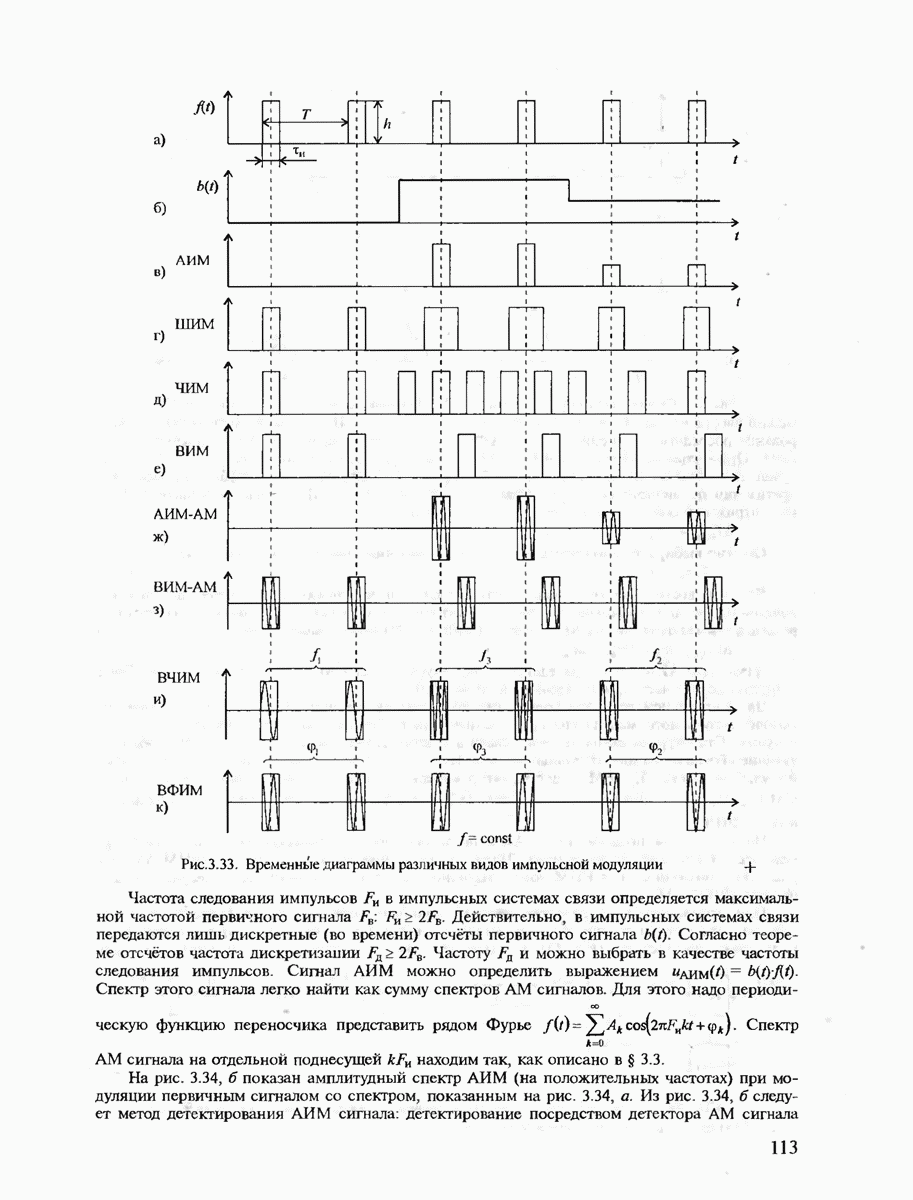
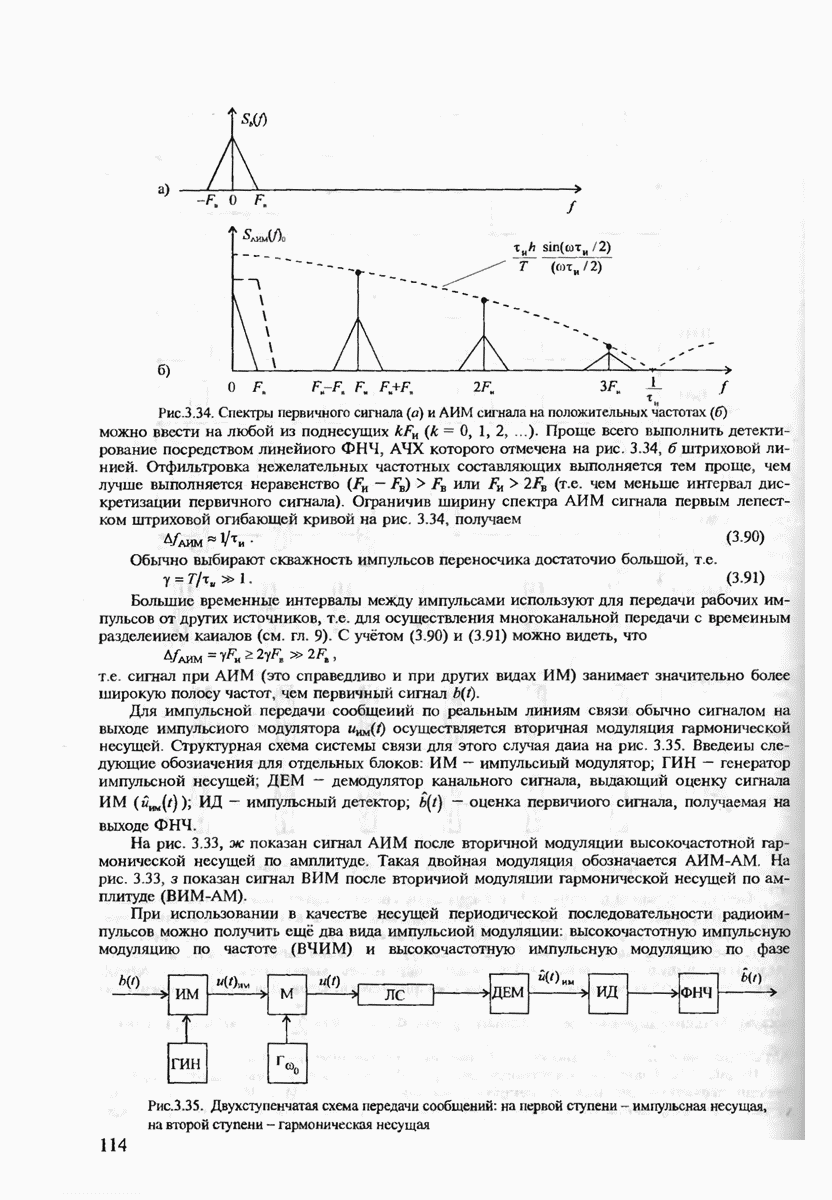
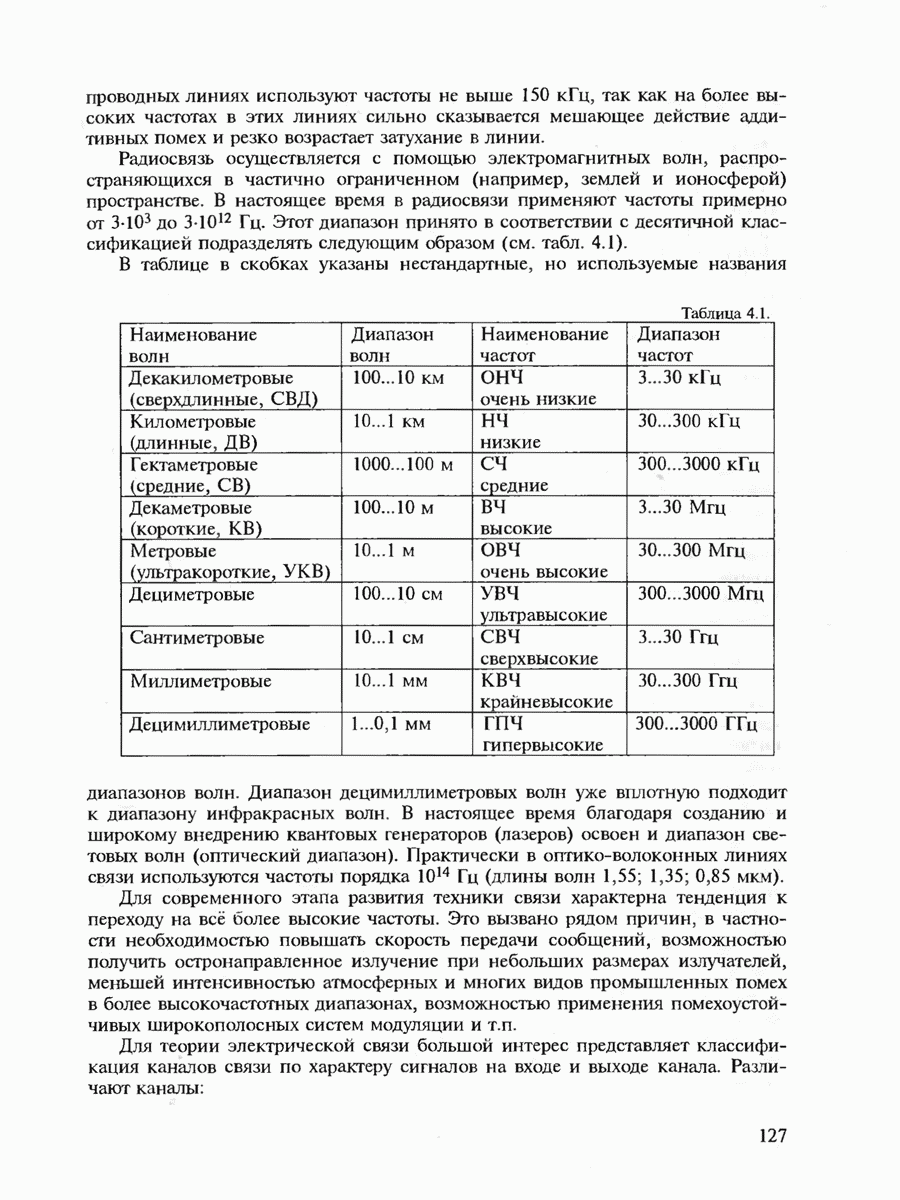
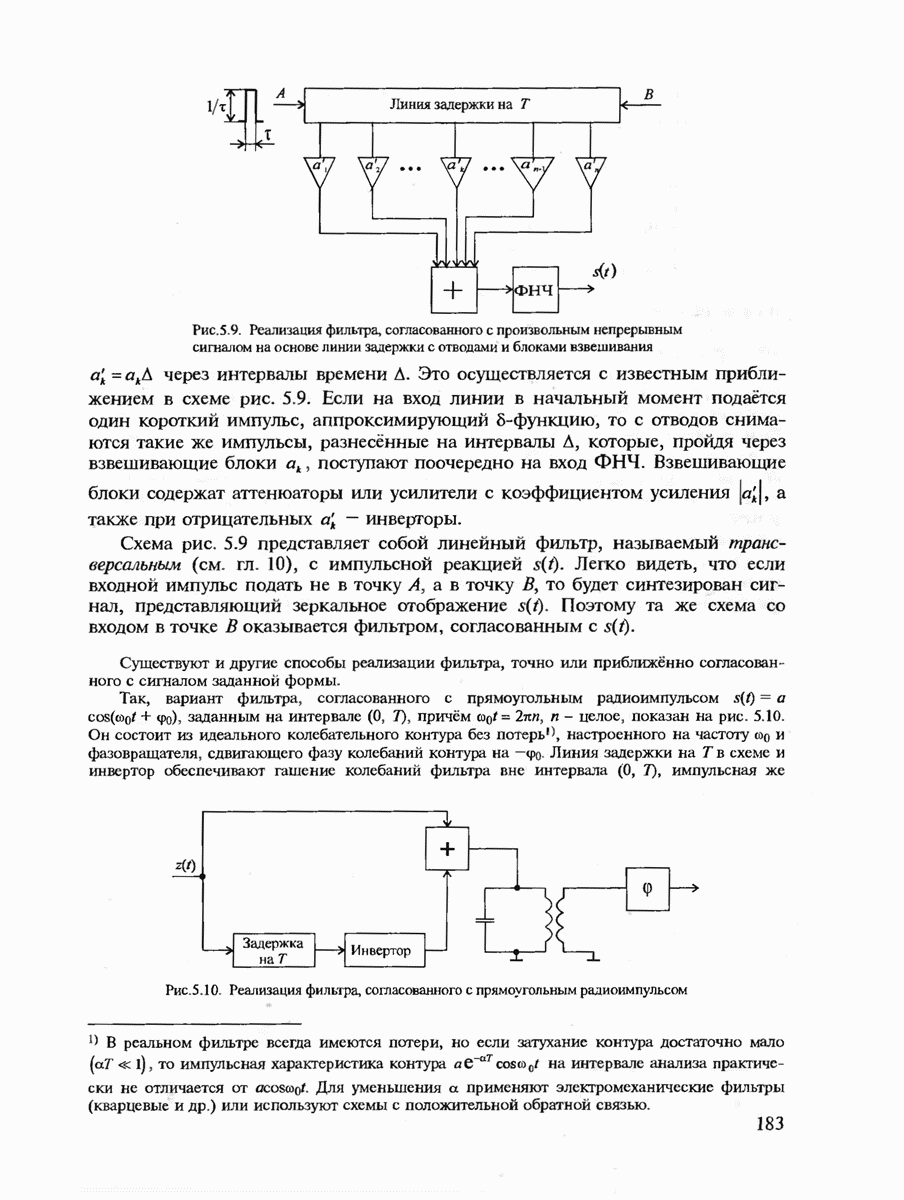
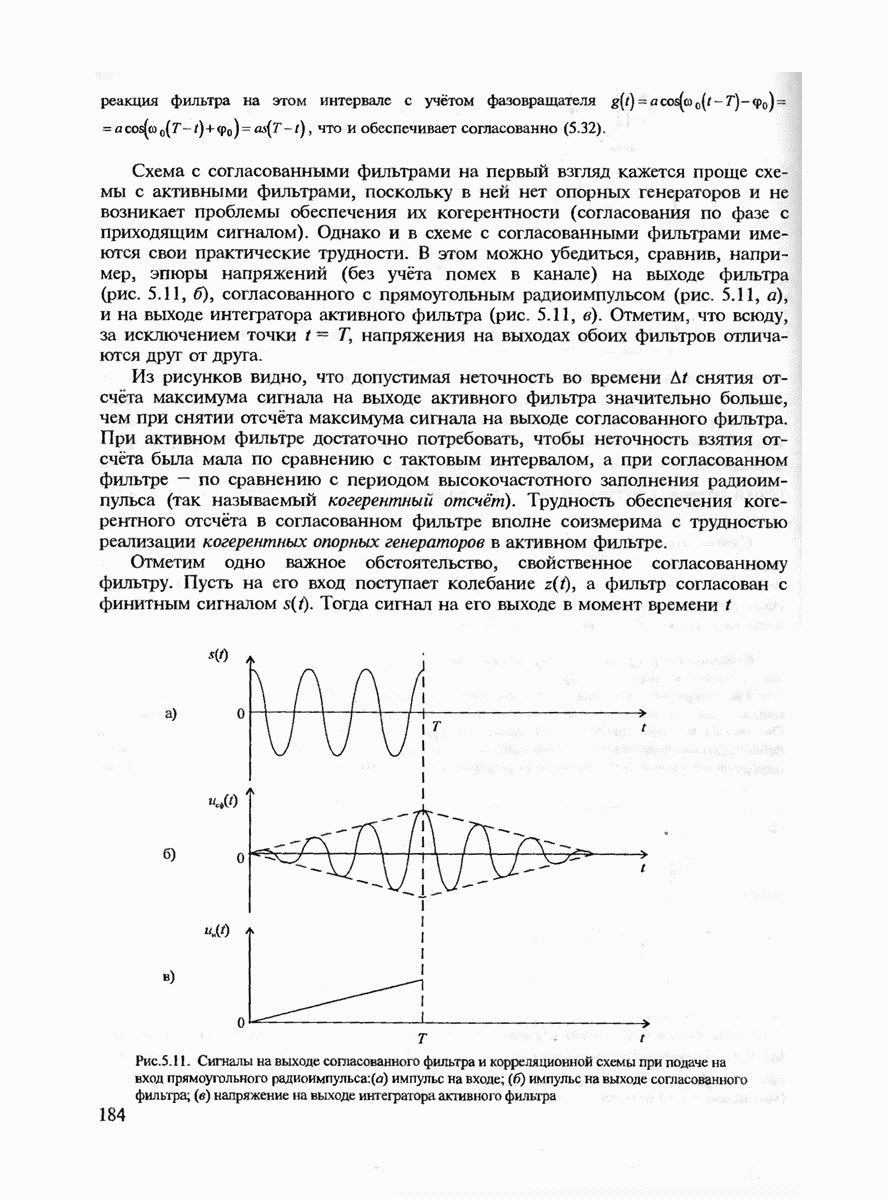
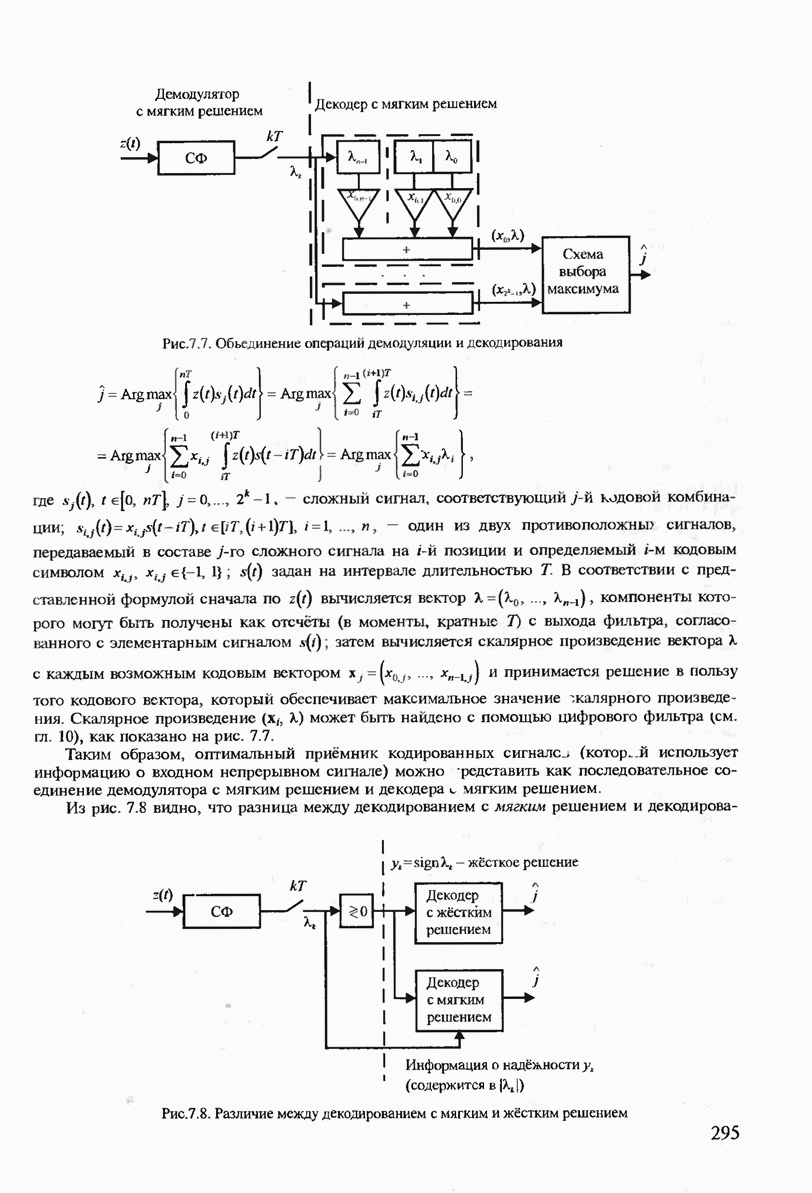
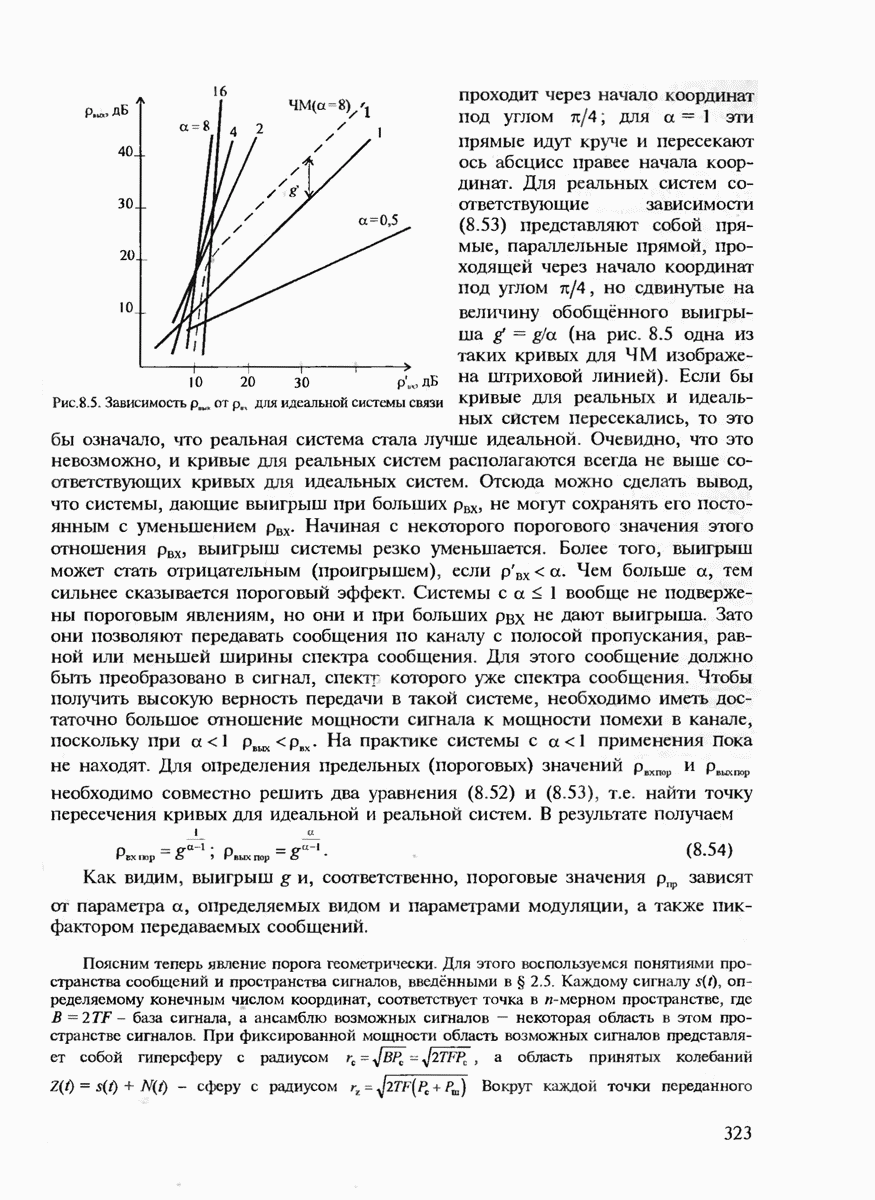
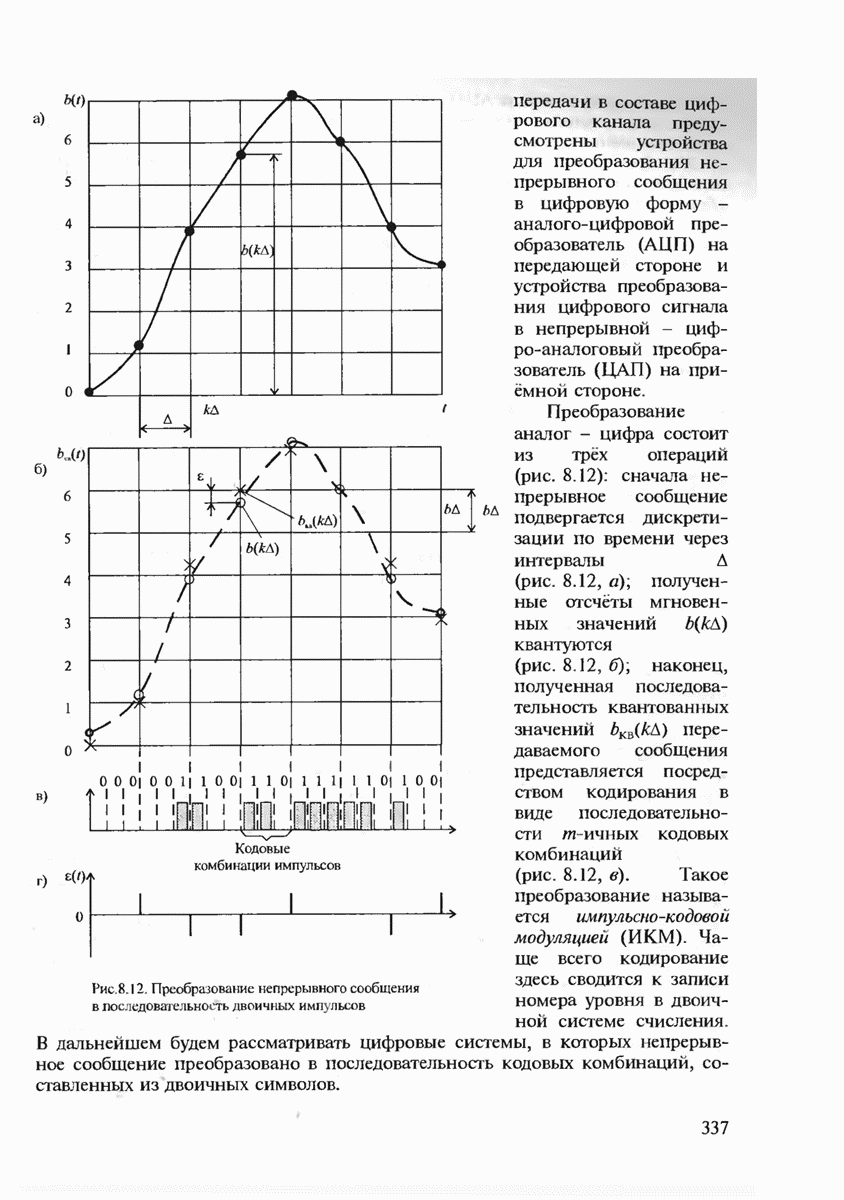
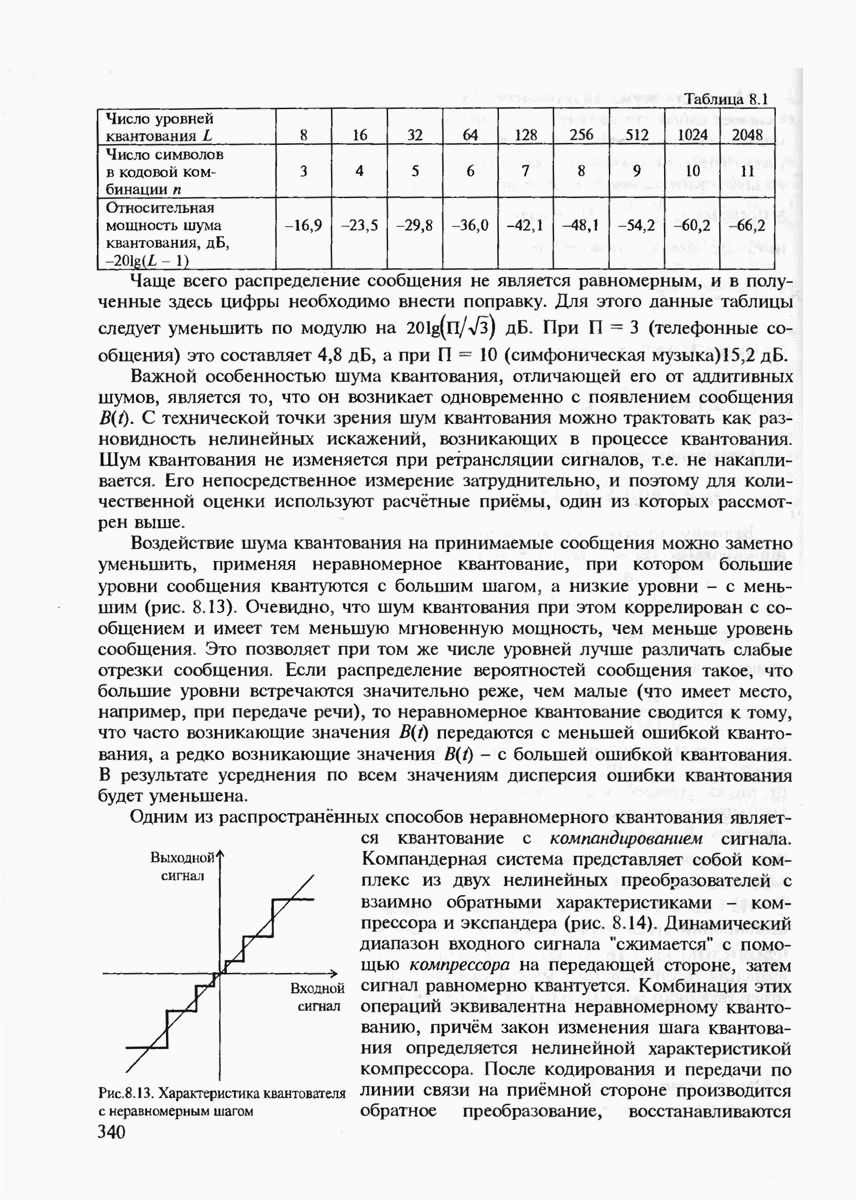
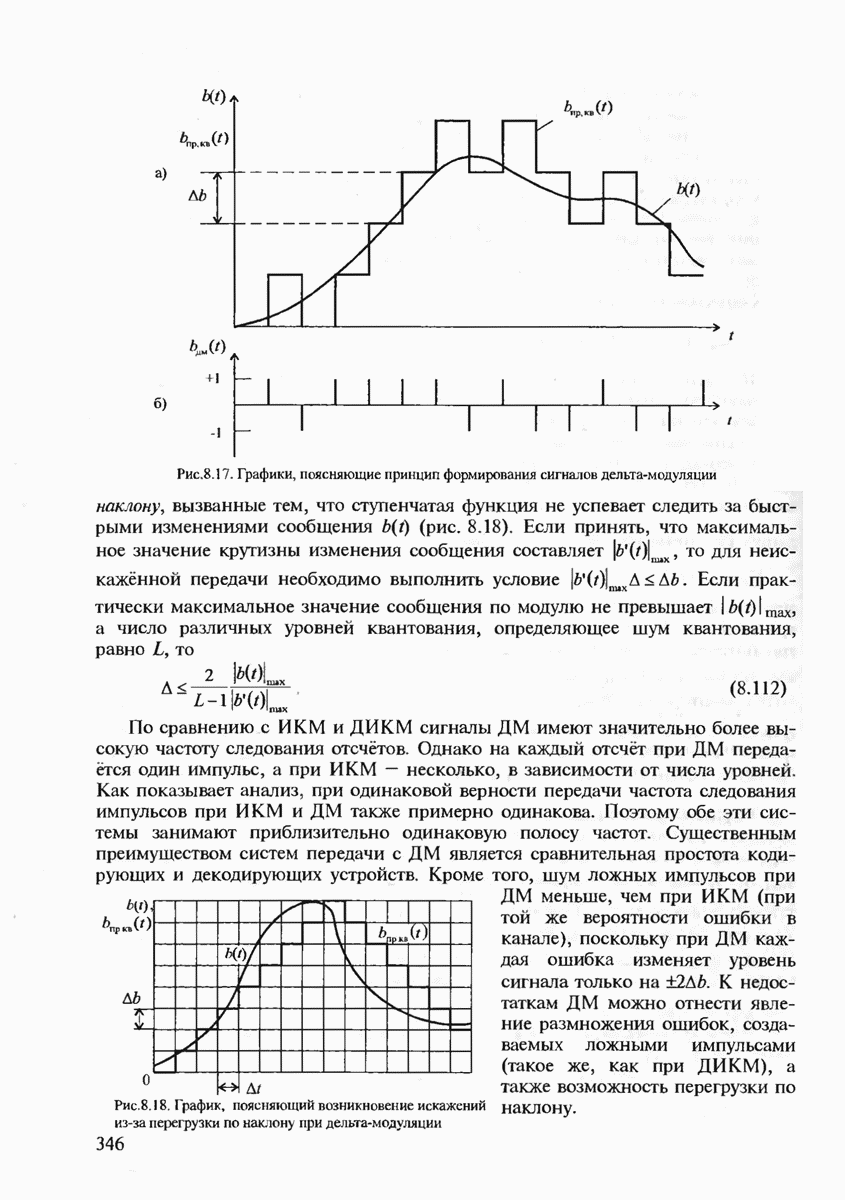
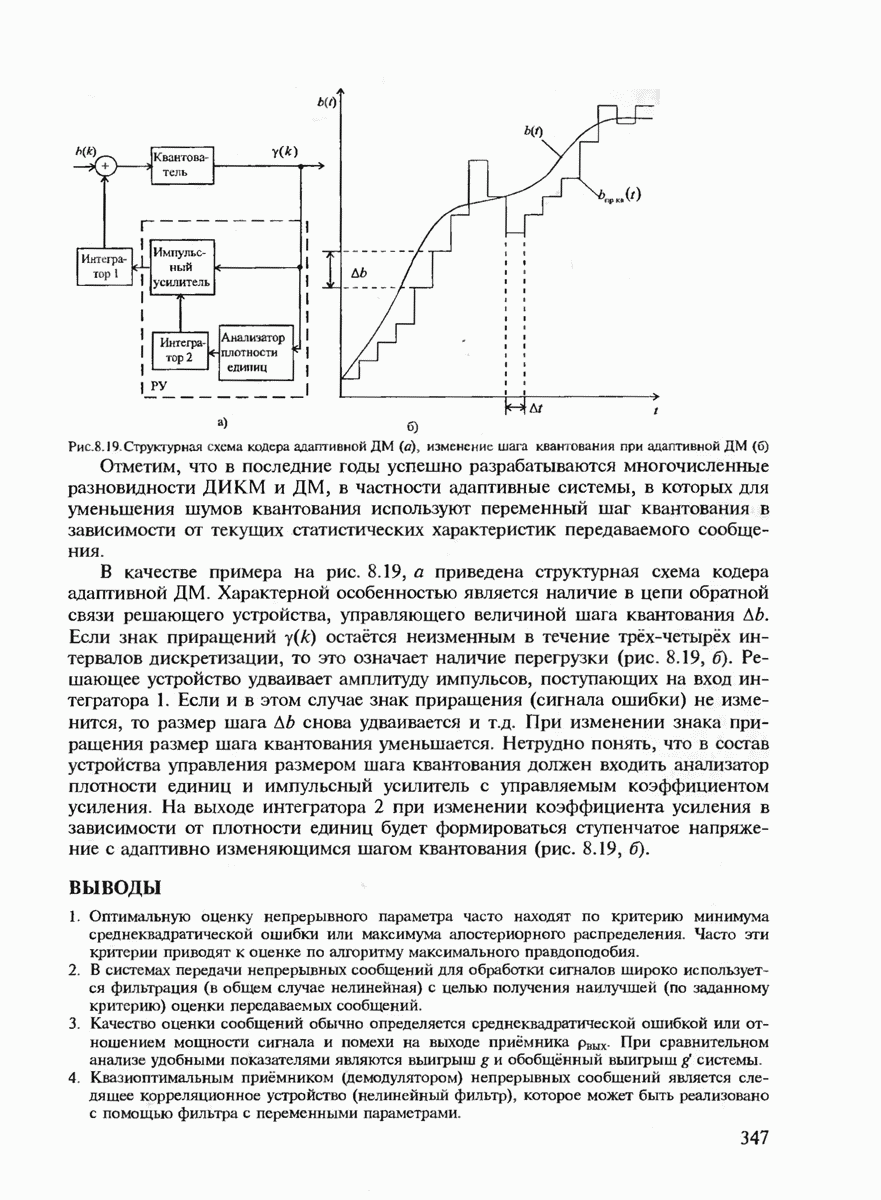
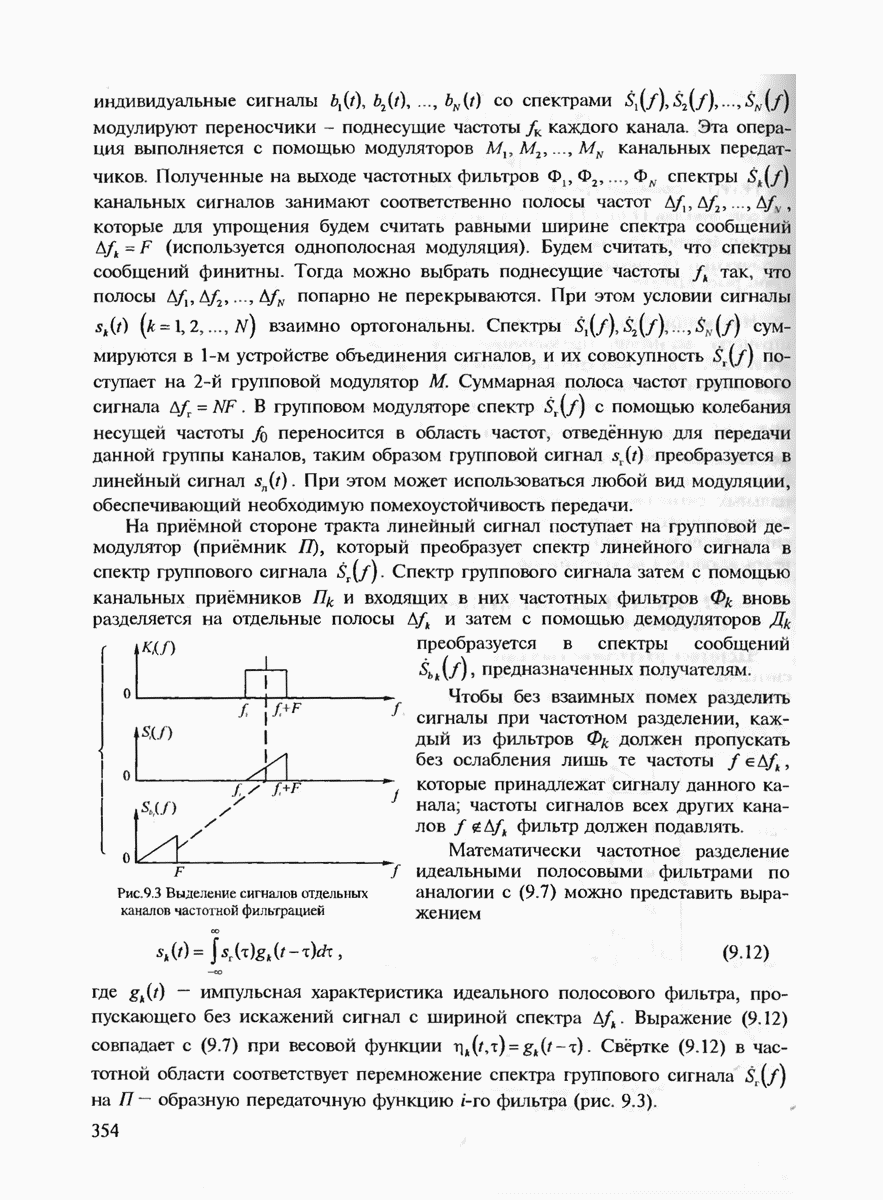
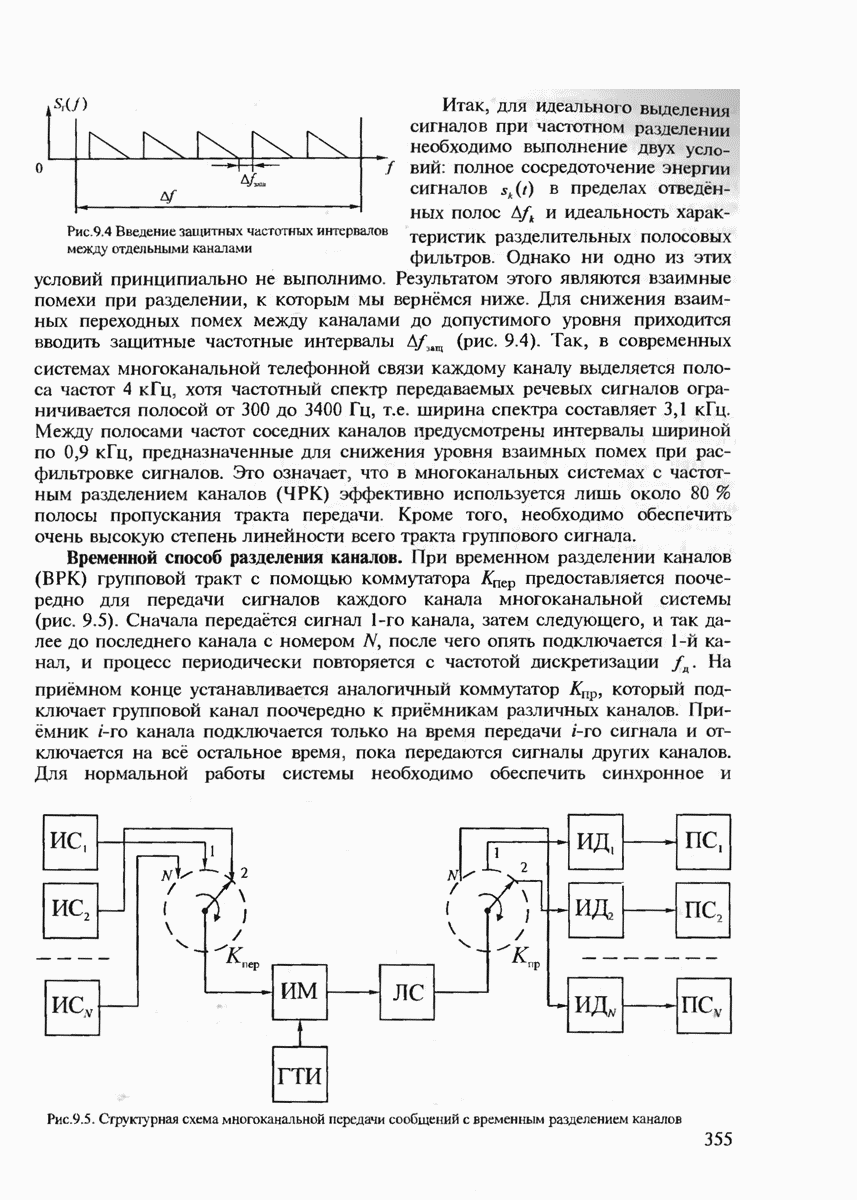
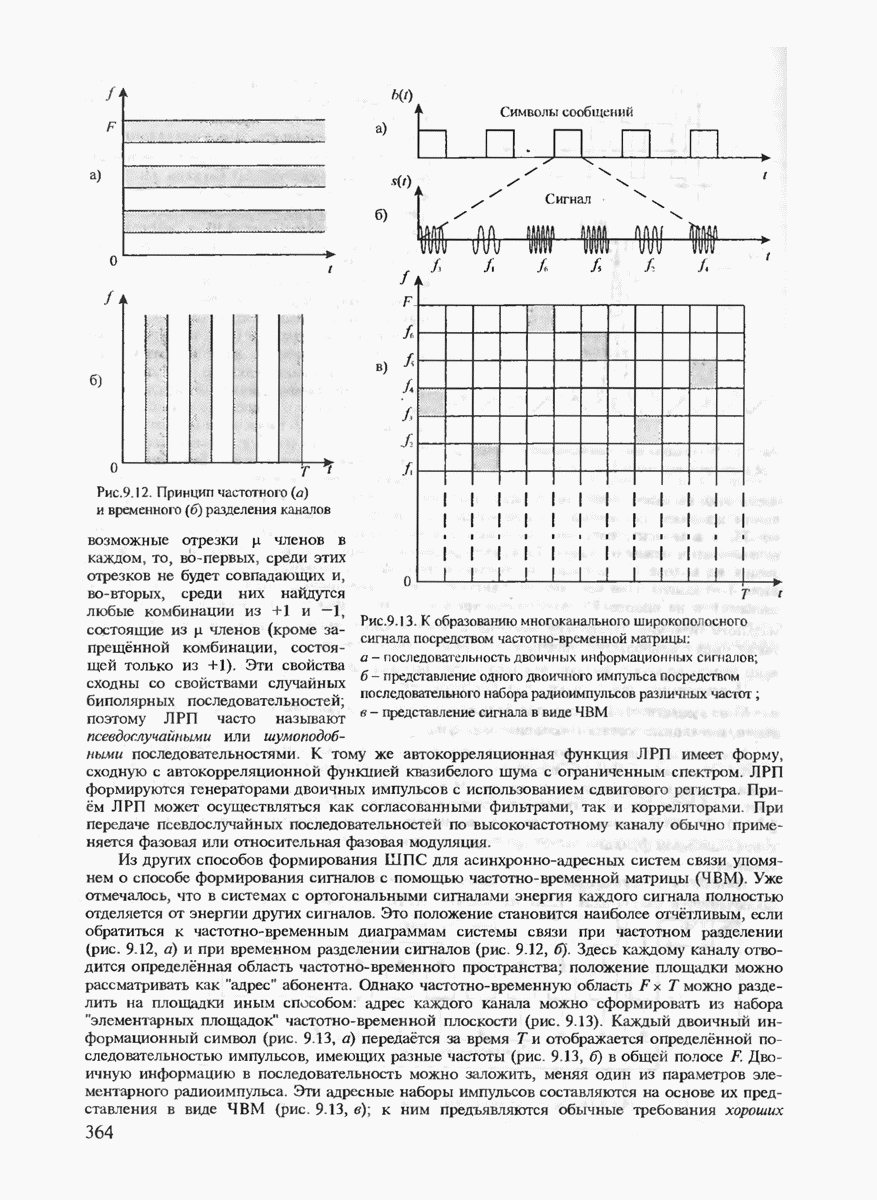
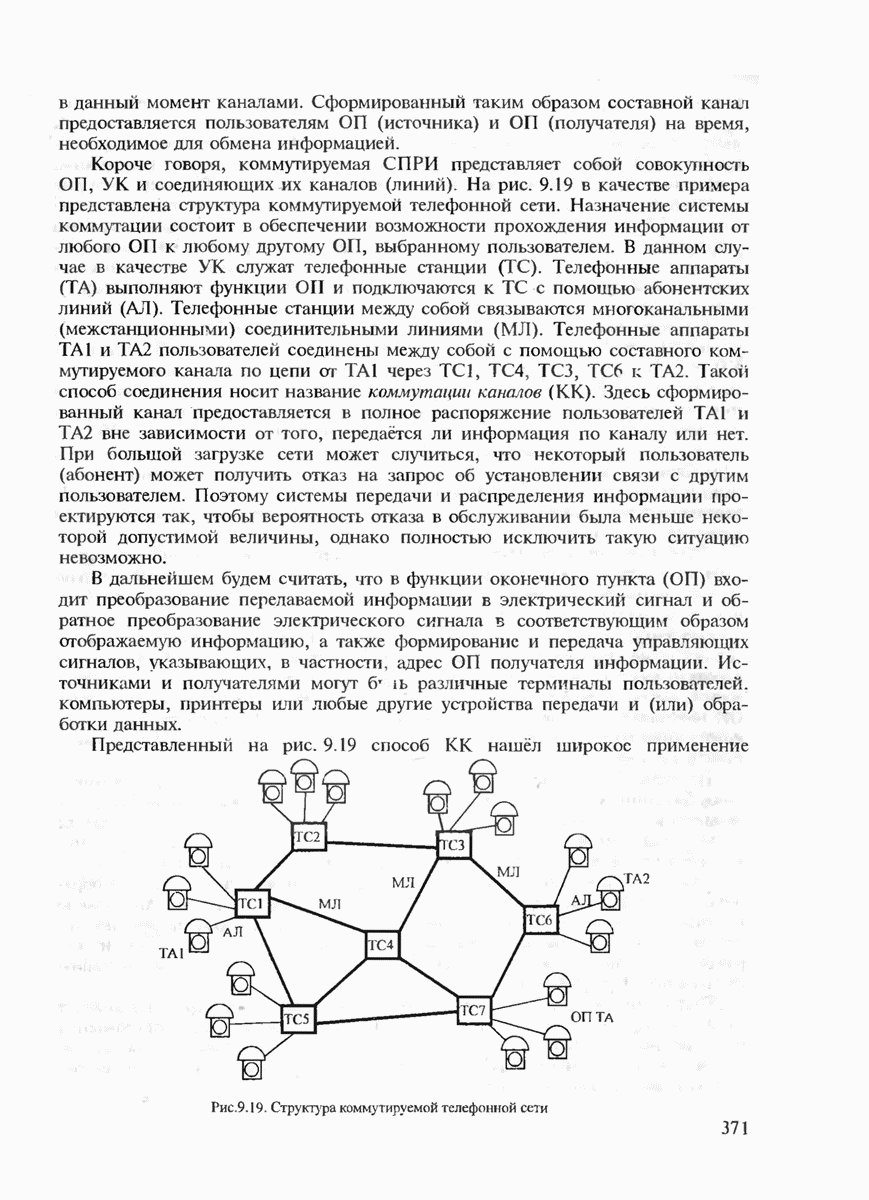
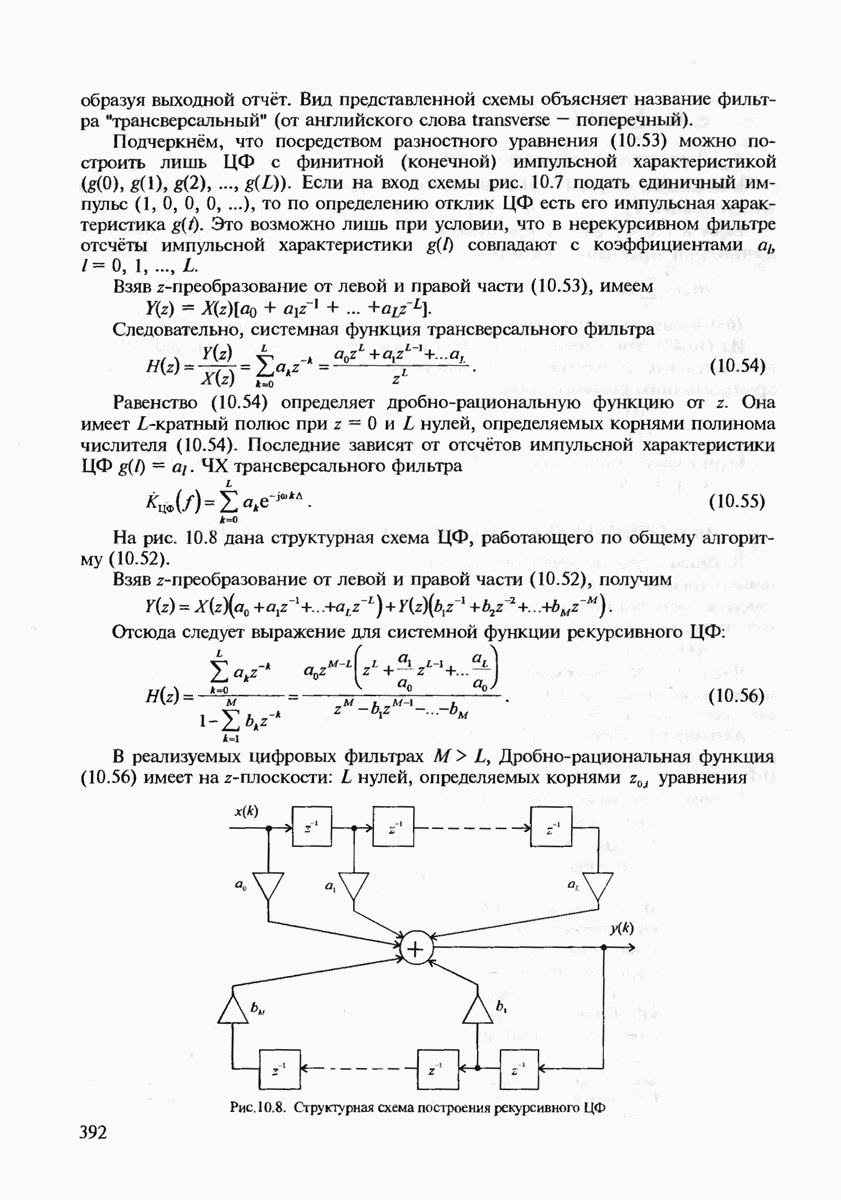
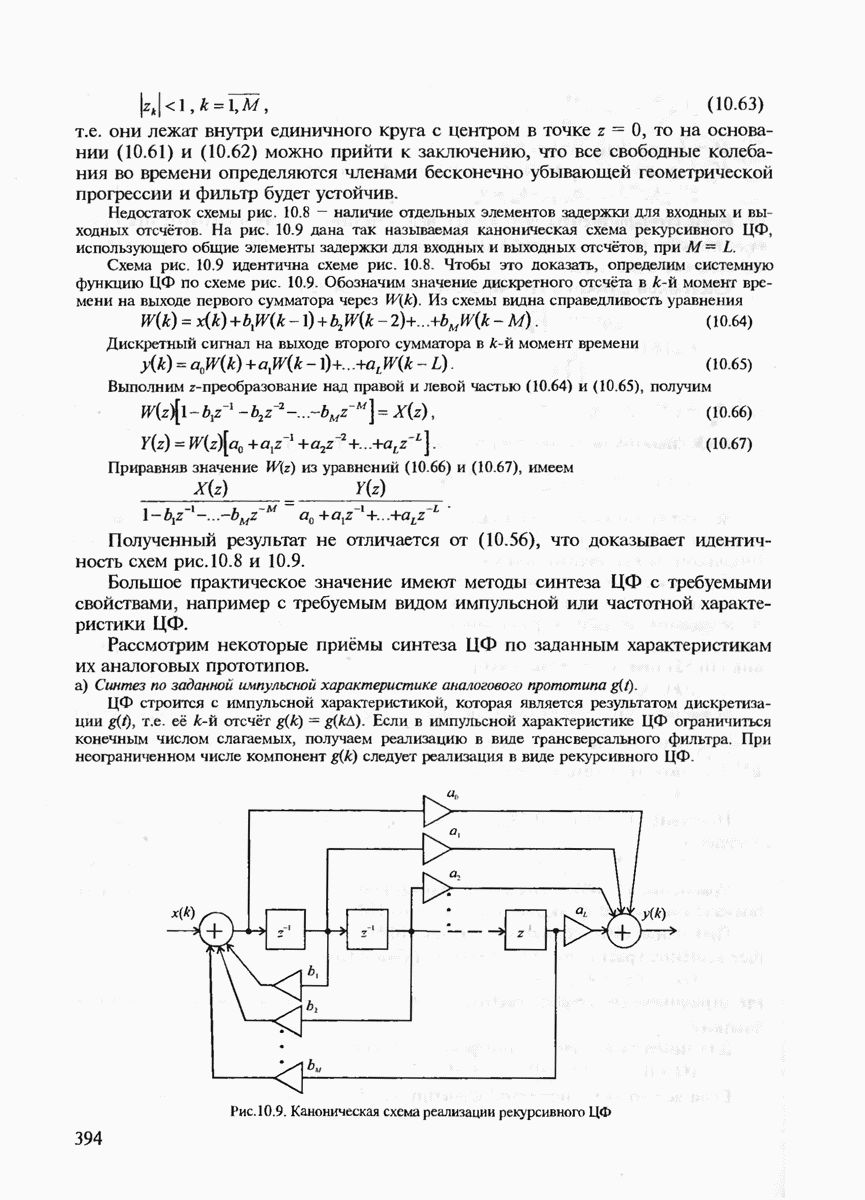
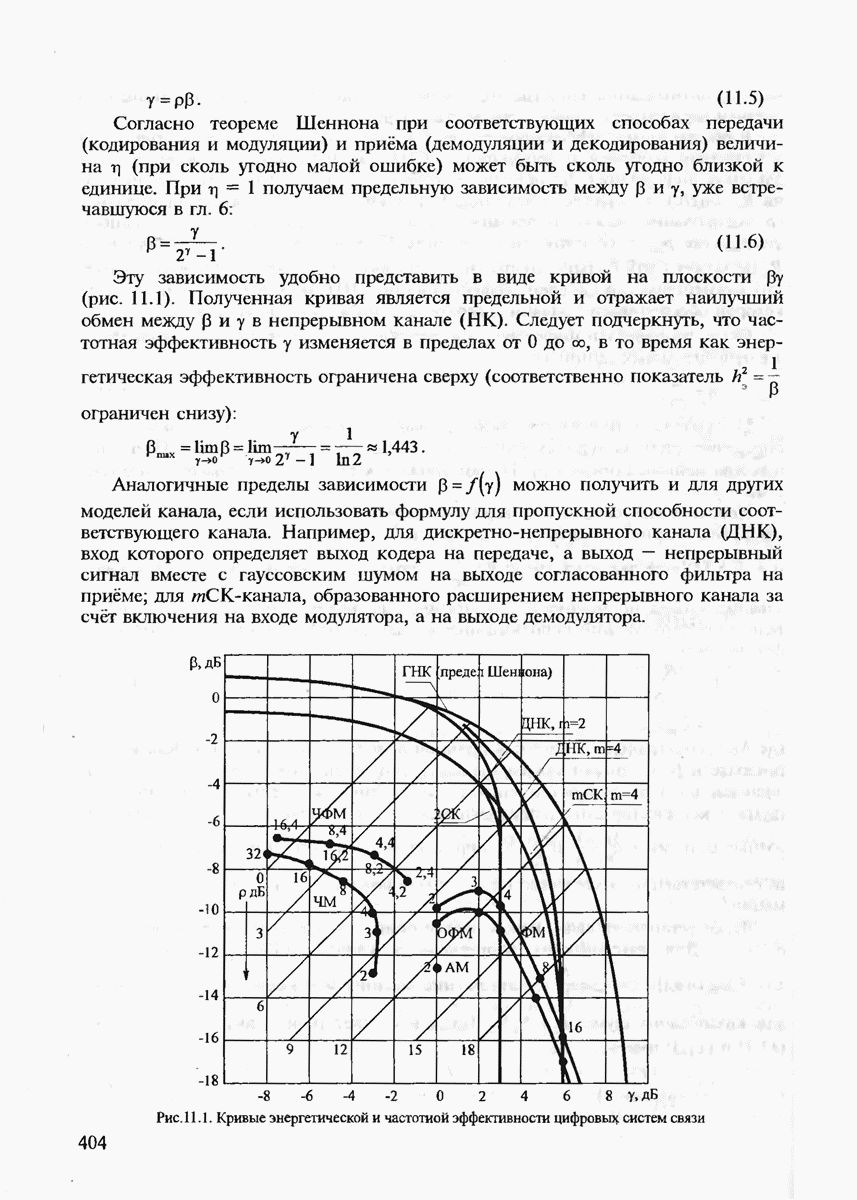
