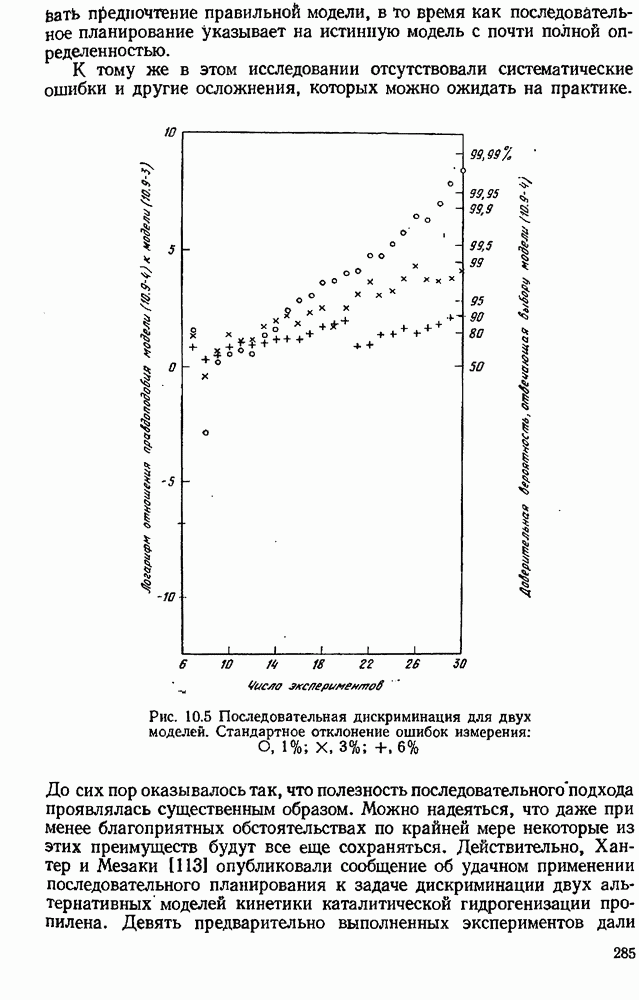
Пред.
След.
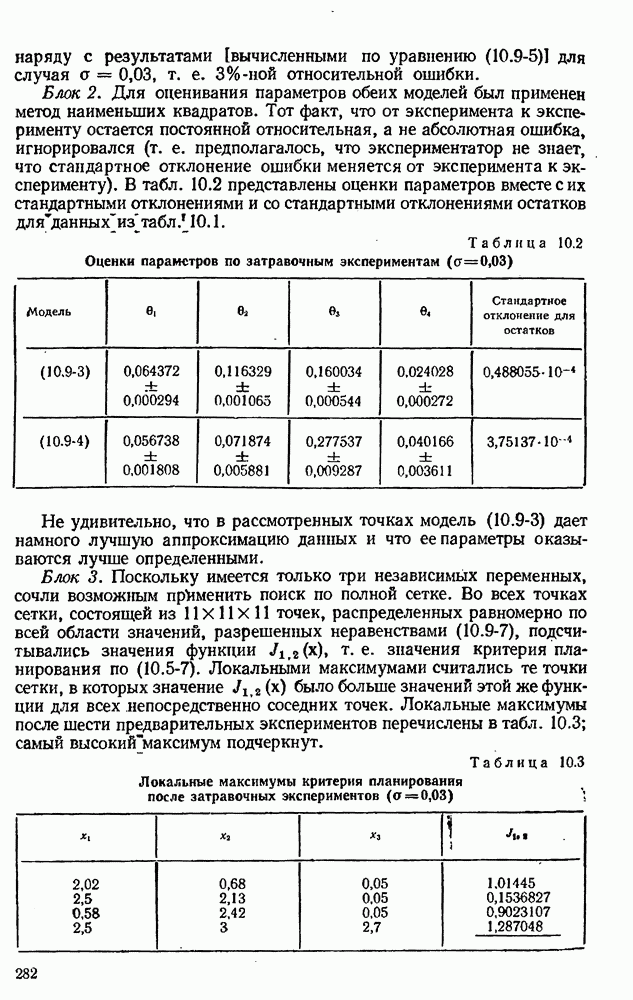
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
7.5. Ковариационная матрица оценокДопустим, что наша оценка представляет собой точку минимума в пространстве без ограничений для некоторой целевой функции
Допустим, что мы слегка изменили данные, заменив
Раскладывая левую часть
так что приблизительно
где, как обычно, Искомая ковариационная матрица
так что
Величины
где
Если мы предположим, что вектор
Эта формула применяется к любой целевой функции независимо от статистических обоснований для ее выбора. Более специальные результаты можно получить, когда целевая функция зависит только от матрицы моментов
где
При допущениях, подобных тем, какие делались при выводе равенства
Подставляя
Вывод, аналогичный тому, какой дается в приложении Предполагая, что наблюдения имеют стандартное отклонение а, в случае единственного уравнения наименьших квадратов мы имеем:
так что равенство
Его сравнение с равенством
Когда дисперсия Приведем теперь результаты для некоторых функций правдоподобия, которые были рассмотрены в разделе 5.9. 1. Нормальное распределение с известной матрицей В соответствии со строкой 1 табл.
2. Как и в пункте 1, но матрица Для широкого класса оценок максимального правдоподобия с нормальными распределениями мы тогда имеем
Качество такой аппроксимации возрастает по мере того, как дисперсия измерений убывает и достигается лучшее соответствие модели и данных наблюдения. Для оценок максимального правдоподобия без ограничений в большинстве случаев можцр показать
Вычисление требуемого математического ожидания очень утомительно, если только вообще возможно; поэтому мы обычно заменяем математическое ожидание на наиболее вероятное значение, т. е. на значение в точке Приведенные здесь и далее оценки для Как иллюстрируется примерами раздела 7.22, эти колебания могут быть довольно большими даже тогда, когда может быть достигнуто хорошее соответствие модели и данных. Мы сами не будем здесь касаться вычисления выборочных дисперсий для Тот факт, что эти аппроксимации рушатся, когда подгонка модели плоха, не должен нас чрезмерно беспокоить, поскольку в этом случае мы так или иначе не слишком доверяем модели и будем пытаться улучшать либо модель, либо данные. Даже очень грубая аппроксимация для
|
 |
Оглавление
|
















































































































