Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
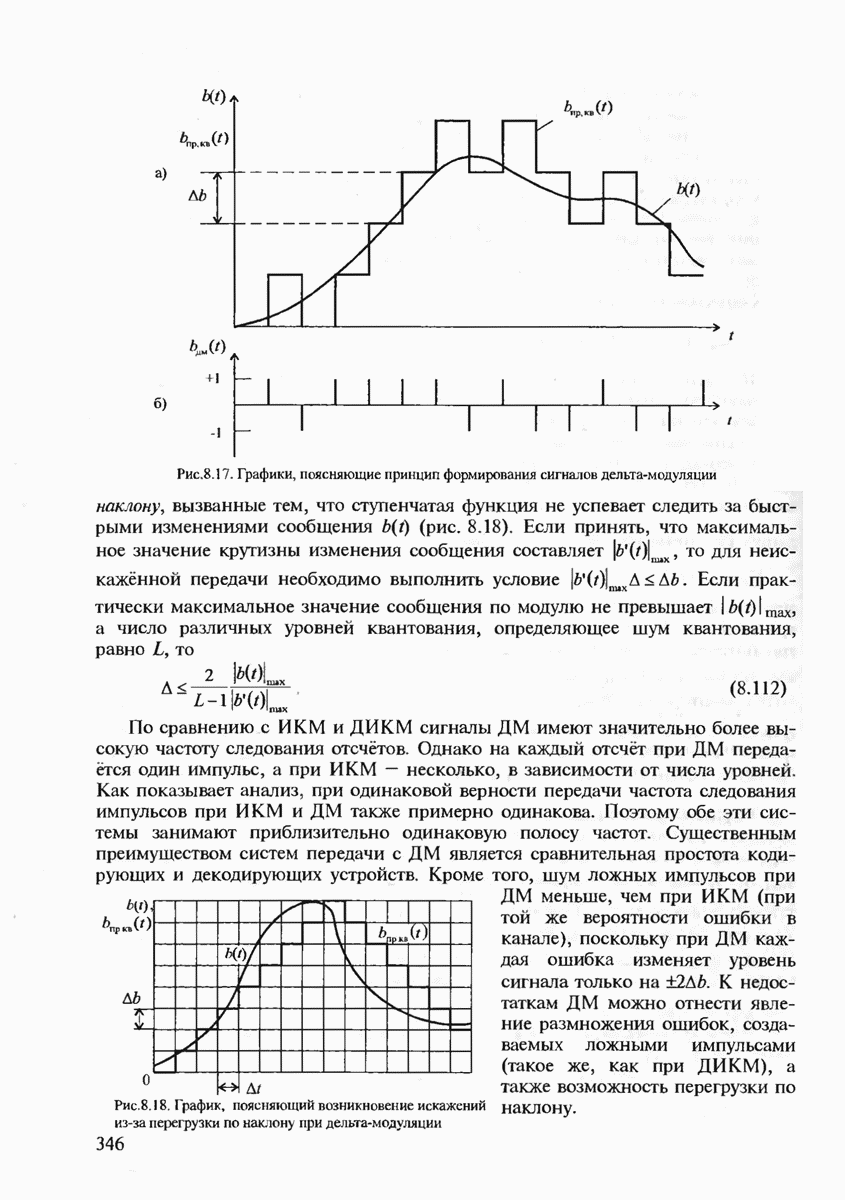
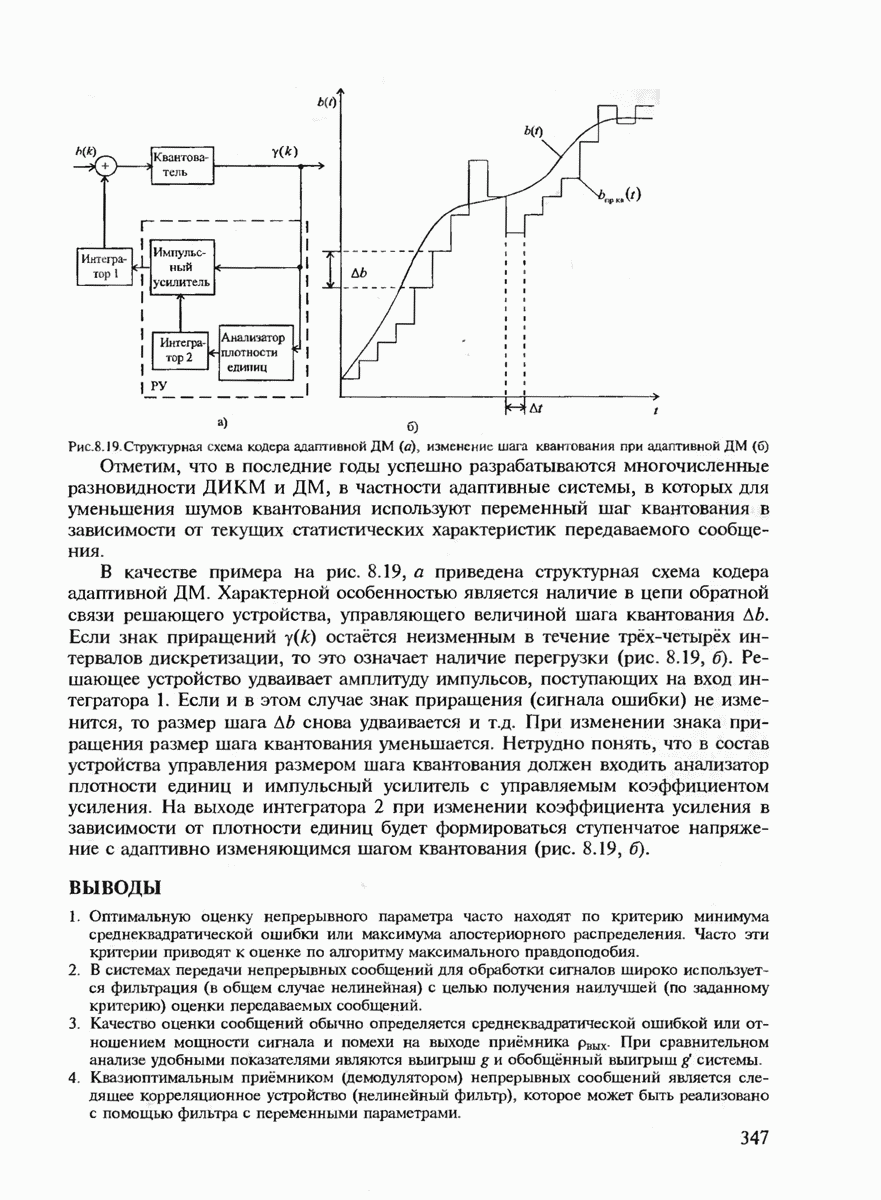
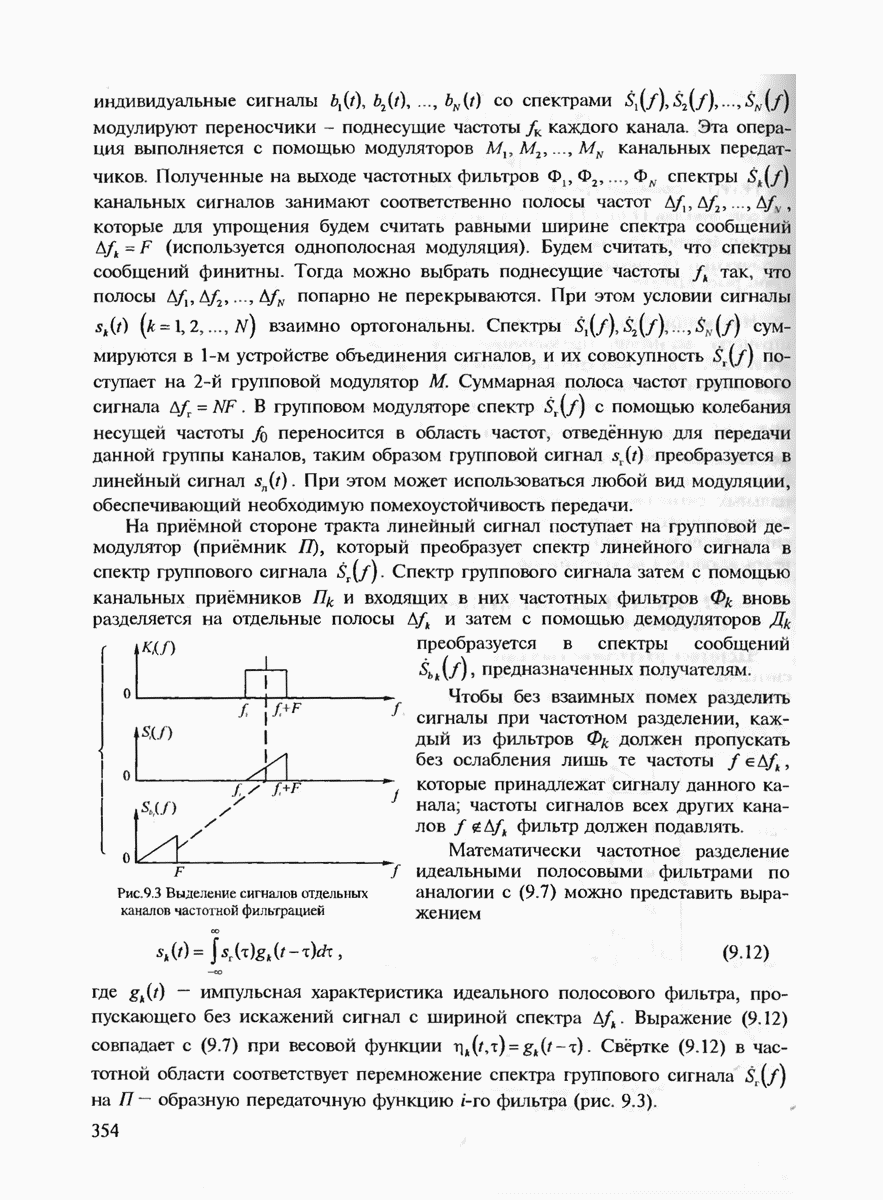
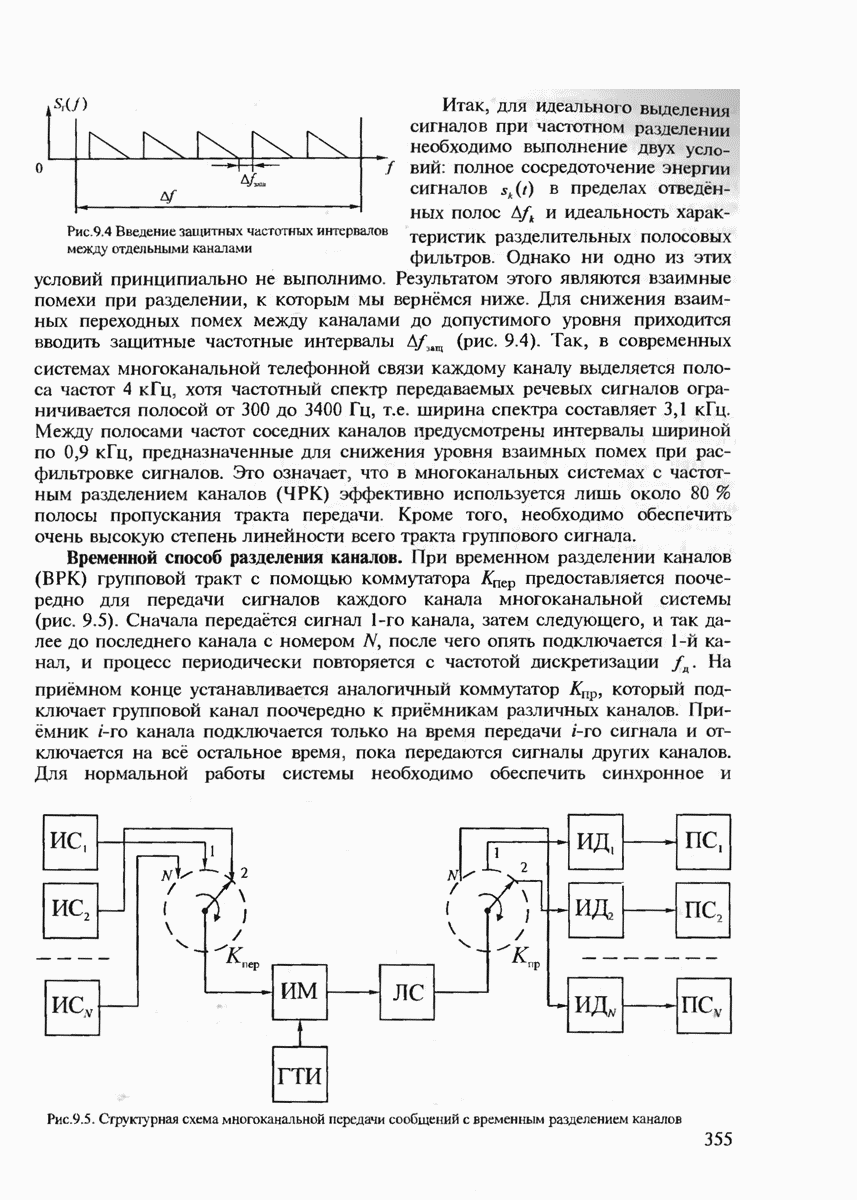
7.2. КОНСТРУКТИВНЫЕ МЕТОДЫ КОДИРОВАНИЯ ИСТОЧНИКОВ СООБЩЕНИЙСуществует множество способов кодирования источников сообщений. Многие способы реализованы на практике, особенно для сжатия сообщений с большой избыточностью, например факсимильных и телевизионных, где они позволяют увеличить скорость передачи сообщений в десятки раз (см гл. 11). В данном параграфе мы рассмотрим сначала кодирование источников с известной статистикой сообщений. Общая идея построения такого кода подсказывается теоремой кодирования 1 для каналов без помех. Поскольку минимизируется средняя длина кодовой последовательности, то код должен быть неравномерным. Очевидно, что средняя длина неравномерного кода будет минимизироваться тогда, когда с более вероятными сообщениями источника будут сопоставляться более короткие комбинации канальных символов. Проблема, однако, состоит в том, что у неравномерного кода на приёмной стороне оказываются неизвестными границы этих комбинаций. Если же мы попытаемся их выделить, используя известный способ кодирования, то декодирование может оказаться неоднозначным. (Действительно, если, например, с буквой А сопоставлена комбинация 0, с буквой Необходимые и достаточные условия существования префиксного кода определяются неравенством Крафта, которое мы сформулируем в виде теоремы. Теорема 7.1. Пусть
Докажем достаточность. Пусть множество
где Далее преобразуем это неравенство, раскрыв сумму
Поскольку все
