Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
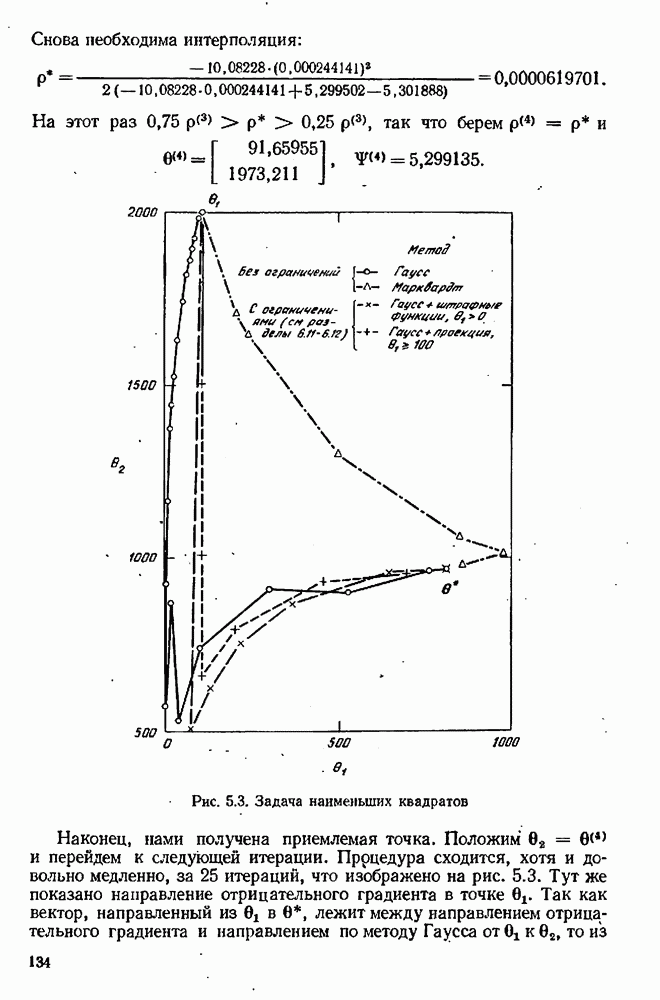
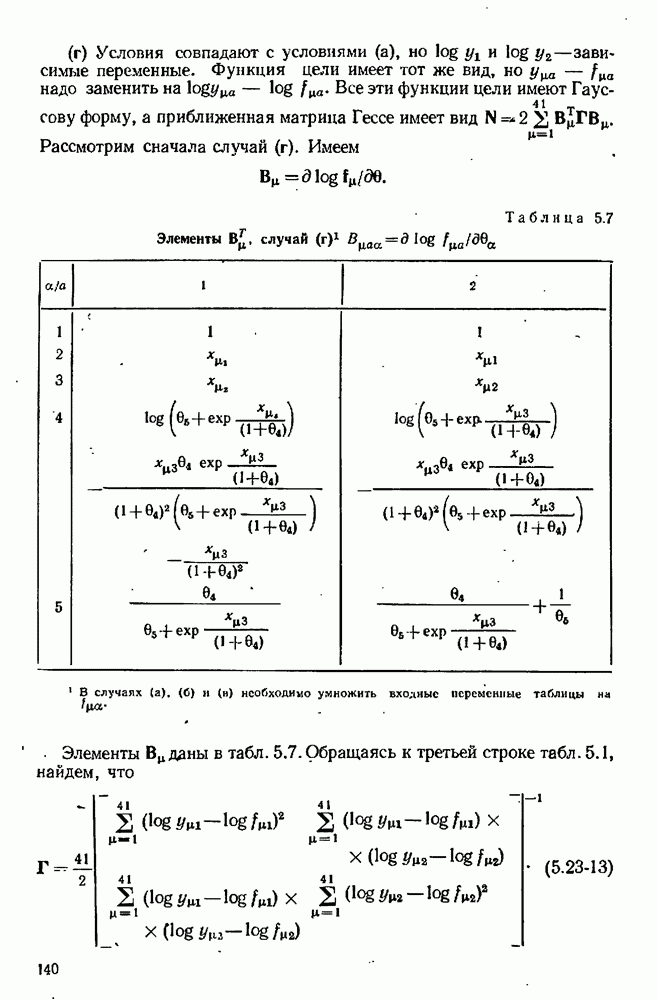
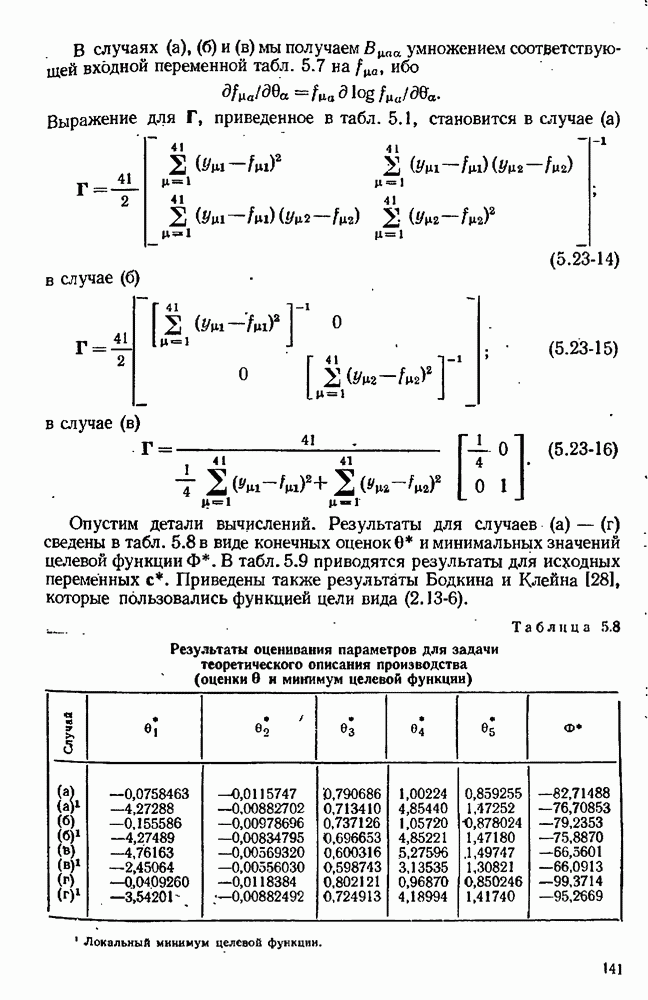
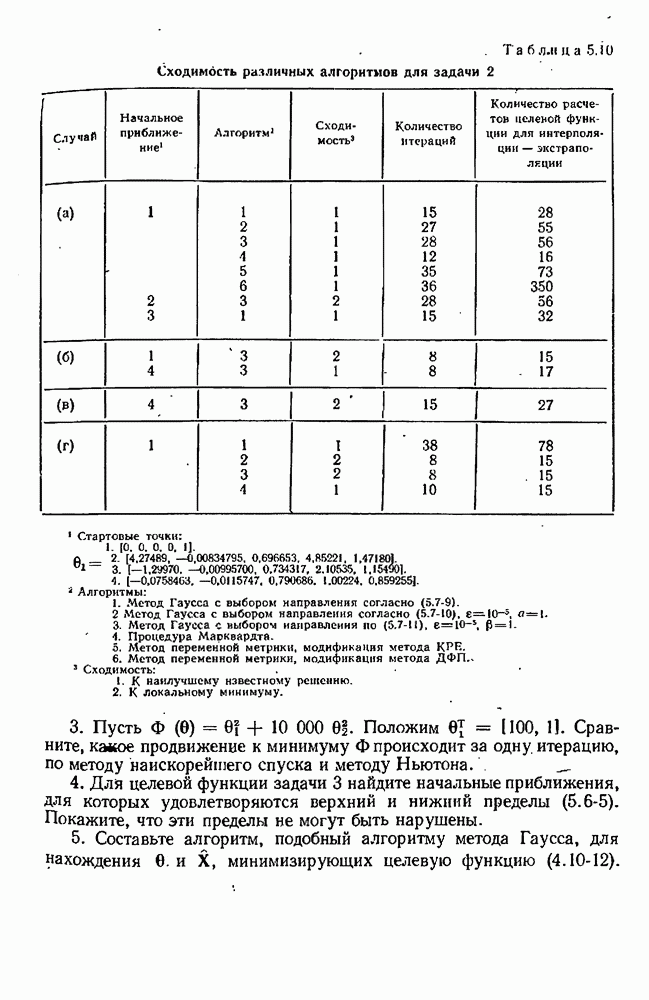
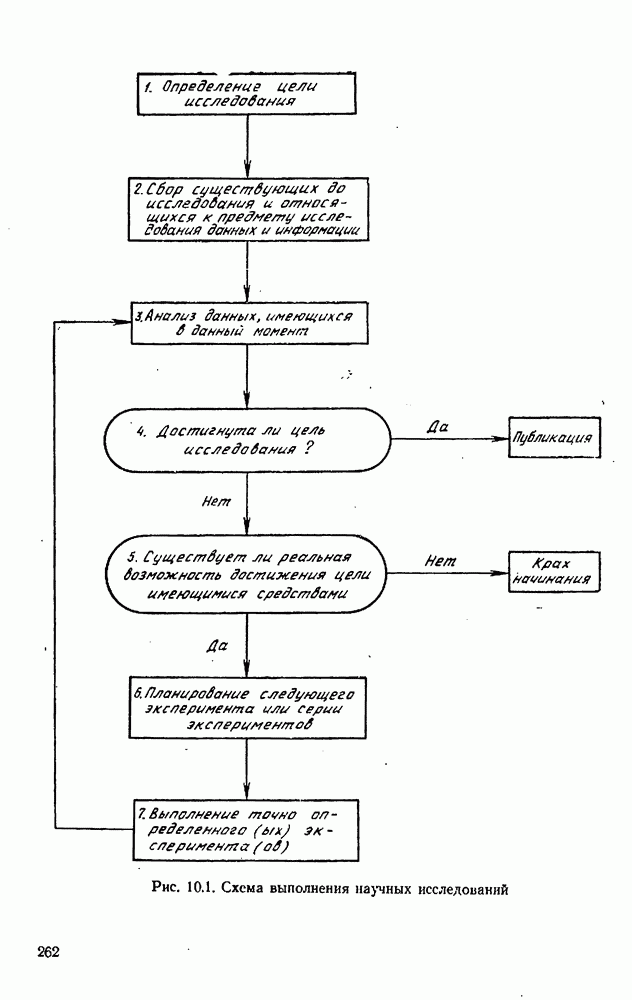
10.9. Имитация экспериментов на вычислительной машинеПрежде чем применять наши методы планирования к реальным экспериментам, разумно, может быть, опробовать их на экспериментах, моделированных с помощью вычислительной машины. При таком подходе мы можем определить без больших затрат, годятся ли они для достижения наших целей. Как мы моделируем эксперименты на вычислительной машине? С нашей точки зрения, эксперимент — это просто механизм, порождающий значение величину
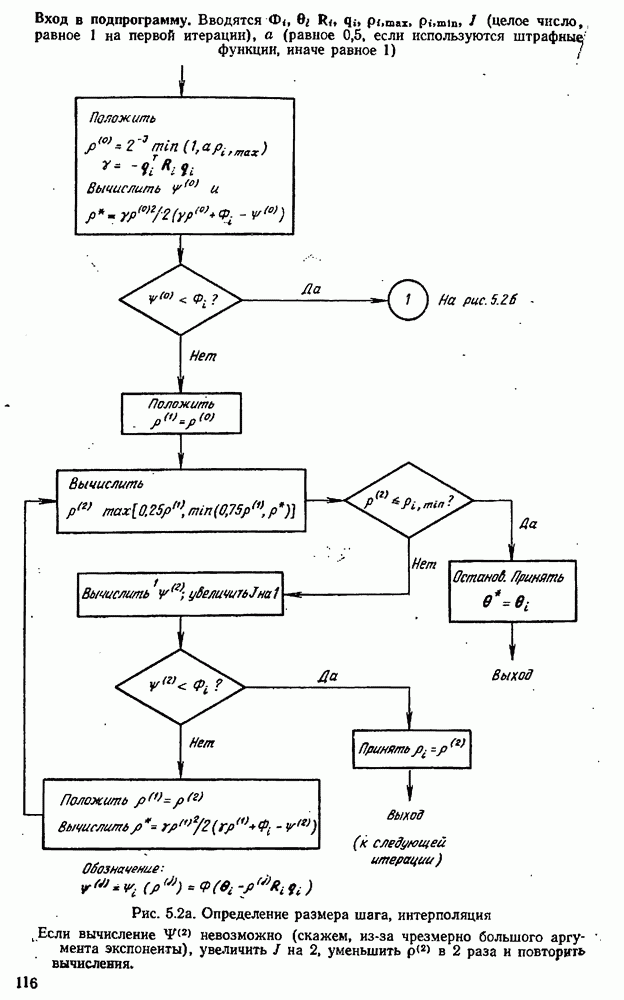
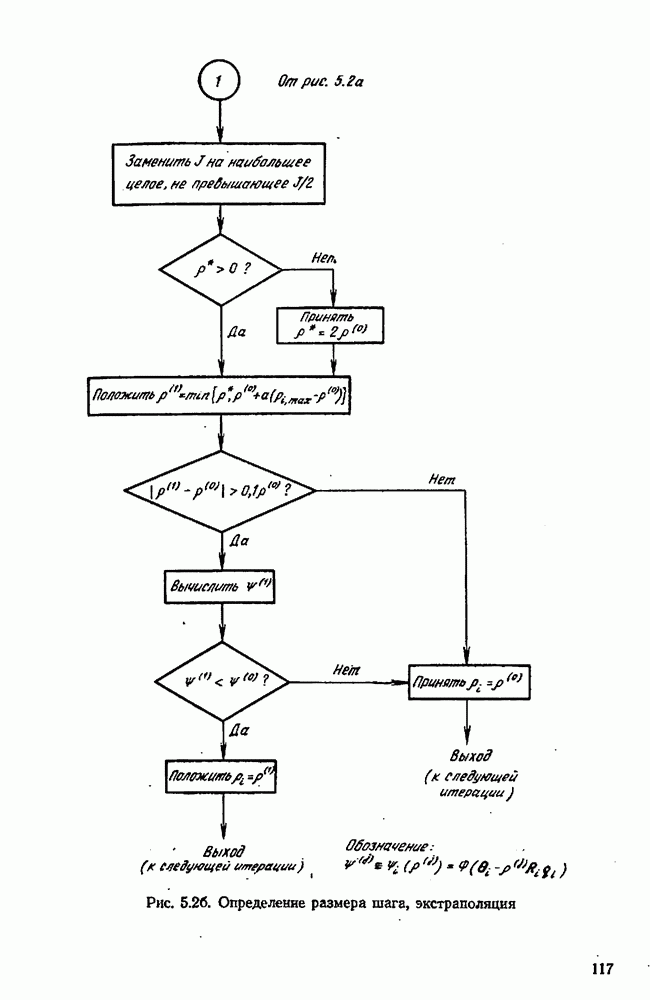
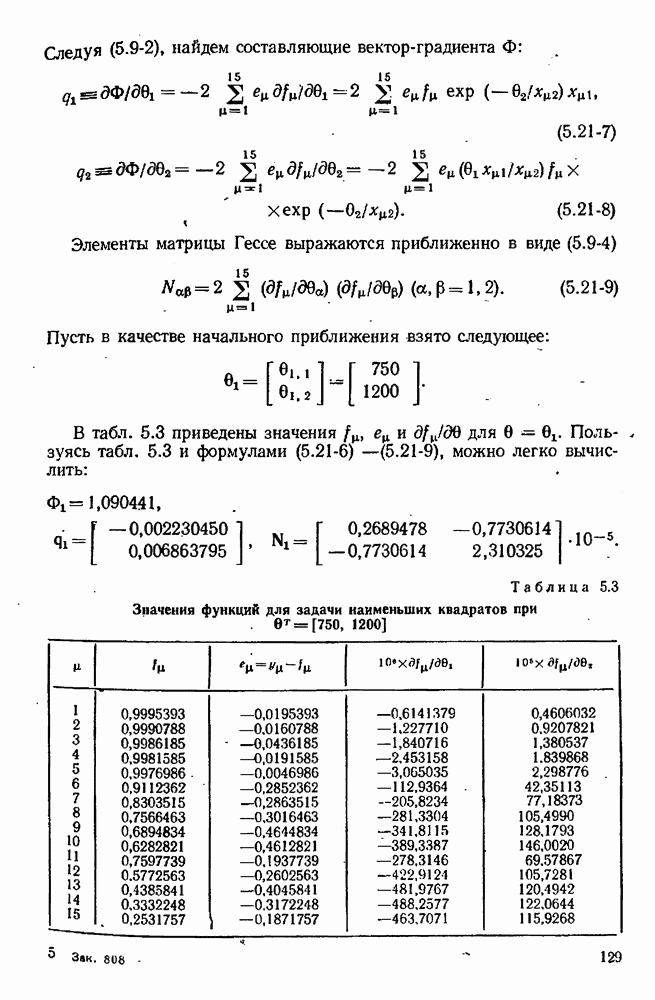
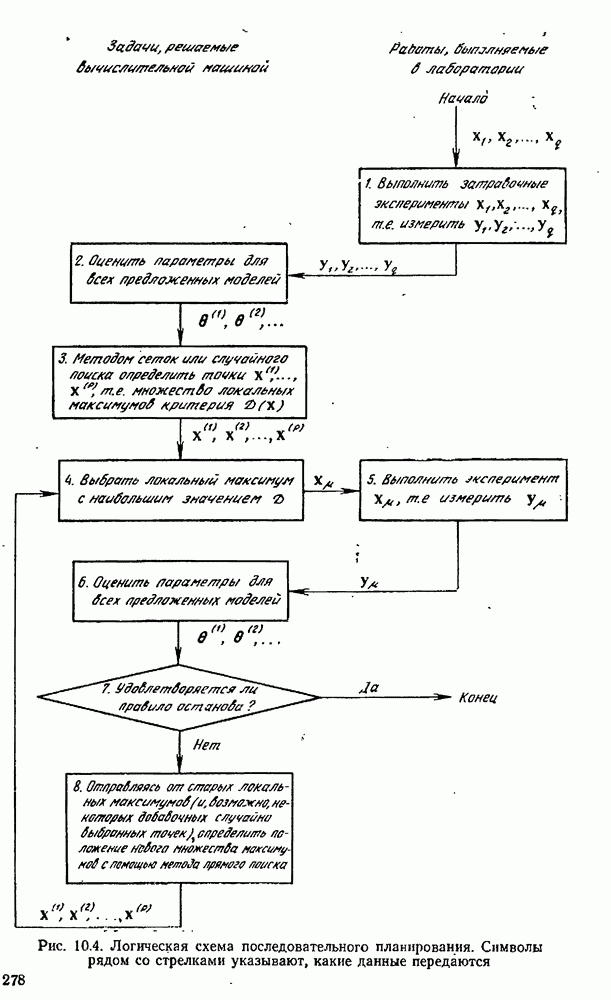
где Проверка процедуры планирования экспериментов осуществляется с помощью логической схемы рис. 10.4, в которой функции блоков (1) и (5) выполняются только что рассмотренной подпрограммой. Заметим, что только эта особая подпрограмма «знает», какая модель была выбрана и какие значения были приписаны параметрам; в точности так же, как в нормальном эксперименте, лабораторная аппаратура «знает» модель и параметры. Единственный способ, с помощью которого другие вычислительные подпрограммы (например, подпрограммы, осуществляющие функции блоков (2) и Теперь мы представим численный пример (1151), в котором к моделированным на вычислительной машине экспериментам применяется