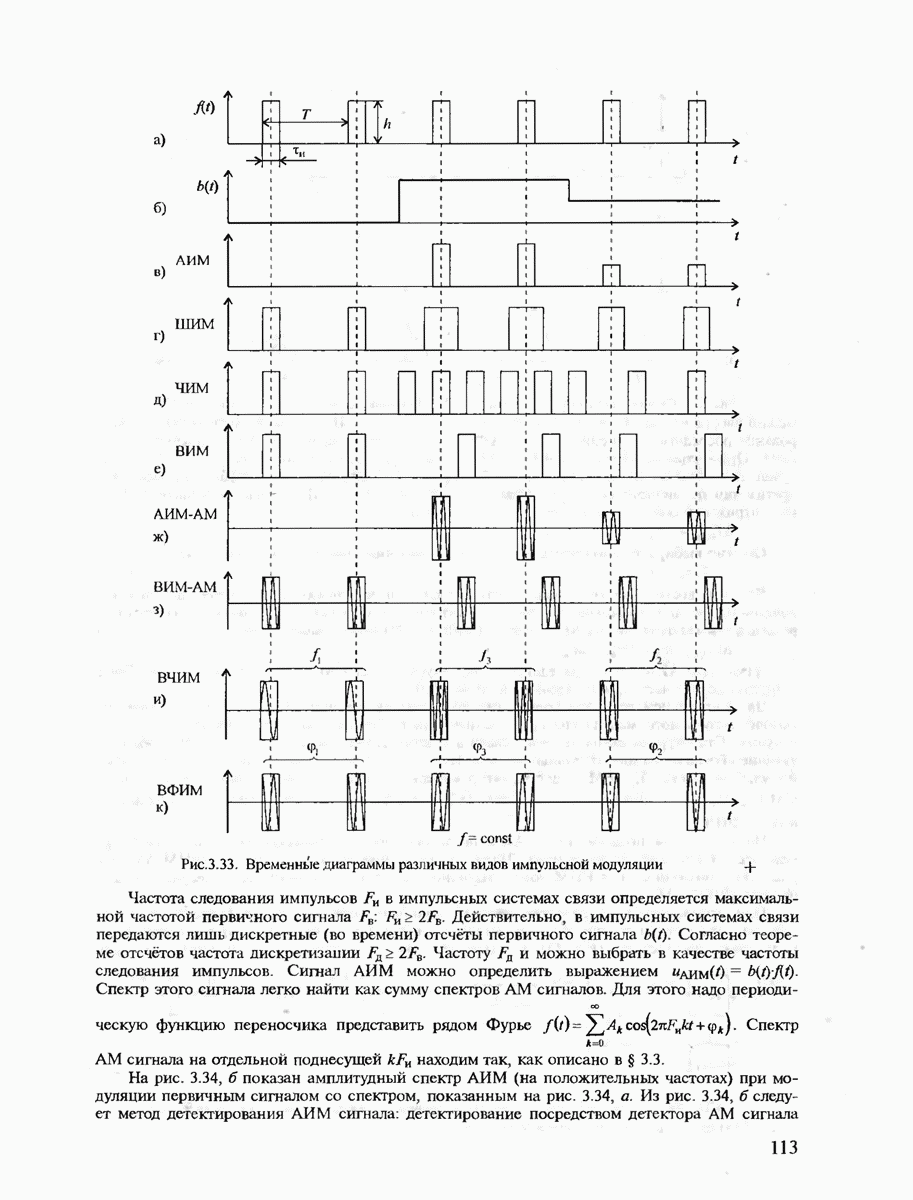
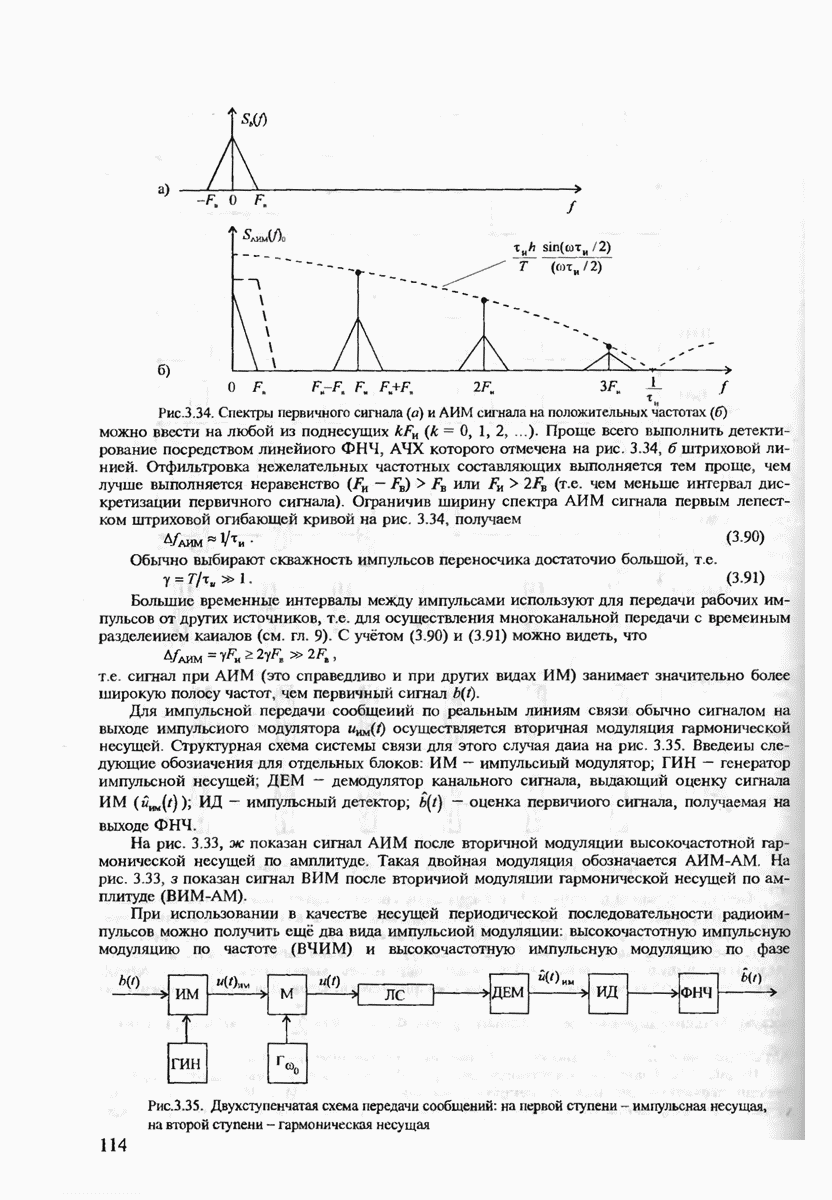
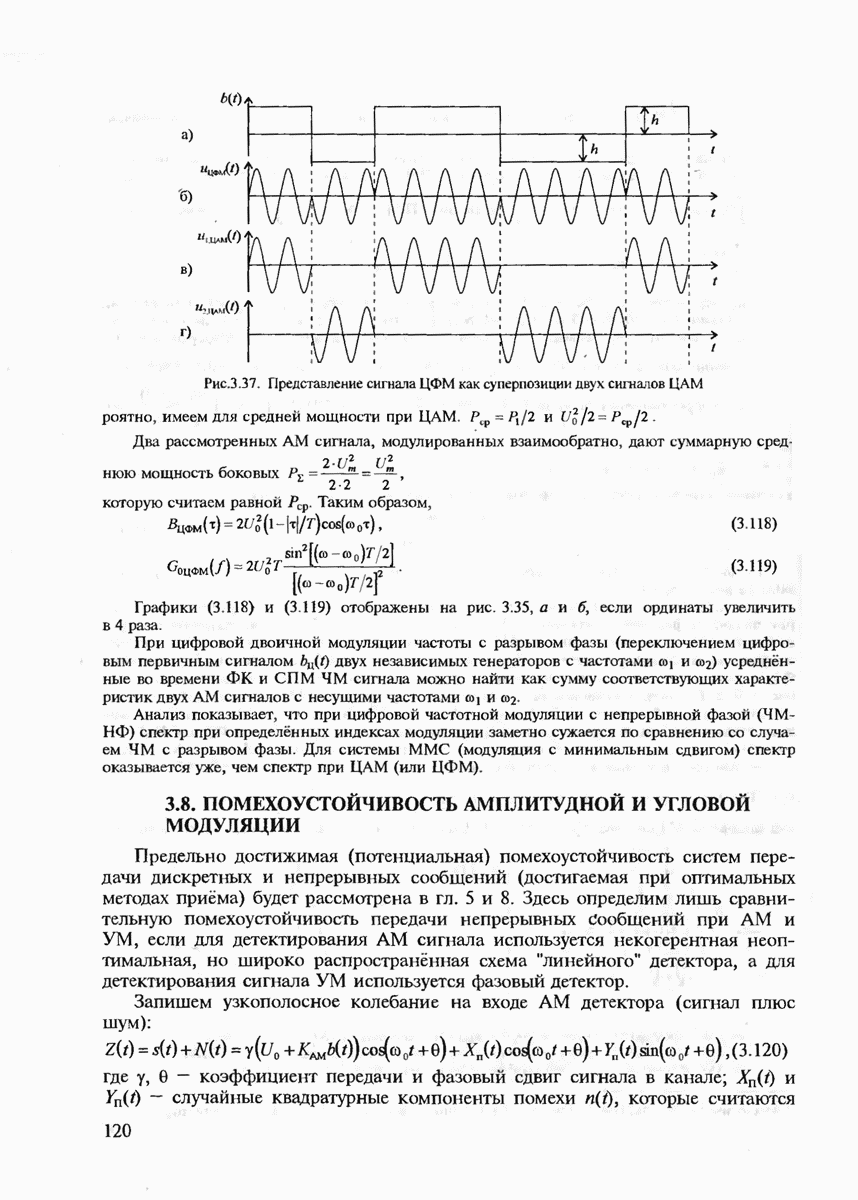
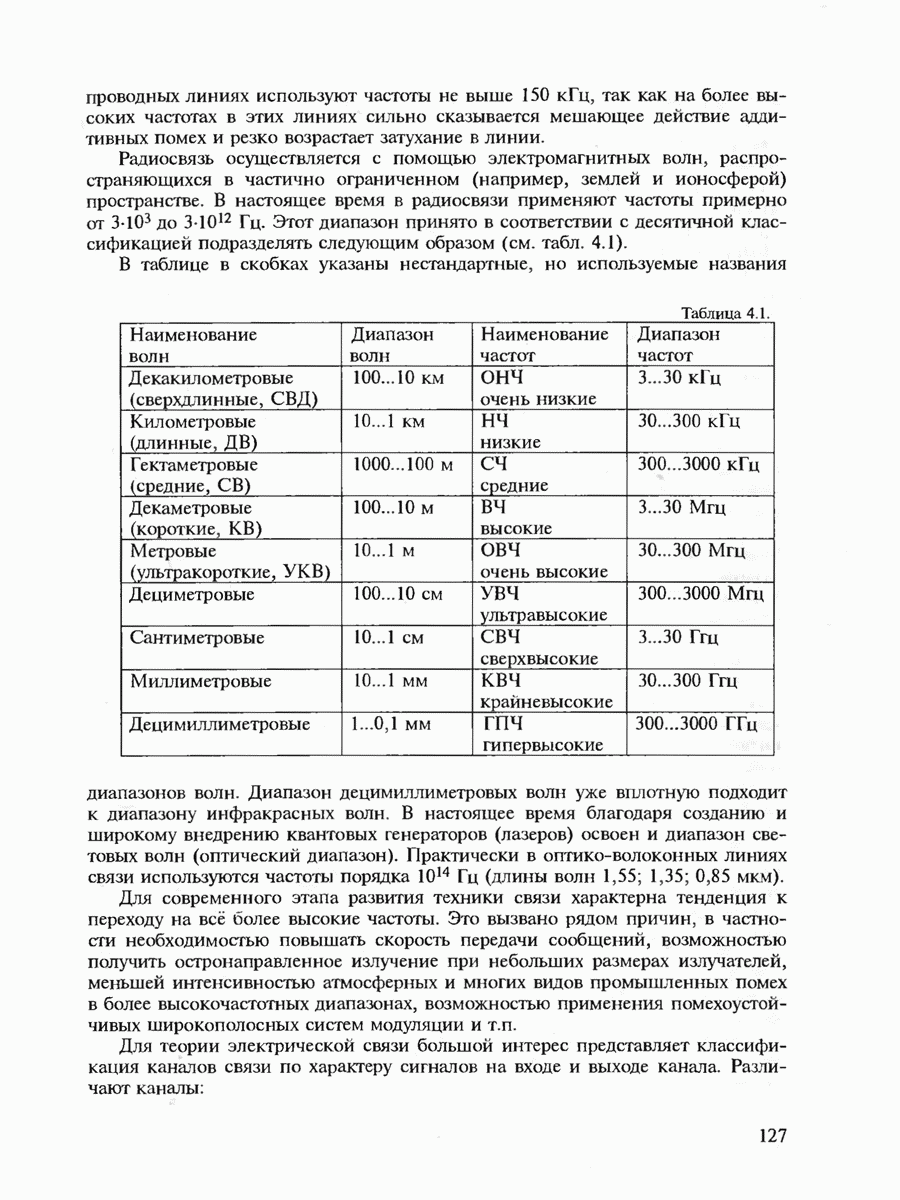
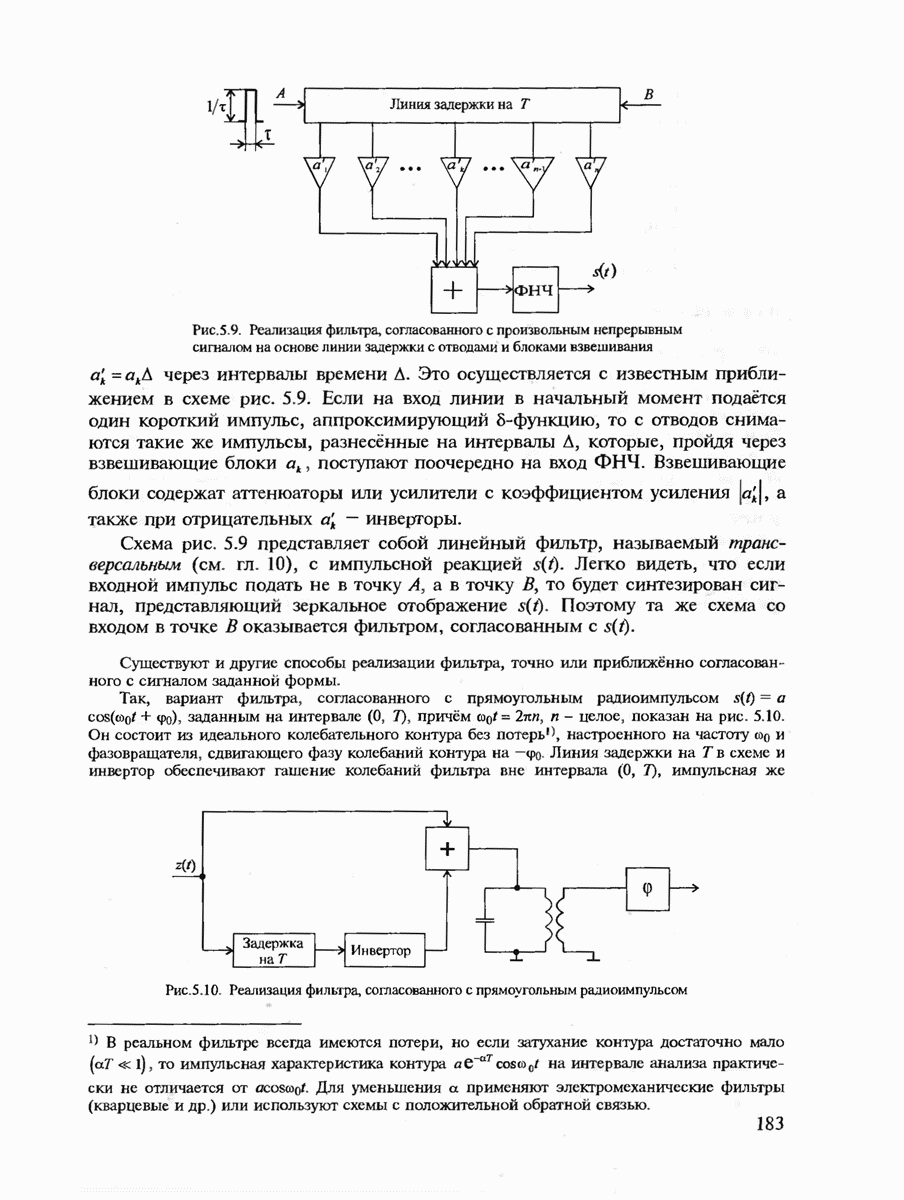
