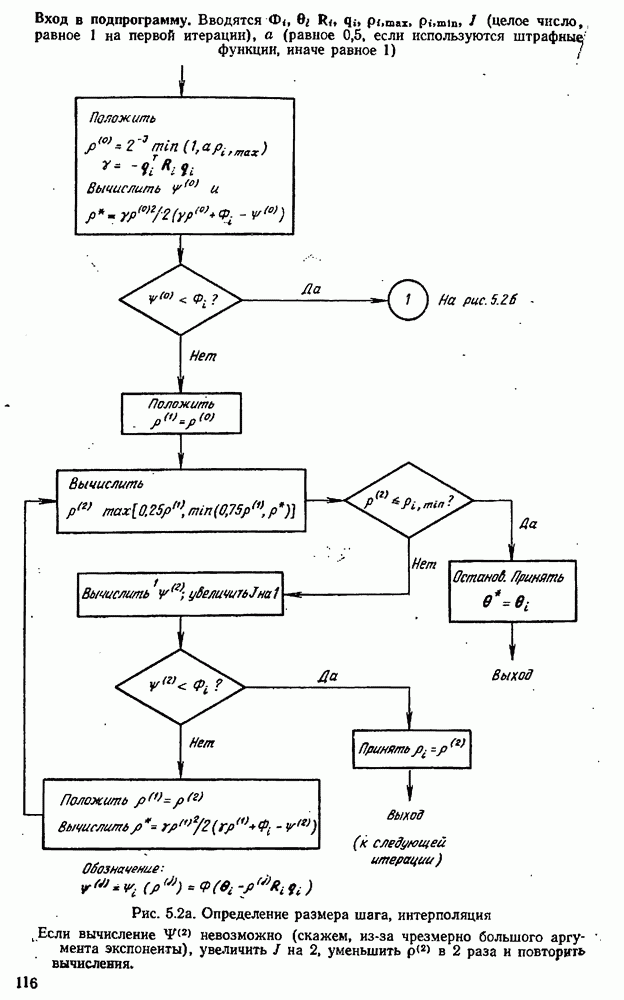
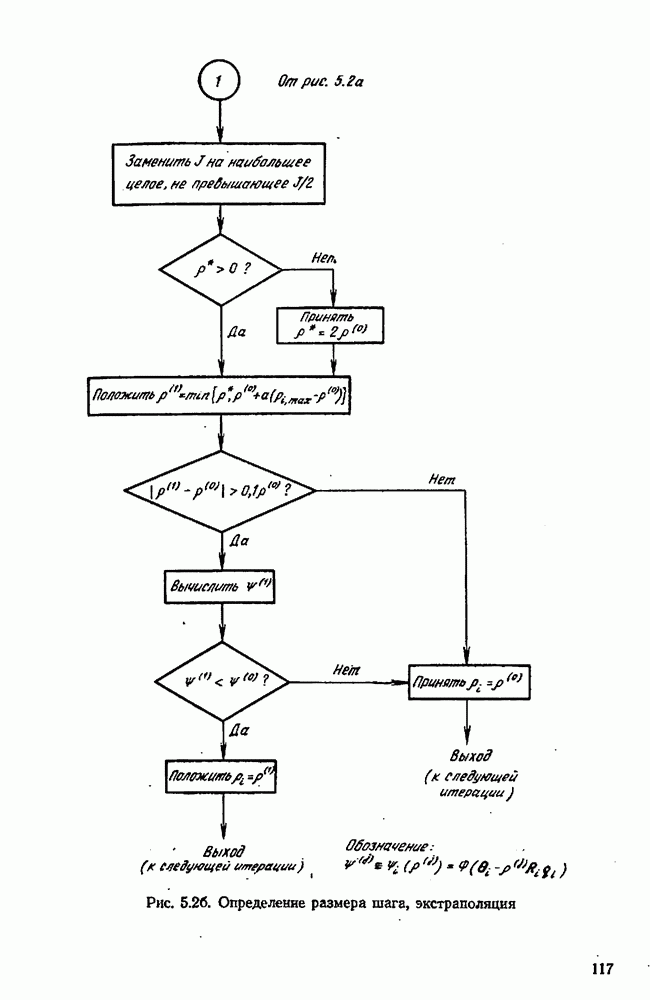
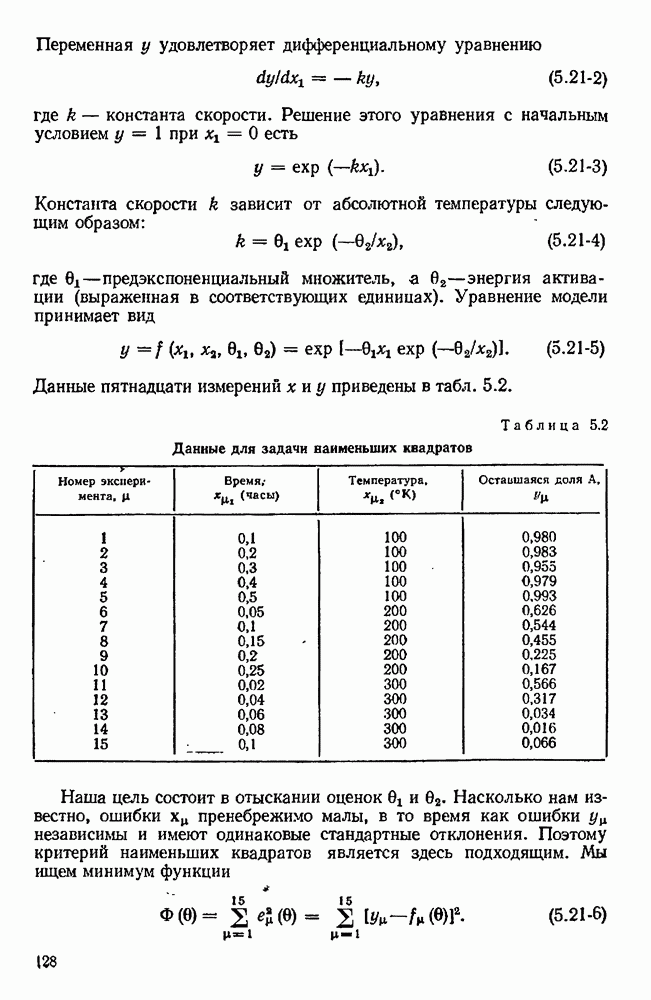
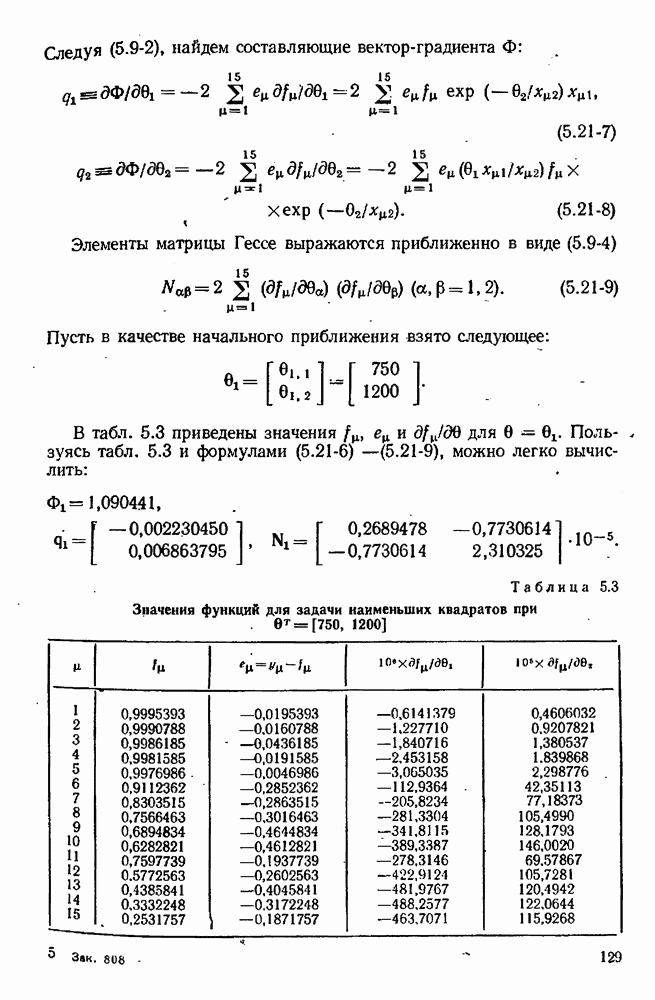
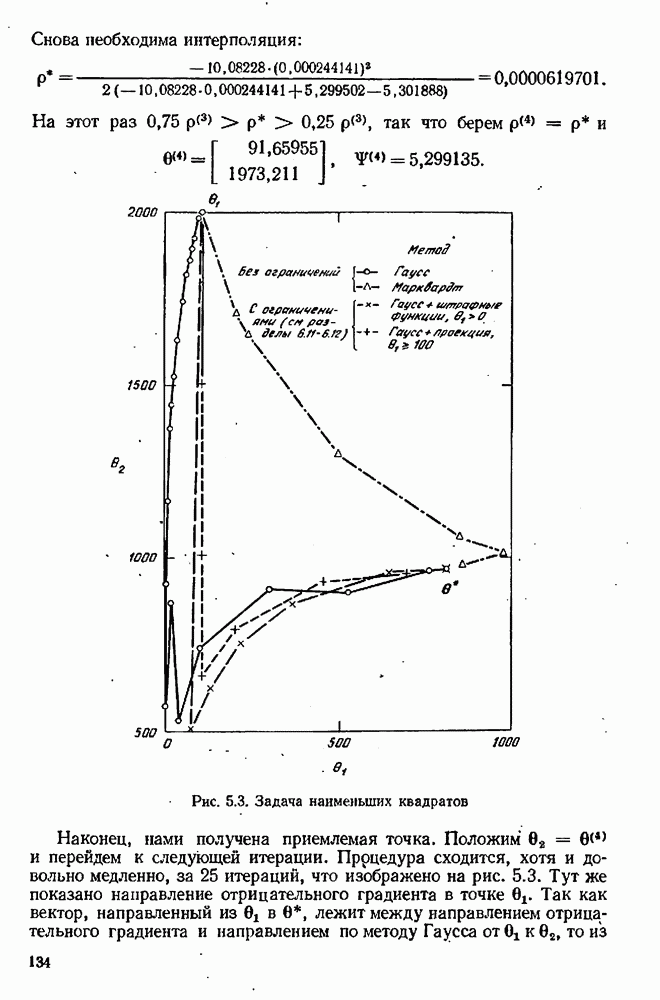
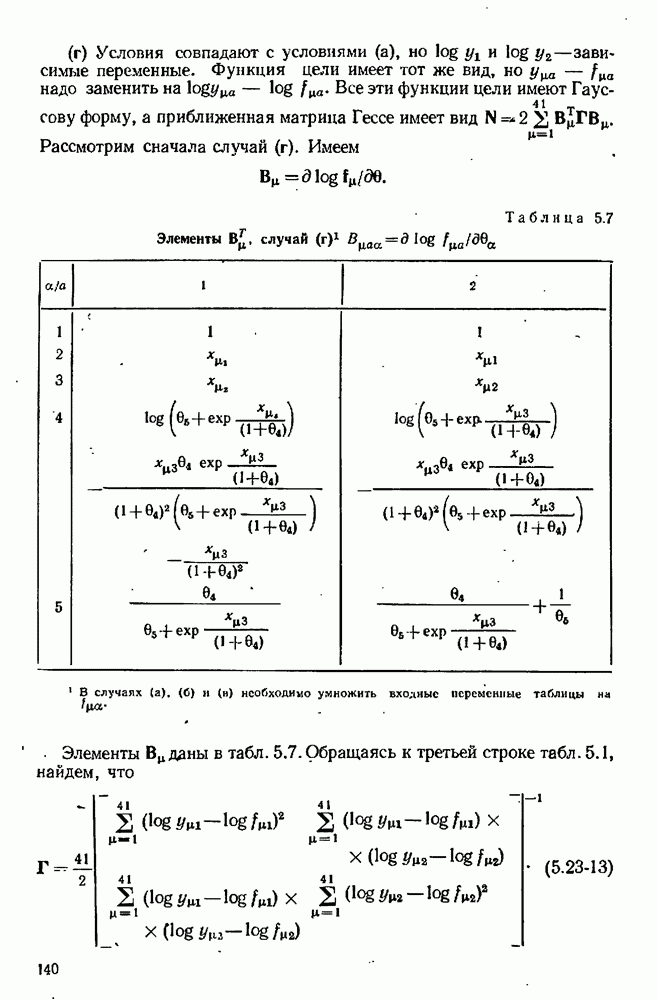
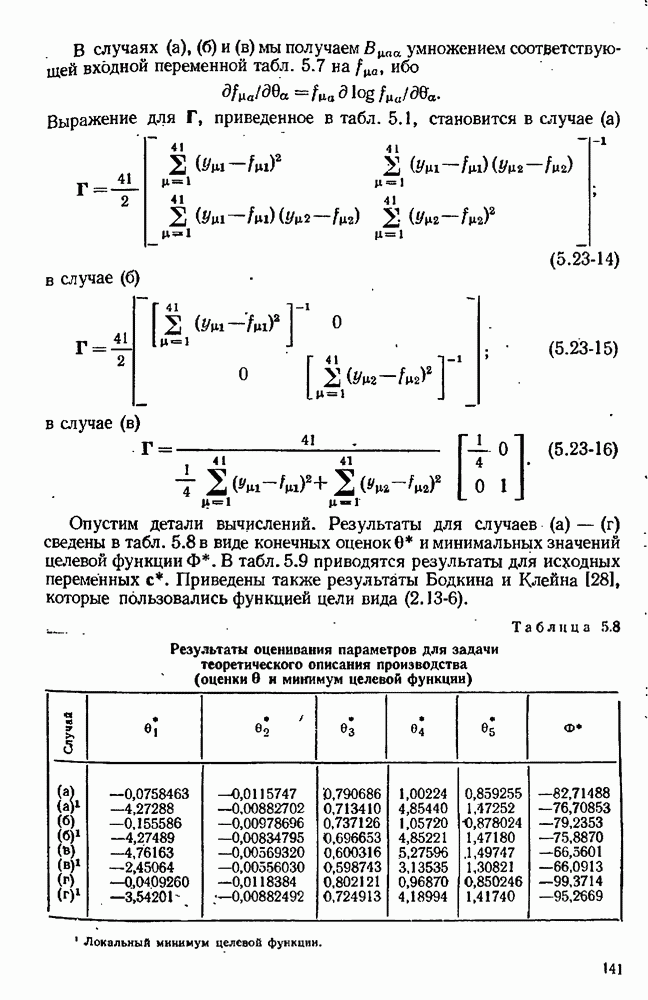