метод планирования для выбора одной из моделей. Этим примером ярко иллюстрируются потенциальные возможности метода. Хоуген и Ватсон [110, с. 943—9581 предложили восемнадцать моделей для определения скорости каталитической гидрогенизации смеси изооктенов в изооктан:
Блэйкмор и Хёрл [271 сделали попытку сопоставить эти модели и две дополнительные с данными, которые можно было почерпнуть из литературы. Они обнаружили, что все модели кроме двух можно было бы отвергнуть немедленно. И не существовало никаких убедительных доказательств в пользу одной из этих двух оставшихся моделей, которые имели вид
и
где у — это скорость реакции, Таким образом, эта система моделей признавалась хорошей для опробования процедуры планирования экспериментов. Чтобы моделировать реакцию на вычислительной машине, мы использовали следующие соотношения: для экспериментов с номерами
и для экспериментов с номерами
где Верна модель
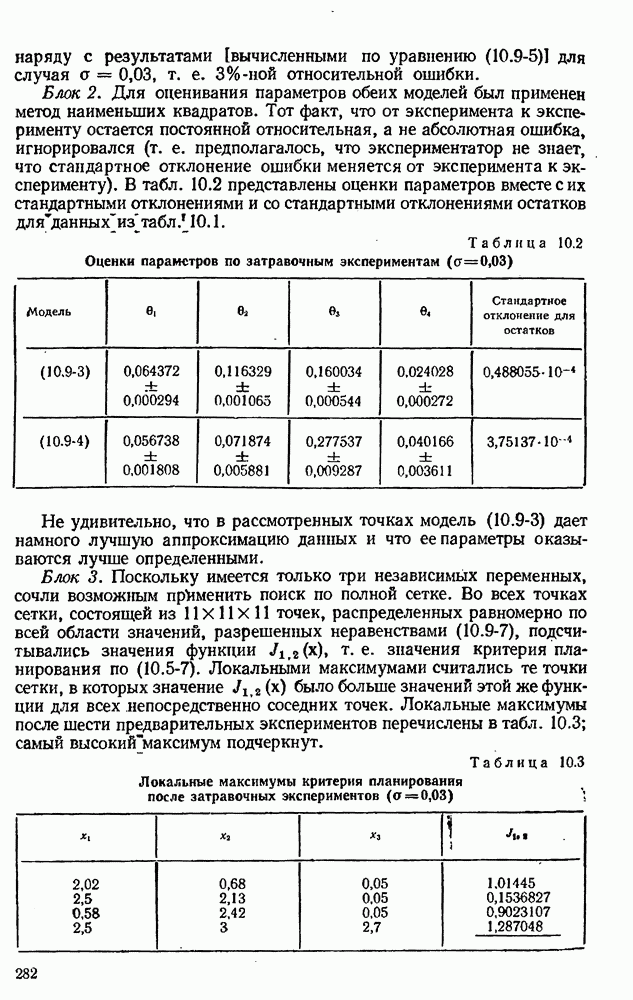
Логическая блок-схема рис. 10.4 была реализована следующим образом. Блок 1. Затравочные эксперименты (их шесть) образованы дробной репликой факторного плана. Они состоят из центров шести поверхностей, ограничивающих область, определенную неравенствами Таблица 10.1 (см. скан) Затравочные эксперименты наряду с результатами [вычисленными по уравнению Блок 2. Для оценивания параметров обеих моделей был применен метод наименьших квадратов. Тот факт, что от эксперимента к эксперименту остается постоянной относительная, а не абсолютная ошибка, игнорировался (т. е. предполагалось, что экспериментатор не знает, что стандартное