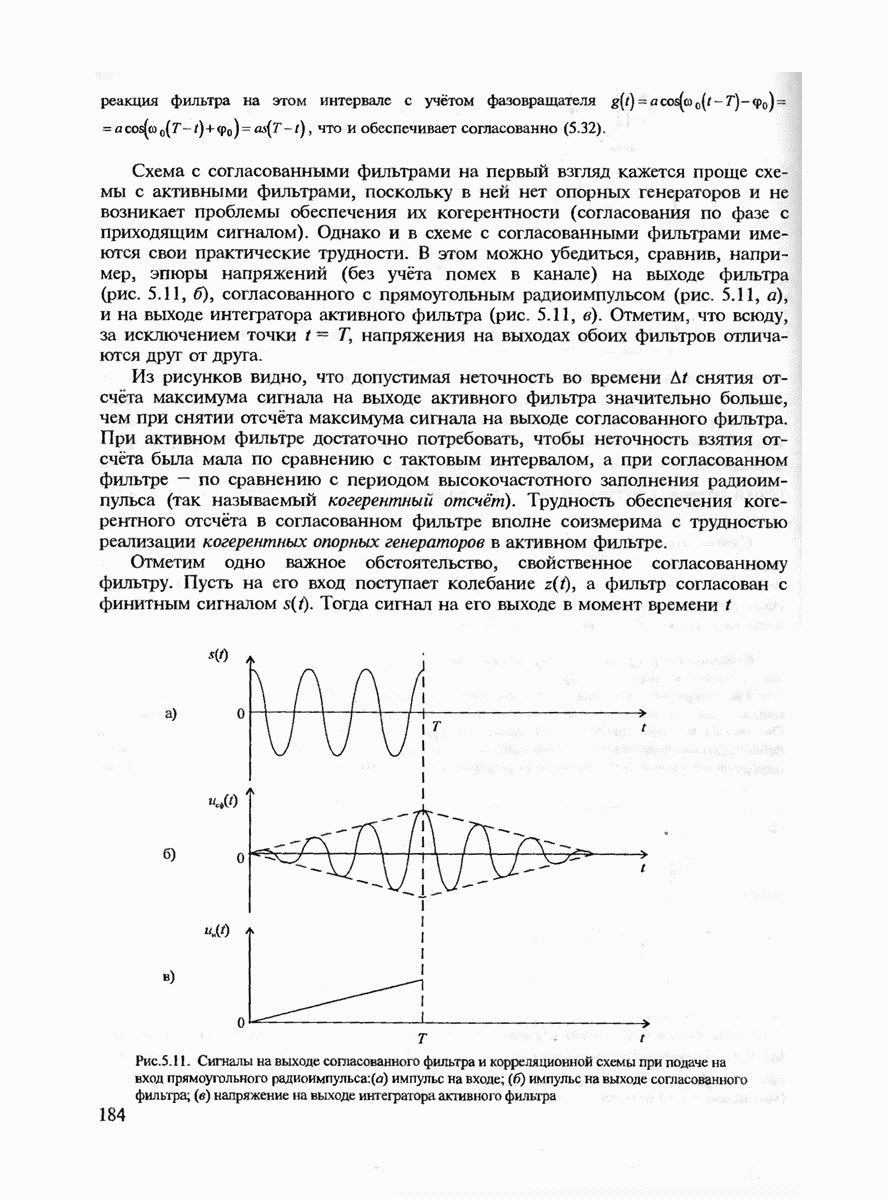
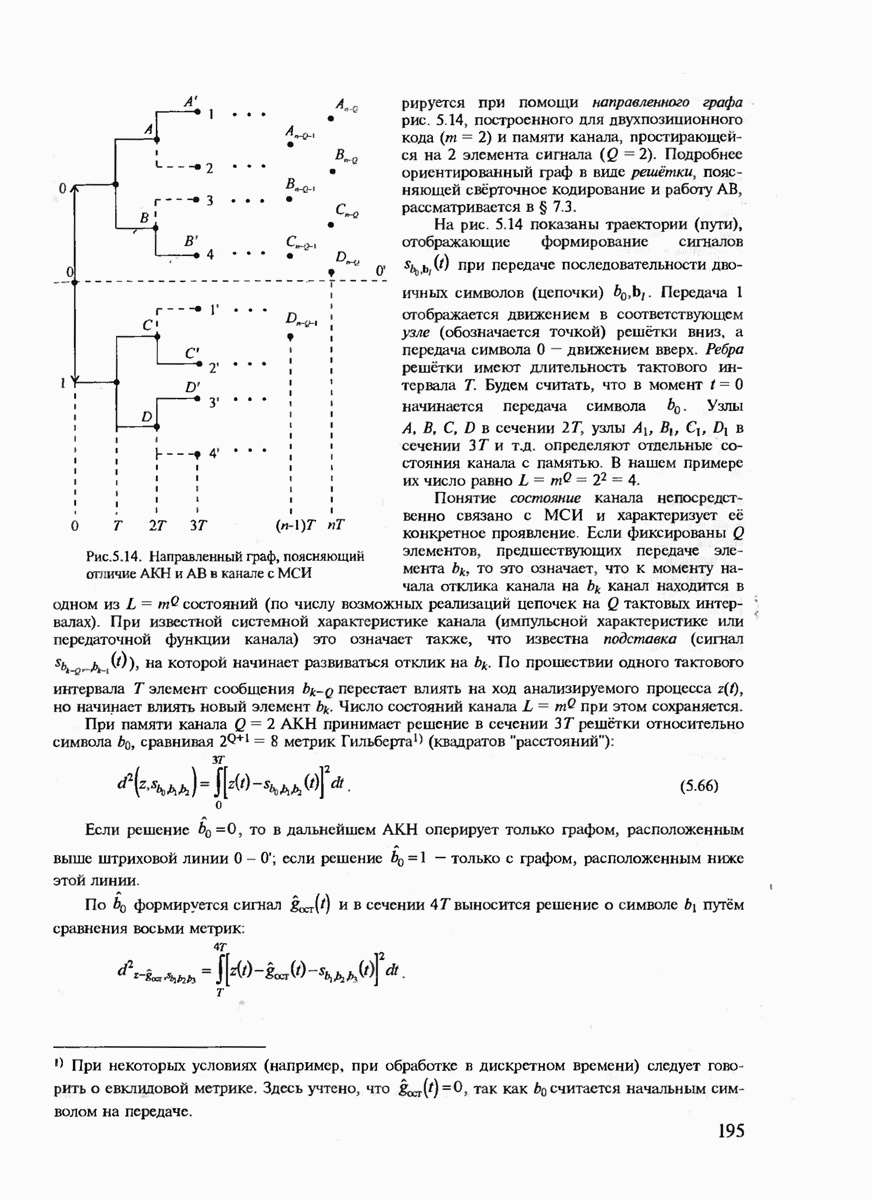
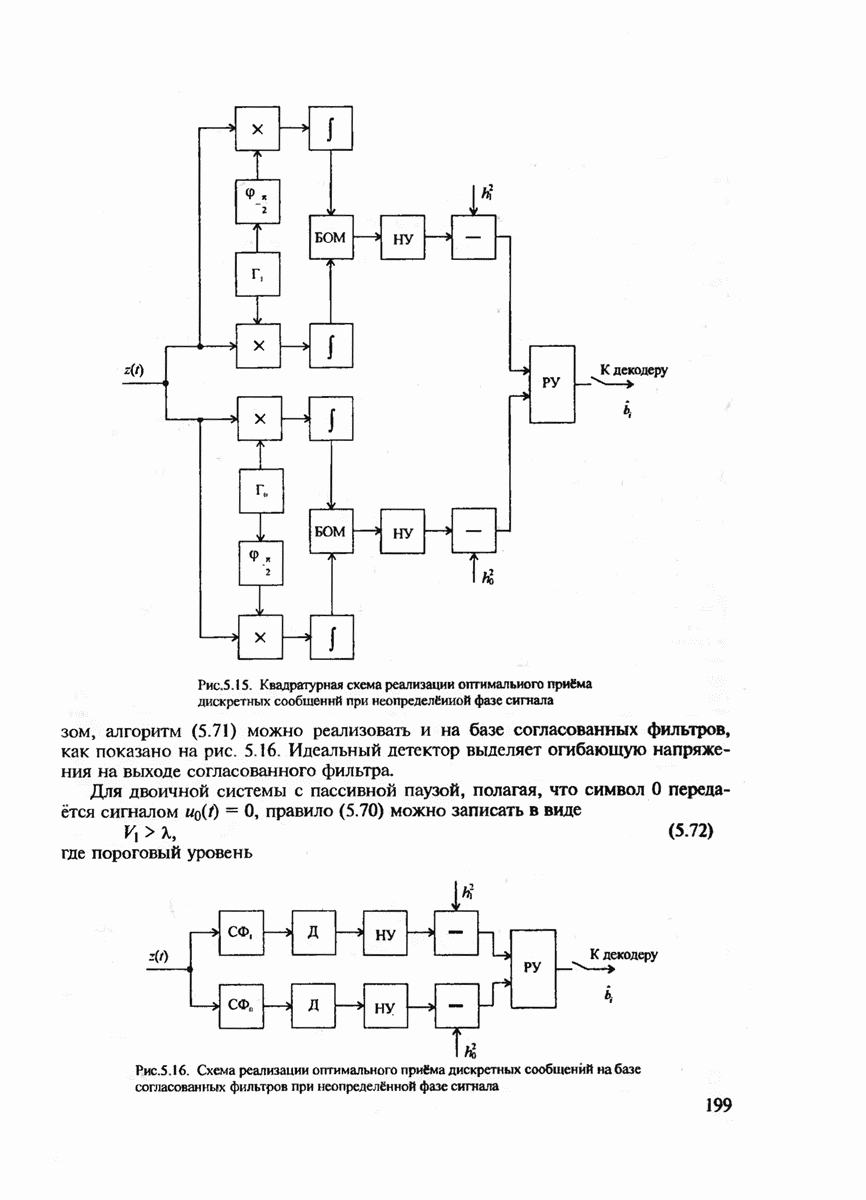
6.2. ПОТЕНЦИАЛЬНЫЕ ВОЗМОЖНОСТИ ДИСКРЕТНЫХ КАНАЛОВ СВЯЗИ
