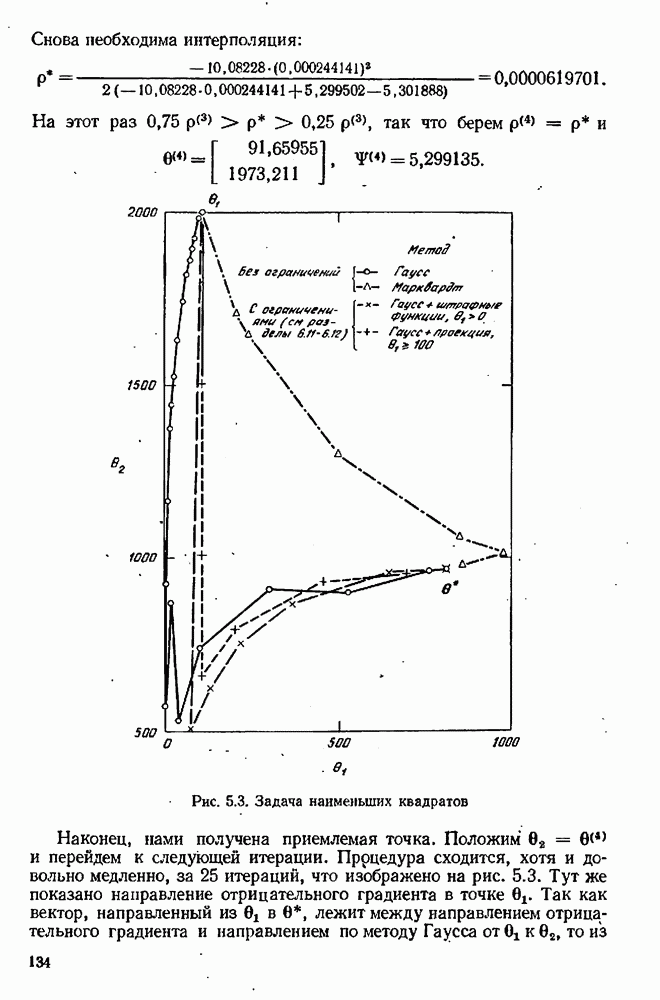
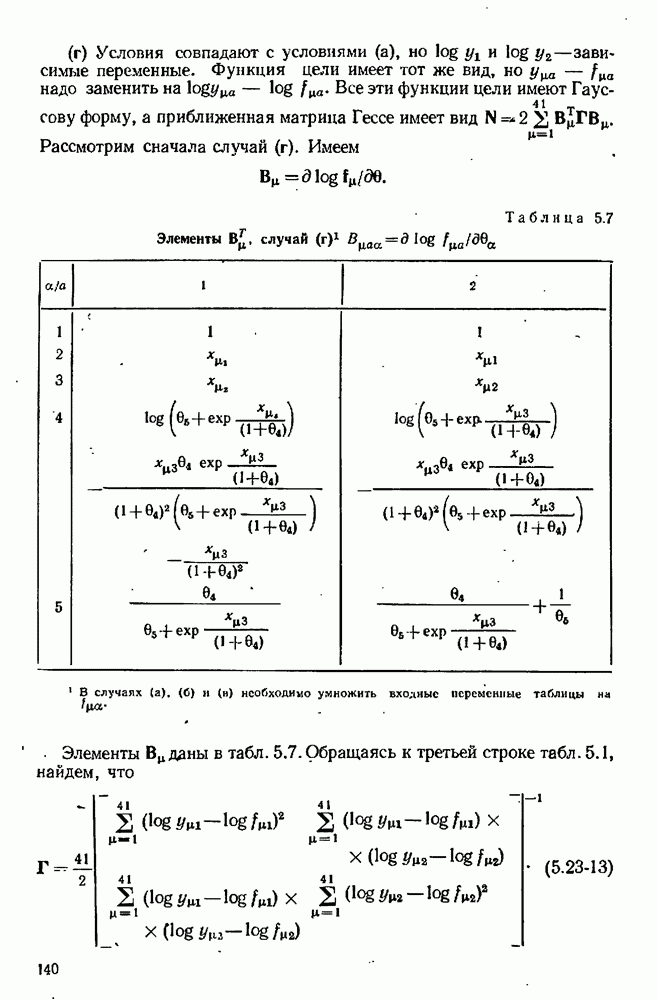
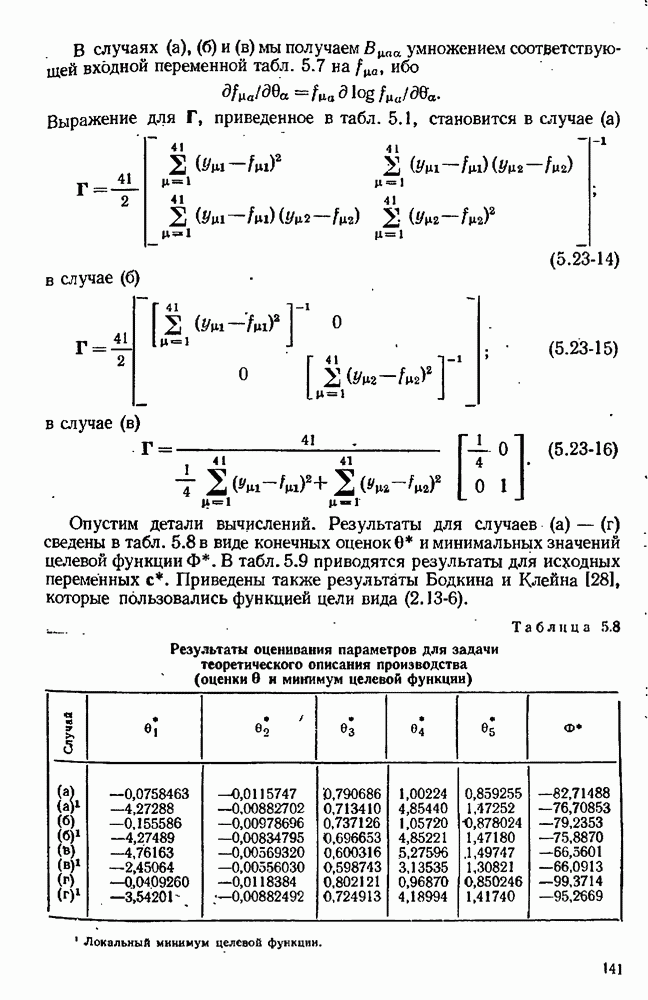
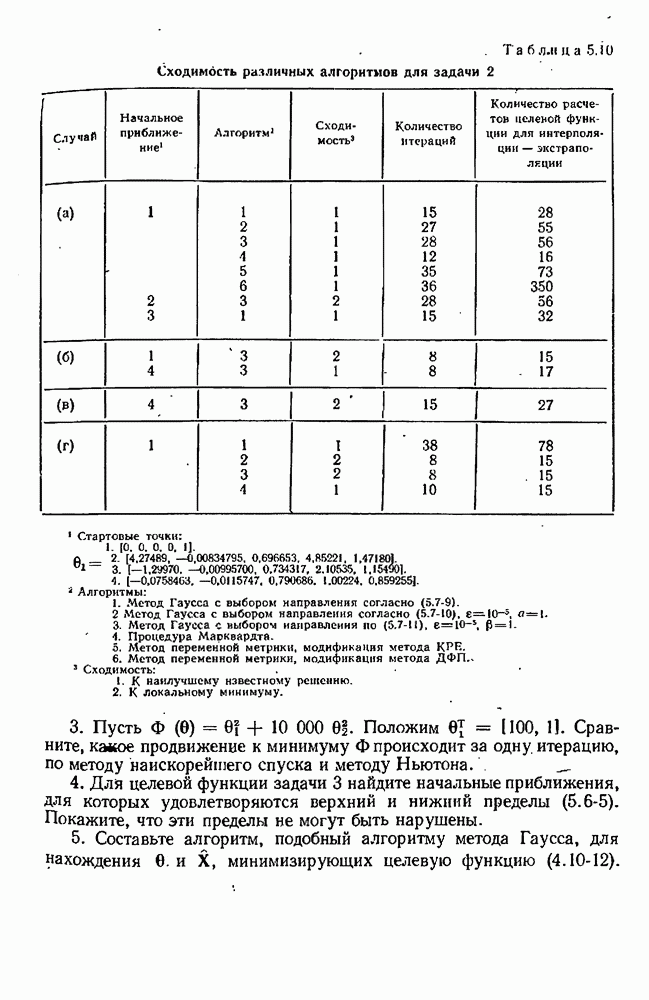
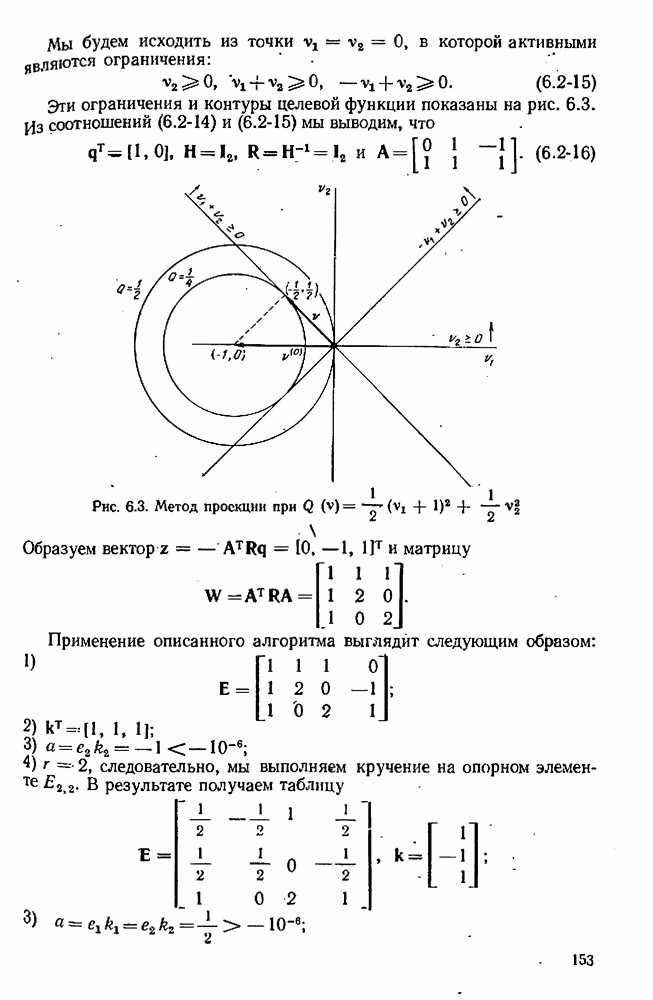
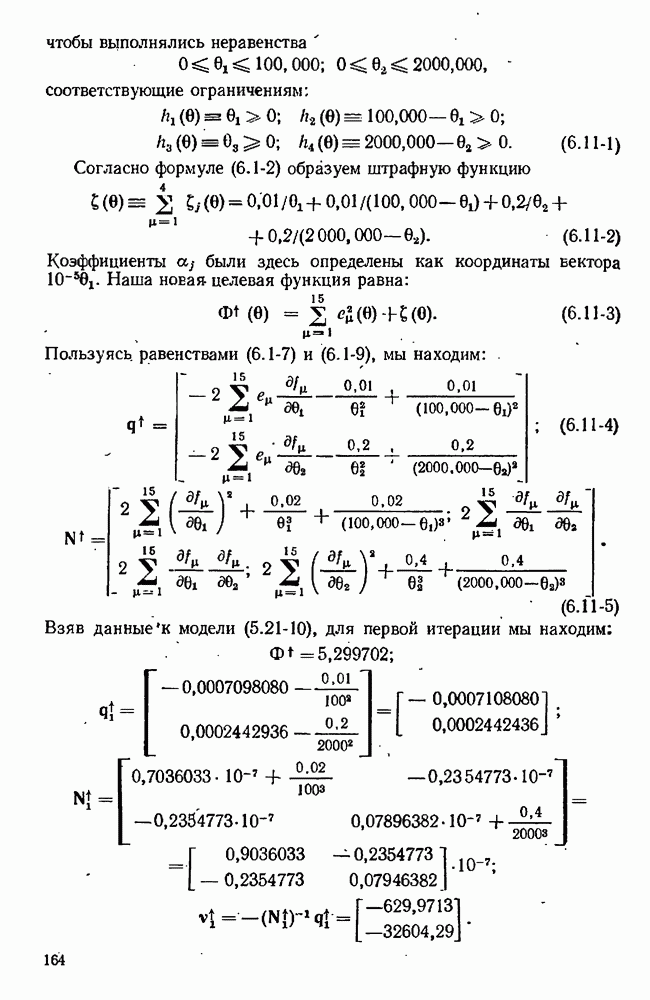
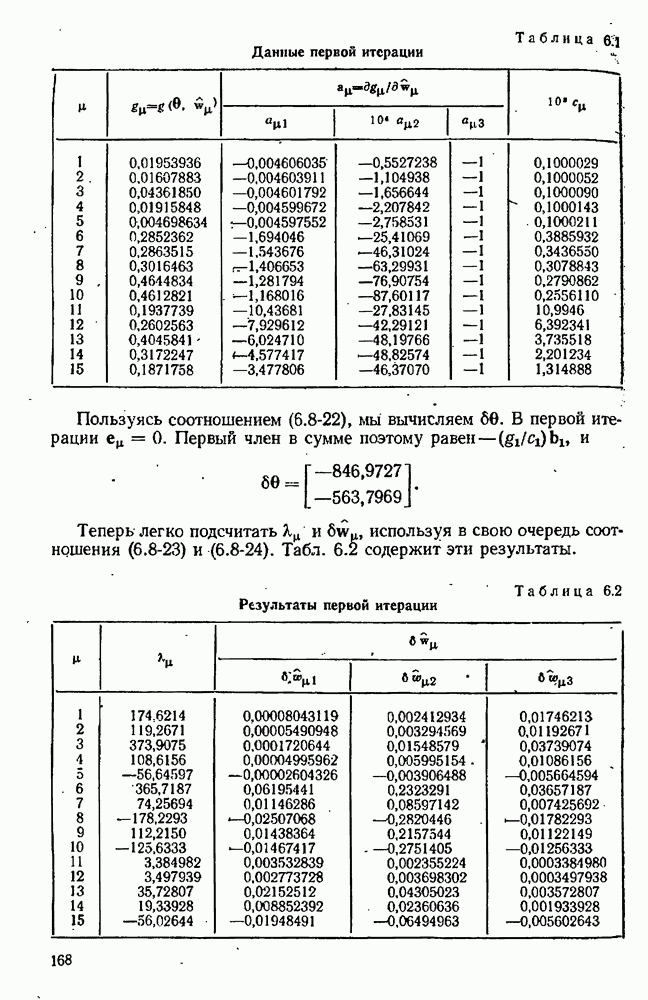
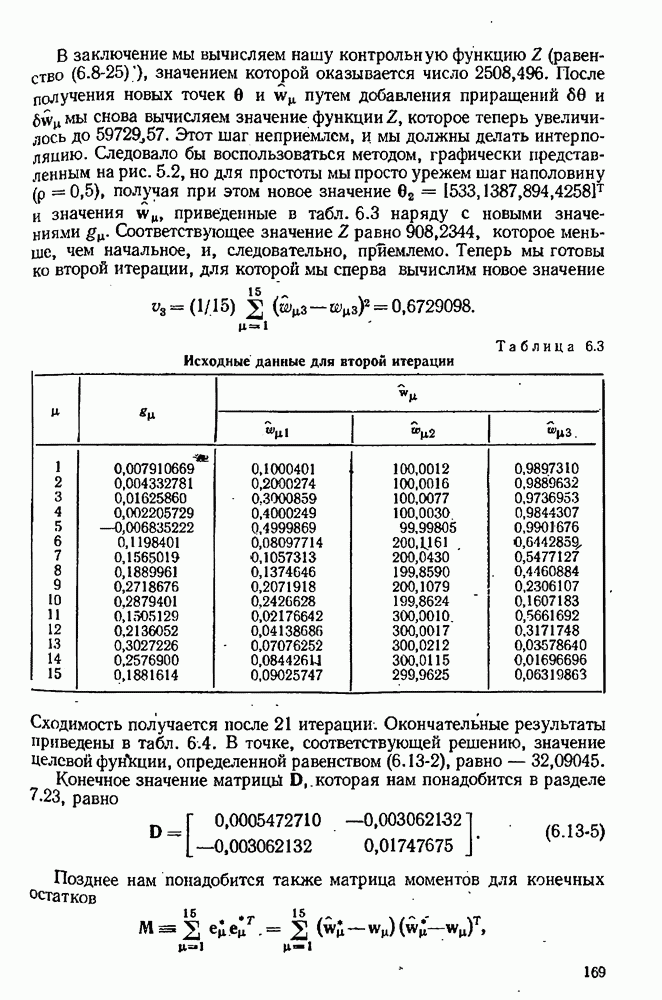