отклонение ошибки меняется от эксперимента к эксперименту). В табл. 10.2 представлены оценки параметров вместе с их стандартными отклонениями и со стандартными отклонениями остатков для данных из табл. 10.1. Таблица 10.2 (см. скан) Оценки параметров по затравочным экспериментам Не удивительно, что в рассмотренных точках модель Блок 3. Поскольку имеется только три независимых переменных, сочли возможным применить поиск по полной сетке. Во всех точках сетки, состоящей из Таблица 10.3 (см. скан) Локальные максимумы критерия планирования после затравочных экспериментов Блок 4. Для проведения следующего эксперимента мы выбираем самый высокий максимум функции Блок 5. Для получения значения у» используется уравнение Блок 6. Выполняются те же операции, что и в блоке 2. Блок 7. Моделирование опытов было прекращено после 30 экспериментов. Однако отношение правдоподобия
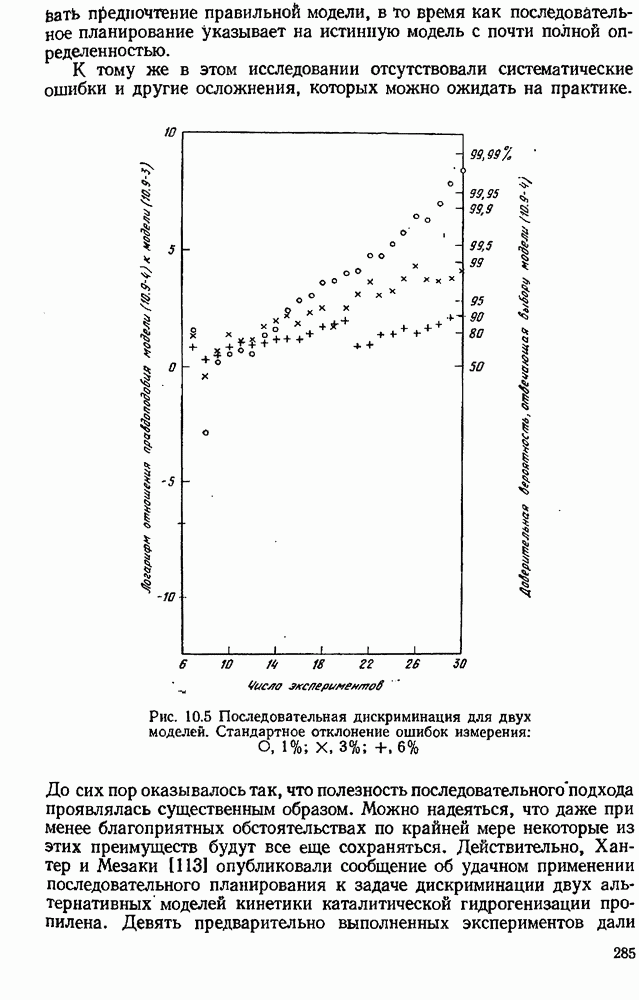
Блок 8. Поиск по полной сетке, приведенной в блоке 3, повторялся после каждого эксперимента. Конечно, это было бы непрактично в задачах большей размерности. Описанная в схеме рис. 10.4 процедура тоже применялась и привела к результатам, которые оказались очень близкими, как и следовало ожидать. В табл. 10.4 даны подробности экспериментов 7—30 в случае Аналогичные опыты были проделаны с В этой задаче применение критерия планирования в виде функции Чтобы определить, дает ли использованная здесь процедура последовательного планирования какие-нибудь улучшения по сравнению с классическими методами планирования, была сделана имитация 27 экспериментов по плану полного факторного эксперимента типа