Эта система неравенств и определяет способ построения кода с данным набором кодовых длин Сначала выберем Рассмотрим теперь некоторый источник дискретных сообщений без памяти, который согласно § 6.1 однозначно определяется своим алфавитом А объёма К и вероятностями появления символов
Тогда из (7.4) получаем, что
и поэтому по теореме 7.1 можно символами источника с укрупнённым алфавитом сопоставить последовательности символов
Учитывая тот факт, что для источника без памяти
Фактически мы доказали теорему кодирования для каналов без помех и источника без памяти. Более того, было доказано, что предельное значение средней длины Алгоритм Шеннона-Фано заключается в следующем. Символы алфавита источника (первичного или укрупнённого) записываются в порядке не возрастающих вероятностей. Затем они разделяются на две части так, чтобы суммы вероятностей символов, входящих в каждую из таких частей, были примерно одинаковыми. Всем символам первой части приписывается в качестве первого символа комбинации неравномерного кода ноль, а символам второй части — единица. Затем каждая из этих частей (если она содержит более одного сообщения) делится в свою очередь на две, по возможности равновероятные части и к ним применяется то же самое правило кодирования. Этот процесс повторяется до тех пор, пока в каждой из полученных частей не останется по одному сообщению. Пример. Пусть алфавит А источника состоит из шести символов Заметим, что хотя деление на части с "примерно равными вероятностями" не является однозначной процедурой, но при увеличении длин блоков Таблица 7.2 (см. скан) Неравномерное префиксное кодирование устраняет избыточность источника, вызванную неодинаковой вероятностью сообщений. Если источник имеет память, то вероятность появления очередного сообщения зависит от того, какое сообщение появилось