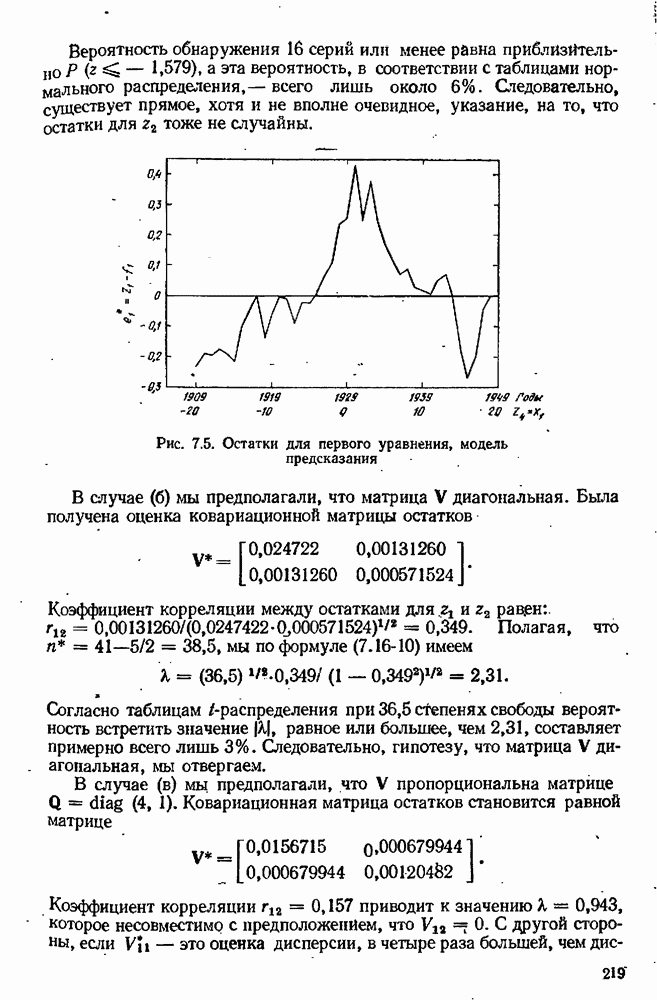
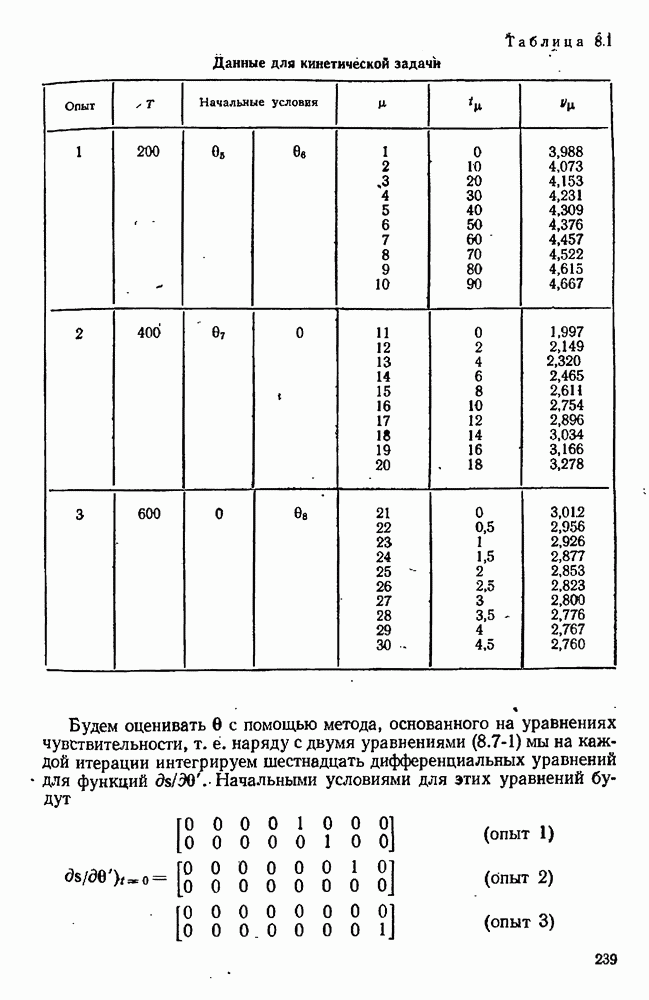
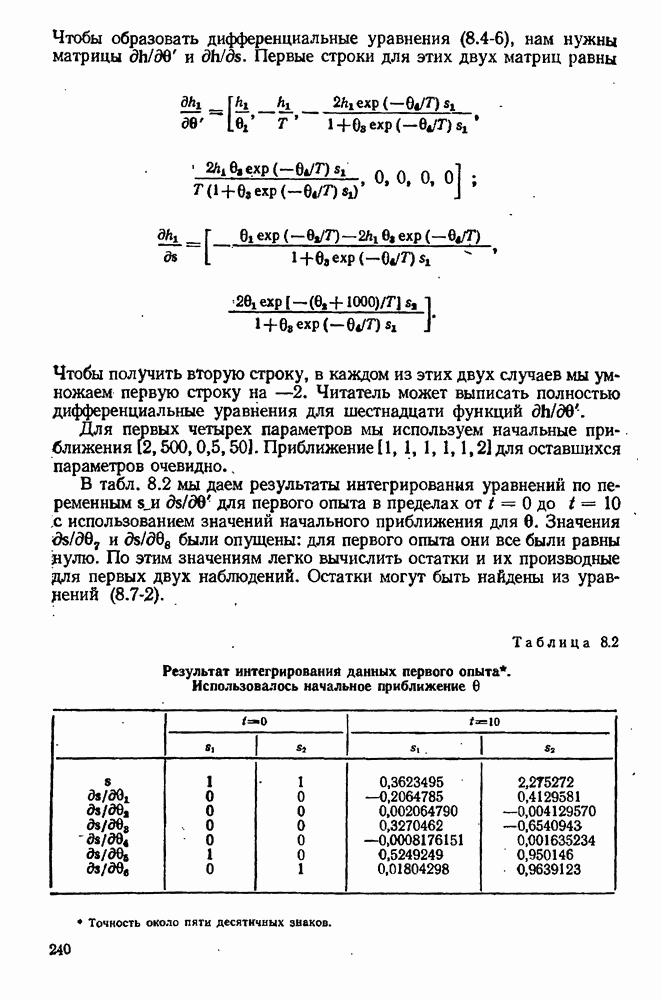
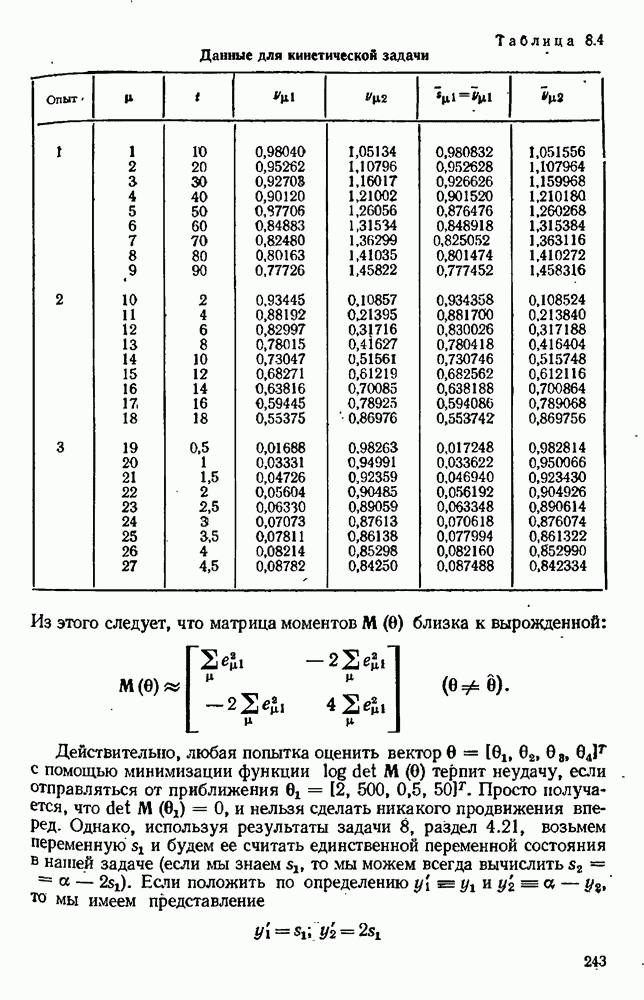
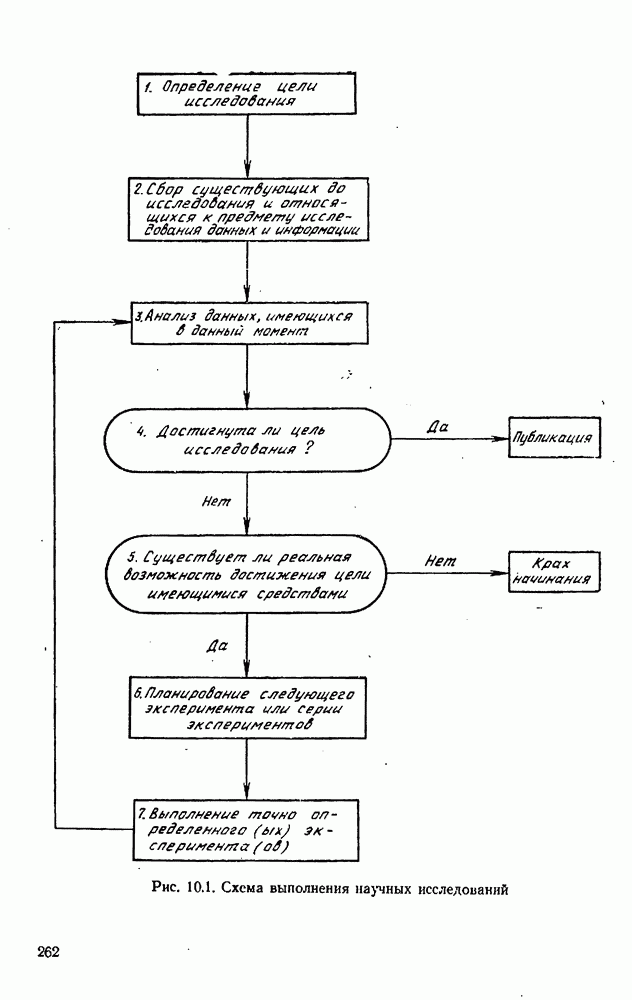
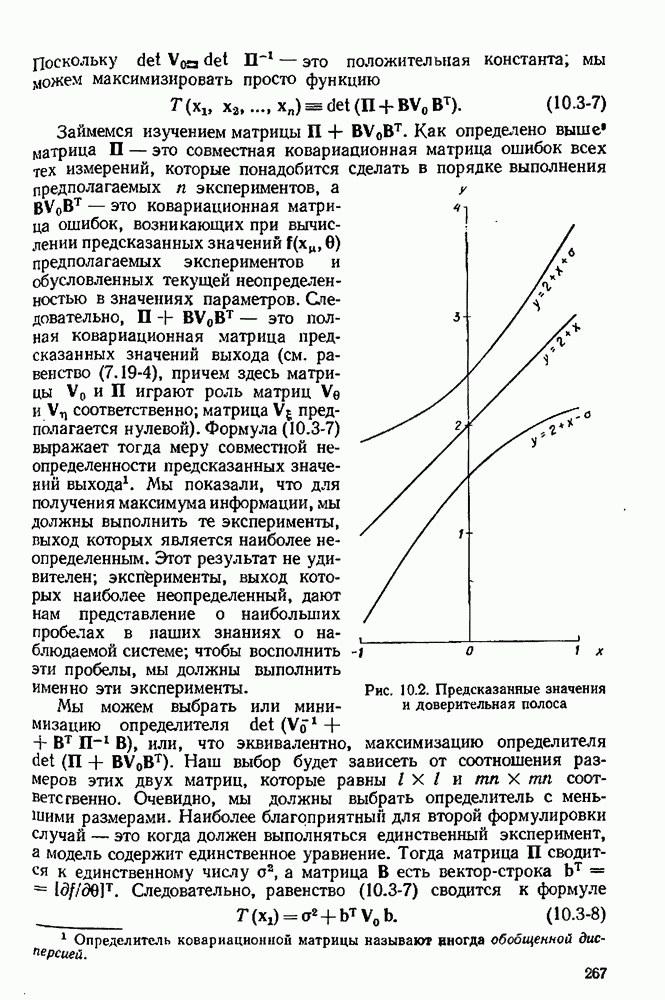
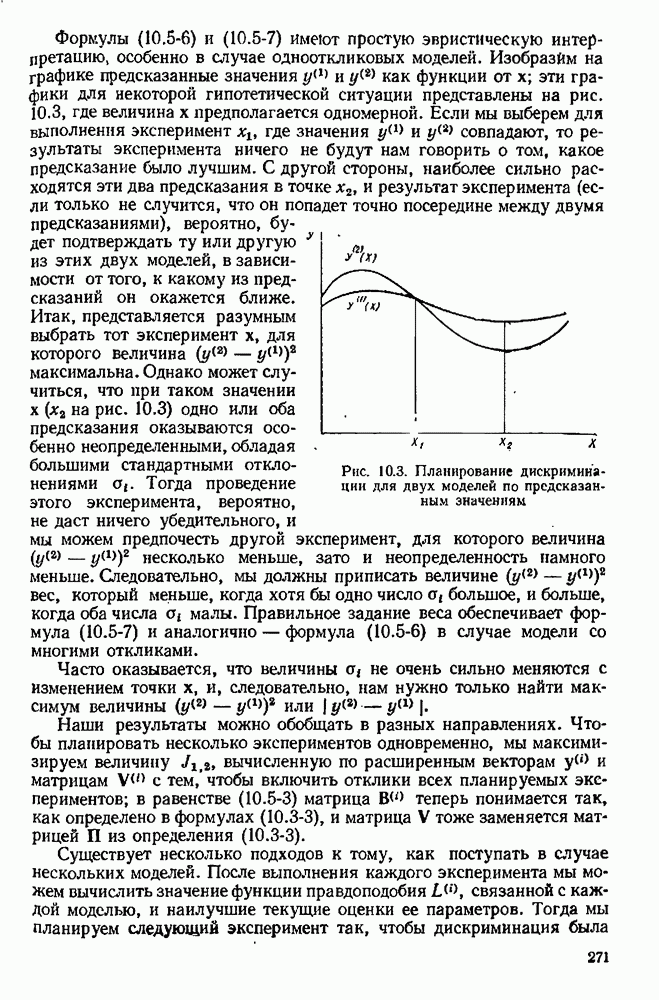
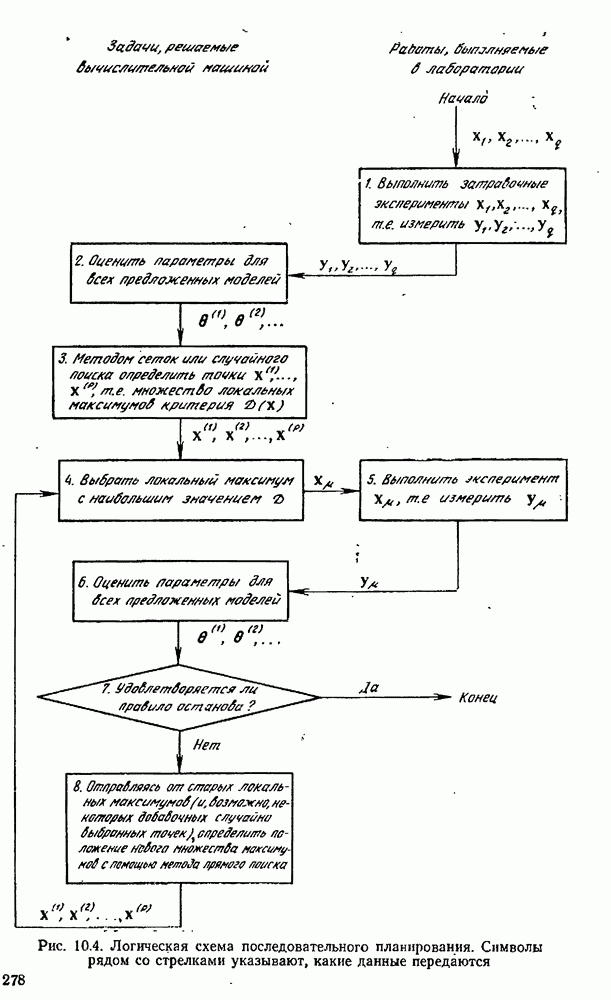