Таблица 10.4 (см. скан) Последовательность экспериментов, определенная вычислительной машиной Они включают в себя шесть затравочных экспериментов из табл. 10.1. Результаты сравниваются с результатами последовательного планирования в табл. 10.5. Чтобы интерпретировать числа в этой таблице, надо помнить, что уровень предпочтения 0,5 означает полную неразличимость двух моделей. Таким образом, при уровнях ошибок от 3% и более полный факторный эксперимент терпит поражение при попытке сделать различие между моделями, в то время как последовательное планирование порождает 83,3%-ную довер ительную вероятность для правильной модели даже в случае 6%-ной ошибки. При 1%-ном уровне ошибки полный факторный эксперимент едва только начинает Таблица 10.5 (см. скан) Сравнение двух схем планирования экспериментов отдавать предпочтение правильной модели, в то время как последовательное планирование указывает на истинную модель с почти полной определенностью. К тому же в этом исследовании отсутствовали систематические ошибки и другие осложнения, которых можно ожидать на практике. Рис. 10.5 (см. скан) Последовательная дискриминация для двух моделей. Стандартное отклонение ошибок измерения: До сих пор оказывалось так, что полезность последовательного подхода проявлялась существенным образом. Можно надеяться, что даже при менее благоприятных обстоятельствах по крайней мере некоторые из этих преимуществ будут все еще сохраняться. Действительно, Хантер и Мезаки [113] опубликовали сообщение об удачном применении последовательного планирования к задаче дискриминации двух альтернативных моделей кинетики каталитической гидрогенизации пропилена. Девять предварительно выполненных экспериментов дали отношение правдоподобия величинои