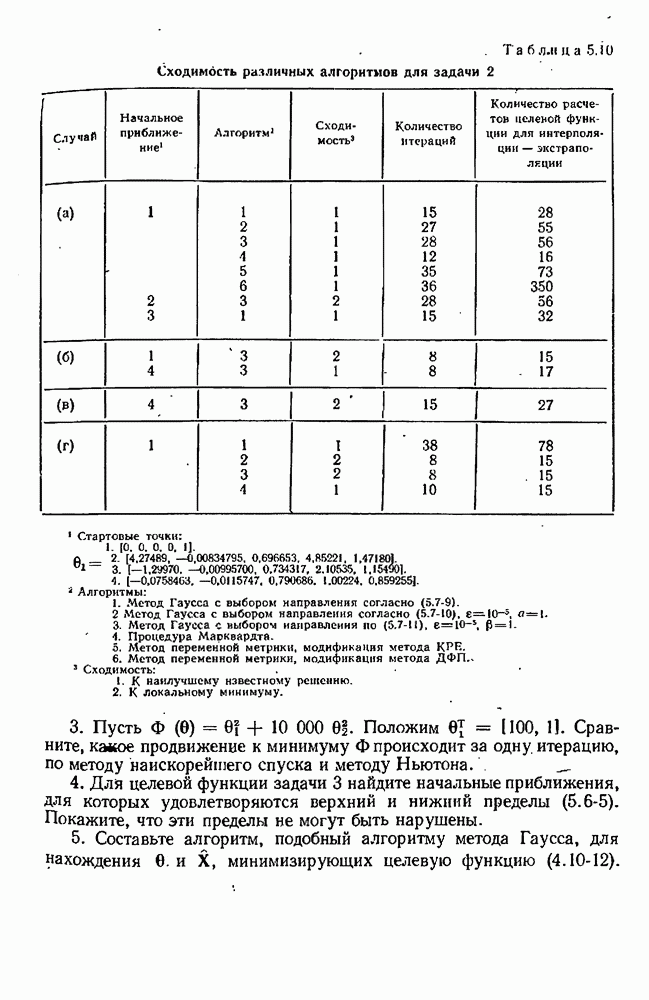
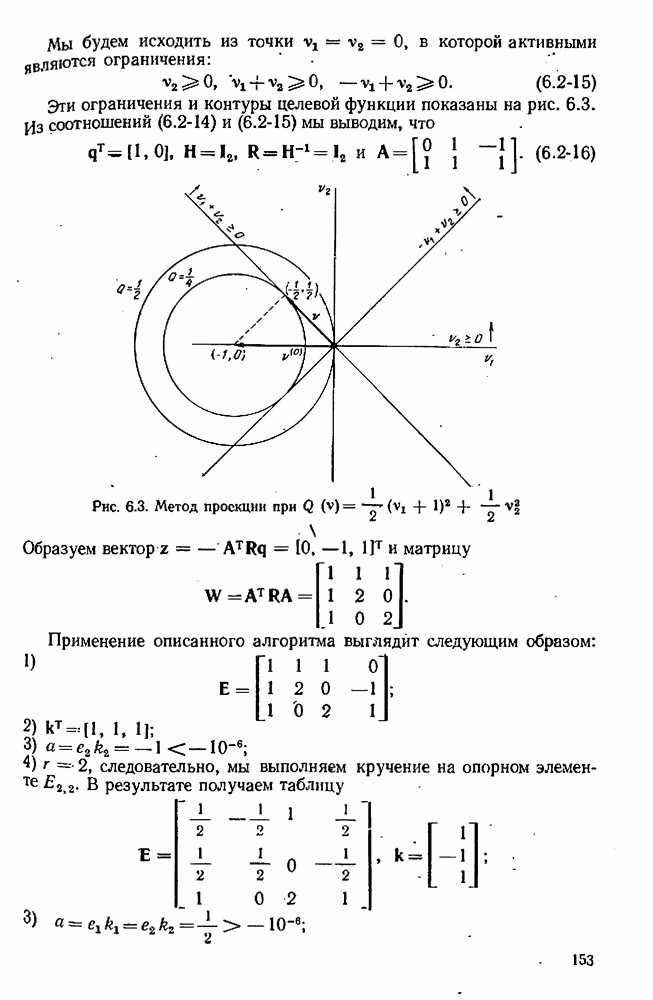
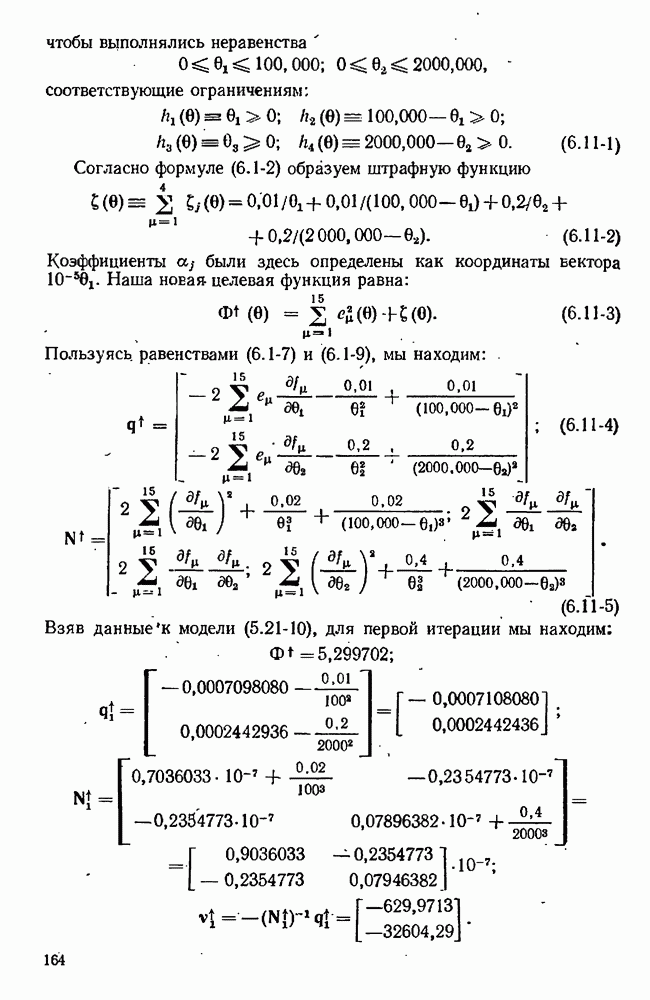
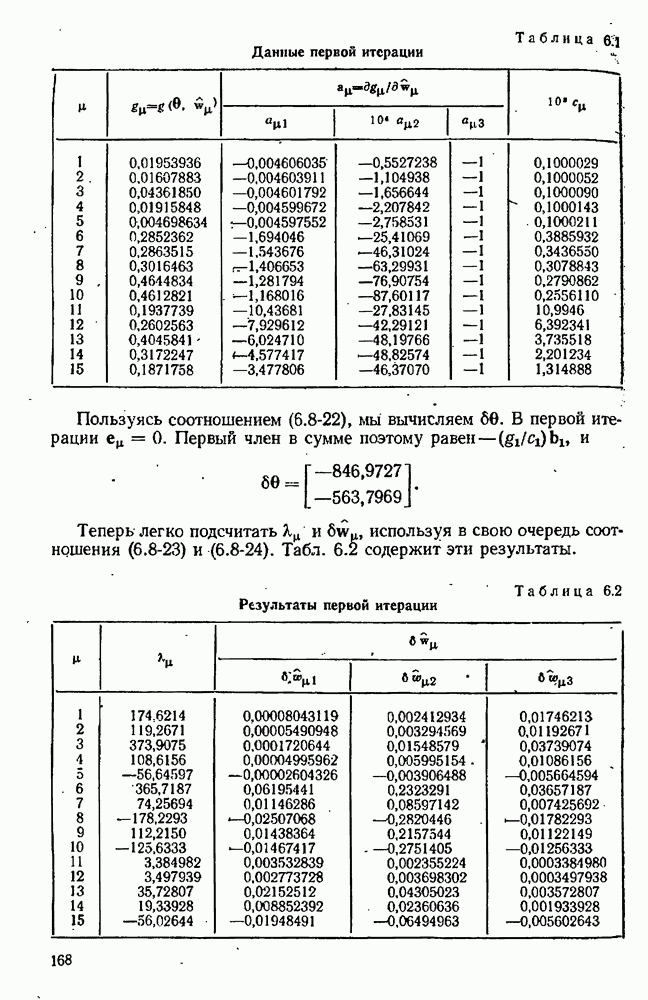
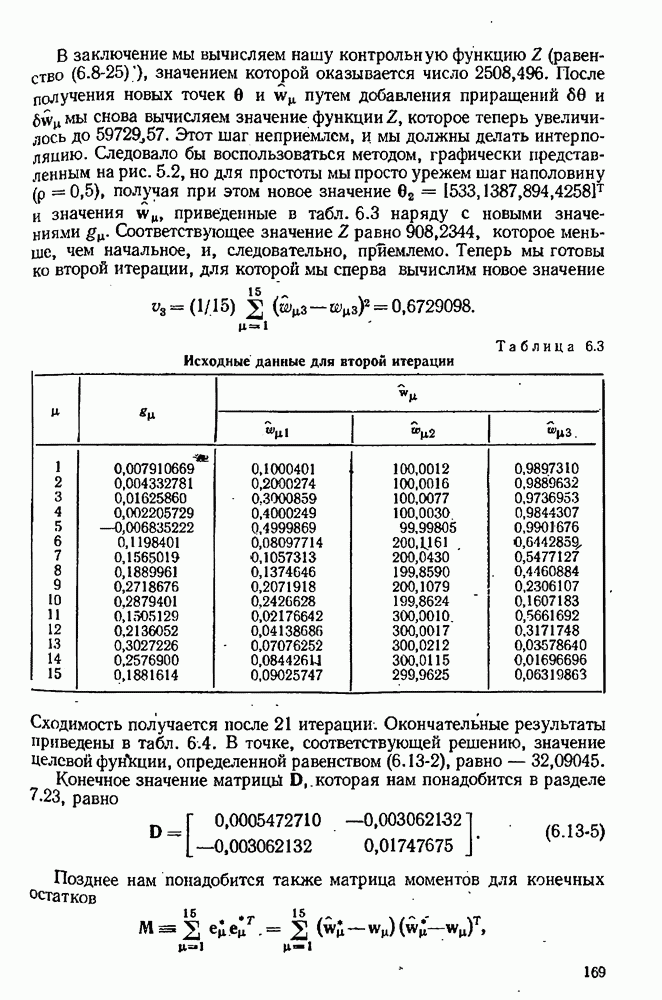
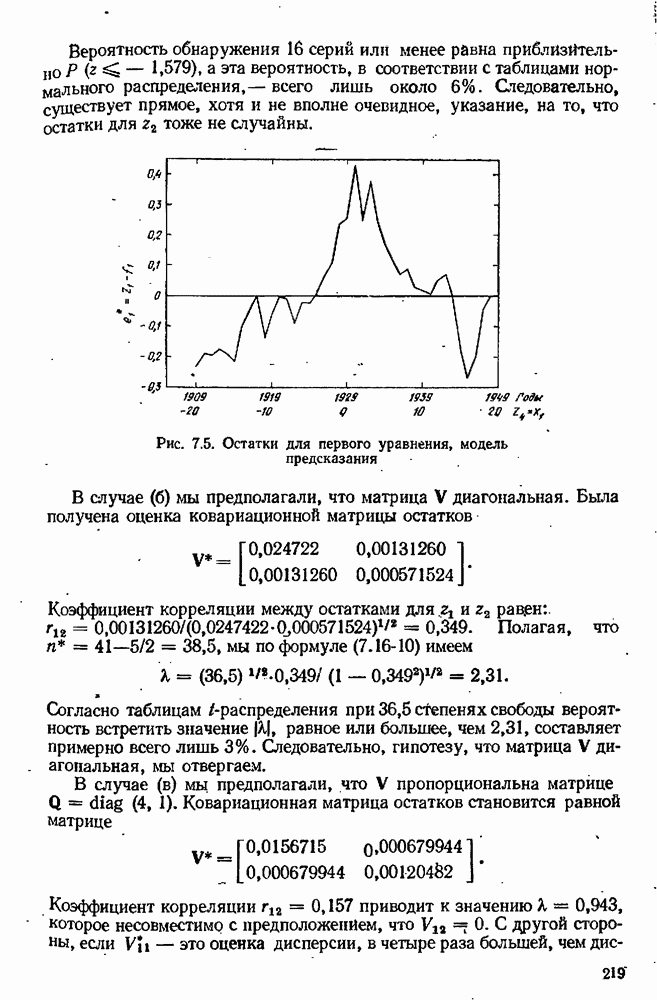