перед ним. На первом этапе устранения избыточности дискретного источника с памятью заданный источник заменяют эквивалентным источником без памяти с помощью метода укрупнения алфавита. Представим, например, дискретный источник с алфавитом имеет памяти, то Более реалистичной является, конечно, ситуация, когда о некотором избыточном источнике известен лишь его алфавит А, но не известно распределение вероятностей последовательностей символов этого источника. Например, необходимо сконструировать двоичный префиксный код для передачи текста на различных языках, имеющих общий алфавит. Казалось бы, эта задача является неразрешимой, но в действительности удаётся сконструировать некоторый универсальный сжимающий код. Рассмотрим кратко метод сжатия подобного типа, известный как алгоритм Зива-Лемпела и широко применяемый в ЭВМ для архивирования файлов. Общая идея данного метода состоит в том, что последовательность символов источника разбивается на кратчайшие различимые цепочки, которые не встречались раньше, а затем эти цепочки кодируются равномерным кодом. Например, если последовательность имела вид 1011010100010, то она будет разбита на цепочки следующим образом: Рассмотренный пример даёт фактически не сжатие, а "растяжение" сообщений, поскольку вместо 13 исходных бит мы получаем 28 бит. Однако для длинных последовательностей сообщений эффективность алгоритма увеличивается, и в асимптотике, т.е. при
Заметим, что фактически для сжатия файлов используется модифицированный алгоритм, называемый алгоритмом сжатия Зива-Лемпела-Велча, на основе этого алгоритма построены наиболее эффективные программы архивирования файлов, такие как PKARC, PKZIP ICE и др.
|
 |
Оглавление
|












































