Подставляя (6.41) в (6.42), получаем, что величина  будет стремиться по вероятности к
будет стремиться по вероятности к

(Аналогично, хотя и более громоздко, доказывается данная теорема и для стационарных источников с памятью).
По существу теорема САР означает, что при достаточно большой величине  все последовательности, выдаваемые источником разбиваются на две группы, называемые соответственно типичными и нетипичными. Первые последовательности примерно равновероятны, и количество их приблизительно
все последовательности, выдаваемые источником разбиваются на две группы, называемые соответственно типичными и нетипичными. Первые последовательности примерно равновероятны, и количество их приблизительно

Что же касается нетипичных последовательностей, то они могут иметь разные вероятности, но вероятность появления хотя бы одной из них стремится к нулю при  Заметим, что число типичных последовательностей определённой длины оказывается значительно меньше общего возможного числа последовательностей такой же длины. Например, общее число последовательностей букв русского языка длины
Заметим, что число типичных последовательностей определённой длины оказывается значительно меньше общего возможного числа последовательностей такой же длины. Например, общее число последовательностей букв русского языка длины  равно
равно  в то время как число типичных последовательностей такой же длины, если положить энтропию русского языка равной 1,5 бит/символ, оказывается всего лишь
в то время как число типичных последовательностей такой же длины, если положить энтропию русского языка равной 1,5 бит/символ, оказывается всего лишь  что примерно соответствует объёму типичного словаря.
что примерно соответствует объёму типичного словаря.
Теорема САР оказывается справедливой и для пар последовательностей  относительно которых утверждается, что при достаточно больших и с вероятностью 1-6 источник выдаёт пару последовательностей, для которых их условные вероятности будут удовлетворять неравенствам
относительно которых утверждается, что при достаточно больших и с вероятностью 1-6 источник выдаёт пару последовательностей, для которых их условные вероятности будут удовлетворять неравенствам

где  сколь угодно малая величина. Теперь мы подготовлены к формулировке и доказательству теорем кодирования.
сколь угодно малая величина. Теперь мы подготовлены к формулировке и доказательству теорем кодирования.
ТЕОРЕМА 1. О кодировании источника.
Существует способ кодирования, при котором средняя длина последовательности канальных символов  приходящаяся на один символ источника сообщений,
приходящаяся на один символ источника сообщений,

Не существует способа кодирования, при котором  меньше, чем
меньше, чем  .
.
Доказательство данной теоремы для источника без памяти будет дано в следующей главе. Прикладной смысл этой теоремы состоит в том, что при наилучшем кодировании в канале без помех мы можем передавать сообщения источника сообщений со скоростью  сколь угодно близкой к величине
сколь угодно близкой к величине