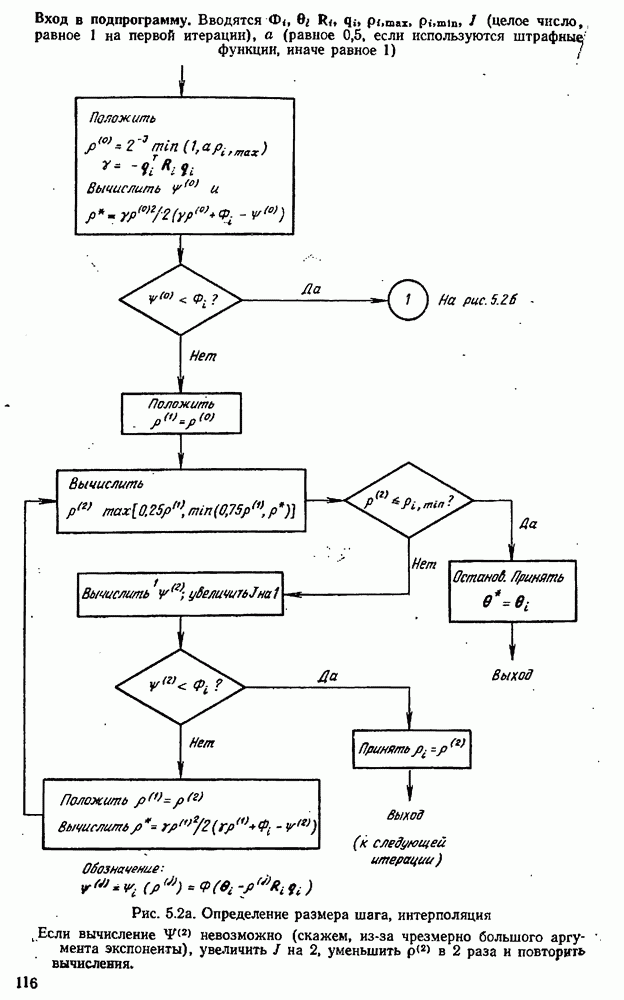
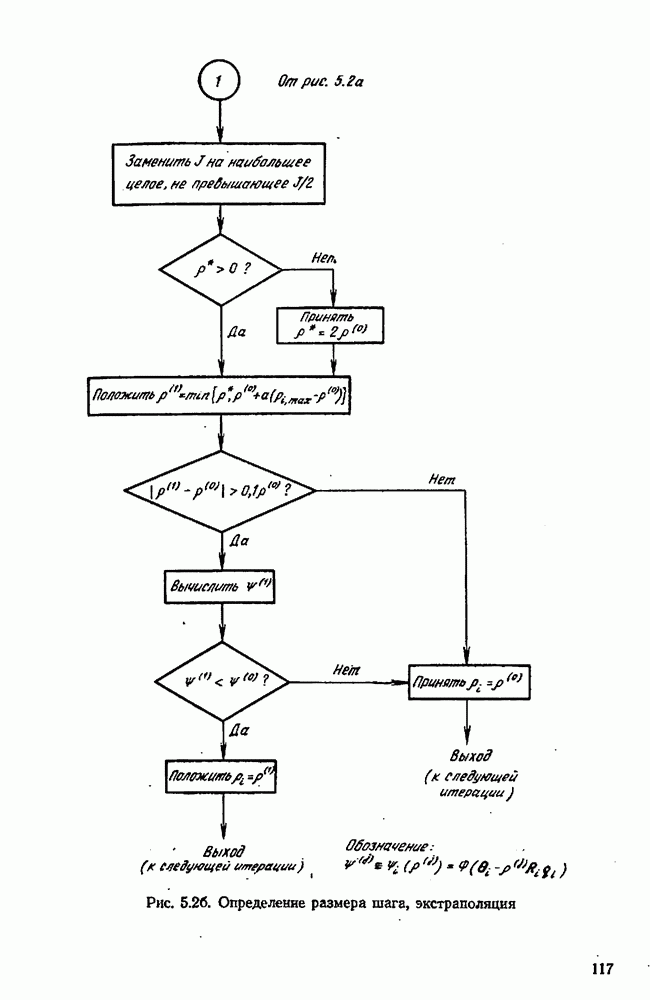





