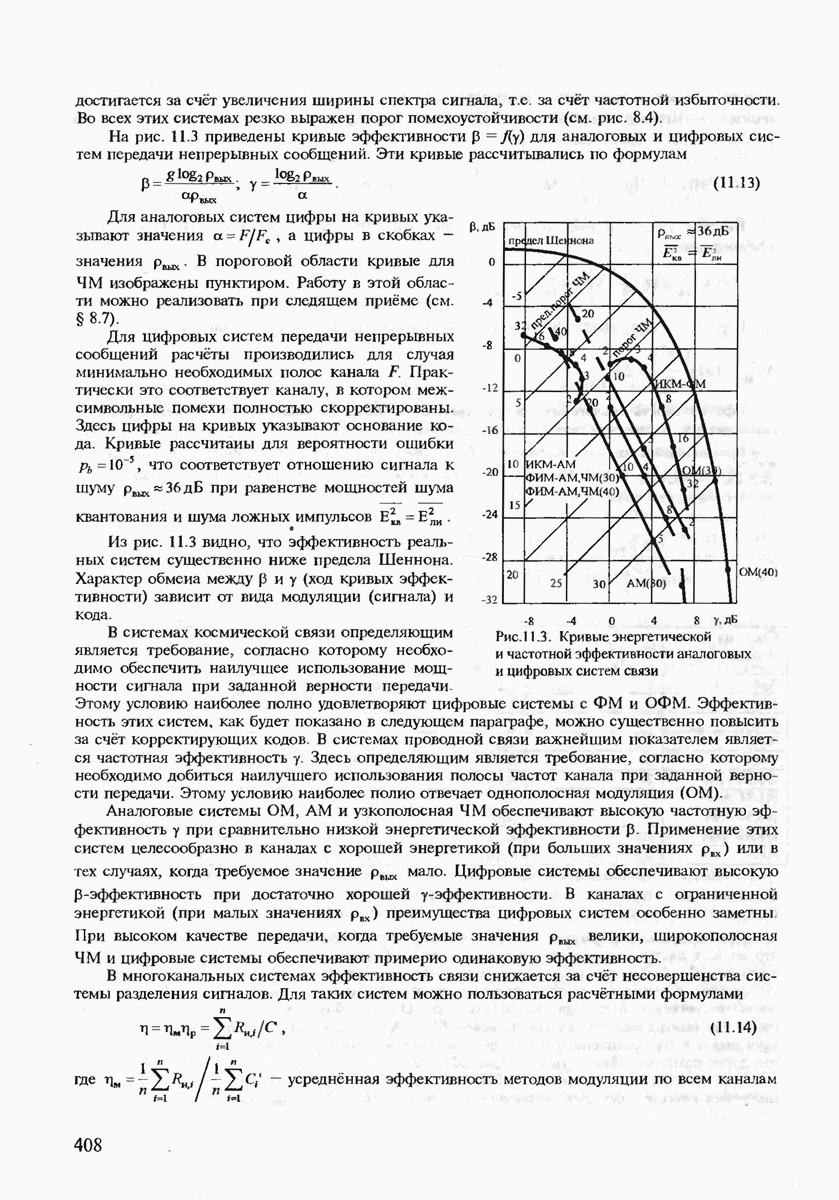
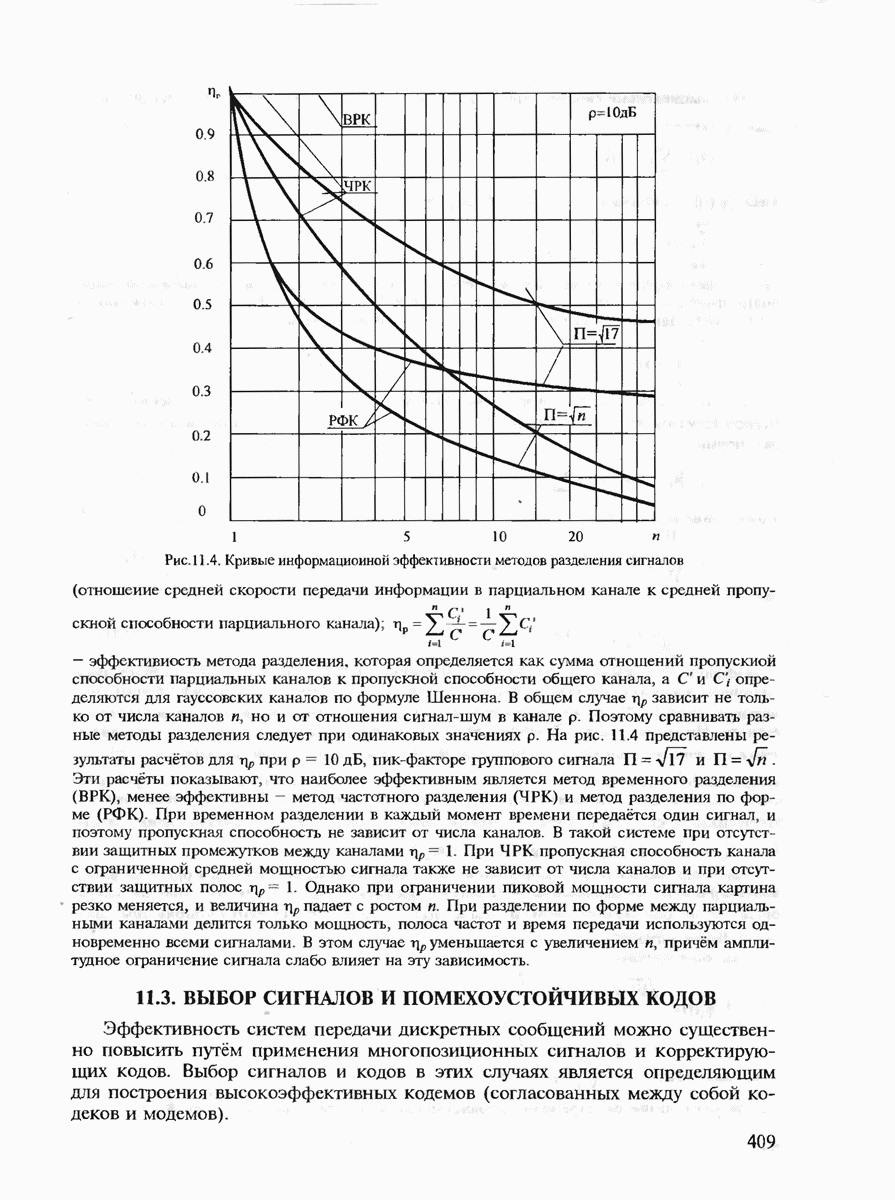
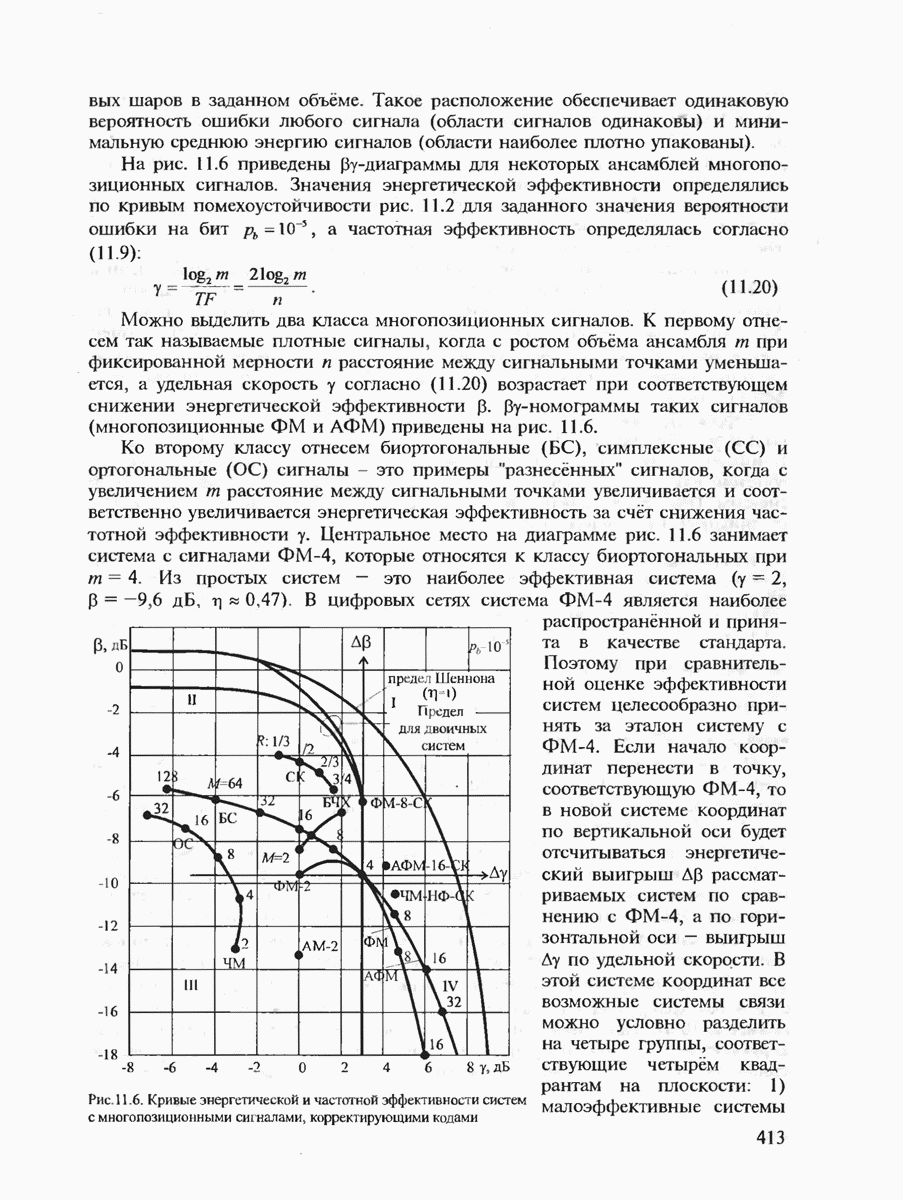
7.3.2. КОДЫ С ГАРАНТИРОВАННЫМ ОБНАРУЖЕНИЕМ И ИСПРАВЛЕНИЕМ ОШИБОК
Пусть задан некоторый блоковый код длины и, состоящий из  комбинаций (блоков, слов, векторов)
комбинаций (блоков, слов, векторов)  Для упрощения определений и доказательств будем всюду считать, что входной X и выходной У алфавиты канала совпадают. В общем случае канал может иметь память и задаваться вероятностями
Для упрощения определений и доказательств будем всюду считать, что входной X и выходной У алфавиты канала совпадают. В общем случае канал может иметь память и задаваться вероятностями  переходов входных блоков х в выходные у.
