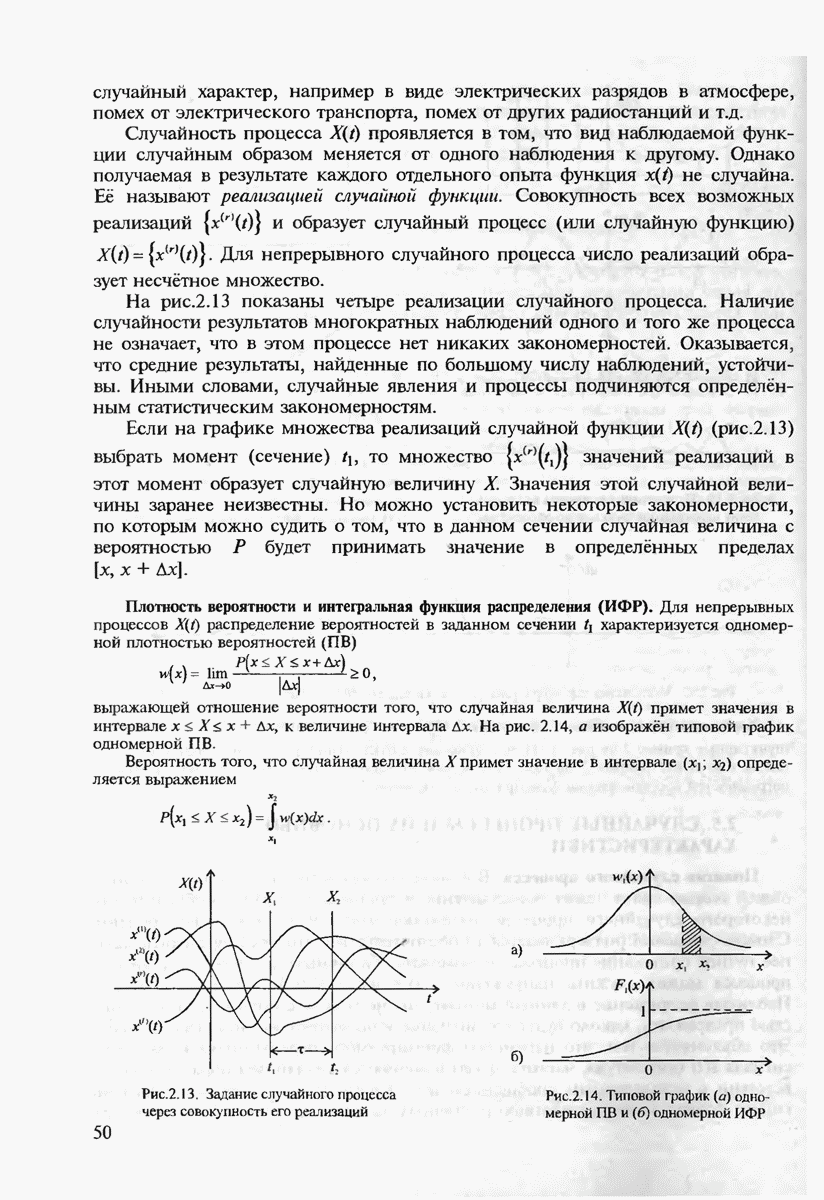
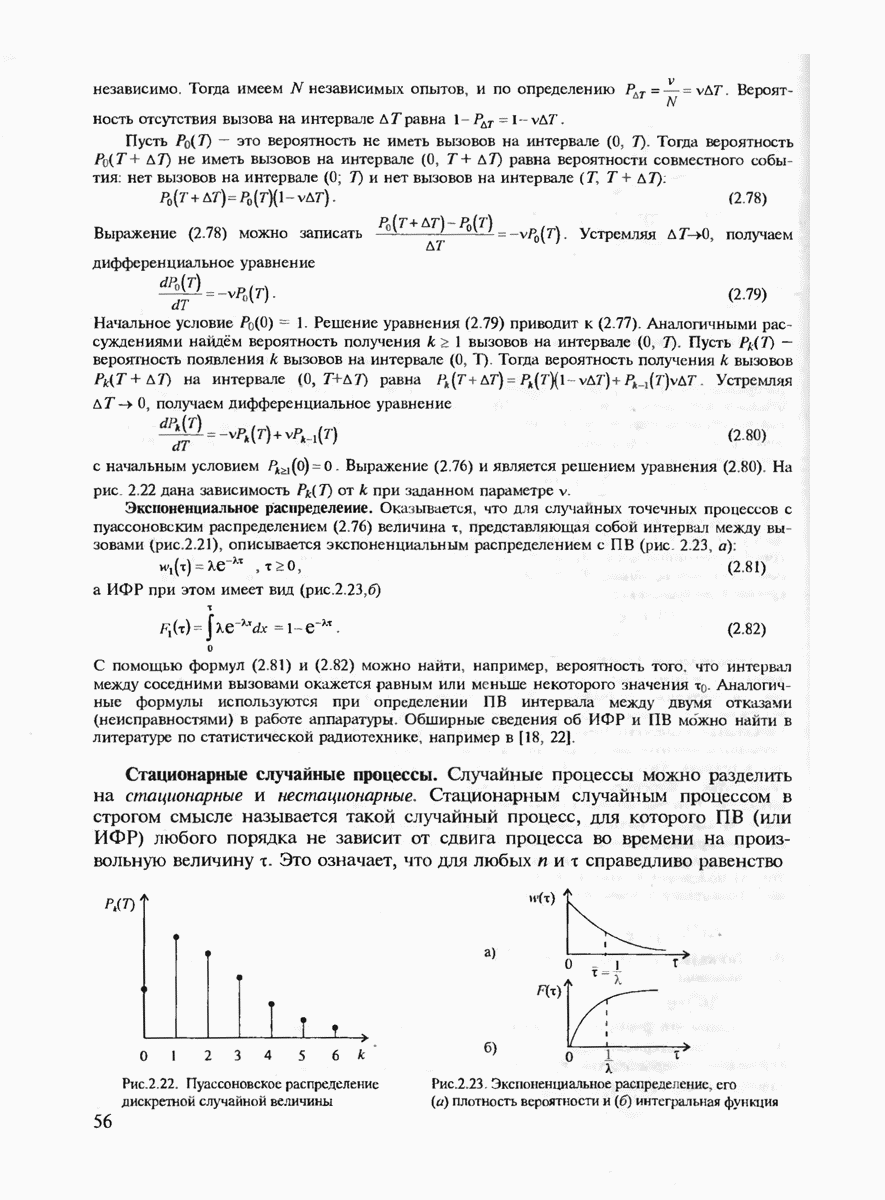
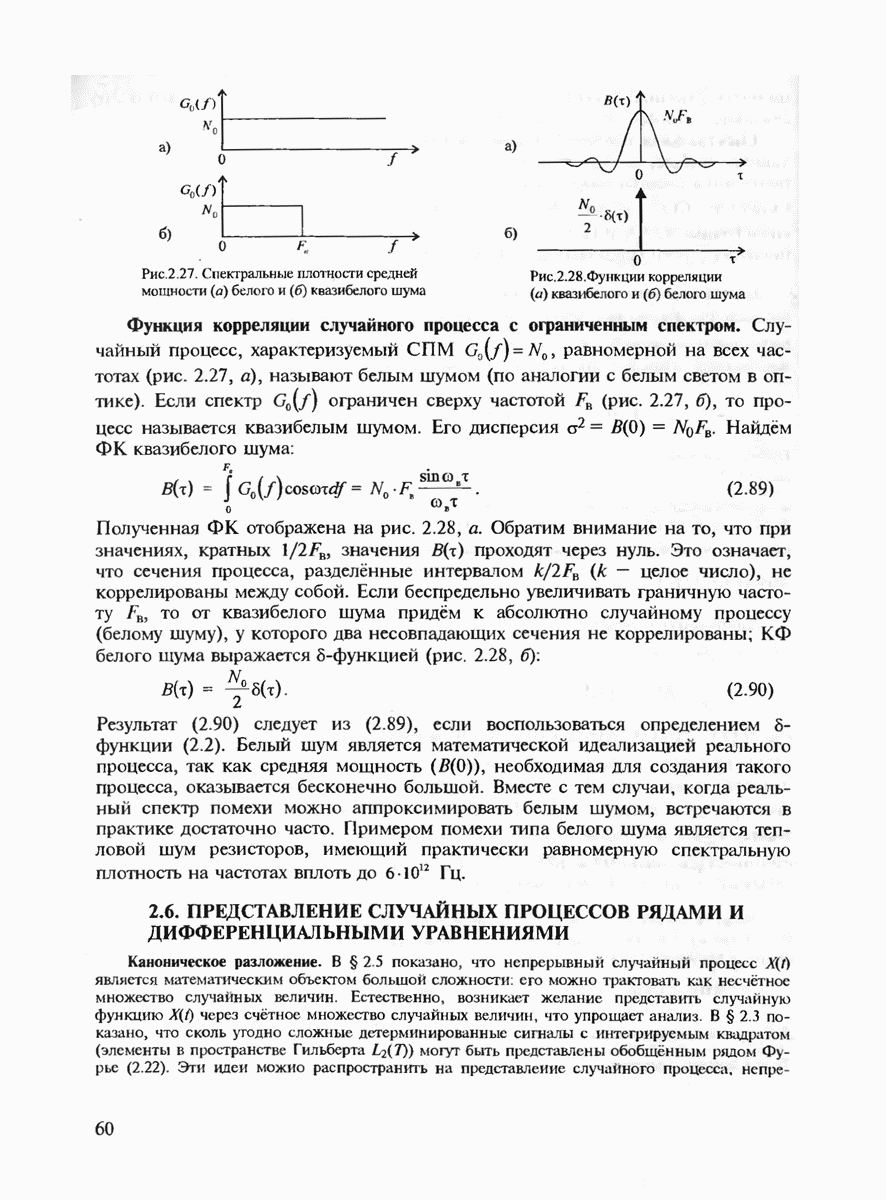
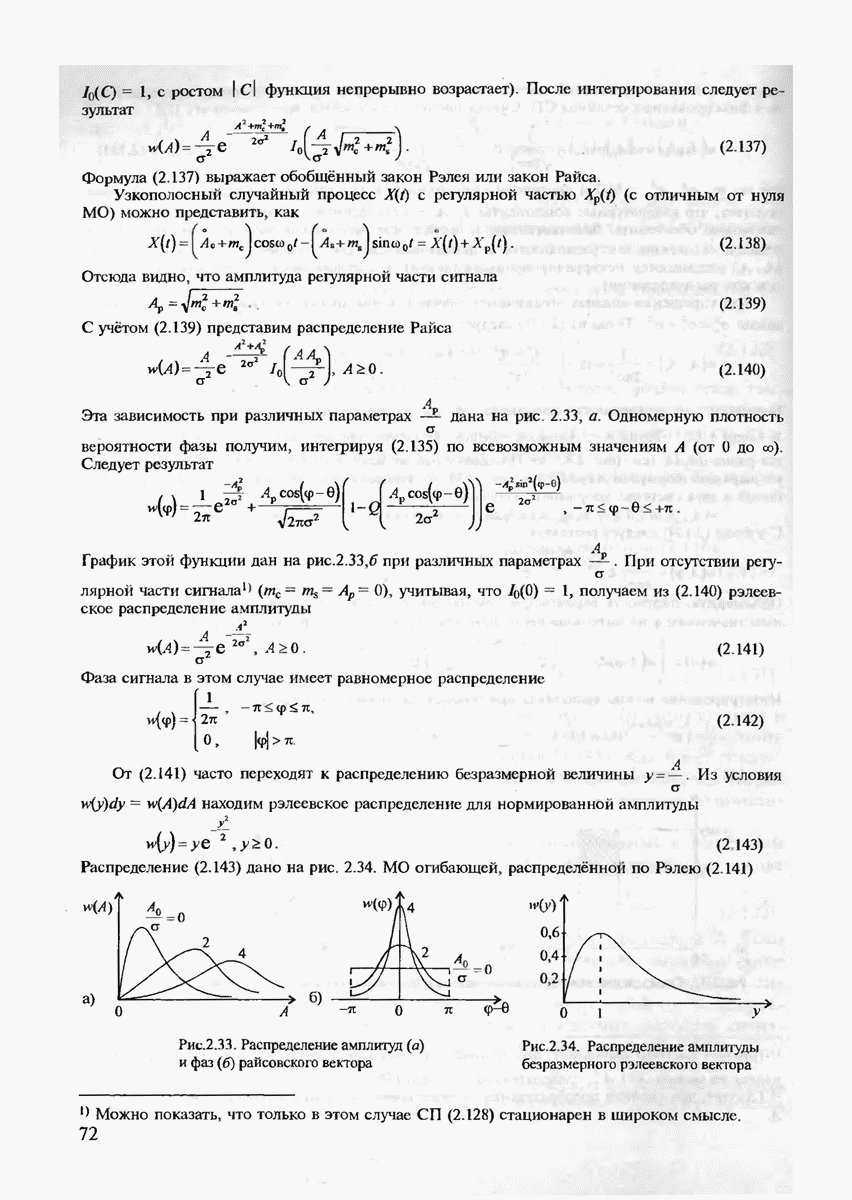
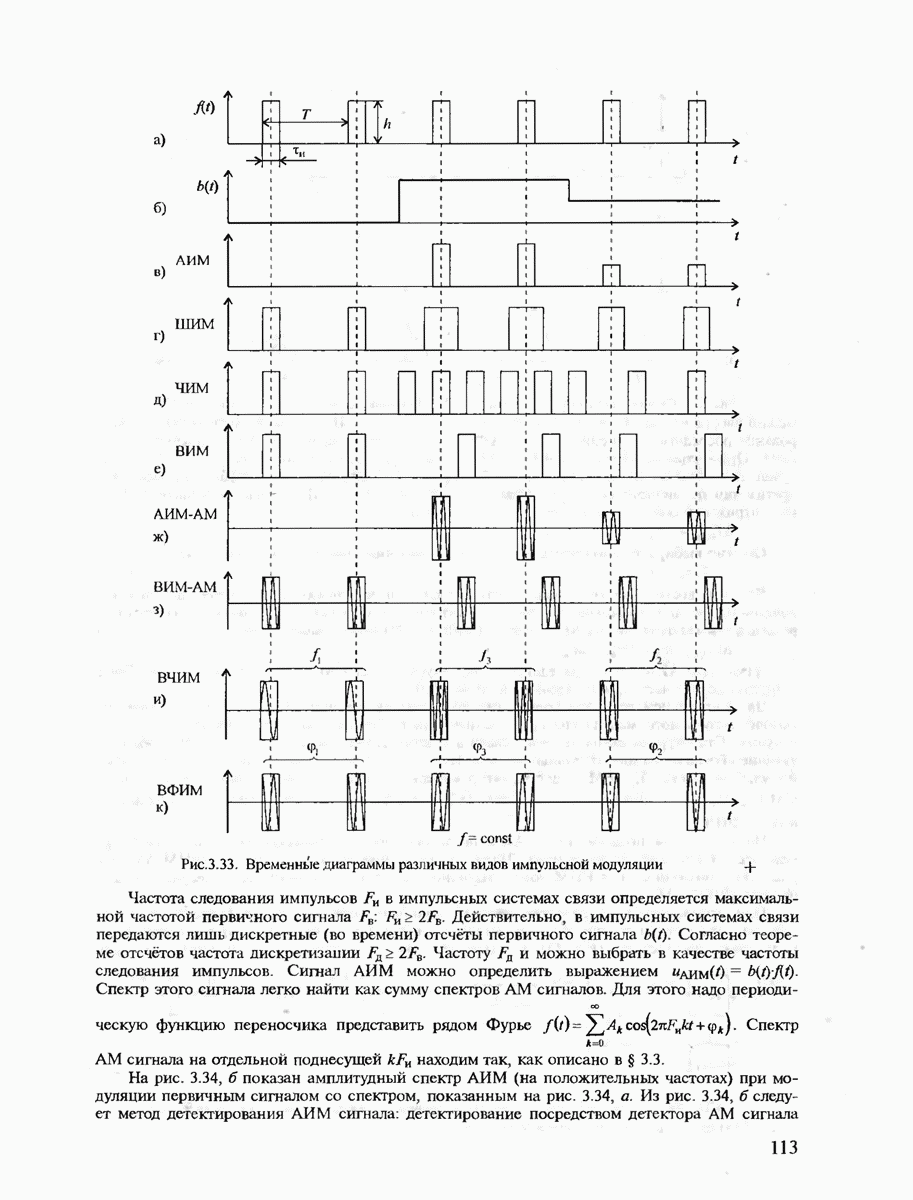
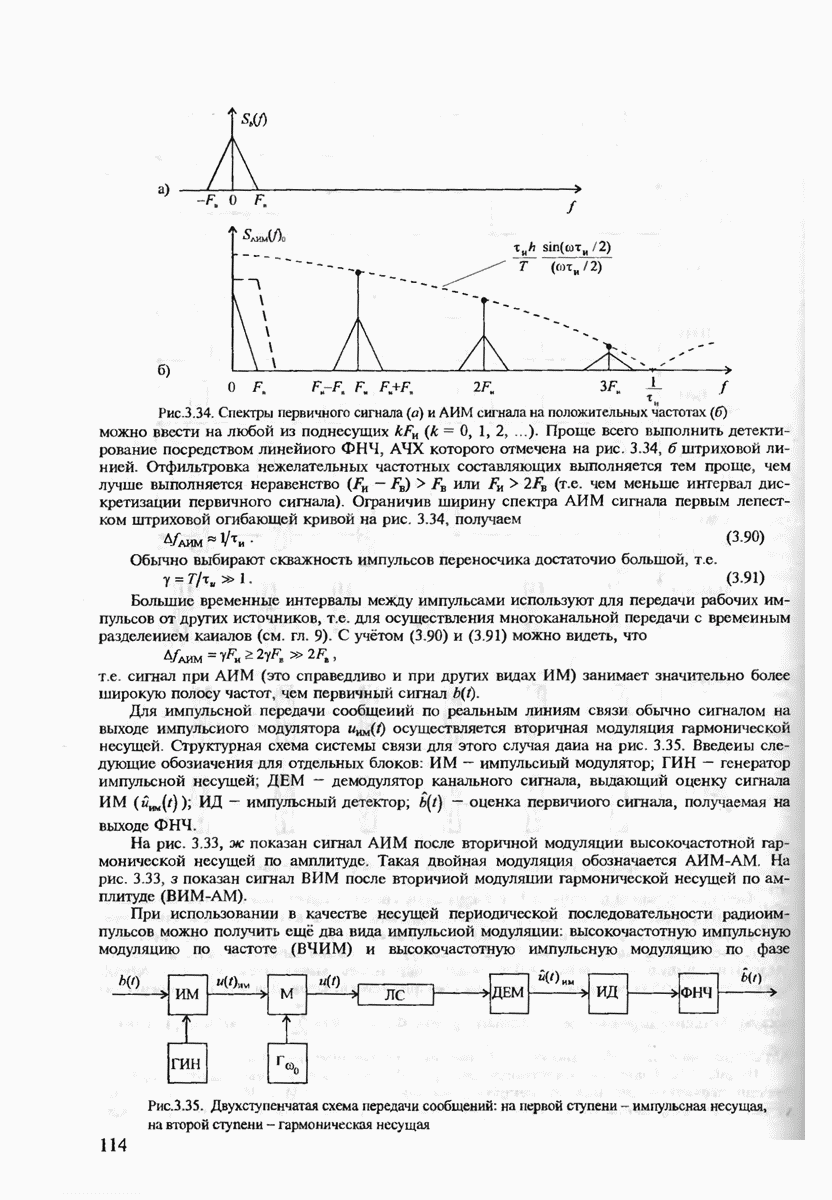
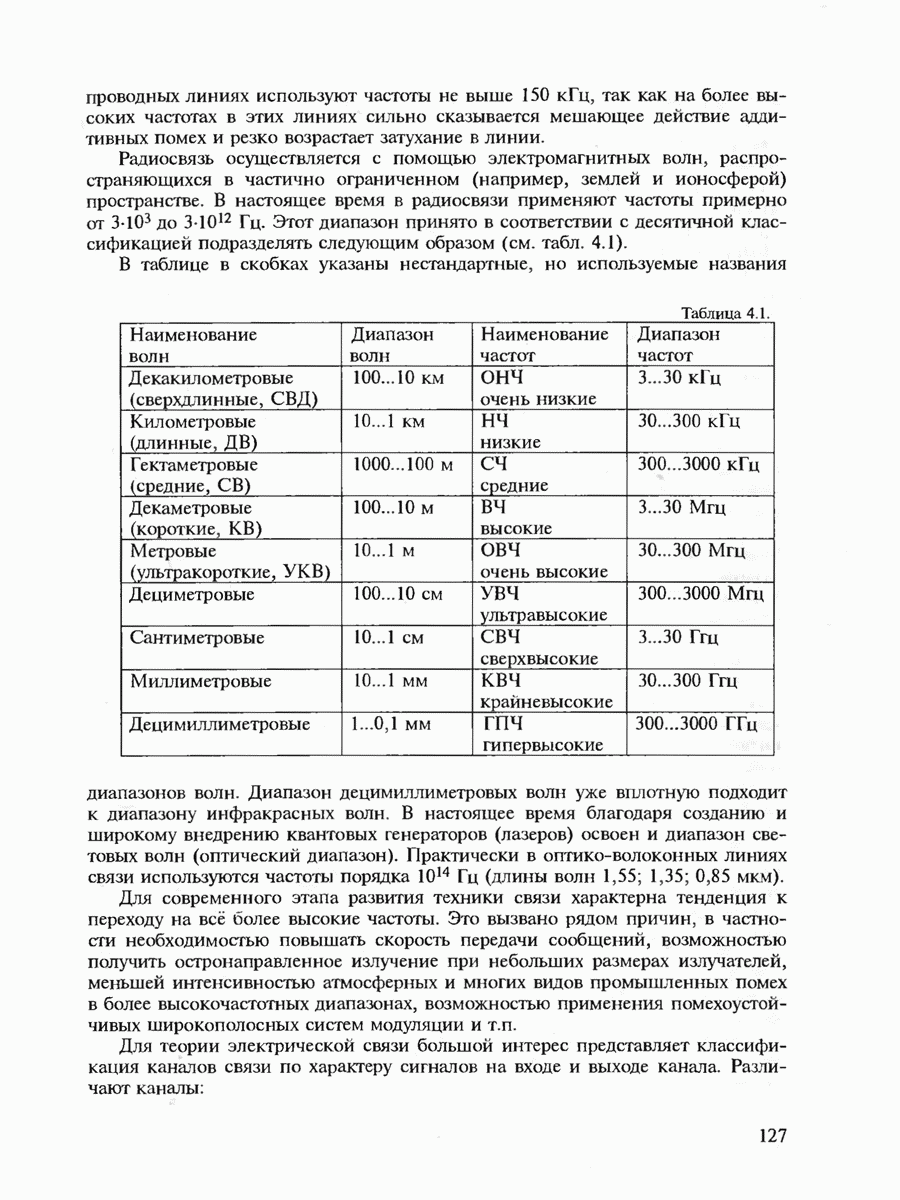
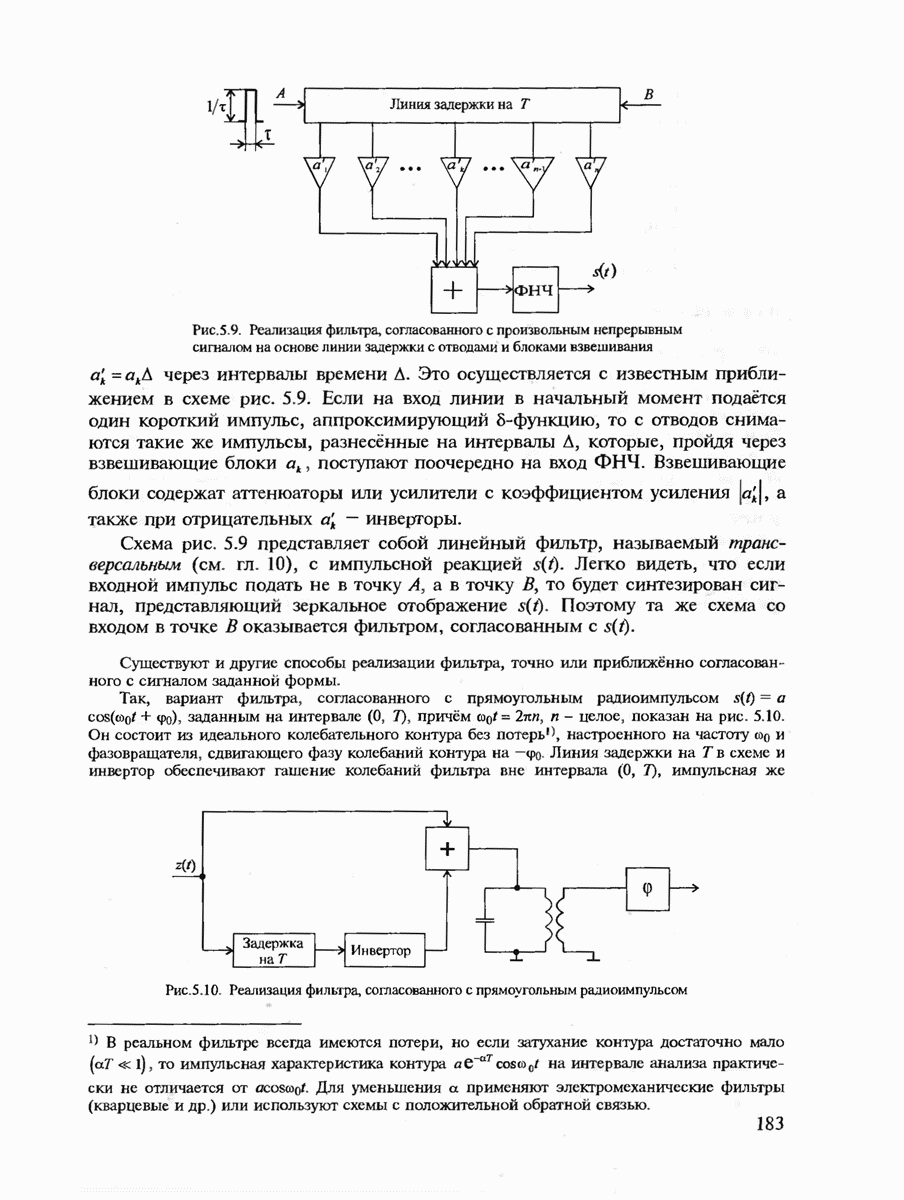
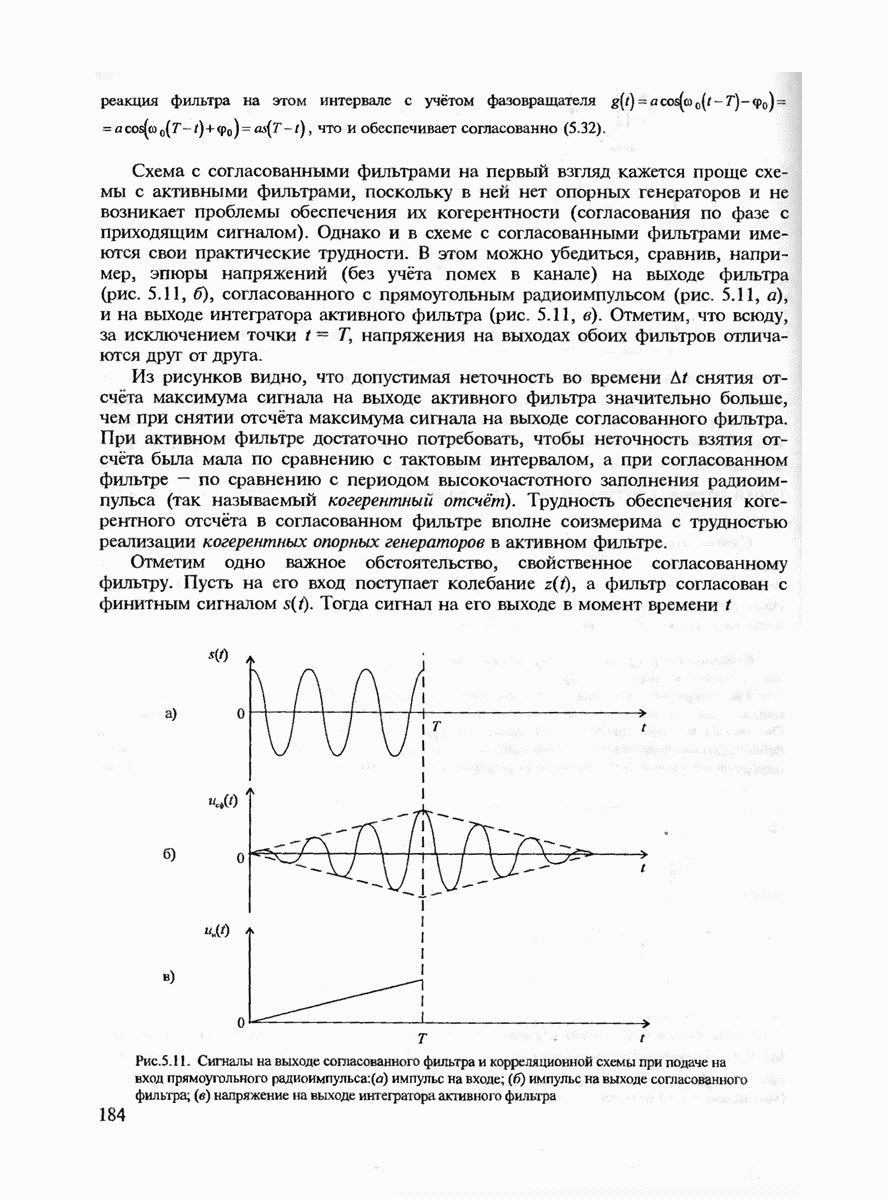
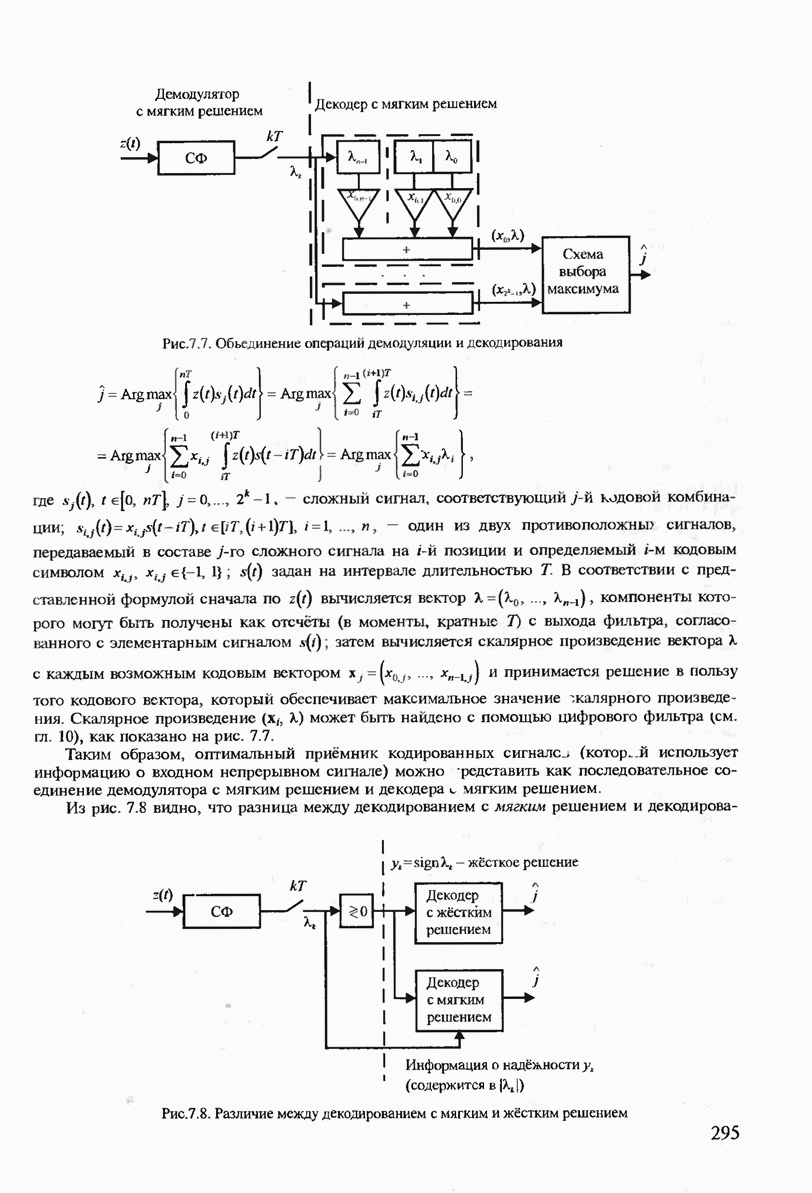
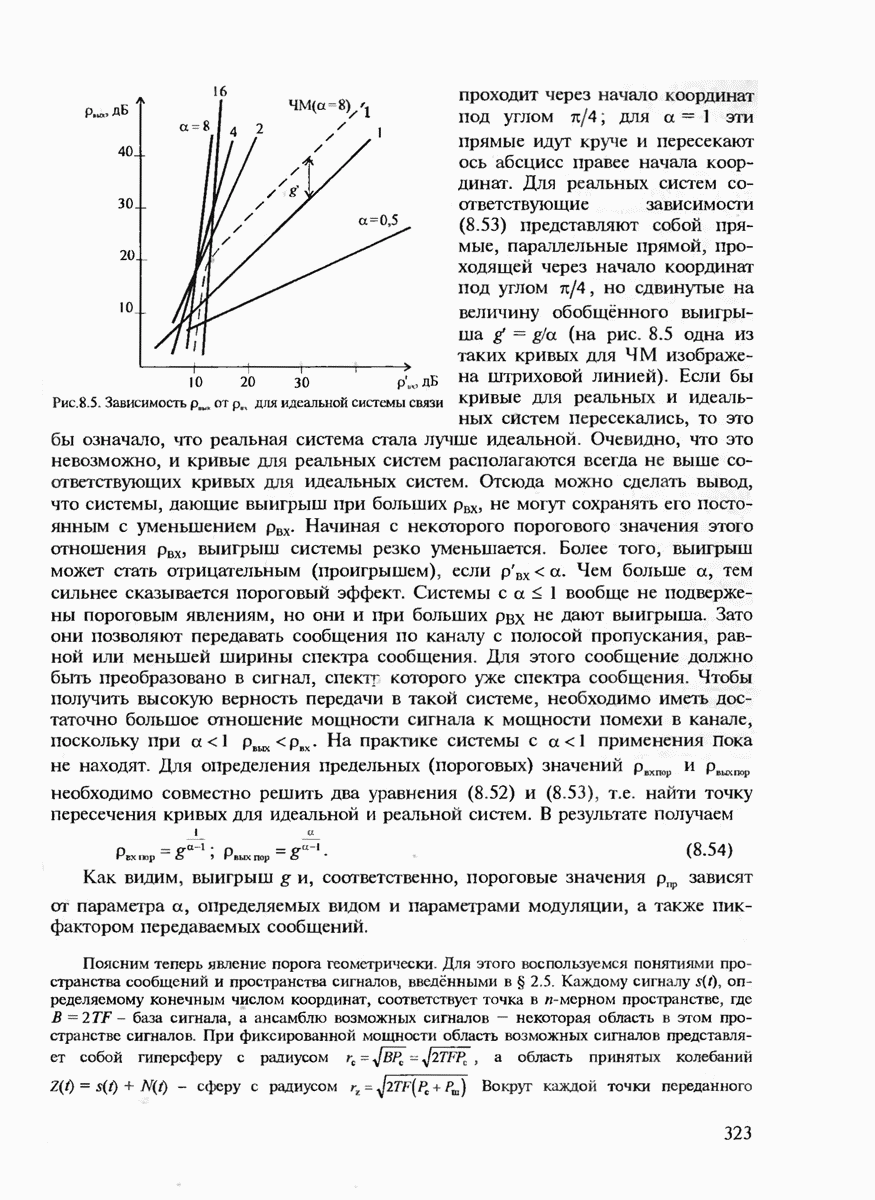
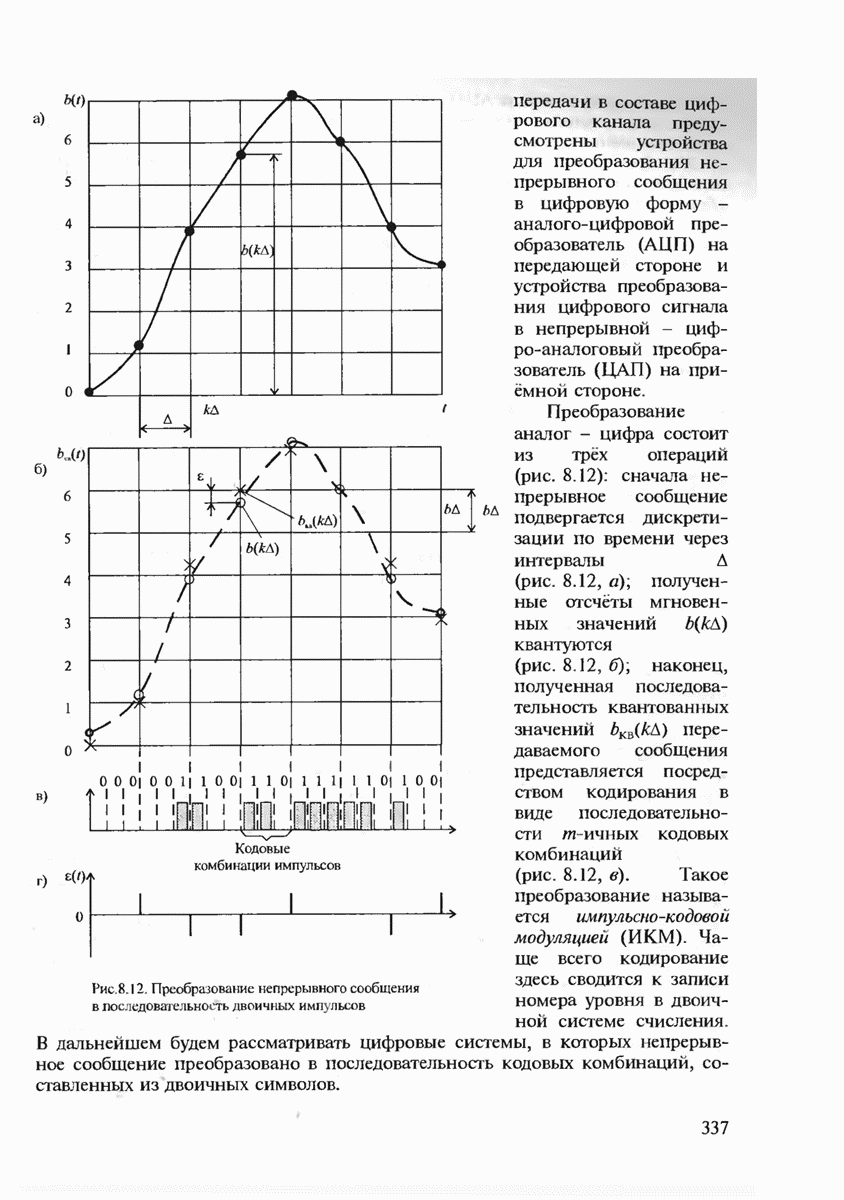
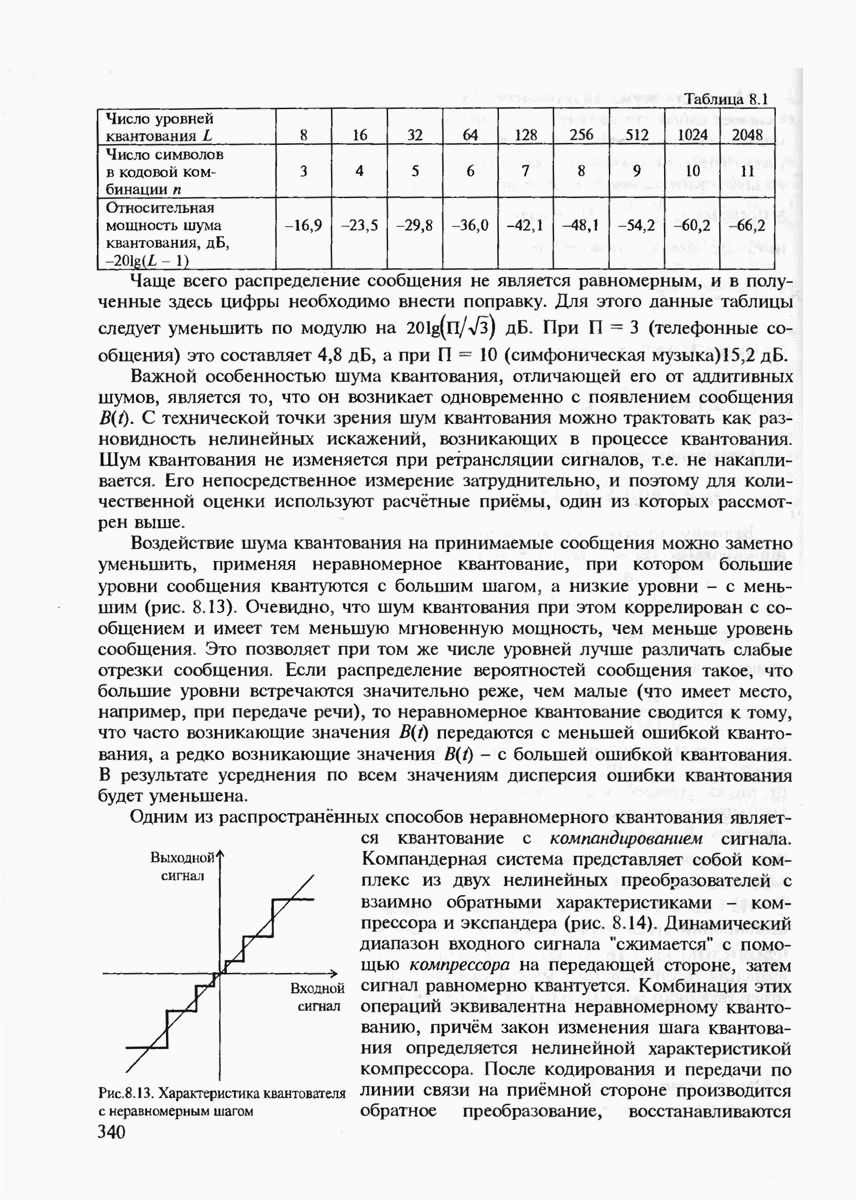
7.3.3. ЛИНЕЙНЫЕ ДВОИЧНЫЕ КОДЫ ДЛЯ ОБНАРУЖЕНИЯ И ИСПРАВЛЕНИЯ ОШИБОК
Здесь мы ограничимся описанием только двоичных кодов, поскольку это не потребует пока использования в качестве математического аппарата такого достаточно сложного раздела современной алгебры, как теория конечных полей. Мы отметим, однако, в конце главы, как все определённые здесь понятия и свойства могут быть распространены на случай  -ичных кодов.
-ичных кодов.
Определение 11. Линейным блочным двоичным кодом длины  называется любое множество двоичных последовательностей длины
называется любое множество двоичных последовательностей длины  которое содержит чисто нулевую последовательность, и для каждой пары последовательностей, принадлежащих этому множеству, их поразрядная сумма по