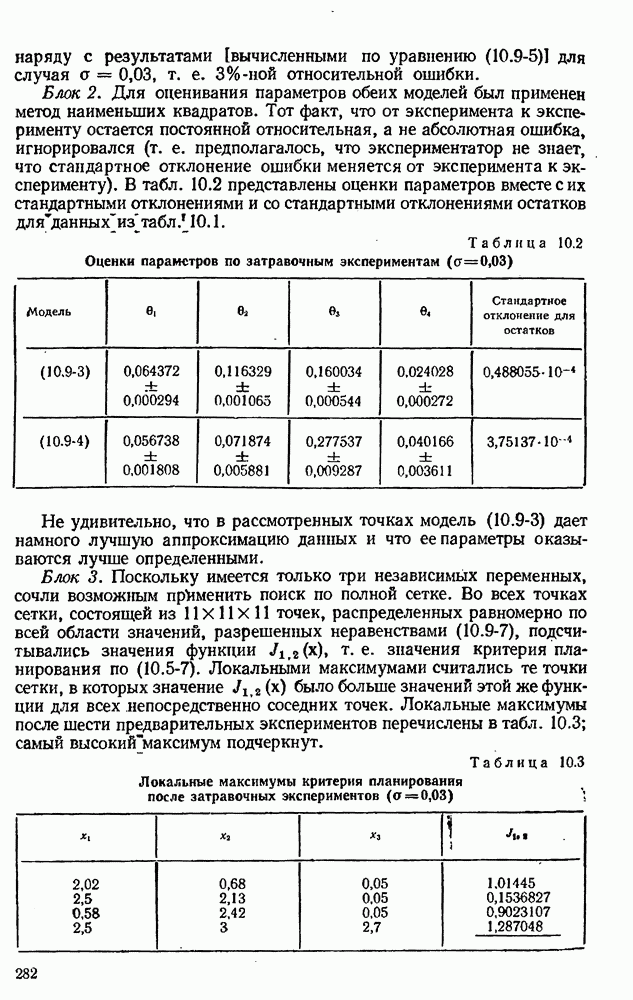
9.6. Задача с пропущенными данными
Мы вернемся к случаю (а) задачи на максимум правдоподобия для модели с двумя уравнениями из раздела 5.23. Однако предположим, что пропущены измерения  Ясно, что полезные данные все еще остаются в точках наблюдений с номерами
Ясно, что полезные данные все еще остаются в точках наблюдений с номерами  и не следует их отбрасывать. Вместо этого мы рассматриваем
и не следует их отбрасывать. Вместо этого мы рассматриваем  как неизвестный параметр
как неизвестный параметр  как неизвестный параметр
как неизвестный параметр  Первое уравнение системы
Первое уравнение системы  теперь имеет вид
теперь имеет вид

и только для  уравнение
уравнение  принимает вид
принимает вид

и только для  Уравнения модели для
Уравнения модели для  остаются неизменными. Матрицы
остаются неизменными. Матрицы  имеют нулевые — шестой и седьмой — столбцы для
имеют нулевые — шестой и седьмой — столбцы для  Для
Для  шестая строка равна
шестая строка равна  а седьмая строка — нулевая; для
а седьмая строка — нулевая; для  шестая строка — нулевая, а седьмая строка равна
шестая строка — нулевая, а седьмая строка равна  За начальные приближения для
За начальные приближения для  мы берем 1,3 и 0,4 соответственно, т. е. значения, которые в силу результатов табл. 5.6 естественны.
