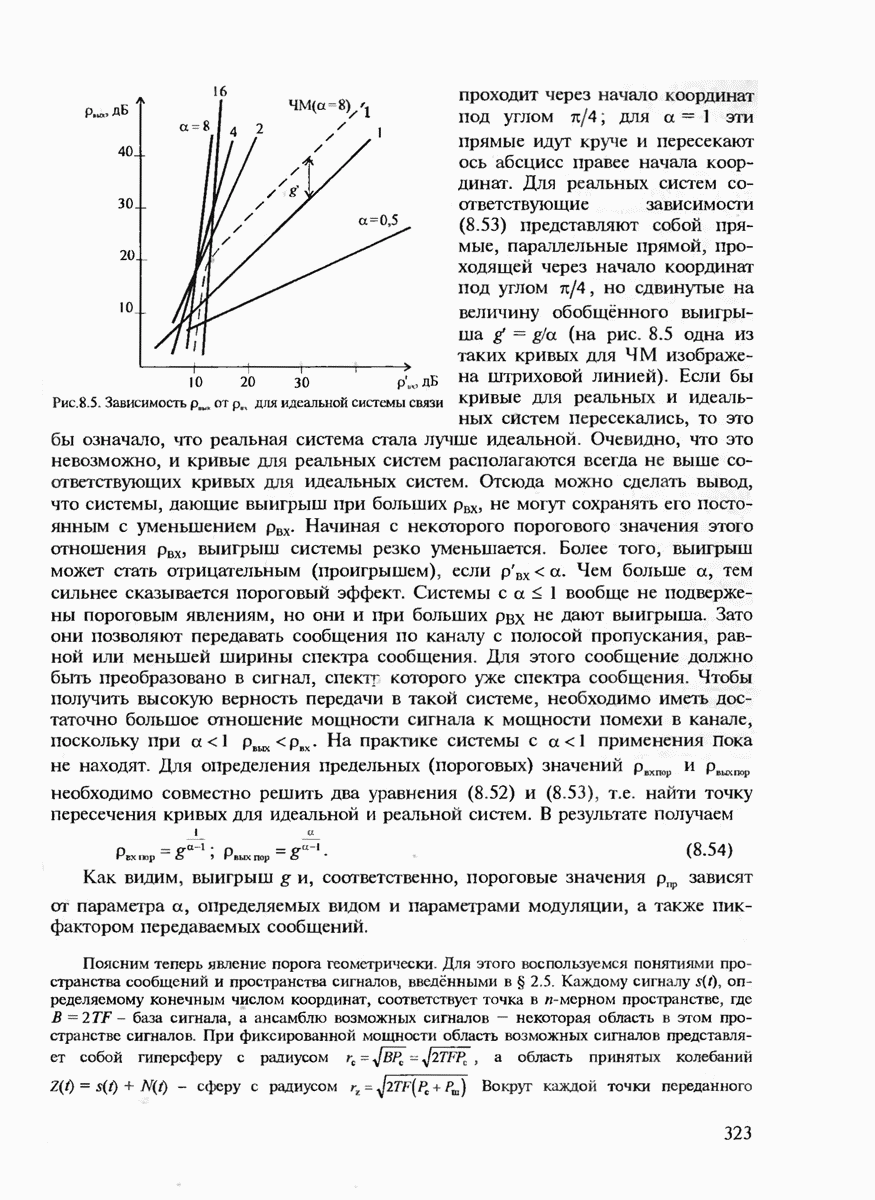
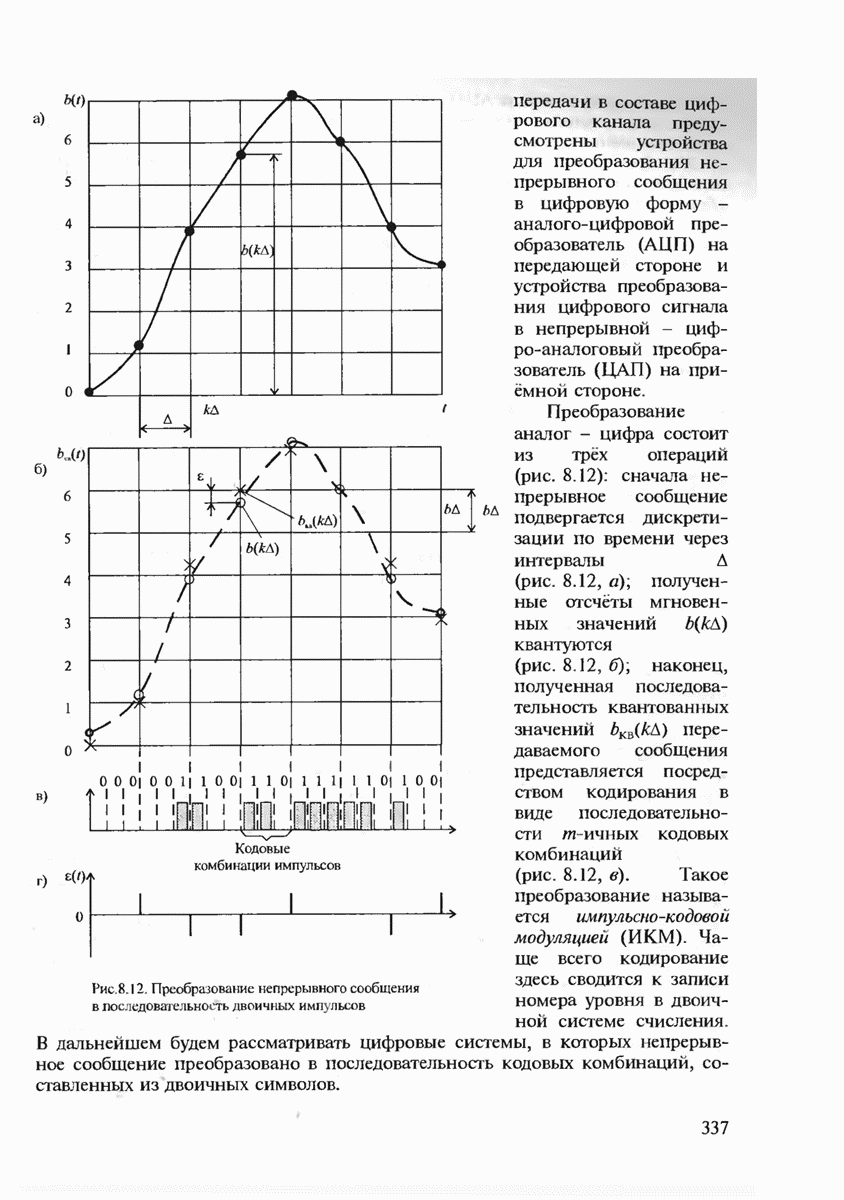
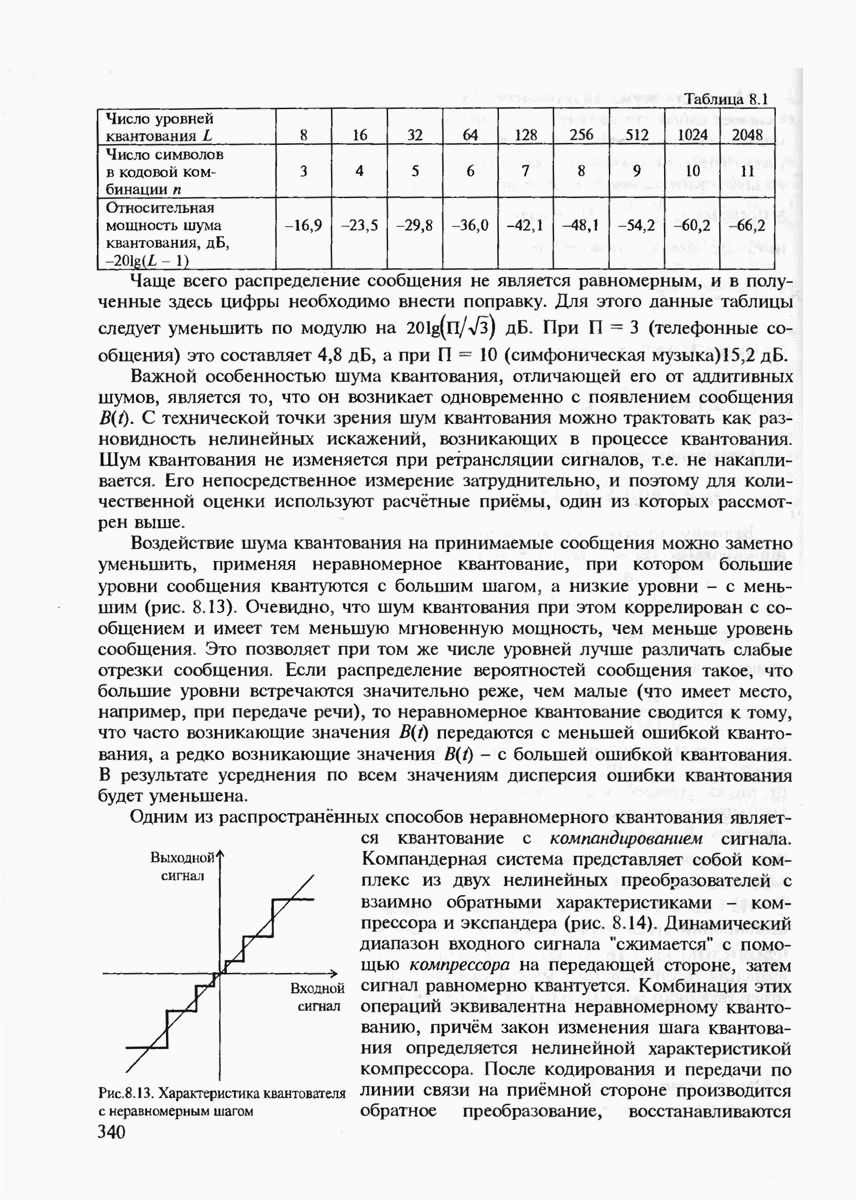
7.3.5. КОНСТРУКТИВНЫЕ АЛГОРИТМЫ ИСПРАВЛЕНИЯ ОШИБОК ЛИНЕЙНЫМИ КОДАМИ
Подытоживая сказанное ранее, можно сделать вывод, что переход к линейным кодам и к их частным случаям — циклическим и БЧХ-кодам практически полностью решает проблему кодирования-декодирования с обнаружением ошибок и построения кодов с большим минимальным расстоянием. Однако проблема исправления ошибок по-прежнему остаётся открытой. Действительно, даже при наиболее экономном способе синдромного декодирования необходимо произвести запоминание таблицы, содержащей  различных синдромов и поиск по этой таблице. (Сложность декодирования экспоненциально зависит от к или от
различных синдромов и поиск по этой таблице. (Сложность декодирования экспоненциально зависит от к или от  Переход к циклическим кодам лишь несколько упрощает вычисление самого синдрома, но не исключает необходимость запоминания
Переход к циклическим кодам лишь несколько упрощает вычисление самого синдрома, но не исключает необходимость запоминания  векторов. В современной теории кодирования разработан ряд конструктивных методов декодирования, которые позволяют перейти от экспоненциальной сложности декодирования к полиномиальной. Это прежде всего:
векторов. В современной теории кодирования разработан ряд конструктивных методов декодирования, которые позволяют перейти от экспоненциальной сложности декодирования к полиномиальной. Это прежде всего:
1. Алгебраические методы декодирования для  и родственных им кодов.
и родственных им кодов.
2. Мажоритарные методы декодирования.
При втором подходе выбираются специальные подклассы линейных кодов, имеющих так называемые "разделённые проверки. Каждый из символов блока такого кода входит только в одну из проверок для любого символа блока. Например, для кода (7, 3), дуального к коду Хэмминга, первый символ  блока связан проверочными соотношениями
блока связан проверочными соотношениями  После приёма кодового блока можно вычислить все эти проверки, включая и тривиальную
После приёма кодового блока можно вычислить все эти проверки, включая и тривиальную  и принять решение о том, равен
и принять решение о том, равен  нулю или единице в зависимости от того, оказывается ли больше среди данных проверок нулей или единиц. Такой метод декодирования называется мажоритарным. Он обобщается и на другие циклические коды, хотя возможен далеко не для всех из них.
нулю или единице в зависимости от того, оказывается ли больше среди данных проверок нулей или единиц. Такой метод декодирования называется мажоритарным. Он обобщается и на другие циклические коды, хотя возможен далеко не для всех из них.
Мажоритарная процедура декодирования допускает итеративное обобщение, когца на первой итерации с использованием проверочных соотношений вычисляются апостериорные вероятности символов кодового блока в предположении, что априорные вероятности всех символов имеют равномерное распределение. Затем на второй итерации вычисляются новые апостериорные вероятности в предположении, что априорными вероятностями в этом случае оказываются апостериорные вероятности, полученные на 1-й итерации, и т.д. При определённых условиях итеративная процедура сходится к действительно передававшемуся кодовому слову, т.е. происходит исправление ошибок.
Рассмотрим более подробно первый подход. Пусть передаётся произвольное кодовое слово  и принято слово
и принято слово  где
где  это образец ошибок, а
это образец ошибок, а  означает поэлементное суммирование в
означает поэлементное суммирование в  Найдём синдром
Найдём синдром  для принятого слова у по известной матрице
для принятого слова у по известной матрице 