|
 |
Оглавление
|













































































































































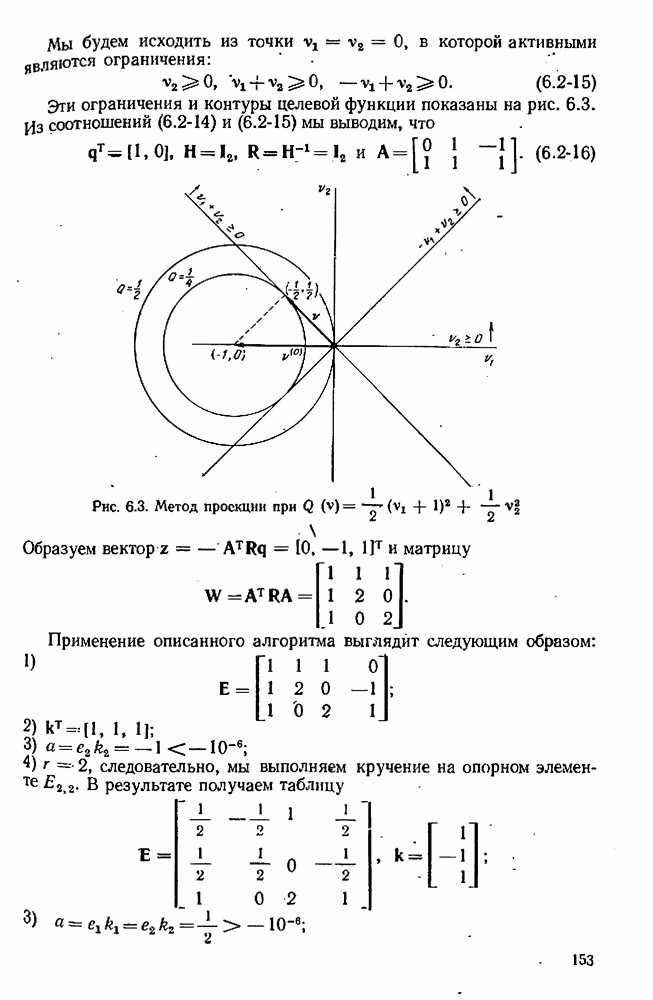










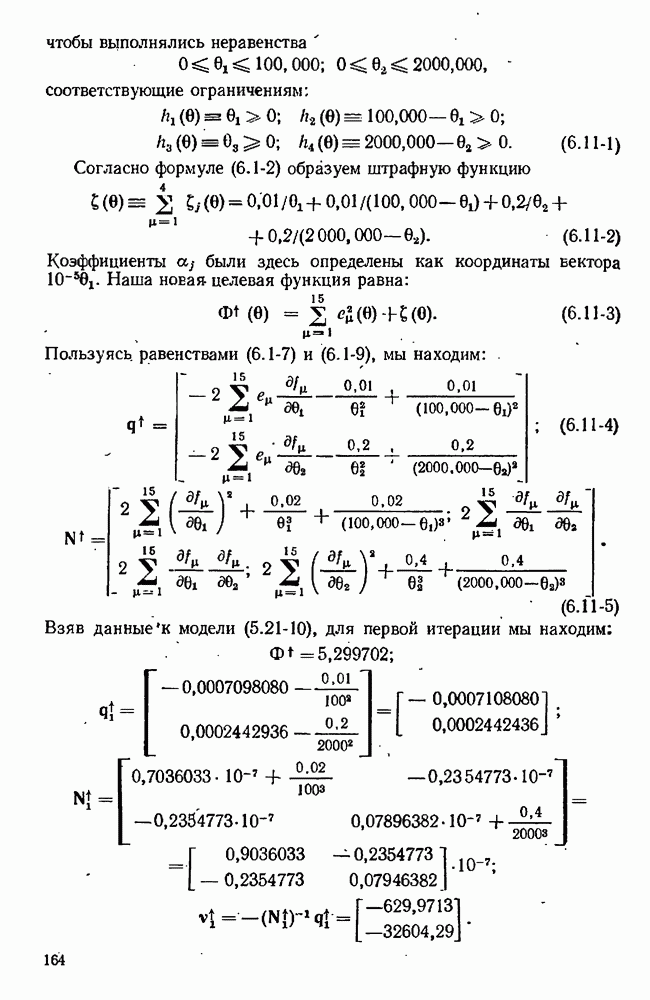



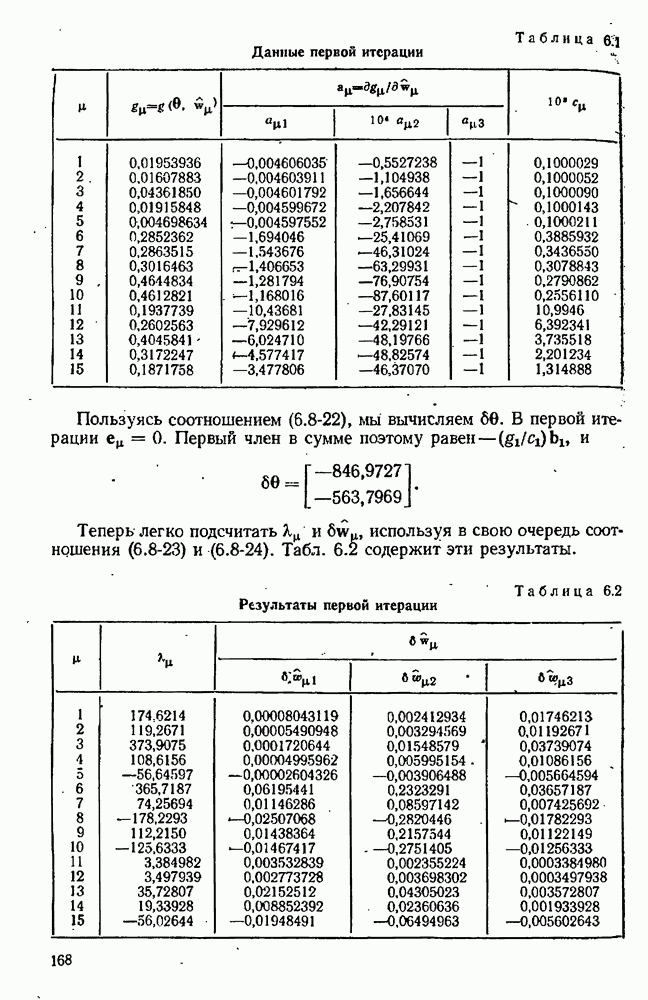
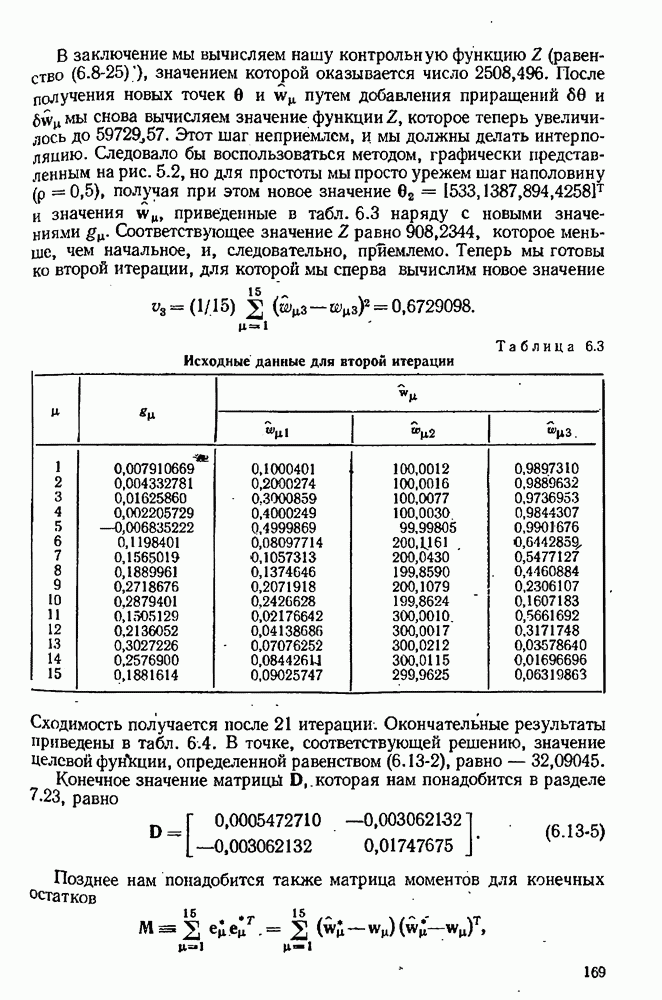








































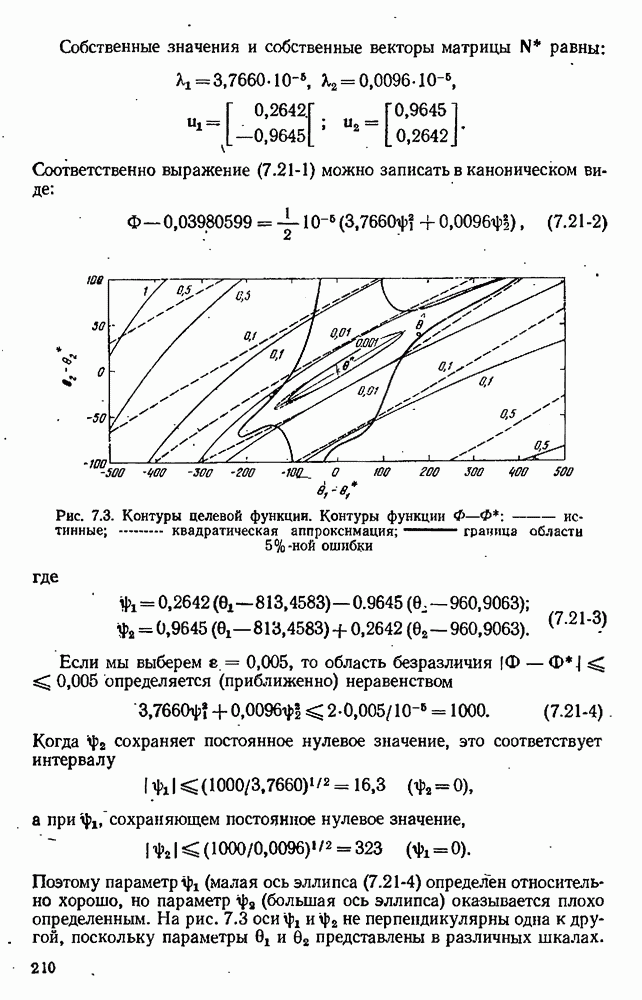

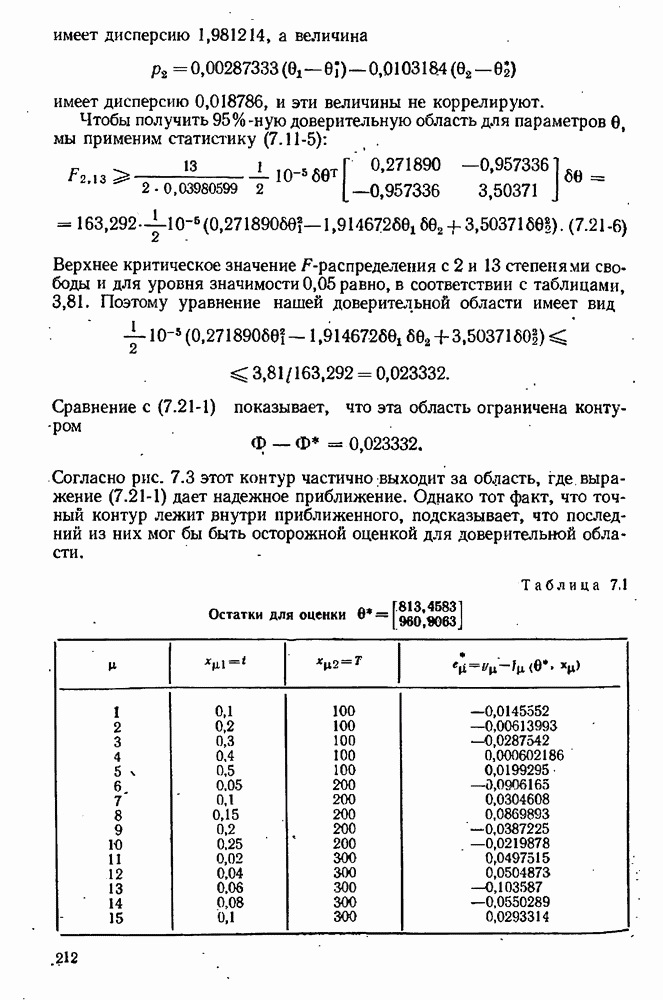
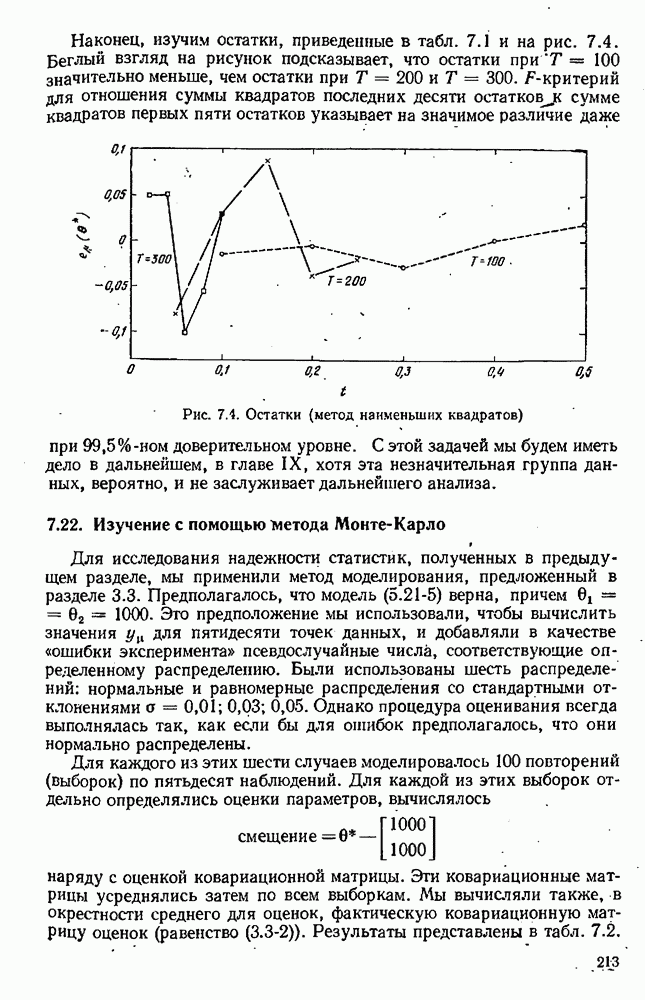
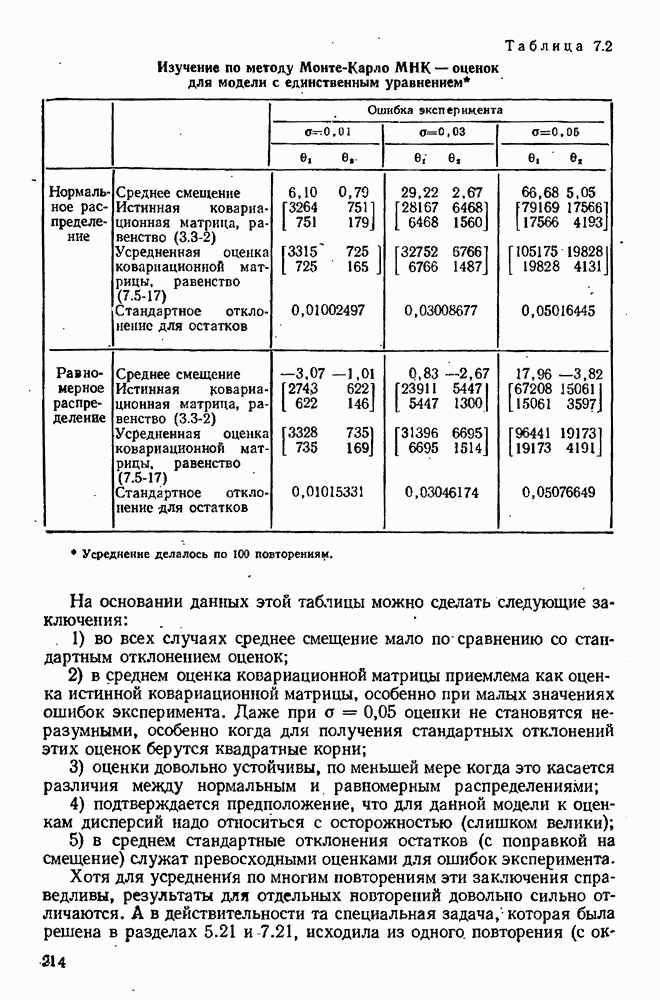

















































































































 для заданного значения
для заданного значения  Тогда все, что нам нужно для моделирования эксперимента, — это вычислительная подпрограмма, воспринимающая значение
Тогда все, что нам нужно для моделирования эксперимента, — это вычислительная подпрограмма, воспринимающая значение  и выдающая в ответ значение
и выдающая в ответ значение  По своей внутренней схеме эта подпрограмма должна вычислять
По своей внутренней схеме эта подпрограмма должна вычислять
 используя формулу типа
используя формулу типа

 это известная вектор-функция, соответствующая одной из моделей, предложенных для изучаемого явления, а