и невозможно передавать сообщения со скоростью  большей, чем (6.47). Видно, что скорость передачи оказывается тем большей, чем меньше энтропия источника или чем больше его избыточность, что очевидно соответствует наей интуиции, подсказывающей возможность более быстрой передачи сообщений за счёт устранения содержащейся в них избыточности. Такой метод кодирования называется также кодированием источников сообщений или иногда — статистическим или экономным кодированием (сжатием) сообщений.
большей, чем (6.47). Видно, что скорость передачи оказывается тем большей, чем меньше энтропия источника или чем больше его избыточность, что очевидно соответствует наей интуиции, подсказывающей возможность более быстрой передачи сообщений за счёт устранения содержащейся в них избыточности. Такой метод кодирования называется также кодированием источников сообщений или иногда — статистическим или экономным кодированием (сжатием) сообщений.
Поскольку теорема 1 даёт условие лишь для средней длины блока канальных символов, то очевидно, что в отдельные моменты времени эти длины могут оказаться значительно больше средней длины, а это потребует для источников с фиксированной скоростью использования специального буферного устройства для поглощения задержки поступающих сообщений. Можно показать, что с вероятностью единица накопитель любой конечной емкости рано или поздно будет переполнен, т.е. произойдёт потеря информации. Заметим, что указанное выше кодирование является обычно неравномерным. Поэтому для источников сообщений с фиксированной скоростью имеет смысл следующее видоизменение теоремы 1, в котором используется равномерное кодирование.
ТЕОРЕМА 2. О кодировании в канале без помех.
Существует способ кодирования и декодирования в канале без помех, при котором для длины  последовательности канальных символов, приходящихся на один символ источника, будет выполняться соотношение (6.46), причём вероятность ошибки не превосходит любой сколь угодно малой величины
последовательности канальных символов, приходящихся на один символ источника, будет выполняться соотношение (6.46), причём вероятность ошибки не превосходит любой сколь угодно малой величины 
Заметим, что здесь под вероятностью ошибки понимается вероятность того, что последовательность символов, выданная получателю, будет отличаться от соответствующей ей последовательности символов, переданной источником сообщений. Несмотря на то, что мы имеем здесь дело с каналом без помех, ошибки в принятом сообщении появляются вследствие специального способа кодирования.
Доказательство. Как следует из (6.43), число типичных последовательностей источника длиной  будет асимптотически (при больших
будет асимптотически (при больших  равно
равно  Условимся кодировать канальными символами только эти типичные последовательности, а любую нетипичную последовательность передавать при помощи одной и той же последовательности, что, очевидно, при декодировании на приёме и будет приводить к ошибкам. Однако поскольку при
Условимся кодировать канальными символами только эти типичные последовательности, а любую нетипичную последовательность передавать при помощи одной и той же последовательности, что, очевидно, при декодировании на приёме и будет приводить к ошибкам. Однако поскольку при  вероятность появления нетипичной последовательности будет стремиться к нулю, то это и означает, что вероятность ошибки может быть сделана сколь угодно малой величиной.
вероятность появления нетипичной последовательности будет стремиться к нулю, то это и означает, что вероятность ошибки может быть сделана сколь угодно малой величиной.
Все типичные последовательности длины  будем кодировать последовательностями длины
будем кодировать последовательностями длины  составленными из канальных символов. Для обеспечения однозначности декодирования (отсутствия ошибок в этом случае) необходимо выполнение условия
составленными из канальных символов. Для обеспечения однозначности декодирования (отсутствия ошибок в этом случае) необходимо выполнение условия  откуда при больших значениях
откуда при больших значениях  получаем
получаем

что и завершает доказательство теоремы.
Интерпретация этой теоремы для заданных скоростей источника и канала приводит также к соотношению (6.47). Разница состоит лишь в том, что возможна ошибка с некоторой малой вероятностью 8, но зато кодирование оказывается равномерным, что не приводит к переполнению буферной памяти кодера.












