6.2.1. ОПРЕДЕЛЕНИЕ ИСТОЧНИКА ДИСКРЕТНЫХ СООБЩЕНИЙ, ДИСКРЕТНОГО КАНАЛА СВЯЗИ, КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ
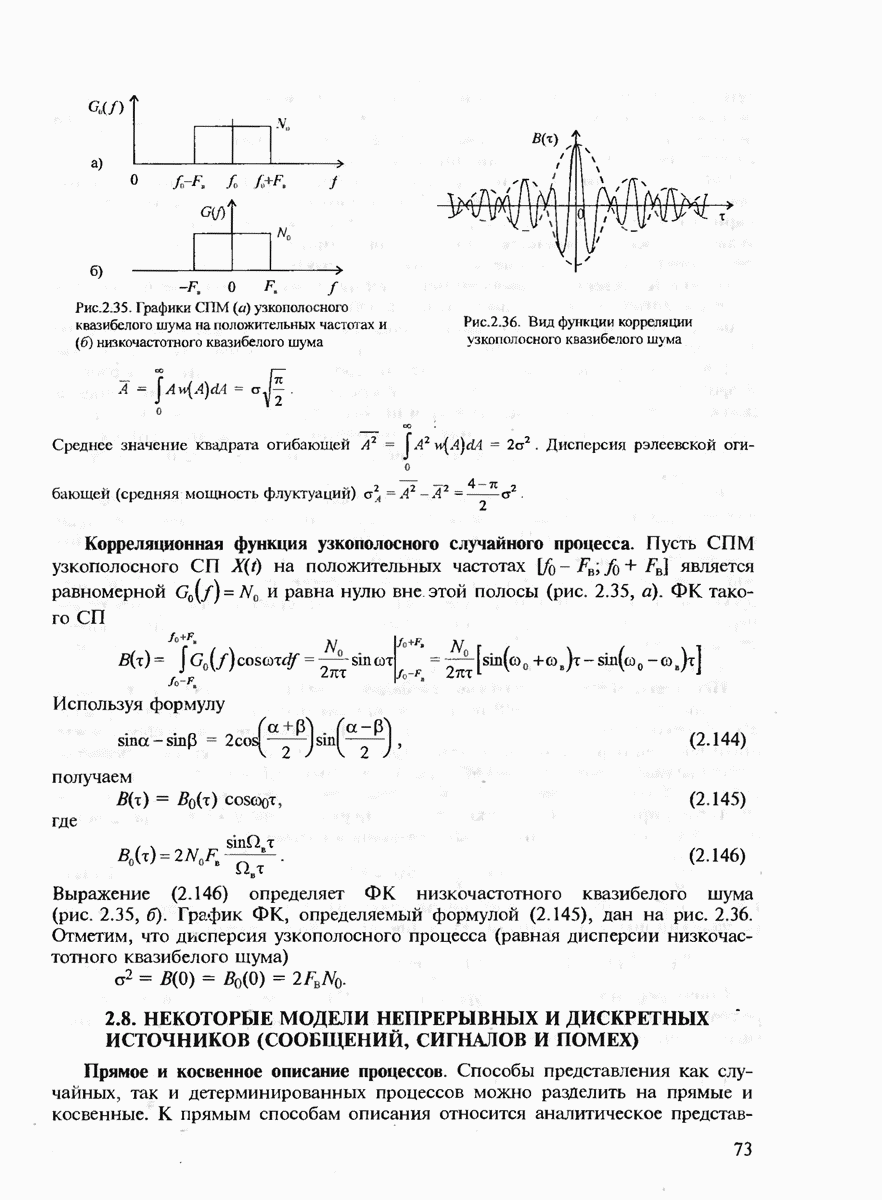
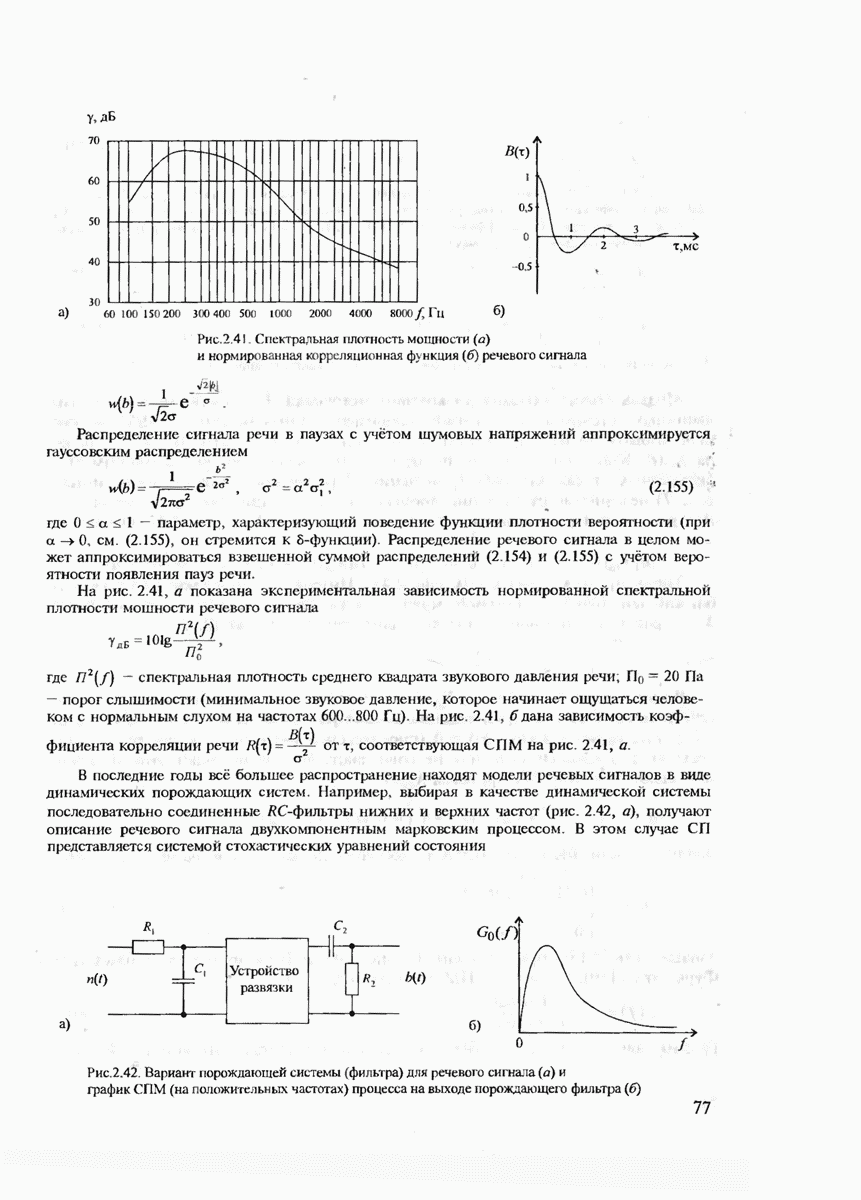