переходов входных блоков х в выходные у.
Определение 1. Расстоянием Хэмминга  между двумя комбинациями
между двумя комбинациями  будем называть число позиций этих комбинаций, в которых отдельные кодовые символы
будем называть число позиций этих комбинаций, в которых отдельные кодовые символы  не совпадают. Очевидно, что
не совпадают. Очевидно, что  для любых и что
для любых и что  для любых
для любых 
Определение 2. Образцом ошибки  будем называть двоичный блок длины
будем называть двоичный блок длины  который имеет единицы в тех позициях, в которых символы переданного х и принятого у блоков отличаются друг от друга, и нули — в остальных позициях.
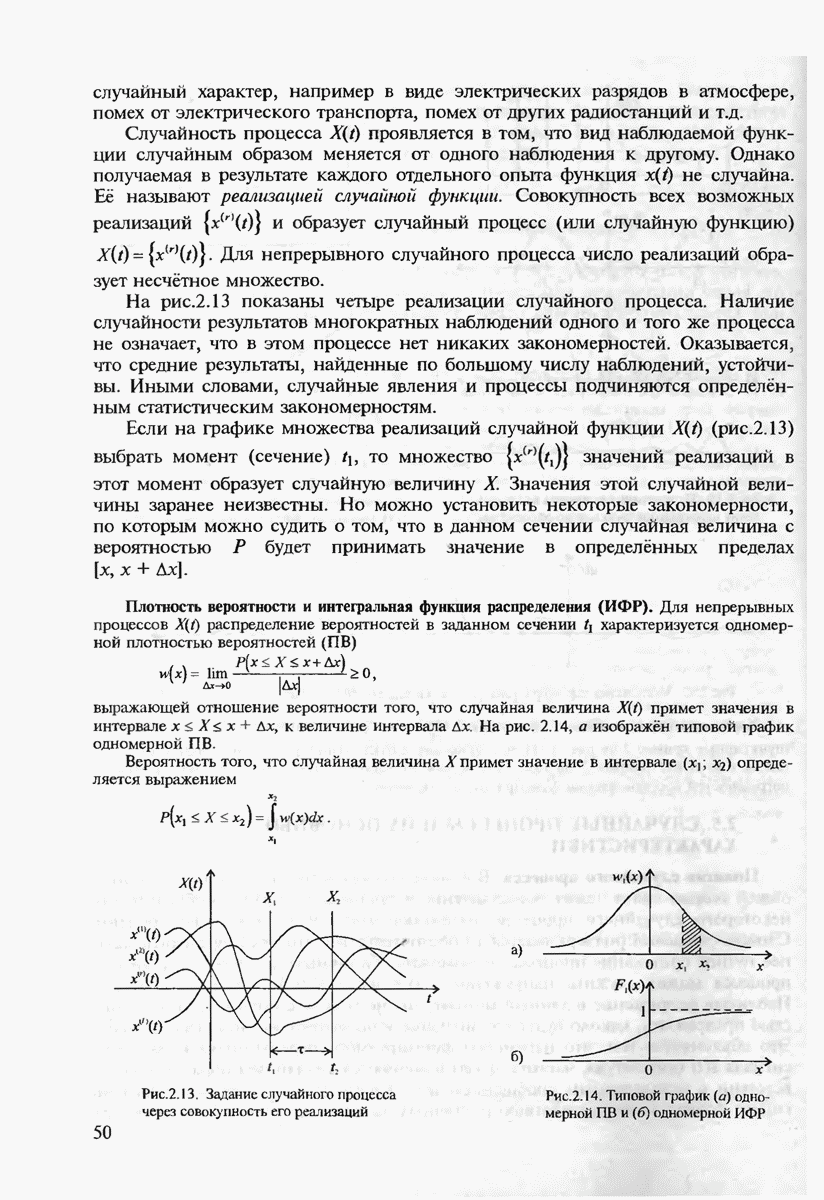
который имеет единицы в тех позициях, в которых символы переданного х и принятого у блоков отличаются друг от друга, и нули — в остальных позициях.
Ранее в гл. 2 были сформулированы аксиомы, которым должно удовлетворять абстрактное определение понятия расстояния в функциональных пространствах сигналов. Покажем, что расстояние Хэмминга удовлетворяет этим аксиомам на пространстве  -ичных последовательностей произвольной длины
-ичных последовательностей произвольной длины  Первые требования:
Первые требования:  удовлетворяются очевидным образом. Остаётся проверить лишь справедливость "неравенства треугольника":
удовлетворяются очевидным образом. Остаётся проверить лишь справедливость "неравенства треугольника":