которое содержит чисто нулевую последовательность, и для каждой пары последовательностей, принадлежащих этому множеству, их поразрядная сумма по  также является элементом этого множества. (Последнее свойство можно назвать замкнутостью относительно поразрядного сложения по
также является элементом этого множества. (Последнее свойство можно назвать замкнутостью относительно поразрядного сложения по 
Пример. Множество последовательностей длины  образует линейный код, что проверяется непосредственно. Поразрядная сумма по
образует линейный код, что проверяется непосредственно. Поразрядная сумма по  комбинации даёт 4-ю комбинацию, сумма 3 и 4 даёт 2-ю, а сумма 2 и 4 даёт 3-ю комбинацию.
комбинации даёт 4-ю комбинацию, сумма 3 и 4 даёт 2-ю, а сумма 2 и 4 даёт 3-ю комбинацию.
Очевидно, что линейный код удовлетворяет определению линейного подпространства V для пространства  всех двоичных последовательностей длины
всех двоичных последовательностей длины  иначе — это подгруппа для группы всех двоичных
иначе — это подгруппа для группы всех двоичных  -последовательностей относительно групповой операции поразрядного сложения по
-последовательностей относительно групповой операции поразрядного сложения по  Поэтому двоичные линейные коды называются также и групповыми.)
Поэтому двоичные линейные коды называются также и групповыми.)
Из алгебры известно, что всякое Л-мерное линейное подпространство  -мерного пространства, состоящего из конечного числа