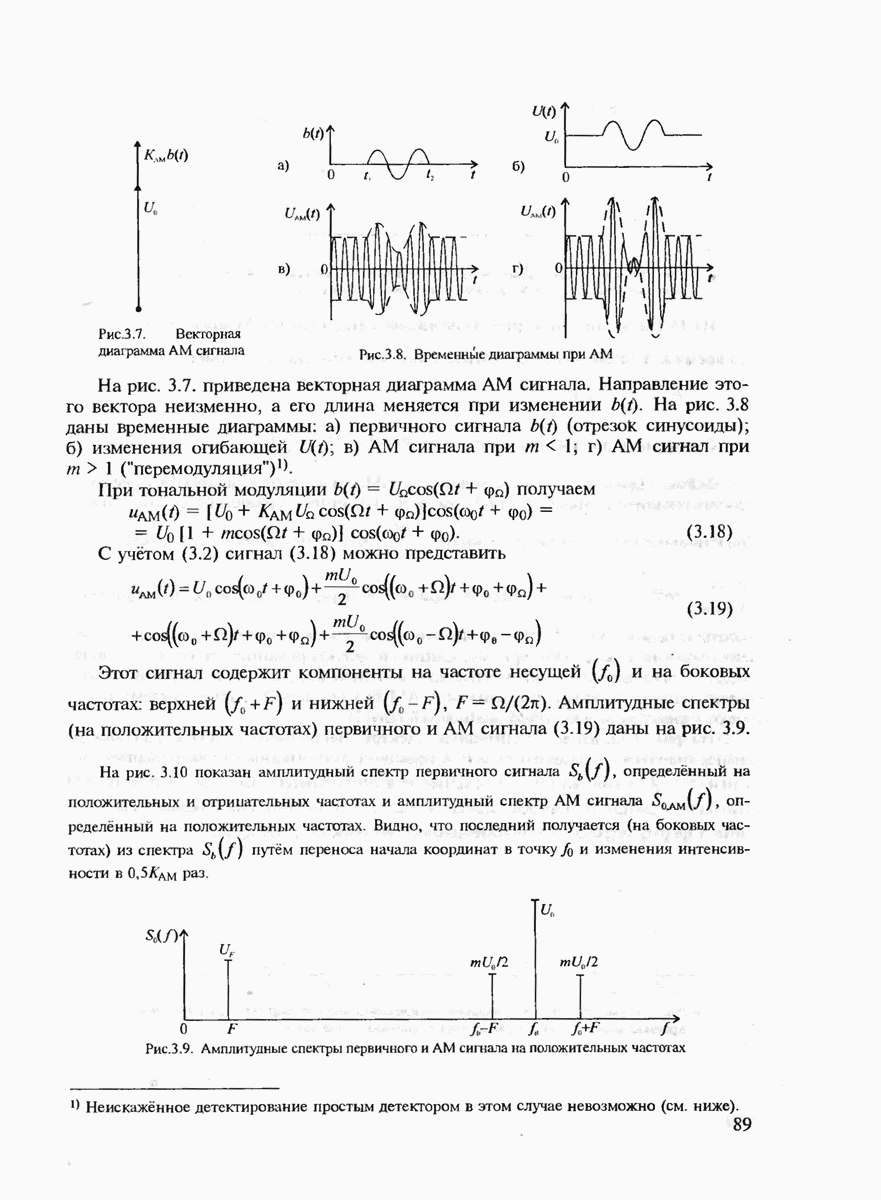
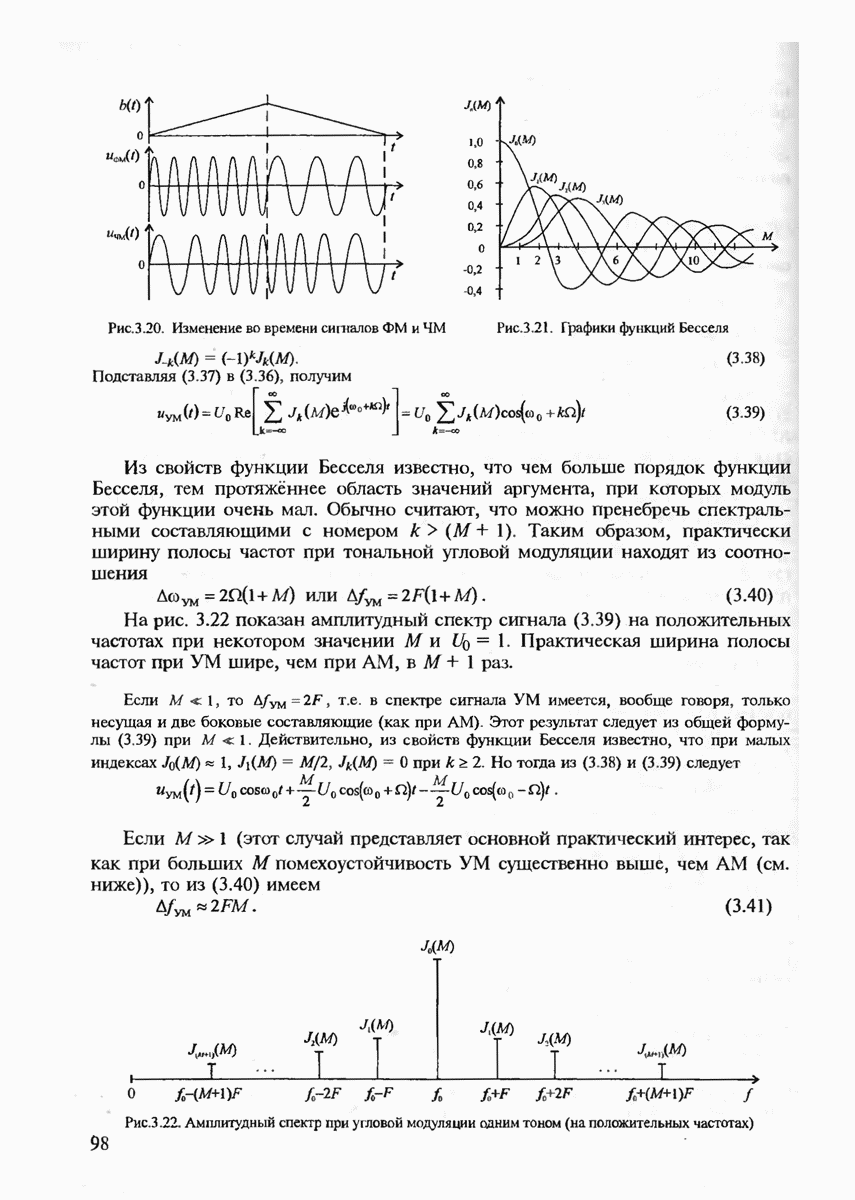
В гл. 1 уже были определены такие понятия, как сообщение, сигнал, кодирование и декодирование, а в гл. 4 описаны некоторые модели дискретных и непрерывных каналов связи. Поэтому в данном разделе мы напомним лишь некоторые из этих определений, которые непосредственно понадобятся нам для изложения материала по теории информации.