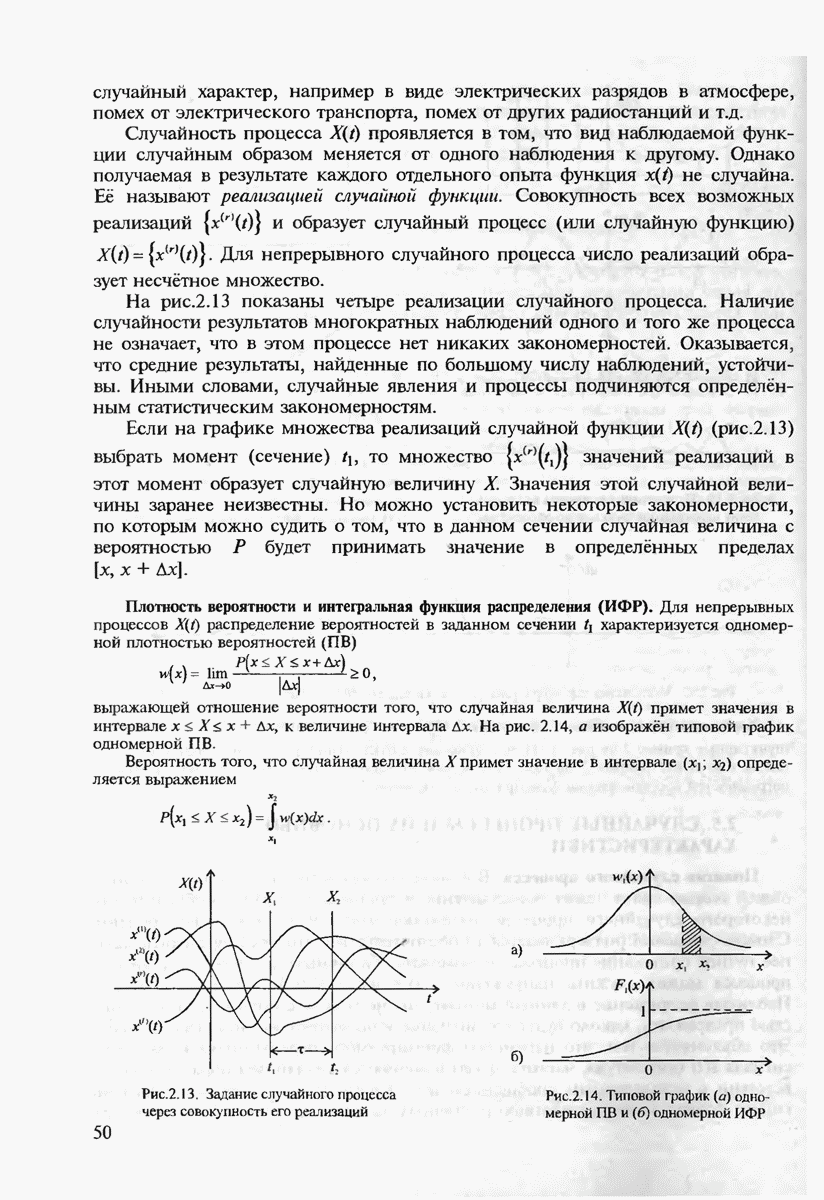























































































































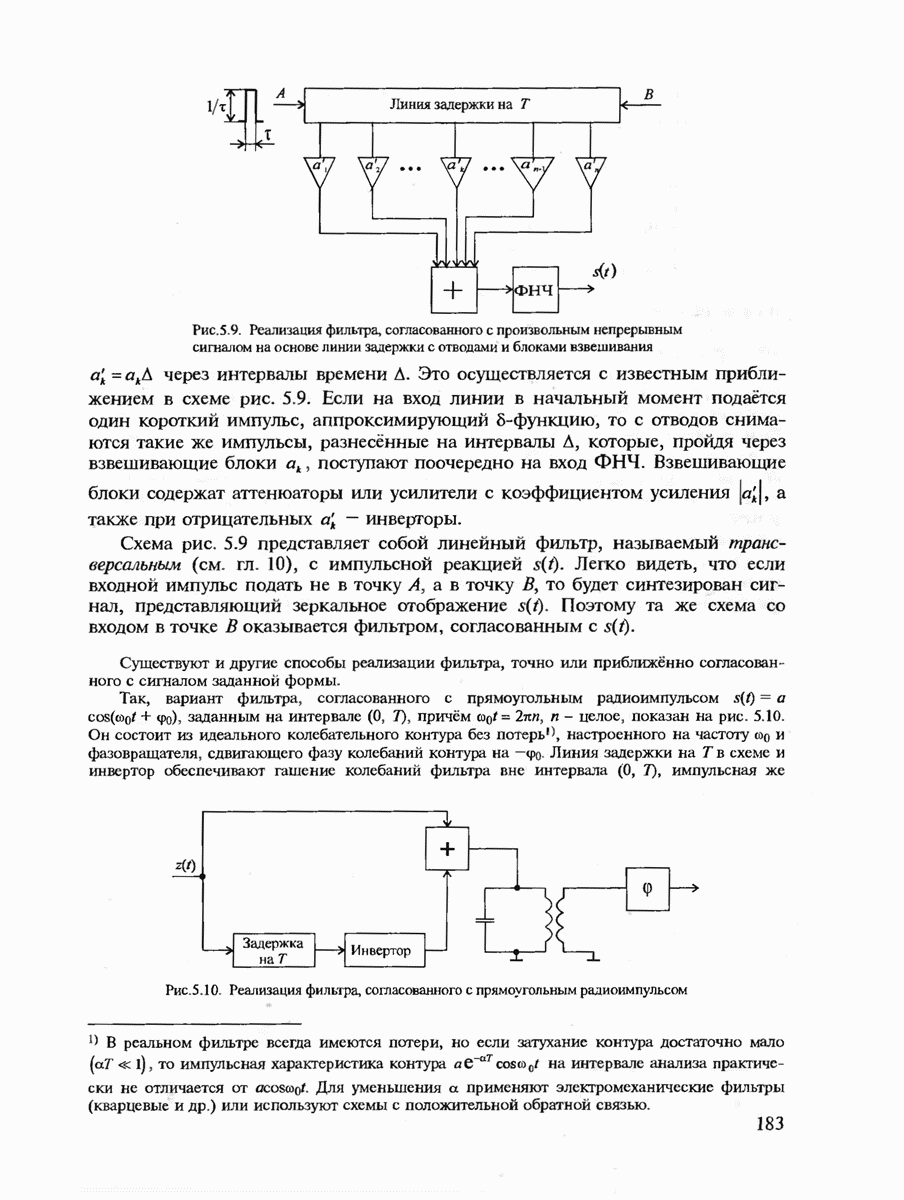
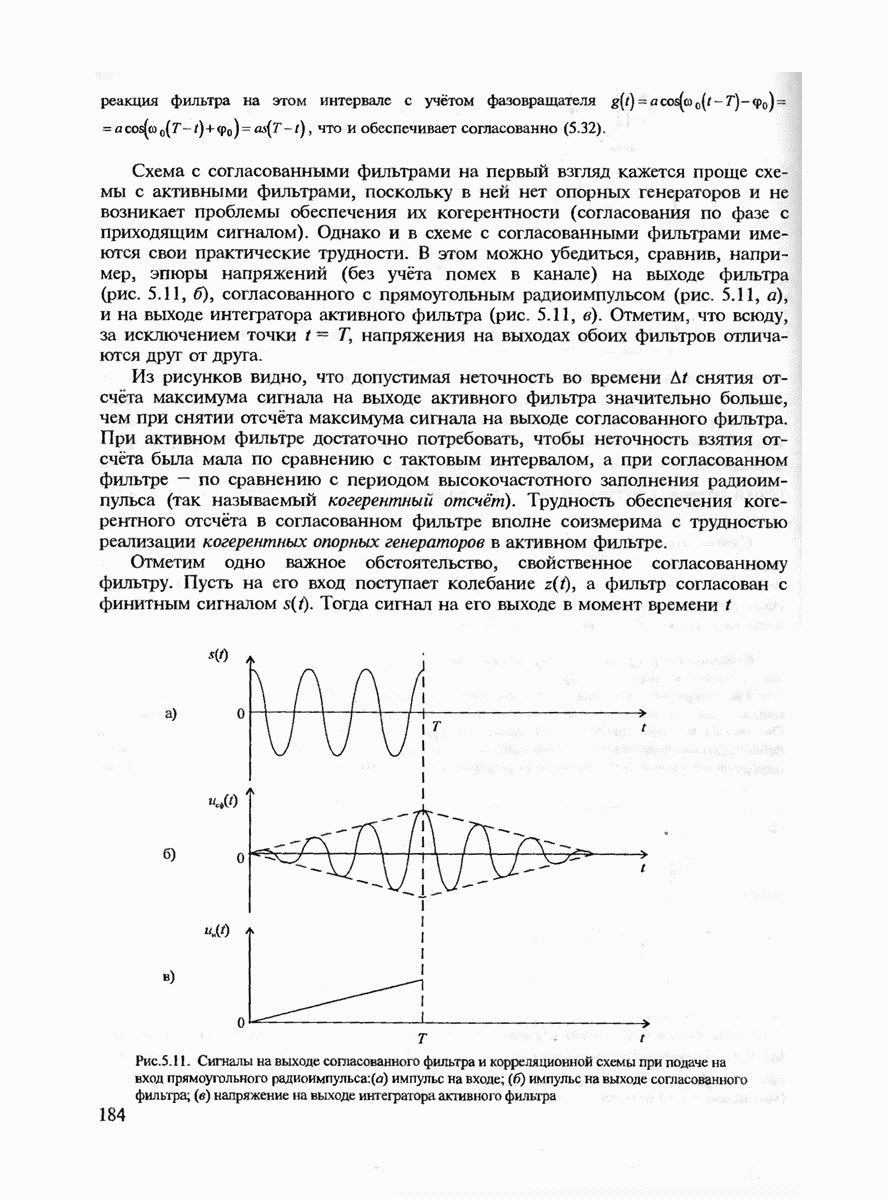