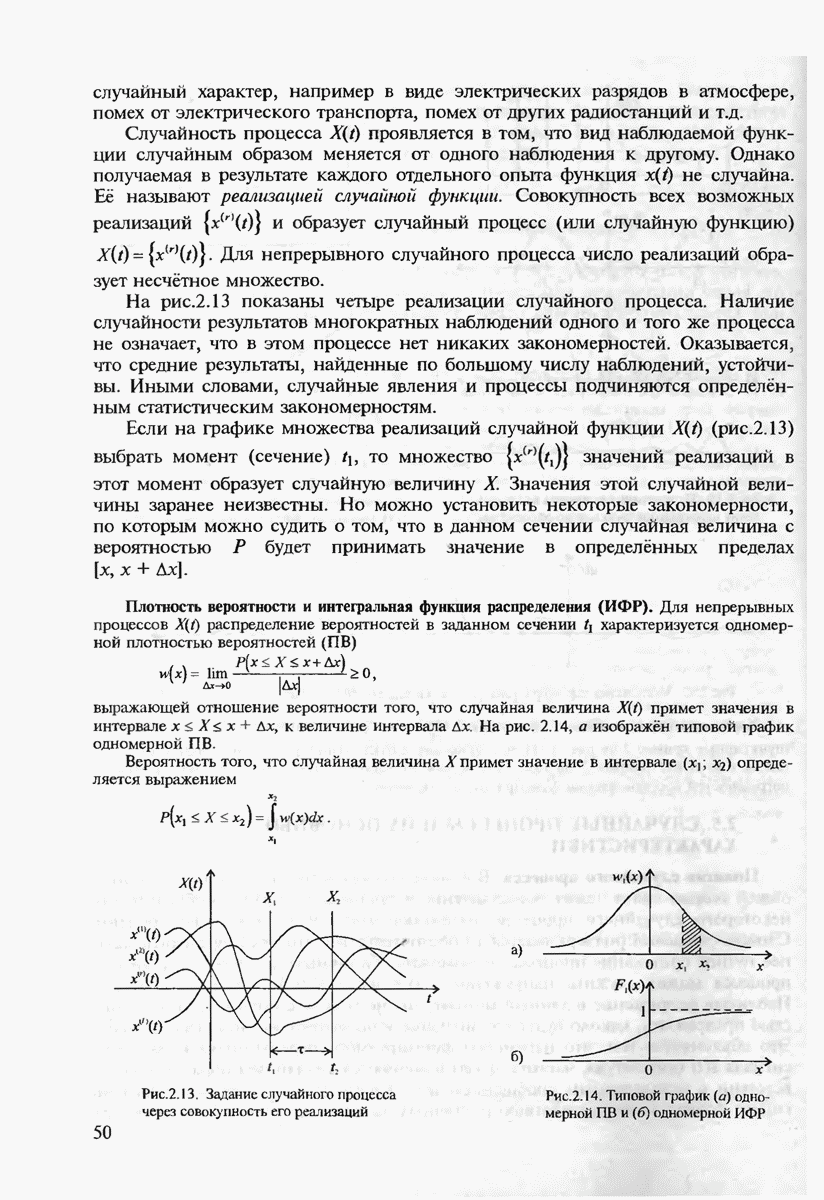





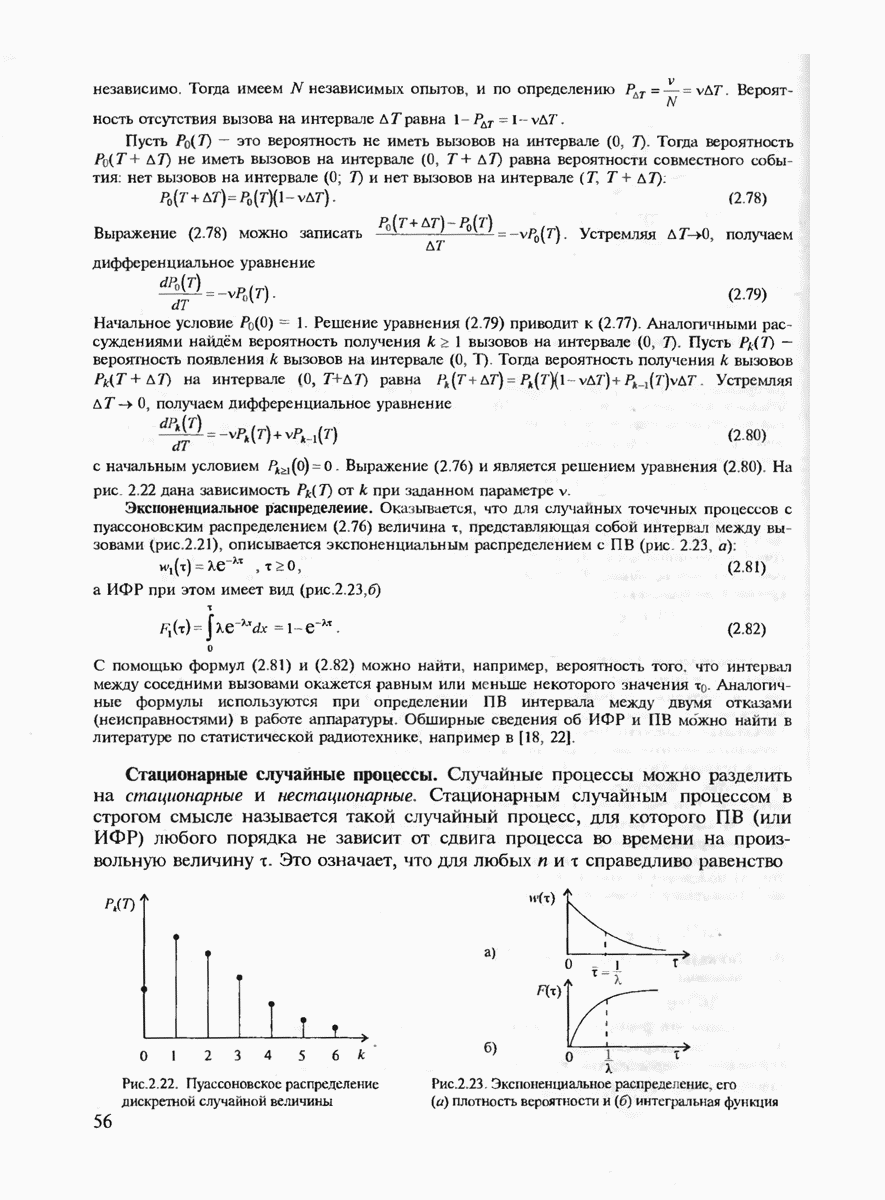



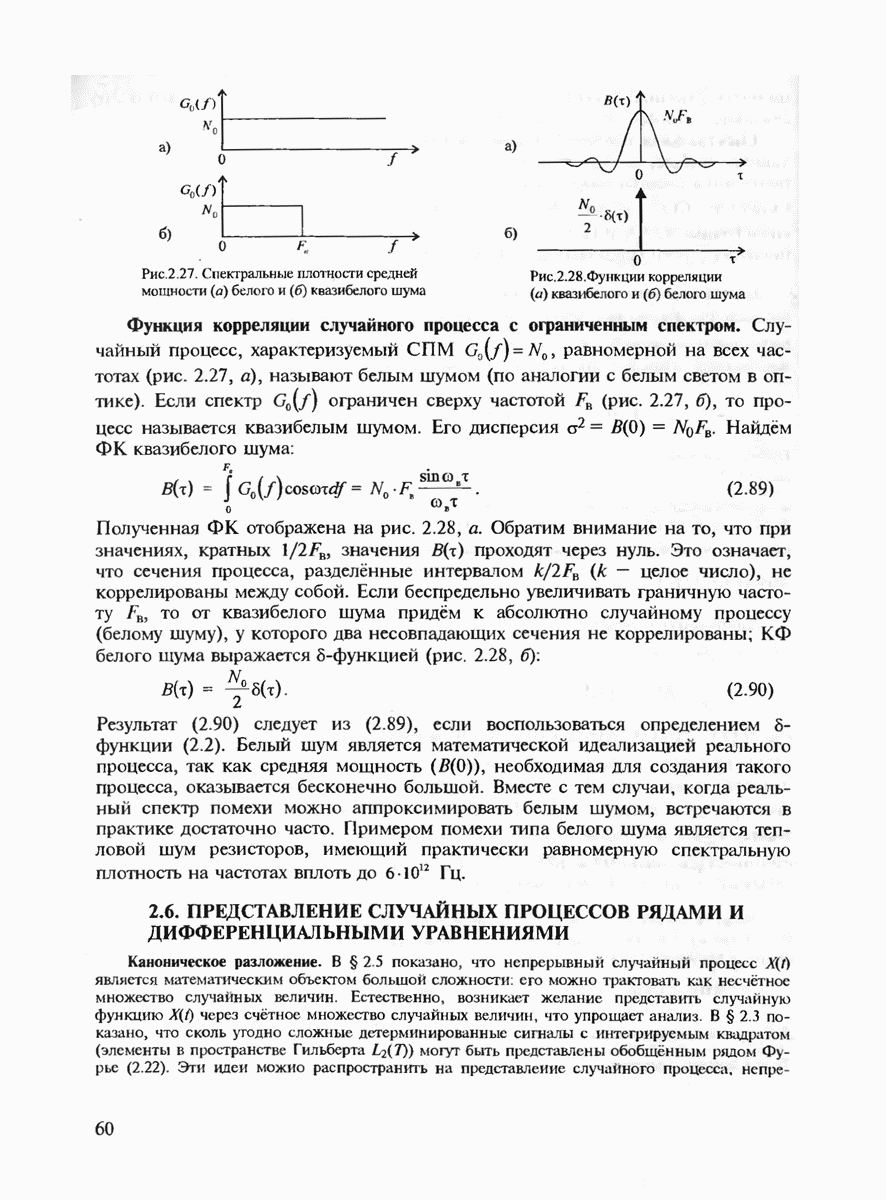









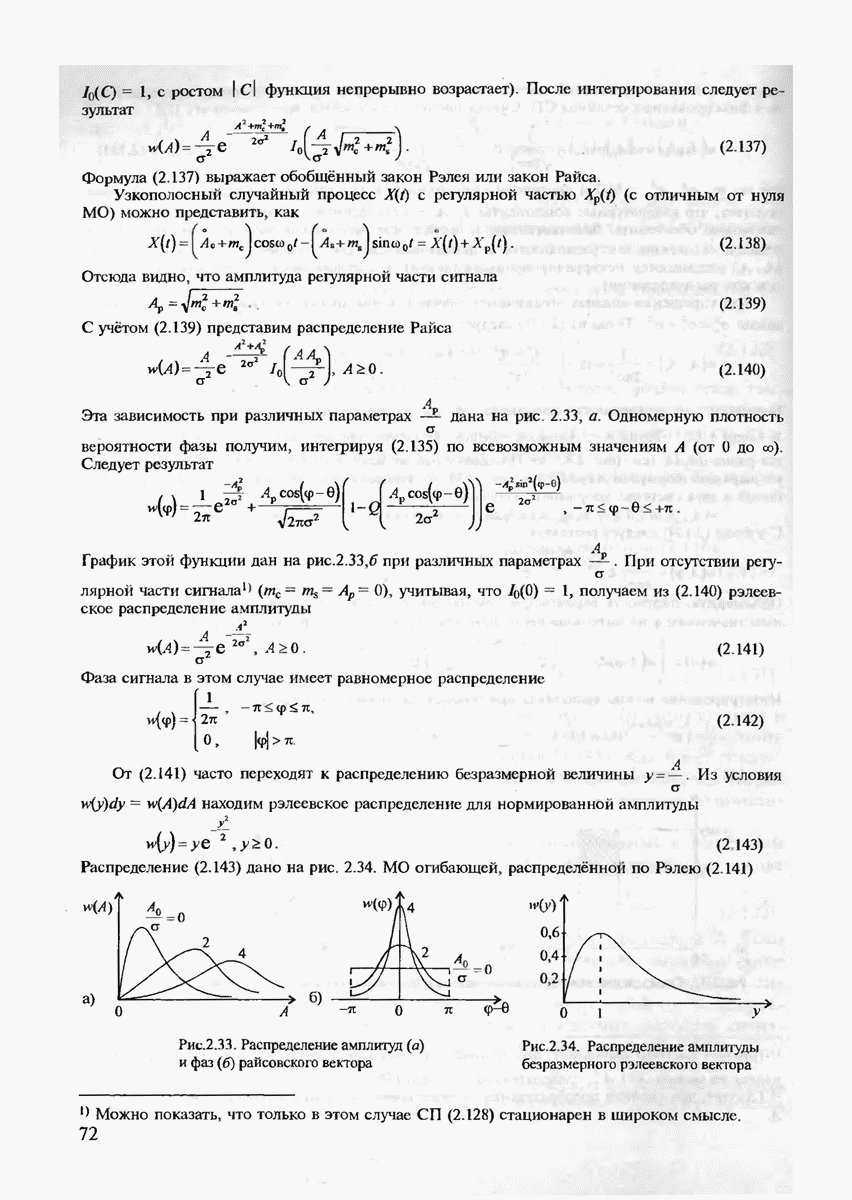






































































































































































































































































































































 и 6 можно найти такое число
и 6 можно найти такое число  (зависящее от
(зависящее от  и свойств источника), что с вероятностью большей, чем 1—6, источник сообщений выдаёт последовательность
и свойств источника), что с вероятностью большей, чем 1—6, источник сообщений выдаёт последовательность  длины
длины  которая имеет вероятность
которая имеет вероятность  удовлетворяющую неравенству
удовлетворяющую неравенству

 энтропия данного источника.