Итак, формально источник дискретных сообщений полностью определяется алфавитом  используемых символов заданного объёма К и распределением вероятностей
используемых символов заданного объёма К и распределением вероятностей  заданным на последовательностях
заданным на последовательностях  произвольной длины
произвольной длины  составленных из символов данного алфавита А. Если источник имеет фиксированную скорость, в отличие от источника с регулируемой скоростью, определяемой кодером, то дополнительно задаётся скорость источника
составленных из символов данного алфавита А. Если источник имеет фиксированную скорость, в отличие от источника с регулируемой скоростью, определяемой кодером, то дополнительно задаётся скорость источника  как число символов, генерируемых таким источником за 1 с. (Мы не будем здесь рассматривать более общий случай, когда длительности различных символов отличаются друг от друга.)
как число символов, генерируемых таким источником за 1 с. (Мы не будем здесь рассматривать более общий случай, когда длительности различных символов отличаются друг от друга.)
Говорят, что источник не имеет памяти, если последовательно выдаваемые им символы взаимно независимы друг от друга. Для полного описания такого источника достаточно задать лишь распределение вероятностей на отдельных символах, т.е.  если источник является стационарным, т.е. распределения
если источник является стационарным, т.е. распределения  не зависят от временных сдвигов.
не зависят от временных сдвигов.
В качестве простого примера источника сообшений можно рассматривать печатный текст на каком-либо языке. Тогда объём алфавита К будет совпадать с объёмом алфавита выбранного языка (26 — для английского, 32 — для русского), а распределение вероятностей будет определяться вероятностям! различных словосочетаний. Очевидно, что это пример источника с памятью, так как буквы в любом языке не следуют как попало, а подчинены детерминированной или вероятностной зависимости. Так, в английском языке всегда после буквы У следует " в русском
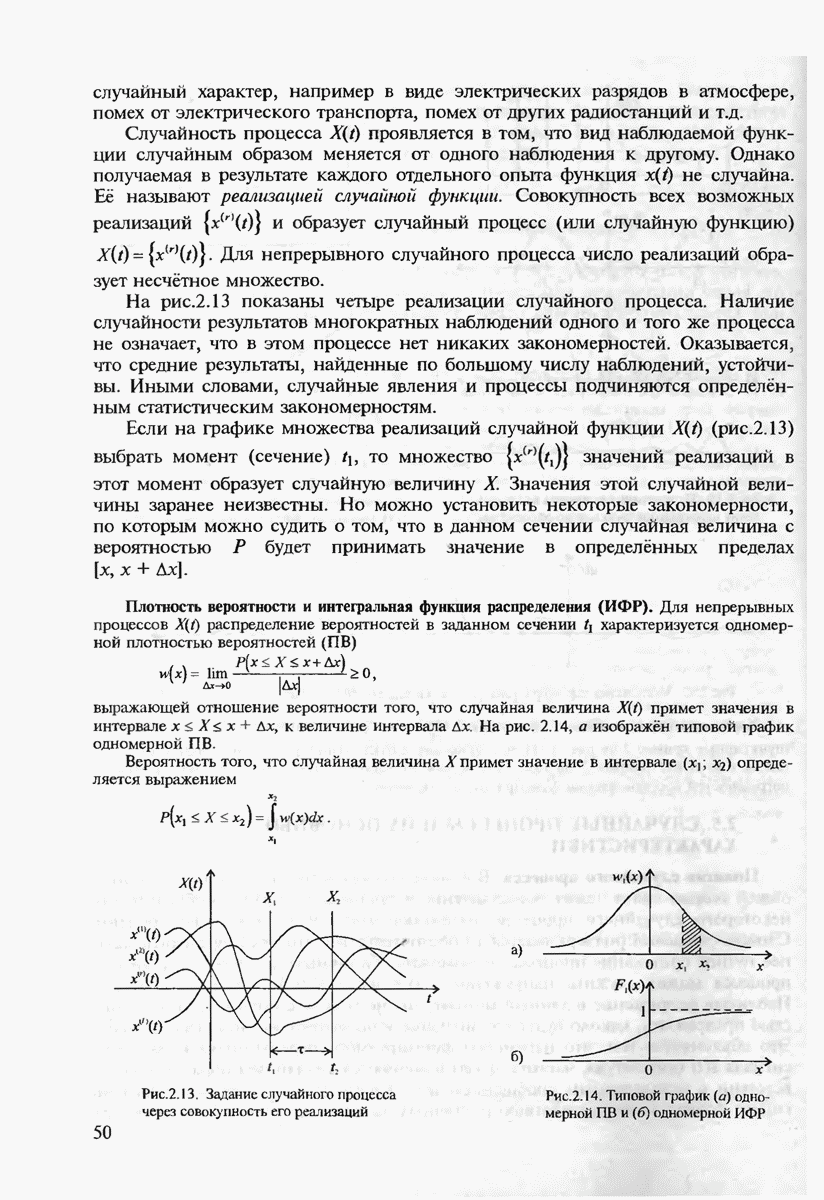
в русском  не может идти после гласной, а три
не может идти после гласной, а три  подряд встречаются лишь в достаточно редких словах "длинношеее" и "змееед".
подряд встречаются лишь в достаточно редких словах "длинношеее" и "змееед".
Формальное описание дискретного канала связи сводится к заданию двух алфавитов на входе и выходе канала  вообще говоря, разных объёмов
вообще говоря, разных объёмов  и условного распределения вероятностей
и условного распределения вероятностей  где
где  последовательности символов из соответствующих алфавитов, имеющие произвольную, но одинаковую длину
последовательности символов из соответствующих алфавитов, имеющие произвольную, но одинаковую длину  Для канала связи также может дополнительно задаваться скорость передачи
Для канала связи также может дополнительно задаваться скорость передачи  как число символов передаваемых по каналу связи за 1 с. Канал не обладает памятью, если последовательные символы принимаются по нему взаимно независимо друг от друга. В этом случае достаточно знать условное распределение
как число символов передаваемых по каналу связи за 1 с. Канал не обладает памятью, если последовательные символы принимаются по нему взаимно независимо друг от друга. В этом случае достаточно знать условное распределение  для полного описания такого канала связи.