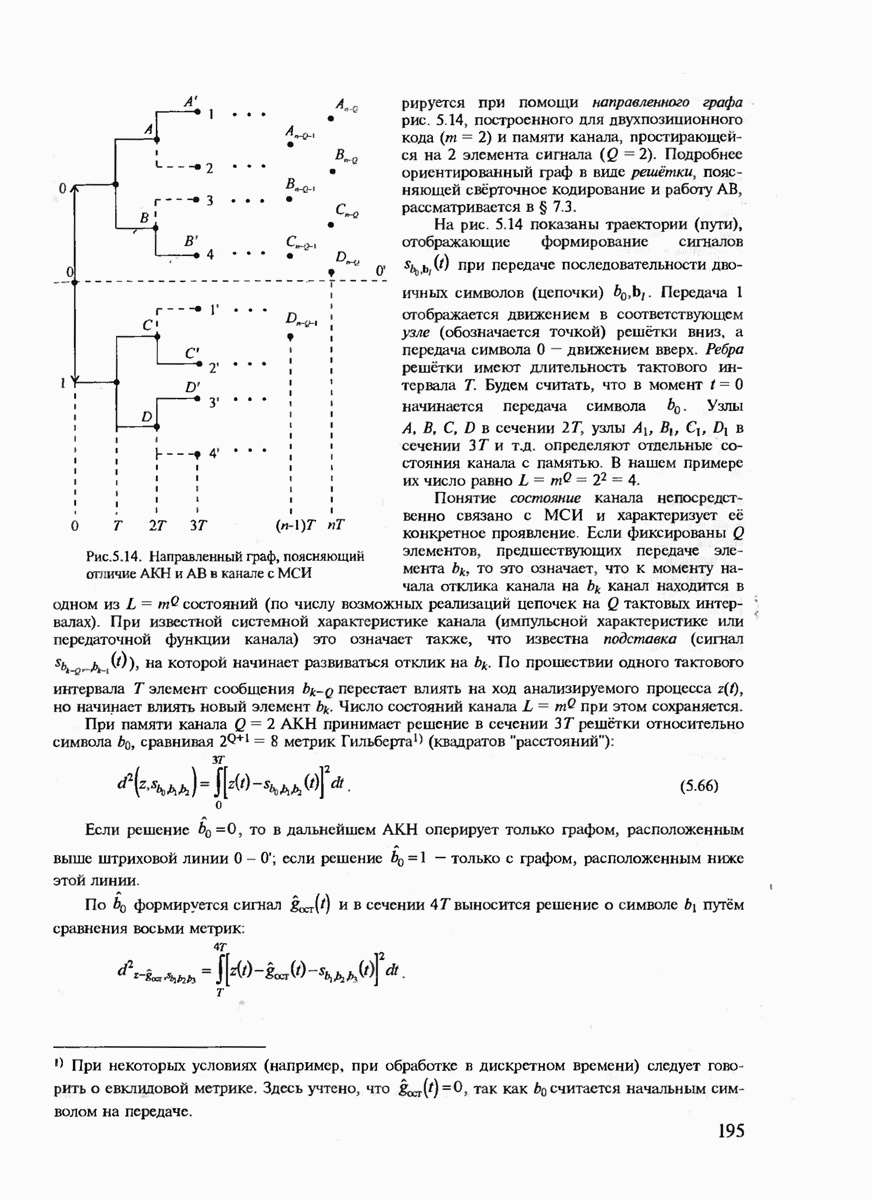



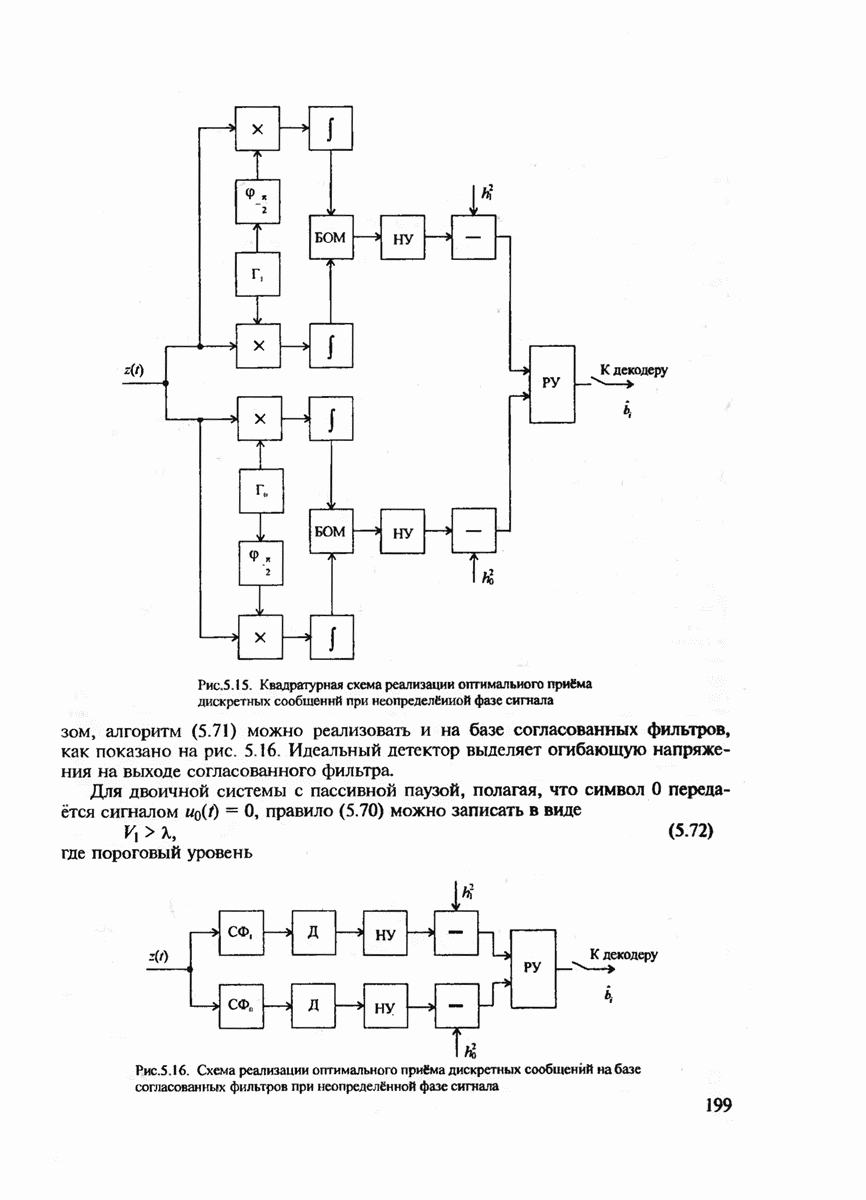



























































































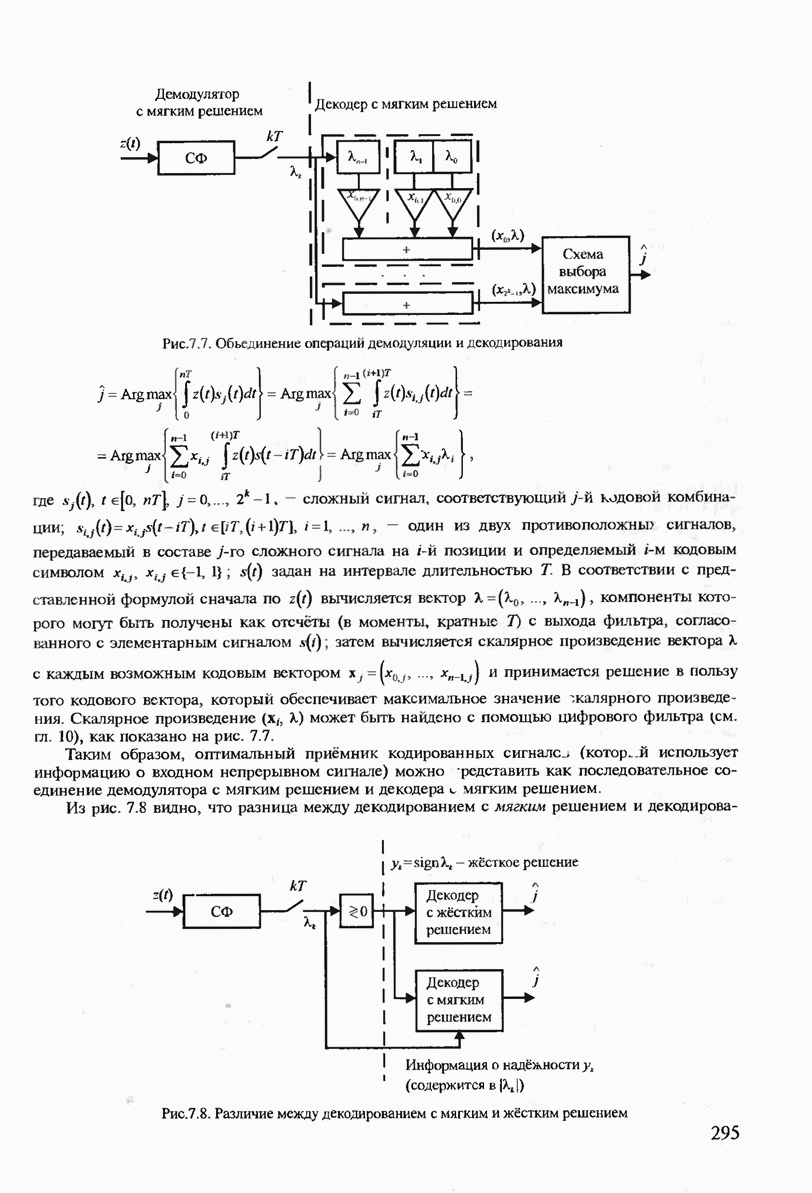



























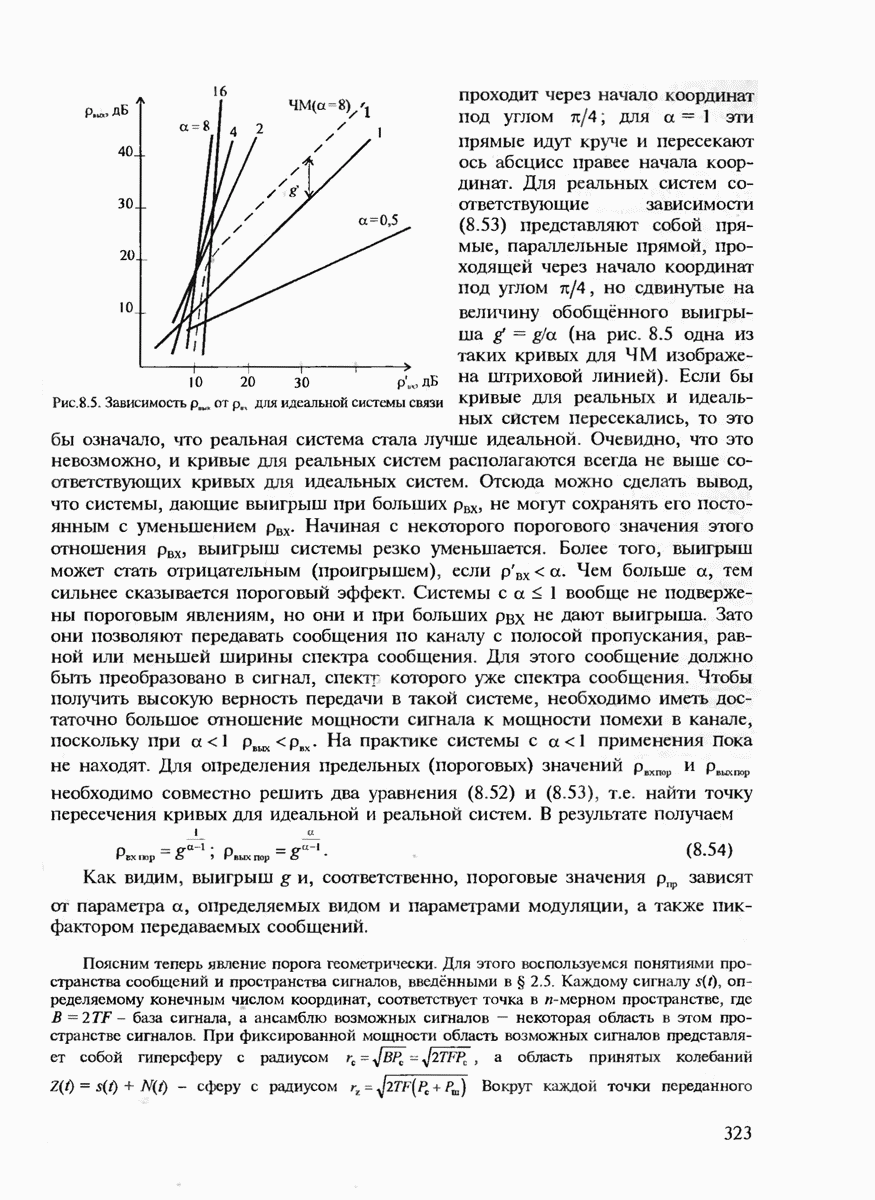













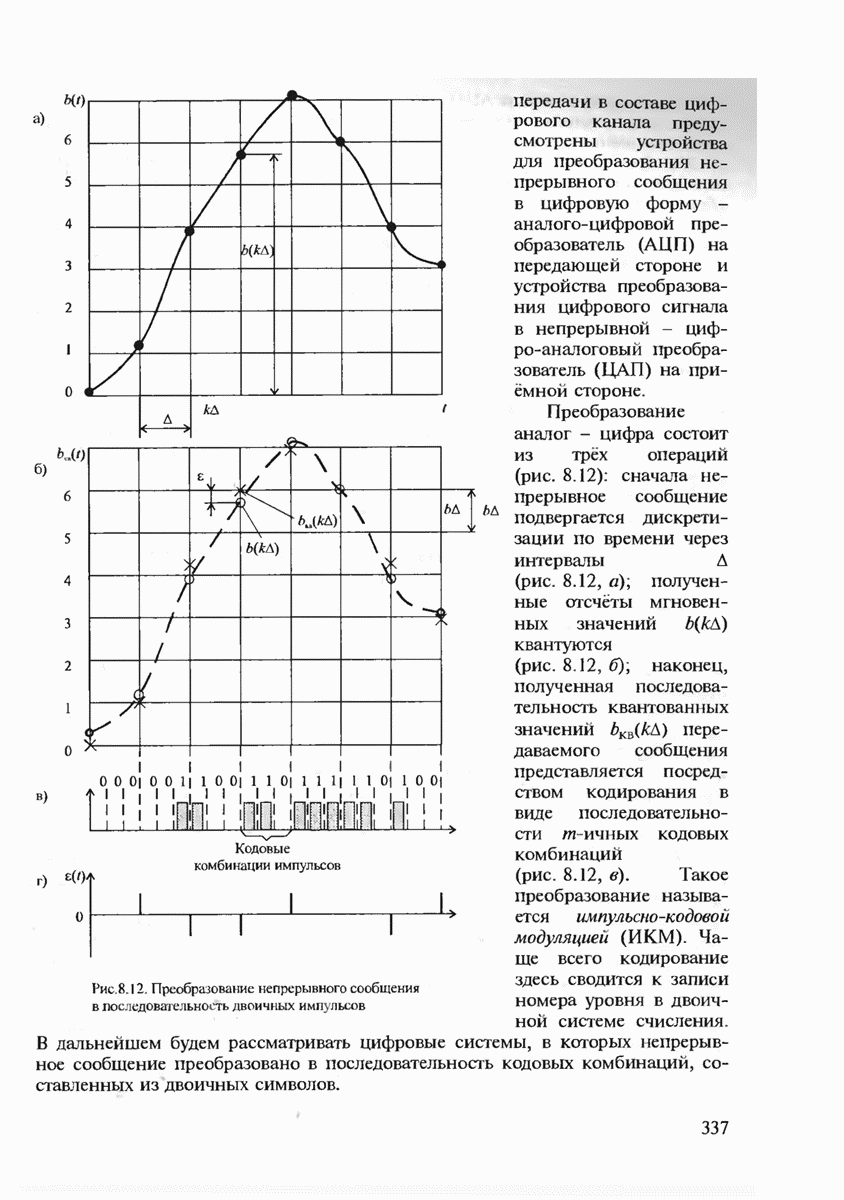


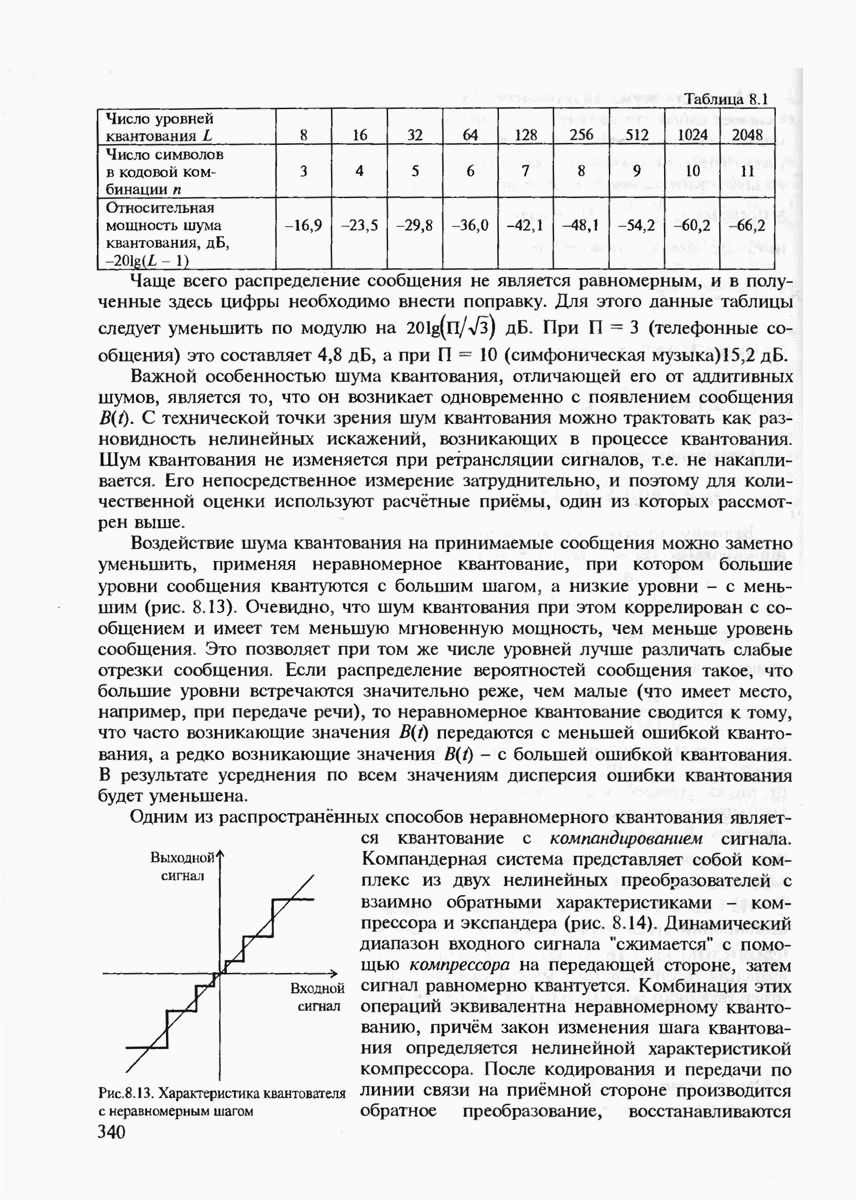














































































 с буквой
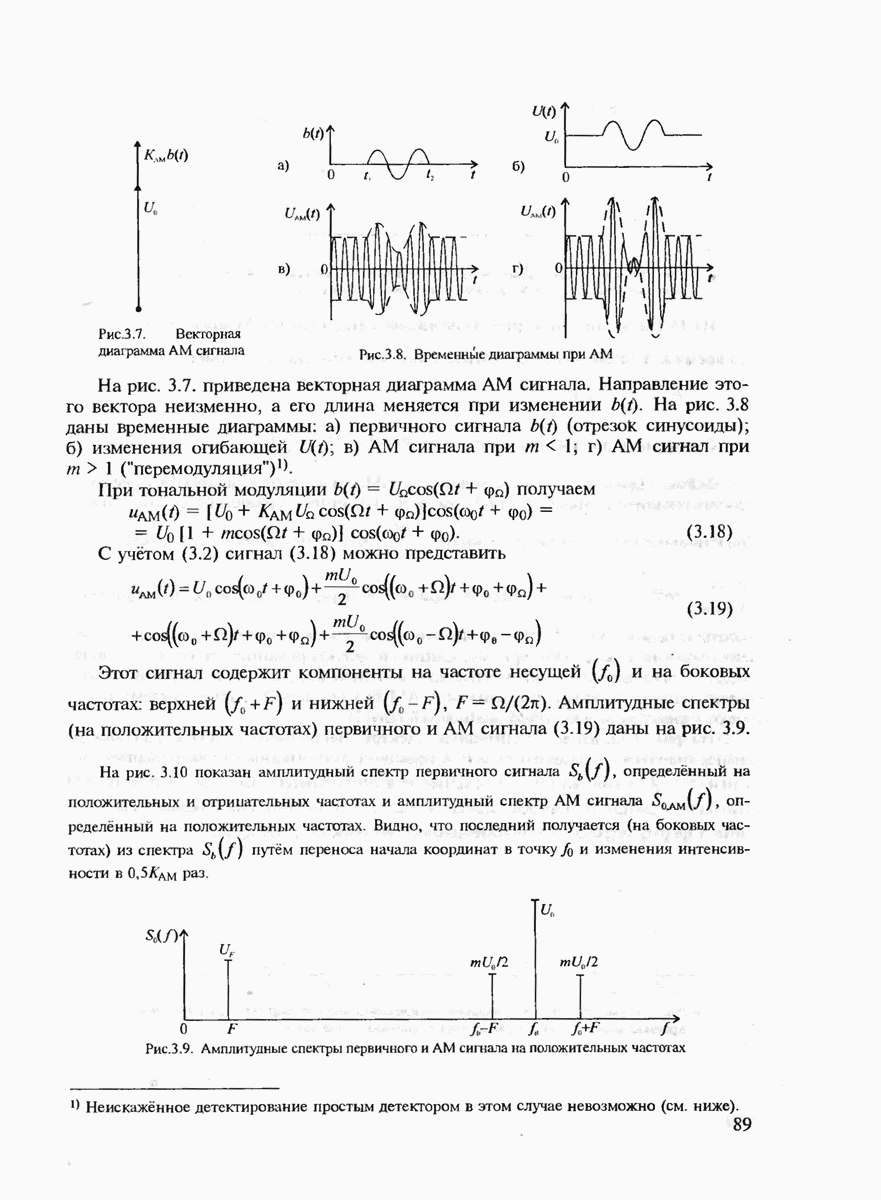
с буквой  то невозможно определить по принятой комбинации 10, передавались ли буква С или пара букв
то невозможно определить по принятой комбинации 10, передавались ли буква С или пара букв  Для того чтобы используемый код обладал свойством однозначной декодируемости, он, очевидно, должен удовлетворять некоторым условиям. Однозначное декодирование будет обеспечено, если ни одно кодовое слово не является началом другого кодового слова. Такие коды называются префиксными.
Для того чтобы используемый код обладал свойством однозначной декодируемости, он, очевидно, должен удовлетворять некоторым условиям. Однозначное декодирование будет обеспечено, если ни одно кодовое слово не является началом другого кодового слова. Такие коды называются префиксными.
 объём алфавита дискретного канала без помех, а
объём алфавита дискретного канала без помех, а  есть конечное множество положительных целых чисел. Для существования семейства
есть конечное множество положительных целых чисел. Для существования семейства  последовательностей с длинами
последовательностей с длинами  обладающего свойством префиксного кода, необходимо и достаточно выполнение следующего неравенства,
обладающего свойством префиксного кода, необходимо и достаточно выполнение следующего неравенства, 