это известная вектор-функция, соответствующая одной из моделей, предложенных для изучаемого явления, а  конкретно определенное множество значений для параметров, появляющихся в этой модели. Случайная ошибка имитируется псевдослучайными числами с надлежащим распределением вероятностей (см. раздел 3.3). В дополнение к ней и для проверки того, что случится, когда ни одна из предложенных моделей в действительности не верна, мы можем включать систематическую ошибку.
конкретно определенное множество значений для параметров, появляющихся в этой модели. Случайная ошибка имитируется псевдослучайными числами с надлежащим распределением вероятностей (см. раздел 3.3). В дополнение к ней и для проверки того, что случится, когда ни одна из предложенных моделей в действительности не верна, мы можем включать систематическую ошибку.
 могут угадывать правильную модель и значения параметров, — это анализ данных (значений
могут угадывать правильную модель и значения параметров, — это анализ данных (значений  поставляемых блоками (1) и (5).
поставляемых блоками (1) и (5).



 парциальные давления водорода, изооктена и изооктана соответственно. Приводим частично заключение, которое сделали Блэйкмор и Хёрл: «Тщательно продуманные эксперименты необходимы... не существует никаких методов аппроксимации, которые могли бы преодолеть недостатки неточно спланированных экспериментов...».
парциальные давления водорода, изооктена и изооктана соответственно. Приводим частично заключение, которое сделали Блэйкмор и Хёрл: «Тщательно продуманные эксперименты необходимы... не существует никаких методов аппроксимации, которые могли бы преодолеть недостатки неточно спланированных экспериментов...».