для полного описания такого канала связи.
Рассмотрим некоторые важные частные случаи дискретного канала.
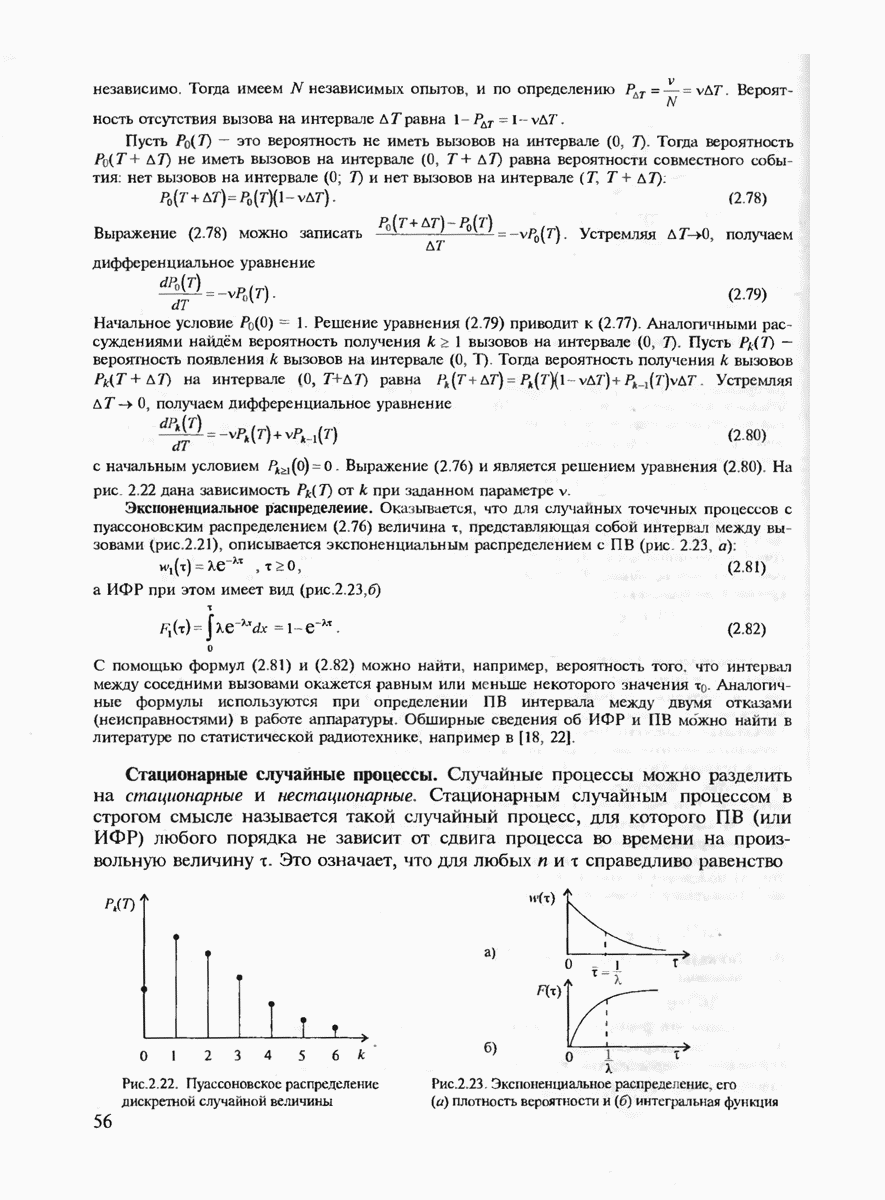
1.  -ичный симметричный канал без памяти (сокращённо —
-ичный симметричный канал без памяти (сокращённо —  Это канал с совпадающими объёмами входного и выходного алфавитов и с условным распределением
Это канал с совпадающими объёмами входного и выходного алфавитов и с условным распределением
Наглядно равенство (6.5) означает, что все символы, передаваемые по такому каналу связи, принимаются правильно с одинаковыми вероятностями  и каждый символ может перейти в любой другой, отличный от переданного, также с одной и той же вероятностью
и каждый символ может перейти в любой другой, отличный от переданного, также с одной и той же вероятностью  . (Напомним (см. гл. 5), что при оптимальном когерентном приёме
. (Напомним (см. гл. 5), что при оптимальном когерентном приёме  -ичных ортогональных сигналов в детерминированном канале с белым шумом мы как раз и получим
-ичных ортогональных сигналов в детерминированном канале с белым шумом мы как раз и получим 
2. Двоичный симметричный канал без памяти (сокращённо  или
или  Это частный случай
Это частный случай

3. Двоичный по входу симметричный канал без памяти со стираниями символов. Это канал без памяти с двоичным входным алфавитом  и троичным выходным алфавитом
и троичным выходным алфавитом  с условным распределением
с условным распределением

где  вероятность стирания (или вероятность приёма ненадёжного символа). Этот пример показывает, что не обязательно объёмы входного и выходного алфавитов должны совпадать. В данном случае третий выходной символ
вероятность стирания (или вероятность приёма ненадёжного символа). Этот пример показывает, что не обязательно объёмы входного и выходного алфавитов должны совпадать. В данном случае третий выходной символ  сформирован "искусственно" как ненадёжно принятый символ
сформирован "искусственно" как ненадёжно принятый символ  или X]. (При когерентном оптимальном приёме сигналов равной энергии решение о нём может приниматься, если абсолютная величина корреляционного интеграла в (5 27) меньше некоторого заданного порога).
или X]. (При когерентном оптимальном приёме сигналов равной энергии решение о нём может приниматься, если абсолютная величина корреляционного интеграла в (5 27) меньше некоторого заданного порога).