Поскольку  то из (7.70) находим
то из (7.70) находим

В действительности можно показать, что в матрице  можно ограничиться лишь нечётными степенями а, т.е. рассматривать в (7.71) матрицу
можно ограничиться лишь нечётными степенями а, т.е. рассматривать в (7.71) матрицу  следующего вида:
следующего вида:

Тогда, если  то из (7.71) получим
то из (7.71) получим

где  многочлен, соответствующий образцу ошибки
многочлен, соответствующий образцу ошибки  Предположим, что вес вектора ошибки равен со и его ненулевыми компонентами являются
Предположим, что вес вектора ошибки равен со и его ненулевыми компонентами являются  т.е. вектор у содержит ошибки в координатах
т.е. вектор у содержит ошибки в координатах 
Определим локаторы ошибок как величины в поле 

и многочлен локаторов ошибок

Из (7.72) и (7.73) получим, что

Покажем, как можно найти коэффициенты многочлена локаторов ошибки  но известным координатам синдрома
но известным координатам синдрома 
Положим  в выражении (7.74), что даёт равенство
в выражении (7.74), что даёт равенство 

Умножим (7.76) на 

и просуммируем по всем  Тогда получим
Тогда получим

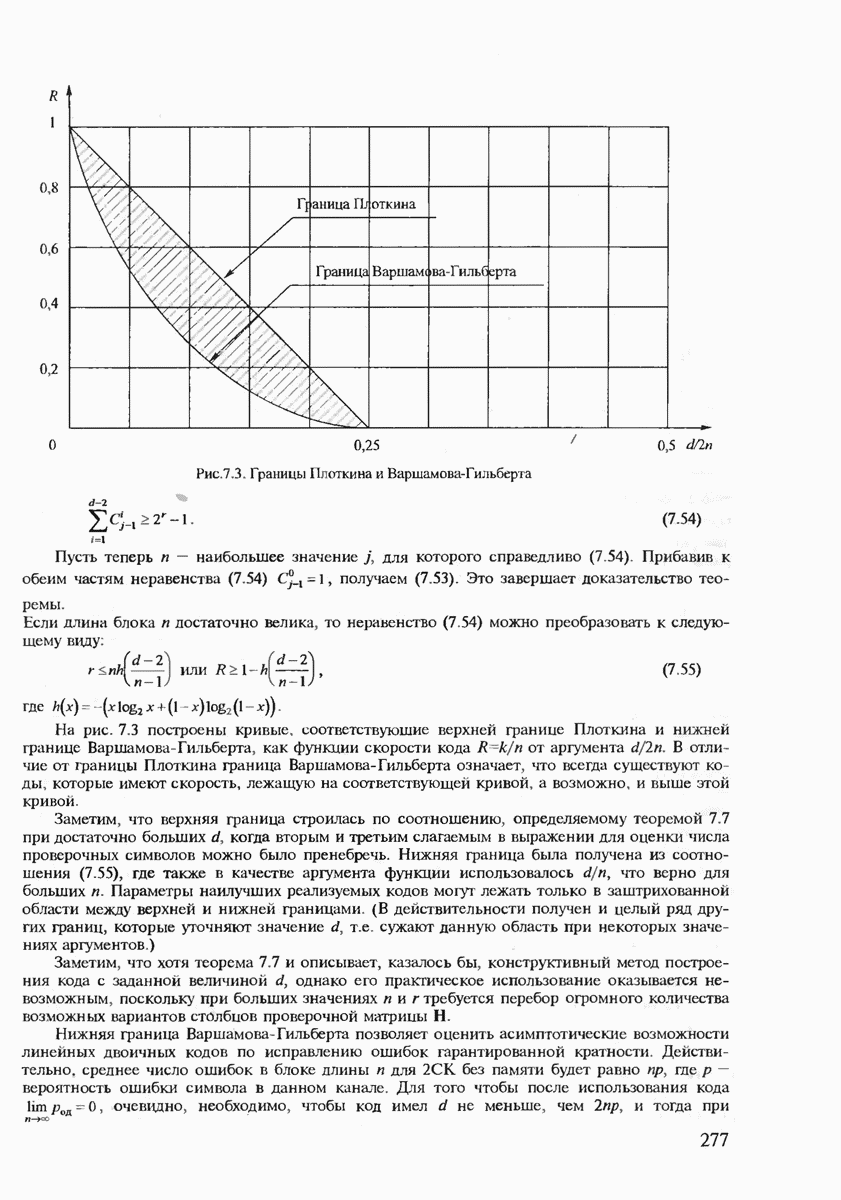
Система уравнений (7.77) является линейной, и поэтому если её решение существует, то оно может быть легко найдено. Доказывается [21], что если число действительно произошедших ошибок не превосходит  то система (7.77) имеет решение. После нахождения неизвестных
то система (7.77) имеет решение. После нахождения неизвестных  можно по (7.74) вычислить многочлен локаторов ошибок. Затем находятся корни этого многочлена