мы берем 1,3 и 0,4 соответственно, т. е. значения, которые в силу результатов табл. 5.6 естественны.
Оценка, получаемая с помощью метода Марквардта, равна: 
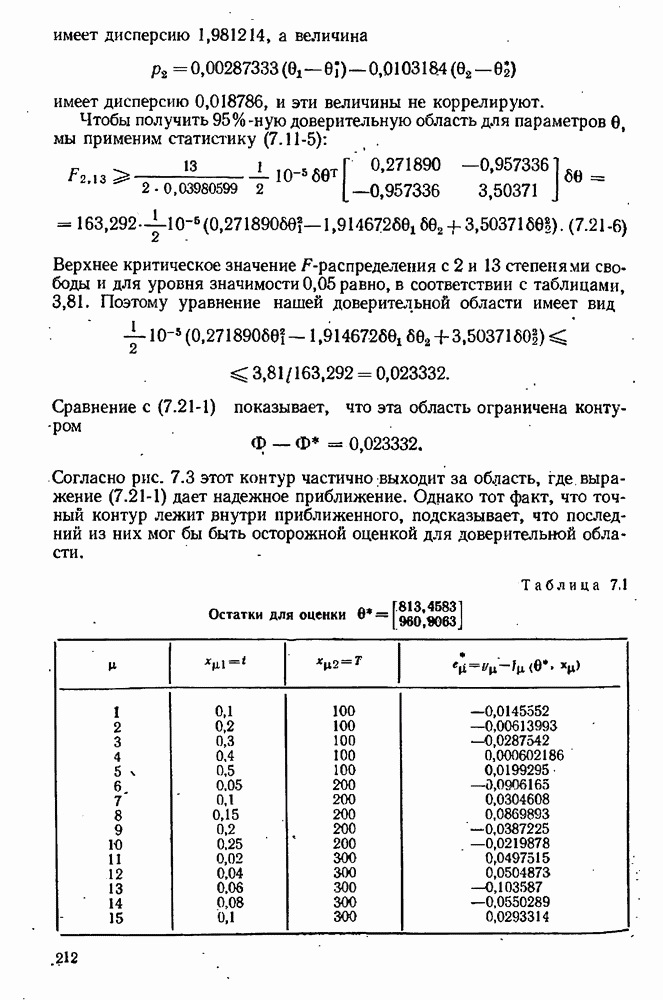
Оценка для 0в, т. е. для  заметно отличается от известного значения 1,33135. Однако это значение приводит к остатку, равному —0,22944 (табл. 7.3), в то время как новой оценке соответствует остаток, равный только
заметно отличается от известного значения 1,33135. Однако это значение приводит к остатку, равному —0,22944 (табл. 7.3), в то время как новой оценке соответствует остаток, равный только  Оценка
Оценка  совеем близка к истинному значению 0,4084 для
совеем близка к истинному значению 0,4084 для 
Параметры  можно, как обычно, перевести в параметры с:
можно, как обычно, перевести в параметры с:

Ковариационная матрица оценок параметров  может быть получена как обычно; маргинальная ковариационная матрица оценок
может быть получена как обычно; маргинальная ковариационная матрица оценок  размерами
размерами  состоит из элементов левого верхнего Угла матрицы,
состоит из элементов левого верхнего Угла матрицы,  размерами
размерами  матрица
матрица  может быть по ней вычислена как обычно.
может быть по ней вычислена как обычно.