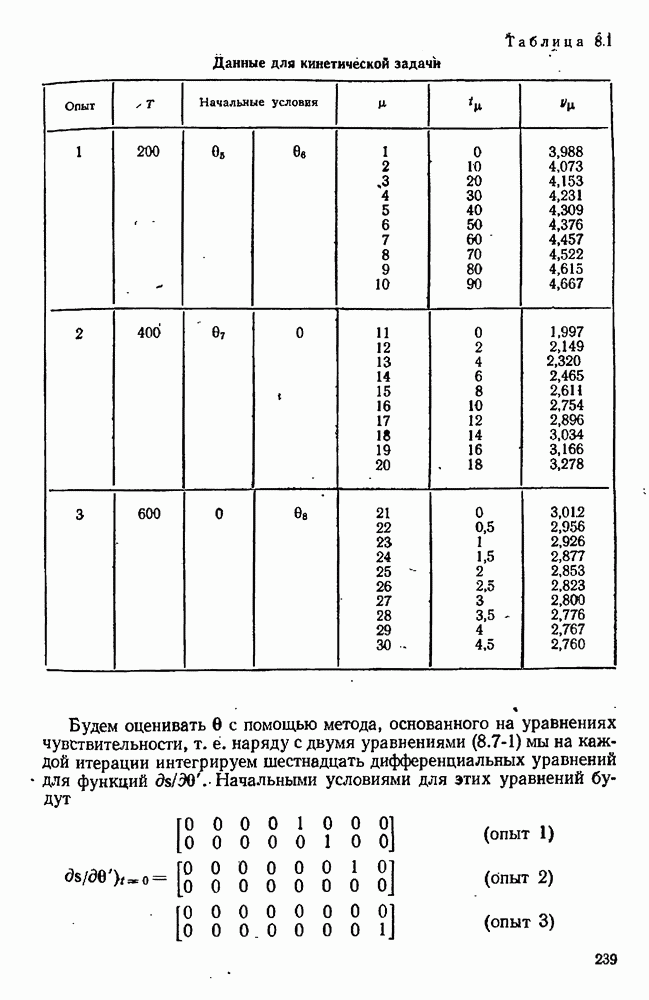
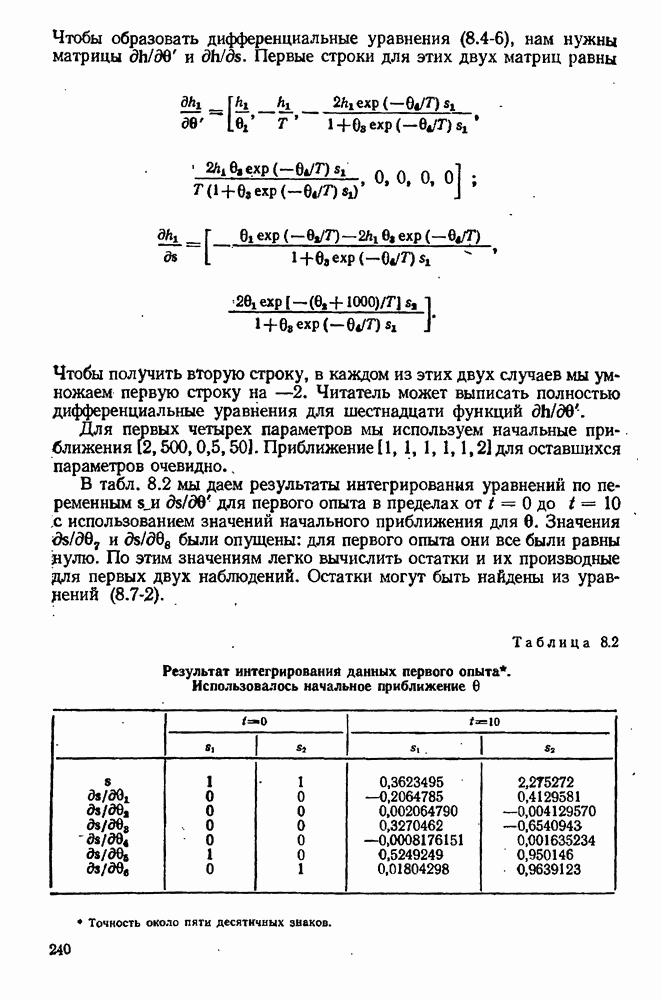
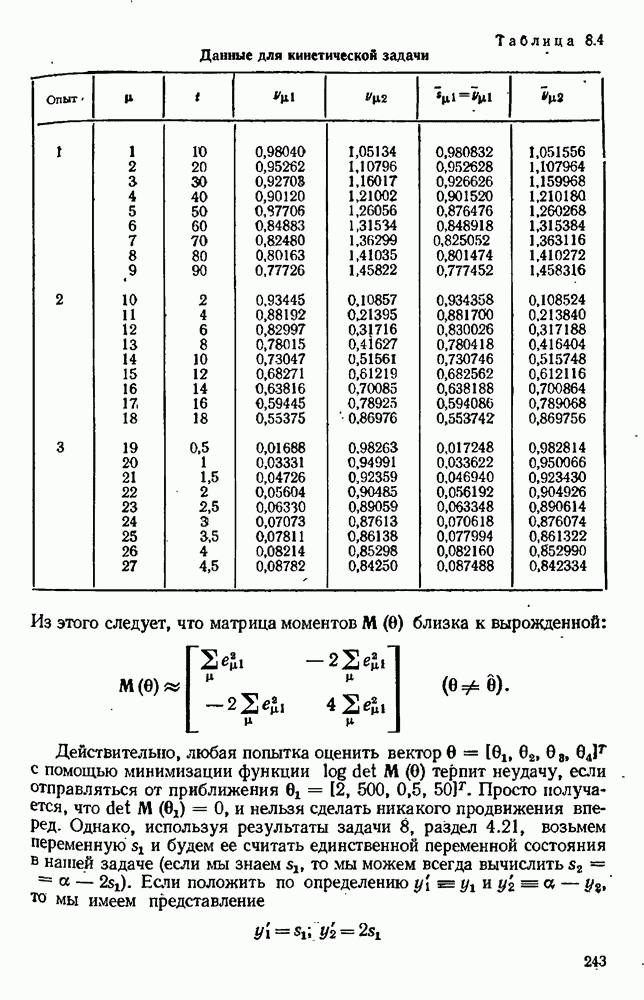
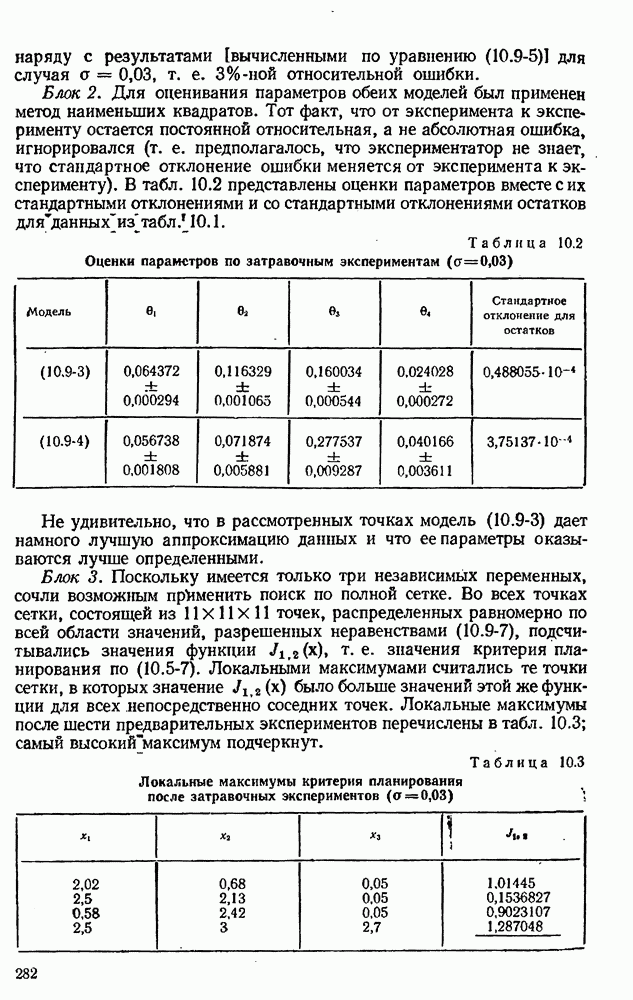
7.17. Серии в наблюдениях и выбросы
Остатки, прошедшие через проверки предыдущего раздела, могут быть все-таки неблагополучными. Находясь по величине в разумных пределах, они могут проявлять тренды и другую несогласованность со случайностью,  что требует дальнейших модификаций в модели. Мы отсылаем читателя к книгам Актона [4, гл. 3] или Дрейпера
что требует дальнейших модификаций в модели. Мы отсылаем читателя к книгам Актона [4, гл. 3] или Дрейпера  Смита [63] с превосходной трактовкой этих проблем на практическом уровне. Кратко — остатки следует представить графиками, у которых аргументами служат различные переменные, включавшиеся в модель, а также время получения наблюдений. Линейные, квадратические или периодические тренды могут проявиться сами собой и потребуют включения в модель соответствующих добавочных членов. Тренды в дисперсиях ошибок тоже можно заметить, и они могут пролить некоторый свет на процесс измерений. Наконец, мы можем контролировать отсутствие случайности подсчетом числа «серий» в остатках, понимая под серией последовательность одного знака. Если число таких серий много меньше ожидаемого, то случайность остатков становится подозрительной.