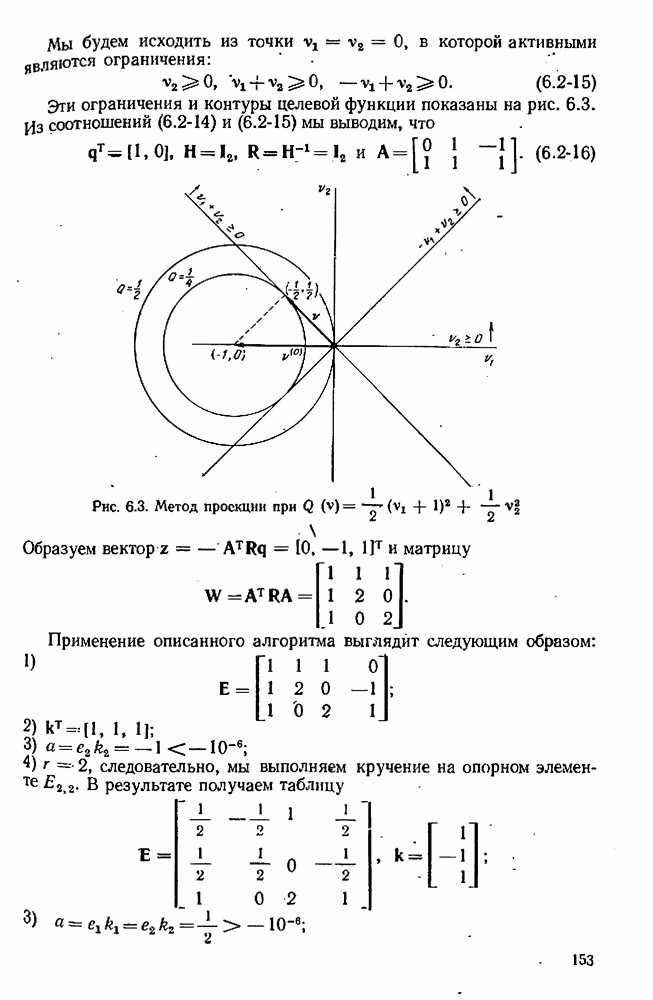










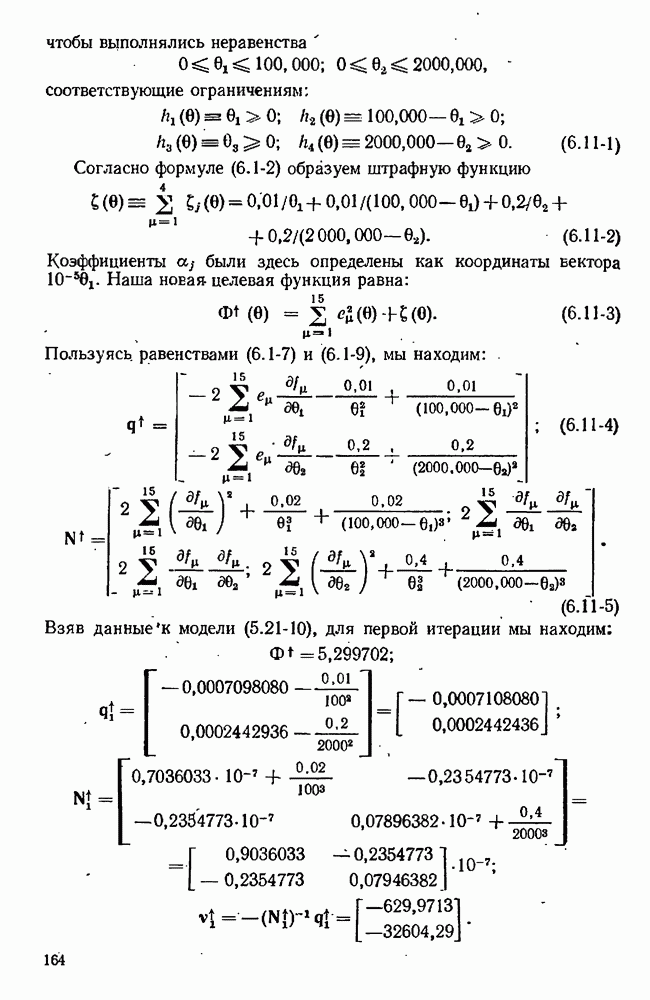