-мерного пространства, состоящего из конечного числа  элементов, содержит базис, т.е. совокупность к линейно независимых элементов, из которых путём поразрядного суммирования по
элементов, содержит базис, т.е. совокупность к линейно независимых элементов, из которых путём поразрядного суммирования по  можно образовать любые элементы данного подпространства, т.е. в данном случае комбинации линейного кода. Доказывается, что все базисы такого подпространства состоят из одного и того же числа элементов к, которое и определяет размерность подпространства. Общее число комбинаций линейного кода
можно образовать любые элементы данного подпространства, т.е. в данном случае комбинации линейного кода. Доказывается, что все базисы такого подпространства состоят из одного и того же числа элементов к, которое и определяет размерность подпространства. Общее число комбинаций линейного кода  поскольку таким будет общее число возможных поразрядных сумм из к элементов базиса, причём среди них не может найтись двух одинаковых сумм ввиду линейной независимости элементов базиса.
поскольку таким будет общее число возможных поразрядных сумм из к элементов базиса, причём среди них не может найтись двух одинаковых сумм ввиду линейной независимости элементов базиса.
Совокупность элементов базиса, записанная в виде линейно независимых строк, образует к  к двоичную матрицу
к двоичную матрицу  которая называется порождающей матрицей кода:
которая называется порождающей матрицей кода:

Множество всех кодовых слов, порождённых  может быть представлено как
может быть представлено как

где  вектор-строка кодовой комбинации размерности
вектор-строка кодовой комбинации размерности  вектор-строка информационных символов длины k. В (7.46) выполняется умножение вектора на матрицу, а все действия осуществлены по
вектор-строка информационных символов длины k. В (7.46) выполняется умножение вектора на матрицу, а все действия осуществлены по  Очевидно, что в качестве вектора
Очевидно, что в качестве вектора  можно использовать к последовательных элементов сообщения, выдаваемых двоичным источником. Переход от избыточных кодов общего вида к линейным кодам практически решает проблему сложности кодирования. Действительно, вместо запоминания
можно использовать к последовательных элементов сообщения, выдаваемых двоичным источником. Переход от избыточных кодов общего вида к линейным кодам практически решает проблему сложности кодирования. Действительно, вместо запоминания  комбинаций длины
комбинаций длины  т.е.
т.е.  бит в общем случае, нам достаточно запомнить лишь порождающую матрицу, состоящую из
бит в общем случае, нам достаточно запомнить лишь порождающую матрицу, состоящую из  бит. Сама же процедура кодирования потребует выполнения не более чем
бит. Сама же процедура кодирования потребует выполнения не более чем  элементарных операций.
элементарных операций.
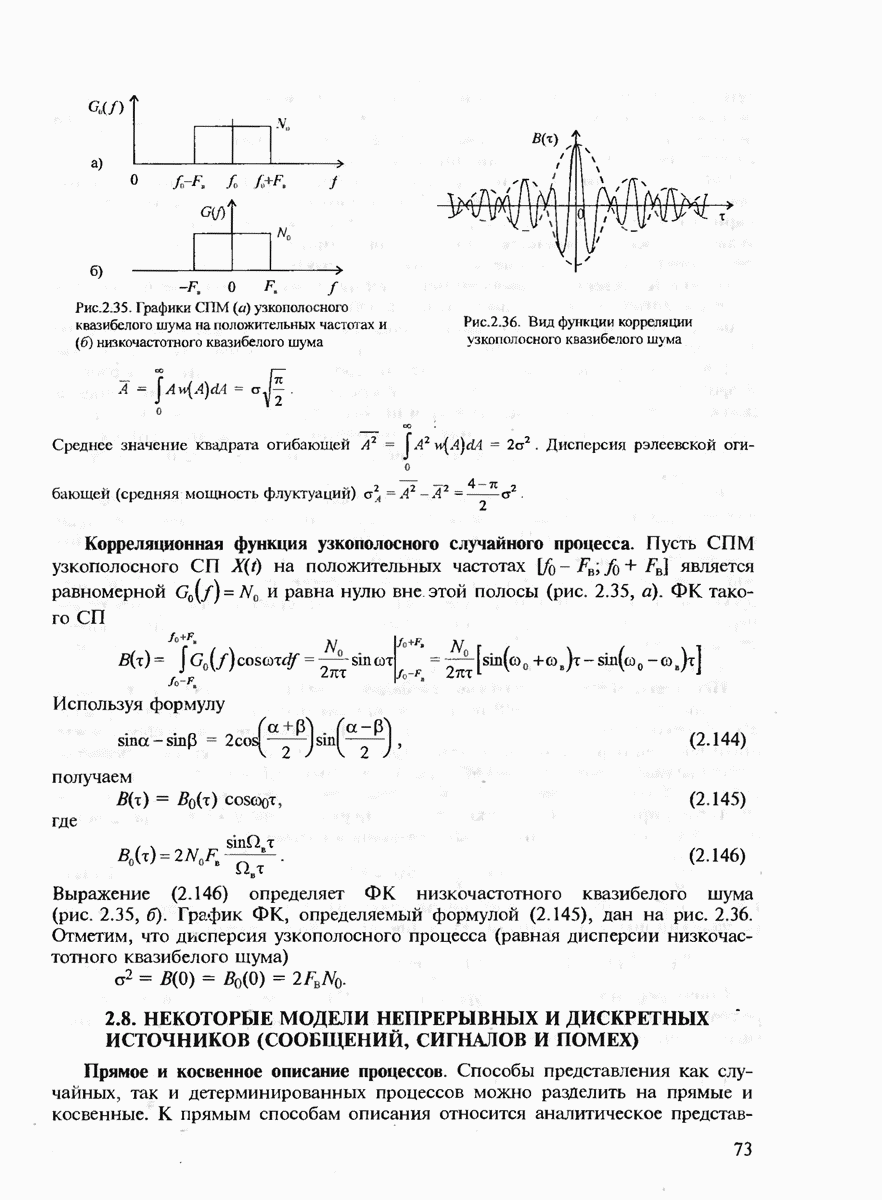
Переход к линейным кодам значительно упрощает анализ (а следовательно, и задание) их обнаруживающей и исправляющей способности. Действительно, пусть V — линейный двоичный код, содержащий комбинации  где
где  нулевая комбинация. Тогда по свойству замкнутости линейного кода для любой пары ненулевых комбинаций
нулевая комбинация. Тогда по свойству замкнутости линейного кода для любой пары ненулевых комбинаций  расстояние Хэмминга между ними
расстояние Хэмминга между ними  будет равно весу Хэмминга
будет равно весу Хэмминга  некоторой третьей комбинации, принадлежащей этому же коду, кроме нулевой. Поэтому получаем важный вывод, что для любого линейного кода минимальное кодовое
некоторой третьей комбинации, принадлежащей этому же коду, кроме нулевой. Поэтому получаем важный вывод, что для любого линейного кода минимальное кодовое
расстояние  равно минимальному весу Хэмминга, которым обладает слово кода, за исключением нулевого, т.е.
равно минимальному весу Хэмминга, которым обладает слово кода, за исключением нулевого, т.е.