 удовлетворяет неравенству (7.1). Перепишем это неравенство в виде
удовлетворяет неравенству (7.1). Перепишем это неравенство в виде

 число последовательностей длины
число последовательностей длины 

 неотрицательны, то из (7.2) последовательно получим систему неравенств
неотрицательны, то из (7.2) последовательно получим систему неравенств

 слов длиной 1, используя для этого различные буквы из алфавита объема
слов длиной 1, используя для этого различные буквы из алфавита объема  Остаётся
Остаётся  неиспользованных символов, и поэтому мы можем построить
неиспользованных символов, и поэтому мы можем построить  слов длиной 2, добавляя к ним по символу из алфавита объёма
слов длиной 2, добавляя к ним по символу из алфавита объёма  Из этих слов длины 2 выберем
Из этих слов длины 2 выберем  произвольных слов, что составляет
произвольных слов, что составляет  "свободных" префиксов длины 2. Добавляя к этим префиксам разные символы алфавита, получаем
"свободных" префиксов длины 2. Добавляя к этим префиксам разные символы алфавита, получаем  слов длиной 3, из которых выберем
слов длиной 3, из которых выберем  произвольных слов и т.д. Продолжая таким образом, мы построим префиксный код, длина комбинаций которого удовлетворяет неравенству Крафта (7.1).
произвольных слов и т.д. Продолжая таким образом, мы построим префиксный код, длина комбинаций которого удовлетворяет неравенству Крафта (7.1).
 Тогда если последовательности символов, выдаваемые этим источником, разбить на блоки длины
Тогда если последовательности символов, выдаваемые этим источником, разбить на блоки длины  то каждый из таких блоков можно рассматривать как символ нового источника с укрупнённым алфавитом
то каждый из таких блоков можно рассматривать как символ нового источника с укрупнённым алфавитом  объёма
объёма  и вероятностями появления символов
и вероятностями появления символов  определяемыми как произведение вероятностей первичных символов, входящих в данные блоки. Определим длины блоков
определяемыми как произведение вероятностей первичных символов, входящих в данные блоки. Определим длины блоков  неравномерного кода, описанного в теореме 7.1, следующим образом:
неравномерного кода, описанного в теореме 7.1, следующим образом:


 -ичного канала без помех, имеющие длины
-ичного канала без помех, имеющие длины  Тогда для средней длины такой последовательности
Тогда для средней длины такой последовательности  выполняются неравенства
выполняются неравенства

 кроме того, относя эту величину к одному символу источника, получаем
кроме того, относя эту величину к одному символу источника, получаем

 может быть получено при кодировании при помощи неравномерного префиксного кода с длинами последовательностей, выбранными в соответствии с (7.4). Остаётся показать, как может быть построен такой префиксный код. Существует несколько алгоритмов построения неравномерных кодов с префиксным свойством. Среди них оптимальным, т.е. позволяющим сколь угодно приближаться к пределу (7.5), является алгоритм Хаффмена [8]. Однако рассмотрим здесь более простой алгоритм Шеннона-Фано, который в большинстве случаев приводит к тем же результатам.
может быть получено при кодировании при помощи неравномерного префиксного кода с длинами последовательностей, выбранными в соответствии с (7.4). Остаётся показать, как может быть построен такой префиксный код. Существует несколько алгоритмов построения неравномерных кодов с префиксным свойством. Среди них оптимальным, т.е. позволяющим сколь угодно приближаться к пределу (7.5), является алгоритм Хаффмена [8]. Однако рассмотрим здесь более простой алгоритм Шеннона-Фано, который в большинстве случаев приводит к тем же результатам.
 с вероятностями
с вероятностями  Процедура построения неравномерного кода без укрупнения алфавита
Процедура построения неравномерного кода без укрупнения алфавита  задаётся табл. 7.2. На первом этапе производится деление на два множества
задаётся табл. 7.2. На первом этапе производится деление на два множества  на втором —
на втором —  на третьем —
на третьем —  и на четвёртом —
и на четвёртом —  Легко проверить, что данный код оказывается префиксным и средняя длина кодовой комбинации
Легко проверить, что данный код оказывается префиксным и средняя длина кодовой комбинации  что менее чем на
что менее чем на  превышает энтропию данного источника, равную 2,16.
превышает энтропию данного источника, равную 2,16.
 укрупнённого источника сообщений эти погрешности будут сглаживаться, а средняя длина
укрупнённого источника сообщений эти погрешности будут сглаживаться, а средняя длина  приближаться к предельному значению (7.5).
приближаться к предельному значению (7.5).
 как новый источник с алфавитом
как новый источник с алфавитом  т.е. в качестве одного укрупнённого сообщения на выходе источника теперь рассматривается два последовательных сообщения. Если источник не
т.е. в качестве одного укрупнённого сообщения на выходе источника теперь рассматривается два последовательных сообщения. Если источник не
 . Если же исходный источник имеет память, то, например,
. Если же исходный источник имеет память, то, например,  что будет учтено при последующем оптимальном префиксном кодировании для нового источника с укрупнённым алфавитом. При такой схеме кодирования остаётся неучтенной статистическая зависимость между укрупнёнными сообщениями. Поэтому алфавит необходимо укрупнять до тех пор, пока избыточность, вызванная статистическими связями между укрупнёнными сообщениями, не станет достаточно малой.
что будет учтено при последующем оптимальном префиксном кодировании для нового источника с укрупнённым алфавитом. При такой схеме кодирования остаётся неучтенной статистическая зависимость между укрупнёнными сообщениями. Поэтому алфавит необходимо укрупнять до тех пор, пока избыточность, вызванная статистическими связями между укрупнёнными сообщениями, не станет достаточно малой.
 При таком способе разбиения все префиксы данной цепочки могут находиться лишь слева от нее. В частности, цепочка, которая отличается от данной лишь в последнем символе (бите), всегда будет располагаться слева. Если
При таком способе разбиения все префиксы данной цепочки могут находиться лишь слева от нее. В частности, цепочка, которая отличается от данной лишь в последнем символе (бите), всегда будет располагаться слева. Если  означает число различных цепочек разбиения для данной последовательности длины
означает число различных цепочек разбиения для данной последовательности длины  то необходимо
то необходимо  бит, чтобы закодировать номер префикса к данной цепочке и ещё один бит для описания последнего элемента этой цепочки. Так, для рассмотренной выше последовательности и её разбиений мы получим следующий равномерный код: (000, 1) (000, 0) (001, 1) (010, 1) (011, 0) (010, 0) (001? 0), где первые три бита определяют номер префикса к очередной цепочке, а последний бит даёт значение последнего символа этой цепочки. Очевидно, что декодирование такого кода производится однозначным образом.
бит, чтобы закодировать номер префикса к данной цепочке и ещё один бит для описания последнего элемента этой цепочки. Так, для рассмотренной выше последовательности и её разбиений мы получим следующий равномерный код: (000, 1) (000, 0) (001, 1) (010, 1) (011, 0) (010, 0) (001? 0), где первые три бита определяют номер префикса к очередной цепочке, а последний бит даёт значение последнего символа этой цепочки. Очевидно, что декодирование такого кода производится однозначным образом.
 сжатие сообщений приближается к предельно возможному, определяемому теоремой кодирования в канале без помех, а именно доказывается, что для любого стационарного эргодического источника сообщений
сжатие сообщений приближается к предельно возможному, определяемому теоремой кодирования в канале без помех, а именно доказывается, что для любого стационарного эргодического источника сообщений