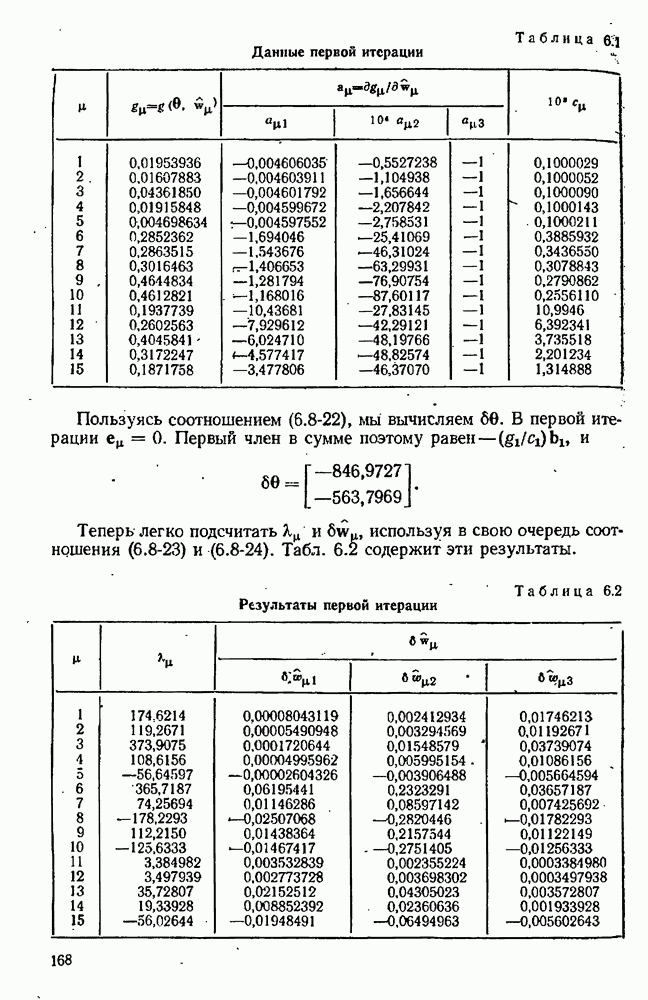
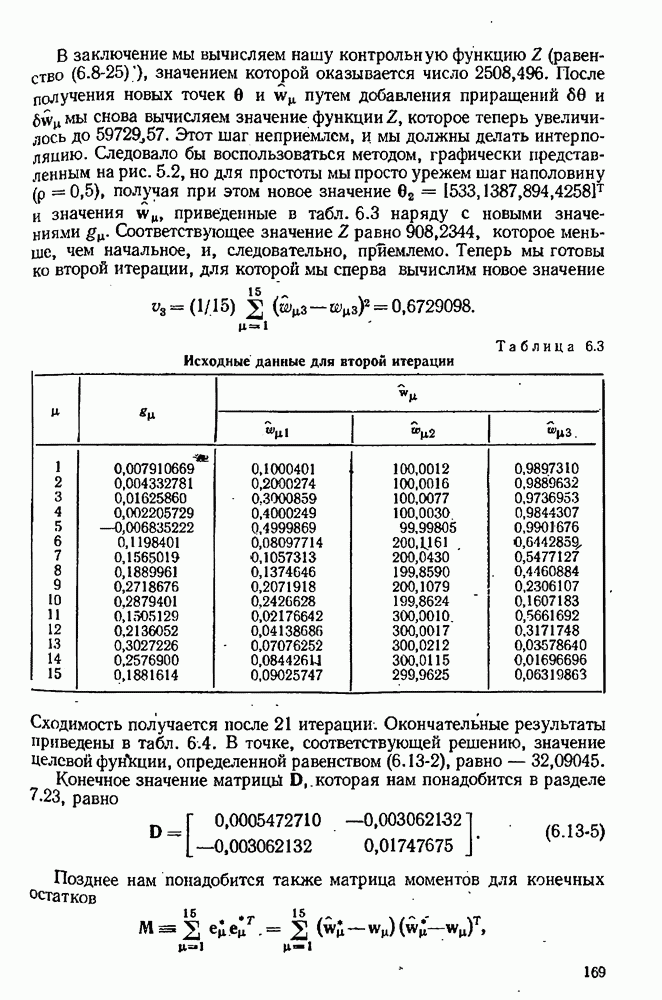








