 псевдослучайное число с распределением
псевдослучайное число с распределением  Заметим, что а это стандартное отклонение относительной ошибки для величин у. Такой выбор модели должен интерпретироваться следующим образом.
Заметим, что а это стандартное отклонение относительной ошибки для величин у. Такой выбор модели должен интерпретироваться следующим образом.
 но случайно получилось, что первые шесть экспериментов дали ложные результаты, которые оказались более близкими к модели
но случайно получилось, что первые шесть экспериментов дали ложные результаты, которые оказались более близкими к модели  Цель состояла в том, чтобы посмотреть, как скоро процедура планирования экспериментов сможет выбрать как верную модель
Цель состояла в том, чтобы посмотреть, как скоро процедура планирования экспериментов сможет выбрать как верную модель  вопреки помехам, внесенным первыми шестью наблюдениями. Значения параметров, принятые в уравнениях
вопреки помехам, внесенным первыми шестью наблюдениями. Значения параметров, принятые в уравнениях  были теми, которые приводили к наилучшей аппроксимации по методу наименьших квадратов данных из литературы, использованных Блэйкмором и Херлом. Интервалы разрешенных значений для независимых переменных были те же самые, что и для упомянутых данных, т. е.
были теми, которые приводили к наилучшей аппроксимации по методу наименьших квадратов данных из литературы, использованных Блэйкмором и Херлом. Интервалы разрешенных значений для независимых переменных были те же самые, что и для упомянутых данных, т. е.