Таким образом, для всех линейных кодов изучение списка хэмминговских расстояний между парами комбинаций эквивалентно изучению списка хэмминговских весов, что, очевидно, значительно проще.
Для любого линейного кода, заданного некоторой порождающей матрицей  очевидно также следующее свойство: любые перестановки столбцов и элементарные преобразования строк, заключающиеся в их перестановках или в суммировании друг с другом, не изменяют список весов данного кода. С другой стороны, можно показать, что при помощи таких преобразований любая
очевидно также следующее свойство: любые перестановки столбцов и элементарные преобразования строк, заключающиеся в их перестановках или в суммировании друг с другом, не изменяют список весов данного кода. С другой стороны, можно показать, что при помощи таких преобразований любая  двоичная матрица
двоичная матрица  с линейно-независимыми строками может быть приведена к каноническому виду
с линейно-независимыми строками может быть приведена к каноническому виду

где  некоторые двоичные элементы; I — единичная к у, к матрица (с единицами на главной диагонали и нулями в других местах);
некоторые двоичные элементы; I — единичная к у, к матрица (с единицами на главной диагонали и нулями в других местах);  матрица к
матрица к  к), состоящая! из двоичных элементов;
к), состоящая! из двоичных элементов;  означает последовательную запись матриц
означает последовательную запись матриц 
Используя представление (7.46) с матрицей  в виде (7.48), получаем
в виде (7.48), получаем

где 
По правилу матричного умножения получаем для  к
к

Из выражений (7.49) и (7.50) следует, что процедура кодирования линейным кодом, определённым канонической матрицей вида (7.48), сводится к формированию кодового слова, состоящего из двух последовательных подслов, причём первое подслово совпадает с информационной последовательностью длины к, выданной источником сообщений, а второе образовано путём линейной комбинации строк матрицы 
Определение 12. Линейные коды, слова которых представимы в виде (7.49), называются систематическими.
Мы фактически показали ранее, что всякий линейный код эквивалентен некоторому систематическому в смысле сохранения списка весов, а следовательно, и расстояний Хэмминга. Первые к символов кодовых слов, совпадающих с символами источника, называются информационными, а последние  к символов — проверочными. Скорость кода
к символов — проверочными. Скорость кода  определённая ранее как
определённая ранее как  для линейного кода будет равна
для линейного кода будет равна  т. е. для систематического — отношению числа информационных символов к к длине кодового блока
т. е. для систематического — отношению числа информационных символов к к длине кодового блока  Систематические коды с длиной блока
Систематические коды с длиной блока  и с числом информационных символов к будем кратко называть
и с числом информационных символов к будем кратко называть  -кодами. Иногда такой код обозначают тремя параметрами
-кодами. Иногда такой код обозначают тремя параметрами  где
где  минимальное кодовое расстояние.
минимальное кодовое расстояние.
В линейной алгебре существует понятие ортогонального пространства или нуль-пространства для заданного линейного пространства  Это по определению такое множество V векторов х длины
Это по определению такое множество V векторов х длины  для которых
для которых  при любом
при любом  где
где  означает скалярное произведение соответствующих векторов. (В нашем случае все операции производятся по
означает скалярное произведение соответствующих векторов. (В нашем случае все операции производятся по  Доказывается, что это множество всегда является линейным пространством, причём если код V имеет размерность к, то код
Доказывается, что это множество всегда является линейным пространством, причём если код V имеет размерность к, то код  будет иметь размерность
будет иметь размерность  т.е. содержать
т.е. содержать  комбинаций. Код V, совпадающий с ортогональным пространством, называется дуальным к коду
комбинаций. Код V, совпадающий с ортогональным пространством, называется дуальным к коду  Он, очевидно, также может быть задан своей порождающей матрицей
Он, очевидно, также может быть задан своей порождающей матрицей  размерностью
размерностью  Тогда комбинации исходного кода К могут быть определены как решения векторно-матричного уравнения
Тогда комбинации исходного кода К могут быть определены как решения векторно-матричного уравнения

где  означает символ транспонирования матрицы
означает символ транспонирования матрицы  т.е. взаимную замену строк и столбцов. Матрица
т.е. взаимную замену строк и столбцов. Матрица  которая является порождающей для кода V, называется проверочной матрицей для исходного кода
которая является порождающей для кода V, называется проверочной матрицей для исходного кода  Матрица
Матрица  так же, как и
так же, как и  может быть представлена в канонической форме, причём можно показать [211, что
может быть представлена в канонической форме, причём можно показать [211, что

где  та же самая матрица, что и в представлении (7.48).
та же самая матрица, что и в представлении (7.48).
В теории линейных кодов найдены границы для минимального расстояния 
Теорема 7.7. Верхняя граница Плоткина.
Если длина кодового блока  то число проверочных символов
то число проверочных символов  необходимых для того, чтобы минимальное расстояние линейного кода достигало значения
необходимых для того, чтобы минимальное расстояние линейного кода достигало значения  равно самое меньшее
равно самое меньшее  (Доказательство можно найти в
(Доказательство можно найти в  Как следствие,
Как следствие,

Теорема 7.8. Нижняя граница Варшамова-Гилъберта.
Существует  -код с минимальным расстоянием по меньшей мере
-код с минимальным расстоянием по меньшей мере  которое удовлетворяет следующему неравенству:
которое удовлетворяет следующему неравенству:

Доказательство. Пусть  проверочная матрица кода
проверочная матрица кода  Тогда из (7.51) следует, что для любого слова
Тогда из (7.51) следует, что для любого слова  хэмминговского веса
хэмминговского веса  существует такой набор из
существует такой набор из  столбцов матрицы
столбцов матрицы  элементы которой при покоординатном сложении по
элементы которой при покоординатном сложении по  дадут нулевой столбец. Верно и обратное, а именно, что если для некоторой проверочной матрицы
дадут нулевой столбец. Верно и обратное, а именно, что если для некоторой проверочной матрицы  любые
любые  и меньшее число столбцов всегда является линейно независимым (т.е. в сумме не дают нулевых столбцов), то соответствующий ей линейный код имеет минимальное расстояние, самое меньшее
и меньшее число столбцов всегда является линейно независимым (т.е. в сумме не дают нулевых столбцов), то соответствующий ей линейный код имеет минимальное расстояние, самое меньшее  Построим проверочную матрицу, обладающую таким свойством. В качестве её первого столбца возьмём любой двоичный набор длины
Построим проверочную матрицу, обладающую таким свойством. В качестве её первого столбца возьмём любой двоичный набор длины  Затем возьмём также любой двоичный набор длины
Затем возьмём также любой двоичный набор длины  не совпадающий с первым, далее — третий набор, не равный их сумме и так далее до столбца длиной
не совпадающий с первым, далее — третий набор, не равный их сумме и так далее до столбца длиной  который не является суммой
который не является суммой  и меньшего числа предыдущих столбцов. Очевидно, что очередной столбец может быть присоединён к матрице в том случае, если совокупность всех сумм из
и меньшего числа предыдущих столбцов. Очевидно, что очередной столбец может быть присоединён к матрице в том случае, если совокупность всех сумм из  или меньшего числа предыдущих столбцов матрицы не исчерпывает всех наборов длины
или меньшего числа предыдущих столбцов матрицы не исчерпывает всех наборов длины  . В наихудшем случае все такие суммы будут различными. Поскольку общее число таких сумм при выборе из общего числа
. В наихудшем случае все такие суммы будут различными. Поскольку общее число таких сумм при выборе из общего числа  столбцов равно
столбцов равно  а число различных вариантов двоичных ненулевых столбцов длины
а число различных вариантов двоичных ненулевых столбцов длины  равно
равно  то достаточное условие существования кода с длиной блока
то достаточное условие существования кода с длиной блока  имеющего самое большее
имеющего самое большее  проверочных символов, принимает вид
проверочных символов, принимает вид