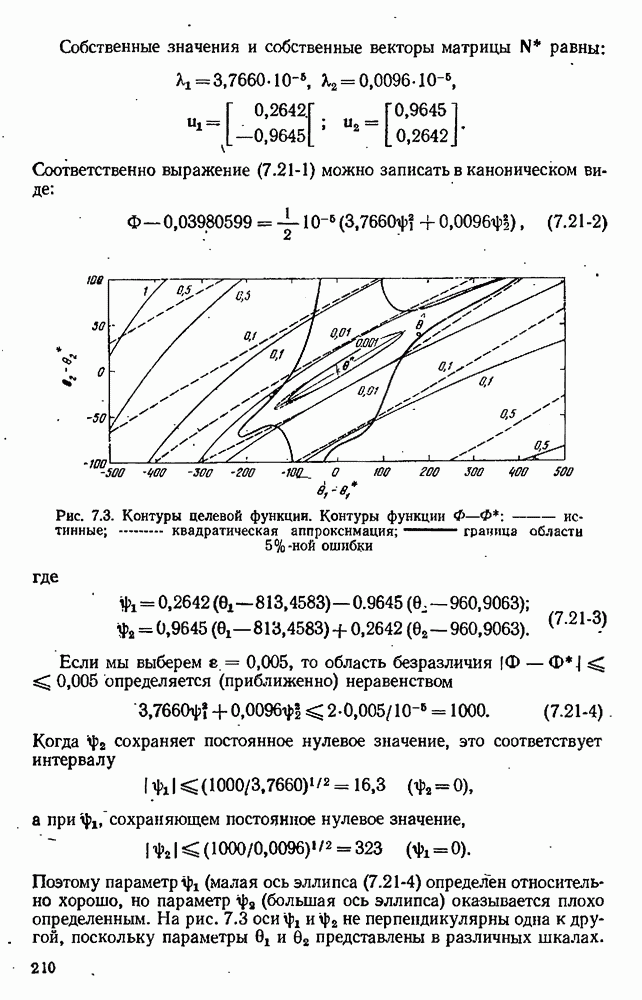

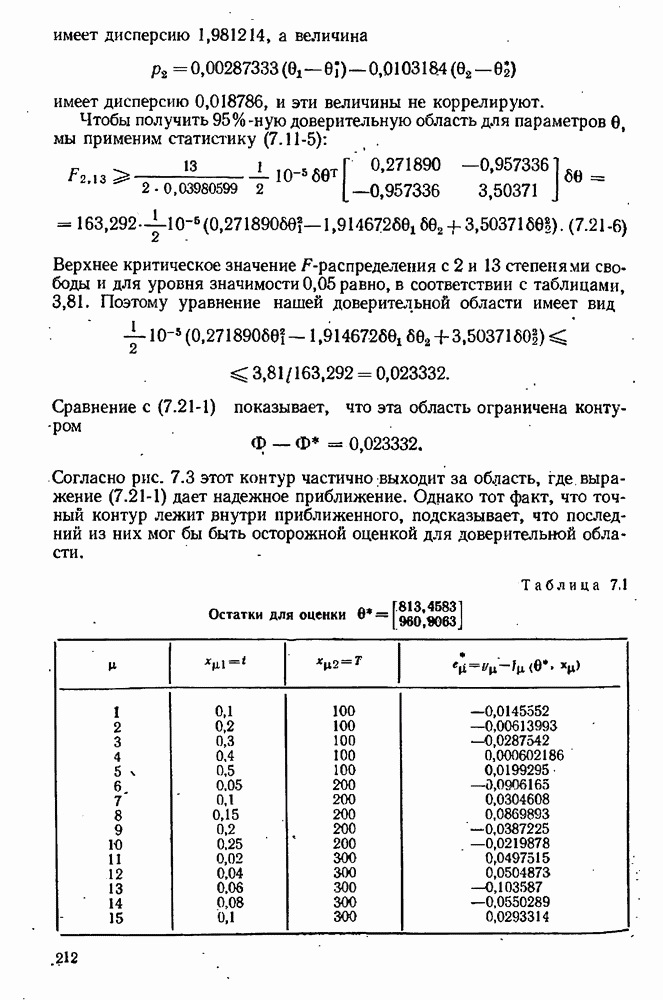
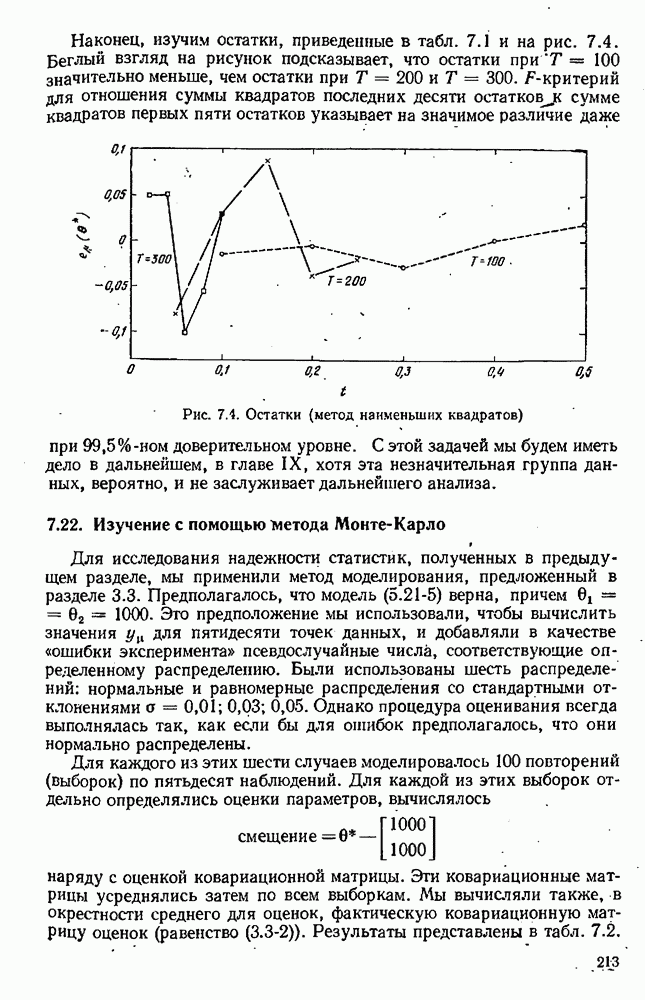