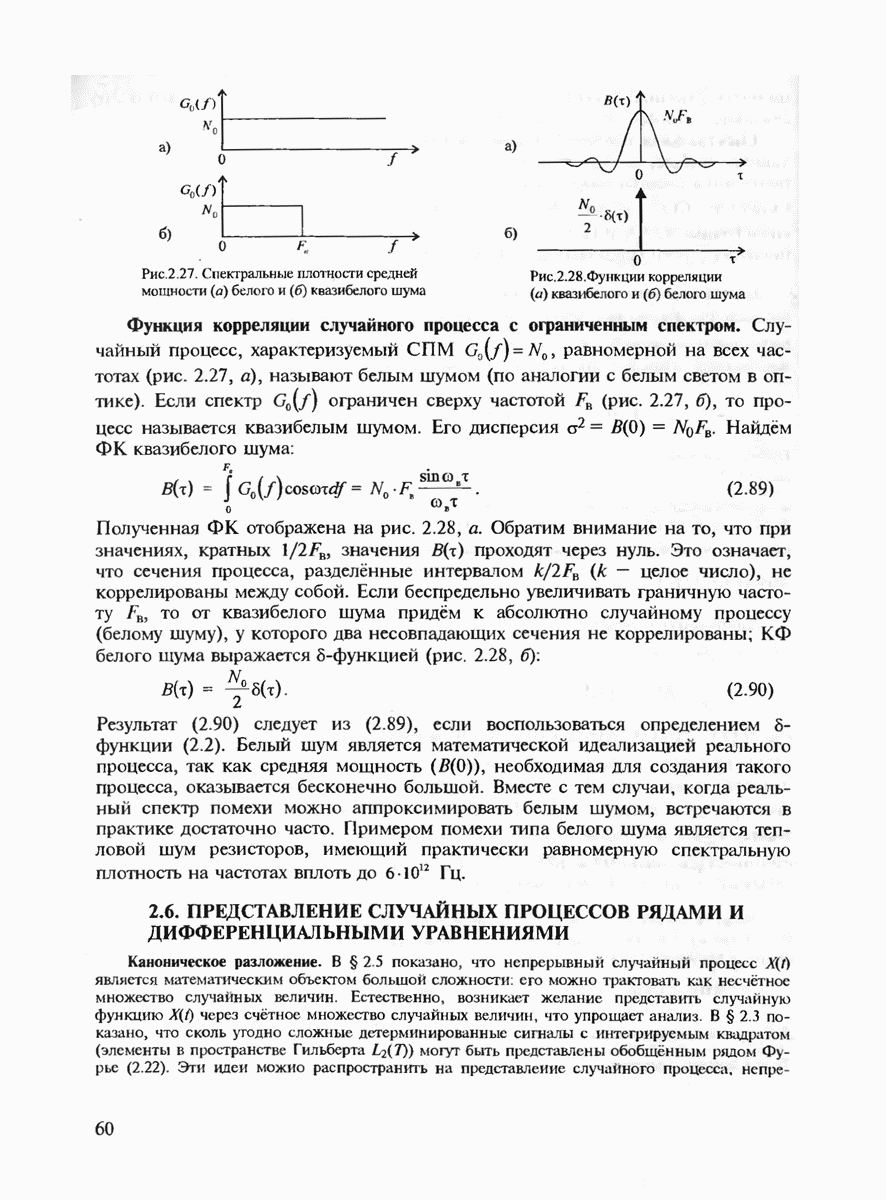
4. Двоичный канал с аддитивным шумом. Это канал с двоичными алфавитами на входе и выходе, обладающий в общем случае памятью. Условные распределения в таком канале связи имеют вид

где  означает попарное сложение по
означает попарное сложение по  всех элементов последовательности
всех элементов последовательности  (напомним, что правила сложения по
(напомним, что правила сложения по  имеют вид
имеют вид  распределение вероятностей, заданное на произвольных двоичных последовательностях. Наглядно равенство (6.7) означает, что переход некоторой входной последовательности х в выходную у однозначно определяется так называемым образцом (или вектором) ошибок
распределение вероятностей, заданное на произвольных двоичных последовательностях. Наглядно равенство (6.7) означает, что переход некоторой входной последовательности х в выходную у однозначно определяется так называемым образцом (или вектором) ошибок  который имеет единицы в тех позициях, где
который имеет единицы в тех позициях, где  отличаются, и нули в остальных позициях.
отличаются, и нули в остальных позициях.
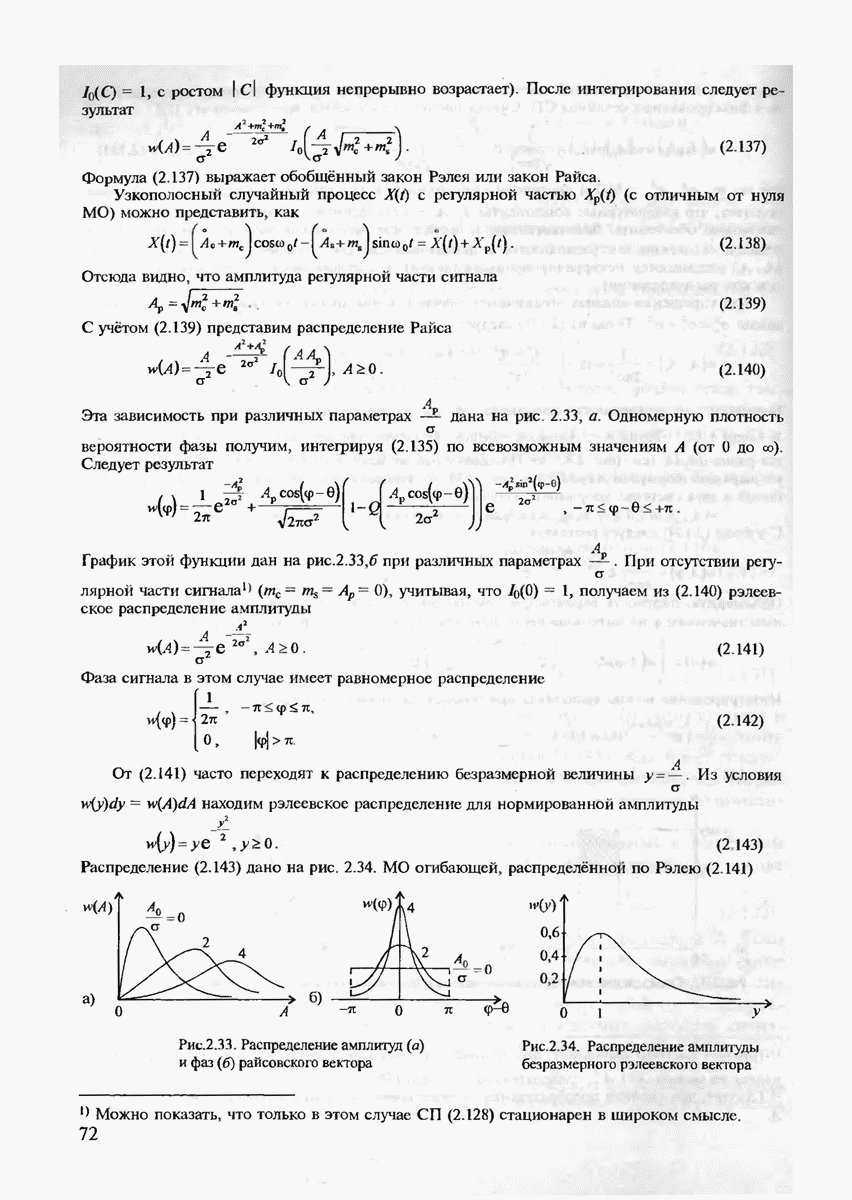
Определим формально кодирование в дискретном канале как однозначное отображение последовательностей, составленных из символов источника, в последовательности, составленные из входных символов канала связи. Декодированием будем называть однозначное отображение последовательностей, составленных из выходных символов канала в последовательности, составленные из символов источника. Здесь мы полагаем, что алфавиты символов источника и получателя информации совпадают. Длины последовательностей на входе канала, соответствующие различным последовательностям символов источника, могут быть, вообще говоря, различными. Тогда кодирование называется неравномерным.
Примером неравномерного кодирования может служить известный код Морзе. Действительно, в этом коде букве  соответствует последовательность из одной точки
соответствует последовательность из одной точки  а букве
а букве  последовательность из четырёх тире
последовательность из четырёх тире  Заметим, что код Морзе - это кодирование не с двоичным входным алфавитом (точка и тире), как может показаться на первый взгляд, а с троичным алфавитом: точка, тире и пробел.
Заметим, что код Морзе - это кодирование не с двоичным входным алфавитом (точка и тире), как может показаться на первый взгляд, а с троичным алфавитом: точка, тире и пробел.
Если длины всех последовательностей одинаковы, то кодирование называется равномерным. Легко определить первую функцию кодирования и декодирования. Она, очевидно, состоит в том, чтобы согласовать алфавит источника
сообщений с алфавитом входа канала и соответственно алфавит выхода канала с алфавитом источника получателя сообщений. Такое согласование действительно обеспечивает принципиальную возможность передавать последовательность символов источника сообщений к получателю через заданный дискретный канал связи. Однако произвольно выбранное "согласование" (кодирование-декодирование) не гарантирует ещё надёжной и быстрой передачи таких сообщений. Задача настоящей главы как раз и будет состоять в том, чтобы найти потенциальные возможности кодирования и декодирования (при отсутствии ограничений на их сложность), когда информация может быть передана со сколь угодно высокой верностью при максимально возможной скорости её передачи от источника к получателю. В следующей главе мы рассмотрим регулярные способы кодирования-декодирования с учётом сложности их реализации на практике. Для формулировки и доказательства теорем кодирования теории информации нам потребуется изложить некоторые новые понятия, которые имеют и самостоятельное значение.