Смита [63] с превосходной трактовкой этих проблем на практическом уровне. Кратко — остатки следует представить графиками, у которых аргументами служат различные переменные, включавшиеся в модель, а также время получения наблюдений. Линейные, квадратические или периодические тренды могут проявиться сами собой и потребуют включения в модель соответствующих добавочных членов. Тренды в дисперсиях ошибок тоже можно заметить, и они могут пролить некоторый свет на процесс измерений. Наконец, мы можем контролировать отсутствие случайности подсчетом числа «серий» в остатках, понимая под серией последовательность одного знака. Если число таких серий много меньше ожидаемого, то случайность остатков становится подозрительной.
Если  число отрицательных и положительных остатков соответственно, то ожидаемое число серий (в предположении полной случайности) равно:
число отрицательных и положительных остатков соответственно, то ожидаемое число серий (в предположении полной случайности) равно:

дисперсия числа серий равна:

Фактические распределения числа серий были введены и табулированы Свед и Эйзенхартом [183]. Таблица приведена также в [63, с. 98]. Когда и  больше 10, величина
больше 10, величина

( равно числу наблюдаемых серий) распределена приближенно нормально
равно числу наблюдаемых серий) распределена приближенно нормально  Численные примеры представлены в разделе 7.24.
Численные примеры представлены в разделе 7.24.
Подчеркнем, что при неудачном результате проверки на число серий нет причин для полного отклонения модели. Обычно это просто указание на то, что мы пренебрегли некоторыми, возможно, слабыми эффектами. В частности, в тех случаях, когда данные почти безошибочны, пренебрежимые эффекты превосходят случайные ошибки в измерениях. Следовательно, неслучайность остатков скорее правило, чем исключение, когда модели подбираются под хорошие данные.
Многие тесты для остатков лучше всего выполнять графическим способом. Если надо исследовать распределение вероятности ошибок, то требуется гистограмма или эмпирическая функция распределения. Допустим, что остатки перенумерованы таким образом, что  это наименьший (алгебраически) остаток, а
это наименьший (алгебраически) остаток, а  наибольший. Пусть
наибольший. Пусть  тогда числа
тогда числа  оценивают вероятности
оценивают вероятности 
В этом случае график чисел  в зависимости от
в зависимости от  аппроксимирует функцию распределения ошибок. Когда этот график выполнен на нормальной вероятностной бумаге, то результатом должны быть прямая линия, если распределение ошибок нормально. Если все точки довольно близки к прямой линии, за исключением нескольких в левом и правом концах, возникает подозрение о существовании выбросов (см. ниже). Если создается впечатление, что точки группируются не около гладкой кривой, а скорее образуют несколько отдельных групп, то можно заключить, что для разных подмножеств наблюдений действуют разные источники ошибок.
аппроксимирует функцию распределения ошибок. Когда этот график выполнен на нормальной вероятностной бумаге, то результатом должны быть прямая линия, если распределение ошибок нормально. Если все точки довольно близки к прямой линии, за исключением нескольких в левом и правом концах, возникает подозрение о существовании выбросов (см. ниже). Если создается впечатление, что точки группируются не около гладкой кривой, а скорее образуют несколько отдельных групп, то можно заключить, что для разных подмножеств наблюдений действуют разные источники ошибок.
Может случиться, что при проведении или регистрации некоторых экспериментов совершаются какие-то грубые ошибки. Естественно, эти ошибочные наблюдения приводят к необычно большим остаткам, называемым выбросами. Что более серьезно, такие ошибочные значения могут сильно исказить оценки параметров. Поэтому желательно исключить такие наблюдения из анализа, и простейший способ подметить их — это исследование остатков. Если существует ясно выраженная дифференциация между «регулярными» остатками, которые попадают на сглаженную часть графика вероятностей, и «выбросами», то следует без колебаний исключить последние и снова вычислить оценки без них. Однако если это разделение Смазывается, то задача диагностирования выбросов — трудная задача. Часто применяемая на практике процедура состоит в том, что исключаются все остатки, величина которых превосходит стандартное отклонение (известное или оцененное с использованием всех остатков) в фиксированное число раз, скажем 2,5 или 3. После установления такого порогового значения принимается в расчет вероятность того, что остатки такой величины могут иметь
место на основе их частости в выборке объема  Например, при нормальном распределении и 100 наблюдениях вероятность получения остатка, превосходящего
Например, при нормальном распределении и 100 наблюдениях вероятность получения остатка, превосходящего  , равна 23,7%, что не дает достаточно оснований для отбрасывания такого остатка без дополнительных рассмотрений. По поводу более систематизированного подхода (см. [8]).
, равна 23,7%, что не дает достаточно оснований для отбрасывания такого остатка без дополнительных рассмотрений. По поводу более систематизированного подхода (см. [8]).