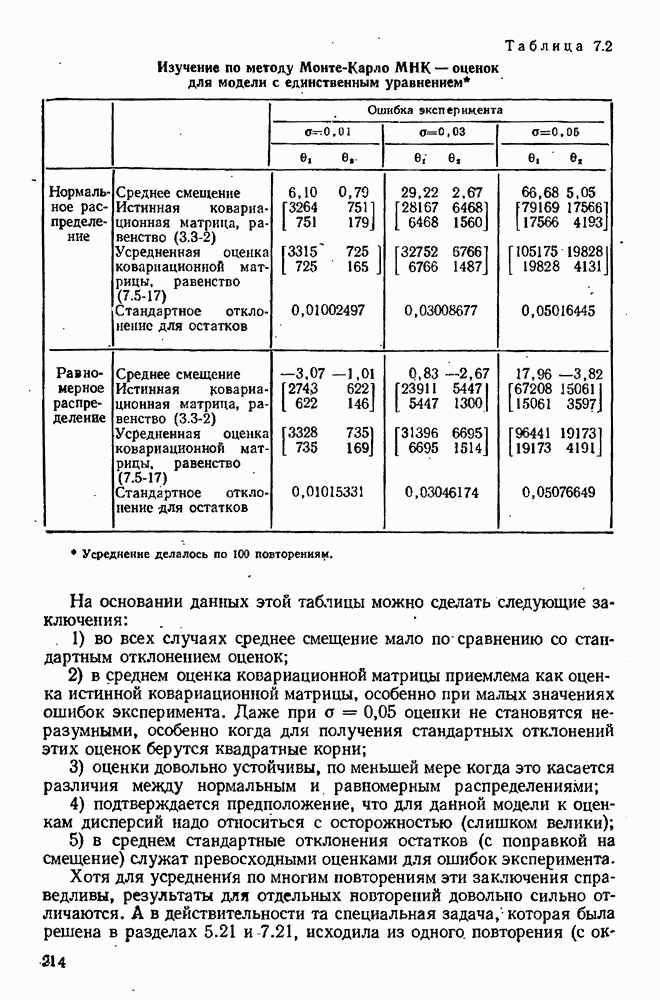

















































































