энтропия данного источника.
 частота
частота  события, состоящего в появлении символа а; в последовательности длины
события, состоящего в появлении символа а; в последовательности длины  стремится к вероятности
стремится к вероятности  т. е.
т. е.

 содержит
содержит  символов
символов  символов а, и т.д.
символов а, и т.д.  символов
символов  то вероятность её появления
то вероятность её появления


 алфавитами, условным распределением
алфавитами, условным распределением  и скоростью передачи
и скоростью передачи  Будем осуществлять кодирование, сопоставляя с различными последовательностями символов источника различные последовательности (комбинации) символов канала длины
Будем осуществлять кодирование, сопоставляя с различными последовательностями символов источника различные последовательности (комбинации) символов канала длины  Назовем последние разрешёнными кодовыми комбинациями блочного кода, обозначив их через
Назовем последние разрешёнными кодовыми комбинациями блочного кода, обозначив их через  где
где  полное число таких комбинаций. Если бы в канале не было помех, то принятые комбинации совпадали бы в точности с разрешёнными кодовыми комбинациями. В канале же с помехами принятая комбинация может стать с некоторой вероятностью любой из
полное число таких комбинаций. Если бы в канале не было помех, то принятые комбинации совпадали бы в точности с разрешёнными кодовыми комбинациями. В канале же с помехами принятая комбинация может стать с некоторой вероятностью любой из  последовательностей длины
последовательностей длины  составленных из выходных канальных символов. Разобьём все множество таких последовательностей
составленных из выходных канальных символов. Разобьём все множество таких последовательностей  на
на  непересекающихся подмножеств
непересекающихся подмножеств  и установим следующее правило декодирования. Если принятая последовательность
и установим следующее правило декодирования. Если принятая последовательность  то принимается решение о том, что передавалась кодовая комбинация
то принимается решение о том, что передавалась кодовая комбинация  Такое разбиение будем называть также (см. гл. 5) решающей схемой. В этом случае можно определить вероятность правильного приёма (или правильного декодирования) как вероятность
Такое разбиение будем называть также (см. гл. 5) решающей схемой. В этом случае можно определить вероятность правильного приёма (или правильного декодирования) как вероятность  того, что при передаче комбинации
того, что при передаче комбинации  принятая комбинация
принятая комбинация  попадает в соответствующее подмножество
попадает в соответствующее подмножество  Кратко будем записывать эту вероятность как Теперь мы в состоянии сформулировать теорему кодирования для канала с помехами.
Кратко будем записывать эту вероятность как Теперь мы в состоянии сформулировать теорему кодирования для канала с помехами.