Предположим, что  отличаются друг от друга в позициях
отличаются друг от друга в позициях  где
где  в позициях
в позициях  где
где  Тогда легко убедиться, что х и у не могут различаться в каких-либо позициях, отличных от
Тогда легко убедиться, что х и у не могут различаться в каких-либо позициях, отличных от  а если
а если  то в этой позиции они могут и совпадать. Поэтому р(х,у)
то в этой позиции они могут и совпадать. Поэтому р(х,у)  что и эквивалентно неравенству (7.30).
что и эквивалентно неравенству (7.30).
Определение 3. Весом Хэмминга  блока (вектора) х (аналогично для
блока (вектора) х (аналогично для  ) будем называть число ненулевых символов этих блоков.
) будем называть число ненулевых символов этих блоков.
Определение 4. Кратностью образца ошибки  (или короче — кратностью ошибки) будем называть его вес Хэмминга
(или короче — кратностью ошибки) будем называть его вес Хэмминга  (По существу это число ошибок, которое произошло при передаче блока
(По существу это число ошибок, которое произошло при передаче блока 
Декодирование в заданном канале связи по максимуму правдоподобия - это принятие решения о передаче такого кодового блока  для которого условная вероятность
для которого условная вероятность  максимальна, где у — принятый блок. Это правило получения оценки можно записать в следующей компактной форме:
максимальна, где у — принятый блок. Это правило получения оценки можно записать в следующей компактной форме:

Как понятно из гл. 5, такое правило приводит к максимально возможной средней вероятности правильного приёма кодовых блоков при равновероятной посылке этих блоков по каналу связи. (Если последнее условие не выполняется то оптимальное декодирование должно соответствовать правилу максимальной апостериорной вероятности.)
Определение 5. Декодированием по минимуму расстояния Хэмминга будем называть следующее правило (алгоритм) принятия решения:

(По существу, правило (7.32) означает, что считается переданной та кодовая комбинация, которая отличается от принятой в наименьшем числе позиций.)
Покажем, что для  без памяти правила (7.31) и (7.32) совпадают, т.е. декодирование по минимуму расстояния Хэмминга совпадает с декодированием по максимуму правдоподобия. Действительно, в соответствии с определением
без памяти правила (7.31) и (7.32) совпадают, т.е. декодирование по минимуму расстояния Хэмминга совпадает с декодированием по максимуму правдоподобия. Действительно, в соответствии с определением  без памяти
без памяти

где  длина блоков
длина блоков  Легко убедиться, что (7.33) является монотонно убывающей функцией
Легко убедиться, что (7.33) является монотонно убывающей функцией  при
при  что и доказывает эквивалентность (7.31) и (7.32) для данного каната связи.
что и доказывает эквивалентность (7.31) и (7.32) для данного каната связи.
В случае использования произвольного канала связи, например несимметричного или с памятью, декодирование по минимуму расстояния Хэмминга не обязательно будет оптимальной процедурой, однако ввиду простаты (7.32) этот алгоритм часто используется и в данных случаях.
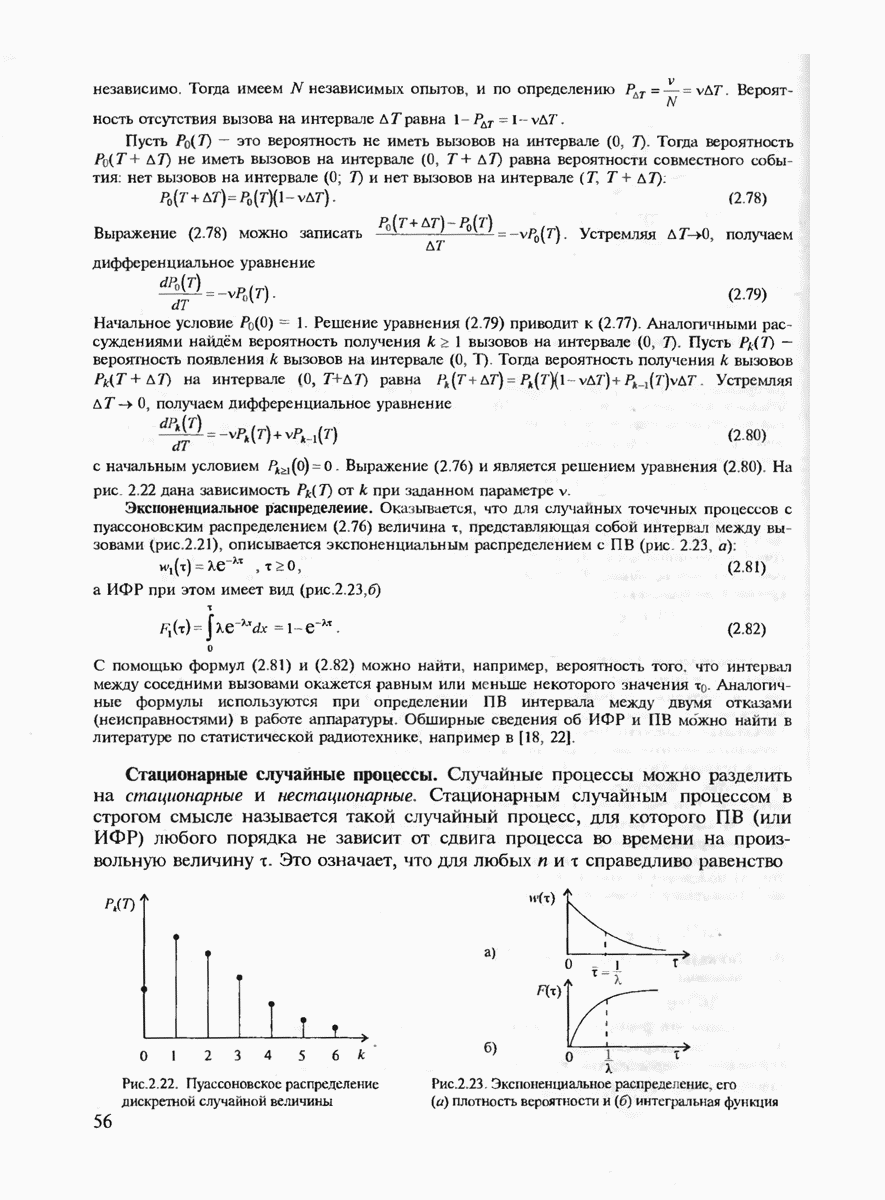
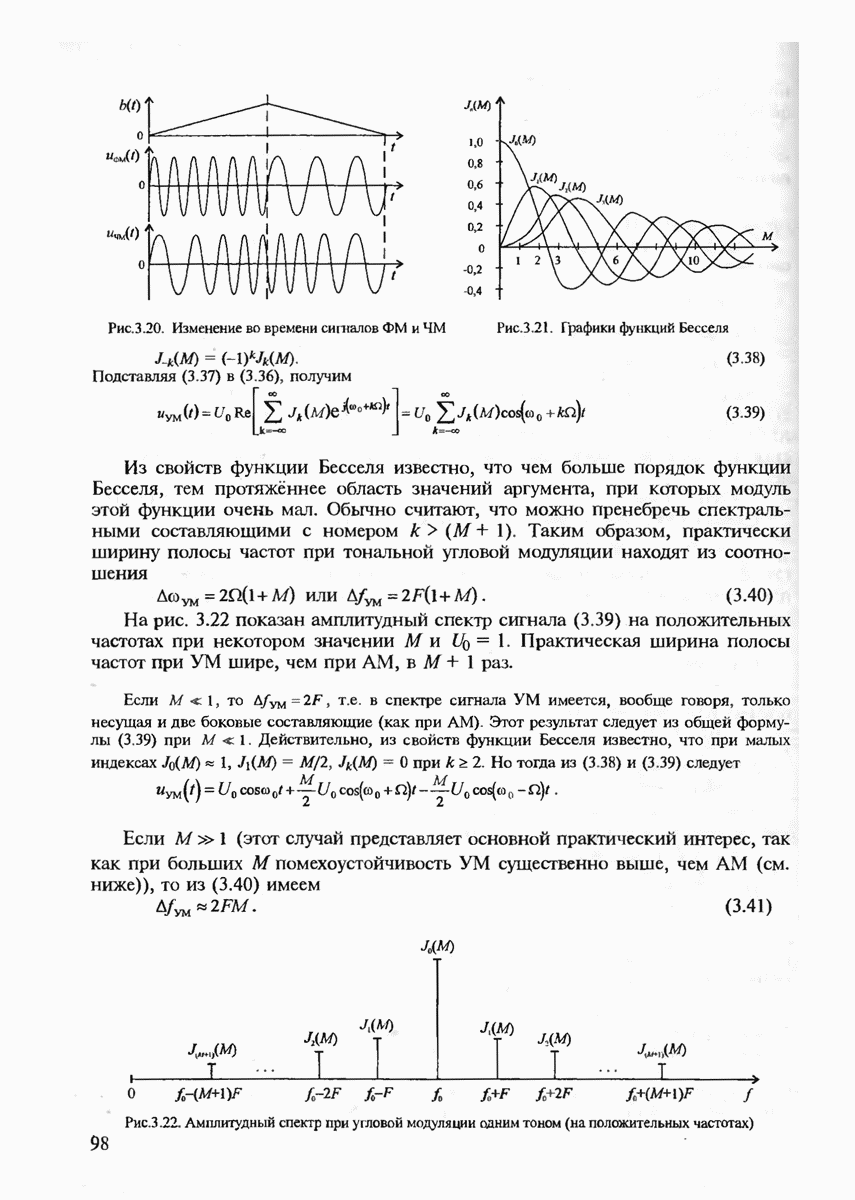
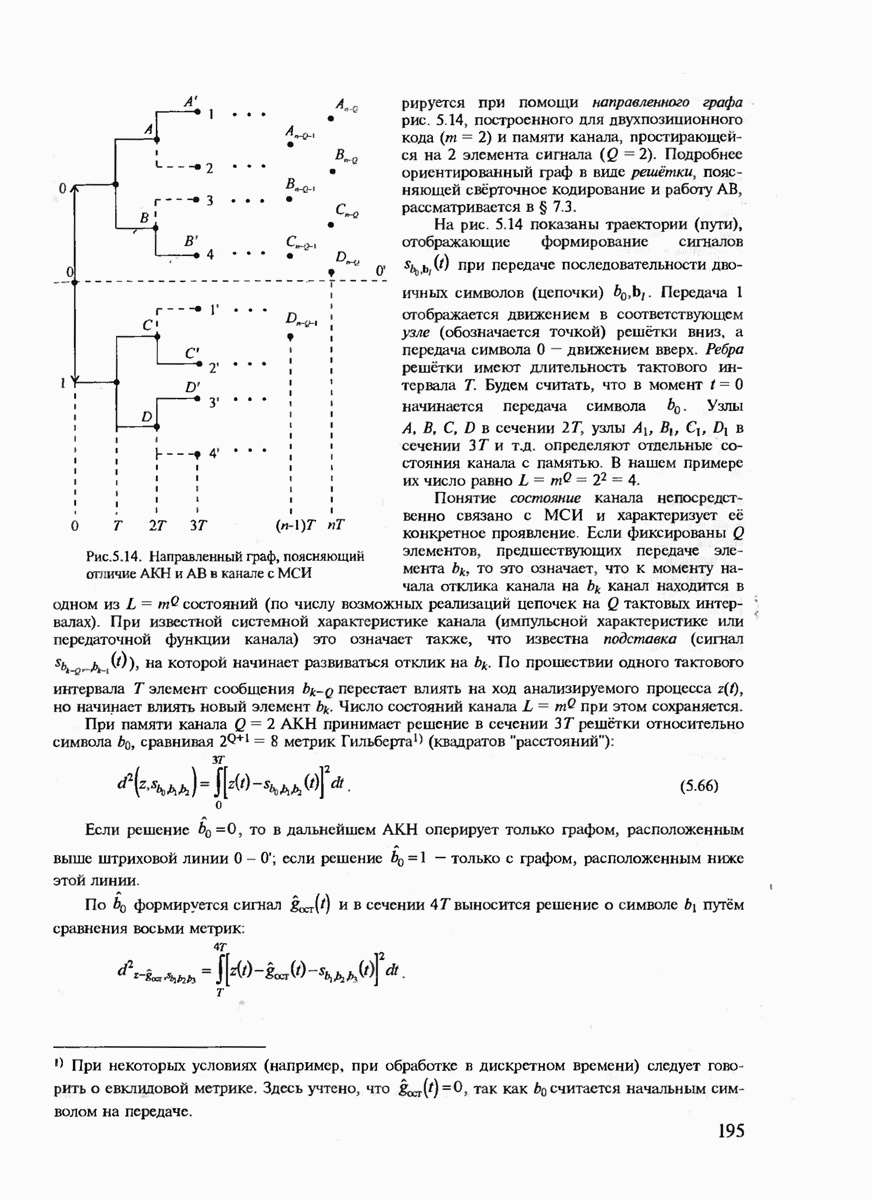
Если канал симметричен, но имеет память, то он может быть преобразован в  без памяти, а следовательно, для него окажется оптимальным хэмминговский алгоритм декодирования после следующего преобразования канала связи, который называют перемежением символов или декорреляциеи. Как показано на рис. 7.2, кодовые блоки, содержащие
без памяти, а следовательно, для него окажется оптимальным хэмминговский алгоритм декодирования после следующего преобразования канала связи, который называют перемежением символов или декорреляциеи. Как показано на рис. 7.2, кодовые блоки, содержащие  символов, номера которых отмечены верхними индексами
символов, номера которых отмечены верхними индексами  после их формирования предварительно заносятся в буферную память. После окончания формирования последнего
после их формирования предварительно заносятся в буферную память. После окончания формирования последнего  блока начинается передача символов этих блоков в канал связи "по столбцам" матрицы, находящейся в буферной памяти, т.е. последовательно передаются символы
блока начинается передача символов этих блоков в канал связи "по столбцам" матрицы, находящейся в буферной памяти, т.е. последовательно передаются символы  На приёме эти символы запоминаются в виде последовательных строк матрицы. После заполнения всех таких строк начинается декодирование по столбцам последовательных кодовых блоков с номерами (1), (2),
На приёме эти символы запоминаются в виде последовательных строк матрицы. После заполнения всех таких строк начинается декодирование по столбцам последовательных кодовых блоков с номерами (1), (2),  Видно, что каждая пара смежных символов в любом из кодовых блоков передаётся в канале связи с разнесением во времени
Видно, что каждая пара смежных символов в любом из кодовых блоков передаётся в канале связи с разнесением во времени  где
где  — длительность канального символа. Если параметр
— длительность канального символа. Если параметр  выбран достаточно большим, а зависимость между ошибками (память канала) убывает при разнесении передаваемых символов, то после такой процедуры можно практически полностью устранить память в канале связи.
выбран достаточно большим, а зависимость между ошибками (память канала) убывает при разнесении передаваемых символов, то после такой процедуры можно практически полностью устранить память в канале связи.