 Целевая функция зависит также от данных, в частности она зависит
Целевая функция зависит также от данных, в частности она зависит  наблюденных значений
наблюденных значений  случайных величин О. Введем эту зависимость обозначением
случайных величин О. Введем эту зависимость обозначением  вместо
вместо  . В точке минимума мы имеем
. В точке минимума мы имеем

 на
на  Поэтому наш минимум переместится из точки в в точку
Поэтому наш минимум переместится из точки в в точку  где должно выполняться равенство
где должно выполняться равенство

 в ряд Тейлора и оставляя только члены вплоть до первого порядка, с учетом равенства
в ряд Тейлора и оставляя только члены вплоть до первого порядка, с учетом равенства  мы получим
мы получим



 по определению равна
по определению равна


 вычисляются в точке
вычисляются в точке  и по фактической выборке
и по фактической выборке  Следовательно, они — константы и могут быть вынесены за знак математического ожидания в равенстве
Следовательно, они — константы и могут быть вынесены за знак математического ожидания в равенстве  т. е.
т. е.

 есть ковариационная матрица данных, т. е.
есть ковариационная матрица данных, т. е.

 (т. е. результаты
(т. е. результаты  эксперимента) имеет ковариационную матрицу и не зависит от
эксперимента) имеет ковариационную матрицу и не зависит от  то равенство
то равенство  примет вид
примет вид

 для остатков Этот Класс функций, который включает в себя сумму квадраюв и логарифм правдоподобия для нормальных распределений, допускает, как мы видели, гауссовскую аппроксимацию
для остатков Этот Класс функций, который включает в себя сумму квадраюв и логарифм правдоподобия для нормальных распределений, допускает, как мы видели, гауссовскую аппроксимацию  для матрицы
для матрицы  Выведем аналогичную аппроксимацию для
Выведем аналогичную аппроксимацию для  Равенство
Равенство  можно переписать в виде
можно переписать в виде


 можно показать, что для стандартных приведенных моделей, когда
можно показать, что для стандартных приведенных моделей, когда 

 в равенство
в равенство  мы получим:
мы получим:

 для теоремы Гаусса — Маркова, показывает, что если
для теоремы Гаусса — Маркова, показывает, что если  то выбор матрицы
то выбор матрицы  пропорциональной матрице
пропорциональной матрице  ведет к наименьшему из возможных значению определителя
ведет к наименьшему из возможных значению определителя  Это на самом деле имеет место в нижеприведенных случаях и объясняет, почему оценки максимального и псевдомаксимального правдоподобия оптимальны, по крайней мере, приближенно.
Это на самом деле имеет место в нижеприведенных случаях и объясняет, почему оценки максимального и псевдомаксимального правдоподобия оптимальны, по крайней мере, приближенно.

 принимает вид
принимает вид

 показывает, что здесь справедливо соотношение
показывает, что здесь справедливо соотношение

 неизвестна, мы заменяем ее оценкой
неизвестна, мы заменяем ее оценкой  Численные примеры даются в разделе 7.21.
Численные примеры даются в разделе 7.21.

 так что ввиду
так что ввиду  равенство
равенство  принимает вид
принимает вид

 неизвестна. Согласно строке 3 табл. 5.1
неизвестна. Согласно строке 3 табл. 5.1  . Но в соответствии с формулой
. Но в соответствии с формулой  оценка максимального правдоподобия для V равна
оценка максимального правдоподобия для V равна  так
так  приблизительно
приблизительно  и равенство
и равенство  все еще остается справедливым.
все еще остается справедливым.

 и далее], что асимптотически (когда последовательность экспериментов повторяется до бесконечности) выборочное распределение стремится (с вероятностью 1) к нормальному, причем его среднее равно истинным значениям параметров, а ковариационная матрица равна:
и далее], что асимптотически (когда последовательность экспериментов повторяется до бесконечности) выборочное распределение стремится (с вероятностью 1) к нормальному, причем его среднее равно истинным значениям параметров, а ковариационная матрица равна:

 Это возвращает нас назад к равенству
Это возвращает нас назад к равенству  И опять-таки приемлемость этой аппроксимации зависит от качества подгонки модели к данным. Если эта подгонка очень хорошая, функция правдоподобия имеет острый пик, а математическое ожидание и наиболее вероятное значение почти совпадают.
И опять-таки приемлемость этой аппроксимации зависит от качества подгонки модели к данным. Если эта подгонка очень хорошая, функция правдоподобия имеет острый пик, а математическое ожидание и наиболее вероятное значение почти совпадают.
 и других статистических параметров вычисляются по данным наблюдений. Следовательно, они сами — случайные величины и подвержены выборочным колебаниям.
и других статистических параметров вычисляются по данным наблюдений. Следовательно, они сами — случайные величины и подвержены выборочным колебаниям.
 Тем не менее мы укажем, что эти дисперсии всегда возможно находить с помощью метода Монте-Карло (раздел 3.3). Обычно же матрицу
Тем не менее мы укажем, что эти дисперсии всегда возможно находить с помощью метода Монте-Карло (раздел 3.3). Обычно же матрицу  вычисленную по некоторой имеющейся выборке данных, можно рассматривать как грубую, правильно отражающую порядок величины оценку и не более.
вычисленную по некоторой имеющейся выборке данных, можно рассматривать как грубую, правильно отражающую порядок величины оценку и не более.
 может принести значительную пользу, как мы увидим это в главе
может принести значительную пользу, как мы увидим это в главе 