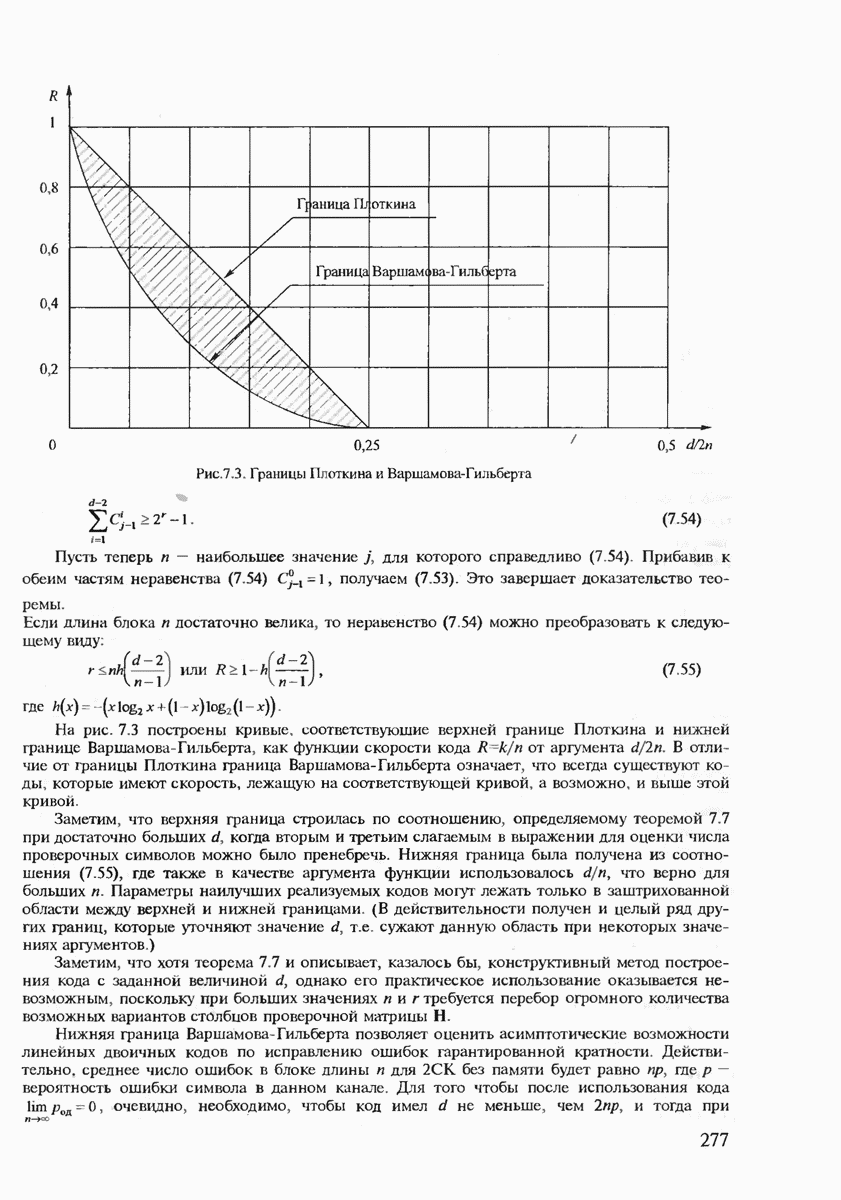
Рис. 7.3. Границы Плоткина и Варшамова-Гильберта

Пусть теперь  наибольшее значение
наибольшее значение  для которого справедливо (7.54). Прибавив к обеим частям неравенства
для которого справедливо (7.54). Прибавив к обеим частям неравенства  получаем (7.53). Это завершает доказательство теоремы.
получаем (7.53). Это завершает доказательство теоремы.
Если длина блока  достаточно велика, то неравенство (7.54) можно преобразовать к следующему виду:
достаточно велика, то неравенство (7.54) можно преобразовать к следующему виду:

где 
На рис. 7.3 построены кривые, соответствующие верхней границе Плоткина и нижней границе Варшамова-Гильберта, как функции скорости кода  от аргумента
от аргумента  . В отличие от границы Плоткина граница Варшамова-Гильберта означает, что всегда существуют коды которые имеют скорость, лежащую на соответствующей кривой, а возможно, и выше этой кривой.
. В отличие от границы Плоткина граница Варшамова-Гильберта означает, что всегда существуют коды которые имеют скорость, лежащую на соответствующей кривой, а возможно, и выше этой кривой.
Заметим, что верхняя граница строилась по соотношению определяемому теоремой 7 7 при достаточно больших  когда вторым и третьим слагаемым в выражении для оценки числа проверочных символов можно было пренебречь. Нижняя граница была получена из соотношения (7.55), где также в качестве аргумента функции использовалось
когда вторым и третьим слагаемым в выражении для оценки числа проверочных символов можно было пренебречь. Нижняя граница была получена из соотношения (7.55), где также в качестве аргумента функции использовалось  что верно для больших
что верно для больших  Параметры наилучших реализуемых кодов могут лежать только в заштрихованной области между верхней и нижней границами. (В действительности получен и целый ряд других границ, которые уточняют значение
Параметры наилучших реализуемых кодов могут лежать только в заштрихованной области между верхней и нижней границами. (В действительности получен и целый ряд других границ, которые уточняют значение  т.е. сужают данную область при некоторых значениях аргументов.)
т.е. сужают данную область при некоторых значениях аргументов.)
Заметим, что хотя теорема 7.7 и описывает, казалось бы, конструктивный метод построения кода с заданной величиной  однако его практическое использование оказывается невозможным, поскольку при больших значениях
однако его практическое использование оказывается невозможным, поскольку при больших значениях  требуется перебор огромного количества возможных вариантов столбцов проверочной матрицы
требуется перебор огромного количества возможных вариантов столбцов проверочной матрицы 
Нижняя граница Варшамова-Гильберта позволяет оценить асимптотические возможности линейных двоичных кодов по исправлению ошибок гарантированной кратности. Действительно. среднее число ошибок в блоке длины  для
для  без памяти будет равно
без памяти будет равно  , где
, где  вероятность ошибки символа в данном канале. Для того чтобы после использования кода
вероятность ошибки символа в данном канале. Для того чтобы после использования кода  рад
рад  очевидно, необходимо, чтобы код имел
очевидно, необходимо, чтобы код имел  не меньше, чем
не меньше, чем  и тогда при
и тогда при
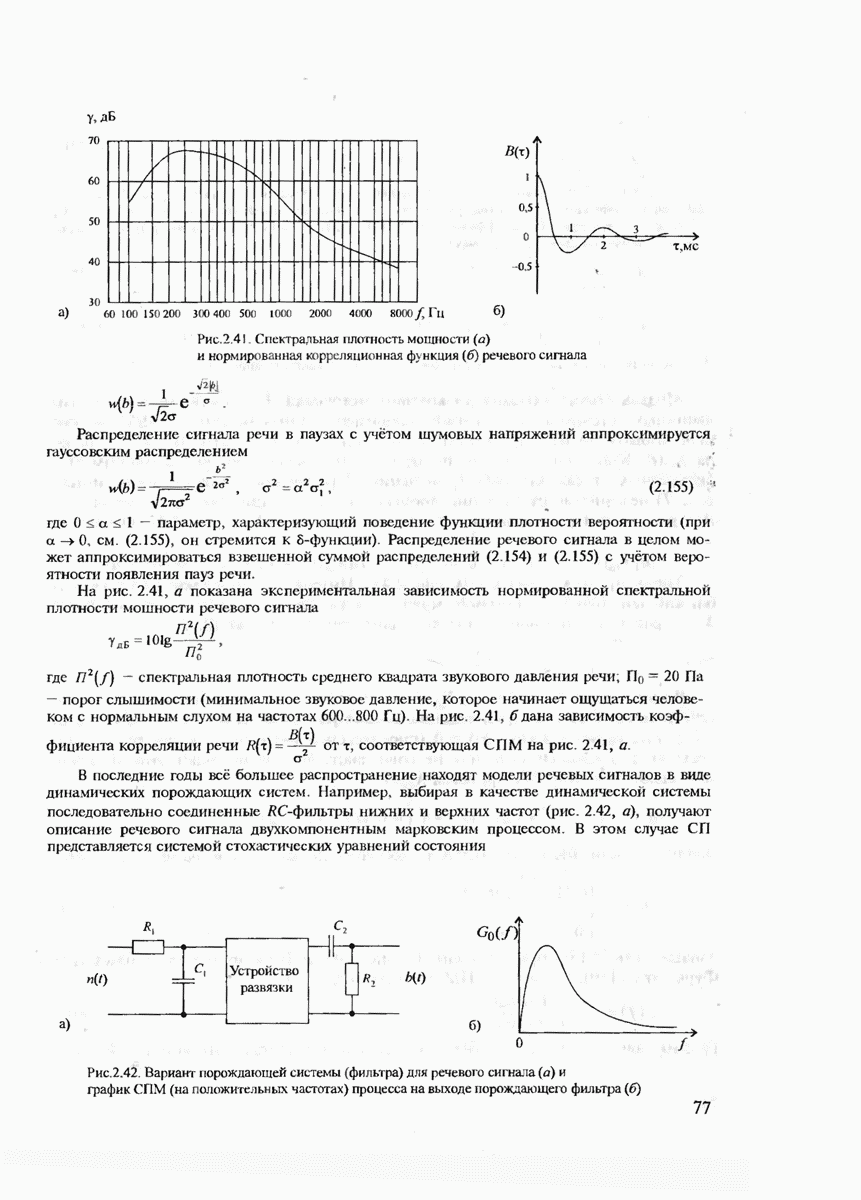
больших  получаем
получаем  а неравенство (7.55) можно переписать в следующей форме:
а неравенство (7.55) можно переписать в следующей форме: 
Интересно сопоставить нижнюю границу Варшамова-Гильберта  с верхней границей для скорости кода, установленной теоремой Шеннона для
с верхней границей для скорости кода, установленной теоремой Шеннона для  Ясно, что при
Ясно, что при  эти границы совпадают. При
эти границы совпадают. При  нижняя граница Варшамова-Гильберта
нижняя граница Варшамова-Гильберта  , в то время как верхняя граница Шеннона
, в то время как верхняя граница Шеннона  (см. рис. 6.3). В области
(см. рис. 6.3). В области  граница Шеннона существенно выше, чем граница Варшамова-Гильберта. Эта разница объясняется тем, что нижняя граница Варшамова-Гильберта соответствует алгоритму исправления ошибок только гарантированной кратности, в то время как граница Шениона определена при оптимальном, сколь угодно сложном декодировании. Однако, хотя скорость кода
граница Шеннона существенно выше, чем граница Варшамова-Гильберта. Эта разница объясняется тем, что нижняя граница Варшамова-Гильберта соответствует алгоритму исправления ошибок только гарантированной кратности, в то время как граница Шениона определена при оптимальном, сколь угодно сложном декодировании. Однако, хотя скорость кода  получаемая из границы Варшамова-Гильберта, меньше, чем значение, следующее из теоремы оптимального кодирования, она является гарантированной и реально достижимой.
получаемая из границы Варшамова-Гильберта, меньше, чем значение, следующее из теоремы оптимального кодирования, она является гарантированной и реально достижимой.
Исследование линейных кодов позволяет также упростить алгоритм декодирования по минимуму расстояния Хэмминга, расчёт род для этого алгоритма и ближе подойти к проблеме оптимизации выбора кодов. Для этого рассмотрим конструкцию, которая называется стандартным расположением по заданному коду  В качестве первой строки такого расположения (таблицы) выберем кодовые комбинации
В качестве первой строки такого расположения (таблицы) выберем кодовые комбинации  самого кода
самого кода  Далее возьмём произвольное двоичное слово
Далее возьмём произвольное двоичное слово  длины
длины  которое не принадлежит коду
которое не принадлежит коду  , и образуем
, и образуем  слов следующей строки по правилу
слов следующей строки по правилу  где
где  означает поразрядное суммирование по
означает поразрядное суммирование по  Затем возьмём двоичное слово
Затем возьмём двоичное слово  длины
длины  так, чтобы
так, чтобы  и построим третью строку
и построим третью строку  и так далее вплоть до исчерпания всех двоичных векторов длины
и так далее вплоть до исчерпания всех двоичных векторов длины  не входящих в предыдущие строки. Легко проверить, что в каждой строке матрицы будут содержаться лишь различные слова и в строках не будет содержать повторения слов. Данная таблица будет содержать все
не входящих в предыдущие строки. Легко проверить, что в каждой строке матрицы будут содержаться лишь различные слова и в строках не будет содержать повторения слов. Данная таблица будет содержать все  двоичных слов длины
двоичных слов длины  Поэтому число строк таблицы всегда в точности
Поэтому число строк таблицы всегда в точности  а число столбцов
а число столбцов  Можно убедиться также в справедливости следующих свойств для данной расстановки: поразрядная сумма по
Можно убедиться также в справедливости следующих свойств для данной расстановки: поразрядная сумма по  любой пары слов, находящихся в одной строке, всегда даёт кодовое слово, а лежащих в разных строках — слово в некоторой строке, отличной от взятых, но не принадлежащих первой строке (т.е. коду). Замена слова
любой пары слов, находящихся в одной строке, всегда даёт кодовое слово, а лежащих в разных строках — слово в некоторой строке, отличной от взятых, но не принадлежащих первой строке (т.е. коду). Замена слова  формирующего
формирующего  строку, на какое-либо слово в этой же строке не изменяет полной совокупности слов, образующих данную строку, а производит лишь их перестановку в строке. В алгебре такие строки, полученные по некоторой группе (коду), называются смежными классами, а слова
строку, на какое-либо слово в этой же строке не изменяет полной совокупности слов, образующих данную строку, а производит лишь их перестановку в строке. В алгебре такие строки, полученные по некоторой группе (коду), называются смежными классами, а слова  называются образующими или лидерами смежных классов. После построения стандартного расположения по некоторому коду К определим способ декодирования, соответствующий этой таблице, следующим образом: если принято некоторое слово у, то декодируется кодовое слово
называются образующими или лидерами смежных классов. После построения стандартного расположения по некоторому коду К определим способ декодирования, соответствующий этой таблице, следующим образом: если принято некоторое слово у, то декодируется кодовое слово  находящееся в том же столбце, что и у. Тогда вероятность перехода
находящееся в том же столбце, что и у. Тогда вероятность перехода  для любого двоичного канала связи с аддитивным шумом будет равна вероятности появления образца ошибки
для любого двоичного канала связи с аддитивным шумом будет равна вероятности появления образца ошибки  совпадающего с лидером смежного класса
совпадающего с лидером смежного класса  к которому принадлежит у Поэтому для того, чтобы сделать декодирование оптимальным по критерию максимума правдоподобия, достаточно выбрать в качестве лидеров образцы ошибок, имеющие максимальные вероятности в каждом смежном классе. (Если несколько слов имеют в некотором смежном классе одинаковые вероятности, то можно в качестве лидера выбрать любое из них
к которому принадлежит у Поэтому для того, чтобы сделать декодирование оптимальным по критерию максимума правдоподобия, достаточно выбрать в качестве лидеров образцы ошибок, имеющие максимальные вероятности в каждом смежном классе. (Если несколько слов имеют в некотором смежном классе одинаковые вероятности, то можно в качестве лидера выбрать любое из них 
Определение 13. Синдромом по коду К для любого принятого на выходе канала связи двоичного слова у длины  будем называть двоичный вектор-строку длины
будем называть двоичный вектор-строку длины  :
:

где  проверочная матрица кода
проверочная матрица кода 
Легко убедиться, что для всех слов, принадлежащих одному и тому же смежному классу кода V, синдромы оказываются одинаковыми, а для

Рис. 7.4. Схема кодера

Рис. 7.5. Схема вычисления синдрома
различных смежных классов синдромы различны. Поэтому с каждым смежным классом можно сопоставить один, и только один синдром. Оптимальное декодирование в  без памяти можно тогда производить, отыскивая слово минимального веса, синдром которого совпадает с синдромом, полученным по принятому слову. Такой алгоритм декодирования называется синдромным. Табличный способ синдромного декодирования состоит в запоминании таблицы, связывающей различные синдромы с лидерами соответствующих им смежных классов.
без памяти можно тогда производить, отыскивая слово минимального веса, синдром которого совпадает с синдромом, полученным по принятому слову. Такой алгоритм декодирования называется синдромным. Табличный способ синдромного декодирования состоит в запоминании таблицы, связывающей различные синдромы с лидерами соответствующих им смежных классов.
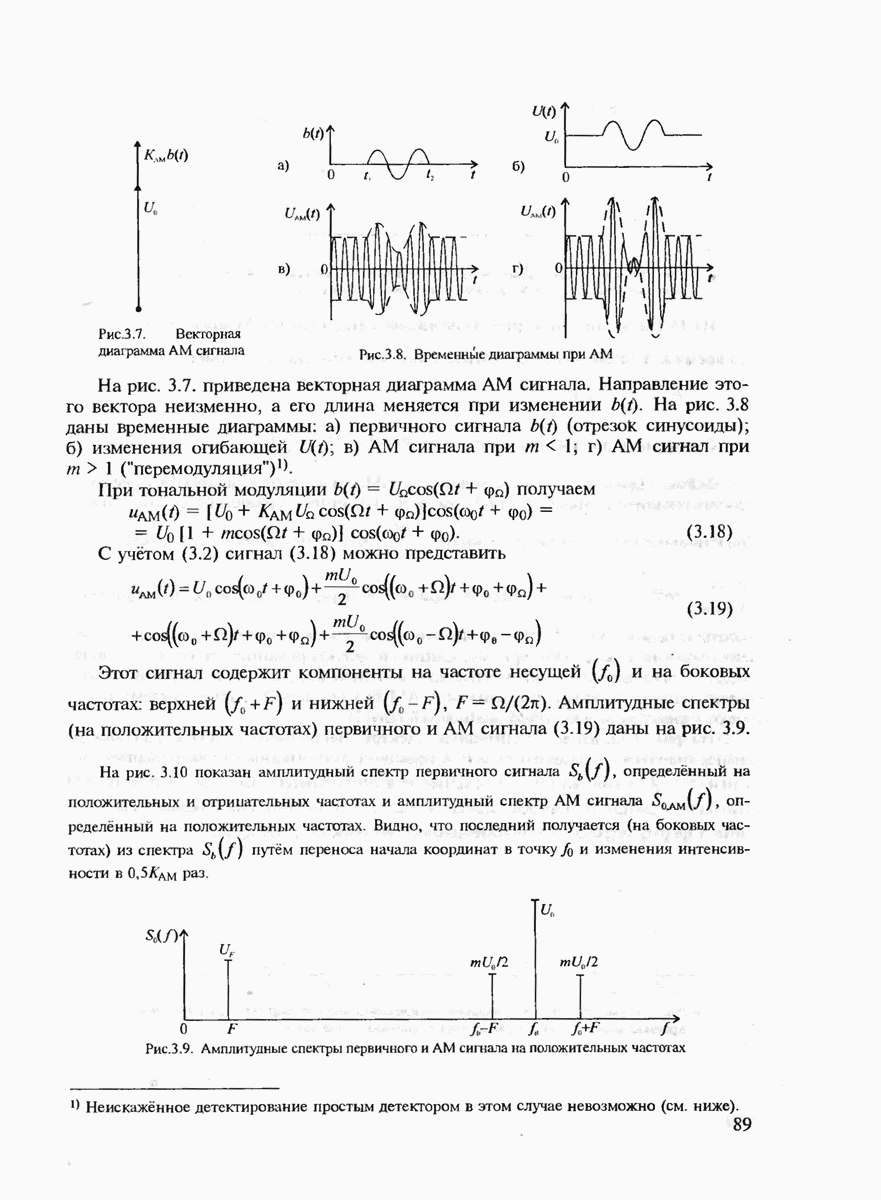
Схемы кодирования и вычисления синдрома для произвольного линейного кода приведены на рис. 7.4 и рис. 7.5. Элемент порождающей матрицы  определяет характер связи
определяет характер связи  ячейки регистра с
ячейки регистра с  сумматором: если
сумматором: если  связь есть, если
связь есть, если  связь отсутствует. Кодирование происходит следующим образом вектор
связь отсутствует. Кодирование происходит следующим образом вектор  записывается в регистр, после чего с выходов сумматоров считывается вектор с. Для кодирования систематического кода необходимо лишь
записывается в регистр, после чего с выходов сумматоров считывается вектор с. Для кодирования систематического кода необходимо лишь  сумматоров, связи которых с регистром задаются матрицей
сумматоров, связи которых с регистром задаются матрицей  При этом вектор х образуется из вектора
При этом вектор х образуется из вектора  и выходов
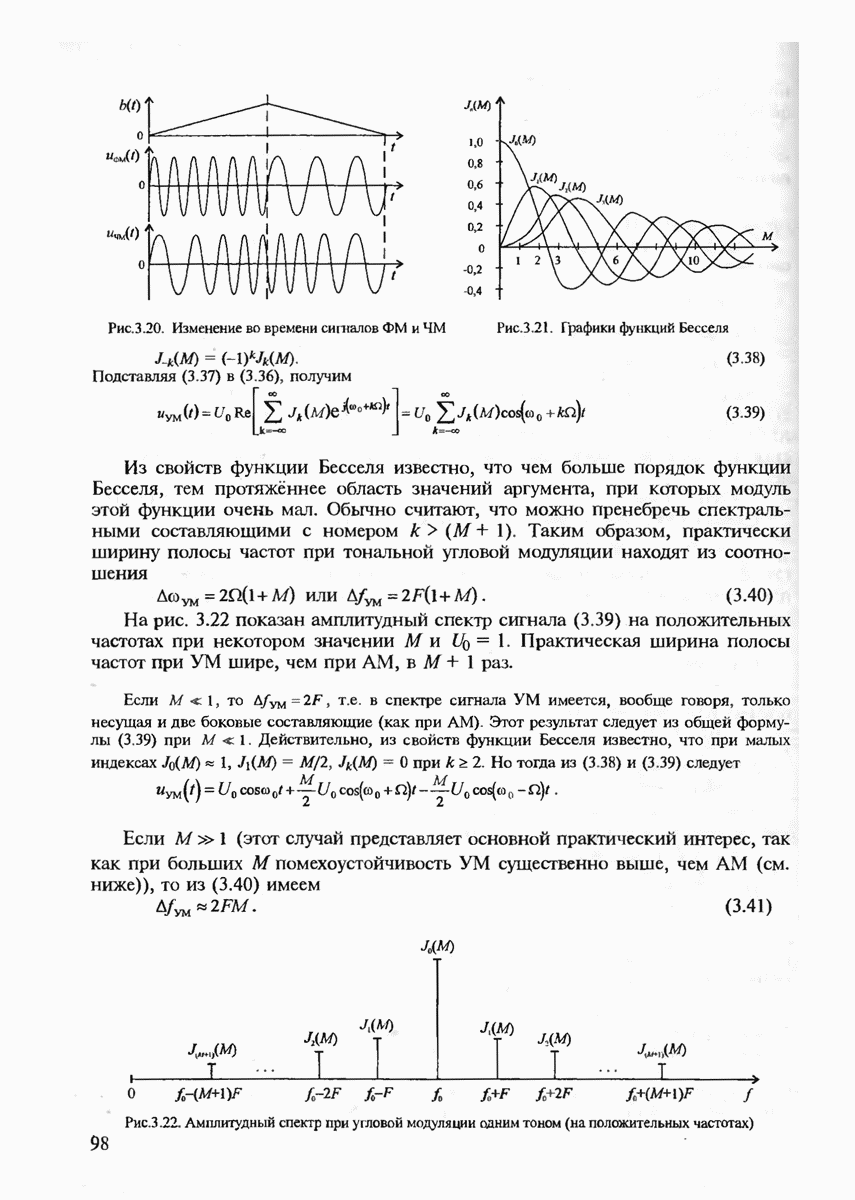
и выходов  сумматоров (вектора с). На рис. 7.5 элемент проверочной матрицы
сумматоров (вектора с). На рис. 7.5 элемент проверочной матрицы  определяет характер связи
определяет характер связи  ячейки регистра с
ячейки регистра с  сумматором: если
сумматором: если  связь есть, если
связь есть, если  связь отсутствует. Для вычисления синдрома вектор у записывается в регистр, после чего с выходов сумматоров считывается
связь отсутствует. Для вычисления синдрома вектор у записывается в регистр, после чего с выходов сумматоров считывается 
При использовании линейных кодов выраженная числом двоичных сложений сложность процедуры кодирования и процедуры вычисления синдрома (декодирование с обнаружением ошибок) не превышает  Это значительно меньше, чем при табличном кодировании и декодировании.
Это значительно меньше, чем при табличном кодировании и декодировании.
Для конкретизации алгоритма декодирования с исправлением ошибок учтем, что принятый вектор у можно записать в виде  где
где  вектор ошибок в канале (размерностью
вектор ошибок в канале (размерностью  Если конкретная реализация
Если конкретная реализация  имеет вес и
имеет вес и  ненулевых компонент) и о меньше
ненулевых компонент) и о меньше  для заданного кода, то ошибки в у могут быть исправлены. Вектор
для заданного кода, то ошибки в у могут быть исправлены. Вектор  входит в выражение для синдрома (7.56), и с учётом (7.54)
входит в выражение для синдрома (7.56), и с учётом (7.54)