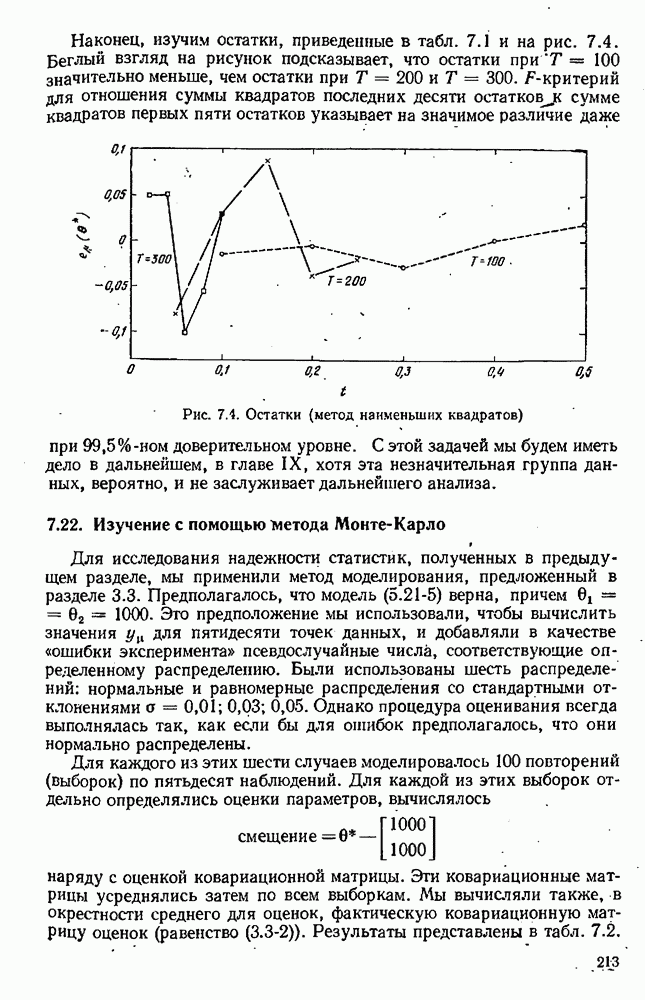
Мы хотим понять, как много информации было потеряно вследствие того, что мы игнорировали значения  а также насколько больше мы потеряли бы ее, если бы отбросили первые два наблюдения полностью, С этой целью мы получили также оценки, основанные на
а также насколько больше мы потеряли бы ее, если бы отбросили первые два наблюдения полностью, С этой целью мы получили также оценки, основанные на
наблюдениях с номерами  Мы вычислили определитель
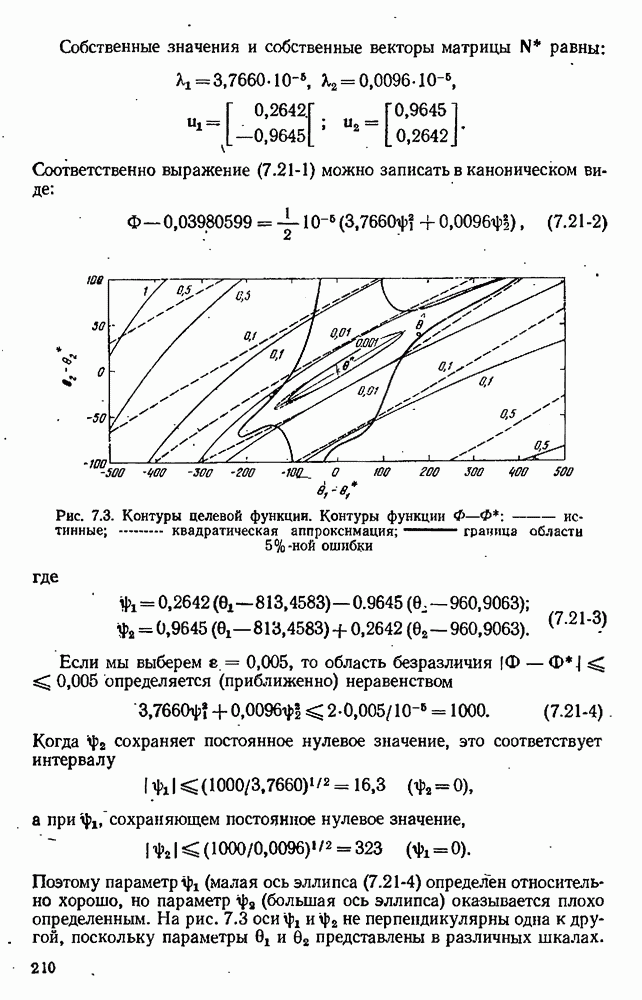
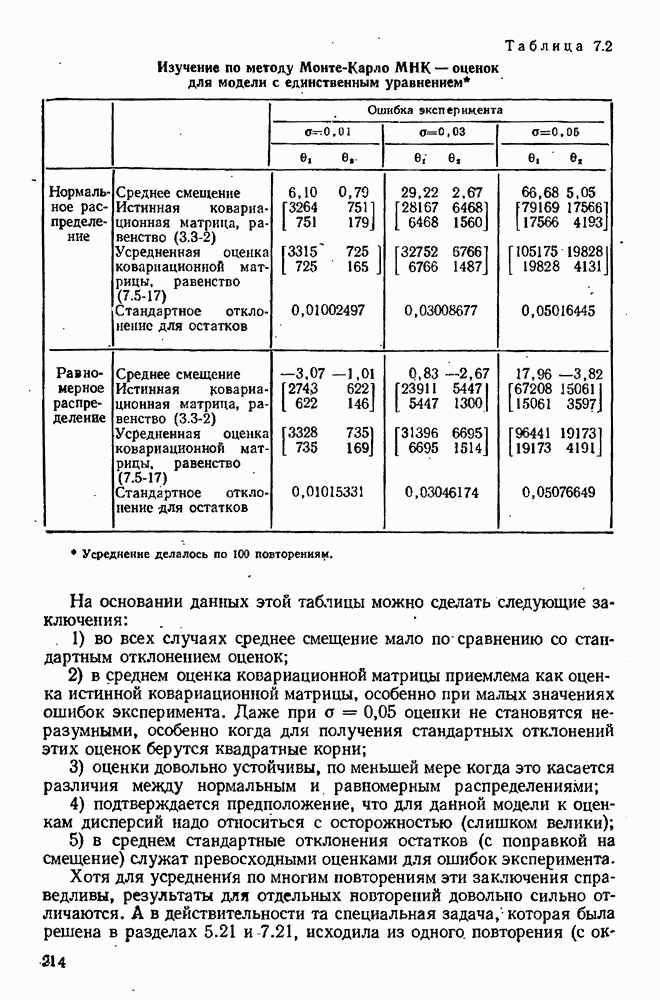
Мы вычислили определитель  для всех трех случаев; эта величина пропорциональна квадрату объема любого доверительного эллипсоида и является также мерой неопределенности в выборочном распределении (см. раздел 10.2). Результаты приведены в табл. 9.1. Мы видим, что чем больше данных потеряно, тем выше неопределенность наших оценок.
для всех трех случаев; эта величина пропорциональна квадрату объема любого доверительного эллипсоида и является также мерой неопределенности в выборочном распределении (см. раздел 10.2). Результаты приведены в табл. 9.1. Мы видим, что чем больше данных потеряно, тем выше неопределенность наших оценок.
Таблица 9.1 (см. скан) Сравнение информации, полученной по данным разного объема