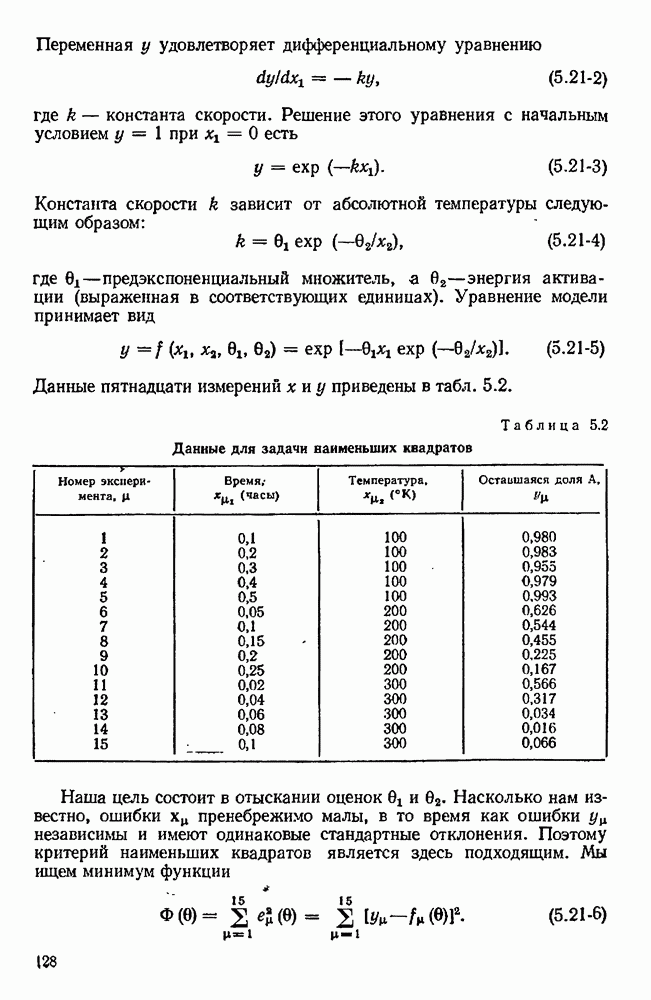
 Условия для этих экспериментов перечисляются в табл. 10.1
Условия для этих экспериментов перечисляются в табл. 10.1
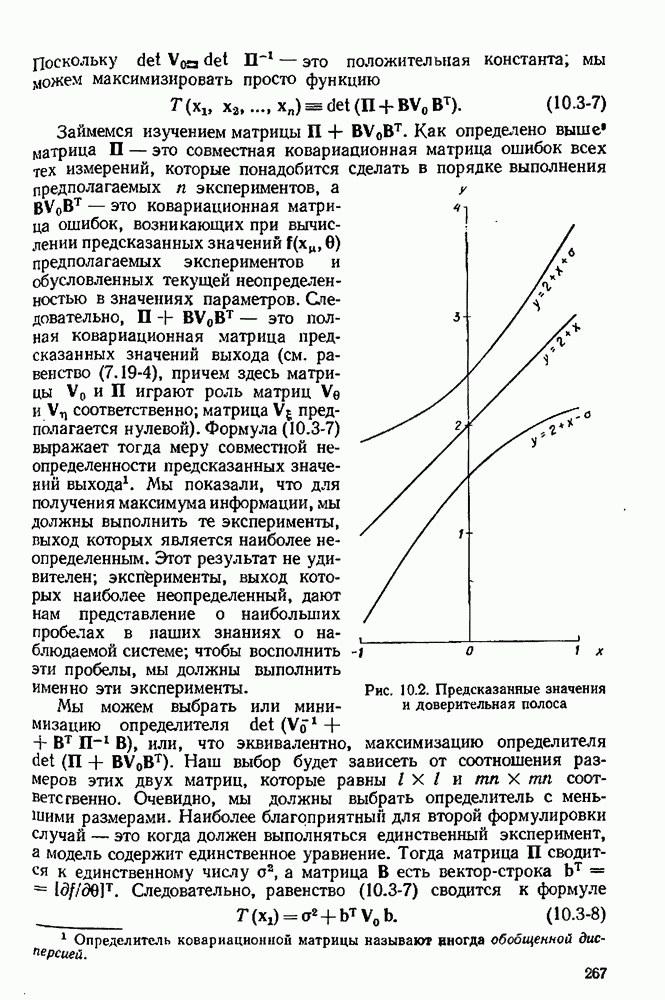
 для случая и — 0,03, т. е. 3%-ной относительной ошибки.
для случая и — 0,03, т. е. 3%-ной относительной ошибки.

 дает намного лучшую аппроксимацию данных и что ее параметры оказываются лучше определенными.
дает намного лучшую аппроксимацию данных и что ее параметры оказываются лучше определенными.
 точек, распределенных равномерно по всей области значений, разрешенных неравенствами
точек, распределенных равномерно по всей области значений, разрешенных неравенствами  подсчитывались значения функции т. е. значения критерия планирования по
подсчитывались значения функции т. е. значения критерия планирования по  Локальными максимумами считались те точки сетки, в которых значение
Локальными максимумами считались те точки сетки, в которых значение  было больше значений этой же функции для всех непосредственно соседних точек. Локальные максимумы после шести предварительных экспериментов перечислены в табл. 10.3; самый высокий максимум подчеркнут.
было больше значений этой же функции для всех непосредственно соседних точек. Локальные максимумы после шести предварительных экспериментов перечислены в табл. 10.3; самый высокий максимум подчеркнут.

 Тогда в согласии с табл. 10.3 седьмой эксперимент мы делаем в точке
Тогда в согласии с табл. 10.3 седьмой эксперимент мы делаем в точке 
 В нашем примере
В нашем примере  оказалось равным 0,09769.
оказалось равным 0,09769.
 вычислялось и печаталось после каждого эксперимента, так что число экспериментов, которые требовались бы при заданных уровнях значимости а и
вычислялось и печаталось после каждого эксперимента, так что число экспериментов, которые требовались бы при заданных уровнях значимости а и  можно было бы определить легко. Пусть после
можно было бы определить легко. Пусть после  экспериментов
экспериментов  и допустим, что
и допустим, что  Тогда решение о прекращении работы после
Тогда решение о прекращении работы после  экспериментов было бы правильным, если
экспериментов было бы правильным, если  мы заранее установили уровень
мы заранее установили уровень  а наша доверительная вероятность, отвечающая выбору второй модели после
а наша доверительная вероятность, отвечающая выбору второй модели после  экспериментов, определяется формулой
экспериментов, определяется формулой

 В дополнение к значениям
В дополнение к значениям  мы приводим список логарифмов отношений правдоподобия и список доверительных вероятностей, отвечающих выбору модели
мы приводим список логарифмов отношений правдоподобия и список доверительных вероятностей, отвечающих выбору модели  вместо модели
вместо модели  и подсчитанных после обработки каждого очередного эксперимента.
и подсчитанных после обработки каждого очередного эксперимента.
 и
и  -ными стандартными отклонениями относительных ошибок. На рис. 10.5 суммированы результаты этих опытов. Следовало бы отметить, что для установления предпочтения к модели
-ными стандартными отклонениями относительных ошибок. На рис. 10.5 суммированы результаты этих опытов. Следовало бы отметить, что для установления предпочтения к модели  -ной доверительной вероятностью нам потребовалось 17 экспериментов при
-ной доверительной вероятностью нам потребовалось 17 экспериментов при  эксперимент — при
эксперимент — при  а по методу раздела 10.6 мы предсказываем, что при
а по методу раздела 10.6 мы предсказываем, что при  потребовалось бы 36 экспериментов.
потребовалось бы 36 экспериментов.
 было ничуть не хуже, чем применение критерия
было ничуть не хуже, чем применение критерия 
 Эти эксперименты образуются с помощью полного перебора всех возможных комбинаций значений независимых переменных на следующих уровнях:
Эти эксперименты образуются с помощью полного перебора всех возможных комбинаций значений независимых переменных на следующих уровнях:



 После всего лишь четырех дополнительных и специально спланированных экспериментов было установлено явное предпочтение для модели 1 с отношением правдоподобия
После всего лишь четырех дополнительных и специально спланированных экспериментов было установлено явное предпочтение для модели 1 с отношением правдоподобия 