можно по (7.74) вычислить многочлен локаторов ошибок. Затем находятся корни этого многочлена  ею и, наконец, локаторы ошибок
ею и, наконец, локаторы ошибок  Очевидно, что нахождение локаторов ошибок позволяет найти положения самих ошибок
Очевидно, что нахождение локаторов ошибок позволяет найти положения самих ошибок  на кодовом блоке, т.е. произвести исправление ошибок.
на кодовом блоке, т.е. произвести исправление ошибок.
Как видно, при использовании алгебраических методов декодирования процедура исправления ошибок имеет полиномиальную сложность в зависимости от числа ошибок  чем она существенно отличается от экспоненциально сложной процедуры декодирования методом перебора всех образцов ошибок. "Платой" за это преимущество является сужение класса всех линейных кодов до БЧХ. Кроме того, доказывается, что достаточно длинные БЧХ-коды имеют минимальное кодовое расстояние значительно худшее, чем то, которое гарантируется границей Варшамова-Гильберта. Впрочем, существуют такие классы кодов, как, например, коды Гоппы обладающие как хорошим
чем она существенно отличается от экспоненциально сложной процедуры декодирования методом перебора всех образцов ошибок. "Платой" за это преимущество является сужение класса всех линейных кодов до БЧХ. Кроме того, доказывается, что достаточно длинные БЧХ-коды имеют минимальное кодовое расстояние значительно худшее, чем то, которое гарантируется границей Варшамова-Гильберта. Впрочем, существуют такие классы кодов, как, например, коды Гоппы обладающие как хорошим  так и конструктивным алгебраическим алгоритмом декодирования.
так и конструктивным алгебраическим алгоритмом декодирования.