Рис. 7.2. Процедура перемещения символов
Определение 6. Минимальным кодовым расстоянием  для заданного кода V будем называть минимальное расстояние по Хэммингу между всеми парами его несовпадающих кодовых комбинаций, т.е.
для заданного кода V будем называть минимальное расстояние по Хэммингу между всеми парами его несовпадающих кодовых комбинаций, т.е.

Избыточный код V может использоваться в канале связи с помехами не только для декодирования (распознавания) действительно передававшихся сообщений,  фактически для исправления ошибок, но и для обнаружения ошибок. Естественным алгоритмом декодирования с обнаружением ошибок является принятие решения об отсутствии ошибок, когда принятая комбинация у совпадает с одной из разрешённых кодовых комбинациях, т.е.
фактически для исправления ошибок, но и для обнаружения ошибок. Естественным алгоритмом декодирования с обнаружением ошибок является принятие решения об отсутствии ошибок, когда принятая комбинация у совпадает с одной из разрешённых кодовых комбинациях, т.е.  и обнаружение ошибок, если для всех
и обнаружение ошибок, если для всех  Очевидно, что в этом случае возможны ошибки декодирования, а именно принятие решения об отсутствии ошибки, в то время как они в действительности имеют место. Будем называть это событие необнаруженной ошибкой, а его вероятность — вероятностью необнаруженной ошибки, обозначая её через
Очевидно, что в этом случае возможны ошибки декодирования, а именно принятие решения об отсутствии ошибки, в то время как они в действительности имеют место. Будем называть это событие необнаруженной ошибкой, а его вероятность — вероятностью необнаруженной ошибки, обозначая её через  или
или  для заданного кода
для заданного кода  При рассмотренном выше алгоритме обнаружения ошибок необнаруженная ошибка может появиться тогда, и только тогда, когда передаваемая по каналу связи кодовая комбинация под воздействием помех перейдёт на выходе в какую-либо другую кодовую (разрешённую) комбинацию. Поэтому при равновероятном выборе кодовых комбинаций
При рассмотренном выше алгоритме обнаружения ошибок необнаруженная ошибка может появиться тогда, и только тогда, когда передаваемая по каналу связи кодовая комбинация под воздействием помех перейдёт на выходе в какую-либо другую кодовую (разрешённую) комбинацию. Поэтому при равновероятном выборе кодовых комбинаций

Определение 7. Будем говорить, что код К гарантированно обнаруживает или исправляет ошибки кратности не больше  при использовании некоторого алгоритма обнаружения или исправления ошибок, если кодовые слова после применения этих алгоритмов не будут содержать необнаруженных или неисправленных ошибок, когда кратность ошибки в канале связи не превосходит 1. (Данный код может исправлять или обнаруживать ошибки и большей кратности, но это может иметь место не для всех образцов ошибок). Возможности кода обнаруживать ошибки определяются следующей теоремой.
при использовании некоторого алгоритма обнаружения или исправления ошибок, если кодовые слова после применения этих алгоритмов не будут содержать необнаруженных или неисправленных ошибок, когда кратность ошибки в канале связи не превосходит 1. (Данный код может исправлять или обнаруживать ошибки и большей кратности, но это может иметь место не для всех образцов ошибок). Возможности кода обнаруживать ошибки определяются следующей теоремой.
Теорема 7.3. Если код имеет минимальное расстояние  то он гарантированно обнаруживает ошибки кратности не более чем
то он гарантированно обнаруживает ошибки кратности не более чем 
Доказательство. Как было отмечено ранее, ошибка оказывается необнаруженной тогда, и только тогда, когда под воздействием помех в канале связи передававшаяся кодовая комбинация переходит в какую-либо другую кодовую комбинацию. Но для этого необходимо, чтобы образец ошибок имел кратность не меньше  поскольку все кодовые комбинации по определению понятия минимального кодового расстояния отличаются друг от друга не меньше, чем в
поскольку все кодовые комбинации по определению понятия минимального кодового расстояния отличаются друг от друга не меньше, чем в  позициях.
позициях.
Определение 8. Будем называть функцией кратности ошибки  в данном канале связи вероятность появления
в данном канале связи вероятность появления  ошибок на кодовом блоке длины
ошибок на кодовом блоке длины  . В частном случае
. В частном случае  без памяти
без памяти

Теорема 7.3 позволяет получить верхнюю границу для вероятности необнаруженной ошибки кодом V с минимальным расстоянием 

(Неравенство в (7.37) возникает потому, что код с минимальным расстоянием  может, вообще говоря, обнаруживать ошибки и кратности большей, чем
может, вообще говоря, обнаруживать ошибки и кратности большей, чем  Подставляя (7.36) в (7.37), получаем, что для
Подставляя (7.36) в (7.37), получаем, что для  (в частном случае
(в частном случае  без памяти
без памяти

Возможности кода по исправлению ошибок определяются следующей теоремой.
Теорема 7.4. Если код имеет минимальное расстояние  то при декодировании по минимуму расстояния Хэмминга он гарантированно исправляет ошибки кратности
то при декодировании по минимуму расстояния Хэмминга он гарантированно исправляет ошибки кратности  не более, чем
не более, чем  где
где  означает целую часть х.
означает целую часть х.
Доказательство. Пусть передавалось кодовое слово х, и принято слово у, причём по условию теоремы  Предположим, что существует кодовое слово
Предположим, что существует кодовое слово  которое находится от принятого слова у на расстоянии Хэмминга не большим, чем слово и, следовательно, может произойти ошибочное декодирование этого слова вместо слова
которое находится от принятого слова у на расстоянии Хэмминга не большим, чем слово и, следовательно, может произойти ошибочное декодирование этого слова вместо слова  Этот факт означает, что
Этот факт означает, что  Применяя неравенство треугольника (7.30) к словам
Применяя неравенство треугольника (7.30) к словам  получаем
получаем

С другой стороны, выполнение (7.39) невозможно, поскольку по определению  для данного кода
для данного кода  Следовательно, действительно передававшееся кодовое слово х, будет декодировано верно, и теорема доказана.
Следовательно, действительно передававшееся кодовое слово х, будет декодировано верно, и теорема доказана.
Теорема 7.4 позволяет построить верхнюю границу вероятности ошибочного декодирования при использовании алгоритма Хэмминга в произвольном канале связи:

В частном случае  без памяти получаем из (7.36) и (7.40)
без памяти получаем из (7.36) и (7.40)

Определение 9. Будем называть алгоритмом совместного исправления ошибок кратности до  и обнаружения ошибок при использовании кода V с минимальным расстоянием
и обнаружения ошибок при использовании кода V с минимальным расстоянием  алгоритм, который по принятому слову у декодирует кодовое слово
алгоритм, который по принятому слову у декодирует кодовое слово  если
если  и обнаруживает наличие ошибки, если
и обнаруживает наличие ошибки, если  для всех кодовых слов
для всех кодовых слов 
Свойства кода с заданными параметрами  по совместному исправлению и обнаружению ошибок определяются следующей теоремой.
по совместному исправлению и обнаружению ошибок определяются следующей теоремой.
Теорема 7.5. Если код имеет минимальное расстояние  то использование алгоритма совместного исправления ошибок кратности до
то использование алгоритма совместного исправления ошибок кратности до  включительно и обнаружения ошибок, обеспечивает гарантированное исправление ошибок кратности не больше
включительно и обнаружения ошибок, обеспечивает гарантированное исправление ошибок кратности не больше  и обнаруживает число ошибок кратности не более
и обнаруживает число ошибок кратности не более 
Доказательство утверждения о гарантированном исправлении ошибок очевидно, а доказательство утверждения о гарантированном обнаружении ошибок производится аналогично доказательству теорем 7.3 и 7.4.
Теорема 7.5 позволяет получить верхнюю границу для вероятности необнаруженной ошибки  и нижнюю границу для вероятности правильного декодирования
и нижнюю границу для вероятности правильного декодирования  при использовании кодов с данным алгоритмом совместного исправления и обнаружения ошибок
при использовании кодов с данным алгоритмом совместного исправления и обнаружения ошибок