Вероятность  правильного декодирования кодового слова в любом канале связи при использовании табличного способа синдромного декодирования (по алгоритму максимального правдоподобия) будет определяться следующим соотношением:
правильного декодирования кодового слова в любом канале связи при использовании табличного способа синдромного декодирования (по алгоритму максимального правдоподобия) будет определяться следующим соотношением:

где  означает нулевое слово, и, следовательно,
означает нулевое слово, и, следовательно,  соответствует вероятности безошибочного приёма кодового слова. (Очевидно, что
соответствует вероятности безошибочного приёма кодового слова. (Очевидно, что  Для
Для  без памяти стандартное расположение даёт правило декодирования по максимуму правдоподобия, если каждый лидер выбирается как слово минимального веса в своём смежном классе. Тогда для вероятности правильного декодирования получаем следующую точную формулу
без памяти стандартное расположение даёт правило декодирования по максимуму правдоподобия, если каждый лидер выбирается как слово минимального веса в своём смежном классе. Тогда для вероятности правильного декодирования получаем следующую точную формулу

где  минимальный вес слова в
минимальный вес слова в  смежном классе.
смежном классе.
К сожалению, использование (7.59) для мощных кодов оказывается затруднительным, поскольку требует построения необходимой таблицы стандартного расположения или знания так называемого спектра смежных классов, т.е. распределения весов Хэмминга для слов, входящих в каждый из смежных классов кода, что удаётся сделать лишь для некоторых частных случаев.
Соотношение (7.59) показывает, что некоторый  -код будет оптимальным в
-код будет оптимальным в  без памяти, т.е. обеспечит максимальную величину
без памяти, т.е. обеспечит максимальную величину  если все его лидеры минимального веса совпадут с набором образцов ошибок от 0 до некоторой кратности
если все его лидеры минимального веса совпадут с набором образцов ошибок от 0 до некоторой кратности  Поскольку полное число таких образцов ошибок равно
Поскольку полное число таких образцов ошибок равно  а число смежных классов равно
а число смежных классов равно  то это требует выполнения условия
то это требует выполнения условия

где  некоторое целое число. Очевидно, соотношение (7.60) выполняется не для всех
некоторое целое число. Очевидно, соотношение (7.60) выполняется не для всех  -кодов. Напротив, его выполнение - это редчайший случай. Коды, которые удовлетворяют этому условию, называются совершенными. Известно лишь два нетривиальных двоичных
-кодов. Напротив, его выполнение - это редчайший случай. Коды, которые удовлетворяют этому условию, называются совершенными. Известно лишь два нетривиальных двоичных  -кот с параметрами, удовлетворяющими (7.60), — это код Хэмминга и код Голея (23,12). (Они будут определены несколько позже.) Максимум в (7.59) может обеспечить и так называемый квазисовершенный код, среди образующих смежных классов которого при некотором
-кот с параметрами, удовлетворяющими (7.60), — это код Хэмминга и код Голея (23,12). (Они будут определены несколько позже.) Максимум в (7.59) может обеспечить и так называемый квазисовершенный код, среди образующих смежных классов которого при некотором  содержатся все последовательности веса
содержатся все последовательности веса  или меньше, часть последовательностей веса
или меньше, часть последовательностей веса  и нет ни одной последовательности большого веса. К сожалению, квазисовершенныс коды также встречаются достаточно редко.
и нет ни одной последовательности большого веса. К сожалению, квазисовершенныс коды также встречаются достаточно редко.
Даже если некоторый линейный код имеет известное значение  расчёт
расчёт  или
или  без памяти по границам (7.38), (7.41) или (7.43) может привести к достаточно грубым оценкам. Это особенно относится к расчёту обнаруживающей способности кода для больших вероятностей ошибок
без памяти по границам (7.38), (7.41) или (7.43) может привести к достаточно грубым оценкам. Это особенно относится к расчёту обнаруживающей способности кода для больших вероятностей ошибок  Поскольку для линейных кодов необнаруженная ошибка происходит тогда, и только тогда, когда образец ошибки совпадает с одним из ненулевых кодовых слов, то можно привести точную формулу для расчёта
Поскольку для линейных кодов необнаруженная ошибка происходит тогда, и только тогда, когда образец ошибки совпадает с одним из ненулевых кодовых слов, то можно привести точную формулу для расчёта  без памяти:
без памяти:

где  число слов кода веса
число слов кода веса  т.е. так называемый весовой спектр кода.
т.е. так называемый весовой спектр кода.
Если, в частности, положить в  то для любого
то для любого  кода получаем
кода получаем  что, как правило, значительно меньше, чем получаемую по (7.38) для этого же значения вероятности ошибки символа в канале связи. (Заметим, что ситуация, соответствующая случаю "обрыва канала, является отнюдь не бессмысленной для обнаружения ошибок, поскольку канал
что, как правило, значительно меньше, чем получаемую по (7.38) для этого же значения вероятности ошибки символа в канале связи. (Заметим, что ситуация, соответствующая случаю "обрыва канала, является отнюдь не бессмысленной для обнаружения ошибок, поскольку канал
может лишь временно перейти в состояние обрыва и мы должны обеспечить практическое отсутствие ошибок у получателя и в таком состоянии.)
Можно доказать, что при любой вероятности ошибки  (это верно и для любых двоичных каналов с памятью) существует такой
(это верно и для любых двоичных каналов с памятью) существует такой  -код
-код  , что
, что

Однако не обязательно для всех  наборов существует один и тот же
наборов существует один и тот же  -коа, который обеспечивает выполнение (7.62) для всех
-коа, который обеспечивает выполнение (7.62) для всех  Если такой код существует, то он называется хорошим кодом. Неравенство (7.62) может быть обеспечено в любом канале связи, если
Если такой код существует, то он называется хорошим кодом. Неравенство (7.62) может быть обеспечено в любом канале связи, если 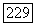 -код используется совместно со стохастическими преобразованиями канала на передаче и приёме. Эти преобразования сохраняют вероятности безошибочного приёма
-код используется совместно со стохастическими преобразованиями канала на передаче и приёме. Эти преобразования сохраняют вероятности безошибочного приёма 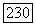 -блока и делают равновероятными все другие образцы ошибок. Однако такой подход требует обеспечения синхронизации между приёмом и передачей для выполнения взаимообратных преобразований, что делает их в действительности псевдослучайными.
-блока и делают равновероятными все другие образцы ошибок. Однако такой подход требует обеспечения синхронизации между приёмом и передачей для выполнения взаимообратных преобразований, что делает их в действительности псевдослучайными.
Известные спектры имеют достаточно редкие классы линейных кодов, однако часто удаётся в точности рассчитать эти спектры путём перебора всех 2 комбинаций данного V кода или 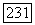 комбинаций дуального к нему кода. Действительно, согласно лемме Мак Вильяма [21]
комбинаций дуального к нему кода. Действительно, согласно лемме Мак Вильяма [21] 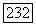 может быть рассчитана по спектру дуального кода N следующим образом:
может быть рассчитана по спектру дуального кода N следующим образом:

где 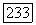 минимальное расстояние для дуального кода
минимальное расстояние для дуального кода 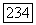 спектр дуального кода.
спектр дуального кода.
Если 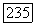 -код V используется для совместного исправления ошибок кратности до
-код V используется для совместного исправления ошибок кратности до 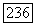 и обнаружения ошибок в соответствии с определением 9, то
и обнаружения ошибок в соответствии с определением 9, то

где 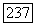
Если для данного кода V в 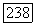 без памяти для любых
без памяти для любых 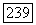 выполняется неравенство
выполняется неравенство

то он называется 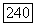 хорошим кодом.
хорошим кодом.
(Существуют необходимые и достаточные условия, при которых код оказывается I - хорошим, но они также требуют знания спектра кода. Если 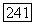 -код V с известным спектром
-код V с известным спектром 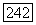 используется для исправления ошибок по максимуму правдоподобия, а не только гарантированной кратности до
используется для исправления ошибок по максимуму правдоподобия, а не только гарантированной кратности до 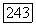 то
то  будет иметь следующую верхнюю границу, которую легко вывести, используя аддитивную верхнюю границу:
будет иметь следующую верхнюю границу, которую легко вывести, используя аддитивную верхнюю границу:

Если нас интересует не безошибочная передача всего сообщения, а среднее число ошибочных информационных символов после декодирования, то в общем случае это требует весьма громоздких расчётов. При мачой вероятности ошибки символа для средней битовой ошибки 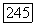 получено для симметричного канала без памяти приближённое выражение [13]
получено для симметричного канала без памяти приближённое выражение [13]

Действительно, если код с расстоянием 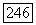 используется для исправления случайных ошибок, то наибольшую роль будет играть неисправленная ошибка, соответствующая комбинации
используется для исправления случайных ошибок, то наибольшую роль будет играть неисправленная ошибка, соответствующая комбинации 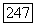 ошибочных символов. В этом случае при реализации алгоритма декодирования выносится ошибочное решение о том, что принятое слово содержит
ошибочных символов. В этом случае при реализации алгоритма декодирования выносится ошибочное решение о том, что принятое слово содержит 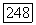 ошибок и эти
ошибок и эти 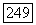 символов меняются, так что последовательность будет содержать
символов меняются, так что последовательность будет содержать 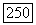 ошибочных символов. Поскольку эти ошибки могут появиться в любых местах последовательности длиной
ошибочных символов. Поскольку эти ошибки могут появиться в любых местах последовательности длиной 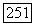 вероятность ошибочного бита при условии, что последовательность содержит ошибки, равна
вероятность ошибочного бита при условии, что последовательность содержит ошибки, равна 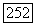 а вероятность средней битовой ошибки определяется (7.67). Заметим, что — эквивалентная вероятность ошибки согласно (7.28) даёт результат, близкий к (7.67).
а вероятность средней битовой ошибки определяется (7.67). Заметим, что — эквивалентная вероятность ошибки согласно (7.28) даёт результат, близкий к (7.67).
Полученные формулы 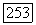 могут оказаться значительно более точными, чем (7.38), (7.41), (7.43) при расчёте
могут оказаться значительно более точными, чем (7.38), (7.41), (7.43) при расчёте 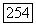 или
или  Однако остаётся открытым вопрос о построении кодов с достаточно большим значением минимального расстояния
Однако остаётся открытым вопрос о построении кодов с достаточно большим значением минимального расстояния 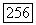 поскольку и в этих формулах данный параметр имеет весьма важное значение, а граница Варшамова-Гильберта является неконструктивной. Для решения данной проблемы необходимо обратиться к некоторым подклассам линейных систематических кодов.
поскольку и в этих формулах данный параметр имеет весьма важное значение, а граница Варшамова-Гильберта является неконструктивной. Для решения данной проблемы необходимо обратиться к некоторым подклассам линейных систематических кодов.