(Подставляя (7.36) в эти неравенства, получаем соответствующие границы для частного случая канала  без памяти.)
без памяти.)
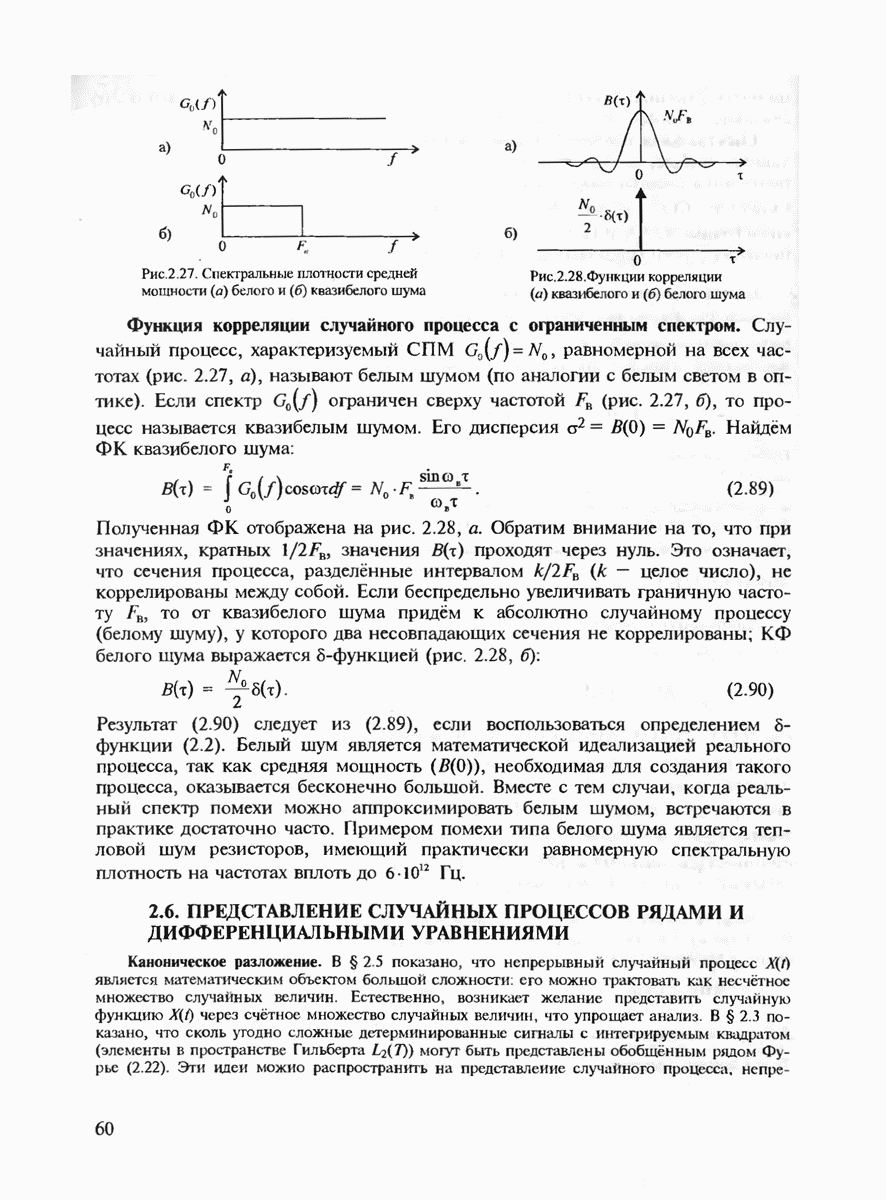
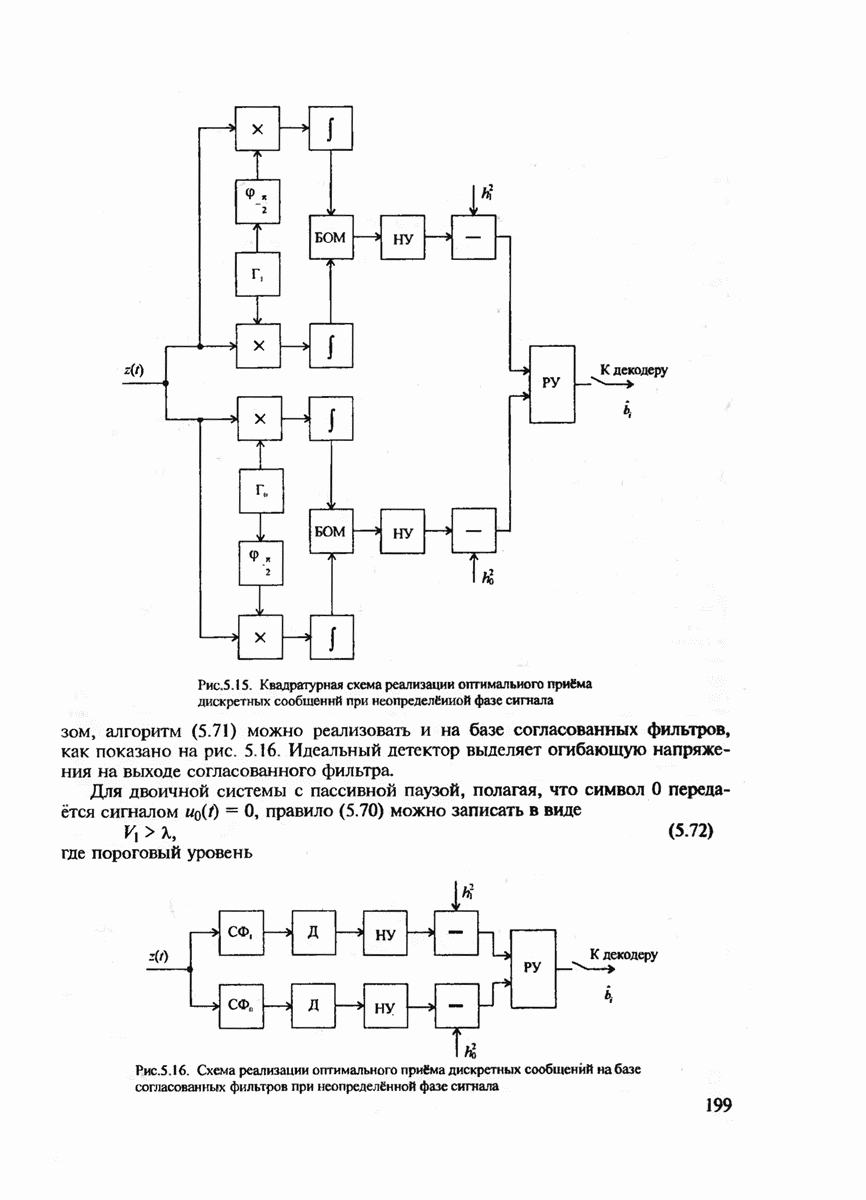
В некоторых случаях на выходе канала могут появляться дополнительные пометки о ненадёжности принятых символов, что приводит к их стиранию. Это может происходить из-за низкого отношения сигнал-шум, соответствующего данному тактовому интервалу.
В качестве признака отсутствия стирания символа на  тактовом интервале при оптимальном когерентном приёме противоположных сигналов
тактовом интервале при оптимальном когерентном приёме противоположных сигналов  на фоне белого шума можно использовать превышение некоторого порога абсолютным значением корреляционного интеграла
на фоне белого шума можно использовать превышение некоторого порога абсолютным значением корреляционного интеграла  где
где  принимаемый непрерывный сигнал,
принимаемый непрерывный сигнал,  длительность элемента сигнала (тактовый интервал, см. гл. 5).
длительность элемента сигнала (тактовый интервал, см. гл. 5).
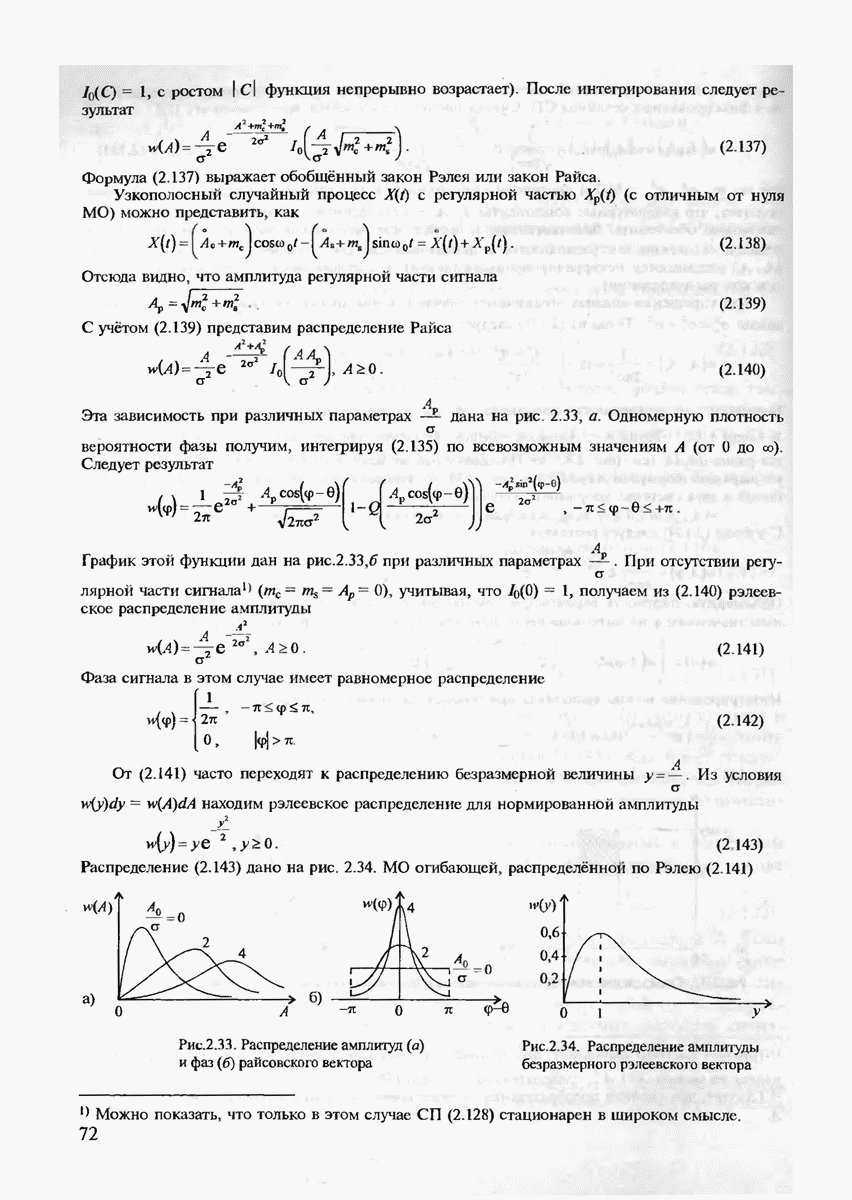
Определение 10. Будем называть алгоритмом исправления стираний и ошибок такой метод декодирования, который измеряет расстояние Хэмминга между принятым блоком у и всеми кодовыми словами в нестёртых позициях и декодирует то кодовое слово, для которого это расстояние минимально
Исправляющая способность алгоритма совместного исправления стираний и ошибок определяется теоремой.
Теорема 7.6. Если код имеет минимальное расстояние  то он может одновременно исправить
то он может одновременно исправить  стираний и
стираний и  ошибок при выполнении следующего условия,
ошибок при выполнении следующего условия,

Доказательство производится совершенно аналогично доказательству теоремы 7.4 с учётом того очевидного факта, что код  с длиной блоков
с длиной блоков  образованный из комбинаций исходного кода V при вычеркивании
образованный из комбинаций исходного кода V при вычеркивании  стёртых позиций, имеет минимальное расстояние не менее, чем
стёртых позиций, имеет минимальное расстояние не менее, чем 
Зная совместные функции кратности ошибок и стираний в канале связи, можно рассчитать верхнюю границу для  используя (7.44).
используя (7.44).
Заметим, что алгоритм исправления ошибок и стираний является промежуточным вариантом между так называемым жёстким декодированием (в дискретном канале) и мягким декодированием (в полунепрерывном канале). Более подробно эта проблема обсуждается в п. 7.3.10.
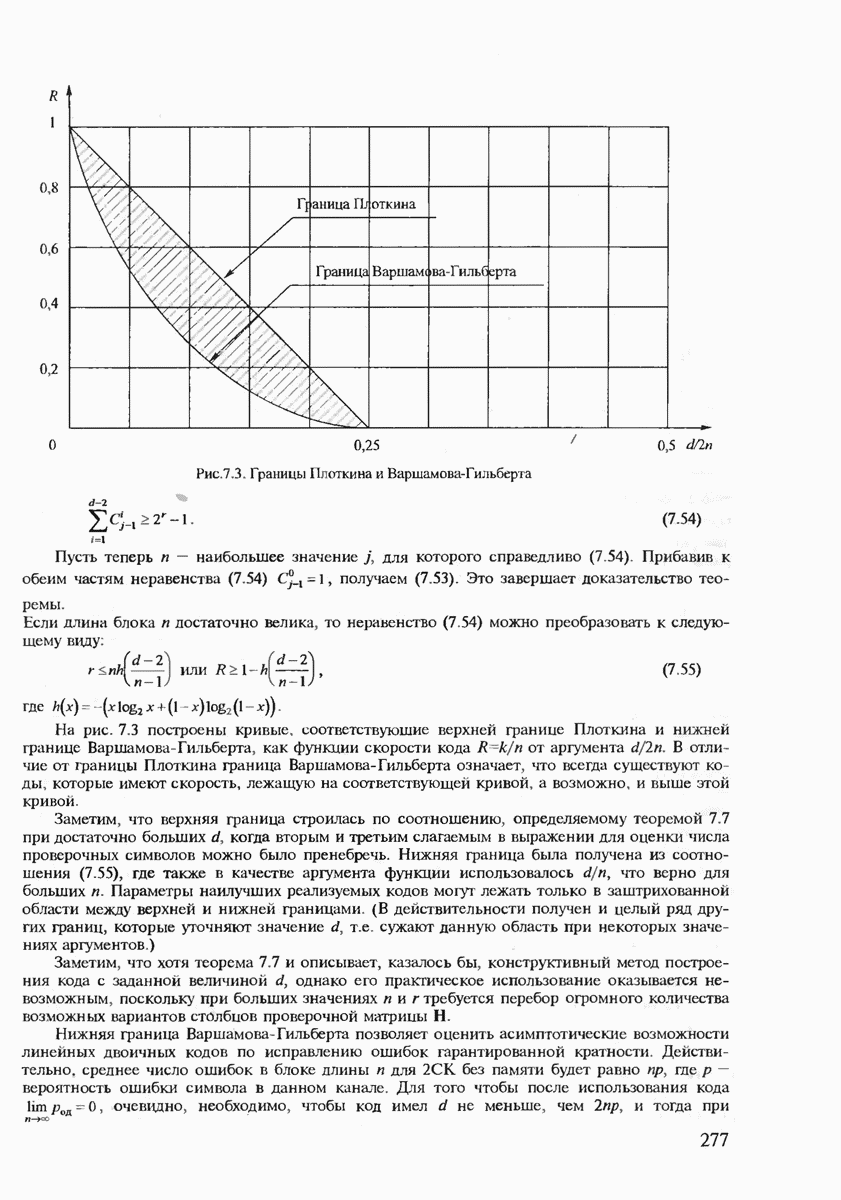
Полученные границы для  показывают, что желательно иметь код с наибольшим возможным значением минимального расстояния
показывают, что желательно иметь код с наибольшим возможным значением минимального расстояния  Однако интуиция подсказывает нам, что мы можем добиться увеличения
Однако интуиция подсказывает нам, что мы можем добиться увеличения  при фиксированной длине блока
при фиксированной длине блока  только уменьшая скорость кода
только уменьшая скорость кода  Хотелось бы иметь точные формулы, определяющие
Хотелось бы иметь точные формулы, определяющие  как функцию
как функцию  или хотя бы верхние и нижние границы для этого параметра. Кроме того, для обеспечения
или хотя бы верхние и нижние границы для этого параметра. Кроме того, для обеспечения  что было обещано теоремой кодирования Шеннона, придется увеличивать и длины кодовых блоков
что было обещано теоремой кодирования Шеннона, придется увеличивать и длины кодовых блоков  но при этом количество комбинаций кода
но при этом количество комбинаций кода  экспоненциально возрастает. Это неизбежно вызовет большие трудности при реализации процедур кодирования и декодирования. (Действительно, при кодировании нужно запомнить
экспоненциально возрастает. Это неизбежно вызовет большие трудности при реализации процедур кодирования и декодирования. (Действительно, при кодировании нужно запомнить  комбинаций и извлекать из памяти каждый раз новую комбинацию, соответствующую поступившему сообщению, а при декодировании вычислить
комбинаций и извлекать из памяти каждый раз новую комбинацию, соответствующую поступившему сообщению, а при декодировании вычислить  хэмминговских расстояний и находить среди них минимальное.) Поэтому мы нуждаемся в более конструктивном (регулярном) задании кода, чем его описание таблицей кодовых комбинаций. Эту проблему удаётся решить при переходе к специальному классу так называемых линейных кодов, который описан в следующем разделе.
хэмминговских расстояний и находить среди них минимальное.) Поэтому мы нуждаемся в более конструктивном (регулярном) задании кода, чем его описание таблицей кодовых комбинаций. Эту проблему удаётся решить при переходе к специальному классу так называемых линейных кодов, который описан в следующем разделе.
Однако, прежде чем перейти к его рассмотрению, сделаем ещё одно замечание. Сравнение границ (7.37) и (7.40) показывает, что в любых каналах связи и для любых кодов  причём это неравенство справедливо не только для границ, но и для точных значений соответствующих вероятностей ошибок. Однако этот факт ещё не означает, что всегда целесообразно использовать обнаружение ошибок, а не их исправление. Действительно, после обнаружения ошибок в блоке он оказывается стёртым, а следовательно, не может быть выдан получателю. Обычно его доставка осуществляется при помощи повторной передачи, что требует затрат дополнительного времени.
причём это неравенство справедливо не только для границ, но и для точных значений соответствующих вероятностей ошибок. Однако этот факт ещё не означает, что всегда целесообразно использовать обнаружение ошибок, а не их исправление. Действительно, после обнаружения ошибок в блоке он оказывается стёртым, а следовательно, не может быть выдан получателю. Обычно его доставка осуществляется при помощи повторной передачи, что требует затрат дополнительного времени.
К вопросам получения более точных оценок для  и
и  а также к сравнению систем с обнаружением и исправлением ошибок мы ещё вернёмся в следующем разделе.
а также к сравнению систем с обнаружением и исправлением ошибок мы ещё вернёмся в следующем разделе.